Seven Concurrency Models in Seven Weeks (2014)
Chapter 4. The Clojure Way-Separating Identity from State
A modern hybrid passenger car combines the strengths of an internal combustion engine with those of an electric motor. Depending on context, it sometimes runs on electric power only, sometimes on gasoline only, and sometimes both simultaneously. Clojure provides a similar hybrid of functional programming and mutable state—the “Clojure Way” leverages the strengths of both to provide a particularly powerful approach to concurrent programming.
The Best of Both Worlds
While functional programming works incredibly well for some problems, some have modifying state as a fundamental element of the solution. Although it may be possible to create a functional solution to such problems, they are easier to think of in a more traditional manner. In this chapter we’ll stray beyond the pure functional subset of Clojure we looked at previously and see how it helps us create concurrent solutions to such problems.
In day 1 we’ll discuss atoms, the simplest of Clojure’s concurrency-aware mutable datatypes, and show how, in concert with persistent data structures, they allow us to separate identity from state. In day 2 we’ll explore Clojure’s other mutable data structures: agents and software transactional memory. Finally, in day 3 we’ll implement an algorithm using both atoms and STM and discuss the trade-offs between the two solutions.
Day 1: Atoms and Persistent Data Structures
A pure functional language provides no support for mutable data whatsoever. Clojure, by contrast, is impure—it provides a number of different types of concurrency-aware mutable variables, each of which is suitable for different use cases. These, in concert with Clojure’s persistent data structures (we’ll cover what persistent means in this context later) allow us to avoid many of the problems that traditionally afflict concurrent programs with shared mutable state.
The difference between an impure functional language and an imperative language is one of emphasis. In an imperative language, variables are mutable by default and idiomatic code modifies them frequently. In an impure functional language, variables are immutable by default and idiomatic code modifies those that aren’t only when absolutely necessary. As we’ll see, Clojure’s mutable variables allow us to handle real-world side effects while remaining safe and consistent.
Today we’ll see how Clojure’s mutable variables work in concert with persistent data structures to separate identity from state. This allows multiple threads to access mutable variables concurrently without locks (and the associated danger of deadlock) and without any of the problems of escaped or hidden mutable state that we saw in The Perils of Mutable State. We’ll start by looking at what is arguably the simplest of Clojure’s mutable variable types, the atom.
Atoms
An atom is an atomic variable, very similar to those we saw in Atomic Variables (in fact, Clojure’s atoms are built on top of java.util.concurrent.atomic). Here’s an example of creating and retrieving the value of an atom:
|
|
user=> (def my-atom (atom 42)) |
|
|
#'user/my-atom |
|
|
user=> (deref my-atom) |
|
|
42 |
|
|
user=> @my-atom |
|
|
42 |
An atom is created with atom, which takes an initial value. We can find the current value of an atom with deref or @.
If you want to update an atom to a new value, use swap!:
|
|
user=> (swap! my-atom inc) |
|
|
43 |
|
|
user=> @my-atom |
|
|
43 |
This takes a function and passes it the current value of the atom. The new value of the atom becomes the return value from the function. We can also pass additional arguments to the function, as in this example:
|
|
user=> (swap! my-atom + 2) |
|
|
45 |
The first argument passed to the function will be the current value of the atom, and then any additional arguments given to swap!. So in this case, the new value becomes the result of (+ 43 2).
Rarely, you might want to set an atom to a value that doesn’t depend on its current value, in which case you can use reset!:
|
|
user=> (reset! my-atom 0) |
|
|
0 |
|
|
user=> @my-atom |
|
|
0 |
Atoms can be any type—many web applications use an atomic map to store session data, as in this example:
|
|
user=> (def session (atom {})) |
|
|
#'user/session |
|
|
user=> (swap! session assoc :username "paul") |
|
|
{:username "paul"} |
|
|
user=> (swap! session assoc :session-id 1234) |
|
|
{:session-id 1234, :username "paul"} |
Now that we’ve played with them in the REPL, let’s see an example of an atom in an application.
A Multithreaded Web Service with Mutable State
In Escapologist Mutable State, we discussed a hypothetical web service that managed a list of players in a tournament. In this section we’ll look at the complete Clojure code for such a web service and show how Clojure’s persistent data structures mean that mutable state cannot escape as it can in Java.
|
Clojure/TournamentServer/src/server/core.clj |
|
|
Line 1 |
(def players (atom ())) |
|
- |
|
|
- |
(defn list-players [] |
|
- |
(response (json/encode @players))) |
|
5 |
|
|
- |
(defn create-player [player-name] |
|
- |
(swap! players conj player-name) |
|
- |
(status (response "") 201)) |
|
- |
|
|
10 |
(defroutes app-routes |
|
- |
(GET "/players" [] (list-players)) |
|
- |
(PUT "/players/:player-name" [player-name] (create-player player-name))) |
|
- |
(defn -main [& args] |
|
- |
(run-jetty (site app-routes) {:port 3000})) |
This defines a couple of routes—a GET request to /players will retrieve a list of the current players (in JSON format), and a PUT request to /players/name will add a player to that list. As with the web service we saw in the last chapter, the embedded Jetty server is multithreaded, so our code will need to be thread-safe.
We’ll talk about how the code works in a moment, but let’s see it in action first. We can exercise it from the command line with curl:
|
|
$ curl localhost:3000/players |
|
|
[] |
|
|
|
|
|
$ curl -X put localhost:3000/players/john |
|
|
$ curl localhost:3000/players |
|
|
["john"] |
|
|
|
|
|
$ curl -X put localhost:3000/players/paul |
|
|
$ curl -X put localhost:3000/players/george |
|
|
$ curl -X put localhost:3000/players/ringo |
|
|
$ curl localhost:3000/players |
|
|
["ringo","george","paul","john"] |
Now let’s see how this code works. The players atom (line 1) is initialized to the empty list (). A new player is added to the list with conj (line 7), and an empty response is returned with an HTTP 201 (created) status. The list of players is returned by JSON-encoding the result of fetching the value of players with @ (line 4).
This all seems very simple (and it is), but something might be worrying you about it. Both the list-players and create-player functions access players—why doesn’t this code suffer from the same problem as the Java code? What happens if one thread adds an entry to the players list while another is iterating over it, converting it to JSON?
This code is thread-safe because Clojure’s data structures are persistent.
Persistent Data Structures
Persistence in this case doesn’t have anything to do with persistence on disk or within a database. Instead it refers to a data structure that always preserves its previous version when it’s modified, which allows code to have a consistent view of the data in the face of modifications. We can see this easily in the REPL:
|
|
user=> (def mapv1 {:name "paul" :age 45}) |
|
|
#'user/mapv1 |
|
|
user=> (def mapv2 (assoc mapv1 :sex :male)) |
|
|
#'user/mapv2 |
|
|
user=> mapv1 |
|
|
{:age 45, :name "paul"} |
|
|
user=> mapv2 |
|
|
{:age 45, :name "paul", :sex :male} |
Persistent data structures behave as though a complete copy is made each time they’re modified. If that were how they were actually implemented, they would be very inefficient and therefore of limited use (like CopyOnWriteArrayList, which we saw in Copy on Write). Happily, the implementation is much more clever than that and makes use of structure sharing.
The easiest persistent data structure to understand is the list. Here’s a simple list:
|
|
user=> (def listv1 (list 1 2 3)) |
|
|
#'user/listv1 |
|
|
user=> listv1 |
|
|
(1 2 3) |
And here’s a diagram of what it looks like in memory:
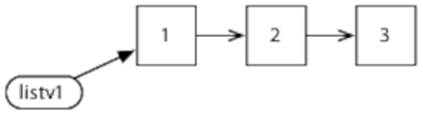
Now let’s create a modified version with cons, which returns a copy of the list with an item added to the front:
|
|
user=> (def listv2 (cons 4 listv1)) |
|
|
#'user/listv2 |
|
|
user=> listv2 |
|
|
(4 1 2 3) |
The new list can share all of the previous list—no copying necessary:
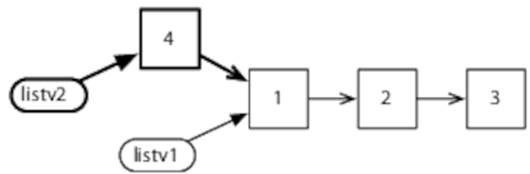
Finally, let’s create another modified version:
|
|
user=> (def listv3 (cons 5 (rest listv1))) |
|
|
#'user/listv3 |
|
|
user=> listv3 |
|
|
(5 2 3) |
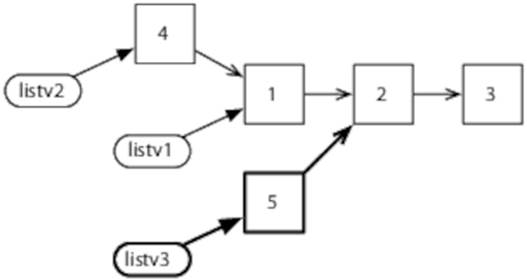
In this instance, the new list only makes use of part of the original, but copying is still not necessary.
We can’t always avoid copying. Lists handle only common tails well—if we want to have two lists with different tails, we have no choice but to copy. Here’s an example:
|
|
user=> (def listv1 (list 1 2 3 4)) |
|
|
#'user/listv1 |
|
|
user=> (def listv2 (take 2 listv1)) |
|
|
#'user/listv2 |
|
|
user=> listv2 |
|
|
(1 2) |
This leads to the following in memory:
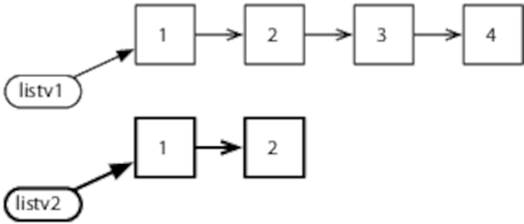
All of Clojure’s collections are persistent. Persistent vectors, maps, and sets are more complex to implement than lists, but for our purposes all we need to know is that they share structure and that they provide similar performance bounds to their nonpersistent equivalents in languages like Ruby and Java.
![]()
Joe asks:
Can Non-functional Data Structures Be Persistent?
It is possible to create a persistent data structure in a non-functional language. We’ve already seen one in Java (CopyOnWriteArrayList), and Clojure’s core data structures are mostly written in Java because Clojure didn’t exist when they were written, so it can certainly be done.
Having said that, implementing a persistent data structure in a non-functional language is difficult—difficult to get right and difficult to do efficiently—because the language gives you no help: it’s entirely up to you to enforce the persistence contract.
Functional data structures, by contrast, are automatically persistent.
Identity or State?
Persistent data structures are invaluable for concurrent programming because once a thread has a reference to a data structure, it will see no changes made by any other thread. Persistent data structures separate identity from state.
What is the fuel level in your car? Right now, it might be half-full. Sometime later it’ll be close to empty, and a few minutes after that (after you stop to fill up) it’ll be full. The identity “fuel level in your car” is one thing, the state of which is constantly changing. “Fuel level in your car” is really a sequence of different values—at 2012-02-23 12:03 it was 0.53; at 2012-02-23 14:30 it was 0.12; and at 2012-02-23 14:31 it was 1.00.
A variable in an imperative language complects (interweaves, interconnects) identity and state—a single identity can only ever have a single value, making it easy to lose sight of the fact that the state is really a sequence of values over time. Persistent data structures separate identity from state—if we retrieve the current state associated with an identity, that state is immutable and unchanging, no matter what happens to the identity from which we retrieved it in the future.
Heraclitus put it this way:
You could not step twice into the same river; for other waters are ever flowing onto you.
Most languages cling to the fallacy that the river is a single consistent entity; Clojure recognizes that it’s constantly changing.
Retries
Because Clojure is functional, atoms can be lockless—internally they make use of the compareAndSet method in java.util.concurrent.AtomicReference. That means that they’re very fast and don’t block (so there’s no danger of deadlock). But it also means that swap! needs to handle the case where the value of the atom has been changed by another thread in between it calling the function to generate a new value and it trying to change that value.
If that happens, swap! will retry. It will discard the value returned by the function and call it again with the atom’s new value. We saw something very similar to this already when using ConcurrentHashMap in the code. This means that it’s essential that the function passed to swap! has no side effects—if it did, then those side effects might happen more than once.
Happily, this is where Clojure’s functional nature pays off—functional code is naturally side effect–free.
Validators
Imagine that we want to have an atom that never has a negative value. We can guarantee that by providing a validator function when we create the atom:
|
|
user=> (def non-negative (atom 0 :validator #(>= % 0))) |
|
|
#'user/non-negative |
|
|
user=> (reset! non-negative 42) |
|
|
42 |
|
|
user=> (reset! non-negative -1) |
|
|
IllegalStateException Invalid reference state |
A validator is a function that’s called whenever an attempt is made to change the value of the atom. If it returns true the attempt can succeed, but if it returns false the attempt will be abandoned.
The validator is called before the value of the atom has been changed and, just like the function that’s passed to swap!, it might be called more than once if swap! retries. Therefore, validators also must not have any side effects.
Watchers
Atoms can also have watchers associated with them:
|
|
user=> (def a (atom 0)) |
|
|
#'user/a |
|
|
user=> (add-watch a :print #(println "Changed from " %3 " to " %4)) |
|
|
#<Atom@542ab4b1: 0> |
|
|
user=> (swap! a + 2) |
|
|
Changed from 0 to 2 |
|
|
2 |
A watcher is added by providing both a key and a watch function. The key is used to identify the watcher (so, for example, if there are multiple watchers, we can remove a specific one by providing the relevant key). The watch function is called whenever the value of the atom changes. It is given four arguments—the key that was given to add-watch, a reference to the atom, the previous value, and the new value.
In the preceding code, we’re using the #(…) reader macro again to define an anonymous function that prints out the old (%3) and new (%4) values of the atom.
Unlike validators, watch functions are called after the value has changed and will only be called once, no matter how often swap! retries. A watch function can, therefore, have side effects. Note, however, that by the time the watch function is called, the value of the atom may already have changed again, so watch functions should always use the values passed as arguments and never dereference the atom.
A Hybrid Web Service
In A Functional Web Service, we created a purely functional web service in Clojure. Although it worked fine, it had a couple of significant limitations—it could only handle a single transcript, and its memory consumption would grow forever. In this section we’ll see how to address both of these issues while preserving the functional flavor of the original.
Session Management
We’re going to allow our web service to handle multiple transcripts by introducing the concept of a session. Each session has a unique numerical identifier, which is generated as follows:
|
Clojure/TranscriptHandler/src/server/session.clj |
|
|
|
(def last-session-id (atom 0)) |
|
|
(defn next-session-id [] |
|
|
(swap! last-session-id inc)) |
This uses an atom, last-session-id, that is incremented each time we want a new session ID. As a result, each time next-session-id is called, it returns a number that is one higher than the last:
|
|
server.core=> (in-ns 'server.session) |
|
|
#<Namespace server.session> |
|
|
server.session=> (next-session-id) |
|
|
1 |
|
|
server.session=> (next-session-id) |
|
|
2 |
|
|
server.session=> (next-session-id) |
|
|
3 |
We’re going to keep track of active sessions with another atom called sessions that contains a map from session IDs to session values:
|
|
(def sessions (atom {})) |
|
|
|
|
|
(defn new-session [initial] |
|
|
(let [session-id (next-session-id)] |
|
|
(swap! sessions assoc session-id initial) |
|
|
session-id)) |
|
|
|
|
|
(defn get-session [id] |
|
|
(@sessions id)) |
We create a new session by passing an initial value to new-session, which gets a new session ID and adds it to sessions by calling swap!. Retrieving a session in get-session is a simple matter of looking it up by its ID.
Session Expiration
If we’re not going to continually increase the amount of memory we use, we’re going to need some way to delete sessions when they’re no longer in use. We could do this explicitly (with a delete-session function, perhaps), but given that we’re writing a web service where we can’t necessarily rely on clients cleaning up after themselves properly, we’re going to implement session expiration (expiry) instead. This requires a small change to the preceding code:
|
Clojure/TranscriptHandler/src/server/session.clj |
|
|
|
(def sessions (atom {})) |
|
|
|
|
* |
(defn now [] |
|
* |
(System/currentTimeMillis)) |
|
|
|
|
|
(defn new-session [initial] |
|
|
(let [session-id (next-session-id) |
|
* |
session (assoc initial :last-referenced (atom (now)))] |
|
|
(swap! sessions assoc session-id session) |
|
|
session-id)) |
|
|
|
|
|
(defn get-session [id] |
|
|
(let [session (@sessions id)] |
|
* |
(reset! (:last-referenced session) (now)) |
|
|
session)) |
We’ve added a utility function called now that returns the current time. When new-session creates a session, it adds a :last-referenced entry to the session, another atom containing the current time. This is updated with reset! whenever get-session accesses the session.
Now that every session has a :last-referenced entry, we can expire sessions by periodically checking to see whether any haven’t been referenced for more than a certain amount of time:
|
Clojure/TranscriptHandler/src/server/session.clj |
|
|
|
(defn session-expiry-time [] |
|
|
(- (now) (* 10 60 1000))) |
|
|
(defn expired? [session] |
|
|
(< @(:last-referenced session) (session-expiry-time))) |
|
|
|
|
|
(defn sweep-sessions [] |
|
|
(swap! sessions #(remove-vals % expired?))) |
|
|
(def session-sweeper |
|
|
(schedule {:min (range 0 60 5)} sweep-sessions)) |
This uses the Schejulure library to create session-sweeper, which schedules sweep-sessions to run once every five minutes.[18] Whenever it runs, it removes (using the remove-vals function provided by the Useful library[19]) any sessions for which expired? returns true, meaning that they were last accessed before session-expiry-time (ten minutes ago).
Putting It All Together
We can now modify our web service to use sessions. First, we need a function that will create a new session:
|
Clojure/TranscriptHandler/src/server/core.clj |
|
|
|
(defn create-session [] |
|
|
(let [snippets (repeatedly promise) |
|
|
translations (delay (map translate |
|
|
(strings->sentences (map deref snippets))))] |
|
|
(new-session {:snippets snippets :translations translations}))) |
We’re still using an infinite lazy sequence of promises to represent incoming snippets and a map over that sequence to represent translations, but these are now both stored in a session.
Next, we need to modify accept-snippet and get-translation to look up :snippets or :translations within a session:
|
Clojure/TranscriptHandler/src/server/core.clj |
|
|
|
(defn accept-snippet [session n text] |
|
|
(deliver (nth (:snippets session) n) text)) |
|
|
|
|
|
(defn get-translation [session n] |
|
|
@(nth @(:translations session) n)) |
Finally, we define the routes that tie these functions to URIs:
|
Clojure/TranscriptHandler/src/server/core.clj |
|
|
|
(defroutes app-routes |
|
|
(POST "/session/create" [] |
|
|
(response (str (create-session)))) |
|
|
|
|
|
(context "/session/:session-id" [session-id] |
|
|
(let [session (get-session (edn/read-string session-id))] |
|
|
(routes |
|
|
(PUT "/snippet/:n" [n :as {:keys [body]}] |
|
|
(accept-snippet session (edn/read-string n) (slurp body)) |
|
|
(response "OK")) |
|
|
|
|
|
(GET "/translation/:n" [n] |
|
|
(response (get-translation session (edn/read-string n)))))))) |
This gives us a web service that makes judicious use of mutable data but still feels primarily functional.
Day 1 Wrap-Up
That brings us to the end of day 1. In day 2 we’ll look at agents and refs, Clojure’s other types of mutable variables.
What We Learned in Day 1
Clojure is an impure functional language, providing a number of types of mutable variables. Today we looked at the simplest of these, the atom.
· The difference between an imperative language and an impure functional language is one of emphasis.
o In an imperative language, variables are mutable by default, and idiomatic code writes to variables frequently.
o In a functional language, variables are immutable by default, and idiomatic code writes to them only when absolutely necessary.
· Because functional data structures are persistent, changes made by one thread will not affect a second thread that already has a reference to that data structure.
· This allows us to separate identity from state, recognizing the fact that the state associated with an identity is really a sequence of values over time.
Day 1 Self-Study
Find
· Karl Krukow’s blog post “Understanding Clojure’s PersistentVector Implementation” for an explanation of how a more complex persistent data structure than a linked list is implemented
· The follow-up to that blog post that describes the implementation of PersistentHashMap using a “Hash Array Mapped Trie”
Do
· Extend the TournamentServer example from A Multithreaded Web Service with Mutable State, to allow players to be removed from as well as added to the list.
· Extend the TranscriptServer example from A Hybrid Web Service, to recover if a snippet doesn’t arrive after more than ten seconds.
Day 2: Agents and Software Transactional Memory
Yesterday we looked at atoms. Today we’ll look at the other types of mutable variables provided by Clojure: agents and refs. Like atoms, agents and refs are both concurrency aware and work in concert with persistent data structures to maintain the separation of identity and state. When talking about refs, we’ll see how Clojure supports software transactional memory, allowing variables to be modified concurrently without locks and yet still retaining consistency.
Agents
An agent is similar to an atom in that it encapsulates a reference to a single value, which can be retrieved with deref or @:
|
|
user=> (def my-agent (agent 0)) |
|
|
#'user/my-agent |
|
|
user=> @my-agent |
|
|
0 |
The value of an agent is modified by calling send:
|
|
user=> (send my-agent inc) |
|
|
#<Agent@2cadd45e: 1> |
|
|
user=> @my-agent |
|
|
1 |
|
|
user=> (send my-agent + 2) |
|
|
#<Agent@2cadd45e: 1> |
|
|
user=> @my-agent |
|
|
3 |
Like swap!, send takes a function together with some optional arguments and calls that function with the current value of the agent. The new value of the agent becomes the return value of the function.
The difference is that send returns immediately (before the value of the agent has been changed)—the function passed to send is called sometime afterward. If multiple threads call send concurrently, execution of the functions passed to send is serialized: only one will execute at a time. This means that they will not be retried and can therefore contain side effects.
![]()
Joe asks:
Is an Agent an Actor?
There are some surface similarities between Clojure’s agents and actors (which we’ll look at in Chapter 5, Actors). They’re different enough that the analogy is likely to be more misleading than helpful, however:
· An agent has a value that can be retrieved directly with deref. An actor encapsulates state but provides no direct means to access it.
· An actor encapsulates behavior; an agent does not—the function that implements an action is provided by the sender.
· Actors provide sophisticated support for error detection and recovery. Agents’ error reporting is much more primitive.
· Actors can be remote; agents provide no support for distribution.
· Composing actors can deadlock; composing agents cannot.
Waiting for Agent Actions to Complete
If you look at the preceding REPL session, you can see that the return value of send is a reference to the agent. And when the REPL displays that reference, it also includes the value of the agent—in this case, 1:
|
|
user=> (send my-agent inc) |
|
|
#<Agent@2cadd45e: 1> |
The next time, however, instead of displaying 3, it displays 1 again:
|
|
user=> (send my-agent + 2) |
|
|
#<Agent@2cadd45e: 1> |
This is because the function passed to send is run asynchronously, and it may or may not finish before the REPL queries the agent for its value. With a quick-running task like this, by the time the REPL retrieves the value, there’s a good chance that it will have already finished; but if we provide a long-running task with Thread/sleep, you can see that this isn’t normally true:
|
|
user=> (def my-agent (agent 0)) |
|
|
#'user/my-agent |
|
|
user=> (send my-agent #((Thread/sleep 2000) (inc %))) |
|
|
#<Agent@224e59d9: 0> |
|
|
user=> @my-agent |
|
|
0 |
|
|
user=> @my-agent |
|
|
1 |
Clojure provides the await function, which blocks until all actions dispatched from the current thread to the given agent(s) have completed (there’s also await-for, which allows you to specify a timeout):
|
|
user=> (def my-agent (agent 0)) |
|
|
#'user/my-agent |
|
|
user=> (send my-agent #((Thread/sleep 2000) (inc %))) |
|
|
#<Agent@7f5ff9d0: 0> |
|
|
user=> (await my-agent) |
|
|
nil |
|
|
user=> @my-agent |
|
|
1 |
![]()
Joe asks:
What About Send-Off and Send-Via?
As well as send, agents also support send-off and send-via. The only difference is that send executes the function it’s given in a common thread pool, whereas send-off creates a new thread and send-via takes an executor as an argument.
You should use send-off or send-via if the function you pass might block (and therefore tie up the thread that it’s executing on) or take a long time to execute. Other than that, the three functions are identical.
Asynchronous updates have obvious benefits over synchronous ones, especially for long-running or blocking operations. They also have added complexity, including dealing with errors. We’ll see the tools that Clojure provides to help with this next.
Error Handling
Like atoms, agents also support both validators and watchers. For example, here’s an agent that has a validator that ensures that the agent’s value never goes negative:
|
|
user=> (def non-negative (agent 1 :validator (fn [new-val] (>= new-val 0)))) |
|
|
#'user/non-negative |
Here’s what happens if we try to decrement the agent’s value until it goes negative:
|
|
user=> (send non-negative dec) |
|
|
#<Agent@6257d812: 0> |
|
|
user=> @non-negative |
|
|
0 |
|
|
user=> (send non-negative dec) |
|
|
#<Agent@6257d812: 0> |
|
|
user=> @non-negative |
|
|
0 |
As we hoped, the value won’t go negative. But what happens if we try to use an agent after it’s experienced an error?
|
|
user=> (send non-negative inc) |
|
|
IllegalStateException Invalid reference state clojure.lang.ARef.validate… |
|
|
|
|
|
user=> @non-negative |
|
|
0 |
Once an agent experiences an error, it enters a failed state by default, and attempts to dispatch new actions fail. We can find out if an agent is failed (and if it is, why) with agent-error, and we can restart it with restart-agent:
|
|
user=> (agent-error non-negative) |
|
|
#<IllegalStateException java.lang.IllegalStateException: Invalid reference state> |
|
|
user=> (restart-agent non-negative 0) |
|
|
0 |
|
|
user=> (agent-error non-negative) |
|
|
nil |
|
|
user=> (send non-negative inc) |
|
|
#<Agent@6257d812: 1> |
|
|
user=> @non-negative |
|
|
1 |
By default, agents are created with the :fail error mode. Alternatively, you can set the error mode to :continue, in which case you don’t need to call restart-agent to allow an agent to process new actions after an error. The :continue error mode is the default if you set an error handler—a function that’s automatically called whenever the agent experiences an error.
Next, we’ll see a more realistic example of using an agent.
An In-Memory Log
Something I’ve often found helpful when working with concurrent programs is an in-memory log—traditional logging can be too heavyweight to be helpful when debugging concurrency issues, involving as it does several context-switches and IO operations for each log operation. Implementing such an in-memory log with threads and locks can be tricky, but an agent-based implementation is almost trivial:
|
Clojure/Logger/src/logger/core.clj |
|
|
|
(def log-entries (agent [])) |
|
|
|
|
|
(defn log [entry] |
|
|
(send log-entries conj [(now) entry])) |
Our log is an agent called log-entries initialized to an empty array. The log function uses conj to append a new entry to this array, which consists of a two-element array—the first element is a timestamp (which will be the time that send is called, not the time that conj is called by the agent—potentially sometime later), and the second element is the log message.
Here’s a REPL session that shows it in action:
|
|
logger.core=> (log "Something happened") |
|
|
#<Agent@bd99597: [[1366822537794 "Something happened"]]> |
|
|
logger.core=> (log "Something else happened") |
|
|
#<Agent@bd99597: [[1366822538932 "Something happened"]]> |
|
|
logger.core=> @log-entries |
|
|
[[1366822537794 "Something happened"] [1366822538932 "Something else happened"]] |
In the next section we’ll look at the remaining type of shared mutable variable supported by Clojure, the ref.
Software Transactional Memory
Refs are more sophisticated than atoms and agents, providing software transactional memory (STM). Unlike atoms and agents, which only support modifications of a single variable at a time, STM allows us to make concurrent, coordinated changes to multiple variables, much like a database transaction allows concurrent, coordinated changes to multiple records.
Like both atoms and agents, a ref encapsulates a reference to single value, which can be retrieved with deref or @:
|
|
user=> (def my-ref (ref 0)) |
|
|
#'user/my-ref |
|
|
user=> @my-ref |
|
|
0 |
The value of a ref can be set with ref-set, and the equivalent of swap! or send is alter. However, using them isn’t as simple as just calling them:
|
|
user=> (ref-set my-ref 42) |
|
|
IllegalStateException No transaction running |
|
|
|
|
|
user=> (alter my-ref inc) |
|
|
IllegalStateException No transaction running |
Modifying the value of a ref is possible only inside a transaction.
Transactions
STM transactions are atomic, consistent, and isolated:
Atomic:
From the point of view of code running in another transaction, either all of the side effects of a transaction take place, or none of them do.
Consistent:
Transactions guarantee preservation of invariants specified through validators (like those we’ve already seen for atoms and agents). If any of the changes attempted by a transaction fail to validate, none of the changes will be made.
Isolated:
Although multiple transactions can execute concurrently, the effect of concurrent transactions will be indistinguishable from those transactions running sequentially.
You may recognize these as the first three of the ACID properties supported by many databases. The missing property is durability—STM data will not survive power loss or crashes. If you need durability, you need to use a database.
A transaction is created with dosync:
|
|
user=> (dosync (ref-set my-ref 42)) |
|
|
42 |
|
|
user=> @my-ref |
|
|
42 |
|
|
user=> (dosync (alter my-ref inc)) |
|
|
43 |
|
|
user=> @my-ref |
|
|
43 |
Everything within the body of dosync constitutes a single transaction.
![]()
Joe asks:
Are Transactions Really Isolated?
Completely isolated transactions are the right choice for most situations, but isolation can be an excessively strong constraint for some use cases. Clojure does allow you to relax it when appropriate by using commute instead of alter.
Although commute can be a useful optimization, understanding when it’s appropriate can be subtle, and we won’t cover it further in this book.
Multiple Refs
Most interesting transactions involve more than one ref (otherwise, we might just as well use an atom or agent). The classic example of a transaction is transferring money between accounts—we never want to see an occasion where money has been debited from one account and not credited to the other. Here’s a function where both the debit and credit will occur, or neither will:
|
Clojure/Transfer/src/transfer/core.clj |
|
|
|
(defn transfer [from to amount] |
|
|
(dosync |
|
|
(alter from - amount) |
|
|
(alter to + amount))) |
Here’s an example of it in use:
|
|
user=> (def checking (ref 1000)) |
|
|
#'user/checking |
|
|
user=> (def savings (ref 2000)) |
|
|
#'user/savings |
|
|
user=> (transfer savings checking 100) |
|
|
1100 |
|
|
user=> @checking |
|
|
1100 |
|
|
user=> @savings |
|
|
1900 |
If the STM runtime detects that concurrent transactions are trying to make conflicting changes, one or more of the transactions will be retried. This means that, as when modifying an atom, transactions should not have side effects.
Retrying Transactions
In the spirit of “show, don’t tell,” let’s see if we can catch a transaction being retried by stress-testing our transfer function. We’re going to start by instrumenting it as follows:
|
Clojure/Transfer/src/transfer/core.clj |
|
|
|
(def attempts (atom 0)) |
|
|
(def transfers (agent 0)) |
|
|
|
|
|
(defn transfer [from to amount] |
|
|
(dosync |
|
* |
(swap! attempts inc) // Side-effect in transaction - DON'T DO THIS |
|
* |
(send transfers inc) |
|
|
(alter from - amount) |
|
|
(alter to + amount))) |
We’re deliberately breaking the "no side effects" rule by modifying an atom within a transaction. In this case, it’s OK because we’re doing it to illustrate that transactions are being retried, but please don’t write code like this in production.
As well as keeping a count in an atom, we’re keeping a count in an agent. We’ll see why very shortly.
Here’s a main method that stress-tests this instrumented transfer function:
|
Clojure/Transfer/src/transfer/core.clj |
|
|
|
(def checking (ref 10000)) |
|
|
(def savings (ref 20000)) |
|
|
|
|
|
(defn stress-thread [from to iterations amount] |
|
|
(Thread. #(dotimes [_ iterations] (transfer from to amount)))) |
|
|
|
|
|
(defn -main [& args] |
|
|
(println "Before: Checking =" @checking " Savings =" @savings) |
|
|
(let [t1 (stress-thread checking savings 100 100) |
|
|
t2 (stress-thread savings checking 200 100)] |
|
|
(.start t1) |
|
|
(.start t2) |
|
|
(.join t1) |
|
|
(.join t2)) |
|
|
(await transfers) |
|
|
(println "Attempts: " @attempts) |
|
|
(println "Transfers: " @transfers) |
|
|
(println "After: Checking =" @checking " Savings =" @savings)) |
It creates two threads. One thread transfers $100 from the checking account to the savings account 100 times, and the other transfers $100 from the savings account to the checking account 200 times. Here’s what I see when I run this:
|
|
Before: Checking = 10000 Savings = 20000 |
|
|
Attempts: 638 |
|
|
Transfers: 300 |
|
|
After: Checking = 20000 Savings = 10000 |
This is excellent news—the final result is exactly what we would expect, so the STM runtime has successfully ensured that our concurrent transactions have given us the right result. The cost is that it had to perform a number of retries (338 on this occasion) to do so, but the payoff is no locking and no danger of deadlock.
Of course, this isn’t a realistic example—two threads both accessing the same refs in a tight loop are guaranteed to conflict with each other. In practice, retries will be much rarer than this in a well-designed system.
Safe Side Effects in Transactions
You may have noticed that although the count maintained by our atom was much larger, the count maintained by our agent was exactly equal to the number of transactions. There is a good reason for this—agents are transaction aware.
If you use send to modify an agent within a transaction, that send will take place only if the transaction succeeds. Therefore, if you want to achieve some side effect when a transaction succeeds, using send is an excellent way to do so.
![]()
Joe asks:
What’s with the Exclamation Marks?
You may have noticed that some functions have names ending in an exclamation mark—what does this naming convention convey?
Clojure uses an exclamation mark to indicate that functions like swap! and reset! are not transaction-safe. By contrast, we know that we can safely update an agent within a transaction because the function that updates an agent’s value is send instead of send!.
Shared Mutable State in Clojure
We’ve now seen all three of the mechanisms that Clojure provides to support shared mutable state. Each has its own use cases.
An atom allows you to make synchronous changes to a single value—synchronous because when swap! returns, the update has taken place. Updates to one atom are not coordinated with other updates.
An agent allows you to make asynchronous changes to a single value—asynchronous because the update takes place after send returns. Updates to one agent are not coordinated with other updates.
Refs allow you to make synchronous, coordinated changes to multiple values.
Day 2 Wrap-Up
That brings us to the end of day 2. In day 3 we’ll see some more extended examples of using mutable variables in Clojure together with some guidance on when to use the different types.
What We Learned in Day 2
In addition to atoms, Clojure also provides agents and refs:
· Atoms enable independent, synchronous changes to single values.
· Agents enable independent, asynchronous changes to single values.
· Refs enable coordinated, synchronous changes to multiple values.
Day 2 Self-Study
Find
· Rich Hickey’s presentation “Persistent Data Structures and Managed References: Clojure’s Approach to Identity and State”
· Rich Hickey’s presentation “Simple Made Easy”
Do
· Extend the TournamentServer from A Multithreaded Web Service with Mutable State, by using refs and transactions to implement a server that runs a tic-tac-toe tournament.
· Implement a persistent binary search tree using lists to represent nodes. What’s the worst-case amount of copying you need to perform? What about the average case?
· Look up finger trees and implement your binary search tree using a finger tree. What effect does that have on the average performance and worst-case performance?
Day 3: In Depth
We’ve now seen all of the ingredients of the “Clojure Way.” Today we’ll look at some more involved examples of those ingredients in use and gain some insights into how to choose between atoms and STM when faced with a particular concurrency problem.
Dining Philosophers with STM
To start off, we’ll revisit the “dining philosophers” problem we examined in Chapter 2, Threads and Locks, and construct a solution using Clojure’s software transactional memory. Our solution will be very similar to (but, as you’ll soon see, much simpler than) the condition-variable-based solution from Condition Variables.
We’re going to represent a philosopher as a ref, the value of which contains the philosopher’s current state (either :thinking or :eating). Those refs are stored in a vector called philosophers:
|
Clojure/DiningPhilosphersSTM/src/philosophers/core.clj |
|
|
|
(def philosophers (into [] (repeatedly 5 #(ref :thinking)))) |
Each philosopher has an associated thread:
|
Clojure/DiningPhilosphersSTM/src/philosophers/core.clj |
|
|
Line 1 |
(defn think [] |
|
- |
(Thread/sleep (rand 1000))) |
|
- |
|
|
- |
(defn eat [] |
|
5 |
(Thread/sleep (rand 1000))) |
|
- |
|
|
- |
(defn philosopher-thread [n] |
|
- |
(Thread. |
|
- |
#(let [philosopher (philosophers n) |
|
10 |
left (philosophers (mod (- n 1) 5)) |
|
- |
right (philosophers (mod (+ n 1) 5))] |
|
- |
(while true |
|
- |
(think) |
|
- |
(when (claim-chopsticks philosopher left right) |
|
15 |
(eat) |
|
- |
(release-chopsticks philosopher)))))) |
|
- |
|
|
- |
(defn -main [& args] |
|
- |
(let [threads (map philosopher-thread (range 5))] |
|
20 |
(doseq [thread threads] (.start thread)) |
|
- |
(doseq [thread threads] (.join thread)))) |
As with the Java solution, each thread loops forever (line 12), alternating between thinking and attempting to eat. If claim-chopsticks succeeds (line 14), the when control structure first calls eat and then calls release-chopsticks.
The implementation of release-chopsticks is straightforward:
|
Clojure/DiningPhilosphersSTM/src/philosophers/core.clj |
|
|
|
(defn release-chopsticks [philosopher] |
|
|
(dosync (ref-set philosopher :thinking))) |
We simply create a transaction with dosync and set our state to :thinking with ref-set.
A First Attempt
The interesting function is claim-chopsticks—here’s a first attempt at an implementation:
|
|
(defn claim-chopsticks [philosopher left right] |
|
|
(dosync |
|
|
(when (and (= @left :thinking) (= @right :thinking)) |
|
|
(ref-set philosopher :eating)))) |
As with release-chopsticks, we start by creating a transaction. Within that transaction we check the state of the philosophers to our left and right—if they’re both :thinking, we set our status to :eating with ref-set. Because when returns nil if the condition it’s given is false, claim-chopstickswill also return nil if we’re unable to claim both chopsticks and start eating.
If you try running with this implementation, at first glance it will appear to work. Occasionally, however, you’ll see adjacent philosophers eating, which should be impossible, as they share a chopstick. So what’s going on?
The problem is that we’re accessing the values of left and right with @. Clojure’s STM guarantees that no two transactions will make inconsistent modifications to the same ref, but we’re not modifying left or right, just examining their values. Some other transaction could modify them, invalidating the condition that adjacent philosophers can’t eat simultaneously.
Ensuring That a Value Does Not Change
The solution is to examine left and right with ensure instead of @:
|
Clojure/DiningPhilosphersSTM/src/philosophers/core.clj |
|
|
|
(defn claim-chopsticks [philosopher left right] |
|
|
(dosync |
|
|
(when (and (= (ensure left) :thinking) (= (ensure right) :thinking)) |
|
|
(ref-set philosopher :eating)))) |
As its name suggests, ensure ensures that the value of the ref it returns won’t be changed by another transaction. It’s worth comparing this solution to our earlier lock-based solutions. Not only is it significantly simpler, but because it’s lockless, it’s impossible for it to deadlock.
In the next section we’ll look at an alternative implementation that uses a single atom instead of multiple refs and transactions.
Dining Philosophers Without STM
An STM-based approach isn’t the only possible solution to dining philosophers in Clojure. Instead of representing each philosopher as a ref and using transactions to ensure that updates to those refs are coordinated, we can use a single atom to represent the state of all the philosophers:
|
Clojure/DiningPhilosphersAtom/src/philosophers/core.clj |
|
|
|
(def philosophers (atom (into [] (repeat 5 :thinking)))) |
Its value is a vector of states. If philosophers 0 and 3 are eating, for example, it would be this:
|
|
[:eating :thinking :thinking :eating :thinking] |
We need to make a small change to philosopher-thread, as we’ll now be referring to a particular philosopher by its index in the array:
|
Clojure/DiningPhilosphersAtom/src/philosophers/core.clj |
|
|
|
(defn philosopher-thread [philosopher] |
|
|
(Thread. |
|
* |
#(let [left (mod (- philosopher 1) 5) |
|
* |
right (mod (+ philosopher 1) 5)] |
|
|
(while true |
|
|
(think) |
|
|
(when (claim-chopsticks! philosopher left right) |
|
|
(eat) |
|
|
(release-chopsticks! philosopher)))))) |
Implementing release-chopsticks! is just a question of using swap! to set the relevant position in the vector to :thinking:
|
Clojure/DiningPhilosphersAtom/src/philosophers/core.clj |
|
|
|
(defn release-chopsticks! [philosopher] |
|
|
(swap! philosophers assoc philosopher :thinking)) |
This code makes use of assoc, which we’ve previously seen used only with a map, but it behaves exactly as you might imagine:
|
|
user=> (assoc [:a :a :a :a] 2 :b) |
|
|
[:a :a :b :a] |
Finally, as before, the most interesting function to implement is claim-chopsticks!:
|
Clojure/DiningPhilosphersAtom/src/philosophers/core.clj |
|
|
|
(defn claim-chopsticks! [philosopher left right] |
|
|
(swap! philosophers |
|
|
(fn [ps] |
|
|
(if (and (= (ps left) :thinking) (= (ps right) :thinking)) |
|
|
(assoc ps philosopher :eating) |
|
|
ps))) |
|
|
(= (@philosophers philosopher) :eating)) |
The anonymous function passed to swap! takes the current value of the philosophers vector and checks the state of the adjacent philosophers. If they’re both thinking, it uses assoc to modify the state of the current philosopher to :eating; otherwise it returns the current value of the vector unmodified.
The last line of claim-chopsticks! checks the new value of philosophers to see whether the swap! successfully modified the state of the current philosopher to :eating.
So we’ve now seen two “dining philosophers” implementations, one that uses STM and one that doesn’t. Is there any reason to prefer one over the other?
Atoms or STM?
As we saw in Shared Mutable State in Clojure, atoms enable independent changes to single values, whereas refs enable coordinated changes to multiple values. These are quite different sets of capabilities, but as we’ve seen in this section, it’s relatively easy to take an STM-based solution that uses multiple refs and turn it into a solution that uses a single atom instead.
It turns out that this isn’t unusual—whenever we need to coordinate modifications of multiple values we can either use multiple refs and coordinate access to them with transactions or collect those values together into a compound data structure stored in a single atom.
So how do you choose?
In many ways it’s a question of style and personal preference—both approaches work, so go with whichever seems clearest to you. There will also be differences in relative performance that will depend on the details of your problem and its access patterns, so you should also let the stopwatch (together with your load-test suite) be your guide.
Having said that, although STM gets the headlines, experienced Clojure programmers tend to find that atoms suffice for most problems, as the language’s functional nature leads to minimal use of mutable data. As always, the simplest approach that will work is your friend.
Custom Concurrency
Our atom-based “dining philosophers” code works, but the implementation of claim-chopsticks! (see the code) isn’t particularly elegant. Surely it should be possible to avoid the check after calling swap! to see if we were able to claim the chopsticks? Ideally, we’d like a version of swap! that takes a predicate and only swaps the value if the predicate is true. That would enable us to rewrite claim-chopsticks! like this:
|
Clojure/DiningPhilosphersAtom2/src/philosophers/core.clj |
|
|
|
(defn claim-chopsticks! [philosopher left right] |
|
|
(swap-when! philosophers |
|
|
#(and (= (%1 left) :thinking) (= (%1 right) :thinking)) |
|
|
assoc philosopher :eating)) |
Although Clojure provides no such function, there’s no reason we shouldn’t write one ourselves:
|
Clojure/DiningPhilosphersAtom2/src/philosophers/util.clj |
|
|
Line 1 |
(defn swap-when! |
|
- |
"If (pred current-value-of-atom) is true, atomically swaps the value |
|
- |
of the atom to become (apply f current-value-of-atom args). Note that |
|
- |
both pred and f may be called multiple times and thus should be free |
|
5 |
of side effects. Returns the value that was swapped in if the |
|
- |
predicate was true, nil otherwise." |
|
- |
[a pred f & args] |
|
- |
(loop [] |
|
- |
(let [old @a] |
|
10 |
(if (pred old) |
|
- |
(let [new (apply f old args)] |
|
- |
(if (compare-and-set! a old new) |
|
- |
new |
|
- |
(recur))) |
|
15 |
nil)))) |
This introduces quite a bit of new stuff. Firstly, the function has a doc-string—a string in between the defn and the parameter list—that describes its behavior. This is good practice for any function, but particularly so for utility functions like this that are designed for reuse. As well as forming documentation within the code, doc-strings can be accessed from within the REPL:
|
|
philosophers.core=> (require '[philosophers.util :refer :all]) |
|
|
nil |
|
|
philosophers.core=> (clojure.repl/doc swap-when!) |
|
|
------------------------- |
|
|
philosophers.util/swap-when! |
|
|
([atom pred f & args]) |
|
|
If (pred current-value-of-atom) is true, atomically swaps the value |
|
|
of the atom to become (apply f current-value-of-atom args). Note that |
|
|
both pred and f may be called multiple times and thus should be free |
|
|
of side effects. Returns the value that was swapped in if the |
|
|
predicate was true, nil otherwise. |
The ampersand (&) in the argument list says that swap-when! can take a variable number of arguments (similar to an ellipsis in Java or asterisk in Ruby). Any additional arguments will be captured as an array and bound to args. We use apply, which unpacks its last argument, to pass these additional arguments to f (line 11)—for example, the following are equivalent ways to invoke +:
|
|
user=> (apply + 1 2 [3 4 5]) |
|
|
15 |
|
|
user=> (+ 1 2 3 4 5) |
|
|
15 |
Instead of using swap!, the implementation makes use of the low-level compare-and-set! function (line 12). This takes an atom together with old and new values—it atomically sets the value of the atom to the new value if and only if its current value is equal to the old one.
If compare-and-set! succeeds, we return the new value. If it doesn’t, we use recur (line 14) to loop back to line 8.
![]()
Joe asks:
What Is Loop/Recur?
Unlike many functional languages, Clojure does not provide tail-call elimination, so idiomatic Clojure makes very little use of recursion. Instead, Clojure provides loop/recur.
The loop macro defines a target that recur can jump to (reminiscent of setjmp and longjmp in C/C++). For more detail on how this works, see the Clojure documentation.
Day 3 Wrap-Up
This brings us to the end of day 3 and our discussion of how Clojure combines functional programming with concurrency-aware mutable variables.
What We Learned in Day 3
Clojure’s functional nature leads to code with few mutable variables. Typically this means that simple atom-based concurrency is sufficient:
· STM-based code in which multiple refs are coordinated through transactions can be transformed into an agent-based solution with those refs consolidated into a single compound data structure accessed via an agent.
· The choice between an STM and an agent-based solution is largely one of style and performance characteristics.
· Custom concurrency constructs can make code simpler and clearer.
Day 3 Self-Study
Find
· Rich Hickey’s presentation “The Database as a Value”—note how Datomic effectively treats the entire database as a single value.[20]
Do
· Modify the extended TournamentServer from the exercises at the end of day 2 to use atoms instead of refs and transactions. Which solution is simpler? Which is easier to read? Which provides better performance?
Wrap-Up
Clojure takes a pragmatic approach to concurrency (very appropriate for this Pragmatic Bookshelf title). Recognizing that most of the difficulties with concurrent programming arise from shared mutable state, Clojure is a functional language that facilitates referentially transparent code that is free from side effects. But recognizing that most interesting problems necessarily involve the maintenance of some mutable state, it supports a number of concurrency-safe types of mutable variables.
Strengths
For obvious reasons, the strengths of the “Clojure Way” build upon those for functional programming that we saw in the previous chapter. Clojure allows you to solve problems functionally when that’s the natural approach, but step outside of pure functional programming when appropriate.
By contrast with variables in traditional imperative languages, which complect identity and state, Clojure’s persistent data structures allow its mutable variables to keep identity and state separate. This eliminates a wide range of common problems with lock-based programs. Experienced Clojure programmers find that the idiomatic solution to a concurrent problem often “just works.”
Weaknesses
The primary weakness of the “Clojure Way” is that it provides no support for distributed (geographically or otherwise) programming. Related to this, it has no direct support for fault tolerance.
Of course, because it runs on the JVM, there are various third-party libraries available that can be used from Clojure to provide such support (one of these is Akka,[21] which, among other things, supports the actor model that we’ll be looking at in the next chapter), but use of such libraries steps outside of idiomatic Clojure.
Other Languages
Although its pure functional nature means that it has a somewhat different “feel,” concurrent Haskell provides very similar functionality to what we’ve seen in this chapter. In particular, it provides a full STM implementation, an excellent introduction to which can be found in Simon Peyton Jones’s Beautiful Concurrency.[22]
In addition, there are STM implementations available for most mainstream languages, not the least of which is GCC.[23] Having said that, there is evidence that STM provides a less compelling solution when coupled with an imperative language.[24]
Final Thoughts
Clojure has found a good balance between functional programming and mutable state, allowing programmers with experience in imperative languages to get started more easily than they might in a pure functional language. And yet it does so while retaining most of functional programming’s benefits, in particular its excellent support for concurrency.
In large part, Clojure accomplishes this by retaining shared mutable state, but with carefully thought-out concurrency-aware semantics. In the next section we’ll look at actors, which do away with shared mutable state altogether.
Footnotes
|
[18] |
https://github.com/AdamClements/schejulure |
|
[19] |
https://github.com/flatland/useful |
|
[20] |
http://www.datomic.com |
|
[21] |
http://blog.darevay.com/2011/06/clojure-and-akka-a-match-made-in/ |
|
[22] |
http://research.microsoft.com/pubs/74063/beautiful.pdf |
|
[23] |
http://gcc.gnu.org/wiki/TransactionalMemory |
|
[24] |
http://www.infoq.com/news/2010/05/STM-Dropped |
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.