Functional Python Programming (2015)
Chapter 12. The Multiprocessing and Threading Modules
When we eliminate complex, shared state and design around non-strict processing, we can leverage parallelism to improve performance. In this chapter, we'll look at the multiprocessing and multithreading techniques that are available to us. Python library packages become particularly helpful when applied to algorithms that permit lazy evaluation.
The central idea here is to distribute a functional program across several threads within a process or across several processes. If we've created a sensible functional design, we don't have complex interactions among application components; we have functions that accept argument values and produce results. This is an ideal structure for a process or a thread.
We'll focus on the multiprocessing and concurrent.futures modules. These modules allow a number of parallel execution techniques.
We'll also focus on process-level parallelism instead of multithreading. The idea behind process parallelism allows us to ignore Python's Global Interpreter Lock (GIL) and achieve outstanding performance.
For more information on Python's GIL, see https://docs.python.org/3.3/c-api/init.html#thread-state-and-the-global-interpreter-lock.
We won't emphasize features of the threading module. This is often used for parallel processing. If we have done our functional programming design well, any issues that stem from multithreaded write access should be minimized. However, the presence of the GIL means that multithreaded applications in CPython suffer from some small limitations. As waiting for I/O doesn't involve the GIL, it's possible that some I/O bound programs might have unusually good performance.
The most effective parallel processing occurs where there are no dependencies among the tasks being performed. With some careful design, we can approach parallel programming as an ideal processing technique. The biggest difficulty in developing parallel programs is coordinating updates to shared resources.
When following functional design patterns and avoiding stateful programs, we can also minimize concurrent updates to shared objects. If we can design software where lazy, non-strict evaluation is central, we can also design software where concurrent evaluation is possible.
Programs will always have some strict dependencies where ordering of operations matters. In the 2*(3+a) expression, the (3+a) subexpression must be evaluated first. However, when working with a collection, we often have situations where the processing order among items in the collection doesn't matter.
Consider the following two examples:
x = list(func(item) for item in y)
x = list(reversed([func(item) for item in y[::-1]]))
Both of these commands have the same result even though the items are evaluated in the reverse order.
Indeed, even this following command snippet has the same result:
import random
indices= list(range(len(y)))
random.shuffle(indices)
x = [None]*len(y)
for k in indices:
x[k] = func(y[k])
The evaluation order is random. As the evaluation of each item is independent, the order of evaluation doesn't matter. This is the case with many algorithms that permit non-strict evaluation.
What concurrency really means
In a small computer, with a single processor and a single core, all evaluations are serialized only through the core of the processor. The operating system will interleave multiple processes and multiple threads through clever time-slicing arrangements.
On a computer with multiple CPUs or multiple cores in a single CPU, there can be some actual concurrent processing of CPU instructions. All other concurrency is simulated through time slicing at the OS level. A Mac OS X laptop can have 200 concurrent processes that share the CPU; this is far more processes than the number of available cores. From this, we can see that the OS time slicing is responsible for most of the apparently concurrent behavior.
The boundary conditions
Let's consider a hypothetical algorithm which has 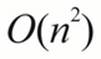 . Assume that there is an inner loop that involves 1,000 bytes of Python code. When processing 10,000 objects, we're executing 100 billion Python operations. This is the essential processing budget. We can try to allocate as many processes and threads as we feel might be helpful, but the processing budget can't change.
. Assume that there is an inner loop that involves 1,000 bytes of Python code. When processing 10,000 objects, we're executing 100 billion Python operations. This is the essential processing budget. We can try to allocate as many processes and threads as we feel might be helpful, but the processing budget can't change.
The individual CPython bytecode doesn't have a simple execution timing. However, a long-term average on a Mac OS X laptop shows that we can expect about 60 MB of code to be executed per second. This means that our 100 billion bytecode operation will take about 1,666 seconds, or 28 minutes.
If we have a dual processor, four-core computer, then we might cut the elapsed time to 25 percent of the original total: 7 minutes. This presumes that we can partition the work into four (or more) independent OS processes.
The important consideration here is that our budget of 100 billion bytecodes can't be changed. Parallelism won't magically reduce the workload. It can only change the schedule to, perhaps, reduce the elapsed time.
Switching to a better algorithm which is 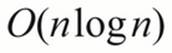 can reduce the workload to 132 MB of operations. At 60 MBps, this workload is considerably smaller. Parallelism won't have the kind of dramatic improvements that algorithm change will have.
can reduce the workload to 132 MB of operations. At 60 MBps, this workload is considerably smaller. Parallelism won't have the kind of dramatic improvements that algorithm change will have.
Sharing resources with process or threads
The OS assures that there is little or no interaction between processes. For two processes to interact, some common OS resource must be explicitly shared. This can be a common file, a specific shared memory object, or a semaphore with a shared state between the processes. Processes are inherently independent, interaction is exceptional.
Multiple threads, on the other hand, are part of a single process; all threads of a process share OS resources. We can make an exception to get some thread-local memory that can be freely written without interference from other threads. Outside thread-local memory, operations that write to memory can set the internal state of the process in a potentially unpredictable order. Explicit locking must be used to avoid problems with these stateful updates. As noted previously, the overall sequence of instruction executions is rarely, strictly speaking, concurrent. The instructions from concurrent threads and processes are generally interleaved in an unpredictable order. With threading comes the possibility of destructive updates to shared variables and the need for careful locking. With parallel processing come the overheads of OS-level process scheduling.
Indeed, even at the hardware level, there are some complex memory write situations. For more information on issues in memory writes, visit http://en.wikipedia.org/wiki/Memory_disambiguation.
The existence of concurrent object updates is what raises havoc with trying to design multithreaded applications. Locking is one way to avoid concurrent writes to shared objects. Avoiding shared objects is another viable design technique. This is more applicable to functional programming.
In CPython, the GIL is used to assure that OS thread scheduling will not interfere with updates to Python data structures. In effect, the GIL changes the granularity of scheduling from machine instructions to Python virtual machine operations. Without the GIL, it's possible that an internal data structure might be corrupted by the interleaved interaction of competing threads.
Where benefits will accrue
A program that does a great deal of calculation and relatively little I/O will not see much benefit from concurrent processing. If a calculation has a budget of 28 minutes of computation, then interleaving the operations in different ways won't have very much impact. Switching from strict to non-strict evaluation of 100 billion bytecodes won't shrink the elapsed execution time.
However, if a calculation involves a great deal of I/O, then interleaving CPU processing and I/O requests can have an impact on performance. Ideally, we'd like to do our computations on some pieces of data while waiting for the OS to complete input of the next pieces of data.
We have two approaches to interleaving computation and I/O. They are as follows:
· We can try to interleave I/O and calculation for the entire problem as a whole. We might create a pipeline of processing with read, compute, and write as operations. The idea is to have individual data objects flowing through the pipe from one stage to the next. Each stage can operate in parallel.
· We can decompose the problem into separate, independent pieces that can be processed from the beginning to the end in parallel.
The differences between these approaches aren't crisp; there is a blurry middle region that's not clearly one or the other. For example, multiple parallel pipelines are a hybrid mixture of both designs. There are some formalisms that make it somewhat easier to design concurrent programs. The Communicating Sequential Processes (CSP) paradigm can help design message-passing applications. Packages such as pycsp can be used to add CSP formalisms to Python.
I/O-intensive programs often benefit from concurrent processing. The idea is to interleave I/O and processing. CPU-intensive programs rarely benefit from attempting concurrent processing.
Using multiprocessing pools and tasks
To make non-strict evaluation available in a larger context, the multiprocessing package introduces the concept of a Pool object. We can create a Pool object of concurrent worker processes, assign tasks to them, and expect the tasks to be executed concurrently. As noted previously, this creation does not actually mean simultaneous creation of Pool objects. It means that the order is difficult to predict because we've allowed OS scheduling to interleave execution of multiple processes. For some applications, this permits more work to be done in less elapsed time.
To make the most use of this capability, we need to decompose our application into components for which non-strict concurrent execution is beneficial. We'd like to define discrete tasks that can be processed in an indefinite order.
An application that gathers data from the Internet via web scraping is often optimized through parallel processing. We can create a Pool object of several identical website scrapers. The tasks are URLs to be analyzed by the pooled processes.
An application that analyzes multiple logfiles is also a good candidate for parallelization. We can create a Pool object of analytical processes. We can assign each logfile to an analyzer; this allows reading and analysis to proceed in parallel among the various workers in the Pool object. Each individual worker will involve serialized I/O and computation. However, one worker can be analyzing the computation while other workers are waiting for I/O to complete.
Processing many large files
Here is an example of a multiprocessing application. We'll scrape Common Log Format (CLF) lines in web logfiles. This is the generally used format for an access log. The lines tend to be long, but look like the following when wrapped to the book's margins:
99.49.32.197 - - [01/Jun/2012:22:17:54 -0400] "GET /favicon.ico HTTP/1.1" 200 894 "-" "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.52 Safari/536.5"
We often have large numbers of large files that we'd like to analyze. The presence of many independent files means that concurrency will have some benefit for our scraping process.
We'll decompose the analysis into two broad areas of functionality. The first phase of any processing is the essential parsing of the logfiles to gather the relevant pieces of information. We'll decompose this into four stages. They are as follows:
1. All the lines from multiple source logfiles are read.
2. Then, create simple namedtuples from the lines of log entries in a collection of files.
3. The details of more complex fields such as dates and URLs are parsed.
4. Uninteresting paths from the logs are rejected; we can also think of this as passing only the interesting paths.
Once past the parsing phase, we can perform a large number of analyses. For our purposes in demonstrating the multiprocessing module, we'll look at a simple analysis to count occurrences of specific paths.
The first portion, reading from source files, involves the most input processing. The Python use of file iterators will translate into lower-level OS requests for buffering of data. Each OS request means that the process must wait for the data to become available.
Clearly, we want to interleave the other operations so that they are not waiting for I/O to complete. We can interleave operations along a spectrum from individual rows to whole files. We'll look at interleaving whole files first, as this is relatively simple to implement.
The functional design for parsing Apache CLF files can look as follows:
data = path_filter(access_detail_iter(access_iter(local_gzip(filename))))
We've decomposed the larger parsing problem into a number of functions that will handle each portion of the parsing problem. The local_gzip() function reads rows from locally-cached GZIP files. The access_iter() function creates a simple namedtuple object for each row in the access log. The access_detail_iter() function will expand on some of the more difficult to parse fields. Finally, the path_filter() function will discard some paths and file extensions that aren't of much analytical value.
Parsing log files – gathering the rows
Here is the first stage in parsing a large number of files: reading each file and producing a simple sequence of lines. As the logfiles are saved in the .gzip format, we need to open each file with the gzip.open() function instead of the io.open() function or the__builtins__.open() function.
The local_gzip() function reads lines from locally cached files, as shown in the following command snippet:
def local_gzip(pattern):
zip_logs= glob.glob(pattern)
for zip_file in zip_logs:
with gzip.open(zip_file, "rb") as log:
yield (line.decode('us-ascii').rstrip() for line in log)
The preceding function iterates through all files. For each file, the yielded value is a generator function that will iterate through all lines within that file. We've encapsulated several things, including wildcard file matching, the details of opening a logfile compressed with the .gzip format, and breaking a file into a sequence of lines without any trailing \n characters.
The essential design pattern here is to yield values that are generator expressions for each file. The preceding function can be restated as a function and a mapping that applies that function to each file.
There are several other ways to produce similar output. For example, here is an alternative version of the inner for loop in the preceding example. The line_iter() function will also emit lines of a given file:
def line_iter(zip_file):
log= gzip.open(zip_file, "rb")
return (line.decode('us-ascii').rstrip() for line in log)
The line_iter() function applies the gzip.open() function and some line cleanup. We can use a mapping to apply the line_iter() function to all files that match a pattern as follows:
map(line_iter, glob.glob(pattern))
While this alternative mapping is succinct, it has the disadvantage of leaving open file objects lying around waiting to be properly garbage-collected when there are no more references. When processing a large number of files, this seems like a needless bit of overhead. For this reason, we'll focus on the local_gzip() function shown previously.
The previous alternative mapping has the distinct advantage of fitting well with the way the multiprocessing module works. We can create a worker pool and map tasks (such as file reading) to the pool of processes. If we do this, we can read these files in parallel; the open file objects will be part of separate processes.
An extension to this design will include a second function to transfer files from the web host using FTP. As the files are collected from the web server, they can be analyzed using the local_gzip() function.
The results of the local_gzip() function are used by the access_iter() function to create namedtuples for each row in the source file that describes a file access.
Parsing log lines into namedtuples
Once we have access to all of the lines of each logfile, we can extract details of the access that's described. We'll use a regular expression to decompose the line. From there, we can build a namedtuple object.
Here is a regular expression to parse lines in a CLF file:
format_pat= re.compile(
r"(?P<host>[\d\.]+)\s+"
r"(?P<identity>\S+)\s+"
r"(?P<user>\S+)\s+"
r"\[(?P<time>.+?)\]\s+"
r'"(?P<request>.+?)"\s+'
r"(?P<status>\d+)\s+"
r"(?P<bytes>\S+)\s+"
r'"(?P<referer>.*?)"\s+' # [SIC]
r'"(?P<user_agent>.+?)"\s*'
)
We can use this regular expression to break each row into a dictionary of nine individual data elements. The use of []and " to delimit complex fields such as the time, request, referrer, and user_agent parameters are handled gracefully by the namedtuple pattern.
Each individual access can be summarized as a namedtuple() function as follows:
Access = namedtuple('Access', ['host', 'identity', 'user', 'time', 'request', 'status', 'bytes', 'referrer', 'user_agent'])
Note
We've taken pains to assure that the namedtuple function's fields match the regular expression group names in the (?P<name>) constructs for each portion of the record. By making sure the names match, we can very easily transform the parsed dictionary into a tuple for further processing.
Here is the access_iter() function that requires each file to be represented as an iterator over the lines of the file:
def access_iter(source_iter):
for log in source_iter:
for line in log:
match= format_pat.match(line)
if match:
yield Access(**match.groupdict())
The output from the local_gzip() function is a sequence of sequences. The outer sequence consists of individual logfiles. For each file, there is an iterable sequence of lines. If the line matches the given pattern, it's a file access of some kind. We can create anAccess namedtuple from the match dictionary.
The essential design pattern here is to build a static object from the results of a parsing function. In this case, the parsing function is a regular expression matcher.
There are some alternative ways to do this. For example, we can revise the use of the map() function as follows:
def access_builder(line):
match= format_pat.match(line)
if match:
return Access(**match.groupdict())
The preceding alternative function embodies just the essential parse and builds an Access object processing. It will either return an Access or a None object. This differs from the version above that also filters items that don't match the regular expression.
Here is how we can use this function to flatten logfiles into a single stream of the Access objects:
map(access_builder, (line for log in source_iter for line in log))
This shows how we can transform the output from the local_gzip() function into a sequence of the Access instances. In this case, we apply the access_builder() function to the nested iterator of iterable structure that results from reading a collection of files.
Our point here is to show that we have a number of functional styles for parsing files. In Chapter 4, Working with Collections we showed very simple parsing. Here, we're performing more complex parsing, using a variety of techniques.
Parsing additional fields of an Access object
The initial Access object created previously doesn't decompose some inner elements in the nine fields that comprise an access log line. We'll parse those items separately from the overall decomposition into high-level fields. It keeps the regular expressions for parsing somewhat simpler if we break this down into separate parsing operations.
The resulting object is a namedtuple object that will wrap the original Access tuple. It will have some additional fields for the details parsed separately:
AccessDetails = namedtuple('AccessDetails', ['access', 'time', 'method', 'url', 'protocol', 'referrer', 'agent'])
The access attribute is the original Access object. The time attribute is the parsed access.time string. The method, url, and protocol attributes come from decomposing the access.request field. The referrer attribute is a parsed URL. The agent attribute can also be broken down into fine-grained fields. Here are the fields that comprise agent details:
AgentDetails= namedtuple('AgentDetails', ['product', 'system', 'platform_details_extensions'])
These fields reflect the most common syntax for agent descriptions. There is considerable variation in this area, but this particular subset of values seems to be reasonably common.
We'll combine three detailed parser functions into a single overall parsing function. Here is the first part with the various detail parsers:
def access_detail_iter(iterable):
def parse_request(request):
words = request.split()
return words[0], ' '.join(words[1:-1]), words[-1]
def parse_time(ts):
return datetime.datetime.strptime(ts, "%d/%b/%Y:%H:%M:%S %z")
agent_pat= re.compile(r"(?P<product>\S*?)\s+"
r"\((?P<system>.*?)\)\s*"
r"(?P<platform_details_extensions>.*)")
def parse_agent(user_agent):
agent_match= agent_pat.match(user_agent)
if agent_match:
return AgentDetails(**agent_match.groupdict())
We've written three parsers for the HTTP request, the time stamp, and the user agent information. The request is usually a three-word string such as GET /some/path HTTP/1.1. The parse_request() function extracts these three space-separated values. In the unlikely event that the path has spaces in it, we'll extract the first word and the last word as the method and protocol; all the remaining words are part of the path.
Time parsing is delegated to the datetime module. We've simply provided the proper format in the parse_time() function.
Parsing the user agent is challenging. There are many variations; we've chosen a common one for the parse_agent() function. If the user agent matches the given regular expression, we'll have the attributes of an AgentDetails namedtuple. If the user agent information doesn't match the regular expression, we'll simply use the None value instead.
We'll use these three parsers to build AccessDetails instances from the given Access objects. The main body of the access_detail_iter() function looks as follows:
for access in iterable:
try:
meth, uri, protocol = parse_request(access.request)
yield AccessDetails(
access= access,
time= parse_time(access.time),
method= meth,
url= urllib.parse.urlparse(uri),
protocol= protocol,
referrer = urllib.parse.urlparse(access.referer),
agent= parse_agent(access.user_agent)
except ValueError as e:
print(e, repr(access))
We've used a similar design pattern to the previous access_iter() function. A new object is built from the results of parsing some input object. The new AccessDetails object will wrap the previous Access object. This technique allows us to use immutable objects, yet still contain more refined information.
This function is essentially a mapping from an Access object to an AccessDetails object. We can imagine changing the design to use map() as follows:
def access_detail_iter2(iterable):
def access_detail_builder(access):
try:
meth, uri, protocol = parse_request(access.request)
return AccessDetails(access= access,time= parse_time(access.time),method= meth,url= urllib.parse.urlparse(uri),protocol= protocol,referrer = urllib.parse.urlparse(access.referer),agent= parse_agent(access.user_agent))
except ValueError as e:
print(e, repr(access))
return filter(None, map(access_detail_builder, iterable))
We've changed the construction of the AccessDetails object to be a function that returns a single value. We can map that function to the iterable input stream of the Access objects. This also fits nicely with the way the multiprocessing module works.
In an object-oriented programming environment, these additional parsers might be method functions or properties of a class definition. The advantage of this design is that items aren't parsed unless they're needed. This particular functional design parses everything, assuming that it's going to be used.
A different function design might rely on the three parser functions to extract and parse the various elements from a given Access object as needed. Rather than using the details.time attribute, we'd use the parse_time(access.time) parameter. The syntax is longer, but the attribute is only parsed as needed.
Filtering the access details
We'll look at several filters for the AccessDetails objects. The first is a collection of filters that reject a lot of overhead files that are rarely interesting. The second filter will be part of the analysis functions, which we'll look at later.
The path_filter() function is a combination of three functions:
1. Exclude empty paths.
2. Exclude some specific filenames.
3. Exclude files that have a given extension.
An optimized version of the path_filter() function looks as follows:
def path_filter(access_details_iter):
name_exclude = {'favicon.ico', 'robots.txt', 'humans.txt', 'crossdomain.xml' ,'_images', 'search.html', 'genindex.html', 'searchindex.js', 'modindex.html', 'py-modindex.html',}
ext_exclude = { '.png', '.js', '.css', }
for detail in access_details_iter:
path = detail.url.path.split('/')
if not any(path):
continue
if any(p in name_exclude for p in path):
continue
final= path[-1]
if any(final.endswith(ext) for ext in ext_exclude):
continue
yield detail
For each individual AccessDetails object, we'll apply three filter tests. If the path is essentially empty or the part includes one of the excluded names or the path's final name has an excluded extension, the item is quietly ignored. If the path doesn't match any of these criteria, it's potentially interesting and is part of the results yielded by the path_filter() function.
This is an optimization because all of the tests are applied using an imperative style for loop body.
The design started with each test as a separate first-class filter-style function. For example, we might have a function like the following to handle empty paths:
def non_empty_path(detail):
path = detail.url.path.split('/')
return any(path)
This function simply assures that the path contains a name. We can use the filter() function as follows:
filter(non_empty_path, access_details_iter)
We can write similar tests for the non_excluded_names() and non_excluded_ext() functions. The entire sequence of filter() functions will look as follows:
filter(non_excluded_ext,
filter(non_excluded_names,
filter(non_empty_path, access_details_iter)))
This applies each filter() function to the results of the previous filter() function. The empty paths are rejected; from this subset, the excluded names and the excluded extensions are rejected. We can also state the preceding example as a series of assignment statements as follows:
ne= filter(non_empty_path, access_details_iter)
nx_name= filter(non_excluded_names, ne)
nx_ext= filter(non_excluded_ext, nx_name)
return nx_ext
This version has the advantage of being slightly easier to expand when we add new filter criteria.
Note
The use of generator functions (such as the filter() function) means that we aren't creating large intermediate objects. Each of the intermediate variables, ne, nx_name, and nx_ext, are proper lazy generator functions; no processing is done until the data is consumed by a client process.
While elegant, this suffers from a small inefficiency because each function will need to parse the path in the AccessDetails object. In order to make this more efficient, we will need to wrap a path.split('/') function with the lru_cache attribute.
Analyzing the access details
We'll look at two analysis functions we can use to filter and analyze the individual AccessDetails objects. The first function, a filter() function, will pass only specific paths. The second function will summarize the occurrences of each distinct path.
We'll define the filter() function as a small function and combine this with the built-in filter() function to apply the function to the details. Here is the composite filter() function:
def book_filter(access_details_iter):
def book_in_path(detail):
path = tuple(l for l in detail.url.path.split('/') if l)
return path[0] == 'book' and len(path) > 1
return filter(book_in_path, access_details_iter)
We've defined a rule, the book_in_path() attribute, that we'll apply to each AccessDetails object. If the path is not empty and the first-level attribute of the path is book, then we're interested in these objects. All other AccessDetails objects can be quietly rejected.
Here is the final reduction that we're interested in:
from collections import Counter
def reduce_book_total(access_details_iter):
counts= Counter()
for detail in access_details_iter:
counts[detail.url.path] += 1
return counts
This function will produce a Counter() object that shows the frequency of each path in an AccessDetails object. In order to focus on a particular set of paths, we'll use the reduce_total(book_filter(details)) method. This provides a summary of only items that are passed by the given filter.
The complete analysis process
Here is the composite analysis() function that digests a collection of logfiles:
def analysis(filename):
details= path_filter(access_detail_iter(access_iter(local_gzip(filename))))
books= book_filter(details)
totals= reduce_book_total(books)
return totals
The preceding command snippet will work with a single filename or file pattern. It applies a standard set of parsing functions, path_filter(), access_detail_iter(), access_iter(), and local_gzip(), to a filename or file pattern and returns an iterable sequence of theAccessDetails objects. It then applies our analytical filter and reduction to that sequence of the AccessDetails objects. The result is a Counter object that shows the frequency of access for certain paths.
A specific collection of saved .gzip format logfiles totals about 51 MB. Processing the files serially with this function takes over 140 seconds. Can we do better using concurrent processing?
Using a multiprocessing pool for concurrent processing
One elegant way to make use of the multiprocessing module is to create a processing Pool object and assign work to the various processes in that pool. We will use the OS to interleave execution among the various processes. If each of the processes has a mixture of I/O and computation, we should be able to assure that our processor is very busy. When processes are waiting for I/O to complete, other processes can do their computation. When an I/O completes, a process will be ready to run and can compete with others for processing time.
The recipe for mapping work to a separate process looks as follows:
import multiprocessing
with multiprocessing.Pool(4) as workers:
workers.map(analysis, glob.glob(pattern))
We've created a Pool object with four separate processes and assigned this Pool object to the workers variable. We've then mapped a function, analysis, to an iterable queue of work to be done, using the pool of processes. Each process in the workers pool will be assigned items from the iterable queue. In this case, the queue is the result of the glob.glob(pattern) attribute, which is a sequence of file names.
As the analysis() function returns a result, the parent process that created the Pool object can collect those results. This allows us to create several concurrently-built Counter objects and merge them into a single, composite result.
If we start p processes in the pool, our overall application will include p+1 processes. There will be one parent process and p children. This often works out well because the parent process will have little to do after the subprocess pools are started. Generally, the workers will be assigned to separate CPUs (or cores) and the parent will share a CPU with one of the children in the Pool object.
Note
The ordinary Linux parent/child process rules apply to the subprocesses created by this module. If the parent crashes without properly collecting final status from the child processes, then "zombie" processes can be left running. For this reason, a process Poolobject is a context manager. When we use a pool via the with statement, at the end of the context, the children are properly terminated.
By default, a Pool object will have a number of workers based on the value of the multiprocessing.cpu_count() function. This number is often optimal, and simply using the with multiprocessing.Pool() as workers: attribute might be sufficient.
In some cases, it can help to have more workers than CPUs. This might be true when each worker has I/O-intensive processing. Having many worker processes waiting for I/O to complete can improve the elapsed running time of an application.
If a given Pool object has p workers, this mapping can cut the processing time to almost ![]() of the time required to process all of the logs serially. Pragmatically, there is some overhead involved with communication between the parent and child processes in thePool object. Therefore, a four-core processor might only cut the processing time in half.
of the time required to process all of the logs serially. Pragmatically, there is some overhead involved with communication between the parent and child processes in thePool object. Therefore, a four-core processor might only cut the processing time in half.
The multiprocessing Pool object has four map-like methods to allocate work to a pool: map(), imap(), imap_unordered(), and starmap(). Each of these is a variation on the common theme of mapping a function to a pool of processes. They differ in the details of allocating work and collecting results.
The map(function, iterable) method allocates items from the iterable to each worker in the pool. The finished results are collected in the order they were allocated to the Pool object so that order is preserved.
The imap(function, iterable) method is described as "lazier" than map. By default, it sends each individual item from the iterable to the next available worker. This might involve more communication overhead. For this reason, a chunk size larger than 1 is suggested.
The imap_unordered(function, iterable) method is similar to the imap() method, but the order of the results is not preserved. Allowing the mapping to be processed out of order means that, as each process finishes, the results are collected. Otherwise, the results must be collected in order.
The starmap(function, iterable) method is similar to the itertools.starmap() function. Each item in the iterable must be a tuple; the tuple is passed to the function using the * modifier so that each value of the tuple becomes a positional argument value. In effect, it's performing function(*iterable[0]), function(*iterable[1]), and so on.
Here is one of the variations on the preceding mapping theme:
import multiprocessing
pattern = "*.gz"
combined= Counter()
with multiprocessing.Pool() as workers:
for result in workers.imap_unordered(analysis, glob.glob(pattern)):
combined.update(result)
We've created a Counter() function that we'll use to consolidate the results from each worker in the pool. We created a pool of subprocesses based on the number of available CPUs and used the Pool object as a context manager. We then mapped our analysis()function to each file in our file-matching pattern. The resulting Counter objects from the analysis() function are combined into a single resulting counter.
This takes about 68 seconds. The time to analyze the logs was cut in half using several concurrent processes.
We've created a two-tiered map-reduce process with the multiprocessing module's Pool.map() function. The first tier was the analysis() function, which performed a map-reduce on a single logfile. We then consolidated these reductions in a higher-level reduce operation.
Using apply() to make a single request
In addition to the map() function's variants, a pool also has an apply(function, *args, **kw) method that we can use to pass one value to the worker pool. We can see that the map() method is really just a for loop wrapped around the apply() method, we can, for example, use the following command:
list(workers.apply(analysis, f) for f in glob.glob(pattern))
It's not clear, for our purposes, that this is a significant improvement. Almost everything we need to do can be expressed as a map() function.
Using map_async(), starmap_async(), and apply_async()
The behavior of the map(), starmap(), and apply() functions is to allocate work to a subprocess in the Pool object and then collect the response from the subprocess when that response is ready. This can cause the child to wait for the parent to gather the results. The_async() function's variations do not wait for the child to finish. These functions return an object that can be queried to get the individual results from the child processes.
The following is a variation using the map_async() method:
import multiprocessing
pattern = "*.gz"
combined= Counter()
with multiprocessing.Pool() as workers:
results = workers.map_async(analysis, glob.glob(pattern))
data= results.get()
for c in data:
combined.update(c)
We've created a Counter() function that we'll use to consolidate the results from each worker in the pool. We created a pool of subprocesses based on the number of available CPUs and used this Pool object as a context manager. We then mapped our analysis()function to each file in our file-matching pattern. The response from the map_async() function is a MapResult object; we can query this for results and overall status of the pool of workers. In this case, we used the get() method to get the sequence of the Counterobjects.
The resulting Counter objects from the analysis() function are combined into a single resulting Counter object. This aggregate gives us an overall summary of a number of logfiles. This processing is not any faster than the previous example. The use of the map_async()function allows the parent process to do additional work while waiting for the children to finish.
More complex multiprocessing architectures
The multiprocessing package supports a wide variety of architectures. We can easily create multiprocessing structures that span multiple servers and provide formal authentication techniques to create a necessary level of security. We can pass objects from process to process using queues and pipes. We can share memory between processes. We can also share lower-level locks between processes as a way to synchronize access to shared resources such as files.
Most of these architectures involve explicitly managing state among several working processes. Using locks and shared memory, in particular, are imperative in nature and don't fit well with a functional programming approach.
We can, with some care, treat queues and pipes in a functional manner. Our objective is to decompose a design into producer and consumer functions. A producer can create objects and insert them into a queue. A consumer will take objects out of a queue and process them, perhaps putting intermediate results into another queue. This creates a network of concurrent processors and the workload is distributed among these various processes. Using the pycsp package can simplify the queue-based exchange of messages among processes. For more information, visit https://pypi.python.org/pypi/pycsp.
This design technique has some advantages when designing a complex application server. The various subprocesses can exist for the entire life of the server, handling individual requests concurrently.
Using the concurrent.futures module
In addition to the multiprocessing package, we can also make use of the concurrent.futures module. This also provides a way to map data to a concurrent pool of threads or processes. The module API is relatively simple and similar in many ways to themultiprocessing.Pool() function's interface.
Here is an example to show just how similar they are:
import concurrent.futures
pool_size= 4
pattern = "*.gz"
combined= Counter()
with concurrent.futures.ProcessPoolExecutor(max_workers=pool_size) as workers:
for result in workers.map(analysis, glob.glob(pattern)):
combined.update(result)
The most significant change between the preceding example and previous examples is that we're using an instance of the concurrent.futures.ProcessPoolExecutor object instead of the multiprocessing.Pool method. The essential design pattern is to map theanalysis() function to the list of filenames using the pool of available workers. The resulting Counter objects are consolidated to create a final result.
The performance of the concurrent.futures module is nearly identical to the multiprocessing module.
Using concurrent.futures thread pools
The concurrent.futures module offers a second kind of executor that we can use in our applications. Instead of creating a concurrent.futures.ProcessPoolExecutor object, we can use the ThreadPoolExecutor object. This will create a pool of threads within a single process.
The syntax is otherwise identical to using a ProcessPoolExecutor object. The performance, however, is remarkably different. The logfile processing is dominated by I/O. All of the threads in a process share the same OS scheduling constraints. Due to this, the overall performance of multithreaded logfile analysis is about the same as processing the logfiles serially.
Using sample logfiles and a small four-core laptop running Mac OS X, these are the kinds of results that indicate the difference between threads that share I/O resources and processes:
· Using the concurrent.futures thread pool, the elapsed time was 168 seconds
· Using a process pool, the elapsed time was 68 seconds
In both cases, the Pool object's size was 4. It's not clear which kind of applications benefit from a multithreading approach. In general, multiprocessing seems to be best for Python applications.
Using the threading and queue modules
The Python threading package involves a number of constructs helpful for building imperative applications. This module is not focused on writing functional applications. We can make use of thread-safe queues in the queue module to pass objects from thread to thread.
The threading module doesn't have a simple way to distribute work to various threads. The API isn't ideally suited to functional programming.
As with the more primitive features of the multiprocessing module, we can try to conceal the stateful and imperative nature of locks and queues. It seems easier, however, to make use of the ThreadPoolExecutor method in the concurrent.futures module. TheProcessPoolExecutor.map() method provides us with a very pleasant interface to concurrent processing of the elements of a collection.
The use of the map() function primitive to allocate work seems to fit nicely with our functional programming expectations. For this reason, it's best to focus on the concurrent.futures module as the most accessible way to write concurrent functional programs.
Designing concurrent processing
From a functional programming perspective, we've seen three ways to use the map() function concept applied to data items concurrently. We can use any one of the following:
· multiprocessing.Pool
· concurrent.futures.ProcessPoolExecutor
· concurrent.futures.ThreadPoolExecutor
These are almost identical in the way we interact with them; all three have a map() method that applies a function to items of an iterable collection. This fits elegantly with other functional programming techniques. The performance is different because of the nature of concurrent threads versus concurrent processes.
As we stepped through the design, our log analysis application decomposed into two overall areas:
· The lower-level parsing: This is generic parsing that will be used by almost any log analysis application
· The higher-level analysis application: This is more specific filtering and reduction focused on our application needs
The lower-level parsing can be decomposed into four stages:
· Reading all the lines from multiple source logfiles. This was the local_gzip() mapping from file name to a sequence of lines.
· Creating simple namedtuples from the lines of log entries in a collection of files. This was the access_iter() mapping from text lines to Access objects.
· Parsing the details of more complex fields such as dates and URLs. This was the access_detail_iter() mapping from Access objects to AccessDetails objects.
· Rejecting uninteresting paths from the logs. We can also think of this as passing only the interesting paths. This was more of a filter than a map operation. This was a collection of filters bundled into the path_filter() function.
We defined an overall analysis() function that parsed and analyzed a given logfile. It applied the higher-level filter and reduction to the results of the lower-level parsing. It can also work with a wild-card collection of files.
Given the number of mappings involved, we can see several ways to decompose this problem into work that can be mapped to into a pool of threads or processes. Here are some of the mappings we can consider as design alternatives:
· Map the analysis() function to individual files. We use this as a consistent example throughout this chapter.
· Refactor the local_gzip() function out of the overall analysis() function. We can now map the revised analysis() function to the results of the local_gzip() function.
· Refactor the access_iter(local_gzip(pattern)) function out of the overall analysis() function. We can map this revised analysis() function against the iterable sequence of the Access objects.
· Refactor the access_detail_iter(access-iter(local_gzip(pattern))) function into a separate iterable. We will then map the path_filter() function and the higher-level filter and reduction against the iterable sequence of the AccessDetail objects.
· We can also refactor the lower-level parsing into a function that is separate from the higher-level analysis. We can map the analysis filter and reduction against the output from the lower-level parsing.
All of these are relatively simple restructurings of the example application. The benefit of using functional programming techniques is that each part of the overall process can be defined as a mapping. This makes it practical to consider different architectures to locate an optimal design.
In this case, however, we need to distribute the I/O processing to as many CPUs or cores as we have available. Most of these potential refactorings will perform all of the I/O in the parent process; these will only distribute the computations to multiple concurrent processes with little resulting benefit. Then, we want to focus on the mappings, as these distribute the I/O to as many cores as possible.
It's often important to minimize the amount of data being passed from process to process. In this example, we provided just short filename strings to each worker process. The resulting Counter object was considerably smaller than the 10 MB of compressed detail data in each logfile. We can further reduce the size of each Counter object by eliminating items that occur only once; or we can limit our application to only the 20 most popular items.
The fact that we can reorganize the design of this application freely doesn't mean we should reorganize the design. We can run a few benchmarking experiments to confirm our suspicion that logfile parsing is dominated by the time required to read the files.
Summary
In this chapter, we've looked at two ways to support concurrent processing of multiple pieces of data:
· The multiprocessing module: Specifically, the Pool class and the various kinds of mappings available to a pool of workers.
· The concurrent.futures module: Specifically the ProcessPoolExecutor and ThreadPoolExecutor class. These classes also support a mapping that will distribute work among workers that are threads or processes.
We've also noted some alternatives that don't seem to fit well with functional programming. There are numerous other features of the multiprocessing module, but they're not a good fit with functional design. Similarly, the threading and queue modules can be used to build multithreaded applications, but the features aren't a good fit with functional programs.
In the next chapter, we'll look at the operator module. This can be used to simplify some kinds of algorithms. We can use a built-in operator function instead of defining a lambda form. We'll also look at some techniques to design flexible decision making and allow expressions to be evaluated in a non-strict order.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.