Learning Python (2013)
Part III. Statements and Syntax
Chapter 14. Iterations and Comprehensions
In the prior chapter we met Python’s two looping statements, while and for. Although they can handle most repetitive tasks programs need to perform, the need to iterate over sequences is so common and pervasive that Python provides additional tools to make it simpler and more efficient. This chapter begins our exploration of these tools. Specifically, it presents the related concepts of Python’s iteration protocol, a method-call model used by the for loop, and fills in some details on list comprehensions, which are a close cousin to the for loop that applies an expression to items in an iterable.
Because these tools are related to both the for loop and functions, we’ll take a two-pass approach to covering them in this book, along with a postscript:
§ This chapter introduces their basics in the context of looping tools, serving as something of a continuation of the prior chapter.
§ Chapter 20 revisits them in the context of function-based tools, and extends the topic to include built-in and user-defined generators.
§ Chapter 30 also provides a shorter final installment in this story, where we’ll learn about user-defined iterable objects coded with classes.
In this chapter, we’ll also sample additional iteration tools in Python, and touch on the new iterables available in Python 3.X—where the notion of iterables grows even more pervasive.
One note up front: some of the concepts presented in these chapters may seem advanced at first glance. With practice, though, you’ll find that these tools are useful and powerful. Although never strictly required, because they’ve become commonplace in Python code, a basic understanding can also help if you must read programs written by others.
Iterations: A First Look
In the preceding chapter, I mentioned that the for loop can work on any sequence type in Python, including lists, tuples, and strings, like this:
>>> for x in [1, 2, 3, 4]: print(x ** 2, end=' ') # In 2.X: print x ** 2,
...
1 4 9 16
>>> for x in (1, 2, 3, 4): print(x ** 3, end=' ')
...
1 8 27 64
>>> for x in 'spam': print(x * 2, end=' ')
...
ss pp aa mm
Actually, the for loop turns out to be even more generic than this—it works on any iterable object. In fact, this is true of all iteration tools that scan objects from left to right in Python, including for loops, the list comprehensions we’ll study in this chapter, in membership tests, the mapbuilt-in function, and more.
The concept of “iterable objects” is relatively recent in Python, but it has come to permeate the language’s design. It’s essentially a generalization of the notion of sequences—an object is considered iterable if it is either a physically stored sequence, or an object that produces one result at a time in the context of an iteration tool like a for loop. In a sense, iterable objects include both physical sequences and virtual sequences computed on demand.
NOTE
Terminology in this topic tends to be a bit loose. The terms “iterable” and “iterator” are sometimes used interchangeably to refer to an object that supports iteration in general. For clarity, this book has a very strong preference for using the term iterable to refer to an object that supports the iter call, and iterator to refer to an object returned by an iterable on iter that supports the next(I)call. Both these calls are defined ahead.
That convention is not universal in either the Python world or this book, though; “iterator” is also sometimes used for tools that iterate. Chapter 20 extends this category with the term “generator”—which refers to objects that automatically support the iteration protocol, and hence are iterable—even though all iterables generate results!
The Iteration Protocol: File Iterators
One of the easiest ways to understand the iteration protocol is to see how it works with a built-in type such as the file. In this chapter, we’ll be using the following input file to demonstrate:
>>> print(open('script2.py').read())
import sys
print(sys.path)
x = 2
print(x ** 32)
>>> open('script2.py').read()
'import sys\nprint(sys.path)\nx = 2\nprint(x ** 32)\n'
Recall from Chapter 9 that open file objects have a method called readline, which reads one line of text from a file at a time—each time we call the readline method, we advance to the next line. At the end of the file, an empty string is returned, which we can detect to break out of the loop:
>>> f = open('script2.py') # Read a four-line script file in this directory
>>> f.readline() # readline loads one line on each call
'import sys\n'
>>> f.readline()
'print(sys.path)\n'
>>> f.readline()
'x = 2\n'
>>> f.readline() # Last lines may have a \n or not
'print(x ** 32)\n'
>>> f.readline() # Returns empty string at end-of-file
''
However, files also have a method named __next__ in 3.X (and next in 2.X) that has a nearly identical effect—it returns the next line from a file each time it is called. The only noticeable difference is that __next__ raises a built-in StopIteration exception at end-of-file instead of returning an empty string:
>>> f = open('script2.py') # __next__ loads one line on each call too
>>> f.__next__() # But raises an exception at end-of-file
'import sys\n'
>>> f.__next__() # Use f.next() in 2.X, or next(f) in 2.X or 3.X
'print(sys.path)\n'
>>> f.__next__()
'x = 2\n'
>>> f.__next__()
'print(x ** 32)\n'
>>> f.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
This interface is most of what we call the iteration protocol in Python. Any object with a __next__ method to advance to a next result, which raises StopIteration at the end of the series of results, is considered an iterator in Python. Any such object may also be stepped through with afor loop or other iteration tool, because all iteration tools normally work internally by calling __next__ on each iteration and catching the StopIteration exception to determine when to exit. As we’ll see in a moment, for some objects the full protocol includes an additional first step to call iter, but this isn’t required for files.
The net effect of this magic is that, as mentioned in Chapter 9 and Chapter 13, the best way to read a text file line by line today is to not read it at all—instead, allow the for loop to automatically call __next__ to advance to the next line on each iteration. The file object’s iterator will do the work of automatically loading lines as you go. The following, for example, reads a file line by line, printing the uppercase version of each line along the way, without ever explicitly reading from the file at all:
>>> for line in open('script2.py'): # Use file iterators to read by lines
... print(line.upper(), end='') # Calls __next__, catches StopIteration
...
IMPORT SYS
PRINT(SYS.PATH)
X = 2
PRINT(X ** 32)
Notice that the print uses end='' here to suppress adding a \n, because line strings already have one (without this, our output would be double-spaced; in 2.X, a trailing comma works the same as the end). This is considered the best way to read text files line by line today, for three reasons: it’s the simplest to code, might be the quickest to run, and is the best in terms of memory usage. The older, original way to achieve the same effect with a for loop is to call the file readlines method to load the file’s content into memory as a list of line strings:
>>> for line in open('script2.py').readlines():
... print(line.upper(), end='')
...
IMPORT SYS
PRINT(SYS.PATH)
X = 2
PRINT(X ** 32)
This readlines technique still works but is not considered the best practice today and performs poorly in terms of memory usage. In fact, because this version really does load the entire file into memory all at once, it will not even work for files too big to fit into the memory space available on your computer. By contrast, because it reads one line at a time, the iterator-based version is immune to such memory-explosion issues. The iterator version might run quicker too, though this can vary per release
As mentioned in the prior chapter’s sidebar, Why You Will Care: File Scanners, it’s also possible to read a file line by line with a while loop:
>>> f = open('script2.py')
>>> while True:
... line = f.readline()
... if not line: break
... print(line.upper(), end='')
...
...same output...
However, this may run slower than the iterator-based for loop version, because iterators run at C language speed inside Python, whereas the while loop version runs Python byte code through the Python virtual machine. Anytime we trade Python code for C code, speed tends to increase. This is not an absolute truth, though, especially in Python 3.X; we’ll see timing techniques later in Chapter 21 for measuring the relative speed of alternatives like these.[30]
NOTE
Version skew note: In Python 2.X, the iteration method is named X.next() instead of X.__next__(). For portability, a next(X) built-in function is also available in both Python 3.X and 2.X (2.6 and later), and calls X.__next__() in 3.X and X.next() in 2.X. Apart from method names, iteration works the same in 2.X and 3.X in all other ways. In 2.6 and 2.7, simply use X.next()or next(X) for manual iterations instead of 3.X’s X.__next__(); prior to 2.6, use X.next() calls instead of next(X).
Manual Iteration: iter and next
To simplify manual iteration code, Python 3.X also provides a built-in function, next, that automatically calls an object’s __next__ method. Per the preceding note, this call also is supported on Python 2.X for portability. Given an iterator object X, the call next(X) is the same asX.__next__() on 3.X (and X.next() on 2.X), but is noticeably simpler and more version-neutral. With files, for instance, either form may be used:
>>> f = open('script2.py')
>>> f.__next__() # Call iteration method directly
'import sys\n'
>>> f.__next__()
'print(sys.path)\n'
>>> f = open('script2.py')
>>> next(f) # The next(f) built-in calls f.__next__() in 3.X
'import sys\n'
>>> next(f) # next(f) => [3.X: f.__next__()], [2.X: f.next()]
'print(sys.path)\n'
Technically, there is one more piece to the iteration protocol alluded to earlier. When the for loop begins, it first obtains an iterator from the iterable object by passing it to the iter built-in function; the object returned by iter in turn has the required next method. The iter function internally runs the __iter__ method, much like next and __next__.
The full iteration protocol
As a more formal definition, Figure 14-1 sketches this full iteration protocol, used by every iteration tool in Python, and supported by a wide variety of object types. It’s really based on two objects, used in two distinct steps by iteration tools:
§ The iterable object you request iteration for, whose __iter__ is run by iter
§ The iterator object returned by the iterable that actually produces values during the iteration, whose __next__ is run by next and raises StopIteration when finished producing results
These steps are orchestrated automatically by iteration tools in most cases, but it helps to understand these two objects’ roles. For example, in some cases these two objects are the same when only a single scan is supported (e.g., files), and the iterator object is often temporary, used internally by the iteration tool.
Moreover, some objects are both an iteration context tool (they iterate) and an iterable object (their results are iterable)—including Chapter 20’s generator expressions, and map and zip in Python 3.X. As we’ll see ahead, more tools become iterables in 3.X—including map, zip, range, and some dictionary methods—to avoid constructing result lists in memory all at once.
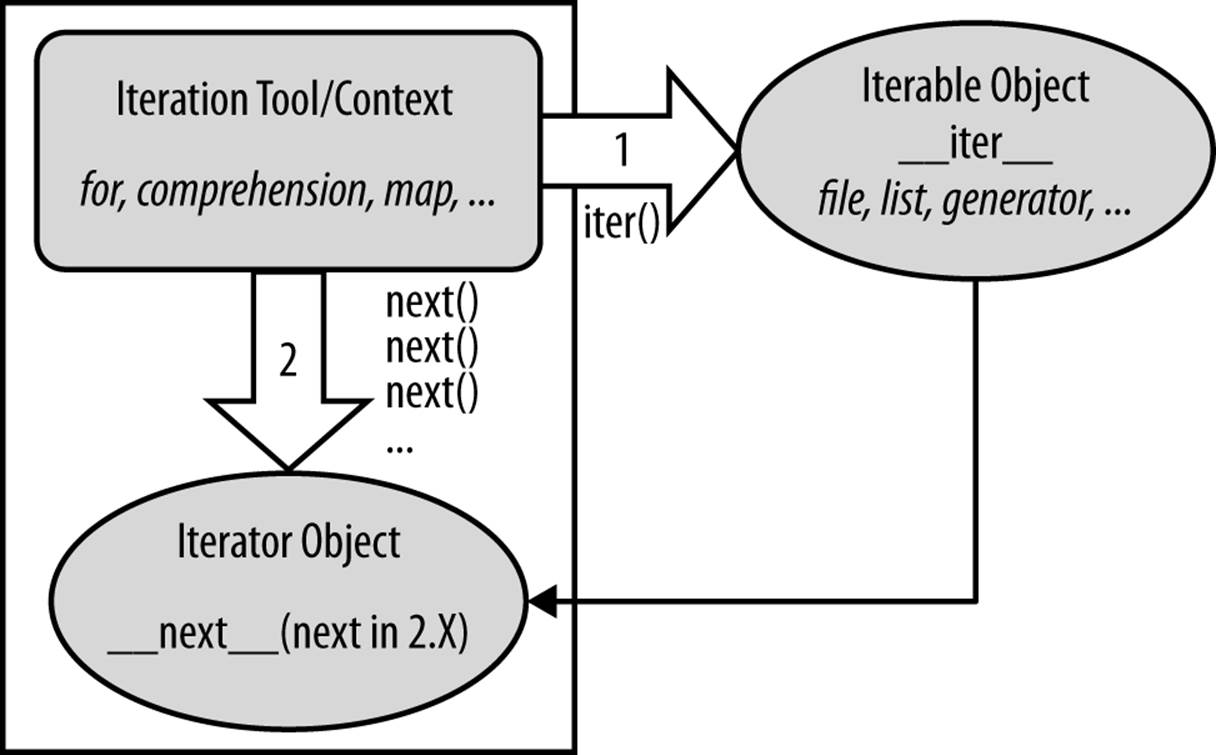
Figure 14-1. The Python iteration protocol, used by for loops, comprehensions, maps, and more, and supported by files, lists, dictionaries, Chapter 20’s generators, and more. Some objects are both iteration context and iterable object, such as generator expressions and 3.X’s flavors of some tools (such as map and zip). Some objects are both iterable and iterator, returning themselves for the iter() call, which is then a no-op.
In actual code, the protocol’s first step becomes obvious if we look at how for loops internally process built-in sequence types such as lists:
>>> L = [1, 2, 3]
>>> I = iter(L) # Obtain an iterator object from an iterable
>>> I.__next__() # Call iterator's next to advance to next item
1
>>> I.__next__() # Or use I.next() in 2.X, next(I) in either line
2
>>> I.__next__()
3
>>> I.__next__()
...error text omitted...
StopIteration
This initial step is not required for files, because a file object is its own iterator. Because they support just one iteration (they can’t seek backward to support multiple active scans), files have their own __next__ method and do not need to return a different object that does:
>>> f = open('script2.py')
>>> iter(f) is f
True
>>> iter(f) is f.__iter__()
True
>>> f.__next__()
'import sys\n'
Lists and many other built-in objects, though, are not their own iterators because they do support multiple open iterations—for example, there may be multiple iterations in nested loops all at different positions. For such objects, we must call iter to start iterating:
>>> L = [1, 2, 3]
>>> iter(L) is L
False
>>> L.__next__()
AttributeError: 'list' object has no attribute '__next__'
>>> I = iter(L)
>>> I.__next__()
1
>>> next(I) # Same as I.__next__()
2
Manual iteration
Although Python iteration tools call these functions automatically, we can use them to apply the iteration protocol manually, too. The following interaction demonstrates the equivalence between automatic and manual iteration:[31]
>>> L = [1, 2, 3]
>>>
>>> for X in L: # Automatic iteration
... print(X ** 2, end=' ') # Obtains iter, calls __next__, catches exceptions
...
1 4 9
>>> I = iter(L) # Manual iteration: what for loops usually do
>>> while True:
... try: # try statement catches exceptions
... X = next(I) # Or call I.__next__ in 3.X
... except StopIteration:
... break
... print(X ** 2, end=' ')
...
1 4 9
To understand this code, you need to know that try statements run an action and catch exceptions that occur while the action runs (we met exceptions briefly in Chapter 11 but will explore them in depth in Part VII). I should also note that for loops and other iteration contexts can sometimes work differently for user-defined classes, repeatedly indexing an object instead of running the iteration protocol, but prefer the iteration protocol if it’s used. We’ll defer that story until we study class operator overloading in Chapter 30.
Other Built-in Type Iterables
Besides files and physical sequences like lists, other types have useful iterators as well. The classic way to step through the keys of a dictionary, for example, is to request its keys list explicitly:
>>> D = {'a':1, 'b':2, 'c':3}
>>> for key in D.keys():
... print(key, D[key])
...
a 1
b 2
c 3
In recent versions of Python, though, dictionaries are iterables with an iterator that automatically returns one key at a time in an iteration context:
>>> I = iter(D)
>>> next(I)
'a'
>>> next(I)
'b'
>>> next(I)
'c'
>>> next(I)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
The net effect is that we no longer need to call the keys method to step through dictionary keys—the for loop will use the iteration protocol to grab one key each time through:
>>> for key in D:
... print(key, D[key])
...
a 1
b 2
c 3
We can’t delve into their details here, but other Python object types also support the iteration protocol and thus may be used in for loops too. For instance, shelves (an access-by-key filesystem for Python objects) and the results from os.popen (a tool for reading the output of shell commands, which we met in the preceding chapter) are iterable as well:
>>> import os
>>> P = os.popen('dir')
>>> P.__next__()
' Volume in drive C has no label.\n'
>>> P.__next__()
' Volume Serial Number is D093-D1F7\n'
>>> next(P)
TypeError: _wrap_close object is not an iterator
Notice that popen objects themselves support a P.next() method in Python 2.X. In 3.X, they support the P.__next__() method, but not the next(P) built-in. Since the latter is defined to call the former, this may seem unusual, though both calls work correctly if we use the full iteration protocol employed automatically by for loops and other iteration contexts, with its top-level iter call (this performs internal steps required to also support next calls for this object):
>>> P = os.popen('dir')
>>> I = iter(P)
>>> next(I)
' Volume in drive C has no label.\n'
>>> I.__next__()
' Volume Serial Number is D093-D1F7\n'
Also in the systems domain, the standard directory walker in Python, os.walk, is similarly iterable, but we’ll save an example until Chapter 20’s coverage of this tool’s basis—generators and yield.
The iteration protocol also is the reason that we’ve had to wrap some results in a list call to see their values all at once. Objects that are iterable return results one at a time, not in a physical list:
>>> R = range(5)
>>> R # Ranges are iterables in 3.X
range(0, 5)
>>> I = iter(R) # Use iteration protocol to produce results
>>> next(I)
0
>>> next(I)
1
>>> list(range(5)) # Or use list to collect all results at once
[0, 1, 2, 3, 4]
Note that the list call here is not required in 2.X (where range builds a real list), and is not needed in 3.X for contexts where iteration happens automatically (such as within for loops). It is needed for displaying values here in 3.X, though, and may also be required when list-like behavior or multiple scans are required for objects that produce results on demand in 2.X or 3.X (more on this ahead).
Now that you have a better understanding of this protocol, you should be able to see how it explains why the enumerate tool introduced in the prior chapter works the way it does:
>>> E = enumerate('spam') # enumerate is an iterable too
>>> E
<enumerate object at 0x00000000029B7678>
>>> I = iter(E)
>>> next(I) # Generate results with iteration protocol
(0, 's')
>>> next(I) # Or use list to force generation to run
(1, 'p')
>>> list(enumerate('spam'))
[(0, 's'), (1, 'p'), (2, 'a'), (3, 'm')]
We don’t normally see this machinery because for loops run it for us automatically to step through results. In fact, everything that scans left to right in Python employs the iteration protocol in the same way—including the topic of the next section.
[30] Spoiler alert: the file iterator still appears to be slightly faster than readlines and at least 30% faster than the while loop in both 2.7 and 3.3 on tests I’ve run with this chapter’s code on a 1,000-line file (while is twice as slow on 2.7). The usual benchmarking caveats apply—this is true only for my Pythons, my computer, and my test file, and Python 3.X complicates such analyses by rewriting I/O libraries to support Unicode text and be less system-dependent. Chapter 21 covers tools and techniques you can use to time these loop statements on your own.
[31] Technically speaking, the for loop calls the internal equivalent of I.__next__, instead of the next(I) used here, though there is rarely any difference between the two. Your manual iterations can generally use either call scheme.
List Comprehensions: A First Detailed Look
Now that we’ve seen how the iteration protocol works, let’s turn to one of its most common use cases. Together with for loops, list comprehensions are one of the most prominent contexts in which the iteration protocol is applied.
In the previous chapter, we learned how to use range to change a list as we step across it:
>>> L = [1, 2, 3, 4, 5]
>>> for i in range(len(L)):
... L[i] += 10
...
>>> L
[11, 12, 13, 14, 15]
This works, but as I mentioned there, it may not be the optimal “best practice” approach in Python. Today, the list comprehension expression makes many such prior coding patterns obsolete. Here, for example, we can replace the loop with a single expression that produces the desired result list:
>>> L = [x + 10 for x in L]
>>> L
[21, 22, 23, 24, 25]
The net result is similar, but it requires less coding on our part and is likely to run substantially faster. The list comprehension isn’t exactly the same as the for loop statement version because it makes a new list object (which might matter if there are multiple references to the original list), but it’s close enough for most applications and is a common and convenient enough approach to merit a closer look here.
List Comprehension Basics
We met the list comprehension briefly in Chapter 4. Syntactically, its syntax is derived from a construct in set theory notation that applies an operation to each item in a set, but you don’t have to know set theory to use this tool. In Python, most people find that a list comprehension simply looks like a backward for loop.
To get a handle on the syntax, let’s dissect the prior section’s example in more detail:
L = [x + 10 for x in L]
List comprehensions are written in square brackets because they are ultimately a way to construct a new list. They begin with an arbitrary expression that we make up, which uses a loop variable that we make up (x + 10). That is followed by what you should now recognize as the header of a for loop, which names the loop variable, and an iterable object (for x in L).
To run the expression, Python executes an iteration across L inside the interpreter, assigning x to each item in turn, and collects the results of running the items through the expression on the left side. The result list we get back is exactly what the list comprehension says—a new list containingx + 10, for every x in L.
Technically speaking, list comprehensions are never really required because we can always build up a list of expression results manually with for loops that append results as we go:
>>> res = []
>>> for x in L:
... res.append(x + 10)
...
>>> res
[31, 32, 33, 34, 35]
In fact, this is exactly what the list comprehension does internally.
However, list comprehensions are more concise to write, and because this code pattern of building up result lists is so common in Python work, they turn out to be very useful in many contexts. Moreover, depending on your Python and code, list comprehensions might run much faster than manual for loop statements (often roughly twice as fast) because their iterations are performed at C language speed inside the interpreter, rather than with manual Python code. Especially for larger data sets, there is often a major performance advantage to using this expression.
Using List Comprehensions on Files
Let’s work through another common application of list comprehensions to explore them in more detail. Recall that the file object has a readlines method that loads the file into a list of line strings all at once:
>>> f = open('script2.py')
>>> lines = f.readlines()
>>> lines
['import sys\n', 'print(sys.path)\n', 'x = 2\n', 'print(x ** 32)\n']
This works, but the lines in the result all include the newline character (\n) at the end. For many programs, the newline character gets in the way—we have to be careful to avoid double-spacing when printing, and so on. It would be nice if we could get rid of these newlines all at once, wouldn’t it?
Anytime we start thinking about performing an operation on each item in a sequence, we’re in the realm of list comprehensions. For example, assuming the variable lines is as it was in the prior interaction, the following code does the job by running each line in the list through the stringrstrip method to remove whitespace on the right side (a line[:−1] slice would work, too, but only if we can be sure all lines are properly \n terminated, and this may not always be the case for the last line in a file):
>>> lines = [line.rstrip() for line in lines]
>>> lines
['import sys', 'print(sys.path)', 'x = 2', 'print(x ** 32)']
This works as planned. Because list comprehensions are an iteration context just like for loop statements, though, we don’t even have to open the file ahead of time. If we open it inside the expression, the list comprehension will automatically use the iteration protocol we met earlier in this chapter. That is, it will read one line from the file at a time by calling the file’s next handler method, run the line through the rstrip expression, and add it to the result list. Again, we get what we ask for—the rstrip result of a line, for every line in the file:
>>> lines = [line.rstrip() for line in open('script2.py')]
>>> lines
['import sys', 'print(sys.path)', 'x = 2', 'print(x ** 32)']
This expression does a lot implicitly, but we’re getting a lot of work for free here—Python scans the file by lines and builds a list of operation results automatically. It’s also an efficient way to code this operation: because most of this work is done inside the Python interpreter, it may be faster than an equivalent for statement, and won’t load a file into memory all at once like some other techniques. Again, especially for large files, the advantages of list comprehensions can be significant.
Besides their efficiency, list comprehensions are also remarkably expressive. In our example, we can run any string operation on a file’s lines as we iterate. To illustrate, here’s the list comprehension equivalent to the file iterator uppercase example we met earlier, along with a few other representative operations:
>>> [line.upper() for line in open('script2.py')]
['IMPORT SYS\n', 'PRINT(SYS.PATH)\n', 'X = 2\n', 'PRINT(X ** 32)\n']
>>> [line.rstrip().upper() for line in open('script2.py')]
['IMPORT SYS', 'PRINT(SYS.PATH)', 'X = 2', 'PRINT(X ** 32)']
>>> [line.split() for line in open('script2.py')]
[['import', 'sys'], ['print(sys.path)'], ['x', '=', '2'], ['print(x', '**', '32)']]
>>> [line.replace(' ', '!') for line in open('script2.py')]
['import!sys\n', 'print(sys.path)\n', 'x!=!2\n', 'print(x!**!32)\n']
>>> [('sys' in line, line[:5]) for line in open('script2.py')]
[(True, 'impor'), (True, 'print'), (False, 'x = 2'), (False, 'print')]
Recall that the method chaining in the second of these examples works because string methods return a new string, to which we can apply another string method. The last of these shows how we can also collect multiple results, as long as they’re wrapped in a collection like a tuple or list.
NOTE
One fine point here: recall from Chapter 9 that file objects close themselves automatically when garbage-collected if still open. Hence, these list comprehensions will also automatically close the file when their temporary file object is garbage-collected after the expression runs. Outside CPython, though, you may want to code these to close manually if this is run in a loop, to ensure that file resources are freed immediately. See Chapter 9 for more on file close calls if you need a refresher on this.
Extended List Comprehension Syntax
In fact, list comprehensions can be even richer in practice, and even constitute a sort of iteration mini-language in their fullest forms. Let’s take a quick look at their syntax tools here.
Filter clauses: if
As one particularly useful extension, the for loop nested in a comprehension expression can have an associated if clause to filter out of the result items for which the test is not true.
For example, suppose we want to repeat the prior section’s file-scanning example, but we need to collect only lines that begin with the letter p (perhaps the first character on each line is an action code of some sort). Adding an if filter clause to our expression does the trick:
>>> lines = [line.rstrip() for line in open('script2.py') if line[0] == 'p']
>>> lines
['print(sys.path)', 'print(x ** 32)']
Here, the if clause checks each line read from the file to see whether its first character is p; if not, the line is omitted from the result list. This is a fairly big expression, but it’s easy to understand if we translate it to its simple for loop statement equivalent. In general, we can always translate a list comprehension to a for statement by appending as we go and further indenting each successive part:
>>> res = []
>>> for line in open('script2.py'):
... if line[0] == 'p':
... res.append(line.rstrip())
...
>>> res
['print(sys.path)', 'print(x ** 32)']
This for statement equivalent works, but it takes up four lines instead of one and may run slower. In fact, you can squeeze a substantial amount of logic into a list comprehension when you need to—the following works like the prior but selects only lines that end in a digit (before the newline at the end), by filtering with a more sophisticated expression on the right side:
>>> [line.rstrip() for line in open('script2.py') if line.rstrip()[-1].isdigit()]
['x = 2']
As another if filter example, the first result in the following gives the total lines in a text file, and the second strips whitespace on both ends to omit blank links in the tally in just one line of code (this file, not included, contains lines describing typos found in the first draft of this book by my proofreader):
>>> fname = r'd:\books\5e\lp5e\draft1typos.txt'
>>> len(open(fname).readlines()) # All lines
263
>>> len([line for line in open(fname) if line.strip() != '']) # Nonblank lines
185
Nested loops: for
List comprehensions can become even more complex if we need them to—for instance, they may contain nested loops, coded as a series of for clauses. In fact, their full syntax allows for any number of for clauses, each of which can have an optional associated if clause.
For example, the following builds a list of the concatenation of x + y for every x in one string and every y in another. It effectively collects all the ordered combinations of the characters in two strings:
>>> [x + y for x in 'abc' for y in 'lmn']
['al', 'am', 'an', 'bl', 'bm', 'bn', 'cl', 'cm', 'cn']
Again, one way to understand this expression is to convert it to statement form by indenting its parts. The following is an equivalent, but likely slower, alternative way to achieve the same effect:
>>> res = []
>>> for x in 'abc':
... for y in 'lmn':
... res.append(x + y)
...
>>> res
['al', 'am', 'an', 'bl', 'bm', 'bn', 'cl', 'cm', 'cn']
Beyond this complexity level, though, list comprehension expressions can often become too compact for their own good. In general, they are intended for simple types of iterations; for more involved work, a simpler for statement structure will probably be easier to understand and modify in the future. As usual in programming, if something is difficult for you to understand, it’s probably not a good idea.
Because comprehensions are generally best taken in multiple doses, we’ll cut this story short here for now. We’ll revisit list comprehensions in Chapter 20 in the context of functional programming tools, and will define their syntax more formally and explore additional examples there. As we’ll find, comprehensions turn out to be just as related to functions as they are to looping statements.
NOTE
A blanket qualification for all performance claims in this book, list comprehension or other: the relative speed of code depends much on the exact code tested and Python used, and is prone to change from release to release.
For example, in CPython 2.7 and 3.3 today, list comprehensions can still be twice as fast as corresponding for loops on some tests, but just marginally quicker on others, and perhaps even slightly slower on some when if filter clauses are used.
We’ll see how to time code in Chapter 21, and will learn how to interpret the file listcomp-speed.txt in the book examples package, which times this chapter’s code. For now, keep in mind that absolutes in performance benchmarks are as elusive as consensus in open source projects!
Other Iteration Contexts
Later in the book, we’ll see that user-defined classes can implement the iteration protocol too. Because of this, it’s sometimes important to know which built-in tools make use of it—any tool that employs the iteration protocol will automatically work on any built-in type or user-defined class that provides it.
So far, I’ve been demonstrating iterators in the context of the for loop statement, because this part of the book is focused on statements. Keep in mind, though, that every built-in tool that scans from left to right across objects uses the iteration protocol. This includes the for loops we’ve seen:
>>> for line in open('script2.py'): # Use file iterators
... print(line.upper(), end='')
...
IMPORT SYS
PRINT(SYS.PATH)
X = 2
PRINT(X ** 32)
But also much more. For instance, list comprehensions and the map built-in function use the same protocol as their for loop cousin. When applied to a file, they both leverage the file object’s iterator automatically to scan line by line, fetching an iterator with __iter__ and calling__next__ each time through:
>>> uppers = [line.upper() for line in open('script2.py')]
>>> uppers
['IMPORT SYS\n', 'PRINT(SYS.PATH)\n', 'X = 2\n', 'PRINT(X ** 32)\n']
>>> map(str.upper, open('script2.py')) # map is itself an iterable in 3.X
<map object at 0x00000000029476D8>
>>> list(map(str.upper, open('script2.py')))
['IMPORT SYS\n', 'PRINT(SYS.PATH)\n', 'X = 2\n', 'PRINT(X ** 32)\n']
We introduced the map call used here briefly in the preceding chapter (and in passing in Chapter 4); it’s a built-in that applies a function call to each item in the passed-in iterable object. map is similar to a list comprehension but is more limited because it requires a function instead of an arbitrary expression. It also returns an iterable object itself in Python 3.X, so we must wrap it in a list call to force it to give us all its values at once; more on this change later in this chapter. Because map, like the list comprehension, is related to both for loops and functions, we’ll also explore both again in Chapter 19 and Chapter 20.
Many of Python’s other built-ins process iterables, too. For example, sorted sorts items in an iterable; zip combines items from iterables; enumerate pairs items in an iterable with relative positions; filter selects items for which a function is true; and reduce runs pairs of items in an iterable through a function. All of these accept iterables, and zip, enumerate, and filter also return an iterable in Python 3.X, like map. Here they are in action running the file’s iterator automatically to read line by line:
>>> sorted(open('script2.py'))
['import sys\n', 'print(sys.path)\n', 'print(x ** 32)\n', 'x = 2\n']
>>> list(zip(open('script2.py'), open('script2.py')))
[('import sys\n', 'import sys\n'), ('print(sys.path)\n', 'print(sys.path)\n'),
('x = 2\n', 'x = 2\n'), ('print(x ** 32)\n', 'print(x ** 32)\n')]
>>> list(enumerate(open('script2.py')))
[(0, 'import sys\n'), (1, 'print(sys.path)\n'), (2, 'x = 2\n'),
(3, 'print(x ** 32)\n')]
>>> list(filter(bool, open('script2.py'))) # nonempty=True
['import sys\n', 'print(sys.path)\n', 'x = 2\n', 'print(x ** 32)\n']
>>> import functools, operator
>>> functools.reduce(operator.add, open('script2.py'))
'import sys\nprint(sys.path)\nx = 2\nprint(x ** 32)\n'
All of these are iteration tools, but they have unique roles. We met zip and enumerate in the prior chapter; filter and reduce are in Chapter 19’s functional programming domain, so we’ll defer their details for now; the point to notice here is their use of the iteration protocol for files and other iterables.
We first saw the sorted function used here at work in, and we used it for dictionaries in Chapter 8. sorted is a built-in that employs the iteration protocol—it’s like the original list sort method, but it returns the new sorted list as a result and runs on any iterable object. Notice that, unlikemap and others, sorted returns an actual list in Python 3.X instead of an iterable.
Interestingly, the iteration protocol is even more pervasive in Python today than the examples so far have demonstrated—essentially everything in Python’s built-in toolset that scans an object from left to right is defined to use the iteration protocol on the subject object. This even includes tools such as the list and tuple built-in functions (which build new objects from iterables), and the string join method (which makes a new string by putting a substring between strings contained in an iterable). Consequently, these will also work on an open file and automatically read one line at a time:
>>> list(open('script2.py'))
['import sys\n', 'print(sys.path)\n', 'x = 2\n', 'print(x ** 32)\n']
>>> tuple(open('script2.py'))
('import sys\n', 'print(sys.path)\n', 'x = 2\n', 'print(x ** 32)\n')
>>> '&&'.join(open('script2.py'))
'import sys\n&&print(sys.path)\n&&x = 2\n&&print(x ** 32)\n'
Even some tools you might not expect fall into this category. For example, sequence assignment, the in membership test, slice assignment, and the list’s extend method also leverage the iteration protocol to scan, and thus read a file by lines automatically:
>>> a, b, c, d = open('script2.py') # Sequence assignment
>>> a, d
('import sys\n', 'print(x ** 32)\n')
>>> a, *b = open('script2.py') # 3.X extended form
>>> a, b
('import sys\n', ['print(sys.path)\n', 'x = 2\n', 'print(x ** 32)\n'])
>>> 'y = 2\n' in open('script2.py') # Membership test
False
>>> 'x = 2\n' in open('script2.py')
True
>>> L = [11, 22, 33, 44] # Slice assignment
>>> L[1:3] = open('script2.py')
>>> L
[11, 'import sys\n', 'print(sys.path)\n', 'x = 2\n', 'print(x ** 32)\n', 44]
>>> L = [11]
>>> L.extend(open('script2.py')) # list.extend method
>>> L
[11, 'import sys\n', 'print(sys.path)\n', 'x = 2\n', 'print(x ** 32)\n']
Per Chapter 8 extend iterates automatically, but append does not—use the latter (or similar) to add an iterable to a list without iterating, with the potential to be iterated across later:
>>> L = [11]
>>> L.append(open('script2.py')) # list.append does not iterate
>>> L
[11, <_io.TextIOWrapper name='script2.py' mode='r' encoding='cp1252'>]
>>> list(L[1])
['import sys\n', 'print(sys.path)\n', 'x = 2\n', 'print(x ** 32)\n']
Iteration is a broadly supported and powerful model. Earlier, we saw that the built-in dict call accepts an iterable zip result, too (see Chapter 8 and Chapter 13). For that matter, so does the set call, as well as the newer set and dictionary comprehension expressions in Python 3.X and 2.7, which we met in Chapter 4, Chapter 5, and Chapter 8:
>>> set(open('script2.py'))
{'print(x ** 32)\n', 'import sys\n', 'print(sys.path)\n', 'x = 2\n'}
>>> {line for line in open('script2.py')}
{'print(x ** 32)\n', 'import sys\n', 'print(sys.path)\n', 'x = 2\n'}
>>> {ix: line for ix, line in enumerate(open('script2.py'))}
{0: 'import sys\n', 1: 'print(sys.path)\n', 2: 'x = 2\n', 3: 'print(x ** 32)\n'}
In fact, both set and dictionary comprehensions support the extended syntax of list comprehensions we met earlier in this chapter, including if tests:
>>> {line for line in open('script2.py') if line[0] == 'p'}
{'print(x ** 32)\n', 'print(sys.path)\n'}
>>> {ix: line for (ix, line) in enumerate(open('script2.py')) if line[0] == 'p'}
{1: 'print(sys.path)\n', 3: 'print(x ** 32)\n'}
Like the list comprehension, both of these scan the file line by line and pick out lines that begin with the letter p. They also happen to build sets and dictionaries in the end, but we get a lot of work “for free” by combining file iteration and comprehension syntax. Later in the book we’ll meet a relative of comprehensions—generator expressions—that deploys the same syntax and works on iterables too, but is also iterable itself:
>>> list(line.upper() for line in open('script2.py')) # See Chapter 20
['IMPORT SYS\n', 'PRINT(SYS.PATH)\n', 'X = 2\n', 'PRINT(X ** 32)\n']
Other built-in functions support the iteration protocol as well, but frankly, some are harder to cast in interesting examples related to files! For example, the sum call computes the sum of all the numbers in any iterable; the any and all built-ins return True if any or all items in an iterable areTrue, respectively; and max and min return the largest and smallest item in an iterable, respectively. Like reduce, all of the tools in the following examples accept any iterable as an argument and use the iteration protocol to scan it, but return a single result:
>>> sum([3, 2, 4, 1, 5, 0]) # sum expects numbers only
15
>>> any(['spam', '', 'ni'])
True
>>> all(['spam', '', 'ni'])
False
>>> max([3, 2, 5, 1, 4])
5
>>> min([3, 2, 5, 1, 4])
1
Strictly speaking, the max and min functions can be applied to files as well—they automatically use the iteration protocol to scan the file and pick out the lines with the highest and lowest string values, respectively (though I’ll leave valid use cases to your imagination):
>>> max(open('script2.py')) # Line with max/min string value
'x = 2\n'
>>> min(open('script2.py'))
'import sys\n'
There’s one last iteration context that’s worth mentioning, although it’s mostly a preview: in Chapter 18, we’ll learn that a special *arg form can be used in function calls to unpack a collection of values into individual arguments. As you can probably predict by now, this accepts any iterable, too, including files (see Chapter 18 for more details on this call syntax; Chapter 20 for a section that extends this idea to generator expressions; and Chapter 11 for tips on using the following’s 3.X print in 2.X as usual):
>>> def f(a, b, c, d): print(a, b, c, d, sep='&')
...
>>> f(1, 2, 3, 4)
1&2&3&4
>>> f(*[1, 2, 3, 4]) # Unpacks into arguments
1&2&3&4
>>>
>>> f(*open('script2.py')) # Iterates by lines too!
import sys
&print(sys.path)
&x = 2
&print(x ** 32)
In fact, because this argument-unpacking syntax in calls accepts iterables, it’s also possible to use the zip built-in to unzip zipped tuples, by making prior or nested zip results arguments for another zip call (warning: you probably shouldn’t read the following example if you plan to operate heavy machinery anytime soon!):
>>> X = (1, 2)
>>> Y = (3, 4)
>>>
>>> list(zip(X, Y)) # Zip tuples: returns an iterable
[(1, 3), (2, 4)]
>>>
>>> A, B = zip(*zip(X, Y)) # Unzip a zip!
>>> A
(1, 2)
>>> B
(3, 4)
Still other tools in Python, such as the range built-in and dictionary view objects, return iterables instead of processing them. To see how these have been absorbed into the iteration protocol in Python 3.X as well, we need to move on to the next section.
New Iterables in Python 3.X
One of the fundamental distinctions of Python 3.X is its stronger emphasis on iterators than 2.X. This, along with its Unicode model and mandated new-style classes, is one of 3.X’s most sweeping changes.
Specifically, in addition to the iterators associated with built-in types such as files and dictionaries, the dictionary methods keys, values, and items return iterable objects in Python 3.X, as do the built-in functions range, map, zip, and filter. As shown in the prior section, the last three of these functions both return iterables and process them. All of these tools produce results on demand in Python 3.X, instead of constructing result lists as they do in 2.X.
Impacts on 2.X Code: Pros and Cons
Although this saves memory space, it can impact your coding styles in some contexts. In various places in this book so far, for example, we’ve had to wrap up some function and method call results in a list(...) call in order to force them to produce all their results at once for display:
>>> zip('abc', 'xyz') # An iterable in Python 3.X (a list in 2.X)
<zip object at 0x000000000294C308>
>>> list(zip('abc', 'xyz')) # Force list of results in 3.X to display
[('a', 'x'), ('b', 'y'), ('c', 'z')]
A similar conversion is required if we wish to apply list or sequence operations to most iterables that generate items on demand—to index, slice, or concatenate the iterable itself, for example. The list results for these tools in 2.X support such operations directly:
>>> Z = zip((1, 2), (3, 4)) # Unlike 2.X lists, cannot index, etc.
>>> Z[0]
TypeError: 'zip' object is not subscriptable
As we’ll see in more detail in Chapter 20, conversion to lists may also be more subtly required to support multiple iterations for newly iterable tools that support just one scan such as map and zip—unlike their 2.X list forms, their values in 3.X are exhausted after a single pass:
>>> M = map(lambda x: 2 ** x, range(3))
>>> for i in M: print(i)
...
1
2
4
>>> for i in M: print(i) # Unlike 2.X lists, one pass only (zip too)
...
>>>
Such conversion isn’t required in 2.X, because functions like zip return lists of results. In 3.X, though, they return iterable objects, producing results on demand. This may break 2.X code, and means extra typing is required to display the results at the interactive prompt (and possibly in some other contexts), but it’s an asset in larger programs—delayed evaluation like this conserves memory and avoids pauses while large result lists are computed. Let’s take a quick look at some of the new 3.X iterables in action.
The range Iterable
We studied the range built-in’s basic behavior in the preceding chapter. In 3.X, it returns an iterable that generates numbers in the range on demand, instead of building the result list in memory. This subsumes the older 2.X xrange (see the upcoming version skew note), and you must uselist(range(...)) to force an actual range list if one is needed (e.g., to display results):
C:\code> c:\python33\python
>>> R = range(10) # range returns an iterable, not a list
>>> R
range(0, 10)
>>> I = iter(R) # Make an iterator from the range iterable
>>> next(I) # Advance to next result
0 # What happens in for loops, comprehensions, etc.
>>> next(I)
1
>>> next(I)
2
>>> list(range(10)) # To force a list if required
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Unlike the list returned by this call in 2.X, range objects in 3.X support only iteration, indexing, and the len function. They do not support any other sequence operations (use list(...) if you require more list tools):
>>> len(R) # range also does len and indexing, but no others
10
>>> R[0]
0
>>> R[-1]
9
>>> next(I) # Continue taking from iterator, where left off
3
>>> I.__next__() # .next() becomes .__next__(), but use new next()
4
NOTE
Version skew note: As first mentioned in the preceding chapter, Python 2.X also has a built-in called xrange, which is like range but produces items on demand instead of building a list of results in memory all at once. Since this is exactly what the new iterator-based range does in Python 3.X, xrange is no longer available in 3.X—it has been subsumed. You may still both see and use it in 2.X code, though, especially since range builds result lists there and so is not as efficient in its memory usage.
As noted in the prior chapter, the file.xreadlines() method used to minimize memory use in 2.X has been dropped in Python 3.X for similar reasons, in favor of file iterators.
The map, zip, and filter Iterables
Like range, the map, zip, and filter built-ins also become iterables in 3.X to conserve space, rather than producing a result list all at once in memory. All three not only process iterables, as in 2.X, but also return iterable results in 3.X. Unlike range, though, they are their own iterators—after you step through their results once, they are exhausted. In other words, you can’t have multiple iterators on their results that maintain different positions in those results.
Here is the case for the map built-in we met in the prior chapter. As with other iterables, you can force a list with list(...) if you really need one, but the default behavior can save substantial space in memory for large result sets:
>>> M = map(abs, (-1, 0, 1)) # map returns an iterable, not a list
>>> M
<map object at 0x00000000029B75C0>
>>> next(M) # Use iterator manually: exhausts results
1 # These do not support len() or indexing
>>> next(M)
0
>>> next(M)
1
>>> next(M)
StopIteration
>>> for x in M: print(x) # map iterator is now empty: one pass only
...
>>> M = map(abs, (-1, 0, 1)) # Make a new iterable/iterator to scan again
>>> for x in M: print(x) # Iteration contexts auto call next()
...
1
0
1
>>> list(map(abs, (-1, 0, 1))) # Can force a real list if needed
[1, 0, 1]
The zip built-in, introduced in the prior chapter, is an iteration context itself, but also returns an iterable with an iterator that works the same way:
>>> Z = zip((1, 2, 3), (10, 20, 30)) # zip is the same: a one-pass iterator
>>> Z
<zip object at 0x0000000002951108>
>>> list(Z)
[(1, 10), (2, 20), (3, 30)]
>>> for pair in Z: print(pair) # Exhausted after one pass
...
>>> Z = zip((1, 2, 3), (10, 20, 30))
>>> for pair in Z: print(pair) # Iterator used automatically or manually
...
(1, 10)
(2, 20)
(3, 30)
>>> Z = zip((1, 2, 3), (10, 20, 30)) # Manual iteration (iter() not needed)
>>> next(Z)
(1, 10)
>>> next(Z)
(2, 20)
The filter built-in, which we met briefly in Chapter 12 and will study in the next part of this book, is also analogous. It returns items in an iterable for which a passed-in function returns True (as we’ve learned, in Python True includes nonempty objects, and bool returns an object’s truth value):
>>> filter(bool, ['spam', '', 'ni'])
<filter object at 0x00000000029B7B70>
>>> list(filter(bool, ['spam', '', 'ni']))
['spam', 'ni']
Like most of the tools discussed in this section, filter both accepts an iterable to process and returns an iterable to generate results in 3.X. It can also generally be emulated by extended list comprehension syntax that automatically tests truth values:
>>> [x for x in ['spam', '', 'ni'] if bool(x)]
['spam', 'ni']
>>> [x for x in ['spam', '', 'ni'] if x]
['spam', 'ni']
Multiple Versus Single Pass Iterators
It’s important to see how the range object differs from the built-ins described in this section—it supports len and indexing, it is not its own iterator (you make one with iter when iterating manually), and it supports multiple iterators over its result that remember their positions independently:
>>> R = range(3) # range allows multiple iterators
>>> next(R)
TypeError: range object is not an iterator
>>> I1 = iter(R)
>>> next(I1)
0
>>> next(I1)
1
>>> I2 = iter(R) # Two iterators on one range
>>> next(I2)
0
>>> next(I1) # I1 is at a different spot than I2
2
By contrast, in 3.X zip, map, and filter do not support multiple active iterators on the same result; because of this the iter call is optional for stepping through such objects’ results—their iter is themselves (in 2.X these built-ins return multiple-scan lists so the following does not apply):
>>> Z = zip((1, 2, 3), (10, 11, 12))
>>> I1 = iter(Z)
>>> I2 = iter(Z) # Two iterators on one zip
>>> next(I1)
(1, 10)
>>> next(I1)
(2, 11)
>>> next(I2) # (3.X) I2 is at same spot as I1!
(3, 12)
>>> M = map(abs, (-1, 0, 1)) # Ditto for map (and filter)
>>> I1 = iter(M); I2 = iter(M)
>>> print(next(I1), next(I1), next(I1))
1 0 1
>>> next(I2) # (3.X) Single scan is exhausted!
StopIteration
>>> R = range(3) # But range allows many iterators
>>> I1, I2 = iter(R), iter(R)
>>> [next(I1), next(I1), next(I1)]
[0 1 2]
>>> next(I2) # Multiple active scans, like 2.X lists
0
When we code our own iterable objects with classes later in the book (Chapter 30), we’ll see that multiple iterators are usually supported by returning new objects for the iter call; a single iterator generally means an object returns itself. In Chapter 20, we’ll also find that generator functions and expressions behave like map and zip instead of range in this regard, supporting just a single active iteration scan. In that chapter, we’ll see some subtle implications of one-shot iterators in loops that attempt to scan multiple times—code that formerly treated these as lists may fail without manual list conversions.
Dictionary View Iterables
Finally, as we saw briefly in Chapter 8, in Python 3.X the dictionary keys, values, and items methods return iterable view objects that generate result items one at a time, instead of producing result lists all at once in memory. Views are also available in 2.7 as an option, but under special method names to avoid impacting existing code. View items maintain the same physical ordering as that of the dictionary and reflect changes made to the underlying dictionary. Now that we know more about iterables here’s the rest of this story—in Python 3.3 (your key order may vary):
>>> D = dict(a=1, b=2, c=3)
>>> D
{'a': 1, 'b': 2, 'c': 3}
>>> K = D.keys() # A view object in 3.X, not a list
>>> K
dict_keys(['a', 'b', 'c'])
>>> next(K) # Views are not iterators themselves
TypeError: dict_keys object is not an iterator
>>> I = iter(K) # View iterables have an iterator,
>>> next(I) # which can be used manually,
'a' # but does not support len(), index
>>> next(I)
'b'
>>> for k in D.keys(): print(k, end=' ') # All iteration contexts use auto
...
a b c
As for all iterables that produce values on request, you can always force a 3.X dictionary view to build a real list by passing it to the list built-in. However, this usually isn’t required except to display results interactively or to apply list operations like indexing:
>>> K = D.keys()
>>> list(K) # Can still force a real list if needed
['a', 'b', 'c']
>>> V = D.values() # Ditto for values() and items() views
>>> V
dict_values([1, 2, 3])
>>> list(V) # Need list() to display or index as list
[1, 2, 3]
>>> V[0]
TypeError: 'dict_values' object does not support indexing
>>> list(V)[0]
1
>>> list(D.items())
[('a', 1), ('b', 2), ('c', 3)]
>>> for (k, v) in D.items(): print(k, v, end=' ')
...
a 1 b 2 c 3
In addition, 3.X dictionaries still are iterables themselves, with an iterator that returns successive keys. Thus, it’s not often necessary to call keys directly in this context:
>>> D # Dictionaries still produce an iterator
{'a': 1, 'b': 2, 'c': 3} # Returns next key on each iteration
>>> I = iter(D)
>>> next(I)
'a'
>>> next(I)
'b'
>>> for key in D: print(key, end=' ') # Still no need to call keys() to iterate
... # But keys is an iterable in 3.X too!
a b c
Finally, remember again that because keys no longer returns a list, the traditional coding pattern for scanning a dictionary by sorted keys won’t work in 3.X. Instead, convert keys views first with a list call, or use the sorted call on either a keys view or the dictionary itself, as follows. We saw this in Chapter 8, but it’s important enough to 2.X programmers making the switch to demonstrate again:
>>> D
{'a': 1, 'b': 2, 'c': 3}
>>> for k in sorted(D.keys()): print(k, D[k], end=' ')
...
a 1 b 2 c 3
>>> for k in sorted(D): print(k, D[k], end=' ') # "Best practice" key sorting
...
a 1 b 2 c 3
Other Iteration Topics
As mentioned in this chapter’s introduction, there is more coverage of both list comprehensions and iterables in Chapter 20, in conjunction with functions, and again in Chapter 30 when we study classes. As you’ll see later:
§ User-defined functions can be turned into iterable generator functions, with yield statements.
§ List comprehensions morph into iterable generator expressions when coded in parentheses.
§ User-defined classes are made iterable with __iter__ or __getitem__ operator overloading.
In particular, user-defined iterables defined with classes allow arbitrary objects and operations to be used in any of the iteration contexts we’ve met in this chapter. By supporting just a single operation—iteration—objects may be used in a wide variety of contexts and tools.
Chapter Summary
In this chapter, we explored concepts related to looping in Python. We took our first substantial look at the iteration protocol in Python—a way for nonsequence objects to take part in iteration loops—and at list comprehensions. As we saw, a list comprehension is an expression similar to afor loop that applies another expression to all the items in any iterable object. Along the way, we also saw other built-in iteration tools at work and studied recent iteration additions in Python 3.X.
This wraps up our tour of specific procedural statements and related tools. The next chapter closes out this part of the book by discussing documentation options for Python code. Though a bit of a diversion from the more detailed aspects of coding, documentation is also part of the general syntax model, and it’s an important component of well-written programs. In the next chapter, we’ll also dig into a set of exercises for this part of the book before we turn our attention to larger structures such as functions. As usual, though, let’s first exercise what we’ve learned here with a quiz.
Test Your Knowledge: Quiz
1. How are for loops and iterable objects related?
2. How are for loops and list comprehensions related?
3. Name four iteration contexts in the Python language.
4. What is the best way to read line by line from a text file today?
5. What sort of weapons would you expect to see employed by the Spanish Inquisition?
Test Your Knowledge: Answers
1. The for loop uses the iteration protocol to step through items in the iterable object across which it is iterating. It first fetches an iterator from the iterable by passing the object to iter, and then calls this iterator object’s __next__ method in 3.X on each iteration and catches theStopIteration exception to determine when to stop looping. The method is named next in 2.X, and is run by the next built-in function in both 3.x and 2.X. Any object that supports this model works in a for loop and in all other iteration contexts. For some objects that are their own iterator, the initial iter call is extraneous but harmless.
2. Both are iteration tools and contexts. List comprehensions are a concise and often efficient way to perform a common for loop task: collecting the results of applying an expression to all items in an iterable object. It’s always possible to translate a list comprehension to a for loop, and part of the list comprehension expression looks like the header of a for loop syntactically.
3. Iteration contexts in Python include the for loop; list comprehensions; the map built-in function; the in membership test expression; and the built-in functions sorted, sum, any, and all. This category also includes the list and tuple built-ins, string join methods, and sequence assignments, all of which use the iteration protocol (see answer #1) to step across iterable objects one item at a time.
4. The best way to read lines from a text file today is to not read it explicitly at all: instead, open the file within an iteration context tool such as a for loop or list comprehension, and let the iteration tool automatically scan one line at a time by running the file’s next handler method on each iteration. This approach is generally best in terms of coding simplicity, memory space, and possibly execution speed requirements.
5. I’ll accept any of the following as correct answers: fear, intimidation, nice red uniforms, a comfy chair, and soft pillows.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.