Python Unlocked (2015)
Chapter 8. Scaling Python
In this chapter, we will try to understand how we can make our program work for more inputs by making the program scalable. We will do this by both optimizing and adding computing power to the system. We will cover the following topics:
· Going multithreaded
· Using multiple processes
· Going asynchronous
· Scaling horizontally
The major reason a system is not able to scale is state. Events can change the state of a system permanently for both that request or further requests from that endpoint.
Normally state is stored in the database, and reactions to events are worked on sequentially, and changes to state due to events are then stored in DB.
Task can be computation intensive (CPU load) or IO bound in which system needs answers from some other entity. Here, taskg and taskng are GIL and nonGIL versions of a task. The taskng task is in C module compiled via SWIG by enabling its threads:
URL = "http://localhost:8080/%s"
def cputask(num,gil=True):
if gil:
return taskg(num)
else:
return taskng(num)
def iotask(num):
req = urllib.request.urlopen(URL%str(num))
text = req.read()
return text
For example, I have created a test server that responds to requests after 1 sec. To create a comparison for scenarios, we first create a simple serial program. As expected, both IO and CPU tasks time add up:
import time
from tasker import cputask, iotask
from random import randint
def process(rep, case=None):
inputs = [[randint(1, 1000), None] for i in range(rep) ]
st = time.time()
if 'cpu' == case:
for i in inputs:
i[1] = cputask(i[0])
elif 'io' == case:
for i in inputs:
i[1] = iotask(i[0])
tot = time.time() - st
for i in inputs:
assert i[0] == int(i[1]), "not same %s" % (i)
return tot
Outputs can be easily summarized as follows:
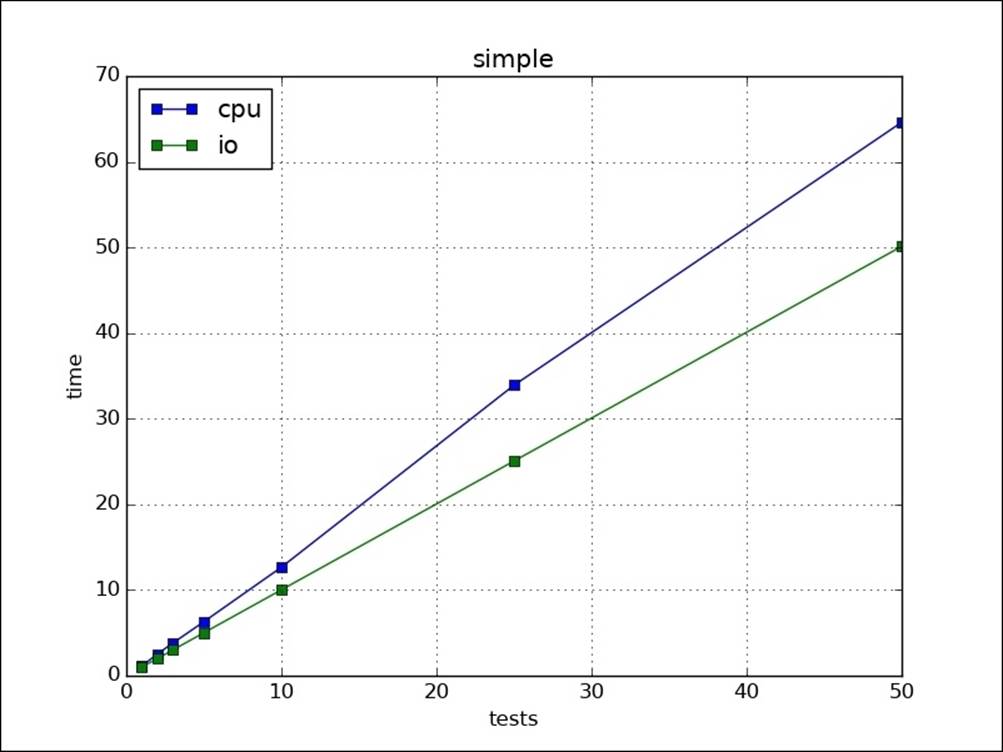
Going multithreaded
Key 1: Using threads to process in parallel.
Let's see how threads can help us in improving performance. In Python, due to Global Interpreter Lock, only one thread runs at a given time. Also, context is switched as all of them are given a chance to run. Hence, this is load in addition to computation. Hence, CPU-intensive tasks should take the same or more time. IO tasks are not doing anything but waiting, so they will get the boost. In the following code segment, threaded_iotask and threaded_cputask are two functions that are executed using separate threads. The code is run for various values to get results. The process function invokes multiple threads for tasks and sums up the timings taken:
import time
from tasker import cputask, iotask
from random import randint
import threading,random,string
def threaded_iotask(i):
i[1] = iotask(i[0])
def threaded_cputask(i):
i[1] = cputask(i[0])
stats = {}
def process(rep, cases=()):
stats.clear()
inputs = [[randint(1, 1000), None] for i in range(rep) ]
threads = []
if 'cpu' in cases:
threads.extend([
threading.Thread(target=threaded_cputask, args=(i,))
for i in inputs])
elif 'io' in cases:
threads.extend([
threading.Thread(target=threaded_iotask, args=(i,))
for i in inputs])
stats['st'] = stats.get('st',time.time())
for t in threads:
t.start()
for t in threads:
t.join()
stats['et'] = stats.get('et',time.time())
tot = stats['et'] - stats['st']
for i in inputs:
assert i[0] == int(i[1])
return tot
Plotting various results onscreen, we can easily see that threading is helping IO tasks but not CPU tasks:
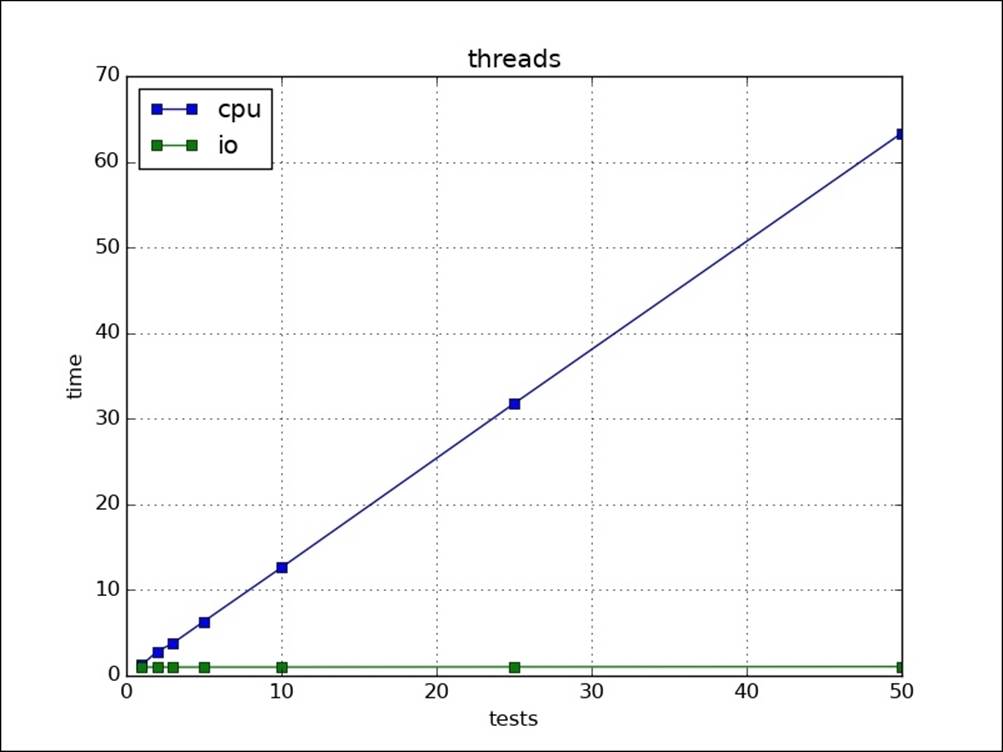
As discussed, this is due to GIL. Our CPU task is defined in C, we can give up GIL to see whether that helps. The following is plot of run with no GIL for tasks. We can see that CPU tasks are now taking a lot less time than before. But, GIL is there for a reason. If wegive up GIL, atomicity for data structures is not guaranteed as there may be two threads working on same data structure at a given time.
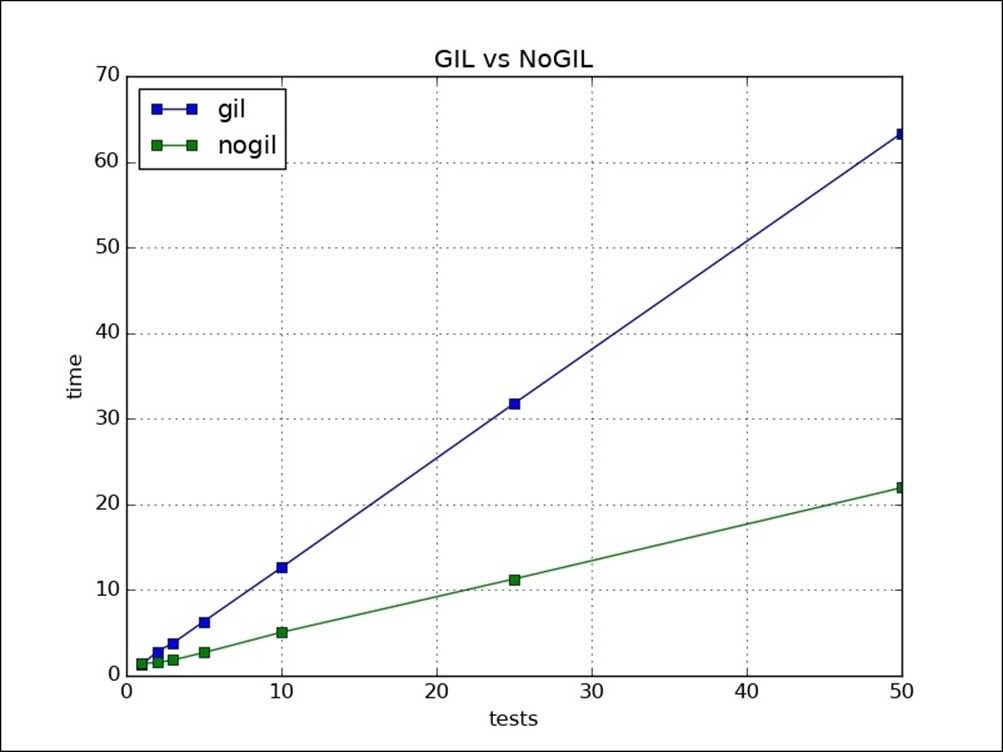
Using multiple processes
Key 2: Churning CPU-intensive tasks.
Multiple processes are helpful to fully utilize all CPU cores. It helps in CPU-intensive work as tasks are run in separate processes, and there is no GIL between actual working processes. The setup and communication cost between processes is higher than threads. In the following code section, proc_iotask, proc_cputask are processes that run them for various inputs:
import time
from tasker import cputask, iotask
from random import randint
import multiprocessing,random,string
def proc_iotask(i,outq):
i[1] = iotask(i[0])
outq.put(i)
def proc_cputask(i,outq):
res = cputask(i[0])
outq.put((i[0],res))
stats = {}
def process(rep, case=None):
stats.clear()
inputs = [[randint(1, 1000), None] for i in range(rep) ]
outq = multiprocessing.Queue()
processes = []
if 'cpu' == case:
processes.extend([
multiprocessing.Process(target=proc_cputask, args=(i,outq))
for i in inputs])
elif 'io' == case:
processes.extend([
multiprocessing.Process(target=proc_iotask, args=(i,outq))
for i in inputs])
stats['st'] = stats.get('st',time.time())
for t in processes:
t.start()
for t in processes:
t.join()
stats['et'] = stats.get('et',time.time())
tot = stats['et'] - stats['st']
while not outq.empty():
item = outq.get()
assert item[0] == int(item[1])
return tot
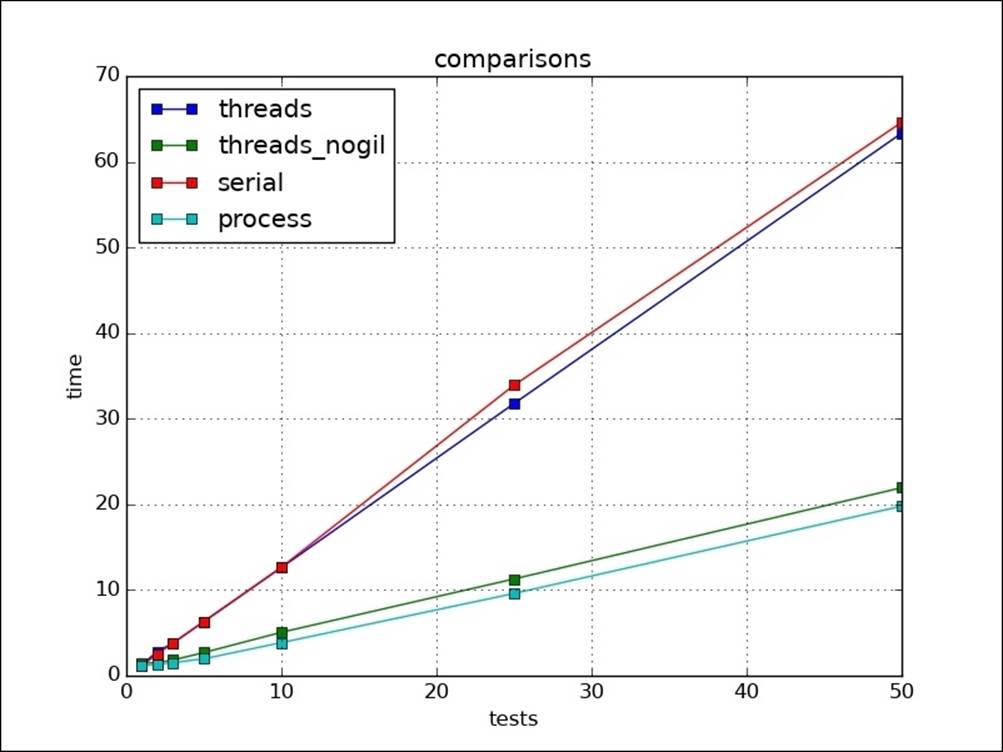
In the following diagram, we can see the multiple IO operations are getting a boost from multiprocessing. CPU tasks are also getting a boost from multiprocessing:
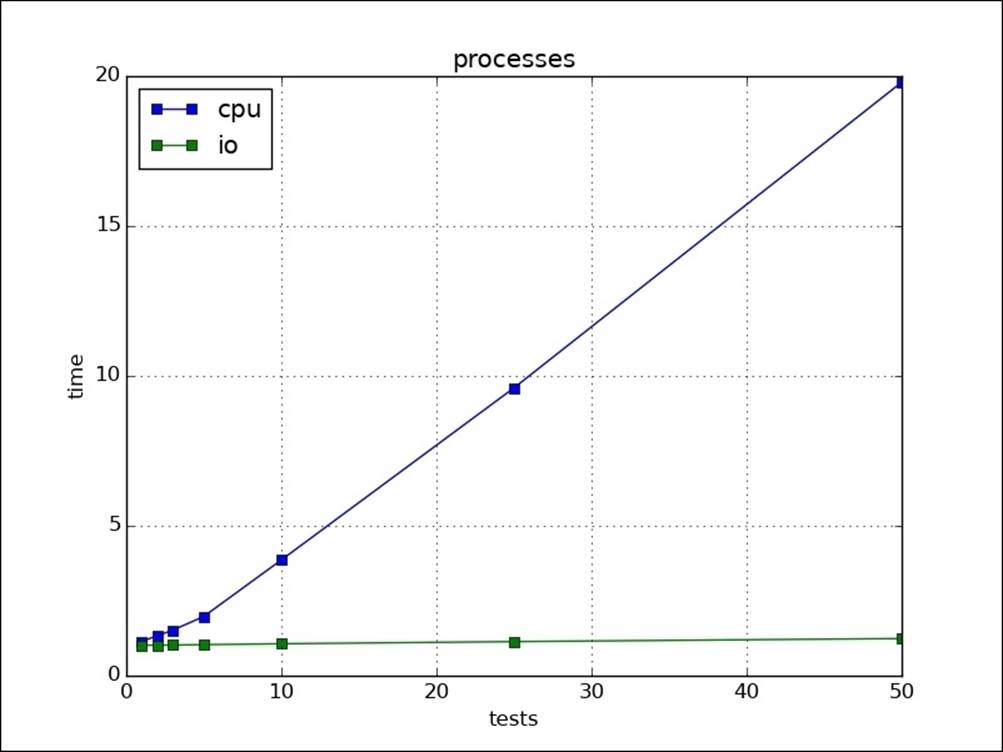
If we compare all four: serial, threads, threads without GIL, and multiprocesses, we will observe that threads without GIL and multiprocesses are taking almost the same time. Also, serial and threads are taking the same time, which shows little benefit of using threads in CPU-intensive tasks:
Going asynchronous
Key 3: Being asynchronous for parallel execution.
We can also process more than one request by being asynchronous as well. In this method, instead of us polling for updates from objects, they tell us when they have a result. Hence, the main thread in the meantime can execute other stuff. Asyncio, Twisted, and Tornado are libraries in Python that can help us write such code. Asyncio, and Tornado are supported in Python 3, and some portions of Twisted also run on Python 3 as of now. Python 3.5 introduced the async and await keywords that helps write asynchronous code. The async keyword defines that the function is an asynchronous function and that the result may not be available right away. The await keyword waits until the results are captured and returns the result.
In the following code, await in the main function waits for all the results to be available:
import time, asyncio
from tasker import cputask, async_iotask
from random import randint
import aiopg, string, random, aiohttp
from asyncio import futures, ensure_future, gather
from functools import partial
URL = "http://localhost:8080/%s"
async def async_iotask(num, loop=None):
res = await aiohttp.get(URL % str(num[0]), loop=loop)
text = await res.text()
num[1] = int(text)
return text
stats = {}
async def main(rep, case=None, loop=None, inputs=None):
stats.clear()
stats['st'] = time.time()
if 'cpu' == case:
for i in inputs:
i[1] = cputask(i[0])
if 'io' == case:
deferreds = []
for i in inputs:
deferreds.append(async_iotask(i, loop=loop))
await gather(*deferreds, return_exceptions=True, loop=loop)
stats['et'] = time.time()
def process(rep, case=None):
loop = asyncio.new_event_loop()
inputs = [[randint(1, 1000), None] for i in range(rep) ]
loop.run_until_complete(main(rep, case=case, loop=loop, inputs=inputs))
loop.close()
tot = stats['et'] - stats['st'] # print(inputs)
for i in inputs:
assert i[0] == int(i[1])
return tot
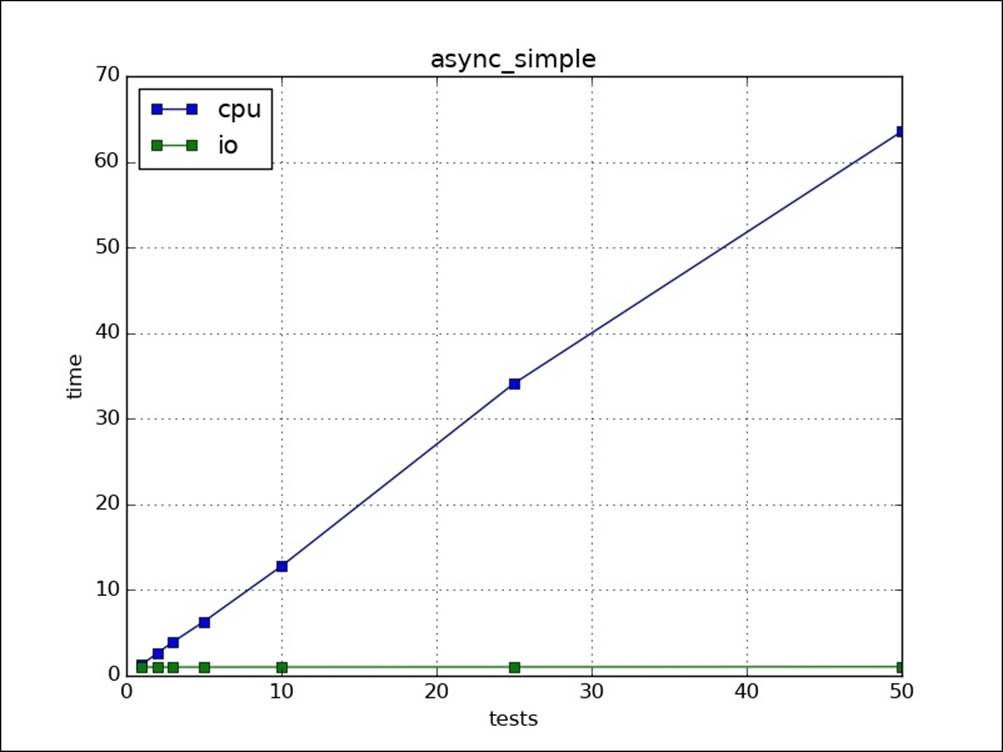
Plotting results on the graph, we can see that we got a boost on the IO portion, but for CPU-intensive work, it takes time similar to serial:
CPU tasks are blocking everything, hence, this is a bad design. We have to use either threads, or better multiprocessing to help in CPU-intensive tasks. To run tasks in threads or processes, we can use ThreadPoolExecutor, and ProcessPoolExecutor from theconcurrent.futures package. The following is the code for ThreadPoolExecutor:
async def main(rep,case=None,loop=None,inputs=[]):
if case == 'cpu':
tp = ThreadPoolExecutor()
futures = []
for i in inputs:
task = partial(threaded_cputask,i)
future = loop.run_in_executor(tp,task)
futures.append(future)
res = await asyncio.gather(*futures,return_exceptions=True,loop=loop)
For ProcessPoolExecutor, we have to use a multiprocessing queue to collect results back, as follows:
def threaded_cputask(i,outq):
res = cputask(i[0])
outq.put((i[0],res))
async def main(rep,case=None,loop=None,outq=None,inputs=[]):
if case == 'cpu':
pp = ProcessPoolExecutor()
futures = []
for i in inputs:
task = partial(threaded_cputask,i,outq)
future = loop.run_in_executor(pp,task)
futures.append(future)
res = await asyncio.gather(*futures,return_exceptions=True,loop=loop)
def process(rep,case=None):
loop = asyncio.new_event_loop()
inputs = [[randint(1, 1000), None] for i in range(rep) ]
st = time.time()
m = multiprocessing.Manager()
outq = m.Queue()
loop.run_until_complete(main(rep,case=case,loop=loop,outq=outq,inputs=inputs))
tot = time.time() - st
while not outq.empty():
item = outq.get()
assert item[0] == int(item[1])
loop.close()
return tot
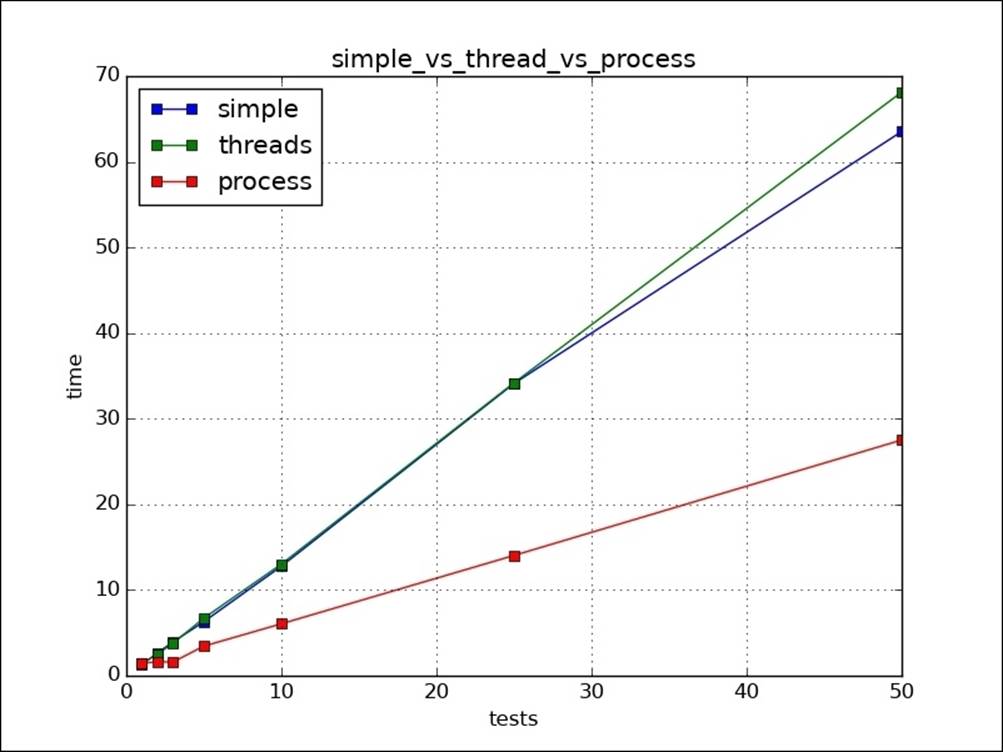
Plotting the results, we can see that threads are taking more or less the same time as without them, but they can still help make the program more responsive as the program will be able to perform other IO tasks in the meantime. Multiprocessing gives the max boost:
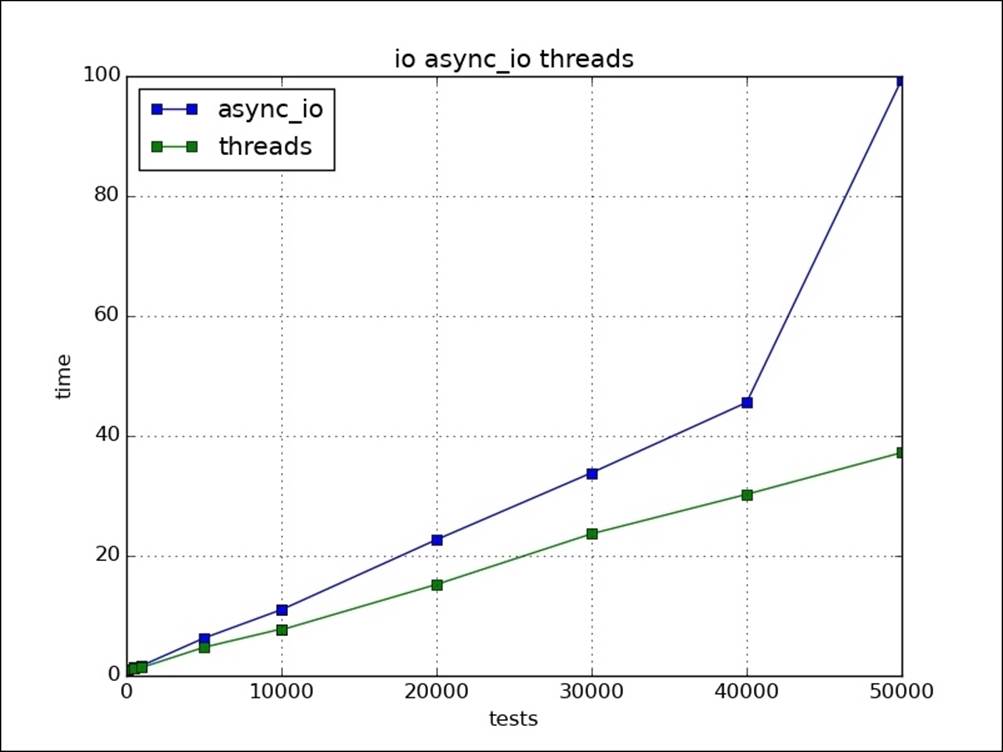
Async systems are used mostly when IO is the main thing. As you can see, it is similar to serial for CPU. Let's now take a look at which one is better, threading or async, for our scalable IO-based application. We used the same IO task but on higher loads. Asyncio gives failures and takes more time than threads. I tested this on Python 3.5:
The last advice will be to look at other implementations as well, such as PyPy, Jython, IronPython, and so on.
Scaling horizontally
If we add further nodes to the application, it must add to the total processing power. To create frontend systems that perform more data transmission than computation, async frameworks are better suited. If we use PyPy, it will give a performance boost to the application. Code for Python 3 or Python 2 compatibility using six or other such libraries so that we can use anything available for optimization.
We can use message pack or JSON for message transfer. I prefer JSON for language agnostic and easy-text representation. Workers can be multiprocessing workers for CPU-bound tasks or thread-based for other scenarios.
The system should not store the state but pass it with messages. Everything doesn't need to be in DB. We can take some things out when not necessary.
ZeroMQ (messageQueue): ZMQ is a wonderful library that acts as a glue to connect your programs together. It has connectors for almost all language. You can easily use multiple languages/frameworks to enable their communication with ZMQ and amongthemselves. It also provides tools to create various utilities. Let's now look at how we can create a load-balanced worker system easily using ZMQ. In the following code snippet, we created a client (requester) that can ask for a result from a group of servers (workers) that are load balanced. In the following code, we can see the socket type is DEALER. Sockets in ZMQ can be thought of as mini servers. The req sockets do not actually transmit until they get a response for the previous one. DEALER and ROUTER sockets are better suited for real-life scenarios. The code for synchronization is as follows:
import sys
import zmq
from zmq.eventloop import ioloop
from zmq.eventloop.ioloop import IOLoop
from zmq.eventloop.zmqstream import ZMQStream
ioloop.install()
class Cli():
def __init__(self, name, addresses):
self.addresses = addresses
self.loop = IOLoop.current()
self.ctx = zmq.Context.instance()
self.skt = None
self.stream = None
self.name = bytes(name, encoding='ascii')
self.req_no = 0
self.run()
def run(self):
self.skt = self.ctx.socket(zmq.DEALER)
for address in self.addresses:
self.skt.connect(address)
self.stream = ZMQStream(self.skt)
self.stream.on_recv(self.handle_request)
self.loop.call_later(1, self.send_request)
def send_request(self):
msg = [self.req_no.to_bytes(1, 'little'), b"hello"]
print("sending", msg)
self.stream.send_multipart(msg)
self.req_no += 1
if self.req_no < 10:
self.loop.call_later(1, self.send_request)
def handle_request(self, msg):
print("received", int.from_bytes(msg[0], 'little'), msg[1])
if __name__ == '__main__':
print("starting client")
loop = IOLoop.current()
serv = Cli(sys.argv[1], sys.argv[2:])
loop.start()
The following is the code for servers or actual workers. We can have many of them and the load is distributed in a round-robin fashion among them:
import sys
import zmq
from zmq.eventloop import ioloop
from zmq.eventloop.ioloop import IOLoop
from zmq.eventloop.zmqstream import ZMQStream
ioloop.install()
class Serv():
def __init__(self, name, address):
self.address = address
self.loop = IOLoop.current()
self.ctx = zmq.Context.instance()
self.skt = None
self.stream = None
self.name = bytes(name, encoding='ascii')
self.run()
def run(self):
self.skt = self.ctx.socket(zmq.ROUTER)
self.skt.bind(self.address)
self.stream = ZMQStream(self.skt)
self.stream.on_recv(self.handle_request)
def handle_request(self, msg):
print("received", msg)
self.stream.send_multipart(msg)
if __name__ == '__main__':
print("starting server")
serv = Serv(sys.argv[1], sys.argv[2])
loop = IOLoop.current()
loop.start()
The following is the result from the run:
For client
(py35) [ scale_zmq ] $ python client.py "cli" "tcp://127.0.0.1:8004" "tcp://127.0.0.1:8005"
starting client
sending [b'\x00', b'hello']
sending [b'\x01', b'hello']
received 1 b'hello'
sending [b'\x02', b'hello']
sending [b'\x03', b'hello']
received 3 b'hello'
sending [b'\x04', b'hello']
sending [b'\x05', b'hello']
received 5 b'hello'
sending [b'\x06', b'hello']
sending [b'\x07', b'hello']
received 7 b'hello'
sending [b'\x08', b'hello']
sending [b'\t', b'hello']
received 9 b'hello'
received 0 b'hello'
received 2 b'hello'
received 4 b'hello'
received 6 b'hello'
received 8 b'hello'
Outputs server/workers:
(py35) [ scale_zmq ] $ python server.py "serv" "tcp://127.0.0.1:8004"
starting server
received [b'\x00k\x8bEg', b'\x00', b'hello']
received [b'\x00k\x8bEg', b'\x02', b'hello']
received [b'\x00k\x8bEg', b'\x04', b'hello']
received [b'\x00k\x8bEg', b'\x06', b'hello']
received [b'\x00k\x8bEg', b'\x08', b'hello']
(py35) [ scale_zmq ] $ python server.py "serv" "tcp://127.0.0.1:8005"
starting server
received [b'\x00k\x8bEg', b'\x01', b'hello']
received [b'\x00k\x8bEg', b'\x03', b'hello']
received [b'\x00k\x8bEg', b'\x05', b'hello']
received [b'\x00k\x8bEg', b'\x07', b'hello']
received [b'\x00k\x8bEg', b'\t', b'hello']
We can use the third-party package Supervisord to make workers restart on failure.
The real power of ZMQ is in creating network architecture and nodes as required by the project from simpler components. You can test the framework easily as it can support IPC, TCP, UDP, and many more protocols. They can also be used interchangeably.
There are other libraries/frameworks as well that can help a lot in this space, such as NSQ, Python parallel. Many projects go for RabbitMQ as the broker and AMQP as the protocol. Choosing good communication is very important for the design and scalability of a system, and it depends on the project requirement.
Summary
Making a program scalable is easy if we separate portions of program and use each part tuned for best performance. In this chapter, we saw how various portions of Python help in vertical as well as horizontal scaling. All this information must be taken into consideration when designing architecture of the application.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.