Algorithms in a Nutshell 2E (2015)
Chapter 7. Path Finding in AI
To solve a problem when there is no clear computation for a valid solution, we turn to path finding. This chapter covers two related path-finding approaches, one using game trees for two player games and the other using search trees for single player games. These approaches rely on a common structure, namely a state tree whose root node represents the initial state and edges represent potential moves that transform the state into a new state. The searches are challenging because the underlying structure is not computed in its entirety due to the explosion of the number of states. In a game of checkers, for example, there are roughly 5*1020 different board configurations (Schaeffer, 2007). Thus the trees over which the search proceeds are constructed on demand as needed. The two path-finding approaches are characterized as follows:
Game tree
Two players take turns alternating moves that modify the game state from its initial state. There are many states in which either player can win the game. There may also be some “draw” states in which no one wins. A path-finding algorithm maximizes the chance that a player will win the game or force a draw.
Search tree
A single player starts from an initial board state and makes valid moves until the desired goal state is reached. A path-finding algorithm identifies the exact sequence of moves that will transform the initial state into the goal state.
Game Trees
The game of tic-tac-toe is played on a three-by-three board where players take turns placing X and O marks on the board. The first player to place three of his marks in a row wins; the game is a draw if no spaces remain and no player has won. In tic-tac-toe there are only 765 unique positions (ignoring reflections and rotations of the board state) and a calculated 26,830 possible games that can be played (Schaeffer, 2002). To see some of the potential games, construct a game tree, as shown partially in Figure 7-1, and find a path from player O’s current game state (represented as the top node in this tree) to some future game state that ensures either a victory or a draw for player O.
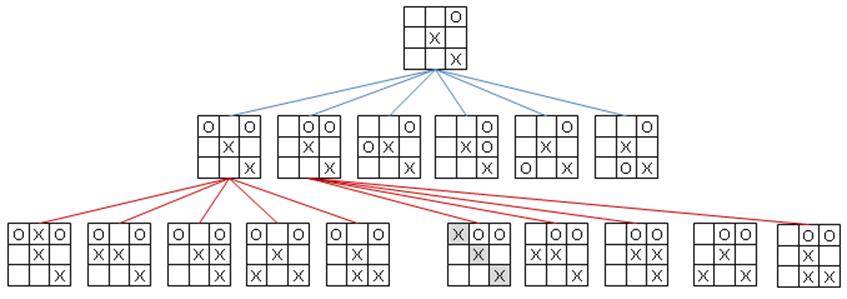
Figure 7-1. Partial game tree given an initial tic-tac-toe game state
A game tree is also known as an AND/OR tree since it is formed by two different types of nodes. The top node is an OR node, because the goal is for player O to select just one of the six available moves in the middle tier. The middle-tier nodes are AND nodes, because the goal (from O’s perspective) is to ensure that all countermoves by X (shown as children nodes in the bottom tier) will still lead to either a victory or a draw for O. The game tree in Figure 7-1 is only partially expanded because there are actually 30 different game states in the bottom tier.
In a sophisticated game, the game tree may never be computed fully because of its size. The goal of a path-finding algorithm is to determine from a game state the player’s move that maximizes (or even guarantees) his chance of winning the game. We thus transform an intelligent set of player decisions into a path-finding problem over the game tree. This approach works for games with small game trees, but it also can scale to solve more complex problems.
The American game of checkers is played on an eight-by-eight board with an initial set of 24 pieces (12 red and 12 black). For decades researchers attempted to determine whether the opening player could force a draw or a win. Although it is difficult to compute exactly, there are roughly 5*1020 possible board positions in checkers. The size of the game tree must therefore be incredibly large. After nearly 18 years of computations (sometimes on as many as 200 computers), researchers at the University of Alberta, Canada demonstrated that perfect play by both players leads to a draw (Schaeffer, 2007).
Path finding in Artificial Intelligence (AI) provides specific algorithms to tackle incredibly complex problems if they can be translated into a combinatorial game of alternating players. Early researchers in AI (Shannon, 1950) considered the challenge of building a chess-playing machine and developed two types of approaches for search problems that continue to define the state of the practice today:
Type A
Consider the various allowed moves for both players a fixed set of turns into the future, and determine the most favorable position that results for the original player. Then, select the initial move that makes progress in that direction.
Type B
Add some adaptive decision based upon knowledge of the game rather than static evaluation functions. More explicitly, (a) evaluate promising positions as far ahead as necessary to find a stable position where the board evaluation truly reflects the strength of the resulting position, and (b) select appropriate available moves. This approach tries to prevent pointless possibilities from consuming precious time.
In this chapter, we describe the family of Type A algorithms that provides a general-purpose approach for searching a game tree to find the best move for a player in a two-player game. These algorithms include Minimax, AlphaBeta, and NegMax.
The algorithms discussed in this chapter become unnecessarily complicated if the underlying information is poorly modelled. Many of the examples in textbooks or on the Internet naturally describe these algorithms in the context of a particular game. However, it may be difficult to separate the arbitrary way in which the game is represented from the essential elements of these algorithms. For this reason, we intentionally designed a set of object-oriented interfaces to maintain a clean separation between the algorithms and the games. We’ll now briefly summarize the core interfaces in our implementation of game trees, which are illustrated in Figure 7-2.
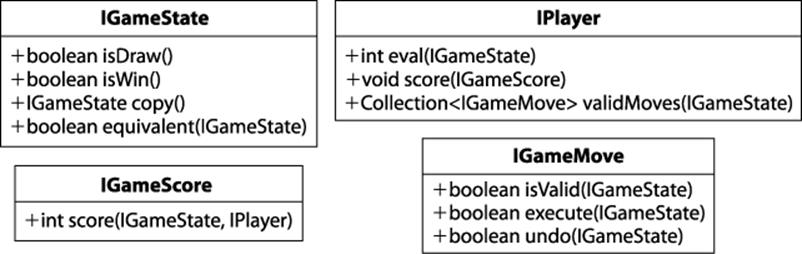
Figure 7-2. Core interfaces for game tree algorithms
The IGameState interface abstracts the essential concepts needed to conduct searches over a game state. It defines how to:
Interpret the game state
isDraw() determines whether the game concludes with neither player winning; isWin() determines whether the game is won.
Manage the game state
copy() returns an identical copy of the game state so moves can be applied without updating the original game state; equivalent(IGameState) determines whether two game state positions are equal.
The IPlayer interface abstracts the abilities of a player to manipulate the game state. It defines how to:
Evaluate a board
eval(IGameState) returns an integer evaluating the game state from the player’s perspective; score(IGameScore) sets the scoring computation the player uses to evaluate a game state.
Generate valid moves
validMoves(IGameState) returns a collection of available moves given the game state.
The IGameMove interface defines how moves manipulate the game state. The move classes are problem-specific, and the search algorithm need not be aware of their specific implementation. IGameScore defines the interface for scoring states.
From a programming perspective, the heart of the path-finding algorithm for a game tree is an implementation of the IEvaluation interface shown in Example 7-1.
Example 7-1. Common interface for game tree path finding
/**
* For game state, player and opponent, return the best move
* for player. If no move is even available, null is returned.
*/
public interface IEvaluation {
IGameMove bestMove(IGameState state, IPlayer player, IPlayer opponent);
}
Given a node representing the current game state, the algorithm computes the best move for player assuming that opponent will play a perfect game in return.
In this chapter, we use the BoardEvaluation scoring function for tic-tac-toe, which was defined by Nil Nilsson (1971). Let nc(gs, p) be the number of rows, columns, or diagonals on a tic-tac-toe game state, gs, in which player p may still get three in a row. We then define score(gs, p) to be:
§ +∞ if player p has won the game in game state gs
§ −∞ if the opponent of player p has won the game in game state gs
§ nc(gs, p) - nc(gs, opponent) if neither player has won the game in game state gs
Minimax
Given a specific position in a game tree from the perspective of an initial player, a search program must find a move that leads to the greatest chance of victory (or at least a draw). Instead of considering only the current game state and the available moves at that state, the program must consider any countermoves that its opponent will make after it makes each move. The program assumes there is an evaluation function score(state, player) that returns an integer representing the score of the game state from player’s perspective; lower integer numbers (which may be negative) reflect weaker positions.
The game tree is expanded by considering future game states after a sequence of n moves have been made. Each level of the tree alternates between MAX levels (where the goal is to benefit the original player by maximizing the evaluated score of a game state) and MIN levels (where the goal is to benefit the opponent by minimizing the evaluated score of a game state). At alternating levels, then, the program selects a move that maximizes score(state, initial), but when the opponent is making its move, the program assumes the opponent will select a move that minimizesscore(state, initial).
Of course, the program can look ahead only a finite number of moves, and each extra move it looks ahead increases memory and time use immensely. The number of moves chosen to look ahead is called the ply. The tradeoff is to select a suitable ply that leads to a search exploration that completes in reasonable time.
The following pseudocode illustrates the Minimax algorithm.
MINIMAX SUMMARY
Best, Average, Worst: O(bply)
bestmove (s, player, opponent)
original = player ![]()
[move, score] = minimax (s, ply, player, opponent)
return move
end
minimax (s, ply, player, opponent)
best = [null, null]
if ply is 0 orthere are no valid moves then ![]()
score = evaluate s for original player
return [null, score]
foreach valid move m for player in state s do
execute move m on s
[move, score] = minimax(s, ply-1, opponent, player) ![]()
undo move m on s
if player is original then ![]()
if score > best.score then best = [m, score]
else
if score < best.score then best = [m, score]
return best
end
![]()
Remember original player since evaluation always from that player’s perspective
![]()
If no more moves remain, player might have won (or lost) which is equivalent to reaching target ply depth
![]()
With each recursive call, swap player and opponent to reflect alternating turns
![]()
Successive levels alternate between MAX or MIN
Figure 7-3 shows an evaluation of a move using Minimax with ply depth of 3. The bottom row of the game tree contains the five possible game states that result after the player makes a move, the opponent responds, and then the player makes a move. Each of these game states is evaluated from the point of view of the original player, and the integer rating is shown in each node. The MAX second row from the bottom contains internal nodes whose scores are the maximum of their respective children. From the point of view of the original player, these represent the best scores that he can attain. However, the MIN third row from the bottom represent the worst positions that the opponent can force upon the player, thus its scores are minimum of its children. As you can see, each level alternates between selecting the maximum and minimum of its children. The final score of 3 demonstrates that the original player can force the opponent to at least concede a game state that evaluates to 3.
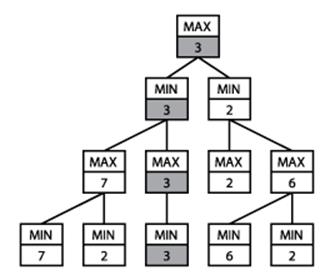
Figure 7-3. Minimax sample game tree
Input/Output
Minimax looks ahead a fixed number of moves, called the ply depth.
Minimax returns a move from among the valid moves that leads to the best future game state for a specific player, as determined by the evaluation function.
Context
Evaluating the game state is complex, and one must resort to heuristic evaluations to determine the better game state. Indeed, developing effective evaluation functions for games such as chess, checkers, or Othello® is the greatest challenge in designing intelligent programs. We assume these evaluation functions are available.
The size of the game tree is determined by the number of available moves at each game state. Assume there are b moves valid at the initial game state and that each move takes away a potential move from the opponent. If the ply depth is d, the number of game states checked is
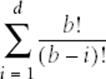
where b! is the factorial of b. To give an example of the scale involved, Minimax evaluates 187,300 states when b=10 and d=6.
During the recursive invocation within Minimax, the score(state, player) evaluation function must be consistently applied using the original player for whom a move is being calculated. This coordinates the minimum and maximum recursive evaluations.
Solution
The helper class MoveEvaluation pairs together an IMove and an int evaluation to be associated with that move. Minimax explores to a fixed ply depth, or when a game state has no valid moves for a player. The Java code in Example 7-2 returns the best move for a player in a given game state.
Example 7-2. Minimax Java implementation
public class MinimaxEvaluation implements IEvaluation {
IGameState state; /** State to be modified during search. */
int ply; /** Ply depth. How far to continue search. */
IPlayer original; /** Evaluate all states from this perspective. */
public MinimaxEvaluation (int ply) {
this.ply = ply;
}
public IGameMove bestMove (IGameState s,
IPlayer player, IPlayer opponent) {
this.original = player;
this.state = s.copy();
MoveEvaluation me = minimax(ply, IComparator.MAX,
player, opponent);
return me.move;
}
MoveEvaluation minimax (int ply, IComparator comp,
IPlayer player, IPlayer opponent) {
// If no allowed moves or a leaf node, return game state score.
Iterator<IGameMove> it = player.validMoves(state).iterator();
if (ply == 0 || !it.hasNext()) {
return new MoveEvaluation (original.eval(state));
}
// Try to improve on this lower bound (based on selector).
MoveEvaluation best = new MoveEvaluation (comp.initialValue());
// Generate game states resulting from valid moves for player
while (it.hasNext()) {
IGameMove move = it.next();
move.execute(state);
// Recursively evaluate position. Compute Minimax and swap
// player and opponent, synchronously with MIN and MAX.
MoveEvaluation me = minimax (ply-1, comp.opposite(),
opponent, player);
move.undo(state);
// Select maximum (minimum) of children if we are MAX (MIN)
if (comp.compare(best.score, me.score) < 0) {
best = new MoveEvaluation (move, me.score);
}
}
return best;
}
}
The MAX and MIN selectors evaluate scores to properly select the minimum or maximum score as desired. This implementation is simplified by defining an IComparator interface, shown in Figure 7-4, that defines MAX and MIN and consolidates how they select the best move from their perspective. Switching between the MAX and MIN selector is done using the opposite() method. The worst score for each of these comparators is returned by initialValue().
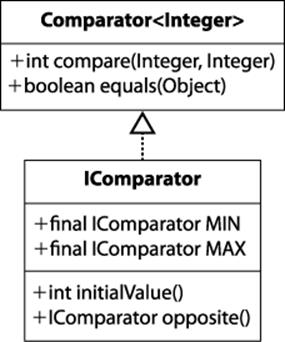
Figure 7-4. IComparator interface abstracts MAX and MIN operators
Minimax can rapidly become overwhelmed by the sheer number of game states generated during the recursive search. In chess, where the average number of moves on a board is 30 (Laramée, 2000), looking ahead just five moves (i.e., b=30, d=5) requires evaluating up to 25,137,931 board positions, as determined by the expression:
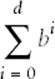
Minimax can take advantage of symmetries in the game state, such as rotations or reflections of the board, by caching past states viewed (and their respective scores), but the savings are game-specific.
Figure 7-5 contains a two-ply exploration of an initial tic-tac-toe game state for player O using Minimax. The alternating levels of MAX and MIN show how the first move from the left—placing an O in the upper-left corner—is the only move that averts an immediate loss. Note that all possible game states are expanded, even when it becomes clear that the opponent X can secure a win if O makes a poor move choice.

Figure 7-5. Sample Minimax exploration
Analysis
When there is a fixed number b of moves at each game state (or even when the number of available moves reduces by one with each level), the total number of game states searched in a d-ply Minimax is O(bd), demonstrating exponential growth. The ply depth restriction can be eliminated if the game tree is small enough to be represented completely in memory.
Given the results of Figure 7-5, is there some way to eliminate exploring useless game states? Because we assume that neither the player nor the opponent makes any mistakes, we need to find a way to stop expanding the game tree once the algorithm determines that an entire subtree is worthless to explore further. AlphaBeta properly implements this capability; we must first explain how to simplify the alternating MAX and MIN levels of the game tree with the NegMax algorithm.
NegMax
NegMax replaces the alternative MAX and MIN levels of Minimax with a single approach used at each level of the game tree. It also forms the basis for the AlphaBeta algorithm presented next.
In Minimax, the game state is always evaluated from the perspective of the player making the initial move (which requires the evaluation function to store this information). The game tree is thus composed of alternating levels that maximize the score of children nodes (when the original player) or minimize the score of children nodes (when the opponent). Instead, NegMax consistently seeks the move that produces the maximum of the negative values of a state’s children nodes.
Intuitively, after a player has made its move, the opponent will try to make its best move; thus, to find the best move for a player, select the one that restricts the opponent from scoring too highly. If you compare the pseudocode examples, you will see that Minimax and NegMax produce two game trees with identical structure; the only difference is how the game states are scored.
NEGMAX SUMMARY
Best, Average, Worst: O(bply)
bestmove (s, player, opponent)
[move, score] = negmax (s, ply, player, opponent)
return move
end
negmax (s, ply, player, opponent)
best = [null, null]
if ply is 0 orthere are no valid moves then
score = evaluate s for player
return [null, score]
foreach valid move m for player in state s do
execute move m on s
[move, score] = negmax (s, ply-1, opponent, player) ![]()
undo move m on s
if -score > best.score then best = [m, -score] ![]()
return best
end
![]()
NegMax swaps players with each successive level
![]()
Choose largest of the negative scores of its children
The structure of the NegMax game tree is identical to the Minimax game tree from Figure 7-3 because it finds the exact same move; the only difference is that the values in levels previously labeled as MIN are negated in NegMax. If you compare the tree in Figure 7-6 with Figure 7-3, you see this behavior.
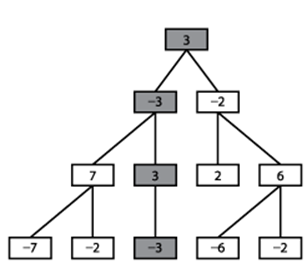
Figure 7-6. NegMax sample game tree
Solution
In Example 7-3, note that the score for each MoveEvaluation is simply the evaluation of the game state from the perspective of the player making that move. Reorienting each evaluation toward the player making the move simplifies the algorithm implementation.
Example 7-3. NegMax implementation
public class NegMaxEvaluation implements IEvaluation {
IGameState state; /** State to be modified during search. */
int ply; /** Ply depth. How far to continue search. */
public NegMaxEvaluation (int ply) {
this.ply = ply;
}
public IGameMove bestMove (IGameState s, IPlayer player, IPlayer opponent) {
state = s.copy();
MoveEvaluation me = negmax(ply, player, opponent);
return me.move;
}
public MoveEvaluation negmax (int ply, IPlayer player, IPlayer opponent) {
// If no allowed moves or a leaf node, return board state score.
Iterator<IGameMove> it = player.validMoves(state).iterator();
if (ply == 0 || !it.hasNext()) {
return new MoveEvaluation(player.eval(state));
}
// Try to improve on this lower-bound move.
MoveEvaluation best = new MoveEvaluation (MoveEvaluation.minimum());
// get moves for this player and generate the boards that result from
// making these moves. Select maximum of the negative scores of children.
while (it.hasNext()) {
IGameMove move = it.next();
move.execute(state);
// Recursively evaluate position using consistent negmax.
MoveEvaluation me = negmax (ply-1, opponent, player);
move.undo(state);
if (-me.score > best.score) {
best = new MoveEvaluation (move, -me.score);
}
}
return best;
}
}
NegMax is useful because it prepares a simple foundation on which to extend to AlphaBeta. Because board scores are routinely negated in this algorithm, we must carefully choose values that represent winning and losing states. Specifically, the minimum value must be the negated value of the maximum value. Note that Integer.MIN_VALUE (defined in Java as 0x80000000 or −2,147,483,648) is not the negated value of Integer.MAX_VALUE (in Java, defined as 0x7fffffff or 2,147,483,647). For this reason, we use Integer.MIN_VALUE+1 as the minimum value, which is retrieved by the static function MoveEvaluation.minimum(). For completeness, we provide MoveEvaluation.maximum() as well.
Figure 7-7 contains a two-ply exploration of an initial tic-tac-toe game state for player O using NegMax. NegMax expands all possible game states, even when it becomes clear that the opponent X can secure a win if O makes a poor move. The scores associated with each of the leaf game states are evaluated from that player’s perspective (in this case, the original player O). The score for the initial game state is −2, because that is the “maximum of the negative scores of its children.”

Figure 7-7. Sample NegMax exploration
Analysis
The number of states explored by NegMax is the same as Minimax, on the order of bd for a d-ply search with fixed number b of moves at each game state. In all other respects, it performs identically to Minimax.
AlphaBeta
Minimax evaluates a player’s best move when considering the opponent’s countermoves, but this information is not used while the game tree is generated! Consider the BoardEvaluation scoring function introduced earlier. Recall Figure 7-5, which shows the partial expansion of the game tree from an initial game state after X has made two moves and O has made just one move.
Note how Minimax plods along even though each of the subsequent searches reveals a losing board if X is able to complete the diagonal. A total of 36 nodes are evaluated. Minimax takes no advantage of the fact that the original decision for O to play in the upper-left corner prevented X from scoring an immediate victory. AlphaBeta defines a consistent strategy to prune unproductive searches from the search tree. Using AlphaBeta, the equivalent expansion of the game tree is shown in Figure 7-8.
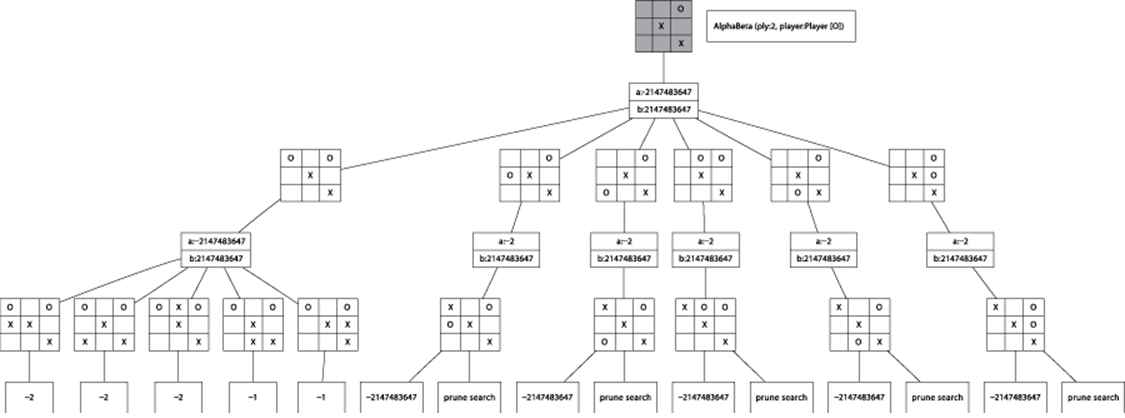
Figure 7-8. AlphaBeta two-ply search
ALPHABETA SUMMARY
Best, Average: O(bply/2) Worst: O(bply)
bestmove (s, player, opponent)
[move, score] = alphaBeta (s, ply, player, opponent, -∞, ∞) ![]()
return move
end
alphaBeta (s, ply, player, opponent, low, high)
best = [null, null]
if ply is 0 orno valid moves then ![]()
score = evaluate s for player
return [null, score]
foreach valid move m for player in state s do
execute move m on s
[move, score] = alphaBeta (s, ply-1, opponent, player,
-high, -low)
undo move m on s
if -score > best.score then
low = -score
best = [m, -low]
if low ≥ high then return best ![]()
return best
end
![]()
At start, worst player can do is lose (low=-∞). Best player can do is win (high=+∞)
![]()
AlphaBeta evaluates leaf nodes as in NegMax
![]()
Stop exploring sibling nodes when worst score possible by opponent equals or exceeds our maximum threshold
After evaluating the sub game tree rooted at (1) in Figure 7-9, AlphaBeta knows that if this move is made the opponent cannot force a worse position than -3, which means the best the player can do is score a 3. When AlphaBeta gets to the game state (2), the first child game state (3) evaluates to 2. This means that if the move for (2) is selected, the opponent can force the player into a game state that is less than the best move found so far (i.e., 3). There is no need to check sibling subtree rooted at (4), so it is pruned away.
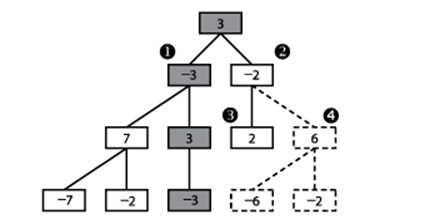
Figure 7-9. AlphaBeta sample game tree
As AlphaBeta searches for the best move in Figure 7-8, it remembers that X can score no higher than 2 if O plays in the upper-left corner. For each subsequent other move for O, AlphaBeta determines that X has at least one countermove that outperforms the first move for O (indeed, in all cases X can win). Thus, the game tree expands only 16 nodes, a savings of more than 50% from Minimax. AlphaBeta selects the same move that Minimax would have selected, with potentially significant performance savings.
AlphaBeta recursively searches through the game tree and maintains two values, α and β, that define a “window of opportunity” for a player as long as α < β. The value α represents the lower bound of the game states found for the player so far (or −∞ if none have been found) and declares that the player has found a move to ensure it can score at least that value. Higher values of α mean the player is doing well; when α=+∞, the player has found a winning move and the search can terminate.
The value β represents the upper bound of game states so far (or +∞ if none have been found) and declares the maximum value that the player can achieve. When β drops lower and lower, it means that the opponent is doing better at restricting the player’s options. Since AlphaBeta has a maximum ply depth beyond which it will not search, any decisions that it makes are limited to this scope.
The game tree in Figure 7-8 shows the [α, β] values as AlphaBeta executes; initially they are [-∞, ∞]. With a two-ply search, AlphaBeta is trying to find the best move for O when considering just the immediate countermove for X.
Because AlphaBeta is recursive, we can retrace its progress by considering a traversal of the game tree. The first move AlphaBeta considers is for O to play in the upper-left corner. After all five of X’s countermoves are evaluated, it is evident that X can ensure only a score of −2 for itself (using the static evaluation BoardEvaluation for tic-tac-toe). When AlphaBeta considers the second move for O (playing in the middle of the left column), its [α, β] values are now [-2, ∞], which means “the worst that O can end up with so far is a state whose score is −2, and the best that O can do is still win the game.” When the first countermove for X is evaluated, AlphaBeta detects that X has won, which falls outside of this “window of opportunity,” so further countermoves by X no longer need to be considered.
To explain how AlphaBeta prunes the game tree to eliminate non-productive nodes, Figure 7-10 presents a three-ply search of Figure 7-5 that expands 66 nodes (whereas the corresponding Minimax game tree would require 156 nodes).

Figure 7-10. AlphaBeta three-ply search
At the initial node n in the game tree, player O must consider one of six potential moves. Pruning can occur on either the player’s turn or the opponent’s turn. In the search shown in Figure 7-10, there are two such examples:
Player’s turn
Assume that O plays in the middle of the left column and X responds by playing in the middle of the top row (this is the leftmost grandchild of the root node in the search tree). From O’s perspective, the best score that O can force is −1 (note that in the diagram the scores are shown as 1 because AlphaBeta uses the same scoring mechanism used by NegMax). This value is remembered when it tries to determine what O can achieve if X had instead countered by playing in the middle of the bottom row. Note that [α, β] is now [−∞, −1]. AlphaBeta evaluates the result when O plays in the middle of the top row and computes the score 1. Because this value is greater than or equal to the −1 value, the remaining three potential moves for O in this level are ignored.
Opponent’s turn
Assume O plays in the middle of the left column and X responds by playing in the upper-right corner, immediately winning the game. AlphaBeta can ignore X’s two other potential moves, because O will prune the remaining nodes in the search subtree “rooted” in the decision to play in the middle of the left column.
The pruning of the search occurs when α≥β, or in other words, when the “window of opportunity” closes. When AlphaBeta is based on Minimax, there are two ways to prune the search, known as α-prune and β-prune; in the simpler AlphaBeta based on NegMax, these two cases are combined into the one discussed here. Because AlphaBeta is recursive, the range [α, β] represents the window of opportunity for the player, and the window of opportunity for the opponent is [-β, -α]. Within the recursive invocation of AlphaBeta the player and opponent are swapped, and the window is similarly swapped.
Solution
The AlphaBeta implementation in Example 7-4 augments NegMax by terminating early the evaluation of game states once it becomes clear that either the player can’t guarantee a better position (an α-prune) or the opponent can’t force a worse position (a β-prune).
Example 7-4. AlphaBeta implementation
public class AlphaBetaEvaluation implements IEvaluation {
IGameState state; /** State to be modified during search. */
int ply; /** Ply depth. How far to continue search. */
public AlphaBetaEvaluation (int ply) { this.ply = ply; }
public IGameMove bestMove (IGameState s,
IPlayer player, IPlayer opponent) {
state = s.copy();
MoveEvaluation move = alphabeta(ply, player, opponent,
MoveEvaluation.minimum(),
MoveEvaluation.maximum());
return move.move;
}
MoveEvaluation alphabeta (int ply, IPlayer player, IPlayer opponent,
int alpha, int beta) {
// If no moves, return board evaluation from player's perspective.
Iterator<IGameMove> it = player.validMoves(state).iterator();
if (ply == 0 || !it.hasNext()) {
return new MoveEvaluation (player.eval(state));
}
// Select "maximum of negative value of children" that improves alpha
MoveEvaluation best = new MoveEvaluation (alpha);
while (it.hasNext()) {
IGameMove move = it.next();
move.execute(state);
MoveEvaluation me = alphabeta (ply-1, opponent, player, -beta, -alpha);
move.undo(state);
// If improved upon alpha, keep track of this move.
if (-me.score > alpha) {
alpha = -me.score;
best = new MoveEvaluation (move, alpha);
}
if (alpha >= beta) { return best; } // search no longer productive.
}
return best;
}
}
The moves found will be exactly the same as those found by Minimax. But because many states are be removed from the game tree as it is expanded, execution time is noticeably less for AlphaBeta.
Analysis
To measure the benefit of AlphaBeta over NegMax, we compare the size of their respective game trees. This task is complicated because AlphaBeta will show its most impressive savings if the opponent’s best move is evaluated first whenever AlphaBeta executes. When there is a fixed number b of moves at each game state, the total number of potential game states to search in a d-ply AlphaBeta is on the order of bd. If the moves are ordered by decreasing favorability (i.e., the best move first), we still have to evaluate all b children for the initiating player (because we are to choose his best move); however, in the best case we need to evaluate only the first move by the opponent. Note in Figure 7-8 that, because of move ordering, the prune occurs after several moves have been evaluated, so the move ordering for that game tree is not optimal.
In the best case, therefore, AlphaBeta evaluates b game states for the initial player on each level, but only one game state for the opponent. So, instead of expanding b*b*b* … *b*b (a total of d times) game states on the dth level of the game tree, AlphaBeta may require only b*1*b* … *b*1(a total of d times). The resulting number of game states is bd/2, an impressive savings.
Instead of simply trying to minimize the number of game states, AlphaBeta could explore the same total number of game states as Minimax. This would extend the depth of the game tree to 2*d, thus doubling how far ahead the algorithm can look.
To empirically evaluate Minimax and AlphaBeta, we construct a set of initial tic-tac-toe board states that are possible after k moves have been made. We then compute Minimax and AlphaBeta with a ply of d=9-k, which ensures all possible moves are explored. The results are shown inTable 7-1. Observe the significant reduction of explored states using AlphaBeta.
Table 7-1. Statistics comparing Minimax versus AlphaBeta
|
k |
Minimax states |
AlphaBeta states |
Aggregate reduction |
Individual variation |
|
1 |
549,945 |
27,565 |
95% |
±1.3% |
|
2 |
549,936 |
47,508 |
91% |
±6.8% |
|
3 |
549,864 |
112,086 |
80% |
±10.2% |
Individual comparisons show the dramatic improvement of AlphaBeta and some of these cases explain why AlphaBeta is so powerful. On the game state shown in Figure 7-11, AlphaBeta explores only 47 game states (instead of 8,232 for Minimax, a 99.4% reduction) to determine that player X should select the center square, after which a win is assured.
Figure 7-11. Sample tic-tac-toe board after two plays
However, the only way to achieve such deep reductions is if the available moves are ordered such that the best move appears first. Because our tic-tac-toe solution does not order moves in this fashion, some anomalies will result. For example, given the same board state rotated 180 degrees (Figure 7-12), AlphaBeta will explore 960 game states (an 88.3% reduction) because it expands the game tree using a different ordering of valid moves.
Figure 7-12. Sample tic-tac-toe board after two plays, rotated
Search Trees
Games that have just one player are similar to game trees, featuring an initial state (the top node in the search tree) and a sequence of moves that transforms the board state until a goal state is reached (labeled “GOAL”). A search tree represents the set of intermediate board states as a path-finding algorithm progresses. The computed structure is a tree because the algorithm ensures that it does not visit a board state twice. The algorithm decides the order of board states to visit as it attempts to reach the goal.
We’ll explore search trees using an 8-puzzle, which is played on a three-by-three grid containing eight square tiles numbered 1 to 8 and an empty space that contains no tile. A tile adjacent (either horizontally or vertically) to the empty space can be moved by sliding it into the empty space. The aim is to start from a shuffled initial state and move tiles to achieve the goal state, as shown in Figure 7-13. The eight-move solution in Figure 7-13 is recorded as the bold path from the initial node to the goal node.
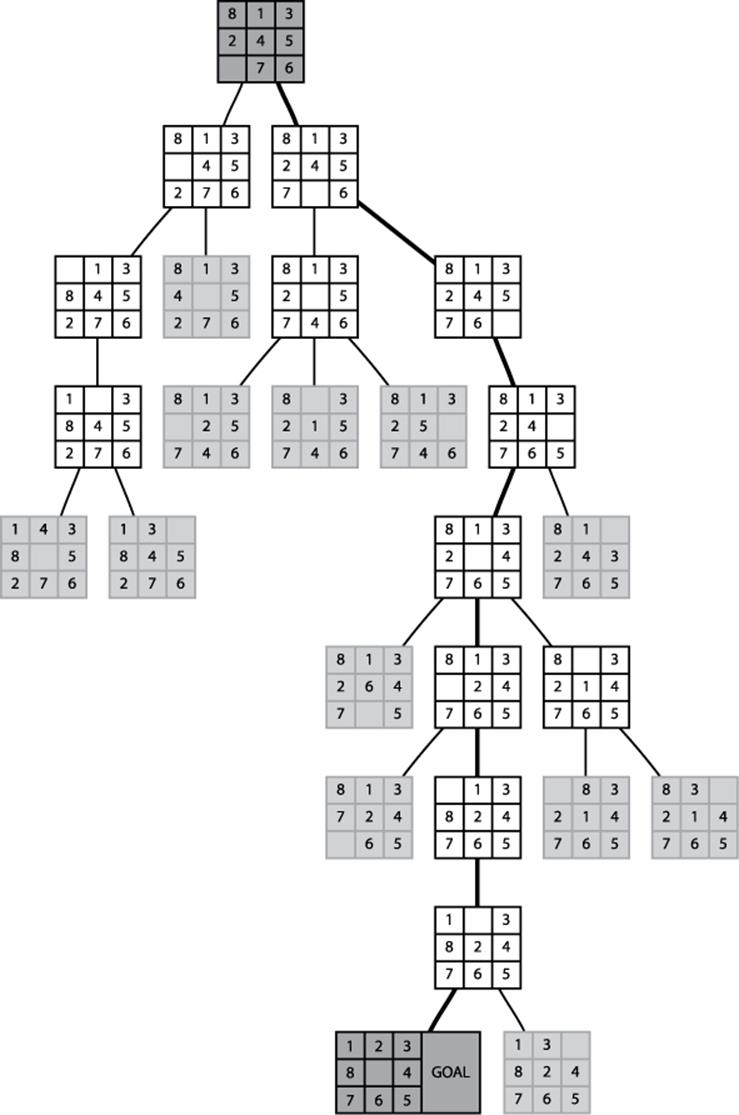
Figure 7-13. Sample 8-puzzle search
Search trees can rapidly explode to contain (potentially) millions of states. The algorithms in this chapter describe how to efficiently search through these trees more rapidly than using a blind search. To describe the inherent complexity of the problem, we introduce Depth-First Search andBreadth-First Search as two potential approaches to path-finding algorithms. We then present the powerful A*Search algorithm for finding a minimal-cost solution (under certain conditions). We’ll now briefly summarize the core classes, illustrated in Figure 7-14, that will be used when discussing search tree algorithms.
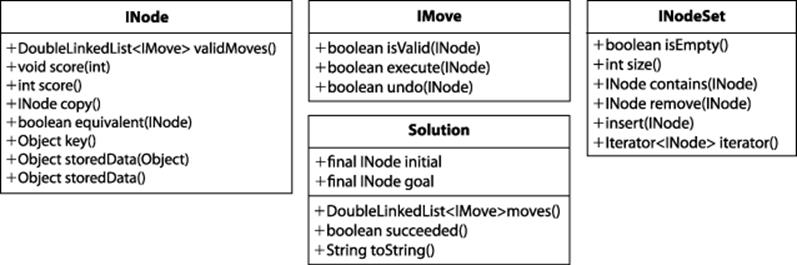
Figure 7-14. Core classes for search tree algorithms
The INode interface abstracts the essential concepts needed to conduct searches over a board state:
Generate valid moves
validMoves() returns a list of available moves for a board state.
Evaluate the board state
score(int) associates an integer score with the board state, representing the result of an evaluation function; score() returns the evaluation result previously associated with the board state.
Manage the board state
copy() returns an identical copy of the board state (except for the optional stored data); equivalent(INode) determines whether two board states are equal (sophisticated implementations may detect rotational symmetries in the board state or other means for equivalence). key()returns an object to support an equivalence check: if two board states have the same key() result, the board states are equivalent.
Managing optional board state data
storedData(Object o) associates the given object with the board state to be used by search algorithms; storedData() returns the optionally stored data that may be associated with the board state.
The INodeSet interface abstracts the underlying implementation of a set of INodes. Some algorithms require a queue of INode objects, some a stack, and others a balanced binary tree. Once properly constructed (using the StateStorageFactory class), the provided operations enable algorithms to manipulate the state of the INode set no matter the underlying data structure used. The IMove interface defines how moves can manipulate the board state; the specific move classes are problem-specific, and the search algorithm need not be aware of their specific implementation.
From a programming perspective, the heart of the path-finding algorithm for a search tree is the implementation of the ISearch interface shown in Example 7-5. Given such a solution, the moves that produced the solution can be extracted.
Example 7-5. Common interface for search tree path finding
/**
* Given an initial state, return a Solution to the final
* state, or null if no such path can be found.
*/
public interface ISearch {
Solution search (INode initial, INode goal);
}
Given a node representing the initial board state and a desired goal node, an ISearch implementation computes a path representing a solution, or returns null if no solution was found. To differentiate from game trees, we use the term board state when discussing search tree nodes.
Representing State
Typically, the board state captures all state information known at that position in the game. For example, in chess, the King can “castle” with the Rook only if (a) neither piece has yet moved, (b) the intervening two squares are empty and not currently attacked by an enemy piece, and (c) the King is not currently in check. Note that (b) and (c) can be computed directly from the board state and therefore do not need to be stored; however, the board state must separately store whether the King or Rooks have moved.
The board state stores information about the game at each node in the search tree. For games with exponentially large search trees, the state must be stored as compactly as possible. If symmetries exist in the state, such as with Connect Four®, Othello, or the 15-puzzle, the search tree can be greatly reduced by detecting and eliminating identical states that may simply be rotated or reflected. More complex representations called bitboards have been used for chess, checkers, or Othello to manage the incredibly large number of states with impressive efficiency gains (Pepicelli, 2005).
Calculate available moves
To find the best move, it must be possible at each board state to compute the available moves allowed to the player making the move. The term branching factor refers to the total number of moves that are allowed at any individual board state. For games such as tic-tac-toe, the branching factor constantly decreases from its high of nine (at the start of the game) as each mark is made. The original three-by-three Rubik’s cube has (on average) a branching factor of 13.5 (Korf, 1985), whereas Connect Four has a branching factor of 7 for most of the game. Checkers is more complicated because of the rule that a player must capture a piece if that move is available. Based on analyzing a large number of checkers databases, the branching factor for capture positions is 1.20, whereas for non-capture positions it is 7.94; Schaeffer (2008) computes the average branching factor during a game to be 6.14. The game of Go has an initial branching factor of over 360 (Berlekamp and Wolfe, 1997).
Algorithms are sensitive to the order by which the available moves are attempted. When the branching factor for a game is high but the moves are not properly ordered based upon some evaluative measure of success, blindly searching a search tree is inefficient.
Using Heuristic Information
A blind search algorithm uses a fixed strategy rather than evaluating the board state. A depth-first blind search simply plays the game forward by arbitrarily choosing the next move from available choices, but backtracks when it realizes it has made a bad decision. A breadth-first blind search methodically explores all possible solutions with k moves before first attempting any solution with k+1 moves.
There are several ways to add intelligence to the search (Barr and Feigenbaum, 1981):
Select board states to expand rather than using a fixed decision
Instead of imposing a depth-first or a breadth-first structure, a search algorithm might alternate between these two strategies.
Select the order and number of allowed moves to be applied
When considering available moves at a board state, one should first evaluate the moves that are likely to lead to a successful outcome. In addition, one might want to discard out of hand specific moves that do not seem to lead to a successful outcome.
Select board states to “prune” from the search tree
As the search progresses, new knowledge may be discovered that can be used to eliminate board states that had (at one time) been selected to be part of the search.
The most common approach is to define static evaluation functions to evaluate the game state at intermediate points in the computation, and then order the set of available moves so that moves with a higher probability of leading to a solution are tried first. However, poor evaluation functions can prevent path-finding algorithms from selecting the best moves to make. As the saying goes, “garbage in, garbage out.”
Instead of restricting the evaluation to the current board state, an evaluation function could temporarily expand the search tree a fixed number of moves and select the move that may ultimately lead to a board state with maximum benefit to the player. This is frowned upon in practice because of (a) the cost in performing the operations, and (b) the sharing of code logic between the evaluation function and the search function, which breaks the clean separation between them.
The discussion of A*Search will show sample searches over the 8-puzzle using different evaluation functions, so you can appreciate the subtle art of crafting effective functions.
A static evaluation function must take into account various features of the search tree position to return an integer score that reflects the relative strength of the position from a player’s perspective. For example, the first successful program to play checkers, developed by Arthur Samuel (1959), evaluated board positions by considering two dozen features of a game, such as the “piece advantage feature” (comparing the number of pieces a player has versus her opponent) and a “winning trade feature” (trading pieces when winning but not when losing). Clearly, a more accurate evaluation function makes the game-solving engine into a better player.
Maximum Expansion Depth
Because of limited memory resources, some search algorithms limit the extent to which they expand the search and game trees. This approach has its limits in games where a sequence of moves forms a calculated strategy. In chess, for example, a piece is often sacrificed for a potential advantage; if the sacrifice occurs at the edge of the maximum expansion, the advantageous game state would not be found. A fixed expansion depth leaves a “horizon” beyond which the search cannot see, often to the detriment of the success of the search.
Depth-First Search
Depth-First Search attempts to locate a path to the goal state by making as much forward progress as possible. Because some search trees explore a high number of board states, Depth-First Search is practical only if a maximum search depth is fixed in advance. Furthermore, loops must be avoided by remembering each state and ensuring it is visited only once.
Depth-First Search maintains a stack of open board states that have yet to be visited and a set of closed board states that have been visited. At each iteration, Depth-First Search pops from the stack an unvisited board state and expands it to compute the set of successor board states given the available valid moves. The search terminates if the goal state is reached. Any successor board states that already exist within the closed set are discarded. The remaining unvisited board states are pushed onto the stack of open board states and the search continues.
DEPTH-FIRST SEARCH SUMMARY
Best: O(b*d) Average, Worst: O(bd)
search (initial, goal, maxDepth)
if initial = goal then return "Solution"
initial.depth = 0
open = new Stack ![]()
closed = new Set
insert (open, copy(initial))
while open is notempty do
n = pop (open) ![]()
insert (closed, n)
foreach valid move m at n do
nextState = state when playing m at n
if closed doesn't contain nextState then
nextState.depth = nextState.depth + 1 ![]()
if nextState = goal then return "Solution"
if nextState.depth < maxDepth then
insert (open, nextState) ![]()
return "No Solution"
end
![]()
Depth-First Search uses a Stack to store open states to be visited
![]()
Pop the most recent state from the stack
![]()
Depth-First Search computes the depth to avoid exceeding maxDepth
![]()
Inserting the next state will be a push operation since open is a stack
Figure 7-15 shows the computed search tree for an initial 8-puzzle board state using a depth limit of 9. Note how a path of eight moves is found to the solution (marked as GOAL) after some exploration to depth 9 in other areas of the tree. In all, 50 board states were processed and 4 remain to be explored (shown in light gray). Thus, we have solved the puzzle in this case, but we cannot be sure we have found the best (shortest) solution.
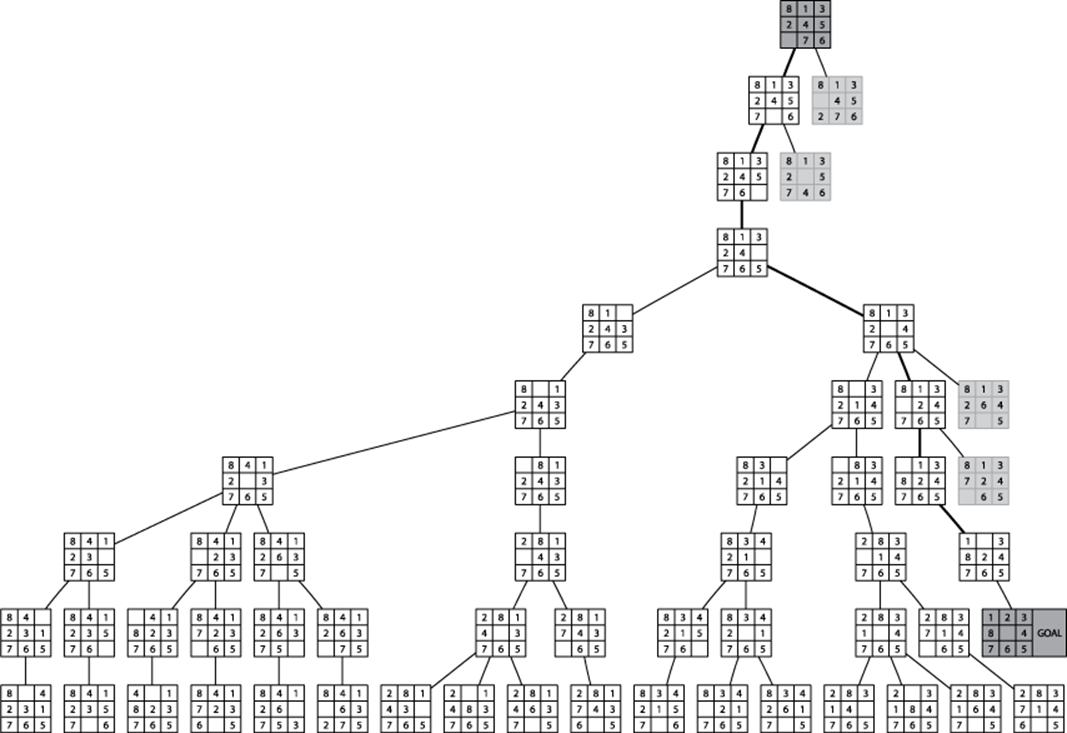
Figure 7-15. Sample Depth-First Search tree for 8-puzzle
Input/Output
The algorithm starts from an initial board state and seeks a goal state. It returns a sequence of moves that represents a path from the initial state to the goal state (or declares that no such solution was found).
Context
Depth-First Search is a blind search that is made practical by restricting the search to stop after a fixed depth bound, maxDepth, is reached, which helps manage memory resources.
Solution
Depth-First Search stores the set of open (i.e., yet to be visited) board states in a stack, and retrieves them one at a time for processing. In the implementation shown in Example 7-6, the closed set is stored in a hashtable to efficiently determine when not to revisit a board state previously encountered within the search tree; the hash function used is based on the key computed for each INode object.
Each board state stores a reference, called a DepthTransition, that records (a) the move that generated it, (b) the previous state, and (c) the depth from the initial position. The algorithm generates copies of each board state, becausee the moves are applied directly to the boards and not undone. As soon as a node is identified as the goal, the search algorithm terminates (this is true for Breadth-First Search as well).
Example 7-6. Depth-First Search implementation
public Solution search(INode initial, INode goal) {
// If initial is the goal, return now.
if (initial.equals(goal)) { return new Solution (initial, goal); }
INodeSet open = StateStorageFactory.create(OpenStateFactory.STACK);
open.insert(initial.copy());
// states we have already visited.
INodeSet closed = StateStorageFactory.create(OpenStateFactory.HASH);
while (!open.isEmpty()) {
INode n = open.remove();
closed.insert(n);
DepthTransition trans = (DepthTransition) n.storedData();
// All successor moves translate into appended OPEN states.
DoubleLinkedList<IMove> moves = n.validMoves();
for (Iterator<IMove> it = moves.iterator(); it.hasNext(); ) {
IMove move = it.next();
// Execute move on a copy since we maintain sets of board states
INode successor = n.copy();
move.execute(successor);
// If already visited, try another state
if (closed.contains(successor) != null) { continue; }
int depth = 1;
if (trans != null) { depth = trans.depth+1; }
// Record previous move for solution trace. If solution, leave now,
// otherwise add to the OPEN set if still within depth bound
successor.storedData(new DepthTransition(move, n, depth));
if (successor.equals(goal)) {
return new Solution (initial, successor);
}
if (depth < depthBound) { open.insert (successor); }
}
}
return new Solution (initial, goal, false); // No solution
}
Board states are stored to avoid visiting the same state twice. We assume there is an efficient function to generate a unique key for a board state, such that if two board states compute to the same key, then the board states are equivalent. This notion of equivalence can include board state characteristics such as symmetry. For example, the board state in Figure 7-16 is a 90-degree rotation of Figure 7-17. If they are considered equivalent and generate the same key, the search engine will not bother expanding the second one that it finds.
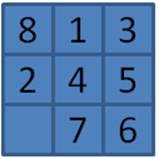
Figure 7-16. Sample board state
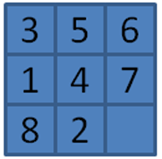
Figure 7-17. Sample board state rotated counterclockwise
Analysis
Assume that d is the maximum depth bound for Depth-First Search and define b to be the branching factor for the underlying search tree.
The performance of the algorithm is governed by problem-specific and generic characteristics. In general, the core operations provided by the open and closed sets may unexpectedly slow the algorithm down, because naïve implementations would require O(n) performance to locate a board state within the set. The key operations include:
open.remove()
Remove the “next” board state to evaluate.
closed.insert(INode state)
Add board state to the closed set.
closed.contains(INode state)
Determine whether board state already exists in closed.
open.insert(INode state)
Add board state into the open set, to be visited later.
Because Depth-First Search uses a stack to store the open set, remove and insert operations are performed in constant time. Because closed is a hashtable that stores the board states using key values (as provided by the board state class implementing INode) the lookup time is amortized to be constant.
The problem-specific characteristics that affect the performance are the (a) number of successor board states for an individual board state, and (b) the ordering of the valid moves. Some games have a large number of potential moves at each board state, which means that many depth-first paths may be ill-advised. Also, the way that moves are ordered will affect the overall search. If any heuristic information is available, make sure that moves most likely leading to a solution appear earlier in the ordered list of valid moves. Take advantage of symmetries within the board state when maintaining the closed set. Specifically, one can compute a key from a board state that is the same regardless of the rotation of the board (either 90, 180, or 270 degrees); additional symmetries exist (horizontal-flip or vertical-flip).
We evaluate Depth-First Search using a set of three examples (N1, N2, and N3) to show how capricious the search is with seemingly slight differences in state. In each example, 10 tiles are moved from the goal state. Occasionally Depth-First Search penetrates quickly to locate a solution. In general, the size of the search tree grows exponentially based upon the branching factor b. For the 8-puzzle, the branching factor is between 1.6 and 3.81, based upon where the empty tile is located (Reinefeld, 1993). We make the following two observations:
An ill-chosen depth level may prevent a solution from being found
For initial position N2 shown in Figure 7-18 and a depth of 25, no solution was found after searching 20,441 board states. How is this even possible? It’s because Depth-First Search will not visit the same board state twice. Specifically, the closest this particular search comes to finding the solution is on the 3,451st board state, which is inspected in the 25th level. That board is only three moves away from the solution! But because the board was visited just as the depth limit was reached, expansion stopped and the board was added to the closed set. If Depth-First Searchlater encountered this node again at an earlier level, it would not explore further because the node would now be in the closed set.
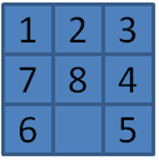
Figure 7-18. Initial position N2
It may seem better, therefore, to set the maximum depth level to be a high value; but as shown in Figure 7-19, this routinely leads to extremely large search trees and may not guarantee that a solution will be found.
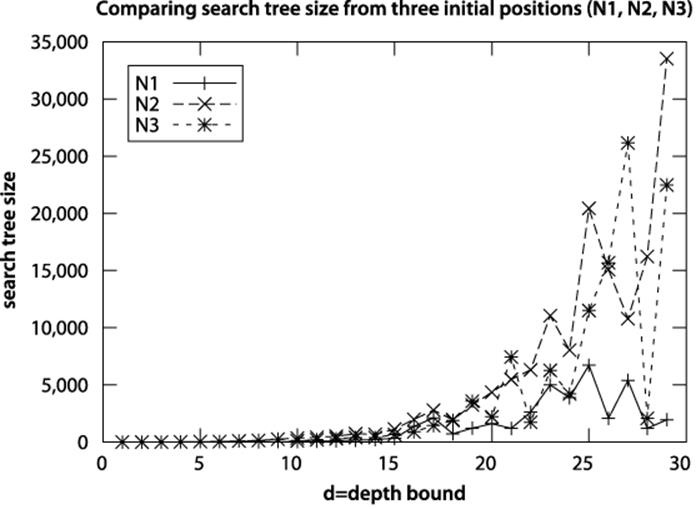
Figure 7-19. Search tree size for Depth-First Search as depth increases
As the depth level increases, the solution found may be suboptimal
The discovered solutions grow as the depth limit increases, sometimes to be two or three times larger than necessary.
Interestingly, given the example N1, an unbounded Depth-First Search actually finds a 30-move solution after processing only 30 board states, with 23 left in its open set to be processed. However, this fortunate series of events is not repeated for examples N2 and N3.
Breadth-First Search
Breadth-First Search attempts to locate a path by methodically evaluating board states closest to the initial board state. Breadth-First Search is guaranteed to find the shortest path to the goal state, if such a path exists.
BREADTH-FIRST SEARCH SUMMARY
Best, Average, Worst: O(bd)
search (initial, goal)
if initial = goal then return "Solution"
open = new Queue ![]()
closed = new Set
insert (open, copy(initial))
while open is notempty do
n = head (open) ![]()
insert (closed, n)
foreach valid move m at n do
nextState = state when playing m at n
if closed doesn't contain nextState then
if nextState = goal then return "Solution"
insert (open, nextState) ![]()
return "No Solution"
end
![]()
Breadth-First Search uses a Queue to store open states to be visited
![]()
Remove the most oldest state from the queue
![]()
Inserting the next state will be an append operation since open is a queue
The essential difference from Depth-First Search is that Breadth-First Search maintains a queue of open states that have yet to be visited, whereas Depth-First Search uses a stack. At each iteration, Breadth-First Search removes from the front of the queue an unvisited board state and expands it to compute the set of successor board states given the valid moves. If the goal state is reached, then the search terminates. Like Depth-First Search, this search makes sure not to visit the same state twice. Any successor board states that already exists within closed is discarded. The remaining unvisited board states are appended to the end of the queue of open board states, and the search continues.
Using the example from the 8-puzzle starting at Figure 7-20, the computed search tree is shown in Figure 7-21. Note how a solution is found with five moves after all paths with four moves are explored (and nearly all five-move solutions were inspected). The 20 light-gray board states in the figure are board states in the open queue waiting to be inspected. In total, 25 board states were processed.
Figure 7-20. Starting board for Breadth-First Search
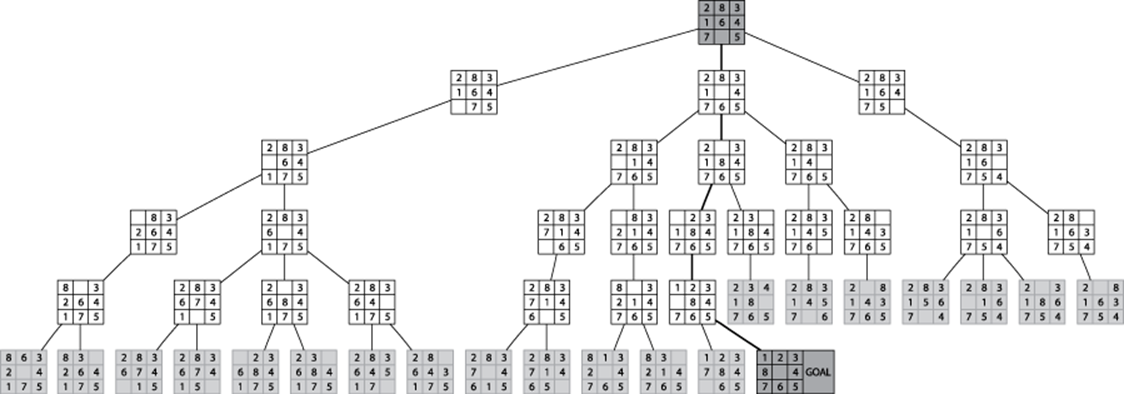
Figure 7-21. Sample Breadth-First Search tree for 8-puzzle
Input/Output
The algorithm starts from an initial board state and seeks a goal state. It returns a sequence of moves that represents a minimal-cost solution from the initial state to the goal state (or declares that no such solution was found given existing resources).
Context
A blind search is practical only if the predicted search space is within the memory space of the computer. Because Breadth-First Search methodically checks all shortest paths first, it may take quite a long time to locate paths that require a large number of moves. This algorithm may not be suitable if you need only some path from an initial state to the goal (i.e., if there is no need for it to be the shortest path).
Solution
Breadth-First Search stores the set of open (i.e., yet to be visited) board states in a queue, and retrieves them one at a time for processing. The closed set is stored using a hashtable. Each board state stores a back link, called a Transition, that records the move that generated it and a reference to the previous state. Breadth-First Search generates copies of each board state, because moves are applied directly to the boards and not undone. Example 7-7 shows the implementation.
Example 7-7. Breadth-First Search implementation
public Solution search(INode initial, INode goal) {
// Return now if initial is the goal
if (initial.equals(goal)) { return new Solution (initial, goal); }
// Start from the initial state
INodeSet open = StateStorageFactory.create(StateStorageFactory.QUEUE);
open.insert(initial.copy());
// states we have already visited.
INodeSet closed = StateStorageFactory.create(StateStorageFactory.HASH);
while (!open.isEmpty()) {
INode n = open.remove();
closed.insert(n);
// All successor moves translate into appended OPEN states.
DoubleLinkedList<IMove> moves = n.validMoves();
for (Iterator<IMove> it = moves.iterator(); it.hasNext(); ) {
IMove move = it.next();
// make move on a copy
INode successor = n.copy();
move.execute(successor);
// If already visited, search this state no more
if (closed.contains(successor) != null) {
continue;
}
// Record previous move for solution trace. If solution, leave
// now, otherwise add to the OPEN set.
successor.storedData(new Transition(move, n));
if (successor.equals(goal)) {
return new Solution (initial, successor);
}
open.insert(successor);
}
}
}
Analysis
As with Depth-First Search, the algorithm’s performance is governed by problem-specific and generic characteristics. The same analysis regarding Depth-First Search applies here, and the only difference is the size of the set of open board states. Breadth-First Search must store on the order of bd board states in open, where b is the branching factor for the board states and d is the depth of the solution found. This is much higher than Depth-First Search, which needs to store only about b*d board states in open at any one time, based upon the actively pursued board state at depth d. Breadth-First Search is guaranteed to find the solution with the least number of moves that transform the initial board state to the goal board state.
A*Search
Breadth-First Search finds an optimal solution (if one exists), but it may explore a tremendous number of nodes because it makes no attempt to intelligently select the order of moves to investigate. In contrast, Depth-First Search tries to rapidly find a path by making as much progress as possible when investigating moves; however, it must be bounded because otherwise it may fruitlessly search unproductive areas of the search tree. A*Search adds heuristic intelligence to guide its search rather than blindly following either of these fixed strategies.
A*Search is an iterative, ordered search that maintains a set of open board states to explore in an attempt to reach the goal state. At each search iteration, A*Search uses an evaluation function f*(n) to select a board state n from open whose f*(n) has the smallest value. f*(n) has the distinctive structure f*(n)=g*(n)+h*(n), where:
§ g*(n) estimates the length of the shortest sequence of moves from the initial state to board state n
§ h*(n) estimates the length of the shortest sequence of moves from n to the goal state
Thus f*(n) estimates the length of the shortest sequence of moves from initial state to goal state, passing through n. A*Search checks whether the goal state is reached only when a board state is removed from the open board states (differing from Breadth-First Search and Depth-First Search, which check when the successor board states are generated). This difference ensures that the solution represents the shortest number of moves from the initial board state.
A*SEARCH SUMMARY
Best: O(b*d) Average, Worst: O(bd)
search (initial, goal)
initial.depth = 0
open = new PriorityQueue ![]()
closed = new Set
insert (open, copy(initial))
while open is notempty do
n = minimum (open)
insert (closed, n)
if n = goal then return "Solution"
foreach valid move m at n do
next = state when playing m at n
next.depth = n.depth + 1
if closed contains next then
prior = state in closed matching next
if next.score < prior.score then ![]()
remove (closed, prior) ![]()
insert (open, next)
else
insert (open, next) ![]()
return "No Solution"
end
![]()
A*Search stores open states in a priority queue by f* evaluated score
![]()
A*Search might revisit a state that now has a lower f* score…
![]()
… so remove old state from closed so it can be revisited
![]()
Since open is a priority queue, next is inserted based on its f* score
The asterisk (*) refers to the use of heuristic information (this is how the algorithm was first defined in 1968), thus f*(n), g*(n), and h*(n) are estimates of the actual costs f(n), g(n), and h(n), which are unknown until a solution is found. In short, having a low f*(n) score suggests that the board state n is close to the final goal state.
The most critical component of f*(n) is the heuristic evaluation that computes h*(n), because g*(n) can be computed on the fly by recording with each board state its depth from the initial state. Note that g*(n) ≥ g(n) because there may, in fact, be a shorter move sequence that achieves the same board state. If h*(n) is unable to accurately separate promising board states from unpromising board states, A*Search will perform no better than the blind searches already described. When h*(n) can provide an accurate estimate such that 0≤h*(n)≤h(n) and g*(n)≥g(n), f*(n) can locate a minimal-cost solution.
Input/Output
The algorithm starts from an initial board state in a search tree and a goal state. It assumes the existence of an evaluation function f*(n). It returns a sequence of moves that represents the solution that most closely approximates the minimal-cost solution from the initial state to the goal state (or declares that no such solution was found given existing resources).
Context
Using the example from the 8-puzzle starting at Figure 7-22, two computed search trees are shown in Figure 7-23 and Figure 7-24. Figure 7-23 uses the GoodEvaluator f*(n) function proposed by Nilsson (1971). Figure 7-24 uses the WeakEvaluator f*(n) function also proposed by Nilsson. The light-gray board states depict the open set when the goal is found.
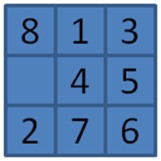
Figure 7-22. Starting board state for A*Search
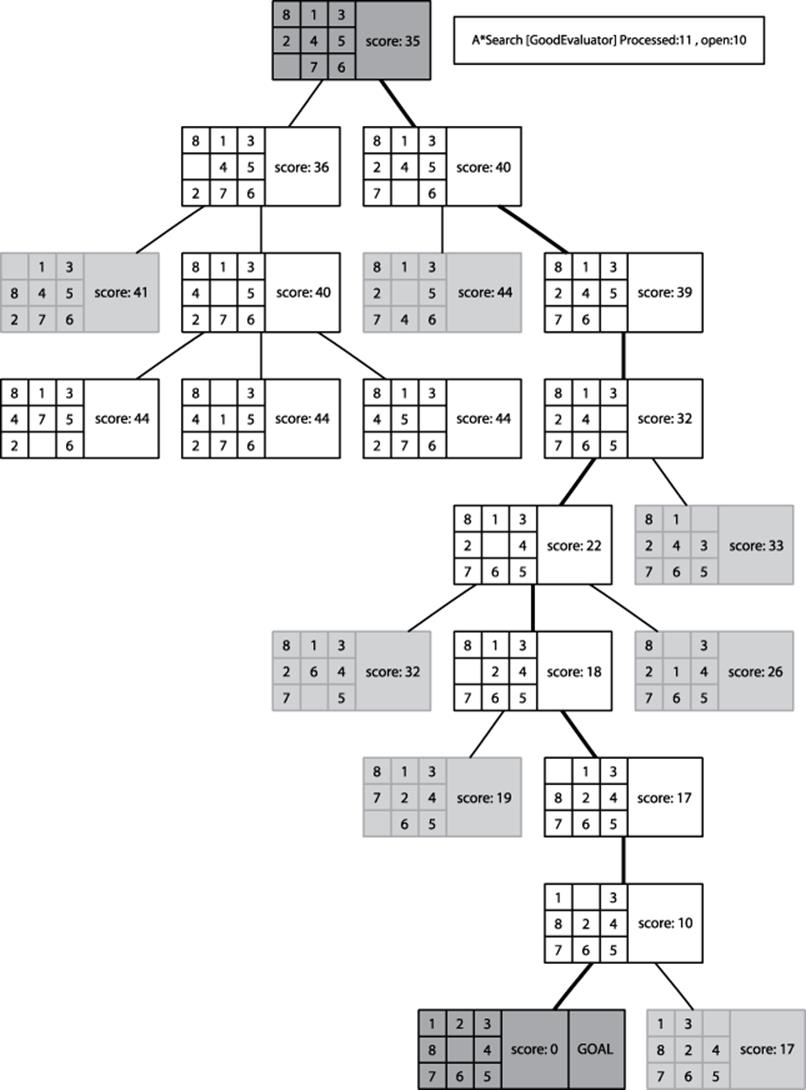
Figure 7-23. Sample A*Search tree in 8-puzzle using GoodEvaluator f*(n)
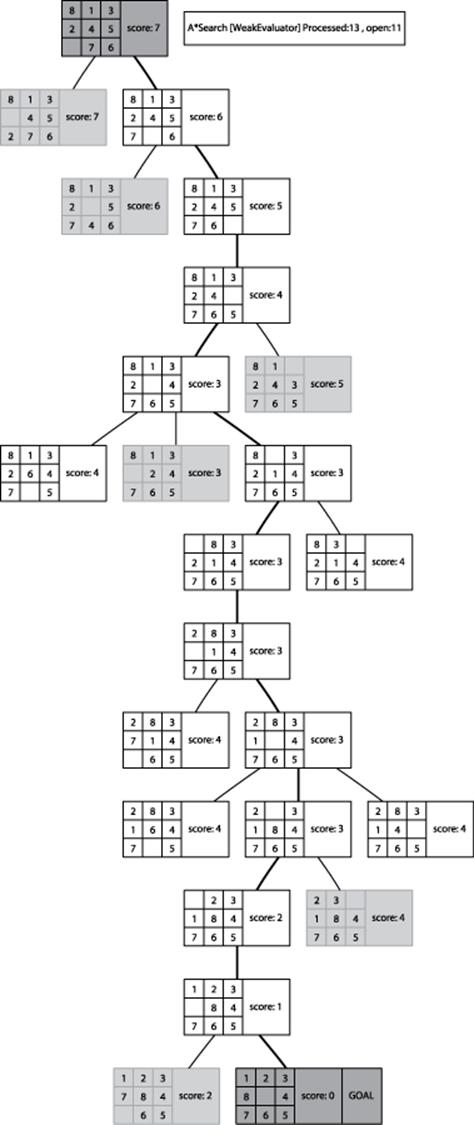
Figure 7-24. Sample A*Search tree in 8-puzzle using WeakEvaluator f*(n)
Both GoodEvaluator and WeakEvaluator locate the same eight-move solution to the goal node (labeled “GOAL”) but GoodEvaluator is more efficient in its search. Let’s review the f*(n) values associated with the nodes in both search trees to see why the WeakEvaluator search tree explores more nodes.
Observe that just two moves away from the initial state in the GoodEvaluator search tree, there is a clear path of nodes with ever-decreasing f*(n) values that lead to the goal node. In contrast, the WeakEvaluator search tree explores four moves away from the initial state before narrowing its search direction. WeakEvaluator fails to differentiate board states; indeed, note how its f*(n) value of the goal node is actually higher than the f*(n) values of the initial node and all three of its children nodes.
The h*(n) component of f*(n) must be carefully designed, and this effort is more of a craft than a science. h*(n) must be efficient to compute; otherwise, the search time becomes onerous. Much of the available A*Search literature describes highly specialized h*(n) functions for different domains, such as route finding on digital terrains (Wichmann and Wuensche, 2004) or project scheduling under limited resources (Hartmann, 1999). Pearl (1984) has written an extensive (and unfortunately out-of-print) reference for designing effective heuristics. Korf (2000) discusses how to design admissible h*(n) functions (defined in the following section). Michalewicz and Fogel (2004) provide a recent perspective on the use of heuristics in problem solving, not just for A*Search.
Solution
A*Search stores the open board states as a balanced binary tree so it can efficiently remove the board state whose evaluation function is smallest. Example 7-8 contains a sample Java implementation.
Example 7-8. A*Search implementation
public Solution search(INode initial, INode goal) {
// Start from the initial state
INodeSet open = StateStorageFactory.create(StateStorageFactory.TREE);
INode copy = initial.copy();
scoringFunction.score(copy);
open.insert(copy);
// Use Hashtable to store states we have already visited.
INodeSet closed = StateStorageFactory.create(StateStorageFactory.HASH);
while (!open.isEmpty()) {
// Remove node with smallest evaluation function and mark closed.
INode n = open.remove();
closed.insert(n);
// Return if goal state reached.
if (n.equals(goal)) { return new Solution (initial, n); }
// Compute successor moves and update OPEN/CLOSED lists.
DepthTransition trans = (DepthTransition) n.storedData();
int depth = 1;
if (trans != null) { depth = trans.depth+1; }
DoubleLinkedList<IMove> moves = n.validMoves(;
for (Iterator<IMove> it = moves.iterator(); it.hasNext(); ) {
IMove move = it.next();
// Make move and score the new board state.
INode successor = n.copy();
move.execute(successor);
// Record previous move for solution trace and compute
// evaluation function to see if we have improved upon
// a state already closed
successor.storedData(new DepthTransition(move, n, depth));
scoringFunction.score(successor);
// If already visited, see if we are revisiting with lower
// cost. If not, just continue; otherwise, pull out of closed
// and process
INode past = closed.contains(successor);
if (past != null) {
if (successor.score() >= past.score()) {
continue;
}
// we revisit with our lower cost.
closed.remove(past);
}
// place into open.
open.insert (successor);
}
}
// No solution.
return new Solution (initial, goal, false);
}
As with Breadth-First Search and Depth-First Search, board states are entered into the closed set when processed. Each board state stores a back link, called a DepthTransition, to record (a) the move that generated it, (b) a reference to the previous board state, and (c) the depth from the initial position. That last value, the depth, is frequently used as the g*(n) component within the evaluation function. The algorithm generates copies of each board state, because the moves are applied directly to the boards and not undone.
Because A*Search incorporates heuristic information that includes a g*(n) computational component, there is one situation when A*Search may review a past decision on boards already visited. A board state to be inserted into the open set may have a lower evaluation score than an identical state that has already been visited. If so, A*Search removes the past board state from closed because that state may be part of the minimum-cost solution. Recall the situation in Depth-First Search where board states at the depth limit were found to be (as it turned out) only three moves away from the goal state (Analysis). These board states were placed into the closed set, never to be processed again. In A*Search, if these same board states are revisited with a lower evaluated score, they become available again.
The success of A*Search is directly dependent upon its heuristic function. If h*(n) is always zero, A*Search is nothing more than Breadth-First Search. Furthermore, if h*(n) > h(n), A*Search may not be able to find the optimal solution, although it may be possible to return some solution, assuming that h*(n) is not wildly off the mark.
One should use A*Search only if you can find a heuristic function h*(n) that is admissible. A heuristic function is admissible if 0≤h*(n) ≤h(n). There are two sides to this constraint. If h*(n) ever returns a negative number (stating, somehow, that the board state n is “past” the goal state), the contribution of g*(n) is negated when computing f*(n). If h*(n)>h(n), the estimate is too high and A*Search may not find the optimal solution. However, it is difficult to determine an effective h*(n) that is admissible and that can be computed effectively. There are numerous examples of inadmissible h*(n) that still lead to solutions that are practical without necessarily being optimal.
A*Search will find an optimal solution if its heuristic function h*(n) is admissible. For the 8-puzzle, Table 7-2 shows the evaluation of three heuristic functions:
GoodEvaluator
P(n) + 3*S(n), where P(n) is the sum of the Manhattan distances that each tile is from “home.” S(n) is a sequence score that checks the non-central squares in turn, allotting 0 for every tile followed by its proper successor and 2 for every tile that is not; having a piece in the center scores 1.
WeakEvaluator
Counts the number of misplaced tiles.
BadEvaluator
Takes the sum of differences of opposite cells (across from the center square) and compares them against the ideal of 16. Ignores the center cell and treats empty tile as 0.
These three functions evaluated the sample board state in Figure 7-25, with the results shown in Table 7-2.
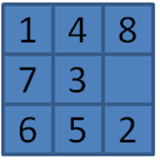
Figure 7-25. Sample board state for evaluation functions
Table 7-2. Comparing three evaluation h*(n) functions
|
Measure name |
Evaluation of h*(n) |
Statistics |
|
GoodEvaluator |
13+3*11=46 |
13-move solution closed:14 open: 12 |
|
WeakEvaluator |
7 |
13-move solution closed:145 open:110 |
|
BadEvaluator |
(7−0) + (6−8) + (5−4) + (2−1) = 7 Score is abs(16-7)=9 |
421-move solution closed: 2499 open: 1583 |
Breadth-First Search and Depth-First Search inspect the closed set to see whether it contains a board state, so we used a hash table for efficiency. However, A*Search may need to reevaluate a board state that had previously been visited if its evaluated score function is lower than the current state. Therefore, a hash table is not appropriate because A*Search must be able to rapidly locate the board state in the open priority queue with the lowest evaluation score.
Note that Breadth-First Search and Depth-First Search retrieve the next board state from the open set in constant time because they use a queue and a stack, respectively. If we stored the open set as an ordered list, performance suffers because inserting a board state into the open set takes O(n). Nor can we use a binary heap to store the open set, because we don’t know in advance how many board states are to be evaluated. Thus, we use a balanced binary tree, which offers O(log n) performance, where n is the size of the open set, when retrieving the lowest-cost board state and for inserting nodes into the open set.
Analysis
The computational behavior of A*Search is entirely dependent upon the heuristic function. Russel and Norvig (2003) show that if |h(x)-h*(x)|≤log h*(x), the performance is O(d), where d reflects the distance to the computed solution, rather than O(bd), where b represents the branching factor for the search tree. However, this condition is rather hard to satisfy; GoodEvaluator, which works so well for the 8-puzzle, for example, does not meet this criterion.
As the board states become more complex, heuristic functions become more important than ever—and more complicated to design. They must remain efficient to compute, or the entire search process is affected. However, even rough heuristic functions are capable of pruning the search space dramatically. For example, the 15-puzzle, the natural extension of the 8-puzzle, includes 15 tiles in a four-by-four board. It requires but a few minutes of work to create a 15-puzzle GoodEvaluator based upon the logic of the 8-puzzle GoodEvaluator. With the goal state of Figure 7-26 and an initial state of Figure 7-27, A*Search rapidly locates a 15-move solution after processing 39 board states. When the search ends, 43 board states remain in the open set waiting to be explored, as shown in Figure 7-28.
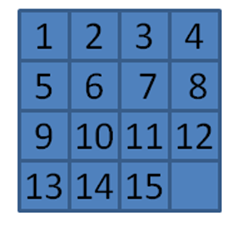
Figure 7-26. Goal for 15-puzzle
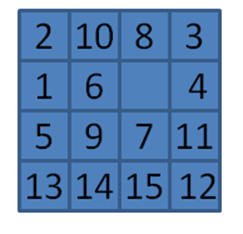
Figure 7-27. Sample starting board for 15-puzzle

Figure 7-28. Sample A*Search tree for 15-puzzle
With a 15-move limit, Depth-First Search fails to locate a solution after exploring 22,125 board states. After 172,567 board states (85,213 in the closed set and 87,354 remaining in the open set), Breadth-First Search runs out of memory when using 64MB of RAM to try the same task. Of course, you could add more memory or increase the depth limit, but this won’t work in all cases since every problem is different.
But do not be fooled by how easily A*Search solved this sample 15-puzzle; A*Search runs out of memory when attempting a more complicated initial board, such as Figure 7-29.
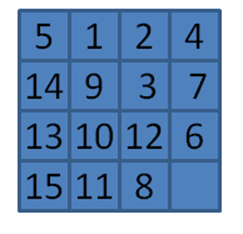
Figure 7-29. Complicated starting board for 15-puzzle
Clearly the rough evaluation function for the 15-puzzle is ineffective for the 15-puzzle, which has over 1025 possible states (Korf, 2000).
Variations
Instead of only searching forward from the initial state, Kaindl and Kain (1997) propose to augment this search by simultaneously searching backwards from the goal state. Initially discarded by early AI researchers as being unworkable, Kaindl and Kainz have presented powerful arguments that the approach should be reconsidered.
A common powerful alternative to A*Search, known as IterativeDeepeningA* (or IDA*), relies on a series of expanding depth-first searches with a fixed cost bound (Korf 1985). For each successive iteration, the bound is increased based upon the results of the prior iteration. IDA* is more efficient than Breadth-First Search or Depth-First Search alone because each computed cost value is based on actual move sequences rather than a heuristic estimate. Korf (2000) has described how powerful heuristics, coupled with IDA*, have been used to solve random instances of the 15-puzzle, evaluating more than 400 million board states during the search process.
Barr and Feigenbaum (1981) present several alternatives to consider when one cannot efficiently compute an admissible h*(n) function.
Although A*Search produces minimal-cost solutions, the search space may be too large for A*Search to complete. The major ideas that augment A*Search and address these very large problems include:
Iterative deepening
This state search strategy uses repeated iterations of limited depth-first search, with each iteration increasing the depth limit. This approach can prioritize the nodes to be searched in successive iterations, thus reducing nonproductive searching and increasing the likelihood of rapidly converging on winning moves. Also, because the search space is fragmented into discrete intervals, real-time algorithms can search as much space as allowed within a time period and return a “best effort” result. The technique was first applied to A*Search by (Korf, 1985) to create IDA*.
Transposition tables
To avoid repeating computations that have already proved fruitless, one can hash game states and store in a transposition table the length of the path (from the source state) needed to reach each state. If the state appears later in the search, and its current depth is greater than what was discovered earlier, the search can be terminated. This approach can avoid searching entire subtrees that will ultimately prove to be unproductive.
Hierarchy
If the game state can be represented as a hierarchy, rather than as a flat model, techniques can be applied to restructure large search spaces into clusters, over which A*Search can be run. Hierarchical Path-Finding A* (HPA*) is an example of this approach (Botea et al., 2004).
Memory-bounded
Instead of restricting the search space by computation time, one could perform a “lossy” search and throw away various nodes as the search progresses, focusing on searches within areas that are deemed relevant. Simplified Memory Bounded A* (SMA*) is an example (Russel, 1992).
Reinefeld and Marsland (1994) summarize a variety of interesting extensions to A*Search. Much information on the use of A*Search in AI systems is available in textbooks and various online sources (Barr and Feigenbaum, 1981).
Comparing Search Tree Algorithms
Breadth-First Search is guaranteed to find the solution with the least number of moves from the initial state, although it may evaluate a rather large number of potential move sequences as it operates. Depth-First Search tries to make as much progress as possible each time it searches, and may locate a solution rather quickly, but it also may waste a lot of time on searching parts of the search tree that seem to offer no hope for success. A*Search, if paired with a good evaluation function, takes the least time and often finds the best solution, but finding a good function may be difficult.
It is thus worthwhile to compare Depth-First Search, Breadth-First Search, and A*Search directly. Using the 8-puzzle as our sample game, we created an initial state by randomly moving n tiles (ranging from 2, 4, 8, and 16); note that the same tile will not be moved twice in a row, because that would “undo” the move. Once n reached 32, the searches ran out of memory. For each board state, we execute Breadth-First Search, Depth-First Search(n), Depth-First Search(2*n), and A*Search. For each move size n:
§ We total the number of board states in the open and closed lists. This reveals the efficiency of the algorithm in locating the solution. The columns marked with # contain the average of these totals over all runs. This analysis focuses on the number of states searched as the prime factor in determining search efficiency.
§ We total the number of moves in the solution once found. This reveals the efficiency of the found solution paths. The columns whose names begin with s contain the average of these totals over all runs. The number in parentheses records the number of trials that failed to locate a solution within the given ply depth.
Table 7-3 contains the aggregate results of 1,000 trials, where n random moves were made (n=2 through 14). Table 7-3 shows two statistics: (a) the average number of states of the generated search trees, and (b) the average number of moves of the identified solutions.
Table 7-3. Comparing search algorithms
|
n |
#A* |
#BFS |
#DFS(n) |
#DFS(2n) |
sA* |
sBFS |
sDFS(n) |
sDFS(2n) |
|
2 |
5.0 |
4.5 |
3 |
6.2 |
2 |
2 |
2 |
2 |
|
3 |
7.0 |
13.3 |
7.1 |
27.7 |
3 |
3 |
3 |
3 |
|
4 |
9.0 |
25.6 |
12.7 |
67.9 |
4 |
4 |
4 |
5.1 |
|
5 |
11.0 |
46.7 |
20.8 |
179.2 |
5 |
5 |
5 |
5.9 |
|
6 |
12.5 |
77.3 |
31.8 |
319.5 |
6 |
6 |
6 |
9.4 (45) |
|
7 |
14.9 |
136.7 |
57.9 |
758.1 |
6.8 |
6.8 |
6.9 |
9.8 (294) |
|
8 |
17.0 |
217.1 |
90.7 |
1124.3 |
7.7 |
7.7 |
7.9 (49) |
12.9 (199) |
|
9 |
22.6 |
369.2 |
149.7 |
2577.3 |
8.9 |
8.7 |
8.8 (74) |
12.8 (357) |
|
10 |
25.9 |
567.6 |
206.8 |
3065.4 |
9.7 |
9.6 |
9.7 (216) |
16.4 (281) |
|
11 |
32.8 |
911.7 |
285.6 |
7033.8 |
10.5 |
10.3 |
10.5 (430) |
17.1 (356) |
|
12 |
42.0 |
1405.2 |
457.4 |
6104 |
11.9 |
11.3 |
11.7 (364) |
20.5 (423) |
|
13 |
54.8 |
2355.8 |
558.5 |
12346 |
13.3 |
12.2 |
12.2 (624) |
21.8 (308) |
|
14 |
60.1 |
3424.9 |
912.5 |
14079.1 |
14.4 |
12.9 |
13.4 (611) |
25.3 (251) |
Note that as n increases by one, the size of the search tree grows exponentially for all blind approaches, but the A*Search tree remains manageable. To be precise, the growth rates of these blind searches are estimated by the following functions:
BFS(n) ≅ 2.0*(n+1)2.6158
DFS(n) ≅ 1.43*(n+1)2.275
DFS(2n) ≅ 3.18*(n+1)3.164
Breadth-First Search always finds the shortest path to the solution, but note that A*Search is not far behind (because of the GoodEvaluator heuristic) even though it explores significantly fewer board states. In separate trials of A*Search with up to 30 random moves, the growth rate of the search tree was O(n1.5147); although not linear, this size is significantly smaller than for the blind searches. The actual exponent in each of these growth rate functions is dependent upon the branching factor for the problem being solved. The results of Table 7-3 are shown graphically inFigure 7-30.
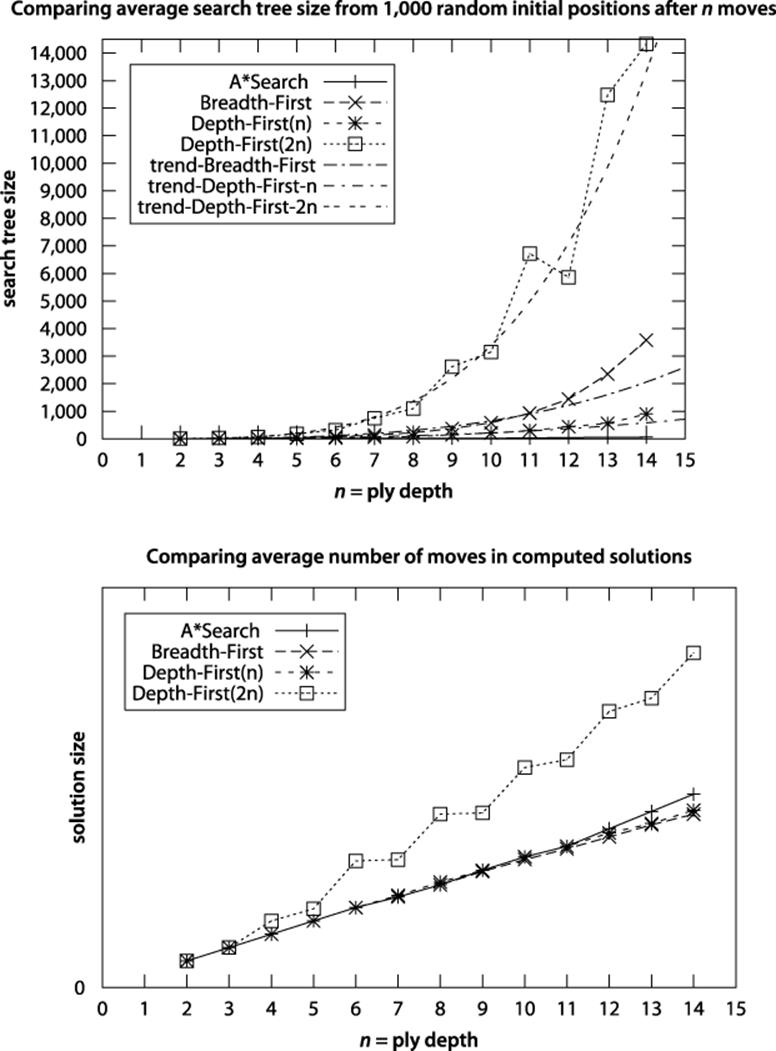
Figure 7-30. Comparing search tree size for random positions
Finally, note how the horizon effect prevents Depth-First Search from solving numerous cases (recall this happens when a board state node that is only a step away from the goal is added to the closed set). In fact, in this example run of 1,000 trials, Depth-First Search failed more than 60% of the time when using a maximum depth bound of 13.
Although all three searches have the potential to explore an exponential number of states, A*Search explores the smallest number given an admissible h*(n) estimation function.
There are other known ways to solve n2−1 sliding tile puzzles besides relying on path finding. One ingenious approach proposed by Parberry (1995) is to use Divide and Conquer. That is, given an n-by-n puzzle, where n > 3, first complete the leftmost column and topmost row and then recursively solve the resulting (n−1)2−1 puzzle. When the inner problem to be solved is the three-by-three square, simply use brute force. This approach is guaranteed to find a solution that uses at most 5*n3 moves.
References
Barr, Avron and Edward A. Feigenbaum, The Handbook of Artificial Intelligence. William Kaufmann, Inc., 1981.
Berlekamp, Elwyn and David Wolfe, Mathematical Go: Chilling Gets the Last Point. A. K. Peters Ltd., May 1997.
Botea, A., M. Müller, and J. Schaeffer, “Near Optimal Hierarchical Path-finding,” Journal of Game Development, 1(1), 2004, http://www.jogd.com/Vol1issue1.html.
Hartmann, Sonke, Project Scheduling Under Limited Resources: Models, Methods, and Applications. Springer, 1999.
Kaindl, Hermann and Gerhard Kainz, “Bidirectional Heuristic Search Reconsidered,” Journal of Artificial Intelligence Research, Volume 7: 283–317, 1997.
Korf, Richard E., “Depth-First Iterative-Deepening: An Optimal Admissible Tree Search,” Artificial Intelligence, Volume 27: 97–109, 1985, http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.91.288.
Korf, Richard E., “Recent Progress in the Design and Analysis of Admissible Heuristic Functions,” Proceedings, Abstraction, Reformulation, and Approximation: 4th International Symposium (SARA), Lecture notes in Computer Science #1864: 45–51, 2000.
Laramée, François Dominic, “Chess Programming Part IV: Basic Search,” GameDev.net, August 26, 2000, http://www.gamedev.net/reference/articles/article1171.asp.
Michalewicz, Zbigniew and David B. Fogel, How to Solve It: Modern Heuristics, Second Edition. Springer, 2004.
Nilsson, Nils, Problem-Solving Methods in Artificial Intelligence. McGraw-Hill, 1971.
Parberry, Ian, “A Real-Time Algorithm for the (n2−1)-Puzzle,” Information Processing Letters, Volume 56: 23–28, 1995, http://www.eng.unt.edu/ian/pubs/saml.pdf.
Pearl, Judea, Heuristics: Intelligent Search Strategies for Computer Problem Solving. Addison-Wesley, 1984.
Pepicelli, Glen, “Bitwise Optimization in Java: Bitfields, Bitboards, and Beyond,” O’Reilly on Java.com, February 2, 2005, http://www.onjava.com/pub/a/onjava/2005/02/02/bitsets.html.
Reinefeld, Alexander, “Complete Solution of the Eight-Puzzle and the Benefit of Node Ordering in IDA*,” Proceedings of the 13th International Joint Conference on Artificial Intelligence (IJCAI), Volume 1, 1993, http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.40.9889.
Reinefeld, Alexander and T. Anthony Marsland, “Enhanced Iterative-Deepening Search,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 16(7): 701–710, 1994. http://citeseer.ist.psu.edu/article/reinefeld94enhanced.html.
Russel, Stuart, “Efficient memory-bounded search methods,” Proceedings, 10th European Conference on Artificial Intelligence (ECAI): 1–5, 1992.
Russell, S. J. and P. Norvig, Artificial Intelligence: A Modern Approach. Prentice Hall, 2003.
Samuel, Arthur, “Some Studies in Machine Learning Using the Game of Checkers,” IBM Journal 3(3): 210–229, http://www.research.ibm.com/journal/rd/033/ibmrd0303B.pdf.
Schaeffer, Jonathan, “Game Over: Black to Play and Draw in Checkers,” Journal of the International Computer Games Association (ICGA), http://www.cs.unimaas.nl/icga/journal/contents/Schaeffer07-01-08.pdf.
Schaeffer, Jonathan, Neil Burch, Yngvi Björnsson, Akihiro Kishimoto, Martin Müller, Robert Lake, Paul Lu, and Steve Sutphen, “Checkers is Solved,” Science Magazine, September 14, 2007, 317(5844): 1518–1522, http://www.sciencemag.org/cgi/content/abstract/317/5844/1518.
Shannon, Claude, “Programming a Computer for Playing Chess,” Philosophical Magazine, 41(314), 1950, http://tinyurl.com/ChessShannon-pdf.
Wichmann, Daniel R. and Burkhard C. Wuensche, “Automated Route Finding on Digital Terrains,” Proceedings of IVCNZ, Akaroa, New Zealand, pp. 107–112, November 2004, http://www.cs.auckland.ac.nz/~burkhard/Publications/IVCNZ04_WichmannWuensche.pdf.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.