Information Security A Practical Guide: Bridging the gap between IT and management (2015)
CHAPTER 8. MAPPING DATA IN THE SYSTEM
Chapter Overview
Ask why a system needs to be secure and the answer will almost always be the data that resides on that system. Add in the fact that most services consist of more than one system and we can assume that our data could reside in multiple places and we may have more than one dataset with a different level of value. So if it’s the data we are trying to protect and it may be in more than one place then it makes sense that we need to map where it is. This chapter uses a similar technique to the previous chapter so I recommend reading that first.
Understanding the location of data is important when considering where the threats are. If multiple threats could attack a service with data that is sensitive then that service needs to be further secured. If a service contains level-sensitive data then we may choose to live with the risks, but unless we know the value of the information and where it is we won’t know which parts of the system to secure.
This chapter shows you a simple technique to document where the data is and understand where more than one dataset may reside together.
Objectives
In this chapter you will learn the following:
• How to map data in your system.
Mapping Data
You can map data by following a similar technique to modelling our threats. To keep the diagram concise you will need a separate diagram. As such I have removed the threat actors from the previous diagram in Chapter 7 and added the data locations:
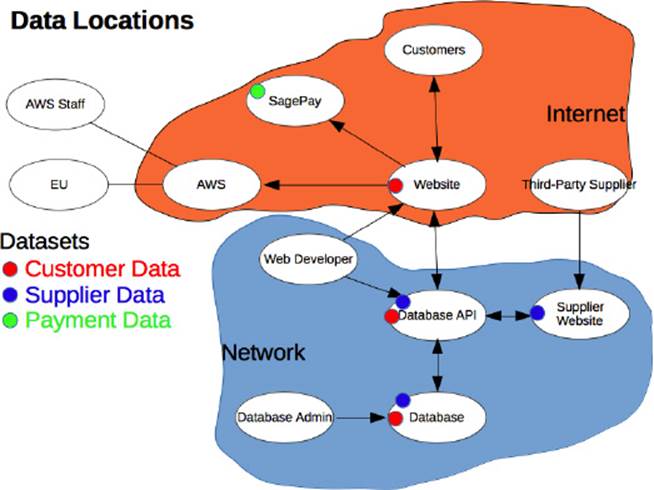
As with the threats diagram I have added markers to show where data not only resides but also passes through. Remember that data in transit is just as much at risk as data at rest. Why hack the database when you can tap the website and intercept the data before it is sent to the database? For this example I identified three key datasets: Customer data, Supplier data and Payment data.
Customer data is all data relating to the customer, such as identity information and order details (excluding card details) including things like wish lists and viewed data. This data is first entered into the website, which is then sent to the Database API where it is sent to be stored in the database. Interms of logic I would expect some basic validation to be done on the website so details are complete and the right length and so on. The real validation comes from the Database API where checks ensure no duplication and that details are valid, for example address details actually exist. Customer data is sensitive in that it identifies a citizen and is considered personal data, which means it is protected by the Data Protection Act.
Supplier data is all data relating to the supplier, so details about the specific supplier but also information about the items they want to sell. These details much like customer data undergo simple website validation before being passed to the Database API for more intensive processing and validation before being stored in the database. This data is less sensitive because item details are public information anyway as they are publicly accessible. Supplier details are also less sensitive as these details are often in the public domain since the company will want to raise its public profile.
Payment data is data relating to the card payments for website transactions. This data only resides with SagePay; customers enter the data directly into SagePay and do not enter payment data into our website before we send it off for processing. This data model makes this very clear and ensures the PCI DSS regulations do not apply to us.
The payment details are the least of my concern because they are separate and never come into our possession. The other two datasets do concern me, however, especially where they reside on the same system in the Database API and Database. The aggregation of these datasets makes these two systems tempting targets and means they need further protection. Moreover, as I suggested in Chapter 7 we may want a separate Customer and Supplier database API system. Had we not completed this exercise we would not have realised that.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.