Crafting the Infosec Playbook (2015)
Chapter 6. Operationalize!
“Everybody has a plan until they get punched in the face.”
Mike Tyson
Everything up to this point, the ideas and questions in the first five chapters, has served to prepare you to create a playbook you can deploy. Your playbook should reflect that you’ve asked relevant questions and built a plan and plays that are as unique as your organization and its assets. Your playbook should reflect that you identified what threats to look for, what assets and information you intend to protect, how to lay out the architecture, how to prepare the data, and how to get the logs flowing. That plan is now ready for operationalization! This chapter will explain, by way of example, how to put your plan into action, how to avoid operational problems, and how to keep it running smoothly.
To really make it work, we’ll discuss some key questions throughout the chapter to ready your playbook for real-world security operations. These questions are core to keeping the playbook a living thing:
§ How can I determine the amount of resources needed to analyze the entire playbook?
§ What systems will I need in place to make my plan work?
§ How can I manage a living playbook?
§ How can I avoid operational problems?
§ How can I make reporting and alerting more efficient?
Simply having a playbook and detection logic is not enough. Your plays must actually run to generate results, those results must be analyzed, and remedial actions must be taken for malicious events. Operationalizing your security monitoring requires solid planning to transition from a set of ideas and requirements into a reliable, measurable, and sustainable functional system.
As South Park has so aptly dramatized, commercial organizations are infamous for skipping the critical, central step of understanding how to execute business plans. The “Gnomes” episode of the animated sitcom illustrates the problem of an incomplete business plan, with their version:
§ Phase 1: Collect underpants
§ Phase 2: ?
§ Phase 3: Profit
In your business plan, the playbook is phase 1. However, unlike the underpants gnomes, you will develop a strategy for your incident response team to achieve success in your monitoring program in phase 2. Regular review and analysis of security event reports from your log management systems will lead to incident detection. The whole point of the playbook is to create a framework that can be applied to real data. The execution, phase 2, is to accurately detect and respond to security incidents leveraging the intelligence and analysis described in your plays. We can convert ideas about detection into actionable items for a team of analysts like opening a tracking case, contacting a sysadmin, or notifying an escalation team. In phase 3, you’ll finally enjoy the profits in the form of well-documented, well-measured, and well-vetted incident detection data that proves your incident response team is capable, effective, and worth the investment to protect your organization.
We want to continue to open the black box that is productized one-size-fits-all security monitoring. Be wary of claims by security product vendors that their tools can do it all. You cannot rely exclusively on canned and opaque logic developed by a third party. When a report returns event data, you should be able to understand why and what to do with it. The types of threats you face, the trends you see in your own environment, and the pressures applied by your management chain determine how you interpret success with the playbook. Your priorities should be to improve the successful detection rate, build reports and queries that are more efficient, justify technology expenditures, and ensure your analysts have adequate resources to analyze results.
PLAYBOOKS CAN’T RESPOND TO INCIDENTS ON THEIR OWN
The playbook is only a plan. It doesn’t find incidents on its own, nor can it predict what issues may arise once deployed into action. There are real-world challenges to consider.
The following are questions we ask of our plays time and again; keep these topics in mind while considering how to operationalize your playbook:
§ Scheduling (Is real time necessary? Are there enough analysts to keep up with the event flow?)
§ What detection metrics are you required to show?
§ Do you have a sufficient process to guide you from detection idea to problem remediation?
§ How do you avoid duplicate cases from repeated alarms?
§ What will you do about changing escalation paths, staff turnover, and analyst responsibilities that require adjustments to your playbook processes?
§ What mitigating capabilities and supporting policies exist to allow you to take action on confirmed malicious events?
We’ll explore some answers to these questions in the following sections, but it’s important to thoroughly understand your business requirements and try to anticipate future requirements before actually building new systems and processes.
You Are Smarter Than a Computer
Even in a utopian world where you have a fully automatic detection and response system, at some point a human must take an action. Whether that’s validating the detections, working on an incident case, contacting a client, or dealing with remediation, there will always be a place for the human security analyst. Automation speeds up the response process and removes additional work required by analysts. However, haphazardly querying log data for unusual events does not always lend well to automation. The path to high fidelity (and thereby more efficiency) is paved by developing, investigating, and tweaking reports until their logic is a guaranteed detector of malicious behavior, and each result can be confirmed a true positive.
Developing reports to detect malicious behavior is only the beginning of a play’s lifecycle and doesn’t cover the full breadth of operationalizing the playbook. Those same reports must be maintained as part of the responsibilities of a security monitoring team. As threats evolve, old reports will fade from relevancy, while newer, more appropriate reports will be created and deployed. Trends in threats help analysts identify areas of the organization that need additional protection, architecture review, or alternative detection tactics, including developing new reports. Even if you were somehow able to defend all your systems and detect all of the threats you face today, the pace of technology ensures we will face something new tomorrow. By including regular maintenance of plays as an integral part of your group’s operations, you’ll keep the playbook fresh with new threat detection techniques and plays that will prepare you for the current threats as they unfold.
People, Process, and Technology
People are the integral part of these processes you’re developing as part of your security monitoring service. No computer or program can replace context-informed human analysis. Unlike flowchart-style decision making like computer software, humans can effectively reason, consult (and develop) contextual indicators, and analyze motivation or other human idiosyncrasies.
Bruce Schneier has said, “Security is a process, not a product”. Supporting your monitoring process requires analysts, data managers, and infrastructure support personnel. You’ll have to determine either how many of those different resources you need, or how best to use the resources you already have. Figuring out how many people are necessary to operationalize your playbook requires taking measurements at various stages in the system. For example:
§ How many alarms are collected every day?
§ How long does it take on average to analyze an alarm or an entire report?
§ Is each report always analyzed in its entirety?
§ Are we spending enough time revisiting the validity of our older reports?
§ What is the projected volume of security alarms in the future, and what would we do in the event of a major outbreak?
§ Is the staff skilled enough to understand our report results?
§ What role do analysts play in remediation efforts, and what about incident recidivism?
§ Can plays be run automatically, or do they require human interaction to retrieve results?
All of these are factors to consider when attempting to put the plan into action, and can help you predict how much analysis work will be necessary. For our own playbook, we regularly revisit these questions to ensure we’re resourcing our program correctly and have appropriate and accurate coverage. We posed these questions because they have had significant resonance with our own playbook deployment. Outbreaks must be handled differently from typical infections to triage properly and ensure the right groups are engaged. Insufficient communication with the IT teams has led us to remediation expediency issues. Some of our early reports created so many results requiring investigation that it was impossible for some analysts to complete their review in a workday.
WARNING
Automate your playbook systems to ensure results are delivered to the analysts. More complex analysis may not lend itself well to automation if the investigation process involves disparate data sources or data across incompatible tools. However, the majority of your saved queries should stand on their own. Ad-hoc approaches to reports can work well for a quick look or query development, but an automatic schedule of report delivery ensures consistent handling and saves the analysts’ time by avoiding any operations. An analyst can simply review the results that have been prepared based on logic from the play and with data from various event sources.
For most reports in your playbook, eventually a human (team) has to review the result data output from the playbook. This is no different from any other security monitoring approach. SIEM, log management, or managed security solutions all require eyes on a screen and cases to document. To keep up with security threats, maintain situational awareness, and ensure proper response, it’s unreasonable to have a network engineer or system administrator work “on security” part-time, as is common practice.
NOTE
Operationalizing your playbook demands additional work processes to go from ideas to security alarms to incident response.
You will need at least one dedicated and full-time human to analyze your security event data.
There are some important considerations to review when (re)establishing your incident response process and working with an analysis team. It’s important to understand how many people and what skills you require for an analysis team. Look for some set of skills that spans topics like threat-centric or security knowledge, computer networking, application layer protocols, databases and query languages, Unix, Windows, basic parsing and command-line familiarity (bash, grep), security monitoring tools (IDS), and basic troubleshooting. Depending on the volume and complexity of data, the network, policies, and the incident response expectations, a small organization may be able to retain only two or three analysts, while a larger corporation could staff dozens.
For organizations with too few dedicated security analysts, the actual available headcount may define with what frequency and what volume alerts can be handled per day or week. Ideally, organizations are staffed to run and process all defined reports, with enough flexibility for new reports to be created and analyzed. Even so, a full staff does not guarantee a complete lack of resource saturation. Resources may be less available during incidents, outbreaks, holidays, or because of sick or personal time off. During these time periods, it is important to provide remaining staff with a prioritization for each report. Priority may be defined because of service-level agreements (SLAs) or regulatory controls, to detect a recent threat, or by event severity. Priorities must be identified so that less critical reports can be temporarily ignored until staffing levels return to normal.
At Cisco, we process millions of log events each day from various event sources, although not all of them require a follow-up investigation. With an insufficient number of analysts, we wouldn’t be able to keep the playbook running sustainably. That is to say, our staff could analyze the reports we already have, but there would be no time for tuning, adjustment, or creating new plays. A playbook can be created and executed, but making some of these considerations regarding staff before enacting anything official improves the potential success. It’s difficult to know precisely how many analysts are required because many of the previous questions cannot be fully answered until the playbook is already in action and measurements taken. A phased approach allows for an ease into the playbook process and routine, and provides early metrics that can help adjust to anything, like the workload, before it’s a completely baked-in process.
Proper IT operations are also critical to support the tools and processes on which your monitoring depends. If analysts depend on running queries and daily reports, the query and reporting system had better be available every day! Given that log analysis is a full-time job, it’s not wise to expect the analysts to be exclusively responsible for monitoring and detecting system health and uptime. An incident response team requires some division of labor to ensure that the complex system runs efficiently and doesn’t overburden the analysts with system administration and housekeeping tasks. Analysts should understand those systems and how they yield the log and event data, but log analysis and incident handling demand significant attention and should be their primary focus.
With regard to analysts and staffing, your options essentially boil down to:
§ Paying a managed security service a regular subscription fee to “do your security,” with little to no context about your network; the service might, however, handle a broad spectrum of security beyond incident response (e.g., vulnerability scanning)
§ Tasking a part-time “security person” to work on a best-effort security monitoring system (e.g., a SIEM) when they have time
§ Hiring a sufficient number of security analysts and tailoring your security operations to your business requirements
§ Calling in an emergency response team after your organization has been compromised
The first two are best effort and may work for very small networks and homogenous environments. However, the third option gives everyone else the most flexibility, the most options (i.e., in-house, relevant metrics) for describing the return on investment, and most importantly, maximum efficacy and overall security. Calling a professional, but temporary, incident response team after the fact will stop the bleeding and may offer helpful consultation, but in the end, the organization is left with the specter of a future compromise whether or not newly recommended controls are deployed. Having the ability to respond to your own incidents, and having as much detail available before it happens, provides total control to an organization when a security incident occurs.
Organizations turn to managed or contracted security services for many reasons, not the least of which are cost and the practicality of running a well-staffed internal security organization. What you save in cost, however, you lose in accuracy and precision when it comes to incident response. Almost anyone can read the output of a SIEM report, but what matters is what happens after the results are delivered. Only with solid context and an understanding of the network can an analyst truly understand the impact of an incident, or even whether to escalate it at all. Beyond the context, a good analyst understands the holistic structure of the organization, its mission, its tolerance for risk, and its culture.
Trusted Insiders
In most incident response teams, the more experienced members naturally serve as the top tier of the escalation chain, while the more junior members are still learning the work. At Cisco, we chose to split the team into two groups—investigators and analysts. Both roles support security monitoring and incident response services; however, the job responsibilities differ.
Investigators handle the long-term investigations, cases involving sensitive or high-profile systems or victims, and escalations from the analysts. This senior team also shapes the incident response strategy and detection methodologies. The analysts are responsible for analyzing and detecting security events in monitoring reports generated from various data sources. Their role involves extensive interaction with the investigators, along with other InfoSec and IT teams to help improve network security and monitoring fidelity.
Playing good defense requires an understanding of the offense’s potential moves. Analysts must understand:
§ Your organization’s environment
§ Software and system vulnerabilities
§ Which threats matter and why
§ How attacks work
§ How to interpret data from playbook reports
§ How to detect new threats
If the primary job is to respond to results from playbook reports, analysts are expected to understand the alarm and why it fired and respond accordingly. Event investigations, often with little context, require critical thinking and connecting the dots between bits of data to make a case, and call upon the analysts’ ability to grasp the situation in its entirety.
For our analyst staff, we look for individuals who display an ability and desire to learn. Security is a mindset, not a skill set.
NOTE
Problem solving, troubleshooting, and critical thinking are more important than knowing a lot of technical minutiae.
Their breadth of experience along with help from others within the team provides a solid foundation for playbook development. The analysts are responsible for owning the playbook: keeping it updated by creating new plays, analyzing results from existing plays, and tuning reports and techniques as necessary. Analysts that are more senior advise and help develop and edit new plays, while assisting in providing context from institutional knowledge.
Don’t Quit the Day Job
Creating new plays is arguably the most important aspect of the analyst’s role. We expect analysts to understand not only how to find suspicious events, but also to understand why it’s important to do so. Fundamental knowledge of security principles coupled with real IT experience is the first step in understanding the need for security monitoring and incident response. To develop additional plays, analysts need to be in tune with what’s happening in the security community. Knowing how to detect the most current or significant threats requires reading about and understanding the latest attack methods, subscribing to security research blogs, Twitter/RSS feeds, and other sources of security information, and then regularly running sample checks against internal log data. Analysts don’t have to understand every component, mutex, registry change, and process launched by a particular malware object, but they must be able to answer the following questions:
§ What’s our risk to the new threat?
§ How does it arrive on a victim host?
§ What signatures does it exhibit that can be used to detect again?
§ How do we confirm a compromise?
§ What’s the best course of action to take for remediation?
§ How can we detect and stop it in the future?
These elements make up the bulk of a new play, and clearly expounding on them in the play objective, analysis, and notes will make it easier for the other analysts to understand the original researcher’s logic.
When it comes to log analysis, the staff must understand the alerts described in log data, or be able to determine when an event is irrelevant. Of course, they could rely on the more senior staff to guide their understanding of tools and analysis techniques, but they are empowered as our first line of defense for detecting malicious behavior. As long as data keeps flowing, the first-tier analysts can review all the predefined security reports and respond appropriately. Having worked hundreds of incidents, it’s clear to us that there are countless examples to learn from. For every security event, we want analysts to have a broad set of experiences to draw from. If something looks bad, they try to come up with hypotheses for how it could be legitimate and then test them against the event and surrounding context. If an event looks normal or benign, we do the opposite. We encourage the analysts to always try to understand both ends of the possible explanation spectrum. This helps to guide the level of response and investigation necessary for each report.
For example, what if you created a report (using a regular expression) that detects suspicious HTTP posts, yet some of the results are clearly not malicious? First-tier analysts don’t necessarily have to fully understand or translate the regular expression in English to realize the event may not be a true positive after reviewing additional attributes of the log (e.g., hostname, URL, source IP, etc.). Thinking about the alarm and what is already defined in the play’s objective, analysts might consider the regular expression imprecise, or perhaps a client coincidentally retrieved a URL that matched the expression perfectly, yet was hosted at a benign domain.
This is where the tuning and updating portion of the analyst’s role comes into play. After analyzing the results, the analysts must be able to incorporate their findings into the playbook notes. We expect that confirmed false positives and notes on how to improve a query will be added to the play as it goes through its regular and ongoing review. The analysts can make their future tasks easier and more efficient by suggesting and implementing tuning of their reports, based on evidential findings in the result data. Tuning ideas and report enhancements are best discussed in regular analyst meetings, so the whole team understands not only what might be changing, but also to understand how they can help optimize other reports. In our experience, group collaboration for event tuning benefits everyone, and makes the detection methods more precise.
Critical Thinking
Besides understanding which events to ignore, analysts must understand when a questionable event is indicative of something more significant. Putting a host on the Internet guarantees it will be probed. Actual web application attacks often look like common web vulnerability scanners; however, common application scanners are often a prelude to many actual, customized attacks. From data logs, skilled analysts should be able to differentiate web application attacks that match the pattern or technique of a commonly available vulnerability scanner or commercial penetration test suite, from attacks that are more directed, might have been successful, or could have a negative impact on a web service. A seasoned sysadmin or webmaster could likely determine the fidelity of the alarm, but we also expect that a good analyst could deduce the propriety of most log messages based on their skills and research.
For our first-tier analysts, we look for these types of analytical skills to ensure quality monitoring and less time wasted on unnecessary process. Analysts must understand why it matters if a host sends repeated failed login requests to a domain controller, or if a client resolves domains on a blacklist. We can prescribe tasks and workflows as explicitly as possible in the analysis section of the play, but there will always be a need for critical thinking, articulation, and a deeper understanding than pattern matching and machine learning.
We can teach security concepts, but understanding how all the moving pieces fit together in a complicated system requires hands-on experience. To mentor junior staff, support your monitoring design, architect new monitoring solutions, and set the threat detection strategy, you need experience. An ideal candidate for a higher-tier team will have a practical, if not operational, background in InfoSec and skill sets rooted in system and network administration, security research, or secure application development. Security events happen on hosts and over networks, against applications running on those hosts, and can involve the entire stack supporting a product infrastructure. Highly skilled system and network engineers understand how to properly build and maintain enterprise systems and networks. Presumably then, they also know how to recognize when the same systems are built or operating improperly or insecurely.
All this assumes you have super-talented, critical-thinking, and well-seasoned analysts. It also assumes that you have the capacity and budget to have such a staff. A staff of one analyst will rely on automation much more than a larger team, and will spend most of their time investigating events that cannot be automated. More often than not, we’re asked to “do more with less.” Because the cost of labor is expensive, hiring a large team of skilled analysts may be out of reach. Although there’s no avoiding the requirement of having at least one full-time analyst for anything but a tiny network, there are steps you can take (depending on the maturity and capability of IT services) with automation that will lessen the impact of insufficient staff. Specifically, focusing on automating high-fidelity events and leveraging some feed-based plays (e.g., sinkhole services, bad domain lists, and filename indicators) will free up time for more investigatory work.
Systematic Approach
We’ve got the plan, we’ve got the right people, and now it’s time to start analysis. To get to analysis and step 3 (profit) of the South Park “Gnomes” example, we need a few more components of the framework in place. Although there are a myriad of methods for achieving a successful data-centric monitoring approach, fundamentally our playbook strategy requires:
§ A playbook management system
§ A log and event query system
§ A result display or presentation system
§ A case tracking system
§ A remediation process system
As you define and design these systems, consider where you might consolidate some of these functions to simplify operational overhead. Although the playbook management system or repository is largely independent, the query and presentation systems may be combined naturally as report results are presented from the log query system after a search. We’ll get into more detail on these systems in the following sections. The key requirement is coherent, repeatable, and explicit report presentation and analysis.
NOTE
We cannot stress enough the importance of building in your core metrics from the beginning of development, rather than attempting to bolt it on at the end.
Figure 6-1 details the various processes and provides example metrics that can, and likely should be, collected at each step.
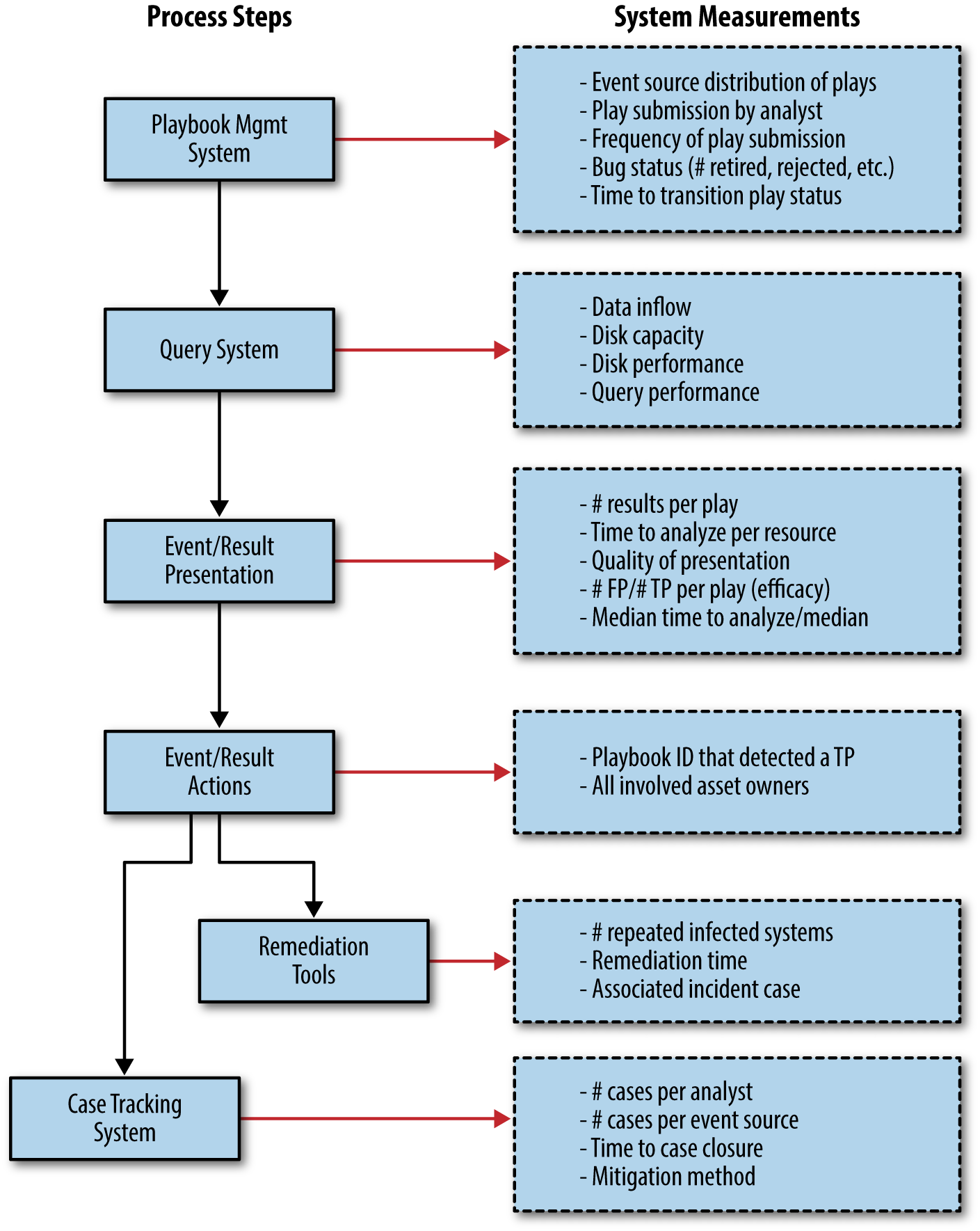
Figure 6-1. Security monitoring process and example metrics
Playbook Management System
As mentioned in Chapter 5, Cisco’s CSIRT uses Bugzilla as its playbook management software. Before moving to a more formalized playbook management process, the analysts were already using and familiar with Bugzilla for IPS tuning and process/report adjustment requests. We didn’t need anything fancy, and we didn’t need an expensive commercial tool with tons of features. We needed a quick ramp up and a tracking system that was easy to use. Bugzilla is not necessarily designed for our purpose (it’s meant for tracking bugs in software development projects), but it works well (Figure 6-2). It is capable of meeting our requirements for maintaining and managing the playbook. Namely, it has the ability to:
§ Create custom fields
§ Track play progress and lifecycle
§ Provide basic notification (email, RSS, etc.)
§ Run queueing and assignment functions
§ Automate reports and metrics
§ Document and log changes
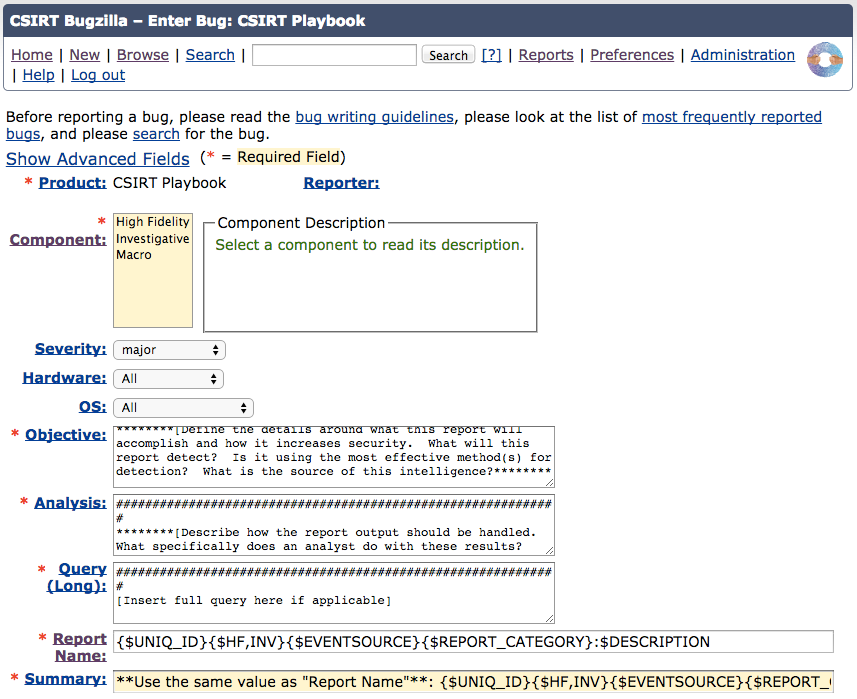
Figure 6-2. Using Bugzilla for playbook management
We can create free text fields to track different attributes (report name, objective, analysis, query). We can track which analysts submitted which reports. The status of each report can be toggled from “submitted” all the way to “retired” or even “reopened.” Bugzilla’s comment section allows our team to collectively track feedback, event samples, tactical changes, and tuning for each report. Over time, the evolution and history of the report can be clearly observed by reading the comment section.
Each of these fields allows us to measure various components of the playbook. At this point in the process, we have no indication of how many results each report generates, how long it takes the reports to run, or which analyst is analyzing which report. However, there are some metrics worth capturing:
§ Frequency of new report submission
§ Distribution of reports over data sources
§ Progress of discussion and preparation for new plays
§ Time to deployment
You don’t want to leave any cards on the table, so any event source that can be used for detection should have plays in the playbook. The report naming structure described in Chapter 4, with specific numerical ranges identifying each event source, demonstrates the distribution of reports across your event sources. However, the goal should not necessarily be to strive for an even distribution of plays across event sources. If one event source excels at detecting the majority of events or the most common threats in your environment, then by all means build as much logic as you can based on that event source. The same advice applies for targeted attack methods. You should invest in the most effective tools first.
To maximize efficiency, ideally you want the most results with the least amount of cost and effort. To achieve that, you need to focus on the right data sources and measure efficacy on a continual basis. In addition to ensuring a layered approach to monitoring by incorporating as many tools into your plays as reasonable, identifying which tools are being used in which plays can help to justify a return on investment (ROI) for new or particularly expensive tools. Still, if you’re asked to prove a new security technology was worth the investment, it’s handy to have quick access to any and all reports based on the event source through a quick Bugzilla search.
Security event monitoring is a constantly changing practice, and to ensure that you’re protected from tomorrow’s threats, you must continually develop new and relevant plays. Measuring the rate of report submission is one way to identify how successfully you’re addressing new or different threats. Haven’t had a new report submitted in over 30 days? Maybe it’s because the analysts are overextended and have had no time for new play creation, or it could be that your team has fallen behind the times.
Measure Twice, Cut Once, Then Measure Again
Plays should go through a QA process before they are fully integrated into production. When first submitted, the plays are open for feedback, restructuring, improvement, and tuning. When deemed production worthy by informal consensus, the plays are moved to a deployed state. Over time, a play may become obsolete for a variety of reasons, including an expired threat, a policy change rendering the detection logic unnecessary, or too little efficacy for the resources required to analyze the play. When obsolete, you should transition the report to a retired state.
Measuring the time to transition between submitted and deployed states can highlight whether reports have received adequate quality assurance (QA). Reports requiring extensive QA may be indicative of other problems—an ill-defined report, a lack of QA effort, or difficulty resolving the play’s objective. It’s also possible that an objective is too complex, or has too many variables that cannot be addressed in a single report. Measuring the time to deploy can also help determine if there are any issues slowing the process of converting detection methods to actions. If play approvals are stuck for weeks in the same state (e.g., “In Progress”), there may be a problem in getting play approval completed properly. Further analysis of the report and initial comments can help spot weaknesses in the process, which can be further addressed by better education or more staffing.
Our playbook contains the collection of statuses shown in Table 6-1, used throughout the lifecycle of a play (Bugzilla bug).
|
Status |
Meaning |
|
NEW |
Submitted for review |
|
IN-PROGRESS |
The QA team is reviewing the bug |
|
DEPLOYED |
The QA team has accepted the bug and the associated query has been moved to the production event query system |
|
REJECTED |
The QA team concluded that the particular bug is not a valid or an acceptable entry to the playbook |
|
RETIRED |
The bug and associated playbook item have been decommissioned |
|
ASSIGNED-TO |
The bug is assigned to a higher-tier analyst for review and long-term ownership |
|
Table 6-1. Report status |
|
Report Guidelines
We have explicitly defined how the playbook review process works and communicated that information to the incident response team. Everyone has an expectation of what makes a good play, and how to turn a good play into a great one.
During the QA process, the team will often reference the checklists presented in Tables 6-2 through 6-4 to ensure that the fundamental questions about a play’s efficacy and reliability have been addressed.
|
Technical accuracy and effectiveness |
§ Does the threat still exist or is the objective still worthwhile? § Does the existing report accurately address the report objective? |
|
Goal and query rot |
§ Is the report criteria (domains, IP addresses, URLs, etc.) still an indicator of malicious activity? § Has the threat evolved enough that criteria should be changed / added / removed? |
|
Current accuracy |
§ Do we have reason to believe the report is missing malicious activity due to a bug, gap in logs, or other technical issue? § Does mitigating an issue affect our ability to detect malicious behavior via the current data source? § Does the analysis section of the report contain sufficient detail that it’s clear how to analyze the bulk of the report’s results? |
|
Future efficacy and goal coverage |
§ Could the report ever produce future results, or has the criteria decayed to the point that it’s useless? § Can any derivative reports be created based off similar, but updated, new, or related threat information? |
|
Table 6-2. Checklist for report accuracy |
|
|
Report quality and cost |
§ Do the report results require expertise or experience to analyze, which limit the number of people capable of analyzing the report effectively? |
|
Documentation and result quality |
§ Is it possible to distinguish between false and true positives, or are there results where there’s no simple way to tell? Can the analysis section be improved to address this? |
|
Cost-benefit trade-offs |
§ Can reasonable tweaks be made to the report that will reduce false positives without affecting true positives? § Are there false negatives that could be converted to true positives without significantly increasing false positives? |
|
Table 6-3. Checklist for report cost and quality |
|
|
Efficient and complete result presentation |
§ Are all of the fields useful for analysis? If not, do they provide vital event context? Are there any useful fields that could be added? § Can context be added from other data sources that would significantly aid the result analysis? |
|
Fields and context |
§ If the report uses a formatting macro, is it the best one to use? If not, is there a good one to use? |
|
Data summarization and aggregation |
§ Are there redundant events that could be collapsed into a single event, or are there ways to aggregate events by a field such that related events could be analyzed together? |
|
Table 6-4. Checklist for report presentation |
|
Reviewing High-Fidelity Reports in Theory
High-fidelity reports, by definition, don’t produce any false positives. Without false positives, there is very little downside or resource expenditure for running the report. As long as a high-fidelity report is technically accurate and the targeted threat still exists, there is no reason to retire a high-fidelity report. Often, as high-fidelity reports age, it is common not to receive any results for weeks or months at a time. When a report hasn’t returned results in a long time, it can be difficult to tell if that’s because the report or the data source is broken, or if the specific threat the report looks for simply hasn’t shown up in a while. Determining the reason requires more research into the threat. Any information about the threat that can help reviewers should be referenced in the bug. While researching the current state of the threat, be on the lookout for new variants or similar threats that could be targeted by new reports.
Reviewing Investigative Reports in Theory
Unlike high-fidelity reports, investigative reports are often quite complicated, and the variety of results that could show up can be staggering. In addition to all of the technical report criteria, investigative reports must be evaluated on a subjective cost-benefit basis.
The cost of an investigative report primarily comes in the form of time spent by analysts reviewing the results to find the actionable, true positive events. The more results in a report, especially false positives, the higher the cost. There is no objective way to compare costs to benefits, so any effort to compare them must be based on a subjective estimation of the threat to the company and the value of the time spent by the report. Even though the cost-benefit ratio of an investigative report is subjective, any measures that can reduce the number of false positives without affecting usable results are clearly beneficial. The same goes for any measure that can increase true positives without affecting false positives.
For reports where the number of false positives is low compared to true positives, the report is worth keeping. It’s only when false positives significantly outnumber true positives or when false positives significantly increase the report analysis time that there is a chance the report is too costly to run and should be retired. The report should be considered for retirement in cases where the report is costly to run, and there are no technical measures available to improve it.
In any case, where there is a question about the efficacy of a report, it should be scheduled for discussion in regular analyst review meetings.
Reviewing Reports in Practice
The first step to reviewing a report is to fully understand the report objective. If the objective isn’t clear, it must be revised. When everyone understands the objective, you should run the report and use the analysis section to help guide you through processing results. If the report doesn’t return any results, you can query a longer period or search case tracking tools for examples from previous reports.
Keep all of the technical report evaluation criteria in mind while analyzing results. Tweaks and improvements to the report query are common and can often save a lot of analysis time in the future. Always consider making additional reports whenever possible if the detection criteria overwhelm a single report. Be on the lookout for ways to relax the query, by making it less specific without adding too many false positives. Relaxing the query can give you a glimpse of legitimate activity the query is currently ignoring but is similar to the report objective.
After reviewing a report using the technical criteria, if the report is investigative, move on to the subjective quality-cost estimation. Based on your time running the report, if you think the evaluation time is significant or if the number of false positives is overly burdensome, do your best to summarize the issue(s) in the comments for the report bug. The more comments you make about the pros and cons of a report, the easier it will be for others to understand and review the report in the future. A regular playbook tuning meeting is also a good place to discuss with your team your experience and concerns with evaluating the report and its overall cost and efficacy.
Event Query System
In Chapter 5, we introduced the data query/code section of the playbook. This is where the play objective changes from an English sentence to a machine-readable event query. The query is the exact question and syntax that will return results based on the objective from the query system. Whereas a play’s objective identifies to a human what the play attempts to accomplish, the query executes within the query system to retrieve the results. Think of the event query system like an Internet search engine. You type in what you want to find, perhaps sprinkling in a few commands to tailor your results, and then you either get what you want or you don’t.
Query systems will vary from organization to organization. They may consist of an open source logging solution, a relational database, a SIEM, a large-scale data warehouse, or a commercial application. Whatever system is used, they all provide a similar function—trigger events based on detection logic.
Security and other event log sources export their alarms to a remote collection system like a SIEM, or display them locally for direct access and processing. It’s up to the SIEM to collect, sort, process, prioritize, store, and report the alarms to the analyst. Whether you choose a SIEM or a log management and query solution, the important part is ensuring you can get regular, concise, actionable, and descriptive alarms from your detection methods.
A NOTE ON SIEM
A SIEM purports to solve the problem of “correlating” event data across disparate log sources to produce valuable incident data. However, it takes a gargantuan effort to ensure that this investment works, as well as a heavy reliance on system performance and proper configuration. Although system and performance issues affect every type of incident detection system, the static logic and limited custom searching are the primary downfalls of the SIEM. A security log management system, however, enables highly flexible and precision searching.
When properly architected, deployed, and manicured, a security log management system can be the most effective and precise tool in the incident detection toolkit, if only because of its searching and indexing capabilities. There’s another bright spot for security log management versus putting everything into the SIEM and analyzing its reports. For incident detection, there are essentially two methods for finding malicious activity: ad-hoc “hunting” or reporting. Log management is the best way to provide these capabilities out of the box.
When measuring query systems, the focus should be more about collecting and analyzing system performance analytics, as opposed to playbook efficiency metrics. After all, the quicker you can process your data, the quicker you can detect threats.
Result Presentation System
You’ve built logic to detect a specific threat, and you have the query running at regular intervals in your query system. Now what? How do you get the results of that query to your resources so they can investigate whether the results indicate malicious behavior? If you have results from high-fidelity reports, is there a process to automatically do something with those results? The possibilities for presenting results are numerous. SIEMs and most products have the ubiquitous “dashboard,” often of questionable value. Emails, email attachments, comma-separated values (CSV) files, custom-built dashboards, custom web pages, and event queues are other options to get result data to your analysts. Keep in mind that investigative reports are just that—they require further investigation to separate the wheat (malicious events) from the chaff (false positives, benign, or indeterminable events). Because employees are your most expensive and valuable asset, you must ensure their time is being used as effectively as possible. The more consistently a report can reliably highlight malicious events, the higher fidelity the report will become and the less investigation your analysts will have to perform.
One of the best ways for your analyst to view investigative results is by looking at the identical data set in different ways. As an example, consider a simple play that identifies the most frequent events over a certain period from a particular sensor. The data has already been sorted by a count of the events. But is that count ascending or descending (meaning, are you viewing the highest or lowest volume events)? Both views warrant equal inspection, but for different reasons. Whereas high-volume alarms can indicate widespread abuse of a vulnerability such as an open mail relay or UDP amplification attack, low-volume events may identify more furtive attacks. In Chapter 9, we’ll discuss ways of actually implementing these different data views. For now, you should be aware of them in the context of how changing the view can affect your understanding of a true positive event.
In our playbook management and event query systems, we are interested in collecting quantitative measurements to determine how well those systems are performing. While keeping your result presentation system in mind, begin thinking about how you might qualitatively measure your system’s effectiveness. Here, the question you strive to answer should be, “Am I viewing this data in the most ideal way to achieve my play objective and identifying a particular threat?” When looking at individual event results, you should consider the following method of manipulating the presentation of the same result set to achieve a potentially better view:
§ Deduplicate events containing identical field values
§ Add necessary or remove superfluous event fields
§ Change result grouping or sorting (e.g., most frequent events, as described earlier)
Let’s assume that you’ve modified the presentation of your results by one of the preceding methods. How do you know if the new view of your results is better than the previous presentation? There are some additional data points that can help you understand the best way to display information to your analysts:
§ Number of total events per result set
§ Time to analyze each result
§ Result efficacy (true positive, false positive, benign, indeterminable)
Capturing the total analysis time per result enables the ability to calculate the average time to analyze the entire play. The summation of this value for every report will give you a total mean time to process the entire playbook. Based on the time required to analyze all reports, you can determine how many resources to allocate to report processing. Ideally, the number of events will be low and the time to analyze those events will be short. Pay attention to how adjusting different result views produce a different number of results.
After being investigated, results should be categorized by their ability to produce a desired or intended result, or efficacy. This efficacy measurement will help you identify the value of a play’s logic. There are four possible categories for a given result that identify the play’s effectiveness:
True Positive
The system correctly detected a valid threat against an extant risk as per the intended detection logic.
False Positive
The system incorrectly detected a threat, or there is no extant risk.
Benign
The system correctly detected a valid threat, but there is no apparent risk due to the condition being expected.
Indeterminable
Not enough evidence to make a decision, or inconclusive.
True positive results are the underpants the South Park gnomes are constantly trying to procure. These confirmed malicious events are the reason you built your monitoring program and the goal of the entire playbook. This is the “bad stuff” we’re attempting to find. Higher ratios of true positives indicate higher fidelity plays. Alternatively, false positives indicate a flaw in the play’s detection logic, which requires review and improvement if possible. It’s a good thing you have a playbook management system to track the progression of a play as the play is constantly being tweaked. Of course, it may be impossible to remove all false positives from some report results, but the more you filter out, the higher the report efficacy and analyst performance. Benign events exist when the event is neither a false positive nor a true positive, even though it matches a subset of attributes from both cases.
Take, for instance, an event that an analyst attributed to an authorized vulnerability scanner. The detection logic achieved its objective—identifying behavior indicative of an attack. However, the “attack” was not malicious in intent. Instead, the vulnerability scanner should be tuned from the report so that it doesn’t appear in subsequent results. It’s considered benign because labeling it as anything else will wrongfully affect the efficacy measurements. An event that cannot be confirmed as true positive, false positive, or benign is considered indeterminable. Indeterminable events occur when there is a lack of information available. An inability to attribute an asset, failure to confirm the detected activity, or nebulous black-box vendor detection logic can all contribute to problems confirming or denying the efficacy of a play’s result. Labeling the event a true positive will positively skew the number of successfully detected threats over time, giving a false impression that the play is more effective at detecting events than in reality. Conversely, labeling the event a false positive will negatively skew the detection system’s efficacy, portraying a poorer play performance than in reality.
One of our goals is to ensure that the playbook is a well-oiled machine. Again, it’s a living document that must be manicured over time. To get an indication of how well your detection logic is working per any given report, you can calculate the median time to analyze a play’s results divided by the median true positives per play execution. Assuming for a minute that a true positive from one report is equivalent in value to a true positive in another report, the more true positives identified per amount of time will indicate a higher value report. However, not all plays are created equal. Your organization will likely have higher value reports than others. Reports that identify exploits against known vulnerabilities in the environment or attacks against high-value assets are likely more valuable than a report identifying policy violations of peer-to-peer traffic. Still, you will find it useful to know how effective your plays are compared to the time it takes to analyze the plays’ results.
PLAYBOOK REMINDERS
Here are some playbook reminders to keep in mind:
Start small
It is important not to get overwhelmed with events. Start with a specific report or network segment, tuning that as much as possible before moving on to the next item. Tuning is an ongoing process, and it is the means by which the monitoring system is made useful. By trying to tune events from all reports, progress on any one particular report will be much slower. Each data source should be tuned as much as possible before adding more sources. Understand thoroughly how “normal” traffic appears before moving on to the next report. By following the tuning process, false positive alerts will be reduced, thus making those events that do fire higher fidelity. Without tuning, alerts will inevitably overwhelm the monitoring staff by producing events irrelevant to the environment being monitored. This ultimately causes the monitoring system to be ignored or disabled.
Timestamps
As we discussed in Chapter 4, you must ensure timestamps on all data sources are in sync. Ideally, they would be standardized on UTC in ISO 8601 format, but at a minimum, all data sources need to be of the same time zone and format throughout your organization. Any discrepancies from different time zones must be accounted for manually, which can slow the correlation process considerably.
Escalation procedures
Use defined, approved, and easily accessible playbooks and escalation procedures. For any actions that require involvement from or are dependent on business units outside of the monitoring team, procedures must be created in partnership with those teams. The resulting processes must also be easily accessible by those teams and regularly tested and documented in your incident response handbook.
Allies in support teams
The larger the network being monitored, the more distributed knowledge becomes about events on the network. Establishing relationships with members of IT teams will help reduce incident resolution time when you know who to go to, and they have your trust to help solve the issue. If a security team becomes known as the “no” team or the group who gets in everyone’s way, then no one will help them. It’s impossible to accomplish anything without the help of system owners.
Ultimately, you should eliminate the results that don’t have context to the objective of the play. Those superfluous results should either be tuned and removed from the report, or if malicious in and of themselves, added to a separate and new report. Each cycle of filtering and tuning the report makes the play more effective at achieving its objective, and therefore of becoming a higher fidelity play.
Incident Handling and Remediation Systems
While not necessarily application based like Bugzilla or a log indexing and management system, there are still additional processes and systems required to complete the overall incident handling process.
As described in previous chapters, the classic incident response lifecycle consists of:
§ Preparation (research, applying lessons learned)
§ Identification (detection)
§ Containment (mitigation)
§ Eradication (remediation)
§ Recovery (restoration of service)
§ Lessons learned
As a short-term fix, each play in the playbook identifies a threat that must be immediately contained. This “stop the bleeding” phase prevents further disruption, and allows for time to investigate and take swift action to eliminate a threat. Ultimately, we eradicate the threat and learn from the incident to improve our detection and response time for future incidents. Measuring when and how quickly a threat was dispatched is just as important as how quickly it was detected. Eradication, or remediation, at some point in the process, will most likely require intervention with the affected asset owner and an agreeable, policy-backed plan to return the asset back to its properly secured state. In other words, depending on policy, how do you get an infected system back online with as little disruption as possible?
To maintain proper separation of duties—that is to say, preventing CSIRT from being judge, jury, and executioner—later phases like remediation are best left to IT and support teams. How then do you ensure timely and thorough completion of all requirements if someone other than you or your team is responsible for remediation tasks? For example, local IT support might be handled by a different group than the incident response team. Or in some cases, the end user may be responsible for restoring their personally owned device back to normalcy and compliance. It’s important to measure time to remediation in order to prevent duplicate detection (i.e., you detect the same host twice for the same malicious activity), as well as to confirm your playbook efficacy. In other words, you can clearly show what risks threatened your organization (and for how long) if you have an accurate timeline of events from start to finish.
You must ensure that the remediation processes are not only effective to prevent recurring infections, but also that the remediation processes are actually followed properly. Many times in the past, we have sent hosts for remediation to the various teams responsible, only to have detected the same compromised host a second and even third time. Further investigation uncovered that the agreed-upon remediation process was not followed. For certain Trojan infections, we require a mandatory operating system reinstallation (also known as a reimage), yet the IT analysts responsible for remediation simply ran a virus scan and then closed the case when it came up empty. This is obviously a big problem, and while it cannot necessarily be solved with a better playbook, it is good to have the relationships we discussed earlier, as well as buy-in from senior leadership to support your efforts. For larger enterprises, it’s also paramount that your remediation expectations extend to wholly owned subsidiaries and extranet partners as well.
Case Tracking Systems
At some point in the incident response process, whether it’s a fully customized data-centric model like ours or a SIEM-based one-size-fits-all model, you’ll have to track and document work in some form of case or incident diary. Case tracking and incident management systems maintain a record of what happened during the incident, the affected assets, and the current state of the incident. When an analyst determines that an investigative play successfully identified a malicious event, they must exercise the subsequent steps in the incident response lifecycle and begin by documenting all relevant details into a case. The case tracking system should track any relevant information necessary to satisfy the lifecycle:
§ The Playbook ID or number that generated the confirmed true positive event
§ Assets/asset owners involved in the incident
§ Initial detection times
§ Source and/or destination host information (i.e., attackers or victims)
§ Theater, region, or business unit(s) affected
§ Remediation state
§ Mitigation method
§ Time to mitigate the threat
§ Escalations and the resources required for short- and long-term fixes
Over time, these data points can be used to identify trends in your monitored environment. Do you repeatedly see issues with assets from the same segment, owner, or type of system? Which reports have been successful in detecting that malicious behavior? Is your average time to remediate within expectations? If containment routinely takes longer than expected, is it due to a broken escalation procedure, ineffective dependent resource, or lack of follow-through by your own analyst? By identifying these problem areas, you now have justifiable audit trails that you can use to improve the entire process. Making this data transparent to everybody involved in the process provides indisputable evidence to hold them accountable and ensure your mitigation and remediation requirements are satisfied.
No one loves working cases, but it’s an indispensable part of the job, and the more detail and accuracy you put into your own case data, the better your chances are for surviving an audit and improving your own understanding of the incident. It’s also your chance to highlight any issues, architectural or otherwise. For example, could this incident have occurred if we had already implemented a better authentication solution or other components that fellow analysts may find helpful? Any decent case tracking system will provide the option to assign cases to various queues or individuals. This makes escalation much simpler, in that an analyst can simply reassign a case to an escalation engineer when they need more help. Our team uses a custom case tracking system, but it has to integrate with the various commercial incident management systems so we can shift case data between them. We chose not to use an already deployed commercial system because the information contained in our case management system is highly confidential and unavailable to the rest of the company. We need to maintain tight control over the data in our system, and our incident response team handles the complete administration of these tools.
Keep It Running
Your playbook is full of plays that produce events for your analysts to investigate. You have systems to record data points to measure your processes. You’re cognizant of how data is presented to your analysts. How do you ensure that your operation continues to run smoothly and that you don’t lose sight of why you collected underpants in the first place? To keep it all running, you must do or have:
§ Research and threat discovery
§ A feedback loop between the operational running of and objective/analysis sections of the playbook
§ A tested QA process for submitted plays
§ Metrics to refine and improve detection
Your monitoring system depends on continued availability of input data to be processed. If attackers stop the logging service on their victim’s host machine, how will you investigate further? Service monitoring and health checks rarely monitor a log process status. Any potential failure point in the system—attackers, hard drive space, processor resources, data feeds, and connectivity—can affect the availability of the data and therefore the entire system. Two fundamental methods of ensuring availability involve building redundancy into your system and monitoring the status of each potential failure point. Redundancy and service monitoring are IT functions not specific to security monitoring. Your senior technical staff with backgrounds in system or network administration should understand the various underlying components that might break, how to detect when they break, and how to build resiliency into the system.
You should perform quality control tests regularly to ensure that your systems are functioning normally. Even with service monitoring of the infrastructure, environment changes can cause unexpected or missing results in reports. Periodic review of tools and processes should include testing detection, analysis, escalation, and mitigation of events. A failure at any of these points may be indicative of a larger problem with the infrastructure. Regulatory compliance or customer/client requirements may also require quality control checks for certain monitored segments. These checks are especially important to ensure reliability when offering monitoring and analysis as a service to clients. As a simple test, we will set up a random DNS lookup or IRC channel join from a host in a sensitive environment, and then wait to see how long it takes the analyst team to discover and escalate it. These types of tests along with coordinated tabletop exercises will keep the team on their toes, and will help ensure that people are always watching the network and ready to pounce on any prescribed or unusual event.
Keep It Fresh
Your organization faces a threat landscape that is ever changing and evolving. Adapting to these changes is the only way to keep your security monitoring program relevant. Ultimately, you are responsible for identifying which threats your organization faces. However, the security community is a collaborative community, sharing intelligence, research, and ideas. If you’re at a loss for where to begin, don’t fret. News articles, blog posts, conferences, and special interest groups are all excellent sources of information identifying trends in the industry that may be relevant to your organization. You can further supplement the community effort with in-house research by combing through the mountains of data you’ve collected. Research and threat discovery are the cornerstone by which any good detection logic is built.
Locally sourced intelligence is highly effective, doesn’t have any of the disadvantages of a giant statistical cloud offering, and can be more precise and effective for your organization. This is particularly true when responding to a targeted attack. If you have gathered evidence from a prior attack, you can leverage that information to detect additional attacks in the future. If they are targeted and unique, there may be no security feed available to tell you about the threat. Another advantage to internal intelligence is that it is much more context aware than a third-party feed. You and the rest of your IT organization—hopefully—know the function and location of your systems. With proper context (that can only be developed internally), external feed data could be extremely helpful, or worthless, depending on your response process and capabilities.
Like the threat landscape, organizations themselves evolve. Staff turnover, reorganizations, new tools, new hires, and promotions all threaten to interrupt the smooth operations of your security monitoring program. Like the aforementioned IT controls, these interruptions are not specific to security monitoring, but also must still be heeded. As discussed in Chapter 5, the playbook itself is structured to include all necessary information relevant to each play. New staff should easily understand what each play is attempting to accomplish, as well as how to analyze results from the play.
In this chapter, we’ve discussed different metrics to identify workload discrepancies and potential knowledge gaps. It is up to you to interpret these measurements to determine adequate training for your staff, or to adjust analyst responsibilities so that detected events can be investigated. Use the guidance we’ve provided, and where possible, predict what metrics will be the most important and include them at the beginning. Proper metrics will provide measurement of human performance, as well as report and operational efficiency. This rings particularly true when you are completely replacing an older system, or attempting to measure the return on investment for your efforts related to your playbook.
Creating a playbook is one thing, but (re)designing your incident response team and capabilities around it is something completely different. Not only do you have to have a talented staff and a solid playbook, but you have to think strategically about how to provide the most efficacious security monitoring for your organization. Writing this all down, it makes a lot more sense than the backwards approach we have taken in the past. We started with the tools and technology, and tried to make it fit our idea of what incident response should be. Perfect hindsight shows that we needed a good plan, a better approach, and a battle-worthy process. Taking a structured approach to data preparation and play construction is foundational to our continuous monitoring process. Grooming data unique to our organization, putting smart people in front of it, keeping it updated and relevant, and developing novel ways to detect bad behavior give us the edge that no product or suite of products could ever match.
Chapter Summary
§ A playbook is just a plan and a list of actions to take, but it’s nothing but an academic exercise without putting it into operation.
§ Proper staffing and training are necessary for an effective incident response team.
§ Nothing can replace human intelligence and institutional knowledge (context).
§ A playbook requires constant tuning and adjustment to stay relevant.
§ Several systems and processes are necessary to keep a playbook running:
§ A playbook management system
§ A log and event query system
§ A result display or presentation system
§ A case tracking system
§ A remediation process system
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.