Network Security Through Data Analysis: Building Situational Awareness (2014)
Part I. Data
Chapter 4. Data Storage for Analysis: Relational Databases, Big Data, and Other Options
This chapter focuses on the mechanics of storing data for traffic analysis. Data storage points to the basic problem in information security analysis: information security events are scattered in a vast number of innocuous logfiles, and effective security analysis requires the ability to process large volumes of data quickly.
There are a number of different approaches available for facilitating rapid data access, the major choices being flat files, traditional databases, and the emergent NoSQL paradigm. Each of these designs offers different strengths and weaknesses based on the structure of the data stored and the skills of the analysts involved.
Flat file systems record data on disk and are accessed directly by analysts, usually using simple parsing tools. Most log systems create flat file data by default: after producing some fixed number of records, they close a file and open up a new file. Flat files are simple to read and analyze, but lack any particular tools for providing optimized access.
Database systems such as Oracle and Postgres are the bedrock of enterprise computing. They use well-defined interface languages, you can find system administrators and maintainers with ease, and they can be configured to provide extremely stable and scalable solutions. At the same time, they are not designed to deal with log data; the data we discuss in this book has a number of features that ensure that much of the power of a relational database will go unused.
Finally, there are the emerging technologies loosely grouped under “NoSQL” and “big data.” These include distributed platforms such as Hadoop, databases like MongoDB and Monet, and specialized tools like Redis and Apache SOLR. These tools are capable, with the right hardware infrastructure, of providing extremely powerful and reliable distributed query tools. However, they require heavy duty programming and system administration skills as well as a significant hardware commitment.
Analysis involves returning to the well multiple times—when working on a problem, analysts will go back to the main data repository and pull related data. The data they choose will be a function of the data they’ve already chosen as patterns become apparent and questions start taking shape (see Chapter 10 for this workflow in more depth). For this reason, efficient data access is a critical engineering effort; the time to access data directly impacts the number of queries an analyst can make, and that concretely impacts the type of analyses they will do.
Choosing the right data system is a function of the volume of data stored, the type of data stored, and the population that’s going to analyze it. There is no single right choice, and depending on the combination of queries expected and data stored, each of these strategies can be the best.
Log Data and the CRUD Paradigm
The CRUD (create, read, update, and delete) paradigm describes the basic operations expected of a persistent storage system. Relational database management systems (RDBMS), the most prevalent form of persistent storage, expect that users will regularly and asynchronously update existing contents. Relational databases are primarily designed for data integrity, not performance.
Ensuring data integrity requires a significant amount of the system’s resources. Databases use a number of different mechanisms to enforce integrity, including additional processing and metadata on each row. These features are necessary for the type of data that RDBMSes were designed for. That data is not log data.
This difference is shown in Figure 4-1. In RDBMSes, users add and query data from a system constantly, and the system spends resources on tracking these interactions. Log data does not change, however; once an event has occurred, it is never updated. This changes the data flow as shown in the figure on the right. In log collection systems, the only things that write to disk are the sensors; users only read from disk.
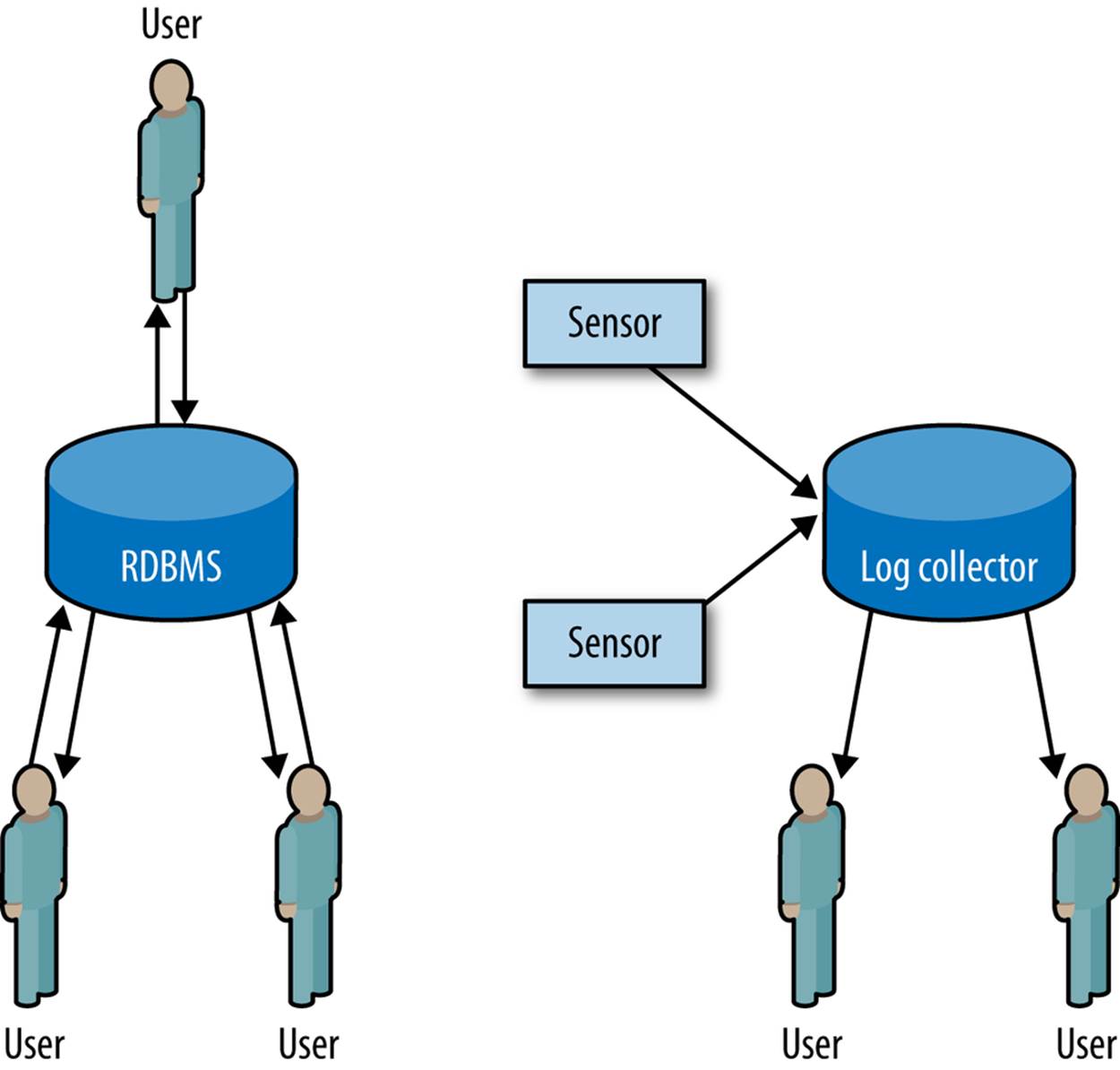
Figure 4-1. Comparing RDBMS and log collection systems
This separation of duties between users and sensors means that, when working with log data, the integrity mechanisms used by databases are wasted. For log data, a properly designed flat file collection system will often be just as fast as a relational database.
Creating a Well-Organized Flat File System: Lessons from SiLK
In Chapter 5, we discuss SiLK, the analysis system CERT developed to handle large Netflows. SiLK was a very early big data system. While it doesn’t use current big data technologies, it was designed around similar principles, and understanding how those principles work can inform the development of more current systems.
Log analysis is primarily I/O bound, meaning that the primary constraint on performance is the number of records read, as opposed to the complexity of the algorithms run on the records. For example, in the original design of SiLK, we found that it was considerably faster to keep compressed files on disk—the performance hit from reading the records off of disk was much higher than the performance hit of decompressing a file in memory.
Because performance is I/O bound, a good query system will read the minimum number of relevant records possible. In log collection systems, the most effective way to reduce the records read is to index them by time and always require a user to specify the time queried. In SiLK, log records are stored in hourly files in a daily hierarchy, for example: /data/2013/03/14/sensor1_20130314.00 to /data/2013/03/14/sensor1_20130314.23. SiLK commands include a globbing function that hides the actual filenames from the user; queries specify a start date and an end date, which in turn is used to derive the files.
This partitioning process does not have to stop with time. Because network traffic (and log data) is usually dominated by a couple of major protocols, those individual protocols can be split off into their own files. In SiLK installations, it’s not unusual to split web traffic from all other traffic because web traffic makes up 40–80% of the traffic on most networks.
As with most data partitioning schemes, there’s more art than science in deciding when to stop subdividing the data. As a rule of thumb, having no more than three to five further partitions after time is acceptable because as you add additional partitions, you increase complexity for users and developers. In addition, determining the exact partitioning scheme usually requires some knowledge of the traffic on the network, so you can’t do it until after you’ve acquired a better understanding of the network’s structure, composition, and the type of data it encounters.
DATA FORMATS AND DATA OPTIMIZATION
You decide to store data in flat files and create a system that accepts a billion records a day. You decide to use ASCII text, and are recording zero-packed source and destination IP addresses. This means that your IPv4 addresses will take 15 bytes of storage each, compared to the 4-byte binary representation. This means that every day, you will sacrifice 22 GB of space for that text representation. If you have a single GigE interface to transfer that data on, you will use three minutes just to transfer the wasted space.
Once you start working in large volume datasets, spatial dependencies become issues on disks (affecting query time and storage duration), as well as on the network (affecting query time and performance). Because your operations are I/O bound, converting representations to a binary format will save space, increase performance, and, far too often, actually make a design implementable.
The problem of actually developing a compact binary representation of data has largely been addressed through a number of different representation schemes developed by Google and other companies. These tools all work in roughly the same way: you specify a schema using an interface definition language (IDL), and then run a tool on the schema to create a linkable library that can read and write data in a compact format. There is a loose similarity to XML and JSON, but with an emphasis on a highly compact, binary representation.
Google developed the first of these systems in the form of Protocol Buffers. Multiple tools are available now, including but not limited to:
Protocol Buffers
Google describes these as a “smaller, faster, simpler” version of XML. Language bindings are available in Java, C++, and Python. Protocol Buffers (PB) are the oldest implementation and, while less feature-rich than other implementations, are very stable.
Thrift
Originally from Facebook and now maintained by the Apache foundation. In addition to providing serialization and deserialization capabilities, Thrift includes data transport and RPC mechanisms.
Avro
Developed in tandem with Hadoop, and more dynamic than either PB or Thrift. Avro specifies schemas using Javascript Object Notation (JSON), and transfers the schema as part of the messsage contents. Avro is consequently more flexible to schema changes.
Other serialization standards exist, including MessagePack, ICE, and Etch. As of the publication of this book, however, PB, Thrift, and Avro are considered the big three.
Taking a record and converting it into an all-ASCII string binary format is a waste of space. The goal of any conversion process should be to reduce the amount of gratuitous data in the record; read the section The Characteristics of a Good Log Message in Chapter 3 for further discussion on how to reduce record sizes.
A Brief Introduction to NoSQL Systems
The major advance in big data in the past decade has been the popularization of NoSQL big data systems, particularly the MapReduce paradigm introduced by Google. MapReduce is based around two concepts from functional programming: mapping, which is the independent application of a function to all elements in a list, and reducing, which is the combination of consecutive elements in a list into a single element. Example 4-1 clearly shows how these elements work.
Example 4-1. Map and reduce functions in Python
>>> # Map works by applying a function to every element in an array, for example, we
... # create a sample array of 1 to 10
>>> sample = range(1,11)
>>> # We now define a doubling function
...
>>> def double(x):
... return x * 2
...
>>> # We now apply the doubling function to the sample data
... # This results in a list whose elements are double the
... # original's
...
>>> map(double, sample)
[2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
>>> # Now we create a 2-parameter function which adds two elements
...
>>> def add(a, b):
... return a + b
...
>>> # We now run reduce with add and the sample, add is applied
... # to every element in turn, so we get add(1,2) which produces
... # 3, the list now looks like [3,3,...] as opposed to
... # [1,2,3....], and the process is repeated, 3 is added to 3
... # and the list now looks like [6,4,...] until everything is
... # added
...
>>> reduce(add, sample)
55
MapReduce is a convenient paradigm for parallelization. Map operations are implicitly parallel because the mapped function is applied to list element individually, and reduction provides a clear description of how the results are combined. This easy parallelization enables the implementation of any of a number of big data approaches.
For our purposes, a big data system is a distributed data storage architecture that relies on massive parallelization. Recall the discussion above about how flat file systems can enhance performance by intelligently indexing data. But now instead of simply storing the hourly file on disk, split it across multiple hosts and run the same query on those hosts in parallel. The finer details depend on the type of storage, for which we can define three major categories:
Key stores
Including MongoDB, Accumulo, Cassandra, Hypertable, and LevelDB. These systems effectively operate as a giant hashtable in that a complete document or data structure is associated with a key for future retrieval. Unlike the other two options, key store systems don’t use schemas; structure and interpretation are dependent on the implementor.
Columnar databases
Including MonetDB, Sensage, and Paraccel. Columnar databases split each record across multiple column files with the same index.
Relational databases
Including MySQL, Postgres, Oracle, and Microsoft’s SQL Server. RDBMSes store complete records as individually distinguishable rows.
Figure 4-2 explains these relations graphically. In a key store, the record is stored by its key while the relationship of the recorded data and any schema is left to the user. In a columnar database, rows are decomposed into their individual fields and then stored, one field per file, in individual column files. In an RDBMS, each row is a unique and distinguishable entity. The schema defines the contents of each row, and rows are stored sequentially in a file.
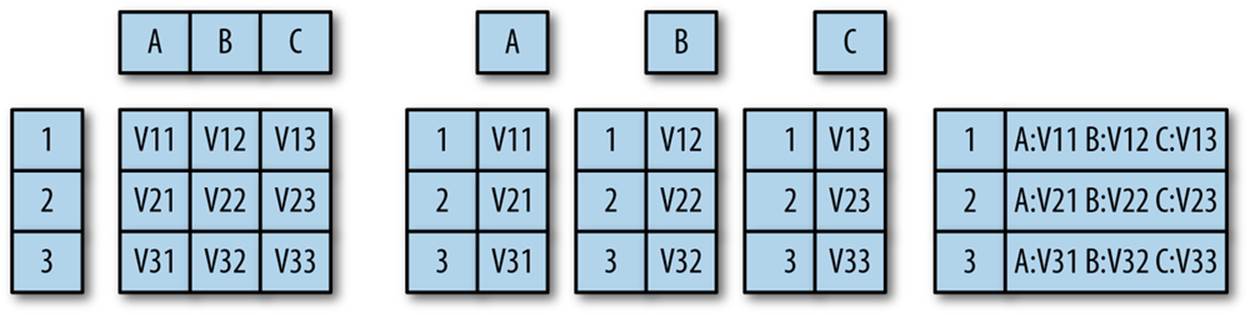
Figure 4-2. Comparing data storage systems
Key stores are a good choice when you have no idea what the structure of the data is, you have to implement your own low level queries (e.g., image processing and anything not easily expressed in SQL), or even if the data has structure. This reflects their original purpose of supporting unstructured text searches across web pages. Key stores will work well with web pages, tcpdump records containing payload, images, and other datasets where the individual records are relatively large (on the order of 60 kb or more, around the size of the HTML on a modern web page). However, if the data possesses some structure, such as the ability to be divided into columns, or extensive and repeated references to the same data, then a columnar or relational model may be preferable.
Columnar databases are preferable when the data is easily divided into individual log records that don’t need to cross-reference each other, and when the contents are relatively small, such as the CLF and ELF record formats discussed in Chapter 3. Columnar databases can optimize queries by picking out and processing data from a subset of the columns in each record; their performance improves when they query on fewer columns or return fewer columns. If your schema has a limited number of columns (for example, an image database containing a small date field, a small ID field, and a large image field), then the columnar approach will not provide a performance boost.
RDBMSes were originally designed for information that’s frequently replicated across multiple records, such as a billing database where a single person may have multiple bills. RDBMSes work best with data that can be subdivided across multiple tables. In security environments, they’re usually best suited to maintaining personnel records, event reports, and other knowledge—things that are produced after processing data or that reflect an organization’s structure. RDBMSes are good at maintaining integrity and concurrency; if you need to update a row, they’re the default choice. The RDBMS approach is probably unwarranted if your data doesn’t change after creating it, individual records don’t have cross-references, or your schemas store large blobs.
OTHER MISCELLANEOUS STORAGE TOOLS
In addition to the three major storage systems discussed earlier, there are a couple of other tools and techniques for improving access speed. These storage systems are less prevalent than the big three, but are generally optimized for specific data or query types.
Graph databases include Neo4j, ArangoDB, and Titan. Graph databases provide scalable, highly efficient queries when working with graph data (see Chapter 13). Traditional database systems, including the three mentioned earlier, are notoriously poor at managing graphs, as any representation involves making multiple queries to generate the graph over time. Graph databases provide queries and tools for analyzing graph structures.
The Lucene library and its companion search engine, Solr, make up an open source text search engine tool.
Redis is a memory-based key value storage system. If you need to rapidly access data which can fit in memory (for example, lookup tables), Redis is a very good choice for handling the lookup and modifications.
Finally, if your wallet is big enough, you should consider the advantages of solid state storage (SSD). SSD solutions can be expensive, but they have the enormous advantage of being functionally transparent as part of the filesystem. At the high end, companies like Violin memory, Fusion-IO, and STEC provide multi-TB rack mounted units that can be configured to receive and process data at wire speeds.
What Storage Approach to Use
When choosing a storage architecture, consider the type of data you will collect and the type of reporting you will do with it. Do you expect that you will mostly generate fixed reports, or do you expect that your analysts will conduct a large number of exploratory queries?
Table 4-1 provides a summary of the types of decisions that go into choosing a storage approach. The decisions are listed in order of preference: 1 is best, 3 is worst, X means don’t bother at all. We will discuss each option in detail in order to explain how they impact storage choices.
Table 4-1. Making decisions about data systems
|
Situation |
Relational |
Columnar |
Key-store |
|
|
Have access to multiple disks and hosts |
2 |
1 |
1 |
|
|
Have access to a single host |
1 |
X |
X |
|
|
Data is less than a terabyte |
1 |
2 |
3 |
|
|
Data is multiterabyte |
2 |
1 |
1 |
|
|
Expect to update rows |
1 |
X |
X |
|
|
Never update rows |
2 |
1 |
1 |
|
|
Data is unstructured text |
2 |
3 |
1 |
|
|
Data has structure |
2 |
1 |
3 |
|
|
Individual records are small |
2 |
1 |
3 |
|
|
Individual records are large |
3 |
2 |
1 |
|
|
Analysts have some development skills |
1 |
1 |
1 |
|
|
Analysts have no development skills |
1 |
1 |
2 |
The first decision is really a hardware decision. Big data systems such as columnar databases and key stores will only provide you with a performance advantage if you can run parallel nodes, and the more the better. If you have a single host, or even less than four hosts available, you are probably better off sticking with more traditional database architectures in order to exploit their more mature administrative and development facilities.
The next pair of questions is really associated with that hardware question: is your data really that big? I use a terabyte as an arbitrary cutoff point for big data because I can realistically buy a 1TB SSD. If your data isn’t that big, again default to relational databases or an in-memory storage system like Redis.
The next question is associated with data flow and the CRUD paradigm. If you expect to regularly update the contents of a row, then the best choice is a relational database. Columnar and other distributed architectures are designed around the idea that their contents are relatively static. It’s possible to update data in them, but it usually involves some kind of batch process where the original data is removed and replacements are put in place.
STREAMING ANALYTICS VERSUS STORING IN ONE PLACE
The classic analytical system is a centralized repository. Data from multiple sensors is fed into a huge database, and then analysts pull data out of the huge database. This is not the only approach, and a hot alternative uses streaming analytics. At the time of writing this book, distributed streaming analytic systems such as Storm and IBM’s Websphere are taking off.
Streaming approaches enable sophisticated real-time analysis by processing the data as a stream of information. In a stream, the data is touched once by a process, and minimal past state is maintained.
Streaming processing is extremely useful in areas where the process is well-defined and there is a need for real-time analysis. As such, it is not particularly useful for exploratory analysis (see Chapter 10). However, when working with well-defined alarms and processes, streaming analytics will reduce the overhead of data required at a central repository, and in large data systems, which can be quite valuable.
After dealing with the question of updates, the next set of questions deal with the structure and size of the data. Columnar and relational databases are preferable when you are dealing with well-structured, small records (such as optimized logfiles). These approaches can take advantage of the schema—for example, if a columnar database is only using two columns, it can return only those for further processing whereas the key store has to return the whole record. If records are small or structured, columnar databases are preferable, followed by relational databases. If records are large or unstructured, then the key-value approach is more flexible.
The final question on the list is arguably more social than technical, but also important when considering the design of an analysis system. If you are going to allow analysts relatively open, unstructured analysis to the data, then you need to have some well-defined and safe framework for letting them do so. If your analysts are capable of writing MapReduce functions, then you can use any system without much difficulty. However, if you expect that analysts will have minimal skills then you may find columnar or relational systems, which have SQL interfaces, to be preferable. There are relatively recent efforts to develop SQL-like interfaces for key stores, notably the Hive and Pig projects from Apache.
Where possible, it’s preferable to limit analysts’ direct access to the data store, instead allowing them to extract samples that can be processed in EDA tools such as SiLK or R.
Storage Hierarchy, Query Times, and Aging
Any collection system will have to deal with a continuous influx of new data, forcing older data to move into slower, less expensive storage systems over time. For the purposes of an analytic system, we can break the storage hierarchy we have for data into four tiers:
§ RAM
§ SSDs and flash storage
§ Hard drives and magnetic storage
§ Tape drives and long-term archives
By setting up a flow monitoring system, you can estimate the volume of incoming traffic and use that data to calculate initial storage requirements. The key question is how much data the analysts need.
A good rule of thumb in a business environment is that analysts need fast access to approximately a week’s worth of data, reasonable access to 90 days’ worth of data, and further data can be deposited in a tape archive. The 90-day rule means that analysts can pull back data to at least the previous quarter. Obviously, if your budget allows it, more data on disk is better, but 90 days is a good minimal requirement. Make sure that if you do archive to tape, that the tape data is reasonably accessible—bots last on most networks for around a year if not longer, and tracing their full activity will involve looking at that archive.
A number of external constraints also have an impact on data storage, notably the data retention requirements for your domain and industry. For example, the EU’s data retention directive (directive 2006/24/EC) establishes retention requirements for telecommunications providers.
As data moves down on the hierarchy, it also often helps to reformat it into a more summarization- or storage-friendly format. For example, for rapid response I might want to keep a rolling archive of packets in high-speed storage in order to facilitate rapid response. As the data moves onto slower sources (from RAM to SSD, from SSD to disk, from disk to tape), I will start relying more on summaries such as NetFlow.
In addition to simple summarization such as NetFlow, long-term storage can be facilitated by identifying and summarizing the most obvious behaviors. For example, scanning and backscatter (see Chapter 11 for more information) take up an enormous amount of disk space on large networks; traffic has no payload, and there’s little value in storing the full packet. Identifying, summarizing, and then compressing or removing scans reduces the footprint of the raw data, especially on larger networks where this type of background traffic can take up a disproprtionate number of records.
Data fusion—removing idential records or fusing them—is another viable technique. When collecting data from multiple sources, combining the records that describe the same phenomenon (by checking IP addresses, ports, and time) can reduce the payload of these separate records.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.