Hacking Web Apps: Detecting and Preventing Web Application Security Problems (2012)
Chapter 7. Leveraging Platform Weaknesses
Information in this chapter:
• Find Flaws in Application Frameworks
• Attack System & Network Weaknesses
• Secure the Application’s Architecture
In July 2001 a computer worm named Code Red squirmed through web servers running Microsoft IIS (http://www.cert.org/advisories/CA-2001-19.html). It was followed a few months later by another worm called Nimda (http://www.cert.org/advisories/CA-2001-26.html). The advent of two high-risk vulnerabilities so close to each other caused sleepless nights for system administrators and ensured profitable consulting engagements for the security industry. Yet the wide spread of Nimda could have been minimized if system administrators had followed certain basic configuration principles for IIS, namely placing the web document root on a volume other than the default C: drive. Nimda spread by using a directory traversal attack to reach the cmd.exe file (the system’s command shell). Without access to cmd.exe the worm would not have reached a reported infection rate of 150,000 computers in the first 24 hours and untold tens of thousands more over the following months.
Poor server configuration harms a web app as much as poor input validation does. Many well-known sites have a history of security flaws that enabled hackers to bypass security restrictions simply by knowing the name of an account, guessing the ID of a blog entry, or compromising a server-level bug with a canned exploit. Attackers don’t need anything other than some intuition, educated guesses, and a web browser to pull off these exploits. They represent the least sophisticated of attacks yet carry a significant risk to information, the application, and even the servers running a web site. This chapter covers errors that arise from poor programming assumptions as well as security problems that lie outside of the app’s code that shouldn’t be ignored.
Understanding the Attacks
Well-designed apps become flawed apps when the implementation fails to live up to the design’s intent. Well-implemented apps become compromised by architecture flaws like missing security patches or incorrect configurations. This section starts off with analyzing a site’s implementation for patterns that hint at underlying data structures and behaviors. Rather than look for errors that indicate a lack of input validation, we’re looking for trends that indicate a naming system for parameters or clues that fill in gaps in parameter values.
One pattern is predictable pages. At its core predictable pages imply the ability of a hacker to access a resource—a system call, a session cookie, a picture—based solely on guessing the identifier used to reference the object. Normally, the identifier would be hidden from the hacker or only provided to users intended to access the resource. If the identifier is neither adequately protected nor cryptographically sound, then this is a weak form of authorization. Stronger authorization would enforce an explicit access control check that verifies the user may view the resource. Predictability-based attacks include examples like guessing that page=index.html parameter references an HTML file, guessing that a document repository with explicit links to docid=1089 and docid=1090 probably also has a page for docid=1091, and reverse-engineering session cookies in order to efficiently brute force your way into spoofing a password-protected account.
Recognizing Patterns, Structures, & Developer Quirks
Attacking predictable resources follows a short procedure: Select a component of a link, change its value, observe the results. This may be guessing whether directories exist (e.g. /admin/ or /install/), looking for common file suffixes (e.g. index.cgi.bak or login.aspx.old), cycling through numeric URI parameters (e.g. userid=1, userid=2, userid=3), or replacing expected values (e.g. page=index.html becomes page=login.cgi). The algorithmic nature of these attacks lend themselves to automation, whereas problems with a site’s design (covered in Chapter 6) involve a more heuristic approach that always requires human analysis.
Automating these attacks still require a human to establish rules. Brute force methods are inelegant (a minor complaint since a successful hack, however brutish, still compromises the site), inefficient, and prone to error. Many vulnerabilities require human understanding and intuition to deduce potential areas of attack and to determine how the attack should proceed. Humans are better at this because many predictability-based attacks rely on a semantic understanding of a link’s structure and parameters. For example, it’s trivial to identify and iterate through a range of numeric values, but determining that a URI parameter is expecting an HTML file, a URI, or is being passed into a shell command requires more sophisticated pattern matching.
The following sections focus on insecure design patterns and mistaken assumptions that either leak information about or fail to protect a resource. Resources are anything from web pages, to photos, to profile data, to cookies.
Relying on HTML & JavaScript to Remain Hidden
A major tenet of web security is that the browser is a hostile, untrusted environment. This means that data from the browser must always be verified on the server (where a hacker cannot bypass security mechanisms) in order to prevent hacks like SQL injection and cross-site scripting. It also means that content delivered to the browser must always be considered transparent to the user. It’s a mistake to tie any security-dependent function to content delivered to the browser, even if the content is ostensibly hidden or obscured from view.
HTTPS connections protect content from eavesdroppers; both ends (one of which is the browser) have decrypted access to the content. HTML (or JavaScript, CSS, XML, etc.) cannot be encrypted within the browser because the browser must have the raw resource in order to render it. Naive attempts at concealing HTML use JavaScript to block the mouse’s right click event. By default, the right click pulls up a context menu to view the HTML source of a web page (among other actions). Blocking the right click, along with any other attempt to conceal HTML source, will fail.
The following JavaScript demonstrates a site’s attempt to prevent visitors from accessing the context menu (i.e. right-click to view HTML source) or selecting text for cut-and-paste.
function ds(){return !1}
function ra(){return !0}
var d=document.getElementById(“protected_div”),
c=d.contentWindow.document;
c.open();
c.oncontextmenu=new Function(“return false”);
c.onmousedown=ds;
c.onclick=ra;
c.onselectstart=new Function(“return false”);
c.onselect=new Function(“return false;”);
The following screenshot shows the page opened with Firefox’s Firebug plugin (http://getfirebug.com/). The oncontextmenu, onselect, and onselectstart properties have been assigned anonymous functions (the functions with “return false;” in the previous code). You could right-click on the function to edit it or delete the property entirely, which would re-enable the context menu (see Figure 7.1).
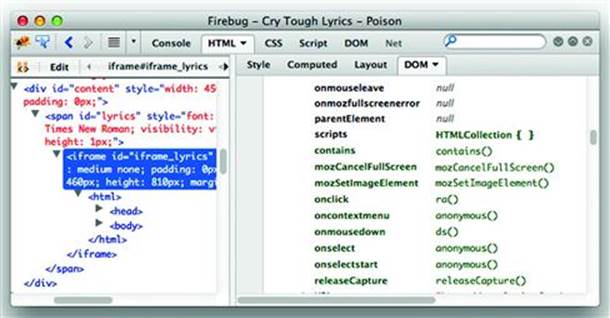
Figure 7.1 A poisoned context menu
It’s just as easy to programmatically disable the contextmenu/select prevention. Type the following code in Firefox’s Web Console. (All modern browsers have a similar development console. Notably, Firefox even provides a setting to prevent sites from overriding the context menu.)
document.getElementById(“protected_div”).contentWindow.document.oncontextmenu=null
HTML and JavaScript files may also contains clues about the site’s infrastructure, code, or bugs. Rarely does an HTML comment lead directly to an exploit, but such clues give a hacker more information when considering attack vectors. Common clues include:
• Code repository paths and files, e.g. SVN data.
• Internal IP addresses or host names.
• Application framework names and versions in meta tags, e.g. Wordpress versions.
• Developer comments related to functions, unexpected behavior, etc.
• SQL statements, including anything from connection strings with database credentials to table and column names that describe a schema.
• Include files hosted in the web document root, in the worst case scenario a .inc file might be served as text/plain rather than parsed by a programming language module.
• Occasionally a username or password might show up inside an HTML comment or include file. However uncommon this may be, it’s one of the most rewarding items to come across.
tip
Many open source web applications provide files and admin directories to help users quickly install the web application. Always remove installation files from the web document root and restrict access to the admin directory to trusted networks.
Authorization By Obfuscation
“If you want to keep a secret, you must also hide it from yourself.” George Orwell, 1984.
Secrets. We keep them, we share them. Web sites rely on them for security. We’ve encountered secrets throughout this book with examples in passwords (shared secrets between the user and the application), encryption keys (known only by the application), and session cookies (an open secret over HTTP). This section focuses on other kinds of tokens in a web application whose security relies primarily on remaining a secret known only to a user or their browser.
Chapter 6 explored problems that occur when cryptographic algorithms are incorrectly implemented to protect a secret. Cryptographic algorithms are intended to provide strong security for secrets; the kind of security used by governments and militaries. A property of a good crypto algorithm is that requires an immense work factor to obtain the original data passed into the algorithm. In other words, it means the time required to decrypt a message by brute force is measured in the billions or trillions of years.
Obfuscation, on the other hand, tries to hide the contents of a secret behind the technical equivalent of smoke and mirrors. Obfuscation tends to be implemented when encryption is impossible or pointless, but developers wish to preserve some sense of secrecy—however false the feeling may be. For example, the previous section explained why JavaScript cannot be encrypted if it is to be executed by the browser. The browser must be able to parse the JavaScript’s variables, functions, and constants. Otherwise it would just be a blob of data. Obfuscation attempts to minimize the amount of useful information discernible to a hacker and maximize their work factor in trying to extract that useful information.
There’s no one rule regarding the recognition or reverse-engineering of obfuscated data. Just some creative thinking and patience. Anagrams are a prime example of obfuscation. Before we dive into some hacking examples, check out a few specimens of obfuscation:
– murder / redrum (From Stephen King’s The Shining.)
– Tom Marvolo Riddle / I Am Voldemort (From J.K. Rowling’s Harry Potter and the Chamber of Secrets.)
– Torchwood / Doctor Who
– Mr Mojo Risin / Jim Morrison
– lash each mime / ?
– wackiest balancing hippo / ?
While it’s difficult to provide solid guidelines for how to use obfuscation effectively, it is not too difficult to highlight where the approach has failed. By shedding light on past mistakes we hope to prevent similar issues from happening in the future.
Many web sites use a content delivery network (CDN) to serve static content such as JavaScript files, CSS files, and images. Facebook, for example, uses the fbcdn.net domain to serve its users’ photos, public and private alike. The usual link to view a photo looks like this, with numeric values for x and y:
http://www.facebook.com/photo.php?pid={x}&id={y}
Behind the scenes the browser maps the parameters from photo.php to a link on fbcdn.net. In the next example, the first link format is the one that appears in the <img> element within the browser’s HTML source. The second is a more concise equivalent that removes 12 characters. Note that a new value, z, appears that wasn’t evident in the photo.php link.
http://photos-a.ak.fbcdn.net/photos-ak-snc1/v2251/50/22/{x}/n{x}_{y}_{z}.jpg
http://photos-a.ak.fbcdn.net/photos-ak-snc1/{x}/n{x}_{y}_{z}.jpg
A few observations of this format reveals that the x typically ranges between six and nine digits, y has seven or eight, and z has four. Altogether this means roughly 270 possible combinations—not a feasible size for brute force enumeration. Further inspection reveals that x (from the URI’spid parameter) is incremental within the user’s photo album, y (from id in the URI) remains static for the user, and z is always four digits. If a starting x can be determined, perhaps from a profile picture, then the target space for a brute force attack is reduced to roughly 240 combinations. Furthermore if y is known, perhaps from a link posted elsewhere, then the effort required to brute force through a user’s (possibly private) photo album is reduced to just the four digit z, about 213 combinations or less than 20 minutes of 10 guesses per second. A more detailed description of this finding is at http://www.lightbluetouchpaper.org/2009/02/11/new-facebook-photo-hacks/.
The Facebook example should reveal a few things about reverse-engineering a URI. First, the image link that appears in the browser’s navigation bar isn’t always the original source of the image. Many web sites employ this type of mapping between links and resources. Second, the effort required to collect hundreds or even thousands of samples of resource references is low given the ease of creating a while loop around a command-line web request. Third, brief inspection of a site’s URI parameters, cookies, and resources can turn up useful correlations for an attacker. In the end, this particular enumeration falls into the blurred distinction between privacy, security, and anonymity.
Failed obfuscation shows up in many places, not just web applications. Old (circa 2006) Windows-hardening checklists recommended renaming the default Administrator account to anything other than Administrator. This glossed over the fact that the Administrator account always has the relative identifier (RID) of 500. An attacker could easily, and remotely, enumerate the username associated with any RID, thus rendering nil the perceived incremental gain of renaming the account. In some cases the change might have defeated an automated tool using default settings (i.e. brute forcing the Administrator username without verifying RID), but without understanding the complete resolution (which involved blocking anonymous account enumeration) the security setting was useless against all but the least skilled attackers. Do not approach obfuscation lightly. The effort spent on hiding a resource might be a waste of time or require vastly fewer resources than expected on the attacker’s part to discover.
Relying on the secrecy of a value to enforce security is not a failing in itself. After all, that is exactly how session cookies are intended to work. The key is whether the obfuscated value is predictable or can be reverse-engineered. Session cookies might be protected by HSTS connections, but if the application serves them as incremental values then they’ll be reverse-engineered quickly—and if the application attempts to obfuscate incremental values with a simple hash or XOR re-arrangement, then they’ll be reverse-engineered just as quickly.
The mistakes of obfuscation lie in
• Not protecting confidentiality of values in transit, i.e. not using HTTPS. It’s not necessary to break an obfuscation scheme if a value captured by a sniffing attack is replayed to detrimental effect.
• Assuming the use of HTTPS sufficiently protects obfuscation. The method of obfuscation is unrelated to and unaffected by whatever transport-layer encryption the site uses.
• Generating values with a predictable mechanism, e.g. incremental, time-based, IP address-based. These are the easiest types of values from which to discern patterns.
• Using non-random values directly tied to or that can be guessed for an account, e.g. username, email address.
• Applying non-cryptographic transformations, e.g. base64, scrambling bytes, improper XOR.
• Assuming no one can or will care to reverse engineer the obfuscation/transformation.
Attempts at obfuscation might appear throughout an application’s platform.
Other examples you may encounter are
• Running network services on non-standard ports.
• Undocumented API calls that have weak access controls or provide privileged actions.
• Admin interfaces to the site “hidden” by not being explicitly linked to.
There is a mantra that “security by obscurity” leads to failure. This manifests when developers naively apply transformations like Base64 encoding to data or system administrators change the banner for an Apache server with the expectation that the obfuscation increases the difficulty of or foils hackers. Obfuscation is not a security boundary; it doesn’t prevent attacks. On the other hand, obfuscation has some utility as a technique to increase a hacker’s time to a successful exploit—the idea being that the longer it takes a hacker to craft an exploit, the more likely site monitoring will identify the attack.
Pattern Recognition
Part of hacking web applications, and breaking obfuscation in particular, is identifying patterns and making educated guesses about developers’ assumptions or coding styles. The crafty human brain excels at such pattern recognition. But there are tools that aid the process. The first step is to collect as many samples as possible.
For numeric values, or values that can be mapped to numbers (e.g. short strings), some analysis to find patterns can be accomplished with mathematical tools like Fourier transforms, linear regression, or statistical methods. These are by no means universal, but can help determine whether values are being derived from a PRNG or a more deterministic generator. Two helpful tools for this kind of analysis are Scilab (http://www.scilab.org/) and R (http://www.r-project.org/). We’ll return to this mathematical approach in an upcoming section.
File Access & Path Traversal
Some web sites reference file names in URI parameters. For example, a templating mechanism might pull static HTML or the site’s navigation might be controlled through a single index.cgi page that loads content based on file names tracked in a parameter. The links for sites like these are generally easy to determine based either on the parameter’s name or its value, as shown below.
/index.aspx?page=UK/Introduction
/index.html?page=index
/index.html?page=0&lang=en
/index.html?page=/../index.html
/index.php?fa=PAGE.view&pageId=7919
/source.php?p=index.php
Items like page and extensions like .html hint to the link’s purpose. Attackers will attempt to exploit these types of URIs by replacing the expected parameter value with the name of a sensitive file on the operating system or a file within the web application. If the web application uses the parameter to display static content, then a successful attack would display a page’s source code.
For example a vulnerability was reported against the MODx web application in January 2008 (http://www.securityfocus.com/bid/27096/). The web application included a page that would load and display the contents of a file named, aptly enough, in the file URI parameter. The exploit required nothing more than a web browser as the following URI shows.
http://site/modx-0.9.6.1/assets/js/htcmime.php?file=../../manager/includes/config.inc.php%00.htc
The config.inc.php contains sensitive passwords for the web site. Its contents can’t be directly viewed because its extension, .php, ensures that the web server will parse it as a PHP file instead of a raw text file. So trying to view /config.inc.php would result in a blank page. This web application’s security broke down in several ways. It permitted directory traversal characters (../) that permit an attacker to access a file anywhere on the file system that the web server’s account has permissions to read. The developers did try to restrict access to files with a .htc extension since only such files were expected to be used by htcmime.php. They failed to properly validate the file parameter which meant that a file name that used a NULL character (%00) followed by .htc would appear to be valid. However, the %00.htc would be truncated because NULL characters designate the end of a string in the operating system’s file access functions. (See Chapter 2 for details on the different interpretations of NULL characters between a web application and the operating system.)
This problem also applies to web sites that offer a download or upload capability for files. If the area from which files may be downloaded isn’t restricted or the types of files aren’t restricted, then an attacker could attempt to download the site’s source code. The attacker might need to use directory traversal characters in order to move out of the download repository into the application’s document root. For example, an attack pattern might look like the following list of URIs.
http://site/app/download.htm?file=profile.png
http://site/app/download.htm?file=download.htm(download.htm cannot be found)
http://site/app/download.htm?file=./download.htm(download.htm cannot be found)
http://site/app/download.htm?file=../download.htm(download.htm cannot be found)
http://site/app/download.htm?file=../../../app/download.htm(success!)
File uploads pose an interesting threat because the file might contain code executable by the web site. For example, an attacker could craft an ASP, JSP, Perl, PHP, Python or similar file, upload it to the web site, then try to directly access the uploaded file. An insecure web site would pass the file through the site’s language parser, executing the file as if it were a legitimate page of the web site. A secure site would not only validate uploaded files for correct format, but place the files in a directory that would either not be directly accessible or whose content would not be passed through the application’s code stack.
File uploads may also be used to create denial of service (DoS) attacks against a web application. An attacker could create 2GB files and attempt to upload them to the site. If 2GB is above the site’s enforced size limit, then the attacker need only create 2000 files of 1MB each (or whatever combination is necessary to meet the limit). Many factors can contribute to a DoS. The attacker might be able to exhaust disk space available to the application. The attacker might overwhelm a file parser or other validation check and take up the server’s CPU time. Some filesystems have limits on the number of files that can be present in a directory or have pathological execution times when reading or writing to directories that contain thousands of files. The attacker might attempt to exploit the filesystem by creating thousands and thousands of small files.
Predictable Identifiers
Random numbers play an important role in web security. Session tokens, the cookie values that uniquely identify each visitor, must be difficult to predict. If the attacker compromises a victim’s session cookie, then the attacker can impersonate that user without much difficulty. One method of compromising the cookie is to steal it via a network sniffing or cross-site scripting attack. Another method would be to guess the value. If the session cookie was merely based on the user’s e-mail address then an attacker need only know the e-mail address of the victim. The other method is to reverse engineer the session cookie algorithm from observed values. An easily predictable algorithm would merely increment session IDs. The first user receives cookie value 1, the next user 2, then 3, 4, 5, and so on. An attacker who receives session ID 8675309 can guess that some other users likely have session IDs 8675308 and 8675310.
Sufficient randomness is a tricky phrase that doesn’t have a strong mathematical definition. Instead, we’ll explore the concept of binary entropy with some examples of analyzing how predictable a sequence might be.
Inside the Pseudo-Random Number Generator (PRNG)
The Mersenne Twister is a strong pseudo-random number generator. In non-rigorous terms, a strong PRNG has a long period (how many values it generates before repeating itself) and a statistically uniform distribution of values (bits 0 and 1 are equally likely to appear regardless of previous values). A version of the Mersenne Twister available in many programming languages, MT19937, has an impressive period of 219937-1. Sequences with too short a period can be observed, recorded, and reused by an attacker. Sequences with long periods force the adversary to select alternate attack methods. The period of MT19937 far outlasts the number of seconds until our world ends in fire or ice (or is wiped out by a Vogon construction fleet1 for that matter). The strength of MT19937 also lies in the fact that one 32-bit value produced by it cannot be used to predict the subsequent 32-bit value. This ensures a certain degree of unpredictability.
Yet all is not perfect in terms of non-predictability. The MT19937 algorithm keeps track of its state in 624 32-bit values. If an attacker were able to gather 624 sequential values, then the entire sequence—forward and backward—could be reverse-engineered. This feature is not specific to the Mersenne Twister, most PRNG have a state mechanism that is used to generate the next value in the sequence. Knowledge of the state effectively compromises the sequence’s predictability. This is another example of where using a PRNG incorrectly can lead to its compromise. It should be impossible for an attacker to enumerate.
Linear congruential generators (LCG) use a different approach to creating numeric sequences. They predate the Internet, going as far back as 1948 [D.H. Lehmer. Mathematical methods in large-scale computing units. In Proc. 2nd Sympos. on Large-Scale Digital Calculating Machinery, Cambridge, MA, 1949, pages 141–146, Cambridge, MA, 1951. Harvard University Press.]. Simple LCG algorithms create a sequence from a formula based on a constant multiplier, a constant additive value, and a constant modulo. The details of an LCG aren’t important at the moment, but here is an example of the formula. The values of a, k, and m must be secret in order to preserve the unpredictability of the sequence.xn=a*xn-1 +kmodm
The period of an LCG is far shorter than MT19937. However, an effective attack does not need to observe more than a few sequential values. In the Journal of Modern Applied Statistical Methods, May 2003, Vol. 2, No. 1,2–280 George Marsaglia describes an algorithm for identifying and cracking a PRNG based on a congruential generator (http://education.wayne.edu/jmasm/toc3.pdf). The crack requires less than two dozen sequential samples from the sequence. The description of the cracking algorithm may sound complicated to math-averse ears, but rest assured the execution is simple. In fancy terms, the attack determines the modulo m of the LCG by finding the greatest common divisor (GCD) of the volumes of parallelepipeds2 described by vectors taken from the LCG sequence. This translates into the following Python script.
#!/usr/bin/env python
import array
from fractions import gcd
from itertools import imap, product
from numpy.linalg import det
from operator import mul, sub
values = array.array(‘l’, [308,785,930,695,864,237,1006,819,204,777,378,495,376,357,70,747,356])
vectors = [ [values[i] - values[0], values[i+1] - values[1]] for i in range(1, len(values)-1) ]
volumes = []
for i in range(0, len(vectors)-2, 2):
v = abs(det([ vectors[i], vectors[i+1] ]))
volumes.insert(-1, v)
print gcd(volumes[0], volumes[1])
The GCD reported by this script will be the modulo m used in the LCG (in some cases more than one GCD may need to be calculated before reaching the correct value). We already have a series of values for x so all that remains is to solve for a and k. The values are easily found by solving two equations for two unknowns.
This section should not be misread as a suggestion to create your own PRNG. The Mersenne Twister is a strong pseudo-random number generator. A similarly strong algorithm is called the Lagged Fibonacci. Instead this section highlights some very simple ways that a generator may inadvertently leak its internal state. Enumerating 624 sequential 32-bit values might not be feasible against a busy web site, or different requests may use different seeds, or may be numbers in the sequence are randomly skipped over. In any case it’s important that the site be aware of how it is generating random numbers and where those numbers are being used. The generation should come from a well-accepted method as opposed to home-brewed algorithms. The values should not be used such that the internal state of a PRNG can be reproduced.
We shouldn’t end this section without recommending a book more salient to random numbers: The Art of Computer Programming, Volume 2 by Donald Knuth. It is a canonical resource regarding the generation and analysis of random numbers.
note
The rise of virtualized computing, whether called cloud or other trendy moniker, poses interesting questions about the underlying sources of entropy that operating systems rely upon for PRNG. The abstraction of CPUs, disk drives, video cards, etc. affects assumptions about a system’s behavior. It’s a narrow topic to watch, but there could be subtle attacks in the future that take advantage of possibly weaker or more predictable entropy in such systems.
Creating a Phase Space Graph
There are many ways to analyze a series of apparently random numbers. A nice visual technique creates a three-dimensional graph of the difference between sequential values. More strictly defined as phase space analysis, this approach graphs the first-order ordinary differential equations of a system [Weisstein, Eric W. “Phase Space.” From MathWorld—A Wolfram Web Resource. http://mathworld.wolfram.com/PhaseSpace.html]. In practice, the procedure is simple. The following Python code demonstrates how to build the x, y, and z coordinates for the graph.
#!/usr/bin/env python
import array
sequence = array.array(‘l’, [308,785,930,695,864,237,1006,819,204,777,378,495,376,357,70,747,356])
diff = [sequence[i+1] - sequence[i] for i in range(len(sequence) - 1)]
coords = [diff[i:i+3] for i in range(len(diff)-2)]
A good random number generator will populate all points in the phase space with equal probability. The resulting graph appears like an evenly distributed cloud of points. Figure 7.2 shows the phase space of random numbers generated by Python’s random.randint() function.
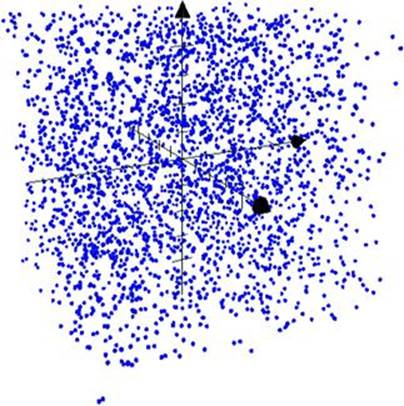
Figure 7.2 Phase space of good PRNG output
The phase space for a linear congruential generator contains patterns that imply a linear dependency between values. Figure 7.3 shows the graph of values generated by an LCG.
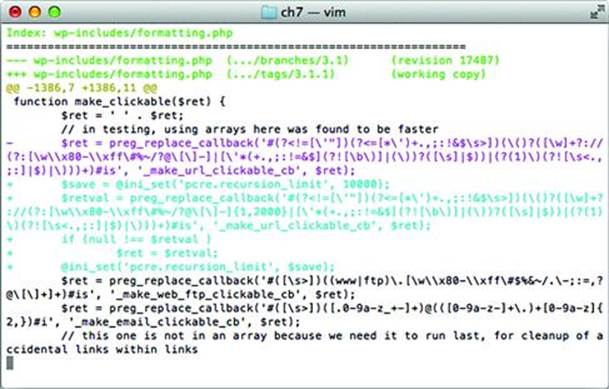
Figure 7.3 Phase space of LCG output
Plotting the phase space of a series of apparently random numbers can give a good hint whether the series is based on some linear function or uses a stronger algorithm that produces a better distribution of random values. Additional steps are necessary to create an algorithm that takes a sequence of numbers and reliably predicts the next value; the phase space graph helps refine the analysis.
A noise sphere is an alternate representation of a data using spherical coordinates (as opposed to Cartesian coordinates of a phase space graph). Creating the points for a noise sphere no more difficult than for a phase space (see http://mathworld.wolfram.com/NoiseSphere.html for the simple math). Figure 7.4 shows data generated by an LCG plotted with spherical coordinates. The data’s underlying pattern is readily apparent, pointing to a weakness in this kind of random number generator’s algorithm.
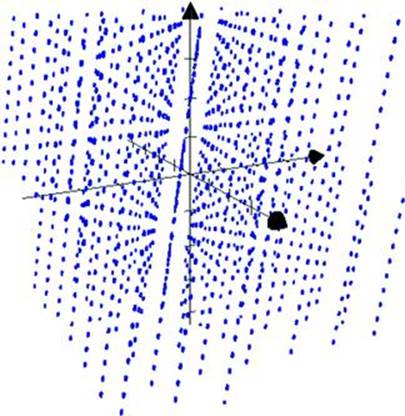
Figure 7.4 Data patterns become evident in a noise sphere
Phase space graphs are easy to generate and have straightforward math: subtracting lagged elements. It’s also possible to use techniques like autocorrelation and spectral analysis to search for patterns in time-based series. The following figure shows the same LCG output passed through thecorr function of Scilab (http://www.scilab.org). The large spikes indicate an underlying periodicity of the data. Random data would not have such distinct spikes. This would be yet one more tool for the narrow topic of analyzing numeric sequences observed in a web app. (Or even numeric sequences found in the site’s platform. For a historic perspective, check out the issues surrounding TCP Initial Sequence Number prediction, http://www.cert.org/advisories/CA-2001-09.html. (see Figure 7.5))
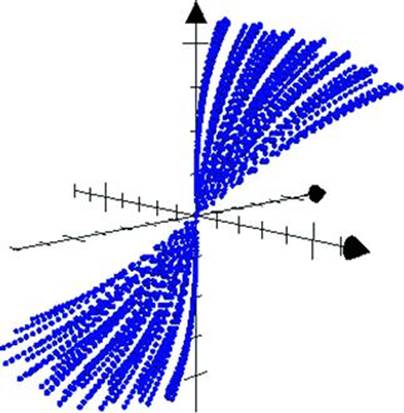
Figure 7.5 Spikes hint at non-random data
There are transformations that improve the apparent randomness of linear functions (even for the simplest function that produces incremental values), but increasing apparent randomness is not the same as increasing effective entropy. For example, the MD5 hash of the output of an LCG produces a phase space graph indistinguishable from the randomness shown in Figure 7.2. Cryptographic transformations can be an excellent way of reducing the predictability of a series, but there are important caveats that we’ll explore in the next section.
The Fallacy of Complex Manipulation
Expecting a strong cryptographic hash or other algorithm to produce a wide range of random values from a small seed. A hash function like MD5 or SHA256 will create a 128- or 256-bit value from any given seed. The incorrect assumption is based on conflating the difficulty of guessing a 256-bit value with the relative ease of guessing a seed based on a few digits. For example, if an attacker sees that the userid for an account is 478f9edcea929e2ae5baf5526bc5fdc7629a2bd19cafe1d9e9661d0798a4ddae the first step would be to attempt to brute force the seed used to generate the hash. Imagine that the site’s developers did not wish to expose the userid, which are generated incrementally. The posited threat was an attacker could cycle through userids if the values were in an easily guessed range such as 100234, 100235, 100236, and so on. An inadequate countermeasure is to obfuscate the id by passing it through the SHA-256 hash function. The expectation would be that the trend would not be discernible which, as the following samples show, seems to be a fair expectation. (The values are generated from the string representation of the numeric userids.)
4bfcc4d35d88fbc17a18388d85ad2c6fc407db7c4214b53c306af0f366529b06
976bddb10035397242c2544a35c8ae22b1f66adfca18cffc9f3eb2a0a1942f15
e3a68030095d97cdaf1c9a9261a254aa58581278d740f0e647f9d993b8c14114
In reality, an attacker can trivially discover the seeds via a brute force attack against the observed hashes. From that point it is easy to start cycling through userids. The SHA-256 algorithm generates a 256 bit number, but it can’t expand the randomness of the seed used to generate the hash. For example, a billion userids equates to roughly a 23 bit number, which is orders of magnitude less than the 256 bit output. Consequently, the attacker need only brute force 223 possible numbers to figure out how userids are created or to reverse map a hash to its seed.
More information regarding the use of randomness can be found in RFC 1750 (http://www.faqs.org/rfcs/rfc1750.html).
Exposed APIs
Web sites that provide Application Programming Interfaces (API) must be careful to match the security of those interfaces with the security applied to the site’s “normal” pages made for browsers. Security problems may stem from
• Legacy versions. Good APIs employ versioning to delineate changes in behavior or assumptions of a function. Poor site administration leaves unused, deprecated, or insecure APIs deployed on a site.
• The site’s developers benefit from verbose error messages and debug information returned by an API. However, such information should be removed or limited in production environments if it leaks internal data about the application.
• Authentication and authorization must be applied equally to API functions that mimic functions accessed by POST or GET requests from a browser.
Poor Security Context
The fact that a resource’s reference can be predicted is not always the true vulnerability. More often the lack of strong authorization checks on the resource causes a vulnerability to arise. All users of a web site should have a clear security context, whether an anonymous visitor or an administrator. The security context identifies the user via authentication and defines what the user may access via authorization. A web site’s security should not rest solely on the difficulty of guessing a reference. While the site’s developers may wish to maintain some measure of secrecy, but the knowledge of a user or document id should not immediately put the resource at risk.
In October 2008 a bug was reported against Twitter that exposed any user’s private messages (http://valleywag.gawker.com/5068550/twitter-bug-reveals-friends%20only-messages). Normally, messages sent only to friends or messages otherwise marked private could only be read by authorized users (i.e. friends). This vulnerability targeted the XML-based RSS feed associated with an account. Instead of trying to directly access the targeted account, the attacker would determine a friend of the account. So, if the attacker wanted to find out the private messages sent by Alice and the attacker knows that Bob is on Alice’s friend list, then the attacker would retrieve the XML feed from Bob’s account. The XML feed would contain the messages received from Alice. The attack required nothing more than requesting a URI based on the friend’s username, as shown below.
http://twitter.com/statuses/friends/username.xml
This vulnerability demonstrates the difficulty of protecting access to information. The security context of private messages was enforced between one account and its associated friends. Unauthorized users were prohibited from accessing the private messages of the original account. However, the messages were leaked through friends’ accounts. This example also shows how alternate access vectors might bypass authorization tests. The security context may be enforced when accessing messages via Twitter’s web site, but the RSS feed—which contained the same information—lacked the same enforcement of authorization. In this case there is no need to obfuscate or randomize account names. In fact, such a step would be counterproductive and fail to address the underlying issue because the problem did not arise from predictable account names. The problem was due to lax authorization tests that leaked otherwise protected information.
Targeting the Operating System
Web application exploits cause plenty of damage without having to gain access to the underlying operating system. Nevertheless, many attackers still have arsenals of exploits awaiting the chance to run a command on the operating system. As we saw in the section titled Referencing files based on client-side parameters some attacks are able to read the filesystem by adding directory traversal characters to URI parameters. In Chapter 3: SQL Injection we covered how shell commands could be executed through the database server. In all these cases a web application vulnerability is leveraged into a deeper attack against the server. This section covers more examples of this class of attacks.
Epic Fail
An interesting archaeological study of web security could be made by examining the development history of phpBB, an open source forum application. The application has survived numerous vulnerabilities and design flaws to finally adopt more secure programming techniques and leave the taint of insecurity to its past. Thus, it was surprising that in February 2009 the phpbb.com web site was hacked (http://www.securityfocus.com/brief/902). For once the vulnerability was not in the forum software, but in a PHPList application that shared the same database as the main web site. The attack resulted in compromising the e-mail and password hash for about 400,000 accounts. Isolation of the PHPList’s application space and segregation of databases used by PHPList and the main phpBB web site might have blocked the attack from causing so much embarrassment to the phpBB team. A more secure application stack (from the operating system to the web server) could have helped the site reduce the impact of a vulnerability in the application layer. More details about the attack and PHP security can be found at this link: http://www.suspekt.org/2009/02/06/ some-facts-about-the-phplist-vulnerability-and-the-phpbbcom-hack/.
Executing Shell Commands
Web application developers with enough years of experience cringe at the thought of passing the value of a URI parameter into a shell command. Modern web applications erect strong bulwarks between the application’s process and the underlying operating system. Shell commands by their nature subvert that separation. At first it may seem strange to discuss these attacks in a chapter about server misconfigurations and predictable pages. In fact, a secure server configuration can mitigate the risk of shell command exploits regardless of whether the payload’s entry point was part of the web application or merely one component of a greater hack.
In the nascent web application environment of 1996 it was not uncommon for web sites to run shell commands with user-supplied data as arguments. In fact, an early 1996 CERT advisory related to web applications described a command-execution vulnerability in an NCSA/Apache CGI module (http://www.cert.org/advisories/CA-1996-06.html). The exploit involved injecting a payload that would be passed into the UNIX popen() function. The following code shows a snippet from the vulnerable source.
strcpy(commandstr, “/usr/local/bin/ph -m “);
if (strlen(serverstr)) {
strcat(commandstr, “-s “);
/∗ RM 2/22/94 oops ∗/
escape_shell_cmd(serverstr);
strcat(commandstr, serverstr);
strcat(commandstr, ““);
}
/∗ ... some more code here ... ∗/
phfp = popen(commandstr,”r”);
send_fd(phfp, stdout);
The developers did not approach this CGI script without some caution. They created a custom escape_shell_cmd() function that stripped certain shell metacharacters and control operators. This was intended to prevent an attacker from appending arbitrary commands. For example, one such risk would be concatenating a command to dump the system’s password file.
/usr/local/bin/ph -m -s ;cat /etc/passwd
The semicolon, being a high-risk metacharacter, was stripped from the input string. In the end attackers discovered that one control operator wasn’t stripped from the input, the newline character (hexadecimal 0x0A). Thus, the exploit looked like this:
http://site/cgi-bin/phf?Qalias=%0A/bin/cat%20/etc/passwd
The phf exploit is infamous because it was used in a May 1999 hack against the White House’s web site. An interview with the hacker posted on May 11th (two days after the compromise) to the alt.2600.moderated Usenet group alluded to an “easily exploitable” vulnerability3. In page 43 of The Art of Intrusion by Kevin Mitnick and William Simon the vulnerability comes to light as a phf bug that was used to execute an xterm command that sent an interactive command shell window back to the hacker’s own server. The command cat /etc/passwd is a cute trick, but xterm -display opens a whole new avenue of attack for command injection exploits.
Lest you doubt the relevance of a vulnerability over 13 years old, consider how simple the vulnerability was to exploit and how success (depending on your point of view) rested on two crucial mistakes. First, the developers failed to understand the complete set of potentially malicious characters. Second, user data was mixed with a command. Malicious characters, the newline included, have appeared in Chapter 1: Cross-Site Scripting (XSS) and Chapter 3: SQL Injection. Both of those chapters also discussed this issue of leveraging the syntax of data to affect the grammar of a command, either by changing HTML to affect an XSS attack or modifying a SQL query to inject arbitrary statements. We’ll revisit these two themes throughout this chapter.
note
A software project’s changelog provides insight into the history of its development, both good and bad. Changelogs, especially for Open Source projects can signal problematic areas of code or call out specific security fixes. The CGI example just mentioned had this phrase in its changelog, “add newline character to list of characters to strip from shell cmds to prevent security hole.” Attackers will take the time to peruse changelogs (when available) for software from the web server to the database to the application. Don’t bother hiding security messages or believe that proprietary binaries without source code available discourages attackers. Modern security analysis is able to track down vulnerabilities just by reverse-engineering the binary patch to a piece of software. Even if a potential vulnerability is discovered by the software’s development team without any known attacks or public reports of its existence, the changes—whether a changelog entry or a binary patch—narrow the space in which sophisticated attackers will search for a way to exploit the hitherto unknown vulnerability.
The primary reason shell commands are dangerous is because they put the attacker outside the web application’s process space and into the operating system. The attacker’s access to files and ability to run commands will only be restricted by the server’s configuration. One of the reasons that shell commands are difficult to secure is that many APIs that expose shell commands offer a mix of secure and insecure methods. There is a tight parallel here with SQL injection. Although programming languages offer prepared statements that prevent SQL injection, developers are still able to craft statements with string concatenation and misuse prepared statements.
In order to attack a shell command the payload typically must contain one of the following metacharacters.
| & ; () < >
Or it must contain a control operator like one of the following. (There’s an overlap between these two groups.)
|| & && ; ;; () |
Or a payload might contain a space, tab, or newline character. In fact, many hexadecimal values are useful to command injection as well as other web-related injection attacks. Some of the usual suspects are shown in Table 7.1.
Table 7.1 Common delimiters for injection attacks
|
Hexadecimal Value |
Typical Meaning |
|
0×00 |
NULL character. String terminator in C-based languages |
|
0×09 |
Horizontal tab |
|
0×0a |
New line |
|
0×0b |
Vertical tab |
|
0×0d |
Carriage return |
|
0×20 |
Space |
|
0×7f |
Maximum 7-bit value |
|
0×ff |
Maximum 8-bit value |
While many of the original vectors of attack for command shells, CGI scripts written in Bash to name one, the vulnerability has not disappeared. Like many vulnerabilities from the dawn of HTTP, the problem seems to periodically resurrect itself through the years. More recently in July 2009 a command injection vulnerability was reported in the web-based administration interface for wireless routers running DD-WRT. The example payload didn’t try to access an /etc/passwd file (which wouldn’t be useful anyway from the device), but it bears a very close resemblance to attacks 13 years earlier. The payload is part of the URI’s path rather than a parameter in the query string, as shown below. It attempts to launch a netcat listener on port 31415.
http://site/cgi-bin/;nc$IFS-l$IFS-p$IFS\31415$IFS-e$IFS/bin/sh
The $IFS token in the URI indicates the Input Field Separator used by the shell environment to split words. The most common IFS is the space character, which is used by default. Referencing the value as $IFS simply instructs the shell to use substitute the current separator, which would create the following command.
nc -l -p \31415 -e /bin/sh
The IFS variable can also be redefined to other characters. Its advantage in command injection payloads is to evade inadequate countermeasures that only strip spaces.
IFS=2&&P=nc2-l2-p2314152-e2/bin/sh&&$P
Creative use of the IFS variable might bypass input validation filters or monitoring systems. As with any situation that commingles data and code, it is imperative to understand the complete command set associated with code if there is any hope of effectively filtering malicious characters.
Injecting PHP Commands
Since its inception in 1995 PHP has suffered many growing pains regarding syntax, performance, adoption, and our primary concern, security. We’ll cover different aspects of PHP security in this chapter, but right now we’ll focus on accessing the operating system via insecure scripts.
PHP provides a handful of functions that execute shell commands.
• exec()
• passthru()
• popen()
• shell_exec()
• system()
• Any string between backticks (ASCII hexadecimal value 0×60)
The developers did not neglect functions for sanitizing user-supplied data. These commands should always be used in combination with functions that execute shell commands.
• escapeshellarg()
• escapeshellcmd()
There is very little reason to pass user-supplied data into a shell command. Keep in mind that any data received from the client is considered user-supplied and tainted.
Loading Commands Remotely
Another quirk of PHP is the ability to include files in code from a URI. A web application’s code is maintained in a directory hierarchy across many files group by function. A function in one file can access a function in another file by including a reference to the file that contains the desired function. In PHP the include, include_once, require, and require_once functions accomplish this task. A common design pattern among PHP application is to use variables within the argument to include. For example, an application might include different strings based on a user’s language settings. The application might load ‘messages_en.php’ for a user who specifies English and ‘messages_fr.php’ for French-speaking users. If ‘en’ or ‘fr’ are taken from a URI parameter or cookie value without validation, then the immediate problem of loading local files should be clear.
PHP allows a URI to be specified as the argument to an include function. Thus, an attacker able to affect the value being passed into include could point the function to a site serving a malicious PHP file, perhaps something as small as this code that executes the value of URI parameter ‘a’ in a shell command.
warning
PHP has several configuration settings like “safe_mode” that have been misused and misunderstood. Many of these settings are deprecated and will be completely removed when PHP 6 is released. Site developers should be proactive about removing deprecated functions or relying on deprecated features to protect the site. Check out the PHP 5.3 migration guide athttp://us3.php.net/migration53 to see what will change and to learn more about the reasons for deprecating items that were supposed to increase security.
Attacking the Server
Any system given network connectivity is a potential target for attackers. The first step of any web application should be deploy a secure environment. This means establishing a secure configuration for network services and isolating components as much as possible. It also means that the environment must be monitored and maintained. A server deployed six months ago is likely to require at least one security patch. The patch may not apply to the web server or the database, but a system that slowly falls behind the security curve will eventually be compromised.
The apache.org site was defaced in 2000 due to insecure configurations. A detailed account of the incident is captured at http://www.dataloss.net/papers/how.defaced.apache.org.txt. Two points regarding filesystem security should be reiterated from the description. First, attackers were able to upload files that would be executed by the web server. This enabled them to upload PHP code via an FTP server. Second, the MySQL database was not configured to prevent SELECT statements from using the INTO OUTFILE technique to write to the filesystem (this technique is mentioned in Chapter 4). The reputation of the Apache web server might remain unchallenged since the attackers did not find any vulnerability in that piece of software. Nevertheless, one security of the entire system was brought down to the lowest common denominator of poor configuration and other insecure applications.
More recently in 2009 the apache.org administrators took down the site in response to another incident involving a compromised SSH account (https://blogs.apache.org/infra/entry/apache_org_downtime_initial_report). The attack was contained and did not affect any source code or content related to the Apache server. What this later incident showed was that sites, no matter how popular or savvy (the Apache administrators live on the web after all), are continuously probed for weaknesses. In the 2009 incident the Apache foundation provided a transparent account of the issue because their monitoring and logging infrastructure was robust enough to help with a forensic investigation—another example of how to handle a security problem before an incident occurs (establishing useful monitoring) and after (provide enough details to reassure customers that the underlying issues have been addressed and the attack contained).
Denial of Service
Denial of Service (DoS) attacks have existed since the beginning of the web. Early attacks relied on straight-forward bandwidth consumption: saturate the target with more packets than it can handle. Bandwidth attacks tended to be symmetric; the resources required to generate the traffic roughly equaled the resources available to the target. Thus, higher-performing targets required more and more systems to launch attacks.
Some DoS attacks took advantage of implementation flaws in an operating system’s TCP/IP stack. These attacks could be more successful because they tended to be asymmetric in resource requirements. The infamous “Ping of Death” (CVE-1999-0128) and ICMP “echo amplification” (CVE-1999-1201) are excellent examples of attacks that required few resources of the hacker in order to bring down a target. That the source packets could be trivially spoofed only made the hack that more superior to pure bandwidth-based attacks.
Concern for DoS attacks seems cyclic. While they are continually executed by hackers, their appearance as news topics or their success against large sites comes and goes. The OWASP Top 10 listed DoS attacks in the first 2004 release, only to drop them in the 2007 update and leave them off in the 2010 revision.
DoS attacks seem more like the background radiation of the Internet, if you will. However, they will remain a problem for web sites, whether motivated by ideology, malice, or money. The next few sections highlight hacks that are more nuanced than coarse bandwidth-exhausting attacks.
Network
Bandwidth isn’t the only measure of a site’s performance potential. The amount of concurrent connections it is able to handle represents one degree of “responsiveness” from a user’s perspective. Attacks that saturate a site’s available bandwidth affect responsiveness for all users, just as an attack that is able to exhaust the site’s ability to accept new connections would affect responsiveness for subsequent users.
In 2009 Robert Hansen popularized a “Slowloris” hack that was able to monopolize a web server’s connection pool such that new connections would be rejected (http://ha.ckers.org/slowloris/). The hack, which built on previous research, demonstrated a technique that relied neither on immense bandwidth utilization nor significantly abnormal traffic (in the sense of overlapping fragmented TCP packets or ICMP attacks like Ping of Death or Echo Amplification). In 2011, Sergey Shekyan expanded on the technique with a tool demonstrating so-called “slow POST” and “slow read” hacks (http://code.google.com/p/slowhttptest/). The slowhttptest tool highlighted how a single attacker could trickle packets in such a way as to overwhelm a server’s connection pool.
A notable aspect of the “slow” type of tests is that they are relatively easy to test for (in other words, they don’t require large computing resources to generate traffic) and that they can highlight configuration deficiencies across the site’s platform. A single web server may be configured to handle thousands of concurrent connections, but an intermediate load balancer or reverse proxy may not have the same level of configuration. More information on this topic is available at https://community.qualys.com/blogs/securitylabs/tags/slow_http_attack.
Attacking Programming Languages
Some previous chapters have alluded to DoS possibilities. SQL, for example, is prone to direct and indirect DoS attacks. A direct SQL hack would be passing a command like SHUTDOWN as part of a SQL injection payload (or an infinite loop, a MySQL BENCHMARK statement, etc.). An indirect SQL DoS would be finding a web page for which a search term could be used that generates a full table scan in the database—preferably one that bypasses any intermediate caching mechanism and forces the database to search a table with tens of thousands or millions of rows. One way to tweak this kind of hack is to use SQL wildcards like _ or % characters to further burden the database’s CPU.
HTML injection (e.g. cross-site scripting) is another vector for a DoS attack against the browser as opposed to the web site. Imagine a situation where an exploit injects a JavaScript while(1){var a=0;} payload into the browser. Modern browsers have some countermeasures for such “runaway scripts,” but for all intents and purposes the web site appears unresponsive to the user—even though the site is performing perfectly well. It’s just another way of coming up with creative hacks against a web application.
Regular Expressions
Regular expressions have a handful of properties that make them nice targets for DoS attacks: their ubiquitous presence in web applications, their potential for recursion, and the relative ease with which large amounts of data can be passed through them.
The underlying regex engine may have bugs that can be leveraged by attackers, e.g. http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2007-1661.
In other cases, the way the application uses the regex engine may be problematic. One example in software not directly related to web applications is syslog-ng. It’s notable because of the subtle interaction of flags it set for certain patterns. (More info available at http://git.balabit.hu/?p=bazsi/syslog-ng-3.2.git;a=commit;h=09710c0b105e579d35c7b5f6c66d1ea5e3a3d3ff.) A more relevant example for web applications is a 2011 advisory released for Wordpress, http://wordpress.org/news/2011/04/wordpress-3-1-1/. The security fix was rather simple, as shown in Figure 7.6. Note two improvements in the diff between Wordpress 3.1 (vulnerable version) and 3.1.1 (fixed version). The pcre.recursion_limit is set to 10,000 and the pattern submitted to the preg_replace_callback() function now has an explicit quantifier: {1,2000}.
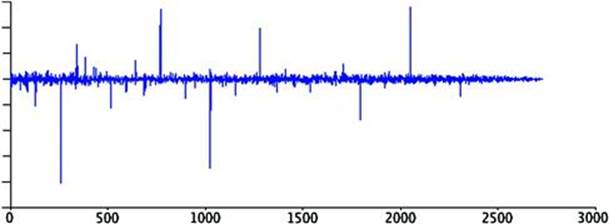
Figure 7.6 PCRE callback recursion error
It’s difficult to identify regex-based denial of service attacks. A good summary of attacks is available at http://www.owasp.org/images/f/f1/OWASP_IL_2009_ReDoS.ppt. Microsoft provides a regular expression fuzzing tool that helps identify problematic patterns in code,http://www.microsoft.com/download/en/details.aspx?id=20095.
Another way to test for regex DoS attacks is to consider how patterns are hardened, and create test cases that try to subvert these assumptions. The following recommendations improve performance and security of regular expressions—as long as you’ve actually tested and measured their effect in order to confirm the improvement!
• Prefer explicit quantifiers to unbounded quantifiers to avoid deep stack recursion or CPU-intensive matches from large input data, e.g. a{0, n} vs. a∗ or a{1, n} vs. a+. For example, Wordpress chose a reasonable limit of 2,000 characters to match a URL.
• Consider non-greedy quantifiers to avoid recursion attacks, e.g. a∗? instead of a∗.
• Limit the number of capture groups in order to prevent back-reference overflows, e.g. (a.c)(d.f)(g.i)(j.l). Alternately, consider using branch resets, i.e. (?|pattern), or non-grouping syntax, i.e. (?:pattern), to limit capture group references.
• Sanity-check ambiguous or indiscriminate patterns in order to prevent CPU-intensive matches, e.g. .∗|..+
• Test boundary conditions, e.g. zero input, several megabytes of input, repeated characters, nested patterns.
• Beware of the performance impact of look-around patterns, e.g. (?=pattern), (?!pattern), (?<=pattern), (?<!pattern).
• Anchor patterns with ^ (beginning) and $ (end) to ensure matches against the entire input. This primarily applies to patterns used as validation filters.
• Be aware of behavioral differences between regular expression engines. For example, Perl, Python, and JavaScript have individual idiosyncrasies. It’s important to avoid assumptions that data matched by a pattern in JavaScript also matches one that is PCRE-compatible. One way to examine such differences is to compare patterns in pcre_exec() (http://www.pcre.org/) with and without the PCRE_JAVASCRIPT_COMPAT option.
Hash Collisions
The preceding SQL injection and regular expression attacks are examples of algorithm complexity attacks. They target some corner-case, worst-case, or pathological behavior of a function. Another example, albeit a narrowly-focused one, is the hash collision attack. The hashes addressed here are the kind used in computer science to form the basics of data structures or otherwise non-cryptographic uses. (It’s still possible to misapply cryptographic hashes like SHA-1; check out Chapter 6 for details.) An overview of these kinds of attacks is in a 2003 paper by Scott A. Crosby and Dan S. Wallach, Denial of Service via Algorithmic Complexity Attacks (http://www.cs.rice.edu/~scrosby/hash/CrosbyWallach_UsenixSec2003.pdf).
An example of hash collisions is the DJBX33A function used by PHP (some background available at http://www.hardened-php.net/hphp/zend_hash_del_key_or_index_vulnerability.html). This particular hash function exhibited a certain property that aids collision attacks. First consider the hash result of the phrase HackingWebApplications passed through a reference implementation of DJBX33A and the PHP5 version:
HackingWebApplications / djb33x33a = 81105082
HackingWebApplications / PHP5 = 1407680383
Finding a hash collision is relatively simple. The phrase HackingWebApplications produces the same value as HackingWebApplicatiooR (note the final two letters have changed from ns to oR). This is further exploited by noticing that long input strings produce the same output. For example, we could concatenate the different phrases to obtain the same hash output:
HackingWebApplicationsHackingWebApplications
HackingWebApplicationsHackingWebApplicatiooR
If this were taken further, such a submitting one or two megabytes of data for a PHP parameter, then the system may spend an inordinate amount of CPU or memory to create an internal data structure that holds the two values. The effectiveness of these types of attacks is debated because at a certain point the practical attack serves much as a bandwidth-based DoS as it does as an algorithm complexity DoS. Nevertheless, attacks continue to be refined rather than thrown away—take the “slow” network attacks in a previous section as an example of years-old vulnerabilities that become revisited and improved.
Hash functions are susceptible to collisions to a different degree. The fnv1a (http://isthe.com/chongo/tech/comp/fnv/) function isn’t immune, but neither does it exhibit the “repeated string” behavior of DJBX33A that makes collision creation so easy. Regardless, it’s not hard to generate examples. These two phrases have the same value for fnv1a32 (0xf6ac3d6d). However, the concatenation of the two strings produce different values, unlike DJBX33A:
HackingWebApplications
HackingWebApplicbaxHV+
Somewhat practical examples of these kinds of attacks are enumerated at http://www.nruns.com/_downloads/advisory28122011.pdf along with the article at http://blogs.technet.com/b/srd/archive/2011/12/27/more-information-about-the-december-2011-asp-net-vulnerability.aspx.
Future attacks may target hashing strategies used by Bloom filters. Bloom filters provide a fast, space-efficient method for tracking an item’s membership of a set. For example, web page caches use a group of hash functions to generate bit patterns that identify a particular page. If the bit patterns are present in the Bloom filter, then the page has been cached. Collision attacks could be leveraged to cause poor cache performance by artificially creating false matches or misses. The Network Applications of Bloom Filters: A Survey explains the creation and use of Bloom filters as you might encounter them in web applications (http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.127.9672).
This hack is mitigated by seeding hashing algorithm with random value rather than a static value. The seed should be chosen with the same care as when PRNGs are used in other areas of the application: use high-entropy sources as opposed to slowly-changing values such as time in seconds or process ID. Seeding the hash makes it more difficult for a hacker to find collisions against a particular instance of the running application. Alternately, choose (and test!) hash functions that provide what you determine to be an acceptable trade-off between speed and collision resistance.
This seed approach has been considered by several software projects, including Lua (http://thread.gmane.org/gmane.comp.lang.lua.general/87491) and libxml2 (http://git.gnome.org/browse/libxml2/commit/?id=8973d58b7498fa5100a876815476b81fd1a2412a). Python’s handling of hash tables is well-described in its source file, Objects/dictobject.c.
Employing Countermeasures
Blocking attacks based on predictable resources involve securing the application’s code against unexpected input, strong random number generation, and authorization checks. Some attacks can also be mitigated by establishing a secure configuration for the file system.
Security checklists with recommended settings for web servers, databases, and operating systems are provided by their respective vendors. Any web site should start with a secure baseline for its servers. If the web application requires some setting to be relaxed in order to work, the exception should be reviewed to determine why there is a need to reduce security or if there is a suitable alternative. Use the following list as a starting point for common web components.
• Apache httpd—http://httpd.apache.org/docs/2.2/misc/security_tips.html and http://www.cgisecurity.com/lib/ryan_barnett_gcux_practical.html
• Microsoft IIS—http://www.microsoft.com/windowsserver2008/en/us/internet-information-services.aspx and http://learn.iis.net/page.aspx/139/iis7-security-improvements/
• General web security checklists—http://www.owasp.org/
• Extensive resource of security checklists for various software at the Center for Internet Security—http://benchmarks.cisecurity.org/
Restricting file Access
If the web application accesses files based on filenames constructed from a client-side parameter, ensure that only one pre-defined path is used to access the file. Web applications have relied on everything from cookie values to URI parameters as variable names of a file. If the web application will be using this method to read templates or language-specific content, you can improve security by doing the following:
• Prepend a static directory to all file reads in order to confine reads to a specific directory.
• Append a static suffix to the file.
• Reject file names that contain directory traversal characters (../../../). All file names should be limited to a known set of characters and format.
• Reject file names that contain characters forbidden by the file system, including NULL characters.
These steps help prevent an attacker from subverting file access to read source code of the site’s pages or access system files outside of the web document root. In general the web server should be restricted to read-only access within the web document root and denied access to sensitive file locations outside of the document root.
Using Object References
Web applications that load files or need to track object names in a client-side parameter can alternately use a reference id rather than the actual name. For example, rather than using index.htm, news.htm, login.htm as parameter values in a URI like /index.php?page=login.htm the site could map the files to a numeric value. So index.htm becomes 1, news.htm becomes 2, login.htm becomes 3, and so on. The new URI uses the numeric reference as in /index.php?page=3 to indicate the login page. An attacker will still try to iterate through the list of numbers to see if any sensitive pages appear, but it is no longer possible to directly name a file to be loaded by the /index.php page.
Object references are a good defense because they create a well-defined set of possible input values and enable the developers to block any access outside of an expected value. It’s much easier to test a number for values between 1 and 50 than it is to figure out if index.htm and index.php are both acceptable values. The indirection prevents an attacker from specifying arbitrary file names.
Blacklisting Insecure Functions
A coding style guide should be established for the web application. Some aspects of coding style guides elicit drawn-out debates regarding the number of spaces to indent code and where curly braces should appear on a line. Set aside those arguments and at the very least define acceptable and unacceptable coding practices. An acceptable practice would define how SQL statements should be created and submitted to the database. An unacceptable practice would define prohibited functions, such as PHP’s passthru(). Part of the site’s release process should then include a step during which the source code is scanned for the presence of any blacklisted function. If one is found, then the offending party needs to fix the code or provide assurances that the function is being used securely.
Enforcing Authorization
Just because a user requests a URI doesn’t mean the user is authorized to access the content represented by the URI. Authorization checks should be made at all levels of the web application. This ensures that a user requesting a URI like http://site/myprofile.htm?name=brahms is allowed to see the profile for brahms.
Authorization also applies to the web server process. The web server should only have access to files that it needs in order to launch and operate correctly. It doesn’t have to have full read access to the filesystem and it typically only needs write access for limited areas.
Restricting Network Connections
Complex firewall rules are unnecessary for web sites. Sites typically only require two ports for default HTTP and HTTPS connections, 80 and 443. The majority of attacks described in this book work over HTTP, effectively bypassing the restrictions enforced by a firewall. This doesn’t completely negate the utility of a firewall; it just puts into perspective where the firewall would be most and least effective.
A rule sure to reduce certain threats is to block outbound connections initiated by servers. Web servers by design always expect incoming connections. Outbound connections, even DNS queries, are strong indicators of suspicious activity. Hacking techniques use DNS to exfiltrate data or tunnel command channels. TCP connections might be anything from a remote file inclusion attack or outbound command shell.
Web Application Firewalls
Web application firewalls (or firewalls that use terms like “deep packet inspection”) address the limitations of network firewalls by applying rules at the HTTP layer. This means they are able to parse and analyze HTTP methods like GET and POST, ensure the syntax of the traffic falls correctly within the protocol, and gives web site operators the chance to block many web-based attacks. Web application firewalls, like their network counterparts, may either monitor traffic and log anomalies or actively block inbound or outbound connections. Inbound connections might be blocked if a parameter contains a pattern common the cross-site scripting or SQL injection. Outbound connections might be blocked if the page’s content appears to contain a database error message or match credit card number patterns.
Configuring and tuning a web application firewall to your site takes time and effort guided by security personnel with knowledge of how the site works. However, even simple configurations can stop automated scans that use trivial, default values like alert(document.cookie) or OR+1=1 in their payloads. The firewalls fare less well against concerted efforts by skilled attackers or many of the problems that we’ll see in Chapter 6: Abusing Design Deficiencies. Nevertheless, these firewalls at least offer the ability to log traffic if forensic investigation is ever needed. A good starting point for learning more about web application firewalls is the ModSecurity (www.modsecurity.org) project for Apache.
Summary
In the early chapters we covered web attacks that employ payloads that attempted to subvert the syntax of some component of the web application. Cross-site scripting attacks (XSS) use HTML formatting characters to change the rendered output of a web page. SQL injection attacks used SQL metacharacters to change the sense of a database query. Yet not all attacks require payloads with obviously malicious content or can be prevented by blocking certain characters. Some attacks require an understanding of the semantic meaning of a URI parameter. For example, changing a parameter like ?id=strauss to ?id=debussy should not reveal information that is supposed to be restricted to the user logged in with the appropriate id. In other cases changing parameters from ?tmpl=index.html to ?tmpl=config.inc.php should not expose the source code of the config.inc.php file. Other attacks might rely on predicting the value of a reference to an object. For example, if an attacker uploads files to a private document repository and notices that the files are accessed by parameter values like ?doc=johannes_1257749073, ?doc=johannes_1257754281, ?doc=johannes_1257840031 then the attacker might start poking around for other user’s files by using the victim’s username followed by a time stamp. In the worst case it would take a few lines of code and 86,400 guesses to look for all files uploaded within a 24 hour period.
The common theme through these examples is that the payloads do not contain particularly malicious characters. In fact, they rarely contain characters that would not pass even the strongest input validation filter. The characters in index.html and config.inc.php should both be acceptable to a function looking for XSS or SQL injection. These types of vulnerabilities take advantage of poor authorization checks within a web application. When the security of an item is only predicated on knowing the reference to it, ?doc=johannes_1257749073 for example, then the reference must be random enough to prevent brute force guessing attacks. Whenever possible, authorization checks should be performed whenever a user accesses some object in the web site.
Some of these attacks bleed into the site’s filesystem or provide the attacker with the chance to execute commands. Secure server configurations may reduce or even negate the impact of such attacks. The web site is only as secure as its weakest link. A well-configured operating system complements a site’s security, where a poorly configured one could very well expose securely written code.
1 From The Hitchhiker’s Guide to the Galaxy by Douglas Adams. You should also read the Hitchhiker’s series to understand why the number 42 appears so often in programming examples.
2 Informally, a six-sided polyhedron. Check out http://mathworld.wolfram.com/Parallelepiped.html for rigorous details.
3 Alas, many Usenet posts languish in Google’s archive and can be difficult to find. This link should produce the original post: http://groups.google.com/group/alt.2600.moderated/browse_thread/thread/d9f772cc3a676720/5f8e60f9ea49d8be.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.