Software Engineering: A Methodical Approach (2014)
PART B. Software Investigation and Analysis
Chapter 5. Information Gathering
In order to accurately and comprehensively specify the system, the software engineer gathers and analyzes information via various methodologies. This chapter discusses these methodologies as outlined below:
· Rationale for Information Gathering
· Interviews
· Questionnaires and Surveys
· Sampling and Experimenting
· Observation and Document Review
· Prototyping
· Brainstorming and Mathematical Proof
· Object Identification
· Summary and Concluding Remarks
5.1 Rationale for Information Gathering
What kind of information is the software engineer looking for? The answer is simple, but profound: You are looking for information that will help to accurately and comprehensively define the requirements of the software to be constructed. The process is referred to as requirements analysis, and involves a range of activities that eventually lead to the deliverable we call the requirements specification (RS). In particular, the software engineer must determine the following:
· Synergistic interrelationships of the system components: This relates to the components and how they (should) fit together.
· System information entities (object types) and their interrelatedness: An entity refers to an object or concept about data is to be stored and managed. Entities and object types will be further discussed in chapters 9 and 10.
· System operations and their interrelatedness: Operations are programmed instructions that enable the requirements of the system to be met. Some operations are system-based and may be oblivious to the end user; others facilitate user interaction with the software; others are internal and often operate in a manner that is transparent to the end user.
· System business rules: Business rules are guidelines that specify how the system should operate. These relate to data access, data flow, relationships among entities, and the behavior of system operations.
· System security mechanism(s) that must be in place: It will be necessary to allow authorized users to access the system while denying access to unauthorized users. Additionally, the privileges of authorized users may be further constrained to ensure that they have access only to resources that they need. These measures protect the integrity and reliability of the system.
As the software engineer embarks on the path towards preparation of the requirements specification, these objectives must be constantly borne in mind. In the early stages of the research, the following questions should yield useful pointers:
· WHAT are the (major) categories of information handled? Further probing will be necessary, but you should continue your pursuit until this question is satisfactorily answered.
· WHERE does this information come from? Does it come from an internal department or from an external organization?
· WHERE does this information go after leaving this office? Does it go to an internal department or to an external organization?
· HOW and in WHAT way is this information used? Obtaining answers to these questions will help you to identify business rules (to be discussed in chapter 7) and operations (to be discussed in chapters 11 and 12).
· WHAT are the main activities of this unit? A unit may be a division or department or section of the organization. Obtaining the answer to this question will also help you to gain further insights into the operations (to be discussed in chapters 11 and 12).
· WHAT information is needed to carry out this activity? Again here, you are trying to refine the requirements of each operation by identifying its input(s).
· WHAT does this activity involve? Obtaining the answer to this question will help you to further refine the operation in question.
· WHEN is it normally done? Obtaining the answer to this question will help you to further refine the operation in question by determining whether there is a time constraint on an operation.
· WHY is this important? WHY is this done? WHY…? Obtaining answers to these probes will help you to gain a better understanding of the requirements of the software system.
Of course, your approach to obtaining answers to these probing questions will be influenced by whether the software system being researched is to be used for in-house purposes, or marketed to the public. The next few sections will examine the commonly used information gathering strategies.
5.2 Interviewing
Interviewing is the most frequent method of information gathering. It can be very effective if carefully planned and well conducted. It is useful when the information needed must be elaborate, or clarification on various issues is required. The interview also provides an opportunity for the software engineer to win the confidence and trust of clients. It should therefore not be squandered.
Steps in Planning the Interview
In panning to conduct an interview, please observe the following steps:
1. Read background information.
2. Establish objectives.
3. Decide whom to interview.
4. Prepare the interviewee(s).
5. Decide on structure and questions.
Basic Guidelines for Interviews
Figure 5-1 provides some guidelines for successfully planning and conducting an interview. These guidelines are listed in the form of a do-list, and a don’t-list.
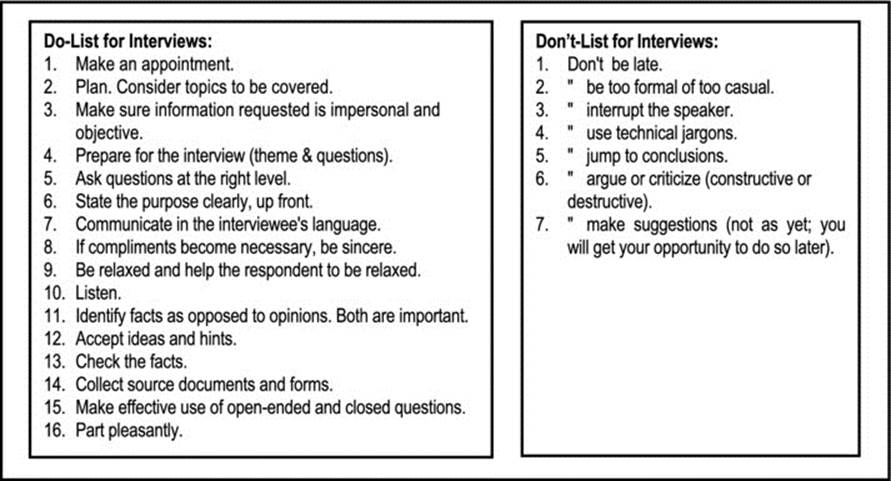
Figure 5-1. Basic Guidelines for Interview
5.3 Questionnaires and Surveys
A questionnaire is applicable when any of the following situations hold:
· A small amount of information is required of a large population.
· The time frame is short but a vast area (and/or dispersed population) must be covered.
· Simple answers are required to a number of standard questions.
5.3.1. Guidelines for Questionnaires
Figure 5-2 provides a set of basic guidelines for preparing a questionnaire.

Figure 5-2. Guidelines for Questionnaires
5.3.2. Using Scales in Questionnaires
Scales may be used to measure the attitudes and characteristics of respondents, or have respondents judge the subject matter in question. There are four forms of measurement as outlined below:
1. Nominal Scale: Used to classify things. A number represents a choice. One can obtain a total for each classification.
2. Ordinal Scale: Similar to nominal, but here the number implies ordering or ranking.
Example 1: The financial status of an individual may be represented as follows:
![]()
3. Interval Scale: Ordinal with equal intervals.
Example 2: Usage of a particular software product by number of modules used (10 means high):

4. Ratio Scale: Interval scale with absolute zero.
Example 3: Distance traveled to obtain a system report:
![]()
Example 4: Average response time of the system:
![]()
5.3.3. Administering the Questionnaire
Options for administering the questionnaire include the following:
· Convening respondents together at one time
· Personally handing out blank questionnaires and collecting completed ones
· Allowing respondents to self-administer the questionnaire at work and leave it at a centrally located place
· Mailing questionnaires with instructions, deadlines, and return postage
· Using the facilities of the World Wide Web (WWW), for example e-mail, user forums and chat rooms
5.4 Sampling and Experimenting
Sampling is useful when the information required is of a quantitative nature or can be quantified, no precise detail is available, and it is not likely that such details will be obtained via other methods. Figure 5-3 provides an example of a situation in which sampling is relevant.
Sampling theory describes two broad categories of samples:
· Probability sampling involving random selection of elements
· Non-probability sampling where judgment is applied in selection of elements
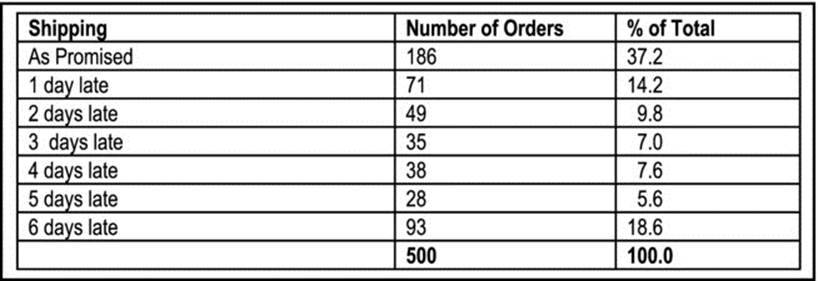
Figure 5-3. Examining the Delivery of Orders after Customer Complaints
5.4.1 Probability Sampling Techniques
There are four types of probability sampling techniques:
· Simple Random Sampling uses a random method of selection of elements.
· Systematic Random Sampling involves selection of elements at constant intervals. Interval = N/n where N is the population size and n is the sample size.
· Stratified Sampling involves grouping of the data in strata. Random sampling is employed within each stratum.
· Cluster Sampling: The population is divided into (geographic) clusters. A random sample is taken from each cluster.
![]() Note The latter three techniques constitute quasi-random sampling. The reason for this is that they are not regarded as perfectly random sampling.
Note The latter three techniques constitute quasi-random sampling. The reason for this is that they are not regarded as perfectly random sampling.
5.4.2 Non-probability Sampling Techniques
There are four types of non-probability sampling techniques:
· Convenience Sampling: Items are selected in the most convenient manner available.
· Judgment Sampling: An experienced individual selects a sample (e.g. a market research).
· Quota Sampling: A subgroup is selected until a limit is reached (e.g. every other employee up to 500).
· Snowball Sampling: An initial set of respondents is selected. They in turn select other respondents; this continues until an acceptable sample size is reached.
5.4.3 Sample Calculations
Figure 5-4 provides a summary of the formulas that are often used in performing calculations about samples:

Figure 5-4. Formulas for Sample Calculations
These formulas are best explained by examining the normal distribution curve (Figure 5-5). From the curve, observe that:
· Prob (-1 <= Z <= 1) = 68.27%
· Prob (-2 <= Z <= 2) = 95.25%
· Prob (-3 <= Z <= 3) = 99.73%
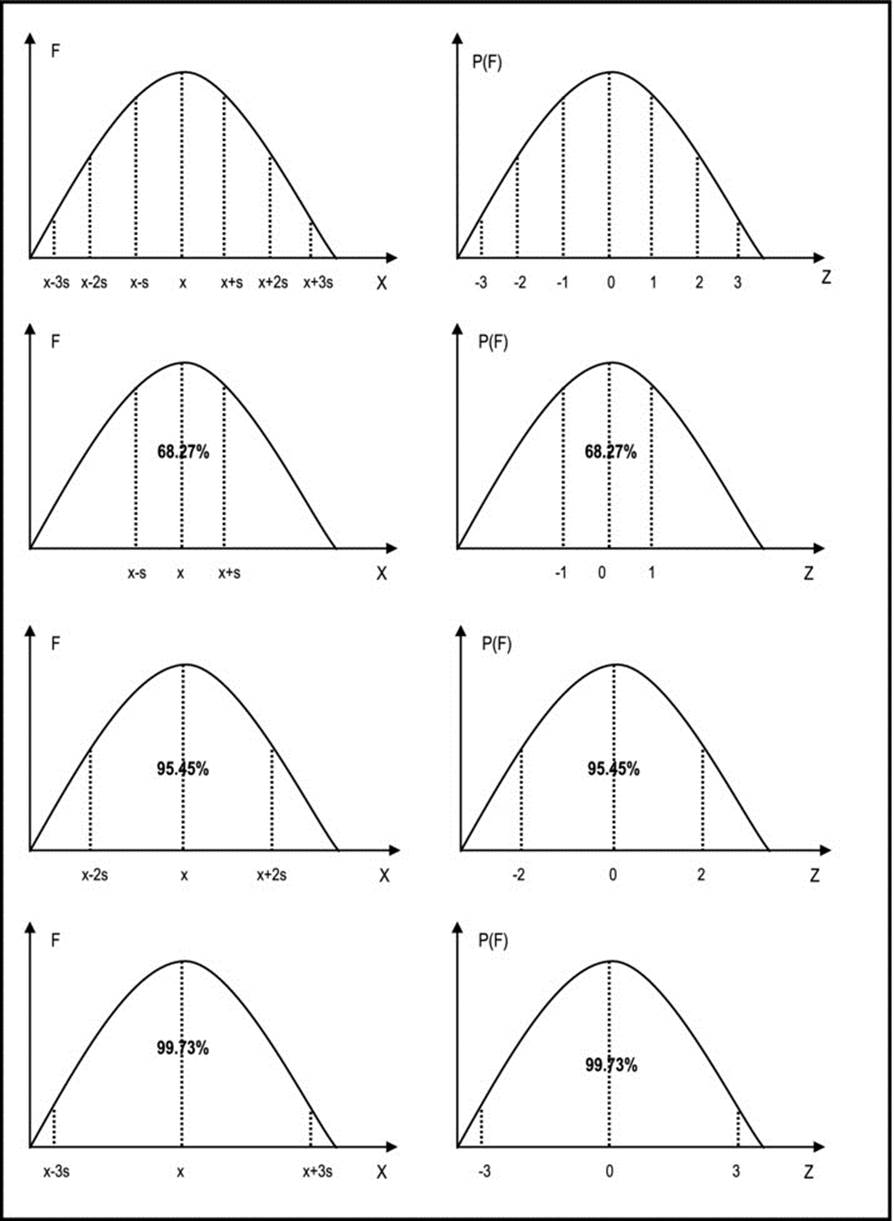
Figure 5-5. The Normal Distribution Table
The confidence limit of a population mean is normally given by X' +/- ZSE where Z is determined by the normal distribution of the curve, considering the percentage confidence limit required. The following Z values should be memorized:
· 68% confidence => Z = 1.64
· 95% confidence => Z = 1.96
· 99% confidence => Z = 2.58
The confidence limit defines where an occurrence X may lie in the range (X' - ZSE) < X < (X' + ZSE), given a certain confidence. As you practice solving sampling problems, your confidence in using the formulas will improve.
5.5 Observation and Document Review
Review of source documents will provide useful information about the input, data storage, and output requirements of the software system. This activity could also provide useful information on the processing requirements of the software system. To illustrate, get a hold of an application form at your organization, and attempt to identify information entities (object types) represented on the form. With a little thought, you should be able to identify some or all of the following entities:
· Personal Information
· Family/Kin Contact Information
· Education History
· Employment History
· Professional References
· Extra Curricular Activities
Internal documents include forms, reports and other internal publications; external documents are mainly in the form of journals and other professional publications. These source documents are the raw materials for gaining insights into the requirements of the system, so you want to pay keen attention to them.
With respect to observation, it is always useful to check what you have been told against what you observe and obtain clarification where deviations exist. Through keen observation, the software engineer could gather useful information not obtained by other means.
5.6 Prototyping
In prototyping, the user gets a “trial model” of the software and is allowed to critique it. User responses are used as feedback information to revise the system. This process continues until a software system meeting user satisfaction is obtained (review section 1.4).
The following are some basic guidelines for developing a prototype:
· Work in manageable modules.
· Build prototype rapidly.
· Modify prototype in successive iterations.
· Emphasize the user interface — it should be friendly and meeting user requirements.
There are various types of prototypes that you will find in software engineering. Among the various categories are the following:
· Patched-up Prototype or Production Model: This prototype is functional the first time, albeit inefficiently constructed. Further enhancements can be made with time.
· Non-operational or Interactive Prototype: This is a prototype that is intended to be tested, in order to obtain user feedback about the requirements of the system represented. A good example is where screens of the proposed system are designed; the user is allowed to pass through these screens, but no actual processing is done. This approach is particularly useful in user interface design (see chapter 11).
· First of Series Prototype: This is an operational prototype. Subsequent releases are intended to have identical features, but without glitches that the users may identify. This prototype is typically used as a marketing experiment: it is distributed free of charge, or for a nominal fee; users are encouraged to use it and submit their comments about the product. These comments are then used to refine the product before subsequent release.
· Selected Features Prototype or Working Model: In this prototype, not all intended features of the (represented) software are included. Subsequent releases are intended to be enhancements with additional features. For this reason, it is sometimes referred to asevolutionary prototype. The initial prototype is progressively refined until an acceptable system is obtained.
· Throw-away Prototype: An initial model is proposed for the sole purpose of eliciting criticism. The criticisms are then used to develop a more acceptable model, and the initial prototype is abandoned.
5.7 Brainstorming and Mathematical Proof
The methodologies discussed so far all assume that there is readily available information which when analyzed, will lead to accurate capture of the requirements of the desired software. However, this is not always the case. There are many situations in which software systems are required, but there is no readily available information that would lead to the specification of the requirements of such systems. Examples include (but are not confined to) the following:
· Writing a new compiler
· Writing a new operating system
· Writing a new CASE tool, RAD tool, or DBMS
· Developing certain expert systems
· Developing a business in a problem domain for which there is no perfect frame of reference
For these kinds of scenarios, a non-standard approach to information gathering is required. Brainstorming is particularly useful here. A close to accurate coverage of the requirements of an original software product may be obtained through brainstorming: a group of software engineering experts and prospective users come together, and through several stages of discussion, hammer out the essential requirements of the proposed software. The requirements are then documented, and through various review processes, are further refined. A prototype of the system can then be developed and subjected to further scrutiny.
Even where more conventional approaches have been employed, brainstorming is still relevant, as it forces the software engineering team to really think about the requirements identified so far, and ask tough questions to ascertain whether the requirements have been comprehensively and accurately defined.
Mathematical proofs can also be used to provide useful revelations about the required computer software. This method is particularly useful in an environment where formal methods are used for software requirements specification. This approach is often used in the synthesis of integrated circuits and chips, where there is a high demand for precision and negligible room for error. As mentioned in chapter 1, formal methods are not applicable to every problem domain. We will revisit the approach later in the course (in chapter 12).
5.8 Object Identification
We have discussed six different information-gathering strategies. As mentioned in section 5.1, these strategies are to be used to identify the core requirements of the software system. As mentioned then, one aspect that we are seeking to define is the set of information entities (object types). Notice that the term information entity is used as an alternative to object type. The two terms are not identical, but for most practical purposes, they are similar. An information entity is a concept, object or thing about which data is to be stored. An object type is a concept, object or thing about which data is to be stored, and upon which a set of operations is to be defined.
In object-oriented environments, the term object type is preferred to information entity. However, as you will more fully appreciate later, in most situations, the software system is likely to be implemented in a hybrid environment as an object-oriented (OO) user interface superimposed on a relational database. This is a loaded statement that will make more sense after learning more about databases (chapter 10). For now, just accept that we can use the terms information entity and object type interchangeably in the early stages of software planning.
Early identification of information entities is critical to successful software engineering in the OO paradigm. This is so because your software will be defined in terms of objects and their interactions. For each object type, you want to be able to describe the data that it will host, and related operations that will act on that data. Approaching the software planning in this way yields a number of significant advantages (see appendix 1); moreover, even if it turns out that the software development environment is not object-oriented, the effort is not lost (in light of the previous paragraph).
Appendix 4 discusses a number of object identification techniques. Among the approaches that have been proposed are the following:
· Using Things to be Modeled
· Using Definitions of Objects, Categories and Types
· Using Decomposition
· Using Generalizations and Subclasses
· Using OO Domain Analysis or Application Framework
· Reusing Individual Hierarchies, Objects and Classes
· Using Personal Experience
· Using the Descriptive Narrative Approach
· Using Class-Responsibility-Collaboration Card
· Using the Rule-of-Thumb Method
Take some time to carefully review appendix 4. To get you adjusted to the idea of object identification, two of the approaches are summarized here.
5.8.1 The Descriptive Narrative Approach
To use the descriptive narrative approach, start with a descriptive overview of the software system. For larger systems consisting of multiple subsystems, prepare a descriptive narrative of each component subsystem. From each descriptive overview, identify nouns (objects) and verbs (operations). Repeatedly refine the process until all nouns and verbs are identified. Represent nouns as object types and verbs as operations, avoiding duplication of effort.
To illustrate, the Purchase Order and Receipt Subsystem (of an Inventory System) might have the following overview (Figure 5-6):

Figure 5-6. Descriptive Narrative of Purchase Order and Invoice Receipt Subsystem
From this narrative, an initial list of object types and associated operations can be constructed, as shown below (Figure 5-7). Further refinement would be required; for instance, additional operations may be defined for each object type (left as an exercise); also, the data description can be further refined (discussed in chapter 10).

Figure 5-7. Object Types and Operations for Purchase Order and Invoice Receipt Subsystem
5.8.2 The Rule-of-Thumb Approach
As an alternative to the descriptive narrative strategy, you may adopt an intuitive approach as follows: Using principles discussed earlier, identify the main information entities (object types) that will make up the system. Most information entities that make up a system will be subject to some combination of the following basic operations:
· ADD: Addition of data items
· MODIFY: Update of existing data items
· DELETE: Deletion of existing data items
· INQUIRE/ANALYZE: Inquiry and/or analysis on existing information
· REPORT/ANALYZE: Reporting and/or analysis of existing information
· RETRIEVE: Retrieval of existing data
· FORECAST: Predict future data based on analysis of existing data
Obviously, not all operations will apply for all object types (data entities); also, some object types (entities) may require additional operations. The software engineer makes intelligent decisions about these exceptions, depending on the situation. Additionally, the level of complexity of each operation will depend to some extent on the object type (data entity).
In a truly OO environment, the operations may be included as part of the object’s services. In a hybrid environment, the information entities may be implemented as part of a relational database, and the operations would be implemented as user interface objects (windows, forms, etc.).
5.9 Summary and Concluding Remarks
Here is a summary of what we have covered in this chapter:
· It is important to conduct a research on the requirements of a software system to be developed. By so doing, we determine the synergistic interrelationships, information entities, operations, business rules, and security mechanisms.
· In conducting the software requirements research obtaining answers to questions commencing with the words WHAT, WHERE, HOW, WHEN and WHY is very important.
· Information gathering strategies include interviews, questionnaires and surveys, sampling and experimenting, observation and document review, prototyping, brainstorming and mathematical proofs.
· The interview is useful when the information needed must be elaborate, or clarification on various issues is required. The interview also provides an opportunity for the software engineer to win the confidence and trust of clients. In preparing to conduct an interview, the software engineer must be thoroughly prepared, and must follow well-known interviewing norms.
· A questionnaire is viable when any of the following situations hold: A small amount of information is required of a large population; the time frame is short but a vast area (and/or dispersed population) must be covered; simple answers are required to a number of standard questions. The software engineer must follow established norms in preparing and administering a questionnaire.
· Sampling is useful when the information required is of a quantitative nature or can be quantified, no precise detail is available, and it is not likely that such details will be obtained via other methods. The software engineer must be familiar with various sampling techniques, and know when to use a particular technique.
· Review of source documents will provide useful information about the input, data storage, and output requirements of the software system. This activity could also provide useful information on the processing requirements of the software system.
· Prototyping involves providing a trial model of the software for user critique. User responses are used as feedback information to revise the system. This process continues until a software system meeting user satisfaction is obtained. The software engineer should be familiar with the different types of prototypes.
· Brainstorming is useful in situations in which software systems are required, but there is no readily available information that would lead to the specification of the requirements of such systems. Brainstorming involves a number of software engineers coming together to discuss and hammer out the requirements of a software system.
· Mathematical proof is particularly useful in an environment where formal methods are used for software requirements specification.
· One primary objective of these techniques is the identification and accurate specification of the information entities (or object types) comprising the software system.
Accurate and comprehensive information gathering is critical to the success of a software engineering venture. In fact, the success of the venture depends to a large extent on this. Your information fathering skills will improve with practice and experience.
In applying these techniques, the software engineer will no doubt gather much information concerning the requirements of the software system to be constructed. How will you record all this information? If you start writing narratives, you will soon wind up with huge books that not many people will bother to read. In software engineering, rather than writing voluminous narratives to document the requirements, we use unambiguous notations and diagrams (of course, you still need to write but not as much as you would without the notations and diagrams). The next chapter will discuss some of these methodologies.
5.10 Review Questions
1. Why is information gathering important in software engineering?
2. Identify seven methods of information gathering that are available to the software engineer. For each method, describe a scenario that would warrant the use of this approach, and provide some basic guidelines for its application.
3. Suppose that you were asked to develop an inventory management system (with point-of-sale facility) for a supermarket. Your system is required to track both purchase and sale of goods in the supermarket. Do the following:
· Prepare a set of questions you would have for the purchasing manager.
· Prepare a set of questions you would have for the sales manager.
· Apart from interviews, what other information gathering method(s) would you use in order to accurately and comprehensively capture the requirements of your system? Explain.
4. Suppose that you are working for a software engineering firm that is interested in developing a software to detect certain types of cancer, based on information fed to it. Your software will also suggest possible treatment for the cancer diagnosed. You are given a list of twelve physicians who are cancer experts; they will form part of your resource team. Answer the following questions:
· What type of software would you seek to develop and why?
· What methodology would you use for obtaining critical information from the cadre of physicians?
· Construct an information gathering instrument that you would use in this project.
5. The manager of seaport wants to be at least 95% certain that there is a serious bug in the current dock scheduling system, before considering its replacement. He contracts a software engineer to advise him. After sampling forty (40) docking schedules, the software engineer runs each through the system and obtains a docking error factor. He summarizes his findings as follows:
Sample Size …......... 40
Margin of error … +/- 1 unit
Standard deviation … 2.795
Mean docking error factor … 10 units
Note: 95% => Z = 1.96 99% => Z = 2.58
a. Should the manager replace the dock scheduling system?
b. What docking error factor will yield a 99% confidence of the presence of a bug in the system?
6. What type of prototype would you construct for the following:
· The cancer diagnosis system of question 4
· A new compiler that you hope to obtain feedback on
· A user workgroup designed to elicit useful information for the requirements of a financial management system
5.11 References and/or Recommended Readings
[Daniel, 1989] Daniel, Wayne, and Terrel, James. Business Statistics for Management and Economics 5th ed. Boston, MA: Houghton Mifflin Co., 1989.
[DeGroot, 1986] DeGroot, Morris H. Probability and Statistics 2nd ed. Reading, MA: Addison-Wesley, 1986.
[Harris, 1995] Harris, David. Systems Analysis and Design: A Project Approach. Fort Worth, TX: Dryden Press, 1995. See chapters 3, 4.
[Kendall, 1999] Kendall, Kenneth E. and Julia E. Kendall. Systems Analysis and Design 4th ed. Upper Saddle River, NJ: Prentice Hall, 1999. See chapters 4 – 8.
[Long, 1989] Long, Larry. Management Information Systems. Eaglewood Cliffs, NJ: Prentice Hall, 1989. See chapter 13.
[Pfleeger, 2006] Pfleeger, Shari Lawrence. Software Engineering Theory and Practice 3rd ed. Upper Saddle River, NJ: Prentice Hall, 2006. See chapter 4.
[Sommerville, 2001] Sommerville, Ian. Software Engineering 6th ed. Reading, MA: Addison-Wesley, 2001. See chapter 8.
[Sommerville, 2006] Sommerville, Ian. Software Engineering 8th ed. Reading, MA: Addison-Wesley, 2006. See chapter 7.
[Van Vliet, 2000] Van Vliet, Hans. Software Engineering 2nd ed. New York, NY: John Wiley & Sons, 2000. See chapter 9.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.