Plan, Activity, and Intent Recognition: Theory and Practice, FIRST EDITION (2014)
Part IV. Multiagent Systems
Chapter 10. Role-Based Ad Hoc Teamwork
Katie Gentera, Noa Agmonb, 1 and Peter Stonea, aUniversity of Texas at Austin, Austin, TX, USA, bBar Ilan University, Ramat Gan, Israel
Abstract
An ad hoc team setting is one in which teammates work together to obtain a common goal, but without any prior agreement regarding how to work together. We introduce a role-based approach for ad hoc teamwork in which each teammate is inferred to be following a specialized role. In such cases, the role an ad hoc agent should select depends on its own capabilities and on the roles selected by its teammates. This chapter formally defines methods for evaluating the influence of an ad hoc agent’s role selection on the team’s utility and shows that use of these methods facilitates efficient calculation of the role yielding maximal team utility. We examine empirically how to choose the best-suited method for role assignment and show that once an appropriate assignment method is determined for a domain, it can be used successfully in new tasks that the team has not encountered before. Unlike much of the rest of the book, this chapter does not focus on methods for recognizing the roles of the other agents. Rather, it examines the question of how to use successful role recognition toward successful multiagent decision making.
Keywords
ad hoc teamwork
role-based ad hoc teamwork
multiagent teamwork
multiagent collaboration
multiagent planning
Acknowledgments
This work has taken place in the Learning Agents Research Group (LARG) at the Artificial Intelligence Laboratory, The University of Texas at Austin. LARG research is supported in part by grants from the National Science Foundation (CNS-1330072, CNS-1305287) and ONR (21C184-01).
10.1 Introduction
As software and robotic agents become increasingly common, there becomes a need for agents to collaborate with unfamiliar teammates. Consider a disaster situation where rescue robots from all around the world are brought in to assist with search and rescue. Ideally, these robots would be able to collaborate immediately—with little to no human assistance—to divide and conquer the necessary tasks according to their relative abilities. Some agents would locate victims, while other agents would lift fallen debris away from trapped victims. However, most existing agents are designed to only collaborate with known teammates that they were specifically preprogrammed to work with. As such, collaborating on the fly with unknown teammates is impossible for most current agents.
Ad hoc teamwork is a relatively new research area that examines this exact problem—how an agent ought to act when placed on a team with other agents such that there was no prior opportunity to coordinate behaviors. In ad hoc teamwork situations, several agents find themselves in a situation where they all have perfectly aligned goals, yet they have had no previous opportunity to coordinate their teamwork [1]. This problem arises quite often for humans who tend to solve the problem quite naturally. However, autonomous agents (e.g., robots and software agents) do not currently handle this problem as gracefully.
Consider briefly that you recently arrived in a foreign country where you do not speak the local language. Now assume that you come across a pickup soccer game. After watching the game for a few minutes, some of the players on one team motion you to join. Despite not being able to verbally communicate with any of your teammates, you can still contribute to the team and work as a cohesive unit with your teammates. Through observing your teammates, you can quickly make a rough analysis of their strengths and weaknesses and determine how you should play to best help the team.
Throughout this chapter we refer to the agents that make up a team as either ad hoc agents or teammates. Ad hoc agents are agents whose behavior we can control. Teammates, on the other hand, are agents that we have no control over, potentially because they were programmed by other groups or at different times such that future collaboration with our agents was unforeseeable.
In some team domains, such as search and rescue missions and many team sports, the team behavior can easily be broken down into roles. Under a role-based approach to ad hoc teamwork, each teammate is inferred to be following a specialized role that accomplishes a specific task or exhibits a particular behavior. Using this information, an ad hoc agent’s main task is to decide which role to assume such that the team’s performance is maximized. This decision is situation-specific: it depends on the task the team performs, the environment in which it acts, the roles currently performed by the team members, and the capabilities of the team members.
One trivial approach is for an ad hoc agent to assume the role at which it is most individually capable. However, the choice of optimal role—one that results in highest team utility—depends not only on the ad hoc agent, but also on the ability and behavior of the other team members. Thus, an ad hoc agent will sometimes not adopt the role that it performs best if adopting a different role is optimal for the team. We examine the contribution of an ad hoc agent to the team by the measure of marginal utility, which is the increase in a team’s utility when an ad hoc agent is added to the team and assumes a particular role. An optimal mapping of an ad hoc agent to a role is, therefore, one that maximizes the marginal utility, thus maximizing the contribution of the ad hoc agent to the team’s utility.
This chapter presents a role-based approach for ad hoc teamwork. We begin by noting related work in Section 10.2. Section 10.3 formally defines the role-based ad hoc teamwork problem. In Section 10.4, we emphasize the importance of accurate role recognition. Section 10.5 defines several methods for modeling the marginal utility of an ad hoc agent’s role selection as a function of the roles performed by the other teammates. Then we empirically show in a foraging domain that each method is appropriate for a different class of role-based tasks. In Section 10.6, we demonstrate that use of these methods can lead to efficient calculation of the role that yields maximal team utility. We then include an empirical examination in a more complex Pacman Capture-the-Flag domain of how to choose the best-suited method for role assignment in a complex environment where it is not trivial to determine the optimal role assignment. Finally, we show that the methods we describe have a predictive nature, meaning that once an appropriate assignment method is determined for a domain, it can be used successfully in new tasks that the team has not encountered before and for which only limited experience is available. Section 10.7 concludes the chapter and presents some avenues for future work.
Unlike much of the rest of the book, this chapter does not focus on methods of role recognition. Instead, it examines the question of how to use successful role recognition to assist in multiagent decision making. Indeed, this work contributes to answering the ad hoc teamwork challenge presented by Stone et al. [1]. Specifically, this ad hoc teamwork challenge is to “create an autonomous agent that is able to efficiently and robustly collaborate with previously unknown teammates on tasks to which they are all individually capable of contributing as team members.” Stone et al. laid out three abstract technical challenges. This chapter presents an approach toward solving one of these challenges—finding theoretically optimal and/or empirically effective algorithms for behavior—in role-based ad hoc teamwork settings.
10.2 Related Work
Although there has been much work in the field of multiagent teamwork, there has been little work towards getting agents to collaborate to achieve a common goal without precoordination. In this section, we review some selected work that is related to the role-based ad hoc teamwork approach presented in this chapter. Specifically, we consider work related to multiagent teamwork, multiagent plan recognition, and our two experimental domains.
10.2.1 Multiagent Teamwork
Most prior multiagent teamwork research requires explicit coordination protocols or communication protocols. Three popular protocols for communication and coordination—SharedPlans [2], Shell for TEAMwork (STEAM) [3], and Generalized Partial Global Planning (GPGP) [4]—all provide collaborative planning or teamwork models to each team member. Each of these protocols works well when all agents know and follow the protocol. However, in ad hoc teamwork settings, we do not assume that any protocol is known by all agents, so protocols such as these cannot be successfully used.
Some multiagent teams are even designed to work specifically with their teammates in predefined ways such as via locker-room agreements [5]. Specifically, a locker-room agreement is formed when there is a team synchronization period during which a team can coordinate their teamwork structure and communication protocols. This work divides the task space via the use of roles like we do, but our work differs in that we do not assume the availability of a team synchronization period.
Liemhetcharat and Veloso formally defined a weighted synergy graph that models the capabilities of robots in different roles and how different role assignments affect the overall team value [6]. They presented a team formation algorithm that can approximate the optimal role assignment policy given a set of teammates to choose from and a task. They applied this algorithm to simulated robots in the RoboCup Rescue domain and to real robots in a foraging task, and found that the resulting role assignments outperformed other existing algorithms. This work determines how to best form a team when given many agents to choose from, while our work determines how a particular agent should behave to best assist a preexisting team.
Wu et al. present an online planning algorithm for ad hoc team settings [7]. Their algorithm constructs and solves a series of stage games, and then uses biased adaptive play to choose actions. They test their algorithm in three domains: cooperative box pushing, meeting in a ![]() grid, and multichannel broadcast. In these tests, they show that they are able to perform well when paired with suboptimal teammates. Their work is different from ours in that we choose the best-suited role assignment method and then assign the ad hoc agent to perform a role using the chosen role assignment method, whereas in their work they optimize each individual action taken by the ad hoc agent.
grid, and multichannel broadcast. In these tests, they show that they are able to perform well when paired with suboptimal teammates. Their work is different from ours in that we choose the best-suited role assignment method and then assign the ad hoc agent to perform a role using the chosen role assignment method, whereas in their work they optimize each individual action taken by the ad hoc agent.
Bowling and McCracken examined the concept of “pick-up” teams in simulated robot soccer [8]. Similar to us, they propose coordination techniques for a single agent that wants to join a previously unknown team of existing agents. However, they take a different approach to the problem in that they provide the single agent with a play book from which it selects the play most similar to the current behaviors of its teammates. The agent then selects a role to perform in the presumed current play.
Jones et al. perform an empirical study of dynamically formed teams of heterogeneous robots in a multirobot treasure hunt domain [9]. They assume that all the robots know they are working as a team and that all the robots can communicate with one another, whereas in our work we do not assume that the ad hoc agent and the teammates share a communication protocol.
Han, Li, and Guo study how one agent can influence the direction in which an entire flock of agents is moving [10]. They use soft control in a flocking model in which each agent follows a simple control rule based on its neighbors. They present a simple model that works well in cases where the agents reflexively determine their behaviors in response to a larger team. However, it is not clear how well this work would apply to more complex role-based tasks such as those studied and discussed in our work.
10.2.2 Multiagent Plan Recognition
An ad hoc team player must observe the actions of its teammates and determine what plan or policy its teammates are using before determining which behavior it should adopt. In this work, we assume that the ad hoc agent is given the policy of each teammate so as to focus on the role-selection problem. However, in many situations this is not a valid assumption, so recognizing the plan or policy of each teammate is an important part of solving the ad hoc teamwork challenge.
Barrett and Stone present an empirical evaluation of various ad hoc teamwork strategies [11]. In their work they show that efficient planning is possible using Monte Carlo Tree Search. Additionally, they show that an ad hoc agent can differentiate between its possible teammates on the fly when given a set of known starting models, even if these models are imperfect or incomplete. Finally, they show that models can be learned for previously unknown teammates. Unlike our work, theirs does not take a role-based approach to solving the ad hoc teamwork problem. Instead, they evaluate the ability of various algorithms to generate ad hoc agent behaviors in an online fashion.
Sukthankar and Sycara present two approaches for recognizing team policies from observation logs, where a team policy is a collection of individual agent policies along with an assignment of individual agents to policies [12]. Each of their approaches—one model-based and one data-driven—seem generally well suited for application to the ad hoc teamwork challenge. Specifically, their approaches would be best suited for ad hoc teamwork settings that (1) are turn-based tasks, (2) do not require analysis of observation logs in real time, and (3) do not require excessive amounts of training data to avoid overfitting.
Zhuo and Li provide a new approach for recognizing multiagent team plans from partial team traces and team plans [13]. Specifically, given a team trace and a library of team plans, their approach is to first create a set of constraints and then solve these constraints using a weighted MAX-SAT solver. The required library of team plans might be difficult to obtain in some ad hoc teamwork settings though, so this approach is not well suited for all ad hoc teamwork settings.
10.2.3 Experimental Domains
In this chapter we use two experimental domains: Capture-the-Flag and foraging. There has been previous research on multiagent teamwork in both the Capture-the-Flag domain and the foraging domain, and we discuss a few examples in this section. However, most of this work focuses on coordination between all teammates instead of coordination of one or more ad hoc agents with existing teammates; thus, this work does not address the ad hoc teamwork problem.
Blake et al. present their Capture-the-Flag domain, which they implemented both physically and in simulation [14]. In their work, the focus is on effective path planning for their robots as they navigate through a mazelike environment. Although similar to our Capture-the-Flag domain, their domain is different from ours because they assume that target coordinates will be communicated to the ground robots from an overhead flying robot. This communication might not be possible in an ad hoc teamwork setting because we cannot assume that the teammates and the ad hoc agent will be able to communicate and exchange data.
Sadilek and Kautz used a real-world game of Capture-the-Flag to validate their ability to understand human interactions, attempted interactions, and intentions from noisy sensor data in a well-defined multiagent setting [15]. Our work currently assumes that the actual behaviors of the teammates are provided to us, such that we can focus on determining the best behavior for the ad hoc agent. However, work like that of Sadilek and Kautz–which focuses on recognizing interactions and inferring their intentions–will be necessary to solve the complete ad hoc teamwork problem.
Mataric introduced the multiagent foraging domain and focused on teaching agents social behaviors in this domain [16]. Specifically, the foraging agents learned yielding and information sharing behaviors. In Mataric’s work, she assumed that all the foraging robots are capable of communicating with each other. However, in our work we do not assume that the foraging robots share a communication protocol.
Lerman et al. considered the problem of dynamic task allocation in a multiagent foraging environment [17]. They designed a mathematical model of a general dynamic task-allocation mechanism. As long as all the agents use this mechanism, a desirable task division can be obtained in the absence of explicit communication and global knowledge. However, such an approach does not work in ad hoc teamwork settings because we cannot assume that the ad hoc agent will be able to use the same mechanism as its teammates.
10.3 Problem Definition
This chapter introduces the role-based ad hoc teamwork problem, which is one that requires or benefits from dividing the task at hand into roles. Throughout we refer to the agents that make up a team as either ad hoc agents or teammates. Ad hoc agents are ones whose behavior we can control. Teammates, on the other hand, are agents that we have no control over, potentially because they were programmed by other groups or at different times such that future collaboration with our agents was unforeseeable.
Under a role-based ad hoc teamwork approach, the ad hoc agent first must infer the role of each teammate and then decide which role to assume such that the team’s performance is maximized. The teammates do not need to believe or understand that they are performing a role. Indeed, the classification of teammates into roles is merely done so that the ad hoc agent can determine the best role for itself. Using the pick-up soccer example presented in Section 10.2.1, under a role-based ad hoc teamwork approach you might determine which positions your teammates are playing and then adopt a position accordingly. You might adopt the most important position that is unfilled or the position you are best at that is unfilled—or more likely you would adopt a position based on a function of these two factors.
Each teammate’s role will be readily apparent to the ad hoc agent in many domains. For example, the goalie in a pickup soccer game is immediately apparent due to her proximity to her team’s goal. However, in some domains it may take more extended observations for the ad hoc agent to determine the actual role of each teammate. In such domains, the role of each teammate may be determined with increasing certainty as observations are made regarding the agent’s behavior and the areas of the environment she explores.
We assume that different roles have different inherent values to the team, and that each agent has some ability to perform each role. As such, an ad hoc agent must take into account both the needs of the team and its own abilities when determining what role to adopt. A team receives a score when it performs a task. Therefore, the goal of an ad hoc agent is to choose a role that maximizes the team’s score and therefore maximizes the marginal utility of adding itself to the team. Thus, an ad hoc agent will sometimes not adopt the role that it performs best if adopting a different role is optimal for the team. Using the pick-up soccer example, if your team is in dire need of a goalie, it may be best for the team if you play goalie even if you are better at another position.
10.3.1 Formal Problem Definition
In this section, we define our problem more formally and introduce the notation that we use throughout the chapter.
Let a task ![]() be drawn from domain
be drawn from domain ![]() , where task
, where task ![]() has
has ![]() roles
roles ![]() . Each role
. Each role ![]() has an associated relative importance value
has an associated relative importance value ![]() , where
, where ![]() is more critical to team utility than
is more critical to team utility than ![]() if
if ![]() . Each
. Each ![]() is constant for a particular task
is constant for a particular task ![]() and set of potential roles
and set of potential roles ![]() but might change if
but might change if ![]() or
or ![]() were different. Let
were different. Let ![]() be the set of ad hoc agents and
be the set of ad hoc agents and ![]() be the set of teammates such that
be the set of teammates such that ![]() is the team that is to perform task
is the team that is to perform task ![]() . Each agent
. Each agent ![]() has a utility
has a utility ![]() for performing each role
for performing each role ![]() . This utility
. This utility ![]() represents player
represents player ![]() ’s ability at role
’s ability at role ![]() in task
in task ![]() .
.
Using the pick-up soccer example, let domain ![]() , task
, task ![]() , and
, and ![]() . If
. If ![]() , then
, then ![]() .
.
Let mapping ![]() be the mapping of the teammates in
be the mapping of the teammates in ![]() to roles
to roles ![]() such that the teammates associated with role
such that the teammates associated with role ![]() are
are ![]() , where
, where ![]() . Without loss of generality, the agents in each
. Without loss of generality, the agents in each ![]() are ordered such that
are ordered such that ![]() . In the pick-up soccer example, assume
. In the pick-up soccer example, assume ![]() . This assumption means that Todd is playing goalie under mapping
. This assumption means that Todd is playing goalie under mapping ![]() , Sam and Jake are playing center midfield under mapping
, Sam and Jake are playing center midfield under mapping ![]() (where Sam’s utility for playing center midfield is greater than Jake’s utility for playing center midfield), and Noa and Peter are playing striker under mapping
(where Sam’s utility for playing center midfield is greater than Jake’s utility for playing center midfield), and Noa and Peter are playing striker under mapping ![]() (where Peter’s utility for playing striker is greater than Noa’s utility for playing striker). Mapping
(where Peter’s utility for playing striker is greater than Noa’s utility for playing striker). Mapping ![]() may be given fully or probabilistically, or it may need to be inferred via observation. However, it is important to note that ad hoc agents cannot alter
may be given fully or probabilistically, or it may need to be inferred via observation. However, it is important to note that ad hoc agents cannot alter ![]() by commanding the teammates to perform particular roles. For simplicity, we assume in this work that the ad hoc agents have perfect knowledge of mapping
by commanding the teammates to perform particular roles. For simplicity, we assume in this work that the ad hoc agents have perfect knowledge of mapping ![]() .
.
Let mapping ![]() be the mapping of the ad hoc agents in
be the mapping of the ad hoc agents in ![]() to roles
to roles ![]() such that the ad hoc agents performing role
such that the ad hoc agents performing role ![]() are
are ![]() , where
, where ![]() and
and ![]() . In the pick-up soccer example, if
. In the pick-up soccer example, if ![]() , then Katie is playing striker under mapping
, then Katie is playing striker under mapping ![]() . Additionally, let mapping
. Additionally, let mapping ![]() be the combination of mappings
be the combination of mappings ![]() and
and ![]() . As such, agents
. As such, agents ![]() are performing role
are performing role ![]() and
and ![]() . In other words, mapping
. In other words, mapping ![]() is the association of all team members to the roles they are performing. Without loss of generality, the agents in each
is the association of all team members to the roles they are performing. Without loss of generality, the agents in each ![]() are ordered such that
are ordered such that ![]() . In the pick-up soccer example, if
. In the pick-up soccer example, if ![]() , then Peter, Katie, and Noa are all playing striker under mapping
, then Peter, Katie, and Noa are all playing striker under mapping ![]() and Peter’s utility for playing striker is greater than Katie’s utility for playing striker, which is greater than Noa’s utility for playing striker. A team score
and Peter’s utility for playing striker is greater than Katie’s utility for playing striker, which is greater than Noa’s utility for playing striker. A team score ![]() results when the set of agents
results when the set of agents ![]() perform a task
perform a task ![]() , with each
, with each ![]() fulfilling some role
fulfilling some role ![]() under mapping
under mapping![]() .
.
Team score ![]() is a function of individual agent utilities, but its precise definition is tied to the particular domain
is a function of individual agent utilities, but its precise definition is tied to the particular domain ![]() and the specific task
and the specific task ![]() . For example, in the pick-up soccer example, the team score might be the goal differential after 90 minutes of play. The marginal utility
. For example, in the pick-up soccer example, the team score might be the goal differential after 90 minutes of play. The marginal utility ![]() obtained by mapping
obtained by mapping ![]() , assuming
, assuming ![]() is the mapping of the teammates in
is the mapping of the teammates in ![]() to roles, is the score improvement obtained when each ad hoc agent
to roles, is the score improvement obtained when each ad hoc agent ![]() chooses role
chooses role ![]() under mapping
under mapping ![]() . Assuming that either
. Assuming that either ![]() can perform the task or that
can perform the task or that ![]() when
when ![]() cannot complete the task, marginal utility
cannot complete the task, marginal utility ![]() .2 Going back to the pick-up soccer example, the marginal utility obtained by mapping
.2 Going back to the pick-up soccer example, the marginal utility obtained by mapping ![]() is the difference in the expected score differential when
is the difference in the expected score differential when ![]() mapped by
mapped by![]() plays a local boys high school team and the expected score differential when
plays a local boys high school team and the expected score differential when ![]() mapped by
mapped by ![]() plays a local boys high school team.
plays a local boys high school team.
Given that mapping ![]() is fixed, the role-based ad hoc team problem is to find a mapping
is fixed, the role-based ad hoc team problem is to find a mapping ![]() that maximizes marginal utility. The preceding problem definition and notation provided are valid for any number of ad hoc team agents. Thus, although for the remainder of this chapter we focus our attention on the case in which there is only one ad hoc agent such that
that maximizes marginal utility. The preceding problem definition and notation provided are valid for any number of ad hoc team agents. Thus, although for the remainder of this chapter we focus our attention on the case in which there is only one ad hoc agent such that ![]() , our general theoretical contributions can be applied to teams to which multiple ad hoc agents are added. For example, multiple ad hoc agents could coordinate and work together as a single “agent” and the theoretical results presented later would still hold. Note that multiple ad hoc agents could not each individually determine a mapping to a role that maximizes marginal utility using the approach presented in the following, since each ad hoc agent would merely choose the role that would be optimal were it the only ad hoc agent to join the team. These mappings would not be guaranteed to collectively maximize marginal utility.
, our general theoretical contributions can be applied to teams to which multiple ad hoc agents are added. For example, multiple ad hoc agents could coordinate and work together as a single “agent” and the theoretical results presented later would still hold. Note that multiple ad hoc agents could not each individually determine a mapping to a role that maximizes marginal utility using the approach presented in the following, since each ad hoc agent would merely choose the role that would be optimal were it the only ad hoc agent to join the team. These mappings would not be guaranteed to collectively maximize marginal utility.
10.4 Importance of Role Recognition
The work presented in this chapter concerns how an ad hoc agent should select a role in order to maximize the team’s marginal utility. However, in order to do that using the role-based ad hoc teamwork we present, the roles of the teammates must be correctly identified. This need for accurate role recognition is what ties this chapter to the other chapters in this book.
We do not focus on how to do role recognition here. Indeed, we assume that the ad hoc agents have complete knowledge concerning the roles of the teammates. As such, accurate role recognition is an important prerequisite for our work. Role recognition might be easy in some situations but extremely difficult in others. However, role recognition always becomes easier as time passes and more experience is gained. For example, in the pick-up soccer example presented in Sections 10.2 and 10.3, it might be easy to recognize that a player positioned in the goal is playing the goalie role. However, a player positioned around midfield could be playing a variety of roles; one might be able to better determine his role as time passes and play continues.
If the ad hoc agents have imperfect or noisy knowledge of the mapping of teammates to roles—in other words, if role recognition is imperfect—the general processes presented in this chapter can still be useful. However, the resulting mapping of the ad hoc agents to roles may not maximize marginal utility when role recognition is imperfect. Such uncertainty can be dealt with formally if the agents have probabilistic knowledge of the mapping of the teammates to roles. Given a prior probability distribution over roles, a Bayesian approach could be used to modify the ad hoc agent’s beliefs over time and to enable it to act optimally given its uncertain knowledge—including acting specifically so as to reduce uncertainty using a value of information approach.
In this work we assume that the roles of the agents remain fixed throughout the task. If the roles were to change, the ad hoc agent would first need a new process to identify such changes, perhaps by noticing that the teammates’ observable behavior has changed. After detecting the change, the processes described in this chapter could be used to find a new mapping of the ad hoc agents to roles that maximizes marginal utility.
10.5 Models for Choosing a Role
The gold standard way for an ad hoc agent to determine the marginal utility from selecting a particular role, and thus determine its optimal role, is to determine ![]() for each possible role it could adopt. However, in practice, the ad hoc agent may only selectone role to adopt. Therefore, the ad hoc agent must predict its marginal utility for all possible roles and then select just one role to adopt. This section lays out three possible models with which the ad hoc agent could do this prediction based on the roles its teammates are currently filling. We also empirically verify that each model is appropriate for a different class of role-based tasks in the multiagent foraging domain described next.
for each possible role it could adopt. However, in practice, the ad hoc agent may only selectone role to adopt. Therefore, the ad hoc agent must predict its marginal utility for all possible roles and then select just one role to adopt. This section lays out three possible models with which the ad hoc agent could do this prediction based on the roles its teammates are currently filling. We also empirically verify that each model is appropriate for a different class of role-based tasks in the multiagent foraging domain described next.
In this foraging domain, a team of agents is required to travel inside a given area, detecting targets and returning them to a preset station [16]. We use a ![]() cell map in our experiments, but an example
cell map in our experiments, but an example ![]() cell map can be seen in Figure 10.1. Each target can be acquired by a single agent that enters the target’s cell as long as the agent is not already carrying a target and has the capability to collect targets of that type. To avoid random wandering when no collectable targets are visible, we assume that each agent has perfect information regarding target locations. Additionally, we allow multiple agents and targets to occupy the same cell simultaneously.
cell map can be seen in Figure 10.1. Each target can be acquired by a single agent that enters the target’s cell as long as the agent is not already carrying a target and has the capability to collect targets of that type. To avoid random wandering when no collectable targets are visible, we assume that each agent has perfect information regarding target locations. Additionally, we allow multiple agents and targets to occupy the same cell simultaneously.
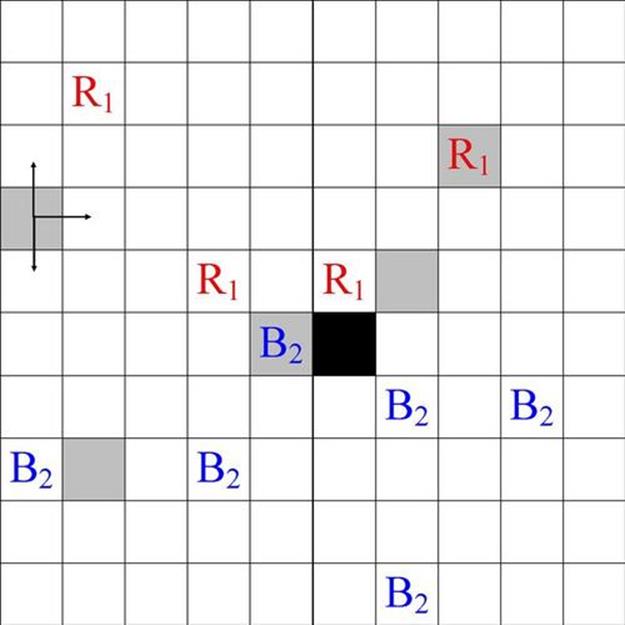
FIGURE 10.1 A sample ![]() cell map of our foraging environment. Each target occupies one cell—blue targets are represented by
cell map of our foraging environment. Each target occupies one cell—blue targets are represented by ![]() and red targets are represented by
and red targets are represented by ![]() , where the subscript denotes the target’s point value. Agents are represented by gray boxes, occupy only one cell at a time, and can move up, down, left, or right one cell each timestep (as long as the move does not carry them off the board). The station to which targets should be delivered is shown as a black box.
, where the subscript denotes the target’s point value. Agents are represented by gray boxes, occupy only one cell at a time, and can move up, down, left, or right one cell each timestep (as long as the move does not carry them off the board). The station to which targets should be delivered is shown as a black box.
The goal of each agent is for the team to collect as many targets as possible, as quickly as possible. We consider a special case of the foraging problem in which targets are divided into two groups: red targets to the North and blue targets to the South, where the blue targets are worth twice as much to the team as the red targets. As such, the blue targets and agents that collect blue targets are randomly initialized on the lower half of the map, while the red targets and agents that collect red targets are randomly initialized on the upper half of the map.
As each model is presented, we also describe a foraging task in which the model has been empirically shown to be most appropriate using the methods described later in this chapter. Results of each model on each task are presented in Table 10.1.
Table 10.1
Number of Statistically Significant Incorrect/Correct Decisions Made by an Ad Hoc Agent
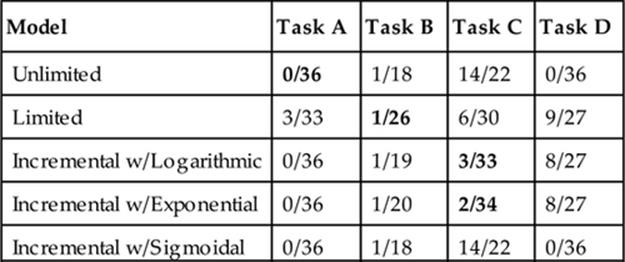
Note: These are for each model in the four different tasks presented throughout Section 10.5.
For all of the models, except the Unlimited Role Mapping model, we assume that the ad hoc agent ![]() knows the utilities
knows the utilities ![]() and the mapping
and the mapping ![]() . Additionally, when considering the following three models, note that the marginal utility of agent
. Additionally, when considering the following three models, note that the marginal utility of agent ![]() choosing to fulfill role
choosing to fulfill role ![]() under mapping
under mapping ![]() is often given by an algorithm
is often given by an algorithm ![]() (see Algorithms 10.1 and 10.2). In these cases,
(see Algorithms 10.1 and 10.2). In these cases, ![]() .
.
10.5.1 Unlimited Role Mapping Model
Consider the multiagent foraging example just presented. Assume there are 100 red targets and 5000 blue targets in a constrained area with limited time (50 time steps) for the agents to collect targets. This example is Task A in Table 10.1. Due to the ample amount of valuable blue targets and the limited time, it would never be optimal for an agent to collect red targets instead of blue targets. The blue targets will be surrounding the base after the agent delivers its first target, and hence easy to collect and deliver quickly. On the other hand, the red targets will be less numerous and likely farther from the base and hence slower to collect and deliver. Therefore, in tasks such as this one, the benefit the team receives for an agent performing a role does not depend on the roles fulfilled by its teammates.
In such a case, the contribution to the team of an agent ![]() performing role
performing role ![]() is simply the agent’s utility
is simply the agent’s utility ![]() at role
at role ![]() multiplied by the value of the role
multiplied by the value of the role ![]() . As such, the team utility can be modeled as
. As such, the team utility can be modeled as
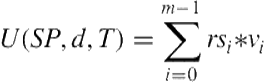 (10.1)
(10.1)
where
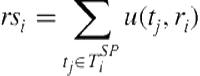 (10.2)
(10.2)
Note that in this model, agent utility ![]() for performing each role
for performing each role ![]() and the importance
and the importance ![]() of each role
of each role ![]() are parameters that can be tuned to match the characteristics of a particular task.
are parameters that can be tuned to match the characteristics of a particular task.
Theorem 10.1 describes the optimal role mapping under this model.
Theorem 10.1 In Unlimited Role Mapping tasks, mapping ![]() , under which
, under which ![]() chooses the role
chooses the role ![]() that obtains
that obtains ![]() , maximizes marginal utility such that
, maximizes marginal utility such that ![]() .
.
10.5.2 Limited Role Mapping Model
Returning to the multiagent foraging example, assume that there are 1000 red targets and 5000 blue targets in a constrained environment with limited time (50 timesteps) for the agents to collect the targets. Also assume that there are rules prohibiting an agent from collecting the valuable blue targets if there is not at least one other agent also collecting blue targets or if more than three other agents are already collecting blue targets. This task is Task B in Table 10.1. Due to the ample amount of valuable blue targets, the ad hoc agent should collect blue targets if the conditions for being able to collect blue targets are satisfied. However, if the conditions are not satisfied, the ad hoc agent should default to collecting the less valuable red targets.
In tasks such as this, each role ![]() has an associated
has an associated ![]() value and
value and ![]() value that represent the minimum and maximum number of agents that should perform role
value that represent the minimum and maximum number of agents that should perform role ![]() . For all
. For all ![]() , let
, let ![]() . If the number of agents performing role
. If the number of agents performing role ![]() is less than
is less than ![]() , then the team gains no score from their actions. On the other hand, if the number of agents performing role
, then the team gains no score from their actions. On the other hand, if the number of agents performing role ![]() is greater than
is greater than ![]() , then only the
, then only the ![]() agents with highest utility,
agents with highest utility, ![]() , will be taken into account when calculating the team score. As such, the team utility for Limited Role Mapping tasks can be modeled as
, will be taken into account when calculating the team score. As such, the team utility for Limited Role Mapping tasks can be modeled as
(10.3)
where
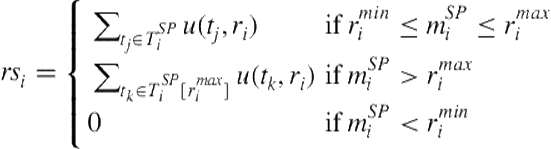
The function ![]() displayed in Algorithm 10.1 gives the marginal utility obtained from the ad hoc agent
displayed in Algorithm 10.1 gives the marginal utility obtained from the ad hoc agent ![]() choosing to perform role
choosing to perform role ![]() , where the current mapping of teammates to roles is described by
, where the current mapping of teammates to roles is described by ![]() . In this model, agent utility
. In this model, agent utility ![]() for performing each role
for performing each role ![]() , the importance
, the importance ![]() of each role
of each role ![]() , and the minimum and maximum number of agents that should perform each role
, and the minimum and maximum number of agents that should perform each role ![]() are all tunable model parameters.
are all tunable model parameters.
Function ![]() uses some special notation. Specifically, let
uses some special notation. Specifically, let ![]() denote the 0-indexed position in
denote the 0-indexed position in ![]() that the ad hoc agent
that the ad hoc agent ![]() occupies. Additionally, let
occupies. Additionally, let ![]() denote the agent that is performing role
denote the agent that is performing role ![]() under mapping
under mapping ![]() with the
with the ![]() highest utility on role
highest utility on role ![]() . For example, if agents
. For example, if agents ![]() , and
, and ![]() are performing role
are performing role ![]() under mapping
under mapping ![]() with the following utilities for role
with the following utilities for role ![]() , then
, then ![]() .
.
Algorithm 10.1 ![]()
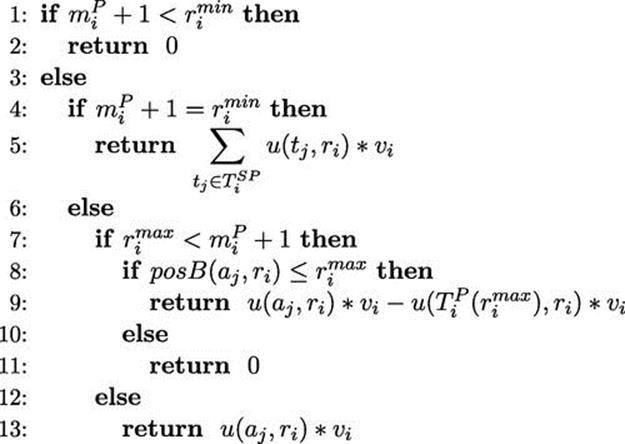
Theorem 10.2 describes the optimal role mapping for the ad hoc agent under this model.
Theorem 10.2 In Limited Role Mapping tasks, mapping ![]() , under which
, under which ![]() chooses the role
chooses the role ![]() that obtains
that obtains ![]() , maximizes marginal utility such that
, maximizes marginal utility such that ![]() .
.
10.5.3 Incremental Value Model
Continuing the multiagent foraging example, consider a task in which there are 500 blue targets and 5000 red targets in a constrained environment with limited time (50 timesteps) for the agents to collect the targets. This example is Task C in Table 10.1. Since the time to collect targets is limited and there are more red targets than blue targets, the optimal role will sometimes be one that collects less plentiful but more valuable blue targets and sometimes be one that collects less valuable but more plentiful red targets. Collecting the less valuable red targets may be optimal if there are many other agents collecting blue targets and few other agents collecting red targets. This is because if there are many other agents collecting blue targets, the blue targets close to the base will be quickly collected, which forces all the agents collecting blue targets to venture farther away from the base in order to collect blue targets. In such a case, collecting less valuable red targets may prove to be optimal since competition for them is less fierce and therefore they can be collected and returned to the station more frequently.
In tasks like this, the value added by agents performing a role may not be linearly correlated with the number of agents performing that role. As such, the team utility in incremental value tasks can be modeled as
(10.4)
where
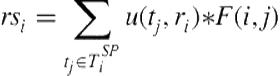 (10.5)
(10.5)
In particular, we consider the following three functions ![]() —each with two parameters that can be tuned to match the characteristics of a particular task—that describe how the value added to the team by each subsequent agent performing a role incrementally increases or decreases as more agents perform that role.
—each with two parameters that can be tuned to match the characteristics of a particular task—that describe how the value added to the team by each subsequent agent performing a role incrementally increases or decreases as more agents perform that role.
Logarithmic function ![]() , where
, where ![]() represents the amount added to the role score
represents the amount added to the role score ![]() for each agent performing role
for each agent performing role ![]() sets the pace at which the function decays for agents performing
sets the pace at which the function decays for agents performing ![]() .
.
Exponential function ![]() , where
, where ![]() is the growth factor and
is the growth factor and ![]() is the time required for the value to decrease by a factor of
is the time required for the value to decrease by a factor of ![]() —both for each agent performing role
—both for each agent performing role ![]() .
.
Sigmoidal function ![]() , where
, where ![]() determines the sharpness of the curve and
determines the sharpness of the curve and ![]() dictates the x-offset of the sigmoid from the origin for each agent performing role
dictates the x-offset of the sigmoid from the origin for each agent performing role ![]() .
.
The function ![]() displayed in Algorithm 10.2 gives the marginal utility obtained when an ad hoc agent
displayed in Algorithm 10.2 gives the marginal utility obtained when an ad hoc agent ![]() chooses to perform role
chooses to perform role ![]() , where the current mapping of teammates to roles is described by
, where the current mapping of teammates to roles is described by ![]() . Remember from function
. Remember from function ![]() that
that ![]() denotes the 0-indexed position in
denotes the 0-indexed position in ![]() that the ad hoc agent
that the ad hoc agent ![]() occupies. In this model, agent utility
occupies. In this model, agent utility ![]() for performing each role
for performing each role ![]() , the importance
, the importance ![]() of each role
of each role ![]() , and the parameters used in function
, and the parameters used in function ![]() are all tunable parameters. Note that although we generally assume benefit is obtained as additional agents join a team, our models can also handle the case in which additional agents add penalty as they join the team.
are all tunable parameters. Note that although we generally assume benefit is obtained as additional agents join a team, our models can also handle the case in which additional agents add penalty as they join the team.
Algorithm 10.2 ![]()
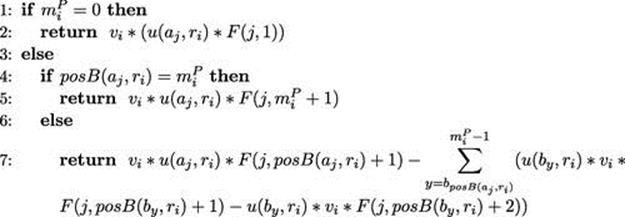
Theorem 10.3 describes the optimal role mapping for the ad hoc agent under this model.
Theorem 10.3 In Incremental Value tasks, mapping ![]() , under which
, under which ![]() chooses the role
chooses the role ![]() that obtains
that obtains ![]() , maximizes marginal utility such that
, maximizes marginal utility such that ![]() .
.
10.5.4 Empirical Validation of Models
As each model was presented, a foraging task in which the model has been empirically shown to be most appropriate was also described. Results of each model on each task are presented in Table 10.1. Task D—a task with 5000 blue targets, 5000 red targets, limited time (50 timesteps), and crowding penalties that only let one agent move from each cell in a timestep—is also included to represent a case where the limited model and two of the incremental models do poorly.
Throughout this chapter, we evaluate models based on how often they lead an ad hoc agent to make the “correct” decision about which role to assume. An ad hoc agent’s decision to perform role ![]() instead of
instead of ![]() is correct if empirical data shows that performing
is correct if empirical data shows that performing ![]() yields a team score that is better by a statistically significant margin than the team score obtained by performing
yields a team score that is better by a statistically significant margin than the team score obtained by performing ![]() . Likewise, an ad hoc agent’s decision to perform role
. Likewise, an ad hoc agent’s decision to perform role ![]() instead of
instead of ![]() is “incorrect” if empirical data shows that performing
is “incorrect” if empirical data shows that performing ![]() yields a team score that is worse by a statistically significant margin than the team score obtained by performing
yields a team score that is worse by a statistically significant margin than the team score obtained by performing ![]() . If the margin is not statistically significant, then the decision is not counted as correct or incorrect. We determine statistical significance by running a two-tailed student’s t-test assuming two-sample unequal variance.
. If the margin is not statistically significant, then the decision is not counted as correct or incorrect. We determine statistical significance by running a two-tailed student’s t-test assuming two-sample unequal variance.
As seen in Table 10.1, each model presented earlier in this section is indeed appropriate for some task. Interestingly enough, no model is best or worst for all tasks. In fact, each model performs poorly in at least one task. Thus, this experiment serves to show that each of the models presented is worth considering. Tasks C and D of this experiment also serve to highlight the differences between the incremental model with sigmoidal function and the incremental model with logarithmic and exponential functions.
10.6 Model Evaluation
The role-based ad hoc teamwork problem lies in determining which role an ad hoc agent should select when faced with a novel teamwork situation. Thus, the main questions in terms of role selection are: given a task in a particular environment, how should the correct model be selected? Additionally, once a model is selected, how should we determine reasonable parameters for the model given limited gold standard data? Answering these questions makes substantial progress toward solving the role-based ad hoc teamwork problem. Therefore, this section examines both questions in the Pacman Capture-the-Flag environment.
10.6.1 Pacman Capture-the-Flag Environment
We empirically examine each of the three models previously described in a Capture-the-Flag style variant of Pacman designed by John DeNero and Dan Klein [18]. The foraging domain used earlier in the chapter was a simple and easily configurable domain. However, we move to the Pacman domain now both as an example of a more complex domain and to validate that our approach works in multiple domains.
The Pacman map is divided into two halves and two teams compete by attempting to eat the food on the opponent’s side of the map while defending the food on its side. A team wins by eating all but two of the food pellets on the opponent’s side or by eating more pellets than the opponent before 3000 moves have been made. When a player is captured, it restarts at its starting point.
The result of each game is the difference between the number of pellets protected by the team and the number of pellets protected by the opponent—we refer to this as the score differential. Wins result in positive score differentials, ties result in zero score differentials, and losses result in negative score differentials. High positive score differentials indicate that the team dominated the opponent, while score differentials closer to zero indicate that the two teams were well matched. We mainly care whether we win or lose, so we transform each score differential using a sigmoid function in order to emphasize differences in score differentials close to zero. We input the score differential from each game into the sigmoid function ![]() to obtain gold standard data. We examined different values for the multiplicand and found that 0.13 yielded the most representative score differential spreads in the three tasks presented in the following.
to obtain gold standard data. We examined different values for the multiplicand and found that 0.13 yielded the most representative score differential spreads in the three tasks presented in the following.
In each experiment, we consider two roles that could be performed: ![]() . Offensive players move toward the closest food on the opponent’s side, making no effort to avoid being captured. Defensive players wander randomly on their own side and chase any invaders they see. These offensive and defensive behaviors are deliberately suboptimal, as we focus solely on role decisions given whatever behaviors the agents execute when performing their roles.
. Offensive players move toward the closest food on the opponent’s side, making no effort to avoid being captured. Defensive players wander randomly on their own side and chase any invaders they see. These offensive and defensive behaviors are deliberately suboptimal, as we focus solely on role decisions given whatever behaviors the agents execute when performing their roles.
We consider the opponents and map to be fixed and part of the environment for each experiment. Half of the opponents perform defensive behaviors and half perform offensive behaviors. Additionally, all the agents run either the offensive or defensive behavior just described. As such, all agents performing a particular role have the same ability to perform that role. In other words, for agents ![]() performing role
performing role ![]() .
.
10.6.2 Determining the Best-Suited Model
We use three tasks to determine which of the models best represents the marginal utility of a role selection for the Pacman Capture-the-Flag environment. In particular, a task is defined by the number of opponents and the map. The first task “vs-2” is against two opponents on the “Basic” map shown in Figure 10.2(a), the second task “vs-6” is against six opponents on the “Basic” map, and the third task “vs-2-SmallDefense” is against two opponents on the “SmallDefense” map shown in Figure 10.2(b).
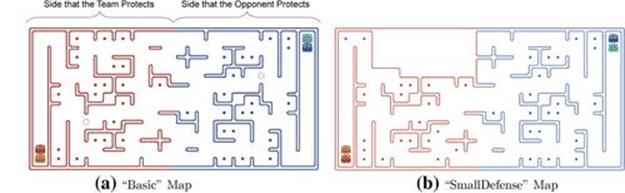
FIGURE 10.2 Maps used to determine which model best represents the marginal utility of a role selection for the Pacman Capture-the-Flag environment.
To decide which of the models is most representative of the marginal utility of a role selection in the Pacman Capture-the-Flag environment, we first gather full sets of gold standard data. In particular, in each task we gather scores over 1000 games for each team of 0 to 6 offensive agents and 0 to 6 defensive agents (i.e., ![]() teams). Then we calculate the gold standard data for each team by putting the score differential from each of the 1000 games through the sigmoidal function given before and then average the results. The gold standard data from the “vs-2” environment is shown in Table 10.2. Note that 0.09 is the worst possible gold standard performance and corresponds to obtaining 0 pellets and losing all 18 pellets to the opponent. Likewise, 0.88 is the best possible gold standard performance, and corresponds to obtaining 18 pellets and losing no pellets to the opponent.
teams). Then we calculate the gold standard data for each team by putting the score differential from each of the 1000 games through the sigmoidal function given before and then average the results. The gold standard data from the “vs-2” environment is shown in Table 10.2. Note that 0.09 is the worst possible gold standard performance and corresponds to obtaining 0 pellets and losing all 18 pellets to the opponent. Likewise, 0.88 is the best possible gold standard performance, and corresponds to obtaining 18 pellets and losing no pellets to the opponent.
Table 10.2
Rounded Gold Standard Data and Decisions from the “vs-2” Environment
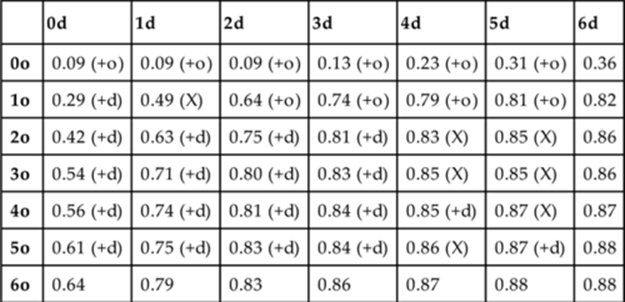
Note: The rows represent the 0…6 agents performing an offensive role, while the columns represent the 0…6 agents performing a defensive role. A ‘+o’ (‘+d’) decision means that the ad hoc agent should adopt an offensive (defensive) role if added to a team with teammates performing the roles indicated by the row and column. An ‘X’ decision means that the decision of which role to perform was not statistically significant at p ![]() 0.05.
0.05.
We then use the gold standard data to determine the gold standard decision of whether an ad hoc agent should perform an offensive role or a defensive role on any team composed of 0 to 5 offensive agents and 0 to 5 defensive agents in each of the three tasks. To determine the gold standard decision of whether it is better for the ad hoc agent to perform an offensive or defensive role when added to a particular team, we look at whether the gold standard data is higher for the team with one extra defensive player or the team with one extra offensive player. If the gold standard data is higher for the team with one extra defensive player, then the gold standard decision is for the ad hoc agent to play defense. Likewise, if the gold standard data is higher for the team with one extra offensive player, then the gold standard decision is for the ad hoc agent to play offense. We determine whether a gold standard decision is statistically significant by running a two-tailed student’s t-test assuming two-sample unequal variance.
As an example, consider the gold standard data from the “vs-2” environment shown in Table 10.2. The gold standard decision of whether an ad hoc agent should perform an offensive role or a defensive role on a team composed of two offensive agents and one defensive agent can be determined by considering whether the data for a team with two offensive agents and two defensive agents is greater than or less than the gold standard data for a team with three offensive agents and one defensive agent. By looking at the data from the “vs-2” environment shown in Table 10.2, we can see that the data for a team with two offensive agents and two defensive agents is 0.75, while the gold standard data for a team with three offensive agents and one defensive agent is 0.71. Since the data for a team with two offensive agents and two defensive agents is greater than the gold standard data for a team with three offensive agents and one defensive agent, the gold standard decision regarding a team composed of two offensive agents and one defensive agent is to perform a defensive role.
Once we calculate the gold standard decisions for the ad hoc agent in each of the three tasks, we can determine which of the three models best captures the actual marginal utility of role selection in each task. First, we input the gold standard data and the model function into MATLAB’s lsqcurvefit algorithm, which uses the trust region reflexive least squares curve-fitting algorithm, and obtain fitted parameters for the model function. The fitted parameters vary in type and number for each of the three models, but always include the role importance value ![]() , the agent’s utility
, the agent’s utility ![]() at performing role
at performing role ![]() , and parameters of the model function—all for each role
, and parameters of the model function—all for each role ![]() . The obtained fitted parameters for each of the models in the “vs-2”, “vs-6”, and “vs-2-SmallDefense” tasks can be found in Tables 10.3–10.7. We use the fitted parameters to calculate fitted results for teams of 0 to 6 offensive agents and 0 to 6 defensive agents. Lastly, we translate these fitted results into fitted decisions using the same methodology used to translate the gold standard score differentials into gold standard decisions.
. The obtained fitted parameters for each of the models in the “vs-2”, “vs-6”, and “vs-2-SmallDefense” tasks can be found in Tables 10.3–10.7. We use the fitted parameters to calculate fitted results for teams of 0 to 6 offensive agents and 0 to 6 defensive agents. Lastly, we translate these fitted results into fitted decisions using the same methodology used to translate the gold standard score differentials into gold standard decisions.
Table 10.3
Obtained Fitted Parameters for the Unlimited Role Mapping Model
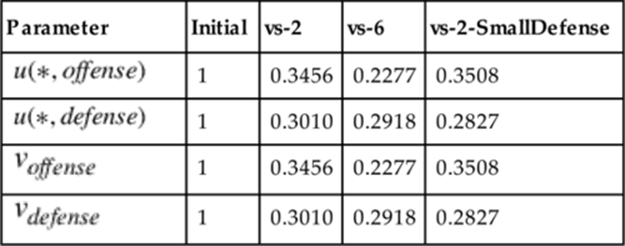
Table 10.4
Obtained Fitted Parameters for the Limited Role Mapping Model
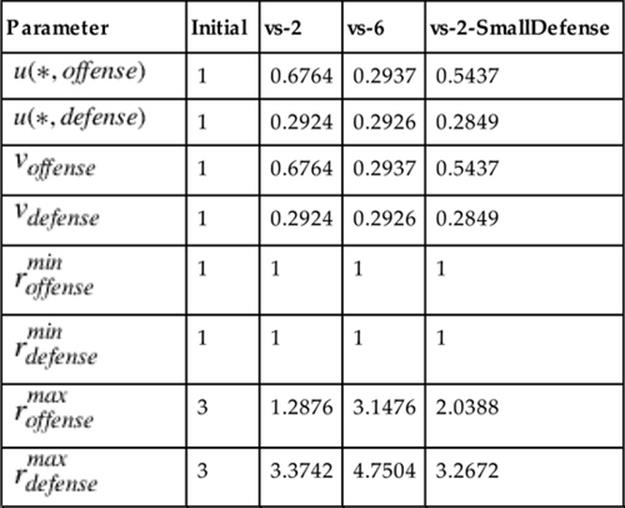
Table 10.5
Obtained Fitted Parameters for the Logarithmic Incremental Value Model
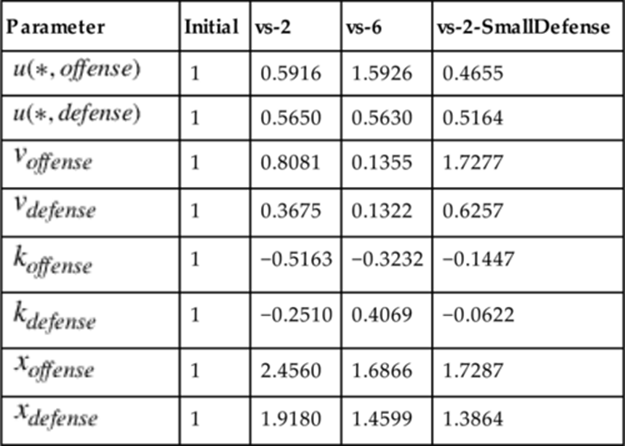
Table 10.6
Obtained Fitted Parameters for the Exponential Incremental Value Model
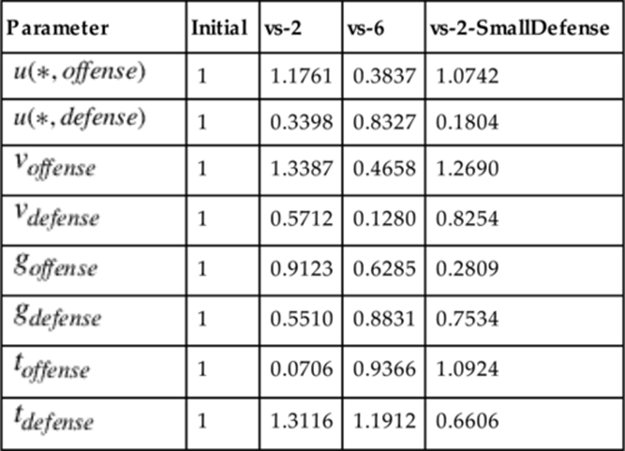
Table 10.7
Obtained Fitted Parameters for the Sigmoidal Incremental Value Model
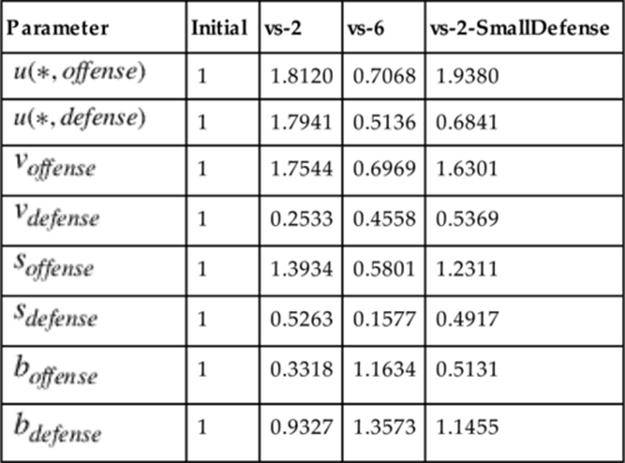
Now that we have gold standard decisions for each of the three tasks and fitted decisions for all three models in the three tasks, we compare the number of times the gold standard decision (e.g., “+o”) is statistically significant but does not match the fitted decision for a particular team arrangement (e.g., “+d”)—in other words, the number of times the ad hoc agent made an incorrect decision.
As is apparent from Table 10.8, all three incremental model functions perform rather well. Unfortunately we have yet to discover any clear insight as to when each of the incremental model functions are most appropriate. Thus, for now, it seems to be something that must be determined empirically for each new domain using gold standard data.
Table 10.8
Number of Statistically Significant Incorrect/Correct Decisions Made by the Ad Hoc Agent
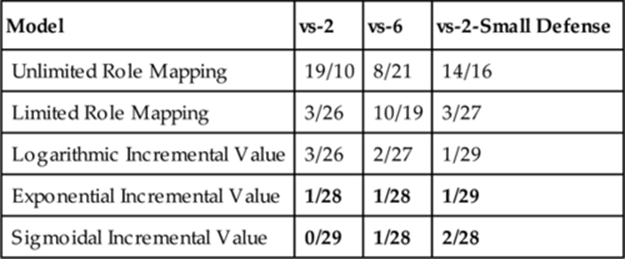
Note: The results here are for each of the three tasks. Fewer incorrect and greater correct decisions is desirable.
In the Pacman domain, as can be seen in Table 10.8, the exponential and sigmoidal functions of the incremental model make the fewest incorrect decisions across the three tasks. Thus, we conclude that in the Pacman Capture-the-Flag domain, at least on the maps and opponents we studied, the incremental model using either an exponential function or a sigmoidal function most accurately models team utility. However, to conclude this we generated a full set of gold standard data for each of the three tasks, amounting to 49,000 games per task, and used this data to fit the parameters of the model. Next we consider how to use the chosen model for predictive modeling when substantially less gold standard data is available.
10.6.3 Predictive Modeling
The main research problem in role-based ad hoc teamwork is how to choose a role for the ad hoc agent that maximizes marginal utility. This problem is particularly important when the ad hoc agent is placed in a situation it has never encountered before.
Once a model type has been selected for a domain, the ad hoc agent can use this model to predict the marginal utility of role selection on new tasks in this domain for which we have limited gold standard data. Essentially we want to be able to determine how the ad hoc agent should behave during a new task—including never seen before situations—without the expense of gathering substantial amounts of gold standard data for every scenario. We do this by choosing fitted parameters for the new task based on the data that is available. Remember that fitted parameters can be obtained by inputting the gold standard data and the chosen model function into MATLAB’s lsqcurvefit algorithm, as this will fit the chosen model to the limited gold standard data using a least squares curve-fitting algorithm. Then these fitted parameters can be used to calculate fitted results and fitted decisions, which represent the decisions chosen by the agent given each possible set of teammates.
In the following we evaluate the accuracy of the incremental value model in our Pacman domain on multiple tasks when various amounts of randomly selected data are available for choosing fitted parameters. We use two new tasks in this section, both against two opponents. One task “vs-2-alley” is on the “AlleyDefense” map shown in Figure 10.3(a) and the other task “vs-2-33%” is on the “33%Defense” map shown in Figure 10.3(b). Both the “AlleyDefense” and “33%Defense” maps include a smaller defensive area than offensive area for the team to which the ad hoc agent is added. However, the alley in “AlleyDefense” calls for the ad hoc agent to behave very differently than in the “33%Defense” map, where the opponent’s food pellets are relatively easy for the ad hoc agent’s team to capture. Specifically, in the “33%Defense” map it is desirable—up to a certain threshold—to add an offensive agent as long as there is at least one defensive agent, whereas in the “AlleyDefense” map it is desirable to have substantially more defensive agents than offensive agents as long as there is at least one offensive agent.
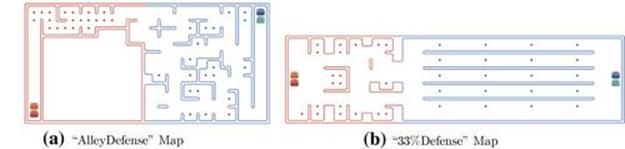
FIGURE 10.3 The maps used for the predictive modeling tasks.
Consider the case in which the ad hoc team agent is given, either through experience or observation, randomly selected data points that represent some sparse experience in a task, where a data point consists of the number of agents fulfilling each role and the average gold standard data calculated over 25 games. We chose 25 games because this proved to be an appropriate trade-off between the time required to collect data and the value of minimizing incorrect predictions. However, in practice the agent will usually not get to determine how many games it receives information about, and instead must do the best it can with whatever experience it is given. Note that if only one data point is used to fit the model, then score differentials from 25 games are required. Likewise, use of 10 data points requires ![]() games. Even if all 49 data points are used, only
games. Even if all 49 data points are used, only ![]() games are required. To put these game numbers in perspective, we can usually run 500 games on our high-throughput computing cluster in under five minutes.
games are required. To put these game numbers in perspective, we can usually run 500 games on our high-throughput computing cluster in under five minutes.
We evaluate the prediction accuracy of each of the three function variations of the incremental value model on two tasks for which we have limited data ranging from 1 to 49 randomly selected data points. In this experiment, we endeavor to determine how many data points are needed to obtain reasonable prediction accuracy—in other words, we want to find the point at which it might not be worth obtaining additional data points. Note that since a data point cannot be selected more than once, all data points are being used when 49 data points are selected. Prediction accuracy is reported as the number of statistically significant incorrect predictions made by the model. Figure 10.4 shows the accuracy of each variation of the chosen model on the “vs-2-alley” task, while Figure 10.5shows accuracy on the “vs-2-33%” task, both when given varying amounts of randomly selected data points calculated from 25 games.
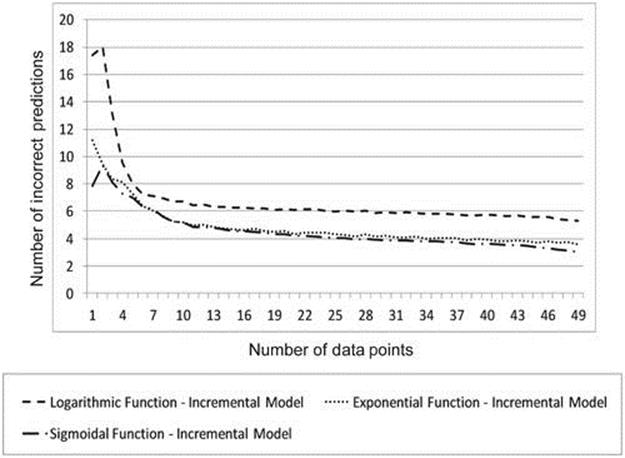
FIGURE 10.4 Accuracy of each variation of the incremental value model. Note: The data were averaged over 1000 trials using various amounts of randomly selected data points from 25 games in the “vs-2-alley” task.
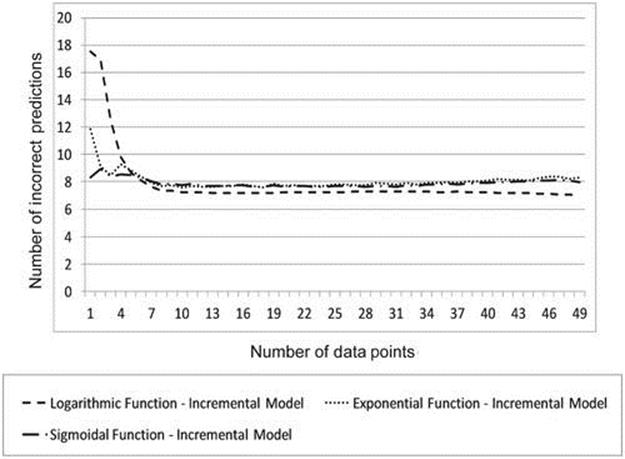
FIGURE 10.5 Accuracy of each variation of the incremental value model. Note: The data were averaged over 1000 trials using various amounts of randomly selected data points from 25 games in the “vs-2-33%” task.
As would be expected, the accuracy of each variation of the chosen model improves steadily in both tasks as additional data points are used to fit the model. Note that in both tasks, using as few as ten data points yields about as many incorrect predictions on average as using all forty-nine data points. One interesting result to note is that in the “vs-2-alley” task, the incremental model with the logarithmic function does the worst of the incremental models, whereas in the “vs-2-33%” task it does the best. This performance variability is acceptable; although the incremental model with either an exponential function or a sigmoidal function was shown in the previous section to be the best for the Pacman Capture-the-Flag domain, it will not always be the absolute best. What is notable is that the chosen model—the incremental model with either an exponential function or a sigmoidal function in our domain—does the best or close to best in both tasks.
10.6.3.1 Importance of Determining the Fitted Parameters
In the previous section we presented the idea that once an ad hoc agent has chosen a model for a particular domain, it can use this chosen model to predict the marginal utility of role selection on new tasks in the same domain by using limited gold standard data to determine new fitted parameters for the model.
However, how important is it to use limited gold standard data to determine appropriate fitted parameters for the chosen model function in a new task? We found experimentally that if parameters fit onto one task are used on another task, the results can be quite poor. For example, using parameters fit for the “vs-6” task, which yield one incorrect decision on the “vs-6” task, yields 14 incorrect decisions on the “vs-2-33%” task. As such, it is almost always important and worthwhile to find new fitted parameters when a new task is encountered and there is opportunity to obtain any gold standard data.
10.7 Conclusion and Future Work
This chapter presented a formalization of role-based ad hoc teamwork settings, introduced several methods for modeling the marginal utility of an ad hoc agent’s role selection, and empirically showed that each of these methods is appropriate for a different class of role-based tasks. We assume in this work that the roles of the teammates are known and that we know how well some team configurations do in a particular task. However, we do not know how much an ad hoc agent could help the team if added to each role. As such, we show that it is possible to use a particular functional form to model the marginal utility of a role selection in a variety of tasks. Additionally, we show that only a limited amount of data is needed on a new task in order to be able to fit the function such that it can be used as a predictive model to determine how an ad hoc agent should behave in situations involving a task that it has not previously encountered.
This research is among the first to study role-based ad hoc teams. As such, there are many potential directions for future work. One such direction would be to expand this work into more complicated environments with more than two potential roles to fulfill and more than one ad hoc agent. Another direction would be to consider the case in which the ad hoc agents encounter teammates that are running unfamiliar behaviors, as this would force the ad hoc agents to model their teammates.
References
1. Stone P, Kaminka GA, Kraus S, Rosenschein JS. Ad hoc autonomous agent teams: Collaboration without pre-coordination. Proceedings of the 24th Conference on Artificial Intelligence. 2010.
2. Grosz BJ, Kraus S. Collaborative plans for complex group action. Artif Intell J. 1996;86(2):269-357.
3. Tambe M. Towards flexible teamwork. J Artif Intell Res. 1997;7:83-124.
4. Decker KS, Lesser VR. Designing a family of coordination algorithms. Proceedings of the First International Conference on Multi-Agent Systems. 1995.
5. Stone P, Veloso M. Task decomposition, dynamic role assignment, and low-bandwidth communication for real-time strategic teamwork. Artif Intell J. 1999;110(2):241-273.
6. Liemhetcharat S, Veloso M. Weighted synergy graphs for role assignment in ad hoc heterogeneous robot teams. Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. 2012.
7. Wu F, Zilberstein S, Chen X. Online planning for ad hoc autonomous agent teams. Proceedings of the 22nd International Joint Conference on Artificial Intelligence. 2011.
8. Bowling M, McCracken P. Coordination and adaptation in impromptu teams. Proceedings of the 20th Conference on Artificial Intelligence. 2005.
9. Jones E, Browning B, Dias MB, Argall B, Veloso M, Stentz AT. Dynamically formed heterogeneous robot teams performing tightly-coordinated tasks. Proceedings of the International Conference on Robotics and Automation. 2006.
10. Han J, Li M, Guo L. Soft control on collective behavior of a group of autonomous agents by a shill agent. J Syst Sci Complex. 2006;19:54-62.
11. Barrett S, Stone P, Kraus S. Empirical evaluation of ad hoc teamwork in the pursuit domain. Proceedings of 11th International Conference on Autonomous Agents and Multiagent Systems. 2011.
12. Sukthankar G, Sycara K. Policy recognition for multi-player tactical scenarios. Proceedings of the Sixth International Conference on Autonomous Agents and Multiagent Systems. 2007.
13. Zhuo HH, Li L. Multi-agent plan recognition with partial team traces and plan libraries. Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence. 2011.
14. Blake M, Sorensen G, Archibald J, Beard R. Human assisted capture-the-flag in an urban environment. Proceedings of the International Conference on Robotics and Automation. 2004.
15. Sadilek A, Kautz H. Modeling and reasoning about success, failure, and intent of multi-agent activities. Proceedings of the 12th International Conference on Ubiquitous Computing, Workshop on Mobile Context-Awareness. 2010.
16. Mataric M. Learning to behave socially. Proceedings of From Animals to Animats 3. Proceedings of the Third International Conference on Simulation of Adaptive Behavior. 1994.
17. Lerman K, Jones C, Galstyan A, Mataric M. Analysis of dynamic task allocation in multi-robot systems. Int J Robot Res. 2006;25:225-242.
18. DeNero J, Klein D. Teaching introductory artificial intelligence with Pac-Man. Proceedings of the First Symposium on Educational Advances in Artificial Intelligence. 2010.
1 This work was done while at the Learning Agents Research Group (LARG) at the University of Texas at Austin.
2 ![]() is actually a function of
is actually a function of ![]() ; however, throughout this chapter we use this more compact notation.
; however, throughout this chapter we use this more compact notation.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.