Knowledge-based Configuration: From Research to Business Cases, FIRST EDITION (2014)
Part V. Configuration Environments
Chapter 23. encoway
Thorsten Krebs, encoway GmbH, Bremen, Germany
Abstract
This chapter describes the basics of the encoway configuration environment. encoway is working with a set of tools that best suits the heterogeneous system landscapes and their very different needs that encoway encounters in real-life customer projects. In the following we give a brief introduction of the configuration environment, including a scientific background, an architecture description, and typical system landscapes in which encoway integrates configuration applications.
Keywords
Knowledge-based Configuration; Configurator Application; Product Configuration; Product Modeling; Data Integration and Maintenance; Quote Generation
23.1 Introduction
This chapter describes the basics of the encoway1 configuration environment. encoway is working with a set of tools for the different tasks of data integration and maintenance, product modeling and configuration, representing and displaying configuration decisions and related rich content, as well as quote generation and handling transaction data in general. This set of tools best suits the heterogeneous system landscapes and their very different needs that encoway encounters in real life customer projects.
The remainder of this chapter is organized as follows. Section 23.2 presents an overview of encoway’s history and its roots within the scientific community. Section 23.3 briefly discusses the configuration and reasoning methods that are implemented within encoway’s configuration environment. Section 23.4 presents an overview of encoway’s system architecture and typical system landscapes in which encoway integrates configuration applications. Section 23.5 describes the necessary data required for such configuration applications. Section 23.6 discusses the quote generation process in which configuration plays a key role between selecting configurable products and generating quote documents. Finally, Section 23.7 summarizes and concludes this chapter.
23.2 History and Scientific Basis
encoway uses methods from structure-based (component-oriented) configuration that have a long history in the research area of Artificial Intelligence (see e.g., Günter, 1995). The declarative approach of representing products by means of structure-based configuration is especially well suited for managing large amounts of product variants and configuring complex products. encoway itself is deeply rooted in research. The company was founded as a spin-off from the research institute TZI (Center for Computing and Communication Technologies)2 located at the University of Bremen, Germany, and intends to transfer know-how between research and practice. One of the first configuration applications encoway has developed is the drive solution designer (DSD), which is a tool for designing and configuring complex drive systems. It is described in the award-winning paper from Ranze et al. (2002).
Up to now, encoway has developed configuration and variant management applications for numerous customers from different domains such as drive systems, component manufacturers, electronics products, furniture fittings, wood products, and many more. These application domains have very different needs and thus need to be addressed uniquely. Depending on the characteristics of the respective application domains, encoway has developed different standardized tooling and best practice approaches that cover the required functionality and can be combined to fulfill the overall task. Configurable products, however, are always represented by using methods known from structure-based configuration, which improves knowledge maintenance over time (see e.g., Krebs, 2009). We give more details about the representation mechanisms in Section 23.3.
Modeling products declaratively is the key to understand product configuration in terms of using a predefined construction kit; for example, assembling a desired product from a set of components belonging to this construction kit as well as improving the construction kit based on the needs of product configuration. The set of components changes over time: new components are developed and older components are replaced or become obsolete. But the physics, the way components interact and thus the reason why specific combinations are possible while others are not, typically does not change.
These raise the importance of building a variant management or configuration application that is fully integrated in an existing customer’s system landscape. Details about the modules of which typical encoway configuration environments consist are provided in Section 23.4.
23.3 Modeling of the Working Example
The term configuration is often used with different meanings (compare Mittal and Frayman, 1989; Stumptner, 1997). In this chapter product configuration describes the task of assembling a product from a predefined set of components and the selection of component characteristics while satisfying a given set of constraints. A configuration model formalizes the knowledge about the application domain in a machine-readable way, abstracting the domains’s complexity to a subset relevant to the configuration process.
The inference engine engcon uses methods known from structure-based configuration. Component types declaratively define configurable products and the components of which they can be assembled. They have a unique name and define a set of attributes. Eachattribute can be of a specific type, string or numeric. The result of a configuration process is a unique value assignment for each of the component attributes that constitute the configuration.
Component types are arranged within two different types of hierarchical relations: taxonomies and partonomies.
• Taxonomies define a classification of objects in a generalization hierarchy: more special component types inherit attributes of more general ones. Inherited attributes can be monotonically refined; no new values may be introduced on lower levels. This, in combination with the closed world assumption3 is the basis for taxonomic inferences. For example, when any CPU can be fast or medium but a CPUD is always fast (refined inherited attribute value), and there is no other fast CPU (closed world assumption) then the system can infer that any fast CPU has to be a CPUD.
• Partonomies define the decomposition of a configurable product. The parts that comprise a product are related to the composite together with a (minimum and maximum) multiplicity definition. For example, a HDUnit has one to four HDisk and one or twoHDController parts. The concept of multiplicity allows for the specification of parts that can be either optional or required. Using the same component types within partonomies for different products is the key to define a large external variance with only a small internal variance.
A component type describes a prototypical product or component, some sort of pattern of which instances are generated within a configuration process according to the multiplicity definition. The generated instances together with the values that have been selected for their attributes form the configuration result. For more information on this topic and structure-based configuration in general see also Günter (1995).
Representing configuration knowledge for the inference engine engcon is based on a hybrid approach consisting of conceptual knowledge and constraint knowledge. Conceptual knowledge describes the products and the components from which products can be assembled. This means that conceptual knowledge describes the search space for possible configuration solutions. Constraint knowledge on the other hand narrows down this search space by defining situations that do not describe allowed configurations and thus must be avoided during the configuration process.
A constraint defines restrictions on one or more attributes of one or more component types. It consists of a condition and an action. The condition describes a situation in which the action definition is relevant with respect to a configuration task. For example, constraint gc1 has the condition that an instance of component type CPUS is present within the configuration. The action is executed when the condition matches the contents of a running configuration process and thus restricts instances of the component types that appear within the condition. The constraint gc1, for example, limits the choice of motherboards to those of compatible type MBDiamond. This means that the component types and their relations describe the search space while the set of constraints restricts this space to the subset of actually buildable combinations (see Mailharro, 1998).
Figure 23.1 shows a screenshot of encoway’s modeling tool K-Build. On the left side there are the two hierarchies: taxonomy on the top and partonomy on the bottom. We can see that an MBDiamond is a special MB (motherboard) that belongs to the component typeHardware and is part of PC. The tool K-Build uses the term “concept” to denote component types. On the right-hand side the attributes of MBDiamond are listed together with a reference to constraints that restrict its extension: gc1 in this example.
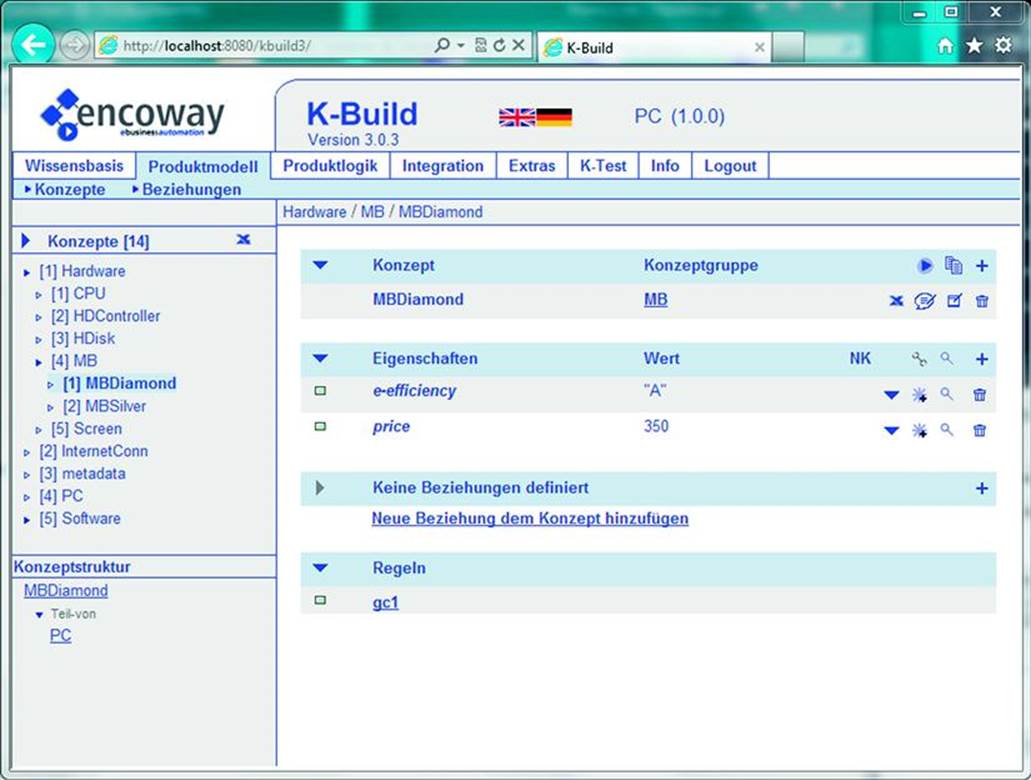
FIGURE 23.1 Screenshot of encoway’s modeling tool K-Build.
engcon distinguishes different types of constraints that restrict the value assignment of attribute values, specialize an instance along the defined taxonomy, or decompose a component type according to its part definitions. A very expressive ready-to-use library comes along with the modeling environment K-Build (see also Section 23.4). Constraints are written as plug-ins using Java and thus the constraint library can be easily extended according to the project’s specific needs. Typically, encoway prefers to use multidirectional constraints: no matter which of the concerned attributes are changed, the constraint evaluates possible values for all affected attributes. This reduces the potential of running into a conflict situation, one in which the currently selected set of values does not conform to the configuration model.
Avoiding conflicts when possible enables a better user experience. Because of this, encoway has developed a mechanism that allows the user to select values that are not possible in the current situation and computes the consequences of this decision: obviously, at least one of the prior decisions cannot persist and the user can decide to take back either that prior decision or the new decision. Computing the consequences of a decision that is not possible is achieved by prioritizing the decisions and executing them again in a specific order: the new decision first. When the prior decisions are executed and at some point a value cannot be set, then the user needs to decide between the existing and the new decision.
Using engcon, the process of steering through the search space is incremental and typically exactly one solution is sought: the one best matching with a given set of requirements. Within this process user decisions and system decisions alternate within each step: a user decision is performed and the system computes consequences such as taxonomic inferences and constraint evaluation. After all consequences are computed the result is displayed to the user and another iteration cycle begins (Ranze et al., 2002).
23.4 System Integration
Typical encoway applications rely on a web-based architecture. A webserver runs the applications to which multiple clients can simultaneously connect via browser via the Internet. A database is used to store different kinds of data; for example, product master data, transaction data, or rich content (see also Sections 23.5 and 23.6). The standard software is 99% Java. Preexisting libraries that encode formulas and other configuration-relevant calculations and that are written in different languages, however, can be integrated for example by using Java Native Interface (JNI).
The customer’s system landscape, into which an encoway solution is integrated, has implications on data migration and modeling configuration knowledge. Figure 23.2 depicts the set of encoway tools grouped into build-time, run-time, production, and logistics as well as marketing tasks. We can see how data flows via the different tools such as K-Build, K-Connect for SAP LO-VC, or the IDoc-Server into the catalog during build-time and read from there during run-time by configuration applications. With this set of tools the whole system landscape is well supported.
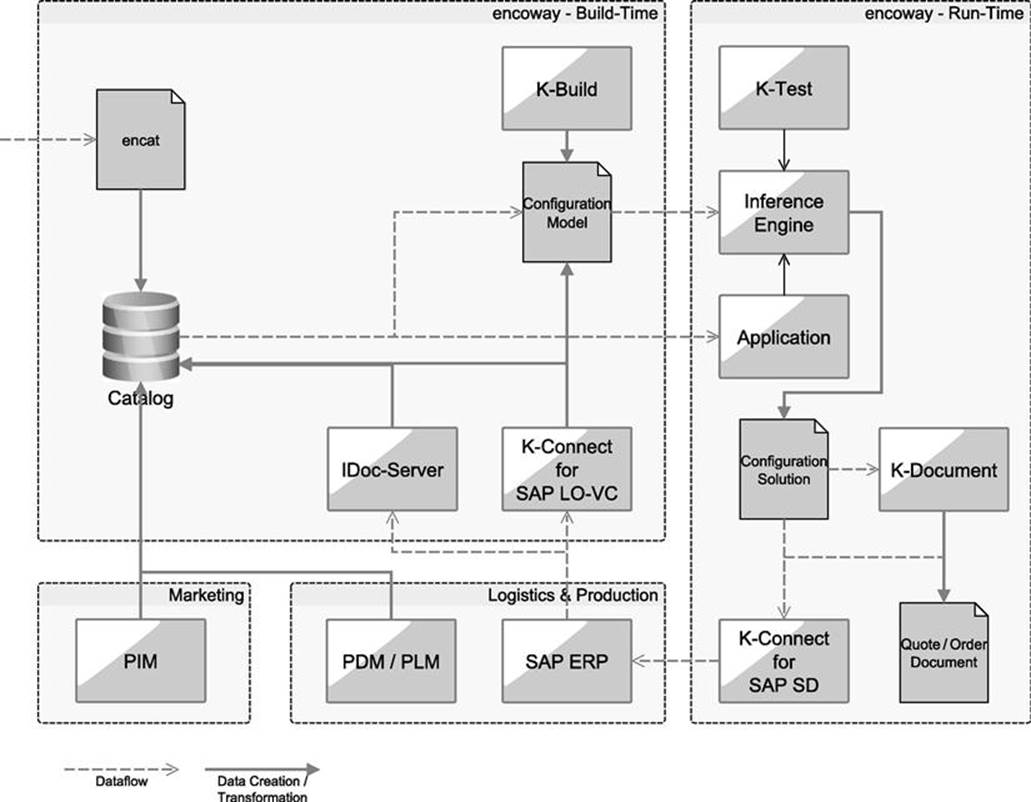
FIGURE 23.2 Big picture of the tool landscape.
Within most configuration projects encoway’s K-Build is used to model the application domain. But because of the fact that a lot of encoway’s customers use SAP systems, encoway has developed standardized tools and an SAP-conform inference engine in order to use preexistent product master data and configuration logic. Both ways of system integration are discussed in the following.
K-Build is one of the first tools developed at encoway and it is still in use. Like most of encoway’s applications, K-Build is a web-based tool that can be installed on a server and accessed from various clients as well as installed on single systems. encoway employees and customers use K-Build to build up configuration models. All configuration models generated with K-Build are based on the inference engine engcon. K-Build includes a test environment called K-Test for analyzing and debugging configuration models. The test environment shows a generic user interface in which every component type of the product model can be configured. All its attributes and parts are displayed with lots of information such as system states and reasons for value changes.
Via the tool K-Connect for SAP LO-VC 4 it is possible to extract knowledge from SAP systems, including procedures, and make it available for offline usage. While engcon is based on a strictly declarative way to represent and reason about configuration knowledge, SAP has different facilities. For more details on this topic see also Chapter 18.
In Section 23.2 we introduced the mechanism of separating product master data and configuration logic. This separation is achieved by sharing a common base of data: a catalog is used to structure the product master data and other information such as rich content. Thus, the catalog is the one place to manage product-related content, which prevents redundant data and improves maintainability. Integrating product master data from different source systems, or simply from files, is achieved by importing the data into the catalog and connecting to this catalog from the configuration model during run-time. This means that the actual master data does not need to be imported into the configuration model. The configuration model does not need to be changed when new revisions of master data are available within the source systems.
23.5 Data Integration
Applications can be connected to the catalog for gaining access to the product data. For example, a selector that does not require an inference engine but can directly work on the catalog data via implementing an API or using a web service. K-Build comes with the functionality to use product groups from the catalog as “branch-off points.” A branch-off point is treated like a component type, while being a pointer to a specific product group within the catalog. This means that the products belonging to the product group are treated like the possible child component types during run-time; that is, during a configuration process. The child component types are filtered according to the attribute values that were already set during the configuration process.
For example, the catalog contains a class MB and two products MBSilver and MBDiamond that belong to this class. Within a configuration model a component type can link to the “branch-off point” MB. During run-time the products MBSilver and MBDiamond from the catalog serve as more specific component types to which an instance of the component type MB can be specialized.
Typical sources for product master data are the following:
• Enterprise Resource Planning (ERP) systems usually define a production relevant view on the materials that are required for assembling products. encoway has already encountered a variety of ERP systems, but for SAP there are two standard tools relying on the intermediate document format (IDoc): K-Connect for SAP LO-VC, for extracting material data and procedures as well as UI-design and translations; and the IDoc-Server, for extracting material data without procedures.
• While Product Data Management (PDM) and Product Lifecycle Management (PLM) systems are also used to maintain production-relevant data, PIM (product information management) systems are used to maintain sales-relevant data such as descriptions, help texts, translations, images, or documents. This information is input for a configuration application.
• Due to the fact that different customers have different system landscapes, encoway has developed a standard product data exchange format: encat is based on XML syntax and allows importing semantically well-specified product data into the catalog. It distinguishes a classification from catalog content, analogous to database schemes.
23.6 Quote Generation Process
Mostly, companies are not aware of the fact that they need a configurator. The problem, as seen by executives, usually is to manage and sell complex products that require explanation. A customer does not know about their technical details. This is the reason why a configurator needs to be embedded in a greater overall process: the quote generation process.
The overall goal is data continuity—integrating data management, configuration, and configuration results seamlessly within one process.
23.6.1 Transaction Data Management
Besides product master data, the catalog also contains transaction data such as quotes, quote documents, and orders. Transaction data is not required for the configuration process itself, but becomes relevant when further processing configuration results; for example as ingredients for document generation.
The following transaction data is stored within the catalog:
• Quotes and /or orders are collected in a quote list. Quotes are typically generated when a configuration process is finished.
• Quotes can be grouped within projects. Projects can combine more than one quote in a structured way, for example when a large construction site is to be equipped with numerous products.
• Addresses are required for quotes. An integrated address list manages data taken over from a Customer Relationship Management (CRM) or ERP system.
All data required for quote generation are managed within the catalog and can be used in online and offline scenarios.
23.6.2 Processing Configuration Results
Quotes do not only need to be managed within a configuration application. When a quote turns into an order, it needs to be transferred to the production site. Mostly, ERP systems are used for tracking production orders. encoway has developed the tool K-Connect for SAP SD for creating sales documents (i.e., both quotes and orders) within SAP systems.
But the producing company does not only need to track the quotes and orders. Also, a customer needs to receive a document containing the offered product(s) together with its price(s), terms and conditions, and so on. encoway has developed the tool K-Documentfor the purpose of creating high quality documents that optimally transport the product’s quality toward customers. K-Document consists of two components: a designer and a server component. The designer is realized as a Word plugin and is used to equip a DOC-file with meta information about the places in which information from configuration, addresses, and rich content should be included at build-time. The server component uses the DOC-file together with the configuration result and information from the catalog to generate high quality sales documents at run-time.
23.7 Conclusion
This chapter described the encoway configuration environment. This environment consists of a set of tools for the tasks of data integration and maintenance, product modeling and configuration, as well as the overall quote generation process. Product master data is separated from configuration logics because the master data is expected to change over time while the logics are expected to be rather stable. Furthermore, the whole configuration knowledge is separated from the presentation layer. With this separation it is possible to use the same knowledge base for different purposes, for example to support sales or an end-customer.
The encoway configuration environment best suits the heterogeneous system landscapes that encoway encounters in the customer projects. It supports all relevant build-time and run-time functionality, integrates product configuration into a quote generation process, and supports integration of PDM, PLM, ERP, and CRM systems. encoway has successfully carried out projects with more than 80 customers over the last 12 years.
References
1. Günter A. Knowledge-based Configuration. St. Augustin: Infix; 1995; (in German: Wissensbasiertes Konfigurieren).
2. Krebs T. A Knowledge Management Framework That Supports Evolution of Configurable Products. Computer Science. vol. 1 Berlin: Rhombos-Verlag; 2009; ISBN 978-3-941216-00-6.
3. Mailharro D. A classification and constraint-based framework for configuration. Artificial Intelligence for Engineering Design, Analysis and Manufacturing (AI EDAM). 1998;12(04):383–397.
4. Mittal S, Frayman F. Towards a generic model of configuration tasks. In: 1989:1395–1401. 11th International Joint Conference on Artificial Intelligence (IJCAI-89), Detroit, MI. vol. 2.
5. Ranze K, Scholz T, Wagner T, et al. A structure-based configuration tool: drive solution designer – DSD. In: 14th Conference on Innovative Applications of AI (IAAI-02), Edmonton, Alberta, Canada. 2002:845–852.
6. Reiter R. On closed world databases. In: Gallaire H, Minker J, eds. Logic and Databases. New York: Plenum Press; 1978:55–76.
7. Russel S, Norvig P. Artificial Intelligence – A Modern Approach. second ed Upper Saddle River, NJ: Prentice Hall; 2003.
8. Stumptner M. An overview of knowledge-based configuration. AI Communications. 1997;10(2):111–126.
1http://www.encoway.de.
2http://www.tzi.de.
3The Closed World Assumption (see Reiter, 1978) postulates that all relevant knowledge is known and that no knowledge beyond this known knowledge is relevant. This means that no absent knowledge will be included in inference mechanisms, in contrast to the Open World Assumption where anything is possible as long as it is not explicitly prohibited. For a description of both closed and open world assumptions, refer to Russel and Norvig (2003).
4LO-VC is the logicvariant configuration module of the SAP system.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.