Product Details Lean Enterprise: How High Performance Organizations Innovate at Scale (2015)
Part III. Exploit
Chapter 10. Implement Mission Command
The more alignment you have, the more autonomy you can grant. The one enables the other.
Stephen Bungay
The best managers figure out how to get great outcomes by setting the appropriate context, rather than by trying to control their people.
Reed Hastings
In his 2009 presentation on Netflix culture, Freedom and Responsibility,162 CEO Reed Hastings describes a dynamic common to many growing organizations. As organizations get larger, they become more complex in terms of the systems they are evolving and running, the business environment in which they operate, and their ability to “get things done.” Eventually the business becomes too complex to run informally, and formal processes are put in place to prevent it from descending into chaos. Processes provide a certain level of predictability, but they slow us down and do little to prevent bad outcomes from events that cannot be managed through process (for example, work that goes according to plan but does not deliver customer value).
Management through process control is acceptable in certain contexts within manufacturing processes (the kind of systems for which Six Sigma makes sense), but not in product development—where its result is optimizing for efficiency and predictability at the expense of innovation and ability to adapt to changing conditions. Geoff Nicholson, the father of the Post-It Note, claims that 3M’s adoption of Six Sigma at the behest of CEO James McNerney (formerly of GE and now of Boeing) “killed innovation.”163 Prescriptive, rule-based processes also act as a brake on continuous improvement unless people operating the process are allowed to modify them. Finally, an overreliance on process tends to drive out people who tinker, take risks, and run safe-to-fail experiments. These kind of people tend to feel suffocated in a process-heavy environment—but they are essential drivers of an innovation culture.
Similarly, as organizations grow, the systems they build and operate increase in complexity. To get new features to market quickly, we often trade off quality for higher velocity. This is a sensible and rational decision. But at some point, the complexity of our systems becomes a limiting factor on our ability to deliver new work, and we hit a brick wall. Many enterprises have thousands of services in production, including mission-critical systems running on legacy platforms. These systems are often interconnected in ways that make it very hard to change any part of the system without also changing others, which acts as a significant drag on their ability to innovate at scale.
These organizational and architectural concerns are often the biggest barriers to executing the strategy for moving fast at scale based on the principles of Mission Command described in Chapter 1. We will start by presenting a virtuoso execution of a strategy to manage organizational and systems complexity in the web age: Amazon. We’ll then present organizational, architectural, and leadership principles that enable organizations to grow successfully.
Amazon’s Approach to Growth
In 2001, Amazon had a problem: the huge, monolithic “big ball of mud” that ran their website, a system called Obidos, was unable to scale. The limiting factor was the databases. CEO Jeff Bezos turned this problem into an opportunity. He wanted Amazon to become a platform that other businesses could leverage, with the ultimate goal of better meeting customer needs. With this in mind, he sent a memo to technical staff directing them to create a service-oriented architecture, which Steve Yegge summarizes thus:164
1. All teams will henceforth expose their data and functionality through service interfaces.
2. Teams must communicate with each other through these interfaces.
3. There will be no other form of interprocess communication allowed: no direct linking, no direct reads of another team’s data store, no shared-memory model, no back-doors whatsoever. The only communication allowed is via service interface calls over the network.
4. It doesn’t matter what technology they use. HTTP, Corba, Pubsub, custom protocols—doesn’t matter. Bezos doesn’t care.
5. All service interfaces, without exception, must be designed from the ground up to be externalizable. That is to say, the team must plan and design to be able to expose the interface to developers in the outside world. No exceptions.
6. Anyone who doesn’t do this will be fired.
Bezos hired West Point Academy graduate and ex-Army Ranger Rick Dalzell to enforce these rules. Bezos mandated another important change along with these rules: each service would be owned by a cross-functional team that would build and run the service throughout its lifecycle. As Werner Vogels, CTO of Amazon, says, “You build it, you run it.”165 This, along with the rule that all service interfaces are designed to be externalizable, has some important consequences. As Vogels points out, this way of organizing teams “brings developers into contact with the day-to-day operation of their software. It also brings them into day-to-day contact with the customer. This customer feedback loop is essential for improving the quality of the service.”
Each team is thus effectively engaged in product development—even the people working on the infrastructural components that comprise Amazon Web Services, such as EC2. It’s hard to overemphasize the importance of this transition from a project-based funding and delivery paradigm to one based on product development.
One of the biggest problems as organizations grow is maintaining effective communication between people and between teams. Once you move people to a different floor, a different building, or a different timezone, communication bandwidth becomes drastically limited and it becomes very hard to maintain shared understanding, trust, and effective collaboration. To control this problem, Amazon stipulated that all teams must conform to the “two pizza” rule: they should be small enough that two pizzas can feed the whole team—usually about 5 to 10 people.
This limit on size has four important effects:
1. It ensures the team has a clear, shared understanding of the system they are working on. As teams get larger, the amount of communication required for everybody to know what’s going on scales in a combinatorial fashion.
2. It limits the growth rate of the product or service being worked on. By limiting the size of the team, we limit the rate at which their system can evolve. This also helps to ensure the team maintains a shared understanding of the system.
3. Perhaps most importantly, it decentralizes power and creates autonomy, following the Principle of Mission. Each two-pizza team (2PT) is as autonomous as possible. The team’s lead, working with the executive team, would decide upon the key business metric that the team is responsible for, known as the fitness function, that becomes the overall evaluation criteria for the team’s experiments. The team is then able to act autonomously to maximize that metric, using the techniques we describe in Chapter 9.
4. Leading a 2PT is a way for employees to gain some leadership experience in an environment where failure does not have catastrophic consequences—which “helped the company attract and retain entrepreneurial talent.”166
An essential element of Amazon’s strategy was the link between the organizational structure of a 2PT and the architectural approach of a service-oriented architecture.
A BRIEF INTRODUCTION TO SERVICE-ORIENTED ARCHITECTURES
A key principle of a service-oriented architecture (SOA) is decomposing systems into components or services. Each component or service provides an interface (also known as an Application Programming Interface, or API) so that other components can communicate with it. Other parts of the system—and the teams that create them—don’t need to know the details of how the components or services they consume are built. Instead, they simply need to know the interface. This also means that there doesn’t need to be a lot of communication between the teams that use a service or component and the team that builds and maintains it. Indeed, if the API is sufficiently well designed and documented, no communication is required.
Any system can be decomposed in multiple ways. Understanding how to decompose a system is an art—and, as the system evolves, the ideal decomposition is likely to change. There are two rules of thumb architects follow when decomposing systems. First, ensure that adding a new feature tends to change only one service or a component at a time. This reduces interface churn.167Second, avoid “chatty” or fine-grained communication between services. Chatty services scale poorly and are harder to impersonate for testing purposes.
All well-designed systems are split into components. What differentiates a service-oriented architecture is that its components can be deployed to production independently of each other. No more “big bang” releases of all the components of the system together: each service has its own independent release schedule. This architectural approach is essential to continuous delivery of large-scale systems. The most important rule that must be followed is this: the team managing a service has to ensure that its consumers don’t break when a new version is released.
To avoid the communication overhead that can kill productivity as we scale software development, Amazon leveraged one of the most important laws of software development—Conway’s Law: “Organizations which design systems…are constrained to produce designs which are copies of the communication structures of these organizations.” One way to apply Conway’s Law is to align API boundaries with team boundaries. In this way we can distribute teams all across the world. So long as we have each service developed and run by a single, co-located, autonomous cross-functional team, rich communication between teams is no longer necessary.
Organizations often try to fight Conway’s Law. A common example is splitting teams by function, e.g., by putting engineers and testers in different locations (or, even worse, by outsourcing testers). Another example is when the front end for a product is developed by one team, the business logic by a second, and the database by a third. Since any new feature requires changes to all three, we require a great deal of communication between these teams, which is severely impacted if they are in separate locations. Splitting teams by function or architectural layer typically leads to a great deal of rework, disagreements over specifications, poor handoffs, and people sitting idle waiting for somebody else.
Amazon’s approach is certainly not the only way to create velocity at scale, but it illustrates the important connection between communication structures, leadership, and systems architecture.
Create Velocity at Scale Through Mission Command
As organizations grow, informal processes and communication channels become increasingly ineffective at achieving the system-level outcomes we desire. Indeed it is easy for people to lose sight of system-level outcomes in the face of rapid growth. As organizations grow, they move into the complex domain. In particular, two characteristics of complex adaptive systems begin to matter. First, there is no privileged perspective from which the system as a whole can be understood—not even the CEO’s office. Second, nobody can hope to understand more than a small part of the whole, depending on the information and context available to them.
Thus if we are not careful in the way we grow our organization, we will end up with a system where people optimize for what is visible to them and for the feedback they get, which is more or less determined by which people they interact with on a day-to-day basis. Thus each department or division optimizes for its own benefit—not because people are stupid or evil but because they simply have insufficient visibility into the effects of their actions on the wider organization. A simplified diagram of a traditionally structured enterprise is shown in Figure 10-1.
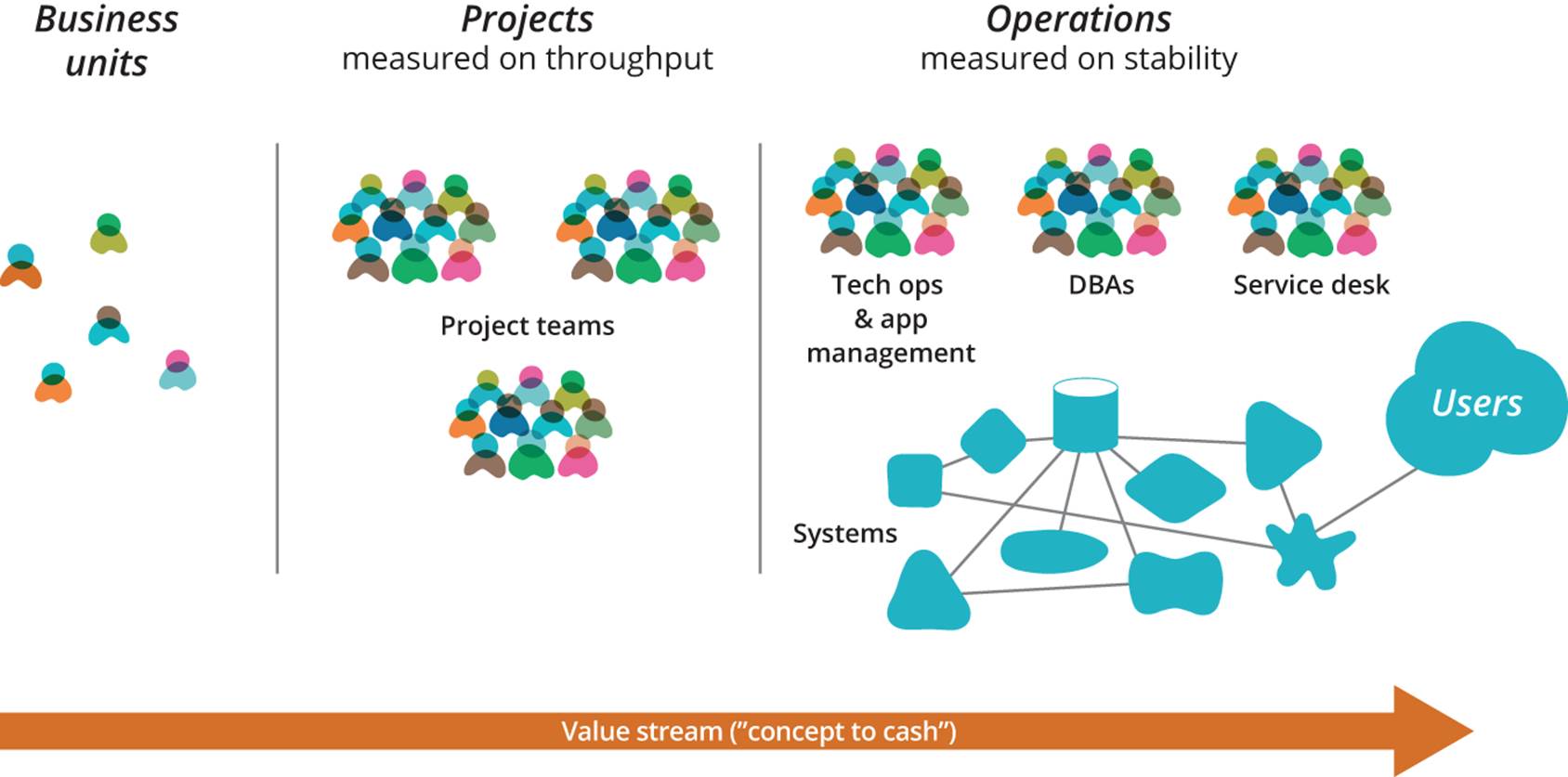
Figure 10-1. An example of a traditional enterprise organization
The key to moving fast at scale is to create many small, decentralized, autonomous teams, based on the model of Mission Command described in Chapter 1. In truly decentralized organizations, we follow the principle of subsidiarity: by default, decisions should be made by the people who are directly affected by those decisions. Higher levels of bureaucracy should only perform tasks that cannot be performed effectively at the local level—that is, the authority of higher levels of bureaucracy should be subsidiary to that of the local levels.168 Several successful large organizations have followed this principle for many years—for example, the Gore Company, Southwest Airlines, and the Swedish bank Handelsbanken, all of which have consistently demonstrated better than average performance in their markets.
Our starting point is to define the basic organizational unit—a team of up to 10 people (following Amazon’s two-pizza rule). Once you get beyond 10 people, group dynamics and coordination become hard to manage, and it becomes difficult to make consensus decisions and achieve a shared understanding of the context for everybody in the team.
In an enterprise context, teams usually collaborate to achieve program-level goals, and larger products and services will require multiple teams, perhaps including dedicated marketing and support people. As Reed Hastings says, our goal is to create teams that are highly aligned but loosely coupled. We ensure teams are aligned by using the Improvement Kata as described in Chapter 6 and Chapter 9—that is, by having iterations at the program level with defined target conditions and having teams collaborate to work out how to achieve them.
Here are some strategies enterprises have successfully applied to create autonomy for individual teams:
Give teams the tools and authority to push changes to production
In companies such as Amazon, Netflix, and Etsy, teams, in many cases, do not need to raise tickets and have changes reviewed by an advisory board to get them deployed to production. In fact, in Etsy this authority is devolved not just to teams but to individual engineers. Engineers are expected to consult with each other before pushing changes, and certain types of high-risk changes (such as database changes or changes to a PCI-DSS cardholder data environment) are managed out of band. But in general, engineers are expected to run automated tests and consult with other people on their team to determine the risk of each change—and are trusted to act appropriately based on this information. ITIL supports this concept in the form of standard changes. All changes that launch dark (and which thus form the basis of A/B tests) should be considered standard changes. In return, it’s essential that teams are responsible for supporting their changes; for more on this, see Chapter 14.
Ensure that teams have the people they need to design, run, and evolve experiments
Each team should have the authority and necessary skills to come up with a hypothesis, design an experiment, put an A/B test into production, and gather the resulting data. Since the teams are small, this usually means they are cross-functional with a mix of people: some generalists with one or two deep specialisms (sometimes known as “T-shaped” people169), along with specialist staff such as a database administrator, a UX expert, and a domain expert. This does not preclude having centralized teams of specialists who can provide support to product teams on demand.
Ensure that teams have the authority to choose the their own toolchain
Mandating a toolchain for a team to use is an example of optimizing for the needs of procurement and finance rather than for the people doing the work. Teams must be free to choose their own tools. One exception to this is the technology stack used to run services in production. Ideally, the team will use a platform or infrastructure service (PaaS or IaaS) provided by internal IT or an external provider, enabling teams to self-service deployments to testing and (where applicable) production environments on demand through an API (not through a ticketing system or email). If no such system exists, or it is unsuitable, the team should be allowed to choose their own stack—but must be prepared to meet any applicable regulatory constraints and bear the costs of supporting the system in production. We cover this thorny topic in more detail in Chapter 14.
Ensure teams do not require funding approval to run experiments
The techniques described in this book make it cheap to run experiments, so funding should not be a barrier to test out new ideas. Teams should not require approval to spend money up to a certain limit (for example, a per-transaction and per-month limit).
Ensure leaders focus on implementing Mission Command
In a growing organization, leaders must continuously work to simplify processes and business complexity, to increase the effectiveness, autonomy, and capabilities of the smallest organizational units, and to grow new leaders within these units.
An example of how this might look is shown in Figure 10-2. In the case of user-installed products, mobile apps, and embedded systems, PaaS/IaaS is used for testing purposes, but the release process happens on demand rather than continuously. Note that this structure does not require a change in who people report to. People can still report up the traditional functional lines (for example, testers to a Director of Testing) even if they work on cross-functional teams on a day-to-day basis. Enterprises often waste a great deal of time on unnecessary, disruptive reorganizations—when they would do better simply by having people who work on the same product or service sit all in the same room (or, for larger products, on the same floor).
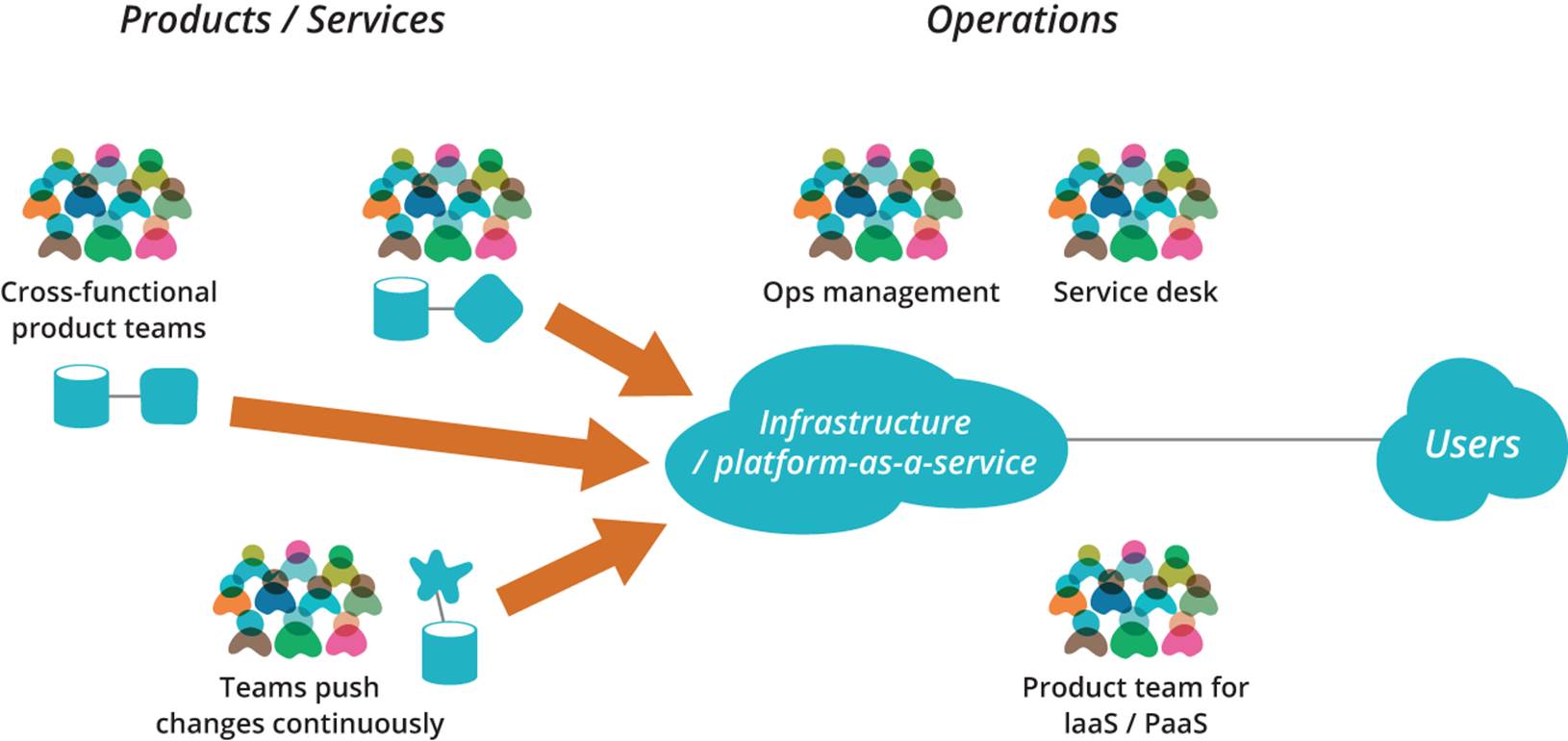
Figure 10-2. Product teams working together, with a service layer for performing deployments
ENSURE REWARDS ARE ALIGNED WITH DESIRED BEHAVIOR
Although it’s not necessary for reporting structures to reflect team organization, poor management can easily destroy collaboration by rewarding people for behavior that optimizes for their function at the expense of customer outcomes or wider organizational goals. Examples of this include rewarding developers for features that are “dev complete” but not production ready, or rewarding testers for the number of bugs they find. In general, rewarding people for output rather than system-level outcomes leads to dysfunction, and in any case monetary rewards or bonuses have been demonstrated to reduce performance in the context of knowledge work. We cover the topic of incentives and culture in more detail in Chapter 1 and Chapter 11.
Creating small, autonomous teams makes it economic for them to work in small batches. When done correctly, this combination has several important benefits:
Faster learning, improved customer service, less time spent on work that does not add value
Autonomy—combined with an enterprise architecture that supports it—reduces dependencies between teams so they can get changes out faster. This is a key component in enabling teams to create prototypes of new products and features to gather customer feedback, run A/B tests, and improve customer service by responding quickly to user requests for improvements and bug fixes. If we can quickly learn what users actually value, we can stop wasting time building things that don’t add value. The most important metric is: how fast can we learn? Change lead time is a useful proxy variable for this metric, and autonomous teams are essential to improving it.
Better understanding of user needs
In organizations where work moves through functional silos, the feedback loop from users to the designers and engineers who create the product is often slow and has low fidelity. When everybody on the team can build small experiments, push them into production, and analyze the metrics, the entire team comes into contact with users on a day-to-day basis.
Highly motivated people
When we can design an experiment or push a bug fix or enhancement to users and see the results almost immediately, it’s an incredibly empowering experience—a proof of your autonomy, mastery, and purpose. Nobody we know who has ever worked in this way wants to go back to the old way of doing things.
Easier to calculate profit and loss
Cross-functional customer-facing teams that own a service over its lifecycle make it much easier to calculate profit and loss (P&L) for the service. The cost of the service is simply the cost of the resources consumed by the team, plus their salaries. This allows us to use simple dollar numbers to identify teams generating the highest margins for the company. Note that this is independent of the idea of internal chargeback, which if implemented dogmatically often requires high levels of business complexity to determine costs with unnecessary precision.
It’s one thing to adopt the principles of Mission Command in a growing startup—but another thing entirely in an enterprise with a more traditional, centralized approach to management and decision making. Mission Command drastically changes the way we think about management—in particular, management of risk, cost, and other system-level outcomes. Many organizations adopt a one-size-fits-all approach to risk and cost management, with centralized processes for software release management (by the IT department) and budgeting (by the finance department). In Mission Command, teams have the authority and responsibility to manage cost and risk appropriately in their particular context. The role of finance, the project management office, enterprise architects, GRC teams, and other centralized groups changes: they specify target outcomes, help to make the current state transparent, and provide support and tools where requested, but do not dictate how cost, processes, and risk are managed. We discuss lean approaches to governance and finance in Part IV.
Evolving Your Architecture Using the Strangler Application Pattern
Autonomous teams will make little difference to customer outcomes if the enterprise architecture prevents teams from running experiments and responding quickly to customer needs. To enable both continuous delivery and decentralization, teams must be able to get changes out quickly and safely. Unfortunately, the reality is that in many enterprises there are thousands of tightly coupled systems, and it is very hard to make changes to any of them without navigating a web of dependencies. Too often, one of the dependencies is a system of record maintained by a team which releases updates every few months at the cost of significant heroics.
Architecting for Continuous Delivery and Service Orientation
Architecting for continuous delivery and service orientation means evolving systems that are testable and deployable. Testable systems are those for which we can quickly gain a high level of confidence in the correctness of the system without relying on extensive manual testing in expensive integrated environments. Deployable systems are those that are designed to be quickly, safely, and independently deployed to testing and (in the case of web-based systems) production environments. These “cross-functional” requirements are just as important as performance, security, scalability, and reliability, but they are often ignored or given second-class status.
A common response to getting stuck in a big ball of mud is to fund a large systems replacement project. Such projects typically take months or years before they deliver any value to users, and the switchover from the old to the new system is often performed in “big bang” fashion. These projects also run an unusually high risk of running late and over budget and being cancelled. Systems rearchitecture should not be done as a large program of work funded from the capital budget. It should be a continuous activity that happens as part of the product development process.
Amazon did not replace their monolithic Obidos architecture in a “big bang” replacement program. Instead, they moved to a service-oriented architecture incrementally, while continuing to deliver new functionality, using a pattern known as the “strangler application.” As described by Martin Fowler, the pattern involves gradual replacement of a system by implementing new features in a new application that is loosely coupled to the existing system, porting existing functionality from the original application only where necessary.170 Over time, the old application is “strangled”—just like a tree enveloped by a tropical strangler fig (Figure 10-3).
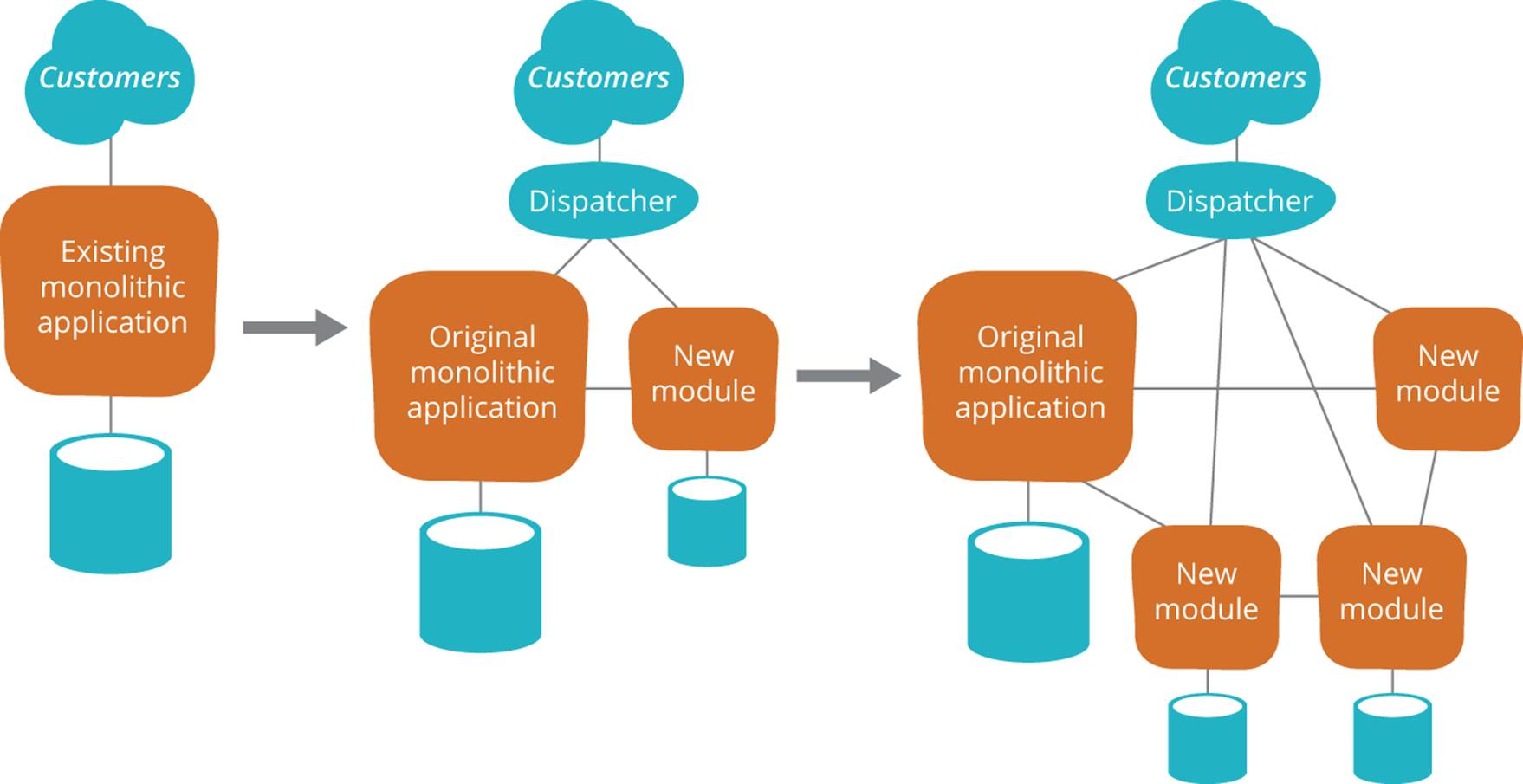
Figure 10-3. The evolution of stranglers
Strangling applications should use the methods described earlier in this book. There are some important rules to follow when implementing the strangler pattern:
Start by delivering new functionality—at least at first
Always find ways to satisfy a need that is not served by the existing software, and prioritize features using the cost of delay divided by duration (CD3), as described in Chapter 7, to ensure you deliver the largest amount of value in the shortest possible time.
Do not attempt to port existing functionality unless it is to support a business process change
The biggest mistake people make is porting existing features over as-is. This generally means reproducing complexity created to serve business processes as they looked years ago, which is enormously wasteful. Whenever you are asked to add a feature which represents a change to a business process, go and observe the process from scratch and look for ways to simplify it before implementing the code to support it. You will find that much accidental complexity in business processes actually comes from being forced to use the old software you are replacing!
Deliver something fast
Make the initial release of your new application small enough that you can get it deployed and providing value in a few weeks to a few months. When building the first module, it’s hard—but essential—to resist feature creep. The measure of success for the first release is how quickly you can do it, not how much functionality is in it. Typically, this is achieved by using the “vertical slice” approach in which we build small increments of functionality end-to-end across the whole technology stack.
Design for testability and deployability
Functionality in the new application must always be built using good software development practices: test-driven development, continuous integration, a well-encapsulated, loosely coupled modular design. Strangler applications are an opportunity to test out such practices, so make sure the team working on it is enthusiastic about these methods and has enough experience to have a good chance at succeeding.
Architect the new software to run on a PaaS
Work with operations to drive the design of the software hand in hand with the platform as a service, as we describe in Chapter 14. If the operations team is not ready to do this, work with them to ensure that the system doesn’t drive up the complexity of the existing operationalenvironment.
There is of course a trade-off to migrating in an incremental way. Overall, it takes longer to do a replacement incrementally compared to a hypothetical “big bang” rearchitecture delivering the same functionality. However, since a strangler application delivers customer value from early on, evolves in response to changing customer needs, and can advance at its own rate, it is almost always to be preferred.
Enterprise architecture is usually driven by expensive, top-down plans to “rationalize” the architecture, move from legacy systems to a modern platform, and remove duplication to create a single source of truth. Often, the end state is represented by a good-looking diagram that fits on a single (large) sheet of paper. However, the end state is rarely achieved because the ecosystem which the architecture serves always changes too fast, and it is even rarer for the promised benefits to materialize. Typically, what happens is that new structures are added, but the systems that were supposed to be replaced never actually get turned off, leading to ever-increasing complexity which makes it even harder to change things in future.
Create Architectural Alignment Through Specifying Target Conditions, Not Standardization and Architectural Epics
Our experience is that standardization on a particular toolchain or technology stack is neither necessary nor sufficient for achieving enterprise architecture goals such as enabling teams to respond rapidly to changing requirements, creating high-performance systems at scale, or reducing the risk of intrusion or data theft. Just like we drive product and process innovation through the Improvement Kata, we can drive architectural alignment through it too. Architectural goals—for example, desired performance, availability, and security—should be approached by iteratively specifying target conditions at the program level. Following the Principle of Mission, set out a clear vision of the goals of your enterprise architecture without specifying how the goals are to be achieved, and create a context in which teams can determine how to achieve them through experimentation and collaboration. We cover alternatives to standardization and related issues in more detail in Chapter 14.
We do much better by accepting that we will always be in a state of change, and working slowly and incrementally to reduce complexity through the strangler application pattern. Find a way to measure the surface area of the systems that you aim to retire, and make it visible so that teams can work to reduce it—and ultimately eliminate such systems—as they continue to deliver value to customers. Accept that evolving enterprise architecture—and reducing unnecessary complexity—is a continuing, unending process.
Conclusion
Moving quickly at scale requires implementing the Mission Command. One commonly used approach is to create small teams that are highly aligned but loosely coupled. However, given the strong coupling between systems architecture and communication flows observed by Melvin Conway and codified in his eponymous law, we also need to evolve a systems architecture that supports this kind of decentralized organization.
Moving from a more traditional centralized model to the kind of structure described in this chapter is hard. We must proceed slowly and incrementally. It requires changes to the existing centralized processes—in particular, budgeting, procurement, risk management, governance, and release management. These are discussed in the last part of this book, Part IV.
Even though change is hard and takes time, we should not be dissuaded. The key is to find ways to make small, incremental changes that deliver improved customer outcomes—and then keep going. Just as we apply the strangler pattern to enterprise architecture, we can also apply it to our organizational culture and processes—this is the topic of the final chapter of this book, Chapter 15.
Questions for readers:
§ Can your teams run experiments and achieve customer outcomes independently, or are they dependent on other teams in order to get anything done?
§ Can you deploy pieces of your system independently of each other, or must you release everything at once?
§ What is the smallest possible amount of work you could do to enable either experimentation or independent deployment for a single team or component/service?
§ How are people on your teams rewarded? Does this encourage or discourage them from collaborating with other people on your team or with other teams?
162 http://slidesha.re/1v71niI
163 http://zd.net/1v71quY
164 Steve Yegge’s legendary “platform rant” is required reading for technical leaders: https://plus.google.com/+RipRowan/posts/eVeouesvaVX.
165 Werner Vogel’s article on Amazon’s move to an SOA is also required reading: http://queue.acm.org/detail.cfm?id=1142065.
166 http://blog.jasoncrawford.org/two-pizza-teams
167 See [parnas] for the original work on this subject.
168 If we take this idea to its logical conclusion, we end up with what is known as holacracy (see http://holacracy.org/constitution). The Brazilian company Semco is an example of an enterprise that follows a radically decentralized model, see [semler].
169 David Guest, “The hunt is on for the Renaissance Man of computing,” The Independent (London), September 17, 1991.
170 http://bit.ly/1v71DOH, following Chris Stevenson and Andy Pols’ paper, http://bit.ly/1v71GtR.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.