Product Details Lean Enterprise: How High Performance Organizations Innovate at Scale (2015)
Part IV. Transform
Chapter 14. Turn IT into a Competitive Advantage
The cost-center pattern fills the vacuum of our inability to define, model, and measure the value most workers create for their organization.
Ken H. Judy
Enterprise IT departments face powerful and conflicting forces. Their first priority is to keep the existing business-critical systems running, even as they age and grow in complexity. There is also an increasing pressure to up the speed at which new products and features can be delivered. Finally, IT has traditionally been seen as a cost center, so there is constant pressure to increase efficiency (which normally plays out as cost-cutting).
These apparently conflicting goals often lead to a downward spiral. Reducing complexity and replacing legacy systems requires investment. However, investment often comes in the form of large, multiyear projects that often get abandoned or deployed uncompleted due to spiraling costs and/or personnel changes at the executive level. This increasing complexity, along with the need for further efficiency gains, reduces the capacity of IT to manage planned work effectively. The increasing demand for changes, when combined with a brittle IT environment, leads to proliferation of unplanned work that further reduces IT capacity.
In this chapter, we discuss some strategies to increase the responsiveness of IT to changing business needs, improve the stability of IT services, and reduce the complexity of our IT systems and infrastructure. Many of these strategies come from the DevOps movement whose goal is to enable us to work safely at scale in a high-tempo and high-consequence environment.
Rethinking the IT Mindset
IT has historically been seen as a cost center and an internal enabler of the business, not a creator of competitive advantage. For years the orthodoxy has been that, as Nicholas Carr infamously said, “IT doesn’t matter.”233 Even amongst lean practitioners, IT is sometimes seen as “just a department.” This has created what Marty Cagan, author of Inspired: How to Create Products Customers Love,234 calls an “IT mindset” in which IT is simply a service provider to “the business” (Figure 14-1).
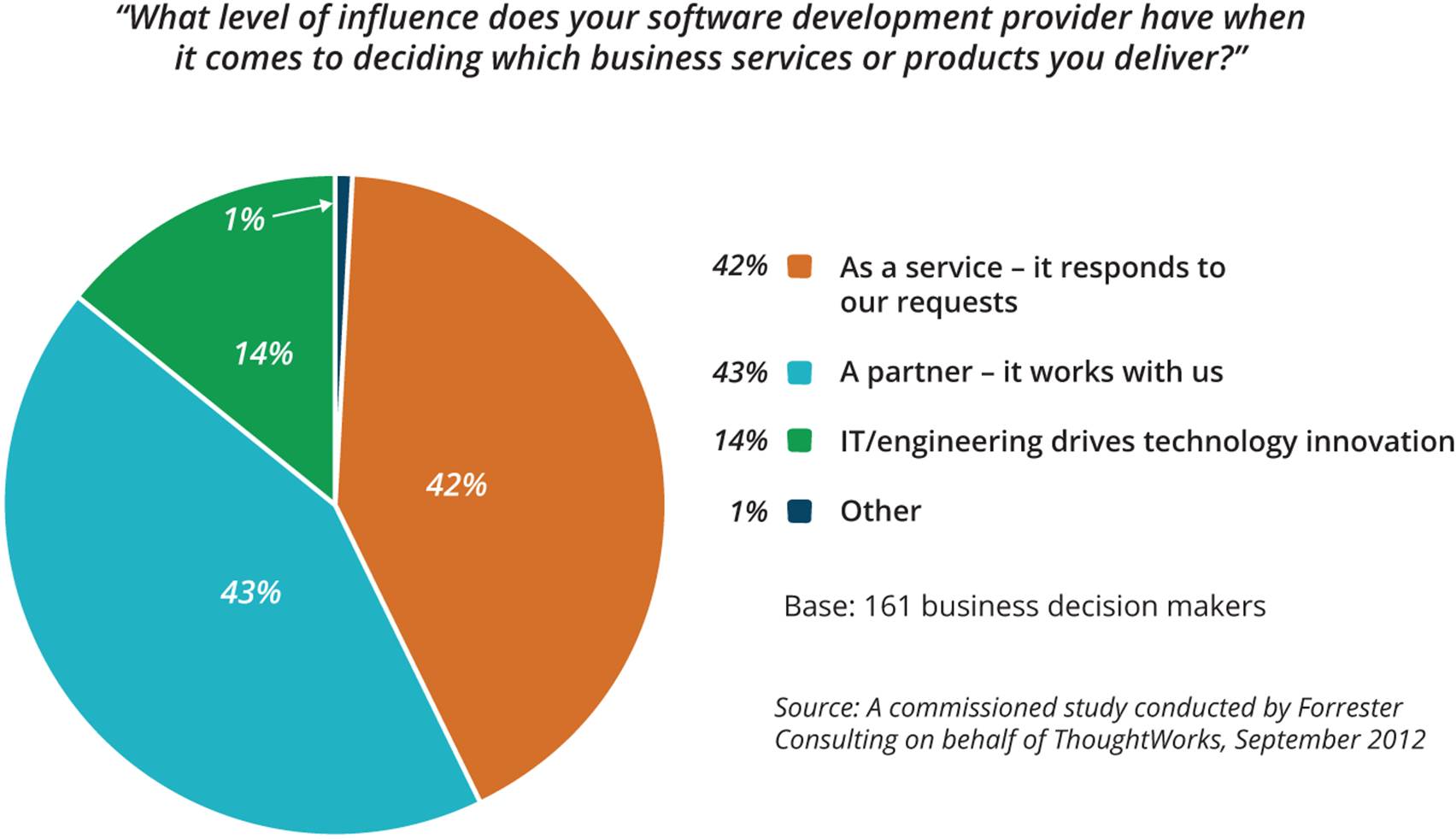
Figure 14-1. What business leaders think about the business-IT relationship
This problem is exacerbated by the typical project model through which IT projects are funded and managed. The work created in IT projects is typically handed over (or thrown over) to IT operations to run, so the people managing the projects have little incentive to think about the long-term consequences of their design decisions—and large incentives to ship as much functionality as possible in what is typically an extremely tight timeframe. This leads to software that is hard to operate, change, deploy, maintain, and monitor, and which adds complexity to operational environments which, in turn, makes further projects harder to deliver.235 As Charles Betz, author of Architecture and Patterns for IT Service Management, Resource Planning, and Governance: Making Shoes for the Cobbler’s Children, says:236
Because it is the best-understood area of IT activity, the project phase is often optimized at the expense of the other process areas, and therefore at the expense of the entire value chain. The challenge of IT project management is that broader value-chain objectives are often deemed “not in scope” for a particular project, and projects are not held accountable for their contributions to overall system entropy.
IT operations—a department within the IT department and perhaps the ultimate cost center—experiences the consequences of these decisions on a daily basis. In particular, the integrated systems they must keep running are incredibly complex and crufty, built up over years, and often fragile, so they tend to avoid changing them. Since stability is their first priority, IT operations has developed a reputation as the department that says “no”—an entirely rational response to the problems they face.
IT operations departments have two primary mechanisms they use to stem the tide: the change management process and standardization. The change management process is used to mitigate the risk of changes to production environments and meet regulatory requirements, and it usually requires every change to production to be reviewed by a team (known as the Change Advisory Board in ITIL terminology) before it can be deployed. Standardization is used to manage the heterogeneity of production environments, reduce cost, and prevent security breaches; it also requires that all software used in production (and often in development environments as well) is approved for usage.
The result of these processes is that the rate of change slows down enormously in production environments and teams cannot use the tools they choose. Under certain circumstances, this might be an acceptable trade-off if these limitations could actually improve the stability of production environments. However, the data shows that they do not. In fact, many of the assumptions that underlie IT departments’ operations and their relationships to other parts of the organization are no longer valid.
In the 2014 State of DevOps Report, over 9,000 people worldwide were polled about what creates high-performance organizations, whether IT does in fact matter to the business, and what factors impact the performance of IT departments.237 The first major result from the survey was a statistically valid way to measure IT performance. High-performing IT organizations are able to achieve both high throughput, measured in terms of change lead time and deployment frequency, and high stability, measured as the time to restore service after an outage or an event that caused degraded quality of service. High-performing IT organizations also have 50% lower change fail rates than medium- and low-performing IT organizations.
The data shows that organizations with high-performing IT are able to achieve higher levels of both throughput and stability. Furthermore, firms with high-performing IT organizations are also twice as likely to exceed their profitability, market share, and productivity goals as those with low IT performance.
The practices most highly correlated with high IT performance (increasing both throughput and stability) are:
§ Keeping systems configuration, application configuration, and application code in version control
§ Logging and monitoring systems that produce failure alerts
§ Developers breaking up large features into small, incremental changes that are merged into trunk daily (as discussed in Chapter 8)
§ Developers and operations regularly achieving win/win outcomes when they interact
There are two other factors that strongly predict high performance in IT. The first is a high-trust organizational culture as described in Chapter 1. The second is a lightweight peer-reviewed change approval process. Many organizations have an independent team to approve changes that go to production. However, the data shows that while such external processes significantly decrease throughput, they have negligible positive impact on stability. Peer-reviewed change approval mechanisms (such as pair programming or code review by other developers) are as effective at creating stable systems as change advisory boards—but have a drastically better throughput.
While this data supports the existing practices of high-performing companies such as Amazon and Google, it directly contradicts the received wisdom that segregation of duties is an effective way to manage risk. However, Westrum’s work on safety culture shows that no process or control can compensate for an environment in which people do not care about customer and organizational outcomes. Instead of creating controls to compensate for pathological cultures, the solution is to create a culture in which people take responsibility for the consequences of their actions—in particular, customer outcomes.
There is a simple but far-reaching prescription to enable this 'margin-top:0cm;margin-right:0cm;margin-bottom:0cm; margin-left:20.0pt;margin-bottom:.0001pt;text-indent:-18.0pt;line-height:15.0pt; vertical-align:baseline'>1. You build it, you run it. Teams that build new products and services must take responsibility for the operation and support of those services, at least until they are stable and the operation and support burden becomes predictable. By doing this, we also ensure that it is easy to measure the cost of running the service and the value it delivers.
2. Turn central IT into a product development organization. The product development lifecycle and strategies described in this book should be used to deliver internal products and services as well as customer-facing ones.
3. Invest in reducing the complexity of existing systems. Use the capacity gained from step 1 to invest in ongoing improvement work with the goal of reducing the cost and risk of making changes to existing services.
Freedom and Responsibility
In order to reduce the burden on IT operations, it’s essential that we shift supporting new products, services, and features to the teams that build them. To do this, we need to give them both the autonomy to release and operate new products and features and the responsibility for supporting them.
In Google, teams working on a new product must pass a “production readiness review” before they can send any services live. The product team is then responsible for its service when it initially goes live (similarly to ITIL’s concept of early life support). After a few months, when the service has stabilized, the product team can ask operations—called Google’s Site Reliability Engineers, or SREs—to take over the day-to-day running of the service, but not before it passes a “handover readiness review” to ensure the system is ready for handover. If the service encounters a serious problem after the handover, responsibility for supporting it is transferred back to the product team until they can pass another handover readiness review.238
As discussed in Chapter 12, this model requires that product teams work with other parts of the organization responsible for compliance, information security, and IT operations throughout the development process. In particular, centralized IT departments are responsible for:
§ Providing clear and up-to-date documentation on which processes and approvals are necessary for new services to go live and on how teams can access them
§ Monitoring lead time and other SLAs for these services, such as approving software packages, provisioning infrastructure (such as testing environments), and working to constantly reduce them
For live services under active development, developers share equal responsibility with operations for:239
§ Responding to outages and being on call
§ Designing and evolving monitoring and alerting systems, and the metrics they rely on
§ Application configuration
§ Architecture design and review
Engineers building new features should be able to push code changes live themselves, following peer review, except in the case of high-risk changes. However, they must be available when their changes go live so they can support them. Many new code changes (particularly high-risk ones) should be launched “dark” (as described in Chapter 8) and either switched off in production or made part of an A/B test.
Some people describe this model as “no-ops,”240 since (if successful) we drastically reduce the amount of reactive support work that operations staff must perform. Indeed teams running all their services in the public cloud can take this model to its logical conclusion where product teams have complete control over—and responsibility for—building, deploying, and running services over their entire lifecycle (a model pioneered at scale by Netflix). This has lead to a great deal of resistance from operations folks who are concerned about losing their jobs. The “no-ops” label is clearly provocative, and we find it problematic; in the model we describe, demand for operations skills is in fact increased, because delivery teams must take responsibility for operating their own services. Many IT staff will move into the teams that build, evolve, operate, and support the organization’s products and services. It is true that traditional operations people will have to go through a period of intense learning and cultural change to succeed in this model—but that is true for all roles within adaptive organizations.
It must be recognized and accepted that this will be scary for many people. Support and training must be provided to help those who wish to make the transition. It must be made clear that the model we describe is not intended to make people redundant—but everyone needs to be willing to learn and change (see Chapter 11). Generous severance packages should be offered to those who are not interested in learning new skills and taking on new roles within the organization.
Removing the burden of creating and supporting new products and services frees up central IT organizations so they can focus on operating and evolving existing services and building tools and platforms to support product teams.
Creating and Evolving Platforms
The most important role of central IT is supporting the rest of the organization, including management of assets such as computers and software licenses, and the provision of services such as telephony, user management, and infrastructure. This is as true for high-performing organizations as it is for the low performers. The difference lies in how these services are managed and provided.
Traditionally, companies have relied on packages supplied by external vendors (such as Oracle, IBM, and Microsoft) to provide infrastructure components such as databases, storage, and computing power. Nobody could have missed the move to the utility computing paradigm known as“cloud.” However, while few companies can avoid the move, many are failing to execute it correctly.
To succeed, IT organizations must take one of the two paths: either outsource to external suppliers of infrastructure or platform as a service (IaaS or PaaS), or build and evolve their own.
While moving to external cloud suppliers carries different risks compared to managing infrastructure in-house, many of the reasons commonly provided for creating a “private cloud” do not stand up to scrutiny. Leaders should treat objections citing cost and data security with skepticism: is it reasonable to suppose your company’s information security team will do a better job than Amazon, Microsoft, or Google, or that your organization will be able to procure cheaper hardware?
Given that break-ins into corporate networks are now routine (and sometimes state-sponsored), the idea that data is somehow safer behind the corporate firewall is absurd. The only way to effectively secure data is strong encryption combined with rigorous hygiene around key management and access controls. This can be done as effectively in the cloud as within a corporate network. Many organizations have been outsourcing IT operations for years; even the CIA has outsourced the building and running of some of its data centers to Amazon.241 Many countries are now updating their regulations to explicitly allow for data to be stored in infrastructure that is externally managed.
There are two good reasons to be cautious about public clouds. The first risk is vendor lock-in, which can be mitigated through careful architectural choices. The second is the issue of data sovereignty. Any company storing its data in the cloud “is subject both to the laws of the nation hosting the server and to their own local laws regarding how that data should be protected, leading to a potential conflict of laws over data sovereignty. The implications of these overlapping legal obligations depend on the specific laws of the nation and the relationship and agreements between governments.”242
Nevertheless, there are compelling reasons to move to public cloud vendors, such as lower costs and faster development. In particular, public clouds enable engineering teams to self-service their own infrastructure instantly on demand. This significantly reduces the time and cost of developing new services and evolving existing ones. Meanwhile, many companies that claim to have implemented “private clouds” still require engineers to raise tickets to request test and production environments, and take days or weeks to provision them.
Any cloud implementation project not resulting in engineers being able to self-service environments or deployments instantly on demand using an API must be considered a failure. The only criterion for the success of a private cloud implementation should be a substantial increase in overall IT performance using the throughput and stability metrics presented above: change lead time, deployment frequency, time to restore service, and change fail rate. This, in turn, results in higher quality and lower costs, as well as freeing up capital to invest in new product development and improving of the existing services and infrastructure.
The alternative to using an external vendor is developing your own service delivery platform in-house. A service delivery platform (SDP) lets you automate all routine activity associated with building, testing, and deploying services, including the provisioning and ongoing management of infrastructure services. It is also the foundation on which deployment pipelines for building, testing, and deploying individual services run. The Practice of Cloud System Administration: Designing and Operating Large Distributed Systems is an excellent guide to designing and running a service delivery platform.243
However, companies who have succeeded at creating their own SDP (per the criteria above) have not typically done so through the traditional IT route of buying, integrating, and operating commercial packages.244 Instead, they have used the product development paradigm described in this book to create and evolve an SDP, preferring to use open source components as a foundation. This approach requires a substantial retooling and realignment of IT to focus on exploring new platforms by testing them with a subset of internal customers (as we discuss in Part II) with the goal of delivering early value and providing performance superior to that of the external vendors. Validated products should be evolved using the principles described in Part III, using cross-functional product teams measuring their success by the IT performance metrics above.
Preparing for Disasters
Organizations that do choose to manage their own SDP must take business continuity extremely seriously. Amazon, Google, and Facebook inject faults into their production systems on a regular basis to test their disaster recovery processes. In these exercises, called Game Days at Amazon and Disaster Recovery Testing (DiRT) at Google, a dedicated team is put together to plan and execute a disaster scenario.
Typically, this includes physically powering down data centers and disconnecting the fiber connections to offices or data centers. This has real consequences but is reversible in the event of an uncontrollable failure. People running affected services are expected to meet their service-level agreements (SLAs), and the disruptions are carefully planned to not exceed the limits of what is necessary to run the service. Crucially, a blameless postmortem is held after every exercise (see Chapter 11), and the proposed improvements are tested some time later.
Kripa Krishnan, Google’s program manager for DiRT exercises, comments that “for DiRT-style events to be successful, an organization first needs to accept system and process failures as a means of learning. Things will go wrong. When they do, the focus needs to be on fixing the error instead of reprimanding an individual or team for a failure of complex systems…we design tests that require engineers from several groups who might not normally work together to interact with each other. That way, should a real large-scale disaster ever strike, these people will already have strong working relationships established.”245
Netflix takes this idea to its logical extreme by running a set of services known as the Simian Army, led by Chaos Monkey, a service that shuts down production servers at regular intervals to test the resilience of the production environment. Like many Netflix systems, the software behind the Simian Army is open source and available on Github. Organizations that do not have the intestinal fortitude to perform real failure injection exercises on at least an annual basis should not be in the business of developing their own infrastructure services—at least, not for mission-critical systems.
Finally, organizations that develop their own infrastructure services must give their internal customers the choice of whether or not to use them. Enterprises rely on standardization of the services and assets provided by IT operations to manage support costs, for example by maintaining a list of approved tools and infrastructure components from which teams may choose. However, trends such as employees bringing their own devices to work (BYOD) and product development teams using nonstandard open source components such as NoSQL databases, present a challenge to this model. We have seen cases in which open source components were necessary to achieve the levels of performance, maintainability, and security required by their customers, but were resisted by IT operations departments—resulting in a great deal of wasted time and money trying to force the products to run on existing packages.
The correct way to address this problem is to allow product teams to use the tools and components they want, but to require them to take on the risks and costs of managing and operating the products and services they build—to repeat Amazon CTO Werner Vogels’ dictum, “You build it, you run it.” Recall the Lean definition of optimal performance from Chapter 7: “Delivering customer value in a way in which the organization incurs no unnecessary expense; the work flows without delays; the organization is 100 percent compliant with all local, state and federal laws; the organization meets all customer-defined requirements; and employees are safe and treated with respect. In other words, the work should be designed to eliminate delays, improve quality, and reduce unnecessary cost, effort, and frustration.”246 Processes inhibiting optimal performance should be a target for improvement.
Managing Existing Systems
A service delivery platform, whether created in-house or provided by a vendor, must ensure standardization and reduced cost to run new systems. However, it will not help reduce the complexity of existing ones. The large number of existing systems is one of the biggest factors limiting the ability of enterprise IT departments to move fast.
In operations departments that must maintain hundreds or thousands of existing services, delivering even an apparently simple new feature can involve touching multiple systems, and any kind of change to production is fraught with risk. Obtaining integrated test environments for such changes is expensive—even a part of the production environment cannot be reproduced without a lot of work (and it’s usually hard to tell how much we need to reproduce, and at what level of detail, for testing purposes). Combine this with functional silos, outsourcing, and distributed teams juggling multiple priorities, and we swiftly find that our feet are encased in concrete.
In this section we present three strategies for mitigating this problem. The short-term strategy is to create transparency of priorities and improve communication between the teams working on these systems. The medium-term solution is to build abstraction layers over systems that are hard to change, and create test doubles for systems that have to integrate with them. The long-term solution is to incrementally rearchitect systems with the ability to move fast at scale as an architectural goal.
The short-term solution—creating transparency of priorities and improving communication—is important and can be extremely effective. IT has to serve multiple stakeholders with often conflicting priorities. Who wins often depends on who is shouting loudest or has the best political connections, not on an economic model such as Cost of Delay (discussed in Chapter 7). It’s important to have a shared understanding at all levels of the organization on what the current priorities are. This can be as simple as a weekly or monthly meeting of the key stakeholders, including all customers of IT, to issue a one-page prioritized list. Regular communication between those responsible for systems that are coupled is also essential.
COUPLING REQUIRES FREQUENT COMMUNICATION
A major travel company wanted to continuously deliver new features to their website. However, the website needed to talk to a legacy booking system. Often new features were delayed due to dependencies on changes to the booking system, which was updated every six months. This was costing the company large amounts of money in lost opportunity costs.
One simple way they eased the problem was by improving communication between the teams. The product manager for the website would regularly meet up with the program manager for the booking system, and they would compare notes on upcoming releases, noting dependencies. They’d find ways to shift their schedules around to help each other deliver features on time, or to push back features that couldn’t be delivered.
The medium-term solution is to find ways to simulate the infrequently changing systems we must integrate with. One technique is to use virtualized versions of these systems. Another is to create a test double that simulates the remote system for testing purposes (Figure 14-2).247 The important thing to bear in mind is that we’re not aiming to faithfully reproduce the real production environment. We’re attempting to discover and fix most of the big integration problems early on, before we go to a full staging environment.
By faking out remote systems or running them in a virtual environment, we can integrate and run system-level tests to validate our changes on a regular basis (say, once per day). This reduces the amount of work we have to do in a properly integrated environment.
The long-term solution is to architect our systems in such a way that we can move fast. In particular, this means being able to independently deploy parts of our system at will, without having to go through complex orchestrated deployments. However, this requires careful rearchitecture using the strangler application pattern described in Chapter 10.
Figure 14-2. Simulating remote systems for test purposes
When starting on this process, an important first step is to map your services and the connections between them. Based on the lifecycle of innovations (see Chapter 2) and the value each service provides to our organization, we can draw value and lifecycle on two axes, and then create a value chain map to visualize each product and its dependencies (Figure 14-3). To create a value chain map, take a product and put it in the appropriate position at the top of a new diagram. Then map the services it depends on and the connections between them. This exercise can be performed quickly and cheaply on a whiteboard using sticky notes.248
Figure 14-3. Value chain map, courtesy of Simon Wardley
The next step is to create a “to-be” version of this diagram, following these principles:
§ Use software-as-a-service providers for all “utility” services, such as payroll, vendor management, email, version control, and so forth. If there are systems we can’t move to the cloud, we should use commercial off-the-shelf software packages (COTS).
§ For strategic services and applications that provide a competitive advantage, we should be doing custom software development as described in the rest of the book. Avoid at all costs the temptation to use packages for these capabilities.
§ Systems of record will typically be the hardest to change, and will be a combination of COTS and older systems including mainframes. These often require consolidation and some amount of abstraction so as to reduce the cost of maintaining and integrating with them. Over time, they can be strangled if necessary.
When using COTS, it is crucial not to customize the packages. We can’t emphasize strongly enough the problems and risks associated with customizing COTS. When organizations begin customizing, it’s hard to stop—but customizations of COTS packages are extremely expensive to build and maintain over time. Once you get beyond a certain amount of customization, the original vendor will often no longer support the package. Upgrading customized packages is incredibly painful, and it’s hard to make changes quickly and safely to a customized COTS system.
Instead, make changes to your business processes to match what the COTS packages can do out of the box. Any time you choose a solution based on COTS, you’ll have a list of features to implement or bugs to fix. These should always be treated as the input to a business process change management activity. Business process changes are much cheaper and more effective than changing COTS packages to match an existing process. If you have gone down the road of customization, take the next major release of your COTS package as an opportunity to migrate to a new, uncustomized version of the package, as Telstra (Australia’s biggest telco) did when it moved from a heavily customized install of Remedy to a completely vanilla one.249
Moving from your current state to your to-be state will likely take years. As with all large-scale changes, the correct way to proceed is incrementally, breaking down large programs of work into small steps that provide the biggest bang for the buck in terms of improving customer and business outcomes.
THE SUNCORP SIMPLIFICATION PROGRAM
by Scott Buckley and John Kordyback
Australia’s Suncorp Group has ambitious plans to decommission their legacy general insurance policy systems, improve their core banking platform, and start an operational excellence program. “By decommissioning duplicate or dated systems, Suncorp aims to reduce operating costs and reinvest those savings in new digital channels,” says Matt Pancino, now CEO of Suncorp Business Systems.
Lean practices and continuous improvement are necessary strategies to deliver the simplification program. Suncorp is investing successfully in automated testing frameworks to support developing, configuring, maintaining, and upgrading systems quickly. These techniques are familiar to people using new technology platforms, especially in the digital space, but Suncorp is successfully applying agile and lean approaches to the “big iron” world of mainframe systems.
Delivery Practices
In their insurance business, Suncorp is combining large and complex insurance policy mainframe systems into a system to support common business processes across the organization and drive more insurance sales through direct channels. Some of the key pieces were in place from the “building blocks” program which provided a functional testing framework for the core mainframe policy system, agile delivery practices, and a common approach to system integration based on web services.
During the first year of the simplification program, testing was extended to support integration of the mainframe policy system with the new digital channels and the pricing systems. Automated acceptance criteria were developed while different systems were in development. This greatly reduced the testing time for integrating the newer pricing and risk assessment system with multiple policy types. Automated testing also supported management and verification of customer policies through different channels, such as online or call center.
Nightly regression testing of core functionality kept pace with development and supported both functional testing and system-to-system integration. As defects were found in end-to-end business scenarios, responsive resolutions were managed in hours or days, not weeks typical for larger enterprise systems.
Outcomes
In the process, Suncorp has reduced 15 complex personal and life insurance systems to 2 and decommissioned 12 legacy systems. Technical upgrades are done once and rolled out across all brands. They have a single code base for customer-facing websites for all their different brands and products. This enables faster response to customer needs and makes redundant separate teams each responsible for one website.
From a business point of view, the simpler system has allowed 580 business processes to be redesigned and streamlined. Teams can now provide new or improved services according to demand, instead of improving each brand in isolation. It has reduced the time to roll out new products and services, such as health cover for APIA customers or roadside assistance for AAMI customers.
The investment in simplification and management of Suncorp’s core systems means they can increase their investment in all their touch points with customers. In both technology and business practices, Suncorp increased their pace of simplification, with most brands now using common infrastructure, services, and processes.
Suncorp’s 2014 annual report notes that “simplification has enabled the Group to operate a more variable cost base, with the ability to scale resources and services according to market and business demand. Simplification activity is anticipated to achieve savings of $225 million in 2015 and $265 million in 2016.”250
Conclusion
If we want to compete in a world of ever shorter product cycles, central IT needs to be business units’ trusted partner, not an order-taking cost center. In turn, IT needs to achieve higher levels of throughput while improving stability and quality and reducing costs. The complexity of existing enterprise IT environments, combined with the amount of planned and unplanned work that must be done to keep them running, are the chief barriers to achieving these outcomes.
We can only begin to address these problems when we consider the effects of new work on IT operations and treat it as an integral part of the product development lifecycle. To manage the additional complexity introduced by new products, services, and features, we must start by moving from a project-based model to a product-centric model, as described in Chapter 10. Product teams must own the costs and service-level agreements of the systems they build; in return for this responsibility, they have the freedom to choose the technologies to use, and to manage their own changes. In this way, we free up people and resources within central IT to focus on reducing the complexity of their systems and infrastructure and building a toolchain and platform that enables the product development lifecycle we describe in this book.
We often treat throughput and stability as opposing forces—increase throughput and you will reduce quality and stability. However, these goals can be complementary if the correct strategy is in place. As with any improvement effort, we must start by clearly articulating our goal and identifying the key performance indicators we care about. Then, we use the Improvement Kata to work towards our goal.
Questions for readers:
§ Does IT consider itself to be a service provider, a partner to business units, or a driver of innovation? What do other leaders in the organization think?
§ Are you measuring change lead time, release frequency, time to restore service, and change fail rate across all your products and services? Are you making them visible to all teams?
§ How many services did you retire in the last year? And how many did you add? How long would it take you to find out how many products and services you are managing? How certain would you be of the answer? How many of them are running on systems that are no longer officially supported by the vendor?
§ How long does it take to approve a change request? How long does it take to get a new open source component approved for use in a production environment?
§ How often do you perform a realistic disaster recovery exercise on your production systems? What is your process for following up on recommendations for improvement that come out of these exercises?
§ Do all developers, development leads, and architects rotate through pager duty and support on a regular basis for the systems they build?
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.