For Immediate Release: Shape Minds, Build Brands, and Deliver Results with Game-Changing Public Relations (2015)
Chapter 23
• Tuesday, October 7
As I drive into work the following Tuesday morning, I get an urgent phone call from Kirsten. Apparently, Brent is now almost a week late delivering on another Phoenix task—allegedly something that Brent said would only take an hour to do. Once again, the entire Phoenix testing schedule is in jeopardy.
On top of that, several other of my group’s critical tasks are late, putting even more pressure on the deadline. This is genuinely dispiriting to hear. I thought all our recent breakthroughs would solve these due-date performance issues.
How can we unfreeze more work if we can’t even keep up now?
I leave Patty a voicemail. To my surprise, it takes her three hours to call me back. She tells me that something is going terribly wrong with our scheduling estimates and that we need to meet right away.
Once again, I’m in a conference room, with Patty at the whiteboard, and Wes scrutinizing the printouts she’s taped up.
“Here’s what I’ve learned so far,” Patty says, pointing at one of the sheets of paper. “The task that Kirsten called about is delivering a test environment to QA. As she said, Brent estimated that it would take only forty-five minutes.”
“Sounds about right,” Wes says. “You just need to create a new virtualized server and then install the OS and a couple of packages on it. He probably even doubled the time estimate to be safe.”
“That’s what I thought, too,” Patty said, but she’s shaking her head. “Except it’s not just one task. What Brent signed up for is more like a small project—there’s over twenty steps involving at least six different teams! You need the OS and all the software packages, license keys, dedicatedIP address, special user accounts set up, mount points configured, and then you need the IP addresses to be added to an ACL list on some file server. In this particular case, the requirements say that we need a physical server, so we also need a router port, cabling, and a server rack where we have enough space.”
“Oh…,” Wes says, sounding exasperated, reading what Patty is pointing at. He mumbles, “Physical servers are such a pain in the ass.”
“You’re missing the point. This would still be happening, even if it were virtualized,” Patty says. “First, Brent’s ‘task’ turns out to be considerably more than just a task. Second, we’re finding that it’s multiple tasks spanning multiple people, each of whom have their own urgent work to do. We’re losing days at each handoff. At this rate, without some dramatic intervention, it’ll be weeks before QA gets what they need.”
“At least we don’t need a firewall change,” Wes says, snidely. “Last time we needed one of those, it took John’s group almost a month. Four weeks for a thirty-second change!”
I nod, knowing exactly what Wes is referring to. The lead time for firewall changes has become legendary.
Wait. Didn’t Erik mention something like this? For a firewall change, even though the work only required thirty seconds of touch time, it still took four weeks of clock time.
That’s just a microcosm of what’s happening with Brent. But what’s happening to us right now is much, much worse, because there are handoffs.
With a groan, I put my head on the conference table.
“You okay?” Patty asks.
“Give me a second,” I say. I walk up to the whiteboard and struggle to draw a graph with one of the markers. After a couple of tries, I end up with a graph that looks like this:
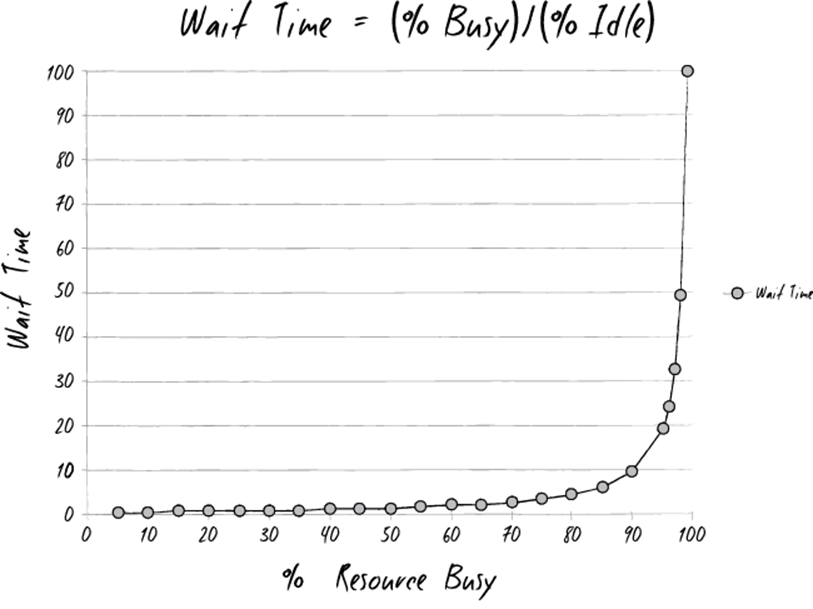
I tell them what Erik told me at MRP-8, about how wait times depend upon resource utilization. “The wait time is the ‘percentage of time busy’ divided by the ‘percentage of time idle.’ In other words, if a resource is fifty percent busy, then it’s fifty percent idle. The wait time is fifty percent divided by fifty percent, so one unit of time. Let’s call it one hour. So, on average, our task would wait in the queue for one hour before it gets worked.
“On the other hand, if a resource is ninety percent busy, the wait time is ‘ninety percent divided by ten percent’, or nine hours. In other words, our task would wait in queue nine times longer than if the resource were fifty percent idle.”
I conclude, “So, for the Phoenix task, assuming we have seven handoffs, and that each of those resources is busy ninety percent of the time, the tasks would spend in queue a total of nine hours times the seven steps…”
“What? Sixty-three hours, just in queue time?” Wes says, incredulously. “That’s impossible!”
Patty says with a smirk, “Oh, of course. Because it’s only thirty seconds of typing, right?”
“Oh, shit,” Wes says, staring at the graph.
Suddenly, I recall my conversation with Wes right before Sarah and Chris decided to deploy Phoenix at Kirsten’s meeting. Wes complained about tickets related to Phoenix bouncing around for weeks, which delayed the deployment.
It was happening then, too. That wasn’t a handoff between IT Operations people. That was a handoff between the Development and IT Operations organization, which is far more complex.
Creating and prioritizing work inside a department is hard. Managing work among departments must be at least ten times more difficult.
Patty says, “What that graph says is that everyone needs idle time, or slack time. If no one has slack time, WIP gets stuck in the system. Or more specifically, stuck in queues, just waiting.”
As we digest this, Patty continues. “Each of those sheets of paper on the board is like this Phoenix ‘task,’ ” she says, making air quotes with her hands. “It looks like a single person task, but it’s not. It’s actually multiple steps with multiple handoffs among multiple people. No wonder Kirsten’s project estimates are off.
“We need to correct this on Kirsten’s schedule and her work breakdown structure, or WBS. Based on what I’ve seen, fully one-third of our commitments to Kirsten fall into this category.”
“Just great,” Wes says. “It’s like Gilligan’s Island. We keep sending people off on three-hour tours, and months later, we wonder why none of them come back.”
Patty says, “I wonder if we could create a kanban lane for each of these ‘tasks?’ ”
“Yes, that’s it,” I say. “Erik was right. You’ve just found a big pile of recurring work! If we can document and standardize this recurring work, and gain some mastery over it, just like you did with laptop replacement, I’m sure we can improve flow!”
I add, “You know, if we can standardize all our recurring deployment work, we’ll finally be able to enforce uniformity of our production configurations. That would be our infrastructure snowflake problem—you know—no two alike. How Brent turned into Brent is that we allowed him to build infrastructure only he can understand. We can’t let that happen again.”
“Good point,” Wes grunts. “You know, it’s odd. So many of these problems we’ve been facing are caused by decisions we made. We have met the enemy. And he is us.”
Patty says, “You know, deployments are like final assembly in a manufacturing plant. Every flow of work goes through it, and you can’t ship the product without it. Suddenly, I know exactly what the kanban should look like.”
Over the next forty-five minutes, we create our plan. Patty is going to work with Wes’ team to assemble the top twenty most frequently recurring tasks.
She will also figure out how to better manage and control tasks when they are queued. Patty proposes a new role, a combination of a project manager and expediter. Instead of day-by-day oversight, they would provide minute-by-minute control. She says, “We need fast and effective handoffs of any completed work to the next work center. If necessary, this person will wait at the work center until the work is completed and carry to the next work center. We’ll never let critical work get lost in a pile of tickets again.”
“What? Someone assigned to carry around tasks from person to person, like a waiter?” Wes asks in disbelief.
“At MRP-8, they have a ‘water spider’ role that does exactly that,” she counters. “Almost all of this latest Phoenix delay was due to tasks waiting in queues or handoffs. This will make sure it doesn’t happen again.
“Eventually,” she adds, “I’ll want to move all the kanbans, so that we don’t need a person acting as the signaling mechanism for work handoffs. Don’t worry. I’ll have it figured out in a couple of days.”
Wes and I don’t dare doubt her.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.