eCommerce in the Cloud (2014)
Part III. To the Cloud!
Chapter 8. Architecture Principles for the Cloud
Cloud computing shouldn’t be all that challenging to adopt, provided that your organization is competent, willing to make changes, and has the resources to do it. If you’ve already embraced the principles found in the first two parts of this book, it shows you’re both competent and willing to make changes and should therefore have few problems embracing cloud computing. More fully adopting cloud computing is an enormous undertaking, but one that can be fairly painless when done properly.
The problem with more fully using cloud computing is that it greatly exacerbates both organizational and technical deficiencies. If you’re already struggling with keeping your platform up today, a cloud is almost certain to make your problems worse. On the other hand, a cloud can be equally transformational in the right hands. Cloud computing is powerful, and those who master it will have a competitive advantage for years to come.
In this chapter, we’ll discuss how ecommerce is unique from an architecture standpoint, followed by how to architect ecommerce for the cloud. Extra attention will be focused on what scalability is and how to achieve it. Subsequent chapters in this part of the book will discuss how to actually adopt various forms of cloud computing.
Why Is eCommerce Unique?
Let’s explore a few of the ways ecommerce is so unique. These reasons are why eCommerce platforms are architected and deployed different than most other systems.
Revenue Generation
With the rise in omnichannel retailing, most revenue now flows through an organization’s ecommerce platform. A platform-wide outage will prevent an entire organization from taking in revenue. It’s the equivalent of barring customers from entering all physical retail stores. Many organizations are now able to accurately calculate how much each second of downtime costs them in lost revenue. However, the real long-term cost of an outage is the damage caused to brand reputation. Many customers won’t come back after an outage.
It is because of how important ecommerce is that most environments are wildly over-provisioned.
Visibility
High visibility characterizes most ecommerce platforms, often serving as the public face and increasingly the back office of an organization. Every HTTP request is a reflection on that brand, just as much as the physical condition of a retail store is. Every millisecond in delayed response time reflects more poorly on that brand. A 100-millisecond response will delight customers and make a brand shine, whereas a 10-second response will upset customers and tarnish a brand.
Traffic Spikiness
A defining feature of ecommerce is that it’s subject to often unpredictable spikes in traffic that are one or two orders of magnitude larger than steady state. Most software simply wasn’t built to handle enormous spikes in traffic. For example, database connection pools in application servers often cannot double or triple the size of a given connection pool instantaneously. Software was architected for a world in which it was statically deployed, with workloads being fairly steady. In today’s world, capacity can be provisioned and immediately slammed with a full load of traffic. Software that is architected well is often able to handle these spikes in traffic, but not always.
Security
Everybody is rightly concerned about security. Organizations are often liable for breaches, with even small breaches costing tens of millions of dollars, not to mention the negative publicity and loss in confidence by customers. Breaches tend to be far-reaching, with all data under management exposed. It’s rare that only a subset of customer information is compromised. The introduction of cloud computing, depending on how it’s used, can mean more data is more often transferred over untrusted networks and processed on shared hardware, further adding to the complexity of securing that data. We’ll discuss this all further in Chapter 9.
Statefulness
HTTP requests can be separated into two classes: those that require state and those that do not require state. State is typically represented as an HTTP session. It’s a temporary storage area that’s unique to a given customer and durable across HTTP requests. Shopping carts, for example, are typically stored in an HTTP session. Authentication status is also persisted for the duration of a session. The HTTP protocol is stateless by definition, but state is added on top by application servers and clients to make basic ecommerce function.
HTTP requests from anonymous customers for static non-transactional pages (e.g., home page, product detail page) generally don’t require state. State generally begins when you log in or add to a cart, as Figure 8-1 shows.
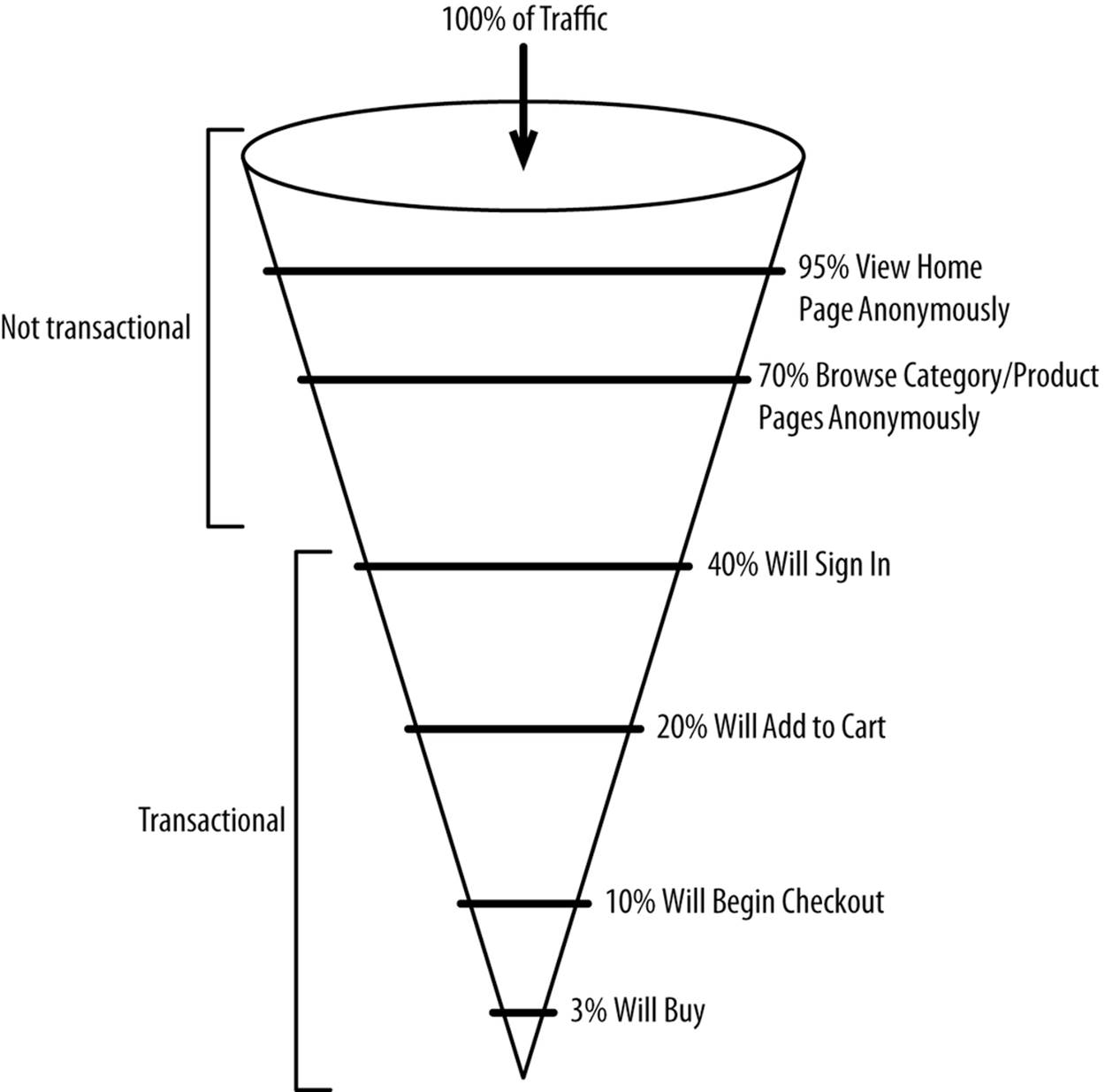
Figure 8-1. ecommerce traffic funnel
The challenge with ecommerce is that customers often browse anonymously for an extended period of time before they identify themselves by logging in. Most large websites force you to log in immediately (e.g., social media, email, online banking) or not at all (news, search engines, Wikipedia). When you log in to an ecommerce website, you have to merge everything that happened throughout the session with the data that’s been persisted about the customer. For example, personalization may be employed to trigger a discount on all Nike shoes after viewing 10 Nike shoes and not purchasing anything. An anonymous customer who has viewed eight pairs of Nike shoes would not trigger the discount. But what happens when that anonymous user logs in to an account that has already registered four Nike page views? The promotion would then be triggered after the anonymous customer profile and logged-in customer profile have been successfully merged.
We’ll discuss this more in Chapter 10, but another issue is the problem of multiple concurrent logins for the same account. What happens if a husband and wife are both logged in to the same account, making changes to the same order and customer profile in the database at the same time? With one data center, this isn’t a problem, because you’re sharing one logical database. But what happens when you’re using public Infrastructure-as-a-Service for hosting, and you span your ecommerce platform across two data centers with each data center having its own database?
Maintaining state across HTTP requests most often means that a given customer must be redirected to the same data center, load balancer, web server (if used), and application server instances. Maintaining this stickiness requires extra attention that many other applications don’t have to deal with.
What Is Scalability?
Strictly speaking, scalability is the ability of a system to increase its output (for example, concurrent users supported or HTTP requests per second) by adding more inputs (for example, an additional server). To be perfectly scalable, your inputs must always equal your outputs in the same proportion. For example, if your first server delivers you 200 page views per second, your 1,000th server should deliver you 200 page views per second as well. If your first server delivers 200 page views per second and your 1,000th server delivers 20 page views per second, your system has a scalability problem.
All layers of the stack must be equally scalable, from DNS down to storage. We will discuss two forms of scalability: scaling up (vertical) and scaling out (horizontal).
Throughput
Throughput refers to the amount of work or capacity that a unit of input (e.g., server, cache grid node, database node) or an entire system can support. Common examples of metrics used to represent throughput include the following:
§ Page views per second
§ Transactions per second
§ Concurrent customers
NOTE
Don’t confuse throughput with overall system-wide scalability, as the two are independent of each other. The throughput of an individual unit of input (e.g., an application server) may be low, but so long as you can continually get the same level of marginal output (e.g., page views per second) as you increase the number of inputs, your system is scalable.
Scaling Up
Scaling up, otherwise known as vertical scalability, is increasing the output (e.g., page views per second) of a fixed unit of input (e.g., an application server running on 8 cores). When you have increased an application server’s output from 200 page views per second to 250 page views per second, you have scaled up that resource. Scaling up (Figure 8-2) can be performed by optimizing (caching more, making code more efficient, and so forth) or adding more physical resources (e.g., going from 8 vCPUs to 12). This is in contrast to scaling out, where the page views per second would be increased by adding another application server instance.
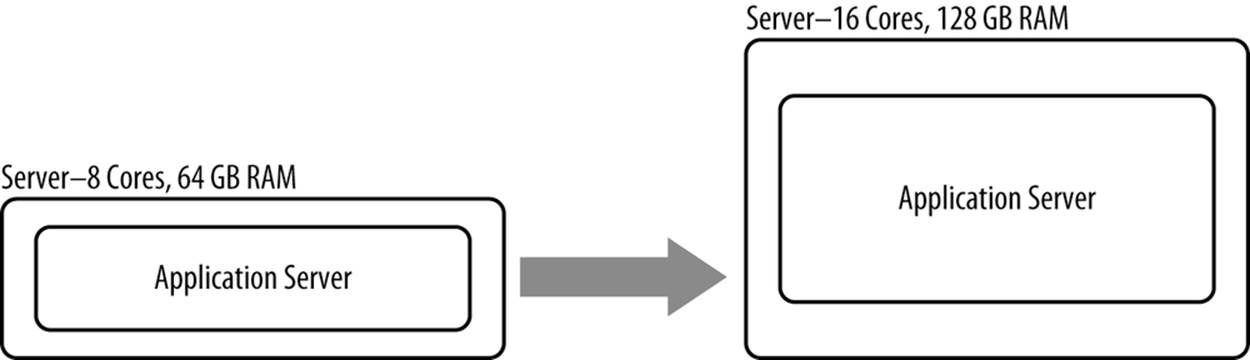
Figure 8-2. Scaling up
No software is truly infinitely scalable. At some point, you start to get diminishing returns. For example, Apache historically hasn’t scaled well beyond more than a handful of physical cores. You would get more total throughput by running four instances of Apache on a single 32 CPU core server than you would if you ran one instance of Apache on that same server. Some software must be scaled up because of constraints in its architecture. Often times, old backend systems don’t scale out very well because they were designed for an era where CPUs had only one core. Multicore CPUs are a fairly modern invention.
CASE STUDY: THE C10K PROBLEM
In 2003, a developer named Dan Kegel published a web page stating that modern web servers should be able to handle 10,000 concurrent clients.[57] He termed the problem C10K, where C means connections and 10K means 10,000. His astute observation was that hardware had made great advances over the previous few years but that the ability of a web server to scale up and use that hardware had not changed. At the time, many web servers were able to support only 1,000. Dan and subsequent work proved that 10,000 concurrent connections could be sustained with changes to the operating system and web server software.
A decade later, in 2013, Robert Graham showed that modern servers could support 10 million concurrent clients.[58] Again, the solution was software.
These two initiatives showed that the bottleneck to vertical scalability was mostly software. Hardware matters, but not nearly as much as good software does.
Scaling Out
Scaling out, otherwise known as horizontal scalability, is increasing output (e.g., page views per second) of a system by adding more inputs (e.g., more application servers running on more hardware). An example of scaling out a resource is adding a server, as opposed to increasing the memory or processing power of an existing server (see Figure 8-3).
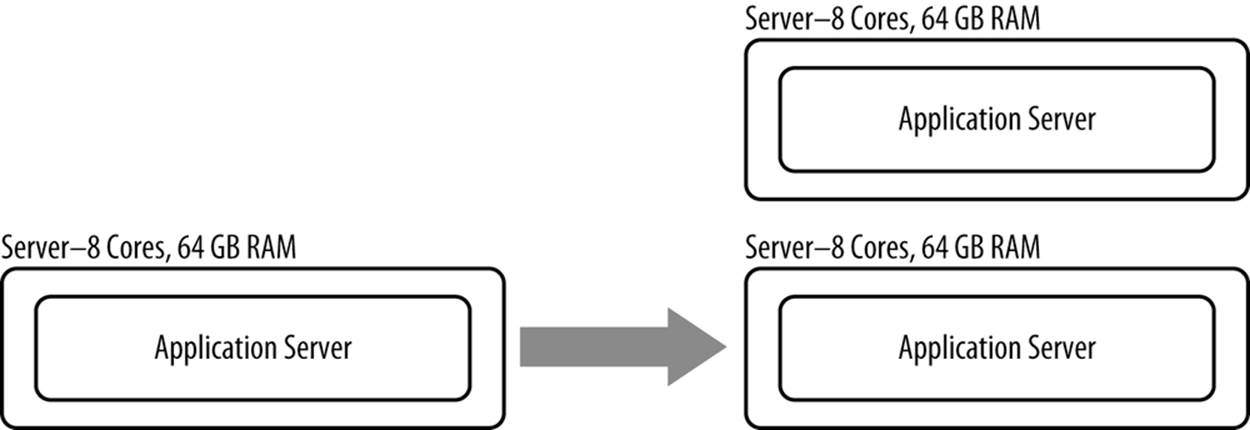
Figure 8-3. Scaling out
If the marginal input (e.g., an additional server) equals the marginal output (e.g., page views per second), you have a perfectly scalable system. If additional units of input (e.g., physical servers) equal fewer and fewer units of output (e.g., page views per second), the system isn’t scalable.Figure 8-4 applies equally to both individual units as well as the entire system.
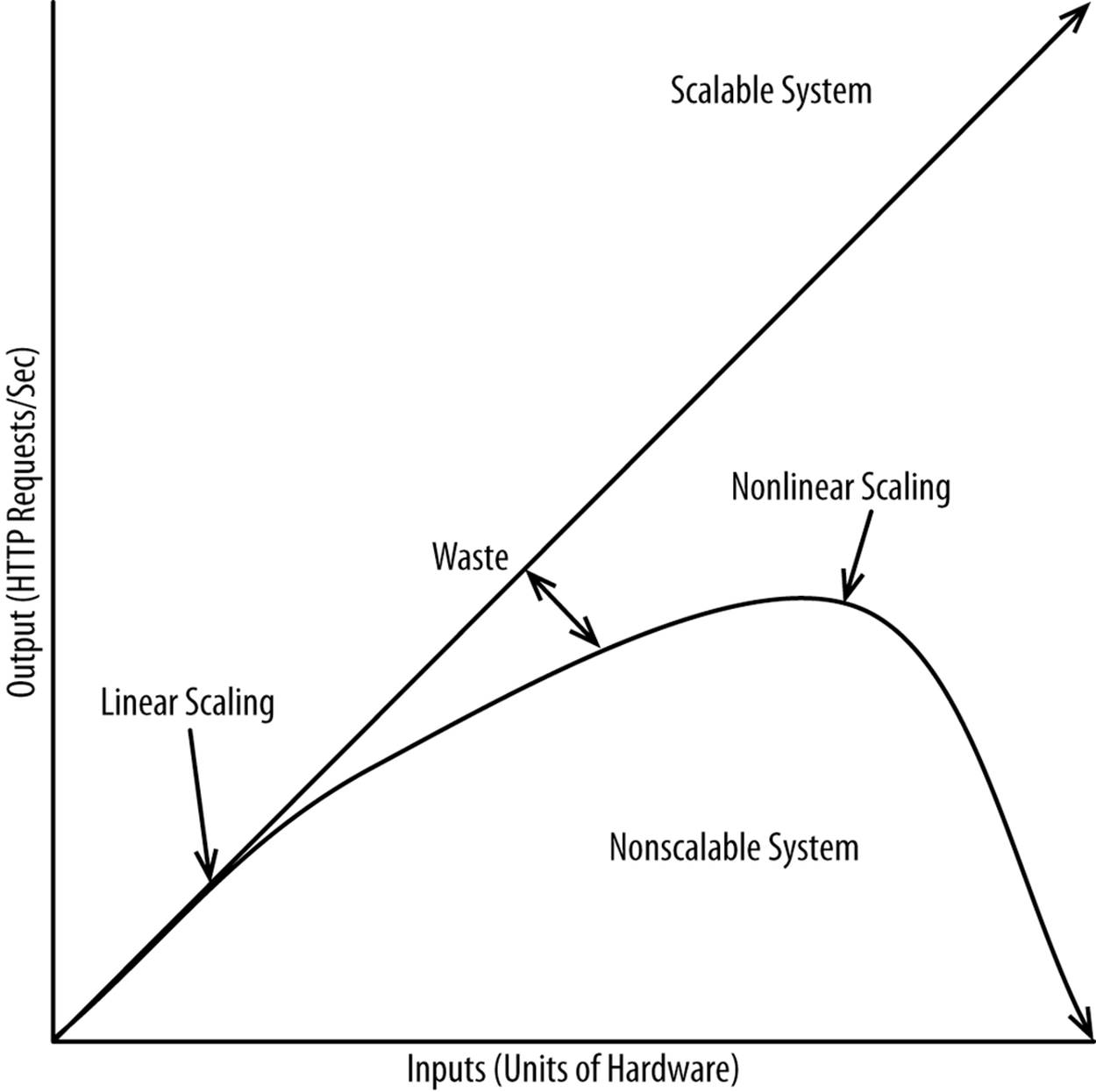
Figure 8-4. Linear versus nonlinear scaling
Rules for Scaling
While scaling out is an absolute necessity, scaling up is important too. The more you scale up, the less you have to scale out and the lower your marginal costs. You can avoid a whole class of problems by better architecting your system to drive more throughput out of each server. Modern commodity x86 servers can handle 10 million concurrent HTTP connections due to the lockless event loop-based architectures favored by newer web servers/load balancers like nginx and Node.js. Apache is now able to support more than a few thousand concurrent HTTP requests on a single commodity server, but that’s largely due to hardware advancements and some tuning. The massive increase in throughput of these newer web servers is purely a function of their better architecture.
Scaling software comes down to two principles. The first is to allow each system to do the work it needs to do with as few impediments as possible. Calls to remote systems are fine, provided they don’t block. Threads that are blocked kill both throughput and performance. Avoiding threads where possible eliminates the problem of blocking threads. A second and even more potent barrier to scalability is the human side of technology. Hiring the right people will pay dividends for decades to come and could make the difference between your company’s success or failure. Individual people are only vertically scalable to a certain point. Scaling out and scaling up of your staff is required for success.
The following section will discuss each of the following principles:
§ Convert synchronous to asynchronous
§ Reduce locking
§ Simplify
§ Remove state
§ Cache intelligently
§ Hire the right people
§ Plan, plan, plan
§ Size properly
§ Use the right technology
For more information on this topic, read The Art of Scalability by Martin L. Abbott and Michael T. Fisher (Addison-Wesley Professional).
Technical Rules
Convert synchronous to asynchronous
In synchronous processing, the execution of one task (e.g., an application server generating an HTTP response) is dependent upon the execution of one or more other tasks (e.g., querying a database). A common example of this is an email confirmation being sent synchronously following an order submission. Assuming transactions are being properly used, the successful placing of an order is entirely dependent upon something as frivolous as an SMTP server’s availability and performance. With proper decoupling of these two systems, an order would be placed as normal, but instead of synchronously sending the message, it would be dumped in a queue and delivered asynchronously to an available SMTP server.
Synchronous calls to any system put it in the critical path, making the entire system’s scalability dependent upon the least scalable resource. For example, your order management system may struggle to handle traffic from your busiest days of the year. If you’re connecting synchronously to your order management system, the scalability of your entire platform will be dependent upon the scalability of that one system. In an omnichannel world, where all channels use the same backend systems, some of your systems will not be able to scale. Any activity that’s not directly tied to generating revenue or doesn’t require an instantaneous response should be performed asynchronously so it doesn’t interfere with generating revenue.
CASE STUDY: NODE.JS
Traditional web and application servers work on the concept of threads, whereby a single HTTP request will tie up a single thread until the response is fully generated. Everything is executed synchronously. With a traditional web and application server combination, this means each web server thread waits for the application server’s response and each application server’s thread waits for responses from various databases, cache grids, third-party systems, and so forth. Threads spend a lot of time blocked, waiting to do something. Threads are expensive, as each one requires dedicated memory. This model was built for a world in which customers passively downloaded static web pages.
Node.js is a JavaScript-based framework that serves as both the web server and client-side development framework. The two work together to offer full bidirectional communication between the web server and client, along with an asynchronous execution model that eschews threads. By not using threads, each instance of Node.js can support a million or more concurrent connections. The way it works is that HTTP requests come in and, as backend systems each do their work (e.g., an inventory lookup, a request to load product details via an HTTP request with a REST response), the response is incrementally pushed to the client. This allows the web browser to begin rendering the response in parallel while the response is actually being generated.
In any platform, but especially in a cloud, databases can serve as a bottleneck. Databases tend to be heavily used in ecommerce because applications are so stateful. Outside the cloud, databases are deployed to dedicated hardware backed by high-grade storage with high-speed networking gear connecting the components of the system. In a public Infrastructure-as-a-Service cloud, you have very little control over your environment. You can’t optimally tune much outside the operating system and you’re dealing with hardware and networks that are shared by many tenants. While cloud vendors do take great precautions to isolate traffic, it’s never perfect. To prevent databases from being the bottleneck, you can use a write-back cache for all or a subset of your writes. This means that your application uses a cache as the system of record, with the cache reading and writing back to the database asynchronously (see Figure 8-5).
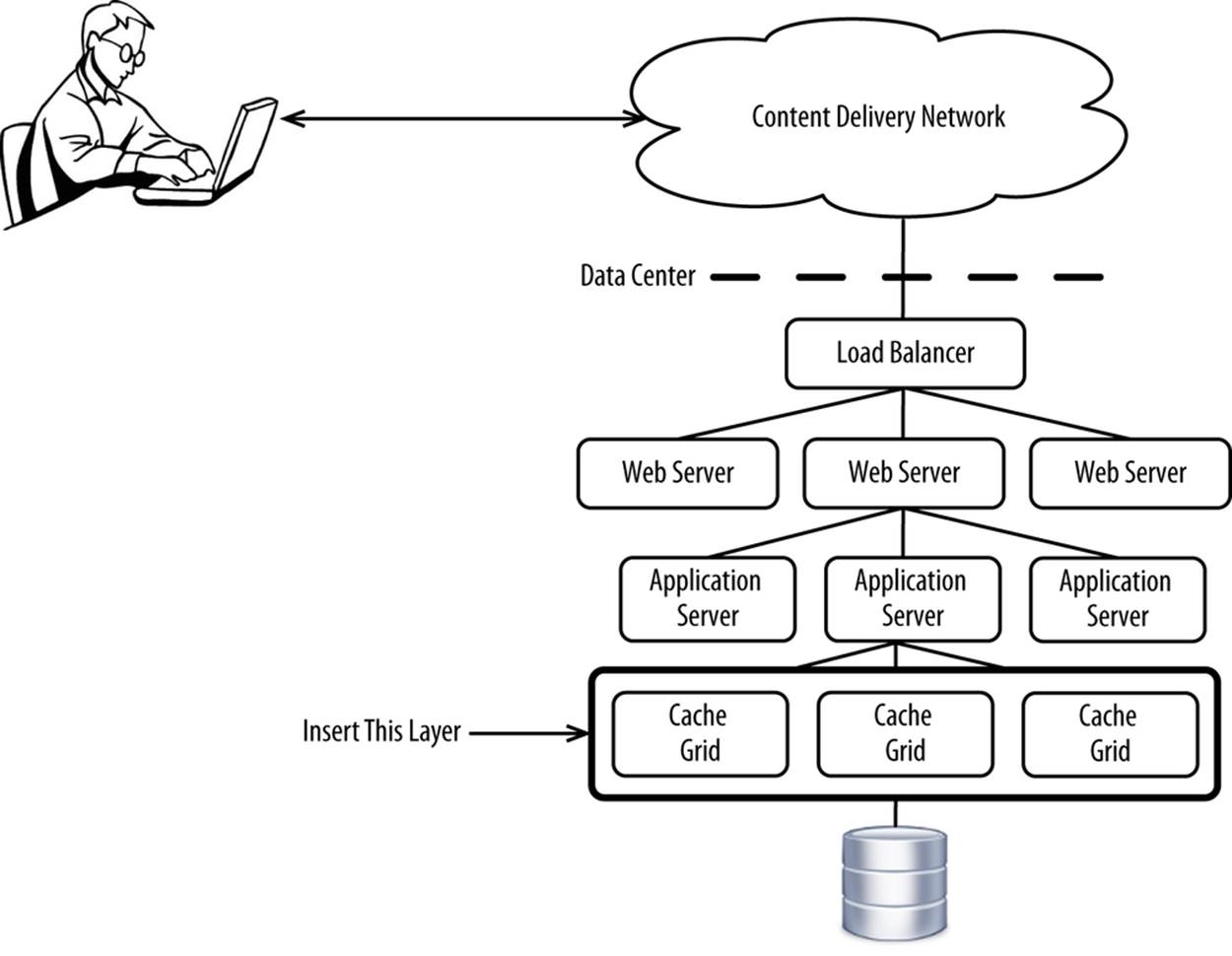
Figure 8-5. Write-back cache to reduce database load
Figure 8-6 shows a sequence diagram.
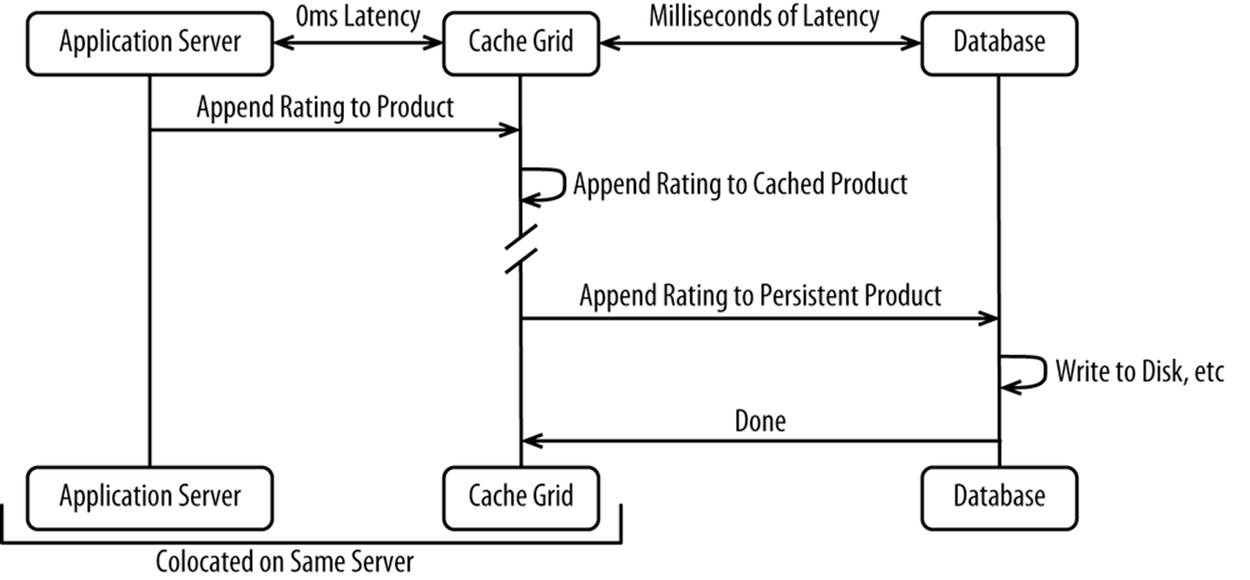
Figure 8-6. Generating a response with a write-back cache
This can allow your system to scale up and out while improving the performance. To customers, the write happens instantaneously to local cache, which allows the response to be generated instantaneously. While this may not be suitable for something important like inventory, it is perfectly suitable for things like product reviews, customer profile updates, cart updates—anything where the source system being out-of-date by a few milliseconds doesn’t matter. We’ll discuss some options for running your database in a cloud in Chapter 11.
The most scalable platforms have completely decoupled their frontends from backends. All calls from the frontend to the backend are asynchronous, with queueing introduced to allow the backend to disappear for periods of time. With the backend down, the frontend continues to accept revenue.
Reduce locking
By definition, work (e.g., HTTP requests) in an ecommerce platform are executed concurrently across multiple threads. These can be threads in a managed runtime environment, threads in a database, or threads in a cache grid. Web servers and load balancers typically don’t lock very much and they are increasingly moving away from threading, so there aren’t issues there.
There are objects that need to be updated by a large number of threads simultaneously. A great example of this is when millions of people are trying to buy the latest smartphone the minute it is available for sale. Inventory across an entire platform typically comes down to updating one record in a centralized cache grid, in a database row, and so forth. Without proper concurrency, your database and application server threads can end up waiting too long to update, causing a cascading lockup across your entire platform. This is a common cause of outages.
Blocking can also occur within a single process, inhibiting its ability to scale up. Your application may have a few common hot objects that are locked by each request-handling thread. When you have too many threads, each thread has to wait longer to lock, and eventually it becomes too long, and you can’t scale up anymore. Blocking can be a quick way to limit your ability to scale out and up. It should therefore be avoided at all cost.
You can largely eliminate locking by using some common sense when architecting your system. Let’s go back to the inventory example. With a traditional database-backed cache, each update of the inventory requires what’s shown in Figure 8-7.
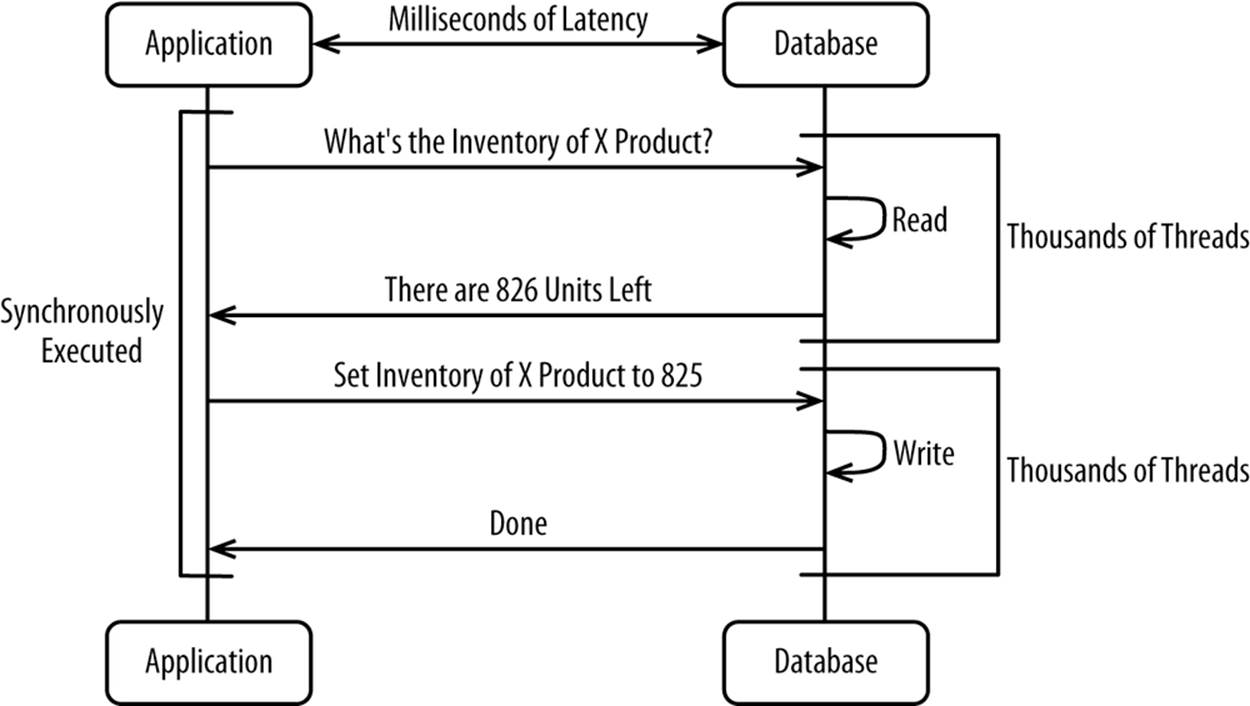
Figure 8-7. Steps required to update inventory
Rather than reading the inventory all the time, you can set low-inventory flags or allot a batch of inventory to each instance if there’s a lot of inventory available. For updating inventory, you can instead make simple increment and decrement calls to a cache grid or similar in-memory system that uses a lockless data structure. The call could be as simple as this:
http://www.website.com/InventoryUpdate?productId=X&value=-1&securityToken=ABC123
You could even execute the call asynchronously if you know you have enough inventory to last for a while.
By simply telling your inventory management system to increment or decrement, you avoid having to read the object, set its value, and wait for the database to commit it to disk. It’s just much faster.
Every programming language has the concept of lockless data structures. Internally, these data structures may use more-efficient nonblocking OS-level techniques, like compare and swap. Using these data structures greatly reduces thread contention within a single process and allows for much greater scaling up.
Simplify
Your architecture should be as simple as possible. Simplicity begets scalability. This covers a wide range of topics, including these:
Removing tiers from your platform
Removing web servers.
Simplifying configuration
Changing IP addresses to hostnames, removing hostnames entirely, eliminating singletons, and so forth.
Removing unnecessary wrappers/envelopes
Switching from SOAP to SOA, not using SSL/TLS when it is not truly necessary, and so forth.
Building discrete interfaces between your systems
This allows you to decouple your systems better. Discrete interfaces can be written to and from a service bus and similar technologies.
Simplification must be built in from the beginning. It’s very hard to go back to simplify old code. Build it properly from the start by hiring the right people and making simplicity a top goal.
Remove state from individual servers
As mentioned earlier in this chapter, state is a temporary storage area that’s unique to a given customer and durable across HTTP requests. Shopping carts, authentication status, promotions, and so on all depend on state. State is always going to be a fixture given the nature of ecommerce.
Maintaining state across HTTP requests most often means that a given customer must be redirected to the same data center, load balancer, web server (if used), and application server instance. When you’re rapidly adding and removing servers in a cloud through auto-scaling, you can’t always guarantee that a given server is going to be available. Servers in a cloud are by nature ephemeral. Forcing a customer to log in again because the state was lost after a server was de-provisioned is not acceptable.
NOTE
Servers in a cloud are by nature ephemeral. Don’t store state in them.
State has substantial technical implications for a few reasons:
§ State can be heavy, typically in terms of memory utilization. Nothing kills your ability to scale up like having 1 MB sessions.
§ Maintaining state for ecommerce requires that it be persisted on the server side and made available to any application server that requests it. Again, servers can quickly go up and down. If you de-provision a server, the customer shouldn’t know.
§ States must be merged. As discussed earlier in the chapter, customers browse anonymously, all the while accumulating state. When the customer logs in, that session state must be merged with the persistent state that is durable across HTTP sessions.
To minimize the harmful effects of state, keep the following rules in mind:
§ State should be as light as possible—a few kilobytes at most. Anything not important should be left out.
§ State should be relegated to as few systems as possible. While it makes sense for your application server to care about state, your application’s call to a standalone inventory management service should probably be stateless. Go through every remote call you’re making and confirm whether state is truly required.
§ State should be avoided unless it is necessary. For example, search engine bots crawling your website have no concept of sessions and will create a brand new HTTP session with every page view. Either prevent the HTTP session from being created in the first place or consider invalidating HTTP sessions created by search engine bots (which can be identified by user-agent string) after each HTTP request. Likewise, anonymous customers pulling up the home page probably don’t need a session either.
The big question is where state should be stored. Traditionally, application servers have been responsible for HTTP session lifecycle management. Applications deployed to the application servers add data to the session. Then you may choose to replicate the HTTP session or not. Replication can be entirely in-memory, through a database, through a cache grid, or by almost any other means of moving around data between processes.
To mitigate the overhead of maintaining state on the server side, it would be natural to push it to the client (e.g., web browser, mobile application), as is common with many other workloads. This is frequently accomplished with web browsers through the use of cookies or HTML 5. But in an omnichannel world, that doesn’t work well because you’re using so many different channels, each requiring client and version-specific means to represent state. Because HTTP is stateless by definition, it’s up to each client to implement state. For example, web browsers use cookies, whereas Android applications use a Java-based API with a native persistence mechanism. Some clients don’t even support the ability to persist data between HTTP requests. Because of the variety of clients and their ever-changing APIs, it’s best to let the application server continue to manage state. Don’t assume clients even support something as rudimentary as cookies.
Applications and application servers should be configured to persist state to a distributed system, like a NoSQL database or cache grid. You can then serve an HTTP request out of any server with access to the NoSQL database or cache grid.
Cache as much as possible, as close to the client as possible
Caching is exceptionally important for ecommerce because customers demand the absolute best available performance. At the same time, caching can save enormous computing resources by making it possible to scale up individual servers much further than would otherwise be possible. The value offered by the multibillion-dollar Content Delivery Network (CDN) industry over the past decade has been almost exclusively their ability to cache content.
The rule with caching is that it’s best to cache as much as possible, as close to the end-customer as possible. The closer you cache, the less each intermediary system between the customer and the source system actually generating the content has to work. Figure 8-8 shows a list of what you can cache where.
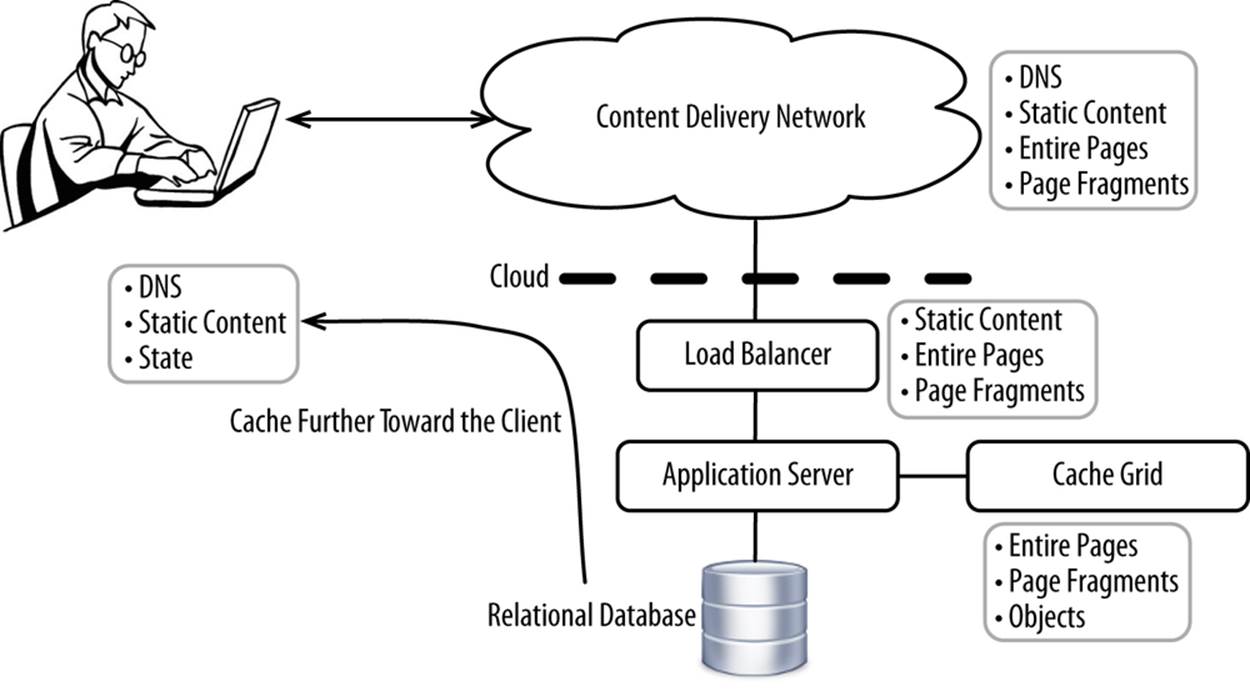
Figure 8-8. Cache as much as possible, as close to the end customer as possible
If you have a proper architecture in place, your system’s bottleneck should be on the CPUs running the application server. Memory, storage, networking, and other layers formerly were the bottlenecks, but now it tends to be the CPUs running the application server. Executing the code to generate pages is what consumes most of the CPU. Most pages are constructed using fragments, as shown in Figure 8-9.
Figure 8-9. Cacheable static page fragments
While an entire page may have too much content to be cacheable in an intermediary layer, individual page fragments themselves are dynamic. For example, this entire fragment shown in Figure 8-10 is unlikely to change.

Figure 8-10. Navigation bar
Rather than constantly executing code to generate a page fragment that you know will never change, you can instead cache the execution of that fragment, passing in variables. Most web frameworks have the ability to cache fragment includes, with input parameters being cache keys.
To cache a fragment, you would take the equivalent of:
<jsp:include page="/menu_bar.jsp" />
and convert it to:
<jsp:include page="/menu_bar.jsp">
<jsp:param name="anonymous" value="false" />
<jsp:param name="user_segment" value="bay_area_male_engineer" />
<jsp:param name="locale" value="us_EN" />
</jsp:include>
With the anonymous, user_segment, and locale parameters forming a key, you can simply create copies of each combination and cache the HTML. It is easier to include a pre-cached block of HTML than execute the thousands of lines of code that go into generating HTML from source. Fragments should be cached wherever possible.
Caching is one of the most fundamental principles in computer science and should be used liberally.
Use the right technology
Technology is an incredibly fashion-driven industry, with decisions on which technology to use often driven by what’s fashionable instead of what’s pragmatic. People confuse using new, unproven technology with innovation, when the two are almost entirely unrelated. Innovation should come from how you use technologies to achieve business objectives as opposed to the technologies themselves. While new technology has its place, you should always balance the marginal benefits a new technology provides with the following characteristics of more-established options:
§ Maturity
§ Availability of skills in the market
§ Support
§ Ongoing maintenance
§ How well it can be monitored
For example, using a new programming language may allow you to write 10% less code, but if you can’t find an IDE or developers, is the 10% really worth it? Probably not. Yet decisions like this are made all the time, often due to the “it won’t scale” excuse. But scalability is far more about how you use the technology than about the technology itself.
It’s generally best to outsource or use well-established technology for any part of your system that you don’t do faster/better/cheaper than your competitors. This principle is exactly why ecommerce should be deployed to a cloud. Innovate on the implementation and/or development of your ecommerce application. Build beautiful and functional user interfaces. Tie in with physical stores by providing functionality such as real-time, store-level inventory, and pricing. Support a wide range of clients. Make it fast and highly available. Leave the development of the building blocks (e.g., hardware, software, services) to technology vendors or the open source community.
Make sure you have a process in place to evaluate the technology that’s selected. Individuals selecting technology may not have a view of the overall cost of using a given technology. Spend time delivering on your core competency—not in building commoditized components.
Nontechnical Rules
Hire the right people
Broadly, you need architects and developers to deliver a high-quality platform. Of course, there are many more supporting roles involved, but you need people to design (architects) and you need people to implement (developers).
Architects are responsible for the design of your entire system, from how and where the code is deployed, all the way down to method-level design. Architecture has changed over the past two decades, from designing systems from scratch to leveraging building blocks. Building blocks today are cloud services (Software-as-a-Service, Platform-as-a-Service, Infrastructure-as-a-Service), web development frameworks, and software products such as cache grids. Very few of these building blocks existed even a decade ago. You had to build everything you wanted by hand. Architects now have many more options available—which is good if you know what you’re doing, but bad if you don’t. The job has shifted more from the how to the what. It’s a fundamental change—one that requires hiring a few very high-skilled architects, as opposed to a large number of average or below-average architects. You just don’t need that many people today.
The entire ecosystem that developers work within has substantially matured over the past decade. Programming languages, web development frameworks, tooling, and runtimes all have the effect of allowing developers to write less code, with higher quality, in less time than ever before. One good developer now has the productivity of 10 or more average developers.[59] With modern tooling, a good developer may be even more productive than that. Modern developers just don’t write all that much low-level code. Those “reverse a linked list on a white board” interview questions are useless at best, as a good developer should simply call a method to do the sorting. Most developers today should be writing glue code, which amounts more to leveraging web development frameworks and using prebuilt libraries than writing a lot of code from scratch. Code that’s written must be commented, unit tested, QA tested, performance tested, and maintained. All of that costs time and money. Good developers shouldn’t be writing much code, and the code itself should be simple and clearly documented. It shouldn’t take a computer science degree to understand what most code does. Good developers also need to have a strong awareness of where and how their code is executed. That’s not just the job of an architect.
While basic computer science skills are often required, it’s more important for architects and developers to be able to communicate with stakeholders, collaborate with colleagues, advocate for positions, figure things out independently, and generally employ soft skills rather than hard skills to advance goals. Going back to the “reverse a linked list” problem, a good developer should be able to use an IDE to find the method to call, do a quick search on the Internet to find the method, or ask the developer sitting next to him what the method is. A bad developer will implement the algorithm by hand rather than using the available tools to find the method.
While soft skills are an important requirement for success, it is enthusiasm, competence, and perseverance that are the three hallmarks of the best architects and developers. Enthusiasm and perseverance are intrinsic characteristics that can’t be taught, while competence comes from experience.
It’s best to build relatively small teams of highly skilled developers. A few good developers colocated can accomplish an enormous amount of work. Many of the best startups were built by a handful of people. Amazon famously uses “two-pizza teams,” which means that any team should be small enough that it could be fed by two pizzas. A great way of structuring a project is to break apart your project into small teams, with each focused on delivering a service exposed by a clear interface. For example, you can assign an architect and a handful of developers to go build an inventory management system. Define the interfaces and let that team go off to build it, while coding the rest of the platform to use those interfaces. Not only are there technical advantages to breaking apart the platform, but it’s easier to assign accountability, and people like owning something. When everybody owns everything, nobody ends up actually owning anything.
TIP
When hiring, it’s all about quality as opposed to quantity.
Hire the best, organize them into small teams, delineate responsibility clearly, and work to remove impediments to people doing their jobs.
Collaboration with lines of business
All too often, important business decisions are made by IT in isolation, based on invalid or outdated assumptions. Communication must be frequent, bidirectional, and without intermediaries. It can take the form of in-person meetings, emails, instant messages, and even text messages. Any medium is fine. Building a platform that doesn’t meet the needs of business is an enormous waste of time and energy. It’s a collaborative effort.
Service-level agreements (SLAs) must be defined for every aspect of the system. This includes server-side and client-side response times, how much the system must be available, how long it should take to recover from an outage (recovery time objective), and how much data loss is acceptable during an outage (recovery point objective). Higher SLAs means higher cost. For example, if the requirement is to never have any platform downtime, you’ll have to deploy your platform to multiple geographic zones across multiple cloud vendors. That gets complicated and expensive. It’s always a tradeoff. What matters is that these numbers are jointly agreed upon and there is accountability when objectives are not met.
Any event that could drive substantial traffic to your platform (e.g., flash sales, coupons, exceptional discounts) needs to be planned ahead of time. With ecommerce platforms available to the whole world, plus the speed at which messages can travel through social media, you can quickly get besieged with traffic. While proper use of a cloud should allow the system to automatically scale up to meet the increased demand, it’s good for high-visibility events to scale up ahead of time for extra safety. Whenever possible, there should be a robust approval system in place so that IT signs off on marketing campaigns. For example, it’s easy to accidentally embed the cookie identifier from your current session (e.g., ;jsessionid=0000000fec3dff553fc1532a937765d43fc42836ed3f8894) in the URL of a link you send out to customers in an email campaign. You can scale out your environment as much as you please, but if you embed your session identifier, all customers will hit the same server if you have session stickiness.
To help IT understand how their decisions are affecting business, it’s great to quantify how much effect various IT metrics have on revenue. For example, calculate how much each minute of downtime costs in lost revenue or how much each additional millisecond of page-loading time negatively impacts revenue. Quantifying these costs helps to put the decisions people make into perspective. It changes the whole way of thinking. For example, a 20-minute outage for maintenance doesn’t seem like much to most IT administrators, but knowing that outage costs $300,000 in lost revenue would make anyone think of ways to reduce the length of the outage or eliminate it entirely.
Increasingly, ecommerce platforms are so important that they’re being deployed to multiple data centers and even different cloud vendors to ensure that the platform is as available as possible. That’s what we’ll discuss in Chapter 10.
[57] Dan Kegel, “The C10K Problem,” (5 February 2014), http://www.kegel.com/c10k.html.
[58] Robert Graham, “C10M,” http://c10m.robertgraham.com
[59] Andy Oram and Greg Wilson, Making Software, (O’Reilly).
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.