Enterprise Web Development (2014)
Part II. Enterprise Considerations
Chapter 9. Introduction to Web Application Security
Every newly deployed web application creates a new security hole and potential access of your organization’s data. Hackers gain access to data by sneaking through ports that are supposedly hidden behind firewalls. There is no way to guarantee that your web application is 100 percent secure. If it has never been attacked by hackers, most likely it’s too small and is of no interest to them.
This chapter provides a brief overview of major security vulnerabilities of which web application developers need to be aware. We also cover delegated authorization with OAuth, and possible authentication and authorization scenarios for our Save The Child application.
There are plenty of books and online articles that cover security, and enterprises usually have dedicated teams handling security for the entire organization. Dealing with security threats is their bread and butter, and this chapter won’t have revelations for security professionals. But a typical enterprise application developer just knows that each person in the organization has an account in some kind of a naming server that stores IDs, passwords, and roles, which takes care of authentication and authorization flows. Application developers should find useful information in this chapter.
If an enterprise developer needs access to an internal application, opening the issue with the technical support team grants the required access privileges. But software developers should have at least a broad understanding of what makes a web application more or less secure, and which threats web applications face—this is what this chapter is about. To implement any of the security mechanisms mentioned in this chapter, you’ll need to do additional research.
TIP
A good starting point for establishing security processes for your enterprise project is Microsoft’s Security Development Lifecycle website. It contains documents describing the software development process that helps developers build more secure software and address security compliance requirements while reducing development costs.
HTTP versus HTTPS
Imagine a popular nightclub with a tall fence and two entry doors. People are waiting in lines to get in. Door number 80 is not guarded in any way: a college student checks tickets but lets people in whether or not they have a ticket. The other door has the number 443 on it, and it’s protected by an armed bully letting only qualified people in. The chances of unwanted people getting into the club through door 443 are pretty slim (unless the bully is corrupt), which is not the case with door 80—once in a while, people who have no right to be there get inside.
On a similar note, your organization has created network security with a firewall (the fence) with only two ports (the doors) open: 80 for HTTP requests and 443 for HTTPS. One door is not secure; the other one is.
WARNING
Don’t assume that your web application is secure if it’s deployed behind a firewall. As long as there are open ports that allow external users to access your web application, you need to invest in the application security, too.
The letter s in HTTPS stands for secure. Technically, HTTPS creates a secure channel over an insecure Internet connection. In the past, only web pages that dealt with logins, payments, or other sensitive data would use URLs starting with https. Today, more and more web pages use HTTPS, and rightly so, because it forces web browsers to use Secure Sockets Layer (SSL) or its successor, Transport Layer Security (TLS) protocol, for encrypting all the data (including request and response headers) that travel between connected Internet resources. High Performance Browser Networking contains a chapter with detailed coverage of the TLS protocol.
Organizations that run web servers create a public-key certificate that has to be signed by a trusted certificate authority (otherwise, browsers will display invalid certificate warnings). The authority certifies that the holder of the certificate is a valid operator of this web server. SSL/TLS layers authenticate the servers by using these certificates to ensure that the browser’s request is being processed by the proper server and not by some hacker’s site.
When a client connects to a server via HTTPS, that client offers to the server a list of supported ciphers (authentication-encryption-decryption algorithms). The server replies with a cipher they both support.
TIP
The annual Black Hat computer security conference is dedicated to information security. This conference is attended by both hackers and security professionals.
If HTTPS is clearly more secure than HTTP, why doesn’t every website use only HTTPS communication? Because HTTPS encrypts all messages that travel between the client’s browser and the server, its communications are slower and need more CPU power compared to HTTP-based data exchanges. But this slowness isn’t noticeable in most web applications (unless thousands of concurrent users hit the web server), whereas the benefits of using HTTPS are huge.
When entering any sensitive or private information in someone’s web application, always pay attention to the URL to make sure that it uses HTTPS.
As a web developer, you should always use HTTPS to prevent an attacker from stealing the user’s session ID. The fact that the National Security Agency has broken the SSL encryption algorithm is not a reason for your application to not use HTTPS.
Authentication and Passwords
Authentication is the ability to confirm that a user is who he claims to be. The fact that the user has provided a valid ID and password combination proves only that he is known to the web application. That’s all.
Specifying the correct user ID/password combination might not be enough for some web applications. Banks often ask for additional information (for example, “What’s your pet’s name?” or “What’s your favorite movie?”).
Large corporations often use RSA SecurID (a.k.a. RSA hard token), which is a physical device with a randomly generated combination of digits. This combination changes every minute or so and has to be entered as a part of the authentication process. In addition to physical devices, programs (soft tokens) can perform user authentication in a similar way. Many financial institutions, social networks, and large web portals support two-factor verification: in addition to asking for a user ID and password, they send you an email, voice mail, or text message with a code that you’ll need to use after entering the right ID/password combination.
To make the authentication process more secure, some systems check the biometrics of the user. For example, in the United States, the Global Entry system is implemented in many international airports. People who successfully pass a special background check are entered into the system deployed at passport-control checkpoints. These applications, deployed in a special kiosks, scan users’ passports and check the face topography and fingerprints. The process takes only a few seconds, and the authenticated person can pass the border without waiting in long lines.
Biometric devices have become more common these days, and fingerprint scanners that can be connected to a user’s computer are very inexpensive. Apple’s iPhone 5S unlocks based on the fingerprint of its owner—no need to enter a passcode. In some places, you can enter a gym only after your fingerprints have been scanned and matched. The National Institute of Standards and Technology hosts a discussion about using biometric web services, and you can participate by sending an email to bws-request@nist.gov with subscribe as the subject.
Basic and Digest Authentication
HTTP defines two types of authentication: Basic and Digest. All modern web browsers support them, but basic authentication uses Base64 encoding and no encryption, which means it should be used only with HTTPS.
A web server administrator can configure certain resources to require basic user authentication. If a web browser requests a protected resource but the user didn’t log in to the site, the web server (not your application) sends the HTTP response containing HTTP status code 401 (Unauthorizedand WWW-Authenticate: Basic). The browser pops up the login dialog box. The user enters the ID/password, which is turned into an encoded userID:password string and sent to the server as a part of HTTP header. Basic authentication provides no confidentiality because it doesn’t encrypt the transmitted credentials. Cookies are not used here.
With digest authentication, the server also responds with 401 (WWW-Authenticate: Digest). However, it sends along additional data that allows the web browser to apply a hash function to the password. Then, the browser sends an encrypted password to the server. Digest authentication is more secure than the basic one, but it’s still less secure than authentication that uses public keys or the Kerberos authentication protocol.
TIP
The HTTP status code 403 (Forbidden) differs from 401. Whereas 401 means that the user needs to log in to access the resource, 403 means that the user is authenticated, but his security level is not high enough to see the data. For example, not every user role is authorized to see a web page that displays salary reports.
In application security, the term man-in-the-middle attack refers to an attacker intercepting and modifying data transmitted between two parties (usually the client and the server). Digest authentication protects the web application from losing the clear-text password to an attacker, but doesn’t prevent man-in-the-middle attacks.
Whereas digest authentication encrypts only the user ID and password, using HTTPS encrypts everything that goes between the web browser and the server.
Single Sign-on
Often, an enterprise user has to work with more than one corporate web application, and maintaining, remembering, and supporting multiple passwords should be avoided. Many enterprises implement internally a single sign-on (SSO) mechanism to eliminate the need for a user to enter login credentials more than once, even if that user works with multiple applications. Accordingly, signing out from one of these applications terminates the user’s access to all of them. SSO solutions make authentication totally transparent to your application.
With SSO, when the user logs on to your application, the logon request is intercepted and handled by preconfigured SSO software (for example, Oracle Enterprise Single Sign-On, CA SiteMinder, IBM Security Access Manager for Enterprise SSO, or Evidian Enterprise SSO). The SSO infrastructure verifies a user’s credentials by making a call to a corporate Lightweight Directory Access Protocol (LDAP) server and creates a user’s session. Usually a web server is configured with some web agent that will add the user’s credentials to the HTTP header, which your application can fetch.
Future access to the protected web application is handled automatically by the SSO server, without even displaying a logon window, as long as the user’s session is active. SSO servers also log all login attempts in a central place, which can be important in meeting enterprise regulatory requirements (for example, Sarbanes-Oxley in the financial industry or medical confidentiality in the insurance business).
In the consumer-oriented Internet space, single (or reduced) sign-on solutions have become more and more popular. For example, some web applications allow you to reuse your Twitter or Facebook credentials (provided that you’ve logged in to one of these applications) without the need to go through additional authentication procedures. Basically, your application can delegate authentication procedures to Facebook, Twitter, Google, and other authorization services, which we’ll discuss later in OAuth-Based Authentication and Authorization.
Back in 2010, Facebook introduced its SSO solution that still helps millions of people log in to other applications. This is especially important in the mobile world, where users’ typing should be minimized. Instead of asking a user to enter credentials, your application can provide a Login with Facebook button.
Facebook has published a JavaScript API with which you can implement Facebook Login in your web applications (it also offers native APIs for iOS and Android apps). For more details, read the online documentation on the FaceBook Login API.
Besides Facebook, other popular social networks offer authentication across applications:
§ If you want your application to have a Login with Twitter button, refer to the Sign in with Twitter API documentation.
§ LinkedIn is a popular social network for professionals. It also offers an API for creating a Sign In with LinkedIn button. For details, visit the LinkedIn online documentation for developers.
§ Google also offers the OAuth-based authentication API. Details about its client library for JavaScript are published online. To implement SAML-based SSO with Google, visit this web page.
§ Mozilla offers a new way to sign in with any of your existing email addresses by using Persona.
§ Several large organizations (for example, Google, Yahoo!, Microsoft, and Facebook) either issue or accept OpenID, which makes it possible for users to sign in to more than 50,000 websites.
Typically, large enterprises don’t want users to use logins from social networks. But some organizations have started integrating their applications with social networks. Especially now, with the spread of mobile devices, users might need to be authenticated and authorized while being outside the enterprise perimeter. We discuss this in more detail in OAuth-Based Authentication and Authorization.
Save The Child and SSO
Does our Save The Child application have a use for SSO? Certainly. In this book, we’re concerned mostly about developing a UI for the consumer-facing part of this application. But there is also a back-office team that is involved with content management and that produces information for the consumer.
For example, the employees of our charity organization create fundraising campaigns in different cities. If an employee of this firm logged in to his desktop, our Save The Child web application shouldn’t ask him to log in. SSO can be a solution here.
Handling Passwords
It might sound obvious, but we’ll still remind you that the web client should never send passwords in clear text. You should always use a Secure Hash Algorithm (SHA). Longer passwords are more secure, because if an attacker tries to guess the password by using dictionaries to generate every possible combination of characters (a brute-force attack), it will take a lot more time with long passwords. Periodically changing passwords makes the hacker’s work more difficult, too. Typically, after successful authentication, the server creates and sends to the web client the session ID, which is stored as a cookie on the client’s computer. Then, on each subsequent request to the server, the web browser places the session ID in the HTTP request object and sends it along with each request. Technically, the user’s identity is always known at the server side, so the server-side code can re-authenticate the user more than once (without the user even knowing it), whenever the web client requests the protected resource.
TIP
Salted hashes increase security by adding salt—randomly generated data that’s concatenated with the password and then processed by a hash function.
Have you ever wondered why automated teller machines (ATMs) often ask you to enter your PIN more than once? Say you’ve deposited a check and then want to see the balance on your account. After the check deposit is completed, your ATM session is invalidated to protect careless users who might rush out from the bank in a hurry as soon as the transaction is finished. This prevents the next person at the ATM from requesting a cash withdrawal from your bank account.
On the same note, if a web application’s session is idling for more than the allowed time interval, the session should be automatically invalidated. For example, if a trader in a brokerage house stops interacting with a web trading application for some time, invalidate the session programmatically to prevent someone else from buying financial products on his behalf when he steps out for a coffee.
Authorization
Authorization is a way to determine which operations the user can perform and what data he can access. For example, the owner of a company can perform money withdrawals and transfers from an online business bank account, whereas the company accountant is provided with read-only access.
NOTE
Similar to authentication, the user’s authorization can be checked more than once during that user’s session. As a matter of fact, authorization can even change during a session (for example, a financial application can allow trades only during business hours of the stock exchange).
Users of an application are grouped by roles, and each role comes with a set of privileges. A user can be given a privilege to read and modify certain data, whereas other data can be hidden. In the relational DBMS realm, the term row-level security means that the same query can produce different results for different users. Such security policies are implemented at the data-source level.
A simple use case for which row-level security is really useful is a salary report. Whereas the employee can see only his salary report, the head of department can see the data of all subordinates.
Authorization is usually linked to a user’s session. HTTP is a stateless protocol, so if a user retrieves a web page from a web server, and then goes to another web page, this second page does not know what has been shown or selected on the first one. In an online store, for example, a user adds an item to a shopping cart and moves to another page to continue shopping. To preserve the data reused in more than one web page (for example, the content of the shopping cart), the server-side code must implement session-tracking. The session information can be passed all the way down to the database level when need be.
NOTE
Session tracking is usually controlled on the server side. To become familiar with session tracking options in greater detail, consult the product documentation for the server or technology being used with your web application. For example, if you use Java, you can read Oracle’s documentation for its WebLogic server that describes options for session management.
OAuth-Based Authentication and Authorization
To put it simply, OAuth is a mechanism for delegated authorization. OpenID Connect is an OAuth-based mechanism for authentication.
Most likely, you have come across web applications that enable you to share your actions via social networks. For example, if you just made a donation, you might want to share this information via social networks.
If our charity application needs to access a user’s Facebook account for authentication, the charity app could ask for the user’s Facebook ID and password. This wouldn’t be the correct approach, however, because the charity application would get the user’s Facebook ID/password in clear text, along with full access to the user’s Facebook account. The charity app needs only to authenticate the Facebook user. Hence, there is a need for a mechanism that gives limited access to Facebook.
OAuth has become one of the mechanisms for providing limited access to an authorizing facility. OAuth is “An open protocol to allow secure authorization in a simple and standard method from web, mobile and desktop applications.” Its current draft specification provides the following definition:
The OAuth 2.0 authorization framework enables a third-party application to obtain limited access to an HTTP service, either on behalf of a resource owner by orchestrating an approval interaction between the resource owner and the HTTP service, or by allowing the third-party application to obtain access on its own behalf.
“OAuth Study Notes” includes the following:
Many luxury cars come with a valet key. It is a special key you give the parking attendant and unlike your regular key, will only allow the car to be driven a short distance while blocking access to the trunk.
This is a good example of limited access to a resource in a real life. The OAuth 2.0 authorization server gives the requesting application an access token (think, valet key) so it can access, say, the charity application.
OAuth allows users to give limited access to third-party applications without giving away their passwords. The access permission is given to the user in the form of an access token with limited privileges and for a limited time. Coming back to our example of communication between the charity app and Facebook (unless we have our own enterprise authentication server), the former would gain limited access to the user’s Facebook account (just the valet key, not the master key).
OAuth has become a standard protocol for developing applications that require authorization. With OAuth, application developers won’t need to use proprietary protocols if they need to add an ability to identify a user via multiple authorization servers.
Federated Identity with OpenID Connect and JSON Web Tokens
Wikipedia defines federated identity as a means of linking a person’s electronic identity and attributes, stored across multiple distinct identity management systems. This is similar to enterprise SSO, but the effect of federated identity is broader because the authentication token with information about a user’s identity can be passed across multiple departments or organizations and software systems.
Microsoft’s “A Guide to Claims-Based Identity and Access Control” includes a section on federated identity for web applications with greater details on this subject.
In the past, the markup language SAML was the most popular open-standard data format for exchanging authentication and authorization data. OpenID Connect is a newer open standard. It’s a layer on top of OAuth 2.0 that simply verifies the identity of a user. OpenID providers that can confirm a user’s identity include such companies as Google, Yahoo!, IBM, Verisign, and more. Typically, OpenID Connect uses JSON Web Token (JWT), which should eventually replace popular XML-based SAML tokens. JWT is a Base64 encoded and signed JSON data structure. Although the OAuth 2.0 spec doesn’t mandate using JWT, it became a de facto standard token format.
To have a better understanding of how JWTs are encoded, visit the Federation Lab, which is a website with a set of tools for testing and verifying various identity protocols. In particular, you can enter a JWT in clear text, select a secret signature, and encode the token by using the HS256 algorithm, as shown in Figure 9-1.
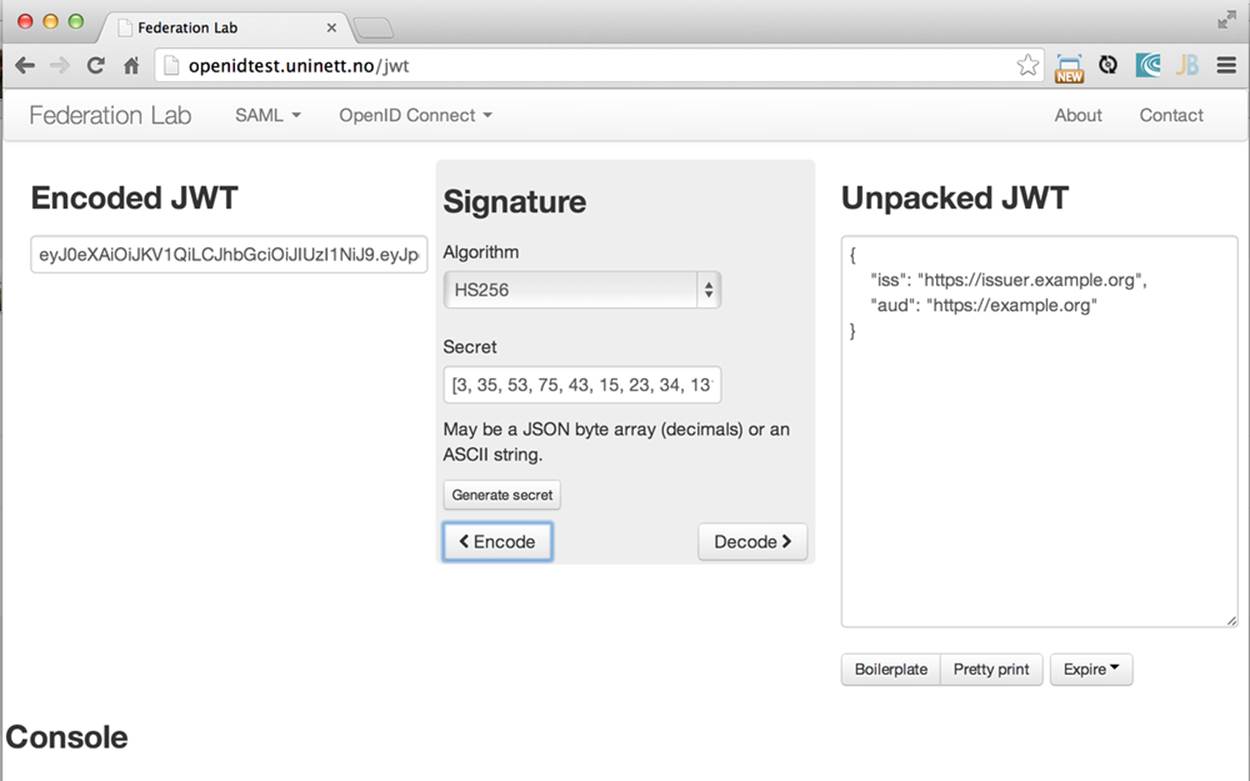
Figure 9-1. Encoding a JSON Web Token
USING THE FACEBOOK API
Facebook is one of the authorization servers that offer an OAuth-based authentication and authorization API. The online document “Quickstart: Facebook SDK for JavaScript” is a good starting point.
Before using the SDK, you need to register your application with Facebook by creating a client ID and obtaining the client secret (the password). Then, use the JavaScript SDK code (provided by Facebook) in your web application. Include the newly created app ID there. During this registration stage, you’ll need to specify the URI where the user should be redirected in case of successful login. Then, add a JavaScript code to support the required Facebook API (for example, for Login) to your application. You can find sample JavaScript code that uses the Facebook Login API in this guide.
The Facebook Login API communicates with your application by sending events as soon as the login status changes. Facebook will send the authorization token to your application’s code. As we mentioned earlier, the authorization token is a secure encoded string that identifies the user and the app, contains information about permissions, and has an expiration time. Your application’s JavaScript code makes calls to the Facebook SDK API, and each of these calls will include the token as a parameter or inside the HTTP request header.
OAuth 2.0 Main Actors
Any communication with OAuth 2.0 servers are made through HTTPS connections. The following are the main actors of the OAuth flows:
§ The user who owns the account with some of the resource servers (for example, an account at Facebook or Google) is called the resource owner.
§ The application that tries to authenticate the resource owner is called the client application. This is an application that offers buttons such as Login with Facebook, Login with Twitter, and the like.
§ The resource server is a place where the resource owner stores his data (for example, Facebook or Google).
§ The authorization server checks the credentials of the resource owner and returns an authorization token with limited information about the user. This server can be the same as the resource server but is not necessarily the same one. Facebook, Google, Windows Live, Twitter, and GitHub are examples of authorization servers. For the current list of OAuth 2.0 implementations, visit oauth.net/2.
To implement OAuth in your client application, you need to pick a resource/authorization server and study its API documentation. Keep in mind that OAuth defines two types of clients: public and confidential. Public clients use embedded passwords while communicating with the authorization server. If you’re going to keep the password inside your JavaScript code, it won’t be safe. To be considered a confidential client, a web application should store its password on the server side.
OAuth has provisions for creating authorization tokens for browser-only applications, for mobile applications, and for server-to-server communications.
Save The Child and OAuth
We can distinguish two major scenarios of a third-party application working with an OAuth server. In one scenario, OAuth authorization servers are publicly available. In the other scenario, the servers are privately owned by the enterprise. Let’s consider these scenarios in the context of our charity nonprofit organization.
Public authorization servers
A Facebook account owner works with the client (the Save The Child application). The client uses an external authorization server (Facebook) to request authorization of the user’s work with the charity application. The client has to be registered (has an assigned client ID, secret, and redirect URL) with the authorization server to be able to participate in this OAuth flow. The authorization server returns a token offering limited access (for example, to Facebook’s account) to the Save The Child application. Figure 9-2 shows Save The Child using Facebook for authentication and authorization.
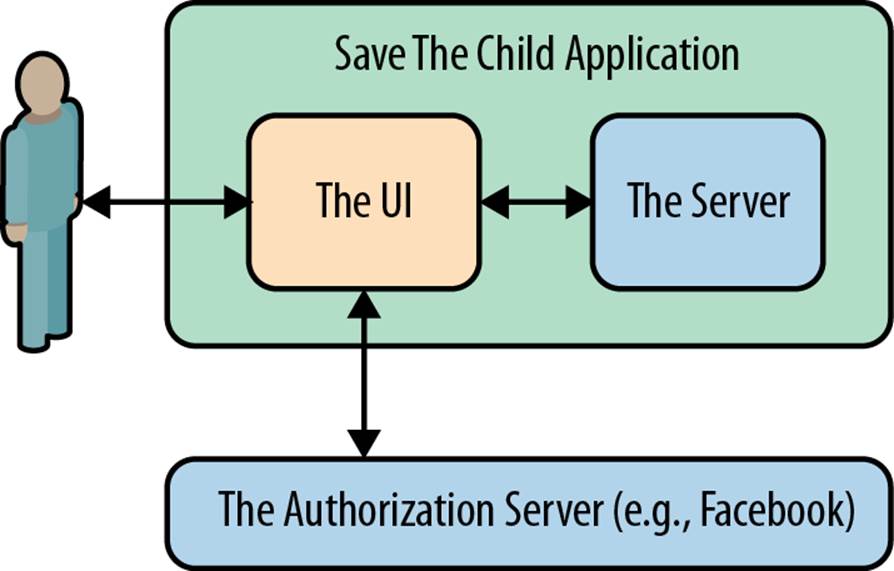
Figure 9-2. Save The Child and OAuth
While the client application tries to get authorization from the authorization server, it can open a so-called consent window that warns the user that the Save The Child application is trying to access certain information from the user’s Facebook or Google account. In this scenario, the user still has a chance to deny such access. It’s a good idea to display a message that the user’s password (to Facebook or Google) will not be given to the client application.
Your application should request only minimum access to the user’s resource server. For example, if the Save The Child application just needs to offer an easy authentication method for all Facebook users, don’t request write access to the user’s Facebook account. On the other hand, if a child was cured as a result of the involvement of our charity application, and he wants to share the good news with his Facebook friends, the Save The Child application needs write permission to the user’s Facebook account.
The UI code of the Save The Child application doesn’t have to know how to parse the token returned by the authorization server. It can simply pass it to Save The Child’s server software (for example, via the HTTP request header). The server has to know how to read and decipher the information from the token. The client application sends to the authorization server only the client ID, and not the client secret needed for deciphering the user’s information from the token.
Private authorization servers
The OAuth authorization server is configured inside the enterprise. However, the server can attend to not only internal employees, but also external partners. Suppose that one of the upcoming charity events is a marathon to fight cancer. To prepare this marathon, our charity organization needs the help of a partner company named Global Marathon Suppliers, which will take care of the logistics (providing banners, water, food, rain ponchos, blankets, branded tents, and so forth).
It would be nice if our supplier could have up-to-date information about the number of participants in this event. If our charity firm sets them up with access to our internal authorization server, the employees of Global Marathon Suppliers can have limited access to the marathon participants. On the other hand, if the suppliers open limited access to their data, this could increase the productivity of the charity company employees. This is a practical and cost-saving setup.
NOTE
The authors of this book have helped the Leukemia and Lymphoma Society (LLS) develop both front- and backend software. LLS ran a number of successful marathons as well as many other campaigns for charity causes. We also use an OAuth solution from Intuit QuickBooks in billing workflows for our insurance industry software product at SuranceBay. Our partner companies get limited access to our billing systems, and our software can access theirs.
Top Security Risks
The Open Web Application Security Project (OWASP) is an open source project focused on improving security of web applications by providing a collection of guides and tools. OWASP publishes and maintains a list of the top 10 security risks. Figure 9-3 shows how this list looked in 2013.
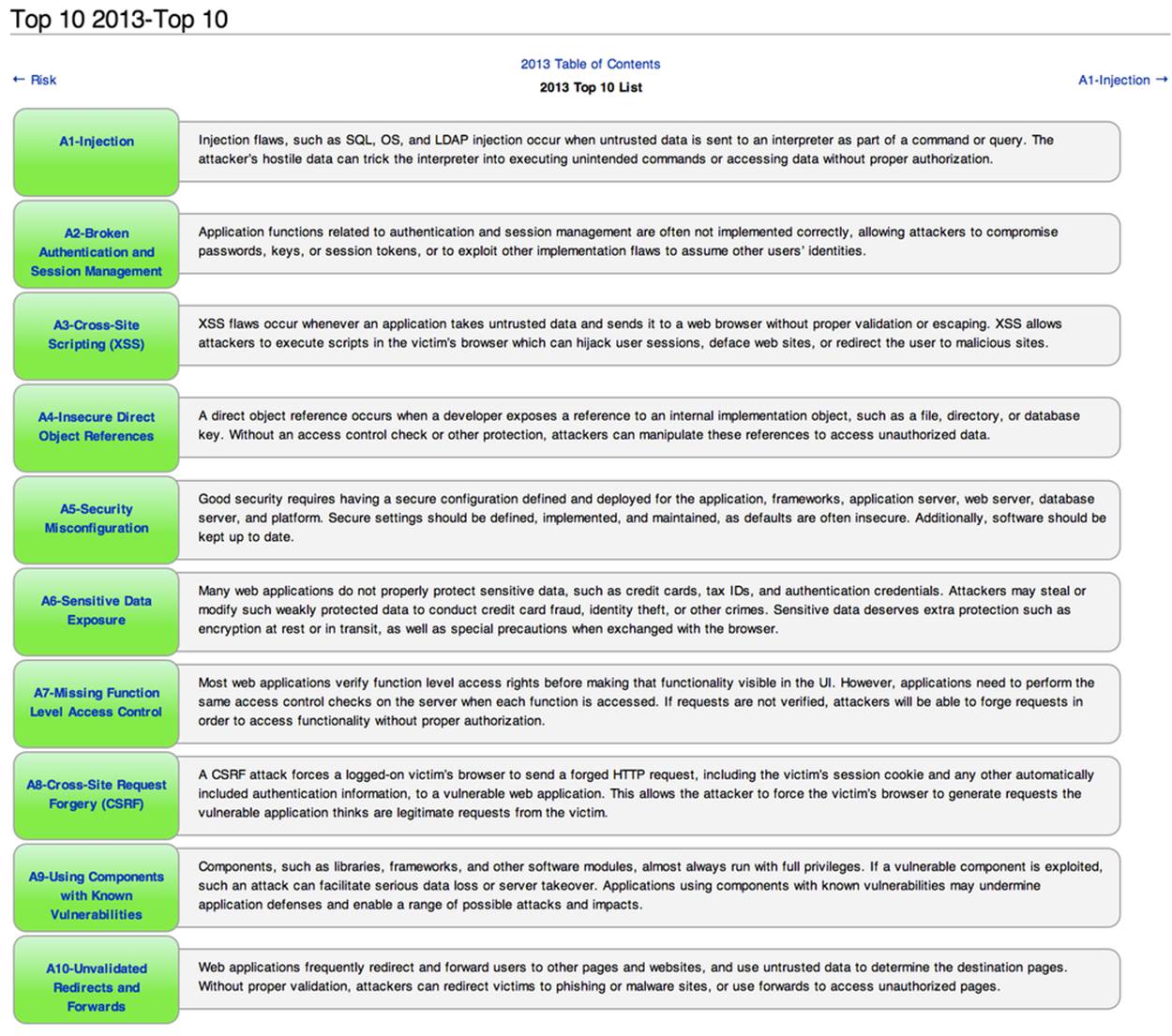
Figure 9-3. Top 10 security risks, circa 2013
On this website, you can drill down into each list item to see the selected security vulnerabilities and recommendations on how to prevent them. You can also download this list as a PDF document. Let’s review a couple of the top-10 security threats: injection and cross-site scripting.
Injection
If a bad guy can inject a piece of code that will run inside your web application, that code could steal or damage data from the application. In the world of compiled libraries and executables, injecting malicious code is a rather difficult task. But if an application uses interpreted languages (for example, JavaScript or clear-text SQL), the task of injecting malicious code becomes a lot easier than you might think. Let’s look at a typical example of SQL injection.
Suppose that your application can search for data based on keywords a user enters into a text input field. For example, to find all donors in the city of New York, a user enters the following:
"New York"; delete from donors;
If the server-side code of your application simply attaches the entered text to the SQL statement, this could result in execution of the following command:
Select * from donors where city="New York"; delete from donors;
This command doesn’t require any additional comments, does it? Is there a way to prevent users of your web application from entering something like this? The first thing that comes to mind is to not allow the user to enter the city, but force her to select it from a list. But such a list of possible values might be huge. Besides, the hacker can modify the HTTP request after the browser sends it to the server.
TIP
Always use precompiled SQL statements that use parameters to pass the user’s input into the database query (for example, PreparedStatement in Java).
The importance of server-side validation shouldn’t be underestimated. In some scenarios, you can come up with a regular expression that checks for matching patterns in data received from clients. In other cases, you can write a regular expression that invalidates data if it contains SQL (or other) keywords that lead to modifications of data on the server.
TIP
Always minimize the interval between validating and using the data.
In an ideal world, client-side code should not even send nonvalidated data to the server. But in the real-world, you’ll end up duplicating some of the validation code in both the client and the server.
Cross-Site Scripting
Cross-site scripting (XSS) occurs when an attacker injects malicious code into a browser-side script of your web application. The user is accessing a trusted website, but gets an injection from a malicious server that reaches the user via the trusted server (hence, cross-site). Single-page Ajax-based applications make lots of under-the-hood requests to servers, which increases the attack surface compared to traditional legacy websites that download web pages a lot less frequently. XSS can happen in three ways:
Reflected (a.k.a. phishing)
The web page contains a link that seems valid, but when the user clicks it, the user’s browser receives and executes the script created by the attacker.
Stored
The external attacker manages to store a malicious script on a server that hosts someone’s web application, so every user gets the script as a part of that web page, and their web browser executes it. For example, if a user’s forum allows posting texts that include JavaScript code, malicious code typed by a “bad guy” can be saved in the server’s database and executed by users’ browsers visiting this forum afterward.
Local
No server is involved. Web page A opens web page B with malicious code, which in turn modifies the code of page A. If your application uses a hash tag (#) in URLs (for example, http://savesickchild.org#something), make sure that before processing, this something doesn’t contain anything like javascript:somecode, which might have been attached to the URL by an attacker.
The World Wide Web Consortium (W3C) has published a draft of the Content Security Policy document, “a mechanism web applications can use to mitigate a broad class of content injection vulnerabilities, such as cross-site scripting.”
STRIDE—CLASSIFICATION OF SECURITY THREATS
Microsoft has published a classification that divides security threats into six categories (hence six letters in the acronym STRIDE):
Spoofing
An attacker pretends to be a legitimate user of an application (for example, a banking system). This can be implemented by using XSS.
Tampering
Modifying data that was not supposed to be modified (for example, via SQL injection).
Repudiation
The user denies sending data (for example, making an online transaction such as a purchase or sale) by modifying the application’s logfiles.
Information disclosure
An attacker gains access to classified information.
Denial of service (a.k.a. DoS)
A server is made unavailable to legitimate users, which often is implemented by generating a large number of simultaneous requests to saturate the server.
Elevation of privilege
Gaining an elevated level of access to data (for example, by obtaining administrative rights).
NOTE
While we were working on a section of this book describing Apple’s developer certificates (Chapter 14), its website was hacked, and was not available for about two weeks.
IMPORTANT
One of the OWASP guides is titled Web Application Penetration Testing. In about 350 pages, it explains the methodology of testing a web application for each vulnerability. OWASP defines penetration test as a method of evaluating the security of a computer system by simulating an attack. Hundreds of security experts from around the world have contributed to this guide. Running penetration tests should become part of your development process, and the sooner you start running them, the better.
For example, the Payment Card Industry published a Data Security Standard, which includes a Requirement 11.3 of penetration testing.
Regulatory Compliance and Enterprise Security
So far in this chapter, we’ve been discussing security vulnerabilities from a technical perspective. But another aspect can’t be ignored: the regulatory compliance of the business you automate.
During the last four years, the authors of this book have developed, deployed, supported, and marketed software that automates certain workflows for insurance agents. We serve several hundred insurance agencies and more than 100,000 agents. In this section, we’ll share our real-world experience of dealing with security while running our company, which sells software as a service. In addition to developing the application, we had to set up data centers and take care of security issues, too.
Our customers are insurance agencies and carriers. We charge for our services, and our customers pay by using credit cards via our application. This opens up a totally different category of security concerns:
§ Where are the credit card numbers stored?
§ What if they are stolen?
§ How secure is the payment portion of the application?
§ How is the card holder’s data protected?
§ Is there a firewall protecting each customer’s data?
§ How is the data encrypted?
One of the first questions our prospective customers ask is whether our application is PCI compliant. They won’t work with us until they review the application-level security implemented in our system. As per the PCI Compliance Guide, “The Payment Card Industry Data Security Standard is used by all card brands to assure the security of the data gathered while an employee is making a transaction at a bank or participating vendor.”
If your application stores PCI data, authenticating via Facebook, Google, or a similar OAuth service isn’t an option. Users are required to authenticate themselves by entering long passwords containing combinations of letters, numbers, and special characters.
Even if you are not dealing with credit card information, there are other areas where application data must be protected. Take a human resources application—Social Security numbers (unique IDs of United States citizens) of employees must be encrypted.
Some of our prospective customers send us a questionnaire to establish whether our security measures are compliant with their requirements. In some cases, this document can include as many as 300 questions.
You might want to implement different levels of security depending on which type of device is being used to access your application—a public computer, an internal corporate computer, an iPad, or an Android tablet. If a desktop user forgets his password, you could implement a recovery mechanism that sends an email to that user and expects to receive a certain response from him. If the user has a smartphone, the application could send a text message to that device.
If the user’s record contains both his email and cell phone number, the application should ask where to send the password recovery instructions. If a mobile device runs a hybrid or native version of the application, the user could be automatically switched to a messaging app of the device so that he can read the text message while the main application remains at the view where authentication is required.
In enterprise web applications, more than one layer of security must be implemented: at the communication protocol level, at the session level, and at the application level. The HTTP server NGINX, besides being a high-performance proxy server and load balancer, can serve as a security layer, too. Your web application can offload authentication tasks and validation of SSL certificates to NGINX.
Most enterprise web applications are deployed on a cluster of servers, which adds another task to your project plan: how to manage sessions in a cluster. The user’s session has to be shared among all servers in a cluster. High-end application servers might implement this feature out of the box. For example, an IBM WebSphere server has an option to tightly integrate HTTP sessions with its application security module. Another example is Terracotta clusters, which utilize Terracotta Web Sessions to allow sessions to survive node hops and failures. But small or mid-sized applications might require custom solutions for distributed sessions.
TIP
Minimize the amount of data stored in a user’s session, to simplify session replication. Store the data in an application cache that can be replicated quickly and efficiently by using open source or commercial products (for example, JGroups or Terracotta).
Here’s another topic to consider: multiple data centers, with each one running a cluster of servers. To speed up the disaster recovery process, your web application has to be deployed in more than one data center, located in different geographical regions. User authentication must work even if one of the data centers becomes nonoperational.
An external computer (for example, a NGINX server) can perform token-based authentication, but inside the system, the token is used only when access to protected resources is required. For example, when the application needs to process a payment, it doesn’t need to know any credit card details; it just uses the token to authorize the transaction of the previously authenticated user.
This grab bag of security considerations mentioned in this section is not a complete list of security-related issues to which your IT organization needs to attend. If you work for a large enterprise on intranet applications, these security issues might not sound overly important. But as soon as your web application starts serving external Internet users, someone has to worry about potential security holes that were not in the picture for internal applications. Our message to you is simple: Take security very seriously if you are planning to develop, deploy, and run a production-grade enterprise web application.
Summary
Every enterprise web application has to run in a secure environment. The mere fact that the application runs inside a firewall doesn’t make it secure. First, if you’re opening at least one port to the outside world, malicious code can sneak in. Second, an “angry employee” or just a “curious programmer” inside the organization could inject unwanted code.
Proper validation of received data is very important. Ideally, use white list validation to compare user input against a list of allowed values. Otherwise, use black list validation to compare against keywords that are not allowed in data entered by users.
There is no way to guarantee that your application is 100 percent protected from security breaches. But you should ensure that your application runs in an environment with the latest available patches for known security vulnerabilities. For example, if your application includes components written in the Java programming language, install critical security patches as soon as they become available.
With the proliferation of clouds, social networks, and sites that offer free or cheap storage, people lose control over security, hoping that Amazon, Google, or Dropbox will take care of it. Besides software solutions, software-as-a-service providers deploy specialized hardware—security appliances that serve as firewalls, perform content filtering, and virus and intrusion detection. Interestingly enough, hardware security appliances are also vulnerable.
In any case, end users upload their personal files without thinking twice. Enterprises are more cautious and prefer private clouds installed on their own servers, where they administer and protect data themselves. Users who access the Internet from their mobile devices have little or no control over how secure their devices are. So the person in charge of the web application has to make sure that it’s as secure as possible.
Part III. Responsive Web Design and Mobile Devices
BYOD stands for bring your own device. It has become a new trend as a result of the increasing number of enterprises that started allowing their employees to access corporate applications from personal tablets or smartphones.
CYOD stands for choose your own device. In this paradigm, corporations let their employees choose from a set of devices that belong to the enterprise. CYOD is about selecting a strategy that organizations should employ while approving new devices.
Developers of new web applications should always think of the users who will try to run the application on a mobile device. This part of the book is about various strategies for developing web applications that look and perform well on both desktop computers and smaller screens.
Today, most enterprise applications are still being developed for desktop computers. The situation is changing, but it’s a slow process. If five years ago it was close to impossible to get permission to bring your own computer to work and use it for work-related activities, the situation is entirely different now with BYOD and CYOD.
Sales people want to use tablets while dealing with prospective clients. Business analysts want to be able to run familiar web applications on their smartphones. Enterprises want to offer external access access to valuable data from a variety of devices.
In Chapter 10 we explain responsive web design (RWD) and how you can build an HTML5 application that has a single code base for desktops, tablets, and smartphones. We’ll apply responsive design principles and redesign our Save The Child application to have a fluid layout so that it will remain usable on smaller screens, too.
Another approach is to have separate versions of the application for desktops and mobile devices. Chapter 11 and Chapter 12 demonstrate how to create dedicated mobile versions of web applications with the jQuery Mobile library and Sencha Touch framework, respectively. And the Save The Child application is rewritten in each of these chapters.
But if using RWD allows you to have a single code base for all devices, you might be wondering, why not just build every web application this way? RWD works fine for sites that mainly publish information. But if users are expected not just to read, but also to input data on small-screen devices, the UI and the navigation might need to be custom designed to include only partial functionality while each page view provides the best user experience. Besides, with responsive design, the code and CSS for all devices is loaded to a user’s smartphone, making the application unnecessarily large and slow when the connection speed is not great.
With small screens, you have to rethink carefully about which widgets are must-haves and what functionality is crucial to the business for which you’re creating a web application. If it’s a restaurant, you need to provide an easy way to find the menu, phone, address, and directions to your location. If it’s a site to collect donations, like Save The Child, the design should provide an easy way to donate, while the rest of the information should be hidden by simple navigational menus.
On rare occasions, an enterprise application is created solely for mobile platforms. More often, the task is to migrate an existing application to a mobile platform or develop separate versions of the same application for desktops and mobile devices. If a decision is made to develop native mobile applications, the choice of programming languages is dictated by the mobile hardware.
If it’s a web application, using the same library or framework for desktop and mobile platforms can shorten the development cycle. That’s why we decided to cover such pairs in this book, namely:
§ jQuery and jQuery Mobile
§ Ext JS and Sencha Touch
But even though each of these pairs shares the same code for core components, do not expect to be able to kill two birds with one stone. You are still going to use different versions of the code—for example, jQuery 2.0 and jQuery Mobile 1.3.1. This means that you might have to deal with separate bugs that sneaked into the desktop and mobile version of the frameworks.
What’s better: jQuery Mobile or Sencha Touch? There is no general answer to this question. It all depends on the application you’re building. If you need a simple mobile application for displaying various information (a publishing type of application), jQuery Mobile will do the job with the least effort. If you are building an application that requires some serious data processing, Sencha Touch is a better choice. Of course, lots of other frameworks and libraries are available that can help you develop a mobile web application. Do your homework and pick the one that best fits your needs.
There’s a website that compares mobile frameworks. It even has a little wizard application with which you can pick a framework that meets your needs and is supported on required devices. Figure 116 is a fragment snapshot from this site. As you can see, jQuery Mobile supports the largest number of platforms.

Figure 116. Platforms supported by jQuery Mobile
TIP
A framework called Zepto is a minimalist JavaScript library with an API compatible to jQuery. Zepto supports both desktop and mobile browsers.
Finally, in Chapter 13 we talk about yet another approach for developing HTML5 applications for mobile devices: hybrid applications. These applications are written in JavaScript but are packaged as native apps. You’ll learn how Adobe’s PhoneGap can package an HTML5 application to be accepted in online stores where native applications are being offered. To illustrate accessing hardware features of a mobile device, we show you how to access the device’s camera; this can be a useful feature for the Save The Child application.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.