EPiServer 7 CMS Development (2014)
II. SITE DEVELOPMENT
Having covered what EPiServer CMS is and how it’s used to edit content in part one the time has (finally) come to learn how to develop websites with EPiServer. In this part of the book we’ll focus on the core concepts of EPiServer CMS development and create a simple but fully functional site.
After a look at core classes and concepts in chapter four and some essential tools in chapter five we get to hands-on development in the subsequent chapters, starting from scratch by creating a new, empty EPiServer site project and building and gradually turning it into a full blown site with page types, templates and dynamic navigation components.
Chapter 4. Core concepts
Learning software development technologies is often a case of the chicken or the egg dilemma. If we start with how to build something we need to take the code at face value without understanding the underlying concepts. If we on the other hand start with the underlying concepts things tend to become abstract and frustrating.
To address this problem, without having found a magical solution for it, we’ll start with a minimum of core concepts and classes in this chapter, and then elaborate on them as we get hands-on with actual development. So, before we delve into hands-on development let’s cover some theory.
PageData
The PageData class located in the EPiServer.Core namespace is used to represent pages in EPiServer CMS. That is, each page shown on in the page tree in edit mode is an instance of the PageData class. In general a PageData object is synonymous to a web page on the site.
The PageData class has a lot of members. Some of the most significant are listed below:
PageName : string
The page’s name that is displayed in the page tree and in other places in edit mode. The page name is often also used as the page’s heading in templates.
Item : Object Allows access to a page’s property values using indexer syntax. For instance, to retrieve a page’s name without using the PageName property the following can be used:
PageData page; //We assume page has been initialized.
var name = page["PageName"] as string;
PageTypeID : int
The ID of the page’s page type. See the section about page types below.
PageLink : PageReference
The PageReference object that is the unique identifier of this page. Think of this property as the ID of the page. See the section about ContentReference and PageReference below.
VisibleInMenu : bool
A built in property for all pages that is intended to be used when rendering navigation components on the site. If the property returns false the page should not be displayed in navigations/menus. The page is however still fully accessible to public visitors. The property corresponds to the “Display in navigation” checkbox in the top area when editing a page in forms editing mode.

The checkbox in forms editing that corresponds to the VisibleInMenu property.
Page types and content types
While all pages are represented as PageData objects in the CMS, pages can have different characteristics in the form of different properties. What properties a page has is defined by its page type.
Think of a page type as a class in code. When an editor creates a new page he or she selects what page type the new page should be of. After doing so a new instance of the class is created. The class defines what properties the page has. The editor can enter values into those properties and then save the page to the database.
In object oriented programming a class acts as a template for objects. The class defines the characteristics of objects created from it. A page type isn’t a class. It’s an entity stored in EPiServer’s database and it can be modified in admin mode. However page types are so closely resembling classes that it’s possible, and indeed the preferred way, to create page types by creating classes. When doing so pages are returned as instance of those classes.
|
|
Being able to create page types in code is a new feature in version 7 of the CMS. However, for versions 5 and 6 there was, and is, an open source project called Page Type Builder that accomplishes the same goal. As defining page types in code is the preferred approach of most EPiServer developers it’s also the main approach used in this book. |

Content types
It’s convenient to think of pages and page types as those concepts those are fairly concrete. However, as we’ll soon see, EPiServer 7 supports other type of content than pages. Therefore there’s a more general concept than page types - content types.
IContent
Prior to version 7 EPiServer only supported a single type of content apart from uploaded files - pages. Therefor, when building sites with older versions of the CMS pages were used by developers for other things than just web pages. For instance, pages of a certain type could be used as data containers for widgets used on other pages.
In version 7 EPiServer CMS’ API is no longer limited to just pages, it supports content. Such content can be just about anything as long as it’s a class that implements the IContent interface. In other words, if you have a an instance of a class that implements IContent EPiServer’s API can be used to save it to the CMS’ database. Obviously pages are content and the PageData class implements IContent.
The IContent interface, located in the EPiServer.Core namespace, has six members that a class that implements it must define:
Name : string
All content must provide a name that the CMS can use when displaying it in edit mode. The Name property can of course also be used when rendering the content for public visitors but that’s up to site developers. The PageData class implements the Name property by returning the value of the page’s PageName property.
ContentLink : ContentReference
Should return a ContentReference object that uniquely identifies the content, optionally with a version, on the site. See the explanation of the ContentReference class below.
ParentLink : ContentReference
Should return a ContentReference for the content item’s parent in the content tree. For page’s this means the page’s parent page in the page tree. However, in practice all content reside in the same tree whereas the page tree is a view of that tree.
IsDeleted : bool
If this property returns true the content is “soft deleted”, meaning it hasn’t been removed from the database but has been moved to the Trash.
ContentTypeID : int
The ID of the content’s content type.
ContentGuid : Guid
While the ContentLink property can be used to uniquely identify a content item on the site where it resides there may very well be some other EPiServer site somewhere that has a content item with the same ContentReference. That’s not a problem, until you try to move the content to that site, for instance using EPiServer’s import/export functionality.
In order to support functionality for moving content between different EPiServer sites all content must also have a Guid, in the form of this property, that can be used to identify it.
ContentReference and PageReference
When an object implementing IContent is saved to EPiServers database it’s inserted into a table with a numeric primary key. In other words, there’s an unique integer ID for each content item, such as a page, stored in EPiServer’s database.
This may lead us to believe that each page or other content in a site can be identified using a numeric ID. However, EPiServer supports plugging in other data sources in addition to it’s own database using a concept called content providers. This means that while each content in EPiServer’s own database is guaranteed to have a unique numeric ID that’s not necessarily true for all content that can be retrieved using the CMS’ API. There may very well be two, or more, contents that have the same numeric IDs if they are retrieved from different content providers. Therefore another component is necessary to uniquely identify a given content item, the provider name.
Furthermore we may want to retrieve a specific version of some content item. Or, we may want to implicitly retrieve the default version, meaning either the published version or the last version if there is no published version.
In order to address these issues EPiServer has a class named ContentReference located in the EPiServer.Core namespace. Not surprisingly the ContentReference class has three properties for identifying content - ID (int), ProviderName (string) and WorkID (int). The latter, if specified, identifies a specific version.
|
|
Heads up! Unfortunately it’s not uncommon to see developers use just the ID property of ContentReference/PageReference objects in their code. Such code is treacherous as it may seemingly work fine for a long time, only to later produce weird bugs when a content provider is introduced on the site. Always use ID + ProviderName to identify content. |

PageReference
In older versions of the CMS there wasn’t the concept of generic “content”, there was only the more specialized concept of pages. The class for unique identifiers for pages was called PageReference. In EPiServer 7 the ContentReference class was introduced making the PageReference class seem redundant. However, the PageReference class is still around. It inherits ContentReference and many of it’s members has been moved up to the ContentReference class.
The PageReference class was partly kept for backwards compatibility reasons. However, in addition to those it also serves a purpose of being more specific than the ContentReference class. A ContentReference can be a reference to a content item of any type. A PageReference is a ContentReference but it should only be a reference to a page (a PageData object).
ContentReference members
In addition to the data bearing properties ID, ProviderName and WorkID ContentReference objects also have a few other useful members that often comes in handy:
Equals(Object) : bool
The ContentReference class overrides the Equals method inherited from Object to compare ContentReference objects by evaluating whether ID, ProviderName and WorkID all match. The ContentReference class also overloads the equality operator (==) with an implementation that invokes theEquals method.
CompareToIgnoreWorkID(ContentReference) : bool
Compares a ContentReference instance to another instance like the Equals method. However, this method only checks ID and ProviderName for equality. In many situations this is the desired behavior. In fact I’d say that I’ve used CompareToIgnoreWorkID a hundred times for every time I’ve used the Equals method during regular site development.
|
|
It’s common to see code such as page.PageLink.ID == someContentReference.ID` and page.PageLink.ID == someContentReference.ID && page.PageLink.ProviderName == someContentReference.ProviderName` in EPiServer projects. The first one, comparing only ID is in most cases flawed and a bug waiting to happen as it doesn’t take ProviderName into account. The second isn’t flawed but clearly using more code than what is needed seeing as we have the CompareToIgnoreWorkID method at our disposal. So, a tip for writing better and shorter code is to remember the CompareToWorkID method. |

ToString() : string
The ContentReference class overloads the ToString method inherited from Object. Its own version returns a string containing the ID property and optionally WorkID and/or ProviderName if those are specified. This is useful for logging and debugging purposes. It’s however even more useful in combination with the parsing methods described below, allowing easy serialization and de-serialization of ContentReference objects.
|
|
It can be worthwhile to know how the ToString method works in order to easily read ContentReference objects in string form. The return value always starts with the ID property. Then, if WorkID isn’t 0, meaning that it has a value, it’s appended to the return value prefixed with a single underscore. Finally, if ProviderName isn’t null it’s appended to the return value prefixed by two underscores. |
In addition to the instance members above, the ContentReference class also provides a number of useful static members. These are listed below.
IsNullOrEmpty(ContentReference) : bool There are situations where a ContentReference can be empty, meaning that the ID and WorkID properties are zero and the ProviderName property is null. As it’s common to check whether a ContentReference variable is either null or empty, or rather validating that it’s neither, the static IsNullOrEmpty method often comes in handy.
Parse(string) : ContentReference The static Parse method creates a ContentReference object from a string assuming the format that the ToString method uses. This provides a convenient way to convert back and forth between ContentReference objects and strings.
var contentLink = new ContentReference(42);
var complexLink = contentLink.ToString();
var parsedLink = ContentReference.Parse(complexLink);
contentLink == parsedLink; //True
If the argument to the Parse method is null or in any way invalid the method throws an exception of type EPiServerException.
TryParse(string, out ContentReference) : bool
Like the Parse method the TryParse method offers a way to convert a string to a ContentReference object. However, as opposed to the Parse method the TryParse method doesn’t throw an exception if the input parameter is invalid. Instead its return value indicates whether the parsing succeeded and the parsed ContentReference is returned in the form of an out parameter.
StartPage : PageReference
The start page on an EPiServer site is important in many ways. It’s the page that both public visitors and editors first see when they visit the site, unless of course they are directly accessing some sub-page. For developers it’s significant as the root page when building navigation components and it’s often also used to hold properties used for site-wide settings.
The ID of the site’s start page is configured in a configuration file. The static StartPage property of the ContentReference class provides a convenient way for developers to get a hold of a reference to the start page.
RootPage : PageReference
Similar to the StartPage property the static RootPage property returns a reference based on configuration. Instead of a reference to the site’s start page the RootPage property returns a reference to the root page, at the very top of the page tree.
WasteBasket, SiteBlockFolder, GlobalBlockFolder
In addition to the StartPage and RootPage properties the ContentReference class has a number of other static properties that return references to, for the CMS, significant content items. One such example is the WasteBasket property that returns a reference to the waste basket, which is a special page under which “soft deleted” content is moved to.
Renderers/templates
After defining a content type, such as a page type, editors can create content of that type and save it to EPiServer’s database. However, for a public visitor to be able to see the content, and for editors to be able to edit it using On Page Editing the CMS needs to know how to present it. That is, it needs to know how to “convert” a content item into HTML.
In older versions of the CMS there was a single way to render each each page type. Page types had a property configurable in admin mode that specified a path to an ASPX file, an ASP.NET Web Forms page. Such files were referred to as templates.
EPiServer 7 is more advanced, and complex, and allows multiple ways to render a single content item depending on context. A page may for instance be rendered as a stand-alone page, as part of another page, as a stand-alone page in a specific channel (a concept allowing tailoring of the site for specific devices or contexts) or as a part of another page in a specific channel. Therefore the terminology when building EPiServer sites has been expanded to include the word “renderer”. A renderer is a component, such as a Web Forms page or user control or an ASP.NET MVC controller or partial view that can take a content item and return HTML.
EPiServer development terminology still includes the word “template” as well and “template” and “renderer” are sometimes used interchangeably. For now, just keep in mind that both templates and renderers are components that render HTML for a specific content item. As you’ll soon see, building these components are a major, and often the largest, part of developing an EPiServer CMS site.
Data Access API
In earlier versions of the CMS its API featured a class called DataFactory. DataFactory implemented the singleton pattern, meaning that developers didn’t instantiate it themselves but instead used the syntax DataFactory.Instance when needing an instance of it.
DataFactory provided methods and events for just about any operation that a site developer and EPiServer’s own developers needed when working with PageData objects. In other words, using DataFactory one could get a page by ID (PageReference), save new and existing pages and retrieve lists of pages such as all pages who had a specific parent. By adding handlers to various events developers could also write code that got notified whenever something happened to a page, such as it being returned or saved.
The DataFactory class provided a fairly convenient API for site developers. As a site developer needing to do anything programmatically with one or more pages one instinctively knew to use one of DataFactory’s methods. Therefore it was well liked by developers. However, EPiServer also received a fair amount of criticism due to it. Part of the criticism was that the class was bloated. However, more loud criticism was voiced because it was very hard to isolate code from DataFactory. As each of it’s methods was defined only within the class, not in an interface, it caused problems when trying to write flexible code that didn’t rely on concrete implementations but instead on abstractions.
When EPiServer’s developers set out to create version 7 of the CMS they decided to address this issue. However, they also faced two other issues. First, the CMS was no longer only going to work with pages (PageData objects) but instead the more general content concept (IContent). Second, they wanted the new version to be as backward compatible as possible, making it easy to upgrade EPiServer 6 sites to the new version.
To solve these problems they added a number of interfaces to the API, such as:
· IContentLoader - Defines methods for retrieving content items.
· IContentRepository - Inherits IContentLoader and adds methods for modifying content items.
· IPageCriteriaQueryService - Defines methods for querying for pages using criteria such as that a certain property has a specific value.
· IContentEvents - Defines events for when content are retrieved or modified.
In these interfaces they defined the methods that were needed for the functionality for the new version. For instance, while DataFactory had a method named GetPage that returned PageData objects the IContentLoader interface defines a generic Get<T> method where the type T must be a content type.
They then made the DataFactory class implement these interfaces while keeping the old methods. Finally they added an inversion of control container through which developers could retrieve objects that implemented, amongst others, the above interfaces. The container is exposed in various ways, one of them being through a singleton class named ServiceLocator which has a Current property exposing an instance of it.
Inversion of Control (IoC)
Inversion of control is a programming technique in which object coupling is bound at runtime instead of at compile time. Imagine the following at compile time:

Here X uses, and is bound to Y, in the code at compile time. Now, instead imagine the following:
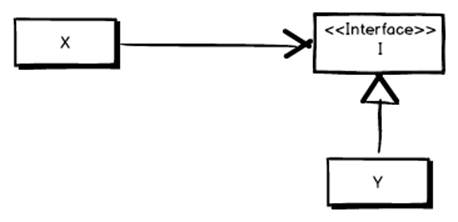
Here X is only bound to an abstraction, I, that it knows can perform the services of Y. However, as X isn’t directly coupled to Y it’s possible to swap it out for something else that implements I. Of course, for this to work X needs to be able to somehow resolve, get a hold of an instance of I. That can be achieved using Dependency Injection, where X requires an instance of I in its constructor, forcing consumers of X to supply an I. It can also be achieved using a Service Locator, in which X knows about a service, the Service Locator, which it asks for an instance of I. For both solutions it’s common to use what’s known as an IoC container, an object that maps between abstractions (I in our case) and concrete implementations (Y in our case.).
For a lengthier introduction to IoC see http://joelabrahamsson.com/inversion-of-control-an-introduction-with-examples-in-net/
By default, the implementation for all of the above interfaces registered with the container is the DataFactory.Instance singleton. This means that there are several ways to invoke the Get<T> method. One way is by using the DataFactory singleton:
var startpage = DataFactory.Instance.Get<PageData>(ContentReference.StartPage);
Another is to retrieve an instance of the IContentLoader interface:
var contentLoader = ServiceLocator.Current.GetInstance<IContentLoader>();
var startpage = contentLoader.Get<PageData>(ContentReference.StartPage);
So, which way should we use? The first way, using DataFactory.Instance is clearly more convenient. However, there are a couple of reasons to favor the second way.
First of all the second way, having developers rely on abstractions rather than concrete implementations, would probably have been the only way to use EPiServer’s API if it hadn’t been for backwards compatibility reasons. As such, using the second approach means using the approach favored and recommended by EPiServer’s developers. It’s also the more future-proof approach.
Second, by using EPiServer’s IoC container to resolve the abstraction that we need we make our code more flexible. Imagine for instance that we wanted to implement logging for every time someone asked the API for a page whose name started with the letter A. We could then create a custom class that implemented the relevant interfaces by wrapping the default implementation (DataFactory) and register that as the default type to use in the IoC container. Of course, that wouldn’t work for when our own code accessed the API if our code bypassed the container and went straight to DataFactory.
Finally, while using the ServiceLocator class to retrieve objects through which we can get and modify content is more verbose, in practice we will often inherit from some base class provided by EPiServer when building sites and many of those offers shortcuts to the IoC container, making the code more succinct.
In this book we’ll only use the second approach and won’t use DataFactory.Instance. There may however be situations where EPiServer’s API for working with pages is referred to a DataFactory. It’s also good to know about the DataFactory class in case you run into a site built on an earlier version of the CMS.
Let’s take a look at some of the most important methods of EPiServer’s API for working with pages that we’ll use when building sites.
IContentLoader.Get<T>(ContentReference) : T
Retrieves a content item of type T represented by the provided reference. The content is either retrieved from the database or from cache.
IContentLoader.GetChildren<T>(ContentReference) : IEnumerable<T>
Retrieves all children of type T of the content item represented by the provided reference. In other words, the GetChildren method returns all content items that are of the type T (or a sub type of T) whose ParentLink property matches the ContentReference argument.
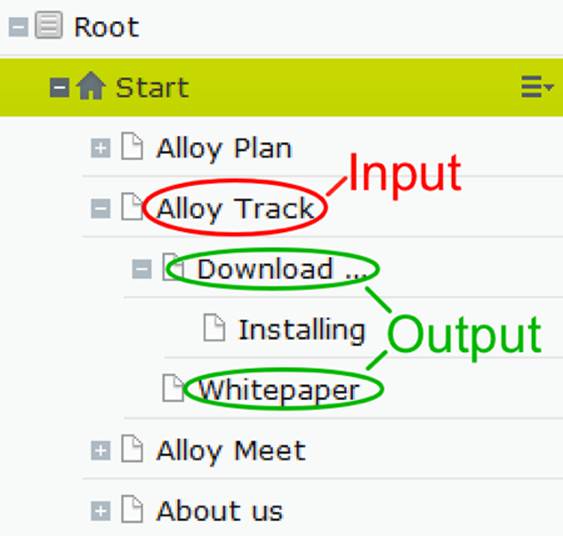
Example input and output for the GetChildren method.
IContentLoader.GetAncestors(ContentReference) : IEnumerable<IContent>
Returns all content items that forms the path to the content represented by the provided reference in the content tree.
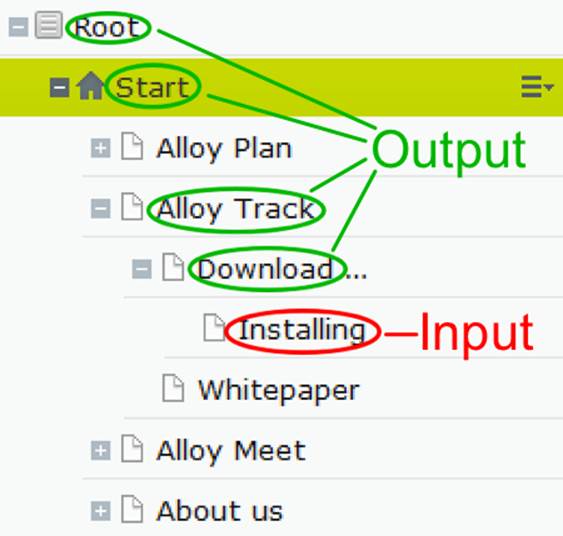
Example input and output for the GetAncestors method.
Summary
In this chapter we’ve looked at the most important classes and interfaces in EPiServer CMS’ API, as well as some important development concepts. Perhaps most significant of all is the IContent interface as that is the definition of a type that can be stored in EPiServer’s content tree.
Also important is the concept of identity where we’ve looked at the ContentReference and PageReference classes. We’ve seen that a ContentReference represents a unique identifier for something that implements IContent. We’ve also seen that PageData, the class that represents a web page on the site in terms of editorial content and settings, implements IContent. While PageData objects can indeed be identified using ContentReferences the CMS’ API also features a class named PageReference. PageReference inherits ContentReference but is only used to identify pages, and certain methods in the API that work only with pages may have PageReferences as parameters instead of ContentReferences.
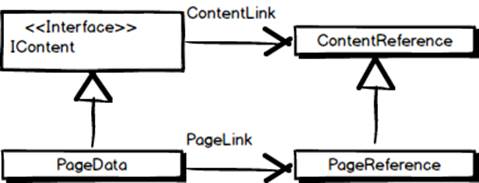
The (simplified) content and identity model in EPiServer’s API.
We also discussed how to access IContent objects using the IContentLoader interface. When needing to save, move or delete content objects we need an instance of the heavier IContentRepository interface. In order to retrieve objects that implements either of these interfaces we can either use the GetInstance method of ServiceLocator.Current or use DataFactory.Instance, although the former approach is recommended.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.