iOS 7 Programming Fundamentals: Objective-C, Xcode, and Cocoa Basics (2014)
Part I. Language
Apple has provided a vast toolbox for programming iOS to make an app come to life and behave the way you want it to. That toolbox is the API (application programming interface). To use the API, you must speak the API’s language. That language, for the most part, is Objective-C, which itself is built on top of C; some pieces of the API use C itself. This part of the book instructs you in the basics of these languages:
§ Chapter 1 explains C. In general, you will probably not need to know all the ins and outs of C, so this chapter restricts itself to those aspects of C that you need to know in order to use both Objective-C and the C-based areas of the API.
§ Chapter 2 prepares the ground for Objective-C, by discussing object-based programming in general architectural terms. It also explains some extremely important words that will be used throughout the book, along with the concepts that lie behind them.
§ Chapter 3 introduces the basic syntax of Objective-C.
§ Chapter 4 continues the explanation of Objective-C, discussing the nature of Objective-C classes, with emphasis on how to create a class in code.
§ Chapter 5 completes the introduction to Objective-C, discussing how instances are created and initialized, along with an explanation of such related topics as polymorphism, instance variables, accessors, self and super, key–value coding, and properties.
We’ll return in Part III to a description of further aspects of the Objective-C language — those that are particularly bound up with the Cocoa frameworks.
Chapter 1. Just Enough C
Do you believe in C? Do you believe in anything that has to do with me?
—Leonard Bernstein and Stephen Schwartz, Mass
To program for iOS, you need to speak to iOS. Everything you say to iOS will be in accordance with the iOS API. (An API, for application programming interface, is a list or specification of things you are allowed to say when communicating.) Therefore, you will need some knowledge of the C programming language, for two reasons:
§ Most of the iOS API involves the Objective-C language, and most of your iOS programming will be in the Objective-C language. Objective-C is a superset of C. This means that Objective-C presupposes C; everything that is true of C trickles up to Objective-C. A common mistake is to forget that “Objective-C is C” and to neglect a basic understanding of C.
§ Some of the iOS API involves C rather than Objective-C. Even in Objective-C code, you often need to use C data structures and C function calls. For example, a rectangle is represented as a CGRect, which is a C struct, and to create a CGRect from four numbers you call CGRectMake, which is a C function. The iOS API documentation will very often show you C expressions and expect you to understand them.
The best way to learn C is to read The C Programming Language (PTR Prentice Hall, 1988) by Brian W. Kernighan and Dennis M. Ritchie, commonly called K&R (Ritchie was the creator of C). It is one of the best computer books ever written: brief, dense, and stunningly precise and clear. K&R is so important for effective iOS programming that I keep a physical copy beside me at all times while coding, and I recommend that you do the same. Another useful manual is The C Book, by Mike Banahan, Declan Brady, and Mark Doran, available online athttp://publications.gbdirect.co.uk/c_book/.
It would be impossible for me to describe all of C in a single chapter. C is not a large or difficult language, but it has some tricky corners and can be extremely subtle, powerful, and low-level. Moreover, since C is described fully and correctly in the manuals I’ve just mentioned, it would be a mistake for me to repeat what they can tell you better than I. So this chapter is not a technical manual of C.
You don’t have to know all about C, though, in order to use Objective-C effectively; so my purpose in this chapter is to outline those aspects of C that are important for you to understand at the outset, before you start using Objective-C for iOS programming. This chapter is “Just Enough C” to start you off comfortably and safely.
If you know no C at all, I suggest that, as an accompaniment to this chapter, you also read select parts of K&R (think of this as “C: The Good Parts Version”). Here’s my proposed K&R syllabus:
§ Quickly skim K&R Chapter 1, the tutorial.
§ Carefully read K&R Chapters 2 through 4.
§ Read the first three sections of K&R Chapter 5 on pointers and arrays. You don’t need to read the rest of Chapter 5 because you won’t typically be doing any pointer arithmetic, but you do need to understand clearly what a pointer is, as Objective-C is all about objects, and every reference to an object is a pointer; you’ll be seeing and using that * character constantly.
§ Read also the first section of K&R Chapter 6, on structures (structs); as a beginner, you probably won’t define any structs, but you will use them quite a lot, so you’ll need to know the notation (for example, as I’ve already said, a CGRect is a struct).
§ Glance over K&R Appendix B, which covers the standard library, because you may find yourself making certain standard library calls, such as the mathematical functions; forgetting that the library exists is a typical beginner mistake.
NOTE
The C defined in K&R is not precisely the C that forms the basis of Objective-C. Developments subsequent to K&R have resulted in further C standards (ANSI C, C89, C99), and the Xcode compiler extends the C language in its own ways. By default, Xcode projects are treated as GNU99, which is itself an extension of C99 (though you could specify another C standard if you really wanted to). Fortunately, the most important differences between K&R’s C and Xcode’s C are small, convenient improvements that are easily remembered, so K&R remains the best and most reliable C reference.
Compilation, Statements, and Comments
C is a compiled language. You write your program as text; to run the program, things proceed in two stages. First your text is compiled into machine instructions; then those machine instructions are executed. Thus, as with any compiled language, you can make two kinds of mistake:
§ Any purely syntactic errors (meaning that you spoke the C language incorrectly) will be caught by the compiler, and the program won’t even begin to run.
§ If your program gets past the compiler, then it will run, but there is no guarantee that you haven’t made some other sort of mistake, which can be detected only by noticing that the program doesn’t behave as intended.
The C compiler is fussy, but you should accept its interference with good grace. The compiler is your friend: learn to love it. It may emit what looks like an irrelevant or incomprehensible error message, but when it does, the fact is that you’ve done something wrong and the compiler has helpfully caught it for you. Also, the compiler can warn you if something seems like a possible mistake, even though it isn’t strictly illegal; these warnings, which differ from outright errors, are also helpful and should not be ignored.
I have said that running a program requires a preceding stage: compilation. But in fact there is another stage that precedes compilation: preprocessing. Preprocessing modifies your text, so when your text is handed to the compiler, it is not identical to the text you wrote. Preprocessing might sound tricky and intrusive, but in fact it proceeds only according to your instructions and is helpful for making your code clearer and more compact.
Xcode allows you to view the effects of preprocessing on your program text (choose Product → Perform Action → Preprocess [Filename]), so if you think you’ve made a mistake in instructing the preprocessor, you can track it down. I’ll talk more later about some of the things you’re likely to say to the preprocessor.
C is a statement-based language; every statement ends in a semicolon. (Forgetting the semicolon is a common beginner’s mistake.) For readability, programs are mostly written with one statement per line, but this is by no means a hard and fast rule: long statements (which, unfortunately, arise very often because of Objective-C’s verbosity) are commonly split over multiple lines, and extremely short statements are sometimes written two or three to a line. You cannot split a line just anywhere, however; for example, a literal string can’t contain a return character. Indentation is linguistically meaningless and is purely a matter of convention (and C programmers argue over those conventions with near-religious fervor); Xcode helps “intelligently” by indenting automatically, and you can use its automatic indentation both to keep your code readable and to confirm that you’re not making any basic syntactic mistakes.
Comments are delimited in K&R C by /* ... */; the material between the delimiters can consist of multiple lines (K&R 1.2). In modern versions of C, a comment also can be denoted by two slashes (//); the rule is that if two slashes appear, they and everything after them on the same line are ignored:
int lower = 0; // lower limit of temperature table
These are sometimes called C++-style comments and are much more convenient for brief comments than the K&R comment syntax.
Throughout the C language (and therefore, throughout Objective-C as well), capitalization matters. All names are case-sensitive. There is no such data type as Int; it’s lowercase “int.” If you declare an int called lower and then try to speak of the same variable as Lower, the compiler will complain. By convention, variable names tend to start with a lowercase letter.
COMPILER HISTORY
Originally, Xcode’s compiler was the free open source GCC (http://gcc.gnu.org). Eventually, Apple introduced its own free open source compiler, LLVM (http://llvm.org), also referred to as Clang, thus allowing for improvements that were impossible with GCC. Changing compilers is scary, so Apple proceeded in stages:
§ In Xcode 3, along with both LLVM and GCC, Apple supplied a hybrid compiler, LLVM-GCC, which provided the advantages of LLVM compilation while parsing code with GCC for maximum backward compatibility, without making it the default compiler.
§ In Xcode 4, LLVM-GCC became the default compiler, but GCC remained available.
§ In Xcode 4.2, LLVM 3.0 became the default compiler, and pure GCC was withdrawn.
§ In Xcode 4.6, LLVM advanced to version 4.2.
§ In Xcode 5, LLVM-GCC has been withdrawn; the compiler is now LLVM 5.0, and the transition from GCC to LLVM is complete.
Variable Declaration, Initialization, and Data Types
C is a strongly typed language. Every variable must be declared, indicating its data type, before it can be used. Declaration can also involve explicit initialization, giving the variable a value; a variable that is declared but not explicitly initialized is of uncertain value (and should be regarded as dangerous until it is initialized). In K&R C, declarations must precede all other statements, but in modern versions of C, this rule is relaxed so that you don’t have to declare a variable until just before you start using it:
int height = 2;
int width = height * 2;
height = height + 1;
int area = height * width;
The basic built-in C data types are all numeric: char (one byte), int (four bytes), float and double (floating-point numbers), and varieties such as short (short integer), long (long integer), unsigned short, and so on. A numeric literal may optionally express its type through a suffixed letter or letters: for example, 4 is an int, but 4UL is an unsigned long; 4.0 is a double, but 4.0f is a float. Objective-C makes use of some further numeric types derived from the C numeric types (by way of the typedef statement, K&R 6.7) designed to respond to the question of whether the processor is 64-bit; the most important of these are NSInteger (along with NSUInteger) and CGFloat. You don’t need to use them explicitly unless an API tells you to, and even when you do, just think of NSInteger as int and CGFloat as float, and you’ll be fine.
To cast (or typecast) a variable’s value explicitly to another type, precede the variable’s name with the other type’s name in parentheses:
int height = 2;
float fheight = (float)height;
In that particular example, the explicit cast is unnecessary because the integer value will be cast to a float implicitly as it is assigned to a float variable, but it illustrates the notation. You’ll find yourself typecasting quite a bit in Objective-C, mostly to subdue the worries of the compiler (examples appear in Chapter 3).
Another form of numeric initialization is the enumeration, or enum (K&R 2.3). It’s a way of assigning names to a sequence of numeric values and is useful when a value represents one of several possible options. The Cocoa API uses this device a lot. For example, the three possible types of status bar animation might be defined like this:
typedef enum {
UIStatusBarAnimationNone,
UIStatusBarAnimationFade,
UIStatusBarAnimationSlide,
} UIStatusBarAnimation;
That definition assigns the value 0 to the name UIStatusBarAnimationNone, the value 1 to the name UIStatusBarAnimationFade, and the value 2 to the name UIStatusBarAnimationSlide. The upshot is that you can use the suggestively meaningful names without caring about, or even knowing, the arbitrary numeric values they represent. It’s a useful idiom, and you may well have reason to define enumerations in your own code.
That definition also assigns the name UIStatusBarAnimation to this enumeration as a whole. A named enumeration is not a data type, but you can pretend that it is, and the compiler can warn you if you mix enumeration types. For example, suppose you were to write this code:
UIStatusBarAnimation anim = UIInterfaceOrientationPortrait;
That isn’t illegal; UIInterfaceOrientationPortrait is another name for 0, just as if you had said UIStatusBarAnimationNone. However, it comes from a different named enumeration, namely UIInterfaceOrientation. The compiler detects this, and warns you. Just as with a real data type, you can even squelch that warning by typecasting.
In iOS 7, the status bar animation types are defined like this:
typedef NS_ENUM(NSInteger, UIStatusBarAnimation) {
UIStatusBarAnimationNone,
UIStatusBarAnimationFade,
UIStatusBarAnimationSlide,
};
That notation was introduced in LLVM compiler version 4.0, which made its debut in Xcode 4.4. NS_ENUM is a macro, a form of preprocessor text substitution discussed at the end of this chapter; when the text substitution is performed, that code turns out to be shorthand for this:
typedef enum UIStatusBarAnimation : NSInteger UIStatusBarAnimation;
enum UIStatusBarAnimation : NSInteger {
UIStatusBarAnimationNone,
UIStatusBarAnimationFade,
UIStatusBarAnimationSlide,
};
That looks almost exactly like the old way of expressing the same enumeration, but the new way involves some notation that isn’t part of standard C, telling the compiler what variety of integer value is being used here (it’s an NSInteger). This makes UIStatusBarAnimation even more like a genuine data type; in addition, the new enum notation lets Xcode help you more intelligently when performing code completion, as discussed in Chapter 9. Another macro, NS_OPTIONS, evaluates in Objective-C as a synonym of NS_ENUM (they are distinct only in C++ code, which is not discussed in this book).
There appears to be a native text type (a string) in C, but this is something of an illusion; behind the scenes, it is a null-terminated array of char. For example, in C you can write a string literal like this:
"string"
But in fact this is stored as 7 bytes, the numeric (ASCII) equivalents of each letter followed by a byte consisting of 0 to signal the end of the string. This data structure, called a C string, is rarely encountered while programming iOS. In general, when working with strings, you’ll use an Objective-C object type called NSString. An NSString is totally different from a C string; it happens, however, that Objective-C lets you write a literal NSString in a way that looks very like a C string:
@"string"
Notice the at-sign! This expression is actually a directive to the Objective-C compiler to form an NSString object. A common mistake is forgetting the at-sign, thus causing your expression to be interpreted as a C string, which is a completely different animal.
Because the notation for literal NSStrings is modeled on the notation for C strings, it is worth knowing something about C strings, even though you won’t generally encounter them. For example, K&R lists a number of escaped characters (K&R 2.3), which you can also use in a literal NSString, including the following:
\n
A Unix newline character
\t
A tab character
\"
A quotation mark (escaped to show that this is not the end of the string literal)
\\
A backslash
NOTE
NSStrings are natively Unicode-based, and it is perfectly legal to type a non-ASCII character directly into an NSString literal; warnings to the contrary are outdated, and you should ignore them. The \x and \u escape sequences are nice to know about, but you are unlikely to need them.
K&R also mention a notation for concatenating string literals, in which multiple string literals separated only by white space are automatically concatenated and treated as a single string literal. This notation is useful for splitting a long string into multiple lines for legibility, and Objective-C copies this convention for literal NSStrings as well, except that you have to remember the at-sign:
@"This is a big long literal string "
@"which I have broken over two lines of code.";
Structs
C offers few simple native data types, so how are more complex data types made? There are three ways: structures, pointers, and arrays. Both structures and pointers are going to be crucial when you’re programming iOS. C arrays are needed less often, because Objective-C has its own NSArray object type.
A C structure, usually called a struct (K&R 6.1), is a compound data type: it combines multiple data types into a single type, which can be passed around as a single entity. Moreover, the elements constituting the compound entity have names and can be accessed by those names through the compound entity, using dot-notation. The iOS API has many commonly used structs, typically accompanied by convenience functions for working with them.
For example, the iOS documentation tells you that a CGPoint is defined as follows:
struct CGPoint {
CGFloat x;
CGFloat y;
};
typedef struct CGPoint CGPoint;
Recall that a CGFloat is basically a float, so this is a compound data type made up of two simple native data types; in effect, a CGPoint has two CGFloat parts, and their names are x and y. (The rather odd-looking last line merely asserts that one can use the term CGPoint instead of the more verbose struct CGPoint.) So we can write:
CGPoint myPoint;
myPoint.x = 4.3;
myPoint.y = 7.1;
Just as we can assign to myPoint.x to set this part of the struct, we can say myPoint.x to get this part of the struct. It’s as if myPoint.x were the name of a variable. Moreover, an element of a struct can itself be a struct, and the dot-notation can be chained. To illustrate, first note the existence of another iOS struct, CGSize:
struct CGSize {
CGFloat width;
CGFloat height;
};
typedef struct CGSize CGSize;
Put a CGPoint and a CGSize together and you’ve got a CGRect:
struct CGRect {
CGPoint origin;
CGSize size;
};
typedef struct CGRect CGRect;
So suppose we’ve got a CGRect variable called myRect, already initialized. Then myRect.origin is a CGPoint, and myRect.origin.x is a CGFloat. Similarly, myRect.size is a CGSize, and myRect.size.width is a CGFloat. You could change just the width part of our CGRect directly, like this:
myRect.size.width = 8.6;
Instead of initializing a struct by assigning to each of its elements, you can initialize it at declaration time by assigning values for all its elements at once, in curly braces and separated by commas, like this:
CGPoint myPoint = { 4.3, 7.1 };
CGRect myRect = { myPoint, {10, 20} };
You don’t have to be assigning to a struct-typed variable to use a struct initializer; you can use an initializer anywhere the given struct type is expected, but you might also have to cast to that struct type in order to explain to the compiler what your curly braces mean, like this:
CGContextFillRect(con, (CGRect){myPoint, {10, 20}});
In that example, CGContextFillRect is a function. I’ll talk about functions later in this chapter, but the upshot of the example is that what comes after the first comma has to be a CGRect, and can therefore be a CGRect initializer provided it is accompanied by a CGRect cast.
Pointers
The other big way that C extends its range of data types is by means of pointers (K&R 5.1). A pointer is an integer (of some size or other) designating the location in memory where the real data is to be found. Knowing the structure of that real data and how to work with it, as well as allocating a block of memory of the required size beforehand and disposing of that block of memory when it’s no longer needed, is a very complicated business. Luckily, this is exactly the sort of complicated business that Objective-C is going to take care of for us. So all you really have to know to use pointers is what they are and what notation is used to refer to them.
Let’s start with a simple declaration. If we wanted to declare an integer in C, we could say:
int i;
That line says, “i is an integer.” Now let’s instead declare a pointer to an integer:
int* intPtr;
That line says, “intPtr is a pointer to an integer.” Never mind how we know there really is going to be an integer at the address designated by this pointer; here, I’m concerned only with the notation. It is permitted to place the asterisk in the declaration before the name rather than after the type:
int *intPtr;
You could even put a space on both sides of the asterisk (though this is rarely done):
int * intPtr;
I prefer the first form, but I do occasionally use the second form, and Apple quite often uses it, so be sure you understand that these are all ways of saying the same thing. No matter how the spaces are inserted, the name of the type is still int*. If you are asked what type intPtr is, the answer is int* (a pointer to an int); the asterisk is part of the name of the type of this variable. If you needed to cast a variable p to this type, you’d cast like this: (int*)p. Once again, it is possible that you’ll see code where there’s a space before the asterisk, like this: (int *)p.
The most general type of pointer is pointer-to-void (void*), the generic pointer. It is legal to use a generic pointer wherever a specific type of pointer is expected. In effect, pointer-to-void casts away type checking as to what’s at the far end of the pointer. Thus, the following is legal:
int* p1; // and pretend p1 has a value
void* p2;
p2 = p1;
p1 = p2;
Pointers are very important in Objective-C, because Objective-C is all about objects (Chapter 2), and every variable referring to an object is itself a pointer. In effect, Objective-C takes advantage of the fact that a C pointer can designate real data whose nature and bookkeeping are arbitrary. In this case, that real data is an Objective-C object. Objective-C knows what this means, but you generally won’t worry about it — you’ll just work with the C pointer and let Objective-C take care of the details. For example, I’ve already mentioned that the Objective-C string type is called NSString. So the way to declare an NSString variable is as a pointer to an NSString:
NSString* s;
An NSString literal is an NSString value, so we can even declare and initialize this NSString object, thus writing a seriously useful line of Objective-C code:
NSString* s = @"Hello, world!";
In pure C, having declared a pointer-to-integer called intPtr, you are liable to speak later in your code of *intPtr. This notation, outside of a declaration, means “the thing pointed to by the pointer intPtr.” You speak of *intPtr because you wish to access the integer at the far end of the pointer; this is called dereferencing the pointer.
But in Objective-C, this is generally not the case. In your code, you’ll be treating the pointer to an object as the object; you’ll never dereference it. So, for example, having declared s as a pointer to an NSString, you will not then proceed to speak of *s; rather, you will speak simply of s, as if it were the string. All the Objective-C stuff you’ll want to do with an object will expect the pointer, not the object at the far end of the pointer; behind the scenes, Objective-C itself will take care of the messy business of following the pointer to its block of memory and doing whatever needs to be done in that block of memory. This fact is extremely convenient for you as a programmer, but it does cause Objective-C users to speak a little loosely; we tend to say that “s is an NSString,” when of course it is actually a pointer to an NSString.
The logic of how pointers work, both in C and in Objective-C, is different from the logic of how simple data types work. The difference is particularly evident with assignment. Assignment to a simple data type changes the data value. Assignment to a pointer repoints the pointer. Supposeptr1 and ptr2 are both pointers, and you say:
ptr1 = ptr2;
Now ptr1 and ptr2 are pointing at the same thing. Any change to the thing pointed to by ptr1 will also change the thing pointed to by ptr2, because they are the same thing (Figure 1-1). Meanwhile, whatever ptr1 was pointing to before the assignment is now not being pointed to byptr1; it might, indeed, be pointed to by nothing (which could be bad). A firm understanding of these facts is crucial when working in Objective-C, and I’ll return to this topic in Chapter 3.
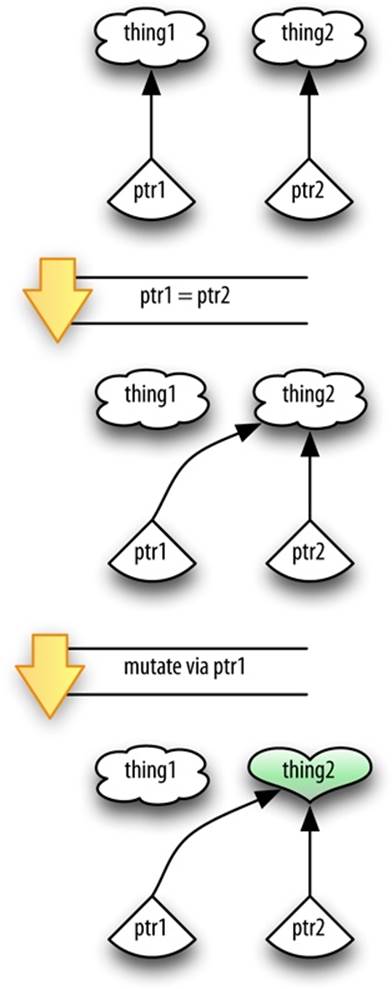
Figure 1-1. Pointers and assignment
Arrays
A C array (K&R 5.3) consists of multiple elements of the same data type. An array declaration states the data type of the elements, followed by the name of the array, along with square brackets containing the number of elements:
int arr[3]; // means: arr is an array consisting of 3 ints
To refer to an element of an array, use the array’s name followed by the element number in square brackets. The first element of an array is numbered 0. So we can initialize an array by assigning values to each element in turn:
int arr[3];
arr[0] = 123;
arr[1] = 456;
arr[2] = 789;
Alternatively, you can initialize an array at declaration time by assigning a list of values in curly braces, just as with a struct. In this case, the size of the array can be omitted from the declaration, because it is implicit in the initialization (K&R 4.9):
int arr[] = {123, 456, 789};
Curiously, the name of an array is the name of a pointer (to the first element of the array). Thus, for example, having declared arr as in the preceding examples, you can use arr wherever a value of type int* (a pointer to an int) is expected. This fact is the basis of some highly sophisticated C idioms that you almost certainly won’t need to know about (which is why I don’t recommend that you read any of K&R Chapter 5 beyond section 3).
Here’s an example where a C array might be useful when programming iOS. The function CGContextStrokeLineSegments is declared like this:
void CGContextStrokeLineSegments (
CGContextRef c,
const CGPoint points[],
size_t count
);
The second parameter is a C array of CGPoints. That’s what the square brackets tell you. So to call this function, you’d need to know at least how to make an array of CGPoints. You might do it like this:
CGPoint arr[] = {{4,5}, {6,7}, {8,9}, {10,11}};
Having done that, you can pass arr as the second argument in a call to CGContextStrokeLineSegments.
Also, a C string, as I’ve already mentioned, is actually an array. For example, the NSString method stringWithUTF8String: takes (according to the documentation) “a NULL-terminated C array of bytes in UTF8 encoding;” but the parameter is declared not as an array, but as a char*.Those are the same thing, and are both ways of saying that this method takes a C string.
(The colon at the end of the method name stringWithUTF8String: is not a misprint; many Objective-C method names end with a colon. I’ll explain why in Chapter 3.)
Operators
Arithmetic operators are straightforward (K&R 2.5), but watch out for the rule that “integer division truncates any fractional part.” This rule is the cause of much novice error in C. If you have two integers and you want to divide them in such a way as to get a fractional result, you must represent at least one of them as a float:
int i = 3;
float f = i/2; // beware! not 1.5
To get 1.5, you should have written i/2.0 or (float)i/2.
The integer increment and decrement operators (K&R 2.8), ++ and --, work differently depending on whether they precede or follow their variable. The expression ++i replaces the value of i by 1 more than its current value and then uses the resulting value; the expression i++ uses the current value of i and then replaces it with 1 more than its current value. This is one of C’s coolest features.
C also provides bitwise operators (K&R 2.9), such as bitwise-and (&) and bitwise-or (|); they operate on the individual binary bits that constitute integers. You are most likely to need bitwise-or, because the Cocoa API often uses bits as switches when multiple options are to be specified simultaneously. For example, when specifying how a UIView is to be animated, you are allowed to pass an options argument whose value comes from the UIViewAnimationOptions enumeration, whose definition begins as follows:
typedef NS_OPTIONS(NSUInteger, UIViewAnimationOptions) {
UIViewAnimationOptionLayoutSubviews = 1 << 0,
UIViewAnimationOptionAllowUserInteraction = 1 << 1,
UIViewAnimationOptionBeginFromCurrentState = 1 << 2,
UIViewAnimationOptionRepeat = 1 << 3,
UIViewAnimationOptionAutoreverse = 1 << 4,
// ...
};
The << symbol is the left shift operator; the right operand says how many bits to shift the left operand. So pretend that an NSUInteger is 8 bits (it isn’t, but let’s keep things simple and short). Then this enumeration means that the following name–value pairs are defined (using binary notation for the values):
UIViewAnimationOptionLayoutSubviews
00000001
UIViewAnimationOptionAllowUserInteraction
00000010
UIViewAnimationOptionBeginFromCurrentState
00000100
UIViewAnimationOptionRepeat
00001000
UIViewAnimationOptionAutoreverse
00010000
The reason for this bit-based representation is that these values can be combined into a single value (a bitmask) that you pass to set the options for this animation. All Cocoa has to do to understand your intentions is to look to see which bits in the value that you pass are set to 1. So, for example, 00011000 would mean that UIViewAnimationOptionRepeat and UIViewAnimationOptionAutoreverse are both true (and that the others, by implication, are all false).
The question is how to form the value 00011000 in order to pass it. You could just do the math, figure out that binary 00011000 is decimal 24, and set the options argument to 24, but that’s not what you’re supposed to do, and it’s not a very good idea, because it’s error-prone and makes your code incomprehensible. Instead, use the bitwise-or operator to combine the desired options:
(UIViewAnimationOptionRepeat | UIViewAnimationOptionAutoreverse)
This notation works because the bitwise-or operator combines its operands by setting in the result any bits that are set in either of the operands, so 00001000 | 00010000 is 00011000, which is just the value we’re trying to convey. (And how does the runtime parse the bitmask to discover whether a given bit is set? With the bitwise-and operator.)
Simple assignment (K&R 2.10) is by the equal sign. But there are also compound assignment operators that combine assignment with some other operation. For example:
height *= 2; // same as saying: height = height * 2;
The ternary operator (?:) is a way of specifying one of two values depending on a condition (K&R 2.11). The scheme is as follows:
(condition) ? exp1 : exp2
If the condition is true (see the next section for what that means), the expression exp1 is evaluated and the result is used; otherwise, the expression exp2 is evaluated and the result is used. For example, you might use the ternary operator while performing an assignment, using this schema:
myVariable = (condition) ? exp1 : exp2;
What gets assigned to myVariable depends on the truth value of the condition. There’s nothing happening here that couldn’t be accomplished more verbosely with flow control, but the ternary operator can greatly improve clarity, and I use it a lot.
Flow Control and Conditions
Basic flow control is fairly simple and usually involves a condition in parentheses and a block of conditionally executed code in curly braces. These curly braces constitute a new scope, into which new variables can be introduced. So, for example:
if (x == 7) {
int i = 0;
i += 1;
}
After the closing curly brace in the fourth line, the i introduced in the second line has ceased to exist, because its scope is the inside of the curly braces. If the contents of the curly braces consist of a single statement, the curly braces can be omitted, but I would advise beginners against this shorthand, as you can confuse yourself. A common beginner mistake (which will be caught by the compiler) is forgetting the parentheses around the condition. The full set of flow control statements is given in K&R Chapter 3, and I’ll just summarize them schematically here (Example 1-1).
Example 1-1. The C flow control constructs
if (condition) {
statements;
}
if (condition) {
statements;
} else {
statements;
}
if (condition) {
statements;
} else if (condition) {
statements;
} else {
statements;
}
while (condition) {
statements;
}
do {
statements;
} while (condition);
for (before-all; condition; after-each) {
statements;
}
The if...else if...else structure can have as many else if blocks as needed, and the else block is optional. Instead of an extended if...else if...else if...else structure, when the conditions would consist of comparing various values against a single value, you can use the switch statement; be careful, though, as it is rather confusing and can easily go wrong (see K&R 3.4 for full details). The main trick is to remember to end every case with a break statement, unless you want it to “fall through” to the next case (Example 1-2).
Example 1-2. A switch statement
NSString* key;
switch (tag) {
case 1: { // i.e., if tag is 1
key = @"lesson";
break;
}
case 2: { // i.e., if tag is 2
key = @"lessonSection";
break;
}
case 3: { // i.e., if tag is 3
key = @"lessonSectionPartFirstWord";
break;
}
}
The C for loop needs some elaboration for beginners (Example 1-1). The before-all statement is executed once as the for loop is first encountered and is usually used for initialization of the counter. The condition is then tested, and if true, the block is executed; the condition is usually used to test whether the counter has reached its limit. The after-each statement is then executed, and is usually used to increment or decrement the counter; the condition is then immediately tested again. Thus, to execute a block using integer values 1, 2, 3, 4, and 5 for i, the notation is:
int i;
for (i = 1; i < 6; i++) {
// ... statements ...
}
The need for a counter intended to exist solely within the for loop is so common that C99 permits the declaration of the counter as part of the before-all statement; the declared variable’s scope is then inside the curly braces:
for (int i = 1; i < 6; i++) {
// ... statements ...
}
The for loop is one of the few areas in which Objective-C extends C’s flow-control syntax. Certain Objective-C objects, such as NSArray, represent enumerable collections of other objects; “enumerable” basically means that you can cycle through the collection, and cycling through a collection is called enumerating the collection. (I’ll discuss the main enumerable collection types in Chapter 10.) To make enumerating easy, Objective-C provides a for...in operator, which works like a for loop:
SomeType* oneItem;
for (oneItem in myCollection) {
// ... statements ....
}
On each pass through the loop, the variable oneItem (or whatever you call it) takes on the next value from within the collection. As with the C99 for loop, oneItem can be declared in the for statement, limiting its scope to the curly braces:
for (SomeType* oneItem in myCollection) {
// ... statements ....
}
To abort a loop from inside the curly braces, use the break statement. To abort the current iteration from within the curly braces and proceed to the next iteration, use the continue statement. In the case of while and do, continue means to perform immediately the conditional test; in the case of a for loop, continue means to perform immediately the after-each statement and then the conditional test.
C also has a goto statement that allows you to jump to a named (labeled) line in your code (K&R 3.8); even though goto is notoriously “considered harmful,” there are situations in which it is pretty much necessary, especially because C’s flow control is otherwise so primitive.
NOTE
It is permissible for a C statement to be compounded of multiple statements, separated by commas, to be executed sequentially. The last of the multiple statements is the value of the compound statement as a whole. This construct, for instance, lets you perform some secondary action before each test of a condition or perform more than one after-each action.
We can now turn to the question of what a condition consists of. C has no separate boolean type; a condition either evaluates to 0, in which case it is considered false, or it doesn’t, in which case it is true. Comparisons are performed using the equality and relational operators (K&R 2.6); for example, == compares for equality, and < compares for whether the first operand is less than the second. Logical expressions can be combined using the logical-and operator (&&) and the logical-or operator (||); using these along with parentheses and the not operator (!) you can form complex conditions. Evaluation of logical-and and logical-or expressions is short-circuited, meaning that if the left condition settles the question, the right condition is never even evaluated.
WARNING
Don’t confuse the logical-and operator (&&) and the logical-or operator (||) with the bitwise-and operator (&) and the bitwise-or operator (|) discussed earlier. Writing & when you mean && (or vice versa) can result in surprising behavior.
The operator for testing basic equality, ==, is not a simple equal sign; forgetting the difference is a common novice mistake. The problem is that such code is legal: simple assignment, which is what the equal sign means, has a value, and any value is legal in a condition. So consider this piece of (nonsense) code:
int i = 0;
while (i = 1) {
i = 0;
}
You might think that the while condition tests whether i is 1. You might then think: i is 0, so the while body will never be performed. Right? Wrong. The while condition does not test whether i is 1; it assigns 1 to i. The value of that assignment is also 1, so the condition evaluates to 1, which means true. So the while body is performed. Moreover, even though the while body assigns 0 to i, the condition is then evaluated again and assigns 1 to i a second time, which means true yet again. And so on, forever; we’ve written an endless loop, and the program will hang.
C programmers revel in the fact that testing for zero and testing for false are the same thing and use it to create compact conditional expressions, which are considered elegant and idiomatic. Such idioms can be confusing, but one of them is commonly used in Objective-C, namely, in order to test an object reference to see whether it is nil. Since nil is a form of zero (as discussed further in Chapter 3), one can ask whether an object s is nil like this:
if (!s) {
// ...
}
Objective-C introduces a BOOL type, which you should use if you need to capture or maintain a condition’s value as a variable, along with constants YES and NO (representing 1 and 0), which you should use when setting a boolean value. Don’t compare anything against a BOOL, not even YES or NO, because a value like 2 is true in a condition but is not equal to YES or NO. (Getting this wrong is a common beginner mistake, and can lead to unintended results.) Just use the BOOL directly as a condition, or as part of a complex condition, and all will be well. For example:
BOOL isnil = (nil == s);
if (isnil) { // not: if (isnil == YES)
// ...
}
Functions
C is a function-based language (K&R 4.1). A function is a block of code defining what should happen; when other code calls (invokes) that function, the function’s code does happen. A function returns a value, which is substituted for the call to that function.
Here’s a definition of a function that accepts an integer and returns its square:
int square(int i) {
return i * i;
}
Now I’ll call that function:
int i = square(3);
Because of the way square is defined, that is exactly like saying:
int i = 9;
That example is extremely simple, but it illustrates many key aspects of functions.
Let’s analyze how a function is defined:
int![]() square
square![]() (
(![]() int i) {
int i) {![]()
return i * i;
}
![]()
We start with the type of value that the function returns; here, it returns an int.
![]()
Then we have the name of the function, which is square.
![]()
Then we have parentheses, and here we place the data type and name of any values that this function expects to receive. Here, square expects to receive one value, an int, which we are calling i. The name i (along with its expected data type) is a parameter; when the function is called, its value will be supplied as an argument. If a function expects to receive more than one value, multiple parameters in its definition are separated by a comma (and when the function is called, the arguments supplied are likewise separated by a comma).
![]()
Finally, we have curly braces containing the statements that are to be executed when the function is called.
Those curly braces constitute a scope; variables declared within them are local to the function. The names used for the parameters in the function definition are also local to the function; in other words, the i in the first line of the function definition is the same as the i in the second line of the function definition, but it has nothing to do with any i used outside the function definition (as when the result of the function call is assigned to a variable called i). The value of the i parameter in the function definition is assigned from the corresponding argument when the function is called; in the previous example, it is 3, which is why the function result is 9. Supplying a function call with arguments is thus a form of assignment. Suppose a function is defined like this:
int myfunction(int i, int j) { // ...
And suppose we call that function:
int result = myfunction(3, 4);
That function call effectively assigns 3 to the function’s i parameter and 4 to the function’s j parameter.
When a return statement is encountered, the value accompanying it is handed back as the result of the function call, and the function terminates. It is legal for a function to return no value; in such a case, the return statement has no accompanying value, and the definition states the type of value returned by the function as void. It is also legal to call a function and ignore its return value even if it has one. For example, we could say:
square(3);
That would be a somewhat silly thing to say, because we have gone to all the trouble of calling the function and having it generate the square of 3 — namely 9 — but we have done nothing to capture that 9. It is exactly as if we had said:
9;
You’re allowed to say that, but it doesn’t seem to serve much purpose. On the other hand, the point of a function might be not so much the value it returns as other things it does as it is executing, so then it might make perfect sense to ignore its result.
The parentheses in a function’s syntax are crucial. Parentheses are how C knows there’s a function. Parentheses after the function name in the function definition are how C knows this is a function definition, and they are needed even if this function takes no parameters. Parentheses after the function name in the function call are how C knows this is a function call, and they are needed even if this function call supplies no arguments. Using the bare name of a function is possible, because the name is the name of something, but it doesn’t call the function. (I’ll talk later about something it does do.)
Let’s return to the simple C function definition and call that I used as my example earlier. Suppose we combine that function definition and the call to that function into a single program:
int square(int i) {
return i * i;
}
int i = square(3);
That is a legal program, but only because the definition of the square function precedes the call to that function. If we wanted to place the definition of the square function elsewhere, such as after the call to it, we would need at least to precede the call with a declaration of the squarefunction (Example 1-3). The declaration looks just like the first line of the definition, but it is a statement, ending with a semicolon rather than a left curly brace.
Example 1-3. Declaring, calling, and defining a function
int square(int i);
int i = square(3);
int square(int i) {
return i * i;
}
The parameter names in the declaration do not have to match the parameter names in the definition, but all the types (and, of course, the name of the function) must match. The types constitute the signature of this function. In other words, it does not matter if the first line, the declaration, is rewritten thus:
int square(int j);
What does matter is that, both in the declaration and in the definition, square is a function taking one int parameter and returning an int. (In a modern Objective-C program, though, the function declaration usually won’t be necessary, even if the function call precedes its definition; seeModern Objective-C Function and Method Declarations.)
In Objective-C, when you’re sending a message to an object (Chapter 2), you won’t use a function call; you’ll use a method call (Chapter 3). But you will most definitely use plenty of C function calls as well. For example, earlier we initialized a CGPoint by setting its x element and its yelement, but what you’ll usually do to make a new CGPoint is to call CGPointMake, which is declared like this:
CGPoint CGPointMake (
CGFloat x,
CGFloat y
);
Despite its multiple lines and its indentations, this is indeed a C function declaration, just like the declaration for our simple square function. It says that CGPointMake is a C function that takes two CGFloat parameters and returns a CGPoint. So now you know (I hope) that it would be legal (and typical) to write this sort of thing:
CGPoint myPoint = CGPointMake(4.3, 7.1);
Pointer Parameters and the Address Operator
Objective-C is chock-a-block with pointers (and asterisks), because that’s how Objective-C refers to an object. Objective-C methods typically work with objects, so they typically expect pointer parameters and return a pointer value. But this doesn’t make things more complicated. Pointers are what Objective-C expects, but pointers are also what Objective-C gives you. Pointers are exactly what you’ve got, so there’s no problem.
For example, one way to concatenate two NSStrings is to call the NSString method stringByAppendingString:, which the documentation tells you is declared as follows:
- (NSString *)stringByAppendingString:(NSString *)aString
This declaration is telling you (after you allow for the Objective-C syntax) that this method expects one NSString* parameter and returns an NSString*. That sounds messy, but it isn’t, because every NSString is really an NSString*. So nothing could be simpler than to obtain a new NSString consisting of two concatenated NSStrings:
NSString* s1 = @"Hello, ";
NSString* s2 = @"World!";
NSString* s3 = [s1 stringByAppendingString: s2];
Sometimes, however, a function or method expects as a parameter a pointer to a thing, but what you’ve got is not that pointer but the thing itself. Thus, you need a way to create a pointer to that thing. The solution is the address operator (K&R 5.1), which is an ampersand before the name of the thing.
For example, there’s an NSString method for reading from a file into an NSString, which is declared like this:
+ (id)stringWithContentsOfFile:(NSString *)path
encoding:(NSStringEncoding)enc
error:(NSError **)error
Never mind for now what an id is, and don’t worry about the Objective-C method declaration syntax. Just consider the types of the parameters. The first one is an NSString*; that’s no problem, as every reference to an NSString is actually a pointer to an NSString. An NSStringEncoding turns out to be merely an alias to a primitive data type, an NSUInteger, so that’s no problem either. But what on earth is an NSError**?
By all logic, it looks like an NSError** should be a pointer to a pointer to an NSError. And that’s exactly what it is. This method is asking to be passed a pointer to a pointer to an NSError. Well, it’s easy to declare a pointer to an NSError:
NSError* err;
But how can we obtain a pointer to that? With the address operator! So our code might look, schematically, like this:
NSString* path = // something or other
NSStringEncoding enc = // something or other
NSError* err = nil;
NSString* result =
[NSString stringWithContentsOfFile: path encoding: enc error: &err];
The important thing to notice is the ampersand. Because err is a pointer to an NSError, &err is a pointer to a pointer to an NSError, which is just what we’re expected to provide. Thus, everything goes swimmingly. I’ll discuss in Chapter 3 how you’re supposed to use result and err after such a method call.
You can use the address operator to create a pointer to any named variable. A C function is technically a kind of named variable, so you can even create a pointer to a function! This is an example of when you’d use the name of the function without the parentheses: you aren’t calling the function, you’re talking about it. For example, &square is a pointer to the square function. Moreover, just as the bare name of an array is implicitly a pointer to its first element, the bare name of a function is implicitly a pointer to the function; the address operator is optional. In Chapter 3, I describe a situation in which specifying a pointer to a function is a useful thing to do.
Files
As your program grows, you can divide and organize it into multiple files. This kind of organization can make a large program much more maintainable — easier to read, easier to understand, easier to change without accidentally breaking things. A large C program therefore usually consists of two kinds of file: code files, whose filename extension is .c, and header files, whose filename extension is .h. The build system will automatically “see” all the files and will know that together they constitute a single program, but there is also a rule in C that code inside one file cannot “see” another file unless it is explicitly told to do so. Thus, a file itself constitutes a scope; this is a deliberate and valuable feature of C, because it helps you keep things nicely pigeonholed.
The way you tell a C file to “see” another file is with the #include directive. The hash sign in the term #include is a signal that this line is an instruction to the preprocessor. In this case, the word #include is followed by the name of another file, and the directive means that the preprocessor should simply replace the directive by the entire contents of the file that’s named.
So the strategy for constructing a large C program is something like this:
§ In each .c file, put the code that only this file needs to know about; typically, each file’s code consists of related functionality.
§ In each .h file, put the function declarations that multiple .c files might need to know about.
§ Have each .c file include those .h files containing the declarations it needs to know about.
So, for example, if function1 is defined in file1.c, but file2.c might need to call function1, the declaration for function1 can go in file1.h. Now file1.c can include file1.h, so all of its functions, regardless of order, can call function1, and file2.c can also include file1.h, so all of itsfunctions can call function1 (Figure 1-2). In short, header files are a way of letting code files share knowledge about one another without actually sharing code (because, if they did share code, that would violate the entire point of keeping the code in separate files).
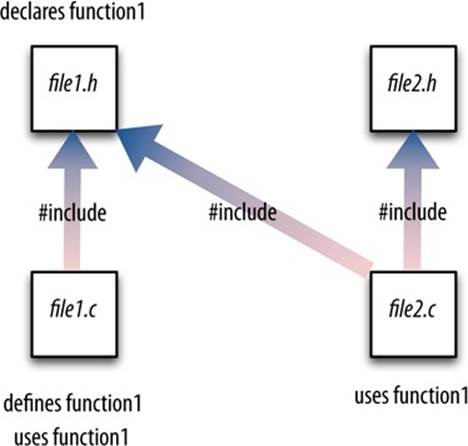
Figure 1-2. How a large C program is divided into files
But how does the compiler know where, among all these multiple .c files, to begin execution? Every real C program contains, somewhere, exactly one function called main, and this is always the entry point for the program as a whole: the compiler sets things up so that when the program executes, main is called.
The organization for large C programs that I’ve just described will also be, in effect, the organization for your iOS programs. The chief difference will be that instead of .c files, you’ll use .m files, because .m is the conventional filename extension for telling Xcode that your files are written in Objective-C, not pure C. Moreover, if you look at any iOS Xcode project, you’ll discover that it contains a file called main.m; and if you look at that file, you’ll find that it contains a function called main. That’s the entry point to your application’s code when it runs.
The big difference between your Objective-C code files and the C code files I’ve been discussing is that instead of saying #include, your files will say #import. The #import preprocessor directive is not mentioned in K&R. It’s an Objective-C addition to the language. It’s based on#include, but it is used instead of #include because it (#import) contains some logic for making sure that the same material is not included more than once. Such repeated inclusion is a danger whenever there are many cross-dependent header files; use of #import solves the problem neatly.
Furthermore, your iOS programs consist not only of your code files and their corresponding .h files, but also of Apple’s code files and their corresponding .h files. The difference is that Apple’s code files (which are what constitutes Cocoa, see Part III) have already been compiled. But your code must still #import Apple’s .h files so as to be able to see Apple’s declarations. If you look at an iOS Xcode project, you’ll find that any .h files it contains by default, as well as its main.m file, contain a line of this form:
#import <UIKit/UIKit.h>
That line is essentially a single massive #import that copies into your program the declarations for the entire basic iOS API. Moreover, each of your .m files imports its corresponding .h file, including whatever the .h file imports. For example, if you have a file AppDelegate.m, it contains this line:
#import "AppDelegate.h"
But AppDelegate.h imports <UIKit/UIKit.h>. Thus, all your code files include the basic iOS declarations.
As those examples demonstrate, the #import directive, like the #include directive (K&R 4.11), can specify a file in angle brackets or in quotation marks. The different delimiters have different meanings to the compiler:
Quotation marks
Look for the named file in the same folder as this file (the .m file in which the #import line occurs).
Angle brackets
Look for the named file among the various header search paths supplied in the build settings. (These search paths are set for you automatically, and you normally won’t need to modify them.)
In general, you’ll use angle brackets to refer to a header file owned by the Cocoa API and quotation marks to refer to a header file that you wrote. If you’re curious as to what an #import directive imports, Command-click the imported file’s name to view the header file directly.
In iOS 7 and Xcode 5, an additional import mechanism is provided, namely modules. Modules are used implicitly, behind the scenes, as part of the build process for any new iOS project (and can be turned on through a build setting for old projects); you’ll never come into direct contact with a module. The chief purpose of modules is to make your projects compile faster.
Without modules, the compilation process must start by quite literally including the headers for UIKit and the iOS API in every one of your files. For example, earlier I said that CGPoint was defined like this:
struct CGPoint {
CGFloat x;
CGFloat y;
};
typedef struct CGPoint CGPoint;
After the preprocessor operates on all your files, your .m files literally contain that definition of CGPoint — which is why your code is able to use a CGPoint. The definition of CGPoint and all the other imported material temporarily adds to every one of your files over 30,000 lines of code that the compiler then has to deal with. Modules avoid this overhead. Instead, the material imported from Apple’s code files is compiled once, automatically (typically when your project is created or opened), and cached in a separate location; that cached code constitutes the modules. At build time, the preprocessor inserts into your code only a few lines such as these:
@import UIKit;
@import Foundation;
(You can choose Product → Perform Action → Preprocess [Filename] to confirm this.) The @import compiler directive, with an at-sign instead of a hash sign, is new in Xcode 5, and refers to a module by name. Since the module is already compiled, there’s no further work for the compiler to do. I’ll talk more about @import and modules when I discuss frameworks and linking in Chapter 6.
MODERN OBJECTIVE-C FUNCTION AND METHOD DECLARATIONS
Starting with LLVM compiler version 3.1, which made its debut in Xcode 4.3, Objective-C no longer requires that a function declaration precede the use of that function, provided that the definition of that function follows in the same file. This applies to both C functions and Objective-C methods. In other words, code inside an Objective-C class can call a C function or an Objective-C method even if that call precedes the definition of that function or method, and even if there is no separate declaration of that function or method. Thus, in modern Objective-C, the order of functions and methods within a .m file doesn’t matter, and it is not necessary to declare functions or methods within a .m file at all! The only place you’ll ever need to declare a function or method will be in a .h file, and only so that some .m file other than the one that defines that function or method can import that .h file and call the function or method.
This convenience is a feature of Objective-C, not of C. I’m talking about .m files, not .c files. I’ll describe more precisely in Chapter 4 the region of a .m file in which this convenience applies — namely, a class’s implementation section.
The Standard Library
You have at your disposal a large collection of built-in C library files. A library file is a centrally located collection of C functions, along with a .h file that you can include so as to make those functions available to your code.
For example, suppose you want to round a float up to the next highest integer. The way to do this is to call some variety of the ceil function. You can read the ceil man page by typing man ceil in the Terminal. The documentation tells you what #include to use to incorporate the correct header and also shows you the function declarations and tells you what those functions do. A small pure C program might thus look like this:
#include <math.h>
float f = 4.5;
int i = ceilf(f); // now i is 5
In your iOS programs, math.h is included for you as part of UIKit, so there’s no need to include it again. But some library functions might require an explicit #import.
The standard library is discussed in K&R Appendix B. But the modern standard library has evolved since K&R; it is a superset of K&R’s library. The ceil function, for example, is listed in K&R appendix B, but the ceilf function is not. Similarly, if you wanted to generate a random number (which is likely if you’re writing a game program that needs to incorporate some unpredictable behavior), you probably wouldn’t use the rand function listed in K&R; you might use some function that supersedes it, such as the random function, or even the arc4random_uniformfunction.
Forgetting that Objective-C is C and that the C library functions are available to your code is a common beginner mistake.
More Preprocessor Directives
Of the many other available preprocessor directives, the one you’ll use most often is #define. It is followed by a name and a value; at preprocess time, the value is substituted for the name down through this code file. As K&R very well explain (K&R 1.4), this is a good way to prevent “magic numbers” from being hidden and hard-coded into your program in a way that makes the program difficult to understand and maintain.
For example, in an iOS app that lays out some text fields vertically, I might want them all to have the same space between them. Let’s say this space is 3.0. I shouldn’t write 3.0 repeatedly throughout my code as I calculate the layout; instead, I write:
#define MIDSPACE 3.0
Now instead of the “magic number” 3.0, my code uses a meaningful name, MIDSPACE; the preprocessor sees to it that the text MIDSPACE is replaced with the text 3.0. As a bonus, if I later decide to change this value and try a different one, all I have to change is the #define line, not every occurrence of the number 3.0.
A #define simply performs text substitution, so any expression can be used as the value. Sometimes you’ll want that expression to be an NSString literal. Here’s why. In Cocoa, NSString literals can be used as a key to a dictionary or the name of a notification. (Never mind for now what a dictionary or a notification is.) This situation is an invitation to error. If you have a dictionary containing a key @"mykey" and you mistype this elsewhere in your code as @"myKey" or @"mikey", the compiler won’t complain, but your program will misbehave. An elegant solution is to define a name for this literal string:
#define MYKEY @"mykey"
Now use MYKEY throughout your code instead of @"mykey", and if you mistype it (as MYKKEY or what have you), the preprocessor won’t perform any substitution and the compiler will complain, catching the mistake for you.
The #define directive can also be used to create a macro (K&R 4.11.2), a more elaborate form of text substitution. You’ll encounter a few Cocoa macros when programming iOS, but they will appear indistinguishable from functions; their secret identity as macros usually won’t concern you.
The #warning directive deliberately triggers a warning in Xcode at compile time; this can be a way to remind yourself of some impending task or requirement:
#warning Don't forget to fix this bit of code
There is also a #pragma mark directive that’s useful with Xcode; I talk about it when discussing the Xcode programming environment (Chapter 9).
Data Type Qualifiers
A variable’s data type can be declared with a qualifier before the name of the type, modifying something about how that variable is to be used. For example, the declaration can be preceded by the term const, which means (K&R 2.4) that it is illegal to change the variable’s value; the variable must be initialized in the same line as the declaration, and that’s the only value it can ever have.
You can use a const variable as an alternative way (instead of #define) to prevent “magic numbers” and similar expressions. For example:
NSString* const MYKEY = @"Howdy";
The Cocoa API itself makes heavy use of this device. For example, in some circumstances Cocoa will pass a dictionary of information to your code. The documentation tells you what keys this dictionary contains. But instead of telling you a key as a literal string value, the documentation tells you the key as a const NSString variable name:
UIKIT_EXTERN NSString *const UIApplicationStatusBarOrientationUserInfoKey;
(Never mind what UIKIT_EXTERN means.) This declaration tells you that UIApplicationStatusBarOrientationUserInfoKey is the name of an NSString, and you are to trust that its value is set for you. You are to go ahead and use this name whenever you want to speak of this particular key, secure in the knowledge that the actual string value will be substituted — even though you don’t know or care what that string value is. In this way, if you make a mistake in typing the variable name, the compiler will catch the mistake because you’ll be using the name of an undefined variable.
Another commonly used qualifier is static. This term is unfortunately used in two rather different ways in C; the way I commonly use it is inside a function or method. Here, static indicates that the memory set aside for a variable should not be released after the function or method returns; rather, the variable remains and maintains its value for the next time the function or method is called. A static variable is useful, for example, when you want to call a function many times without the overhead of calculating the result each time (after the first time). First test to see whether the static value has already been calculated: if it hasn’t, this must be the first time the function is being called, so you calculate it; if it has, you just return it. Here’s a schematic version:
int myfunction() {
static int result = 0; // 0 means we haven't done the calculation yet
if (result == 0) {
// calculate result and set it
}
return result;
}
A very common use of a static variable in Objective-C is to implement a singleton instance returned by a class factory method. If that sounds complicated, don’t worry; it isn’t. Here’s an example from my own code, which you can grasp even though we haven’t discussed Objective-C yet:
+ (CardPainter*) sharedPainter {
static CardPainter* sp = nil;
if (nil == sp)
sp = [CardPainter new];
return sp;
}
That code says: If the CardPainter instance sp has never been created, create it, and in any case, now return it. Thus, no matter how many times this method is called, the instance will be created just once and that same instance will be returned every time.
WARNING
Static variables are a C language feature, not an Objective-C language feature. Therefore, a static variable knows nothing of classes and instances; even if it appears inside a function or a method, it is defined at the level of a file, which means, in effect, at the level of your program as a whole. That’s fine when you’re using it in a class factory method, because a class is unique to your program as a whole. But never use a static variable in an Objective-C instance method, because your program can have multiple such instances, and the value of this one static variable will apply across all of them. In other words, don’t use a C static variable as a lazy substitute for an Objective-C instance variable (Chapter 2). I’ve made that mistake, and trust me, the results are not pretty.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.