iOS 7 Programming Fundamentals: Objective-C, Xcode, and Cocoa Basics (2014)
Part I. Language
Chapter 3. Objective-C Objects and Messages
One of the first object-based programming languages to achieve maturity and widespread dissemination was Smalltalk. It was developed during the 1970s at Xerox PARC under the leadership of Alan Kay and started becoming widely known in 1980. The purpose of Objective-C, created by Brad Cox and Tom Love in 1986, was to build Smalltalk-like syntax and behavior on top of C. Objective-C was licensed by NeXT in 1988 and was the basis for its application framework API, NeXTStep. Eventually, NeXT and Apple merged, and the NeXT application framework evolved into Cocoa, the framework for OS X applications, still revolving around Objective-C. That history explains why Objective-C is the base language for iOS programming. (It also explains why Cocoa class names often begin with “NS” — it stands for “NeXTStep.”)
Having learned the basics of C (Chapter 1) and the nature of object-based programming (Chapter 2), you are ready to meet Objective-C. This chapter describes Objective-C structural fundamentals; the next two chapters provide more detail about how Objective-C classes and instances work. (A few additional features of the language are discussed in Chapter 10.) As with the C language, my intention is not to describe the Objective-C language completely, but to provide a practical linguistic grounding, founded on my own experience of those aspects of the language that need to be firmly understood as a basis for iOS programming.
An Object Reference Is a Pointer
A reference is just what you think it is: it’s a way of picking out some definite individual thing. A particularly good form of reference is to give something a name. If we want to refer to Socrates, it is tedious to have to keep describing him as “that fat bald fellow who keeps asking annoying questions in the marketplace.” It’s simpler to refer to him by his name, “Socrates.” The C equivalent of a name is a variable. Assigning a value to a variable causes that variable (the name) to become a reference to that value.
In C, every variable must be declared to be of some type. The C language includes very few basic data types; it is certainly unprepared for object types. In order to impose objects onto C and turn C into an object-based language, Objective-C takes advantage of the flexibility of C pointers (seeChapter 1). A pointer is a C data type, but what is pointed to can be anything at all. Therefore, in Objective-C, every reference to an object is a pointer (and Objective-C itself takes care of dealing with the question of what’s being pointed to).
The fact that object references are pointers in Objective-C is particularly evident in the case of a reference to an instance (see Chapter 2). In an object-based language such as Objective-C, an instance’s type is its class. Thus, we would like to use a class name in Objective-C much as we use any data type name in C. Pointers allow us to do this. Pointers satisfy the requirement of C, on the one hand, that a reference should be of some definite C data type, as well as the requirement of Objective-C, on the other hand, that we should be able to specify any of a vast multiplicity of class types. In Objective-C, if a variable is to refer explicitly to an instance of the class MyClass, that variable is of type MyClass* — a pointer to a MyClass. In general, in Objective-C, a reference to an instance is a pointer and the name of the data type of what’s at the far end of that pointer is the name of the instance’s class.
TIP
Note the convention for capitalization. Variable names tend to start with a lowercase letter; class names tend to start with an uppercase letter.
As I mentioned in Chapter 1, the fact that a reference to an instance is a pointer in Objective-C will generally not cause you any difficulties, because pointers are used consistently throughout the language. For example, a message to an instance is directed at the pointer, so there is no need to dereference the pointer. Indeed, having established that a variable representing an instance is a pointer, you’re likely to forget that this variable even is a pointer and just work directly with that variable:
NSString* s = @"Hello, world!";
NSString* s2 = [s uppercaseString];
Having established that s is an NSString*, you would never dereference s (that is, you would never speak of *s) to access the “real” NSString. So it feels as if the pointer is the real NSString. Thus, in the previous example, once the variable s is declared as a pointer to an NSString, theuppercaseString message is sent directly to the variable s. (The uppercaseString message asks an NSString to generate and return an uppercase version of itself; so, after that code, s2 is @"HELLO, WORLD!")
The tie between a pointer, an instance, and the class of that instance is so close that it is natural to speak of an expression like MyClass* as meaning “a MyClass instance,” and of a MyClass* value as “a MyClass.” An Objective-C programmer will say simply that, in the previous example, sis an NSString, that uppercaseString returns “an NSString,” and so forth. It is fine to speak like that, and I do it myself — provided you remember that this is a shorthand. Such an expression means “an NSString instance,” and because an instance is represented as a C pointer, it means anNSString*, a pointer to an NSString.
Although the fact that instance references in Objective-C are pointers does not cause any special difficulty, you must still be conscious of what pointers are and how they work. As I emphasized in Chapter 1, when you’re working with pointers, your actions have a special meaning. So here are some basic facts about pointers that you should keep in mind when working with instance references in Objective-C.
WARNING
Forgetting the asterisk in an instance declaration is a common beginner mistake, and will net you a mysterious compiler error message, such as “Interface type cannot be statically allocated.”
Instance References, Initialization, and nil
Merely declaring an instance reference’s type doesn’t bring any instance into existence. For example:
NSString* s; // only a declaration; no instance is pointed to
After that declaration, s is typed as a pointer to an NSString, but it is not in fact pointing to an NSString. You have created a pointer, but you haven’t supplied an NSString for it to point to. It’s just sitting there, waiting for you to point it at an NSString, typically by assignment (as we did with@"Hello, world!" earlier). Such assignment initializes the variable, giving it, for the first time, an actual meaningful value of the proper type.
You can declare a variable as an instance reference in one line of code and initialize it later, like this:
NSString* s;
// ... time passes ...
s = @"Hello, world!";
But that is not common. It is much more common, wherever possible, to declare and initialize a variable all in one line of code:
NSString* s = @"Hello, world!";
Declaration without initialization, before the advent of ARC (Chapter 12), created a downright dangerous situation:
NSString* s;
Without ARC, s could be anything after a mere declaration like that. The trouble is, however, that it is claiming to be a pointer to an NSString. Fooled by this, you might then proceed to treat it as a pointer to an NSString. But it is pointing at garbage. A pointer pointing at garbage is liable to cause serious trouble down the road when you accidentally try to use it as an instance. Sending a message to a garbage pointer, or otherwise treating it as a meaningful instance, can crash your program. Even worse, it might not crash your program: it might cause your program to behave very, very oddly instead — and figuring out why can be difficult.
Setting a reference to nil, on the other hand, doesn’t point that reference at an actual instance, but at least it ensures that the reference isn’t a garbage pointer. To defend against garbage pointers, therefore, it was common, before ARC, if you weren’t going to initialize an instance reference pointer at the moment you declared it by assigning it a real value, to assign nil to it:
NSString* s = nil;
A small but delightful bonus feature of ARC is that this assignment is performed for you, implicitly and invisibly, as soon as you declare a variable without initializing it:
NSString* s; // under ARC, s is immediately set to nil for you
What is nil? It’s a form of zero — the form of zero appropriate to an instance reference. The nil value simply means: “This instance reference isn’t pointing to any instance.” Indeed, you can test an instance reference against nil as a way of finding out whether it is in fact pointing to a real instance. This is an extremely common thing to do:
if (nil == s) // ...
As I mentioned in Chapter 1, the explicit comparison with nil isn’t strictly necessary; because nil is a form of zero, and because zero means false in a condition, you can perform the same test like this:
if (!s) // ...
I do in fact write nil tests in that second form all the time, but some programmers would take me to task for bad style. The first form has the advantage that its real meaning is made explicit, rather than relying on a cute implicit feature of C. The first form also deliberately places nil first in the comparison so that if the programmer accidentally omits an equal sign, performing an assignment instead of a comparison, the compiler will catch the error (because assignment to nil is illegal).
Many Cocoa methods use a return value of nil, instead of an expected instance, to signify that something went wrong. You are supposed to capture this return value and test it for nil in order to discover whether something did go wrong. For example, the documentation for the NSString class method stringWithContentsOfFile:encoding:error: says that it returns “a string created by reading data from the file named by path using the encoding, enc. If the file can’t be opened or there is an encoding error, returns nil.” So, as I described in Chapter 1, you call that method like this:
NSString* path = // something or other
NSStringEncoding enc = // something or other
NSError* err = nil;
NSString* result =
[NSString stringWithContentsOfFile: path encoding: enc error: &err];
Why is stringWithContentsOfFile:encoding:error: structured in this way? In effect, it’s so that this method can return two results. It returns a real result, which we have captured by assigning it to the NSString pointer we’re calling result. But if there’s an error, it also wants to set the value of another object, an NSError object; the idea is that you can then study that NSError object to find out what went wrong. (Perhaps the file wasn’t where you said it was, or it wasn’t stored in the encoding you claimed it was.) By passing a pointer to a pointer to an NSError, you give the method free rein to do that. Before the call to stringWithContentsOfFile:encoding:error:, err was initialized to nil; during the call to stringWithContentsOfFile:encoding:error:, if there’s an error, the pointer is repointed, thus giving err a meaningful NSError value describing that error. (Repointing a pointer in this way is sometimes called indirection.)
Thus, your next move after calling this method and capturing the result should be to test that result against nil, just to make sure you’ve really got an instance now. If the result isn’t nil, fine; it’s the string you asked for. If the result is nil, you then study the NSError that err is now pointing to, to learn what went wrong:
NSString* path = // something or other
NSStringEncoding enc = // something or other
NSError* err = nil;
NSString* result =
[NSString stringWithContentsOfFile:path encoding:enc error:&err];
if (nil == result) { // oops! something went wrong...
// examine err to find out what went wrong
}
This pattern is frequently used in Cocoa. Don’t get the pattern wrong. A very common beginner mistake is to call a method such as stringWithContentsOfFile:encoding:error: and then immediately check the value of the error variable (here, err). Don’t do that! If there was no error, nothing about the value of the error variable is guaranteed. Instead, start by checking the result (here, result); if the result indicates (by turning out to be nil) that there was an error, then and only then should you examine the NSError value that was set by indirection.
NOTE
In pure C code, you will sometimes see a pointer-to-nothing expressed as NULL. NULL and nil are functionally equivalent nowadays, so feel free to use nil exclusively.
Instance References and Assignment
As I said in Chapter 1, assigning to a pointer does not mutate the value at the far end of the pointer; rather, it repoints the pointer. Moreover, assigning one pointer to another repoints the pointer in such a way that both pointers are now pointing to the very same thing. Failure to keep these simple facts firmly in mind can have results that range from surprising to disastrous.
Pretend that we’ve implemented the Stack class described in Chapter 2, and consider the following code:
Stack* myStack1 = // ... create Stack instance and initialize myStack1 ...
Stack* myStack2 = myStack1;
A common misunderstanding is to imagine that the assignment myStack2 = myStack1 somehow makes a new, separate instance that duplicates myStack1. That’s not at all the case. The assignment doesn’t make a new instance; it just points myStack2 at the very same instance thatmyStack1 is pointing at. It may be possible to make a new instance that duplicates a given instance, but the ability to do so is not a given and it is not going to happen through mere assignment. (For how a separate duplicate instance might be generated, see the NSCopying protocol and thecopy method mentioned in Chapter 10.)
Moreover, instances in general are usually mutable: they typically have instance variables that can change. If two references are pointing at one and the same instance, then when the instance is mutated by way of one reference, that mutation also affects the instance as seen through the other reference:
Stack* myStack1 = // ... create Stack instance and initialize myStack1 ...
Stack* myStack2 = myStack1;
[myStack1 push: @"Hello"];
[myStack1 push: @"World"];
NSString* s = [myStack2 pop];
After we pop myStack2, s is @"World" even though nothing was ever pushed onto myStack2 — and the stack myStack1 contains only @"Hello" even though nothing was ever popped off of myStack1. That’s because we did push two strings onto myStack1 and then pop one string offmyStack2, and myStack1 is myStack2 — in the sense that they are both pointers to the very same stack instance. That’s perfectly fine, as long as you understand and intend this behavior.
Sometimes, however, such behavior is not perfectly fine. When your program has more than one reference to the same instance, surprising results can ensue, because (just as in the preceding example) that instance can be mutated by way of one reference at a time when the holder of the other reference is not expecting any such thing to happen. In real life, problems of this kind can arise particularly because instances can have instance variables that point to other objects, and those pointers can persist as long as the instances themselves do. Suppose we have an object myObjectand we hand it a reference to our stack object:
Stack* myStack = // ... create Stack instance and initialize myStack ...
[myObject doSomethingWithThis: myStack]; // pass myStack to myObject
After that code, myObject has a pointer to the very same instance we’re already pointing to as myStack. So we must be careful and thoughtful. The object myObject might now mutate myStack right under our very noses! Even more, the object myObject might keep its reference to the stack instance (by way of an instance variable) and mutate it later — possibly much later, in a way that could surprise us. This kind of shared referent situation can be intentional, but it is also something to watch out for and be conscious of (Figure 3-1).
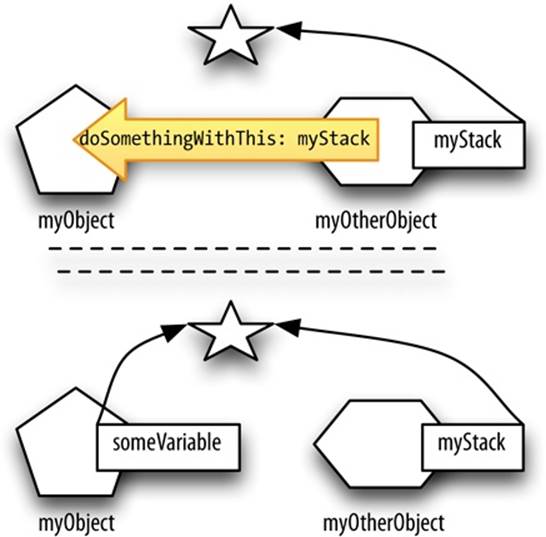
Figure 3-1. Two instances end up with pointers to the same third instance
Instance References and Memory Management
The pointer nature of instance references in Objective-C also has implications for management of memory. The scope, and in particular the lifetime, of variables in pure C is typically quite straightforward: if you bring a piece of variable storage into existence by declaring that variable within a certain scope, then when that scope ceases to exist, the variable storage ceases to exist. That sort of variable is called automatic (K&R 1.10). So, for example:
void myFunction() {
int i; // storage for an int is set aside
i = 7; // 7 is placed in that storage
} // the scope ends, so the int storage and its contents vanish
But in the case of a pointer, there are two pieces of memory to worry about: the pointer itself, which is an integer signifying an address in memory, and whatever is at that address, at the far end of that pointer. Nothing about the C language causes the destruction of what a pointer points to when the pointer itself is automatically destroyed as it goes out of scope:
void myFunction() {
NSString* s = @"Hello, world!"; // pointer and NSString
NSString* s2 = [s uppercaseString]; // pointer and NSString
} // the two pointers go out of existence...
// ... but what about the two NSStrings they point to?
Some object-based programming languages in which a reference to an instance is a pointer do manage automatically the memory pointed to by instance references (REALbasic and Ruby are examples). But Objective-C is not one of those languages. Because the C language has nothing to say about the automatic destruction of what is pointed to by a reference to an instance, Objective-C implements an explicit mechanism for the management of memory. I’ll talk in a later chapter (Chapter 12) about what that mechanism is and what responsibilities for the programmer it entails. Fortunately, under ARC, those responsibilities are fewer than they used to be; but memory must still be managed, and you must still understand how memory management of instances works.
Methods and Messages
An Objective-C method is defined as part of a class. It has three aspects:
Whether it’s a class method or an instance method
If it’s a class method, you call it by sending a message to the class itself. If it’s an instance method, you call it by sending a message to an instance of the class.
Its parameters and return value
As with a C function (see Chapter 1), an Objective-C method takes some number of parameters; each parameter is of some specified type. And, as with a C function, it may return a value, which is also of some specified type; if the method returns nothing, its return type is declared asvoid.
Its name
An Objective-C method’s name must contain exactly as many colons as the method takes parameters, and, if the method takes any parameters, the name must end with a colon.
Calling a Method
To send a message to an object, you use a message expression, also referred to, for simplicity and by analogy with C functions, as a method call. As you’ve doubtless gathered, the syntax for sending a message to an object involves square brackets. The first thing in the square brackets is the object to which the message is to be sent; this object is the message’s receiver. Then follows the message:
NSString* s2 = [s uppercaseString]; // send "uppercaseString" message to s ...
// ... (and assign result to s2)
If the message is a method that takes parameters, each corresponding argument value comes after a colon:
[myStack1 push: @"Hello"]; // send "push:" message to myStack1 ...
// ...with one argument, the NSString @"Hello"
To send a message to a class (calling a class method), you can represent the class by the literal name of the class:
NSString* s = [NSString string]; // send "string" message to NSString class
To send a message to an instance (calling an instance method), you’ll need a reference to an instance, which (as you know) is a pointer:
NSString* s = @"Hello, world!"; // s is initialized as an NSString instance
NSString* s2 = [s uppercaseString]; // send "uppercaseString" message to s
You can send a class method to a class, and an instance method to an instance, no matter how you obtain and represent the class or the instance. For example, @"Hello, world!" is itself an NSString instance, so it’s legal to say:
NSString* s2 = [@"Hello, world!" uppercaseString];
If a method takes no parameters, then its name contains no colons, like the NSString instance method uppercaseString. If a method takes one parameter, then its name contains one colon, which is the final character of the method name, like the hypothetical Stack instance method push:. If a method takes two or more parameters, its name contains that number of colons, and the last colon is the final character of the method name. In the minimal case, the method name ends with all its colons. For example, a method taking three parameters might be calledhereAreThreeStrings:::. To call it, we split the name after each colon and follow each colon with an argument, which looks like this:
[someObject hereAreThreeStrings: @"string1" : @"string2" : @"string3"];
That’s a legal way to name and call a method, but it isn’t very common, mostly because it isn’t very informative. Usually the name will have more text; in particular, the part of the name before each colon will describe the parameter that follows that colon.
For example, there’s a UIColor class method for generating an instance of a UIColor from four CGFloat numbers representing its red, green, blue, and alpha (transparency) components, and it’s called colorWithRed:green:blue:alpha:. Notice the clever construction of this name. ThecolorWith part tells something about the method’s purpose: it generates a color, starting with some set of information. All the rest of the name, Red:green:blue:alpha:, describes the meaning of each parameter. And you call it like this:
UIColor* c = [UIColor colorWithRed: 0.0 green: 0.5 blue: 0.25 alpha: 1.0];
Similarly, I’ve referred several times in this chapter to an NSString class method stringWithContentsOfFile:encoding:error:. The name is beautifully descriptive. Even before we learn the exact data types of the parameters, we can guess that the first parameter is a reference to a file, the second parameter describes the file’s encoding, and the third parameter is used to return an error by indirection (and that this method returns a string).
The rules for naming an Objective-C method, along with the conventions governing such names (like trying to make the name informative about the method’s purpose and the meanings of its parameters), lead to some rather long and unwieldy method names, such asgetBytes:maxLength:usedLength:encoding:options:range:remainingRange:. Such verbosity of nomenclature is characteristic of Objective-C. Method calls, and even method declarations, are often split across multiple lines, both for clarity and to prevent a single line of code from becoming so long that it wraps within the editor.
Declaring a Method
A method declaration is the definitive public statement of that method’s name, the data type of its return value, and the data types of each of its parameters. For example, the Apple documentation of a class consists chiefly of a list of the declarations of its methods. Thus, it is crucial that you know how to read a method declaration.
The declaration for a method has three parts:
§ Either + or -, meaning that the method is a class method or an instance method, respectively.
§ The data type of the return value, in parentheses.
§ The name of the method, split after each colon. Following each colon is the corresponding parameter, expressed as the data type of the parameter, in parentheses, followed by a placeholder name for the parameter.
So, for example, Apple’s documentation tells us that the declaration for the UIColor class method colorWithRed:green:blue:alpha: is:
+ (UIColor*) colorWithRed: (CGFloat) red green: (CGFloat) green
blue: (CGFloat) blue alpha: (CGFloat) alpha
(Note that I’ve split the declaration into two lines, for legibility and to fit onto this page. The documentation puts it all on a single line.)
Make very sure you can read this declaration! You should be able to look at it and say to yourself instantly, “The name of this method is colorWithRed:green:blue:alpha:. It’s a class method that takes four CGFloat parameters and returns a UIColor.”
NOTE
The space after each colon in a method call or declaration is optional. Space before a colon is also legal, though in practice one rarely sees this. Space before or after any of the parentheses in a method declaration is also optional.
A USEFUL SHORTHAND
It is not uncommon, outside of code, to refer to a method by writing its name preceded by a plus sign or a minus sign, to make clear whether this is a class method or an instance method. A semiofficial shorthand is to write the plus sign or the minus sign followed by square brackets containing the class name and the method name. For example, the release notes for iOS 7 say that this method, not present in iOS 6, was added in iOS 7:
-[NSScanner scanUnsignedLongLong:]
That’s not a method call or a declaration. It isn’t Objective-C code at all. It’s just a shorthand way of describing a method, saying that it’s an instance method of NSScanner called scanUnsignedLongLong:.
Nesting Method Calls
Wherever in a method call an object of a certain type is supposed to appear, you can put another method call that returns that type. Thus you can nest method calls. A method call can appear as the receiver in a method call:
NSString* s = [[NSString string] uppercaseString]; // silly but legal
That’s legal because the result of NSString’s class method string is an NSString instance (formally, an NSString* value), so we can send an NSString instance method to that result. Similarly, a method call can appear as an argument in a method call:
[myStack push: [NSString string]]; // ok if push: expects NSString* parameter
However, I must caution you against overdoing that sort of thing. Code with a lot of nested square brackets is very difficult to read (and to write). Furthermore, if one of the nested method calls happens to return an unexpected value, you have no way to detect this fact. It is often better, then, to be even more verbose and declare a temporary variable for each piece of the method call. Just to take an example from my own code, instead of writing this:
NSArray* arr = [[MPMediaQuery albumsQuery] collections];
I might write this:
MPMediaQuery* query = [MPMediaQuery albumsQuery];
NSArray* arr = [query collections];
Even though the first version is quite short and legible, and even though in the second version the variable query will never be used again — it exists solely in order to be the receiver of the collections message in the second line — it is worth creating it as a separate variable. For one thing, it makes this code far easier to step through in the debugger later on, when I want to pause after the albumsQuery call and see whether the expected sort of result is being returned (see Chapter 9).
NOTE
An incorrect number or pairing of nested square brackets can net you some curious messages from the compiler. For example, too many pairs of square brackets ([[query collections]]) or an unbalanced left square bracket ([[query collections]) is reported as “Expected identifier.”
No Overloading
The data type returned by a method, together with the data types of each of its parameters in order, constitute that method’s signature. It is illegal for two methods of the same type (class method or instance method) to exist in the same class with the same name, even if they have different signatures.
So, for example, you could not have two MyClass instance methods called myMethod, one of which returns void and one of which returns an NSString. Similarly, you could not have two MyClass instance methods called myMethod:, both returning void, one taking a CGFloat parameter and one taking an NSString parameter. An attempt to violate this rule will be stopped dead in its tracks by the compiler, which will announce a “duplicate declaration” error. The reason for this rule is that if two such conflicting methods were allowed to exist, there would be no way to determine from a method call to one of them which method was being called.
You might think that the issue could be decided by looking at the types involved in the call. If one myMethod: takes a CGFloat parameter and the other myMethod: takes an NSString parameter, you might think that when myMethod: is called, Objective-C could look at the actual argument and realize that the former method is meant if the argument is a CGFloat and the latter if the argument is an NSString. But Objective-C doesn’t work that way. There are languages that permit this feature, called overloading, but Objective-C is not one of them.
Parameter Lists
It isn’t uncommon for an Objective-C method to require an unknown number of parameters. A good example is the NSArray class method arrayWithObjects:, which looks from the name as if it takes one parameter but in fact takes any number of parameters, separated by comma. The parameters are the objects that are to constitute the elements of the NSArray. The trick here, however, which you must discover by reading the documentation, is that the list must end with nil. The nil is not one of the objects to go into the NSArray (nil isn’t an object, so an NSArray can’t contain nil); it’s to show where the list ends.
So, here’s a correct way to call the arrayWithObjects: method:
NSArray* pep = [NSArray arrayWithObjects:@"Manny", @"Moe", @"Jack", nil];
The declaration for arrayWithObjects: uses three dots to show that a comma-separated list is legal:
+ (id)arrayWithObjects:(id)firstObj, ... ;
(I’ll explain later in this chapter what id means.) Without the nil terminator, the program will not know where the list ends, and bad things will happen when the program runs, as it goes hunting off into the weeds of memory, incorporating all sorts of unintended garbage into the NSArray.
Forgetting the nil terminator used to be a common beginner error, but nowadays the Objective-C compiler notices if you’ve forgotten the nil, and warns you (“missing sentinel in method dispatch”). Even though it’s just a warning, don’t run that code! Another way to avoid forgetting the nil terminator in this particular example is to avoid calling arrayWithObjects: altogether; this has been possible ever since LLVM compiler version 4.0 (Xcode 4.4 or later), which allows you to form a literal NSArray object directly, using @[...] syntax, like this:
NSArray* pep = @[@"Manny", @"Moe", @"Jack"];
That’s just a notation, a kind of syntactic sugar; behind the scenes, arrayWithObjects: is still being called for you. But it’s being called for you correctly, nil terminator and all, so this notation is much more bullet-proof than explicitly calling arrayWithObjects: yourself; plus it’s a lot less typing.
Nevertheless, you will still encounter many other Objective-C methods that do have a parameter that’s a nil-terminated list of variable length. For example, there’s the UIAppearance protocol class method appearanceWhenContainedIn:, or UIAlertView’sinitWithTitle:message:delegate:cancelButtonTitle:otherButtonTitles:. It’s a pity that Apple hasn’t somehow tweaked Objective-C or these methods to avoid the use of the nil terminator; for instance, they could have made the variable-length list parameter into an NSArray parameter instead. But until they do, knowing how to call such methods remains important.
The C language has explicit provision for argument lists of unspecified length, which Objective-C methods such as arrayWithObjects: are using behind the scenes. I’m not going to explain the C mechanism, because I don’t expect you’ll ever write a method or function that requires it; see K&R 7.3 if you need the gory details.
When Message Sending Goes Wrong
The message-sending mechanism is fundamental to Objective-C. For that very reason, it is a major locus of problems. When a message is sent to an object, it is all too easy for things to go wrong. How can things go wrong with such a simple and basic mechanism? Consider the following seemingly trivial expression:
[s uppercaseString]
In that expression, s is a reference, and uppercaseString is a message. The uppercaseString message is being sent to the reference s. What could possibly go wrong here?
The reference might be to the wrong thing
An object reference is a pointer. The thing being pointed to is the actual object — supposedly. The reference is only a name. How do you know, from that expression, what s is pointing to? You didn’t see me initialize it. It might be nil. It might not be a string. It might be a different string from the one I think it is. A reference might not be a reference to what you think.
The message might be the wrong message
This possibility goes hand in hand with the previous possibility. If the reference can be to the wrong thing, that thing might not like being sent this message. Or, it might accept being sent this message, but, being the wrong thing, it might produce an outcome different from what you expect.
This isn’t mere nit-picking; it’s a common and pervasive reality. A vast proportion of the questions I see posed on the Internet about why some code is going wrong turn out to be due to these problems. Programming is deceptive; you can easily fool yourself into making false assumptions. You think you know what a certain reference is, but you don’t. The result is that things misbehave mysteriously, or your program crashes. Be conscious of how message sending can go wrong, and when it does go wrong — as I assure you it will — you’ll be prepared.
The rest of this section will focus on two particularly insidious ways in which message sending can go wrong: a message is sent to a nil reference, and a message is sent to an object that doesn’t like that message.
Messages to nil
It is all too easy for a supposed instance reference to refer accidentally to a noninstance — that is, to nil. I’ve already said that merely declaring an instance without also initializing it sets that reference to nil (under ARC), and that many Cocoa methods deliberately return nil as a way of indicating that something went wrong. Also, an instance variable declared as an object reference starts out life as nil; if it isn’t subsequently set to point to an actual object in the way that you expect, it can go on being nil. (In Chapter 7, I’ll discuss an all too common way in which that can happen, namely, when an intended outlet into a nib file hasn’t been configured correctly.)
Let’s examine the implications of a nil-value pointer for sending a message to a noninstance. You can send a message to an NSString instance like this:
NSString* s2 = [s uppercaseString];
That code sends the uppercaseString message to s. So s is supposedly an NSString instance. But what if s is nil? With some object-based programming languages, sending a message to nil constitutes a runtime error and will cause your program to terminate prematurely (REALbasic and Ruby are examples). But Objective-C doesn’t work like that. In Objective-C, sending a message to nil is legal and does not interrupt execution. Moreover, if you capture the result of the method call, it will be a form of zero — which means that if you assign that result to an instance reference pointer, it too will be nil:
NSString* s = nil; // now s is nil
NSString* s2 = [s uppercaseString]; // now s2 is nil
Whether this behavior of Objective-C is a good thing is a quasi-religious issue and a subject of vociferous debate among programmers. It is useful, but it is also extremely easy to be tricked by it. The usual scenario is that you accidentally send a message to a nil reference without realizing it, and then later your program doesn’t behave as expected. Because the point where the unexpected behavior occurs is later than the moment when the nil pointer arose in the first place, the genesis of the nil pointer can be difficult to track down (indeed, it often fails to occur to the programmer that a nil pointer is the cause of the trouble in the first place).
Short of peppering your code with tests to ascertain that your instance reference pointers are not accidentally nil, there isn’t much you can do about this. This behavior is strongly built into the language and is not going to change. So be aware of it! Believing that you have a reference to an instance when in fact you have a reference to nil is a very, very common beginner mistake — and because the runtime doesn’t complain when you start using that reference to nil, sending messages to it and possibly generating even more references to nil, nothing happens to disabuse you of this misconception (except that the program doesn’t seem to behave quite as expected). If things quietly and mysteriously go wrong, suspect a nil reference, and use debugging techniques (Chapter 9) to investigate.
Certainly, if you know in advance that a particular method call can return nil, don’t assume that everything will go well and that it won’t return nil. On the contrary, if something can go wrong, it probably will. For example, to omit the nil test after callingstringWithContentsOfFile:encoding:error: is just stupid. I don’t care if you know perfectly well that the file exists and the encoding is what you say it is — test the result for nil!
Unrecognized Selectors
It is possible to direct a message at an object with no corresponding method. When this happens, the consequences can be fatal: your app can crash. The only guardian against such a contingency is the compiler; but it isn’t a very strong guardian. In some cases the compiler will warn you that you might be doing something inadvisable; in other cases the compiler will happily let you proceed.
Here’s a situation where the compiler will actually save you from yourself:
NSString* s = @"Hello, world!";
[s rockTheCasbah];
An NSString has no method rockTheCasbah. Before ARC, the compiler would permit that code to compile, but it would warn you that there might be trouble. Under ARC, however, the compiler refuses to compile that code, declaring a fatal error: “No visible @interface for ‘NSString’ declares the selector ‘rockTheCasbah’.” (The ARC compiler is strict, because ARC has to do with memory management, and ARC can’t manage memory effectively if you are allowed to send messages that make no sense whatever.)
By muddying the waters just a little, however, we can slip past ARC’s stringent guardianship. Suppose now that we have a class MyClass which does declare a method rockTheCasbah. Then we can write this:
MyClass* m = @"Hello, world!";
[m rockTheCasbah];
We have claimed that m is a MyClass instance, but in fact we have then set it to an NSString instance. That’s a strange thing to do, but it isn’t strictly illegal. The compiler warns (“incompatible pointer types”), but compilation succeeds, and we are free to laugh recklessly and run that code anyway. What happens?
When the program runs, and when we send an NSString the rockTheCasbah message, our program crashes, with a message (in the console log) of this form:
-[__NSCFConstantString rockTheCasbah]:
unrecognized selector sent to instance 0x8650.
That console message describes in great detail what happened:
§ The phrase unrecognized selector is the heart of the matter. The term “selector” is roughly equivalent to “message,” so this is a way of saying that a certain object was sent a message it couldn’t deal with.
§ -[__NSCFConstantString rockTheCasbah] describes the message and its receiver, using the shorthand I described earlier: an NSCFConstantString instance was sent an instance message rockTheCasbah. (The description of an NSString as an NSCFConstantString is an internal bookkeeping detail.)
§ 0x8650 is the value of the instance pointer; it is the address in memory to which m was actually pointing.
NOTE
An unrecognized selector situation generates an exception, an internal message as the program runs signifying that something bad has happened. It is possible for Objective-C code to “catch” an exception, in which case the program will not crash. The reason the program crashes, technically, is not that a message was sent to an object that couldn’t handle it, but that the exception generated in response wasn’t caught. That’s why the crash log may also say, “Terminating app due to uncaught exception.”
In that example, we deliberately got ourselves into trouble, in order to demonstrate what happens when an unrecognized selector situation arises. The example is fanciful; but the consequences are not. I assure you that this kind of thing will happen to you, though of course it will come about unintentionally. It will happen because, as I said at the start of this section, your reference is not referring to the thing you think it is. There are many ways in which such a situation can arise; for example, as I’ll explain in the next section, you may lie to the compiler accidentally about the class of an object, or the compiler may have no information about the class of an object, so it won’t even warn you when you write a method call that will ultimately send an object a message it can’t deal with. Watch for that phrase “unrecognized selector” when your program crashes, and know what it means and how to interpret the console message! The details of the console message will help you figure out what went wrong and where.
Typecasting and the id Type
Sometimes, the compiler, attempting to save you from an unrecognized selector situation, will issue a warning or an error when you know very well that what you’re trying to do is safe and correct. The problem here is that you know more than the compiler does about what’s really going to happen when the program runs. In order to proceed, you need to share your extra knowledge with the compiler. Typically, you’ll do this by typecasting an object reference (see Chapter 1). Here, a typecast serves as a declaration of what class an object will be when the program runs. The compiler will believe whatever you say in a typecast; thus, typecasting can allay the compiler’s worries.
This situation quite often arises in connection with class inheritance. We haven’t discussed class inheritance yet (see Chapter 4), but I’ll give an example anyway.
Let’s take the built-in Cocoa class UINavigationController. Its topViewController method is declared to return a UIViewController instance. In real life, though, it is likely to return an instance of some particular UIViewController subclass that you’ve created. So in order to call a method of the class you’ve created on the instance returned by topViewController without upsetting the compiler, you have to reassure the compiler that this instance really will be an instance of the class you’ve created.
Here’s an example from one of my own apps:
[[navigationController topViewController] setAlbums: arr];
That line of code won’t compile; we get the same “no visible @interface” error that I discussed in the previous section. The built-in topViewController method returns a UIViewController, and UIViewController has no setAlbums method.
I happen to know, however, that in this case the navigation controller’s top view controller is an instance of my own RootViewController class. And my RootViewController class does have a setAlbums method; that’s exactly why I’m trying to call that method. What I’m doing is reasonable, legal, and desirable. I need to do it! In order to prevent the compiler from stopping me, I need to assure it that I know what I’m doing, by telling it that the object returned from the topViewController method call will in fact be a RootViewController. I do that by typecasting:
[(RootViewController*)[navigationController topViewController] setAlbums: arr];
That succeeds. There is no error and no warning. The typecast silences the compiler when I propose to send this instance the setAlbums: message, because my RootViewController class has a setAlbums: instance method and the compiler knows this. And the program, when it runs, doesn’t crash, because I’m not lying: this topViewController method call really will return a RootViewController instance.
With great power, however, comes great responsibility. Don’t lie to the compiler! Recall this example from the previous section:
MyClass* m = @"Hello, world!";
[m rockTheCasbah];
The first line caused the compiler to warn us about “incompatible pointer types”; and the compiler was right to be concerned — we were heading for a crash at runtime (“unrecognized selector”) when the rockTheCasbah message was sent to an NSString. We can silence the compiler by typecasting:
MyClass* m = (MyClass*)@"Hello, world!";
[m rockTheCasbah];
Now there’s no warning. But we’ve lied to the compiler, and we’re still heading for the very same unrecognized selector crash at runtime (because, just as before, the rockTheCasbah message is going to be sent to an NSString). The moral is simple: the compiler will believe whatever you say when you typecast, so don’t use typecasting to lie to the compiler.
NOTE
Typecasting does not miraculously change any actual object types. It’s just a way of communicating a hint about type information to the compiler. The underlying object being referred to is completely unaffected. The typecast expression (MyClass*)@"Hello, world!" does not magically change the NSString instance @"Hello, world!" into a MyClass instance! Typecasting in the belief that you’re actually performing some kind of type conversion is a surprisingly common beginner mistake.
Objective-C also provides a special type designed to silence the compiler’s worries about object data types altogether. This is the id type. An id is a pointer, so you don’t say id*. It is defined to mean “an object pointer,” plain and simple, with no further specification. Thus, every instance reference is also an id.
Use of the id type causes the compiler to stop worrying about the relationship between object types and messages. The compiler can’t know anything about what the object will really be, so it throws up its hands and doesn’t warn about anything. Moreover, any object value can be assigned or typecast to an id, and a value typed as an id can be assigned where any object type is expected. The notion of assignment includes parameter passing. So you can pass a value typed as an id as an argument where a parameter of some particular object type is expected, and you can pass any object as an argument where a parameter of type id is expected. (I like to think of an id as analogous to both type AB blood and type O blood: it is both a universal recipient and a universal donor.) So, for example:
NSString* s = @"Hello, world!";
id unknown = s;
[unknown rockTheCasbah];
The second line is legal, because any object value can be assigned to an id. The third line doesn’t generate any compiler warning, because any message can be sent to an id. (Of course the program will still crash when it actually runs and unknown turns out to be an NSString — which is incapable of receiving of the rockTheCasbah message!)
Actually, that’s an oversimplification. Under ARC, that code might not compile. Instead, you might get an error: “No known instance method for selector ‘rockTheCasbah’.” This means that the compiler knows of no rockTheCasbah method in any class. If, however, rockTheCasbah is declared in the header file of any class imported into this one, or if rockTheCasbah is implemented in the current class, that code will compile, with no warning.
If an id’s ability to receive any message reminds you of nil, it should. I have already said that nil is a form of zero; I can now specify what form of zero it is. It’s zero cast as an id. Of course, it still makes a difference at runtime whether an id is nil or something else; sending a message to nil won’t crash the program, but sending an unknown message to an actual object probably will.
Thus, id has the effect of turning off the compiler’s type checking altogether. Concerns about what type an object is are postponed until the program is actually running. I do not recommend that you make extensive use of id in this way. The compiler is your friend; you should let its intelligence catch possible mistakes in your code. Thus, I almost never declare a variable or parameter as an id. I want my object types to be specific, so that the compiler can help check my code. On the other hand, the Cocoa API does make frequent use of id — and this is exactly the sort of thing that, as I warned you in the previous section, can result in an unrecognized selector crash down the road.
Consider, for example, the NSArray class, which is the object-based version of an array. In pure C, you have to declare what type of thing lives in an array; for example, you could have “an array of int.” In Objective-C, using an NSArray, you can’t do that. Every NSArray is an array of id, meaning that each element of the array can be of any object type. You can put a specific type of object into an NSArray because any type of object can be assigned to an id (id is the universal recipient). You can get any specific type of object back out of an NSArray because an id can be assigned to any type of object (id is the universal donor).
NSArray’s lastObject method is thus defined as returning an id. Given an NSArray arr, I can fetch its last element like this:
id unknown = [arr lastObject];
We are now in a potentially dangerous situation. After that code, unknown can be sent any message at all; the compiler won’t interfere. Therefore, if I happen to know what type of object an array element is, I always assign or cast it to that type as I fetch it from the array. For example, let’s say I happen to know that arr contains nothing but NSString instances (because I put them there in the first place). Then I will say:
NSString* s = [arr lastObject];
The compiler doesn’t complain, because an id can be assigned to any specific type of object (id is the universal donor). Moreover, from here on in, the compiler regards s as an NSString, and uses its type checking abilities to make sure I don’t send s any non-NSString messages, which is just what I wanted. And I didn’t lie to the compiler; at runtime, s really is an NSString, so everything is fine.
There is a further danger, however: this situation is an open invitation for me to lie accidentally to the compiler. Suppose the last element in this NSArray is not an NSString. The compiler doesn’t know this — it knows nothing of what the NSArray will actually contain at runtime — andlastObject returns an id, which the compiler will happily allow me to assign to a reference declared as an NSString. We are now courting disaster. Suppose, for example, that in the next line I send the uppercaseString message to s. The compiler won’t bat an eye: after all, I’ve declared this reference as an NSString, and uppercaseString is an NSString method. But if s is not an NSString, this will probably be an unrecognized selector situation, and we’ll crash at runtime.
Another pitfall of using id has to do with method name conflicts. Earlier, I said that it is illegal for the same class to define methods of the same type (class method or instance method) with the same name but different signatures. But I did not say what happens when two different classes declare a method with the same name but different signatures. If the type of the object receiving the message is specified in your code, there’s no problem, because there’s no doubt which method is being called: it’s the one in that object’s class. But if the object receiving the message is an id, under ARC, you’ll get an error: “Multiple methods named ‘rockTheCasbah’ found with mismatched result, parameter type or attributes.” This is another reason why method names are so verbose: it’s in order to make each method name unique, preventing two different classes from declaring conflicting signatures for the same method.
Messages as Data Type
The previous sections revolved around the fact that Objective-C doesn’t have to know until runtime what object a message will be sent to. But there’s more: Objective-C doesn’t have to know until runtime what message to send to an object. Certain important methods actually accept both the message and the receiver as parameters; they won’t be assembled and used to form an actual message expression until runtime.
For example, consider this method declaration from Cocoa’s NSNotificationCenter class:
- (void)addObserver:(id)notificationObserver
selector:(SEL)notificationSelector
name:(NSString *)notificationName
object:(id)notificationSender
I’ll explain later in detail what this method does (in Chapter 11); the important thing to understand here is that it constitutes an instruction to send a certain message to a certain object at some later, appropriate time. For example, our purpose in calling this method might be to arrange to have the message tickleMeElmo: sent at some later, appropriate time to the object myObject. To do so, we need to supply appropriate arguments to the first two parameters.
Let’s consider what arguments we would actually pass for the first two parameters. The object to which the message will be sent, the first parameter (observer:), is typed as an id, making it possible to specify any type of object to send the message to. So, for the observer: argument, we’re going to pass myObject. The message itself is the selector: parameter, which has a special data type, SEL (for “selector,” the technical term for a message name). The question now is how to express the message name tickleMeElmo:.
You can’t just put tickleMeElmo: as a bare term; that doesn’t work syntactically. You might think you could express it as an NSString, @"tickleMeElmo:", but surprisingly, that doesn’t work either. It turns out that the correct way to do it is like this:
@selector(tickleMeElmo:)
The term @selector() is a directive to the compiler, telling it that what’s in parentheses is a message name. Notice that what’s in parentheses is not an NSString; it’s the bare message name. And because it is the name, it must have no spaces and must include any colons that are part of the message name.
So the rule is extremely easy: when a SEL is expected, you’ll usually pass a @selector expression. Failure to get this syntax right is a common beginner error.
Unfortunately, this syntax is also an invitation to make a typing mistake, with possibly devastating results. If myObject implements a tickleMeElmo: method and I accidentally type, say, @selector(tickleMeElmo), forgetting the colon, then if the tickleMeElmo message without the colon is ever sent to myObject, the app will probably crash with an unrecognized selector exception.
Xcode 5, for the first time in the history of Objective-C, introduces a compiler warning in the case where the selector matches no known method (“Undeclared selector ‘tickleMeElmo’”). Thus, you might be alerted to the possibility of a future crash — or not. The compiler can’t peer into the class of your observer: argument and see whether it implements this method; instead, the compiler complains only if no class is already known to have such a method. Thus, the converse applies: if the compiler happens to know of any tickleMeElmo method in any class, you’ll get no warning, even if the object to which you’ll actually be sending the tickleMeElmo message at runtime has no such method.
C Functions
Although your code will certainly call many Objective-C methods, it will also probably call quite a few C functions. For example, I mentioned in Chapter 1 that the usual way of describing a CGPoint based on its x and y values is to call CGPointMake, which is declared like this:
CGPoint CGPointMake (
CGFloat x,
CGFloat y
);
Make certain that you can see at a glance that this is a C function, not an Objective-C method, and be sure you understand the difference in the calling syntax. To call an Objective-C method, you send a message to an object, in square brackets, with each argument following a colon in the method’s name; to call a C function, you use the function’s name followed by parentheses containing the arguments.
You might even have reason to write your own C functions as part of a class, instead of writing a method. A C function has lower overhead than a full-fledged method; so even though it lacks the object-oriented abilities of a method, it is sometimes useful to write one, as when some utility calculation must be performed rapidly and frequently.
Also, once in a while you might encounter a Cocoa method or function that requires you to supply a C function as a “callback.” An example is the NSArray method sortedArrayUsingFunction:context:. The first parameter is typed like this:
NSInteger (*)(id, id, void *)
That expression denotes, in the rather tricky C syntax used for these things, a pointer to a function that takes three parameters and returns an NSInteger. The three parameters of the function are an id, an id, and a pointer-to-void (which means any C pointer). The bare name of a C function (see Chapter 1) can be used as a pointer to that function. So to call sortedArrayUsingFunction:context: you’d need to write a C function that meets this description, and use its name as the first argument.
To illustrate, I’ll write a “callback” function to help me sort an NSArray of NSStrings on the last character of each string. (This would be an odd thing to do, but it’s only an example!) The NSInteger returned by the function has a special meaning: it indicates whether the first parameter is to be considered less than, equal to, or larger than the second. I’ll obtain it by calling the NSString compare: method, which returns an NSInteger with that same meaning. Example 3-1 defines the function and shows how we’d call sortedArrayUsingFunction:context: with that function as our callback.
Example 3-1. Using a pointer to a callback function
NSInteger sortByLastCharacter(id string1, id string2, void* context) {
NSString* s1 = string1;
NSString* s2 = string2;
NSString* string1end = [s1 substringFromIndex:[s1 length] - 1];
NSString* string2end = [s2 substringFromIndex:[s2 length] - 1];
return [string1end compare:string2end];
}
// and here's how you'd use it; assume that arr is an NSArray of NSStrings
NSArray* arr2 = [arr sortedArrayUsingFunction:sortByLastCharacter context:nil];
CFTypeRefs
Many Objective-C object types have lower-level C counterparts, along with C functions for manipulating them.
For example, besides the Objective-C NSString, there is also something called a CFString; the “CF” stands for “Core Foundation,” which is a lower-level C-based API. A CFString is an opaque C struct; “opaque” means that the elements constituting this struct are kept secret, and that you should operate on a CFString only by means of appropriate C functions. As with an NSString or any other object, in your code you’ll typically refer to a CFString by way of a C pointer; the pointer to a CFString has a type name, CFStringRef.
You might, on occasion, decide to work with a Core Foundation type even when a corresponding object type exists. For example, you might find that NSString, for all its power, fails to implement a needed piece of functionality, one that is available for a CFString. Luckily, an NSString (a value typed as NSString*) and a CFString (a value typed as CFStringRef) are interchangeable: you can use one where the other is expected, though you may have to typecast in order to quiet the worries of the compiler. The documentation describes this interchangeability by saying that NSString and CFString are toll-free bridged to one another.
To illustrate, I’ll use a CFString to convert an NSString representing an integer to that integer (this use of CFString is unnecessary, and is just by way of demonstrating the syntax; NSString has an intValue method):
NSString* answer = @"42";
int ans = CFStringGetIntValue((CFStringRef)answer);
The pointer-to-struct C object types, whose names typically end in “Ref”, may be referred to collectively as CFTypeRef, which is actually just the generic pointer-to-void. Thus, crossing the toll-free bridge may usefully be thought of as a cast between an object pointer and a generic pointer — that is, in general terms, from id to void* or from void* to id. Even where there is no toll-free bridging between specific types (as there is with NSString and CFString), there is always bridging at the top of the hierarchy, so to speak, between id or NSObject (the base object class, as explained in Chapter 4) and CFTypeRef.
Blocks
A block is an extension to the C language, introduced in OS X 10.6 and available in iOS 4.0 and later. It’s a way of bundling up some code and handing off that entire bundle as an argument to a C function or Objective-C method. This is similar to what we did in Example 3-1, handing off a pointer to a function as an argument, but instead we’re handing off the code itself. The latter has some major advantages over the former, which I’ll discuss in a moment.
To illustrate, I’ll rewrite Example 3-1 to use a block instead of a function pointer. Instead of calling sortedArrayUsingFunction:context:, I’ll call sortedArrayUsingComparator:, which takes a block as its parameter. The block is typed like this:
NSComparisonResult (^)(id obj1, id obj2)
That expression is similar to the syntax for specifying the type of a pointer to a function, but a caret is used instead of an asterisk. It denotes a block that takes two id parameters and returns an NSComparisonResult (which is merely an NSInteger, with just the same meaning as in Example 3-1). We can define the block inline as the argument within our call to sortedArrayUsingComparator:, as in Example 3-2.
Example 3-2. Using an inline block instead of a callback function
NSArray* arr2 = [arr sortedArrayUsingComparator: ^(id obj1, id obj2) {
NSString* s1 = obj1;
NSString* s2 = obj2;
NSString* string1end = [s1 substringFromIndex:[s1 length] - 1];
NSString* string2end = [s2 substringFromIndex:[s2 length] - 1];
return [string1end compare:string2end];
}];
The syntax of the inline block definition is:
^![]() (id obj1, id obj2)
(id obj1, id obj2)![]() {
{![]()
// ...
}
![]()
First, the caret.
![]()
Then, parentheses containing the parameters, similar to the parameters of a C function definition.
![]()
Finally, curly braces containing the block’s content. These curly braces constitute a scope.
NOTE
The return type in an inline block definition is usually omitted. If included, it follows the caret, not in parentheses. If omitted, you may have to use typecasting in the return line to make the returned type match the expected type.
A block defined inline, as in Example 3-2, isn’t reusable; if we had two calls to sortedArrayUsingComparator: using the same callback, we’d have to write out the callback in full twice. To avoid such repetition, or simply for clarity, a block can be assigned to a variable, which is then passed as an argument to a method that expects a block, as in Example 3-3.
Example 3-3. Assigning a block to a variable
NSComparisonResult (^sortByLastCharacter)(id, id) = ^(id obj1, id obj2) {
NSString* s1 = obj1;
NSString* s2 = obj2;
NSString* string1end = [s1 substringFromIndex:[s1 length] - 1];
NSString* string2end = [s2 substringFromIndex:[s2 length] - 1];
return [string1end compare:string2end];
};
NSArray* arr2 = [arr sortedArrayUsingComparator: sortByLastCharacter];
NSArray* arr4 = [arr3 sortedArrayUsingComparator: sortByLastCharacter];
Perhaps the most remarkable feature of blocks is this: variables in scope at the point where a block is defined keep their value within the block at that moment, even though the block may be executed at some later moment. (Technically, we say that a block is a closure, and that variable values outside the block may be captured by the block.) This aspect of blocks makes them useful for specifying functionality to be executed at some later time, or even in some other thread.
Here’s a real-life example:
CGPoint p = [v center];
CGPoint pOrig = p;
p.x += 100;
void (^anim) (void) = ^{
[v setCenter: p];
};
void (^after) (BOOL) = ^(BOOL f) {
[v setCenter: pOrig];
};
NSUInteger opts = UIViewAnimationOptionAutoreverse;
[UIView animateWithDuration:1 delay:0 options:opts
animations:anim completion:after];
That code does something quite surprising. The method animateWithDuration:delay:options:animations:completion: configures a view animation using blocks. But the view animation itself is not performed until later; the animation, and therefore the blocks, will be executed at an indeterminate moment in the future, long after the method call has completed and your code has gone on to other things. Now, there is a UIView object v in scope, along with a CGPoint p and another CGPoint pOrig. The variables p and pOrig are local and automatic; they will go out of scope and cease to exist before the animation starts and the blocks are executed. Nevertheless, the values of those variables are being used inside the blocks, as parameters of messages to be sent to v.
Because a block might be executed at some later time, it is not normally legal, inside a block, to assign directly to a local automatic variable defined outside the block; the compiler will stop us (“variable is not assignable”):
CGPoint p;
void (^aBlock) (void) = ^{
p = CGPointMake(1,2); // error
};
A local automatic variable can be made to obey special storage rules by declaring the variable using the __block qualifier. This qualifier promotes the variable’s storage so that the variable stays alive along with the block that refers to it, and has two chief uses. Here’s the first use: If a block will be executed immediately, the __block qualifier permits the block to set a variable outside the block to a value that will be needed after the block has finished.
For example, the NSArray method enumerateObjectsUsingBlock: takes a block and calls it immediately for each element of the array. It is a block-based equivalent of a for...in loop, cycling through the elements of an enumerable collection (Chapter 1). Here, we propose to cycle through the array until we find the value we want; when we find it, we set a variable (dir) to that value. That variable, though, is declared outside the block, because we intend to use its value after executing the block — we need its scope to extend outside the curly braces of the block. Therefore we qualify the variable’s declaration with __block, so that we can assign to it from inside the block:
CGFloat h = newHeading.magneticHeading;
__block NSString* dir = @"N";
NSArray* cards = @[@"N", @"NE", @"E", @"SE",
@"S", @"SW", @"W", @"NW"];
[cards enumerateObjectsUsingBlock:^(id obj, NSUInteger idx, BOOL *stop) {
if (h < 45.0/2.0 + 45*idx) {
dir = obj;
*stop = YES;
}
}];
// now we can use dir
(Note also the assignment to a dereferenced pointer-to-BOOL. This is a way of interrupting the loop prematurely; we have found the value we’re looking for, so there’s no point looping any further. We can’t use a break statement, because this isn’t really a for loop. The methodenumerateObjectsUsingBlock: therefore hands the block a pointer-to-BOOL parameter, which the block can set by indirection to YES as a signal to the method that it’s time to stop. This is one of the few situations in iOS programming where it is necessary to dereference a pointer.)
The second chief use of the __block qualifier is the converse of the first. It arises when a block will be executed at some time after it is defined, and we want the block to use the value that a variable has at the time the block is executed, rather than capturing the value that it has when the block is defined. Typically this is because the very same method call that accepts the block (for later execution) also sets the value of this variable (now).
For example, the method beginBackgroundTaskWithExpirationHandler: takes a block to be executed at some future time (if ever). It also generates and returns a UIBackgroundTaskIdentifier, which is really just an integer — and we are going to want to use that integer inside the block, if and when the block is executed. So we’re trying to do things in an oddly circular order: the block is handed as an argument to the method, the method is called, the method returns a value, and the block uses that value. The __block qualifier makes this possible:
__block UIBackgroundTaskIdentifier bti =
[[UIApplication sharedApplication]
beginBackgroundTaskWithExpirationHandler: ^{
[[UIApplication sharedApplication] endBackgroundTask:bti];
}];
At the same time that blocks were introduced into Objective-C, Apple introduced a system library of C functions called Grand Central Dispatch (GCD) that makes heavy use of them. GCD’s chief purpose is thread management, but it also comes in handy for expressing neatly and compactly certain notions about when code should be executed. For example, GCD can help us delay execution of our code (delayed performance). The following code uses a block to say, “change the bounds of the UIView v1, but not right this moment — wait two seconds and then do it”:
dispatch_time_t popTime = dispatch_time(DISPATCH_TIME_NOW, 2 * NSEC_PER_SEC);
dispatch_after(popTime, dispatch_get_main_queue(), ^(void){
CGRect r = [v1 bounds];
r.size.width += 40;
r.size.height -= 50;
[v1 setBounds: r];
});
This final example of a block in action rewrites the code from the end of Chapter 1, where a class method vends a singleton object. The GCD function dispatch_once, which is very fast and (unlike the Chapter 1 example) thread-safe, promises that its block, here creating the singleton object, will execute only once in the entire life of our program — thus guaranteeing that the singleton is a singleton:
+ (CardPainter*) sharedPainter {
static CardPainter* sp = nil;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
sp = [CardPainter new];
});
return sp;
}
The block is able to assign to the local variable sp without a __block qualifier because sp has a static qualifier, which has the same effect but even stronger: just as __block promotes the lifetime of its variable to live as long as the block, static promotes the lifetime of its variable to live as long as the program itself. Thus it also has the side-effect of making sp assignable from within the block, just as __block would do.
For further explanation of blocks, see Apple’s helpful documentation at http://developer.apple.com/library/ios/#documentation/cocoa/Conceptual/Blocks/, or look up “Blocks Programming Topics” in Xcode’s help window. For a complete technical syntax specification for blocks, seehttp://clang.llvm.org/docs/BlockLanguageSpec.html.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.