Discovering Modern C++. An Intensive Course for Scientists, Engineers, and Programmers(2016)
Chapter 2. Classes
“Computer science is no more about computers than astronomy is about telescopes.”
—Edsger W. Dijkstra
Accordingly, computer science is more than drilling on programming language details. That said, this chapter will not only provide information on declaring classes but also give an idea of how we can make the best use of them, how they best serve our needs. Or even better: how a class can be used conveniently and efficiently in a broad spectrum of situations. We see classes primarily as instruments to establish new abstractions in our software.
2.1 Program for Universal Meaning Not for Technical Details
Writing leading-edge engineering or scientific software with a mere focus on performance details is very painful and likely to fail. The most important tasks in scientific and engineering programming are
• Identifying the mathematical abstractions that are important in the domain, and
• Representing these abstractions comprehensively and efficiently in software.
Focusing on finding the right representation for domain-specific software is so important that this approach evolved into a programming paradigm: Domain-Driven Design (DDD). The core idea is that software developers regularly talk with the domain experts about how software components should be named and behave so that the resulting software is as intuitive as possible (not only for the programmer but for the user as well). The paradigm is not thoroughly discussed in this book and we rather refer to other literature like [50].
Common abstractions that appear in almost every scientific application are vector spaces and linear operators. The latter project from one vector space into another.
First, we should decide how to represent these abstractions in a program. Let v be an element of a vector space and L a linear operator. Then C++ allows us to express the application of L on v as
L(v)
or
L * v
Which one is better suited in general is not so easy to say. However, it is obvious that both notations are much better than
apply_symm_blk2x2_rowmajor_dnsvec_multhr_athlon(L.data_addr, L.nrows,
L.ncols, L.ldim, L.blksch, v.data_addr, v.size);
which exposes lots of technical details and distracts from the principal tasks.
Developing software in that style is far from being fun. It wastes so much energy of the programmer. Even getting the function calls right is much more work than with a simple and clear interface. Slight modifications of the program—like using another data structure for some object—can cause a cascade of modifications that must be meticulously made. Remember that the person who implements the linear projection wants to do science, actually.
The cardinal error of scientific software providing such interfaces (we have seen even worse than our example) is to commit to too many technical details in the user interface. The reason lies partly in the usage of simpler programming languages such as C and Fortran 77 or in the effort to interoperate with software written in one those languages.
Advice
If you ever are forced to write software that interoperates with C or Fortran, write your software first with a concise and intuitive interface in C++ for yourself and other C++ programmers and encapsulate the interface to the C and Fortran libraries so that it is not exposed to the developers.
It is admittedly easier to call a C or Fortran function from a C++ application than the other way around. Nonetheless, developing large projects in those languages is so much more inefficient that the extra effort for calling C++ functions from C or Fortran is absolutely justified. Stefanus Du Toit demonstrated in his Hourglass API an example of how to interface programs in C++ and other languages through a thin C API [12].
The elegant way of writing scientific software is to provide the best abstraction. A good implementation reduces the user interface to the essential behavior and omits all unnecessary commitments to technical details. Applications with a concise and intuitive interface can be as efficient as their ugly and detail-obsessed counterparts.
Our abstractions here are linear operators and vector spaces. What is important for the developer is how these abstractions are used, in our case, how a linear operator is applied on a vector. Let’s say the application is denoted by the symbol * as in L * v or A * x. Evidently, we expect that the result of this operation yields an object of a vector type (thus, the statement w= L * v; should compile) and that the mathematical properties of linearity hold. That is all that developers need to know for using a linear operator.
How the linear operator is stored internally is irrelevant for the correctness of the program—as long as the operation meets all mathematical requirements and the implementation has no accidental side effect like overwriting other objects’ memory. Therefore, two different implementations that provide the necessary interface and semantic behavior are interchangeable; i.e., the program still compiles and yields the same results. The different implementations can of course vary dramatically in their performance. For that reason, it is important that choosing the best implementation for a target platform or a specific application can be achieved with little (or no) program modifications.
This is why the most important benefit of classes in C++ for us is not the inheritance mechanisms (Chapter 6) but the ability to establish new abstractions and to provide alternative realizations for them. This chapter will lay the foundations for it, and we will elaborate on this programming style in the subsequent chapters with more advanced techniques.
2.2 Members
After the long plea for classes, it is high time to define one. A class defines a new data type which can contain
• Data: referred to as Member Variables or for short as Members; the standard also calls it Data Member;
• Functions: referred to as Methods or Member Functions;
• Type definitions; and
• Contained classes.
Data members and methods are discussed in this section.
2.2.1 Member Variables
A concise class example is a type for representing complex numbers. Of course, there already exists such a class in C++ but for illustration purposes we write our own:
class complex
{
public:
double r, i;
};
The class contains variables to store the real and the imaginary parts of a complex number. A common mental picture for the role of a class definition is a blueprint. That is, we have not yet defined any single complex number. We only said that complex numbers contain two variables of typedouble which are named r and i.
Now we are going to create Objects of our type:
complex z, c;
z.r= 3.5; z.i= 2;
c.r= 2; c.i= -3.5;
std::cout ![]() "z is ("
"z is (" ![]() z.r
z.r ![]() ", "
", " ![]() z.i
z.i ![]() ")\n";
")\n";
This snippet defines the objects z and c with variable declarations. Such declarations do not differ from intrinsic types: a type name followed by a variable name or a list thereof. The members of an object can be accessed with the dot operator . as illustrated above. As we can see, member variables can be read and written like ordinary variables—when they are accessible.
2.2.2 Accessibility
Each member of a class has a specified Accessibility. C++ provides three of them:
• public: accessible from everywhere;
• protected: accessible in the class itself and its derived classes.
• private: accessible only within the class; and
This gives the class designer good control of how the class users can work with each member. Defining more public members gives more freedom in usage but less control. On the other hand, more private members establish a more restrictive user interface.
The accessibility of class members is controlled by Access Modifiers. Say we want to implement a class rational with public methods and private data:
class rational
{
public:
...
rational operator+(...) {...}
rational operator-(...) {...}
private:
int p;
int q;
};
An access modifier applies to all following members until another modifier appears. We can put as many modifiers as we want. Please note our linguistic distinction between a specifier that declares a property of a single item and a modifier that characterizes multiple items: all methods and data members preceding the next modifier. It is better to have many access modifiers than a confusing order of class members. Class members before the first modifier are all private.
2.2.2.1 Hiding Details
Purists of object-oriented programming declare all data members private. Then it is possible to guarantee properties for all objects, for instance, when we want to establish in the before-mentioned class rational the invariant that the denominator is always positive. Then we declare our numerator and denominator private (as we did) and implement all methods such that they keep this invariant. If the data members were public, we could not guarantee this invariant because users can violate it in their modifications.
private members also increase our freedom regarding code modifications. When we change the interface of private methods or the type of a private variable, all applications of this class will continue working after recompilation. Modifying the interfaces of public methods can (and usually will) break user code. Differently phrased: the public variables and the interfaces of public methods build the interface of a class. As long as we do not change this interface, we can modify a class and all applications will still compile (and work when we did not introduce bugs). And when the public methods keep their behavior, all applications will. How we design our private members is completely up to us (as long as we do not waste all memory or compute power). By solely defining the behavior of a class in its external interface but not how it is implemented, we establish an Abstract Data Type (ADT).
On the other hand, for small helper classes it can be unnecessarily cumbersome to access their data only through getter and setter functions:
z.set_real(z.get_real()*2);
instead of
z.real*= 2;
Where to draw the line between simple classes with public members and full-blown classes with private data is a rather subjective question (thus offering great potential for arguing in developer teams). Herb Sutter and Andrei Alexandrescu phrased the distinction nicely: when you establish a new abstraction, make all internal details private; and when you merely aggregate existing abstractions, the data member can be public [45, Item 11]. We like to add a more provocative phrasing: when all member variables of your abstract data type have trivial getters and setters, the type is not abstract at all and you can turn your variables public without losing anything except the clumsy interface.
protected members only make sense for types with derived classes. Section 6.3.2.2 will give an example for a good use case of protected.
C++ also contains the struct keyword from C. It declares a class as well, with all features available for classes. The only difference is that all members are by default public. Thus,
struct xyz
{
...
};
is the same as
class xyz
{
public:
...
};
As a rule of thumb:
Advice
Prefer class and use struct only for helper types with limited functionality and without invariants.
2.2.2.2 Friends
Although we do not provide our internal data to everybody, we might make an exception for a good friend. Within our class, we can grant free functions and classes the special allowance to access private and protected members, for instance:
class complex
{
...
friend std::ostream& operator![]() (std::ostream&, const complex&);
(std::ostream&, const complex&);
friend class complex_algebra;
};
We permitted in this example the output operator and a class named complex_algebra access to internal data and functionality. A friend declaration can be located in the public, private, or protected part of the class. Of course, we should use the friend declaration as rarely as possible because we must be certain that every friend preserves the integrity of our internal data.
2.2.3 Access Operators
There are four such operators. The first one we have already seen: the member selection with a dot, x.m. All other operators deal with pointers in one way or another.
First, we consider a pointer to the class complex and how to access member variables through this pointer:
complex c;
complex* p= &c;
*p.r= 3.5; // Error: means *(p.r)
(*p).r= 3.5; // okay
Accessing members through pointers is not particularly elegant since the selection operator . has a higher priority than the dereference *. Just for the sake of self-torturing, imagine the member itself is a pointer to another class whose member we want to access. Then we would need another parenthesis to precede the second selection:
(*(*p).pm).m2= 11; // oh boy
A more convenient member access through pointers is provided by ->:
p->r= 3.5; // looks so much better ;-)
Even the before-mentioned indirect access is no problem any longer:
p->pm->m2= 11; // even more so
In C++, we can define Pointers to Members which are probably not relevant to all readers (the author has not used them outside this book till today). If you can think of a use case, please read Appendix A.4.1.
2.2.4 The Static Declarator for Classes
Member variables that are declared static exist only once per class. This allows us to share a resource between the objects of a class. Another use case is for creating a Singleton: a design pattern ensuring that only one instance of a certain class exists [14, pages 127–136].
Thus, a data member that is both static and const exists only once and cannot be changed. As a consequence, it is available at compile time. We will use this for meta-programming in Chapter 5.
Methods can also be declared static. This means that they can only access static data and call static functions. This might enable extra optimizations when a method does not need to access object data.
Our examples use static data members only in their constant form and no static methods. However, the latter appears in the standard libraries in Chapter 4.
2.2.5 Member Functions
Functions in classes are called Member Functions or Methods. Typical member functions in object-oriented software are getters and setters:
Listing 2–1: Class with getters and setters
class complex
{
public:
double get_r() { return r; } // Causes clumsy
void set_r(double newr) { r = newr; } // code
double get_i() { return i; }
void set_i(double newi) { i = newi; }
private:
double r, i;
};
Methods are like every member by default private; i.e., they can only be called by functions within the class. Evidently, this would not be particularly useful for our getters and setters. Therefore, we give them public accessibility. Now, we can write c.get_r() but not c.r. The class above can be used in the following way:
Listing 2–2: Using getters and setters
int main()
{
complex c1, c2;
// set c1
c1.set_r(3.0); // Clumsy init
c1.set_i(2.0);
// copy c1 to c2
c2.set_r(c1.get_r()); // Clumsy copy
c2.set_i(c1.get_i());
return 0;
}
At the beginning of our main function, we create two objects of type complex. Then we set one of the objects and copy it to the other one. This works but it is a bit clumsy, isn’t it?
Our member variables can only be accessed via functions. This gives the class designer the maximal control over the behavior. For instance, we could limit the range of values that are accepted by the setters. We could count for each complex number how often it is read or written during the execution. The functions could have additional printouts for debugging (a debugger is usually a better alternative than putting printouts into programs). We could even allow reading only at certain times of the day or writing only when the program runs on a computer with a certain IP. We will most likely not do the latter, at least not for complex numbers, but we could. If the variables are public and accessed directly, such behavior would not be possible. Nevertheless, handling the real and imaginary parts of a complex number in this fashion is cumbersome and we will discuss better alternatives.
Most C++ programmers would not implement it this way. What would a C++ programmer then do first? Write constructors.
2.3 Setting Values: Constructors and Assignments
Construction and assignment are two mechanisms to set the value of an object, either at its creation or later. Therefore, these two mechanisms have much in common and are introduced here together.
2.3.1 Constructors
Constructors are methods that initialize objects of classes and create a working environment for member functions. Sometimes such an environment includes resources like files, memory, or locks that have to be freed after their use. We come back to this later.
Our first constructor will set the real and imaginary values of our complex:
class complex
{
public:
complex(double rnew, double inew)
{
r= rnew; i= inew;
}
// ...
};
A constructor is a member function with the same name as the class itself. It can possess an arbitrary number of arguments. This constructor allows us to set the values of c1 directly in the definition:
complex c1(2.0, 3.0);
There is a special syntax for setting member variables and constants in constructors called Member Initialization List or for short Initialization List:
class complex
{
public:
complex(double rnew, double inew) : r(rnew), i(inew) {}
// ...
};
An initialization list starts with a colon after the constructor’s function head. It is in principle a non-empty list of constructor calls for the member variables (and base classes) or a subset thereof (whereby compilers emit warnings when the order of initialization doesn’t match the definition order). The compiler wants to ascertain that all member variables are initialized. Therefore, it generates a call to the constructor with no arguments for all those members that we do not initialize ourselves. This argumentless constructor is called Default Constructor (we will discuss it more in §2.3.1.1). Thus, our first constructor example is (somehow) equivalent to
class complex
{
public:
complex(double rnew, double inew)
: r(), i() // generated by the compiler
{
r= rnew; i= inew;
}
};
For simple arithmetic types like int and double, it is not important whether we set their values in the initialization list or the constructor body. Data members of intrinsic types that do not appear in the initialization list remain uninitialized. A member data item of a class type is implicitly default-constructed when it is not contained in the initialization list.
How members are initialized becomes more important when the members themselves are classes. Imagine we have written a class that solves linear systems with a given matrix which we store in our class:
class solver
{
public:
solver(int nrows, int ncols)
// : A() #1 Error: calls non-existing default constructor
{
A(nrows, ncols); // #2 Error: not a ctor call here
}
// ...
private:
matrix_type A;
};
Suppose our matrix class has a constructor setting the two dimensions. This constructor cannot be called in the function body of the constructor (#2). The expression in #2 is not interpreted as a constructor but as a function call: A.operator()(nrows, ncols); see §3.8.
As all member variables are constructed before the constructor body is reached, our matrix A will be default-constructed at #1. Unfortunately, matrix is not Default-Constructible causing the following error message:
Operator ![]() matrix_type::matrix_type()
matrix_type::matrix_type()![]() not found.
not found.
Thus, we need to write:
class solver
{
public:
solver(int nrows, int ncols) : A(nrows, ncols) {}
// ...
};
to call the right constructor of the matrix.
In the preceding examples, the matrix was part of the solver. A more likely scenario is that the matrix already exists. Then we would not want to waste all the memory for a copy but refer to the matrix. Now our class contains a reference as a member and we are again obliged to set the reference in the initialization list (since references are not default-constructible either):
class solver
{
public:
solver(const matrix_type& A) : A(A) {}
// ...
private:
const matrix_type& A;
};
The code also demonstrates that we can give the constructor argument(s) the same name(s) as the member variable(s). This raises the question of to which objects the names are referring, in our case which A is meant in the different occurrences? The rule is that names in the initialization list outside the parentheses always refer to members. Inside the parentheses, the names follow the scoping rules of a member function. Names local to the member function—including argument names—hide names from the class. The same applies to the body of the constructor: names of arguments and of local variables hide the names in the class. This is confusing at the beginning but you will get used to it quicker than you think.
Let us return to our complex example. So far, we have a constructor allowing us to set the real and the imaginary parts. Often only the real part is set and the imaginary is defaulted to 0.
class complex
{
public:
complex(double r, double i) : r(r), i(i) {}
complex(double r) : r(r), i(0) {}
// ...
};
We can also say that the number is 0 + 0i when no value is given, i.e., if the complex number is default-constructed:
complex() : r(0), i(0) {}
We will focus more on the default constructor in the next section.
The three different constructors above can be combined into a single one by using default arguments:
class complex
{
public:
complex(double r= 0, double i= 0) : r(r), i(i) {}
// ...
};
This constructor now allows various forms of initialization:
complex z1, // default-constructed
z2(), // default-constructed ????????
z3(4), // short for z3(4.0, 0.0)
z4= 4;, // short for z4(4.0, 0.0)
z5(0, 1);
The definition of z2 is a mean trap. It looks absolutely like a call for the default constructor but it is not. Instead it is interpreted as the declaration of the function named z2 that takes no argument and returns a complex. Scott Meyers called this interpretation the Most Vexing Parse. Construction with a single argument can be written with an assignment-like notation using = as for z4. In old books you might read sometimes that this causes an overhead because a temporary is first built and then copied. This is not true; it might have been in the very early days of C++ but today no compiler will do that.
C++ knows three special constructors:
• The before-mentioned default constructor,
• The Copy Constructor, and
• The Move Constructor (in C++11 and higher; §2.3.5.1).
In the following sections, we will look more closely at them.
2.3.1.1 Default Constructor
A Default Constructor is nothing more than a constructor without arguments or one that has default values for every argument. It is not mandatory that a class contains a default constructor.
At first glance, many classes do not need a default constructor. However, in real life it is much easier having one. For the complex class, it seems that we could live without a default constructor since we can delay its declaration until we know the object’s value. The absence of a default constructor creates (at least) two problems:
• Variables that are initialized in an inner scope but live for algorithmic reasons in an outer scope must be already constructed without a meaningful value. In this case, it is more appropriate to declare the variable with a default constructor.
• The most important reason is that it is quite cumbersome (however possible) to implement containers—like lists, trees, vectors, matrices—of types without default constructors.
In short, one can live without a default constructor but sooner or later it becomes a hard life.
Advice
Define a default constructor whenever possible.
For some classes, however, it is very difficult to define a default constructor, e.g., when some of the members are references or contain them. In those cases, it can be preferable to accept the before-mentioned drawbacks instead of building badly designed default constructors.
2.3.1.2 Copy Constructor
In the main function of our introductory getter-setter example (Listing 2–2), we defined two objects, one being a copy of the other. The copy operation was realized by reading and writing every member variable in the application. Better for copying objects is using a copy constructor:
class complex
{
public:
complex(const complex& c) : i(c.i), r(c.r) {}
// ...
};
int main()
{
complex z1(3.0, 2.0),
z2(z1); // copy
z3{z1}; // C++11: non-narrowing
}
If the user does not write a copy constructor, the compiler will generate one in the standard way: calling the copy constructors of all members (and base classes) in the order of their definition, just as we did in our example.
In cases like this where copying all members is precisely what we want for our copy constructor we should use the default for the following reasons:
• It is less verbose;
• It is less error-prone;
• Other people directly know what our copy constructor does without reading our code; and
• Compilers might find more optimizations.
In general, it is not advisable to use a mutable reference as an argument:
complex(complex& c) : i(c.i), r(c.r) {}
Then one can copy only mutable objects. However, there may be situations where we need this.
The arguments of the copy constructor must not be passed by value:
complex(complex c) // Error!
Please think about why for few minutes. We will tell you at the end of this section.
![]() c++03/vector_test.cpp
c++03/vector_test.cpp
There are cases where the default copy constructor does not work, especially when the class contains pointers. Say we have a simple vector class with a copy constructor:
class vector
{
public:
vector(const vector& v)
: my_size(v.my_size), data(new double[my_size])
{
for (unsigned i= 0; i < my_size; ++i)
data[i]= v.data[i];
}
// Destructor, anticipated from §2.4.2
∼vector() { delete[] data; }
// ...
private:
unsigned my_size;
double *data;
};
If we omitted this copy constructor, the compiler would not complain and voluntarily build one for us. We are glad that our program is shorter and sexier, but sooner or later we find that it behaves bizarrely. Changing one vector modifies another one as well, and when we observe this strange behavior we have to find the error in our program. This is particularly difficult because there is no error in what we have written but in what we have omitted. The reason is that we did not copy the data but only the address to it. Figure 2–1 illustrates this: when we copy v1 to v2 with the generated constructor, pointer v2.data will refer to the same data as v1.data.
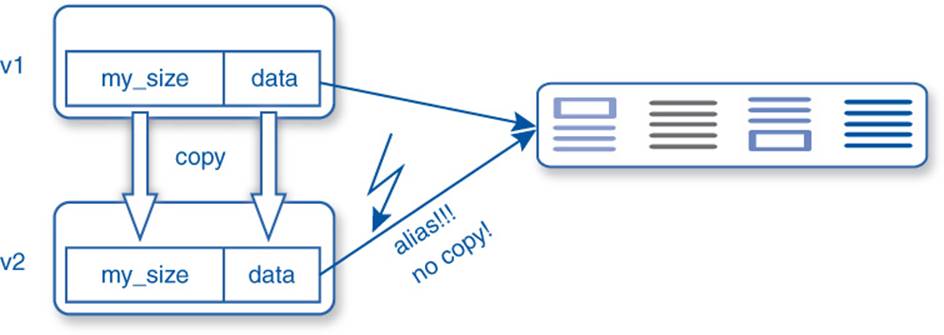
Figure 2–1: Generated vector copy
Another problem we would observe is that the run-time library will try to release the same memory twice.1 For illustration purposes, we anticipated the destructor from Section 2.4.2 here: it deletes the memory addressed by data. Since both pointers contain the same memory address, the second destructor call will fail.
1. This is an error message every programmer experiences at least once in his/her life (or he/she is not doing serious business). I hope I am wrong. My friend and proofreader Fabio Fracassi is optimistic that future programmers using modern C++ consequently will not run into such trouble. Let’s hope that he is right.
![]() c++11/vector_unique_ptr.cpp
c++11/vector_unique_ptr.cpp
Since our vector is intended as the unique owner of its data, unique_ptr sounds like a better choice for data than the raw pointer:
![]()
class vector
{
// ...
std::unique_ptr<double[]> data;
};
Not only would the memory be released automatically, the compiler could not generate the copy constructor automatically because the copy constructor is deleted in unique_ptr. This forces us to provide a user implementation.
Back to our question of why the argument of a copy constructor cannot be passed by value. You have certainly figured it out in the meantime. To pass an argument by value, we need the copy constructor which we are about to define. Thus, we create a self-dependency that might lead compilers into an infinite loop. Fortunately, compilers do not stall on this and even give us a meaningful error message in this case (from the experience in the sense of Oscar Wilde that many programmers made this mistake before and some will in the future).
2.3.1.3 Conversion and Explicit Constructors
In C++, we distinguish between implicit and explicit constructors. Implicit constructors enable implicit conversion and assignment-like notation for construction. Instead of
complex c1{3.0}; // C++11 and higher
complex c1(3.0); // all standards
we can also write:
complex c1= 3.0;
or
complex c1= pi * pi / 6.0;
This notation is more readable for many scientifically educated people, while current compilers generate the same code for both notations.
The implicit conversion kicks in when one type is needed and another one is given, e.g., a double instead of a complex. Assume we have a function:2
2. The definitions of real and imag will be given soon.
double inline complex_abs(complex c)
{
return std::sqrt(real(c) * real(c) + imag(c) * imag(c));
}
and call this with a double, e.g.:
cout ![]() "|7| = "
"|7| = " ![]() complex_abs(7.0)
complex_abs(7.0) ![]() '\n';
'\n';
The literal 7.0 is a double but there is no function overload for complex_abs accepting a double. We have, however, an overload for a complex argument and complex has a constructor accepting double. So, the complex value is implicitly built from the double literal.
The implicit conversion can be disabled by declaring the constructor as explicit:
class complex { public:
explicit complex(double nr= 0.0, double i= 0.0) : r(nr), i(i) {}
};
Then complex_abs would not be called with a double. To call this function with a double, we can write an overload for double or construct a complex explicitly in the function call:
cout ![]() "|7| = "
"|7| = " ![]() complex_abs(complex{7.0})
complex_abs(complex{7.0}) ![]() '\n';
'\n';
The explicit attribute is really important for some classes, e.g., vector. There is typically a constructor taking the size of the vector as an argument:
class vector
{
public:
vector(int n) : my_size(n), data(new double[my_size]) {}
};
A function computing a scalar product expects two vectors as arguments:
double dot(const vector& v, const vector& w) { ... }
This function can be called with integer arguments:
double d= dot(8, 8);
What happens? Two temporary vectors of size 8 are created with the implicit constructor and passed to the function dot. This nonsense can be easily avoided by declaring the constructor explicit.
Which constructor will be explicit is in the end the class designer’s decision. It is pretty obvious in the vector example: no right-minded programmer wants the compiler converting integers automatically into vectors.
Whether the constructor of the complex class should be explicit depends on the expected usage. Since a complex number with a zero imaginary part is mathematically identical to a real number, the implicit conversion does not create semantic inconsistencies. An implicit constructor is more convenient because a double value or literal can be used wherever a complex value is expected. Functions that are not performance-critical can be implemented only once for complex and used for double.
In C++03, the explicit attribute only mattered for single-argument constructors. From C++11 on, explicit is also relevant for constructors with multiple arguments due to uniform initialization, Section 2.3.4.
2.3.1.4 Delegation
![]()
In the examples before, we had classes with multiple constructors. Usually such constructors are not entirely different and have some code in common; i.e., there is often some redundancy. In C++03, it was typically ignored when it only concerned the setup of primitive variables; otherwise the suitable common code fragments were outsourced into a method that was then called by multiple constructors.
C++11 offers Delegating Constructors; these are constructors that call other constructors. Our complex class could use this feature instead of default values:
class complex
{
public:
complex(double r, double i) : r{r}, i{i} {}
complex(double r) : complex{r, 0.0} {}
complex() : complex{0.0} {}
...
};
Obviously, the benefit is not impressive for this small example. Delegating constructors becomes more useful for classes where the initialization is more elaborate (more complex than our complex).
2.3.1.5 Default Values for Members
![]()
Another new feature in C++11 is default values for member variables. Then we only need to set values in the constructor that are different from the defaults:
class complex
{
public:
complex(double r, double i) : r{r}, i{i} {}
complex(double r) : r{r} {}
complex() {}
...
private:
double r= 0.0, i= 0.0;
};
Again, the benefit is certainly more pronounced for large classes.
2.3.2 Assignment
In Section 2.3.1.2, we have seen that we can copy objects of user classes without getters and setters—at least during construction. Now, we want to copy into existing objects by writing:
x= y;
u= v= w= x;
To this end, the class must provide an assignment operator (or refrain from stopping the compiler to generate one). As usual, we consider first the class complex. Assigning a complex value to a complex variable requires an operator like
complex& operator=(const complex& src)
{
r= src.r; i= src.i;
return *this;
}
Evidently, we copy the members r and i. The operator returns a reference to the object for enabling multiple assignments. this is a pointer to the object itself, and since we need a reference, we dereference the this pointer. The operator that assigns values of the object’s type is calledCopy Assignment and can be synthesized by the compiler. In our example, the generated code would be identical to ours and we could omit our implementation here.
What happens if we assign a double to a complex?
c= 7.5;
It compiles without the definition of an assignment operator for double. Once again, we have an implicit conversion: the implicit constructor creates a complex on the fly and assigns this one. If this becomes a performance issue, we can add an assignment for double:
complex& operator=(double nr)
{
r= nr; i= 0;
return *this;
}
As before, vector’s synthesized operator is not satisfactory because it only copies the address of the data and not the data itself. The implementation is very similar to the copy constructor:
1 vector& operator=(const vector& src)
2 {
3 if (this == &src)
4 return *this;
5 assert(my_size == src.my_size);
6 for (int i= 0; i < my_size; ++i)
7 data[i]= src.data[i];
8 return *this;
9 }
It is advised [45, p. 94] that copy assignment and constructor be consistent to avoid utterly confused users.
An assignment of an object to itself (source and target have the same address) can be skipped (lines 3 and 4). In line 5, we test whether the assignment is a legal operation by checking the equality of the vector sizes. Alternatively the assignment could resize the target if the sizes are different. This is a technically legitimate option but scientifically rather questionable. Just think of a context in mathematics or physics where a vector space all of a sudden changes its dimension.
2.3.3 Initializer Lists
![]()
C++11 introduces the Initializer Lists as a new feature—not to be confused with “member initialization list” (§2.3.1). To use it, we must include the header <initializer_list>. Although this feature is orthogonal to the class concept, the constructor and assignment operator of a vector are excellent use cases, making this a suitable location for introducing initializer lists. It allows us to set all entries of a vector at the same time (up to reasonable sizes).
Ordinary C arrays can be initialized entirely within their definition:
float v[]= {1.0, 2.0, 3.0};
This capability is generalized in C++11 so that any class may be initialized with a list of values (of the same type). With an appropriate constructor, we could write:
vector v= {1.0, 2.0, 3.0};
or
vector v{1.0, 2.0, 3.0};
We could also set all vector entries in an assignment:
v= {1.0, 2.0, 3.0};
Functions that take vector arguments could be called with a vector that is set up on the fly:
vector x= lu_solve(A, vector{1.0, 2.0, 3.0});
The previous statement solves a linear system for the vector (1, 2, 3)T with an LU factorization on A.
To use this feature in our vector class, we need a constructor and an assignment accepting initializer_list<double> as an argument. Lazy people can implement the constructor only and use it in the copy assignment. For demonstration and performance purposes, we will implement both. It also allows us to verify in the assignment that the vector size matches:
#include <initializer_list>
#include <algorithm>
class vector
{
// ...
vector(std::initializer_list<double> values)
: my_size(values.size()), data(new double[my_size])
{
std::copy(std::begin(values), std::end(values),
std::begin(data));
}
self& operator=(std::initializer_list<double> values)
{
assert(my_size == values.size());
std::copy(std::begin(values), std::end(values),
std::begin(data));
return *this;
}
};
To copy the values within the list into our data, we use the function std::copy from the standard library. This function takes three iterators3 as arguments. These three arguments represent the begin and the end of the input and the begin of the output. The free functions begin andend were introduced in C++11. In C++03, we have to use the corresponding member functions, e.g., values.begin().
3. Which are kind of generalized pointers; see §4.1.2.
2.3.4 Uniform Initialization
![]()
Braces {} are used in C++11 as universal notation for all forms of variable initialization by
• Initializer-list constructors,
• Other constructors, or
• Direct member setting.
The latter is only allowed for arrays and classes if all (non-static) variables are public and the class has no user-defined constructor.4 Such types are called Aggregates and setting their values with braced lists accordingly Aggregate Initialization.
4. Further conditions are that the class has no base classes and no virtual functions (§6.1).
Assuming we would define a kind of sloppy complex class without constructors, we could initialize it as follows:
struct sloppy_complex
{
double r, i;
};
sloppy_complex z1{3.66, 2.33},
z2= {0, 1};
Needless to say, we prefer using constructors over the aggregate initialization. However, it comes in handy when we have to deal with legacy code.
The complex class from this section which contains constructors can be initialized with the same notation:
complex c{7.0, 8}, c2= {0, 1}, c3= {9.3}, c4= {c};
const complex cc= {c3};
The notation with = is not allowed when the relevant constructor is declared explicit.
There remain the initializer lists that we introduced in the previous section. Using a list as an argument of uniform initialization would actually require double braces:
vector v1= {{1.0, 2.0, 3.0}},
v2{{3, 4, 5}};
To simplify our life, C++11 provides Brace Elision in a uniform initializer; i.e., braces can be omitted and the list entries are passed in their given order to constructor arguments or data members. So, we can shorten the declaration to
vector v1= {1.0, 2.0, 3.0},
v2{3, 4, 5};
Brace elision is a blessing and a curse. Assume we integrated our complex class in the vector to implement a vector_complex which we can conveniently set up:
vector_complex v= {{1.5, -2}, {3.4}, {2.6, 5.13}};
However, the following example:
vector_complex v1d= {{2}};
vector_complex v2d= {{2, 3}};
vector_complex v3d= {{2, 3, 4}};
std::cout ![]() "v1d is "
"v1d is " ![]() v1d
v1d ![]() std::endl; ...
std::endl; ...
might be a bit surprising:
v1d is [(2,0)]
v2d is [(2,3)]
v3d is [(2,0), (3,0), (4,0)]
In the first line, we have one argument so the vector contains one complex number which is initialized with the one-argument constructor (imaginary part is 0). The next statement creates a vector with one element whose constructor is called with two arguments. This scheme cannot continue obviously: complex has no constructor with three arguments. So, here we switch to multiple vector entries that are constructed with one argument each. Some more experiments are given for the interested reader in Appendix A.4.2.
Another application of braces is the initialization of member variables:
class vector
{
public:
vector(int n)
: my_size{n}, data{new double[my_size]} {}
...
private:
unsigned my_size;
double *data;
};
This protects us from occasional sloppiness: in the example above we initialize an unsigned member with an int argument. This narrowing is denounced by the compiler and we will substitute the type accordingly:
vector(unsigned n) : my_size{n}, data{new double[my_size]} {}
We already showed that initializer lists allow us to create non-primitive function arguments on the fly, e.g.:
double d= dot(vector{3, 4, 5}, vector{7, 8, 9});
When the argument type is clear—when only one overload is available, for instance—the list can be passed typeless to the function:
double d= dot({3, 4, 5}, {7, 8, 9});
Accordingly, function results can be set by the uniform notation as well:
complex subtract(const complex& c1, const complex& c2)
{
return {c1.r - c2.r, c1.i - c2.i};
}
The return type of this function is a complex and we initialize it with a two-argument braced list.
In this section, we demonstrated the possibilities of uniform initialization and illustrated some risks. We are convinced that it is a very useful feature but one that should be used with some care for tricky corner cases.
2.3.5 Move Semantics
![]()
Copying large amounts of data is expensive, and people use a lot of tricks to avoid unnecessary copies. Several software packages use shallow copy. That would mean for our vector example that we only copy the address of the data but not the data itself. As a consequence, after the assignment:
v= w;
the two variables contain pointers to the same data in memory. If we change v[7], then we also change w[7] and vice versa. Therefore, software with shallow copy usually provides a function for explicitly calling a deep copy:
copy(v, w);
This function must be used instead of the assignment every time variables are assigned. For temporary values—for instance, a vector that is returned as a function result—the shallow copy is not critical since the temporary is not accessible otherwise and we have no aliasing effects. The price for avoiding the copies is that the programmer must pay utter attention that in the presence of aliasing, memory is not released twice; i.e., reference counting is needed.
On the other hand, deep copies are expensive when large objects are returned as function results. Later, we will present a very efficient technique to avoid copies (see §5.3). Now, we introduce another feature from C++11 for it: Move Semantics. The idea is that variables (in other words all named items) are copied deeply and temporaries (objects that cannot be referred to by name) transfer their data.
This raises the question: How to tell the difference between temporary and persistent data? The good news is: the compiler does this for us. In the C++ lingo, the temporaries are called Rvalues because they can only appear on the right side in an assignment. C++11 introduces rvalue references that are denoted by two ampersands &&. Values with a name, so-called lvalues, cannot be passed to rvalue references.
2.3.5.1 Move Constructor
![]()
By providing a move constructor and a move assignment, we can assure that rvalues are not expensively copied:
class vector
{
// ...
vector(vector&& v)
: my_size(v.my_size), data(v.data)
{
v.data= 0;
v.my_size= 0;
}
};
The move constructor steals the data from its source and leaves it in an empty state.
An object that is passed as an rvalue to a function is considered expired after the function returns. This means that all data can be entirely random. The only requirement is that the destruction of the object (§2.4) must not fail. Utter attention must be paid to raw pointers (as usual). They must not point to random memory so that the deletion fails or some other user data is freed. If we would have left the pointer v.data unchanged, the memory would be released when v goes out of scope and the data of our target vector would be invalidated. Usually a raw pointer should benullptr (0 in C++03) after a move operation.
Note that an rvalue reference like vector&& v is not an rvalue itself but an lvalue as it possesses a name. If we wanted to pass our v to another method that helps the move constructor with the data robbery, we would have to turn it into an rvalue again with the standard functionstd::move (see §2.3.5.4).
2.3.5.2 Move Assignment
![]()
The move assignment can be implemented in a simple manner by swapping the pointers to the data:
class vector
{
// ...
vector& operator=(vector&& src)
{
assert(my_size == 0 || my_size == src.my_size);
std::swap(data, src.data);
return *this;
}
};
This relieves us from releasing our own existing data because this is done when the source is destroyed.
Say we have an empty vector v1 and a temporarily created vector v2 within function f() as depicted in the upper part of Figure 2–2. When we assign the result of f() to v1:
v1= f(); // f returns v2
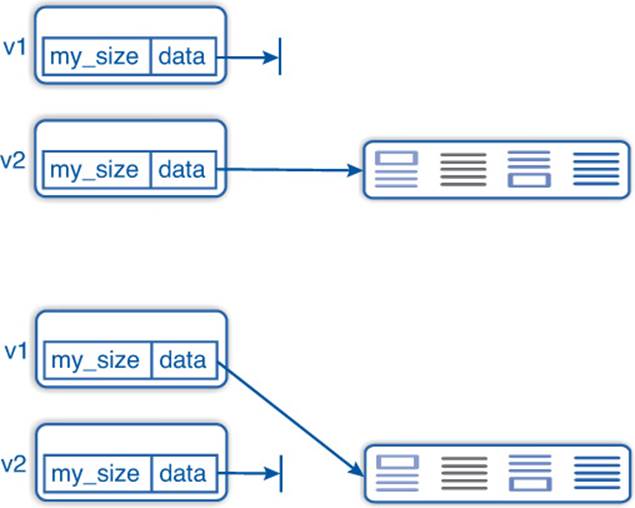
Figure 2–2: Moved data
the move assignment will swap the data pointers so that v1 contains the values of v2 afterward while the latter is empty as in the lower part of Figure 2–2.
2.3.5.3 Copy Elision
If we add logging in these two functions, we might realize that our move constructor is not called as often as we thought. The reason for this is that modern compilers provide an even better optimization than stealing the data. This optimization is called Copy Elision where the compiler omits a copy of the data and modifies the generation of the data such that it is immediately stored to the target address of the copy operation.
Its most important use case is Return Value Optimization (RVO), especially when a new variable is initialized with a function result like
inline vector ones(int n)
{
vector v(n);
for (unsigned i= 0; i < n; ++i)
v[i]= 1.0;
return v;
}
...
vector w(ones(7));
Instead of constructing v and copying (or moving) it to w at the end of the function, the compiler can create w immediately and perform all operations directly on it. The copy (or move) constructor is never called. We simply check this with a log output or a debugger.
Copy elision was already available in many compilers before move semantics. However, that should not mean that move constructors are useless. The rules for moving data are mandatory by the standard whereas the RVO optimization is not guaranteed. Often minor details can turn it off, for instance, if the function has multiple return statements.
2.3.5.4 Where We Need Move Semantics
![]()
One situation where a move constructor is definitely used is with the function std::move. Actually this function does not move, it only casts an lvalue to an rvalue. In other words, it pretends that the variable is a temporary; i.e., it makes it movable. As a consequence, subsequent constructors or assignments will call the overload for an rvalue reference, as in the following code snippet:
vector x(std::move(w));
v= std::move(u);
In the first line, x steals the data of w and leaves it as an empty vector. The second statement will swap v and u.
Our move constructor and assignment are not perfectly consistent when used with std::move. As long as we deal only with true temporaries, we would not see the difference. However, for stronger consistency we can also leave the source of a move assignment in an empty state:
class vector
{
// ...
vector& operator=(vector&& src)
{
assert(my_size == src.my_size);
delete[] data;
data= src.data;
src.data= nullptr;
src.my_size= 0;
return *this;
}
};
Another take on this is that objects are considered expired after std::move. Phrased differently, they are not dead yet but retired, and it does not matter what value they have as long as they are in a legal state (i.e., the destructor must not crash).
A nice application of move semantics is the default implementation std::swap in C++11 and higher; see Section 3.2.3.
2.4 Destructors
A destructor is a function that is called every time when an object is destroyed, for example:
∼complex()
{
std::cout ![]() "So long and thanks for the fish.\n";
"So long and thanks for the fish.\n";
}
Since the destructor is the complementary operation of the default constructor, it uses the notation for the complement (∼). Opposed to the constructor, there is only one single overload and arguments are not allowed.
2.4.1 Implementation Rules
There are two very important rules:
1. Never throw an exception in a destructor! It is likely that your program will crash and the exception will never be caught. In C++11 or higher, it is always treated as a run-time error which aborts the execution (destructors are implicitly declared noexcept, §1.6.2.4). In C++03, what happens depends on the compiler implementation, but a program abortion is the most likely reaction.
2. If a class contains a virtual function, the destructor should be virtual, too. We come back to this in Section 6.1.3.
2.4.2 Dealing with Resources Properly
What we do in a destructor is our free choice; we have no limitations from the language. Practically, the main task of a destructor is releasing the resources of an object (memory, file handles, sockets, locks, . . . ) and cleaning up everything related to the object that is not needed any longer in the program. Because a destructor must not throw exceptions, many programmers are convinced that releasing resources should be the only activity of a destructor.
![]() c++03/vector_test.cpp
c++03/vector_test.cpp
In our example, there is nothing to do when a complex number is destroyed and we can omit the destructor. A destructor is needed when the object acquires resources like memory. In such cases, the memory or the other resource must be released in the destructor:
class vector
{
public:
// ...
∼vector()
{
delete[] data;
}
// ...
private:
unsigned my_size;
double *data;
};
Note that delete already tests whether a pointer is nullptr (0 in C++03). Similarly, files that are opened with old C handles require explicit closing (and this is only one reason for not using them).
2.4.2.1 Resource Acquisition Is Initialization
Resource Acquisition Is Initialization (RAII) is a paradigm mainly developed by Bjarne Stroustrup and Andrew Koenig. The idea is tying resources to objects and using the mechanism of object construction and destruction to handle resources automatically in programs. Each time we want to acquire a resource, we do so by creating an object that owns it. Whenever the object goes out of scope, the resource (memory, file, socket, . . . ) is released automatically, as in our vector example above.
Imagine a program that allocates 37,186 memory blocks in 986 program locations. Can we be sure that all the memory blocks are freed? And how much time will we spend to get to this certainty or at least to an acceptable level of confidence? Even with tools like valgrind (§B.3), we can only test the absence of memory leaks for a single run but cannot guarantee in general that memory is always released. On the other hand, when all memory blocks are allocated in constructors and freed in destructors, we can be sure that no leaks exist.
2.4.2.2 Exceptions
Releasing all resources is even more challenging when exceptions are thrown. Whenever we detect a problem, we have to release all resources acquired so far before we throw the exception. Unfortunately, this is not limited to resources in the current scope but extends to those of surrounding scopes depending on where the exception is caught. This means that changing the error handling needs tedious adaption of the manual resource management.
2.4.2.3 Managed Resources
All the problems mentioned before can be solved by introducing classes that manage the resources. C++ already offers such managers in the standard library. File streams manage the file handles from C. unique_ptr and shared_ptr handle memory in a leak-free, exception-safe manner.5 Also in our vector example, we can benefit from unique_ptr by not needing to implement a destructor.
5. Only cyclic references need special treatment.
2.4.2.4 Managing Ourselves
The smart pointers show that there can be different treatments of a resource type. However, when none of the existing classes handles a resource in the fashion we want, it is a great occasion to entertain ourselves writing a resource manager tailored to our needs.
When we do so, we should not manage more than one resource in a class. The motivation for this guideline is that exceptions can be thrown in constructors, and it is quite tedious to write the constructor in a way that guarantees that all resources acquired so far are released.
Thus, whenever we write a class that deals with two resources (even of the same type) we should introduce a class that manages one of the resources. Better yet, we should write managers for both resources and separate the resource handling entirely from the scientific content. Even in the case that an exception is thrown in the middle of the constructor, we have no problem with leaking resources since the destructors of their managers are called automatically and will take care of it.
The term “RAII” puts linguistically more weight on the initialization. However, the finalization is even more important technically. It is not mandatory that a resource is acquired in a constructor. This can happen later in the lifetime of an object. Fundamental is that one single object is responsible for the resource and releases it at the end of its lifetime. Jon Kalb calls this approach an application of the Single Responsibility Principle (SRP), and it is worthwhile to see his talk, which is available on the web.
2.4.2.5 Resource Rescue
![]()
In this section, we introduce a technique for releasing resources automatically even when we use a software package with explicit resource handling. We will demonstrate the technique with the Oracle C++ Call Interface (OCCI) [33] for accessing an Oracle database from a C++ program. This example allows us to show a realistic application, and we assume that many scientists and engineers have to deal with databases from time to time. Although the Oracle database is a commercial product, our example can be tested with the free Express edition.
OCCI is a C++ extension of the C library OCI and adds only a thin layer with some C++ features on top while keeping the entire software architecture in C style. Sadly, this applies to most inter-language interfaces of C libraries. Since C does not support destructors, one cannot establish RAII and resources must be released explicitly.
In OCCI, we first have to create an Environment which can be used to establish a Connection to the database. This in turn allows us to write a Statement that returns a ResultSet. All these resources are represented by raw pointers and must be released in reverse order.
As an example, we look at Table 2–1 where our friend Herbert keeps track of his solutions to (allegedly) unsolved mathematical problems. The second column indicates whether he is certain to deserve an award for his work. For size reasons, we cannot print the complete list of his tremendous discoveries here.

Table 2–1: Herbert’s Solutions
![]() c++03/occi_old_style.cpp
c++03/occi_old_style.cpp
From time to time, Herbert looks up his award-worthy discoveries with the following C++ program:
#include <iostream>
#include <string>
#include <occi.h>
using namespace std; // import names (§3.2.1)
using namespace oracle::occi;
int main()
{
string dbConn= "172.17.42.1", user= "herbert",
password= "NSA_go_away";
Environment *env = Environment::createEnvironment();
Connection *conn = env->createConnection(user, password,
dbConn);
string query= "select problem from my_solutions"
" where award_worthy != 0";
Statement *stmt = conn->createStatement(query);
ResultSet *rs = stmt->executeQuery();
while (rs->next())
cout ![]() rs->getString(1)
rs->getString(1) ![]() endl;
endl;
stmt->closeResultSet(rs);
conn->terminateStatement(stmt);
env->terminateConnection(conn);
Environment::terminateEnvironment(env);
}
This time, we cannot blame Herbert for his old-style programming; it is forced by the library. Let us have a look at the code. Even for people not familiar with OCCI, it is evident what happens. First, we acquire the resources, then we iterate over Herbert’s ingenious achievements, and finally we release the resources in reverse order. We highlighted the resource release operations as we will have to pay closer attention to them.
The release technique works reasonably well when our (or Herbert’s) program is a monolithic block as above. The situation changes entirely when we try building functions with queries:
ResultSet *rs = makes_me_famous();
while (rs->next())
cout ![]() rs->getString(1)
rs->getString(1) ![]() endl;
endl;
ResultSet *rs2 = needs_more_work();
while (rs2->next())
cout ![]() rs2->getString(1)
rs2->getString(1) ![]() endl;
endl;
Now we have result sets without the corresponding statements to close them; they were declared within the query functions and are out of scope now. Thus, for every object we have to keep additionally the object that was used for its generation. Sooner or later this becomes a nightmare of dependencies with an enormous potential for errors.
![]() c++11/occi_resource_rescue.cpp
c++11/occi_resource_rescue.cpp
The question is: How can we manage resources that depend on other resources? The solution is to use deleters from unique_ptr or shared_ptr. They are called whenever managed memory is released. An interesting aspect of deleters is that they are not obliged to actually release the memory. We will explore this liberty to manage our resources. The Environment has the easiest handling because it does not depend on another resource:
struct environment_deleter {
void operator()( Environment* env )
{ Environment::terminateEnvironment(env); }
};
shared_ptr<Environment> environment(
Environment::createEnvironment(), environment_deleter {});
Now, we can create as many copies of the environment as we like and have the guarantee that the deleter executing terminateEnvironment(env) is called when the last copy goes out of scope.
A Connection requires an Environment for its creation and termination. Therefore, we keep a copy in connection_deleter:
struct connection_deleter
{
connection_deleter(shared_ptr<Environment> env)
: env(env) {}
void operator()(Connection* conn)
{ env->terminateConnection(conn); }
shared_ptr<Environment> env;
};
shared_ptr<Connection> connection(environment->createConnection(...),
connection_deleter{environment});
Now, we have the guarantee that the Connection is terminated when it is not needed any longer. Having a copy of the Environment in the connection_deleter ensures that it is not terminated as long as a Connection exists.
We can handle the database more conveniently when we create a manager class for it:
class db_manager
{
public:
using ResultSetSharedPtr= std::shared_ptr<ResultSet>;
db_manager(string const& dbConnection, string const& dbUser,
string const& dbPw)
: environment(Environment::createEnvironment(),
environment_deleter{}),
connection(environment->createConnection(dbUser, dbPw,
dbConnection),
connection_deleter{environment} )
{}
// some getters ...
private:
shared_ptr<Environment> environment;
shared_ptr<Connection> connection;
};
Note that the class has no destructor since the members are managed resources now.
To this class, we can add a query method that returns a managed ResultSet:
struct result_set_deleter
{
result_set_deleter(shared_ptr<Connection> conn,
Statement* stmt)
: conn(conn), stmt(stmt) {}
void operator()( ResultSet *rs ) // call op. like in (§3.8)
{
stmt->closeResultSet(rs);
conn->terminateStatement(stmt);
}
shared_ptr<Connection> conn;
Statement* stmt;
};
class db_manager
{
public:
// ...
ResultSetSharedPtr query(const std::string& q) const
{
Statement *stmt= connection->createStatement(q);
ResultSet *rs= stmt->executeQuery();
auto deleter= result_set_deleter{connection, stmt};
return ResultSetSharedPtr{rs, deleter};
}
};
Thanks to this new method and our deleters, the application becomes as easy as
int main()
{
db_manager db("172.17.42.1", "herbert", "NSA_go_away");
auto rs= db.query("select problem from my_solutions "
" where award_worthy != 0");
while (rs->next())
cout ![]() rs->getString(1)
rs->getString(1) ![]() endl;
endl;
}
The more queries we have, the more our effort pays off. Not being ashamed to repeat ourselves: all resources are implicitly released.
The careful reader has realized that we violated the single-responsibility principle. To express our gratitude for this discovery we invite you to improve our design in Exercise 2.8.4.
2.5 Method Generation Résumé
C++ has six methods (four in C++03) with a default 'margin-top:4.0pt;margin-right:0cm;margin-bottom:4.0pt; margin-left:40.0pt;text-indent:-9.0pt;line-height:normal'>• Default constructor
• Copy constructor
• Move constructor (C++11 or higher)
• Copy assignment
• Move assignment (C++11 or higher)
• Destructor
The code for those can be generated by the compiler—saving us from boring routine work and thus preventing oversights.
There is a fair amount of detail involved in the rules determining which method is generated implicitly. These details are covered in more detail in Appendix A, Section A.5. Here we only want to give you our final conclusions for C++11 and higher:
Rule of Six
Regarding the six operations above, implement as little as possible and declare as much as possible. Any operation not implemented shall be declared as default or delete.
2.6 Accessing Member Variables
C++ offers multiple ways to access the members of our classes. In this section, we present different options and discuss their advantages and disadvantages. Hopefully, you will get a feeling for how to design your classes in the future in a way that suits your domain best.
2.6.1 Access Functions
In §2.2.5, we introduced getters and setters to access the variables of the class complex. This becomes cumbersome when we want, for instance, to increment the real part:
c.set_r(c.get_r() + 5.);
This does not really look like a numeric operation and is not very readable either. A better way to realize this operation is writing a member function that returns a reference:
class complex {
public:
double& real() { return r; }
};
With this function we can write
c.real()+= 5.;
This already looks much better but is still a little bit weird. Why not increment the calculation like this:
real(c)+= 5.;
To this end, we write a free function:
inline double& real(complex& c) { return c.r; }
Unfortunately, this function accesses the private member r. We can modify the free function calling the member function:
inline double& real(complex& c) { return c.real(); }
Or alternatively declare the free function as friend of complex to access its private data:
class complex {
friend double& real(complex& c);
};
Accessing the real part should also work when the complex number is constant. Thus, we further need a constant version of this function, regarding argument and result:
inline const double& real(const complex& c) { return c.r; }
This function requires a friend declaration, too.
In the last two functions we returned references, but those are guaranteed not to be out of date. The functions—in free as well as in member form—can evidently only be called when the referred object is already created. The references of the number’s real part that we use in the statement
real(c)+= 5.;
exist only until the end of the statement in contrast to the referred variable c which lives longer: until the end of the scope in which it is defined. We can create a reference variable:
double &rr= real(c);
that lives till the end of the current scope. Even in the case that c is declared in the same scope, the reverse order of object destruction in C++ guarantees that c lives longer than rr.
Member references of temporary objects can safely be used within the same expression, e.g.:
double r2= real(complex(3, 7)) * 2.0; // okay!
The temporary complex number lives only in the statement but at least longer than the reference of its real part so that this statement is correct. However, if we keep that reference to the real part, it will be outdated:
const double &rr= real(complex(3, 7)); // Really bad!!!
cout ![]() "The real part is "
"The real part is " ![]() rr
rr ![]() '\n';
'\n';
The complex variable is created temporarily and only exists until the end of the first statement. The reference to its real part lives till the end of the surrounding scope.
Rule
Do not keep references of temporary expressions!
They are invalid before we use them the first time.
2.6.2 Subscript Operator
To iterate over a vector, we could write a function like
class vector
{
public:
double at(int i)
{
assert(i >= 0 && i < my_size);
return data[i];
}
};
Summing the entries of vector v reads:
double sum= 0.0;
for (int i= 0; i < v.size(); ++i)
sum+= v.at(i);
C++ and C access entries of (fixed-size) arrays with the subscript operator. It is, thus, only natural to do the same for (dynamically sized) vectors. Then we could rewrite the previous example as
double sum= 0.0;
for (int i= 0; i < v.size(); ++i)
sum+= v[i];
This is more concise and shows more clearly what we are doing.
The operator overloading has the same syntax as the assignment operator and the implementation from function at:
class vector
{
public:
double& operator[](int i)
{
assert(i >= 0 && i < my_size);
return data[i];
}
};
With this operator, we can access vector elements with brackets but (in this form) only if the vector is mutable.
2.6.3 Constant Member Functions
This raises the more general question: How can we write operators and member functions that accept constant objects? In fact, operators are a special form of member functions and can be called like a member function:
v[i]; // is syntactic sugar for:
v.operator[](i);
Of course, the long form is almost never used, but it illustrates that operators are regular methods that only provide an additional call syntax.
Free functions allow qualifying the const-ness of each argument. Member functions do not even mention the processed object in the signature. How can we then specify that the current object must be const? There is a special notation to add qualifiers after the function header:
class vector
{
public:
const double& operator[](int i) const
{
assert(i >= 0 && i < my_size);
return data[i];
}
};
The const attribute is not just a casual indication that the programmer does not mind calling this member function with a constant object. The C++ compiler takes this constancy very seriously and will verify that the function does not modify the object (i.e., some of its members) and that the object is only passed as a const argument to other functions. Thus, when other methods are called they must be const, too.
This constancy guarantee also impedes returning non-constant pointers or references to data members. One can return constant pointers or references as well as objects. A returned value does not need to be constant (but it could) because it is a copy of the current object, of one of its member variables (or constants), or of a temporary variable. None of those copies bears the risk of modifying the current object.
Constant member functions can be called with non-constant objects as arguments (because C++ implicitly converts non-constant references into constant references when necessary). Therefore, it is often sufficient to provide only the constant member function. For instance, here is a function that returns the size of the vector:
class vector
{
public:
int size() const { return my_size; }
// int size() { return my_size; } // futile
};
The non-constant size function does the same as the constant one and is therefore useless.
For our subscript operator, we need both the constant and the mutable version. If we only had the constant member function, we could use it to read the elements of both constant and mutable vectors but we could not modify the latter.
Data members can be declared mutable. Then they can even be changed in const methods. This is intended for internal states—like caches—that do not affect the observable behavior. We do not use this feature in this book and recommend that you apply it only when really necessary, as it undermines the language’s data protection.
2.6.4 Reference-Qualified Members
![]()
In addition to the constancy of an object (i.e., that of *this), we can also require in C++11 that an object be an lvalue or rvalue reference. Assume we have a vector addition (see §2.7.3). Its result will be a temporary object that is not constant. Thus we can assign values to its entries:
(v + w)[i]= 7.3; // nonsense
Admittedly, this is a quite artificial example, but it illustrates that there is room for improvement.
Assignments should only accept mutable lvalues on the left-hand side. This applies uncompromisingly to intrinsic types. This raises the question: Why is (v + w)[i] a mutable lvalue? The vector’s bracket operator has two overloads: for mutable and constant objects. v+w is not constant so the overload for mutable vectors is preferred. Thus, we access a mutable reference to a mutable object’s member which is legitimate.
The problem is that (v + w)[i] is an lvalue while v+w is not. What we are missing here is the requirement that the bracket operator can only be applied on lvalues:
class vector
{
public:
double& operator[](int i) & { ... } // #1
const double& operator[](int i) const& { ... } // #2
};
When we qualify one overload of a member with a reference, we have to qualify the other overloads as well. With this implementation, overload #1 cannot be used for temporary vectors, and overload #2 returns a constant reference to which no value can be assigned. As a consequence, we will see a compiler error for the nonsensical assignment above:
vector_features.cpp:167:15: error: read-only variable is not assignable
(v + w)[i]= 3;
~~~~~~~~~~^
Likewise, we can Ref-Qualify the vector’s assignment operators to disable them for temporary objects:
v + w= u; // nonsense, should be forbidden
As expected, two ampersands allow us to restrict a member function to rvalues; that is, the method should only be callable on temporaries:
class my_class
{
something_good donate_my_data() && { ... }
};
Use cases could be conversions where huge copies (e.g., of matrices) should be avoided.
Multi-dimensional data structures like matrices can be accessed in different ways. First, we can use the application operator (§3.8) which allows us to pass multiple indices as arguments. The bracket operator unfortunately accepts only one argument, and we discuss some ways to deal with this in Appendix A.4.3 of which none is satisfying. An advanced approach to call the application operator from concatenated bracket operators will be presented later in Section 6.6.2.
2.7 Operator Overloading Design
With few exceptions (§1.3.10), most operators can be overloaded in C++. However, some operators make sense to overload only for specific purposes; e.g., the dereferred member selection p->m is useful for implementing new smart pointers. In a scientific or engineering context, it is much less obvious how to use this operator intuitively. Along the same lines, a customized meaning of the address operator &o needs a good reason.
2.7.1 Be Consistent!
As mentioned before, the language gives us a high degree of freedom in the design and implementation of operators for our classes. We can freely choose the semantics of every operator. However, the closer our customized behavior is to that of the standard types, the easier it is for others (co-developers, open-source users, . . . ) to understand what we do and to trust our software.
The overloading can of course be used to represent operations in a certain application domain concisely, i.e., to establish a Domain-Specific Embedded Language (DSEL). In this case, it can be productive to deviate from the typical meanings of the operators. Nonetheless, the DSEL should be consistent in itself. For instance, if the operators =, +, and += are user-defined, then the expressions a= a + b and a+= b should have the same effect.
Consistent Overloads
Define your operators consistently with each other and whenever appropriate provide semantics similar to those of standard types.
We are also free to choose the return type of each operator arbitrarily; e.g., x == y could return a string or a file handle. Again, the closer we stay to the typical return types in C++, the easier it is for everybody (including ourselves) to work with our customized operators.
The only predefined aspect of operators is their Arity: the number of arguments and the relative priority of the operators. In most cases this is inherent in the represented operation: a multiplication always takes two arguments. For some operators, one could imagine a variable arity. For instance, it would be nice if the subscription operator accepted two arguments in addition to the subscribed object so that we could access a matrix element like this: A[i, j]. The only operator allowing for an arbitrary arity (including variadic implementations, §3.10) is the application operator: operator().
Another freedom that the language provides us is the choice of the arguments’ types. We can, for instance, implement a subscription operator for an unsigned (returning a single element), for a range (returning a sub-vector), and a set (returning a set of vector elements). This is indeed realized in MTL4. Compared to MATLAB, C++ offers fewer operators, but we have the unlimited opportunity of overloading them infinitely to create every amount of functionality we like.
2.7.2 Respect the Priority
When we redefine operators, we have to ascertain that the expected priority of the operation corresponds to the operator precedence. For instance, we might have the idea of using the LATEX notation for exponentiation of matrices:
A= B^2;
A is B squared. So far so good. That the original meaning of ^ is a bitwise exclusive OR does not worry us as we never planned to implement bitwise operations on matrices.
Now we add C to B2:
A= B^2 + C;
Looks nice. But it does not work (or does something weird). Why? Because + has a higher priority than ^. Thus, the compiler understands our expression as
A= B ^ (2 + C);
Oops. Although the operator notation gives a concise and intuitive interface, non-trivial expressions might not meet our expectations. Therefore:
Respect Priorities
Pay attention that the semantic/intended priority of your overloaded operators matches the priorities of C++ operators.
2.7.3 Member or Free Function
Most operators can be defined as members or as free functions. The following operators—any kind of assignment, operator[], operator->, and operator()—must be non-static methods to ensure that their first argument is an lvalue. We have shown examples of operator[] andoperator() in Section 2.6. In contrast, binary operators with an intrinsic type as first argument can only be defined as free functions.
The impact of different implementation choices can be demonstrated with the addition operator for our complex class:
class complex
{
public:
explicit complex(double rn = 0.0, double in = 0.0) : r(rn), i(in) {}
complex operator+(const complex& c2) const
{
return complex(r + c2.r, i + c2.i);
}
...
private:
double r, i;
};
int main()
{
complex cc(7.0, 8.0), c4(cc);
std::cout ![]() "cc + c4 is "
"cc + c4 is " ![]() cc + c4
cc + c4 ![]() std::endl;
std::endl;
}
Can we also add a complex and a double?
std::cout ![]() "cc + 4.2 is "
"cc + 4.2 is " ![]() cc + 4.2
cc + 4.2 ![]() std::endl;
std::endl;
Not with the implementation above. We can add an overload for the operator accepting a double as a second argument:
class complex
{
...
complex operator+(double r2) const
{
return complex(r + r2, i);
}
...
};
Alternatively, we can remove the explicit from the constructor. Then a double can be implicitly converted to a complex and we add two complex values.
Both approaches have pros and cons: the overloading needs only one addition operation, and the implicit constructor is more flexible in general as it allows for passing double values to complex function arguments. Or we do both the implicit conversion and the overloading, then we have the flexibility and the efficiency.
Now we turn the arguments around:
std::cout ![]() "4.2 + c4 is "
"4.2 + c4 is " ![]() 4.2 + c4
4.2 + c4 ![]() std::endl;
std::endl;
This will not compile. In fact, the expression 4.2 + c4 can be considered as a short notion of
4.2.operator+(c4)
In other words, we are looking for an operator in double which is not even a class.
To provide an operator with a primitive type as a first argument, we must write a free function:
inline complex operator+(double d, const complex& c2)
{
return complex(d + real(c2), imag(c2));
}
In the same manner, it is advisable to implement the addition of two complex values as free functions:
inline complex operator+(const complex& c1, const complex& c2)
{
return complex(real(c1) + real(c2), imag(c1) + imag(c2));
}
To avoid an ambiguity, we have to remove the member function with the complex argument.
All this said, the main difference between a member and a free function is that the former allows the implicit conversion only for the second argument (here summand) and the latter for both arguments. If concise program sources are more important than performance, we could omit all the overloads with a double argument and rely on the implicit conversion.
Even if we keep all three overloads, it is more symmetric to implement them as free functions. The second summand is in any case subject to implicit conversion, and it is better to have the same behavior for both arguments. In short:
Binary Operators
Implement binary operators as free functions.
We have the same distinction for unary operands: only free functions, e.g.:
complex operator-(const complex& c1)
{ return complex(-real(c1), -imag(c1)); }
allow for implicit conversions, in contrast to members:
class complex
{
public:
complex operator-() const { return complex(-r, -i); }
};
Whether this is desirable depends on the context. Most likely, a user-defined dereference operator* should not involve conversion.
Last but not least, we want to implement an output operator for streams. This operator takes a mutable reference to std::ostream and a usually constant reference to the user type. For simplicity’s sake let us stick with our complex class:
std::ostream& operator![]() (std::ostream& os, const complex& c)
(std::ostream& os, const complex& c)
{
return os ![]() '('
'(' ![]() real(c)
real(c) ![]() ','
',' ![]() imag(c)
imag(c) ![]() ")";
")";
}
As the first argument is ostream&, we cannot write a member function in complex, and adding a member to std::ostream is not really an option. With this single implementation we provide output on all standardized output streams, i.e., classes derived from std::ostream.
2.8 Exercises
2.8.1 Polynomial
Write a class for polynomials that should at least contain:
• A constructor giving the degree of the polynomial;
• A dynamic array/vector/list of double to store the coefficients;
• A destructor; and
• A output function for ostream.
Further members like arithmetic operations are optional.
2.8.2 Move Assignment
Write a move assignment operator for the polynomial in Exercise 2.8.1. Define the copy constructor as default. To test whether your assignment is used write a function polynomial f(double c2, double c1, double c0) that takes three coefficients and returns a polynomial. Print out a message in your move assignment or use a debugger to make sure your assignment is used.
2.8.3 Initializer List
Expand the program from Exercise 2.8.1 with a constructor and an assignment operator for a initializer list. The degree of the polynomial should be the length of the initializer list minus one afterward.
2.8.4 Resource Rescue
Refactor the implementation from Section 2.4.2.5. Implement a deleter for Statement and use managed statements in a managed ResultSet.