Understanding and Using C Pointers (2013)
Chapter 6. Pointers and Structures
Structures in C can represent data structure elements, such as the nodes of a linked list or tree. Pointers provide the glue that ties these elements together. Understanding the versatility supported by pointers for common data structures will facilitate your ability to create your own data structures. In this chapter, we will explore the fundamentals of structure memory allocation in C and the implementation of several common data structures.
Structures enhance the utility of collections such as arrays. To create an array of entities such as a color type with multiple fields without using a structure, it is necessary to declare an array for each field and keep each value for a field in the same index of each array. However, with a structure, we can declare a single array where each element is an instance of the structure.
This chapter expands on the pointer concepts learned so far. This includes the introduction of pointer notation as used with structures, a discussion of how memory is allocated for a structure, a technique for managing memory used by structures, and uses of function pointers.
We will start with a discussion of how memory is allocated for a structure. An understanding of this allocation will explain how various operations work. This is followed by the introduction of a technique to minimize the overhead of heap management.
The last section illustrates how to create a number of data structures using pointers. The linked list is discussed first and will serve as the basis for several other data structures. The tree data structure is discussed last and does not use a linked list.
Introduction
A structure in C can be declared in a number of ways. In this section we will only examine two approaches, as our focus is on their use with pointers. In the first approach, we declare a structure using the struct keyword. In the second approach, we use a type definition. In the following declaration, the structure’s name is prefixed with an underscore. This is not necessary but is often used as a naming convention. The _person structure includes fields for name, title, and age:
struct _person {
char* firstName;
char* lastName;
char* title;
unsigned int age;
};
A structure’s declaration frequently uses the typedef keyword to simplify its use later in a program. The following illustrates its use with the _person structure:
typedef struct _person {
char* firstName;
char* lastName;
char* title;
unsigned int age;
} Person;
An instance of a person is declared as follows:
Person person;
Alternately, we can declare a pointer to a Person and allocate memory for it, as shown below:
Person *ptrPerson;
ptrPerson = (Person*) malloc(sizeof(Person));
If we use a simple declaration of a structure as we did with person, we use the dot notation to access its fields. In the following example, we assign values to the firstName and age fields:
Person person;
person.firstName = (char*)malloc(strlen("Emily")+1);
strcpy(person.firstName,"Emily");
person.age = 23;
However, if we are using a pointer to a structure, we need to use the points-to operator, as follows. This operator consists of a dash followed by the greater than symbol:
Person *ptrPerson;
ptrPerson = (Person*)malloc(sizeof(Person));
ptrPerson->firstName = (char*)malloc(strlen("Emily")+1);
strcpy(ptrPerson->firstName,"Emily");
ptrPerson->age = 23;
We do not have to use the points-to operator. Instead, we can dereference the pointer first and then apply the dot operator. This is illustrated below, where we duplicate the previous assignments:
Person *ptrPerson;
ptrPerson = (Person*)malloc(sizeof(Person));
(*ptrPerson).firstName = (char*)malloc(strlen("Emily")+1);
strcpy((*ptrPerson).firstName,"Emily");
(*ptrPerson).age = 23;
This approach is more awkward but you may see it used at times.
How Memory Is Allocated for a Structure
When a structure is allocated memory, the amount allocated to the structure is at minimum the sum of the size of its individual fields. However, the size is often larger than this sum because padding can occur between fields of a structure. This padding can result from the need to align certain data types on specific boundaries. For example, a short is typically aligned on an address evenly divisible by two while an integer is aligned on an address even divisible by four.
Several implications are related to this allocation of extra memory:
§ Pointer arithmetic must be used with care
§ Arrays of structures may have extra memory between their elements
For example, when an instance of the Person structure presented in the previous section is allocated memory, it will be allocated 16 bytes—4 bytes for each element. The following alternate version of Person uses a short instead of an unsigned integer for age. This will result in the same amount of memory being allocated. This is because two bytes are padded at the end of the structure:
typedef struct _alternatePerson {
char* firstName;
char* lastName;
char* title;
short age;
} AlternatePerson;
In the following sequence, we declare an instance of both a Person and an AlternatePerson structure. The structures’ sizes are then displayed. Their size will be the same, 16 bytes:
Person person;
AlternatePerson otherPerson;
printf("%d\n",sizeof(Person)); // Displays 16
printf("%d\n",sizeof(AlternatePerson)); // Displays 16
If we create an array of AlternatePerson, as shown below, there will be padding between the array’s elements. This is illustrated in Figure 6-1. The shaded area shows the gaps between the array elements.
AlternatePerson people[30];
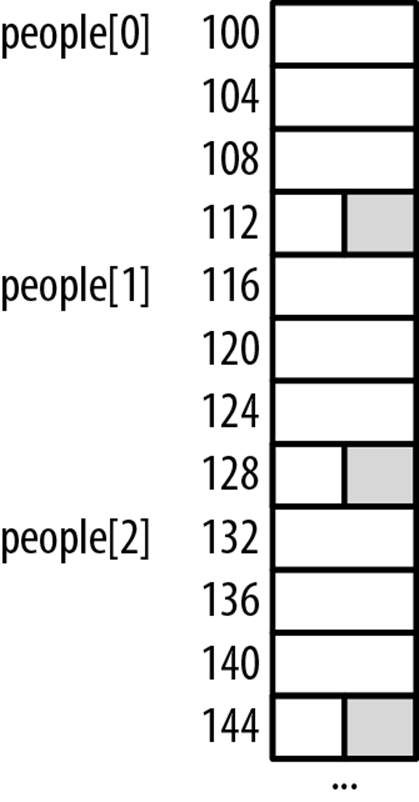
Figure 6-1. Array of AlternativePerson
If we had moved the age field between two fields of the structure, the gap would be internal to the structure. Depending on how the structure is accessed, this may be significant.
Structure Deallocation Issues
When memory is allocated for a structure, the runtime system will not automatically allocate memory for any pointers defined within it. Likewise, when the structure goes away, the runtime system will not automatically deallocate memory assigned to the structure’s pointers.
Consider the following structure:
typedef struct _person {
char* firstName;
char* lastName;
char* title;
uint age;
} Person;
When we declare a variable of this type or dynamically allocate memory for this type, the three pointers will contain garbage. In the next sequence, we declare a Person. Its memory allocation is shown in Figure 6-2. The three dots indicate uninitialized memory:
void processPerson() {
Person person;
...
}
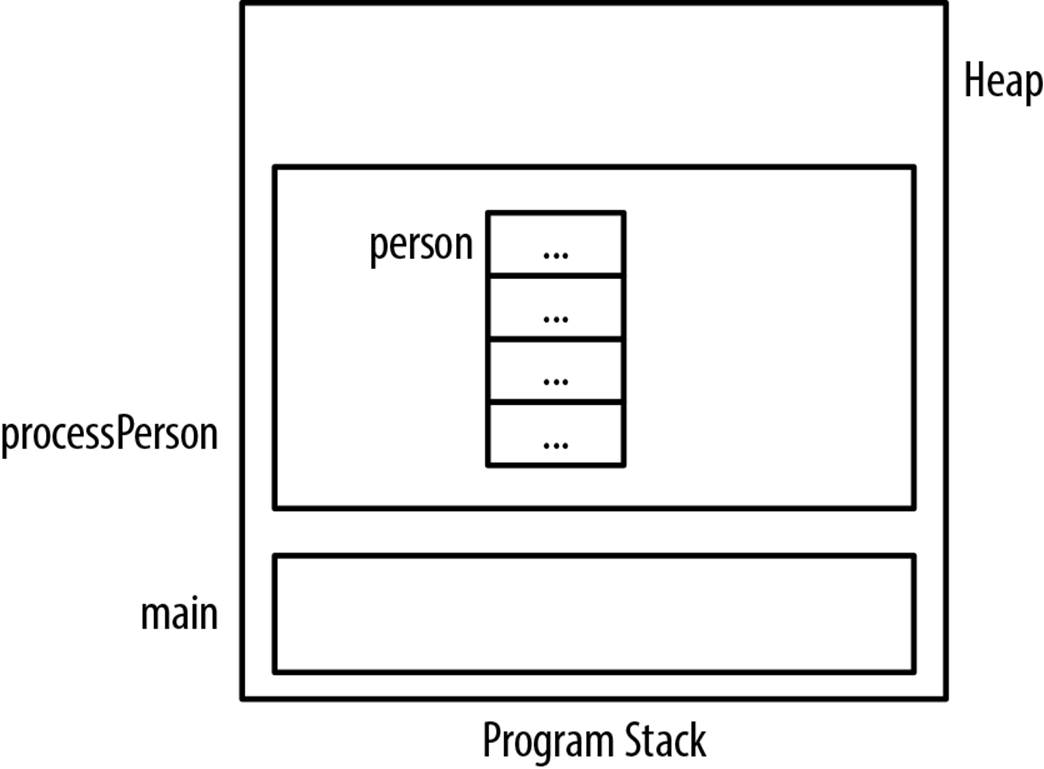
Figure 6-2. Person structure uninitialized
During the initialization of this structure, each field will be assigned a value. The pointer fields will be allocated from the heap and assigned to each pointer:
void initializePerson(Person *person, const char* fn,
const char* ln, const char* title, uint age) {
person->firstName = (char*) malloc(strlen(fn) + 1);
strcpy(person->firstName, fn);
person->lastName = (char*) malloc(strlen(ln) + 1);
strcpy(person->lastName, ln);
person->title = (char*) malloc(strlen(title) + 1);
strcpy(person->title, title);
person->age = age;
}
We can use this function as shown below. Figure 6-3 illustrates how memory is allocated:
void processPerson() {
Person person;
initializePerson(&person, "Peter", "Underwood", "Manager", 36);
...
}
int main() {
processPerson();
...
}
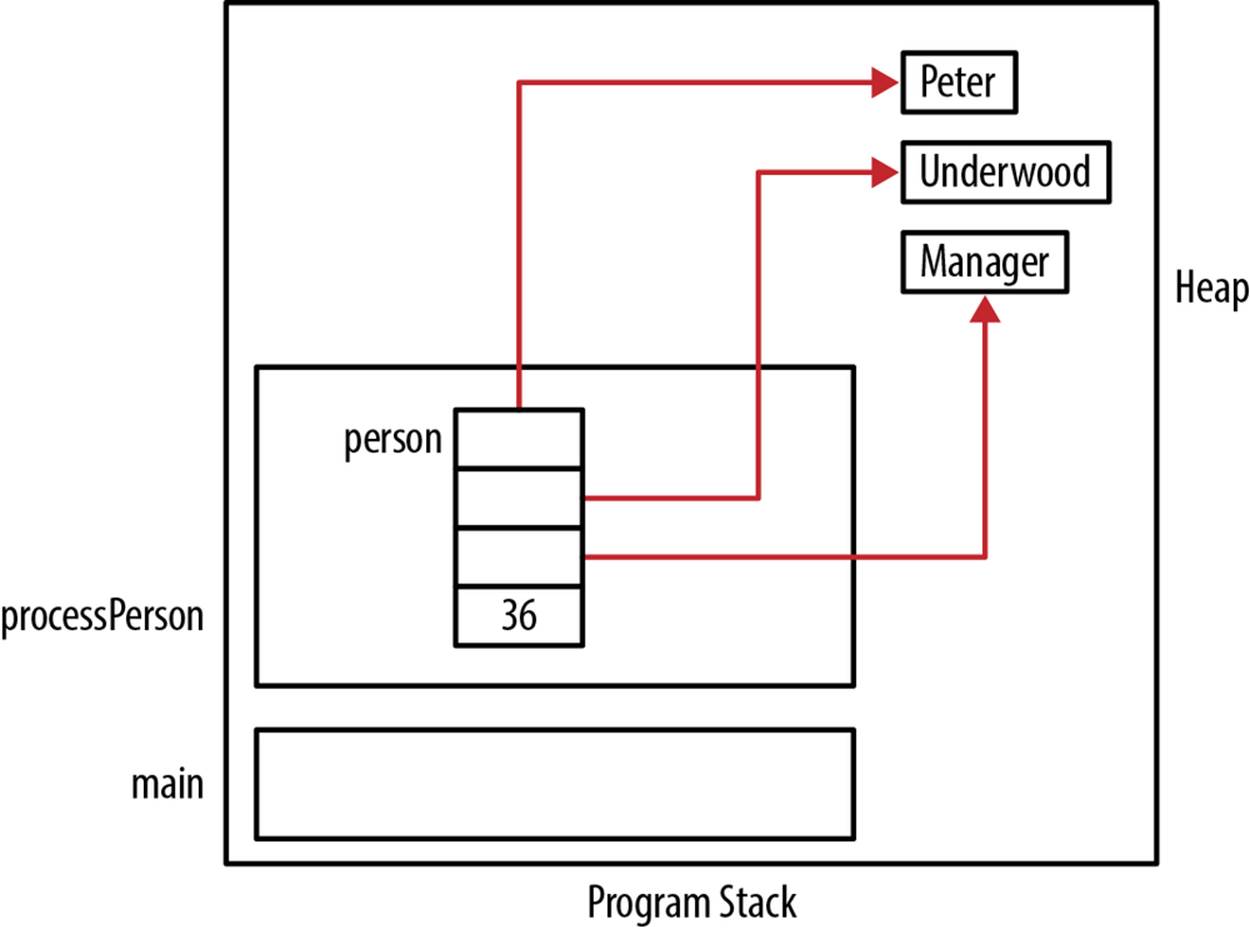
Figure 6-3. Person structure initialized
Since this declaration was part of a function, when the function returns the memory for person will go away. However, the dynamically allocated strings were not released and are still in the heap. Unfortunately, we have lost their address and we cannot free them, resulting in a memory leak.
When we are through with the instance, we need to deallocate the memory. The following function will free up the memory we previously allocated when we created the instance:
void deallocatePerson(Person *person) {
free(person->firstName);
free(person->lastName);
free(person->title);
}
This function needs to be invoked before the function terminates:
void processPerson() {
Person person;
initializePerson(&person, "Peter", "Underwood", "Manager", 36);
...
deallocatePerson(&person);
}
Unfortunately, we must remember to call the initialize and deallocate functions. The automatic invocation of these operations against an object is performed in object-oriented programming languages such as C++.
If we use a pointer to a Person, we need to remember to free up the person as shown below:
void processPerson() {
Person *ptrPerson;
ptrPerson = (Person*) malloc(sizeof(Person));
initializePerson(ptrPerson, "Peter", "Underwood", "Manager", 36);
...
deallocatePerson(ptrPerson);
free(ptrPerson);
}
Figure 6-4 illustrates how memory is allocated.
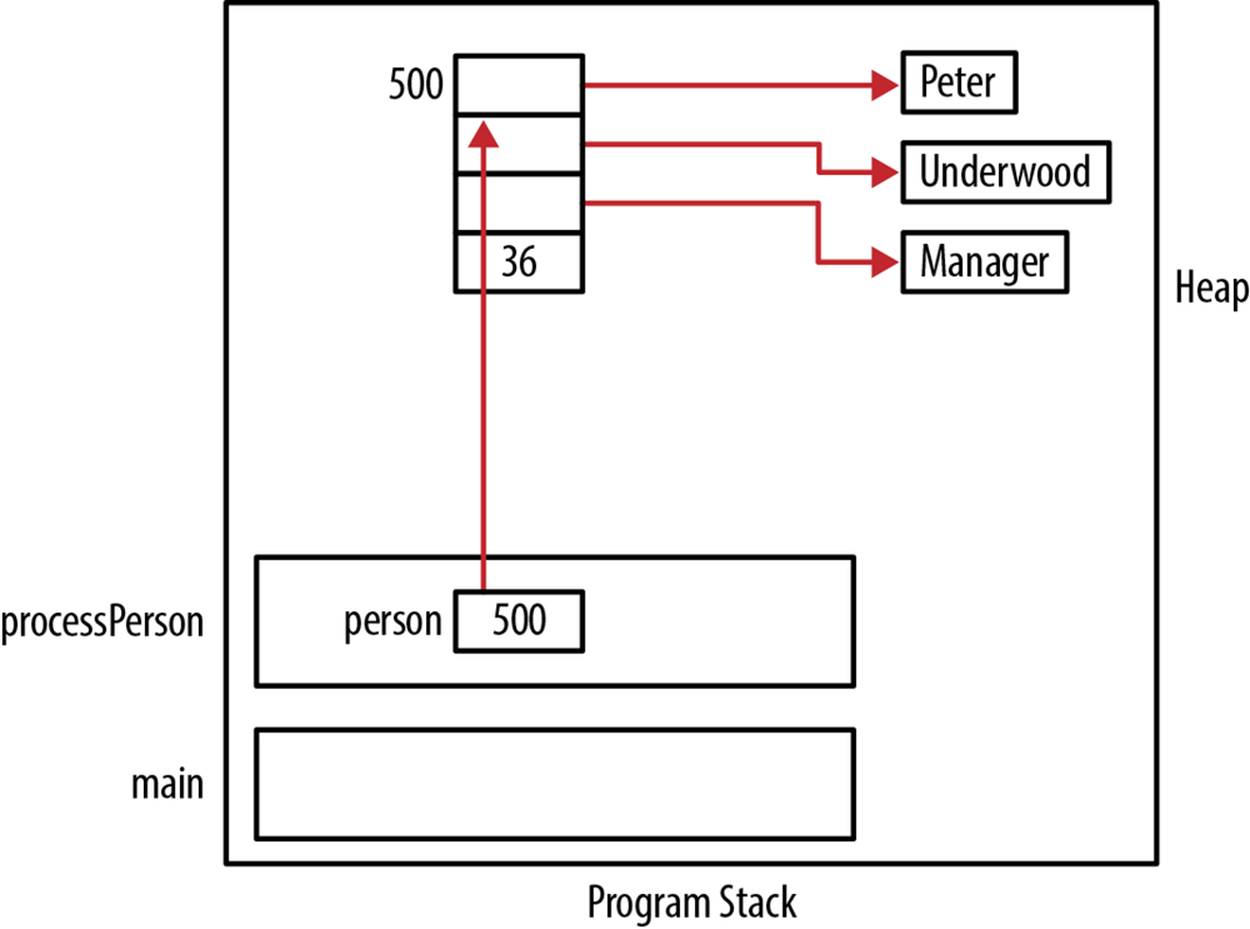
Figure 6-4. Pointer to a person instance
Avoiding malloc/free Overhead
When structures are allocated and then deallocated repeatedly, some overhead will be incurred, resulting in a potentially significant performance penalty. One approach to deal with this problem is to maintain your own list of allocated structures. When a user no longer needs an instance of a structure, it is returned to the pool. When an instance is needed, it obtains the object from the pool. If there are no elements available in the pool, a new instance is dynamically allocated. This approach effectively maintains a pool of structures that can be used and reused as needed.
To demonstrate this approach we will use the Person structure previously defined. A pool of persons is maintained in an array. A more complex list, such as a linked list, can also be used, as illustrated in the section Single-Linked List. To keep this example simple, an array of pointers is used, as declared below:
#define LIST_SIZE 10
Person *list[LIST_SIZE];
Before the list can be used, it needs to be initialized. The following function assigns NULL to each element of the array:
void initializeList() {
for(int i=0; i<LIST_SIZE; i++) {
list[i] = NULL;
}
}
Two functions are used to add and retrieve persons. The first is the getPerson function, as shown below. This function retrieves a person from the list if possible. The array’s elements are compared to NULL. The first non-null element is returned, and its position in list is then assigned a value of NULL. If there is no person available, then a new instance of a Person is created and returned. This avoids the overhead of dynamically allocating memory for a person every time a new one is needed. We only allocate memory if there is none in the pool. The initialization of the instance returned can be done either before it is returned or by the caller, depending on the needs of the application:
Person *getPerson() {
for(int i=0; i<LIST_SIZE; i++) {
if(list[i] != NULL) {
Person *ptr = list[i];
list[i] = NULL;
return ptr;
}
}
Person *person = (Person*)malloc(sizeof(Person));
return person;
}
The second function is the returnPerson, which either adds the person to the list or frees it up. The array’s elements are checked to see whether there are any NULL values. If it does, then person is added to that position and the pointer is returned. If the list is full, then the pointers withinperson are freed using the deallocatePerson function, person is freed, and then NULL is returned:
Person *returnPerson(Person *person) {
for(int i=0; i<LIST_SIZE; i++) {
if(list[i] == NULL) {
list[i] = person;
return person;
}
}
deallocatePerson(person);
free(person);
return NULL;
}
The following illustrates the initialization of the list and adding a person to the list:
initializeList();
Person *ptrPerson;
ptrPerson = getPerson();
initializePerson(ptrPerson,"Ralph","Fitsgerald","Mr.",35);
displayPerson(*ptrPerson);
returnPerson(ptrPerson);
One problem associated with this approach deals with the list size. If the list is too small, then more dynamic allocation and deallocation of memory will be necessary. If the list is large and the structures are not being used, a potentially large amount of memory may be tied up and unavailable for other uses. A more sophisticated list management scheme can be used to manage the list’s size.
Using Pointers to Support Data Structures
Pointers can provide more flexible support for simple and complex data structures. The flexibility can be attributed to the dynamic allocation of memory and the ease of changing pointer references. The memory does not have to be contiguous, as is the case with arrays. Only the exact amount of memory needs to be allocated.
In this section, we will examine how several commonly used data structures can be implemented using pointers. Numerous C libraries provide equivalent and more extensive support than those illustrated here. However, understanding how they can be implemented can prove to be useful when implementing nonstandard data structures. On some platforms, the libraries may not be available, and the developer will need to implement their own version.
We will examine four different data structures:
Linked list
A single-linked list
Queue
A simple first-in first-out queue
Stack
A simple stack
Tree
A binary tree
Along with these data structures, we will incorporate function pointers to illustrate their power in dealing with generic structures. The linked list is a very useful data structure, and we will use it as the foundation of the queue’s and stack’s implementation.
We will illustrate each of these data structures using an employee structure. For example, a linked list consists of nodes connected to one another. Each node will hold user-supplied data. The simple employee structure is listed below. The unsigned char data type is used for age, as this will be large enough to hold people’s ages:
typedef struct _employee{
char name[32];
unsigned char age;
} Employee;
A simple array is used for a single name. While a pointer to char may prove to be a more flexible data type for this field, we have elected to use an array of char to simplify the examples.
Two comparison functions will be developed. The first one compares two employees and returns an integer. This function is modeled after the strcmp function. A return value of 0 means the two employee structures are considered to be equal to each other. A return value of –1 means the first employee precedes the second employee alphabetically. A return value of 1 means the first employee follows the second employee. The second function displays a single employee:
int compareEmployee(Employee *e1, Employee *e2) {
return strcmp(e1->name, e2->name);
}
void displayEmployee(Employee* employee) {
printf("%s\t%d\n", employee->name, employee->age);
}
In addition, two function pointers will be used as defined below. The DISPLAY function pointer designates a function that is passed void and returns void. Its intent is to display data. The second pointer, COMPARE, represents a function used to compare data referenced by two pointers. The function should compare the data and return either a 0, –1, or 1, as explained with the compareEmployee function:
typedef void(*DISPLAY)(void*);
typedef int(*COMPARE)(void*, void*);
Single-Linked List
A linked list is a data structure that consists of a series of nodes interconnected with links. Typically, one node is called the head node and subsequent nodes follow the head, one after another. The last node is called the tail. The links connecting the nodes are easily implemented using a pointer. Each node can be dynamically allocated as needed.
This approach is preferable to an array of nodes. Using an array results in the creation of a fixed number of nodes regardless of how many nodes may be needed. Links are implemented using the index of the array’s elements. Using an array is not as flexible as using dynamic memory allocation and pointers.
For example, if we wanted to change the order of elements of the array, it would be necessary to copy both elements, and that can be large for a structure. In addition, adding or removing an element may require moving large portions of the array to make room for the new element or to remove an existing element.
There are several types of linked lists. The simplest is a single-linked list where there is a single link from one node to the next. The links start at the head and eventually leads to the tail. A circular-linked list has no tail. The linked list’s last node points back to the head. A doubly linked list uses two links, one pointing forward and one pointing backward so that you can navigate through the list in both directions. This type of linked list is more flexible but is more difficult to implement. Figure 6-5 conceptually illustrates these types of linked lists.
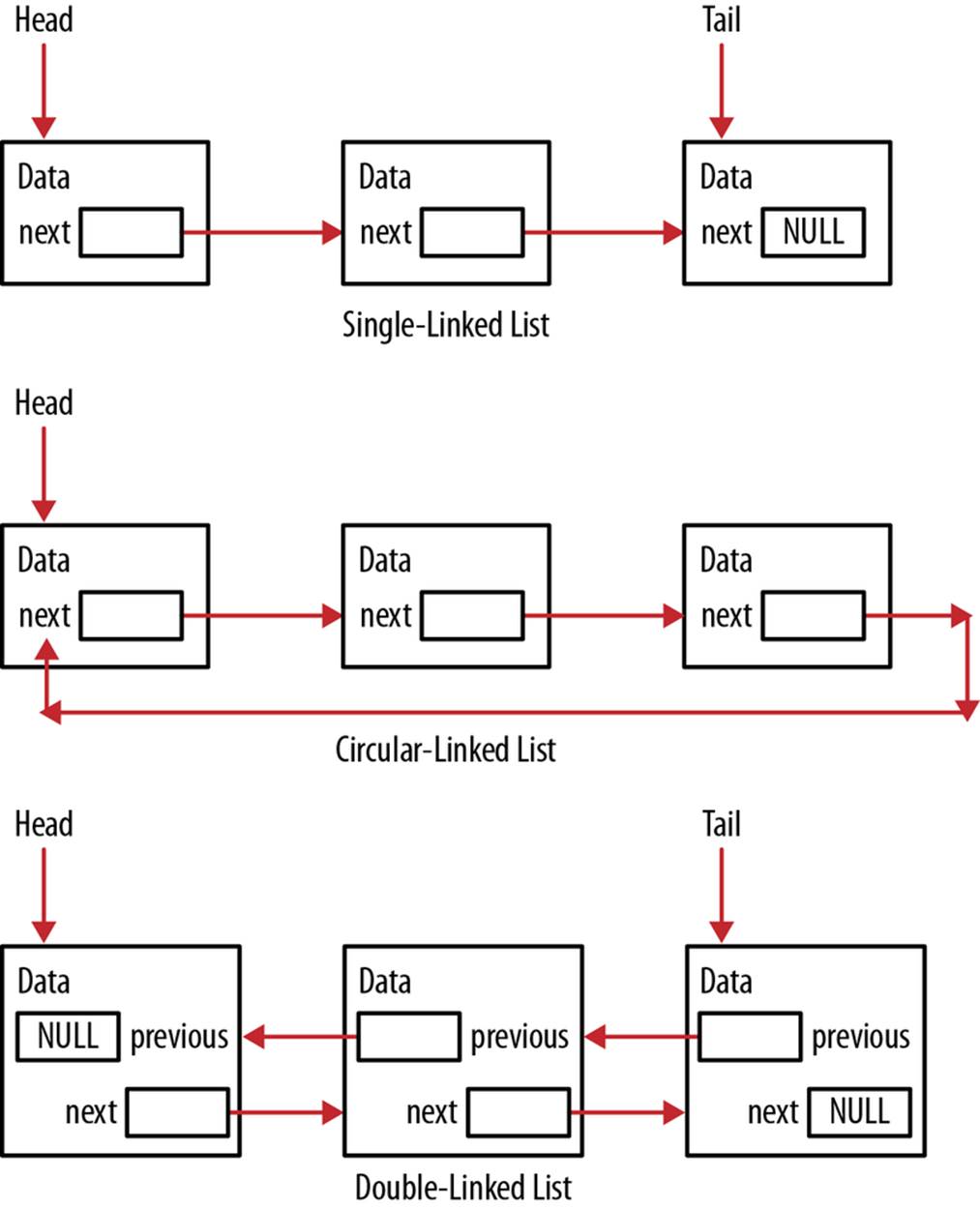
Figure 6-5. Linked list types
In this section, we will illustrate the construction and use of a single-linked list. The following shows the structure used to support the linked list. A Node structure is defined to represent a node. It consists of two pointers. The first one, a pointer to void, holds an arbitrary data type. The second is a pointer to the next node. The LinkedList structure represents the linked list and holds a pointer to the head and the tail. The current pointer will help traverse the linked list:
typedef struct _node {
void *data;
struct _node *next;
} Node;
typedef struct _linkedList {
Node *head;
Node *tail;
Node *current;
} LinkedList;
We will develop several functions that use these structures to support linked list functionality:
|
void initializeList(LinkedList*) |
Initializes the linked list |
|
void addHead(LinkedList*, void*) |
Adds data to the linked list’s head |
|
void addTail(LinkedList*, void*) |
Adds data to the linked list’s tail |
|
void delete(LinkedList*, Node*) |
Removes a node from the linked list |
|
Node *getNode(LinkedList*, COMPARE, void*) |
Returns a pointer to the node containing a specific data item |
|
void displayLinkedList(LinkedList*, DISPLAY) |
Displays the linked list |
Before the linked list can be used it needs to be initialized. The initializeList function, shown below, performs this task. A pointer to the LinkedList object is passed to the function where each pointer in the structure is set to NULL:
void initializeList(LinkedList *list) {
list->head = NULL;
list->tail = NULL;
list->current = NULL;
}
The addHead and addTail functions add data to the linked list’s head and tail, respectively. In this linked list implementation, the add and delete functions are responsible for allocating and freeing memory used by the linked list’s nodes. This removes this responsibility from the user of the linked list.
In the addHead function listed below, memory is first allocated for the node and the data passed to the function is assigned to the structure’s data field. By passing the data as a pointer to void, the linked list is able to hold any type of data the user wants to use.
Next, we check to see whether the linked list is empty. If so, we assign the tail pointer to the node and assign NULL to the node’s next field. If not, the node’s next pointer is assigned to the list’s head. Regardless, the list’s head is assigned to the node:
void addHead(LinkedList *list, void* data) {
Node *node = (Node*) malloc(sizeof(Node));
node->data = data;
if (list->head == NULL) {
list->tail = node;
node->next = NULL;
} else {
node->next = list->head;
}
list->head = node;
}
The following code sequence illustrates using the initializeList and addHead functions. Three employees are added to the list. Figure 6-6 shows how memory is allocated after these statements execute. Some arrows have been removed to simplify the diagram. In addition, theEmployee structure’s name array has been simplified:
LinkedList linkedList;
Employee *samuel = (Employee*) malloc(sizeof(Employee));
strcpy(samuel->name, "Samuel");
samuel->age = 32;
Employee *sally = (Employee*) malloc(sizeof(Employee));
strcpy(sally->name, "Sally");
sally->age = 28;
Employee *susan = (Employee*) malloc(sizeof(Employee));
strcpy(susan->name, "Susan");
susan->age = 45;
initializeList(&linkedList);
addHead(&linkedList, samuel);
addHead(&linkedList, sally);
addHead(&linkedList, susan);
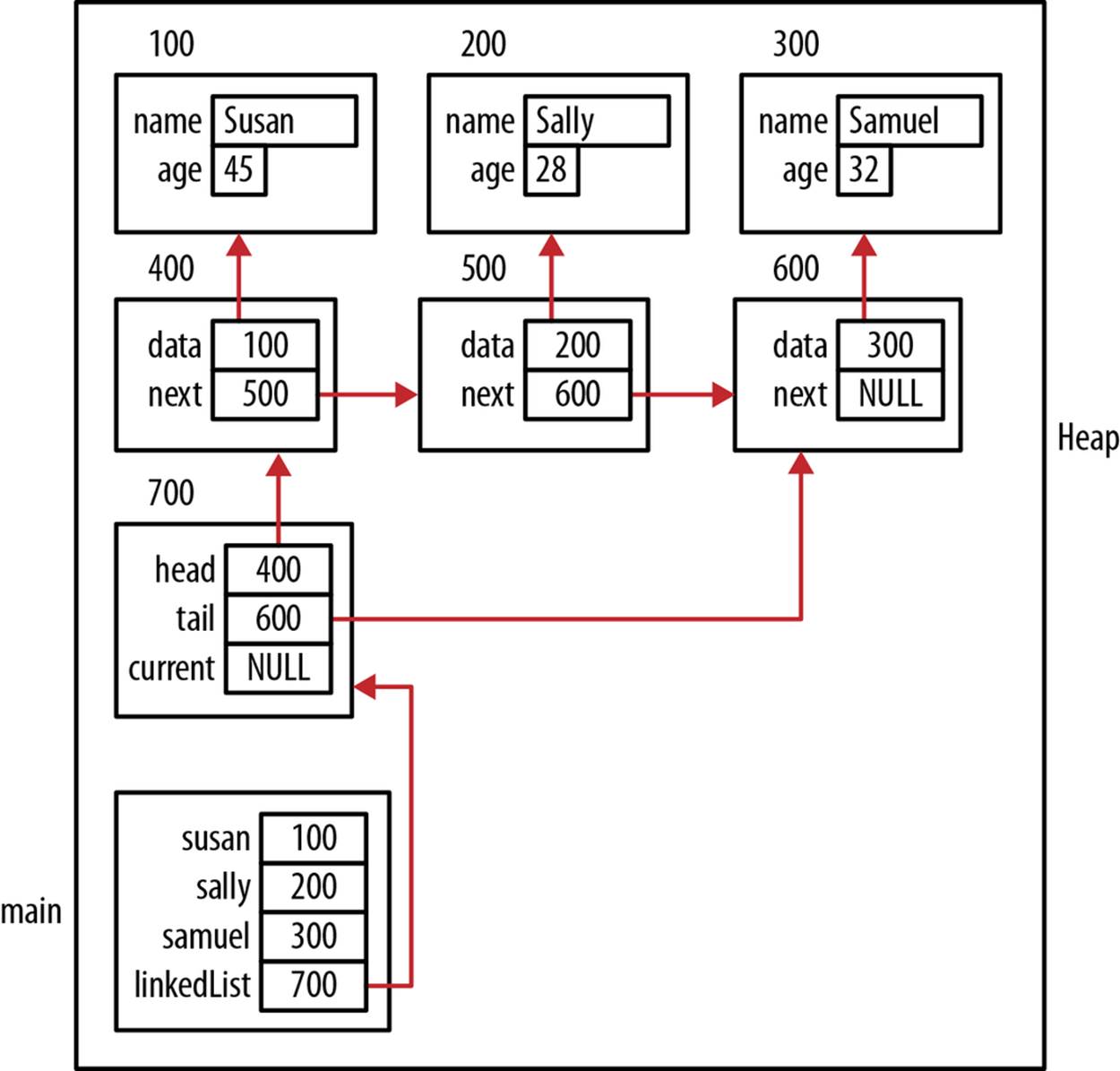
Figure 6-6. addHead example
The addTail function is shown below. It starts by allocating memory for a new node and assigning the data to the data field. Since the node will always be added to the tail, the node’s next field is assigned to NULL. If the linked list is empty, then the head pointer will be NULL and headcan be assigned to the new node. If it is not NULL, then the tail’s next pointer is assigned to the new node. Regardless, the linked list’s tail pointer is assigned to the node:
void addTail(LinkedList *list, void* data) {
Node *node = (Node*) malloc(sizeof(Node));
node->data = data;
node->next = NULL;
if (list->head == NULL) {
list->head = node;
} else {
list->tail->next = node;
}
list->tail = node;
}
In the following sequence, the addTail function is illustrated. The creation of the employee objects has not been duplicated here. The employees have been added in the opposite order from the previous example using the addTail function. This results in the memory allocation being the same as shown in Figure 6-6:
initializeList(&linkedList);
addTail(&linkedList, susan);
addTail(&linkedList, sally);
addTail(&linkedList, samuel);
The delete function will remove a node from the linked list. To simplify this function, a pointer to the node to be deleted is passed to it. The function’s user probably has a pointer to the data but not to the node holding the data. To aid in identifying the node, a helper function has been provided to return a pointer to the node: getNode. The getNode function is passed three parameters:
§ A pointer to the linked list
§ A pointer to a comparison function
§ A pointer to the data to be found
The code for the getNode function follows. The variable node initially points to the list’s head and traverses the list until either a match is found or the linked list’s end is encountered. The compare function is invoked to determine whether a match is found. When the two data items are equal, it returns a zero.
Node *getNode(LinkedList *list, COMPARE compare , void* data) {
Node *node = list->head;
while (node != NULL) {
if (compare(node->data, data) == 0) {
return node;
}
node = node->next;
}
return NULL;
}
The compare function illustrates using a function pointer at runtime to determine which function to use to perform a comparison. This adds considerable flexibility to the linked list implementation because we do not need to hard code the comparison function’s name in the getNodefunction.
The delete function follows. To keep the function simple, it does not always check for null values in the linked list or the node passed. The first if statement handles a node to be deleted from the head. If the head node is the only node, then the head and tail are assigned null values. Otherwise, the head is assigned to the node following the head.
The else statement traverses the list from head to tail using a tmp pointer. The while loop will terminate if either tmp is assigned NULL, indicating the node does not exist in the list, or the node following tmp is the node we are looking for. Since this is a single-linked list, we need to know which node precedes the target node to be deleted. This knowledge is needed to assign the node following the target node to the preceding node’s next field. At the end of the delete function, the node is freed. The user is responsible for deleting the data pointed to by this node before thedelete function is called.
void delete(LinkedList *list, Node *node) {
if (node == list->head) {
if (list->head->next == NULL) {
list->head = list->tail = NULL;
} else {
list->head = list->head->next;
}
} else {
Node *tmp = list->head;
while (tmp != NULL && tmp->next != node) {
tmp = tmp->next;
}
if (tmp != NULL) {
tmp->next = node->next;
}
}
free(node);
}
The next sequence demonstrates the use of this function. The three employees are added to the linked list’s head. We will use the compareEmployee function as described in the section Using Pointers to Support Data Structures to perform comparisons:
addHead(&linkedList, samuel);
addHead(&linkedList, sally);
addHead(&linkedList, susan);
Node *node = getNode(&linkedList,
(int (*)(void*, void*))compareEmployee, sally);
delete(&linkedList, node);
When this sequence executes, the program stack and heap will appear as illustrated in Figure 6-7.
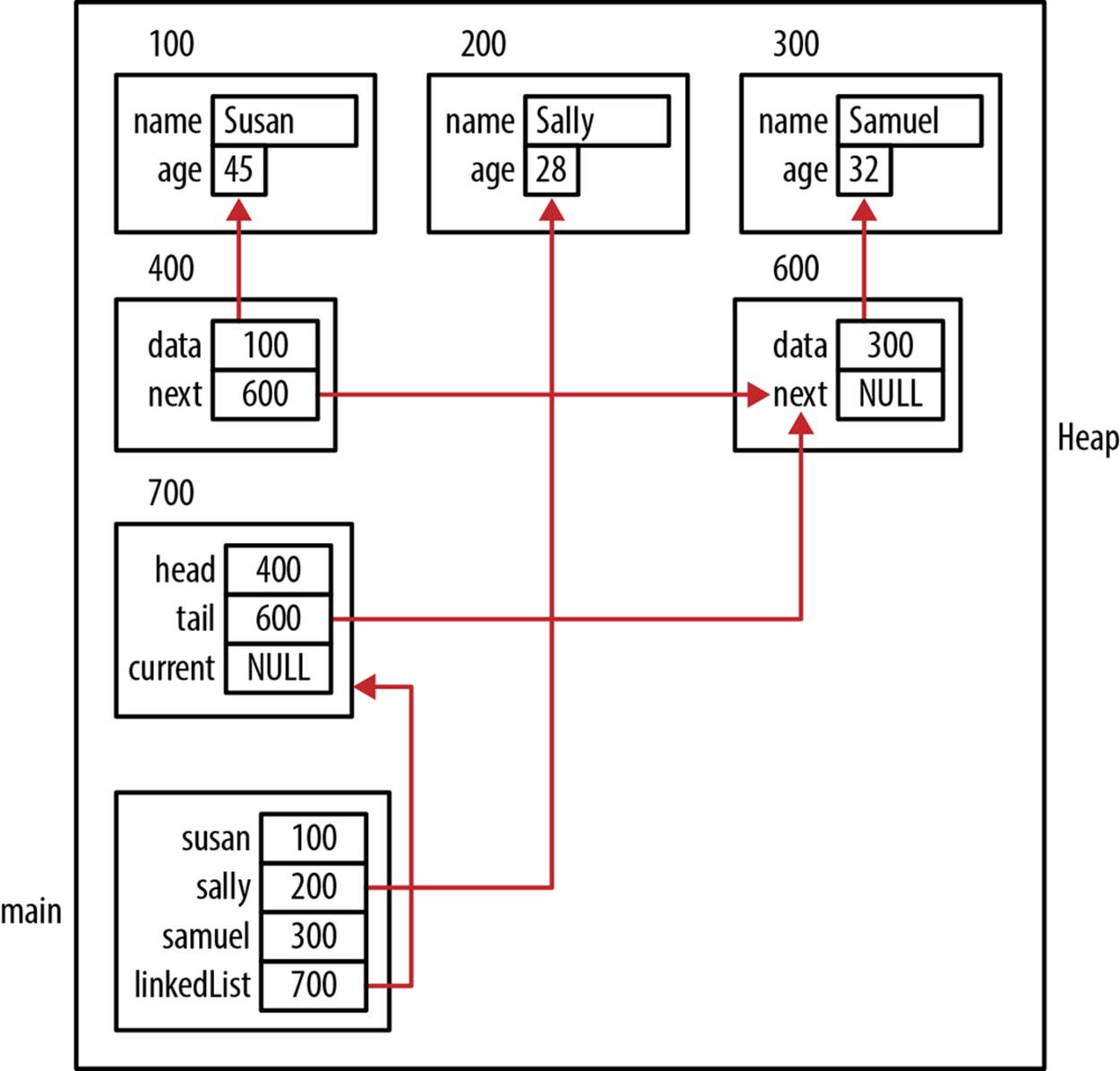
Figure 6-7. Deletion example
The displayLinkedList function illustrates how to traverse a linked list as shown below. It starts at the head and displays each element using the function passed as the second argument. The node pointer is assigned the next field’s value and will terminate when the last node is displayed:
void displayLinkedList(LinkedList *list, DISPLAY display) {
printf("\nLinked List\n");
Node *current = list->head;
while (current != NULL) {
display(current->data);
current = current->next;
}
}
The following illustrates this function using the displayEmployee function developed in the section Using Pointers to Support Data Structures:
addHead(&linkedList, samuel);
addHead(&linkedList, sally);
addHead(&linkedList, susan);
displayLinkedList(&linkedList, (DISPLAY)displayEmployee);
The output of this sequence follows:
Linked List
Susan 45
Sally 28
Samuel 32
Using Pointers to Support a Queue
A queue is a linear data structure whose behavior is similar to a waiting line. It typically supports two primary operations: enqueue and dequeue. The enqueue operation adds an element to the queue. The dequeue operation removes an element from the queue. Normally, the first element added to a queue is the first element dequeued from a queue. This behavior is referred to as First-In-First-Out (FIFO).
A linked list is frequently used to implement a queue. The enqueue operation will add a node to the linked list’s head and the dequeue operation will remove a node from the tail. To illustrate the queue, we will use the linked list developed in the Single-Linked List.
Let’s start by using a type definition statement to define a term for queue. It will be based on a linked list as shown below. We can now use Queue to clearly designate our intent:
typedef LinkedList Queue;
To implement the initialization operation, all we need to do is use the function initializeList. Instead of calling this function directly, we will use the following initializeQueue function:
void initializeQueue(Queue *queue) {
initializeList(queue);
}
In a similar manner, the following will add a node to a queue using the addHead function:
void enqueue(Queue *queue, void *node) {
addHead(queue, node);
}
The previous linked list implementation does not have an explicit function to remove the tail node. The dequeue function that follows removes the last node. Three conditions are handled:
An empty queue
NULL is returned
A single node queue
Handled by the else if statement
A multiple node queue
Handled by the else clause
In the latter case, the tmp pointer is advanced node by node until it points to the node immediately preceding the tail node. Three operations are then performed in the following sequence:
1. The tail is assigned to the tmp node
2. The tmp pointer is advanced to the next node
3. The tail’s next field is set to NULL to indicate there are no more nodes in the queue
This order is necessary to ensure the list’s integrity, as illustrated conceptually in Figure 6-8. The circled numbers correspond to the three steps listed above:
void *dequeue(Queue *queue) {
Node *tmp = queue->head;
void *data;
if (queue->head == NULL) {
data = NULL;
} else if (queue->head == queue->tail) {
queue->head = queue->tail = NULL;
data = tmp->data;
free(tmp);
} else {
while (tmp->next != queue->tail) {
tmp = tmp->next;
}
queue->tail = tmp;
tmp = tmp->next;
queue->tail->next = NULL;
data = tmp->data;
free(tmp);
}
return data;
}
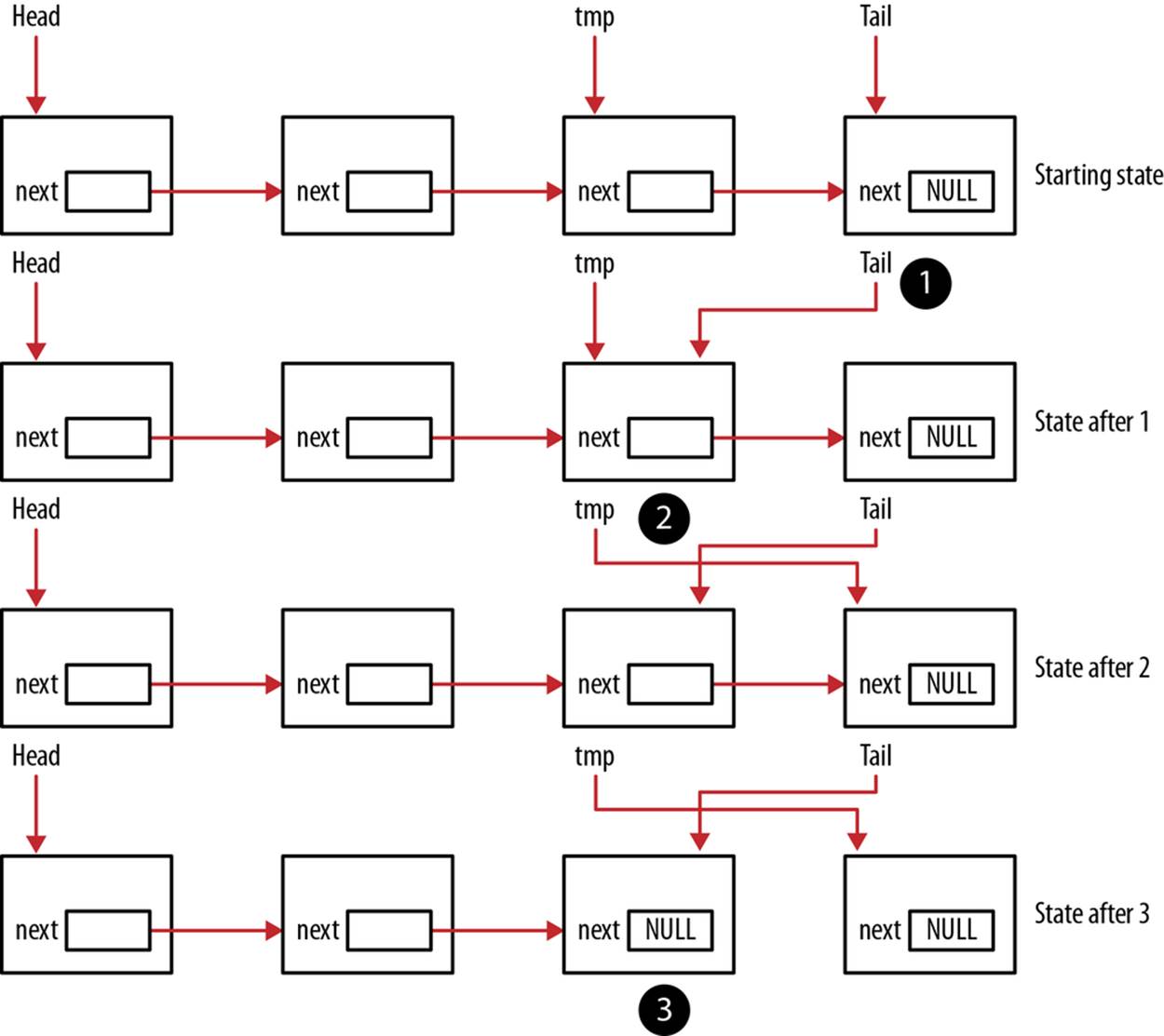
Figure 6-8. dequeue function example
The data assigned to the node is returned, and the node is freed. These functions are illustrated in the following code sequence using the employees created earlier:
Queue queue;
initializeQueue(&queue);
enqueue(&queue, samuel);
enqueue(&queue, sally);
enqueue(&queue, susan);
void *data = dequeue(&queue);
printf("Dequeued %s\n", ((Employee*) data)->name);
data = dequeue(&queue);
printf("Dequeued %s\n", ((Employee*) data)->name);
data = dequeue(&queue);
printf("Dequeued %s\n", ((Employee*) data)->name);
The output of this sequence follows:
Dequeued Samuel
Dequeued Sally
Dequeued Susan
Using Pointers to Support a Stack
The stack data structure is also a type of list. In this case, elements are pushed onto the stack’s top and then popped off. When multiple elements are pushed and then popped, the stack exhibits First-In-Last-Out (FILO) behavior. The first element pushed on to the stack is the last element popped off.
Like the queue’s implementation, we can use a linked list to support stack operations. The two most common operations are the push and pop operations. The push operation is effected using the addHead function. The pop operation requires adding a new function to remove the head node. We start by defining a stack in terms of a linked list as follows:
typedef LinkedList Stack;
To initialize the stack, we add an initializeStack function. This function calls the initializeList function:
void initializeStack(Stack *stack) {
initializeList(stack);
}
The push operation calls the addHead function as shown below:
void push(Stack *stack, void* data) {
addHead(stack, data);
}
The pop operation’s implementation follows. We start by assigning the stack’s head to a node pointer. It involves handling three conditions:
The stack is empty
The function returns NULL
The stack contains a single element
If the node points to the tail then the head and tail are the same element. The head and tail are assigned NULL, and the data is returned.
The stack contains more than one element
In this case, the head is assigned to the next element in the list, and the data is returned.
In the latter two cases, the node is freed:
void *pop(Stack *stack) {
Node *node = stack->head;
if (node == NULL) {
return NULL;
} else if (node == stack->tail) {
stack->head = stack->tail = NULL;
void *data = node->data;
free(node);
return data;
} else {
stack->head = stack->head->next;
void *data = node->data;
free(node);
return data;
}
}
We will reuse the employees’ instances created in the section Single-Linked List to demonstrate the stack. The following code sequence will push three employees and then pop them off the stack:
Stack stack;
initializeStack(&stack);
push(&stack, samuel);
push(&stack, sally);
push(&stack, susan);
Employee *employee;
for(int i=0; i<4; i++) {
employee = (Employee*) pop(&stack);
printf("Popped %s\n", employee->name);
}
When executed, we get the following output. Because we used the pop function four times, NULL was returned the last time:
Popped Susan
Popped Sally
Popped Samuel
Popped (null)
Other stack operations sometime include a peek operation where the top element is returned but is not popped off the stack.
Using Pointers to Support a Tree
The tree is a very useful data structure whose name is derived from the relationship between its elements. Typically, child nodes are attached to a parent node. The overall form is an inverted tree where a root node represents the data structure’s starting element.
A tree can have any number of children nodes. However, binary trees are more common where each node possesses zero, one, or two children nodes. The children are designated as either the left child or the right child. Nodes with no children are called leaf nodes, similar to the leaves of a tree. The examples presented in this section will illustrate a binary tree.
Pointers provide an obvious and dynamic way of maintaining the relationship between tree nodes. Nodes can be dynamically allocated and added to a tree as needed. We will use the following structure for a node. Using a pointer to void allows us to handle any type of data that we need:
typedef struct _tree {
void *data;
struct _tree *left;
struct _tree *right;
} TreeNode;
When we add nodes to a tree, it makes sense to add them in a particular order. This will make many operations, such as searching, easier. A common ordering is to add a new node to a tree such that all of the node’s children possess a value less than the parent node and all of the children on the right possess a value greater than the parent node. This is called a binary search tree.
The following insertNode function will insert a node into a binary search tree. However, to insert a node, a comparison needs to be performed between the new node and the tree’s existing nodes. We use the COMPARE function pointer to pass the comparison function’s address. The first part of the function allocates memory for a new node and assigns the data to the node. The left and right children are set to NULL since new nodes are always added as leaves to a tree:
void insertNode(TreeNode **root, COMPARE compare, void* data) {
TreeNode *node = (TreeNode*) malloc(sizeof(TreeNode));
node->data = data;
node->left = NULL;
node->right = NULL;
if (*root == NULL) {
*root = node;
return;
}
while (1) {
if (compare((*root)->data, data) > 0) {
if ((*root)->left != NULL) {
*root = (*root)->left;
} else {
(*root)->left = node;
break;
}
} else {
if ((*root)->right != NULL) {
*root = (*root)->right;
} else {
(*root)->right = node;
break;
}
}
}
}
First, the root is checked to determine whether the tree is empty. If it is, then a new node is assigned to the root and the function returns. The root is passed as a pointer to a pointer to a TreeNode. This is necessary because we want to modify the pointer passed to the function, not what the pointer points to. This use of two levels of indirection is detailed in Multiple Levels of Indirection.
If the tree is not empty, then an infinite loop is entered and will terminate when the new node has been added to the tree. With each loop’s iteration, the new node and current parent node are compared. On the basis of this comparison, the local root pointer will be reassigned to either the left or right child. This root pointer points to the current node in the tree. If the left or right child is NULL, then the node is added as a child and the loop terminates.
To demonstrate insertNode function, we will reuse the employee instances created in the section Using Pointers to Support Data Structures. The following sequence initializes an empty TreeNode and then inserts the three employees. The resulting program stack’s and heap’s state is illustrated in Figure 6-9. Some lines pointing to the employees have been removed to simplify the diagram. The nodes’ placement in the heap have also been arranged to reflect the tree structure’s order:
TreeNode *tree = NULL;
insertNode(&tree, (COMPARE) compareEmployee, samuel);
insertNode(&tree, (COMPARE) compareEmployee, sally);
insertNode(&tree, (COMPARE) compareEmployee, susan);
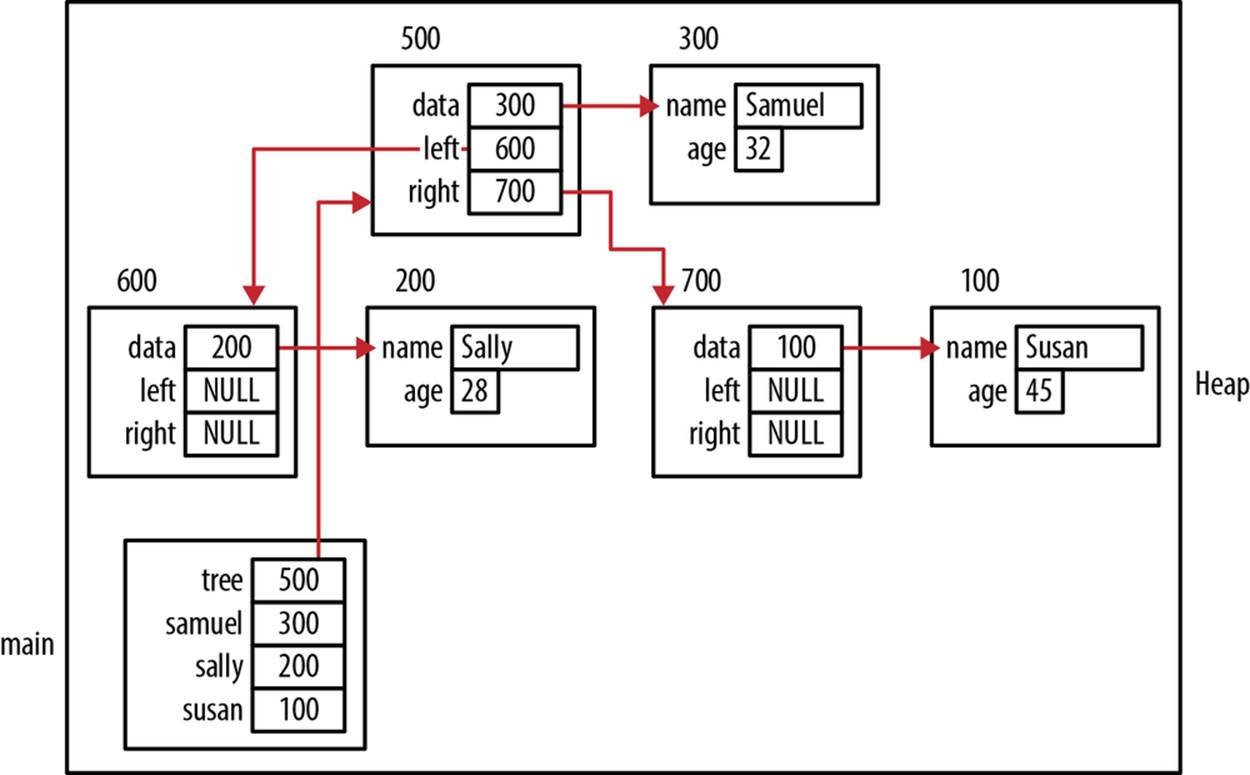
Figure 6-9. insertNode function
Figure 6-10 illustrates the logical structure of this tree.
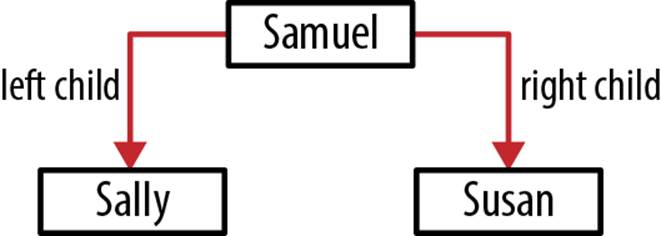
Figure 6-10. Logical tree organization
Binary trees are used for a number of purposes and can be traversed in three different ways: pre-order, in-order, and post-order. The three techniques use the same steps, but they are performed in different orders. The three steps are:
Visit the node
Process the node
Go left
Transfer to the left node
Go right
Transfer to the right node
For our purposes, visiting a node means we will display its contents. The three orders are:
In-order
Go left, visit the node, go right
Pre-order
Visit the node, go left, go right
Post-order
Go left, go right, visit the node
The functions’ implementations are shown below. Each passes the tree’s root and a function pointer for the display function. They are recursive and will call themselves as long as the root node passed to it is not null. They only differ in the order the three steps are executed:
void inOrder(TreeNode *root, DISPLAY display) {
if (root != NULL) {
inOrder(root->left, display);
display(root->data);
inOrder(root->right, display);
}
}
void postOrder(TreeNode *root, DISPLAY display) {
if (root != NULL) {
postOrder(root->left, display);
postOrder(root->right, display);
display(root->data);
}
}
void preOrder(TreeNode *root, DISPLAY display) {
if (root != NULL) {
display(root->data);
preOrder(root->left, display);
preOrder(root->right, display);
}
}
The following code sequence invokes these functions:
preOrder(tree, (DISPLAY) displayEmployee);
inOrder(tree, (DISPLAY) displayEmployee);
postOrder(tree, (DISPLAY) displayEmployee);
Table 6-1 shows the output of each function call based on the previous initialization of the tree.
Table 6-1. Traversal techniques
|
pre-order |
Samuel 32 Sally 28 Susan 45 |
|
in-order |
Sally 28 Samuel 32 Susan 45 |
|
post-order |
Sally 28 Susan 45 Samuel 32 |
The in-order traversal will return a sorted list of the tree’s members. The pre-order and post-order traversal can be used to evaluate arithmetic expressions when used in conjunction with a stack and queue.
Summary
The power and flexibility of pointers is exemplified when used to create and support data structures. Combined with dynamic memory allocation of structures, pointers enable the creation of data structures that use memory efficiently and can grow and shrink to meet the application’s needs.
We started this chapter with a discussion of how memory is allocated for structures. Padding between the field’s structures and between arrays of structures is possible. Dynamic memory allocation and deallocation can be expensive. We examined one technique to maintain a pool of structures to minimize this overhead.
We also demonstrated the implementation of several commonly used data structures. The linked list was used to support several of these data structures. Function pointers were used to add flexibility to these implementations by allowing the comparison or display function to be determined at runtime.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.