Programming: Principles and Practice Using C++ (2014)
Part II: Input and Output
10. Input and Output Streams
“Science is what we have learned about how to keep from fooling ourselves.”
—Richard P. Feynman
In this chapter and the next, we present the C++ standard library facilities for handling input and output from a variety of sources: I/O streams. We show how to read and write files, how to deal with errors, how to deal with formatted input, and how to provide and use I/O operators for user-defined types. This chapter focuses on the basic model: how to read and write individual values, and how to open, read, and write whole files. The final example illustrates the kinds of considerations that go into a larger piece of code. The next chapter addresses details.
10.1 Input and output
10.2 The I/O stream model
10.3 Files
10.4 Opening a file
10.5 Reading and writing a file
10.6 I/O error handling
10.7 Reading a single value
10.7.1 Breaking the problem into manageable parts
10.7.2 Separating dialog from function
10.8 User-defined output operators
10.9 User-defined input operators
10.10 A standard input loop
10.11 Reading a structured file
10.11.1 In-memory representation
10.11.2 Reading structured values
10.11.3 Changing representations
10.1 Input and output
![]()
Without data, computing is pointless. We need to get data into our program to do interesting computations and we need to get the results out again. In §4.1, we mentioned the bewildering variety of data sources and targets for output. If we don’t watch out, we’ll end up writing programs that can receive input only from a specific source and deliver output only to a specific output device. That may be acceptable (and sometimes even necessary) for specialized applications, such as a digital camera or a sensor for an engine fuel injector, but for more common tasks, we need a way to separate the way our program reads and writes from the actual input and output devices used. If we had to directly address each kind of device, we’d have to change our program each time a new screen or disk came on the market, or limit our users to the screens and disks we happen to like. That would be absurd.
Most modern operating systems separate the detailed handling of I/O devices into device drivers, and programs then access the device drivers through an I/O library that makes I/O from/to different sources appear as similar as possible. Generally, the device drivers are deep in the operating system where most users don’t see them, and the I/O library provides an abstraction of I/O so that the programmer doesn’t have to think about devices and device drivers:
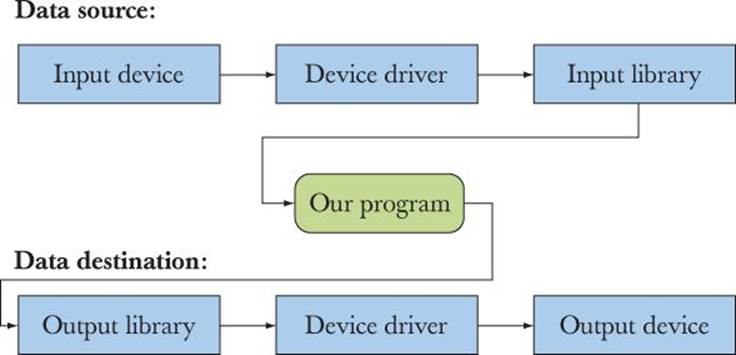
When a model like this is used, input and output can be seen as streams of bytes (characters) handled by the input/output library. More complex forms of I/O require specialized expertise and are beyond the scope of this book. Our job as programmers of an application then becomes
1. To set up I/O streams to the appropriate data sources and destinations
2. To read and write from/to those streams
The details of how our characters are actually transmitted to/from the devices are dealt with by the I/O library and the device drivers. In this chapter and the next, we’ll see how I/O consisting of streams of formatted data is done using the C++ standard library.
From the programmer’s point of view there are many different kinds of input and output. One classification is
![]()
• Streams of (many) data items (usually to/from files, network connections, recording devices, or display devices)
• Interactions with a user at a keyboard
• Interactions with a user through a graphical interface (outputting objects, receiving mouse clicks, etc.)
This classification isn’t the only classification possible, and the distinction between the three kinds of I/O isn’t as clear as it might appear. For example, if a stream of output characters happens to be an HTTP document aimed at a browser, the result looks remarkably like user interaction and can contain graphical elements. Conversely, the results of interactions with a GUI (graphical user interface) may be presented to a program as a sequence of characters. However, this classification fits our tools: the first two kinds of I/O are provided by the C++ standard library I/O streams and supported rather directly by most operating systems. We have been using the iostream library since Chapter 1 and will focus on that for this and the next chapter. The graphical output and graphical user interactions are served by a variety of different libraries, and we will focus on that kind of I/O in Chapters 12 to 16.
10.2 The I/O stream model
The C++ standard library provides the type istream to deal with streams of input and the type ostream to deal with streams of output. We have used the standard istream called cin and the standard ostream called cout, so we know the basics of how to use this part of the standard library (usually called the iostream library).
An ostream
![]()
• Turns values of various types into character sequences
• Sends those characters “somewhere” (such as to a console, a file, the main memory, or another computer)
We can represent an ostream graphically like this:
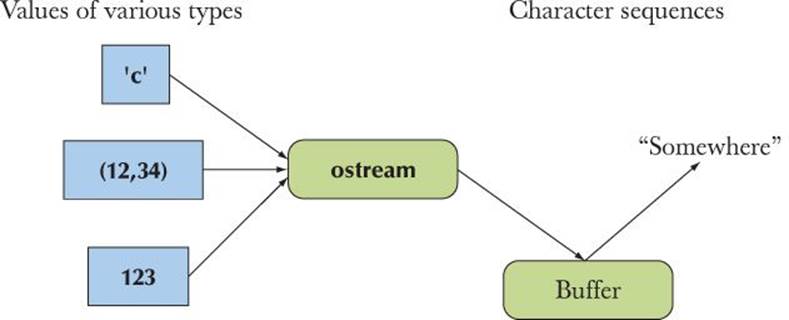
The buffer is a data structure that the ostream uses internally to store the data you give it while communicating with the operating system. If you notice a “delay” between your writing to an ostream and the characters appearing at their destination, it’s usually because they are still in the buffer. Buffering is important for performance, and performance is important if you deal with large amounts of data.
![]()
An istream
• Turns character sequences into values of various types
• Gets those characters from somewhere (such as a console, a file, the main memory, or another computer)
We can represent an istream graphically like this:
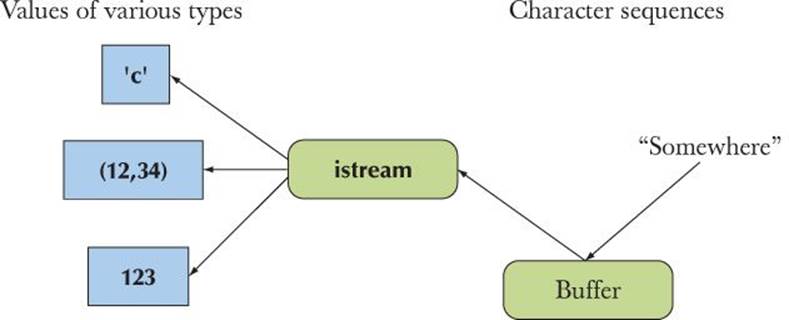
As with an ostream, an istream uses a buffer to communicate with the operating system. With an istream, the buffering can be quite visible to the user. When you use an istream that is attached to a keyboard, what you type is left in the buffer until you hit Enter (return/newline), and you can use the erase (Backspace) key “to change your mind” (until you hit Enter).
One of the major uses of output is to produce data for humans to read. Think of email messages, scholarly articles, web pages, billing records, business reports, contact lists, tables of contents, equipment status readouts, etc. Therefore, ostreams provide many features for formatting text to suit various tastes. Similarly, much input is written by humans or is formatted to make it easy for humans to read it. Therefore, istreams provide features for reading the kind of output produced by ostreams. We’ll discuss formatting in §11.2 and how to read non-character input in §11.3.2. Most of the complexity related to input has to do with how to handle errors. To be able to give more realistic examples, we’ll start by discussing how the iostream model relates to files of data.
10.3 Files
We typically have much more data than can fit in the main memory of our computer, so we store most of it on disks or other large-capacity storage devices. Such devices also have the desirable property that data doesn’t disappear when the power is turned off — the data is persistent. At the most basic level, a file is simply a sequence of bytes numbered from 0 upward:
![]()

A file has a format; that is, it has a set of rules that determine what the bytes mean. For example, if we have a text file, the first 4 bytes will be the first four characters. On the other hand, if we have a file that uses a binary representation of integers, those very same first 4 bytes will be taken to be the (binary) representation of the first integer (see §11.3.2). The format serves the same role for files on disk as types serve for objects in main memory. We can make sense of the bits in a file if (and only if) we know its format (see §11.2-3).
For a file, an ostream converts objects in main memory into streams of bytes and writes them to disk. An istream does the opposite; that is, it takes a stream of bytes from disk and composes objects from them:
![]()
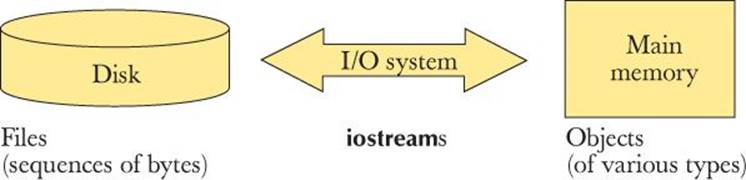
Most of the time, we assume that these “bytes on disk” are in fact characters in our usual character set. That is not always so, but we can get an awfully long way with that assumption, and other representations are not that hard to deal with. We also talk as if all files were on disks (that is, on rotating magnetic storage). Again, that’s not always so (think of flash memory), but at this level of programming the actual storage makes no difference. That’s one of the beauties of the file and stream abstractions.
To read a file, we must
1. Know its name
2. Open it (for reading)
3. Read in the characters
4. Close it (though that is typically done implicitly)
To write a file, we must
1. Name it
2. Open it (for writing) or create a new file of that name
3. Write out our objects
4. Close it (though that is typically done implicitly)
We already know the basics of reading and writing because an ostream attached to a file behaves exactly as cout for what we have done so far, and an istream attached to a file behaves exactly as cin for what we have done so far. We’ll present operations that can only be done for files later (§11.3.3), but for now we’ll just see how to open files and then concentrate on operations and techniques that apply to all ostreams and all istreams.
10.4 Opening a file
If you want to read from a file or write to a file you have to open a stream specifically for that file. An ifstream is an istream for reading from a file, an ofstream is an ostream for writing to a file, and an fstream is an iostream that can be used for both reading and writing. Before a file stream can be used it must be attached to a file. For example:
![]()
cout << "Please enter input file name: ";
string iname;
cin >> iname;
ifstream ist {iname}; // ist is an input stream for the file named name
if (!ist) error("can't open input file ",iname);
Defining an ifstream with a name string opens the file of that name for reading. The test of !ist checks if the file was properly opened. After that, we can read from the file exactly as we would from any other istream. For example, assuming that the input operator, >>, was defined for a typePoint, we could write
![]()
vector<Point> points;
for (Point p; ist>>p; )
points.push_back(p);
Output to files is handled in a similar fashion by ofstreams. For example:
cout << "Please enter name of output file: ";
string oname;
cin >> oname;
ofstream ost {oname}; // ost is an output stream for a file named oname
if (!ost) error("can't open output file ",oname);
Defining an ofstream with a name string opens the file with that name for writing. The test of !ost checks if the file was properly opened. After that, we can write to the file exactly as we would to any other ostream. For example:
for (int p : points)
ost << '(' << p.x << ',' << p.y << ")\n";
When a file stream goes out of scope its associated file is closed. When a file is closed its associated buffer is “flushed”; that is, the characters from the buffer are written to the file.
It is usually best to open files early in a program before any serious computation has taken place. After all, it is a waste to do a lot of work just to find that we can’t complete it because we don’t have anywhere to write our results.
Opening the file implicitly as part of the creation of an ostream or an istream and relying on the scope of the stream to take care of closing the file is the ideal. For example:
void fill_from_file(vector<Point>& points, string& name)
{
ifstream ist {name}; // open file for reading
if (!ist) error("can't open input file ",name);
// . . . use ist . . .
// the file is implicitly closed when we leave the function
}
![]()
You can also perform explicit open() and close() operations (§B.7.1). However, relying on scope minimizes the chances of someone trying to use a file stream before it has been attached to a stream or after it was closed. For example:
ifstream ifs;
// . . .
ifs >> foo; // won’t succeed: no file opened for ifs
// . . .
ifs.open(name,ios_base::in); // open file named name for reading
// . . .
ifs.close(); // close file
// . . .
ifs >> bar; // won’t succeed: ifs’ file was closed
// . . .
In real-world code the problems would typically be much harder to spot. Fortunately, you can’t open a file stream a second time without first closing it. For example:
fstream fs;
fs.open("foo", ios_base::in) ; // open for input
// close() missing
fs.open("foo", ios_base::out); // won’t succeed: fs is already open
if (!fs) error("impossible");
Don’t forget to test a stream after opening it.
Why would you use open() or close() explicitly? Well, occasionally the lifetime of a connection to a file isn’t conveniently limited by a scope so you have to. But that’s rare enough for us not to have to worry about it here. More to the point, you’ll find such use in code written by people using styles from languages and libraries that don’t have the scoped idiom used by iostreams (and the rest of the C++ standard library).
As we’ll see in Chapter 11, there is much more to files, but for now we know enough to use them as a data source and a destination for data. That’ll allow us to write programs that would be unrealistic if we assumed that a user had to directly type in all the input. From a programmer’s point of view, a great advantage of a file is that you can repeatedly read it during debugging until your program works correctly.
10.5 Reading and writing a file
Consider how you might read a set of results of some measurements from a file and represent them in memory. These might be the temperature readings from a weather station:
0 60.7
1 60.6
2 60.3
3 59.22
. . .
This data file contains a sequence of (hour,temperature) pairs. The hours are numbered 0 to 23 and the temperatures are in Fahrenheit. No further formatting is assumed; that is, the file does not contain any special header information (such as where the reading was taken), units for the values, punctuation (such as parentheses around each pair of values), or termination indicator. This is the simplest case.
We could represent a temperature reading by a Reading type:
struct Reading { // a temperature reading
int hour; // hour after midnight [0:23]
double temperature; // in Fahrenheit
};
Given that, we could read like this:
vector<Reading> temps; // store the readings here
int hour;
double temperature;
while (ist >> hour >> temperature) {
if (hour < 0 || 23 <hour) error("hour out of range");
temps.push_back(Reading{hour,temperature});
}
This is a typical input loop. The istream called ist could be an input file stream (ifstream) as shown in the previous section, (an alias for) the standard input stream (cin), or any other kind of istream. For code like this, it doesn’t matter exactly from where the istream gets its data. All that our program cares about is that ist is an istream and that the data has the expected format. The next section addresses the interesting question of how to detect errors in the input data and what we can do after detecting a format error.
Writing to a file is usually simpler than reading from one. Again, once a stream is initialized we don’t have to know exactly what kind of stream it is. In particular, we can use the output file stream (ofstream) from the section above just like any other ostream. For example, we might want to output the readings with each pair of values in parentheses:
for (int i=0; i<temps.size(); ++i)
ost << '(' << temps[i].hour << ',' << temps[i].temperature << ")\n";
The resulting program would then be reading the original temperature reading file and producing a new file with the data in (hour,temperature) format.
![]()
Because the file streams automatically close their files when they go out of scope, the complete program becomes
#include "std_lib_facilities.h"
struct Reading { // a temperature reading
int hour; // hour after midnight [0:23]
double temperature; // in Fahrenheit
};
int main()
{
cout << "Please enter input file name: ";
string iname;
cin >> iname;
ifstream ist {iname}; // ist reads from the file named iname
if (!ist) error("can't open input file ",iname);
string oname;
cout << "Please enter name of output file: ";
cin >> oname;
ofstream ost {oname}; // ost writes to a file named oname
if (!ost) error("can't open output file ",oname);
vector<Reading> temps; // store the readings here
int hour;
double temperature;
while (ist >> hour >> temperature) {
if (hour < 0 || 23 <hour) error("hour out of range");
temps.push_back(Reading{hour,temperature});
}
for (int i=0; i<temps.size(); ++i)
ost << '(' << temps[i].hour << ','
<< temps[i].temperature << ")\n";
}
10.6 I/O error handling
When dealing with input we must expect errors and deal with them. What kind of errors? And how? Errors occur because humans make mistakes (misunderstanding instructions, mistyping, letting the cat walk on the keyboard, etc.), because files fail to meet specifications, because we (as programmers) have the wrong expectations, etc. The possibilities for input errors are limitless! However, an istream reduces all to four possible cases, called the stream state:

Unfortunately, the distinction between fail() and bad() is not precisely defined and subject to varying opinions among programmers defining I/O operations for new types. However, the basic idea is simple: If an input operation encounters a simple format error, it lets the stream fail(), assuming that you (the user of our input operation) might be able to recover. If, on the other hand, something really nasty, such as a bad disk read, happens, the input operation lets the stream go bad(), assuming that there is nothing much you can do except to abandon the attempt to get data from that stream. A stream that is bad() is also fail(). This leaves us with this general logic:
![]()
int i = 0;
cin >> i;
if (!cin) { // we get here (only) if an input operation failed
if (cin.bad()) error("cin is bad"); // stream corrupted: let’s get out of here!
if (cin.eof()) {
// no more input
// this is often how we want a sequence of input operations to end
}
if (cin.fail()) { // stream encountered something unexpected
cin.clear(); // make ready for more input
// somehow recover
}
}
The !cin can be read as “cin is not good” or “Something went wrong with cin” or “The state of cin is not good().” It is the opposite of “The operation succeeded.” Note the cin.clear() where we handle fail(). When a stream has failed, we might be able to recover. To try to recover, we explicitly take the stream out of the fail() state, so that we can look at characters from it again; clear() does that — after cin.clear() the state of cin is good().
Here is an example of how we might use the stream state. Consider how to read a sequence of integers that may be terminated by the character * or an “end of file” (Ctrl+Z on Windows, Ctrl+D on Unix) into a vector. For example:
1 2 3 4 5 *
This could be done using a function like this:
void fill_vector(istream& ist, vector<int>& v, char terminator)
// read integers from ist into v until we reach eof() or terminator
{
for (int I; ist >> I; ) v.push_back(i);
if (ist.eof()) return; // fine: we found the end of file
if (ist.bad()) error("ist is bad"); // stream corrupted; let’s get out of here!
if (ist.fail()) { // clean up the mess as best we can and report the problem
ist.clear(); // clear stream state,
// so that we can look for terminator
char c;
ist>>c; // read a character, hopefully terminator
if (c != terminator) { // unexpected character
ist.unget(); // put that character back
ist.clear(ios_base::failbit); // set the state to fail()
}
}
}
Note that when we didn’t find the terminator, we still returned. After all, we may have collected some data and the caller of fill_vector() may be able to recover from a fail(). Since we cleared the state to be able to examine the character, we have to set the stream state back to fail(). We do that with ist.clear(ios_base::failbit). Note this potentially confusing use of clear(): clear() with an argument actually sets the iostream state flags (bits) mentioned and (only) clears flags not mentioned. By setting the state to fail(), we indicate that we encountered a format error, rather than something more serious. We put the character back into ist using unget(); the caller of fill_vector() might have a use for it. The unget() function is a shorter version of putback() (§6.8.2, §B.7.3) that relies on the stream remembering which character it last produced, so that you don’t have to mention it.
If you called fill_vector() and want to know what terminated the read, you can test for fail() and eof(). You could also catch the runtime_error exception thrown by error(), but it is understood that getting more data from istream in the bad() state is unlikely. Most callers won’t bother. This implies that in almost all cases the only thing we want to do if we encounter bad() is to throw an exception. To make life easier, we can tell an istream to do that for us:
![]()
// make ist throw if it goes bad
ist.exceptions(ist.exceptions()|ios_base::badbit);
The notation may seem odd, but the effect is simply that from that statement onward, ist will throw the standard library exception ios_base::failure if it goes bad(). We need to execute that exceptions() call only once in a program. That’ll allow us to simplify all input loops on ist by ignoringbad():
void fill_vector(istream& ist, vector<int>& v, char terminator)
// read integers from ist into v until we reach eof() or terminator
{
for (int I; ist >> I; ) v.push_back(i);
if (ist.eof()) return; // fine: we found the end of file
// not good() and not bad() and not eof(), ist must be fail()
ist.clear(); // clear stream state
char c;
ist>>c; // read a character, hopefully terminator
if (c != terminator) { // ouch: not the terminator, so we must fail
ist.unget(); // maybe my caller can use that character
ist.clear(ios_base::failbit); // set the state to fail()
}
}
The ios_base that appears here and there is the part of an iostream that holds constants such as badbit, exceptions such as failure, and other useful stuff. You refer to them using the :: operator, for example, ios_base::badbit (§B.7.2). We don’t plan to go into the iostream library in that much detail; it could take a whole course to explain all of iostreams. For example, iostreams can handle different character sets, implement different buffering strategies, and also contain facilities for formatting monetary amounts in various languages; we once had a bug report relating to the formatting of Ukrainian currency. You can read up on whatever bits you need to know about if you need to; see The C++ Programming Language by Stroustrup and Standard C++ IOStreams and Locales by Langer.
You can test an ostream for exactly the same states as an istream: good(), fail(), eof(), and bad(). However, for the kinds of programs we write here, errors are much rarer for output than for input, so we don’t do it as often. For programs where output devices have a more significant chance of being unavailable, filled, or broken, we would test after each output operation just as we test after each input operation.
10.7 Reading a single value
So, we know how to read a series of values ending with the end of file or a terminator. We’ll show more examples as we go along, but let’s just have a look at the ever popular idea of repeatedly asking for a value until an acceptable one is entered. This example will allow us to examine several common design choices. We’ll discuss these alternatives through a series of alternative solutions to the simple problem of “how to get an acceptable value from the user.” We start with an unpleasantly messy obvious “first try” and proceed through a series of improved versions. Our fundamental assumption is that we are dealing with interactive input where a human is typing input and reading the messages from the program. Let’s ask for an integer in the range 1 to 10 (inclusive):
cout << "Please enter an integer in the range 1 to 10 (inclusive):\n";
int n = 0;
while (cin>>n) { // read
if (1<=n && n<=10) break; // check range
cout << "Sorry "
<< n << " is not in the [1:10] range; please try again\n";
}
// ... use n here ...
This is pretty ugly, but it “sort of works.” If you don’t like using the break (§A.6), you can combine the reading and the range checking:
cout << "Please enter an integer in the range 1 to 10 (inclusive):\n";
int n = 0;
while (cin>>n && !(1<=n && n<=10)) // read and check range
cout << "Sorry "
<< n << " is not in the [1:10] range; please try again\n";
// ... use n here ...
![]()
However, that’s just a cosmetic change. Why does it only “sort of work”? It works if the user carefully enters integers. If the user is a poor typist and hits t rather than 6 (t is just below 6 on most keyboards), the program will leave the loop without changing the value of n, so that n will have an out-of-range value. We wouldn’t call that quality code. A joker (or a diligent tester) might also send an “end of file” from the keyboard (Ctrl+Z on a Windows machine and Ctrl+D on a Unix machine). Again, we’d leave the loop with n out of range. In other words, to get a robust read we have to deal with three problems:
1. The user typing an out-of-range value
2. Getting no value (end of file)
3. The user typing something of the wrong type (here, not an integer)
What do we want to do in those three cases? That’s often the question when writing a program: What do we really want? Here, for each of those three errors, we have three alternatives:
1. Handle the problem in the code doing the read.
2. Throw an exception to let someone else handle the problem (potentially terminating the program).
3. Ignore the problem.
As it happens, those are three very common alternatives for dealing with an error condition. Thus, this is a good example of the kind of thinking we have to do about errors.
![]()
It is tempting to say that the third alternative, ignoring the problem, is always unacceptable, but that would be patronizing. If I’m writing a trivial program for my own use, I can do whatever I like, including forgetting about error checking with potential nasty results. However, for a program that I might want to use for more than a few hours after I wrote it, I would probably be foolish to leave such errors, and if I want to share that program with anyone, I should not leave such holes in the error checking in the code. Please note that we deliberately use the first-person singular here; “we” would be misleading. We do not consider alternative 3 acceptable even when just two people are involved.
The choice between alternatives 1 and 2 is genuine; that is, in a given program there can be good reasons to choose either way. First we note that in most programs there is no local and elegant way to deal with no input from a user sitting at the keyboard: after the input stream is closed, there isn’t much point in asking the user to enter a number. We could reopen cin (using cin.clear()), but the user is unlikely to have closed that stream by accident (how would you hit Ctrl+Z by accident?). If the program wants an integer and finds “end of file,” the part of the program trying to read the integer must usually give up and hope that some other part of the program can cope; that is, our code requesting input from the user must throw an exception. This implies that the choice is not between throwing exceptions and handling problems locally, but a choice of which problems (if any) we should handle locally.
10.7.1 Breaking the problem into manageable parts
Let’s try handling both an out-of-range input and an input of the wrong type locally:
cout << "Please enter an integer in the range 1 to 10 (inclusive):\n";
int n = 0;
while (true) {
cin >> n;
if (cin) { // we got an integer; now check it
if (1<=n && n<=10) break;
cout << "Sorry "
<< n << " is not in the [1:10] range; please try again\n";
}
else if (cin.fail()) { // we found something that wasn’t an integer
cin.clear(); // set the state back to good();
// we want to look at the characters
cout << "Sorry, that was not a number; please try again\n";
for (char ch; cin>>ch && !isdigit(ch); ) // throw away non-digits
/* nothing */ ;
if (!cin) error("no input"); // we didn’t find a digit: give up
cin.unget(); // put the digit back, so that we can read the number
}
else {
error("no input"); // eof or bad: give up
}
}
// if we get here n is in [1:10]
This is messy, and rather long-winded. In fact, it is so messy that we could not recommend that people write such code each time they needed an integer from a user. On the other hand, we do need to deal with the potential errors because people do make them, so what can we do? The reason that the code is messy is that code dealing with several different concerns is all mixed together:
![]()
• Reading values
• Prompting the user for input
• Writing error messages
• Skipping past “bad” input characters
• Testing the input against a range
![]()
The way to make code clearer is often to separate logically distinct concerns into separate functions. For example, we can separate out the code for recovering after seeing a “bad” (i.e., unexpected) character:
void skip_to_int()
{
if (cin.fail()) { // we found something that wasn’t an integer
cin.clear(); // we’d like to look at the characters
for (char ch; cin>>ch; ) { // throw away non-digits
if (isdigit(ch) || ch=="-") {
cin.unget(); // put the digit back,
// so that we can read the number
return;
}
}
}
error("no input"); // eof or bad: give up
}
Given the skip_to_int() “utility function,” we can write
cout << "Please enter an integer in the range 1 to 10 (inclusive):\n";
int n = 0;
while (true) {
if (cin>>n) { // we got an integer; now check it
if (1<=n && n<=10) break;
cout << "Sorry " << n
<< " is not in the [1:10] range; please try again\n";
}
else {
cout << "Sorry, that was not a number; please try again\n";
skip_to_int();
}
}
// if we get here n is in [1:10]
This code is better, but it is still too long and too messy to use many times in a program. We’d never get it consistently right, except after (too) much testing.
What operation would we really like to have? One plausible answer is “a function that reads an int, any int, and another that reads an int of a given range”:
int get_int(); // read an int from cin
int get_int(int low, int high); // read an int in [low:high] from cin
If we had those, we would at least be able to use them simply and correctly. They are not that hard to write:
int get_int()
{
int n = 0;
while (true) {
if (cin >> n) return n;
cout << "Sorry, that was not a number; please try again\n";
skip_to_int();
}
}
Basically, get_int() stubbornly keeps reading until it finds some digits that it can interpret as an integer. If we want to get out of get_int(), we must supply an integer or end of file (and end of file will cause get_int() to throw an exception).
Using that general get_int(), we can write the range-checking get_int():
int get_int(int low, int high)
{
cout << "Please enter an integer in the range "
<< low << " to " << high << " (inclusive):\n";
while (true) {
int n = get_int();
if (low<=n && n<=high) return n;
cout << "Sorry "
<< n << " is not in the [" << low << ':' << high
<< "] range; please try again\n";
}
}
This get_int() is as stubborn as the other. It keeps getting ints from the non-range get_int() until the int it gets is in the expected range.
We can now reliably read integers like this:
int n = get_int(1,10);
cout << "n: " << n << '\n';
int m = get_int(2,300);
cout << "m: " << m << '\n';
Don’t forget to catch exceptions somewhere, though, if you want decent error messages for the (probably rare) case when get_int() really couldn’t read a number for us.
10.7.2 Separating dialog from function
The get_int() functions still mix up reading with writing messages to the user. That’s probably good enough for a simple program, but in a large program we might want to vary the messages written to the user. We might want to call get_int() like this:
int strength = get_int(1,10, "enter strength", "Not in range, try again");
cout << "strength: " << strength << '\n';
int altitude = get_int(0,50000,
"Please enter altitude in feet",
"Not in range, please try again");
cout << "altitude: " << altitude << "f above sea level\n";
We could implement that like this:
int get_int(int low, int high, const string& greeting, const string& sorry)
{
cout << greeting << ": [" << low << ':' << high << "]\n";
while (true) {
int n = get_int();
if (low<=n && n<=high) return n;
cout << sorry << ": [" << low << ':' << high << "]\n";
}
}
It is hard to compose arbitrary messages, so we “stylized” the messages. That’s often acceptable, and composing really flexible messages, such as are needed to support many natural languages (e.g., Arabic, Bengali, Chinese, Danish, English, and French), is not a task for a novice.
Note that our solution is still incomplete: the get_int() without a range still “blabbers.” The deeper point here is that “utility functions” that we use in many parts of a program shouldn’t have messages “hardwired” into them. Further, library functions that are meant for use in many programs shouldn’t write to the user at all — after all, the library writer may not even know that the program in which the library runs is used on a machine with a human watching. That’s one reason that our error() function doesn’t just write an error message (§5.6.3); in general, we wouldn’t know where to write.
10.8 User-defined output operators
Defining the output operator, <<, for a given type is typically trivial. The main design problem is that different people might prefer the output to look different, so it is hard to agree on a single format. However, even if no single output format is good enough for all uses, it is often a good idea to define << for a user-defined type. That way, we can at least trivially write out objects of the type during debugging and early development. Later, we might provide a more sophisticated << that allows a user to provide formatting information. Also, if we want output that looks different from what a << provides, we can simply bypass the << and write out the individual parts of the user-defined type the way we happen to like them in our application.
Here is a simple output operator for Date from §9.8 that simply prints the year, month, and day comma-separated in parentheses:
ostream& operator<<(ostream& os, const Date& d)
{
return os << '(' << d.year()
<< ',' << d.month()
<< ',' << d.day() << ')';
}
This will print August 30, 2004, as (2004,8,30). This simple list-of-elements representation is what we tend to use for types with a few members unless we have a better idea or more specific needs.
![]()
In §9.6, we mention that a user-defined operator is handled by calling its function. Here we can see an example of how that’s done. Given the definition of << for Date, the meaning of
cout << d1;
where d1 is a Date is the call
operator<<(cout,d1);
Note how operator<<() takes an ostream& as its first argument and returns it again as its return value. That’s the way the output stream is passed along so that you can “chain” output operations. For example, we could output two dates like this:
cout << d1 << d2;
This will be handled by first resolving the first << and after that the second <<:
cout << d1 << d2; // means operator<<(cout,d1) << d2;
// means operator<<(operator<<(cout,d1),d2);
That is, first output d1 to cout and then output d2 to the output stream that is the result of the first output operation. In fact, we can use any of those three variants to write out d1 and d2. We know which one is easier to read, though.
10.9 User-defined input operators
Defining the input operator, >>, for a given type and input format is basically an exercise in error handling. It can therefore be quite tricky.
Here is a simple input operator for the Date from §9.8 that will read dates as written by the operator << defined above:
istream& operator>>(istream& is, Date& dd)
{
int y, m, d;
char ch1, ch2, ch3, ch4;
is >> ch1 >> y >> ch2 >> m >> ch3 >> d >> ch4;
if (!is) return is;
if (ch1!='(' || ch2!=',' || ch3!=',' || ch4!=')') { // oops: format error
is.clear(ios_base::failbit);
return is;
}
dd = Date{y,Date::Month(m),d}; // update dd
return is;
}
This >> will read items like (2004,8,20) and try to make a Date out of those three integers. As ever, input is harder to deal with than output. There is simply more that can — and often does — go wrong with input than with output.
If this >> doesn’t find something in the ( integer , integer , integer ) format, it will leave the stream in a not-good state (fail, eof, or bad) and leave the target Date unchanged. The clear() member function is used to set the state of the istream. Obviously, ios_base::failbit puts the stream into the fail() state. Leaving the target Date unchanged in case of a failure to read is the ideal; it tends to lead to cleaner code. The ideal is for an operator>>() not to consume (throw away) any characters that it didn’t use, but that’s too difficult in this case: we might have read lots of characters before we caught a format error. As an example, consider (2004, 8, 30}. Only when we see the final } do we know that we have a format error on our hands and we cannot in general rely on putting back many characters. One character unget() is all that’s universally guaranteed. If thisoperator>>() reads an invalid Date, such as (2004,8,32), Date’s constructor will throw an exception, which will get us out of this operator>>().
10.10 A standard input loop
In §10.5, we saw how we could read and write files. However, that was before we looked more carefully at errors (§10.6), so the input loop simply assumed that we could read a file from its beginning until end of file. That can be a reasonable assumption, because we often apply separate checks to ensure that a file is valid. However, we often want to check our reads as we go along. Here is a general strategy, assuming that ist is an istream:
for (My_type var; ist>>var; ) { // read until end of file
// maybe check that var is valid
// do something with var
}
// we can rarely recover from bad; don’t try unless you really have to:
if (ist.bad()) error("bad input stream");
if (ist.fail()) {
// was it an acceptable terminator?
}
// carry on: we found end of file
That is, we read a sequence of values into variables and when we can’t read any more values, we check the stream state to see why. As in §10.6, we can improve this a bit by letting the istream throw an exception of type failure if it goes bad. That saves us the bother of checking for it all the time:
// somewhere: make ist throw an exception if it goes bad:
ist.exceptions(ist.exceptions()|ios_base::badbit);
We could also decide to designate a character as a terminator:
for (My_type var; ist>>var; ) { // read until end of file
// maybe check that var is valid
// do something with var
}
if (ist.fail()) { // use '|' as terminator and/or separator
ist.clear();
char ch;
if (!(ist>>ch && ch=='|')) error("bad termination of input");
}
// carry on: we found end of file or a terminator
If we don’t want to accept a terminator — that is, to accept only end of file as the end — we simply delete the test before the call of error(). However, terminators are very useful when you read files with nested constructs, such as a file of monthly readings containing daily readings, containing hourly readings, etc., so we’ll keep considering the possibility of a terminating character.
Unfortunately, that code is still a bit messy. In particular, it is tedious to repeat the terminator test if we read a lot of files. We could write a function to deal with that:
// somewhere: make ist throw if it goes bad:
ist.exceptions(ist.exceptions()|ios_base::badbit);
void end_of_loop(istream& ist, char term, const string& message)
{
if (ist.fail()) { // use term as terminator and/or separator
ist.clear();
char ch;
if (ist>>ch && ch==term) return; // all is fine
error(message);
}
}
This reduces the input loop to
for (My_type var; ist>>var; ) { // read until end of file
// maybe check that var is valid
// . . . do something with var . . .
}
end_of_loop(ist,'|',"bad termination of file"); // test if we can continue
// carry on: we found end of file or a terminator
The end_of_loop() does nothing unless the stream is in the fail() state. We consider that simple enough and general enough for many purposes.
10.11 Reading a structured file
Let’s try to use this “standard loop” for a concrete example. As usual, we’ll use the example to illustrate widely applicable design and programming techniques. Assume that you have a file of temperature readings that has been structured like this:
• A file holds years (of months of readings).
• A year starts with { year followed by an integer giving the year, such as 1900, and ends with }.
• A year holds months (of days of readings).
• A month starts with { month followed by a three-letter month name, such as jan, and ends with }.
• A reading holds a time and a temperature.
• A reading starts with a ( followed by day of the month, hour of the day, and temperature and ends with a ).
For example:
{ year 1990 }
{year 1991 { month jun }}
{ year 1992 { month jan ( 1 0 61.5) } {month feb (1 1 64) (2 2 65.2) } }
{year 2000
{ month feb (1 1 68 ) (2 3 66.66 ) ( 1 0 67.2)}
{month dec (15 15 -9.2 ) (15 14 -8.8) (14 0 -2) }
}
This format is somewhat peculiar. File formats often are. There is a move toward more regular and hierarchically structured files (such as HTML and XML files) in the industry, but the reality is still that we can rarely control the input format offered by the files we need to read. The files are the way they are, and we just have to read them. If a format is too awful or files contain too many errors, we can write a format conversion program to produce a format that suits our main program better. On the other hand, we can typically choose the in-memory representation of data to suit our needs, and we can often pick output formats to suit needs and tastes.
![]()
So, let’s assume that we have been given the temperature reading format above and have to live with it. Fortunately, it has self-identifying components, such as years and months (a bit like HTML or XML). On the other hand, the format of individual readings is somewhat unhelpful. For example, there is no information that could help us if someone flipped a day-of-the-month value with an hour of day or if someone produced a file with temperatures in Celsius and the program expected them in Fahrenheit or vice versa. We just have to cope.
10.11.1 In-memory representation
How should we represent this data in memory? The obvious first choice is three classes, Year, Month, and Reading, to exactly match the input. Year and Month are obviously useful when manipulating the data; we want to compare temperatures of different years, calculate monthly averages, compare different months of a year, compare the same month of different years, match up temperature readings with sunshine records and humidity readings, etc. Basically, Year and Month match the way we think about temperatures and weather in general: Month holds a month’s worth of information and Year holds a year’s worth of information. But what about Reading? That’s a low-level notion matching some piece of hardware (a sensor). The data of a Reading (day of month, hour of day, temperature) is “odd” and makes sense only within a Month. It is also unstructured: we have no promise that readings come in day-of-the-month or hour-of-the-day order. Basically, whenever we want to do anything of interest with the readings we have to sort them.
For representing the temperature data in memory, we make these assumptions:
• If we have any readings for a month, then we tend to have lots of readings for that month.
• If we have any readings for a day, then we tend to have lots of readings for that day.
When that’s the case, it makes sense to represent a Year as a vector of 12 Months, a Month as a vector of about 30 Days, and a Day as 24 temperatures (one per hour). That’s simple and easy to manipulate for a wide variety of uses. So, Day, Month, and Year are simple data structures, each with a constructor. Since we plan to create Months and Days as part of a Year before we know what temperature readings we have, we need to have a notion of “not a reading” for an hour of a day for which we haven’t (yet) read data.
const int not_a_reading = -7777; // less than absolute zero
Similarly, we noticed that we often had a month without data, so we introduced the notion “not a month” to represent that directly, rather than having to search through all the days to be sure that no data was lurking somewhere:
const int not_a_month = -1;
The three key classes then become
struct Day {
vector<double> hour {vector<double>(24,not_a_reading)};
};
That is, a Day has 24 hours, each initialized to not_a_reading.
struct Month { // a month of temperature readings
int month {not_a_month}; // [0:11] January is 0
vector<Day> day {32}; // [1:31] one vector of readings per day
};
We “waste” day[0] to keep the code simple.
struct Year { // a year of temperature readings, organized by month
int year; // positive == A.D.
vector<Month> month {12}; // [0:11] January is 0
};
Each class is basically a simple vector of “parts,” and Month and Year have an identifying member month and year, respectively.
![]()
There are several “magic constants” here (for example, 24, 32, and 12). We try to avoid such literal constants in code. These are pretty fundamental (the number of months in a year rarely changes) and will not be used in the rest of the code. However, we left them in the code primarily so that we could remind you of the problem with “magic constants”; symbolic constants are almost always preferable (§7.6.1). Using 32 for the number of days in a month definitely requires explanation; 32 is obviously “magic” here.
Why didn’t we write
struct Day {
vector<double> hour {24,not_a_reading};
};
That would have been simpler, but unfortunately, we would have gotten a vector of two elements (24 and -1). When we want to specify the number of elements for a vector for which an integer can be converted to the element type, we unfortunately have to use the ( ) initializer syntax (§18.2).
10.11.2 Reading structured values
The Reading class will be used only for reading input and is even simpler:
struct Reading {
int day;
int hour;
double temperature;
};
istream& operator>>(istream& is, Reading& r)
// read a temperature reading from is into r
// format: ( 3 4 9.7 )
// check format, but don’t bother with data validity
{
char ch1;
if (is>>ch1 && ch1!='(') { // could it be a Reading?
is.unget();
is.clear(ios_base::failbit);
return is;
}
char ch2;
int d;
int h;
double t;
is >> d >> h >> t >> ch2;
if (!is || ch2!=')') error("bad reading"); // messed-up reading
r.day = d;
r.hour = h;
r.temperature = t;
return is;
}
Basically, we check if the format begins plausibly, and if it doesn’t we set the file state to fail() and return. This allows us to try to read the information in some other way. On the other hand, if we find the format wrong after having read some data so that there is no real chance of recovering, we bail out with error().
The Month input operation is much the same, except that it has to read an arbitrary number of Readings rather than a fixed set of values (as Reading’s >> did):
istream& operator>>(istream& is, Month& m)
// read a month from is into m
// format: { month feb . . . }
{
char ch = 0;
if (is >> ch && ch!='{') {
is.unget();
is.clear(ios_base::failbit); // we failed to read a Month
return is;
}
string month_marker;
string mm;
is >> month_marker >> mm;
if (!is || month_marker!="month") error("bad start of month");
m.month = month_to_int(mm);
int duplicates = 0;
int invalids = 0;
for (Reading r; is >> r; ) {
if (is_valid(r)) {
if (m.day[r.day].hour[r.hour] != not_a_reading)
++duplicates;
m.day[r.day].hour[r.hour] = r.temperature;
}
else
++invalids;
}
if (invalids) error("invalid readings in month",invalids);
if (duplicates) error("duplicate readings in month", duplicates);
end_of_loop(is,'}',"bad end of month");
return is;
}
We’ll get back to month_to_int() later; it converts the symbolic notation for a month, such as jun, to a number in the [0:11] range. Note the use of end_of_loop() from §10.10 to check for the terminator. We keep count of invalid and duplicate Readings; someone might be interested.
Month’s >> does a quick check that a Reading is plausible before storing it:
constexpr int implausible_min = -200;
constexpr int implausible_max = 200;
bool is_valid(const Reading& r)
// a rough test
{
if (r.day<1 || 31<r.day) return false;
if (r.hour<0 || 23<r.hour) return false;
if (r.temperature<implausible_min|| implausible_max<r.temperature)
return false;
return true;
}
Finally, we can read Years. Year’s >> is similar to Month’s >>:
istream& operator>>(istream& is, Year& y)
// read a year from is into y
// format: { year 1972 . . . }
{
char ch;
is >> ch;
if (ch!='{') {
is.unget();
is.clear(ios::failbit);
return is;
}
string year_marker;
int yy;
is >> year_marker >> yy;
if (!is || year_marker!="year") error("bad start of year");
y.year = yy;
while(true) {
Month m; // get a clean m each time around
if(!(is >> m)) break;
y.month[m.month] = m;
}
end_of_loop(is,'}',"bad end of year");
return is;
}
We would have preferred “boringly similar” to just “similar,” but there is a significant difference. Have a look at the read loop. Did you expect something like the following?
for (Month m; is >> m; )
y.month[m.month] = m;
You probably should have, because that’s the way we have written all the read loops so far. That’s actually what we first wrote, and it’s wrong. The problem is that operator>>(istream& is, Month& m) doesn’t assign a brand-new value to m; it simply adds data from Readings to m. Thus, the repeated is>>m would have kept adding to our one and only m. Oops! Each new month would have gotten all the readings from all previous months of that year. We need a brand-new, clean Month to read into each time we do is>>m. The easiest way to do that was to put the definition of minside the loop so that it would be initialized each time around. The alternatives would have been for operator>>(istream& is, Month& m) to assign an empty month to m before reading into it, or for the loop to do that:
for (Month m; is >> m; ) {
y.month[m.month] = m;
m = Month{}; // “reinitialize” m
}
Let’s try to use it:
// open an input file:
cout << "Please enter input file name\n";
string iname;
cin >> iname;
ifstream ist {iname};
if (!ifs) error("can't open input file",iname);
ifs.exceptions(ifs.exceptions()|ios_base::badbit); // throw for bad()
// open an output file:
cout << "Please enter output file name\n";
string oname;
cin >> oname;
ofstream ost {oname};
if (!ofs) error("can't open output file",oname);
// read an arbitrary number of years:
vector<Year> ys;
while(true) {
Year y; // get a freshly initialized Year each time around
if (!(ifs>>y)) break;
ys.push_back(y);
}
cout << "read " << ys.size() << " years of readings\n";
for (Year& y : ys) print_year(ofs,y);
We leave print_year() as an exercise.
10.11.3 Changing representations
To get Month’s >> to work, we need to provide a way of reading symbolic representations of the month. For symmetry, we’ll provide a matching write using a symbolic representation. The tedious way would be to write an if-statement convert:
if (s=="jan")
m = 1;
else if (s=="feb")
m = 2;
. . .
This is not just tedious; it also builds the names of the months into the code. It would be better to have those in a table somewhere so that the main program could stay unchanged even if we had to change the symbolic representation. We decided to represent the input representation as avector<string> plus an initialization function and a lookup function:
![]()
vector<string> month_input_tbl = {
"jan", "feb", "mar", "apr", "may", "jun", "jul",
"aug", "sep", "oct", "nov", "dec"
};
int month_to_int(string s)
// is s the name of a month? If so return its index [0:11] otherwise -1
{
for (int i=0; i<12; ++i) if (month_input_tbl[i]==s) return i;
return -1;
}
In case you wonder: the C++ standard library does provide a simpler way to do this. See §21.6.1 for a map<string,int>.
When we want to produce output, we have the opposite problem. We have an int representing a month and would like a symbolic representation to be printed. Our solution is fundamentally similar, but instead of using a table to go from string to int, we use one to go from int to string:
vector<string> month_print_tbl = {
"January", "February", "March", "April", "May", "June", "July",
"August", "September", "October", "November", "December"
};
string int_to_month(int i)
// months [0:11]
{
if (i<0 || 12<=i) error("bad month index");
return month_print_tbl[i];
}
![]()
So, did you actually read all of that code and the explanations? Or did your eyes glaze over and skip to the end? Remember that the easiest way of learning to write good code is to read a lot of code. Believe it or not, the techniques we used for this example are simple, but not trivial to discover without help. Reading data is fundamental. Writing loops correctly (initializing every variable used correctly) is fundamental. Converting between representations is fundamental. That is, you will learn to do such things. The only questions are whether you’ll learn to do them well and whether you learn the basic techniques before losing too much sleep.
 Drill
Drill
1. Start a program to work with points, discussed in §10.4. Begin by defining the data type Point that has two coordinate members x and y.
2. Using the code and discussion in §10.4, prompt the user to input seven (x,y) pairs. As the data is entered, store it in a vector of Points called original_points.
3. Print the data in original_points to see what it looks like.
4. Open an ofstream and output each point to a file named mydata.txt. On Windows, we suggest the .txt suffix to make it easier to look at the data with an ordinary text editor (such as WordPad).
5. Close the ofstream and then open an ifstream for mydata.txt. Read the data from mydata.txt and store it in a new vector called processed_points.
6. Print the data elements from both vectors.
7. Compare the two vectors and print Something's wrong! if the number of elements or the values of elements differ.
Review
1. When dealing with input and output, how is the variety of devices dealt with in most modern computers?
2. What, fundamentally, does an istream do?
3. What, fundamentally, does an ostream do?
4. What, fundamentally, is a file?
5. What is a file format?
6. Name four different types of devices that can require I/O for a program.
7. What are the four steps for reading a file?
8. What are the four steps for writing a file?
9. Name and define the four stream states.
10. Discuss how the following input problems can be resolved:
a. The user typing an out-of-range value
b. Getting no value (end of file)
c. The user typing something of the wrong type
11. In what way is input usually harder than output?
12. In what way is output usually harder than input?
13. Why do we (often) want to separate input and output from computation?
14. What are the two most common uses of the istream member function clear()?
15. What are the usual function declarations for << and >> for a user-defined type X?
Terms
bad()
buffer
clear()
close()
device driver
eof()
fail()
file
good()
ifstream
input device
input operator
iostream
istream
ofstream
open()
ostream
ouput device
ouput operator
stream state
structured file
terminator
unget()
Exercises
1. Write a program that produces the sum of all the numbers in a file of whitespace-separated integers.
2. Write a program that creates a file of data in the form of the temperature Reading type defined in §10.5. For testing, fill the file with at least 50 “temperature readings.” Call this program store_temps.cpp and the file it creates raw_temps.txt.
3. Write a program that reads the data from raw_temps.txt created in exercise 2 into a vector and then calculates the mean and median temperatures in your data set. Call this program temp_stats.cpp.
4. Modify the store_temps.cpp program from exercise 2 to include a temperature suffix c for Celsius or f for Fahrenheit temperatures. Then modify the temp_stats.cpp program to test each temperature, converting the Celsius readings to Fahrenheit before putting them into the vector.
5. Write the function print_year() mentioned in §10.11.2.
6. Define a Roman_int class for holding Roman numerals (as ints) with a << and >>. Provide Roman_int with an as_int() member that returns the int value, so that if r is a Roman_int, we can write cout << "Roman" << r << " equals " << r.as_int() << '\n';.
7. Make a version of the calculator from Chapter 7 that accepts Roman numerals rather than the usual Arabic ones, for example, XXI + CIV == CXXV.
8. Write a program that accepts two file names and produces a new file that is the contents of the first file followed by the contents of the second; that is, the program concatenates the two files.
9. Write a program that takes two files containing sorted whitespace-separated words and merges them, preserving order.
10. Add a command from x to the calculator from Chapter 7 that makes it take input from a file x. Add a command to y to the calculator that makes it write its output (both standard output and error output) to file y. Write a collection of test cases based on ideas from §7.3 and use that to test the calculator. Discuss how you would use these commands for testing.
11. Write a program that produces the sum of all the whitespace-separated integers in a text file. For example, bears: 17 elephants 9 end should output 26.
Postscript
Much of computing involves moving lots of data from one place to another, for example, copying text from a file to a screen or moving music from a computer onto an MP3 player. Often, some transformation of the data is needed on the way. The iostream library is a way of handling many such tasks where the data can be seen as a sequence (a stream) of values. Input and output can be a surprisingly large part of common programming tasks. This is partly because we (or our programs) need a lot of data and partly because the point where data enters a system is a place where lots of errors can happen. So, we must try to keep our I/O simple and try to minimize the chances that bad data “slips through” into our system.