Programming: Principles and Practice Using C++ (2014)
Part III: Data and Algorithms
17. Vector and Free Store
“Use vector as the default!”
—Alex Stepanov
This chapter and the next four describe the containers and algorithms part of the C++ standard library, traditionally called the STL. We describe the key facilities from the STL and some of their uses. In addition, we present the key design and programming techniques used to implement the STL and some low-level language features used for that. Among those are pointers, arrays, and free store. The focus of this chapter and the next two is the design and implementation of the most common and most useful STL container: vector.
17.1 Introduction
17.2 vector basics
17.3 Memory, addresses, and pointers
17.3.1 The sizeof operator
17.4 Free store and pointers
17.4.1 Free-store allocation
17.4.2 Access through pointers
17.4.3 Ranges
17.4.4 Initialization
17.4.5 The null pointer
17.4.6 Free-store deallocation
17.5 Destructors
17.5.1 Generated destructors
17.5.2 Destructors and free store
17.6 Access to elements
17.7 Pointers to class objects
17.8 Messing with types: void* and casts
17.9 Pointers and references
17.9.1 Pointer and reference parameters
17.9.2 Pointers, references, and inheritance
17.9.3 An example: lists
17.9.4 List operations
17.9.5 List use
17.10 The this pointer
17.10.1 More link use
17.1 Introduction
![]()
![]()
The most useful container in the C++ standard library is vector. A vector provides a sequence of elements of a given type. You can refer to an element by its index (subscript), extend the vector by using push_back(), ask a vector for the number of its elements using size(), and have access to the vector checked against attempts to access out-of-range elements. The standard library vector is a convenient, flexible, efficient (in time and space), statically type-safe container of elements. The standard string has similar properties, as have other useful standard container types, such aslist and map, which we will describe in Chapter 20. However, a computer’s memory doesn’t directly support such useful types. All that the hardware directly supports is sequences of bytes. For example, for a vector<double>, the operation v.push_back(2.3) adds 2.3 to a sequence of doubles and increases the element count of v (v.size()) by 1. At the lowest level, the computer knows nothing about anything as sophisticated as push_back(); all it knows is how to read and write a few bytes at a time.
In this and the following two chapters, we show how to build vector from the basic language facilities available to every programmer. Doing so allows us to illustrate useful concepts and programming techniques, and to see how they are expressed using C++ language features. The language facilities and programming techniques we encounter in the vector implementation are generally useful and very widely used.
Once we have seen how vector is designed, implemented, and used, we can proceed to look at other standard library containers, such as map, and examine the elegant and efficient facilities for their use provided by the C++ standard library (Chapters 20 and 21). These facilities, called algorithms, save us from programming common tasks involving data ourselves. Instead, we can use what is available as part of every C++ implementation to ease the writing and testing of our libraries. We have already seen and used one of the standard library’s most useful algorithms: sort().
![]()
We approach the standard library vector through a series of increasingly sophisticated vector implementations. First, we build a very simple vector. Then, we see what’s undesirable about that vector and fix it. When we have done that a few times, we reach a vector implementation that is roughly equivalent to the standard library vector — shipped with your C++ compiler, the one that you have been using in the previous chapters. This process of gradual refinement closely mirrors the way we typically approach a new programming task. Along the way, we encounter and explore many classical problems related to the use of memory and data structures. The basic plan is this:
• Chapter 17 (this chapter): How can we deal with varying amounts of memory? In particular, how can different vectors have different numbers of elements and how can a single vector have different numbers of elements at different times? This leads us to examine free store (heap storage), pointers, casts (explicit type conversion), and references.
• Chapter 18: How can we copy vectors? How can we provide a subscript operation for them? We also introduce arrays and explore their relation to pointers.
• Chapter 19: How can we have vectors with different element types? And how can we deal with out-of-range errors? To answer those questions, we explore the C++ template and exception facilities.
In addition to the new language facilities and techniques that we introduce to handle the implementation of a flexible, efficient, and type-safe vector, we will also (re)use many of the language facilities and programming techniques we have already seen. Occasionally, we’ll take the opportunity to give those a slightly more formal and technical definition.
So, this is the point at which we finally get to deal directly with memory. Why do we have to? Our vector and string are extremely useful and convenient; we can just use those. After all, containers, such as vector and string, are designed to insulate us from some of the unpleasant aspects of real memory. However, unless we are content to believe in magic, we must examine the lowest level of memory management. Why shouldn’t you “just believe in magic”? Or — to put a more positive spin on it — why shouldn’t you “just trust that the implementers of vector knew what they were doing”? After all, we don’t suggest that you examine the device physics that allows our computer’s memory to function.
![]()
Well, we are programmers (computer scientists, software developers, or whatever) rather than physicists. Had we been studying device physics, we would have had to look into the details of computer memory design. However, since we are studying programming, we must look into the detailed design of programs. In theory, we could consider the low-level memory access and management facilities “implementation details” just as we do the device physics. However, if we did that, you would not just have to “believe in magic”; you would be unable to implement a new container (should you need one, and that’s not uncommon). Also, you would be unable to read huge amounts of C and C++ code that directly uses memory. As we will see over the next few chapters, pointers (a low-level and direct way of referring to an object) are also useful for a variety of reasons not related to memory management. It is not easy to use C++ well without sometimes using pointers.
![]()
More philosophically, I am among the large group of computer professionals who are of the opinion that if you lack a basic and practical understanding of how a program maps onto a computer’s memory and operations, you will have problems getting a solid grasp of higher-level topics, such as data structures, algorithms, and operating systems.
17.2 vector basics
We start our incremental design of vector by considering a very simple use:
vector<double> age(4); // a vector with 4 elements of type double
age[0]=0.33;
age[1]=22.0;
age[2]=27.2;
age[3]=54.2;
Obviously, this creates a vector with four elements of type double and gives those four elements the values 0.33, 22.0, 27.2, and 54.2. The four elements are numbered 0, 1, 2, 3. The numbering of elements in C++ standard library containers always starts from 0 (zero). Numbering from 0 is very common, and it is a universal convention among C++ programmers. The number of elements of a vector is called its size. So, the size of age is 4. The elements of a vector are numbered (indexed) from 0 to size-1. For example, the elements of age are numbered 0 to age.size()-1. We can represent age graphically like this:

How do we make this “graphical design” real in a computer’s memory? How do we get the values stored and accessed like that? Obviously, we have to define a class and we want to call this class vector. Furthermore, it needs a data member to hold its size and one to hold its elements. But how do we represent a set of elements where the number of elements can vary? We could use a standard library vector, but that would — in this context — be cheating: we are building a vector here.
So, how do we represent that arrow in the drawing above? Consider doing without it. We could define a fixed-size data structure:
class vector {
int size, age0, age1, age2, age3;
// . . .
};
Ignoring some notational details, we’ll have something like this:

![]()
That’s simple and nice, but the first time we try to add an element with push_back() we are sunk: we have no way of adding an element; the number of elements is fixed to four in the program text. We need something more than a data structure holding a fixed number of elements. Operations that change the number of elements of a vector, such as push_back(), can’t be implemented if we defined vector to have a fixed number of elements. Basically, we need a data member that points to the set of elements so that we can make it point to a different set of elements when we need more space. We need something like the memory address of the first element. In C++, a data type that can hold an address is called a pointer and is syntactically distinguished by the suffix *, so that double* means “pointer to double.” Given that, we can define our first version of a vectorclass:
// a very simplified vector of doubles (like vector<double>)
class vector {
int sz; // the size
double* elem; // pointer to the first element (of type double)
public:
vector(int s); // constructor: allocate s doubles,
// let elem point to them
// store s in sz
int size() const { return sz; } // the current size
};
Before proceeding with the vector design, let us study the notion of “pointer” in some detail. The notion of “pointer” — together with its closely related notion of “array” — is key to C++’s notion of “memory.”
17.3 Memory, addresses, and pointers
![]()
A computer’s memory is a sequence of bytes. We can number the bytes from 0 to the last one. We call such “a number that indicates a location in memory” an address. You can think of an address as a kind of integer value. The first byte of memory has the address 0, the next the address 1, and so on. We can visualize a megabyte of memory like this:

Everything we put in memory has an address. For example:
int var = 17;
This will set aside an “int-size” piece of memory for var somewhere and put the value 17 into that memory. We can also store and manipulate addresses. An object that holds an address value is called a pointer. For example, the type needed to hold the address of an int is called a “pointer toint” or an “int pointer” and the notation is int*:
int* ptr = &var; // ptr holds the address of var
The “address of” operator, unary &, is used to get the address of an object. So, if var happens to start at address 4096 (also known as 212), ptr will hold the value 4096:

Basically, we view our computer’s memory as a sequence of bytes numbered from 0 to the memory size minus 1. On some machines that’s a simplification, but as an initial programming model of the memory, it will suffice.
Each type has a corresponding pointer type. For example:
int x = 17;
int* pi = &x; // pointer to int
double e = 2.71828;
double* pd = &e; // pointer to double
If we want to see the value of the object pointed to, we can do that using the “contents of” operator, unary *. For example:
cout << "pi==" << pi << "; contents of pi==" << *pi << "\n";
cout << "pd==" << pd << "; contents of pd==" << *pd << "\n";
The output for *pi will be the integer 17 and the output for *pd will be the double 2.71828. The output for pi and pd will vary depending on where the compiler allocated our variables x and e in memory. The notation used for the pointer value (address) may also vary depending on which conventions your system uses; hexadecimal notation (§A.2.1.1) is popular for pointer values.
The contents of operator (often called the dereference operator) can also be used on the left-hand side of an assignment:
*pi = 27; // OK: you can assign 27 to the int pointed to by pi
*pd = 3.14159; // OK: you can assign 3.14159 to the double pointed to by pd
*pd = *pi; // OK: you can assign an int (*pi) to a double (*pd)
![]()
Note that even though a pointer value can be printed as an integer, a pointer is not an integer. “What does an int point to?” is not a well-formed question; ints do not point, pointers do. A pointer type provides the operations suitable for addresses, whereas int provides the (arithmetic and logical) operations suitable for integers. So pointers and integers do not implicitly mix:
int i = pi; // error: can’t assign an int* to an int
pi = 7; // error: can’t assign an int to an int*
Similarly, a pointer to char (a char*) is not a pointer to int (an int*). For example:
char* pc = pi; // error: can’t assign an int* to a char*
pi = pc; // error: can’t assign a char* to an int*
Why is it an error to assign pc to pi? Consider one answer: a char is usually much smaller than an int, so consider this:
char ch1 = 'a';
char ch2 = 'b';
char ch3 = 'c';
char ch4 = 'd';
int* pi = &ch3; // point to ch3, a char-size piece of memory
// error: we cannot assign a char* to an int*
// but let’s pretend we could
*pi = 12345; // write to an int-size piece of memory
*pi = 67890;
Exactly how the compiler allocates variables in memory is implementation defined, but we might very well get something like this:
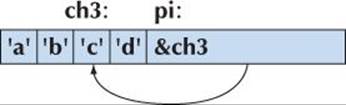
Now, had the compiler allowed the code, we would have been writing 12345 to the memory starting at &ch3. That would definitely have changed the value of some nearby memory, such as ch2 or ch4. If we were really unlucky (which is likely), we would have overwritten part of pi itself! In that case, the next assignment *pi=67890 would place 67890 in some completely different part of memory. Be glad that such assignment is disallowed, but this is one of the very few protections offered by the compiler at this low level of programming.
In the unlikely case that you really need to convert an int to a pointer or to convert one pointer type to another, you can use reinterpret_cast; see §17.8.
We are really close to the hardware here. This is not a particularly comfortable place to be for a programmer. We have only a few primitive operations available and hardly any support from the language or the standard library. However, we had to get here to know how higher-level facilities, such as vector, are implemented. We need to understand how to write code at this level because not all code can be “high-level” (see Chapter 25). Also, we might better appreciate the convenience and relative safety of the higher levels of software once we have experienced their absence. Our aim is always to work at the highest level of abstraction that is possible given a problem and the constraints on its solution. In this chapter and in Chapters 18-19, we show how to get back to a more comfortable level of abstraction by implementing a vector.
17.3.1 The sizeof operator
![]()
So how much memory does an int really take up? A pointer? The operator sizeof answers such questions:
void sizes(char ch, int i, int* p)
{
cout << "the size of char is " << sizeof(char) << ' ' << sizeof (ch) << '\n';
cout << "the size of int is " << sizeof(int) << ' ' << sizeof (i) << '\n';
cout << "the size of int* is " << sizeof(int*) << ' ' << sizeof (p) << '\n';
}
As you can see, we can apply sizeof either to a type name or to an expression; for a type, sizeof gives the size of an object of that type, and for an expression, it gives the size of the type of the result. The result of sizeof is a positive integer and the unit is sizeof(char), which is defined to be 1. Typically, a char is stored in a byte, so sizeof reports the number of bytes.
 Try This
Try This
Execute the example above and see what you get. Then extend the example to determine the size of bool, double, and some other type.
The size of a type is not guaranteed to be the same on every implementation of C++. These days, sizeof(int) is typically 4 on a laptop or desktop machine. With an 8-bit byte, that means that an int is 32 bits. However, embedded systems processors with 16-bit ints and high-performance architectures with 64-bit ints are common.
How much memory is used by a vector? We can try
vector<int> v(1000); // vector with 1000 elements of type int
cout << "the size of vector<int>(1000) is " << sizeof (v) << '\n';
The output will be something like
the size of vector<int>(1000) is 20
The explanation will become obvious over this chapter and the next (see also §19.2.1), but clearly, sizeof is not counting the elements.
17.4 Free store and pointers
![]()
Consider the implementation of vector from the end of §17.2. From where does the vector get the space for the elements? How do we get the pointer elem to point to them? When you start a C++ program, the compiler sets aside memory for your code (sometimes called code storage or text storage) and for the global variables you define (called static storage). It also sets aside some memory to be used when you call functions, and they need space for their arguments and local variables (that’s called stack storage or automatic storage). The rest of the computer’s memory is potentially available for other uses; it is “free.” We can illustrate that graphically:
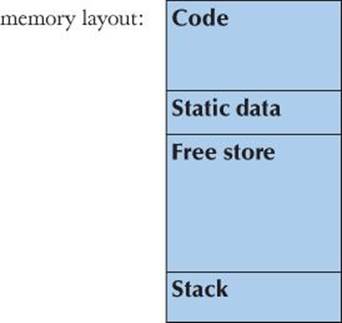
The C++ language makes this “free store” (also called the heap) available through an operator called new. For example:
double* p = new double[4]; // allocate 4 doubles on the free store
This asks the C++ run-time system to allocate four doubles on the free store and return a pointer to the first double to us. We use that pointer to initialize our pointer variable p. We can represent this graphically:
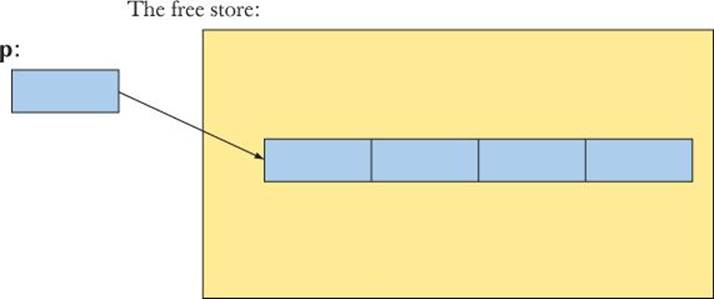
The new operator returns a pointer to the object it creates. If it created several objects (an array), it returns a pointer to the first of those objects. If that object is of type X, the pointer returned by new is of type X*. For example:
char* q = new double[4]; // error: double* assigned to char*
That new returns a pointer to a double and a double isn’t a char, so we should not (and cannot) assign it to the pointer to char variable q.
17.4.1 Free-store allocation
We request memory to be allocated on the free store by the new operator:
• The new operator returns a pointer to the allocated memory.
![]()
• A pointer value is the address of the first byte of the memory.
• A pointer points to an object of a specified type.
• A pointer does not know how many elements it points to.
The new operator can allocate individual elements or sequences (arrays) of elements. For example:
int* pi = new int; // allocate one int
int* qi = new int[4]; // allocate 4 ints (an array of 4 ints)
double* pd = new double; // allocate one double
double* qd = new double[n]; // allocate n doubles (an array of n doubles)
Note that the number of objects allocated can be a variable. That’s important because that allows us to select how many objects we allocate at run time. If n is 2, we get
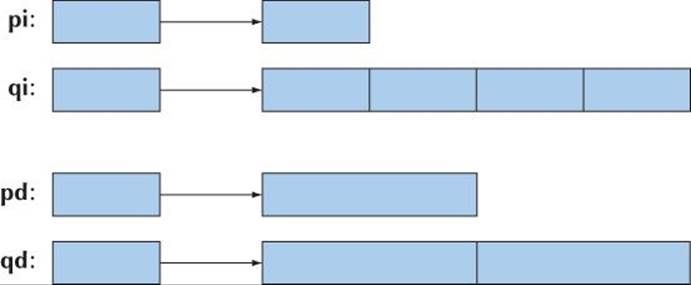
Pointers to objects of different types are different types. For example:
pi = pd; // error: can’t assign a double* to an int*
pd = pi; // error: can’t assign an int* to a double*
Why not? After all, we can assign an int to a double and a double to an int. The reason is the [ ] operator. It relies on the size of the element type to figure out where to find an element. For example, qi[2] is two int sizes further on in memory than qi[0], and qd[2] is two double sizes further on in memory than qd[0]. If the size of an int is different from the size of double, as it is on many computers, we could get some rather strange results if we allowed qi to point to the memory allocated for qd.
That’s the “practical explanation.” The theoretical explanation is simply “Allowing assignment of pointers to different types would allow type errors.”
17.4.2 Access through pointers
In addition to using the dereference operator * on a pointer, we can use the subscript operator [ ]. For example:
double* p = new double[4]; // allocate 4 doubles on the free store
double x = *p; // read the (first) object pointed to by p
double y = p[2]; // read the 3rd object pointed to by p
Unsurprisingly, the subscript operator counts from 0 just like vector’s subscript operator, so p[2] refers to the third element; p[0] is the first element so p[0] means exactly the same as *p. The [ ] and * operators can also be used for writing:
*p = 7.7; // write to the (first) object pointed to by p
p[2] = 9.9; // write to the 3rd object pointed to by p
A pointer points to an object in memory. The “contents of” operator (also called the dereference operator) allows us to read and write the object pointed to by a pointer p:
double x = *p; // read the object pointed to by p
*p = 8.8; // write to the object pointed to by p
When applied to a pointer, the [ ] operator treats memory as a sequence of objects (of the type specified by the pointer declaration) with the first one pointed to by a pointer p:
double x = p[3]; // read the 4th object pointed to by p
p[3] = 4.4; // write to the 4th object pointed to by p
double y = p[0]; // p[0] is the same as *p
That’s all. There is no checking, no implementation cleverness, just simple access to our computer’s memory:

This is exactly the simple and optimally efficient mechanism for accessing memory that we need to implement a vector.
17.4.3 Ranges
![]()
The major problem with pointers is that a pointer doesn’t “know” how many elements it points to. Consider:
double* pd = new double[3];
pd[2] = 2.2;
pd[4] = 4.4;
pd[-3] = -3.3;
![]()
Does pd have a third element pd[2]? Does it have a fifth element pd[4]? If we look at the definition of pd, we find that the answers are yes and no, respectively. However, the compiler doesn’t know that; it does not keep track of pointer values. Our code will simply access memory as if we had allocated enough memory. It will even access pd[-3] as if the location three doubles before what pd points to was part of our allocation:

We have no idea what the memory locations marked pd[-3] and pd[4] are used for. However, we do know that they weren’t meant to be used as part of our array of three doubles pointed to by pd. Most likely, they are parts of other objects and we just scribbled all over those. That’s not a good idea. In fact, it is typically a disastrously poor idea: “disastrous” as in “My program crashes mysteriously” or “My program gives wrong output.” Try saying that aloud; it doesn’t sound nice at all. We’ll go a long way to avoid that. Out-of-range access is particularly nasty because apparently unrelated parts of a program are affected. An out-of-range read gives us a “random” value that may depend on some completely unrelated computation. An out-of-range write can put some object into an “impossible” state or simply give it a totally unexpected and wrong value. Such writes typically aren’t noticed until long after they occurred, so they are particularly hard to find. Worse still: run a program with an out-of-range error twice with slightly different input and it may give different results. Bugs of this kind (“transient bugs”) are some of the most difficult bugs to find.
![]()
We have to ensure that such out-of-range access doesn’t happen. One of the reasons we use vector rather than directly using memory allocated by new is that a vector knows its size so that it (or we) can easily prevent out-of-range access.
One thing that can make it hard to prevent out-of-range access is that we can assign one double* to another double* independently of how many objects each points to. A pointer really doesn’t know how many objects it points to. For example:
double* p = new double; // allocate a double
double* q = new double[1000]; // allocate 1000 doubles
q[700] = 7.7; // fine
q = p; // let q point to the same as p
double d = q[700]; // out-of-range access!
Here, in just three lines of code, q[700] refers to two different memory locations, and the last use is an out-of-range access and a likely disaster.
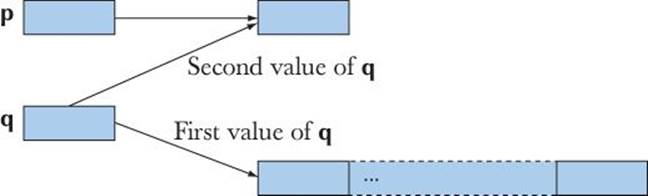
By now, we hope that you are asking, “But why can’t pointers remember the size?” Obviously, we could design a “pointer” that did exactly that — a vector is almost that, and if you look through the C++ literature and libraries, you’ll find many “smart pointers” that compensate for weaknesses of the low-level built-in pointers. However, somewhere we need to reach the hardware level and understand how objects are addressed — and a machine address does not “know” what it addresses. Also, understanding pointers is essential for understanding lots of real-world code.
17.4.4 Initialization
As ever, we would like to ensure that an object has been given a value before we use it; that is, we want to be sure that our pointers are initialized and also that the objects they point to have been initialized. Consider:
double* p0; // uninitialized: likely trouble
double* p1 = new double; // get (allocate) an uninitialized double
double* p2 = new double{5.5}; // get a double initialized to 5.5
double* p3 = new double[5]; // get (allocate) 5 uninitialized doubles
Obviously, declaring p0 without initializing it is asking for trouble. Consider:
*p0 = 7.0;
![]()
![]()
This will assign 7.0 to some location in memory. We have no idea which part of memory that will be. It could be harmless, but never, never ever, rely on that. Sooner or later, we get the same result as for an out-of-range access: “My program crashed mysteriously” or “My program gives wrong output.” A scary percentage of serious problems with old-style C++ programs (“C-style programs”) is caused by access through uninitialized pointers and out-of-range access. We must do all we can to avoid such access, partly because we aim at professionalism, partly because we don’t care to waste our time searching for that kind of error. There are few activities as frustrating and tedious as tracking down this kind of bug. It is much more pleasant and productive to prevent bugs than to hunt for them.
![]()
Memory allocated by new is not initialized for built-in types. If you don’t like that for a single object, you can specify a value, as we did for p2: *p2 is 5.5. Note the use of ( ) for initialization. This contrasts to the use of [ ] to indicate “array.”
We can specify an initializer list for an array of objects allocated by new. For example:
double* p4 = new double[5] {0,1,2,3,4};
double* p5 = new double[] {0,1,2,3,4};
Now p4 points to objects of type double containing the values 0.0, 1.0, 2.0, 3.0, and 4.0. So does p5; the number of elements can be left out when a set of elements is provided.
![]()
As usual, we should worry about uninitialized objects and make sure we give them a value before we read them. Beware that compilers often have a “debug mode” where they by default initialize every variable to a predictable value (often 0). That implies that when turning off the debug features to ship a program, when running an optimizer, or simply when compiling on a different machine, a program with uninitialized variables may suddenly run differently. Don’t get caught with an uninitialized variable.
When we define our own types, we have better control of initialization. If a type X has a default constructor, we get
X* px1 = new X; // one default-initialized X
X* px2 = new X[17]; // 17 default-initialized Xs
If a type Y has a constructor, but not a default constructor, we have to explicitly initialize:
Y* py1 = new Y; // error: no default constructor
Y* py2 = new Y{13}; // OK: initialized to Y{13}
Y* py3 = new Y[17]; // error: no default constructor
Y* py4 = new Y[17] {0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16};
Long initializer lists for new can be impractical, but they can come in very handy when we want just a few elements, and that is typically the most common case.
17.4.5 The null pointer
If you have no other pointer to use for initializing a pointer, use the null pointer, nullptr:
double* p0 = nullptr; // the null pointer
When assigned to a pointer, the value zero is called the null pointer, and often we test whether a pointer is valid (i.e., whether it points to something) by checking whether it is nullptr. For example:
if (p0 != nullptr) // consider p0 valid
This is not a perfect test, because p0 may contain a “random” value that happens to be nonzero (e.g., if we forgot to initialize) or the address of an object that has been deleted (see §17.4.6). However, that’s often the best we can do. We don’t actually have to mention nullptr explicitly because an if-statement really checks whether its condition is nullptr:
if (p0) // consider p0 valid; equivalent to p0!=nullptr
![]()
We prefer this shorter form, considering it a more direct expression of the idea “p0 is valid,” but opinions vary.
We need to use the null pointer when we have a pointer that sometimes points to an object and sometimes not. That’s rarer than many people think; consider: If you don’t have an object for a pointer to point to, why did you define that pointer? Couldn’t you wait until you have an object?
The name nullptr for the null pointer is new in C++11, so in older code, people often use 0 (zero) or NULL instead of nullptr. Both older alternatives can lead to confusion and/or errors, so prefer the more specific nullptr.
17.4.6 Free-store deallocation
The new operator allocates (“gets”) memory from the free store. Since a computer’s memory is limited, it is usually a good idea to return memory to the free store once we are finished using it. That way, the free store can reuse that memory for a new allocation. For large programs and for long-running programs such freeing of memory for reuse is essential. For example:
double* calc(int res_size, int max) // leaks memory
{
double* p = new double[max];
double* res = new double[res_size];
// use p to calculate results to be put in res
return res;
}
double* r = calc(100,1000);
As written, each call of calc() “leaks” the doubles allocated for p. For example, the call calc(100,1000) will render the space needed for 1000 doubles unusable for the rest of the program.
The operator for returning memory to the free store is called delete. We apply delete to a pointer returned by new to make the memory available to the free store for future allocation. The example now becomes
double* calc(int res_size, int max)
// the caller is responsible for the memory allocated for res
{
double* p = new double[max];
double* res = new double[res_size];
// use p to calculate results to be put in res
delete[] p; // we don’t need that memory anymore: free it
return res;
}
double* r = calc(100,1000);
// use r
delete[] r; // we don’t need that memory anymore: free it
Incidentally, this example demonstrates one of the major reasons for using the free store: we can create objects in a function and pass them back to a caller.
There are two forms of delete:
• delete p frees the memory for an individual object allocated by new.
• delete[ ] p frees the memory for an array of objects allocated by new.
It is the programmer’s tedious job to use the right version.
Deleting an object twice is a bad mistake. For example:
![]()
int* p = new int{5};
delete p; // fine: p points to an object created by new
// . . . no use of p here . . .
delete p; // error: p points to memory owned by the free-store manager
There are two problems with the second delete p:
• You don’t own the object pointed to anymore so the free-store manager may have changed its internal data structure in such a way that it can’t correctly execute delete p again.
• The free-store manager may have “recycled” the memory pointed to by p so that p now points to another object; deleting that other object (owned by some other part of the program) will cause errors in your program.
Both problems occur in a real program; they are not just theoretical possibilities.
Deleting the null pointer doesn’t do anything (because the null pointer doesn’t point to an object), so deleting the null pointer is harmless. For example:
int* p = nullptr;
delete p; // fine: no action needed
delete p; // also fine (still no action needed)
Why do we have to bother with freeing memory? Can’t the compiler figure out when we don’t need a piece of memory anymore and just recycle it without human intervention? It can. That’s called automatic garbage collection or just garbage collection. Unfortunately, automatic garbage collection is not cost-free and not ideal for all kinds of applications. If you really need automatic garbage collection, you can plug a garbage collector into your C++ program. Good garbage collectors are available (see www.stroustrup.com/C++.html). However, in this book we assume that you have to deal with your own “garbage,” and we show how to do so conveniently and efficiently.
![]()
When is it important not to leak memory? A program that needs to run “forever” can’t afford any memory leaks. An operating system is an example of a program that “runs forever,” and so are most embedded systems (see Chapter 25). A library should not leak memory because someone might use it as part of a system that shouldn’t leak memory. In general, it is simply a good idea not to leak. Many programmers consider leaks as proof of sloppiness. However, that’s slightly overstating the point. When you run a program under an operating system (Unix, Windows, whatever), all memory is automatically returned to the system at the end of the program. It follows that if you know that your program will not use more memory than is available, you might reasonably decide to “leak” until the operating system does the deallocation for you. However, if you decide to do that, be sure that your memory consumption estimate is correct, or people will have good reason to consider you sloppy.
17.5 Destructors
Now we know how to store the elements for a vector. We simply allocate sufficient space for the elements on the free store and access them through a pointer:
// a very simplified vector of doubles
class vector {
int sz; // the size
double* elem; // a pointer to the elements
public:
vector(int s) // constructor
:sz{s}, // initialize sz
elem{new double[s]} // initialize elem
{
for (int i=0; i<s; ++i) elem[i]=0; // initialize elements
}
int size() const { return sz; } // the current size
// . . .
};
So, sz is the number of elements. We initialize it in the constructor, and a user of vector can get the number of elements by calling size(). Space for the elements is allocated using new in the constructor, and the pointer returned from the free store is stored in the member pointer elem.
Note that we initialize the elements to their default value (0.0). The standard library vector does that, so we thought it best to do the same from the start.
Unfortunately, our first primitive vector leaks memory. In the constructor, it allocates memory for the elements using new. To follow the rule stated in §17.4, we must make sure that this memory is freed using delete. Consider:
void f(int n)
{
vector v(n); // allocate n doubles
// . . .
}
When we leave f(), the elements created on the free store by v are not freed. We could define a clean_up() operation for vector and call that:
void f2(int n)
{
vector v(n); // define a vector (which allocates another n ints)
// . . . use v . . .
v.clean_up(); // clean_up() deletes elem
}
![]()
That would work. However, one of the most common problems with the free store is that people forget to delete. The equivalent problem would arise for clean_up(); people would forget to call it. We can do better than that. The basic idea is to have the compiler know about a function that does the opposite of a constructor, just as it knows about the constructor. Inevitably, such a function is called a destructor. In the same way that a constructor is implicitly called when an object of a class is created, a destructor is implicitly called when an object goes out of scope. A constructor makes sure that an object is properly created and initialized. Conversely, a destructor makes sure that an object is properly cleaned up before it is destroyed. For example:
// a very simplified vector of doubles
class vector {
int sz; // the size
double* elem; // a pointer to the elements
public:
vector(int s) // constructor
:sz{s}, elem{new double[s]} // allocate memory
{
for (int i=0; i<s; ++i) elem[i]=0; // initialize elements
}
~vector() // destructor
{ delete[] elem; } // free memory
// . . .
};
Given that, we can write
void f3(int n)
{
double* p = new double[n]; // allocate n doubles
vector v(n); // the vector allocates n doubles
// . . . use p and v . . .
delete[ ] p; // deallocate p’s doubles
} // vector automatically cleans up after v
Suddenly, that delete[ ] looks rather tedious and error-prone! Given vector, there is no reason to allocate memory using new just to deallocate it using delete[ ] at the end of a function. That’s what vector does and does better. In particular, a vector cannot forget to call its destructor to deallocate the memory used for the elements.
![]()
We are not going to go into great detail about the uses of destructors here, but they are great for handling resources that we need to first acquire (from somewhere) and later give back: files, threads, locks, etc. Remember how iostreams clean up after themselves? They flush buffers, close files, free buffer space, etc. That’s done by their destructors. Every class that “owns” a resource needs a destructor.
17.5.1 Generated destructors
If a member of a class has a destructor, then that destructor will be called when the object containing the member is destroyed. For example:
struct Customer {
string name;
vector<string> addresses;
// . . .
};
void some_fct()
{
Customer fred;
// initialize fred
// use fred
}
When we exit some_fct(), so that fred goes out of scope, fred is destroyed; that is, the destructors for name and addresses are called. This is obviously necessary for destructors to be useful and is sometimes expressed as “The compiler generated a destructor for Customer, which calls the members’ destructors.” That is indeed often how the obvious and necessary guarantee that destructors are called is implemented.
The destructors for members — and for bases — are implicitly called from a derived class destructor (whether user-defined or generated). Basically, all the rules add up to: “Destructors are called when the object is destroyed” (by going out of scope, by delete, etc.).
17.5.2 Destructors and free store
Destructors are conceptually simple but are the foundation for many of the most effective C++ programming techniques. The basic idea is simple:
![]()
• Whatever resources a class object needs to function, it acquires in a constructor.
• During the object’s lifetime it may release resources and acquire new ones.
• At the end of the object’s lifetime, the destructor releases all resources still owned by the object.
The matched constructor/destructor pair handling free-store memory for vector is the archetypical example. We’ll get back to that idea with more examples in §19.5. Here, we will examine an important application that comes from the use of free-store and class hierarchies in combination. Consider:
Shape* fct()
{
Text tt {Point{200,200},"Annemarie"};
// . . .
Shape* p = new Text{Point{100,100},"Nicholas"};
return p;
}
void f()
{
Shape* q = fct();
// . . .
delete q;
}
This looks fairly plausible — and it is. It all works, but let’s see how, because that exposes an elegant, important, simple technique. Inside fct(), the Text (§13.11) object tt is properly destroyed at the exit from fct(). Text has a string member, which obviously needs to have its destructor called — string handles its memory acquisition and release exactly like vector. For tt, that’s easy; the compiler just calls Text’s generated destructor as described in §17.5.1. But what about the Text object that was returned from fct()? The calling function f() has no idea that q points to a Text; all it knows is that it points to a Shape. Then how does delete q get to call Text’s destructor?
In §14.2.1, we breezed past the fact that Shape has a destructor. In fact, Shape has a virtual destructor. That’s the key. When we say delete q, delete looks at q’s type to see if it needs to call a destructor, and if so it calls it. So, delete q calls Shape’s destructor ~Shape(). But ~Shape() isvirtual, so — using the virtual call mechanism (§14.3.1) — that call invokes the destructor of Shape’s derived class, in this case ~Text(). Had Shape::~Shape() not been virtual, Text::~Text() would not have been called and Text’s string member wouldn’t have been properly destroyed.
![]()
As a rule of thumb: if you have a class with a virtual function, it needs a virtual destructor. The reason is:
1. If a class has a virtual function it is likely to be used as a base class, and
2. If it is a base class its derived class is likely to be allocated using new, and
3. If a derived class object is allocated using new and manipulated through a pointer to its base, then
4. It is likely to be deleted through a pointer to its base
Note that destructors are invoked implicitly or indirectly through delete. They are not called directly. That saves a lot of tricky work.
Try This
Write a little program using base classes and members where you define the constructors and destructors to output a line of information when they are called. Then, create a few objects and see how their constructors and destructors are called.
17.6 Access to elements
For vector to be usable, we need a way to read and write elements. For starters, we can provide simple get() and set() member functions:
// a very simplified vector of doubles
class vector {
int sz; // the size
double* elem; // a pointer to the elements
public:
vector(int s) :sz{s}, elem{new double[s]} { /* . . . */ } // constructor
~vector() { delete[] elem; } // destructor
int size() const { return sz; } // the current size
double get(int n) const { return elem[n]; } // access: read
void set(int n, double v) { elem[n]=v; } // access: write
};
Both get() and set() access the elements using the [ ] operator on the elem pointer: elem[n].
Now we can make a vector of doubles and use it:
vector v(5);
for (int i=0; i<v.size(); ++i) {
v.set(i,1.1*i);
cout << "v[" << i << "]==" << v.get(i) << '\n';
}
This will output
v[0]==0
v[1]==1.1
v[2]==2.2
v[3]==3.3
v[4]==4.4
This is still an overly simple vector, and the code using get() and set() is rather ugly compared to the usual subscript notation. However, we aim to start small and simple and then grow our programs step by step, testing along the way. As ever, this strategy of growth and repeated testing minimizes errors and debugging.
17.7 Pointers to class objects
The notion of “pointer” is general, so we can point to just about anything we can place in memory. For example, we can use pointers to vectors exactly as we use pointers to chars:
vector* f(int s)
{
vector* p = new vector(s); // allocate a vector on free store
// fill *p
return p;
}
void ff()
{
vector* q = f(4);
// use *q
delete q; // free vector on free store
}
Note that when we delete a vector, its destructor is called. For example:
vector* p = new vector(s); // allocate a vector on free store
delete p; // deallocate
Creating the vector on the free store, the new operator
• First allocates memory for a vector
• Then invokes the vector’s constructor to initialize that vector; the constructor allocates memory for the vector’s elements and initializes those elements
Deleting the vector, the delete operator
• First invokes the vector’s destructor; the destructor invokes the destructors for the elements (if they have destructors) and then deallocates the memory used for the vector’s elements
• Then deallocates the memory used for the vector
Note how nicely that works recursively (see §8.5.8). Using the real (standard library) vector we can also do
vector<vector<double>>* p = new vector<vector<double>>(10);
delete p;
Here, delete p invokes the destructor for vector<vector<double>>; this destructor in turn invokes the destructor for its vector<double> elements, and all is neatly cleaned up, leaving no object undestroyed and leaking no memory.
Because delete invokes destructors (for types, such as vector, that have one), delete is often said to destroy objects, not just deallocate them.
![]()
As usual, please remember that a “naked” new outside a constructor is an opportunity to forget to delete the object that new created. Unless you have a good (that is, really simple, such as Vector_ref from §13.10 and §E.4) strategy for deleting objects, try to keep news in constructors anddeletes in destructors.
So far, so good, but how do we access the members of a vector, given only a pointer? Note that all classes support the operator . (dot) for accessing members, given the name of an object:
vector v(4);
int x = v.size();
double d = v.get(3);
Similarly, all classes support the operator -> (arrow) for accessing members, given a pointer to an object:
vector* p = new vector(4);
int x = p->size();
double d = p->get(3);
Like . (dot), -> (arrow) can be used for both data members and function members. Since built-in types, such as int and double, have no members, -> doesn’t apply to built-in types. Dot and arrow are often called member access operators.
17.8 Messing with types: void* and casts
Using pointers and free-store-allocated arrays, we are very close to the hardware. Basically, our operations on pointers (initialization, assignment, *, and [ ]) map directly to machine instructions. At this level, the language offers only a bit of notational convenience and the compile-time consistency offered by the type system. Occasionally, we have to give up even that last bit of protection.
Naturally, we don’t want to make do without the protection of the type system, but sometimes there is no logical alternative (e.g., we need to interact with another language that doesn’t know about C++’s types). There are also an unfortunate number of cases where we need to interface with old code that wasn’t designed with static type safety in mind. For that, we need two things:
• A type of pointer that points to memory without knowing what kinds of objects reside in that memory
• An operation to tell the compiler what kind of type to assume (without proof) for memory pointed to by one of those pointers
![]()
The type void* means “pointer to some memory that the compiler doesn’t know the type of.” We use void* when we want to transmit an address between pieces of code that really don’t know each other’s types. Examples are the “address” arguments of a callback function (§16.3.1) and the lowest level of memory allocators (such as the implementation of the new operator).
There are no objects of type void, but as we have seen, we use void to mean “no value returned”:
void v; // error: there are no objects of type void
void f(); // f() returns nothing — f() does not return an object of type void
A pointer to any object type can be assigned to a void*. For example:
void* pv1 = new int; // OK: int* converts to void*
void* pv2 = new double[10]; // OK: double* converts to void*
Since the compiler doesn’t know what a void* points to, we must tell it:
void f(void* pv)
{
void* pv2 = pv; // copying is OK (copying is what void*s are for)
double* pd = pv; // error: cannot convert void* to double*
*pv = 7; // error: cannot dereference a void*
// (we don’t know what type of object it points to)
pv[2] = 9; // error: cannot subscript a void*
int* pi = static_cast<int*>(pv); // OK: explicit conversion
// . . .
}
![]()
A static_cast can be used to explicitly convert between related pointer types, such as void* and double* (§A.5.7). The name static_cast is a deliberately ugly name for an ugly (and dangerous) operation — use it only when absolutely necessary. You shouldn’t find it necessary very often — if at all. An operation such as static_cast is called an explicit type conversion (because that’s what it does) or colloquially a cast (because it is used to support something that’s broken).
C++ offers two casts that are potentially even nastier than static_cast:
• reinterpret_cast can cast between unrelated types, such as int and double*.
• const_cast can “cast away const.”
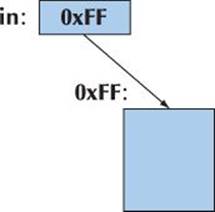
For example:
Register* in = reinterpret_cast<Register*>(0xff);
void f(const Buffer* p)
{
Buffer* b = const_cast<Buffer*>(p);
// . . .
}
The first example is the classical necessary and proper use of a reinterpret_cast. We tell the compiler that a certain part of memory (the memory starting with location 0xFF) is to be considered a Register (presumably with special semantics). Such code is necessary when you write things like device drivers.
![]()
In the second example, const_cast strips the const from the const Buffer* called p. Presumably, we know what we are doing.
![]()
At least static_cast can’t mess with the pointer/integer distinction or with “const-ness,” so prefer static_cast if you feel the need for a cast. When you think you need a cast, reconsider: Is there a way to write the code without the cast? Is there a way to redesign that part of the program so that the cast is not needed? Unless you are interfacing to other people’s code or to hardware, there usually is a way. If not, expect subtle and nasty bugs. Don’t expect code using reinterpret_cast to be portable.
17.9 Pointers and references
You can think of a reference as an automatically dereferenced immutable pointer or as an alternative name for an object. Pointers and references differ in these ways:
![]()
• Assignment to a pointer changes the pointer’s value (not the pointed-to value).
• To get a pointer you generally need to use new or &.
• To access an object pointed to by a pointer you use * or [ ].
• Assignment to a reference changes the value of the object referred to (not the reference itself).
• You cannot make a reference refer to a different object after initialization.
• Assignment of references does deep copy (assigns to the referred-to object); assignment of pointers does not (assigns to the pointer object itself).
• Beware of null pointers.
For example:
int x = 10;
int* p = &x; // you need & to get a pointer
*p = 7; // use * to assign to x through p
int x2 = *p; // read x through p
int* p2 = &x2; // get a pointer to another int
p2 = p; // p2 and p both point to x
p = &x2; // make p point to another object
The corresponding example for references is
int y = 10;
int& r = y; // the & is in the type, not in the initializer
r = 7; // assign to y through r (no * needed)
int y2 = r; // read y through r (no * needed)
int& r2 = y2; // get a reference to another int
r2 = r; // the value of y is assigned to y2
r = &y2; // error: you can’t change the value of a reference
// (no assignment of an int* to an int&)
Note the last example; it is not just this construct that will fail — there is no way to get a reference to refer to a different object after initialization. If you need to point to something different, use a pointer. For ideas of how to use pointers, see §17.9.3.
A reference and a pointer are both implemented by using a memory address. They just use that address differently to provide you — the programmer — slightly different facilities.
17.9.1 Pointer and reference parameters
When you want to change the value of a variable to a value computed by a function, you have three choices. For example:
int incr_v(int x) { return x+1; } // compute a new value and return it
void incr_p(int* p) { ++*p; } // pass a pointer
// (dereference it and increment the result)
void incr_r(int& r) { ++r; } // pass a reference
How do you choose? We think returning the value often leads to the most obvious (and therefore least error-prone) code; that is:
int x = 2;
x = incr_v(x); // copy x to incr_v(); then copy the result out and assign it
We prefer that style for small objects, such as an int. In addition, if a “large object” has a move constructor (§18.3.4) we can efficiently pass it back and forth.
How do we choose between using a reference argument and using a pointer argument? Unfortunately, either way has both attractions and problems, so again the answer is less than clear-cut. You have to make a decision based on the individual function and its likely uses.
Using a pointer argument alerts the programmer that something might be changed. For example:
int x = 7;
incr_p(&x) // the & is needed
incr_r(x);
The need to use & in incr_p(&x) alerts the user that x might be changed. In contrast, incr_r(x) “looks innocent.” This leads to a slight preference for the pointer version.
![]()
On the other hand, if you use a pointer as a function argument, the function has to beware that someone might call it with a null pointer, that is, with a nullptr. For example:
incr_p(nullptr); // crash: incr_p() will try to dereference the null pointer
int* p = nullptr;
incr_p(p); // crash: incr_p() will try to dereference the null pointer
This is obviously nasty. The person who writes incr_p() can protect against this:
void incr_p(int* p)
{
if (p==nullptr) error("null pointer argument to incr_p()");
++*p; // dereference the pointer and increment the object pointed to
}
But now incr_p() suddenly doesn’t look as simple and attractive as before. Chapter 5 discusses how to cope with bad arguments. In contrast, users of a reference (such as incr_r()) are entitled to assume that a reference refers to an object.
If “passing nothing” (passing no object) is acceptable from the point of view of the semantics of the function, we must use a pointer argument. Note: That’s not the case for an increment operation — hence the need for throwing an exception for p==nullptr.
So, the real answer is: “The choice depends on the nature of the function”:
![]()
• For tiny objects prefer pass-by-value.
• For functions where “no object” (represented by nullptr) is a valid argument use a pointer parameter (and remember to test for nullptr).
• Otherwise, use a reference parameter.
See also §8.5.6.
17.9.2 Pointers, references, and inheritance
In §14.3, we saw how a derived class, such as Circle, could be used where an object of its public base class Shape was required. We can express that idea in terms of pointers or references: a Circle* can be implicitly converted to a Shape* because Shape is a public base of Circle. For example:
void rotate(Shape* s, int n); // rotate *s n degrees
Shape* p = new Circle{Point{100,100},40};
Circle c {Point{200,200},50};
rotate(p,35);
rotate(&c,45);
And similarly for references:
void rotate(Shape& s, int n); // rotate s n degrees
Shape& r = c;
rotate(r,55);
rotate(*p,65);
rotate(c,75);
This is crucial for most object-oriented programming techniques (§14.3-4).
17.9.3 An example: lists
Lists are among the most common and useful data structures. Usually, a list is made out of “links” where each link holds some information and pointers to other links. This is one of the classical uses of pointers. For example, we could represent a short list of Norse gods like this:
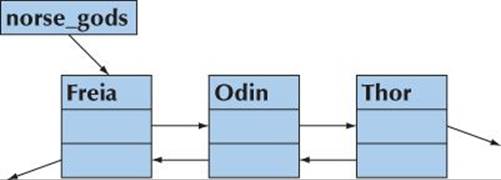
![]()
A list like this is called a doubly-linked list because given a link, we can find both the predecessor and the successor. A list where we can find only the successor is called a singly-linked list. We use doubly-linked lists when we want to make it easy to remove an element. We can define these links like this:
struct Link {
string value;
Link* prev;
Link* succ;
Link(const string& v, Link* p = nullptr, Link* s = nullptr)
: value{v}, prev{p}, succ{s} { }
};
That is, given a Link, we can get to its successor using the succ pointer and to its predecessor using the prev pointer. We use the null pointer to indicate that a Link doesn’t have a successor or a predecessor. We can build our list of Norse gods like this:
Link* norse_gods = new Link{"Thor",nullptr,nullptr};
norse_gods = new Link{"Odin",nullptr,norse_gods};
norse_gods->succ->prev = norse_gods;
norse_gods = new Link{"Freia",nullptr,norse_gods};
norse_gods->succ->prev = norse_gods;
We built that list by creating the Links and tying them together as in the picture: first Thor, then Odin as the predecessor of Thor, and finally Freia as the predecessor of Odin. You can follow the pointer to see that we got it right, so that each succ and prev points to the right god. However, the code is obscure because we didn’t explicitly define and name an insert operation:
Link* insert(Link* p, Link* n) // insert n before p (incomplete)
{
n->succ = p; // p comes after n
p->prev->succ = n; // n comes after what used to be p’s predecessor
n->prev = p->prev; // p’s predecessor becomes n’s predecessor
p->prev = n; // n becomes p’s predecessor
return n;
}
This works provided that p really points to a Link and that the Link pointed to by p really has a predecessor. Please convince yourself that this really is so. When thinking about pointers and linked structures, such as a list made out of Links, we invariably draw little box-and-arrow diagrams on paper to verify that our code works for small examples. Please don’t be too proud to rely on this effective low-tech design technique.
That version of insert() is incomplete because it doesn’t handle the cases where n, p, or p->prev is nullptr. We add the appropriate tests for the null pointer and get the messier, but correct, version:
Link* insert(Link* p, Link* n) // insert n before p; return n
{
if (n==nullptr) return p;
if (p==nullptr) return n;
n->succ = p; // p comes after n
if (p->prev) p->prev->succ = n;
n->prev = p->prev; // p’s predecessor becomes n’s predecessor
p->prev = n; // n becomes p’s predecessor
return n;
}
Given that, we could write
Link* norse_gods = new Link{"Thor"};
norse_gods = insert(norse_gods,new Link{"Odin"});
norse_gods = insert(norse_gods,new Link{"Freia"});
![]()
Now all the error-prone fiddling with the prev and succ pointers has disappeared from sight. Pointer fiddling is tedious and error-prone and should be hidden in well-written and well-tested functions. In particular, many errors in conventional code come from people forgetting to test pointers against nullptr — just as we (deliberately) did in the first version of insert().
Note that we used default arguments (§15.3.1, §A.9.2) to save users from mentioning predecessors and successors in every constructor use.
17.9.4 List operations
The standard library provides a list class, which we will describe in §20.4. It hides all link manipulation, but here we will elaborate on our notion of list based on the Link class to get a feel for what goes on “under the covers” of list classes and see more examples of pointer use.
What operations does our Link class need to allow its users to avoid “pointer fiddling”? That’s to some extent a matter of taste, but here is a useful set:
• The constructor
• insert: insert before an element
• add: insert after an element
• erase: remove an element
• find: find a Link with a given value
• advance: get the nth successor
We could write these operations like this:
Link* add(Link* p, Link* n) // insert n after p; return n
{
// much like insert (see exercise 11)
}
Link* erase(Link* p) // remove *p from list; return p’s successor
{
if (p==nullptr) return nullptr;
if (p->succ) p->succ->prev = p->prev;
if (p->prev) p->prev->succ = p->succ;
return p->succ;
}
Link* find(Link* p, const string& s) // find s in list;
// return nullptr for “not found”
{
while (p) {
if (p->value == s) return p;
p = p->succ;
}
return nullptr;
}
Link* advance(Link* p, int n) // move n positions in list
// return nullptr for “not found”
// positive n moves forward, negative backward
{
if (p==nullptr) return nullptr;
if (0<n) {
while (n--) {
if (p->succ == nullptr) return nullptr;
p = p->succ;
}
}
else if (n<0) {
while (n++) {
if (p->prev == nullptr) return nullptr;
p = p->prev;
}
}
return p;
}
Note the use of the postfix n++. This form of increment (“post-increment”) yields the value before the increment as its value.
17.9.5 List use
As a little exercise, let’s build two lists:
Link* norse_gods = new Link("Thor");
norse_gods = insert(norse_gods,new Link{"Odin"});
norse_gods = insert(norse_gods,new Link{"Zeus"});
norse_gods = insert(norse_gods,new Link{"Freia"});
Link* greek_gods = new Link("Hera");
greek_gods = insert(greek_gods,new Link{"Athena"});
greek_gods = insert(greek_gods,new Link{"Mars"});
greek_gods = insert(greek_gods,new Link{"Poseidon"});
“Unfortunately,” we made a couple of mistakes: Zeus is a Greek god, rather than a Norse god, and the Greek god of war is Ares, not Mars (Mars is his Latin/Roman name). We can fix that:
Link* p = find(greek_gods, "Mars");
if (p) p->value = "Ares";
Note how we were cautious about find() returning a nullptr. We think that we know that it can’t happen in this case (after all, we just inserted Mars into greek_gods), but in a real example someone might change that code.
Similarly, we can move Zeus into his correct Pantheon:
Link* p = find(norse_gods,"Zeus");
if (p) {
erase(p);
insert(greek_gods,p);
}
Did you notice the bug? It’s quite subtle (unless you are used to working directly with links). What if the Link we erase() is the one pointed to by norse_gods? Again, that doesn’t actually happen here, but to write good, maintainable code, we have to take that possibility into account:
Link* p = find(norse_gods, "Zeus");
if (p) {
if (p==norse_gods) norse_gods = p->succ;
erase(p);
greek_gods = insert(greek_gods,p);
}
While we were at it, we also corrected the second bug: when we insert Zeus before the first Greek god, we need to make greek_gods point to Zeus’s Link. Pointers are extremely useful and flexible, but subtle.
Finally, let’s print out those lists:
void print_all(Link* p)
{
cout << "{ ";
while (p) {
cout << p->value;
if (p=p->succ) cout << ", ";
}
cout << " }";
}
print_all(norse_gods);
cout<<"\n";
print_all(greek_gods);
cout<<"\n";
This should give
{ Freia, Odin, Thor }
{ Zeus, Poseidon, Ares, Athena, Hera }
17.10 The this pointer
Note that each of our list functions takes a Link* as its first argument and accesses data in that object. That’s the kind of function that we often make member functions. Could we simplify Link (or link use) by making the operations members? Could we maybe make the pointers private so that only the member functions have access to them? We could:
class Link {
public:
string value;
Link(const string& v, Link* p = nullptr, Link* s = nullptr)
: value{v}, prev{p}, succ{s} { }
Link* insert(Link* n) ; // insert n before this object
Link* add(Link* n) ; // insert n after this object
Link* erase() ; // remove this object from list
Link* find(const string& s); // find s in list
const Link* find(const string& s) const; // find s in const list (see §18.5.1)
Link* advance(int n) const; // move n positions in list
Link* next() const { return succ; }
Link* previous() const { return prev; }
private:
Link* prev;
Link* succ;
};
This looks promising. We defined the operations that don’t change the state of a Link into const member functions. We added (nonmodifying) next() and previous() functions so that users could iterate over lists (of Links) — those are needed now that direct access to succ and prev is prohibited. We left value as a public member because (so far) we have no reason not to; it is “just data.”
Now let’s try to implement Link::insert() by copying our previous global insert() and modifying it suitably:
Link* Link::insert(Link* n) // insert n before p; return n
{
Link* p = this; // pointer to this object
if (n==nullptr) return p; // nothing to insert
if (p==nullptr) return n; // nothing to insert into
n->succ = p; // p comes after n
if (p->prev) p->prev->succ = n;
n->prev = p->prev; // p’s predecessor becomes n’s predecessor
p->prev = n; // n becomes p’s predecessor
return n;
}
![]()
But how do we get a pointer to the object for which Link::insert() was called? Without help from the language we can’t. However, in every member function, the identifier this is a pointer that points to the object for which the member function was called. Alternatively, we could simply usethis instead of p:
Link* Link::insert(Link* n) // insert n before this object; return n
{
if (n==nullptr) return this;
if (this==nullptr) return n;
n->succ = this; // this object comes after n
if (this->prev) this->prev->succ = n;
n->prev = this->prev; // this object’s predecessor
// becomes n’s predecessor
this->prev = n; // n becomes this object’s predecessor
return n;
}
This is a bit verbose, but we don’t need to mention this to access a member, so we can abbreviate:
Link* Link::insert(Link* n) // insert n before this object; return n
{
if (n==nullptr) return this;
if (this==nullptr) return n;
n->succ = this; // this object comes after n
if (prev) prev->succ = n;
n->prev = prev; // this object’s predecessor becomes n’s predecessor
prev = n; // n becomes this object’s predecessor
return n;
}
In other words, we have been using the this pointer — the pointer to the current object — implicitly every time we accessed a member. It is only when we need to refer to the whole object that we need to mention it explicitly.
Note that this has a specific meaning: it points to the object for which a member function is called. It does not point to any old object. The compiler ensures that we do not change the value of this in a member function. For example:
struct S {
// . . .
void mutate(S* p)
{
this = p; // error: this is immutable
// . . .
}
};
17.10.1 More link use
Having dealt with the implementation issues, we can see how the use now looks:
Link* norse_gods = new Link{"Thor"};
norse_gods = norse_gods->insert(new Link{"Odin"});
norse_gods = norse_gods->insert(new Link{"Zeus"});
norse_gods = norse_gods->insert(new Link{"Freia"});
Link* greek_gods = new Link{"Hera"};
greek_gods = greek_gods->insert(new Link{"Athena"});
greek_gods = greek_gods->insert(new Link{"Mars"});
greek_gods = greek_gods->insert(new Link{"Poseidon"});
That’s very much like before. As before, we correct our “mistakes.” Correct the name of the god of war:
Link* p = greek_gods->find("Mars");
if (p) p->value = "Ares";
Move Zeus into his correct Pantheon:
Link* p2 = norse_gods->find("Zeus");
if (p2) {
if (p2==norse_gods) norse_gods = p2->next();
p2->erase();
greek_gods = greek_gods->insert(p2);
}
Finally, let’s print out those lists:
void print_all(Link* p)
{
cout << "{ ";
while (p) {
cout << p->value;
if (p=p->next()) cout << ", ";
}
cout << " }";
}
print_all(norse_gods);
cout<<"\n";
print_all(greek_gods);
cout<<"\n";
This should again give
{ Freia, Odin, Thor }
{ Zeus, Poseidon, Ares, Athena, Hera }
So, which version do you like better: the one where insert(), etc. are member functions or the one where they are freestanding functions? In this case the differences don’t matter much, but see §9.7.5.
![]()
One thing to observe here is that we still don’t have a list class, only a link class. That forces us to keep worrying about which pointer is the pointer to the first element. We can do better than that — by defining a class List — but designs along the lines presented here are very common. The standard library list is presented in §20.4.
 Drill
Drill
This drill has two parts. The first exercises/builds your understanding of free-store-allocated arrays and contrasts arrays with vectors:
1. Allocate an array of ten ints on the free store using new.
2. Print the values of the ten ints to cout.
3. Deallocate the array (using delete[]).
4. Write a function print_array10(ostream& os, int* a) that prints out the values of a (assumed to have ten elements) to os.
5. Allocate an array of ten ints on the free store; initialize it with the values 100, 101, 102, etc.; and print out its values.
6. Allocate an array of 11 ints on the free store; initialize it with the values 100, 101, 102, etc.; and print out its values.
7. Write a function print_array(ostream& os, int* a, int n) that prints out the values of a (assumed to have n elements) to os.
8. Allocate an array of 20 ints on the free store; initialize it with the values 100, 101, 102, etc.; and print out its values.
9. Did you remember to delete the arrays? (If not, do it.)
10. Do 5, 6, and 8 using a vector instead of an array and a print_vector() instead of print_array().
The second part focuses on pointers and their relation to arrays. Using print_array() from the last drill:
1. Allocate an int, initialize it to 7, and assign its address to a variable p1.
2. Print out the value of p1 and of the int it points to.
3. Allocate an array of seven ints; initialize it to 1, 2, 4, 8, etc.; and assign its address to a variable p2.
4. Print out the value of p2 and of the array it points to.
5. Declare an int* called p3 and initialize it with p2.
6. Assign p1 to p2.
7. Assign p3 to p2.
8. Print out the values of p1 and p2 and of what they point to.
9. Deallocate all the memory you allocated from the free store.
10. Allocate an array of ten ints; initialize it to 1, 2, 4, 8, etc.; and assign its address to a variable p1.
11. Allocate an array of ten ints, and assign its address to a variable p2.
12. Copy the values from the array pointed to by p1 into the array pointed to by p2.
13. Repeat 10-12 using a vector rather than an array.
Review
1. Why do we need data structures with varying numbers of elements?
2. What four kinds of storage do we have for a typical program?
3. What is the free store? What other name is commonly used for it? What operators support it?
4. What is a dereference operator and why do we need one?
5. What is an address? How are memory addresses manipulated in C++?
6. What information about a pointed-to object does a pointer have? What useful information does it lack?
7. What can a pointer point to?
8. What is a leak?
9. What is a resource?
10. How can we initialize a pointer?
11. What is a null pointer? When do we need to use one?
12. When do we need a pointer (instead of a reference or a named object)?
13. What is a destructor? When do we want one?
14. When do we want a virtual destructor?
15. How are destructors for members called?
16. What is a cast? When do we need to use one?
17. How do we access a member of a class through a pointer?
18. What is a doubly-linked list?
19. What is this and when do we need to use it?
Terms
address
address of: &
allocation
cast
container
contents of: *
deallocationa
delete
delete[]
dereference
destructor
free store
link
list
member access: ->
member destructor
memory
memory leak
new
null pointer
nullptr
pointer
range
resource leak
subscripting
subscript: [ ]
this
type conversion
virtual destructor
void*
Exercises
1. What is the output format of pointer values on your implementation? Hint: Don’t read the documentation.
2. How many bytes are there in an int? In a double? In a bool? Do not use sizeof except to verify your answer.
3. Write a function, void to_lower(char* s), that replaces all uppercase characters in the C-style string s with their lowercase equivalents. For example, Hello, World! becomes hello, world!. Do not use any standard library functions. A C-style string is a zero-terminated array of characters, so if you find a char with the value 0 you are at the end.
4. Write a function, char* strdup(const char*), that copies a C-style string into memory it allocates on the free store. Do not use any standard library functions.
5. Write a function, char* findx(const char* s, const char* x), that finds the first occurrence of the C-style string x in s.
6. This chapter does not say what happens when you run out of memory using new. That’s called memory exhaustion. Find out what happens. You have two obvious alternatives: look for documentation, or write a program with an infinite loop that allocates but never deallocates. Try both. Approximately how much memory did you manage to allocate before failing?
7. Write a program that reads characters from cin into an array that you allocate on the free store. Read individual characters until an exclamation mark (!) is entered. Do not use a std::string. Do not worry about memory exhaustion.
8. Do exercise 7 again, but this time read into a std::string rather than to memory you put on the free store (string knows how to use the free store for you).
9. Which way does the stack grow: up (toward higher addresses) or down (toward lower addresses)? Which way does the free store initially grow (that is, before you use delete)? Write a program to determine the answers.
10. Look at your solution of exercise 7. Is there any way that input could get the array to overflow; that is, is there any way you could enter more characters than you allocated space for (a serious error)? Does anything reasonable happen if you try to enter more characters than you allocated?
11. Complete the “list of gods” example from §17.10.1 and run it.
12. Why did we define two versions of find()?
13. Modify the Link class from §17.10.1 to hold a value of a struct God. struct God should have members of type string: name, mythology, vehicle, and weapon. For example, God{"Zeus", "Greek", "", "lightning"} and God{"Odin", "Norse", "Eight-legged flying horse called Sleipner", "Spear called Gungnir"}. Write a print_all() function that lists gods with their attributes one per line. Add a member function add_ordered() that places its new element in its correct lexicographical position. Using the Links with the values of type God, make a list of gods from three mythologies; then move the elements (gods) from that list to three lexicographically ordered lists — one for each mythology.
14. Could the “list of gods” example from §17.10.1 have been written using a singly-linked list; that is, could we have left the prev member out of Link? Why might we want to do that? For what kind of examples would it make sense to use a singly-linked list? Re-implement that example using only a singly-linked list.
Postscript
Why bother with messy low-level stuff like pointers and free store when we can simply use vector? Well, one answer is that someone has to design and implement vector and similar abstractions, and we’d like to know how that’s done. There are programming languages that don’t provide facilities equivalent to pointers and thus dodge the problems with low-level programming. Basically, programmers of such languages delegate the tasks that involve direct access to hardware to C++ programmers (and programmers of other languages suitable for low-level programming). Our favorite reason, however, is simply that you can’t really claim to understand computers and programming until you have seen how software meets hardware. People who don’t know about pointers, memory addresses, etc. often have the strangest ideas of how their programming language facilities work; such wrong ideas can lead to code that’s “interestingly poor.”
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.