Programming: Principles and Practice Using C++ (2014)
Part III: Data and Algorithms
19. Vector, Templates, and Exceptions
“Success is never final.”
—Winston Churchill
This chapter completes the design and implementation of the most common and most useful STL container: vector. Here, we show how to implement containers where the number of elements can vary, how to specify containers where the element type is a parameter, and how to deal with range errors. As usual, the techniques used are generally applicable, rather than simply restricted to the implementation of vector, or even to the implementation of containers. Basically, we show how to deal safely with varying amounts of data of a variety of types. In addition, we add a few doses of realism as design lessons. The techniques rely on templates and exceptions, so we show how to define templates and give the basic techniques for resource management that are the keys to good use of exceptions.
19.1 The problems
19.2 Changing size
19.2.1 Representation
19.2.2 reserve and capacity
19.2.3 resize
19.2.4 push_back
19.2.5 Assignment
19.2.6 Our vector so far
19.3 Templates
19.3.1 Types as template parameters
19.3.2 Generic programming
19.3.3 Concepts
19.3.4 Containers and inheritance
19.3.5 Integers as template parameters
19.3.6 Template argument deduction
19.3.7 Generalizing vector
19.4 Range checking and exceptions
19.4.1 An aside: design considerations
19.4.2 A confession: macros
19.5 Resources and exceptions
19.5.1 Potential resource management problems
19.5.2 Resource acquisition is initialization
19.5.3 Guarantees
19.5.4 unique_ptr
19.5.5 Return by moving
19.5.6 RAII for vector
19.1 The problems
At the end of Chapter 18, our vector reached the point where we can
• Create vectors of double-precision floating-point elements (objects of class vector) with whatever number of elements we want
• Copy our vectors using assignment and initialization
• Rely on vectors to correctly release their memory when they go out of scope
• Access vector elements using the conventional subscript notation (on both the right-hand side and the left-hand side of an assignment)
That’s all good and useful, but to reach the level of sophistication we expect (based on experience with the standard library vector), we need to address three more concerns:
• How do we change the size of a vector (change the number of elements)?
• How do we catch and report out-of-range vector element access?
• How do we specify the element type of a vector as an argument?
For example, how do we define vector so that this is legal:
vector<double> vd; // elements of type double
for (double d; cin>>d; )
vd.push_back(d); // grow vd to hold all the elements
vector<char> vc(100); // elements of type char
int n;
cin>>n;
vc.resize(n); // make vc have n elements
![]()
Obviously, it is nice and useful to have vectors that allow this, but why is it important from a programming point of view? What makes it interesting to someone collecting useful programming techniques for future use? We are using two kinds of flexibility. We have a single entity, the vector, for which we can vary two things:
• The number of elements
• The type of elements
Those kinds of variability are useful in rather fundamental ways. We always collect data. Looking around my desk, I see piles of bank statements, credit card bills, and phone bills. Each of those is basically a list of lines of information of various types: strings of letters and numeric values. In front of me lies a phone; it keeps lists of phone numbers and names. In the bookcases across the room, there is shelf after shelf of books. Our programs tend to be similar: we have containers of elements of various types. We have many different kinds of containers (vector is just the most widely useful), and they contain information such as phone numbers, names, transaction amounts, and documents. Essentially all the examples from my desk and my room originated in some computer program or another. The obvious exception is the phone: it is a computer, and when I look at the numbers on it I’m looking at the output of a program just like the ones we’re writing. In fact, those numbers may very well be stored in a vector<Number>.
Obviously, not all containers have the same number of elements. Could we live with a vector that had its size fixed by its initial definition; that is, could we write our code without push_back(), resize(), and equivalent operations? Sure we could, but that would put an unnecessary burden on the programmer: the basic trick for living with fixed-size containers is to move the elements to a bigger container when the number of elements grows too large for the initial size. For example, we could read into a vector without ever changing the size of a vector like this:
// read elements into a vector without using push_back:
vector<double>* p = new vector<double>(10);
int n = 0; // number of elements
for (double d; cin>>d; ) {
if (n==p->size()) {
vector<double>* q = new vector<double>(p->size()*2);
copy(p->begin(), p->end(), q->begin());
delete p;
p = q;
}
(*p)[n] = d;
++n;
}
That’s not pretty. Are you convinced that we got it right? How can you be sure? Note how we suddenly started to use pointers and explicit memory management. What we did was to imitate the style of programming we have to use when we are “close to the machine,” using only the basic memory management techniques dealing with fixed-size objects (arrays; see §18.6). One of the reasons to use containers, such as vector, is to do better than that; that is, we want vector to handle such size changes internally to save us — its users — the bother and the chance to make mistakes. In other words, we prefer containers that can grow to hold the exact number of elements we happen to need. For example:
vector<double> vd;
for (double d; cin>>d; ) vd.push_back(d);
![]()
Are such changes of size common? If they are not, facilities for changing size are simply minor conveniences. However, such size changes are very common. The most obvious example is reading an unknown number of values from input. Other examples are collecting a set of results from a search (we don’t in advance know how many results there will be) and removing elements from a collection one by one. Thus, the question is not whether we should handle size changes for containers, but how.
![]()
Why do we bother with changing sizes at all? Why not “just allocate enough space and be done with it!”? That appears to be the simplest and most efficient strategy. However, it is that only if we can reliably allocate enough space without allocating grossly too much space — and we can’t. People who try that tend to have to rewrite code (if they carefully and systematically checked for overflows) and deal with disasters (if they were careless with their checking).
Obviously, not all vectors have the same type of elements. We need vectors of doubles, temperature readings, records (of various kinds), strings, operations, GUI buttons, shapes, dates, pointers to windows, etc. The possibilities are endless.
There are many kinds of containers. This is an important point, and because it has important implications it should not be accepted without thought. Why can’t all containers be vectors? If we could make do with a single kind of container (e.g., vector), we could dispense with all the concerns about how to program it and just make it part of the language. If we could make do with a single kind of container, we needn’t bother learning about different kinds of containers; we’d just use vector all the time.
Well, data structures are the key to most significant applications. There are many thick and useful books about how to organize data, and much of that information could be described as answers to the question “How do I best store my data?” So, the answer is that we need many different kinds of containers, but it is too large a subject to adequately address here. However, we have already used vectors and strings (a string is a container of characters) extensively. In the next chapters, we will see lists, maps (a map is a tree of pairs of values), and matrices. Because we need many different containers, the language features and programming techniques needed to build and use containers are widely useful. In fact, the techniques we use to store and access data are among the most fundamental and most useful for all nontrivial forms of computing.
![]()
At the most basic memory level, all objects are of a fixed size and no types exist. What we do here is to introduce language facilities and programming techniques that allow us to provide containers of objects of various types for which we can vary the number of elements. This gives us a fundamentally useful degree of flexibility and convenience.
19.2 Changing size
What facilities for changing size does the standard library vector offer? It provides three simple operations. Given
vector<double> v(n); // v.size()==n
we can change its size in three ways:
v.resize(10); // v now has 10 elements
v.push_back(7); // add an element with the value 7 to the end of v
// v.size() increases by 1
v = v2; // assign another vector; v is now a copy of v2
// v.size() now equals v2.size()
The standard library vector offers more operations that can change a vector’s size, such as erase() and insert() (§B.4.7), but here we will just see how we can implement those three operations for our vector.
19.2.1 Representation
In §19.1, we showed the simplest strategy for changing size: just allocate space for the new number of elements and copy the old elements into the new space. However, if you resize often, that’s inefficient. In practice, if we change the size once, we usually do so many times. In particular, we rarely see just one push_back(). So, we can optimize our programs by anticipating such changes in size. In fact, all vector implementations keep track of both the number of elements and an amount of “free space” reserved for “future expansion.” For example:
class vector {
int sz; // number of elements
double* elem; // address of first element
int space; // number of elements plus “free space”/“slots”
// for new elements (“the current allocation”)
public:
// . . .
};
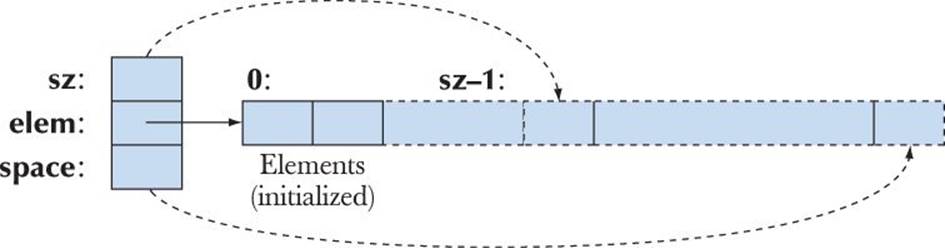
We can represent this graphically like this:
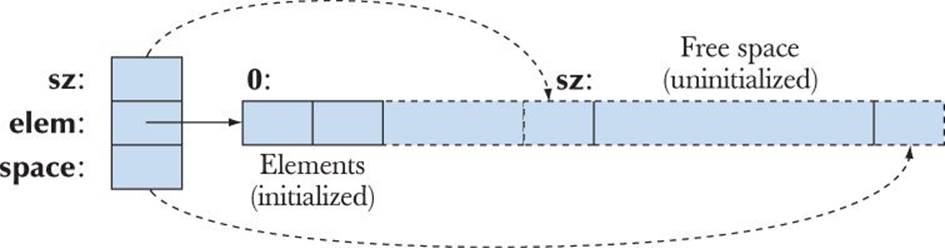
Since we count elements starting with 0, we represent sz (the number of elements) as referring to one beyond the last element and space as referring to one beyond the last allocated slot. The pointers shown are really elem+sz and elem+space.
When a vector is first constructed, space==sz; that is, there is no “free space”:
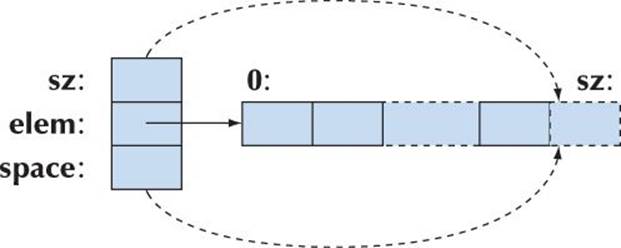
We don’t start allocating extra slots until we begin changing the number of elements. Typically, space==sz, so there is no memory overhead unless we use push_back().
The default constructor (creating a vector with no elements) sets the integer members to 0 and the pointer member to nullptr:
vector::vector() :sz{0}, elem{nullptr}, space{0} { }
That gives
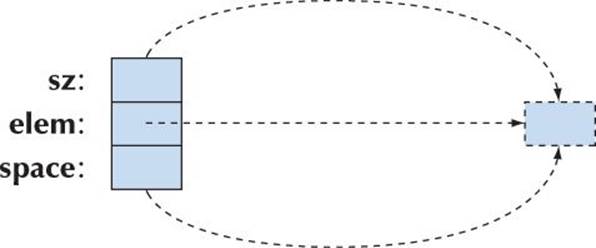
That one-beyond-the-end element is completely imaginary. The default constructor does no free-store allocation and occupies minimal storage (but see exercise 16).
Please note that our vector illustrates techniques that can be used to implement a standard vector (and other data structures), but a fair amount of freedom is given to standard library implementations so that std::vector on your system may use different techniques.
19.2.2 reserve and capacity
The most fundamental operation when we change sizes (that is, when we change the number of elements) is vector::reserve(). That’s the operation we use to add space for new elements:
void vector::reserve(int newalloc)
{
if (newalloc<=space) return; // never decrease allocation
double* p = new double[newalloc]; // allocate new space
for (int i=0; i<sz; ++i) p[i] = elem[i]; // copy old elements
delete[] elem; // deallocate old space
elem = p;
space = newalloc;
}
Note that we don’t initialize the elements of the reserved space. After all, we are just reserving space; using that space for elements is the job of push_back() and resize().
Obviously the amount of free space available in a vector can be of interest to a user, so we (like the standard) provide a member function for obtaining that information:
int vector::capacity() const { return space; }
That is, for a vector called v, v.capacity()-v.size() is the number of elements we could push_back() to v without causing reallocation.
19.2.3 resize
Given reserve(), implementing resize() for our vector is fairly simple. We have to handle several cases:
• The new size is larger than the old allocation.
• The new size is larger than the old size, but smaller than or equal to the old allocation.
• The new size is equal to the old size.
• The new size is smaller than the old size.
Let’s see what we get:
void vector::resize(int newsize)
// make the vector have newsize elements
// initialize each new element with the default value 0.0
{
reserve(newsize);
for (int i=sz; i<newsize; ++i) elem[i] = 0; // initialize new elements
sz = newsize;
}
We let reserve() do the hard work of dealing with memory. The loop initializes new elements (if there are any).
We didn’t explicitly deal with any cases here, but you can verify that all are handled correctly nevertheless.
 Try This
Try This
What cases do we need to consider (and test) if we want to convince ourselves that this resize() is correct? How about newsize == 0? How about newsize == -77?
19.2.4 push_back
When we first think of it, push_back() may appear complicated to implement, but given reserve() it is quite simple:
void vector::push_back(double d)
// increase vector size by one; initialize the new element with d
{
if (space==0)
reserve(8); // start with space for 8 elements
else if (sz==space)
reserve(2*space); // get more space
elem[sz] = d; // add d at end
++sz; // increase the size (sz is the number of elements)
}
In other words, if we have no spare space, we double the size of the allocation. In practice that turns out to be a very good choice for the vast majority of uses of vector, and that’s the strategy used by most implementations of the standard library vector.
19.2.5 Assignment
We could have defined vector assignment in several different ways. For example, we could have decided that assignment was legal only if the two vectors involved had the same number of elements. However, in §18.3.2 we decided that vector assignment should have the most general and arguably the most obvious meaning: after assignment v1=v2, the vector v1 is a copy of v2. Consider:
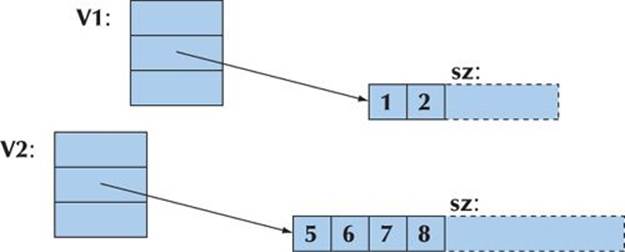
Obviously, we need to copy the elements, but what about the spare space? Do we “copy” the “free space” at the end? We don’t: the new vector will get a copy of the elements, but since we have no idea how that new vector is going to be used, we don’t bother with extra space at the end:
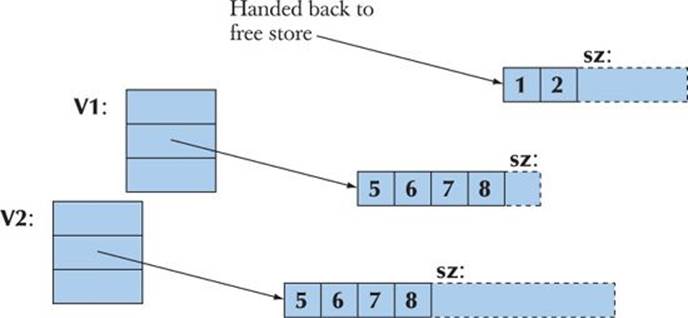
The simplest implementation of that is:
• Allocate memory for a copy.
• Copy the elements.
• Delete the old allocation.
• Set the sz, elem, and space to the new values.
Like this:
vector& vector::operator=(const vector& a)
// like copy constructor, but we must deal with old elements
{
double* p = new double[a.sz]; // allocate new space
for (int i = 0; i<a.sz; ++i) p[i] = a.elem[i]; // copy elements
delete[] elem; // deallocate old space
space = sz = a.sz; // set new size
elem = p; // set new elements
return *this; // return self-reference
}
By convention, an assignment operator returns a reference to the object assigned to. The notation for that is *this, which is explained in §17.10.
This implementation is correct, but when we look at it a bit we realize that we do a lot of redundant allocation and deallocation. What if the vector we assign to has more elements than the one we assign? What if the vector we assign to has the same number of elements as the vector we assign? In many applications, that last case is very common. In either case, we can just copy the elements into space already available in the target vector:
vector& vector::operator=(const vector& a)
{
if (this==&a) return *this; // self-assignment, no work needed
if (a.sz<=space) { // enough space, no need for new allocation
for (int i = 0; i<a.sz; ++i) elem[i] = a.elem[i]; // copy elements
sz = a.sz;
return *this;
}
double* p = new double[a.sz]; // allocate new space
for (int i = 0; i<a.sz; ++i) p[i] = a.elem[i]; // copy elements
delete[] elem; // deallocate old space
space = sz = a.sz; // set new size
elem = p; // set new elements
return *this; // return a self-reference
}
Here, we first test for self-assignment (e.g., v=v); in that case, we just do nothing. That test is logically redundant but sometimes a significant optimization. It does, however, show a common use of the this pointer checking if the argument a is the same object as the object for which a member function (here, operator=()) was called. Please convince yourself that this code actually works if we remove the this==&a line. The a.sz<=space is also just an optimization. Please convince yourself that this code actually works if we remove the a.sz<=space case.
19.2.6 Our vector so far
Now we have an almost real vector of doubles:
// an almost real vector of doubles:
class vector {
/*
invariant:
if 0<=n<sz, elem[n] is element n
sz<=space;
if sz<space there is space for (space-sz) doubles after elem[sz-1]
*/
int sz; // the size
double* elem; // pointer to the elements (or 0)
int space; // number of elements plus number of free slots
public:
vector() : sz{0}, elem{nullptr}, space{0} { }
explicit vector(int s) :sz{s}, elem{new double[s]}, space{s}
{
for (int i=0; i<sz; ++i) elem[i]=0; // elements are initialized
}
vector(const vector&); // copy constructor
vector& operator=(const vector&); // copy assignment
vector(vector&&); // move constructor
vector& operator=(vector&&); // move assignment
~vector() { delete[] elem; } // destructor
double& operator[ ](int n) { return elem[n]; } // access: return reference
const double& operator[](int n) const { return elem[n]; }
int size() const { return sz; }
int capacity() const { return space; }
void resize(int newsize); // growth
void push_back(double d);
void reserve(int newalloc);
};
Note how it has the essential operations (§18.4): constructor, default constructor, copy operations, destructor. It has an operation for accessing data (subscripting: [ ]) and for providing information about that data (size() and capacity()) and for controlling growth (resize(), push_back(), andreserve()).
19.3 Templates
But we don’t just want vectors of doubles; we want to freely specify the element type for our vectors. For example:
vector<double>
vector<int>
vector<Month>
vector<Window*> // vector of pointers to Windows
vector<vector<Record>> // vector of vectors of Records
vector<char>
![]()
To do that, we must see how to define templates. We have used templates from day one, but until now we haven’t had a need to define one. The standard library provides what we have needed so far, but we mustn’t believe in magic, so we need to examine how the designers and implementers of the standard library provided facilities such as the vector type and the sort() function (§21.1, §B.5.4). This is not just of theoretical interest, because — as usual — the tools and techniques used for the standard library are among the most useful for our own code. For example, in Chapters 21 and 22, we show how templates can be used for implementing the standard library containers and algorithms. In Chapter 24, we show how to design matrices for scientific computation.
![]()
Basically, a template is a mechanism that allows a programmer to use types as parameters for a class or a function. The compiler then generates a specific class or function when we later provide specific types as arguments.
19.3.1 Types as template parameters
![]()
We want to make the element type a parameter to vector. So we take our vector and replace double with T where T is a parameter that can be given “values” such as double, int, string, vector<Record>, and Window*. The C++ notation for introducing a type parameter T is thetemplate<typename T> prefix, meaning “for all types T.” For example:
// an almost real vector of Ts:
template<typename T>
class vector { // read “for all types T” (just like in math)
int sz; // the size
T* elem; // a pointer to the elements
int space; // size + free space
public:
vector() : sz{0}, elem{nullptr}, space{0} { }
explicit vector(int s) :sz{s}, elem{new T[s]}, space{s}
{
for (int i=0; i<sz; ++i) elem[i]=0; // elements are initialized
}
vector(const vector&); // copy constructor
vector& operator=(const vector&); // copy assignment
vector(vector&&); // move constructor
vector& operator=(vector&&); // move assignment
~vector() { delete[] elem; } // destructor
T& operator[](int n) { return elem[n]; } // access: return reference
const T& operator[](int n) const { return elem[n]; }
int size() const { return sz; } // the current size
int capacity() const { return space; }
void resize(int newsize); // growth
void push_back(const T& d);
void reserve(int newalloc);
};
That’s just our vector of doubles from §19.2.6 with double replaced by the template parameter T. We can use this class template vector like this:
vector<double> vd; // T is double
vector<int> vi; // T is int
vector<double*> vpd; // T is double*
vector<vector<int>> vvi; // T is vector<int>, in which T is int
![]()
One way of thinking about what a compiler does when we use a template is that it generates the class with the actual type (the template argument) in place of the template parameter. For example, when the compiler sees vector<char> in the code, it (somewhere) generates something like this:
class vector_char {
int sz; // the size
char* elem; // a pointer to the elements
int space; // size + free space
public:
vector() : sz{0}, elem{nullptr}, space{0} { }
explicit vector_char(int s) :sz{s}, elem{new char[s]}, space{s}
{
for (int i=0; i<sz; ++i) elem[i]=0; // elements are initialized
}
vector_char(const vector_char&); // copy constructor
vector_char& operator=(const vector_char&); // copy assignment
vector_char(vector_char&&); // move constructor
vector_char& operator=(vector_char&&); // move assignment
~vector_char (); // destructor
char& operator[] (int n) ) { return elem[n]; // access: return reference
const char& operator[] (int n) const ) { return elem[n]; }
int size() const; // the current size
int capacity() const;
void resize(int newsize); // growth
void push_back(const char& d);
void reserve(int newalloc);
};
For vector<double>, the compiler generates roughly the vector (of double) from §19.2.6 (using a suitable internal name meaning vector<double>).
![]()
Sometimes, we call a class template a type generator. The process of generating types (classes) from a class template given template arguments is called specialization or template instantiation. For example, vector<char> and vector<Poly_line*> are said to be specializations of vector. In simple cases, such as our vector, instantiation is a pretty simple process. In the most general and advanced cases, template instantiation is horrendously complicated. Fortunately for the user of templates, that complexity is in the domain of the compiler writer, not the template user. Template instantiation (generation of template specializations) takes place at compile time or link time, not at run time.
Naturally, we can use member functions of such a class template. For example:
void fct(vector<string>& v)
{
int n = v.size();
v.push_back("Norah");
// . . .
}
When such a member function of a class template is used, the compiler generates the appropriate function. For example, when the compiler sees v.push_back("Norah"), it generates a function
void vector<string>::push_back(const string& d) { /* . . . */ }
from the template definition
template<typename T> void vector<T>::push_back(const T& d) { /* . . . */ };
That way, there is a function for v.push_back("Norah") to call. In other words, when you need a function for given object and argument types, the compiler will write it for you based on its template.
Instead of writing template<typename T>, you can write template<class T>. The two constructs mean exactly the same thing, but some prefer typename “because it is clearer” and “because nobody gets confused by typename thinking that you can’t use a built-in type, such as int, as a template argument.” We are of the opinion that class already means type, so it makes no difference. Also, class is shorter.
19.3.2 Generic programming
![]()
Templates are the basis for generic programming in C++. In fact, the simplest definition of “generic programming” in C++ is “using templates.” That definition is a bit too simpleminded, though. We should not define fundamental programming concepts in terms of programming language features. Programming language features exist to support programming techniques — not the other way around. As with most popular notions, there are many definitions of “generic programming.” We think that the most useful simple definition is
Generic programming: Writing code that works with a variety of types presented as arguments, as long as those argument types meet specific syntactic and semantic requirements.
![]()
For example, the elements of a vector must be of a type that we can copy (by copy construction and copy assignment), and in Chapters 20 and 21 we will see templates that require arithmetic operations on their arguments. When what we parameterize is a class, we get a class template, what is often called a parameterized type or a parameterized class. When what we parameterize is a function, we get a function template, what is often called a parameterized function and sometimes also called an algorithm. Thus, generic programming is sometimes referred to as “algorithm-oriented programming”; the focus of the design is more the algorithms than the data types they use.
Since the notion of parameterized types is so central to programming, let’s explore the somewhat bewildering terminology a bit further. That way we have a chance of not getting too confused when we meet such notions in other contexts.
![]()
This form of generic programming relying on explicit template parameters is often called parametric polymorphism. In contrast, the polymorphism you get from using class hierarchies and virtual functions is called ad hoc polymorphism and that style of programming is called object-oriented programming (§14.3-4). The reason that both styles of programming are called polymorphism is that each style relies on the programmer to present many versions of a concept by a single interface. Polymorphism is Greek for “many shapes,” referring to the many different types you can manipulate through a common interface. In the Shape examples from Chapters 16-19 we literally accessed many shapes (such as Text, Circle, and Polygon) through the interface defined by Shape. When we use vectors, we use many vectors (such as vector<int>, vector<double>, andvector<Shape*>) through the interface defined by the vector template.
There are several differences between object-oriented programming (using class hierarchies and virtual functions) and generic programming (using templates). The most obvious is that the choice of function invoked when you use generic programming is determined by the compiler at compile time, whereas for object-oriented programming, it is not determined until run time. For example:
v.push_back(x); // put x into the vector v
s.draw(); // draw the shape s
For v.push_back(x) the compiler will determine the element type for v and use the appropriate push_back(), but for s.draw() the compiler will indirectly call some draw() function (using s’s vtbl; see §14.3.1). This gives object-oriented programming a degree of freedom that generic programming lacks, but leaves run-of-the-mill generic programming more regular, easier to understand, and better performing (hence the “ad hoc” and “parametric” labels).
To sum up:
• Generic programming: supported by templates, relying on compile-time resolution
![]()
• Object-oriented programming: supported by class hierarchies and virtual functions, relying on run-time resolution
Combinations of the two are possible and useful. For example:
void draw_all(vector<Shape*>& v)
{
for (int I = 0; i<v.size(); ++i) v[i]->draw();
}
Here we call a virtual function (draw()) on a base class (Shape) using a virtual function — that’s certainly object-oriented programming. However, we also kept Shape*s in a vector, which is a parameterized type, so we also used (simple) generic programming.
So — assuming you have had your fill of philosophy for now — what do people actually use templates for? For unsurpassed flexibility and performance:
![]()
• Use templates where performance is essential (e.g., numerics and hard real time; see Chapters 24 and 25).
• Use templates where flexibility in combining information from several types is essential (e.g., the C++ standard library; see Chapters 20-21).
19.3.3 Concepts
![]()
Templates have many useful properties, such as great flexibility and near-optimal performance, but unfortunately they are not perfect. As usual, the benefits have corresponding weaknesses. For templates, the main problem is that the flexibility and performance come at the cost of poor separation between the “inside” of a template (its definition) and its interface (its declaration). This manifests itself in poor error diagnostics — often spectacularly poor error messages. Sometimes, these error messages come much later in the compilation process than we would prefer.
When compiling a use of a template, the compiler “looks into” the template and also into the template arguments. It does so to get the information to generate optimal code. To have all that information available, current compilers tend to require that a template must be fully defined wherever it is used. That includes all of its member functions and all template functions called from those. Consequently, template writers tend to place template definitions in header files. This is not actually required by the standard, but until radically improved implementations are widely available, we recommend that you do so for your own templates: place the definition of any template that is to be used in more than one translation unit in a header file.
![]()
Initially, write only very simple templates yourself and proceed carefully to gain experience. One useful development technique is to do as we did for vector: First develop and test a class using specific types. Once that works, replace the specific types with template parameters and test with a variety of template arguments. Use template-based libraries, such as the C++ standard library, for generality, type safety, and performance. Chapters 20 and 21 are devoted to the containers and algorithms of the standard library and will give you examples of the use of templates.
C++14 provides a mechanism for vastly improved checking of template interfaces. For example, in C++11 we write
template<typename T> // for all types T
class vector {
// . . .
};
We cannot precisely state what is expected of an argument type T. The standard says what these requirements are, but only in English, rather than in code that the compiler can understand. We call a set of requirements on a template argument a concept. A template argument must meet the requirements, the concepts, of the template to which it is applied. For example, a vector requires that its elements can be copied or moved, can have their address taken, and be default constructed (if needed). In other words, an element must meet a set of requirements, which we could callElement. In C++14, we can make that explicit:
template<typename T> // for all types T
requires Element<T>() // such that T is an Element
class vector {
// . . .
};
This shows that a concept is really a type predicate, that is, a compile-time-evaluated (constexpr) function that returns true if the type argument (here, T) has the properties required by the concept (here, Element) and false if it does not. This is a bit long-winded, but a shorthand notation brings us to
template<Element T> // for all types T, such that Element<T>() is true
class vector {
// . . .
};
If we don’t have a C++14 compiler that supports concepts, we can specify our requirements in names and in comments:
template<typename Elem> // requires Element<Elem>()
class vector {
// . . .
};
The compiler doesn’t understand our names or read our comments, but being explicit about concepts helps us think about our code, improves our design of generic code, and helps other programmers understand our code. As we go along, we will use some common and useful concepts:
• Element<E>(): E can be an element in a container.
• Container<C>(): C can hold Elements and be accessed as a [begin():end()) sequence.
• Forward_iterator<For>(): For can be used to traverse a sequence [b:e) (like a linked list, a vector, or an array).
• Input_iterator<In>(): In can be used to read a sequence [b:e) once only (like an input stream).
• Output_iterator<Out>(): A sequence can be output using Out.
• Random_access_iterator<Ran>(): Ran can be used to read and write a sequence [b:e) repeatedly and supports subscripting using [ ].
• Allocator<A>(): A can be used to acquire and release memory (like the free store).
• Equal_comparable<T>(): We can compare two Ts for equality using == to get a Boolean result.
• Equal_comparable<T,U>(): We can compare a T to a U for equality using == to get a Boolean result.
• Predicate<P,T>(): We can call P with an argument of type T to get a Boolean result.
• Binary_predicate<P,T>(): We can call P with two arguments of type T to get a Boolean result.
• Binary_predicate<P,T,U>(): We can call P with arguments of types T and U to get a Boolean result.
• Less_comparable<L,T>(): We can use L to compare two Ts for less than using < to get a Boolean result.
• Less_comparable<L,T,U>(): We can use L to compare a T to a U for less than using < to get a Boolean result.
• Binary_operation<B,T,U>(): We can use B to do an operation on two Ts.
• Binary_operation<B,T,U>(): We can use B to do an operation on a T and a U.
• Number<N>(): N behaves like a number, supporting +, -, *, and /.
For standard library containers and algorithms, these concepts (and many more) are specified in excruciating detail. Here, especially in Chapters 20 and 21, we will use them informally to document our containers and algorithms.
A container type and an iterator type, T, have a value type (written as Value_type<T>), which is the element type. Often, that Value_type<T> is a member type T::value_type; see vector and list (§20.5).
19.3.4 Containers and inheritance
There is one kind of combination of object-oriented programming and generic programming that people always try, but it doesn’t work: attempting to use a container of objects of a derived class as a container of objects of a base class. For example:
vector<Shape> vs;
vector<Circle> vc;
vs = vc; // error: vector<Shape> required
void f(vector<Shape>&);
f(vc); // error: vector<Shape> required
![]()
But why not? After all, you say, I can convert a Circle to a Shape! Actually, no, you can’t. You can convert a Circle* to a Shape* and a Circle& to a Shape&, but we deliberately disabled assignment of Shapes, so that you wouldn’t have to wonder what would happen if you put a Circle with a radius into a Shape variable that doesn’t have a radius (§14.2.4). What would have happened — had we allowed it — would have been what is called “slicing” and is the class object equivalent of integer truncation (§3.9.2).
So we try again using pointers:
vector<Shape*> vps;
vector<Circle*> vpc;
vps = vpc; // error: vector<Shape*> required
void f(vector<Shape*>&);
f(vpc); // error: vector<Shape*> required
Again, the type system resists; why? Consider what f() might do:
void f(vector<Shape*>& v)
{
v.push_back(new Rectangle{Point{0,0},Point{100,100}});
}
![]()
Obviously, we can put a Rectangle* into a vector<Shape*>. However, if that vector<Shape*> was elsewhere considered to be a vector<Circle*>, someone would get a nasty surprise. In particular, had the compiler accepted the example above, what would a Rectangle* be doing in vpc? Inheritance is a powerful and subtle mechanism and templates do not implicitly extend its reach. There are ways of using templates to express inheritance, but they are beyond the scope of this book. Just remember that “D is a B” does not imply “C<D> is a C<B>” for an arbitrary template C— and we should value that as a protection against accidental type violations. See also §25.4.4.
19.3.5 Integers as template parameters
![]()
Obviously, it is useful to parameterize classes with types. How about parameterizing classes with “other things,” such as integer values and string values? Basically, any kind of argument can be useful, but we’ll consider only type and integer parameters. Other kinds of parameters are less frequently useful, and C++’s support for other kinds of parameters is such that their use requires quite detailed knowledge of language features.
Consider an example of the most common use of an integer value as a template argument, a container where the number of elements is known at compile time:
template<typename T, int N> struct array {
T elem[N]; // hold elements in member array
// rely on the default constructors, destructor, and assignment
T& operator[] (int n); // access: return reference
const T& operator[] (int n) const;
T* data() { return elem; } // conversion to T*
const T* data() const { return elem; }
int size() const { return N; }
};
We can use array (see also §20.7) like this:
array<int,256> gb; // 256 integers
array<double,6> ad = { 0.0, 1.1, 2.2, 3.3, 4.4, 5.5 };
const int max = 1024;
void some_fct(int n)
{
array<char,max> loc;
array<char,n> oops; // error: the value of n not known to compiler
// . . .
array<char,max> loc2 = loc; // make backup copy
// . . .
loc = loc2; // restore
// . . .
}
Clearly, array is very simple — much simpler and less powerful than vector — so why would anyone want to use an array rather than a vector? One answer is “efficiency.” We know the size of an array at compile time, so the compiler can allocate static memory (for global objects, such as gb) and stack memory (for local objects, such as loc) rather than using the free store. When we do range checking, the checks can be against constants (the size parameter N). For most programs the efficiency improvement is insignificant, but if you are writing a crucial system component, such as a network driver, even a small difference can matter. More importantly, some programs simply can’t be allowed to use the free store. Such programs are typically embedded systems programs and/or safety-critical programs (see Chapter 25). In such programs, array gives us many of the advantages of vector without violating a critical restriction (no free-store use).
Let’s ask the opposite question: not “Why can’t we just use vector?” but “Why not just use built-in arrays?” As we saw in §18.6, arrays can be rather ill behaved: they don’t know their own size, they convert to pointers at the slightest provocation, they don’t copy properly; like vector,array doesn’t have those problems. For example:
double* p = ad; // error: no implicit conversion to pointer
double* q = ad.data(); // OK: explicit conversion
template<typename C> void printout(const C& c) // function template
{
for (int i = 0; i<c.size(); ++i) cout << c[i] <<'\n';
}
This printout() can be called by an array as well as a vector:
printout(ad); // call with array
vector<int> vi;
// . . .
printout(vi); // call with vector
This is a simple example of generic programming applied to data access. It works because the interface used for array and vector (size() and subscripting) is the same. Chapters 20 and 21 will explore this style of programming in some detail.
19.3.6 Template argument deduction
For a class template, you specify the template arguments when you create an object of some specific class. For example:
array<char,1024> buf; // for buf, T is char and N is 1024
array<double,10> b2; // for b2, T is double and N is 10
![]()
For a function template, the compiler usually deduces the template arguments from the function arguments. For example:
template<class T, int N> void fill(array<T,N>& b, const T& val)
{
for (int i = 0; i<N; ++i) b[i] = val;
}
void f()
{
fill(buf,'x'); // for fill(), T is char and N is 1024
// because that’s what buf has
fill(b2,0.0); // for fill(), T is double and N is 10
// because that’s what b2 has
}
Technically, fill(buf,'x') is shorthand for fill<char,1024>(buf,'x'), and fill(b2,0) is shorthand for fill<double,10>(b2,0), but fortunately we don’t often have to be that specific. The compiler figures it out for us.
19.3.7 Generalizing vector
When we generalized vector from a class “vector of double” to a template “vector of T,” we didn’t review the definitions of push_back(), resize(), and reserve(). We must do that now because as they are defined in §19.2.2 and §19.2.3 they make assumptions that are true for doubles, but not true for all types that we’d like to use as vector element types:
• How do we handle a vector<X> where X doesn’t have a default value?
• How do we ensure that elements are destroyed when we are finished with them?
![]()
Must we solve those problems? We could say, “Don’t try to make vectors of types without default values” and “Don’t use vectors for types with destructors in ways that cause problems.” For a facility that is aimed at “general use,” such restrictions are annoying to users and give the impression that the designer hasn’t thought the problem through or doesn’t really care about users. Often, such suspicions are correct, but the designers of the standard library didn’t leave these warts in place. To mirror the standard library vector, we must solve these two problems.
We can handle types without a default by giving the user the option to specify the value to be used when we need a “default value”:
template<typename T> void vector<T>::resize(int newsize, T def = T());
That is, use T() as the default value unless the user says otherwise. For example:
vector<double> v1;
v1.resize(100); // add 100 copies of double(), that is, 0.0
v1.resize(200, 0.0); // add 100 copies of 0.0 — mentioning 0.0 is redundant
v1.resize(300, 1.0); // add 100 copies of 1.0
struct No_default {
No_default(int); // the only constructor for No_default
// . . .
};
vector<No_default> v2(10); // error: tries to make 10 No_default()s
vector<No_default> v3;
v3.resize(100, No_default(2)); // add 100 copies of No_default(2)
v3.resize(200); // error: tries to add 100 No_default()s
The destructor problem is harder to address. Basically, we need to deal with something really awkward: a data structure consisting of some initialized data and some uninitialized data. So far, we have gone a long way to avoid uninitialized data and the programming errors that usually accompany it. Now — as implementers of vector — we have to face that problem so that we — as users of vector — don’t have to in our applications.
First, we need to find a way of getting and manipulating uninitialized storage. Fortunately, the standard library provides a class allocator, which provides uninitialized memory. A slightly simplified version looks like this:
template<typename T> class allocator {
public:
// . . .
T* allocate(int n); // allocate space for n objects of type T
void deallocate(T* p, int n); // deallocate n objects of type T starting at p
void construct(T* p, const T& v); // construct a T with the value v in p
void destroy(T* p); // destroy the T in p
};
Should you need the full story, have a look in The C++ Programming Language, <memory> (§B.1.1), or the standard. However, what is presented here shows the four fundamental operations that allow us to
• Allocate memory of a size suitable to hold an object of type T without initializing
• Construct an object of type T in uninitialized space
• Destroy an object of type T, thus returning its space to the uninitialized state
• Deallocate uninitialized space of a size suitable for an object of type T
Unsurprisingly, an allocator is exactly what we need for implementing vector<T>::reserve(). We start by giving vector an allocator parameter:
template<typename T, typename A = allocator<T>> class vector {
A alloc; // use allocate to handle memory for elements
// . . .
};
Except for providing an allocator — and using the standard one by default instead of using new — all is as before. As users of vector, we can ignore allocators until we find ourselves needing a vector that manages memory for its elements in some unusual way. As implementers of vector and as students trying to understand fundamental problems and learn fundamental techniques, we must see how a vector can deal with uninitialized memory and present properly constructed objects to its users. The only code affected is vector member functions that directly deal with memory, such as vector<T>::reserve():
template<typename T, typename A>
void vector<T,A>::reserve(int newalloc)
{
if (newalloc<=space) return; // never decrease allocation
T* p = alloc.allocate(newalloc); // allocate new space
for (int i=0; i<sz; ++i) alloc.construct(&p[i],elem[i]); // copy
for (int i=0; i<sz; ++i) alloc.destroy(&elem[i]); // destroy
alloc.deallocate(elem,space); // deallocate old space
elem = p;
space = newalloc;
}
We move an element to the new space by constructing a copy in uninitialized space and then destroying the original. We can’t use assignment because for types such as string, assignment assumes that the target area has been initialized.
Given reserve(), vector<T,A>::push_back() is simple to write:
template<typename T, typename A>
void vector<T,A>::push_back(const T& val)
{
if (space==0) reserve(8); // start with space for 8 elements
else if (sz==space) reserve(2*space); // get more space
alloc.construct(&elem[sz],val); // add val at end
++sz; // increase the size
}
Similarly, vector<T,A>::resize() is not too difficult:
template<typename T, typename A>
void vector<T,A>::resize(int newsize, T val = T())
{
reserve(newsize);
for (int i=sz; i<newsize; ++i) alloc.construct(&elem[i],val); // construct
for (int i = newsize; i<sz; ++i) alloc.destroy(&elem[i]); // destroy
sz = newsize;
}
Note that because some types do not have a default constructor, we again provide the option to supply a value to be used as an initial value for new elements.
The other new thing here is the destruction of “surplus elements” in the case where we are resizing to a smaller vector. Think of the destructor as turning a typed object into “raw memory.”
![]()
“Messing with allocators” is pretty advanced stuff, and tricky. Leave it alone until you are ready to become an expert.
19.4 Range checking and exceptions
We look at our vector so far and find (with horror?) that access isn’t range checked. The implementation of operator[] is simply
template<typename T, typename A> T& vector<T,A>::operator[](int n)
{
return elem[n];
}
So, consider:
vector<int> v(100);
v[-200] = v[200]; // oops!
int i;
cin>>i;
v[i] = 999; // maul an arbitrary memory location
This code compiles and runs, accessing memory not owned by our vector. This could mean big trouble! In a real program, such code is unacceptable. Let’s try to improve our vector to deal with this problem. The simplest approach would be to add a checked access operation, called at():
struct out_of_range { /* . . . */ }; // class used to report range access errors
template<typename T, typename A = allocator<T>> class vector {
// . . .
T& at(int n); // checked access
const T& at(int n) const; // checked access
T& operator[](int n); // unchecked access
const T& operator[](int n) const; // unchecked access
// . . .
};
template<typename T, typename A > T& vector<T,A>::at(int n)
{
if (n<0 || sz<=n) throw out_of_range();
return elem[n];
}
template<typename T, typename A > T& vector<T,A>::operator[](int n)
// as before
{
return elem[n];
}
Given that, we could write
void print_some(vector<int>& v)
{
int i = -1;
while(cin>>i && i!=-1)
try {
cout << "v[" << i << "]==" << v.at(i) << "\n";
}
catch(out_of_range) {
cout << "bad index: " << i << "\n";
}
}
Here, we use at() to get range-checked access, and we catch out_of_range in case of an illegal access.
The general idea is to use subscripting with [ ] when we know that we have a valid index and at() when we might have an out-of-range index.
19.4.1 An aside: design considerations
So far, so good, but why didn’t we just add the range check to operator[]()? Well, the standard library vector provides checked at() and unchecked operator[]() as shown here. Let’s try to explain how that makes some sense. There are basically four arguments:
![]()
1. Compatibility: People have been using unchecked subscripting since long before C++ had exceptions.
2. Efficiency: You can build a checked-access operator on top of an optimally fast unchecked-access operator, but you cannot build an optimally fast access operator on top of a checked-access operator.
3. Constraints: In some environments, exceptions are unacceptable.
4. Optional checking: The standard doesn’t actually say that you can’t range check vector, so if you want checking, use an implementation that checks.
19.4.1.1 Compatibility
People really, really don’t like to have their old code break. For example, if you have a million lines of code, it could be a very costly affair to rework it all to use exceptions correctly. We can argue that the code would be better for the extra work, but then we are not the ones who have to pay (in time or money). Furthermore, maintainers of existing code usually argue that unchecked code may be unsafe in principle, but their particular code has been tested and used for years and all the bugs have already been found. We can be skeptical about that argument, but again nobody who hasn’t had to make such decisions about real code should be too judgmental. Naturally, there was no code using the standard library vector before it was introduced into the C++ standard, but there were many millions of lines of code that used very similar vectors that (being pre-standard) didn’t use exceptions. Much of that code was later modified to use the standard.
19.4.1.2 Efficiency
![]()
Yes, range checking can be a burden in extreme cases, such as buffers for network interfaces and matrices in high-performance scientific computations. However, the cost of range checking is rarely a concern in the kind of “ordinary computing” that most of us spend most of our time on. Thus, we recommend and use a range-checked implementation of vector whenever we can.
19.4.1.3 Constraints
Again, the argument holds for some programmers and some applications. In fact, it holds for a whole lot of programmers and shouldn’t be lightly ignored. However, if you are starting a new program in an environment that doesn’t involve hard real time (see §25.2.1), prefer exception-based error handling and range-checked vectors.
19.4.1.4 Optional checking
The ISO C++ standard simply states that out-of-range vector access is not guaranteed to have any specific semantics, and that such access should be avoided. It is perfectly standards-conforming to throw an exception when a program tries an out-of-range access. So, if you like vector to throw and don’t need to be concerned by the first three reasons for a particular application, use a range-checked implementation of vector. That’s what we are doing for this book.
![]()
The long and the short of this is that real-world design can be messier than we would prefer, but there are ways of coping.
19.4.2 A confession: macros
Like our vector, most implementations of the standard library vector don’t guarantee to range check the subscript operator ([ ]) but provide at() that checks. So where did those std::out_of_range exceptions in our programs come from? Basically, we chose “option 4” from §19.4.1: a vectorimplementation is not obliged to range check [ ], but it is not prohibited from doing so either, so we arranged for checking to be done. What you might have been using is our debug version, called Vector, which does check [ ]. That’s what we use when we develop code. It cuts down on errors and debug time at little cost to performance:
struct Range_error : out_of_range { // enhanced vector range error reporting
int index;
Range_error(int i) :out_of_range("Range error"), index(i) { }
};
template<typename T> struct Vector : public std::vector<T> {
using size_type = typename std::vector<T>::size_type;
using vector<T>::vector; // use vector<T>’s constructors (§20.5)
T& operator[](size_type i) // rather than return at(i);
{
if (i<0||this->size()<=i) throw Range_error(i);
return std::vector<T>::operator[](i);
}
const T& operator[](size_type i) const
{
if (i<0||this->size()<=i) throw Range_error(i);
return std::vector<T>::operator[](i);
}
};
We use Range_error to make the offending index available for debugging. Deriving from std::vector gives us all of vector’s member functions for Vector. The first using introduces a convenient synonym for std::vector’s size_type; see §20.5. The second using gives us all of vector’s constructors for Vector.
This Vector has been useful in debugging nontrivial programs. The alternative is to use a systematically checked implementation of the complete standard library vector — in fact, that may indeed be what you have been using; we have no way of knowing exactly what degree of checking your compiler and library provide (beyond what the standard guarantees).
![]()
In std_lib_facilities.h, we use the nasty trick (a macro substitution) of redefining vector to mean Vector:
// disgusting macro hack to get a range-checked vector:
#define vector Vector
That means that whenever you wrote vector, the compiler saw Vector. This trick is nasty because what you see looking at the code is not what the compiler sees. In real-world code, macros are a significant source of obscure errors (§27.8, §A.17.2).
We did the same to provide range-checked access for string.
Unfortunately, there is no standard, portable, and clean way of getting range checking from an implementation of vector’s [ ]. It is, however, possible to do a much cleaner and more complete job of a range-checked vector (and string) than we did. However, that usually involves replacement of a vendor’s standard library implementation, adjusting installation options, or messing with standard library source code. None of those options is appropriate for a beginner’s first week of programming — and we used string in Chapter 2.
19.5 Resources and exceptions
So, vector can throw exceptions, and we recommend that when a function cannot perform its required action, it throws an exception to tell that to its callers (Chapter 5). Now is the time to consider what to do when we write code that must deal with exceptions thrown by vector operations and other functions that we call. The naive answer — “Use a try-block to catch the exception, write an error message, and then terminate the program” — is too crude for most nontrivial systems.
![]()
One of the fundamental principles of programming is that if we acquire a resource, we must — somehow, directly or indirectly — return it to whatever part of the system manages that resource. Examples of resources are
• Memory
• Locks
• File handles
• Thread handles
• Sockets
• Windows
![]()
Basically, we define a resource as something that is acquired and must be given back (released) or reclaimed by some “resource manager.” The simplest example is free-store memory that we acquire using new and return to the free store using delete. For example:
void suspicious(int s, int x)
{
int* p = new int[s]; // acquire memory
// . . .
delete[] p; // release memory
}
As we saw in §17.4.6, we have to remember to release the memory, and that’s not always easy to do. When we add exceptions to the picture, resource leaks can become common; all it takes is ignorance or some lack of care. In particular, we view code, such as suspicious(), that explicitly usesnew and assigns the resulting pointer to a local variable with great suspicion.
![]()
We call an object, such as a vector, that is responsible for releasing a resource the owner or a handle of the resource for which it is responsible.
19.5.1 Potential resource management problems
![]()
One reason for suspicion of apparently innocuous pointer assignments such as
int* p = new int[s]; // acquire memory
is that it can be hard to verify that the new has a corresponding delete. At least suspicious() has a delete[] p; statement that might release the memory, but let’s imagine a few things that might cause that release not to happen. What could we put in the . . . part to cause a memory leak? The problematic examples we find should give you cause for thought and make you suspicious of such code. They should also make you appreciate the simple and powerful alternative to such code.
Maybe p no longer points to the object when we get to the delete:
void suspicious(int s, int x)
{
int* p = new int[s]; // acquire memory
// . . .
if (x) p = q; // make p point to another object
// . . .
delete[] p; // release memory
}
We put that if (x) there to be sure that you couldn’t know whether we had changed the value of p. Maybe we never get to the delete:
void suspicious(int s, int x)
{
int* p = new int[s]; // acquire memory
// . . .
if (x) return;
// . . .
delete[] p; // release memory
}
Maybe we never get to the delete because we threw an exception:
void suspicious(int s, int x)
{
int* p = new int[s]; // acquire memory
vector<int> v;
// . . .
if (x) p[x] = v.at(x);
// . . .
delete[] p; // release memory
}
![]()
It is this last possibility that concerns us most here. When people first encounter this problem, they tend to consider it a problem with exceptions rather than a resource management problem. Having misclassified the root cause, they come up with a solution that involves catching the exception:
void suspicious(int s, int x) // messy code
{
int* p = new int[s]; // acquire memory
vector<int> v;
// . . .
try {
if (x) p[x] = v.at(x);
// . . .
} catch (. . .) { // catch every exception
delete[] p; // release memory
throw; // re-throw the exception
}
// . . .
delete[] p; // release memory
}
This solves the problem at the cost of some added code and a duplication of the resource release code (here, delete[] p;). In other words, this solution is ugly; worse, it doesn’t generalize well. Consider acquiring more resources:
void suspicious(vector<int>& v, int s)
{
int* p = new int[s];
vector<int>v1;
// . . .
int* q = new int[s];
vector<double> v2;
// . . .
delete[] p;
delete[] q;
}
Note that if new fails to find free-store memory to allocate, it will throw the standard library exception bad_alloc. The try . . . catch technique works for this example also, but you’ll need several try-blocks, and the code is repetitive and ugly. We don’t like repetitive and ugly code because “repetitive” translates into code that is a maintenance hazard, and “ugly” translates into code that is hard to get right, hard to read, and a maintenance hazard.
Try This
Add try-blocks to this last example to ensure that all resources are properly released in all cases where an exception might be thrown.
19.5.2 Resource acquisition is initialization
Fortunately, we don’t need to plaster our code with complicated try . . . catch statements to deal with potential resource leaks. Consider:
void f(vector<int>& v, int s)
{
vector<int> p(s);
vector<int> q(s);
// . . .
}
![]()
This is better. More importantly, it is obviously better. The resource (here, free-store memory) is acquired by a constructor and released by the matching destructor. We actually solved this particular “exception problem” when we solved the memory leak problems for vectors. The solution is general; it applies to all kinds of resources: acquire a resource in the constructor for some object that manages it, and release it again in the matching destructor. Examples of resources that are usually best dealt with in this way include database locks, sockets, and I/O buffers (iostreams do it for you). This technique is usually referred to by the awkward phrase “Resource Acquisition Is Initialization,” abbreviated to RAII.
Consider the example above. Whichever way we leave f(), the destructors for p and q are invoked appropriately: since p and q aren’t pointers, we can’t assign to them, a return-statement will not prevent the invocation of destructors, and neither will throwing an exception. This general rule holds: when the thread of execution leaves a scope, the destructors for every fully constructed object and sub-object are invoked. An object is considered constructed when its constructor completes. Exploring the detailed implications of those two statements might cause a headache, but they simply mean that constructors and destructors are invoked as needed.
![]()
In particular, use vector rather than explicit new and delete when you need a nonconstant amount of storage within a scope.
19.5.3 Guarantees
What can we do where we can’t keep the vector within a single scope (and its sub-scopes)? For example:
vector<int>* make_vec() // make a filled vector
{
vector<int>* p = new vector<int>; // we allocate on free store
// . . . fill the vector with data; this may throw an exception . . .
return p;
}
This is an example of a common kind of code: we call a function to construct a complicated data structure and return that data structure as the result. The snag is that if an exception is thrown while “filling” the vector, make_vec() leaks that vector. An unrelated problem is that if the function succeeds, someone will have to delete the object returned by make_vec() (see §17.4.6).
We can add a try-block to deal with the possibility of a throw:
vector<int>* make_vec() // make a filled vector
{
vector<int>* p = new vector<int>; // we allocate on free store
try {
// fill the vector with data; this may throw an exception
return p;
}
catch (. . .) {
delete p; // do our local cleanup
throw; // re-throw to allow our caller to deal with the fact
// that make_vec() couldn’t do what was
// required of it
}
}
![]()
This make_vec() function illustrates a very common style of error handling: it tries to do its job and if it can’t, it cleans up any local resources (here the vector on the free store) and indicates failure by throwing an exception. Here, the exception thrown is one that some other function (e.g.,vector::at()) threw; make_vec() simply re-throws it using throw;. This is a simple and effective way of dealing with errors and can be used systematically.
![]()
• The basic guarantee: The purpose of the try . . . catch code is to ensure that make_vec() either succeeds or throws an exception without having leaked any resources. That’s often called the basic guarantee. All code that is part of a program that we expect to recover from an exceptionthrow should provide the basic guarantee. All standard library code provides the basic guarantee.
• The strong guarantee: If, in addition to providing the basic guarantee, a function also ensures that all observable values (all values not local to the function) are the same after failure as they were when we called the function, that function is said to provide the strong guarantee. The strong guarantee is the ideal when we write a function: either the function succeeded at doing everything it was asked to do or else nothing happened except that an exception was thrown to indicate failure.
• The no-throw guarantee: Unless we could do simple operations without any risk of failing and throwing an exception, we would not be able to write code to meet the basic guarantee and the strong guarantee. Fortunately, essentially all built-in facilities in C++ provide the no-throw guarantee: they simply can’t throw. To avoid throwing, simply avoid throw itself, new, and dynamic_cast of reference types (§A.5.7).
The basic guarantee and the strong guarantee are most useful for thinking about correctness of programs. RAII is essential for implementing code written according to those ideals simply and with high performance.
![]()
Naturally, we should always avoid undefined (and usually disastrous) operations, such as dereferencing 0, dividing by 0, and accessing an array beyond its range. Catching exceptions does not save you from violations of the fundamental language rules.
19.5.4 unique_ptr
So, make_vec() is a useful kind of function that obeys the basic rules for good resource management in the presence of exceptions. It provides the basic guarantee — as all good functions should — when we want to recover from exception throws. Unless something nasty is done with nonlocal data in the “fill the vector with data” part, it even provides the strong guarantee. However, that try . . . catch code is still ugly. The solution is obvious: somehow we must use RAII; that is, we need to provide an object to hold that vector<int> so that it can delete the vector if an exception occurs. In <memory>, the standard library provides unique_ptr for that:
vector<int>* make_vec() // make a filled vector
{
unique_ptr<vector<int>> p {new vector<int>}; // allocate on free store
// . . . fill the vector with data; this may throw an exception . . .
return p.release(); // return the pointer held by p
}
A unique_ptr is an object that holds a pointer. We immediately initialize it with the pointer we got from new. You can use -> and * on a unique_ptr exactly like a built-in pointer (e.g., p->at(2) or (*p).at(2)), so we think of unique_ptr as a kind of pointer. However, the unique_ptr owns the object pointed to: when the unique_ptr is destroyed, it deletes the object it points to. That means that if an exception is thrown while the vector<int> is being filled, or if we return prematurely from make_vec, the vector<int> is properly destroyed. The p.release() extracts the contained pointer (to the vector<int>) from p so that we can return it, and it also makes p hold the nullptr so that destroying p (as is done by the return) does not destroy anything.
Using unique_ptr simplifies make_vec() immensely. Basically, it makes make_vec() as simple as the naive but unsafe version. Importantly, having unique_ptr allows us to repeat our recommendation to look upon explicit try-blocks with suspicion; most can — as in make_vec() — be replaced by some variant of the “Resource Acquisition Is Initialization” technique.
The version of make_vec() that uses a unique_ptr is fine, except that it still returns a pointer, so that someone still has to remember to delete that pointer. Returning a unique_ptr would solve that:
unique_ptr<vector<int>> make_vec() // make a filled vector
{
unique_ptr<vector<int>> p {new vector<int>}; // allocate on free store
// . . . fill the vector with data; this may throw an exception . . .
return p;
}
A unique_ptr is very much like an ordinary pointer, but it has one significant restriction: you cannot assign one unique_ptr to another to get two unique_ptrs to the same object. That has to be so, or confusion could arise about which unique_ptr owned the pointed-to object and had to delete it. For example:
void no_good()
{
unique_ptr<X> p { new X };
unique_ptr<X> q {p}; // error: fortunately
// . . .
} // here p and q both delete the X
If you want to have a “smart” pointer that both guarantees deletion and can be copied, use a shared_ptr (§B.6.5). However, that is a more heavyweight solution that involves a use count to ensure that the last copy destroyed destroys the object referred to.
A unique_ptr has the interesting property of having no overhead compared to an ordinary pointer.
19.5.5 Return by moving
The technique of returning a lot of information by placing it on the free store and returning a pointer to it is very common. It is also a source of a lot of complexity and one of the major sources of memory management errors: Who deletes a pointer to the free store returned from a function? Are we sure that a pointer to an object on the free store is properly deleted in case of an exception? Unless we are systematic about the management of pointers (or use “smart” pointers such as unique_ptr and shared_ptr), the answer will be something like “Well, we think so,” and that’s not good enough.
Fortunately, when we added move operations to vector, we solved that problem for vectors: just use a move constructor to get the ownership of the elements out of the function. For example:
vector<int> make_vec() // make a filled vector
{
vector<int> res;
// . . . fill the vector with data; this may throw an exception . . .
return res; // the move constructor efficiently transfers ownership
}
This (final) version of make_vec() is the simplest and the one we recommend. The move solution generalizes to all containers and further still to all resource handles. For example, fstream uses this technique to keep track of file handles. The move solution is simple and general. Using resource handles simplifies code and eliminates a major source of errors. Compared to the direct use of pointers, the run-time overhead of using such handles is nothing, or very minor and predictable.
19.5.6 RAII for vector
Even using a smart pointer, such as unique_ptr, may seem to be a bit ad hoc. How can we be sure that we have spotted all pointers that require protection? How can we be sure that we have released all pointers to objects that should not be destroyed at the end of a scope? Consider reserve()from §19.3.7:
template<typename T, typename A>
void vector<T,A>::reserve(int newalloc)
{
if (newalloc<=space) return; // never decrease allocation
T* p = alloc.allocate(newalloc); // allocate new space
for (int i=0; i<sz; ++i) alloc.construct(&p[i],elem[i]); // copy
for (int i=0; i<sz; ++i) alloc.destroy(&elem[i]); // destroy
alloc.deallocate(elem,space); // deallocate old space
elem = p;
space = newalloc;
}
![]()
Note that the copy operation for an old element, alloc.construct(&p[i],elem[i]), might throw an exception. So, p is an example of the problem we warned about in §19.5.1. Ouch! We could apply the unique_ptr solution. A better solution is to step back and realize that “memory for a vector” is a resource; that is, we can define a class vector_base to represent the fundamental concept we have been using all the time, the picture with the three elements defining a vector’s memory use:
In code, that is (after adding the allocator for completeness)
template<typename T, typename A>
struct vector_base {
A alloc; // allocator
T* elem; // start of allocation
int sz; // number of elements
int space; // amount of allocated space
vector_base(const A& a, int n)
: alloc{a}, elem{alloc.allocate(n)}, sz{n}, space{n}{ }
~vector_base() { alloc.deallocate(elem,space); }
};
Note that vector_base deals with memory rather than (typed) objects. Our vector implementation can use that to hold objects of the desired element type. Basically, vector is simply a convenient interface to vector_base:
template<typename T, typename A = allocator<T>>
class vector : private vector_base<T,A> {
public:
// . . .
};
We can then rewrite reserve() to something simpler and more correct:
template<typename T, typename A>
void vector<T,A>::reserve(int newalloc)
{
if (newalloc<=this->space) return; // never decrease allocation
vector_base<T,A> b(this->alloc,newalloc); // allocate new space
uninitialized_copy(b.elem,&b.elem[this->sz],this->elem); // copy
for (int i=0; i<this->sz; ++i)
this->alloc.destroy(&this->elem[i]); // destroy old
swap<vector_base<T,A>>(*this,b); // swap representations
}
We use the standard library function uninitialized_copy to construct copies of the elements from b because it correctly handles throws from an element copy constructor and because calling a function is simpler than writing a loop. When we exit reserve(), the old allocation is automatically freed by vector_base’s destructor if the copy operation succeeded. If instead that exit is caused by the copy operation throwing an exception, the new allocation is freed. The swap() function is a standard library algorithm (from <algorithm>) that exchanges the value of two objects. We usedswap<vector_base<T,A>>(*this,b) rather than the simpler swap(*this,b) because *this and b are of different types (vector and vector_base, respectively), so we had to be explicit about which swap specialization we wanted. Similarly, we have to explicitly use this-> when we refer to a member of the base class vector_base<T,A> from a member of the derived class vector<T,A>, such as vector<T,A>::reserve().
Try This
Modify reserve to use unique_ptr. Remember to release before returning. Compare that solution to the vector_base one. Consider which is easier to write and which is easier to get correct.
 Drill
Drill
1. Define template<typename T> struct S { T val; };.
2. Add a constructor, so that you can initialize with a T.
3. Define variables of types S<int>, S<char>, S<double>, S<string>, and S<vector<int>>; initialize them with values of your choice.
4. Read those values and print them.
5. Add a function template get() that returns a reference to val.
6. Put the definition of get() outside the class.
7. Make val private.
8. Do 4 again using get().
9. Add a set() function template so that you can change val.
10. Replace set() with an S<T>::operator=(const T&). Hint: Much simpler than §19.2.5.
11. Provide const and non-const versions of get().
12. Define a function template<typename T> read_val(T& v) that reads from cin into v.
13. Use read_val() to read into each of the variables from 3 except the S<vector<int>> variable.
14. Bonus: Define input and output operators (>> and <<) for vector<T>s. For both input and output use a { val, val, val } format. That will allow read_val() to also handle the S<vector<int>> variable.
Remember to test after each step.
Review
1. Why would we want to change the size of a vector?
2. Why would we want to have different element types for different vectors?
3. Why don’t we just always define a vector with a large enough size for all eventualities?
4. How much spare space do we allocate for a new vector?
5. When must we copy vector elements to a new location?
6. Which vector operations can change the size of a vector after construction?
7. What is the value of a vector after a copy?
8. Which two operations define copy for vector?
9. What is the default meaning of copy for class objects?
10. What is a template?
11. What are the two most useful types of template arguments?
12. What is generic programming?
13. How does generic programming differ from object-oriented programming?
14. How does array differ from vector?
15. How does array differ from the built-in array?
16. How does resize() differ from reserve()?
17. What is a resource? Define and give examples.
18. What is a resource leak?
19. What is RAII? What problem does it address?
20. What is unique_ptr good for?
Terms
#define
at()
basic guarantee
exception
guarantees
handle
instantiation
macro
owner
push_back()
RAII
resize()
resource
re-throw
self-assignment
shared_ptr
specialization
strong guarantee
template
template parameter
this
throw;
unique_ptr
Exercises
For each exercise, create and test (with output) a couple of objects of the defined classes to demonstrate that your design and implementation actually do what you think they do. Where exceptions are involved, this can require careful thought about where errors can occur.
1. Write a template function f() that adds the elements of one vector<T> to the elements of another; for example, f(v1,v2) should do v1[i]+=v2[i] for each element of v1.
2. Write a template function that takes a vector<T> vt and a vector<U> vu as arguments and returns the sum of all vt[i]*vu[i]s.
3. Write a template class Pair that can hold a pair of values of any type. Use this to implement a simple symbol table like the one we used in the calculator (§7.8).
4. Modify class Link from §17.9.3 to be a template with the type of value as the template argument. Then redo exercise 13 from Chapter 17 with Link<God>.
5. Define a class Int having a single member of class int. Define constructors, assignment, and operators +, -, *, / for it. Test it, and improve its design as needed (e.g., define operators << and >> for convenient I/O).
6. Repeat the previous exercise, but with a class Number<T> where T can be any numeric type. Try adding % to Number and see what happens when you try to use % for Number<double> and Number<int>.
7. Try your solution to exercise 2 with some Numbers.
8. Implement an allocator (§19.3.7) using the basic allocation functions malloc() and free() (§B.11.4). Get vector as defined by the end of §19.4 to work for a few simple test cases. Hint: Look up “placement new” and “explicit call of destructor” in a complete C++ reference.
9. Re-implement vector::operator=() (§19.2.5) using an allocator (§19.3.7) for memory management.
10. Implement a simple unique_ptr supporting only a constructor, destructor, ->, *, and release(). In particular, don’t try to implement an assignment or a copy constructor.
11. Design and implement a counted_ptr<T> that is a type that holds a pointer to an object of type T and a pointer to a “use count” (an int) shared by all counted pointers to the same object of type T. The use count should hold the number of counted pointers pointing to a given T. Let thecounted_ptr’s constructor allocate a T object and a use count on the free store. Let counted_ptr’s constructor take an argument to be used as the initial value of the T elements. When the last counted_ptr for a T is destroyed, counted_ptr’s destructor should delete the T. Give thecounted_ptr operations that allow us to use it as a pointer. This is an example of a “smart pointer” used to ensure that an object doesn’t get destroyed until after its last user has stopped using it. Write a set of test cases for counted_ptr using it as an argument in calls, container elements, etc.
12. Define a File_handle class with a constructor that takes a string argument (the file name), opens the file in the constructor, and closes it in the destructor.
13. Write a Tracer class where its constructor prints a string and its destructor prints a string. Give the strings as constructor arguments. Use it to see where RAII management objects will do their job (i.e., experiment with Tracers as local objects, member objects, global objects, objects allocated by new, etc.). Then add a copy constructor and a copy assignment so that you can use Tracer objects to see when copying is done.
14. Provide a GUI interface and a bit of graphical output to the “Hunt the Wumpus” game from the exercises in Chapter 18. Take the input in an input box and display a map of the part of the cave currently known to the player in a window.
15. Modify the program from the previous exercise to allow the user to mark rooms based on knowledge and guesses, such as “maybe bats” and “bottomless pit.”
16. Sometimes, it is desirable that an empty vector be as small as possible. For example, someone might use vector<vector<vector<int>>> a lot but have most element vectors empty. Define a vector so that sizeof(vector<int>)==sizeof(int*), that is, so that the vector itself consists only of a pointer to a representation consisting of the elements, the number of elements, and the space pointer.
Postscript
Templates and exceptions are immensely powerful language features. They support programming techniques of great flexibility — mostly by allowing people to separate concerns, that is, to deal with one problem at a time. For example, using templates, we can define a container, such asvector, separately from the definition of an element type. Similarly, using exceptions, we can write the code that detects and signals an error separately from the code that handles that error. The third major theme of this chapter, changing the size of a vector, can be seen in a similar light:push_back(), resize(), and reserve() allow us to separate the definition of a vector from the specification of its size.