Programming: Principles and Practice Using C++ (2014)
Part III: Data and Algorithms
21. Algorithms and Maps
“In theory, practice is simple.”
—Trygve Reenskaug
This chapter completes our presentation of the fundamental ideas of the STL and our survey of the facilities it offers. Here, we focus on algorithms. Our primary aim is to introduce you to about a dozen of the most useful ones, which will save you days, if not months, of work. Each is presented with examples of its uses and of programming techniques that it supports. Our second aim here is to give you sufficient tools to write your own — elegant and efficient — algorithms if and when you need more than what the standard library and other available libraries have to offer. In addition, we introduce three more containers: map, set, and unordered_map.
21.1 Standard library algorithms
21.2 The simplest algorithm: find()
21.2.1 Some generic uses
21.3 The general search: find_if()
21.4 Function objects
21.4.1 An abstract view of function objects
21.4.2 Predicates on class members
21.4.3 Lambda expressions
21.5 Numerical algorithms
21.5.1 Accumulate
21.5.2 Generalizing accumulate()
21.5.3 Inner product
21.5.4 Generalizing inner_product()
21.6 Associative containers
21.6.1 map
21.6.2 map overview
21.6.3 Another map example
21.6.4 unordered_map
21.6.5 set
21.7 Copying
21.7.1 Copy
21.7.2 Stream iterators
21.7.3 Using a set to keep order
21.7.4 copy_if
21.8 Sorting and searching
21.9 Container algorithms
21.1 Standard library algorithms
The standard library offers about 80 algorithms. All are useful for someone sometimes; we focus on some that are often useful for many and on some that are occasionally very useful for someone:


![]()
By default, comparison for equality is done using == and ordering is done based on < (less than). The standard library algorithms are found in <algorithm>. For more information, see §B.5 and the sources listed in §21.2-21.5. These algorithms take one or more sequences. An input sequence is defined by a pair of iterators; an output sequence is defined by an iterator to its first element. Typically an algorithm is parameterized by one or more operations that can be defined as function objects or as functions. The algorithms usually report “failure” by returning the end of an input sequence. For example, find(b,e,v) returns e if it doesn’t find v.
21.2 The simplest algorithm: find()
Arguably, the simplest useful algorithm is find(). It finds an element with a given value in a sequence:
template<typename In, typename T>
// requires Input_iterator<In>()
// && Equality_comparable<Value_type<T>>() (§19.3.3)
In find(In first, In last, const T& val)
// find the first element in [first,last) that equals val
{
while (first!=last && *first != val) ++first;
return first;
}
Let’s have a look at the definition of find(). Naturally, you can use find() without knowing exactly how it is implemented — in fact, we have used it already (e.g., §20.6.2). However, the definition of find() illustrates many useful design ideas, so it is worth looking at.
![]()
First of all, find() operates on a sequence defined by a pair of iterators. We are looking for the value val in the half-open sequence [first:last). The result returned by find() is an iterator. That result points either to the first element of the sequence with the value val or to last. Returning an iterator to the one-beyond-the-last element of a sequence is the most common STL way of reporting “not found.” So we can use find() like this:
void f(vector<int>& v, int x)
{
auto p = find(v.begin(),v.end(),x);
if (p!=v.end()) {
// we found x in v
}
else {
// no x in v
}
// . . .
}
Here, as is common, the sequence consists of all the elements of a container (an STL vector). We check the returned iterator against the end of our sequence to see if we found our value. The type of the value returned is the iterator passed as an argument.
To avoid naming the type returned, we used auto. An object defined with the “type” auto gets the type of its initializer. For example:
auto ch = 'c'; // ch is a char
auto d = 2.1; // d is a double
The auto type specifier is particularly useful in generic code, such as find() where it can be tedious to name the actual type (here, vector<int>::iterator).
We now know how to use find() and therefore also how to use a bunch of other algorithms that follow the same conventions as find(). Before proceeding with more uses and more algorithms, let’s just have a closer look at that definition:
template<typename In, typename T>
// requires Input_iterator<In>()
// && Equality_comparable<Value_type<T>>() (§19.3.3)
In find(In first, In last, const T& val)
// find the first element in [first,last) that equals val
{
while (first!=last && *first != val) ++first;
return first;
}
Did you find that loop obvious at first glance? We didn’t. It is actually minimal, efficient, and a direct representation of the fundamental algorithm. However, until you have seen a few examples, it is not obvious. Let’s write it “the pedestrian way” and see how that version compares:
template<typename In, typename T>
// requires Input_iterator<In>()
// && Equality_comparable<Value_type<T>>() (§19.3.3)
In find(In first, In last, const T& val)
// find the first element in [first,last) that equals val
{
for (In p = first; p!=last; ++p)
if (*p == val) return p;
return last;
}
These two definitions are logically equivalent, and a really good compiler will generate the same code for both. However, in reality many compilers are not good enough to eliminate that extra variable (p) and to rearrange the code so that all the testing is done in one place. Why worry and explain? Partly, because the style of the first (and preferred) version of find() has become very popular, and you must understand it to read other people’s code; partly, because performance matters exactly for small, frequently used functions that deal with lots of data.
 Try This
Try This
Are you sure those two definitions are logically equivalent? How would you be sure? Try constructing an argument for their being equivalent. That done, try both on some data. A famous computer scientist (Don Knuth) once said, “I have only proven the algorithm correct, not tested it.” Even mathematical proofs can contain errors. To be confident, you need to both reason and test.
21.2.1 Some generic uses
![]()
The find() algorithm is generic. That means that it can be used for different data types. In fact, it is generic in two ways; it can be used for
• Any STL-style sequence
• Any element type
Here are some examples (consult the diagrams in §20.4 if you get confused):
void f(vector<int>& v, int x) // works for vector of int
{
vector<int>::iterator p = find(v.begin(),v.end(),x);
if (p!=v.end()) { /* we found x */ }
// . . .
}
![]()
Here, the iteration operations used by find() are those of a vector<int>::iterator; that is, ++ (in ++first) simply moves a pointer to the next location in memory (where the next element of the vector is stored) and * (in *first) dereferences such a pointer. The iterator comparison (in first!=last) is a pointer comparison, and the value comparison (in *first!=val) simply compares two integers.
Let’s try with a list:
void f(list<string>& v, string x) // works for list of string
{
list<string>::iterator p = find(v.begin(),v.end(),x);
if (p!=v.end()) { /* we found x */ }
// . . .
}
![]()
Here, the iteration operations used by find() are those of a list<string>::iterator. The operators have the required meaning, so that the logic is the same as for the vector<int> above. The implementation is very different, though; that is, ++ (in ++first) simply follows a pointer in the Link part of the element to where the next element of the list is stored, and * (in *first) finds the value part of a Link. The iterator comparison (in first!=last) is a pointer comparison of Link*s and the value comparison (in *first!=val) compares strings using string’s != operator.
So, find() is extremely flexible: as long as we obey the simple rules for iterators, we can use find() to find elements for any sequence we can think of and for any container we care to define. For example, we can use find() to look for a character in a Document as defined in §20.6:
void f(Document& v, char x) // works for Document of char
{
Text_iterator p = find(v.begin(),v.end(),x);
if (p!=v.end()) { /* we found x */ }
// . . .
}
This kind of flexibility is the hallmark of the STL algorithms and makes them more useful than most people imagine when they first encounter them.
21.3 The general search: find_if()
We don’t actually look for a specific value all that often. More often, we are interested in finding a value that meets some criteria. We could get a much more useful find operation if we could define our search criteria ourselves. Maybe we want to find a value larger than 42. Maybe we want to compare strings without taking case (upper case vs. lower case) into account. Maybe we want to find the first odd value. Maybe we want to find a record where the address field is "17 Cherry Tree Lane".
The standard algorithm that searches based on a user-supplied criterion is find_if():
template<typename In, typename Pred>
// requires Input_iterator<In>() && Predicate<Pred,Value_type<In>>()
In find_if(In first, In last, Pred pred)
{
while (first!=last && !pred(*first)) ++first;
return first;
}
Obviously (when you compare the source code), it is just like find() except that it uses !pred(*first) rather than *first!=val; that is, it stops searching once the predicate pred() succeeds rather than when an element equals a value.
![]()
A predicate is a function that returns true or false. Clearly, find_if() requires a predicate that takes one argument so that it can say pred(*first). We can easily write a predicate that checks some property of a value, such as “Does the string contain the letter x?” “Is the value larger than 42?” “Is the number odd?” For example, we can find the first odd value in a vector of ints like this:
bool odd(int x) { return x%2; } // % is the modulo operator
void f(vector<int>& v)
{
auto p = find_if(v.begin(), v.end(), odd);
if (p!=v.end()) { /* we found an odd number */ }
// . . .
}
For that call of find_if(), find_if() calls odd() for each element until it finds the first odd value. Note that when you pass a function as an argument, you don’t add () to its name because doing so would call it.
Similarly, we can find the first element of a list with a value larger than 42 like this:
bool larger_than_42(double x) { return x>42; }
void f(list<double>& v)
{
auto p = find_if(v.begin(), v.end(), larger_than_42);
if (p!=v.end()) { /* we found a value > 42 */ }
// . . .
}
This last example is not very satisfying, though. What if we next wanted to find an element larger than 41? We would have to write a new function. Find an element larger than 19? Write yet another function. There has to be a better way!
If we want to compare to an arbitrary value v, we need somehow to make v an implicit argument to find_if()’s predicate. We could try (choosing v_val as a name that is less likely to clash with other names)
double v_val; // the value to which larger_than_v() compares its argument
bool larger_than_v(double x) { return x>v_val; }
void f(list<double>& v, int x)
{
v_val = 31; // set v_val to 31 for the next call of larger_than_v
auto p = find_if(v.begin(), v.end(), larger_than_v);
if (p!=v.end()) { /* we found a value > 31 */ }
v_val = x; // set v_val to x for the next call of larger_than_v
auto q = find_if(v.begin(), v.end(), larger_than_v);
if (q!=v.end()) { /* we found a value > x */ }
// . . .
}
![]()
Yuck! We are convinced that people who write such code will eventually get what they deserve, but we pity their users and anyone who gets to maintain their code. Again: there has to be a better way!
Try This
Why are we so disgusted with that use of v? Give at least three ways this could lead to obscure errors. List three applications in which you’d particularly hate to find such code.
21.4 Function objects
So, we want to pass a predicate to find_if(), and we want that predicate to compare elements to a value we specify as some kind of argument. In particular, we want to write something like this:
void f(list<double>& v, int x)
{
auto p = find_if(v.begin(), v.end(), Larger_than(31));
if (p!=v.end()) { /* we found a value > 31 */ }
auto q = find_if(v.begin(), v.end(), Larger_than(x));
if (q!=v.end()) { /* we found a value > x */ }
// . . .
}
Obviously, Larger_than must be something that
• We can call as a predicate, e.g., pred(*first)
• Can store a value, such as 31 or x, for use when called
![]()
For that we need a “function object,” that is, an object that can behave like a function. We need an object because objects can store data, such as the value with which to compare. For example:
class Larger_than {
int v;
public:
Larger_than(int vv) : v(vv) { } // store the argument
bool operator()(int x) const { return x>v; } // compare
};
Interestingly, this definition makes the example above work as specified. Now we just have to figure out why it works. When we say Larger_than(31) we (obviously) make an object of class Larger_than holding 31 in its data member v. For example:
find_if(v.begin(),v.end(),Larger_than(31))
Here, we pass that object to find_if() as its parameter called pred. For each element of v, find_if() makes a call
pred(*first)
This invokes the call operator, called operator(), for our function object using the argument *first. The result is a comparison of the element’s value, *first, with 31.
![]()
What we see here is that a function call can be seen as an operator, the “( ) operator,” just like any other operator. The “( ) operator” is also called the function call operator and the application operator. So ( ) in pred(*first) is given a meaning by Larger_than::operator(), just as subscripting in v[i] is given a meaning by vector::operator[ ].
21.4.1 An abstract view of function objects
![]()
We have here a mechanism that allows for a “function” to “carry around” data that it needs. Clearly, function objects provide us with a very general, powerful, and convenient mechanism. Consider a more general notion of a function object:
class F { // abstract example of a function object
S s; // state
public:
F(const S& ss) :s(ss) { /* establish initial state */ }
T operator() (const S& ss) const
{
// do something with ss to s
// return a value of type T (T is often void, bool, or S)
}
const S& state() const { return s; } // reveal state
void reset(const S& ss) { s = ss; } // reset state
};
An object of class F holds data in its member s. If needed, a function object can have many data members. Another way of saying that something holds data is that it “has state.” When we create an F, we can initialize that state. Whenever we want to, we can read that state. For F, we provided an operation, state(), to read that state and another, reset(), to write it. However, when we design a function object we are free to provide any way of accessing its state that we consider appropriate. And, of course, we can directly or indirectly call the function object using the normal function call notation. We defined F to take a single argument when it is called, but we can define function objects with as many parameters as we need.
![]()
Use of function objects is the main method of parameterization in the STL. We use function objects to specify what we are looking for in searches (§21.3), for defining sorting criteria (§21.4.2), for specifying arithmetic operations in numerical algorithms (§21.5), for defining what it means for values to be equal (§21.8), and for much more. The use of function objects is a major source of flexibility and generality.
![]()
Function objects are usually very efficient. In particular, passing a small function object by value to a template function typically leads to optimal performance. The reason is simple, but surprising to people more familiar with passing functions as arguments: typically, passing a function object leads to significantly smaller and faster code than passing a function! This is true only if the object is small (something like zero, one, or two words of data) or passed by reference and if the function call operator is small (e.g., a simple comparison using <) and defined to be inline (e.g., has its definition within its class itself). Most of the examples in this chapter — and in this book — follow this pattern. The basic reason for the high performance of small and simple function objects is that they preserve sufficient type information for compilers to generate optimal code. Even older compilers with unsophisticated optimizers can generate a simple “greater-than” machine instruction for the comparison in Larger_than rather than calling a function. Calling a function typically takes 10 to 50 times longer than executing a simple comparison operation. In addition, the code for a function call is several times larger than the code for a simple comparison.
21.4.2 Predicates on class members
As we have seen, standard algorithms work well with sequences of elements of basic types, such as int and double. However, in some application areas, containers of class values are far more common. Consider an example that is key to applications in many areas, sorting a record by several criteria:
struct Record {
string name; // standard string for ease of use
char addr[24]; // old style to match database layout
// . . .
};
vector<Record> vr;
Sometimes we want to sort vr by name, and sometimes we want to sort it by address. Unless we can do both elegantly and efficiently, our techniques are of limited practical interest. Fortunately, doing so is easy. We can write
// . . .
sort(vr.begin(), vr.end(), Cmp_by_name()); // sort by name
// . . .
sort(vr.begin(), vr.end(), Cmp_by_addr()); // sort by addr
// . . .
![]()
Cmp_by_name is a function object that compares two Records by comparing their name members. Cmp_by_addr is a function object that compares two Records by comparing their addr members. To allow the user to specify such comparison criteria, the standard library sort algorithm takes an optional third argument specifying the sorting criteria. Cmp_by_name() creates a Cmp_by_name for sort() to use to compare Records. That looks OK — meaning that we wouldn’t mind maintaining code that looked like that. Now all we have to do is to define Cmp_by_name andCmp_by_addr:
// different comparisons for Record objects:
struct Cmp_by_name {
bool operator()(const Record& a, const Record& b) const
{ return a.name < b.name; }
};
struct Cmp_by_addr {
bool operator()(const Record& a, const Record& b) const
{ return strncmp(a.addr, b.addr, 24) < 0; } // !!!
};
The Cmp_by_name class is pretty obvious. The function call operator, operator()(), simply compares the name strings using the standard string’s < operator. However, the comparison in Cmp_by_addr is ugly. That is because we chose an ugly representation of the address: an array of 24 characters (not zero terminated). We chose that partly to show how a function object can be used to hide ugly and error-prone code and partly because this particular representation was once presented to me as a challenge: “an ugly and important real-world problem that the STL can’t handle.” Well, the STL could. The comparison function uses the standard C (and C++) library function strncmp() that compares fixed-length character arrays, returning a negative number if the second “string” comes lexicographically after the first. Look it up should you ever need to do such an obscure comparison (e.g., §B.11.3).
21.4.3 Lambda expressions
Defining a function object (or a function) in one place in a program and then using it in another can be a bit tedious. In particular, it is a nuisance if the action we want to perform is very easy to specify, easy to understand, and will never again be needed. In that case, we can use a lambda expression (§15.3.3). Probably the best way of thinking about a lambda expression is as a shorthand notation for defining a function object (a class with an operator ( )) and then immediately creating an object of it. For example, we could have written
// . . .
sort(vr.begin(), vr.end(), // sort by name
[](const Record& a, const Record& b)
{ return a.name < b.name; }
);
// . . .
sort(vr.begin(), vr.end(), // sort by addr
[](const Record& a, const Record& b)
{ return strncmp(a.addr, b.addr, 24) < 0; }
);
// . . .
In this case, we wonder if a named function object wouldn’t give more maintainable code. Maybe Cmp_by_name and Cmp_by_addr have other uses.
However, consider the find_if() example from §21.4. There, we needed to pass an operation as an argument and that operation needed to carry data with it:
void f(list<double>& v, int x)
{
auto p = find_if(v.begin(), v.end(), Larger_than(31));
if (p!=v.end()) { /* we found a value > 31 */ }
auto q = find_if(v.begin(), v.end(), Larger_than(x));
if (q!=v.end()) { /* we found a value > x */ }
// . . .
}
Alternatively, and equivalently, we could write
void f(list<double>& v, int x)
{
auto p = find_if(v.begin(), v.end(), [](double a) { return a>31; });
if (p!=v.end()) { /* we found a value > 31 */ }
auto q = find_if(v.begin(), v.end(), [&](double a) { return a>x; });
if (q!=v.end()) { /* we found a value > x */ }
// . . .
}
The comparison to the local variable x makes the lambda version attractive.
21.5 Numerical algorithms
Most of the standard library algorithms deal with data management issues: they copy, sort, search, etc. data. However, a few help with numerical computations. These numerical algorithms can be important when you compute, and they serve as examples of how you can express numerical algorithms within the STL framework.
There are just four STL-style standard library numerical algorithms:

They are found in <numeric>. We’ll describe the first two here and leave it for you to explore the other two if you feel the need.
21.5.1 Accumulate
The simplest and most useful numerical algorithm is accumulate(). In its simplest form, it adds a sequence of values:
template<typename In, typename T>
// requres Input_iterator<T>() && Number<T>()
T accumulate(In first, In last, T init)
{
while (first!=last) {
init = init + *first;
++first;
}
return init;
}
Given an initial value, init, it simply adds every value in the [first:last) sequence to it and returns the sum. The variable in which the sum is computed, init, is often referred to as the accumulator. For example:
int a[] = { 1, 2, 3, 4, 5 };
cout << accumulate(a, a+sizeof(a)/sizeof(int), 0);
This will print 15, that is, 0+1+2+3+4+5 (0 is the initial value). Obviously, accumulate() can be used for all kinds of sequences:
void f(vector<double>& vd, int* p, int n)
{
double sum = accumulate(vd.begin(), vd.end(), 0.0);
int sum2 = accumulate(p,p+n,0);
}
The type of the result (the sum) is the type of the variable that accumulate() uses to hold the accumulator. This gives a degree of flexibility that can be important. For example:
void g(int* p, int n)
{
int s1 = accumulate(p, p+n, 0); // sum into an int
long sl = accumulate(p, p+n, long{0}); // sum the ints into a long
double s2 = accumulate(p, p+n, 0.0); // sum the ints into a double
}
A long has more significant digits than an int on some computers. A double can represent larger (and smaller) numbers than an int, but possibly with less precision. We’ll revisit the role of range and precision in numerical computations in Chapter 24.
![]()
Using the variable in which you want the result as the initializer is a popular idiom for specifying the type of the accumulator:
void f(vector<double>& vd, int* p, int n)
{
double s1 = 0;
s1 = accumulate(vd.begin(), vd.end(), s1);
int s2 = accumulate(vd.begin(), vd.end(), s2); // oops
float s3 = 0;
accumulate(vd.begin(), vd.end(), s3); // oops
}
![]()
Do remember to initialize the accumulator and to assign the result of accumulate() to the variable. In this example, s2 was used as an initializer before it was itself initialized; the result is therefore undefined. We passed s3 to accumulate() (pass-by-value; see §8.5.3), but the result is never assigned anywhere; that compilation is just a waste of time.
21.5.2 Generalizing accumulate()
So, the basic three-argument accumulate() adds. However, there are many other useful operations, such as multiply and subtract, that we might like to do on a sequence, so the STL offers a second four-argument version of accumulate() where we can specify the operation to be used:
template<typename In, typename T, typename BinOp>
// requires Input_iterator<In>() && Number<T>()
// && Binary_operator<BinOp,Value_type<In>,T>()
T accumulate(In first, In last, T init, BinOp op)
{
while (first!=last) {
init = op(init, *first);
++first;
}
return init;
}
Any binary operation that accepts two arguments of the accumulator’s type can be used here. For example:
vector<double> a = { 1.1, 2.2, 3.3, 4.4 };
cout << accumulate(a.begin(),a.end(), 1.0, multiplies<double>());
This will print 35.1384, that is, 1.0*1.1*2.2*3.3*4.4 (1.0 is the initial value). The binary operator supplied here, multiplies<double>(), is a standard library function object that multiplies; multiplies<double> multiplies doubles, multiplies<int> multiplies ints, etc. There are other binary function objects: plus (it adds), minus (it subtracts), divides, and modulus (it takes the remainder). They are all defined in <functional> (§B.6.2).
Note that for products of floating-point numbers, the obvious initial value is 1.0.
![]()
As in the sort() example (§21.4.2), we are often interested in data within class objects, rather than just plain built-in types. For example, we might want to calculate the total cost of items given the unit prices and number of units:
struct Record {
double unit_price;
int units; // number of units sold
// . . .
};
We can let accumulate’s operator extract the units from a Record element as well as multiplying it to the accumulator value:
double price(double v, const Record& r)
{
return v + r.unit_price * r.units; // calculate price and accumulate
}
void f(const vector<Record>& vr)
{
double total = accumulate(vr.begin(), vr.end(), 0.0, price);
// . . .
}
We were “lazy” and used a function, rather than a function object, to calculate the price — just to show that we could do that also. We tend to prefer function objects
• If they need to store a value between calls, or
• If they are so short that inlining can make a difference (at most a handful of primitive operations)
In this example, we might have chosen a function object for the second reason.
Try This
Define a vector<Record>, initialize it with four records of your choice, and compute their total price using the functions above.
21.5.3 Inner product
Take two vectors, multiply each pair of elements with the same subscript, and add all of those products. That’s called the inner product of the two vectors and is a most useful operation in many areas (e.g., physics and linear algebra; see §24.6). If you prefer code to words, here is the STL version:
template<typename In, typename In2, typename T>
// requires Input_iterator<In> && Input_iterator<In2>
// && Number<T> (§19.3.3)
T inner_product(In first, In last, In2 first2, T init)
// note: this is the way we multiply two vectors (yielding a scalar)
{
while(first!=last) {
init = init + (*first) * (*first2); // multiply pairs of elements
++first;
++first2;
}
return init;
}
This generalizes the notion of inner product to any kind of sequence of any type of element. As an example, consider a stock market index. The way that works is to take a set of companies and assign each a “weight.” For example, in the Dow Jones Industrial index Alcoa had a weight of 2.4808 when last we looked. To get the current value of the index, we multiply each company’s share price with its weight and add all the resulting weighted prices together. Obviously, that’s the inner product of the prices and the weights. For example:
// calculate the Dow Jones Industrial index:
vector<double> dow_price = { // share price for each company
81.86, 34.69, 54.45,
// . . .
};
list<double> dow_weight = { // weight in index for each company
5.8549, 2.4808, 3.8940,
// . . .
};
double dji_index = inner_product( // multiply (weight,value) pairs and add
dow_price.begin(), dow_price.end(),
dow_weight.begin(),
0.0);
cout << "DJI value " << dji_index << '\n';
![]()
Note that inner_product() takes two sequences. However, it takes only three arguments: only the beginning of the second sequence is mentioned. The second sequence is supposed to have at least as many elements as the first. If not, we have a run-time error. As far as inner_product() is concerned, it is OK for the second sequence to have more elements than the first; those “surplus elements” will simply not be used.
![]()
The two sequences need not be of the same type, nor do they need to have the same element types. To illustrate this point, we used a vector to hold the prices and a list to hold the weights.
21.5.4 Generalizing inner_product()
The inner_product() can be generalized just as accumulate() was. For inner_product() we need two extra arguments, though: one to combine the accumulator with the new value, exactly as for accumulate(), and one for combining the element value pairs:
template<typename In, typename In2, typename T, typename BinOp,
typename BinOp2>
// requires Input_iterator<In> && Input_iterator<In2> && Number<T>
// && Binary_operation<BinOp,T, Value_type<In>()
// && Binary_operation<BinOp2,T, Value_type<In2>()
T inner_product(In first, In last, In2 first2, T init, BinOp op, BinOp2 op2)
{
while(first!=last) {
init = op(init, op2(*first, *first2));
++first;
++first2;
}
return init;
}
In §21.6.3, we return to the Dow Jones example and use this generalized inner_product() as part of a more elegant solution.
21.6 Associative containers
![]()
After vector, the most useful standard library container is probably the map. A map is an ordered sequence of (key,value) pairs in which you can look up a value based on a key; for example, my_phone_book["Nicholas"] could be the phone number of Nicholas. The only potential competitor to map in a popularity contest is unordered_map (see §21.6.4), and that’s a map optimized for keys that are strings. Data structures similar to map and unordered_map are known under many names, such as associative arrays, hash tables, and red-black trees. Popular and useful concepts always seem to have many names. In the standard library, we collectively call all such data structures associative containers.
The standard library provides eight associative containers:

These containers are found in <map>, <set>, <unordered_map>, and <unordered_set>.
21.6.1 map
Consider a conceptually simple task: make a list of the number of occurrences of words in a text. The obvious way of doing this is to keep a list of words we have seen together with the number of times we have seen each. When we read a new word, we see if we have already seen it; if we have, we increase its count by one; if not, we insert it in our list and give it the value 1. We could do that using a list or a vector, but then we would have to do a search for each word we read. That could be slow. A map stores its keys in a way that makes it easy to see if a key is present, thus making the searching part of our task trivial:
int main()
{
map<string,int> words; // keep (word,frequency) pairs
for (string s; cin>>s; )
++words[s]; // note: words is subscripted by a string
for (const auto& p : words)
cout << p.first << ": " << p.second << '\n';
}
The really interesting part of the program is ++words[s]. As we can see from the first line of main(), words is a map of (string,int) pairs; that is, words maps strings to ints. In other words, given a string, words can give us access to its corresponding int. So, when we subscript words with astring (holding a word read from our input), words[s] is a reference to the int corresponding to s. Let’s look at a concrete example:
words["sultan"]
![]()
If we have not seen the string "sultan" before, "sultan" will be entered into words with the default value for an int, which is 0. Now, words has an entry ("sultan",0). It follows that if we haven’t seen "sultan" before, ++words["sultan"] will associate the value 1 with the string "sultan". In detail: the map will discover that "sultan" wasn’t found, insert a ("sultan",0) pair, and then ++ will increment that value, yielding 1.
Now look again at the program: ++words[s] takes every “word” we get from input and increases its value by one. The first time a new word is seen, it gets the value 1. Now the meaning of the loop is clear:
for (string s; cin>>s; )
++words[s]; // note: words is subscripted by a string
This reads every (whitespace-separated) word on input and computes the number of occurrences for each. Now all we have to do is to produce the output. We can iterate through a map, just like any other STL container. The elements of a map<string,int> are of type pair<string,int>. The first member of a pair is called first and the second member second, so the output loop becomes
for (const auto& p : words)
cout << p.first << ": " << p.second << '\n';
As a test, we can feed the opening statements of the first edition of The C++ Programming Language to our program:
C++ is a general purpose programming language designed to make programming more enjoyable for the serious programmer. Except for minor details, C++ is a superset of the C programming language. In addition to the facilities provided by C, C++ provides flexible and efficient facilities for defining new types.
We get the output
C: 1
C++: 3
C,: 1
Except: 1
In: 1
a: 2
addition: 1
and: 1
by: 1
defining: 1
designed: 1
details,: 1
efficient: 1
enjoyable: 1
facilities: 2
flexible: 1
for: 3
general: 1
is: 2
language: 1
language.: 1
make: 1
minor: 1
more: 1
new: 1
of: 1
programmer.: 1
programming: 3
provided: 1
provides: 1
purpose: 1
serious: 1
superset: 1
the: 3
to: 2
types.: 1
If we don’t like to distinguish between upper- and lowercase letters or would like to eliminate punctuation, we can do so: see exercise 13.
21.6.2 map overview
![]()
So what is a map? There is a variety of ways of implementing maps, but the STL map implementations tend to be balanced binary search trees; more specifically, they are red-black trees. We will not go into the details, but now you know the technical terms, so you can look them up in the literature or on the web, should you want to know more.
A tree is built up from nodes (in a way similar to a list being built from links; see §20.4). A Node holds a key, its corresponding value, and pointers to two descendant Nodes.

Here is the way a map<Fruit,int> might look in memory assuming we had inserted (Kiwi,100), (Quince,0), (Plum,8), (Apple,7), (Grape,2345), and (Orange,99) into it:
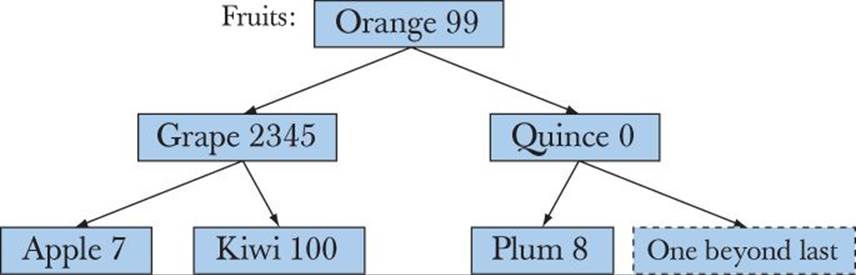
Given that the name of the Node member that holds the key value is first, the basic rule of a binary search tree is
left->first<first && first<right->first
That is, for every node,
• Its left sub-node has a key that is less than the node’s key, and
• The node’s key is less than the key of its right sub-node
![]()
You can verify that this holds for each node in the tree. That allows us to search “down the tree from its root.” Curiously enough, in computer science literature trees grow downward from their roots. In the example, the root node is (Orange, 99). We just compare our way down the tree until we find what we are looking for or the place where it should have been. A tree is called balanced when (as in the example above) each sub-tree has approximately as many nodes as every other sub-tree that’s equally far from the root. Being balanced minimizes the average number of nodes we have to visit to reach a node.
A Node may also hold some more data which the map will use to keep its tree of nodes balanced. A tree is balanced when each node has about as many descendants to its left as to its right. If a tree with N nodes is balanced, we have to at most look at log2(N) nodes to find a node. That’s much better than the average of N/2 nodes we would have to examine if we had the keys in a list and searched from the beginning (the worst case for such a linear search is N). (See also §21.6.4.) For example, have a look at an unbalanced tree:
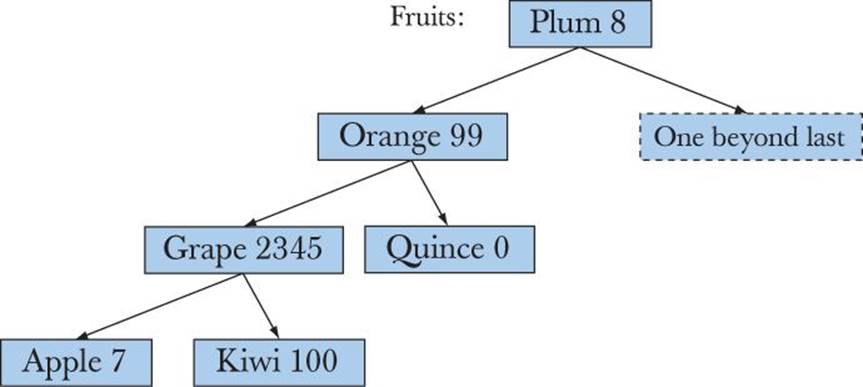
This tree still meets the criteria that the key of every node is greater than that of its left sub-node and less than that of its right sub-node:
left->first<first && first<right->first
However, this version of the tree is unbalanced, so we now have three “hops” to reach Apple and Kiwi, rather than the two we had in the balanced tree. For trees of many nodes the difference can be very significant, so the trees used to implement maps are balanced.
We don’t have to understand about trees to use map. It is just reasonable to assume that professionals understand at least the fundamentals of their tools. What we do have to understand is the interface to map provided by the standard library. Here is a slightly simplified version:
template<typename Key, typename Value, typename Cmp = less<Key>>
// requires Binary_operation<Cmp,Value>() (§19.3.3)
class map {
// . . .
using value_type = pair<Key,Value>; // a map deals in (Key,Value) pairs
using iterator = sometype1; // similar to a pointer to a tree node
using const_iterator = sometype2;
iterator begin(); // points to first element
iterator end(); // points one beyond the last element
Value& operator[](const Key& k); // subscript with k
iterator find(const Key& k); // is there an entry for k?
void erase(iterator p); // remove element pointed to by p
pair<iterator, bool> insert(const value_type&); // insert a (key,value) pair
// . . .
};
![]()
You can find the real version in <map>. You can imagine the iterator to be similar to a Node*, but you cannot rely on your implementation using that specific type to implement iterator.
The similarity to the interfaces for vector and list (§20.5 and §B.4) is obvious. The main difference is that when you iterate, the elements are pairs — of type pair<Key,Value>. That type is another useful STL type:
template<typename T1, typename T2>
struct pair { // simplified version of std::pair
using first_type = T1;
using second_type = T2;
T1 first;
T2 second;
// . . .
};
template<typename T1, typename T2>
pair<T1,T2> make_pair(T1 x, T2 y)
{
return {x,y};
}
We copied the complete definition of pair and its useful helper function make_pair() from the standard.
![]()
Note that when you iterate over a map, the elements will come in the order defined by the key. For example, if we iterated over the fruits in the example, we would get
(Apple,7) (Grape,2345) (Kiwi,100) (Orange,99) (Plum,8) (Quince,0)
The order in which we inserted those fruits doesn’t matter.
The insert() operation has an odd return value, which we most often ignore in simple programs. It is a pair of an iterator to the (key,value) element and a bool which is true if the (key,value) pair was inserted by this call of insert(). If the key was already in the map, the insertion fails and thebool is false.
![]()
Note that you can define the meaning of the order used by a map by supplying a third argument (Cmp in the map declaration). For example:
map<string, double, No_case> m;
No_case defines case-insensitive compare; see §21.8. By default the order is defined by less<Key>, meaning “less than.”
21.6.3 Another map example
To better appreciate the utility of map, let’s return to the Dow Jones example from §21.5.3. The code there was correct if and only if all weights appear in the same position in their vector as their corresponding name. That’s implicit and could easily be the source of an obscure bug. There are many ways of attacking that problem, but one attractive one is to keep each weight together with its company’s ticker symbol, e.g., (“AA”,2.4808). A “ticker symbol” is an abbreviation of a company name used where a terse representation is needed. Similarly we can keep the company’s ticker symbol together with its share price, e.g., (“AA”,34.69). Finally, for those of us who don’t regularly deal with the U.S. stock market, we can keep the company’s ticker symbol together with the company name, e.g., (“AA”,“Alcoa Inc.”); that is, we could keep three maps of corresponding values.
First we make the (symbol,price) map:
map<string,double> dow_price = { // Dow Jones Industrial index (symbol,price);
// for up-to-date quotes see
// www.djindexes.com
{"MMM",81.86},
{"AA",34.69},
{"MO",54.45},
// . . .
};
The (symbol,weight) map:
map<string,double> dow_weight = { // Dow (symbol,weight)
{"MMM", 5.8549},
{"AA",2.4808},
{"MO",3.8940},
// . . .
};
The (symbol,name) map:
map<string,string> dow_name = { // Dow (symbol,name)
{"MMM","3M Co."},
{"AA"] = "Alcoa Inc."},
{"MO"] = "Altria Group Inc."},
// . . .
};
Given those maps, we can conveniently extract all kinds of information. For example:
double alcoa_price = dow_price ["AAA"]; // read values from a map
double boeing_price = dow_price ["BA"];
if (dow_price.find("INTC") != dow_price.end()) // find an entry in a map
cout << "Intel is in the Dow\n";
Iterating through a map is easy. We just have to remember that the key is called first and the value is called second:
// write price for each company in the Dow index:
for (const auto& p : dow_price) {
const string& symbol = p.first; // the “ticker” symbol
cout << symbol << '\t'
<< p.second << '\t'
<< dow_name[symbol] << '\n';
}
We can even do some computation directly using maps. In particular, we can calculate the index, just as we did in §21.5.3. We have to extract share values and weights from their respective maps and multiply them. We can easily write a function for doing that for any twomap<string,double>s:
double weighted_value(
const pair<string,double>& a,
const pair<string,double>& b
) // extract values and multiply
{
return a.second * b.second;
}
Now we just plug that function into the generalized version of inner_product() and we have the value of our index:
double dji_index =
inner_product(dow_price.begin(), dow_price.end(), // all companies
dow_weight.begin(), // their weights
0.0, // initial value
plus<double>(), // add (as usual)
weighted_value); // extract values and weights
// and multiply
![]()
Why might someone keep such data in maps rather than vectors? We used a map to make the association between the different values explicit. That’s one common reason. Another is that a map keeps its elements in the order defined by its key. When we iterated through dow above, we output the symbols in alphabetical order; had we used a vector we would have had to sort. The most common reason to use a map is simply that we want to look up values based on the key. For large sequences, finding something using find() is far slower than looking it up in a sorted structure, such as a map.
Try This
Get this little example to work. Then add a few companies of your own choice, with weights of your choice.
21.6.4 unordered_map
![]()
To find an element in a vector, find() needs to examine all the elements from the beginning to the element with the right value or to the end. On average, the cost is proportional to the length of the vector (N); we call that cost O(N).
To find an element in a map, the subscript operator needs to examine all the elements of the tree from the root to the element with the right value or to a leaf. On average the cost is proportional to the depth of the tree. A balanced binary tree holding N elements has a maximum depth of log2(N); the cost is O(log2(N)). O(log2(N)) — that is, cost proportional to log2(N) — is actually pretty good compared to O(N):
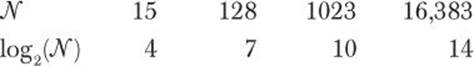
The actual cost will depend on how soon in our search we find our values and how expensive comparisons and iterations are. It is usually somewhat more expensive to chase pointers (as the map lookup does) than to increment a pointer (as find() does in a vector).
![]()
For some types, notably integers and character strings, we can do even better than a map’s tree search. We will not go into details, but the idea is that given a key, we compute an index into a vector. That index is called a hash value and a container that uses this technique is typically called a hash table. The number of possible keys is far larger than the number of slots in the hash table. For example, we often use a hash function to map from the billions of possible strings into an index for a vector with 1000 elements. This can be tricky, but it can be handled well and is especially useful for implementing large maps. The main virtue of a hash table is that on average the cost of a lookup is (near) constant and independent of the number of elements in the table, that is, O(1). Obviously, that can be a significant advantage for large maps, say a map of 500,000 web addresses. For more information about hash lookup, you can look at the documentation for unordered_map (available on the web) or just about any basic text on data structures (look for “hash table” and “hashing”).
We can illustrate lookup in an (unsorted) vector, a balanced binary tree, and a hash table graphically like this:
• Lookup in unsorted vector:
![]()
• Lookup in map (balanced binary tree):
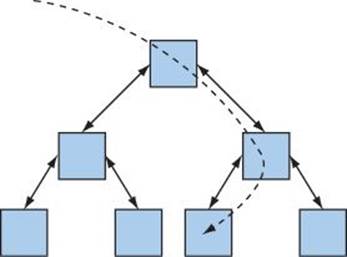
• Lookup in unordered_map (hash table):
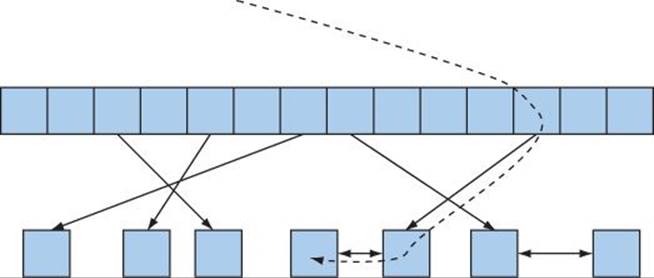
The STL unordered_map is implemented using a hash table, just as the STL map is implemented using a balanced binary tree, and an STL vector is implemented using an array. Part of the utility of the STL is to fit all of these ways of storing and accessing data into a common framework together with algorithms. The rule of thumb is:
![]()
• Use vector unless you have a good reason not to.
• Use map if you need to look up based on a value (and if your key type has a reasonable and efficient less-than operation).
• Use unordered_map if you need to do a lot of lookup in a large map and you don’t need an ordered traversal (and if you can find a good hash function for your key type).
Here, we will not describe unordered_map in any detail. You can use an unordered_map with a key of type string or int exactly like a map, except that when you iterate over the elements, the elements will not be ordered. For example, we could rewrite part of the Dow Jones example from §21.6.3 like this:
unordered_map<string,double> dow_price;
for (const auto& p : dow_price) {
const string& symbol = p.first; // the “ticker” symbol
cout << symbol << '\t'
<< p.second << '\t'
<< dow_name[symbol] << '\n';
}
Lookup in dow might now be faster. However, that would not be significant because there are only 30 companies in that index. Had we been keeping the prices of all the companies on the New York Stock Exchange, we might have noticed a performance difference. We will, however, notice a logical difference: the output from the iteration will now not be in alphabetical order.
The unordered maps are new in the context of the C++ standard and not yet quite “first-class members,” as they are defined in a Technical Report rather than in the standard proper. They are widely available, though, and where they are not you can often find their ancestors, called something like hash_map.
Try This
Write a small program using #include<unordered_map>. If that doesn’t work, unordered_map wasn’t shipped with your C++ implementation. If your C++ implementation doesn’t provide unordered_map, you have to download one of the available implementations (e.g., seewww.boost.org).
21.6.5 set
![]()
We can think of a set as a map where we are not interested in the values, or rather as a map without values. We can visualize a set node like this:
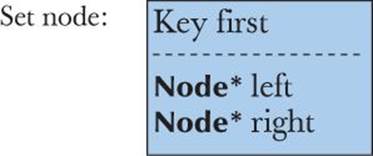
We can represent the set of fruits used in the map example (§21.6.2) like this:
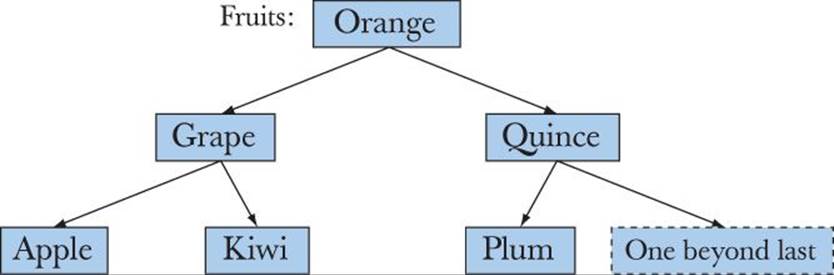
What are sets useful for? As it happens, there are lots of problems that require us to remember if we have seen a value. Keeping track of which fruits are available (independently of price) is one example; building a dictionary is another. A slightly different style of usage is having a set of “records”; that is, the elements are objects that potentially contain “lots of” information — we simply use a member as the key. For example:
struct Fruit {
string name;
int count;
double unit_price;
Date last_sale_date;
// . . .
};
struct Fruit_order {
bool operator()(const Fruit& a, const Fruit& b) const
{
return a.name<b.name;
}
};
set<Fruit, Fruit_order> inventory; // use Fruit_order(x,y) to compare Fruits
Here again, we see how using a function object can significantly increase the range of problems for which an STL component is useful.
![]()
Since set doesn’t have a value type, it doesn’t support subscripting (operator[]()) either. We must use “list operations,” such as insert() and erase(), instead. Unfortunately, map and set don’t support push_back() either — the reason is obvious: the set and not the programmer determines where the new value is inserted. Instead use insert(). For example:
inventory.insert(Fruit("quince",5));
inventory.insert(Fruit("apple",200,0.37));
One advantage of set over map is that you can use the value obtained from an iterator directly. Since there is no (key,value) pair as for map (§21.6.3), the dereference operator gives a value of the element type:
for (auto p = inventory.begin(), p!=inventory.end(); ++p)
cout << *p << '\n';
Assuming, of course, that you have defined << for Fruit. Or we could equivalently write
for (const auto& x : inventory)
cout << x << '\n';
21.7 Copying
In §21.2, we deemed find() “the simplest useful algorithm.” Naturally, that point can be argued. Many simple algorithms are useful — even some that are trivial to write. Why bother to write new code when you can use what others have written and debugged for you, however simple? When it comes to simplicity and utility, copy() gives find() a run for its money. The STL provides three versions of copy:

21.7.1 Copy
The basic copy algorithm is defined like this:
template<typename In, typename Out>
// requires Input_iterator<In>() && Output_iterator<Out>()
Out copy(In first, In last, Out res)
{
while (first!=last) {
*res = *first; // copy element
++res;
++first;
}
return res;
}
Given a pair of iterators, copy() copies a sequence into another sequence specified by an iterator to its first element. For example:
void f(vector<double>& vd, list<int>& li)
// copy the elements of a list of ints into a vector of doubles
{
if (vd.size() < li.size()) error("target container too small");
copy(li.begin(), li.end(), vd.begin());
// . . .
}
Note that the type of the input sequence of copy() can be different from the type of the output sequence. That’s a useful generality of STL algorithms: they work for all kinds of sequences without making unnecessary assumptions about their implementation. We remembered to check that there was enough space in the output sequence to hold the elements we put there. It’s the programmer’s job to check such sizes. STL algorithms are programmed for maximal generality and optimal performance; they do not (by default) do range checking or other potentially expensive tests to protect their users. At times, you’ll wish they did, but when you want checking, you can add it as we did above.
21.7.2 Stream iterators
![]()
You will have heard the phrases “copy to output” and “copy from input.” That’s a nice and useful way of thinking of some forms of I/O, and we can actually use copy() to do exactly that.
Remember that a sequence is something
• With a beginning and an end
• Where we can get to the next element using ++
• Where we can get the value of the current element using *
We can easily represent input and output streams that way. For example:
ostream_iterator<string> oo{cout}; // assigning to *oo is to write to cout
*oo = "Hello, "; // meaning cout << "Hello, "
++oo; // “get ready for next output operation”
*oo = "World!\n"; // meaning cout << "World!\n"
You can imagine how this could be implemented. The standard library provides an ostream_iterator type that works like that; ostream_iterator<T> is an iterator that you can use to write values of type T.
Similarly, the standard library provides the type istream_iterator<T> for reading values of type T:
istream_iterator<string> ii{cin}; // reading *ii is to read a string from cin
string s1 = *ii; // meaning cin>>s1
++ii; // “get ready for the next input operation”
string s2 = *ii; // meaning cin>>s2
Using ostream_iterator and istream_iterator, we can use copy() for our I/O. For example, we can make a “quick and dirty” dictionary like this:
int main()
{
string from, to;
cin >> from >> to; // get source and target file names
ifstream is {from}; // open input stream
ofstream os {to}; // open output stream
istream_iterator<string> ii {is}; // make input iterator for stream
istream_iterator<string> eos; // input sentinel
ostream_iterator<string> oo {os,"\n"}; // make output iterator for stream
vector<string> b {ii,eos}; // b is a vector initialized from input
sort(b.begin() ,b.end()); // sort the buffer
copy(b.begin() ,b.end() ,oo); // copy buffer to output
}
The iterator eos is the stream iterator’s representation of “end of input.” When an istream reaches end of input (often referred to as eof), its istream_iterator will equal the default istream_iterator (here called eos).
![]()
Note that we initialized the vector by a pair of iterators. As the initializers for a container, a pair of iterators (a,b) means “Read the sequence [a:b) into the container.” Naturally, the pair of iterators that we used was (ii,eos) — the beginning and end of input. That saves us from explicitly using >> and push_back(). We strongly advise against the alternative
vector<string> b(max_size); // don’t guess about the amount of input!
copy(ii,eos,b.begin());
People who try to guess the maximum size of input usually find that they have underestimated, and serious problems emerge — for them or for their users — from the resulting buffer overflows. Such overflows are also a source of security problems.
Try This
First get the program as written to work and test it with a small file of, say, a few hundred words. Then try the emphatically not recommended version that guesses about the size of input and see what happens when the input buffer b overflows. Note that the worst-case scenario is that the overflow led to nothing bad in your particular example, so that you would be tempted to ship it to users.
In our little program, we read in the words and then sorted them. That seemed an obvious way of doing things at the time, but why should we put words in “the wrong place” so that we later have to sort? Worse yet, we find that we store a word and print it as many times as it appears in the input.
We can solve the latter problem by using unique_copy() instead of copy(). A unique_copy() simply doesn’t copy repeated identical values. For example, using plain copy() the program will take
the man bit the dog
and produce
bit
dog
man
the
the
If we used unique_copy(), the program would write
bit
dog
man
the
![]()
Where did those newlines come from? Outputting with separators is so common that the ostream_iterator’s constructor allows you to (optionally) specify a string to be printed after each value:
ostream_iterator<string> oo {os,"\n"}; // make output iterator for stream
Obviously, a newline is a popular choice for output meant for humans to read, but maybe we prefer spaces as separators? We could write
ostream_iterator<string> oo {os," "}; // make output iterator for stream
This would give us the output
bit dog man the
21.7.3 Using a set to keep order
There is an even easier way of getting that output; use a set rather than a vector:
int main()
{
string from, to;
cin >> from >> to; // get source and target file names
ifstream is {from}; // make input stream
ofstream os {to}; // make output stream
set<string> b {istream_iterator<string>{is}, istream_iterator<string>{}};
copy(b.begin() ,b.end() , ostream_iterator<string>{os," "}); // copy buffer
// to output
}
![]()
When we insert values into a set, duplicates are ignored. Furthermore, the elements of a set are kept in order so no sorting is needed. With the right tools, most tasks are easy.
21.7.4 copy_if
The copy() algorithm copies unconditionally. The unique_copy() algorithm suppresses adjacent elements with the same value. The third copy algorithm copies only elements for which a predicate is true:
template<typename In, typename Out, typename Pred>
// requires Input_iterator<In>() && Output_operator<Out>() &&
// Predicate<Pred, Value_type<In>>()
Out copy_if(In first, In last, Out res, Pred p)
// copy elements that fulfill the predicate
{
while (first!=last) {
if (p(*first)) *res++ = *first;
++first;
}
return res;
}
Using our Larger_than function object from §21.4, we can find all elements of a sequence larger than 6 like this:
void f(const vector<int>& v)
// copy all elements with a value larger than 6
{
vector<int> v2(v.size());
copy_if(v.begin(), v.end(), v2.begin(), Larger_than(6));
// . . .
}
![]()
Thanks to a mistake I made, this algorithm is missing from the 1998 ISO standard. This mistake has now been remedied, but you can still find implementations without copy_if. If so, just use the definition from this section.
21.8 Sorting and searching
![]()
Often, we want our data ordered. We can achieve that either by using a data structure that maintains order, such as map and set, or by sorting. The most common and useful sort operation in the STL is the sort() that we have already used several times. By default, sort() uses < as the sorting criterion, but we can also supply our own criteria:
template<typename Ran>
// requires Random_access_iterator<Ran>()
void sort(Ran first, Ran last);
template<typename Ran, typename Cmp>
// requires Random_access_iterator<Ran>()
// && Less_than_comparable<Cmp,Value_type<Ran>>()
void sort(Ran first, Ran last, Cmp cmp);
As an example of sorting based on a user-specified criterion, we’ll show how to sort strings without taking case into account:
struct No_case { // is lowercase(x) < lowercase(y)?
bool operator()(const string& x, const string& y) const
{
for (int i = 0; i<x.length(); ++i) {
if (i == y.length()) return false; // y<x
char xx = tolower(x[i]);
char yy = tolower(y[i]);
if (xx<yy) return true; // x<y
if (yy<xx) return false; // y<x
}
if (x.length()==y.length()) return false; // x==y
return true; // x<y (fewer characters in x)
}
};
void sort_and_print(vector<string>& vc)
{
sort(vc.begin(),vc.end(),No_case());
for (const auto& s : vc)
cout << s << '\n';
}
![]()
Once a sequence is sorted, we no longer need to search from the beginning using find(); we can use the order to do a binary search. Basically, a binary search works like this:
Assume that we are looking for the value x; look at the middle element:
• If the element’s value equals x, we found it!
• If the element’s value is less than x, any element with value x must be to the right, so we look at the right half (doing a binary search on that half).
• If the value of x is less than the element’s value, any element with value x must be to the left, so we look at the left half (doing a binary search on that half).
• If we have reached the last element (going left or right) without finding x, then there is no element with that value.
![]()
For longer sequences, a binary search is much faster than find() (which is a linear search). The standard library algorithms for binary search are binary_search() and equal_range(). What do we mean by “longer”? It depends, but ten elements are usually sufficient to give binary_search() an advantage over find(). For a sequence of 1000 elements, binary_search() will be something like 200 times faster than find() because its cost is O(log2(N)); see §21.6.4.
The binary_search algorithm comes in two variants:
template<typename Ran, typename T>
bool binary_search(Ran first, Ran last, const T& val);
template<typename Ran, typename T, typename Cmp>
bool binary_search(Ran first, Ran last, const T& val, Cmp cmp);
![]()
These algorithms require and assume that their input sequence is sorted. If it isn’t, “interesting things,” such as infinite loops, might happen. A binary_search() simply tells us whether a value is present:
void f(vector<string>& vs) // vs is sorted
{
if (binary_search(vs.begin(),vs.end(),"starfruit")) {
// we have a starfruit
}
// . . .
}
![]()
So, binary_search() is ideal when all we care about is whether a value is in a sequence or not. If we care about the element we find, we can use lower_bound(), upper_bound(), or equal_range() (§B.5.4, §23.4). In the cases where we care which element is found, the reason is usually that it is an object containing more information than just the key, that there can be many elements with the same key, or that we want to know which element met a search criterion.
21.9 Container algorithms
So, we define standard library algorithms in terms of sequences of elements specified by iterators. An input sequence is defined as a pair of iterators [b:e) where b points to the first element of the sequence and e to the one-past-the-end element of the sequence (§20.3). An output sequence is specified as simply an iterator to its first element. For example:
void test(vector<int> & v)
{
sort(v.begin(),v.end()); // sort v’s element from v.begin() to v.end()
}
This is nice and general. For example, we can sort half a vector:
void test(vector<int> & v)
{
sort(v.begin(),v.begin()+v.size()); // sort first half of v’s elements
sort(v.begin()+v.size(),v.end()); // sort second half of v’s elements
}
However, specifying the range of elements is a bit verbose, and most of the time, we sort all of a vector and not just half. So, most of the time, we want to write
void test(vector<int> & v)
{
sort(v); // sort v
}
That variant of sort() is not provided by the standard library, but we can define it for ourselves:
template<typename C> // requires Container<C>()
void sort(C& c)
{
std::sort(c.begin(),c.end());
}
In fact, we found it so useful that we added it to std_lib_facilities.h.
Input sequences are easily handled like that, but to keep things simple, we tend to leave return types as iterators. For example:
template<typename C, typename V> // requires Container<C>()
Iterator<C> find(C& c, Val v)
{
return std::find(c.begin(),c.end(),v);
}
Naturally, Iterator<C> is C’s iterator type.
 Drill
Drill
After each operation (as defined by a line of this drill) print the vector.
1. Define a struct Item { string name; int iid; double value; /* . . . */ };, make a vector<Item>, vi, and fill it with ten items from a file.
2. Sort vi by name.
3. Sort vi by iid.
4. Sort vi by value; print it in order of decreasing value (i.e., largest value first).
5. Insert Item("horse shoe",99,12.34) and Item("Canon S400", 9988,499.95).
6. Remove (erase) two Items identified by name from vi.
7. Remove (erase) two Items identified by iid from vi.
8. Repeat the exercise with a list<Item> rather than a vector<Item>.
Now try a map:
1. Define a map<string,int> called msi.
2. Insert ten (name,value) pairs into it, e.g., msi["lecture"]=21.
3. Output the (name,value) pairs to cout in some format of your choice.
4. Erase the (name,value) pairs from msi.
5. Write a function that reads value pairs from cin and places them in msi.
6. Read ten pairs from input and enter them into msi.
7. Write the elements of msi to cout.
8. Output the sum of the (integer) values in msi.
9. Define a map<int,string> called mis.
10. Enter the values from msi into mis; that is, if msi has an element ("lecture",21), mis should have an element (21,"lecture").
11. Output the elements of mis to cout.
More vector use:
1. Read some floating-point values (at least 16 values) from a file into a vector<double> called vd.
2. Output vd to cout.
3. Make a vector vi of type vector<int> with the same number of elements as vd; copy the elements from vd into vi.
4. Output the pairs of (vd[i],vi[i]) to cout, one pair per line.
5. Output the sum of the elements of vd.
6. Output the difference between the sum of the elements of vd and the sum of the elements of vi.
7. There is a standard library algorithm called reverse that takes a sequence (pair of iterators) as arguments; reverse vd, and output vd to cout.
8. Compute the mean value of the elements in vd; output it.
9. Make a new vector<double> called vd2 and copy all elements of vd with values lower than (less than) the mean into vd2.
10. Sort vd; output it again.
Review
1. What are examples of useful STL algorithms?
2. What does find() do? Give at least five examples.
3. What does count_if() do?
4. What does sort(b,e) use as its sorting criterion?
5. How does an STL algorithm take a container as an input argument?
6. How does an STL algorithm take a container as an output argument?
7. How does an STL algorithm usually indicate “not found” or “failure”?
8. What is a function object?
9. In which ways does a function object differ from a function?
10. What is a predicate?
11. What does accumulate() do?
12. What does inner_product() do?
13. What is an associative container? Give at least three examples.
14. Is list an associative container? Why not?
15. What is the basic ordering property of binary tree?
16. What (roughly) does it mean for a tree to be balanced?
17. How much space per element does a map take up?
18. How much space per element does a vector take up?
19. Why would anyone use an unordered_map when an (ordered) map is available?
20. How does a set differ from a map?
21. How does a multimap differ from a map?
22. Why use a copy() algorithm when we could “just write a simple loop”?
23. What is a binary search?
Terms
accumulate()
algorithm
application: ()
associative container
balanced tree
binary_search()
copy()
copy_if()
equal_range()
find()
find_if()
function object
generic
hash function
inner_product()
lambda
lower_bound()
map
predicate
searching
sequence
set
sort()
sorting
stream iterator
unique_copy()
unordered_map
upper_bound()
Exercises
1. Go through the chapter and do all Try this exercises that you haven’t already done.
2. Find a reliable source of STL documentation and list every standard library algorithm.
3. Implement count() yourself. Test it.
4. Implement count_if() yourself. Test it.
5. What would we have to do if we couldn’t return end() to indicate “not found”? Redesign and re-implement find() and count() to take iterators to the first and last elements. Compare the results to the standard versions.
6. In the Fruit example in §21.6.5, we copy Fruits into the set. What if we didn’t want to copy the Fruits? We could have a set<Fruit*> instead. However, to do that, we’d have to define a comparison operation for that set. Implement the Fruit example using a set<Fruit*, Fruit_comparison>. Discuss the differences between the two implementations.
7. Write a binary search function for a vector<int> (without using the standard one). You can choose any interface you like. Test it. How confident are you that your binary search function is correct? Now write a binary search function for a list<string>. Test it. How much do the two binary search functions resemble each other? How much do you think they would have resembled each other if you had not known about the STL?
8. Take the word-frequency example from §21.6.1 and modify it to output its lines in order of frequency (rather than in lexicographical order). An example line would be 3: C++ rather than C++: 3.
9. Define an Order class with (customer) name, address, data, and vector<Purchase> members. Purchase is a class with a (product) name, unit_price, and count members. Define a mechanism for reading and writing Orders to and from a file. Define a mechanism for printing Orders. Create a file of at least ten Orders, read it into a vector<Order>, sort it by name (of customer), and write it back out to a file. Create another file of at least ten Orders of which about a third are the same as in the first file, read it into a list<Order>, sort it by address (of customer), and write it back out to a file. Merge the two files into a third using std::merge().
10. Compute the total value of the orders in the two files from the previous exercise. The value of an individual Purchase is (of course) its unit_price*count.
11. Provide a GUI interface for entering Orders into files.
12. Provide a GUI interface for querying a file of Orders; e.g., “Find all orders from Joe,” “Find the total value of orders in file Hardware,” and “List all orders in file Clothing.” Hint: First design a non-GUI interface; then, build the GUI on top of that.
13. Write a program to “clean up” a text file for use in a word query program; that is, replace punctuation with whitespace, put words into lower case, replace don’t with do not (etc.), and remove plurals (e.g., ships becomes ship). Don’t be too ambitious. For example, it is hard to determine plurals in general, so just remove an s if you find both ship and ships. Use that program on a real-world text file with at least 5000 words (e.g., a research paper).
14. Write a program (using the output from the previous exercise) to answer questions such as: “How many occurrences of ship are there in a file?” “Which word occurs most frequently?” “Which is the longest word in the file?” “Which is the shortest?” “List all words starting with s.” “List all four-letter words.”
15. Provide a GUI for the program from the previous exercise.
Postscript
![]()
The STL is the part of the ISO C++ standard library concerned with containers and algorithms. As such it provides very general, flexible, and useful basic tools. It can save us a lot of work: reinventing the wheel can be fun, but it is rarely productive. Unless there are strong reasons not to, use the STL containers and basic algorithms. What is more, the STL is an example of generic programming, showing how concrete problems and concrete solutions can give rise to a collection of powerful and general tools. If you need to manipulate data — and most programmers do — the STL provides an example, a set of ideas, and an approach that often can help.