Beginning HTML5 & CSS3 For Dummies® (2013)
Part I
Getting Started with HTML and CSS on the Web
2
Meeting the Structure and Components of HTML
In This Chapter
![]() Understanding syntax and rules in markup languages
Understanding syntax and rules in markup languages
![]() Examining entities in markup
Examining entities in markup
![]() Organizing web pages
Organizing web pages
![]() Exploring a web page
Exploring a web page
Working with a markup language such as HTML requires that you understand the conventions used to insert markup into a text file and make sense of the sometimes-cryptic strings of text you may see as a result. But as you dig into the details, it all starts to make a certain kind of sense — a sense you should seek to develop and cultivate if you want to build or edit markup on web pages. Stick with us here, please, as we talk you through some important details involved in reading and understanding HTML.
Like Any Language: Syntax and Rules
HTML is called a markup language for a very good reason: It grabs ordinary, normal text and inserts various strings into that text to define, organize, and manage the flow and sequence of content on web pages. The inserted strings define the markup, which web browsers — or other special programs known as user agents — pore over and use (along with CSS, of course) to guide their display of the content included.
Like any language, HTML is subject to a specific syntax, which defines the order in which markup must or can appear in a web page. There are also lots of interesting rules about what kinds of markup is legal in certain places but illegal in others. This may seem like a difficult concept, but these restrictions in HTML illustrate what this means and why it makes very good sense:
![]() The <caption> element is for providing a caption for a table. Thus it can appear only inside <table> markup. If you want to provide a caption for a figure, you must use the <figcaption> element instead. You need to employ the right markup for the right uses in HTML.
The <caption> element is for providing a caption for a table. Thus it can appear only inside <table> markup. If you want to provide a caption for a figure, you must use the <figcaption> element instead. You need to employ the right markup for the right uses in HTML.
![]() HTML recognizes various kinds of lists, which can organize text items with numbers or bullets, as the markup directs. List items employ the <li></li> tags to identify individual items in such lists. That's why those particular tags are legal only if they occur within some kind of list element, such as <ul></ul> (an unordered, or bulleted list) or <ol></ol> (an ordered, or numbered list).
HTML recognizes various kinds of lists, which can organize text items with numbers or bullets, as the markup directs. List items employ the <li></li> tags to identify individual items in such lists. That's why those particular tags are legal only if they occur within some kind of list element, such as <ul></ul> (an unordered, or bulleted list) or <ol></ol> (an ordered, or numbered list).
Chapter 5 covers lists in great detail. That chapter tells you about the markup to create various lists in web pages using HTML.
![]() HTML supports all kinds of fields and input controls for online forms. As with tables, forms-related elements can appear only inside a pair of <form></form> tags. There are lots of forms-related elements and attributes that can appear only in such a context. These include numerous input types, various kinds of text boxes, button controls, and more. All of them are legal only in a form, so they must occur between <form> and </form> on a web page if they are to work.
HTML supports all kinds of fields and input controls for online forms. As with tables, forms-related elements can appear only inside a pair of <form></form> tags. There are lots of forms-related elements and attributes that can appear only in such a context. These include numerous input types, various kinds of text boxes, button controls, and more. All of them are legal only in a form, so they must occur between <form> and </form> on a web page if they are to work.
Chapter 7 covers forms in great detail. That chapter explains the markup to create all kinds of forms on web pages using HTML.
Understanding HTML largely boils down to grasping how to create the markup it uses (that’s the syntax) and understanding the order (or context) in which individual markup elements may appear. Those are the rules for creating valid or legal HTML. Much of this book is devoted to one or both of these topics. The same observations are true for CSS also, by the way, except that the syntax and the rules for its expression are different because CSS is a different markup language from HTML.
Color-coding the markup
As we present HTML and CSS information in our code examples in this book, we use color-coding to help you distinguish what’s what by way of markup. Here is a color key that you should keep in mind as you peruse our various code listings elsewhere in the book:

We colorize markup only in code listings and code blocks because it affects readability too much when code appears in body copy — that is, within ordinary paragraphs of text like this one. In paragraphs like this, we simply use a different, monospaced font — as you've already seen in our discussions of <form> and <table> markup (and other HTML elements) in the preceding section.
One more thing: If you use an HTML editor, such as Aptana Studio, HTML-Kit, Dreamweaver, KompoZer, or whatever, you find these tools also use text color to help you identify different kinds of markup. Alas, none of them do this in the exact same way, so the color scheme we present here in this book will be different depending on the HTML editor you use.
Breaking down the elements
Elements are the building blocks for HTML. You use them to describe each piece of text on your web page. Elements are made up of tags and the content within (or between) those tags. In HTML, there are two main kinds of elements:
![]() Elements with content made up of a tag pair and whatever text sits between the opening and closing tags in the pair
Elements with content made up of a tag pair and whatever text sits between the opening and closing tags in the pair
![]() Elements that insert something into the page, using a single tag
Elements that insert something into the page, using a single tag
Tag pairs in HTML
Elements that describe content use a tag pair to mark the beginning and end, with everything inbetween representing the element content. Tag pairs begin with an opening tag, followed by some content, and end with a closing tag, like this: <title>Titles Are Easy, Content Is Hard</title>.
Content — such as articles, asides, paragraphs, headings, tables, and lists — always uses tag pairs, where
![]() The opening tag (<tag>) tells the browser, "The element begins here."
The opening tag (<tag>) tells the browser, "The element begins here."
![]() The closing tag (</tag>) tells the browser, "The element ends here."
The closing tag (</tag>) tells the browser, "The element ends here."
Actual content is the stuff between the opening and closing tags. Here's a paragraph snippet from Ed's bio at www.edtittel.com/about/about-ed.html:
<p>Ed Tittel has worked over 30 years in the computing
industry. He's worked as a software developer and
development manager, a networking consultant, a trainer
and course developer, and a technical evangelist . . . </p>
Single tags
Elements that insert something into a page are called empty elements (because they enclose no content) and use a single tag, like this: <single-tag>. Images and line breaks insert something into an HTML file and use a single tag (empty element) — namely, <img . . .> and <br>, respectively.
 In HTML5, empty elements don't require special treatment. In an earlier version known as XHTML (based on the XML markup language), empty elements are required to end with a slash just before the closing angle bracket, so what we wrote as <single-tag> on the previous page in HTML5 (and HTML4, for that matter) would be written as <single-tag/>. For backward compatibility with HTML4, this would often be written as <single-tag /> because that space preceding the slash enabled older browsers to recognize the element properly even if they didn't parse the markup as XHTML. You may encounter the extra space and the closing slash in pages you look at, so don't let it bother you. These contortions no longer apply in HTML5.
In HTML5, empty elements don't require special treatment. In an earlier version known as XHTML (based on the XML markup language), empty elements are required to end with a slash just before the closing angle bracket, so what we wrote as <single-tag> on the previous page in HTML5 (and HTML4, for that matter) would be written as <single-tag/>. For backward compatibility with HTML4, this would often be written as <single-tag /> because that space preceding the slash enabled older browsers to recognize the element properly even if they didn't parse the markup as XHTML. You may encounter the extra space and the closing slash in pages you look at, so don't let it bother you. These contortions no longer apply in HTML5.
For example, the <img> element references an image. When the browser displays the page, it replaces the <img> element with the file that it points to. (An attribute does the pointing, as is shown in the next section.)
 However appealing the concept may seem, you can't make up your own HTML elements. Legal elements for HTML belong to a very specific set — if you use elements that don't belong to that set, the browser simply ignores them. The elements you can use are defined in the various HTML specifications. (The version of the HTML5 specification that was current as we were writing this book can be found at www.w3.org/TR/html51.)
However appealing the concept may seem, you can't make up your own HTML elements. Legal elements for HTML belong to a very specific set — if you use elements that don't belong to that set, the browser simply ignores them. The elements you can use are defined in the various HTML specifications. (The version of the HTML5 specification that was current as we were writing this book can be found at www.w3.org/TR/html51.)
Nesting markup
Some HTML page structures can contain nested elements. Think of them as suitcases that fit neatly inside one another. For example, a bulleted list uses two kinds of elements:
![]() The <ul> element specifies that the list is unordered (bulleted).
The <ul> element specifies that the list is unordered (bulleted).
![]() The <li> element marks each item in the list. (The li stands for "list item.")
The <li> element marks each item in the list. (The li stands for "list item.")
When you combine elements using this approach, you must close all inside list item elements before you close the unordered list element, like this:
<ul>
<li>Item 1</li>
<li>Item 2</li>
</ul>
Adding Attributes to Your HTML
Attributes introduce variety or specificity into how an element describes content or how that element works or behaves. Attributes let you use elements differently depending on the circumstances. For example, the <img> element uses the src attribute to specify a location for an image you want to display:
<img src="images/header.png" alt="header graphic"
width="800" height="160" title="banner graphic">
In this bit of HTML, the <img> element is a general flag to the browser that you want to include an image. The attributes handle all the fine details:
![]() The src attribute provides the specifics for the image you want to use — header.png in this case.
The src attribute provides the specifics for the image you want to use — header.png in this case.
![]() The width and height attributes provide information about how to display that image on the page.
The width and height attributes provide information about how to display that image on the page.
![]() The alt attribute provides a text alternative to the image, which is useful because a text-only browser can display the text, or a text-to-speech reader can say it aloud for the visually impaired.
The alt attribute provides a text alternative to the image, which is useful because a text-only browser can display the text, or a text-to-speech reader can say it aloud for the visually impaired.
![]() The title attribute creates a pop-up text message that appears over the image when a user moves the mouse inside its borders.
The title attribute creates a pop-up text message that appears over the image when a user moves the mouse inside its borders.
Chapter 9 describes the <img> element and its attributes in glorious detail.
If you want to define attributes for any HTML element, they must appear inside the opening tag for that element, or inside the only tag for an empty element. They belong after the element name but before the closing angle bracket in that tag, like this:
<tag attribute1="value" attribute2="value">
 HTML5 syntax rules decree that attribute values must always appear inside quotation marks, but you can include attributes and their values in any order you like within the opening tag or a single tag for an empty element.
HTML5 syntax rules decree that attribute values must always appear inside quotation marks, but you can include attributes and their values in any order you like within the opening tag or a single tag for an empty element.
Every HTML element has a collection of attributes that may be used with it, but you can't mix and match attributes and elements however you please. Some attributes can take any text as a value because that value might be anything, such as the location of an image or a page to which you'd like to link. Other attributes impose a specific list of values they can take, such as your options for aligning text in a table cell (left, right, center, and so on).
The various HTML specifications define exactly which attributes you can use with any given element, and which values (if explicitly defined) each attribute can take.
Each chapter in Parts II and III covers the attributes you can use with each HTML element mentioned therein. Also, please see our online content for complete lists of deprecated HTML (and XHTML) tags and attributes. (Note: In HTML-speak, deprecated means that a tag or attribute should no longer be used, as it may become obsolete soon and will no longer be legal markup.)
Examining Entities in Markup
Text makes the web possible, but it’s subject to limitations. Entities, also known as character entities, define codes to display special characters in your web pages.
Non-ASCII characters
Basic American Standard Code for Information Interchange (ASCII) text defines a fairly small number of characters (127 in the basic 7-bit codes; 255 in the 8-bit extended codes). It doesn’t include some special characters, such as trademark symbols, fractions, and accented characters.
For example, if we translate a paragraph of text from Ed’s bio into German, the result includes three u characters with umlauts (ü), depicted in Figure 2-1.
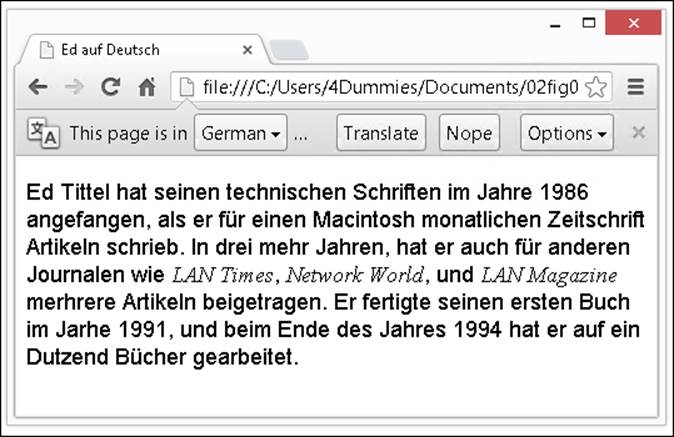
Figure 2-1: ASCII text can’t represent all text characters, so HTML uses entities, too.
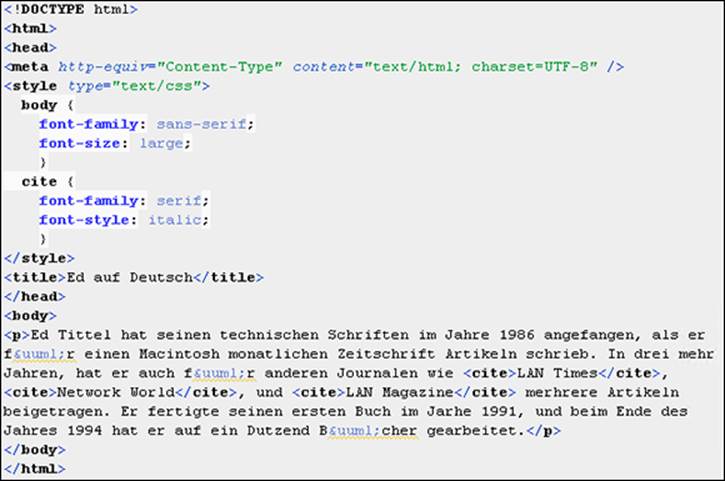
ASCII text doesn't include an umlauted u, so HTML uses entities to represent such characters. The browser replaces the entity reference with the character it stands for. Each entity begins with an ampersand (&) and ends with a semicolon (;). Entities originate from a markup language called SGML and appear in a light blue font in Aptana Studio. In Listing 2-1, look in the paragraph of text to find all three instances of the ü entity for each umlauted u therein.
Listing 2-1: Adding an Umlaut
Character codes
Encodings for the ISO Latin-1 character set are supplied by default in all modern web browsers. (Search for “ISO Latin-1 character set” to find a complete table of values.) Thus, the character entities in that set may be used directly in HTML markup without going through any special contortions. However, using other encodings requires inclusion of special markup to tell the browser to interpret Unicode character codes. (Unicode is an international standard — ISO standard 10645, in fact — that embraces enough codes to handle most human alphabets, plus plenty of symbols and non-alphabetic characters, too.) This special markup takes this form:
<meta charset="UTF-8">
Because the charset value reads UTF-8, you can reference all common Unicode values. (UTF-8 stands for UCS Transformation Format 8-bit, an encoding format that represents all Unicode characters. Search for "Unicode UTF-8 character table" to skim over its one-million-plus character codes.)
Although today’s browsers support UTF-8 more or less universally, expect to see support for UTF-16 character codes sometime soon. UTF-16 character codes let browsers deal more effectively with non-Roman alphabets such as Arabic, katakana (Japanese ideographs), and Hangul (Korean ideographs), which some browsers struggle to render correctly and completely today.
(Special) tag characters
HTML-savvy software assumes that certain HTML characters, such as the left and right angle brackets (less-than and greater-than signs in math notation) are meant to be hidden and not displayed on your finished web pages. If you actually want to display these characters on your pages, you must make your wishes clear to the browser. The following entities enable display of characters that are normally part of hidden HTML markup:
![]() left angle bracket (<): <
left angle bracket (<): <
![]() right angle bracket (>): >
right angle bracket (>): >
![]() ampersand (&): &
ampersand (&): &
If you need these symbols to appear, include their entities in your markup like this:
<p>The paragraph element identifies some text as a Paragraph: </p>
<p><p>This is a paragraph</p></p>
Figure 2-2 shows how these entities appear inside a browser window.
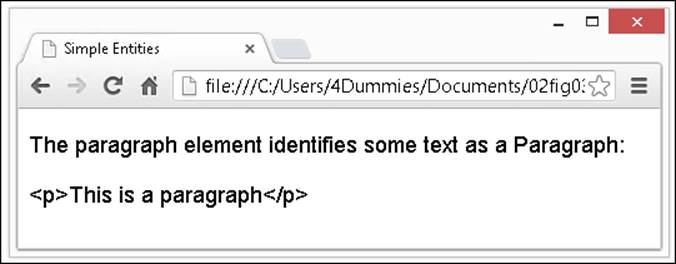
Figure 2-2: Character entities enable display of special characters in a browser window.
Organizing Web Pages
HTML documents — also known as web pages — always follow a regular, predictable structure. There’s also one special type of markup element, called a comment, that lets content developers (that’s you) insert remarks that won’t be displayed in any web browser, but will be readable to anyone who looks at the HTML markup itself. You can do this for any web page you visit by choosing View⇒Source in Internet Explorer or choosing equivalent operations in Chrome (Tools⇒View Source), Firefox (Tools⇒Web Developer⇒Page Source), and so forth.
In HTML, two special sequences of markup characters enclose a comment:
![]() Begin a comment with the string <!--
Begin a comment with the string <!--
![]() End a comment with the string -->
End a comment with the string -->
HTML elements are organized into a structure, where
![]() Some elements may occur only inside other specific elements.
Some elements may occur only inside other specific elements.
![]() Certain elements must appear within any well-structured HTML document, err, web page.
Certain elements must appear within any well-structured HTML document, err, web page.
In Listing 2-2, we use HTML comments to document basic HTML document structure.
Listing 2-2: Documenting Basic HTML Structure
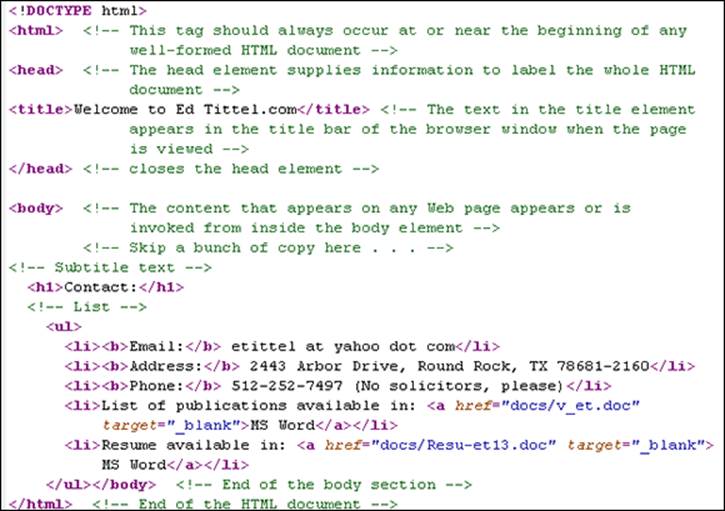
The preceding document is broken into two major divisions: a <head> and a <body>. Within each of those divisions, certain kinds of elements appear. Many combinations are possible: That's what you see throughout this book!
 The file for the preceding example is named 02Listing01.html and appears under the menu at the HTML5 Cafe (our complete collection of examples and markup files found in this book, along with live links to any URLs you encounter, organized by chapter number):
The file for the preceding example is named 02Listing01.html and appears under the menu at the HTML5 Cafe (our complete collection of examples and markup files found in this book, along with live links to any URLs you encounter, organized by chapter number):
www.dummies.html\html5cafe\menu.html
Files associated with figures are named ccfigurenn.html, where cc is the two-digit chapter number, and nn is the two-digit figure number.
Organizing HTML text
Beyond their mandatory division into head and body sections, text in the body of an HTML document may be organized in any number of ways.
Document heads
Inside the <head> section, you may (and probably should) define all kinds of labels and information, including a title. Such definitions help you describe the document that follows, including the character sets it uses, metadata for search engines and page descriptions, and instructions to the web server that delivers your page, default style sheets, page refresh behavior, and lots more. (Note: Metadata literally means "data about data" — in this case, it means information about the web page that follows.) To find out more about the HTML <meta> element, please visit these sites:
www.w3schools.com/tags/tag_meta.asp
www.quackit.com/html_5/tags/html_meta_tag.cfm
www.w3.org/TR/2011/WD-html5-author-20110705/the-meta-element.html
The <body> section is where real content lives in HTML documents and where the vast majority of HTML elements and markup appears. In the following sections, we cover typical elements in an HTML <body>.
Document headings
Headings in HTML are usually denoted using elements <h1> through <h6>. These are different from an HTML document <head> because they establish running heads within document content in the <body>.
Text containers
The paragraph (<p>) element in HTML is probably the best known text container, but HTML supports all kinds of other text containers, too. Other such elements include the following (in alphabetical order):
![]() <article>: Represents an article, a piece of standalone content.
<article>: Represents an article, a piece of standalone content.
![]() <aside>: Represents content related to surround content that could stand alone. (We use sidebars in For Dummies books for this kind of thing.)
<aside>: Represents content related to surround content that could stand alone. (We use sidebars in For Dummies books for this kind of thing.)
![]() <nav>: Declares the navigation section in an HTML document. This element is usually reserved for tabs, buttons, or links to access major site components.
<nav>: Declares the navigation section in an HTML document. This element is usually reserved for tabs, buttons, or links to access major site components.
![]() <header>: Presents standard content or information at the top of a web page (banner, navigation aids, shared text, and so forth).
<header>: Presents standard content or information at the top of a web page (banner, navigation aids, shared text, and so forth).
![]() <footer>: Presents standard content or information at the bottom of a web page (copyright notices, minor navigation, feedback solicitation, and so on).
<footer>: Presents standard content or information at the bottom of a web page (copyright notices, minor navigation, feedback solicitation, and so on).
HTML also includes all kinds of ways to emphasize or identify text inside paragraphs or other text containers; Parts II and III of this book introduce the important ones.
Lists
HTML supports easy definition of numerous kinds of lists, including bulleted (unordered) lists, numbered (ordered) lists, and even lists of definitions (which include terms and descriptions). You can nest lists within lists to create as many levels of hierarchy as you might need. (Nesting your lists is particularly useful when outlining a complex subject or modeling a table of contents with numerous heading levels.) Chapter 5 covers lists in more detail.
Tables
In addition to a variety of listing mechanisms, HTML includes markup for defining tables. Tables were really popular in the 1990s for managing complex page layouts; today they’re used primarily for tables of information, as they should be. Structure is part of how markup works, so within the definitions for an HTML table, you can
![]() Distinguish between column heads, table data, and table footers or comments.
Distinguish between column heads, table data, and table footers or comments.
![]() Manage how rows and columns are defined, with controls that let you span rows or columns for grouping and organization.
Manage how rows and columns are defined, with controls that let you span rows or columns for grouping and organization.
Cascading Style Sheets (CSS) markup
CSS markup may occur in separate style sheet documents, in a block of text inside an HTML document <head>, in a style attribute for an individual HTML element within the document body, or in some combination of all three forms. CSS provides detailed control over font selection, use of color for text and backgrounds, positioning of text and other elements on a page, and (as the old Ronco ad intones) much, much more!
You can dig into CSS in more detail in Parts IV and V of this book, but we cover bits and pieces of CSS throughout the book as appropriate for the subject matter at hand. You can build a website without using CSS (using CSS requires more work), but it’s the right tool for precise control over look and layout. Highly recommended!
Complementing and enhancing text
Text-only web pages get boring fast. A spot of color, a few links, and some nice-looking images can do a lot to add visual interest to your pages and to help you retain your viewers’ interest and attention. That’s why we devote considerable attention to this subject matter in various parts of this book.
Inserting images in HTML documents
Adding an image to any HTML document is easy. Careful and well-planned use of images adds greatly to web pages. Chapter 9 explains how to grab images from text files and shows you how to include them in your web pages. It also explains how to use complex markup to position and flow text around graphics or images. Along the way, you discover how to select and use interesting, compelling images to add allure and information to your content.
Links and navigation tools
Web page structure should help visitors find their way around collections of pages, look for items of interest, and get where they want to go quickly and easily. Links provide the mechanism to bring people and your web pages together, so Chapter 8 shows how to do the following:
![]() Reference external items or resources
Reference external items or resources
![]() Jump from one page to the next
Jump from one page to the next
![]() Jump around inside a page
Jump around inside a page
![]() Add structure and organization to your pages
Add structure and organization to your pages
The importance of structure and organization increases in direct relation to the amount of information you want to present to visitors. The more you’ve got to say or show, the more structure and organization count.
Navigation tools (which establish standard mechanisms and tools for moving around inside a website) provide ways to create and present your web page (and site) structure to visitors so they can use organized menus of choices.
When you add it all up, your result should be a well-organized set of information and images that is easy to understand, use, and navigate.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.