Java 8 in Action: Lambdas, streams, and functional-style programming (2015)
Part 4. Beyond Java 8
Chapter 16. Conclusions and where next for Java
This chapter covers
· New Java 8 features and their evolutionary effect on programming style
· A few unfinished-business ideas started by Java 8
· What Java 9 and Java 10 might bring
We covered a lot of material in this book, and we hope you now feel that you’re ready to start using the new Java 8 features in your own code, perhaps building on our examples and quizzes. In this chapter we review the journey of learning about Java 8 and the gentle push toward functional-style programming. In addition, we speculate on what future enhancements and great new features may be in Java’s pipeline beyond Java 8.
16.1. Review of Java 8 features
A good way to help you understand Java 8 as a practical, useful language is to revisit the features in turn. Instead of simply listing them, we’d like to present them as being interlinked to help you understand them not merely as a set of features but as a high-level overview of the coherent language design that is Java 8. Our other aim in this review chapter is to emphasize how most of the new features in Java 8 are facilitating functional-style programming in Java. Remember, this isn’t a capricious design choice but a conscious design strategy, centered on two trends, which we regard as climate change in the model from chapter 1:
· The increasing need to exploit the power of multicore processors now that, for silicon technology reasons, the additional transistors annually provided by Moore’s law no longer translate into higher clock speeds of individual CPU cores. Put simply, making your code run faster requires parallel code.
· The increasing tendency to concisely manipulate collections of data with a declarative style for processing data, such as taking some data source, extracting all data that matches a given criterion, and applying some operation to the result—either summarizing it or making a collection of the result for further processing later. This style is associated with the use of immutable objects and collections, which are then processed to produce further immutable values.
Neither motivation is effectively supported by the traditional, object-oriented, imperative approach, centered on mutating fields and applying iterators. Mutating data on one core and reading it from another is surprisingly expensive, not to mention the need for error-prone locking; similarly when your mind-set is focused on iterating over and mutating existing objects, then the stream-like programming idiom can feel very alien. But these two trends are easily supported using ideas from functional programming, and this explains why the Java 8 center of gravity has moved a bit from what we’ve come to expect from Java.
Let’s now review, in a big-picture unifying view, what you’ve learned from this book, and see how it all fits together in the new climate.
16.1.1. Behavior parameterization (lambdas and method references)
To be able to write a reusable method such as filter, you need to be able to specify as its argument a description of the filtering criterion. Although Java experts could achieve this in previous versions of Java (by wrapping the filtering criterion as a method inside a class and passing an instance of that class), this solution was unsuitable for general use because it was too cumbersome to write and maintain.
As you discovered in chapters 2 and 3, Java 8 provides a way, borrowed from functional programming, of passing a piece of code to a method. It conveniently provides two variants of this:
· Passing a lambda, a one-off piece of code such as
apple -> apple.getWeight() > 150
· Passing a method reference, to an existing method, as code such as Apple::isHeavy
These values have types such as Function<T, R>, Predicate<T>, and BiFunction<T, U, R> and have ways for the recipient to execute them using the methods apply, test, and so on. Of themselves, lambdas can seem rather a niche concept, but it’s the way Java 8 uses them in much of the new Streams API that propels them to the center of Java.
16.1.2. Streams
The collection classes in Java, along with iterators and the for-each construct, have served us honorably for a long time. It would have been easy for the Java 8 designers to add methods like filter and map to collections, exploiting the lambdas mentioned previously to express database-like queries. But they didn’t—instead they added a whole new Streams API, the subject of chapters 4–7—and it’s worth pausing to consider why.
What’s wrong with collections that requires them to be replaced or augmented with a similar but different notion of streams? We’ll summarize it like this: if you have a large collection and apply three operations to it, perhaps mapping the objects in the collection to sum two of their fields, then filtering the sums satisfying some criterion, and then sorting the result, you’ll make three separate traversals of the collection. The Streams API instead lazily forms these operations into a pipeline, and then does a single stream traversal performing all the operations together. This is much more efficient for large datasets, and for reasons such as memory caches, the larger the dataset the more important it is to minimize the number of traversals.
The other, no less important, reasons concern the ability to process elements in parallel, which is vital to efficiently exploit multicore CPUs. Streams, in particular the method parallel, allow a stream to be marked as suitable for parallel processing. Recall here that parallelism and mutable state fit badly together, so core functional concepts (side-effect-free operations and methods parameterized with lambdas and method references that permit internal iteration instead of external iteration, as discussed in chapter 4) are central to exploiting streams in parallel using map, filter, and the like.
Let’s now look at how these ideas, which we introduced in terms of streams, have a direct analog in the design of CompletableFuture.
16.1.3. CompletableFuture
Java has provided the Future interface since Java 5. Futures are useful for exploiting multicore because they allow a task to be spawned onto another thread or core and allow the spawning task to continue executing along with the spawned task. When the spawning task needs the result, it can use the get method to wait for the Future to complete (produce its value).
Chapter 11 explains the Java 8 CompletableFuture implementation of Future. Again this exploits lambdas. A useful, if slightly imprecise, motto is that “Completable-Future is to Future as Stream is to Collection.” Let’s compare:
· Stream lets you pipeline operations and provides behavior parameterization with map, filter, and the like, thus avoiding the boilerplate code you typically have to write using iterators.
· Similarly, CompletableFuture provides operations such as thenCompose, thenCombine, and allOf, which give functional-programming-style concise encodings of common design patterns involving Futures, and let you avoid similar imperative-style boilerplate code.
This style of operations, albeit in a simpler scenario, also applies to the Java 8 operations on Optional, which we now revisit.
16.1.4. Optional
The Java 8 library provides the class Optional<T>, which allows your code to specify that a value is either a proper value of type T or is a missing value returned by the static method Optional.empty. This is great for program comprehension and documentation; it provides a data type with an explicit missing value—instead of the previous error-prone use of the null pointer to indicate missing values, which we could never be sure was a planned missing value or an accidental null resulting from an earlier erroneous computation.
As chapter 10 discusses, if Optional<T> is used consistently, then programs should never produce NullPointerExceptions. Again you could see this as a one-off, unrelated to the rest of Java 8, and ask, “How does changing from one form of missing value to another help me write programs?” Closer inspection shows that the class Optional<T> provides map, filter, and ifPresent. These have similar behavior to corresponding methods in the Streams class and can be used to chain computations, again in functional style, with the tests for missing value done by the library instead of user code. This internal testing versus external testing choice is directly analogous to how the Streams library does internal iteration versus external iteration in user code.
Our final topic of this section concerns not functional-style programming but instead Java 8 support for upward-compatible library extensions driven by software-engineering desires.
16.1.5. Default methods
There are other additions to Java 8, none of which particularly affect the expressiveness of any individual program. But one thing that is helpful for library designers is the addition to allow default methods to be added to an interface. Prior to Java 8, interfaces defined method signatures; now they can also provide default implementations for methods that the interface designer suspects not all clients will want to provide explicitly.
This is a great new tool for library designers, because it provides them with the ability to augment an interface with a new operation, without having to require all clients (classes implementing this interface) to add code to define this method. Therefore, default methods are also relevant to users of libraries because they shield them from future interface changes. Chapter 9 explains this in more detail.
So far we’ve summarized the concepts of Java 8. We now turn to the thornier subject of what future enhancements and great new features may be in Java’s pipeline beyond Java 8.
16.2. What’s ahead for Java?
Let’s look at some of these points, most of which are discussed in more detail on the JDK Enhancement Proposal website at http://openjdk.java.net/jeps/0. Here we take care to explain why seemingly sensible ideas have subtle difficulties or interaction with existing features that inhibit their direct incorporation into Java.
16.2.1. Collections
Java’s development has been evolutionary rather than “big bang.” There have been many great ideas added to Java, for example, arrays being replaced by collections and later augmented with the power of streams. Occasionally a new feature is so obviously better (for example, collections over arrays) that we fail to notice that some aspect of the supplanted feature hasn’t been carried across. One example is initializers for containers. For example, Java arrays can be declared and initialized with syntax such as
Double [] a = {1.2, 3.4, 5.9};
which is a convenient abbreviation for
Double [] a = new Double[]{1.2, 3.4, 5.9};
Java collections (via the Collection interface) were introduced as a better and more uniform way of dealing with sequences of data such as that represented by arrays. But their initialization has been rather neglected. Think about how you’d initialize a HashMap. You’d have to write the following:
Map<String, Integer> map = new HashMap<>();
map.put("raoul", 23);
map.put("mario", 40);
map.put("alan", 53);
What you’d like to be able to say is something like
Map<String, Integer> map = #{"Raoul" -> 23, "Mario" -> 40, "Alan" -> 53};
where #{...} is a collection literal—a list of the values that are to appear in the collection. This seems uncontroversial as a feature,[1] but it’s not yet part of Java.
1 The current Java proposal is described in http://openjdk.java.net/jeps/186.
16.2.2. Type system enhancements
We discuss two possible enhancements to Java type’s system: declaration-site variance and local variable type inference.
Declaration-site variance
Java supports wildcards as a flexible mechanism to allow subtyping for generics (more generally referred to as use-site variance). This is why the following assignment is valid:
List<? extends Number> numbers = new ArrayList<Integer>();
But the following assignment, omitting the ? extends, gives a compile-time error:
![]()
Many programming languages such as C# and Scala support a different variance mechanism called declaration-site variance. They allow programmers to specify variance when defining a generic class. This feature is useful for classes that are inherently variant. Iterator, for example, is inherently covariant and Comparator is inherently contravariant. You shouldn’t need to think in terms of ? extends or ? super when you use them. This is why adding declaration-site variance to Java would be useful because these specifications instead appear at the declaration of classes. As a result, it would reduce some cognitive overhead for programmers. Note that at the time of this writing (June 2014) there’s a proposal investigating declaration-site variance for Java 9.[2]
2 See https://bugs.openjdk.java.net/browse/JDK-8043488.
More type inference
Originally in Java, whenever we introduced a variable or method, we gave its type at the same time. For example,
double convertUSDToGBP(double money) { ExchangeRate e = ...; }
contains three types; these give the result type of convertUSDToGBP, the type of its argument money, and the type of its local variable e. Over time this has been relaxed in two ways. First, you may omit type parameters of generics in an expression when the context determines them. For example,
Map<String, List<String>> myMap = new HashMap<String, List<String>>();
can be abbreviated to the following since Java 7:
Map<String, List<String>> myMap = new HashMap<>();
Second, using the same idea—propagating the type determined by context into an expression—a lambda expression such as
Function<Integer, Boolean> p = (Integer x) -> booleanExpression;
can be shortened to
Function<Integer, Boolean> p = x -> booleanExpression;
by omitting types. In both cases the compiler infers the omitted types.
Type inference gives a few advantages when a type consists of a single identifier, the main one being reduced editing work when replacing one type with another. But as types grow in size, generics parameterized by further generic types, then type inference can aid readability.[3] The Scala and C# languages permit a type in a local-variable-initialized declaration to be replaced with the keyword var, and the compiler fills in the appropriate type from the right side. For example, the declaration of myMap shown previously using Java syntax could be rendered like this:
3 Of course, it’s important that type inference be done sensibly. Type inference works best when there’s only one way, or one easily documentable way, to re-create the type the user has omitted. It’s a source of problems if the system infers a different type from the one the user was thinking of; so a good design of type inference will give a fault when there are two different incomparable types that could be inferred instead of appearing just to pick the wrong one seemingly at random.
var myMap = new HashMap<String, List<String>>();
This idea is called local variable type inference; you can expect similar developments in Java because they decrease clutter caused by redundant type repetition.
There’s some small cause for concern, however; given a class Car that subclasses a class Vehicle and then does the declaration
var x = new Vehicle();
do you declare x to have type Car or Vehicle? In this case a simple explanation that the missing type is the type of the initializer (here Vehicle) is perfectly clear, and it can be backed up with a statement that var may not be used when there’s no initializer.
16.2.3. Pattern matching
As we discussed in chapter 14, functional-style languages typically provide some form of pattern matching—an enhanced form of switch—in which you can ask, “Is this value an instance of a given class?” and, optionally, recursively ask whether its fields have certain values.
It’s worth reminding you here that traditional object-oriented design discourages the use of switch and instead encourages patterns such as the visitor pattern where data-type-dependent control flow is done by method dispatch instead of by switch. This isn’t the case at the other end of the programming language spectrum—in functional-style programming where pattern matching over values of data types is often the most convenient way to design a program.
Adding Scala-style pattern matching in full generality to Java seems quite a big job, but following the recent generalization to switch to allow Strings, you can imagine a more-modest syntax extension, which allows switch to operate on objects, using the instanceof syntax. Here we revisit our example from section 14.4 and assume a class Expr, which is subclassed into BinOp and Number:
switch (someExpr) {
case (op instanceof BinOp):
doSomething(op.opname, op.left, op.right);
case (n instanceof Number):
dealWithLeafNode(n.val);
default:
defaultAction(someExpr);
}
There are a couple of things to note. We steal from pattern matching the idea that in case (op instanceof BinOp):, op is a new local variable (of type BinOp), which becomes bound to the same value as someExpr; similarly, in the Number case, n becomes a variable of type Number. In the default case, no variable is bound. This proposal avoids much boilerplate code compared with using chains of if-then-else and casting to subtype. A traditional object-oriented designer would probably argue that such data-type dispatch code would better be expressed using visitor-style methods overridden in subtypes, but to functional-programming eyes this results in related code being scattered over several class definitions. This is a classical design dichotomy discussed in the literature under the name of the “expression problem.”[4]
4 For a more complete explanation, see http://en.wikipedia.org/wiki/Expression_problem.
16.2.4. Richer forms of generics
This section discusses two limitations of Java generics and looks at a possible evolution to mitigate them.
Reified generics
When generics were introduced in Java 5, they had to be backward-compatible with the existing JVM. To this end, the runtime representations of ArrayList<String> and ArrayList<Integer> are identical. This is called the erasure model of generic polymorphism. There are certain small runtime costs associated with this choice, but the most significant effect for programmers is that parameters to generic types can only be Objects. Suppose Java allowed, say, ArrayList<int>. Then you could allocate an ArrayList object on the heap containing a primitive value such as int 42, but the Array-List container wouldn’t contain any indicator of whether it contained an Object value such as a String or a primitive int value such as 42.
As some level this seems harmless—if you get a primitive 42 from an ArrayList<int> and a String object “abc” from an ArrayList<String>, then why should you worry that the ArrayList containers are indistinguishable? Unfortunately, the answer is garbage collection, because the absence of run-time type information about the contents of the ArrayList would leave the JVM unable to determine whether element 13 of your ArrayList was an Integer reference (to be followed and marked as “in use” by GC) or an int primitive value (most definitely not to be followed).
In the C# language, the runtime representations of ArrayList<String>, ArrayList<Integer>, and ArrayList<int> are all in principle different. But even if they are the same, sufficient type information is kept at run-time to allow, for example, garbage collection to determine whether a field is a reference or a primitive. This is called the reified model of generic polymorphism or, more simply, reified generics. The word reification means “making explicit something that otherwise would just be implicit.”
Reified generics are clearly desirable; they enable a more full unification of primitive types and their corresponding object types—something that you’ll see as problematic in the next sections. The main difficulty for Java is backward compatibility, both in the JVM and in existing programs that use reflection and expect generics to be erased.
Additional syntactic flexibility in generics for function types
Generics proved a wonderful feature when added to Java 5. They’re also fine for expressing the type of many Java 8 lambdas and method references. You can express a one-argument function:
Function<Integer, Integer> square = x -> x * x;
If you have a two-argument function, you use the type BiFunction<T, U, R>, where T is the type of the first parameter, U the second, and R the result. But there’s no TriFunction unless you declare it yourself!
Similarly, you can’t use Function<T, R> for references to methods taking zero arguments and returning result type R; you have to use Supplier<R> instead.
In essence, Java 8 lambdas have enriched what you can write, but the type system hasn’t kept up with the flexibility of the code. In many functional languages, you can write, for example, the type (Integer, Double) => String, to represent what Java 8 calls BiFunction<Integer,Double, String>, along with Integer => String to represent Function<Integer, String>, and even () => String to represent Supplier<String>. You can understand => as an infix version of Function, BiFunction, Supplier, and the like. A simple extension to Java syntax for types would allow this, resulting in more readable types analogously to what Scala provides, as discussed in chapter 15.
Primitive specializations and generics
In Java all primitive types (int, for example) have a corresponding object type (here java.lang.Integer); often we refer to these as unboxed and boxed types. Although this distinction has the laudable aim of increasing runtime efficiency, the types can become confusing. For example, why in Java 8 do we write Predicate<Apple> instead of Function<Apple, Boolean>? It turns out that an object of type Predicate<Apple>, when called using the method test, returns a primitive boolean.
By contrast, like all generics, a Function can only be parameterized by object types, which in the case of Function<Apple, Boolean> is the object type Boolean, not the primitive type boolean. Predicate<Apple> is therefore more efficient because it avoids boxing the boolean to make a Boolean. This issue has led to the creation of multiple, similar interfaces such as LongToIntFunction and BooleanSupplier, which add further conceptual overload. Another example concerns the question of the differences between void, which can only qualify method return types and has no values, and the object type Void, which has null as its only value—a question that regularly appears on forums. The special cases of Function such as Supplier<T>, which could be written () => T in the new notation proposed previously, further attest to the ramifications caused by the distinction between primitive and object types. We discussed earlier how reified generics could address many of these issues.
16.2.5. Deeper support for immutability
Some expert readers may have been a little upset when we said that Java 8 has three forms of values:
· Primitive values
· (References to) objects
· (References to) functions
At one level we’re going to stick to our guns and say, “But these are the values that a method may now take as arguments and return as results.” But we also wish to concede that this is a little problematic: to what extent do you return a (mathematical) value when you return a reference to a mutable array? A String or an immutable array clearly is a value, but the case is far less clear-cut for a mutable object or array—your method may return an array with its elements in ascending order, but some other code may change one of its elements later.
If we’re really interested in functional-style programming in Java, then there needs to be linguistic support for saying “immutable value.” As noted in chapter 13, the keyword final doesn’t really achieve this—it only stops the field it qualifies from being updated; consider this:
final int[] arr = {1, 2, 3};
final List<T> list = new ArrayList<>();
The former forbids another assignment arr = ... but doesn’t forbid arr[1]=2; the latter forbids assignments to list but doesn’t forbid other methods from changing the number of elements in list! The keyword final works well for primitive values, but for references to objects, it often merely gives a false sense of security.
What we’re leading up to is this: given that functional-style programming puts a strong emphasis on not mutating existing structure, there’s a strong argument for a keyword such as transitively_final, which can qualify fields of reference type and which ensures that no modification can take place to the field nor to any object directly or indirectly accessible via that field.
Such types represent one intuition about values: values are immutable, and only variables (which contain values) may be mutated to contain a different immutable value. As we remarked at the head of this section, Java authors including ourselves sometimes have inconsistently talked about the possibility of a Java value being a mutable array. In the next section, we return to proper intuition and discuss the idea of a value type; these can only contain immutable values, even if variables of value type can still be updated, unless qualified with final.
16.2.6. Value types
In this section, we discuss the difference between primitive types and object types, linking into the discussion earlier about the desire for value types, which help you to write programs functionally, just as object types are necessary for object-oriented programming. Many of the issues we discuss are interrelated, so there’s no easy way to explain one problem in isolation. Instead we identify the problem by its various facets.
Can’t the compiler treat Integer and int identically?
Given all the implicit boxing and unboxing that Java has slowly acquired since Java 1.1, you might ask whether it’s time for Java to treat, for example, Integer and int identically and to rely on the Java compiler to optimize into the best form for the JVM.
This would be a wonderful idea in principle, but let’s consider the problems surrounding adding the type Complex to Java to see why boxing is problematic. The type Complex, which models so-called complex numbers having real and imaginary parts, is naturally introduced as follows:
class Complex {
public final double re;
public final double im;
public Complex(double re, double im) {
this.re = re;
this.im = im;
}
public static Complex add(Complex a, Complex b) {
return new Complex(a.re+b.re, a.im+b.im);
}
}
But values of type Complex are reference types, and every operation on Complex needs to do an object allocation—dwarfing the cost of the two additions in add. What we need is a primitive-type analog of Complex, perhaps called complex.
The issue here is that we want an “unboxed object,” and neither Java nor the JVM has any real support for this. Now we can return to the lament, “Oh, but surely the compiler can optimize this.” Sadly, this is much harder than it appears; although there is a compiler optimization based on so-called escape analysis, which can sometimes determine that unboxing is okay, its applicability is limited by Java’s assumptions on Objects, which have been present since Java 1.1. Consider the following puzzler:
double d1 = 3.14;
double d2 = d1;
Double o1 = d1;
Double o2 = d2;
Double ox = o1;
System.out.println(d1 == d2 ? "yes" : "no");
System.out.println(o1 == o2 ? "yes" : "no");
System.out.println(o1 == ox ? "yes" : "no");
The result is “yes”, “no”, “yes.” An expert Java programmer would probably say, “What silly code, everyone knows you should use equals on the last two lines instead of ==.” But let us persist. Even though all these primitives and objects contain the immutable value 3.14 and should really be indistinguishable, the definitions of o1 and o2 create new objects, and the == operator (identity comparison) can tell them apart. Note that on primitives, the identity comparison does bitwise comparison but on objects it does reference equality. So often, we accidentally create a new distinct Double object, which the compiler needs to respect because the semantics of Object, from which Double inherits, require this. You’ve seen this discussion before, both in the earlier discussion of value types and in chapter 14, where we discussed referential transparency of methods that functionally update persistent data structures.
Value types—not everything is a primitive or an object
We suggest that the resolution of this problem is to rework the Java assumptions (1) that everything that isn’t a primitive is an object and hence inherits Object, and (2) that all references are references to objects.
The development starts like this. There are two forms of values: those of Object type that have mutable fields unless forbidden with final, and those of identity, which may be tested with ==. There are also value types, which are immutable and which don’t have reference identity; primitive types are a subset of this wider notion. We could then allow user-defined value types (perhaps starting with a lowercase letter to emphasize their similarity to primitive types such as int and boolean). On value types, == would, by default, perform an element-by-element comparison in the same way that hardware comparison on int performs a bit-by-bit comparison. You can see this being overridden for floating-point comparison, which performs a somewhat more sophisticated operation. The type Complex would be a perfect example of a non-primitive value type; such types resemble C# structs.
In addition, value types can reduce storage requirements because they don’t have reference identity. Figure 16.1 illustrates an array of size three, whose elements 0, 1, and 2 are light gray, white, and dark gray, respectively. The left diagram shows a typical storage requirement when Pair andComplex are Objects and the right shows the better layout when Pair and Complex are value types (note that we called them pair and complex in lowercase in the diagram to emphasize their similarity to primitive types). Note also that value types are also likely to give better performance, not only for data access (multiple levels of pointer indirection replaced with a single indexed-addressing instruction) but also for hardware cache utilization (due to data contiguity).
Figure 16.1. Objects vs. value types
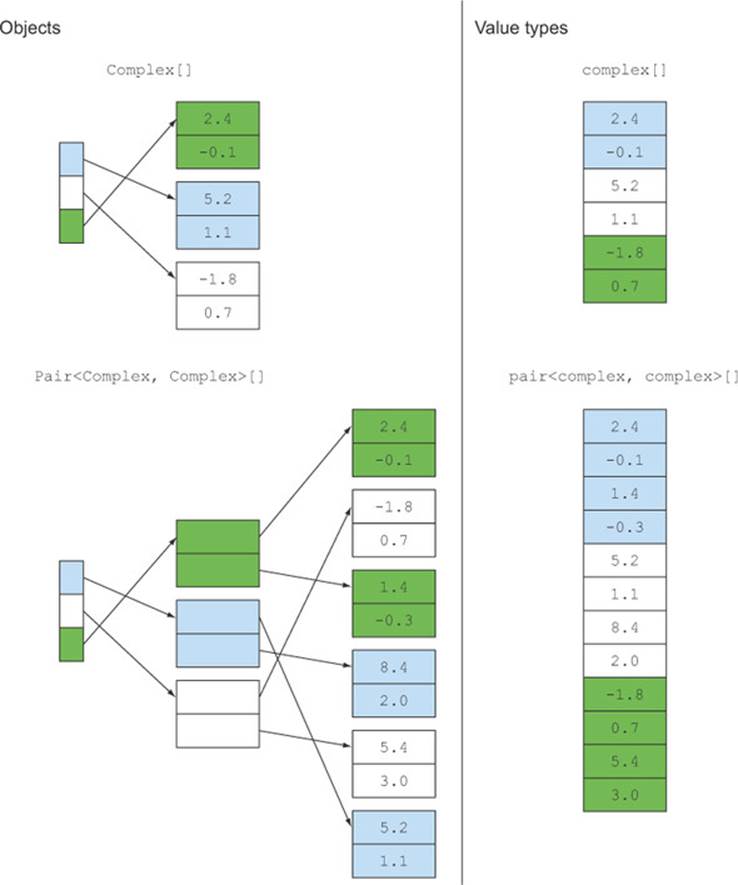
Note that because value types don’t have reference identity, the compiler can then box and unbox them at its choice. If you pass a complex as argument from one function to another, then the compiler can naturally pass it as two separate doubles. (Returning it without boxing is trickier in the JVM, of course, because the JVM only provides method-return instructions passing values representable in a 64-bit machine register.) But if you pass a larger value type as an argument (perhaps a large immutable array), then the compiler can instead, transparently to the user, pass it as a reference once it has been boxed. Similar technology already exists in C#; quoting Microsoft:[5]
5 To learn about the syntax and usage of structs and the differences between classes and structs, see http://msdn.microsoft.com/en-us/library/aa288471(v=vs.71).aspx.
Structs may seem similar to classes, but there are important differences that you should be aware of. First of all, classes are [C#] reference types and structs are value types. By using structs, you can create objects [sic] that behave like the built-in [primitive] types and enjoy their benefits as well.
At the time of writing (June 2014) there’s a concrete proposal for value types in Java.[6]
6 John Rose, et al., “State of the Values,” April 2014 Infant Edition, http://cr.openjdk.java.net/~jrose/values/values-0.html.
Boxing, generics, value types—the interdependency problem
We’d like to have value types in Java, because functional-style programs deal with immutable values that don’t have identity. We’d like to see primitive types as a special case of value types, but the erasure model of generics, which Java currently has, means that value types can’t be used with generics without boxing. Object (boxed) versions (for example, Integer) of primitive types (for example, int) continue to be vital for collections and Java generics because of their erasure model, but now their inheriting Object (and hence reference equality) is seen as a drawback. Addressing any one of these problems means addressing them all.
16.3. The final word
This book has explored the new features added by Java 8; these represent perhaps the biggest evolution step ever taken by Java—the only comparably large evolution step was the introduction, 10 years previously, of generics in Java 5. In this chapter we also looked at pressures for further Java evolution. In conclusion, we propose the following statement:
Java 8 is an excellent place to pause but not to stop!
We hope you’ve enjoyed the adventure that is Java 8, and that we’ve sparked your interests in exploring functional programming and in the further evolution of Java.