Java 8 in Action: Lambdas, streams, and functional-style programming (2015)
Appendix C. Performing multiple operations in parallel on a stream
One of the biggest limitations of a Java 8 stream is that you can operate on it only once and get only one result while processing it. Indeed, if you try to traverse a stream for a second time, the only thing you can achieve is an exception like this:
java.lang.IllegalStateException: stream has already been operated upon or closed
Despite this, there are situations where you’d like to get several results when processing a single stream. For instance, you may want to parse a log file in a stream, as we did in section 5.7.3, but gather multiple statistics in a single step. Or, keeping with the menu data model used to explainStream’s features in chapters 4–6, you may want to retrieve different information while traversing the stream of dishes.
In other words, you’d like to push a stream through more than one lambda on a single pass, and to do this you need a type of fork method and to apply different functions to each forked stream. Even better, it would be great if you could perform those operations in parallel, using different threads to calculate the different required results.
Unfortunately, these features aren’t currently available on the stream implementation provided in Java 8, but in this appendix we’ll show you a way to use a Spliterator and in particular its late-binding capacity, together with BlockingQueues and Futures, to implement this useful feature and make it available with a convenient API.[1]
1 The implementation presented in the rest of this appendix is based on the solution posted by Paul Sandoz in the email he sent to the lambda-dev mailing list: http://mail.openjdk.java.net/pipermail/lambda-dev/2013-November/011516.html.
C.1. Forking a stream
The first thing necessary to execute multiple operations in parallel on a stream is to create a StreamForker that wraps the original stream, on which you can define the different operations you want to perform. Take a look at the following listing.
Listing C.1. Defining a StreamForker to execute multiple operations on a stream

Here the fork method accepts two arguments:
· A Function, which transforms the stream into a result of any type representing one of these operations
· A key, which will allow you to retrieve the result of that operation and accumulates these key/function pairs in an internal Map
The fork method returns the StreamForker itself; therefore, you can build a pipeline by forking several operations. Figure C.1 shows the main ideas behind the StreamForker.
Figure C.1. The StreamForker in action
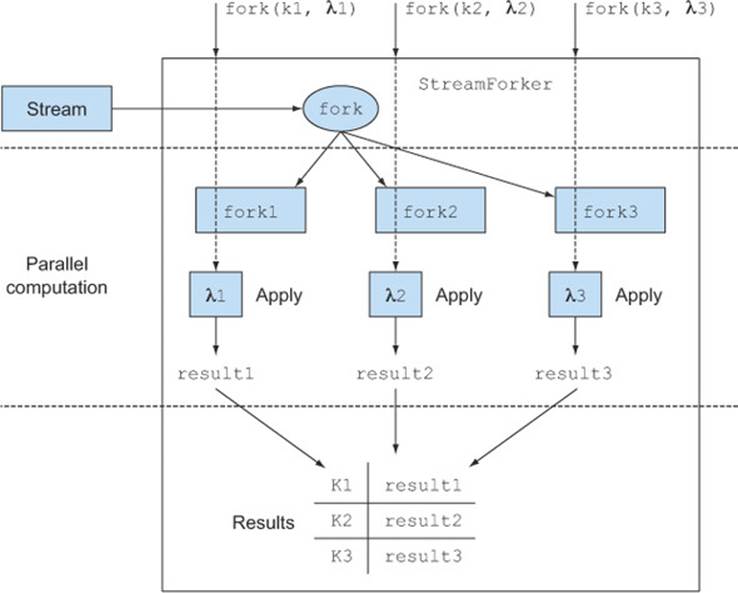
Here the user defines three operations to be performed on a stream indexed by three keys. The StreamForker then traverses the original stream and forks it into three other streams. At this point the three operations can be applied in parallel on the forked streams, and the results of these function applications, indexed with their corresponding keys, are used to populate the resulting Map.
The execution of all the operations added through the fork method is triggered by the invocation of the method getResults, which returns an implementation of the Results interface defined as follows:
public static interface Results {
public <R> R get(Object key);
}
This interface has only one method to which you can pass one of the key Objects used in one of the fork methods, and that method returns the result of the operation corresponding to that key.
C.1.1. Implementing the Results interface with the ForkingStreamConsumer
The getResults method can be implemented as follows:
public Results getResults() {
ForkingStreamConsumer<T> consumer = build();
try {
stream.sequential().forEach(consumer);
} finally {
consumer.finish();
}
return consumer;
}
The ForkingStreamConsumer implements both the Results interface defined previously and the Consumer interface. As you’ll see when we analyze its implementation in more detail, its main task is to consume all the elements in the stream and multiplex them to a number ofBlockingQueues equal to the number of operations submitted via the fork method. Note that it is ensured that the stream is sequential, because if the method forEach were performed on a parallel stream, its elements could be pushed to the queues out of order. The finish method adds special elements to those queues to signal that there are no more items to be processed. The build method used to create the ForkingStreamConsumer is shown in the next listing.
Listing C.2. The build method used to create ForkingStreamConsumer

In listing C.2, you first create the List of BlockingQueues mentioned previously. Then you create a Map, having as keys the same keys used to identify the different operations to be executed on the stream, and having as values the Futures that will contain the corresponding results of these operations. The List of BlockingQueues and the Map of Futures are then passed to the constructor of the ForkingStreamConsumer. Each Future is created with this getOperationResult method, as shown in the next listing.
Listing C.3. Futures created with the getOperationResult method

The method getOperationResult creates a new BlockingQueue and adds it to the List of queues. This queue is passed to a new BlockingQueueSpliterator, which is a late-binding Spliterator, reading the item to be traversed from the queue; we’ll examine how it’s made shortly.
You then create a sequential stream traversing this Spliterator, and finally you create a Future to calculate the result of applying the function representing one of the operations you want to perform on this stream. This Future is created using a static factory method of theCompletableFuture class that implements the Future interface. This is another new class introduced in Java 8, and we investigated it in detail in chapter 11.
C.1.2. Developing the ForkingStreamConsumer and the BlockingQueueSpliterator
The last two outstanding parts you need to develop are the ForkingStreamConsumer and BlockingQueueSpliterator classes we introduced previously. The first one can be implemented as follows.
Listing C.4. A ForkingStreamConsumer to add stream elements to multiple queues

This class implements both the Consumer and Results interfaces and holds a reference to the List of BlockingQueues and to the Map of Futures executing the different operations on the stream.
The Consumer interface requires an implementation for the method accept. Here, every time ForkingStreamConsumer accepts an element of the stream, it adds that element to all the BlockingQueues. Also, after all the elements of the original stream have been added to all queues, thefinish method causes one last item to be added to all of them. This item, when met by BlockingQueueSpliterators, will make the queues understand that there are no more elements to be processed.
The Results interface requires an implementation for the get method. Here, it retrieves the Future that’s indexed in the Map with the argument key and unwraps its result or waits until a result is available.
Finally, there will be a BlockingQueueSpliterator for each operation to be performed on the stream. Each BlockingQueueSpliterator will have a reference to one of the BlockingQueues populated by the ForkingStreamConsumer, and it can be implemented as shown in the following listing.
Listing C.5. A Spliterator reading the elements it traverses from a BlockingQueue
class BlockingQueueSpliterator<T> implements Spliterator<T> {
private final BlockingQueue<T> q;
BlockingQueueSpliterator(BlockingQueue<T> q) {
this.q = q;
}
@Override
public boolean tryAdvance(Consumer<? super T> action) {
T t;
while (true) {
try {
t = q.take();
break;
} catch (InterruptedException e) { }
}
if (t != ForkingStreamConsumer.END_OF_STREAM) {
action.accept(t);
return true;
}
return false;
}
@Override
public Spliterator<T> trySplit() {
return null;
}
@Override
public long estimateSize() {
return 0;
}
@Override
public int characteristics() {
return 0;
}
}
In this listing a Spliterator is implemented, not to define the policy of how to split a stream but only to use its late-binding capability. For this reason the trySplit method is unimplemented.
Also, it’s impossible to return any meaningful value from the estimatedSize method because you can’t foresee how many elements can be still taken from the queue. Further, because you’re not attempting any split, this estimation will be useless. This implementation doesn’t have any of the Spliterator characteristics we listed in table 7.2, so the characteristic method returns 0.
The only method implemented here is tryAdvance, which waits to take from its BlockingQueue the elements of the original stream added to it by the ForkingStreamConsumer. It sends those elements to a Consumer that (based on how this Spliterator was created in thegetOperationResult method) is the source of a further stream (on which the corresponding function, passed to one of the fork method invocations, has to be applied). The tryAdvance method returns true, to notify its invoker that there are other elements to be consumed, until it finds on the queue the special Object added by ForkingStreamConsumer to signal that there are no more elements to be taken from the queue. Figure C.2 shows an overview of the StreamForker and its building blocks.
Figure C.2. The StreamForker building blocks
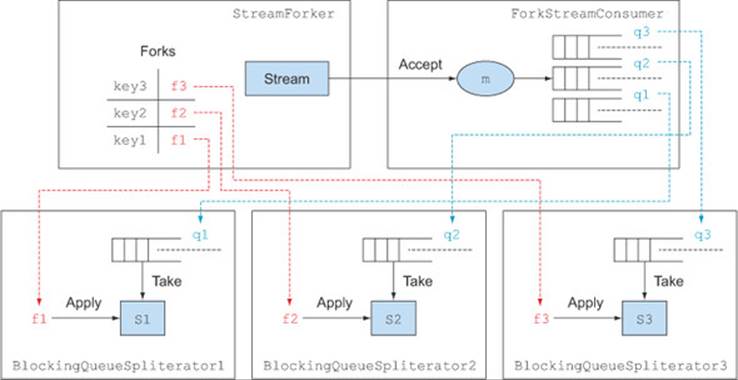
In the figure, the StreamForker in the upper left has a Map, where each operation to be performed on the stream, defined by a function, is indexed by a key. The ForkingStreamConsumer on the right holds a queue for each of these operations and consumes all the elements in the original stream, multiplexing them to all the queues.
At the bottom of the figure, each queue has a BlockingQueueSpliterator pulling its items and acting as a source for a different stream. Finally, each of these streams, forked by the original one, is passed as argument to one of the functions, thus executing one of the operations to be performed. You now have all the components of your StreamForker, so it’s ready to use.
C.1.3. Putting the StreamForker to work
Let’s put the StreamForker to work on the menu data model that we defined in chapter 4, by forking the original stream of dishes to perform four different operations in parallel on it, as shown in the next listing. In particular, you want to generate a comma-separated list of the names of all available dishes, calculate the total calories of the menu, find the dish with the most calories, and group all dishes by their type.
Listing C.6. Putting the StreamForker to work
Stream<Dish> menuStream = menu.stream();
StreamForker.Results results = new StreamForker<Dish>(menuStream)
.fork("shortMenu", s -> s.map(Dish::getName)
.collect(joining(", ")))
.fork("totalCalories", s -> s.mapToInt(Dish::getCalories).sum())
.fork("mostCaloricDish", s -> s.collect(reducing(
(d1, d2) -> d1.getCalories() > d2.getCalories() ? d1 : d2))
.get())
.fork("dishesByType", s -> s.collect(groupingBy(Dish::getType)))
.getResults();
String shortMenu = results.get("shortMenu");
int totalCalories = results.get("totalCalories");
Dish mostCaloricDish = results.get("mostCaloricDish");
Map<Dish.Type, List<Dish>> dishesByType = results.get("dishesByType");
System.out.println("Short menu: " + shortMenu);
System.out.println("Total calories: " + totalCalories);
System.out.println("Most caloric dish: " + mostCaloricDish);
System.out.println("Dishes by type: " + dishesByType);
The StreamForker provides a convenient, fluent API to fork a stream and assign a different operation to each forked stream. These operations are expressed in terms of functions applied on the stream and can be identified by any arbitrary object; in this case we’ve chosen to use Strings. When you have no more forks to add, you can invoke getResults on the StreamForker to trigger the execution of all the defined operations and obtain StreamForker.Results. Because these operations are internally performed asynchronously, the getResults method returns immediately, without waiting for all the results to be available.
You can obtain the result of a specific operation by passing the key used to identify it to the StreamForker.Results interface. If in the meantime the computation of that operation completes, the get method will return the corresponding result; otherwise, it will block until such a result isn’t available.
As expected, this piece of code generates the following output:
Short menu: pork, beef, chicken, french fries, rice, season fruit, pizza, prawns, salmon
Total calories: 4300
Most caloric dish: pork
Dishes by type: {OTHER=[french fries, rice, season fruit, pizza], MEAT=[pork, beef, chicken], FISH=[prawns, salmon]}
C.2. Performance considerations
For performance reasons you shouldn’t take for granted that this approach is more efficient than traversing the stream several times. The overhead caused by the use of the blocking queues can easily outweigh the advantages of executing the different operations in parallel when the stream is made of data that’s all in memory.
Conversely, accessing the stream only once could be a winning choice when this involves some expensive I/O operations, such as when the source of the stream is a huge file; so (as usual) the only meaningful rule when optimizing the performance of your application is to “Just measure it!”
This example demonstrates how it can be possible to execute multiple operations on the same stream in one shot. More importantly, we believe this proves that even when a specific feature isn’t provided by the native Java API, the flexibility of lambda expressions and a bit of creativity in reusing and combining what’s already available can let you implement the missing feature on your own.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.