Java 8 in Action: Lambdas, streams, and functional-style programming (2015)
Part 3. Effective Java 8 programming
The third part of this book explores various Java 8 topics that will make you more effective at using Java 8 and enhance your codebase with modern idioms.
Chapter 8 explores how you can improve your existing code using new Java 8 features and a few recipes. In addition, it explores vital software development techniques such as design patterns, refactoring, testing, and debugging.
In chapter 9, you’ll learn what default methods are, how you can use them to evolve APIs in a compatible way, some practical usage patterns, and rules for using default methods effectively.
Chapter 10 covers the new java.util.Optional class, which allows you to both design better APIs and reduce null pointer exceptions.
Chapter 11 explores CompletableFuture, which lets you express complex asynchronous computations in a declarative way—paralleling the design of the Streams API.
Chapter 12 investigates the new Date and Time API, which greatly improves the previous error-prone APIs for working with dates and time.
Chapter 8. Refactoring, testing, and debugging
This chapter covers
· How to refactor code to use lambda expressions
· The impact of lambda expressions on object-oriented design patterns
· Testing lambda expressions
· Debugging code that uses lambda expressions and the Streams API
In the first seven chapters of this book, you saw the expressive power of lambdas and the Streams API. You were mainly creating new code that made use of these features. This is great if you have to start a new Java project—you can use lambdas and streams immediately.
Unfortunately, you don’t always get to start a new project from scratch. Most of the time you’ll have to deal with an existing codebase written in an older version of Java.
This is the purpose of this chapter. It presents several recipes showing how you can refactor existing code to make use of lambda expressions and gain more readability and flexibility. In addition, we discuss how several object-oriented design patterns including strategy, template method, observer, chain of responsibility, and factory can be made more concise thanks to lambda expressions. Finally, we explore how you can test and debug code that uses lambda expressions and the Streams API.
8.1. Refactoring for improved readability and flexibility
Right from the start of this book we’ve argued that lambda expressions can let you write more concise and flexible code. It’s more concise because lambda expressions let you represent a piece of behavior in a more compact form in comparison to using anonymous classes. We also showed inchapter 3 that method references let you write even more concise code when all you want to do is pass an existing method as argument to another method.
Your code is more flexible because lambda expressions encourage the style of behavior parameterization that we introduced in chapter 2. Your code can use and execute multiple behaviors passed as arguments to cope with requirement changes.
In this section, we bring it all together and show you simple steps you can follow to refactor code to gain readability and flexibility, using the features you learned in the previous chapters: lambdas, method references, and streams.
8.1.1. Improving code readability
What does it mean to improve the readability of code? It’s hard to define what good readability means, because it can be very subjective. The general view is that it means “how easily this code can be understood by another human.” Improving code readability means ensuring your code is understandable and maintainable by people besides you. There are a few steps you can take to make sure your code is understandable by other people, such as making sure your code is well documented and follows coding standards.
Java 8 features can also help improve code readability compared to previous versions:
· You can reduce the verbosity of your code, making it easier to understand.
· You can improve the intent of your code by using method references and the Streams API.
We describe three simple refactorings that use lambdas, method references, and streams, which you can apply to your code to improve its readability:
· Refactoring anonymous classes to lambda expressions
· Refactoring lambda expressions to method references
· Refactoring imperative-style data processing to streams
8.1.2. From anonymous classes to lambda expressions
The first simple refactoring you should consider is converting uses of anonymous classes implementing one single abstract method to lambda expressions. Why? We hope we convinced you in earlier chapters that anonymous classes are extremely verbose and error-prone. By adopting lambda expressions, you produce code that is more succinct and readable. For example, as shown in chapter 3, here’s an anonymous class for creating a Runnable object and its lambda expression counterpart:

But converting anonymous classes to lambda expressions can be a difficult process in certain situations.[1] First, the meanings of this and super are different for anonymous classes and lambda expressions. Inside an anonymous class, this refers to the anonymous class itself, but inside a lambda it refers to the enclosing class. Second, anonymous classes are allowed to shadow variables from the enclosing class. Lambda expressions can’t (they’ll cause a compile error), as shown in the following code:
1 This excellent paper describes the process in more detail: http://dig.cs.illinois.edu/papers/lambda-Refactoring.pdf.

Finally, converting an anonymous class to a lambda expression can make the resulting code ambiguous in the context of overloading. Indeed, the type of anonymous class is explicit at instantiation, but the type of the lambda depends on its context. Here’s an example of how this can be problematic. Let’s say you’ve declared a functional interface with the same signature as Runnable, here called Task (this might occur when you need interface names that are more meaningful in your domain model):
interface Task{
public void execute();
}
public static void doSomething(Runnable r){ r.run(); }
public static void doSomething(Task a){ r.execute(); }
You can now pass an anonymous class implementing Task without a problem:
doSomething(new Task() {
public void execute() {
System.out.println("Danger danger!!");
}
});
But converting this anonymous class to a lambda expression results in an ambiguous method call, because both Runnable and Task are valid target types:

You can solve the ambiguity by providing an explicit cast (Task):
doSomething((Task)() -> System.out.println("Danger danger!!"));
Don’t be turned off by these issues though; there’s good news! Most integrated development environments (IDEs) such as NetBeans and IntelliJ support this refactoring and will automatically ensure these gotchas don’t arise.
8.1.3. From lambda expressions to method references
Lambda expressions are great for short code that needs to be passed around. But consider using method references when possible to improve code readability. A method name states more clearly the intent of your code. For example, in chapter 6 we showed you the following code to group dishes by caloric levels:
Map<CaloricLevel, List<Dish>> dishesByCaloricLevel =
menu.stream()
.collect(
groupingBy(dish -> {
if (dish.getCalories() <= 400) return CaloricLevel.DIET;
else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
}));
You can extract the lambda expression into a separate method and pass it as argument to groupingBy. The code becomes more concise and its intent is now more explicit:

You need to add the method getCaloricLevel inside the Dish class itself for this to work:
public class Dish{
...
public CaloricLevel getCaloricLevel(){
if (this.getCalories() <= 400) return CaloricLevel.DIET;
else if (this.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
}
}
In addition, consider making use of helper static methods such as comparing and maxBy when possible. These methods were designed for use with method references! Indeed, this code states much more clearly its intent than its counterpart using a lambda expression, as we showed inchapter 3:

Moreover, for many common reduction operations such as sum, maximum there are built-in helper methods that can be combined with method references. For example, we showed that using the Collectors API you can find the maximum or sum in a clearer way than using a combination of a lambda expression and a lower-level reduce operation. Instead of writing
int totalCalories =
menu.stream().map(Dish::getCalories)
.reduce(0, (c1, c2) -> c1 + c2);
try using alternative built-in collectors, which state more clearly what the problem statement is. Here we use the collector summingInt (names go a long way in documenting your code):
int totalCalories = menu.stream().collect(summingInt(Dish::getCalories));
8.1.4. From imperative data processing to Streams
Ideally, you should try to convert all code that processes a collection with typical data processing patterns with an iterator to use the Streams API instead. Why? The Streams API expresses more clearly the intent of a data processing pipeline. In addition, streams can be optimized behind the scenes making use of short-circuiting and laziness, as well as leveraging your multicore architecture, as we explained in chapter 7.
For example, the following imperative code expresses two patterns (filtering and extracting) that are mangled together, which forces the programmer to carefully understand the whole implementation before figuring out what the code does. In addition, an implementation that executes in parallel would be a lot more difficult to write (see section 7.2 in the previous chapter about the fork/join framework to get an idea):
List<String> dishNames = new ArrayList<>();
for(Dish dish: menu){
if(dish.getCalories() > 300){
dishNames.add(dish.getName());
}
}
The alternative using the Streams API reads more like the problem statement, and it can be easily parallelized:
menu.parallelStream()
.filter(d -> d.getCalories() > 300)
.map(Dish::getName)
.collect(toList());
Unfortunately, converting imperative code to the Streams API can be a difficult task, because you need to think about control-flow statements such as break, continue, and return and infer the right stream operations to use. The good news is that some tools can help you with this task as well.[2]
2 See http://refactoring.info/tools/LambdaFicator/.
8.1.5. Improving code flexibility
We argued in chapters 2 and 3 that lambda expressions encourage the style of behavior parameterization. You can represent multiple different behaviors with different lambdas that you can then pass around to execute. This style lets you cope with requirement changes (for example, creating multiple different ways of filtering with a Predicate or comparing with a Comparator). We now look at a couple of patterns that you can apply to your codebase to immediately benefit from lambda expressions.
Adopting functional interfaces
First, you can’t use lambda expressions without functional interfaces. You should therefore start introducing them in your codebase. That sounds good, but in which situations? We discuss two common code patterns that can be refactored to leverage lambda expressions: conditional deferred execution and execute around. In addition, in the next section we show how many object-oriented design patterns such as strategy and template method can be rewritten more concisely using lambda expressions.
Conditional deferred execution
It’s common to see control-flow statements mangled inside business logic code. Typical scenarios include security checks and logging. For example, consider the following code that uses the built-in Java Logger class:
if (logger.isLoggable(Log.FINER)){
logger.finer("Problem: " + generateDiagnostic());
}
What’s wrong with it? A couple of things:
· The state of the logger (what level it supports) is exposed in the client code through the method isLoggable.
· Why should you have to query the state of the logger object every time before you can log a message? It just clutters your code.
A better alternative is to make use of the log method, which internally checks to see if the logger object is set to the right level before logging the message:
logger.log(Level.FINER, "Problem: " + generateDiagnostic());
This is a better approach because your code isn’t cluttered with if checks, and the state of the logger is no longer exposed. Unfortunately, there’s still an issue with this code. The logging message is always evaluated, even if the logger isn’t enabled for the message level passed as argument.
This is where lambda expressions can help. What you need is a way to defer the construction of the message so it can be generated only under a given condition (here, when the logger level is set to FINER). It turns out that the Java 8 API designers knew about this problem and introduced an overloaded alternative to log that takes a Supplier as argument. This alternative log method has the following signature:
public void log(Level level, Supplier<String> msgSupplier)
You can now call it as follows:
logger.log(Level.FINER, () -> "Problem: " + generateDiagnostic());
The log method will internally execute the lambda passed as argument only if the logger is of the right level. The internal implementation of the log method is along the lines of this:

What’s the takeaway from the story? If you see yourself querying the state of an object many times in client code (for example, the state of the logger), only to call some method on this object with arguments (for example, log a message), then consider introducing a new method that calls that method (passed as a lambda or method reference) only after internally checking the state of the object. Your code will be more readable (less clutter) and better encapsulated (the state of the object isn’t exposed in client code)!
Execute around
In chapter 3 we discussed another pattern that you can adopt: execute around. If you find yourself surrounding different code with the same preparation and cleanup phases, you can often pull that code into a lambda. The benefit is that you reuse the logic dealing with the preparation and cleanup phases, thus reducing code duplication.
To refresh, here’s the code you saw in chapter 3. It reuses the same logic to open and close a file but can be parameterized with different lambdas to process the file:

This was made possible by introducing the functional interface BufferedReader-Processor, which lets you pass different lambdas to work with a BufferedReader object.
In this section, you’ve seen how to apply different recipes to improve the readability and flexibility of your code. You’ll now see how lambda expressions can often remove boilerplate code associated with common object-oriented design patterns.
8.2. Refactoring object-oriented design patterns with lambdas
New language features often make existing code patterns or idioms less popular. For example, the introduction of the for-each loop in Java 5 has replaced many uses of explicit iterators because it’s less error prone and more concise. The introduction of the diamond operator <> in Java 7 has reduced the use of explicit generics at instance creation (and slowly pushed Java programmers toward embracing type inference).
A specific class of patterns is called design patterns.[3] They’re a reusable blueprint, if you will, for a common problem when designing software. It’s a bit like how construction engineers have a set of reusable solutions to construct bridges for specific scenarios (such as suspension bridge, arch bridge, and so on). For example, the visitor design pattern is a common solution for separating an algorithm from a structure on which it needs to operate. The singleton pattern is a common solution to restrict the instantiation of a class to only one object.
3 See http://c2.com/cgi/wiki?GangOfFour.
Lambda expressions provide yet another new tool in the programmer’s toolbox. They can provide alternative solutions to the problems the design patterns are tackling but often with less work and in a simpler way. Many existing object-oriented design patterns can be made redundant or written in a more concise way using lambda expressions. In this section, we explore five design patterns:
· Strategy
· Template method
· Observer
· Chain of responsibility
· Factory
We show how lambda expressions can provide an alternative way to solve the same problem each design pattern is intended for.
8.2.1. Strategy
The strategy pattern is a common solution for representing a family of algorithms and letting you choose among them at runtime. You briefly saw this pattern in chapter 2, when we showed you how to filter an inventory with different predicates (for example, heavy apples or green apples). You can apply this pattern to a multitude of scenarios, such as validating an input with different criteria, using different ways of parsing, or formatting an input.
The strategy pattern consists of three parts, as illustrated in figure 8.1:
Figure 8.1. The strategy design pattern

· An interface to represent some algorithm (the interface Strategy)
· One or more concrete implementations of that interface to represent multiple algorithms (the concrete classes ConcreteStrategyA, ConcreteStrategyB)
· One or more clients that use the strategy objects
Let’s say you’d like to validate whether a text input is properly formatted for different criteria (for example, it consists of only lowercase letters or is numeric). You start by defining an interface to validate the text (represented as a String):
public interface ValidationStrategy {
boolean execute(String s);
}
Second, you define one or more implementation(s) of that interface:
public class IsAllLowerCase implements ValidationStrategy {
public boolean execute(String s){
return s.matches("[a-z]+");
}
}
public class IsNumeric implements ValidationStrategy {
public boolean execute(String s){
return s.matches("\\d+");
}
}
You can then use these different validation strategies in your program:

Using lambda expressions
By now you should recognize that ValidationStrategy is a functional interface (in addition, it has the same function descriptor as Predicate<String>). This means that instead of declaring new classes to implement different strategies, you can pass lambda expressions directly, which are more concise:

As you can see, lambda expressions remove the boilerplate code inherent to the strategy design pattern. If you think about it, lambda expressions encapsulate a piece of code (or strategy), which is what the strategy design pattern was created for, so we recommend that you use lambda expressions instead for similar problems.
8.2.2. Template method
The template method design pattern is a common solution when you need to represent the outline of an algorithm and have the additional flexibility to change certain parts of it. Okay, it sounds a bit abstract. In other words, the template method pattern is useful when you find yourself in a situation such as “I’d love to use this algorithm but I need to change a few lines so it does what I want.”
Let’s look at an example of how this pattern works. Say you need to write a simple online banking application. Users typically enter a customer ID, and then the application fetches the customer’s details from the bank database and finally does something to make the customer happy. Different online banking applications for different banking branches may have different ways of making a customer happy (for example, adding a bonus on their account or just sending them less paperwork). You can write the following abstract class to represent the online banking application:
abstract class OnlineBanking {
public void processCustomer(int id){
Customer c = Database.getCustomerWithId(id);
makeCustomerHappy(c);
}
abstract void makeCustomerHappy(Customer c);
}
The processCustomer method provides a sketch for the online banking algorithm: fetch the customer given its ID and then make the customer happy. Different branches can now provide different implementations of the method makeCustomerHappy by subclassing the OnlineBankingclass.
Using lambda expressions
You can tackle the same problem (creating an outline of an algorithm and letting implementers plug in some parts) using your favorite lambdas! The different components of the algorithms you want to plug in can be represented by lambda expressions or method references.
Here we introduce a second argument to the method processCustomer of type Consumer<Customer> because it matches the signature of the method makeCustomerHappy defined earlier:
public void processCustomer(int id, Consumer<Customer> makeCustomerHappy){
Customer c = Database.getCustomerWithId(id);
makeCustomerHappy.accept(c);
}
You can now plug in different behaviors directly without subclassing the OnlineBanking class by passing lambda expressions:
new OnlineBankingLambda().processCustomer(1337, (Customer c) ->
System.out.println("Hello " + c.getName());
This is another example of how lambda expressions can help you remove the boilerplate inherent to design patterns!
8.2.3. Observer
The observer design pattern is a common solution when an object (called the subject) needs to automatically notify a list of other objects (called observers) when some event happens (for example, a state change). You typically come across this pattern when working with GUI applications. You register a set of observers on a GUI component such as button. If the button is clicked, the observers are notified and can execute a specific action. But the observer pattern isn’t limited to GUIs. For example, the observer design pattern is also suitable in a situation where several traders (observers) may wish to react to the change of price of a stock (subject). Figure 8.2 illustrates the UML diagram of the observer pattern.
Figure 8.2. The observer design pattern

Let’s write some code to see how the observer pattern is useful in practice. You’ll design and implement a customized notification system for an application like Twitter. The concept is simple: several newspaper agencies (NY Times, The Guardian, and Le Monde) are subscribed to a feed of news tweets and may want to receive a notification if a tweet contains a particular keyword.
First, you need an Observer interface that groups the different observers. It has just one method called notify that will be called by the subject (Feed) when a new tweet is available:
interface Observer {
void notify(String tweet);
}
You can now declare different observers (here, the three newspapers) that produce a different action for each different keyword contained in a tweet:
class NYTimes implements Observer{
public void notify(String tweet) {
if(tweet != null && tweet.contains("money")){
System.out.println("Breaking news in NY! " + tweet);
}
}
}
class Guardian implements Observer{
public void notify(String tweet) {
if(tweet != null && tweet.contains("queen")){
System.out.println("Yet another news in London... " + tweet);
}
}
}
class LeMonde implements Observer{
public void notify(String tweet) {
if(tweet != null && tweet.contains("wine")){
System.out.println("Today cheese, wine and news! " + tweet);
}
}
}
You’re still missing the crucial part: the subject! Let’s define an interface for him:
interface Subject{
void registerObserver(Observer o);
void notifyObservers(String tweet);
}
The subject can register a new observer using the registerObserver method and notify his observers of a tweet with the notifyObservers method. Let’s go ahead and implement the Feed class:
class Feed implements Subject{
private final List<Observer> observers = new ArrayList<>();
public void registerObserver(Observer o) {
this.observers.add(o);
}
public void notifyObservers(String tweet) {
observers.forEach(o -> o.notify(tweet));
}
}
It’s a pretty straightforward implementation: the feed keeps an internal list of observers that it can then notify when a tweet arrives. You can now create a demo application to wire up the subject and observers:
Feed f = new Feed();
f.registerObserver(new NYTimes());
f.registerObserver(new Guardian());
f.registerObserver(new LeMonde());
f.notifyObservers("The queen said her favourite book is Java 8 in Action!");
Unsurprisingly, The Guardian will pick up this tweet!
Using lambda expressions
You may be wondering how lambda expressions are useful with the observer design pattern. Notice that the different classes implementing the Observer interface are all providing implementation for a single method: notify. They’re all just wrapping a piece of behavior to execute when a tweet arrives! Lambda expressions are designed specifically to remove that boilerplate. Instead of instantiating three observer objects explicitly, you can pass a lambda expression directly to represent the behavior to execute:
f.registerObserver((String tweet) -> {
if(tweet != null && tweet.contains("money")){
System.out.println("Breaking news in NY! " + tweet);
}
});
f.registerObserver((String tweet) -> {
if(tweet != null && tweet.contains("queen")){
System.out.println("Yet another news in London... " + tweet);
}
});
Should you use lambda expressions all the time? The answer is no! In the example we described, lambda expressions work great because the behavior to execute is simple, so they’re helpful to remove boilerplate code. But the observers may be more complex: they could have state, define several methods, and the like. In those situations, you should stick with classes.
8.2.4. Chain of responsibility
The chain of responsibility pattern is a common solution to create a chain of processing objects (such as a chain of operations). One processing object may do some work and pass the result to another object, which then also does some work and passes it on to yet another processing object, and so on.
Generally, this pattern is implemented by defining an abstract class representing a processing object that defines a field to keep track of a successor. Once it has finished its work, the processing object hands over its work to its successor. In code it looks like this:
public abstract class ProcessingObject<T> {
protected ProcessingObject<T> successor;
public void setSuccessor(ProcessingObject<T> successor){
this.successor = successor;
}
public T handle(T input){
T r = handleWork(input);
if(successor != null){
return successor.handle(r);
}
return r;
}
abstract protected T handleWork(T input);
}
Figure 8.3 illustrates the chain of responsibility pattern in UML.
Figure 8.3. The chain of responsibility design pattern
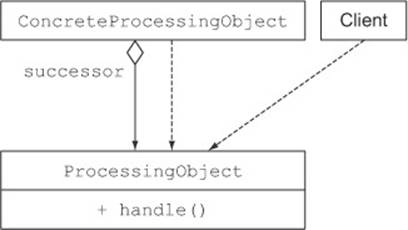
Here you may recognize the template method design pattern, which we discussed in section 8.2.2. The method handle provides an outline of how to deal with a piece of work. Different kinds of processing objects can be created by subclassing the class ProcessingObject and by providing an implementation for the method handleWork.
Let’s look at example of how to use this pattern. You can create two processing objects doing some text processing:

You can now connect two processing objects to construct a chain of operations!

Using lambda expressions
Wait a minute! This pattern looks like chaining (that is, composing) functions! We discussed how to compose lambda expressions in chapter 3. You can represent the processing objects as an instance of Function<String, String> or more precisely a UnaryOperator<String>. To chain them you just need to compose these functions by using the andThen method!

8.2.5. Factory
The factory design pattern lets you create objects without exposing the instantiation logic to the client. For example, let’s say you’re working for a bank and they need a way of creating different financial products: loans, bonds, stocks, and so on.
Typically you’d create a Factory class with a method that’s responsible for the creation of different objects, as shown here:
public class ProductFactory {
public static Product createProduct(String name){
switch(name){
case "loan": return new Loan();
case "stock": return new Stock();
case "bond": return new Bond();
default: throw new RuntimeException("No such product " + name);
}
}
}
Here, Loan, Stock, and Bond are all subtypes of Product. The createProduct method could have additional logic to configure each created product. But the benefit is that you can now create these objects without exposing the constructor and the configuration to the client, which makes the creation of products simpler for the client:
Product p = ProductFactory.createProduct("loan");
Using lambda expressions
You saw in chapter 3 that you can refer to constructors just like you refer to methods, by using method references. For example, here’s how to refer to the Loan constructor:
Supplier<Product> loanSupplier = Loan::new;
Loan loan = loanSupplier.get();
Using this technique, you could rewrite the previous code by creating a Map that maps a product name to its constructor:
final static Map<String, Supplier<Product>> map = new HashMap<>();
static {
map.put("loan", Loan::new);
map.put("stock", Stock::new);
map.put("bond", Bond::new);
}
You can now use this Map to instantiate different products, just as you did with the factory design pattern:
public static Product createProduct(String name){
Supplier<Product> p = map.get(name);
if(p != null) return p.get();
throw new IllegalArgumentException("No such product " + name);
}
This is quite a neat way to make use of the Java 8 feature to achieve the same intent as the factory pattern. But this technique doesn’t scale very well if the factory method createProduct needs to take multiple arguments to pass on to the product constructors! You’d have to provide a different functional interface than a simple Supplier.
For example, suppose you want to store constructors for products that take three arguments (two Integers and a String); you’d need to create a special functional interface TriFunction to support this. As a result, the signature of the Map becomes more complex:
public interface TriFunction<T, U, V, R>{
R apply(T t, U u, V v);
}
Map<String, TriFunction<Integer, Integer, String, Product>> map
= new HashMap<>();
You’ve seen how to write and refactor code using lambda expressions. You’ll now see how you can ensure your new code is correct.
8.3. Testing lambdas
You’ve now sprinkled your code with lambda expressions, and it looks nice and concise. But in most developer jobs you’re not paid for writing nice code but for writing code that’s correct.
Generally, good software engineering practice involves using unit testing to ensure that your program behaves as intended. You write test cases, which assert that small individual parts of your source code are producing the expected results. For example, consider a simple Point class for a graphical application:
public class Point{
private final int x;
private final int y;
private Point(int x, int y) {
this.x = x;
this.y = y;
}
public int getX() { return x; }
public int getY() { return y; }
public Point moveRightBy(int x){
return new Point(this.x + x, this.y);
}
}
The following unit test checks whether the method moveRightBy behaves as expected:
@Test
public void testMoveRightBy() throws Exception {
Point p1 = new Point(5, 5);
Point p2 = p1.moveRightBy(10);
assertEquals(15, p2.getX());
assertEquals(5, p2.getY());
}
8.3.1. Testing the behavior of a visible lambda
This works nicely because the method moveRightBy is public. Therefore, it can be tested inside the test case. But lambdas don’t have a name (they’re anonymous functions, after all), so it’s trickier to test them in your code because you can’t refer to them by a name!
Sometime you may have access to a lambda via a field so you can reuse it, and you’d really like to test the logic encapsulated in that lambda. What can you do? You could test the lambda just like when calling methods. For example, let’s say you add a static field compareByXAndThenY in the Point class that gives you access to a Comparator object that’s generated from method references:
public class Point{
public final static Comparator<Point> compareByXAndThenY =
comparing(Point::getX).thenComparing(Point::getY);
...
}
Remember that lambda expressions generate an instance of a functional interface. As a result, you can test the behavior of that instance. Here, you can now call the method compare on the Comparator object compareByXAndThenY with different arguments to test that its behavior is as intended:
@Test
public void testComparingTwoPoints() throws Exception {
Point p1 = new Point(10, 15);
Point p2 = new Point(10, 20);
int result = Point.compareByXAndThenY.compare(p1 , p2);
assertEquals(-1, result);
}
8.3.2. Focusing on the behavior of the method using a lambda
But the purpose of lambdas is to encapsulate a one-off piece of behavior to be used by another method. In that case you shouldn’t make lambda expressions available publicly; they’re only an implementation detail. Instead, we argue that you should test the behavior of the method that uses a lambda expression. For example, consider the method moveAllPointsRightBy shown here:
public static List<Point> moveAllPointsRightBy(List<Point> points, int x){
return points.stream()
.map(p -> new Point(p.getX() + x, p.getY()))
.collect(toList());
}
There’s no point (pun intended) in testing the lambda p -> new Point(p.getX() + x, p.getY()); it’s only an implementation detail for the method moveAllPointsRightBy. Rather, you should focus on testing the behavior of the method moveAllPointsRightBy:
@Test
public void testMoveAllPointsRightBy() throws Exception{
List<Point> points =
Arrays.asList(new Point(5, 5), new Point(10, 5));
List<Point> expectedPoints =
Arrays.asList(new Point(15, 5), new Point(20, 5));
List<Point> newPoints = Point.moveAllPointsRightBy(points, 10);
assertEquals(expectedPoints, newPoints);
}
Note that in the unit test just shown, it’s important that the Point class implement the equals method appropriately; otherwise it will rely on the default implementation from Object!
8.3.3. Pulling complex lambdas into separate methods
Perhaps you come across a really complicated lambda expression that contains a lot of logic (for example, a technical pricing algorithm with corner cases). What do you do, because you can’t refer to the lambda expression inside your test? One strategy is to convert the lambda expression into a method reference (which involves declaring a new regular method), as we explained earlier in section 8.1.3. You can then test the behavior of the new method in your test as you would with any regular method.
8.3.4. Testing high-order functions
Methods that take a function as argument or return another function (so-called higher-order functions, explained more in chapter 14) are a little harder to deal with. One thing you can do if a method takes a lambda as argument is test its behavior with different lambdas. For example, you can test the filter method created in chapter 2 with different predicates:
@Test
public void testFilter() throws Exception{
List<Integer> numbers = Arrays.asList(1, 2, 3, 4);
List<Integer> even = filter(numbers, i -> i % 2 == 0);
List<Integer> smallerThanThree = filter(numbers, i -> i < 3);
assertEquals(Arrays.asList(2, 4), even);
assertEquals(Arrays.asList(1, 2), smallerThanThree);
}
What if the method that needs to be tested returns another function? You can test the behavior of that function by treating it as an instance of a functional interface, as we showed earlier with a Comparator.
Unfortunately, not everything works the first time, and your tests may report some errors related to your use of lambda expressions. So we now turn to debugging!
8.4. Debugging
There are two main old-school weapons in a developer’s arsenal to debug problematic code:
· Examining the stack trace
· Logging
Lambda expressions and streams can bring new challenges to your typical debugging routine. We explore these in this section.
8.4.1. Examining the stack trace
When your program has stopped (for example, because an exception was thrown), the first thing you need to know is where it stopped and how it got there. This is where stack frames are useful. Each time your program performs a method call, information about the call is generated, including the location of the call in your program, the arguments of the call, and the local variables of the method being called. This information is stored on a stack frame.
When your program fails, you get a stack trace, which is a summary of how your program got to that failure, stack frame by stack frame. In other words, you get a list of valuable method calls up to when the failure appeared. This helps you understand how the problem occurred.
Lambdas and stack traces
Unfortunately, due to the fact that lambda expressions don’t have names, stack traces can be slightly puzzling. Consider the following simple code made to fail on purpose:
import java.util.*;
public class Debugging{
public static void main(String[] args) {
List<Point> points = Arrays.asList(new Point(12, 2), null);
points.stream().map(p -> p.getX()).forEach(System.out::println);
}
}
Running it will produce a stack trace along the lines of this:

Yuck! What’s going on? Of course the program will fail, because the second element of the list of points is null. You then try to process a null reference. Because the error occurs in a stream pipeline, the whole sequence of method calls that make a stream pipeline work is exposed to you. But notice that the stack trace produces the following cryptic lines:
at Debugging.lambda$main$0(Debugging.java:6)
at Debugging$$Lambda$5/284720968.apply(Unknown Source)
They mean that the error occurred inside a lambda expression. Unfortunately, because lambda expressions don’t have a name, the compiler has to make up a name to refer to them. In this case it’s lambda$main$0, which isn’t very intuitive. This can be problematic if you have large classes containing several lambda expressions.
Even if you use method references, it’s still possible that the stack won’t show you the name of the method you used. Changing the previous lambda p -> p.getX() to the method reference Point::getX will also result in a problematic stack trace:

Note that if a method reference refers to a method declared in the same class as where it’s used, then it will appear in the stack trace. For instance, in the following example
import java.util.*;
public class Debugging{
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3);
numbers.stream().map(Debugging::divideByZero).forEach(System
.out::println);
}
public static int divideByZero(int n){
return n / 0;
}
}
the method divideByZero is reported correctly in the stack trace:

In general, keep in mind that stack traces involving lambda expressions may be more difficult to understand. This is an area where the compiler can be improved in a future version of Java.
8.4.2. Logging information
Let’s say you’re trying to debug a pipeline of operations in a stream. What can you do? You could use forEach to print or log the result of a stream as follows:
List<Integer> numbers = Arrays.asList(2, 3, 4, 5);
numbers.stream()
.map(x -> x + 17)
.filter(x -> x % 2 == 0)
.limit(3)
.forEach(System.out::println);
It will produce the following output:
20
22
Unfortunately, once you call forEach, the whole stream is consumed. What would be really useful is to understand what each operation (map, filter, limit) produces in the pipeline of a stream.
This is where the stream operation peek can help. Its purpose is to execute an action on each element of a stream as it’s consumed. But it doesn’t consume the whole stream like forEach does; it forwards the element it performed an action on to the next operation in the pipeline. Figure 8.4illustrates the peek operation.
Figure 8.4. Examining values flowing in a stream pipeline with peek

In the following code, you use peek to print the intermediate value before and after each operation in the stream pipeline:

This will produce a useful output at each step of the pipeline:
from stream: 2
after map: 19
from stream: 3
after map: 20
after filter: 20
after limit: 20
from stream: 4
after map: 21
from stream: 5
after map: 22
after filter: 22
after limit: 22
8.5. Summary
Following are the key concepts you should take away from this chapter:
· Lambda expressions can make your code more readable and flexible.
· Consider converting anonymous classes to lambda expressions, but be wary of subtle semantic differences such as the meaning of the keyword this and shadowing of variables.
· Method references can make your code more readable compared to lambda expressions.
· Consider converting iterative collection processing to use the Streams API.
· Lambda expressions can help remove boilerplate code associated with several object-oriented design patterns such as strategy, template method, observer, chain of responsibility, and factory.
· Lambda expressions can be unit tested, but in general you should focus on testing the behavior of the methods where the lambda expressions appear.
· Consider extracting complex lambda expressions into regular methods.
· Lambda expressions can make stack traces less readable.
· The peek method of a stream is useful to log intermediate values as they flow past at certain points in a stream pipeline.