Full Stack Web Development with Backbone.js (2014)
Chapter 7. Synchronizing State
The previous chapters offered a preliminary glance of state in the browser. We covered the basics of Backbone views, models, and collections to manage state. But to build a real app, you must connect your collections and models to an API. These are the enhancements of Backbone collections that we haven’t yet discussed.
One of the main purposes of a Backbone collection is to fetch new information (or state) over a network. To understand the basic ideas here, you need to understand a bit of RESTful principles for APIs and how Backbone maps these internally to the API of collections and models.
In the case of the Munich Cinema example, when a collection manages tens or hundreds of movies, new questions on filtering and sorting them arise. Dealing with more data also takes an important role in our customer’s project: Munich Cinema wants to allow its customers to search for movies by release date and genres. To help customers decide which movies to watch, Munich Cinema prepared ratings of movies that might further distill a movie search.
So we must expand our application with a number of features. In this chapter, we’ll cover the following:
§ Setting up a mock of a RESTful API
§ Enabling fetching of remote data from an API
§ Dealing with time effects around fetching
§ Understanding the basics of hosted API services
Fetching Remote Movies
So far, the examples were based on a few movies directly linked with the initial page load. Munich Cinema’s movie program is much larger though, especially during festival season. For this, users can select movie genres or browse lists with with many more movies. Let’s look at important ideas behind requests for more movies with Backbone.
RESTful Web Services
Web services make data over a network accessible—for example, to query information. In most application stacks based on Backbone.js, the user interface is the client of a web service. The part of Backbone.js that handles access to RESTful web services is Backbone.Sync. By default, Backbone.js expects a web service to follow the RESTful principles. Let’s have a look at Figure 7-1 to see what it means.
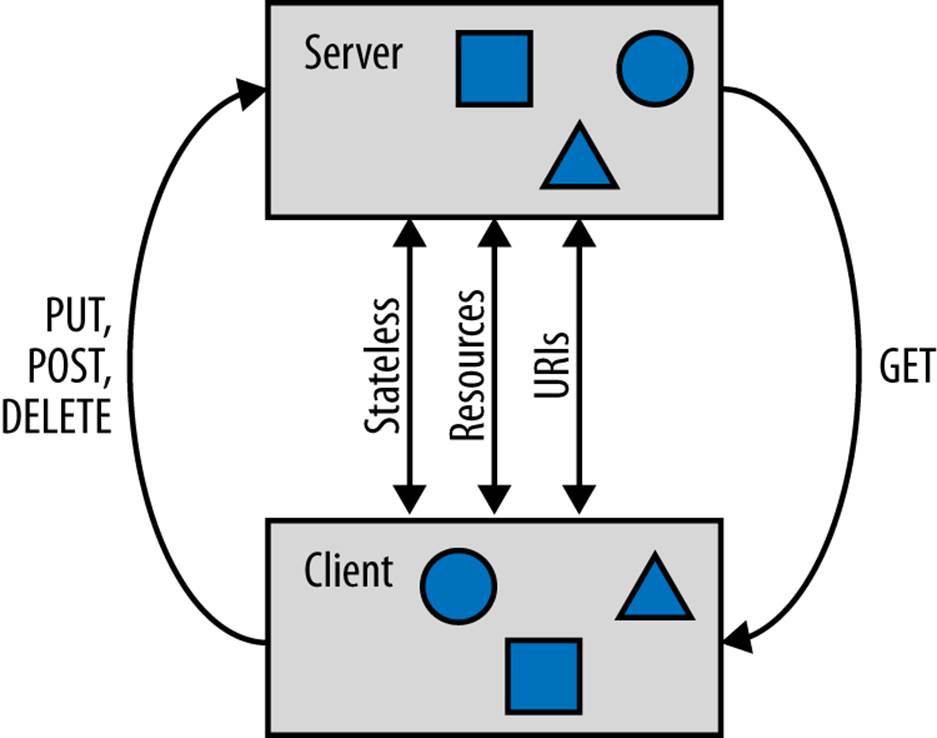
Figure 7-1. In a RESTful web service, we use the basic verbs GET, POST, PUT, and DELETE from HTTP to transfer state between client and server—addressability, representations, and statelesness are some core ideas for RESTful API design; in HTML, links and forms are the main tools to modify state, but with Backbone.js, you can reference state with collections and models
Let’s quickly review some of the core concepts of a RESTful web service:
Statelessness
Transferring and changing state over a network is the origin of the REpresentational State Transfer concept, or REST. Yet, resources should be stateless with respect to requests from clients, meaning the application state in a browser does not affect the response of the server. Modifying state of a resource, however, is possible with POST, PUT, or DELETE requests. Modifying client state from the server is done with GET requests.
Different representations
A client accesses a representation of a resource, not the resource itself. In general, a server exposes different representations. For a Backbone.js client, we are mainly interested in a JSON representation, but the same data might be requested in HTML or XML. While HTML representations are convenient for humans, JSON and XML are representations that can be more easily used by machines such as Backbone.js-based clients, or an RSS reader.
Addressability
In a network of information, information resources should clearly be identified with a URI, a uniform resource identifier. For example, to show data about movies, we would define a clear path for how to get these in the application, similar to a filename in a filesystem. A URI is basically the name of a resource and acts as input to clients of web services.
With these principles, we build web architectures that focus on connecting resources. As such, we can easily build different (Backbone.js) clients acting on the same resources on a server.
For example, for Munich Cinema, we developed a client to browse movies. Similarly, we could develop an admin interface that allows us to modify movies or another interface for sharing feedback of movies on a dashboard.
Mocking an API
Instead of using remote data from a remote data store, it can make sense to mock responses for data first. By mocking API data, frontend and backend development can be separated—and you can continue developing the Backbone application without thinking too much about server-side requirements. For the purposes of the book, a mock API can help to illustrate timing effects when loading data.
There are two approaches we can take: mocking an API on the server or mocking an API in the browser. You already have some experience with using npm, so we’ll discuss mocking an API on the server first.
To mock data from a remote data store, we use the canned library written by Philip Fehre. The idea of this library is to map files from a directory to HTTP requests.
For example, by having files in the ./api/movies/ directory, you would automatically get responses as follows:
File | HTTP Path
-------------------------------+-----------------
./movies/index.get.json | GET /api/movies
./movies/any.get.json | GET /api/movies/:id
You can install canned with:
$ npm install canned --save-dev
Next, you can create some example movies in the api/movies/index.get.json file. One example looks like:
{
"title": "Ice Age: Dawn of the Dinosaurs",
"director": "Carlos Saldanha",
"rating": 0,
"showtime": 1388279380,
"description": "Ellie and Manny are expecting their
first child, and Manny is nervously obsessed with
making life perfect and safe for Ellie. ... ",
"id": 10,
"year": 2009,
"length": 94,
"genres": [
"Animation",
"Action",
"Adventure"
]
}
Canned can be called stand-alone or combined with middleware applications in a server stack. This will allow us to serve static files too, besides the API data. Therefore, our server in a ./server.js file can look as follows:
var http = require('http');
// Setup the can to mock data
var canned = require('canned');
var opts = { cors: true, logger: process.stdout };
can = canned('.', opts); // canned configuration
var express = require('express');
var app = express();
// adding middlewares
app.use(express.static(__dirname + '/static'));
app.use(can);
// startup server
http.createServer(app).listen(5000);
You can start this server with:
$ node server.js
When you now make a request to the /api/movies path, you are ready to serve movies data with canned.
To check that your setup is working, you have several options. First, you could use curl, a command-line HTTP client:
$ curl 0.0.0.0:5000/api/movies
Alternatively, you could open the URL http://0.0.0.0:5000/api/movies in your web browser.
And in the context of a Backbone app, you could set up an Ajax request with jQuery in app/main.js:
$.ajax({
url: "/api/movies",
headers: {"content-type": "application/json"}
});
A working API setup should return a result similar to Figure 7-2.
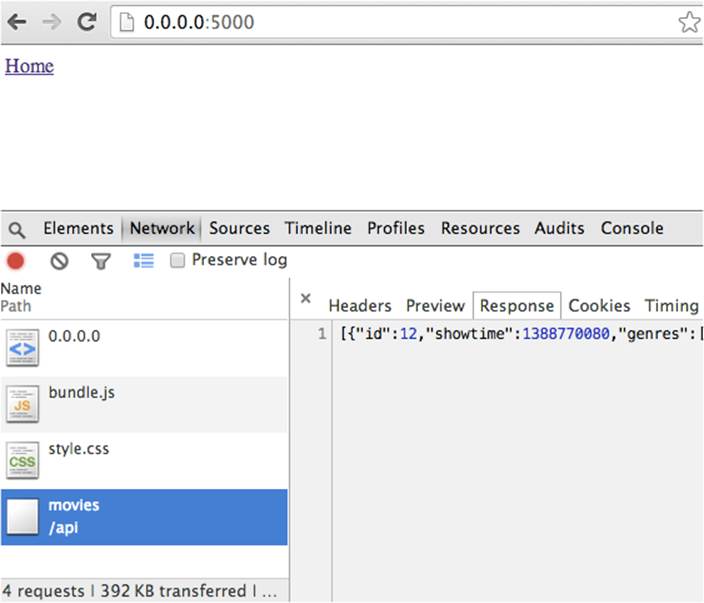
Figure 7-2. To see the API mock for a server in action, you can run an Ajax request with jQuery and inspect the Network tab in the browser console
Once this setup is working, let’s delve deeper into the enhancements of a Backbone collection to fetch data from an API.
Basic Sync and Fetch
Backbone collections and models provide important enhancements to work with a RESTful API through Backbone.Sync. Conceptually, you can see the place for Backbone.Sync in Figure 7-3.
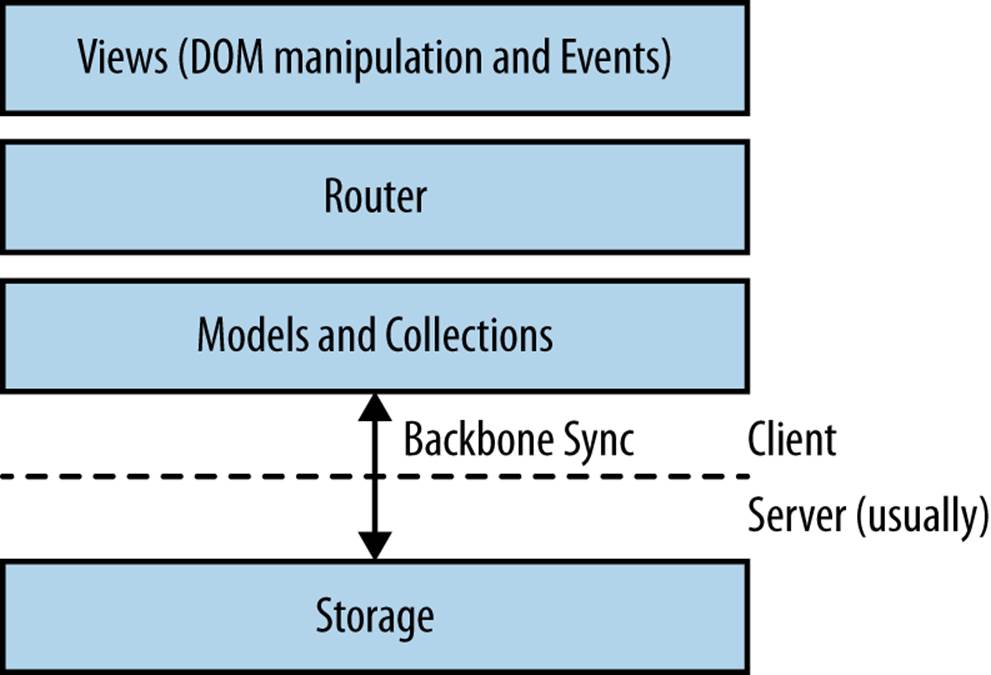
Figure 7-3. In the previous chapters, we discussed mainly DOM manipulation and tracking basic static with Backbone models and collections; to synchronize state over the network, we need to talk about Backbone.Sync
Every request from and to servers pass through Backbone.Sync. State in collections can not only be synchronized through a RESTful JSON API but also via sockets, XML, or with an HTML5 localStorage adapter.
However, for the Munich Cinema example, the main use case is synchronizing state through HTTP. To synchronize state via an API, you need to solve a number of problems:
§ A Backbone.Model resolves data on the server by using a primary key. Backbone.Sync adds an ID to requests when data is stored.
§ The attributes of Backbone models will be serialized as JSON. Backbone.Syncs provides help to serialize and de-serialize data.
§ Last, we must set some HTTP headers, such as content-type, so that the interpretation at the other end of the line understands what is going on. The HTTP headers are also managed by Backbone.Sync.
Backbone.Sync manages actions for writing and reading data from a server. For this, Backbone defines its own verbs: create, read, update, and delete with the following mappings to the routes of a RESTful API:
Backbone verb vs RESTful API endpoint
create movie <--> POST /movies
read movie <--> GET /movies[/id]
update movie <--> PUT /movies/id
delete movie <--> DELETE /movies/id
By default, Backbone.Sync expects the JSON going and coming from a server to comply with the following pattern:
[{ 'id': 1, 'title: 'The Artist', ... }, ... ]
This means that you don’t have root elements indicating the name of the movies collection, for example. Some APIs, however, use a JSON syntax with a root element. For example, many web applications that are based on older versions of Ruby on Rails would deliver JSON in the following syntax:
{ "movies": [ { "movie" : { "id" : 1, ... } } ] }
For such kinds of APIs, you must take care of parsing the raw data that comes out from Backbone.Sync. Parsing raw data also applies to situations where you are working with non-RESTful APIs, such as data from sockets. For those cases, you can overwrite parts (or the complete) synching behavior.
NOTE
The documentation will be a good start if you need to overwrite the default Backbone sync behavior (e.g., when you want to connect application state to websockets). The annotated source code of Backbone.js has a nice list of use cases when overwriting Backbone.Sync, which might be important.
To start working with an API, we first explore the mapping of Backbone.Sync to “read” movies. The data is provided by canned with the setup described in Mocking an API.
First, the Movies collection can be extended such that data is read from the API instead of embedded JSON. To do this, you add a url property to the collection. This url property points a collection to an API endpoint as follows in app/collection/movies.js:
var Movies = Backbone.Collection.extend({
model: require('models/movie'),
url: '/api/movies',
// ... same as before
});
module.exports = Movies;
Let’s bundle the collection up with the following browserify command:
$ browserify -r ./app/collections/movies:movies > static/movies.js
and add the file to static/index.html:
<script src="movies"></script>
Now you are ready to experiment in the browser console:
> Movies = require('collections/movies');
> movies = new Movies();
To read remote data and populate a collection, Backbone provides the fetch() command. By invoking fetch(), an Ajax request is made to the url path as defined in /api/movies. The response is provided by canned, and you can quickly observe new data in the Backbone collection:
> movies.fetch()
As a response you should see:
XHR finished loading: GET "http://0.0.0.0:5000/api/movies"
and the collection should be populated:
> movies.size()
20
However, what looks simple can quickly become more complicated. First, there are a number of events that can result from fetch(). Let’s first learn about these.
If you activate again the events monitor from Basic Events, you will see that fetch triggers the following events:
request
add // for each new model
sort
sync
Often, you want to hook into the add event to render new information from an API. In case of populating a model, you will see a change event. It can be necessary to observe the events request and sync, too—for example, to notify observers that new data is available or that loading of data has stopped.
To illustrate the effects of request and sync events, you could hook into these events to see how long it takes to fetch data:
beginSync: function() {
console.log("before sync: " + Date.now());
},
finishSync: function() {
console.log("after sync: " + Date.now());
},
initialize: function() {
this.on('request', this.beginSync);
this.on('sync', this.finishSync);
}
If you fetch new data now, you can see from the browser console that it takes just some fractions of milliseconds to complete loading movies on the development machine.
Alternatively, you could hook into request and sync and show a small spinner while movies are loaded. For showing a spinner, you would add a new HTML element with class .movies-loading that contains a spinning wheel or loading animation.
Then, you could hook into the collection loading events from app/views/layout.js. When the loading starts (a request event is triggered), the loading div with class .movies-loading is shown. And, when the loading stops (a sync event is triggered), the loading div is faded out. This idea translates to the following code outline:
// start spinner
beginSync: function(){
$('.movies-loading').fadeIn({duration: 100});
},
// stop spinner
finishSync: function(){
$('.movies-loading').fadeOut({duration: 100});
}
The behavior and events of fetch can be influenced by some options. First, you can add {reset: true} to clear a collection before it is populated. If you try this:
> movies.fetch({reset: true})
You can observe the events: request, reset, and sync.
Also, fetch() accepts a number of options from the collection set command: these are add, remove, and merge, and work as follows.
For example, with {merge: false} you can avoid overwriting existing models. To see this, you can prepopulate a Movies collection with a dummy model as follows in the browser:
> movies.add({id: 12, title: "my test"})
Now, when you fetch the collection with:
> movies.fetch({merge: false})
you can see that collection will be populated with 20 models, but only 19 add events will be fired.
Also, fetch() accepts parameters that can directly be passed to an Ajax call. For example, in app/collections/movies.js, you can define a function fetchPage() to fetch a certain page in a collection:
fetchPage: function(num) {
return this.fetch({data: {page: num}});
}
If you try this function in the browser, you can see:
> movies.fetchPage(2)
XHR finished loading: GET "http://0.0.0.0:5000/api/movies?page=2".
This behavior can be useful if you want to provide server-side support for pagination of collections.
Modifying the way an Ajax request is made also works for HTTP headers. Using HTTP headers is especially interesting for passing meta information of an app to a server.
To illustrate some points about asynchronous effects of loading data, let’s imagine a custom HTTP header to simulate a delay. A delay parameter could be passed with a HTTP header, which can then be processed at the server. To define a fetch() function with a delay, you could pass a header X-DELAY as follows:
delayedFetch: function(delay) {
return this.fetch({headers: {"X-DELAY": delay}});
}
The X-DELAY header can then be read out at the server and cause an artifical delay in the response. To see this idea in action, you can add the following middleware application to server.js:
app.use(function(req, res, next) {
var delay = parseFloat(req.headers['x-delay']);
if (delay) {
setTimeout(function() {
next();
}, delay);
} else {
next();
}
});
Now, if you restart the server and go back to the browser, you can run:
> movies.delayedFetch(2000)
And, you should see that it now takes two seconds to populate a collection. With these background concepts, let’s look closer at problems caused by the asynchronous operation of JavaScript.
Asynchronous Effects
It takes time to transport data over a network, so working with remote data brings in a hidden time dependency into our application. Dealing with time dependencies might be new if you are accustomed to the “blocking” behavior of programming statements that are common in programming languages such as Java or Ruby.
With the “nonblocking” behavior of JavaScript, applications quickly run into asynchronous effects between data transport and code execution. You must take into account that transport of data over a network, which takes a couple of milliseconds, is different than the time for executing JavaScript statements in a browser, which takes only a fraction of milliseconds.
To illustrate the effects of high-latency, low-bandwith network connections, let’s experiment a bit with a small simulator.
In the previous section, we wrote a function delayedFetch(). To examine the effects of time on the collection state, we process the size of the collection at different times with the following probe in app/probe.js:
simTransport = function(movies, simDelay, probeDelay) {
movies.reset();
movies.delayedFetch(simDelay);
window.setTimeout(function() {
console.log('Probe delay: ' + probeDelay + ' milliseconds.');
console.log('Simulation delay: ' + simDelay + ' milliseconds.');
console.log('Collection size: ' + movies.size());
}, probeDelay);
}
module.exports = simTransport;
You can bundle this probe up with:
$ browserify -r ./app/probe.js:probe > static/probe.js
We first check what happens if we probe the data before it arrives, at around one second after the fetch:
> simTransport(movies, 2000, 1000)
Probe delay: 1000 milliseconds.
Simulation delay: 2000 milliseconds.
Collection size: 0
Appropriately, the size of the collection is still 0, although we might have expected a populated collection. Simply put, the response time for the remote data takes a couple of milliseconds, while we check the collection size too early.
Without further precautions, we will get errors in the UI. One option to get the correct population is to wait longer. Let’s see what happens at three seconds after the fetch:
> simTransport(movies, 2000, 3000)
Probe delay: 3000 milliseconds.
Simulation delay: 2000 milliseconds.
Collection size: 20
Indeed, we get the expected size for the collection. But guessing network latency is not really an approach to base our engineering efforts upon. We need to find better mechanisms that will allow the loading event to finish.
A first approach to avoid asynchronous problems is to pass a callback function to fetch. This can look like:
movies.reset();
movies.fetch({ success: function(results) {
console.log("Collection size: " + movies.size());
}
});
The success callback is automatically called when the Ajax call has been succesfully finished.
Callbacks can be hard to read, especially when exceptions occur within a callback, so there is another approach we can use. This alternative approach is the “deferred” syntax that is supported by jQuery.
The basic idea is that instead of letting fetch return an uncertain result, we return a representation of the asynchronous operation, a promise. We can chain this promise with callbacks that should be executed when an operation finishes.
To see this callback idea in action, let’s instantiate an empty movies collection in the browser and do the following:
> var deferred = movies.fetch();
> deferred.done(function() { console.log(movies.size()) });
We first bind the fetch to a deferred variable and ensure then that data is loaded with the done() method. The size of the collection is now correct without using error-prone guesswork. We can also respond to problems while fetching a movie with the fail() method.
Note that calling done() multiple times on a promise always yields the same resolved value (i.e., another “sync” operation will not be run after the promise was resolved). This may prevent multiple Ajax requests and may have advantages, depending on the application you are working on.
The full example can be found on the book’s GitHub page.
NOTE
We will return to promises when we build our data backend in a later chapter. You can also see Learning jQuery Deferreds (O’Reilly, 2013) by Terry Jones and Nicholas H. Tollervey.
Firebase
To round out the basics of fetching remote data, let’s point the Movies collection to a hosted service.
There are a number of “noBackend” providers offering API hosting that can take away the pains to build and maintain a backend yourself. In this case, you can apply some ideas of this chapter and fetch data from a hosted backend service.
Let’s look at an approach to drive your Backbone application with Firebase, one of the popular backend-as-a-service providers. In the next chapter, we get more into API details, when your application requires its own backend design.
To get started with Firebase, you can signup with your GitHub account or simply with your email. On Firebase’s dashboard, you then can create as many apps as you like, and there is a free plan available for developing projects.
To have collections and models talk with Firebase, you need to include the Firebase sync adapter, which is provided by the Backfire module.
You can get Backfire with the following npm command:
$ npm install client-backfire --save-dev
Now, you can include the sync adapter for Firebase in your application main at app/main.js:
var Backbone = require('backbone');
var $ = require('jquery-untouched');
Backbone.$ = $;
var backfire = require("client-backfire");
backfire.Backbone = Backbone;
To reference movies from Firebase, you can make the Movies collection reference Firebase as follows:
var Backbone = require('backbone');
var Movie = require('models/movie');
var _ = require('underscore');
var Movies = Backbone.Firebase.Collection.extend({
model: Movie,
firebase: "https://movies-demo.firebaseio.com/movies",
// ... same as previously
});
From here on, the Firebase sync() function takes over. With some minor adaptations, you can get the example of Munich Cinema running, and you can see a demo on the book’s website.
With Firebase, you now have a dashboard to easily import more movies and track movies usage. You can also wire up Firebase with other APIs via Zapier to trigger sending emails or other tasks. This might be interesting for some applications, but for others, you want to build your API yourself. This will be the topic of the next chapter.
Conclusion
In this chapter, you made quite some progress toward a full, single-page application that fetches data from a remote data store.
To prevent developing a full backend at this stage, we saw a strategy to mock a RESTful API with canned. We then used the mock API to learn about different approaches to populate the Movies collection over a network. First, we learned about the basic events that are evolved. Then, we discussed the different options to influence fetch() for different needs. We covered asynchronous effects and how to use a promise to prevent making multiple Ajax requests.
We also saw an approach for building web apps with Backbone.js with Firebase. Firebase is a backend-as-a-service provider and allows you to easily access and manage data over an API. Backend-as-a-service does not work for every application. That is why the next chapter brings in more ideas to build APIs yourself and will also discuss some strategies for authentication of an application with Backbone.js.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.