Client-Server Web Apps with JavaScript and Java (2014)
Chapter 11. Packaging and Deployment
The thought occurred to me, as I waited around that day, that it would be easier to lift my trailer up and, without any of its contents being touched, put it on the ship.
—Malcom McLean
Malcom McLean had an idea in 1937 that would lead to his legacy as the “the father of containerization.” It came to him while waiting in Hoboken for cotton bales he had delivered to be loaded for transport overseas. It wasn’t until 1956 that McLean developed the metal shipping container, which greatly simplified cargo handling and revolutionized the shipping industry. Innovations in packaging lead to efficiencies in shipping. In technology, deployment and distribution of applications is analogous to shipping. Java provides standardized packaging, which is foundational to the distribution of code and deployment of applications.
Java and JEE Packaging
Java packaging formats are fundamental building blocks in JEE applications. They are also used in more recent deployment processes that do not adhere strictly to the JEE specification.
Java developers initially develop code outside of deployment packages. A Java class corresponds with a file on the operating system. Confusingly enough, a Java package is not really related to packaging but instead is a namespace that reflects the path from an application root to a directory where a class resides. It is rare to encounter classes and packages on their own outside of a programmer’s development environment. An application or module is compressed and packaged as a unit before it is deployed to a production environment or end user.
The Java Archive (JAR) file is used to bundle Java class files and related resources into a single archive. JAR files are compressed using a ZIP file format and include a manifest file with path name of META-INF/MANIFEST.MF. They can be created using the jar utility included in the JDK. At its simplest, a JAR is a .zip file with a few additional characteristics defined in its META-INF directory.
JARs are not JEE-specific. They are part of standard JDKs and their specification is included in the JDK documentation. JEE does describe several special usages of JAR files. Application client modules and EJB modules are packaged as JARs. All other JEE packaging formats are based on the JAR format as well. In fact, the remaining JEE-specific file formats are JAR files with a file extension specific to their function and contents. JEE archives can be constructed manually but are more often assembled using build tools like Ant, Maven, or Gradle.
A web module is the smallest deployable unit in the JEE world. Such a module contains web components and web resources, primarily static content. A web module can be packaged into a web archive or WAR. A WAR includes a /WEB-INF directory that contains a file named web.xml that defines the structure of the web application and references other assets included in the archive. WARs are very flexible and can be deployed to a web container which supports a relatively small subset of the JEE specification.
Popular web containers include Tomcat and Jetty. Web container development tends to precede definition of technologies in the JEE specification, and significantly different sets of features are available in each one.
An enterprise archive, or EAR file, contains WAR files, JAR files, and an application.xml that references the included modules and defined security roles. As suggested by the name, EARs are intended for enterprise applications. EARs must be deployed to an application server, which supports a much greater portion of the JEE specification than a web container. They cannot be run on a web container because they require EJB support and other services. Application servers include JBoss, IBM’s WebSphere, and Oracle’s WebLogic Server.
A less familiar JEE archive mentioned for the sake of completeness is the resource adapter module (RAR). This type of archive is used to allow connectivity to an Enterprise Information System (EIS). An EIS is typically a legacy system such as an ERP, MainFrame, Queue, or other such service. A RAR’s purpose is similar to that of a JDBC driver. It provides a consistent interface to a backend system but is not limited like JDBC to accessing relational databases. See Table 11-1 for a list with related file extensions.
Table 11-1. Java packaging formats
|
Extension |
Name |
Description |
|
.jar |
Java archive |
Standard Java package format |
|
.war |
Web archive |
Maps to a single web context root |
|
.ear |
Enterprise application archive |
Contains multiple WARs and JARs |
|
.rar |
Resource adapter module |
Communication with an EIS |
WARs are of particular interest to web application developers, and their popularity is reflected in their adoption by modern frameworks based on other languages. The Play framework can create a WAR containing Scala resources, and a Ruby gem called Warbler can be used to make a Java JAR or WAR file out of a Ruby application.
Existing Java and JEE packaging works well for client-server web development. The main consideration is maintaining independent server and client code in separate archives for projects that are of any significant size. An application can be deployed as an EAR that references a server WAR containing API code and a separate client WAR containing HTML, CSS, and JavaScript. The same two WARs could be deployed outside of the EAR to separate web containers. Unlike other areas that have been covered, there are no major innovations related to packaging itself.
SAMPLE WAR
A single WAR used in illustrations later can be built from the code associated with this chapter using Maven. It includes both client and server code in a single WAR to provide minimal usage examples.
An archive considered as an independent package of related Java resources does not do much good in isolation. The archive has to be executed (if written as a self-contained executable) or deployed to a runtime environment. While packaging practices have remained constant, choices related to deployment have changed quite a bit.
JEE Deployment
At one time, options for deployment were severely limited. Decisions revolved primarily around the degree of automation to use. At the time of application deployment, it was assumed that the application server would have been previously installed and configured by a developer or systems administrator. To this day, the JEE specification itself remains oriented toward this expectation, particularly in the description of the actors involved in the deployment of an application. A JEE web app deployment setup is shown in Figure 11-1.
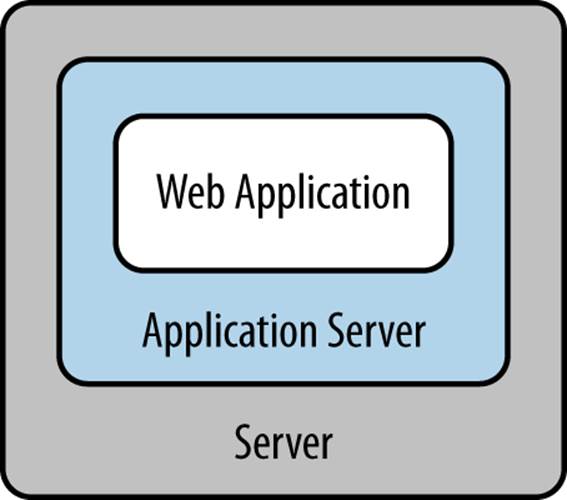
Figure 11-1. JEE web app deployment
JEE roles indicate functions that people fill during the development process, including a deployer and system administrator. The person or people acting as deployers are responsible for configuring the application for the operational environment, verifying that modules conform to the JEE specification, and installing the application modules on the server or servers. It is evident from this description that the target environment for a JEE application is expected to be an already-installed application server under the active management of the person or group. (It also suggests manual intervention at the time of deployment as opposed to the continuous delivery common in large-scale deployments.) As was already suggested, this is not the only possible way to deploy a Java web application, but it does appear to be the only one that conforms with the specification.
JEE AND CLOUD DEPLOYMENTS
JEE, like other somewhat monolithic efforts, seeks to maintain continuity with previous releases. It is also intended to relflect a wide range of deployment environments. This wide applicability is its strength in some cases and its weakness in others. It has been updated in more recent versions to reflect cloud deployments, but these seem to suggest minimal responsibilities for a deployer that are often absorbed in practice by the same person acting as systems administrator:
For example, in the case of cloud deployments, the Deployer would be responsible for configuring the application to run in the cloud environment. The Deployer would install the application into the cloud environment, configure its external dependencies, and might handle aspects of provisioning its required resources...
...in a cloud scenario, the System Administrator would be responsible for installing, configuring, managing, and maintaining the cloud environment, including the resources that are made available to applications running in the environment.
—JEE7
Having an already-installed application server following the JEE specification limits processes but does not dictate all deployment practices. It is possible to build a project on the server where the deployment will reside. This requires that build tools be available on all relevant servers and can result in performance degradation or disruption of service to the server. There is also the possibility of security vulnerabilities due to the installation of additional software or the deployment of untested code to a production server. These challenges suggest that it is better to build outside of the production server and transfer the packaged application to the machine for deployment.
With the advent of modern deployment involving large numbers of servers, it is even less common to build on a server that is a deployment target. In rare situations it might make sense; but in general, it is better to build archives on a nonproduction machine and transfer them to the target servers for installation. Even if not required in the early stages of a project, this provides greater flexibility should application usage grow over time and it becomes necessary to add additional servers. A variety of projects have been developed in recent years specifically geared to distributed remote execution of shell commands, which makes this sort of deployment much more manageable.
GUI Administration
Active application server administration involves user interaction through a graphical user interface. This is not always the case with web containers. In the distant past, some interfaces were old-school, native-client applications that made remote network connections to the application server. Today the GUIs are web applications in their own right. Those available after installation require additional configuration. Steps need to be taken to prevent the admin portal from being publicly available, which would present a security vulnerability. Adjustments need to be made to avoid an admin server’s context root from conflicting with other deployed web applications. These configuration concerns lead many administrators to simply disable the administrative web application during initial installation.
One example of an application server with a web-based graphical administrative site is Red Hat JBoss Enterprise Application Platform 6 (JBoss EAP 6), as shown in Figure 11-2. After downloading it and adding an administrative user, the standalone server can be started where the administrative console is available by default. By clicking a few buttons, an administrator can deploy and enable a WAR. This deploys the web application and makes it available from the indicated context root.
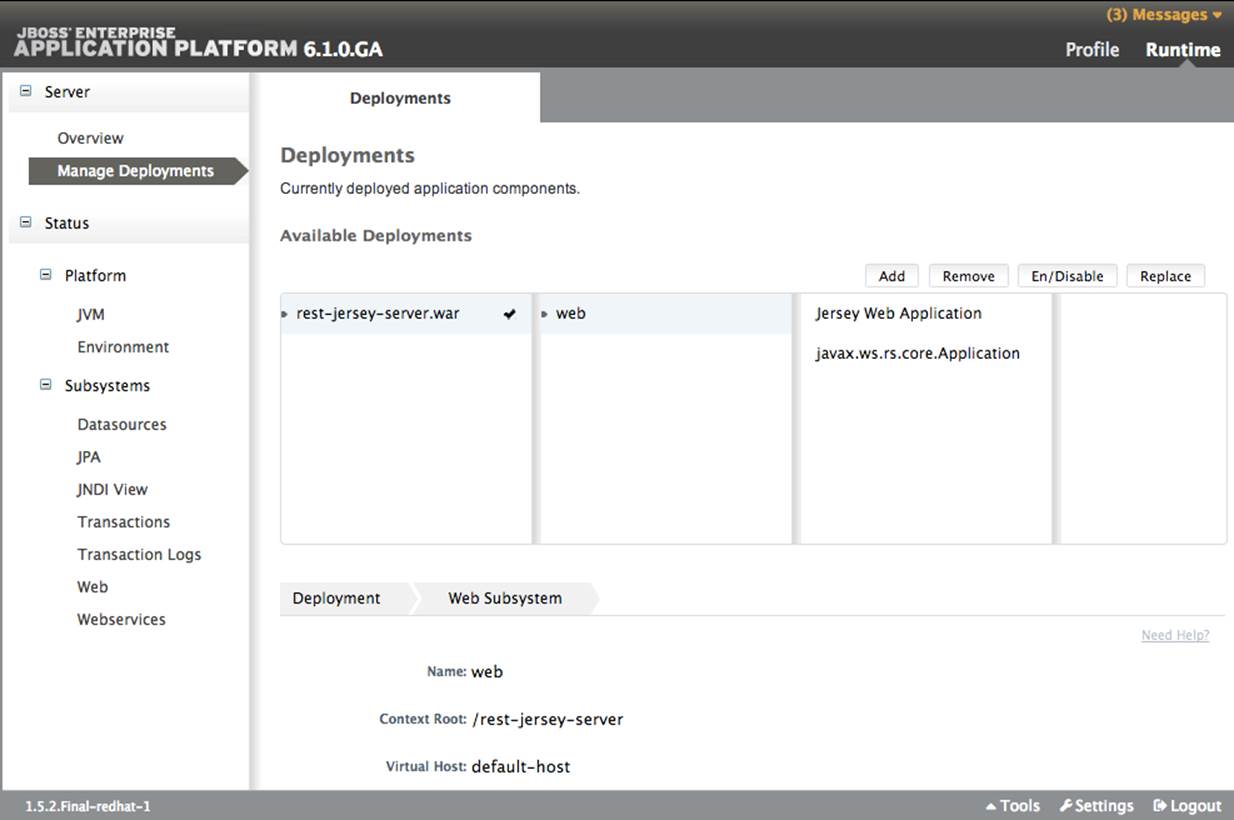
Figure 11-2. JBoss web admin
JBoss, being a full-featured application server, bundles many useful modules, which can minimize the amount of code you need to include with a WAR. It can also result in some obscure errors if similar modules exist both within JBoss and within your application. The WAR associated with this chapter includes Jersey among its dependencies. Including Jersey could result in an error during deployment. The error is reported by RestEasy (included with JBoss), which scans by default and identifies Jersey as a conflicting JAX-RS implementation. The solution is to add context parameters to the web.xml to disable this scan:
<context-param>
<param-name>resteasy.scan</param-name>
<param-value>false</param-value>
</context-param>
<context-param>
<param-name>resteasy.scan.providers</param-name>
<param-value>false</param-value>
</context-param>
<context-param>
<param-name>resteasy.scan.resources</param-name>
<param-value>false</param-value>
</context-param>
The solution is simple enough but highlights the point that although JEE specifies clearly defined packing mechanisms, it is ambiguous about which services will be included in a given deployment environment. These types of idiosyncracies are a major reason why mantras like, “Write once, deploy anywhere” can only be true with significant qualifications when applied to JEE deployment.
Command-Line Administration
Administrative GUIs are convenient for initial setup of an application. They present available administrative options in an easy-to-understand user interface. This clarity makes them ideal for learning an application server and reviewing available functionality. Like all GUIs, they do not lend themselves to scripting and subsequent automation as command-line alternatives. Though a mere convenience for small-scale deployment scenarios, they are essential to complex deployment scenarios (or even simple ones with a large number of servers).
JBoss includes a command-line interface that allows adminstrative actions to be taken from a prompt or script. Almost any action available in a GUI is available through a command-line equivalent. A command-line session is initiated by accessing the command-line interface and connect to a running application server. To do so, call the cli with the -c option (which immediately establishes a connection to the application server):
$bash bin/jboss-cli.sh -c
Once logged in, you can type help to get a list of available commands:
[standalone@localhost:9999 /] help
Knowledge of few basic ones is enough to perform most common actions. To view a list of contents available at the particular node path, use the ls command:
[standalone@localhost:9999 /] ls
The JBoss environment can then be navigated like an operating system file system using cd to change directory and ls to list the content at a given node path. To view the WAR that was deployed earlier:
[standalone@localhost:9999 /] ls deployment
rest-jersey-server.war
The syntax is not completely consistent with the corresponding operating system commands. For instance, additional information about the WAR in the deployment directory can be obtained by using the ls command and identifying the deployment using an equals sign:
[standalone@localhost:9999 /] ls /deployment=rest-jersey-server.war
This design does lend itself to executing JBoss CLI commands from an external script. The following command prints out the current list of deployments straight from an OS command prompt:
$bash bin/jboss-cli.sh -c --commands='ls deployment'
The availability of a CLI opens up the possibility of creating sophisticated scripts to interact with the application server as well as the operating system and other applications. The examples to this point have been limited to query operations, but the CLI is not limited to these. It can also take actions which modify the state of the application server, such as deploying or undeploying a WAR:
[standalone@localhost:9999 /] undeploy rest-jersey-server.war
[standalone@localhost:9999 /] deploy /tmp/rest-jersey-server.war
Administrators can replace manual GUI interaction with CLI scripting for a wide range of adminstrative tasks, but the CLI does have its own syntax and organization that takes some time to understand and use effectively. If the only administrative concern is to deploy the application, both the GUI and the CLI can be avoided by copying files to a designated deployment directory. Applications copied to this directory are detected by the JBoss deployment scanner and automatically deployed. Copying can be done interactively or via a script, so automated deployment is possible without learning the CLI at all. Developers requiring frequent deployment can copy applications and rely on the deployment scanner or rely on hooks integrated into their standard toolchain. Plug-ins have been written for Maven and other build tools and IDEs that couple the deployment of the application with the build process itself.
Non-JEE Deployment
For many years, Java web development was synonymous with Java Enterprise Edition. It can be jarring (pun intended) for Java developers to realize that the JEE model for web application deployment is not the only one available, and in fact, might not be the best one for a given system. Java technology encompasses far more than web application development, and JEE is but one approach to web application development possible on the Java platform. Figure 11-3 shows the Java web application development model.
Figure 11-3. Web development in Java
A non-JEE web application deployment does not require the existence of a previously installed application server. From the perspective of a Java web application, the application server providing its context might be outside, inside, or alongside it. These options are not unique to application servers but also might apply to other software that provides an independent service (such as a database).
Server Outside
Application servers are complex, mature pieces of software that have been around for years. At one time, due to space and processing limitations as well as configuration complexities, the only real option was to expend a fair amount of time and effort up front installing them. Once installed, a web application could be installed and configured to connect to these existing services. The web app ran “on” a server, as shown in Figure 11-4. The app server functioned as the deployment target for the web application, outside of the web app itself.
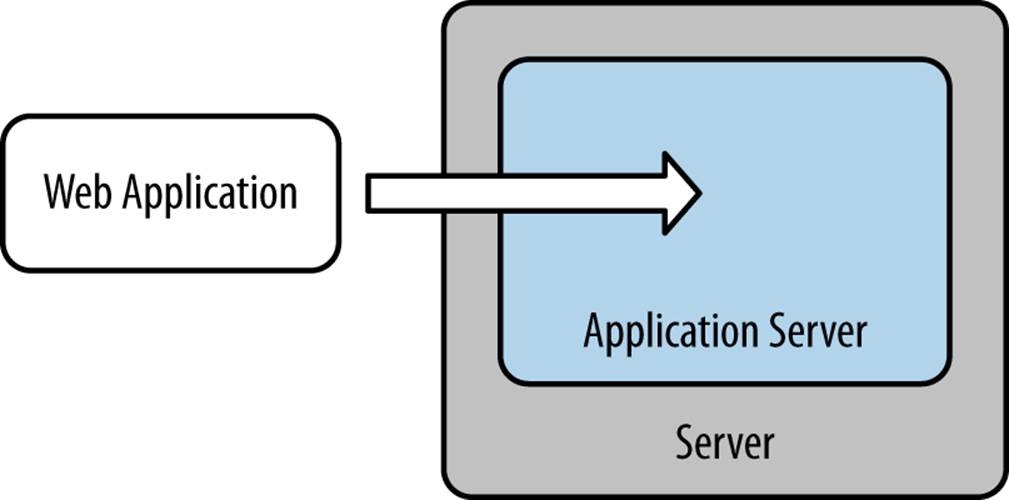
Figure 11-4. Server outside the web application
This approach is the de facto JEE method for deployment described earlier in the chapter. It works well when your application needs to be deployed to an internal system that is already running an application server, or when you want to host multiple web applications and JEE packages on a single web application. In many cases, there is precious little administration required for an application. An application server or servlet container might be required to run it, but no administration is expected. This led developers to defer deployment of the application server until the web application itself was deployed.
THE TREND TOWARD LIGHTWEIGHT CONTAINERS
The trend away from large, monolithic, manually configured installations of application servers is part of a larger trend toward virtualization and lightweight deployment of applications. The advent of cloud-based deployments has led to a much more transient view of servers and their contents. This view mandates an approach to deployments to make them fast, as simple as possible, and highly automated.
Server Alongside
There are a few different ways to deploy a web application without first installing an application server. One is to bundle the web application with the application server. The application server, though separate and distinct, is installed alongside the application at the time of deployment, as shown in Figure 11-5.
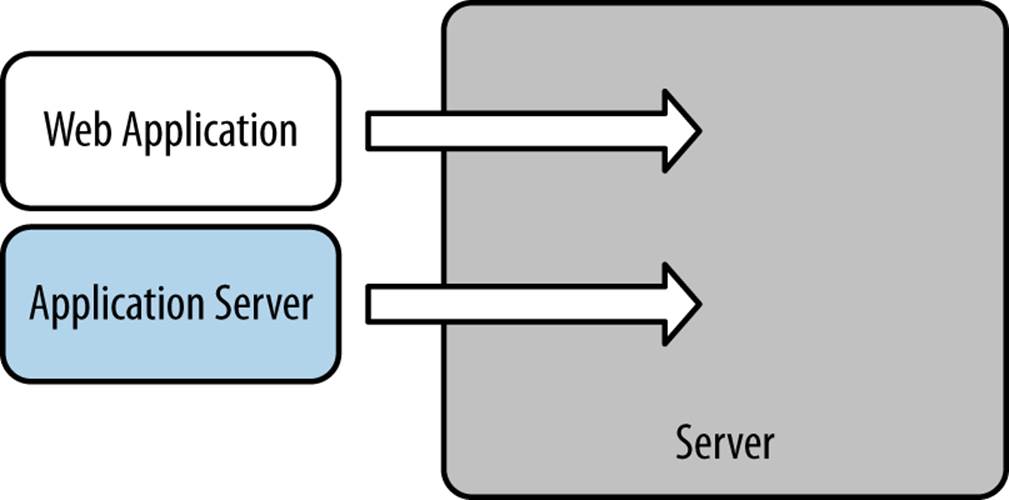
Figure 11-5. Server alongside the web application
This type of deployment was popularized with Rails, which includes a server (WEBrick) with the framework itself. Play and Roo took a cue from Rails and use this type of deployment, but rely on Java web containers. The Maven Jetty plug-in (shown in Figure 11-6) is another example that allows an web application to be deployed and run immediately in a servlet container that requires no external maintenance or administration. Using the project provided in this chapter, you can build the web module and run the resulting WAR on Jetty with the following command:
mvn clean install jetty:run
Figure 11-6. Web app running in Maven Jetty plug-in
The application is then available on port 9090.
Maven is not needed to run a web application using Jetty. Jetty can also be included as a JAR at the command line using Jetty Runner. From the build directory, the Jetty runner can be called passing the path and WAR as arguments:
curl -O http://repo2.maven.org/maven2/org/mortbay/jetty/jetty-runn
er/8.1.9.v20130131/jetty-runner-8.1.9.v20130131.jar
java -jar jetty-runner-8.1.9.v20130131.jar \
--path /jersey-server \
target/rest-jersey-server.war
Tomcat Runner is a similar project that uses Tomcat. It takes the same arguments as the Jetty Runner:
java -jar webapp-runner-7.0.40.0.jar \
--path /jersey-server \
target/rest-jersey-server.war
Server Inside
Rather than using an external server, a Java server library can be included inside an application’s code base, as illustrated in Figure 11-7. The server is run from inside the web application itself. Chapter 6 included several examples of libraries and frameworks that can be used to this end.
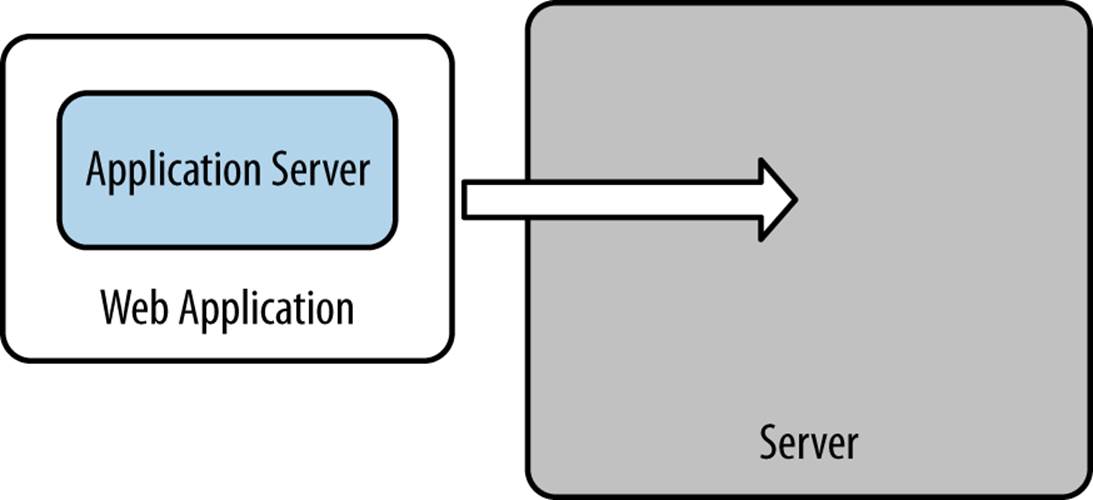
Figure 11-7. Server inside the web application
With a server available inside of an application, distribution can be reduced to creating and deploying a single executable JAR and executing it on a server. The JEE standard does not consider JARs or application servers in this way, but as described earlier, presumes that applications will be deployed to environments that provide services like HTTP processing, database connections, and related configuration.
CONSOLIDATED EXECUTABLE JARS
Although it is common for Java projects to reference multiple JARs, a project can be packaged and deployed as a single executable unit. Utilities to package JARs inside of JARs include one-jar and build tool plug-ins like the Maven Shade plug-in.
Implications of Deployment Choice
The method of deployment chosen has significant implications for security, scalability, and overall support of an application. Deployment methods vary in their flexibility for quick changes.
It is possible in simple deployments with a single server and an exploded EAR or WAR to hot-patch a system. A change to code or a configuration file can update the application without the overhead of doing a full deploy. This practice itself raises a host of process and security concerns, but is highlighted since it is not even possible to do this type of change in more complex deployment scenarios.
Credentials and connection strings are easy to modify in an externally administered application server. This is not the case in systems where the application server is deployed alongside or built into an application’s packaging.
Deployments that do not rely on externally administered application servers provide tremendous flexibility in regards to horizontal scaling. By building intelligence into load balancers, it is possible to make quick changes with little downtime by creating new server instances with the desired configuration data rather than changing existing servers.
The nature of the deployment can impact the development process and the choice of modules that comprise the foundation of an application. The deployment target is best identified early in the development process to ensure that the required resources are available and the relevant processes enacted.
Load Balancing
Load balancing is closely related to deployment in that its implementation determines the network and server topology required to run an application. The goal of load balancing is to distribute incoming requests as efficiently as possible with available processing power. In the case of a web application, incoming HTTP requests are redirected from a designated load-balancing server (or cluster of servers) onto multiple web servers.
The decision of how to distribute the load varies based upon the amount of work involved to process each request, the power of the servers, and the choice of hardware and/or software that will perform load balancing operations. Tasks can be distributed evenly between the servers in a round-robin fashion, or weighted to distribute more work to servers with greater processing power. There are more sophisticated schemes that track the requests being processed by each server or allow each server to essentially pull tasks when they are available, which makes better use of available processing power. Some load balancers are able to detect node failures and will not route requests to dead nodes. Load balancing is illustrated in Figure 11-8.
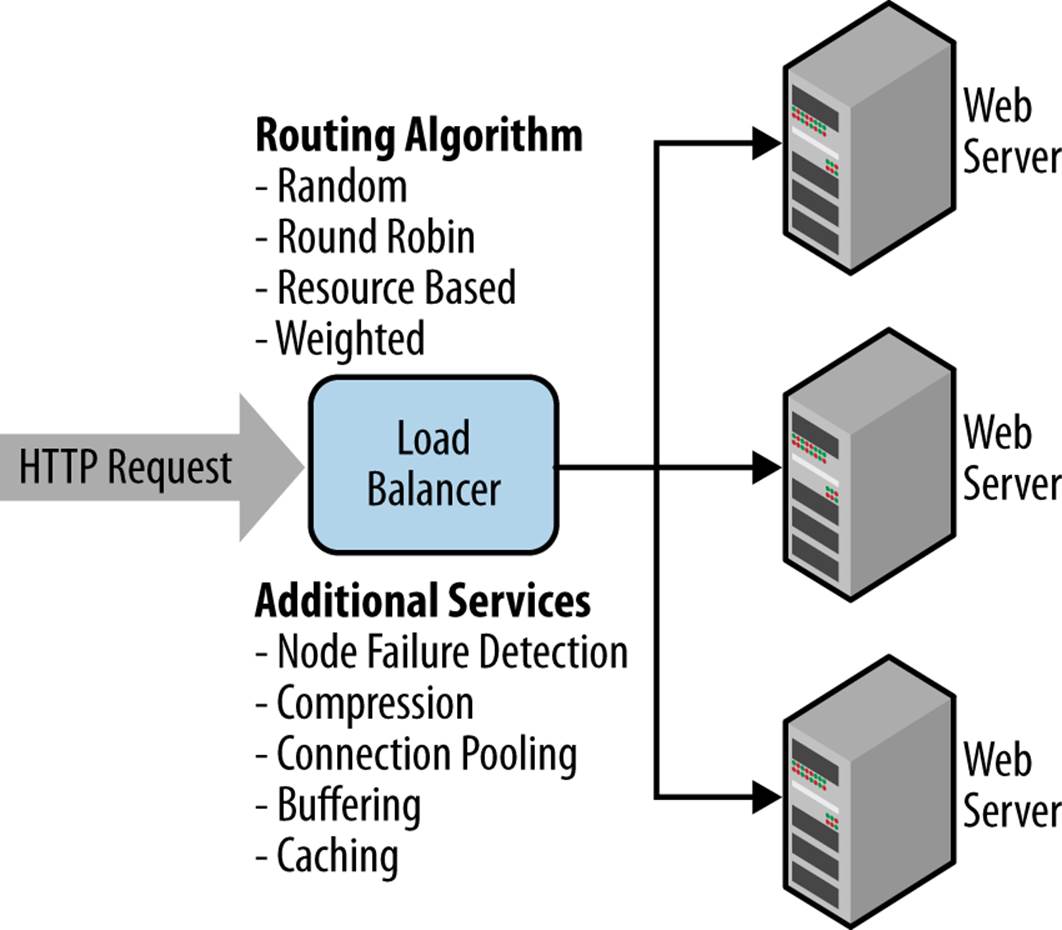
Figure 11-8. Load balancing
Not all of the functionality available in physical load balancers is replicated in software load balancers. This includes security concerns like distributed denial of service protection and SSL termination, as well as performance-enhancing features like compression, connection pooling, buffering, and caching. Such features are not necessarily inherent to load balancing, but in some cases are essential to use it effectively.
LOADS MORE ON LOAD BALANCING
There are many facets to load balancing that are not really relevant in the context of client-server web development. JBoss includes internal load balancing for JNDI, RMI, and EJBs within a cluster. It and other Java web containers include a clustering feature to make sessions available to multiple application servers. Load balancing schemes vary in regard to whether multiple requests from the same client will be directed to the same server. DNS-based load balancing provides a similar functionality to round-robin processing, but clients that cache the IP will return to the same server after the initial lookup. Sticky sessions can be used to HTTP requests associated with the same session to be sent to the same server. The range of possibilities is very large and can range from internal management of load balancers for independent operations to cloud deployments like AWS Elastic Load Balancing. Documentation from these as well as older discussions of the basic techniques can provide information in greater depth.
Even if a developer is not involved directly with load balancing, it is important for him to understand enough to make relevant design and deployment decisions. Stateless processing where sessions are not used requires major adjustments. Security configuration can be affected. Ongoing support requires the interpretation of application of logs. Without knowing something about how networking is set up, the requests and responses recorded in the logs cannot be used effectively for troubleshooting.
APPLICATION SERVER CLUSTERING
Clustering of application servers or web containers can be a viable alternative to load balancing. It can be used to achieve the same goal of distributing server-side application load. The implementation details are not standard and not available for all servers. Clustering is particularly common in commercial projects, but like other enterprise solutions, it can be expensive. Load balancing might involve expensive hardware and software but does not necessarily require it. In its basic form, load balancing is well understood and can be implemented with common, vendor-neutral networking configuration that does not jeopardize portability across different application servers.
Automating Application Deployment
A number of tools have been developed in an effort to tame the complexity of possible deployment scenarios. Ad hoc scripts gave way to cfengine as a way to automate the management of workstations in the 1990s. It is extremely lightweight and remains actively maintained. It supports a wide range of OS platforms (including Windows, Mac OS X, and others), which sets it apart from more specialized tools designed for the particular idiosyncrasies of web applications.
Capistrano is a utility for executing SSH commands in parallel on multiple remote machines. It is Ruby-based and geared toward web application deployment due to its origins in the Ruby on Rails ecosystem. A typical usage of Capistrano is to check out a web application from SCM and deploy it to multiple remote servers. Fabric is a Python-based Capistrano alternative. Because of the relatively transient server life span in cloud-based deployments, these utilities are often considered alongside configuration management tools like Puppet, Chef, Ansible, and Salt.
Project
Deployment of this chapter’s project was illustrated earlier. The project itself is a simple client-server web application that provides CRUD operations to add, update, and delete books. This example has no backend data store. An array holds books that are added, so the data is lost when the server is restarted.
The structure of the application is reflected in the pom.xml and web.xml. The pom.xml includes Jersey-related modules as the dependencies that are used in the implementation of a JAX-RS-style API that produces JSON. The web.xml distinguishes the client and server portions of the API and lists the index.html welcome page as the client entry point to the application.
Client
The index.html contains the HTML, CSS, and JavaScript related to the application. jQuery is served by a CDN. The JavaScript for the application is included inline between script tags. The jQuery getJSON and ajax methods are used to make API calls. The jQuery $( document ).ready() function calls the list function, which retrieves a list of books in JSON format and iterates through the results, displaying each in a div (containing an anchor with the delete class) that is appended to the paragraph identified the listing CSS class. The DELETE call is bound to the document (rather than to each div) to ensure that all hrefs with the delete class respond to the event (if it were instead bound directly to the delete class, it would only be bound to elements that existed at the time the page was initially loaded). Bootstrap is also served by a separate CDN. It is not used much in the application to keep it minimal, but is included as a starting point for more detailed styling.
Again, this is minimal implementation, but writing an application to this point helps to highlight the limitations of this starting point, based on DOM manipulation and no MV* or significant use of a CSS framework.
For one thing, an inline style is included to center the page, which is a terribly un-Bootstrappy thing to do. Instead, Bootstrap and other responsive frameworks rely on grid-based layouts. Modifying the HTML to use a grid would make it better suited to viewing on different device displays.
In addition, DOM manipulation can be difficult to visualize. The state of the initial HTML does not closely resemble the state of the DOM after a few records have been loaded, suggesting that a view-templating system might be useful. Besides the JavaScript being a bit unwieldy inline, it is not split into distinct units that reflect the functionality of each chunk of code. An MV* framework provides an initial structure for an application that suggests better arrangement of JavaScript code.
Server
The web API is contained in a single BookService class that is mapped in the web.xml to the /api URL path. The @Path annotation at the top of the class indicates that the class is referenced under /books. The GET, PUT, and DELETE methods are included to retrieve, create, and destroy book resources. The @produces annotation indicates application/json as the expected format returned in each JSON call. The {book} referenced in several @Path annotations at the method level maps to the @PathParam passed as an argument in the corresponding methods.
Normally, a library is used to create JSON. In this case, Mention Apache IO Utils is used in the context of string concatenation to create JSON. The API calls can be validated and tested in the browser, or by using a tool like Curl. With the context path that is used by the Maven plug-in, a record can be added using:
curl -X PUT http://127.0.0.1:9090/api/books/4?title=Client+Server+Web+Apps
Conclusion
In years past, deployment of Java applications followed JEE processes that were rather well defined. While JEE style deployments remain applicable in many situations, the Java community has also adopted new approaches to deployment that are of particular interest to designers of client-server-style web applications. The next chapter will describe the rise of virtualization techniques used in cloud-based environments that contribute to the argument that, in many cases, it is better to deploy an application server inside or alongside an application rather than outside it, as has been done traditionally.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.