Client-Server Web Apps with JavaScript and Java (2014)
Chapter 3. REST and JSON
Good fences make good neighbors.
—Robert Frost
Whenever a technology is introduced, there is an instantaneous response about what it does not do. This response can be puzzling to those who have already learned to operate within its limits. Fences can be viewed in a negative sense, as barriers that restrict or prevent movement. In the positive sense, in the quote by Robert Frost, they provide a clear, visible demarcation of a boundary and indicate the purpose, use, and dangers of a given space. In a similar manner, constraints on a software system impose limitations in the interest of providing better functionality, efficiency, and clarity of roles. Good constraints are specified not simply to block or restrict, but for the purpose of achieving a positive goal. REST is an architectural style characterized by a set of constraints that represent how the Web (or other similar construct) should work. These constraints, though limiting, promote the design of systems that are well suited to the nature of the Web itself.
Descriptions of REST are often articulated from a substantially different starting point: REST as a web services protocol. It is true that REST can be understood when compared with SOAP or other messaging services. In relation to SOAP, it is considered a minimalistic protocol, lacking extensive definitions and additional constructs required in SOAP implementations. It is characterized as relying directly upon underlying features of HTTP, including request methods, URI addressing, and response codes. REST can also be compared with Remote Procedure Call (RPC)-style APIs, which use URLs to indicate actions, whereas REST uses URLs to access resources. In this regard, REST is noun-oriented while RPC is verb-oriented.
WHY REST OVER SOAP?
Involved debates have taken place over the virtues of REST over SOAP, or vice versa. Although SOAP does provide a formal contract and is suitable as a sophisticated RPC architecture, it introduces additional overhead and complexity without providing substantial advantages for most web application development. SOAP remains in heavy use as an RPC platform due to nontechnical considerations such as the fact that it is firmly entrenched in existing large-scale legacy applications.
SOAP messages are large, require extensive processing, and are expressed in verbose XML envelopes. This makes the protocol unattractive for client-server-style web applications, which can so easily process JSON using JavaScript.
Many developers initially encounter REST as a web services protocol characterized by pretty URLs and free-form, lightweight messages. While this perspective has great practical value, it is important to understand REST as it was articulated by its author Roy Fielding.
What Is REST?
Fielding states that the “Representational State Transfer (REST) architectural style…[was] developed to represent the model for how the modern Web should work.” Although technically protocol-agnostic, it was developed in conjunction with HTTP. And because of this association, a few of the salient features of HTTP should be kept in mind.
Resources
A web resource is simply something available on the Web. The definition of a web resource has expanded over time. It originally referred to a static addressable document or file. It was later given a more abstract definition and now encompasses every entity that can be identified, named, addressed, or handled on the Web. Some examples of resources are a traditional HTML web page, a document, an audio file, and an image file. Resources can refer to things that you might not find in your typical digital library as well, such as a hardware device, a person, or a collection of other resources.
REST uses web addresses (URIs) to access and manipulate resources using verbs (HTTP request methods).
Verbs (HTTP Request Methods)
HTTP 1.1 defines a set of verbs (or request methods) that indicate an action taken on a resource. Of those available, the ones of greatest signficance using a RESTful approach are GET, POST, PUT, and DELETE. One way of thinking about these verbs is by comparing them with commands used to manipulate data in a database.
In a database, a data entity is typically referred to as a record. In REST, the corresponding entity is the resource. The HTTP verbs (POST/GET/PUT/DELETE) roughly correspond to traditional CRUD (create/read/update/delete) operations in a database or object-relational management(ORM) system. A REST architecture stipulates that resources on the Web are retrieved or changed in much the same way that SQL or similar query language is used to access or modify records in a database. A full listing of HTTP 1.1 options related to REST can be found in Appendix B.
|
HTTP verb |
Action to take on a resource |
Analogous database operation |
|
POST |
Create (or append) |
insert |
|
GET |
Retrieve |
select |
|
PUT |
Update (or create) |
update |
|
DELETE |
Delete |
delete |
OTHER HTTP METHODS
Several other HTTP methods are useful but don’t correspond to traditional CRUD database operations. The HEAD method is identical to GET except that the response does not include a response body. This is applicable when using REST-related technologies that take advantage of HTTP Headers. Cross-Origin Resource Sharing (CORS) returns JSON otherwise forbidden due to browser’s same origin security policy and manages its negotiations with servers through HTTP headers. Certain methods of specifying links for documents use headers as the location to store links. So at times when the salient information resides in the response header rather than the body, it makes sense to use a HEAD call rather than incurring additional overhead of returning the response body through a standard GET.
The HTTP OPTIONS method can be used to retrieve a listing of HTTP request methods available for a resource. This has implications not only for debugging and support but also for creating systems with a uniform interface of links available through a single entry point embodying a self-describing system. In conjunction with such links, which represent the access points for all resources in a system, a proper implementation of HTTP OPTIONS would return a comprehensive list of methods available for each resource available through a link.
Uniform Resource Identifiers
In a networked system there needs to be some sort of handle or address that allows a resource to be acted upon. Uniform Resource Identifier (URI) is the general term for a string of characters used to accomplish this. A URI can be further differentiated as either a Uniform Resource Name(URN) that represents the name of a resource or a Uniform Resource Locator (URL) that represents the address of a resource.
Most URL schemes base their URL syntax on this general format:
<scheme>://<user>:<password>@<host>:<port>/<path>;<parameters>?<query key/value pairs>#<fragment identifier>
See HTTP: The Definitive Guide (O’Reilly) for more details about URIs and HTTP in general.
In REST, resources are specifically identified as path elements. Slashes within the URL are used to delimit resources and express their relationship in a hierarchical manner. REST URLs are demonstrated in examples and explained in greater detail in Chapter 8.
In web-based APIs, URL names used to identify resources and specify their relationship to others typically adhere to some additional conventions. These are not required by REST, but are stylistic concerns that promote readability and consistency of URLs. For the most part, URLs should be lowercase, use hyphens but no underscores, and include trailing slashes. An individual resource is referred to using a singular noun. A collection of resources is identified using a plural noun. File extensions are discouraged but tend to show up when an API supports multiple formats such as XML and JSON. A more suitable alternative is to use “Accept” and “Content-Type” headers to control the format. The REST API Design Rulebook by Mark Masse (O’Reilly) includes the conventions listed above and many others, but in practice, there is a fair amount of latitude in the structure and format of URLs.
HYPHENS INSTEAD OF UNDERSCORES?
It should be emphasized that all of the URL naming conventions mentioned above are not etched in stone. Many popular APIs, including Twitter and Dropbox, use underscores. There are other considerations such as search engine optimization that had caused this to be considered a bad practice in the past (underscored elements were concatenated together in Google’s search indexes, while hyphenated strings were broken into separate words). Though there are differences of opinion in these details, there is clear agreement that URLs should be as short as possible, readable, clear, and consistent across an API.
REST Constraints
REST is defined as a specific software architectural style characterized by a group of selected constraints. Benefical system properties and sound engineering principles are evident in a system designed to conform to these constraints.
Client–Server
A client-server architecture provides an immediate separation of concerns. It makes the best use of the processing power available in modern clients—once only available to high-end computers. The server side is simplified due to the shift of many responsibilities to the client. Such a system tends to be easily scalable, and the separation between tiers allows for independent development of each.
Stateless
REST requires a stateless design. Session data is stored client-side. Each request made by the client must be “context-free” and self-contained. This means that a request will include the entire client state. This requires all data needed for the server to respond without doing additional outside retrieval of data related to application state. It is much easier to comprehend the intent of a given interaction since all data is available in each request. Fault tolerance and scalability are also improved because session data is not maintained server-side. Server resources are not consumed by the storage and retrieval processing otherwise required.
There are a number of challenges in designing systems that conform to REST’s stateless nature. One is the additional network traffic caused by larger and more frequent requests. (These would be reduced through the use of server-side sessions in nonRESTful client-server applications that do maintain server-side state). Because each request includes all state-related data, there are bound to be certain data elements that are repeatedly sent. The fact that the server is not maintaining sessions means that the client has more responsibility and is therefore typically more complex (this is one reason for the increasing sophistication of JavaScript in modern RESTful applications). Browser storage mechanisms are of greater interest in such systems. And since REST systems typically support multiple client versions, considerable planning and effort is required for the client tier.
Even with these challenges, the benefits of statelessness are many, especially deployments involving several servers that receive requests distributed by a load balancer. If a server-based session is used, two basic options are available. One is to require the same server to respond to all requests for a given session. The other is to create a centralized session data store available to all servers. This centralized data store then needs to be accessed each time a request is made. This practice (sometimes called session-affinity or the use of sticky sessions) makes scaling much more difficult. Large-scale deployments typically roll out changes to servers over time. If server-side sessions are in use, there is a need to wait for old sessions to expire before migrating incoming requests to servers with the latest changes. This is a complex and difficult operational process. The entire situation is nonexistent if no state is stored server-side. In addition, standard browser functions like navigating to previous history or reloading the current page require no special handling when server-maintained sessions are eliminated.
The stateless design of REST is one of the most challenging aspects for many developers to comprehend. It requires some significant adjustments to typical web development practices. But the benefits are many, and the performance concerns due to the entire state being contained in each request are not insurmountable, especially when REST’s next constraint is considered.
Cacheable
The performance issues associated with REST’s stateless constraint can largely be compensated for via caching. REST requires that data be labeled to indicate whether or not it is cacheable. This allows a client application to reuse cacheable responses rather than making equivalent requests at a later point. Like caching in any system, this can provide quite a performance boost to the client application but also introduces the standard complexities associated with proper cache invalidation to avoid stale data. In the context of the Web, caches can be maintained client-side (in the browser), server-side, or in between (in a gateway or proxy server).
Uniform Interface
A uniform interface stipulates a common way to address resources that all RESTful applications use. Every REST system therefore has a common structure immediately evident to those familiar with the architecture. This severely restricts the ability to customize an interface for application-specific needs, but there is a great deal of flexibility within the constraint bounds. HTTP itself has been enhanced in each version to provide additional mechanisms available to RESTful design (the inclusion of new request methods, for instance). This particular constraint actually includes a number of other constraints that comprise it (see Table 3-1).
Table 3-1. Uniform interface constraints
|
Uniform interface constraint |
Description |
|
Identification of resources |
Resources are addressable through URIs. |
|
Manipulation of resources through representations |
The resource is the thing represented. Its representation is what is sent in the request (e.g., the XML/JSON document). |
|
Self-descriptive messages |
Stateless requests that use HTTP verbs. |
|
Hypermedia as the engine of application state |
HATEOAS: Availability of links that dictate how the application state can be changed. |
Layered
A layered design allows for network components to interact with each request en route. Each component does not have visibility beyond the layer with which it is communicating. This means that familiar network devices like firewalls and gateways can be in use, and caching or translation can be done by proxy servers.
Code on Demand
The ability to provide code on demand—through JavaScript or embedded browser applications—is allowed in REST but not required. This opens up a wide range of possibilities in how an application might be extended. The downside is a reduction in visibility otherwise inherent to RESTful systems (especially in the case of objects like Java Applets).
HTTP Response Codes
When developing REST APIs, standard HTTP status codes (shown in Appendix B) provide feedback to the client and report potential errors. The exact nature of a given response can be dependent upon the HTTP method in use.
What Is Success?
There is no widespread agreement on the use of HTTP codes in web APIs. In part, this is because the responses are not aligned with the HTTP verbs, but with five categories of occurences: general information, a successful request, redirect, error on the client side, or error on the server tier. In some cases, the applicable response code appropriate to a call is evident, but in others, it is dependent on the specific API call or the discretion or preferences of the API designer.
Take for instance a (nonspecific) success (200). This is recognized as the proper response to a succesful GET in most cases. In fact, in HTTP 1.1, it is specifically listed in regards to GET and POST. The response depends on the HTTP request type, as indicated in Table 3-2.
Table 3-2. HTTP 1.1 success (200)
|
HTTP verb |
Expected response content |
|
GET |
An entity corresponding to the requested resource |
|
HEAD |
The entity-header fields corresponding to the requested resource without any message-body |
|
POST |
An entity describing or containing the result of the action |
|
TRACE |
An entity containing the request message as received by the end server |
And though some would also use an HTTP 200 in response to a PUT or DELETE, other codes might be used. A HTTP 201 (created) is used by some APIs in the case of a PUT or POST. A 204 (no content) might be used for a DELETE that returned no other response, but might also apply to other verbs (even a GET) if a request is successful but the server intentionally does not return content. If a web application is using basic authentication, the logoff can be accomplished by returning an HTTP 401 (not authorized) response code to the browser. So the definition of success depends on the context, and so the selection of a proper response code requires an understanding of the meaning of the codes and the nature of the request being made.
The first digit of each code specifies the classes of response. Since the bare minimum for a client is that it recognize the class of the response, there is expected flexibility and variance in the use of response codes (see Table 3-3).
Table 3-3. Classes of HTTP response codes
|
First digit |
Meaning |
|
1 |
Informational |
|
2 |
Success |
|
3 |
Redirection |
|
4 |
Client Error |
|
5 |
Server Error |
Mozilla, Yahoo Social APIs, and the REST API Design Rulebook include thoughtful presentations on the use of response codes. The similarities highlight the conventions and best practices that have emerged, and the differences demonstrate variance in design opinion and distinctions that are predicated on the particular nature of a given API.
JSON (JavaScript Object Notation)
Douglas Crockford is well known not for emphasizing every feature that JavaScript has, but for focusing on a subset. In essence, he sets constraints on language usage. Another application of his approach is his design of JavaScript Object Notation (JSON) as a data interchange format derived from JavaScript.
A variety of data interchange formats have been in use since the advent of modern computing. Besides binary and proprietary formats, some types attempted to incorporate some degree of human as well as machine readability. Fixed-width and delimited file formats were used initially (and still can be found in use today). The first XML working draft was produced in 1996. XML specifically sought to be both machine-readable and human-readable, but over time has been criticized as verbose and unnecessarily complex. In reaction, smaller languages that included aspects of XML such as hierarchical organization have been created (such as YAML). In 2002 Douglas Crockford acquired the http://www.json.org domain where he described JSON as:
§ A data interchange format (a lightweight alternative to XML)
§ A programming language model that is a subset of JavaScript
§ A format that is is trivial to parse (in fact, in JavaScript you can simply call eval() on a JSON string to convert it into a JavaScript object, though this not a particularly safe option)
He also emphasized JSON’s advantages over XML:
§ Response sizes are smaller because begin and end tags and metadata require additional space in XML.
§ JSON interoperability is better with web pages. It is a subset of JavaScript making client-side integration trivial.
§ The previous two characteristics result in performance benefits and ease of integration in the context of Ajax calls.
JSON does have a few quirks worth noting:
§ JSON is “almost valid” JavaScript.
§ There is no way to specify a comment in JSON.
§ As previously mentioned, because it is a subset of JavaScript, it can be consumed by JavaScript eval(). However, the use of eval() is dangerous. It is often said that "eval() is evil.”
§ The “same origin policy” that is in force in most modern web browsers prevents JSON from being evaluated from a separate site. JSONP (sometimes also referred to as JSON-P or “JSON with padding”) has been used to request data from a server in a different domain (via HTTP GET). A call to a function already defined in the caller’s environment is used manipulate the JSON data. This function is the cause of the “padding” used in this approach. More recently, Cross-Origin Resource Sharing (CORS) has been developed as a more robust, secure alternative to JSONP. CORS uses HTTP headers to allow servers from specified domains to serve resources. It also requires specific server-side configuration for the service emitting the JSON to operate.
COMMENTS IN JSON
The fact that JSON does not allow comments is a bit surprising and has led to various workarounds. One is to add “comment” elements to JSON objects with comment content as a corresponding value. One possibility that should be avoided is creating two elements with the same name and assume that the parser will choose the last one. For example:
({"a":"This is a comment", "a":"CONTENT"})
Although this happens to work in a number of JSON parsers, it is a result of their implementation and not a part of the specification.
HATEOAS
JSON is a very simple and terse format. Unlike other formats that provide elaborate type systems for the data they represent, only a few data types are available in JSON. These data types—strings, numbers, booleans, objects, arrays, and null—are more than expressive and extensible enough for most applications. Because of JSON’s popularity as a data interchange format used by RESTful APIs, you might expect a specific data type for hyperlinks, but no such type exists! This is especially problematic since REST includes a constraint called Hypermedia as the Engine of Application State (HATEOAS).
This constraint restricts a client to interactions through links that are included under the term “hypermedia.” Therefore, a web API cannot possibly be classified as “RESTful” in a strict sense because there is no link data type in JSON or in JavaScript (upon which it is based).
XML-based REST APIs often use Atom Syndication Format (where links consist of a rel, href, hreflang, and type) or links in headers. Likewise, JSON extensions that provide for standardized linking within JSON documents have been developed:
§ HAL
§ Siren
§ JSON-LD
§ JSON Reference
§ Collection+JSON
§ JSON API (extracted from the Ember JS REST Adapter)
The W3C has a JSON-based Serialization for Linked Data posted on its site (at the time of this writing: W3C Recommendation 16 January 2014).
Many links conform to a similar category or relationship regardless of the entity represented. For example, in a collection, there is a convention of referencing the first, last, next, or previous member of the collection. A help, glossary, or about link appears and is relevant in many different contexts. Because of these commonalities, there have been efforts to standardize link relations as well. An established set of link relations would make automatic generation of links much more specific and attainable.
It is worth being aware of the debate and work related to defining HATEOAS, but it is far from clear what the final outcome will be. The issues involved are complex, and there is no general consensus that a full implementation is required in every API design.
HYPERMEDIA LINKABILITY CONTINUUM
A range of linkability possibilities exist in resources that appear on the Web. At one end of the spectrum are formats that require strict, well-defined links. At the other end are formats that forbid the use of links by definition.
|
Format |
Description |
Examples |
|
1 |
Automatically generated standard links |
Atom Publishing Protocol (APP) |
|
2 |
Manually specified standard links |
XHTML |
|
3 |
Extension-format links |
Links as an extension to an existing format (HAL) |
|
4 |
Character links |
Links as character strings |
|
5 |
No links |
Specified data interchange format forbids their use |
REST as defined by Fielding requires proper use of a format of 1. Many web APIs that might be REST-inspired fall somewhere else on the scale.
REST and JSON
Certain implied values became evident as REST (as expressed in Fielding’s dissertation) was interpreted and applied to real-world projects other than the Web itself. Fielding has expressed frustration at APIs termed RESTful that are not hypertext-driven:
REST is software design on the scale of decades: every detail is intended to promote software longevity and independent evolution. Many of the constraints are directly opposed to short-term efficiency. Unfortunately, people are fairly good at short-term design, and usually awful at long-term design. Most don’t think they need to design past the current release. There are more than a few software methodologies that portray any long-term thinking as wrong-headed, ivory tower design (which it can be if it isn’t motivated by real requirements).
Fielding’s intention for REST to be a viable long-term solution is admirable. He promotes ideas that will remain relevant as long as the Web and its underlying technologies retain their fundamental structure. That said, HATEOAS and its relevance to JSON are not going to be investigated, demonstrated, or critiqued in depth. After the dust settles a bit, this book might be expanded and revised or accompanying content added to reflect an emerging consensus or convergence of opinion on the topic.
In general, Fielding’s perspective is important because he is a seminal thinker and he invented REST. But many systems designed today are not intended (or billed) to exist for decades. His articulation of REST is excellent and should be understood as he has expressed it. But for better or for worse, the term REST has been adopted in a broader context, and has become a useful shorthand for identifying the architectual style of minimal web API design that is based largely on the underlying functionality of HTTP.
PRAGMATIC REST
Why have many APIs been designed in this “pragmatic” way? In part, it is because the HATEOAS principle places such a high bar for the client-side programmer. A programmer who, inadvertently or on purpose, hardcodes a URI path into an application may be in for a rude shock in the future, and the server-side API team may simply tell the client that they failed to follow the spec.
Although HATEOAS is a good theoretical approach to designing an API, it may not apply in practice. It is important to take into account the audiences of the API and their possible approaches to building apps against it and factor that into your design decisions. HATEOAS, in some cases, may not be the right choice.
— APIs: A Strategy Guide (O’Reilly)
It is fascinating that Fielding does recognize JavaScript in his dissertation in relation to REST. He discusses the reasons for JavaScript’s success on the Web as opposed to embedded Java “applets,” which were not widely adopted as a client-side development technology. He points out that JavaScript fits the deployment model of the Web, is consistent with the principle of visibility evident with HTML, includes fewer additional security complications, involves less user-perceived latency, and does not require a separate, independent, monolithic download.
Typical JavaScript usage is consistent with the design principles of the Web. Its extensive use in the browser made JSON an attractive option for data interchange that could be easily produced and consumed.
Unfortunately, the very fact that JSON was specified as a subset of JavaScript rather than a hypermedia format means that there remains an impedance mismatch between JSON and strictly RESTful APIs. Although a browser running JavaScript is consistent with the design of the Web and the formal definition of REST, the use of JSON as a data interchange format is not.
Not everyone is interested in using the strict definition to classify whether a web API is RESTful or not. The fact that JSON web APIs are so popular and REST design is so influential has led to the development of a few different measures for classifying REST compatibility on a spectrum.
API Measures and Classification
The Richardson Maturity Model introduced by Leonard Richardson in 2008 expresses a continuum by which services can be evaluated against the REST standard.
|
Level |
Service |
Description |
|
Level 0 |
HTTP |
HTTP as a transport system for remote interactions (remote procedure calls). |
|
Level 1 |
Resources |
Rather than making all requests to a singular service endpoint, reference specific individual resources. |
|
Level 2 |
HTTP methods |
Utilize HTTP verbs. |
Jan Algermissen proposed a similar classification that describes APIs based upon adherence to REST constraints (Table 3-4).
Table 3-4. Classification of HTTP-based APIs adapted from Jan Algermissen
|
Name |
Verbs |
Generic media types |
Specific media types |
HATEOAS |
|
|
WS-* web services (SOAP) |
N |
N |
N |
N |
|
|
RPC URI-tunneling |
Y |
N |
N |
N |
|
|
HTTP-based Type I |
Y |
Y |
N |
N |
|
|
HTTP-based Type II |
Y |
Y |
Y |
N |
|
|
REST |
Y |
Y |
Y |
Y |
Both of these classification systems serve the admirable purpose of preserving Fielding’s strict definition of REST while recognizing the compromises that have been made in implementing web APIs.
Functional Programming and REST
Functional programming and REST share a number of common traits. Both are declarative in nature and include very little description of control flow. Both have a similar view about controlling side effects, maintaining referential transparency, and operating in a stateless manner. So, as in the case with JavaScript, having a clear understanding of a functional paradigm is certainly helpful for effectively utilizing REST and recognizing its benefits.
THE WEB-CALCULUS WEB
Beyond the pragmatic comparison of REST and functional programming, Tyler Close prevents a view of the Web as a lambda-calculus derivative. Because functional programming languages are also based on lambda-calculus, the connection is even closer than mere appearances or benefits:
Recognizing the primacy of the resource web in HTTP reveals that the WWW is a lambda-calculus derivative. A resource is a closure. The POST method is the “apply” operation. A web of resources is a web of closures. The key innovation of the WWW is the addition of introspection of the web of closures: the GET method…Understanding HTTP as a lambda-calculus derivative opens the possibility of using HTTP as a basis for distributed computation, not just distributed hypermedia.
In their book Programming Scala (O’Reilly), Wampler and Payne pointed out that in many cases, object-oriented systems did not deliver on the promise of widespread software component reuse. Instead, component models that have succeeded tend to be relatively simple. They conclude their chapter on functional programming by reiterating the relative simplicity of this approach:
Components should interoperate by exchanging a few immutable data structures, e.g., lists and maps, that carry both data and commands. Such a component model would have the simplicity necessary for success and the richness required to perform real work. Notice how that sounds a lot like HTTP and REST.
Project
The following project involves the creation of a minimal API that responds to GET, POST, UPDATE, and DELETE requests and returns information about how the server interpreted the request to the client. This will be used to demonstrate various tools available when testing REST or other web APIs.
To set up the project:
1. Download the project from GitHub.
2. Navigate to the jruby-sinatra-rest directory.
3. While connected to the Internet, build the project:
$ mvn clean install
This will download any Ruby or Java resources required for the project. It should end with:
[INFO] ---------------------------------------------------------------------
[INFO] BUILD SUCCESSFUL
[INFO] ---------------------------------------------------------------------
[INFO] Total time: 32 seconds
[INFO] Finished at: Tue Apr 30 12:59:15 EDT 2013
[INFO] Final Memory: 13M/1019M
[INFO] ---------------------------------------------------------------------
4. Start the server:
$ mvn test -Pserver
Within a few seconds, you will see that the application server is running and ready to handle requests:
== Sinatra/1.3.1 has taken the stage on 4579 for development...
[2013-04-30 13:00:24] INFO WEBrick::HTTPServer#start: pid=29937 port=4579
5. Navigate to the about page in a browser: http://localhost:4579/about.
You should see something like the following in response:
{
"ruby.platform": "java",
"ruby.version": "1.8.7",
"java.millis": 1367342095907
}
This indicates that JRuby is available, required RubyGems (packages) are available, and Java (system) can be called successfully.
Now that the server is running, you can experiment with REST calls in a client of your choice. A few examples follow using Curl. Curl is a command-line tool for transferring data that is accessible via URLs. It works for a wide variety of protocols beyond HTTP and is capable of performing a variety of tasks usually done in a web browser.
To get started, GET can be called with an arbitrary URL. It returns the response, which in the case of our server, is information about the request:
$ curl http://localhost:4579/about
{
"ruby.platform": "java",
"ruby.version": "1.8.7",
"java.millis": 1367342095907
}
Curl has a huge number of options available to modify the behavior of the call and the information reported. One bit of information not readily available in a typical browser is HTTP header information. The -i (include the HTTP header) and -I (fetch the HTTP header only) can be used to display HTTP header information in the response:
$ curl -iI http://localhost:4579/about
The server is relatively simple. It is written in Ruby (and so runs via JRuby). It uses a microframework called Sinatra that is described as “a DSL for quickly creating web applications in Ruby with minimal effort.” As such, it provides a great way of creating a server that exposes the underlying HTTP functionality without including a lot of additional code and constructs that might obscure its functionality.
The first few lines describe packages to be imported and some configuration options. Then, the “before” section defines what is, in essence, a before filter. In each case, the content type is set to JSON, the response is assigned some values from the incoming request, and the response status is set either to 200 or to the value passed in on the httpErrorCode request parameter. To see both the response from the server as well as the HTTP header, simply specify the -i option:
$ curl -i http://localhost:4579/?httpErrorCode=400
This example returns an HTTP 400 (Bad Request) error as specified in the parameter:
HTTP/1.1 400 Bad Request
Content-Type: application/json;charset=utf-8
Content-Length: 197
X-Content-Type-Options: nosniff
Server: WEBrick/1.3.1 (Ruby/1.8.7/2011-07-07)
Date: Tue, 30 Apr 2013 17:43:17 GMT
Connection: Keep-Alive
Examples that POST or PUT JSON are as follows:
$ curl -i -H "Accept: application/json" -X POST -d "['test',1,2]" \
http://localhost:4579
$ curl -i -H "Accept: application/json" -X PUT -d "{phone: 1-800-999-9999}" \
http://localhost:4579
And similarly, to DELETE:
$ curl -i -H "Accept: application/json" -X DELETE http://localhost:4579
The server processes arbitrary paths (matched using a wildcard), so you can pass arbitrary paths and query parameters to be reported back in the response:
curl -i -H "Accept: application/json" -X POST -d "['test',1,2]" \
http://localhost:4579/customer?filter=current
HTTP/1.1 200 OK
Several browser plug-ins can be used to test REST calls as well. Rather than introduce these, our application includes a minimal REST client using jQuery. The call just described using Curl appears as follows in Figure 3-1 when parameters are entered in http://localhost:4579/testrest.html.
In the Network tab of Chrome’s Developer Tools, you can view header information and response codes as well. Figure 3-2 shows what would appear if the previous call is modified to return a 401.
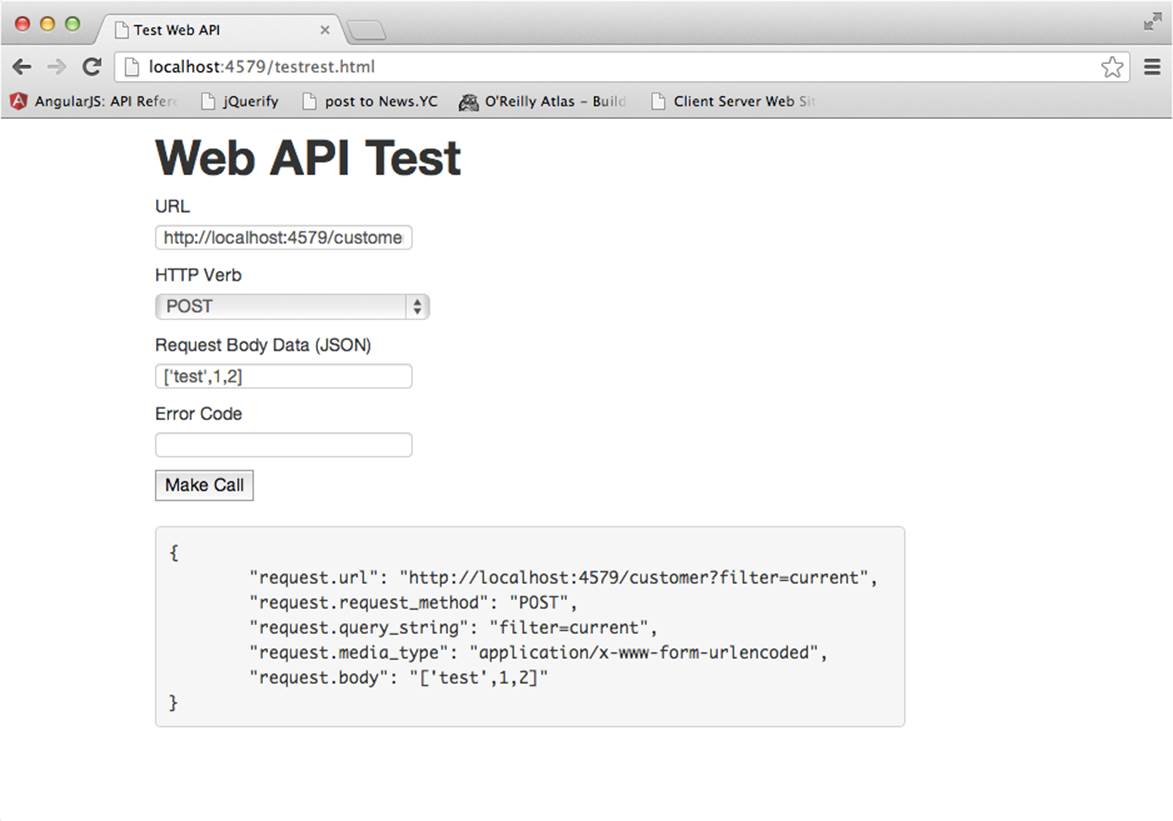
Figure 3-1. Testing REST
This simple application also introduces how, in just a few lines of code, you can set up a web API with a minimal implementation to serve as a backend for client developers working in parallel with server developers implementing the complete set of server functionality. Here are the lines of code at a glance:
$ cd jruby-sinatra-rest/src/main
$ find scripts -name *.* | xargs cat | wc -l
141
This does not include jQuery and bootstrap being served from publicly hosted Content Delivery Networks (CDNs), but still indicates the possibilities available in only a few lines of code.
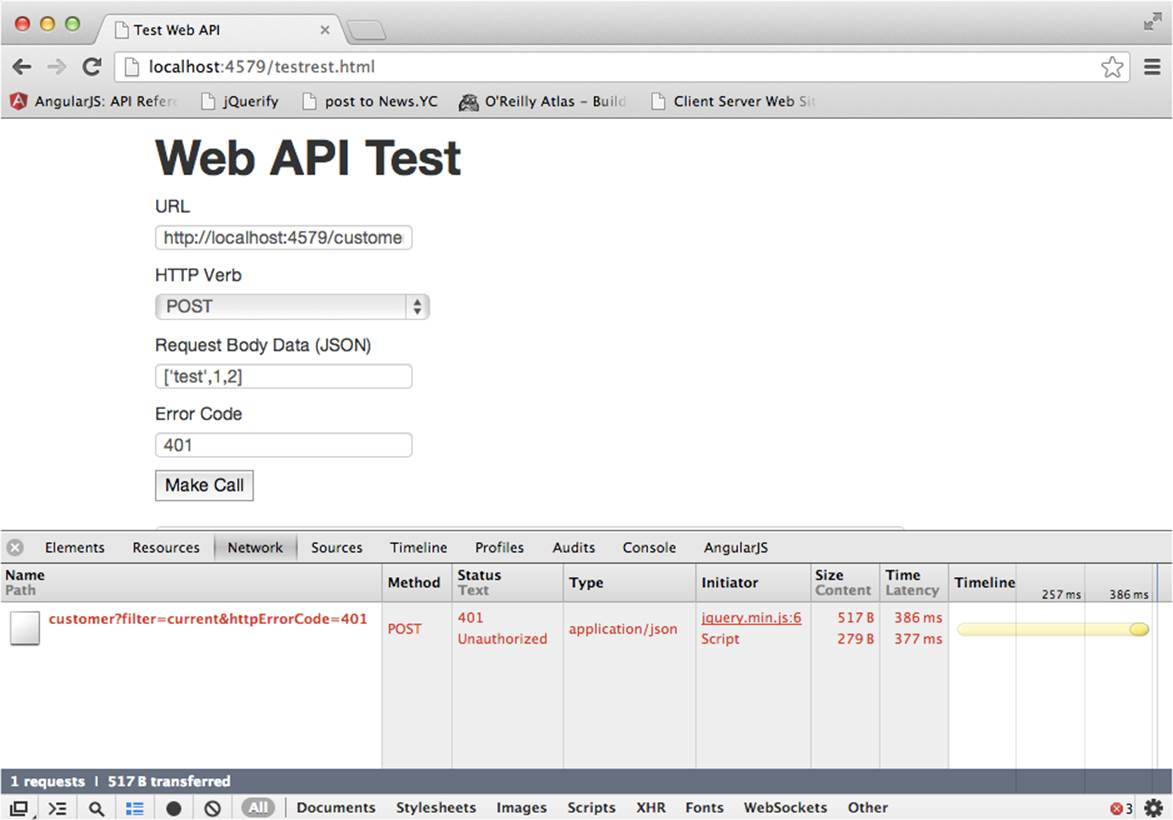
Figure 3-2. Test REST error
Other Web API Tools
Web APIs are not tied to a particular platform, so the tools used to debug them are more of a matter of developer preference and culture. Browsers and browser plug-ins are certainly useful, and as demonstrated, Curl is a flexible command-line option. Java-based web clients, REST frameworks, and Eclipse IDE plug-ins appeal to the Java community, while Fiddler is a popular choice among Microsoft aficionados.
Constraints Redux
The idea of a creative genius who throws off all external influences is largely mythological. This approach has absolutely no application in software development and little to do with most great work accomplished in the arts. Instead, it is far more profitable to identify the best set of constraints to apply in a creative activity. The New York Times described composer Igor Stravinsky as identifying constraints at the onset of music composition geared to “obtain precision of execution”:
To Stravinsky, composing music was a process of solving musical problems: problems that he insisted on defining before he started to work.
Before writing “Apollon Musagete,” for example, he wrote to Elizabeth Sprague Coolidge, who had commissioned the ballet, for the exact dimensions of the hall in which it would be performed, the number of seats in the hall, even the direction in which the orchestra would be facing.
“The more constraints one imposes, the more one frees one’s self,” he would say. “And the arbitrariness of the constraint serves only to obtain precision of execution.”
— New York Times
The constraints that resulted in REST and JSON are anything but arbitrary, but they do promote precision of execution in the development of client-server web applications.