Java eLearning Kit For Dummies (2014)
Chapter 13. Manipulating XML Data
· Use Java to read, write, and manipulate XML data as part of your application strategy.
· Read XML from disk to create data displays onscreen.
· Write XML to disk to save data in an organized manner without loss of context.

1. How can I use XML data in my Java applications?
Java provides full access to standardized XML data files so you can save both data and its context, save user settings using the same method across platforms, and access information in other locations such as web services. You can get an overview of this technology beginning on page 389
2. Is it possible to read XML data from disk and use it without a lot of hassle?
It’s relatively easy to read XML data from disk and use the information in a consistent way to present information, asdescribed on page 390
3. Will I have to do a lot for formatting to write my XML data to disk?
Creating XML output is relatively straightforward in Java — you worry about the data, Java worries about the formatting, asshown on page 396
You have many different ways to store your data, but the majority of them are either unique to a particular platform or are implemented inconsistently across platforms. In the past, developers often had to use text files to transfer data between platforms, but text files suffer from a loss of context. The data is there, but what the data means is missing. The eXtensible Markup Language (XML), one of the better innovations when it comes to data storage, was developed in order to address this issue. XML provides the means to describe data in a way that none of the context or meaning is lost. This Chapter builds on what you discovered in Chapter 12 to provide a basic overview of XML usage in Java.
Understanding How XML and Java Interact
It’s important not to become overwhelmed by XML before you even get started using it. At its core, XML is simply a fancy sort of text file. So, when you read XML into your application, the underlying technology is simply reading a text file — just as you’ve already done in Chapter 12. The difference is in the way the text is interpreted. XML relies on tags — information between angle brackets (<>) — to describe the data contained within the text file. So, on top of reading the file into the application as text, Java must also provide a means to interpret the data in order to obtain the meaning that the text contains. For example, an entry such as <Name>John</Name> could mean that the user’s name is John.
GO ONLINE
This book doesn’t offer a tutorial on XML — it assumes that you have at least a basic knowledge of XML already. However, if you don’t know anything about XML, be sure to investigate some of the many well-written online tutorials about XML. Of all the available tutorials, the one on the w3schools.com site at http://www.w3schools.com/xml is probably the easiest to understand and provides the best examples. As your knowledge increases, try the tutorial on the XMLFiles.com site athttp://www.xmlfiles.com/xml. When you have the basics down, try the Java-specific tutorial at http://docs.oracle.com/javase/tutorial_intro.html.
Java follows all the standards-based rules regarding XML. In addition, it implements these standards in the same way across all platforms that Java supports. Consequently, when you write an application that uses XML on your PC, the same code works in the same way on a Macintosh or a Linux system. It’s this ability to move data anywhere and yet maintain the data context and meaning that makes XML such a great choice for data storage.
Even though this chapter discusses only Java’s use of XML with disk-based files, XML is used in a considerable number of environments. For example, you can use XML to request information from other people or vendors using any of the methods that the other person or vendor supports (such as REpresentational State Transfer or REST for web services). XML is so useful that any book on Java has to at least tell you that the technology exists and that it’s relatively straightforward to use, as this book has done.
Reading XML Data from Files
To work with XML, you must read the data from some source. Keep in mind that, no matter what source you use, the XML data follows the same convention. So, whether you get the data from your local disk drive or from a website, the essential process is the same. You read the data from the source and then use code to interpret the information it contains.
This chapter uses a simple XML file for demonstration purposes named, MyData.xml. This file contains a few bits of interesting information in a particular format. Here’s the content of that file:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<Root>
<Name>Sally</Name>
<Fruits>
<Fruit>Apple</Fruit>
<Fruit>Pear</Fruit>
</Fruits>
<Color>Blue</Color>
</Root>
The first line is the processing instruction found in every fully formed XML document. Every XML document also has a root node that defines the beginning and end of the document content. The three child nodes define the name of the person involved, a list of favorite fruits, and her favorite color. The list of fruits consists of <Fruit> nodes, each of which contains a single fruit. Most XML files are more complicated than this one, but this serves as a good starting point.
The following example demonstrates how to read this file and display its content onscreen.
Files needed:ReadXML.java, MyData.xml
1. Open the editor or IDE that you’ve chosen to use for this book.
2. Type the following code into the editor screen.
// Import the required API classes.
import java.io.File;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.xml.sax.SAXException;
import java.io.IOException;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.w3c.dom.Element;
public class ReadXML
{
public static void main(String[] args)
{
// Create a File object to access the file on disk.
File InputFile = new File("MyData.xml");
// Create a factory for building an XML document.
DocumentBuilderFactory Factory =
DocumentBuilderFactory.newInstance();
// Create an object to build a document.
DocumentBuilder Builder = null;
try
{
Builder = Factory.newDocumentBuilder();
}
catch (ParserConfigurationException e)
{
// Display an error message and exit.
System.out.println("Could not create document builder!"
+ e.getMessage());
return;
}
// Use the factory to build an XML document based
// on the file content.
Document XMLDoc = null;
try
{
XMLDoc = Builder.parse(InputFile);
}
catch (SAXException e)
{
// Display an error message and exit.
System.out.println("Could not parse the file!"
+ e.getMessage());
return;
}
catch (IOException e)
{
// Display an error message and exit.
System.out.println("Could not access the file!"
+ e.getMessage());
return;
}
// Obtain the root node and process it, along with all of
// the child nodes it contains.
Element Root = XMLDoc.getDocumentElement();
ProcessElements(Root, 0);
}
public static void ProcessElements(Element ThisElement,
int Level)
{
// Display the current level.
System.out.print(Level);
// Add tabs to the output.
for (int Count = 0; Count <= Level; Count++)
System.out.print("\t");
// Display the node name.
System.out.print(ThisElement.getNodeName());
// If the child node is a value, then print it as well.
if (ThisElement.hasChildNodes())
if (ThisElement.getFirstChild().getNodeType() ==
Node.TEXT_NODE)
System.out.print("\t" +
ThisElement.getFirstChild().getNodeValue());
// End this line of output.
System.out.println();
// Check for child nodes.
if (ThisElement.hasChildNodes())
{
// Obtain a list of the nodes contained in this element.
NodeList ChildNodes = ThisElement.getChildNodes();
// Process each of the nodes.
for (int Index = 0; Index < ChildNodes.getLength();
Index++)
{
if (ChildNodes.item(Index).getNodeType() ==
Node.ELEMENT_NODE)
{
Element ChildElement =
(Element)ChildNodes.item(Index);
ProcessElements(ChildElement, Level + 1);
}
}
}
}
}
This is one of the most complex examples in the book, so it requires a substantial number of imports. Normally, you’d start to use the wildcard character for this number of imports. For example, instead of using import javax.xml.parsers.DocumentBuilderFactory;, you’d type import javax.xml.parsers.*; instead so that you don’t need to individually type the classes from the package. The reason the example uses this approach is so that you can see precisely which classes to import. The imports also appear in the order in which they’re used in the example code.
 The example begins by creating a File object, InputFile, to access the XML file on disk. This file contains XML data; it doesn’t contain an XML document. The difference between the two is that the XML data is simply text that contains information in a specific format. An XML document adds intelligence to that data so that you can tell the difference between a color and a fruit.
The example begins by creating a File object, InputFile, to access the XML file on disk. This file contains XML data; it doesn’t contain an XML document. The difference between the two is that the XML data is simply text that contains information in a specific format. An XML document adds intelligence to that data so that you can tell the difference between a color and a fruit.
To create an XML document, you begin by creating a Document Builder Factory — Factory, in this case. Think of Factory as a special object that outputs a kind of product, which turns out to be a DocumentBuilder named Builder. You can use Builder to create an XML document based on the content in MyData.xml. To do this, Builder must read the content of MyData.xml and interpret it in a process called parsing. The output of the Builder.parse() method call is an XML Document object, XMLDoc.
LINGO
The act of parsing any kind of data involves reading and interpreting the data to create a particular kind of object output. When working with XML data, the act of parsing interprets the special symbols within the text document and uses them to create a Document object that has intelligence about the design of the XML data. The result is that you can request information from the Document about the content of the XML document in context. A <Color> node becomes different from a <Fruit> node.
At this point, you have access to an XML document that contains a number of elements, beginning with the processing instruction and the topmost element, <Root>. The next step is to process this information to provide useful output. Calling ProcessElements() with the RootElementand the current document level (0) starts the process.
The ProcessElements() method shows how to use recursion in Java. Recursion is a special programming technique where a method calls itself to perform work. The idea is to divide a complex task consisting of multiple subtasks into a really simple single task and then use the result from that task to work upward into more complex parts of the task. You use recursion when you can’t be sure how many levels a complex task will contain.
LINGO
You use recursion to break tasks down into simple pieces in Java. A recursive method keeps breaking down the task until only a simple task is left. It then uses the result of that task to make higher-level tasks easier to manage and perform. Recursive routines are an elegant way to handle situations where you don’t know how complex the task will become at the outset. For example, there isn’t any way to know how many elements an XML file will contain, so using recursion provides one method for dealing with that complexity.
The ProcessElements() method begins by displaying the current level. It then adds a number of tabs to indent the information at higher levels to a greater degree. The method displays the element name next and then displays the value contained within that element, if any. Notice how the code uses the getNodeType() method to obtain the type of the current node and compare it against a known node type, which is Node.TEXT_NODE for an element value.
At this point, the code must ask whether there are any child nodes to process. For example, the <Root> element will have child nodes, but the <Fruit> element doesn’t. When there are child elements to process, the code creates a NodeList object, ChildNodes, to access them. It then processes each node in turn. When the node type is Node.ELEMENT_NODE, the method coerces the type (changes it, essentially) into an Element, ChildElement, and uses ChildElement to recursively call ProcessElements(). Notice that performing this recursive call increases the Levelvalue.
 Any time you use recursion, you must provide a method for the recursive routine to stop. In this case, recursion continues only as long as there are nodes of type Node.ELEMENT_NODE to process. When the code runs out of these nodes to process, the application automatically stops calling the ProcessElements() method recursively. If you don’t provide an escape mechanism, the code will continue to run infinitely, and the system will eventually run out of memory (causing a system crash).
Any time you use recursion, you must provide a method for the recursive routine to stop. In this case, recursion continues only as long as there are nodes of type Node.ELEMENT_NODE to process. When the code runs out of these nodes to process, the application automatically stops calling the ProcessElements() method recursively. If you don’t provide an escape mechanism, the code will continue to run infinitely, and the system will eventually run out of memory (causing a system crash).
3. Type javac ReadXML.java and press Enter.
The compiler compiles your application and creates a .class file from it.
4. Type java ReadXML and press Enter.
The application displays a hierarchical list of the nodes within the XML file, as shown in Figure 13-1. Notice how the level numbering and the indentation show precisely how the data is organized within the file.
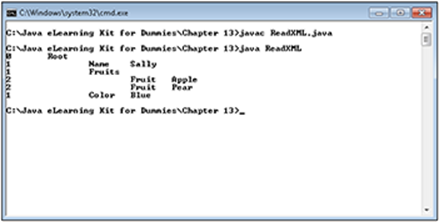
Figure 13-1:
Writing XML Data to Disk
Reading XML data and creating a document that is stored in memory from it is only half the process. If you want to use XML to permanently store information on disk, you must also know how to write it.
The following example demonstrates how to create the XML document used in the ReadXML example, MyData.xml. The example will then add some information to the XML document stored in memory and write the data to disk as an XML file.
Files needed: WriteXML.java
1. Open the editor or IDE that you’ve chosen to use for this book.
2. Type the following code into the editor screen.
// Import the required API classes.
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Text;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.dom.DOMSource;
import java.io.File;
import javax.xml.transform.stream.StreamResult;
public class WriteXML
{
public static void main(String[] args)
{
// Create a factory for building an XML document.
DocumentBuilderFactory Factory =
DocumentBuilderFactory.newInstance();
// Create an object to build a document.
DocumentBuilder Builder = null;
try
{
Builder = Factory.newDocumentBuilder();
}
catch (ParserConfigurationException e)
{
// Display an error message and exit.
System.out.println("Could not create document builder!"
+ e.getMessage());
return;
}
// Create a document using the document builder.
Document XMLDoc = Builder.newDocument();
// Every XML document must have a root element.
Element Root = XMLDoc.createElement("Root");
// Add the root element to the document.
XMLDoc.appendChild(Root);
// Add a name element to the root.
Element Child = XMLDoc.createElement("Name");
Text ChildData = XMLDoc.createTextNode("Sally");
Child.appendChild(ChildData);
Root.appendChild(Child);
// Create a favorite fruits list.
Element Fruits = XMLDoc.createElement("Fruits");
Root.appendChild(Fruits);
// Add a favorite fruit element to Fruits.
Child = XMLDoc.createElement("Fruit");
ChildData = XMLDoc.createTextNode("Apple");
Child.appendChild(ChildData);
Fruits.appendChild(Child);
// Add a favorite fruit element to Fruits.
Child = XMLDoc.createElement("Fruit");
ChildData = XMLDoc.createTextNode("Pear");
Child.appendChild(ChildData);
Fruits.appendChild(Child);
// Add a favorite color element to the root.
Child = XMLDoc.createElement("Color");
ChildData = XMLDoc.createTextNode("Blue");
Child.appendChild(ChildData);
Root.appendChild(Child);
// Create a factory for transforming the memory
// representation of the XML document into an
// actual XML document.
TransformerFactory TFactory =
TransformerFactory.newInstance();
// Create a transformer to perform the work.
Transformer CreateResult = null;
try
{
CreateResult = TFactory.newTransformer();
}
catch (TransformerConfigurationException e)
{
// Display an error message and exit.
System.out.println("Could not create transformer!"
+ e.getMessage());
return;
}
// Define a Document Object Model source used as a
// basis for the output document.
DOMSource Source = new DOMSource(XMLDoc);
// Define a file to receive the XML document.
File OutputFile = new File("MyData.xml");
// Define a stream to transfer the file.
StreamResult Result = new StreamResult(OutputFile);
// Perform the transformation required to output
// the document to disk.
try
{
CreateResult.transform(Source, Result);
}
catch (TransformerException e)
{
// Display an error message and exit.
System.out.println("Could not save XML document!"
+ e.getMessage());
}
// Display a success message.
System.out.println("Document successfully saved!");
}
}
As with the ReadXML example, this example requires a relatively large number of imports that are listed in the order in which they’re used. The application begins with the same process used for reading an XML file: creating a DocumentBuilderFactory, using the Factory to create aDocumentBuilder, and then calling on Builder to create a new XML document, XMLDoc. This same process occurs in just about every XML application you create.
Every XML document starts with a RootElement that the code creates using createElement(). The code appends Root to XMLDoc to begin building the XML document.
When working with an Element — Child, in this case — that contains a value, the value is contained within a Text object — ChildData here. The code appends ChildData to Child (the element contains the value) and then appends Child to Root (the root-element contains all of the top level elements). Each top-level element follows the same process.
Second-level elements are appended to first-level elements. For example, Fruits is a first-level element. It contains two second-level Fruit elements, one with a value of Apple and another with a value of Pear. Notice how the code appends the Child elements to the appropriate parent.
At some point, the code has created an XML document. This isn’t XML data suitable for writing to disk because it’s in a form that’s more useful for working with the data in memory. The code creates a TransformerFactory, TFactory, to create a Transformer object, CreateResult, that transforms the XML document into XML data that the application can then write to disk.
GO ONLINE
Several standards exist for creating XML data stored in files. This example uses the Document Object Model (DOM). Discussing the precise differences between the XML storage techniques is well outside the scope of this book. The best place to learn about DOM is http://www.w3.org/DOM. You can find a DOM tutorial athttp://www.w3schools.com/htmldom/default.asp.
The code creates a DOMSource, Source, to provide access to the information in XMLDoc. It also creates a File object, OutputFile, to hold the data on disk. To send data to OutputFile, the application must also create a StreamResult object, Result. At this point, the code transforms the data found in XMLDoc by accessing it through Source. It then sends the transformed result through Result to OutputFile for storage as text.
3. Type javac WriteXML.java and press Enter.
The compiler compiles your application and creates a .class file from it.
4. Type java WriteXML and press Enter.
The application displays a success message. Of course, you have no idea whether or not the application output something useful.
5. Open MyData.xml using your favorite XML viewer (most browsers can perform this task).
You see the final XML document, as shown in Figure 13-2. Your output may vary a little from that shown in the screenshot — this output is for Internet Explorer.
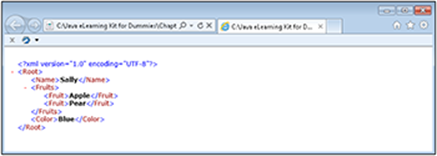
Figure 13-2:
 Summing Up
Summing Up
Here are the key points you learned about in this chapter:
· Reading an XML file from disk provides data to your application.
· Your application must parse an XML file in order to convert it from text to an actual document.
· The process for creating an XML document begins with a factory that creates an XML document builder, which is used to build the XML document.
· To create an XML document, you must build it out of component objects such as Element and Text.
· Each node in an XML document is appended to its parent, including element values, which are actually Text objects.
· Saving an XML document as XML data means transforming it and then sending it to a file on disk.
Try-it-yourself lab
For more practice with the features covered in this chapter, try the following exercise on your own:
1. Open the MyData.xml file supplied with the source code for this book.
2. Add more nodes to the file so that it includes additional data to process. Use the following code additions (in bold) as an example.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<Root>
<Name>Sally</Name>
<Fruits>
<Fruit>Apple</Fruit>
<Fruit>Pear</Fruit>
</Fruits>
<Color>Blue</Color>
<Likes>
<Movies>
<Movie>Princess Bride</Movie>
<Movie>Sleeping Beauty</Movie>
</Movies>
</Likes>
</Root>
3. Type java ReadXML and press Enter.
The application displays a hierarchical list of the nodes within the XML file. How does the output from the application change with the change in the data file? How many levels does the output include now?
Know this tech talk
· element: A major division of data within an XML document. It consists of a start tag, an end tag, and everything between. An element commonly contains attributes, other elements, and a single value. However, an element can contain a wealth of other data types.
· eXtensible Markup Language (XML): A markup language specifically designed to make it easy to transfer data between applications and disparate computer platforms. Even though XML relies on text as an underlying storage technology, it actually conveys considerable information about the context and properties of the data it transports.
· node: Any discrete object within an XML document.
· parse: The act of reading information from a source, interpreting it, and creating a new object from it as output. Parsing is one way to convert information from one type to another. In many cases, parsers read data in text format and create an intelligent object from it that can use the textual information in unique ways.
· recursion: A programming technique where a method calls itself to break a complex task down into simpler pieces. The result of the simple task is then used to make completing the complex task possible. A recursive method must always include some means of escape so that the routine will exit once the task is simple enough.
· value: The single text value between the start tag and end tag of an element that defines the content of that element. For example, when looking at <Name>Sally</Name>, the value is Sally.