JavaScript Regular Expressions (2015)
Chapter 2. The Basics
In the previous chapter, we have already seen that in order to match a substring, you simply need to write the string inside a regular expression. For example, to match hello, you would create this variable:
var pattern = /hello/;
We also learned that if we want to match all occurrences of the string or character of the regular expression, we can use the g flag within Regex. However, situations where you have as clear a pattern like these are rare, and even when they come up, it's arguable whether Regex is even required. You really see the true power of regular expressions when you have less concrete information.
There are two main features the Regex engine implements that allow you to correctly represent 80 percent of your patterns. We will cover these two main features in this chapter:
· Vague matchers
· Multipliers
Defining vague matchers in Regex
In this topic, we will cover character classes that tell the Regex to match a single vague character. Among the vague matches, there can be a character, digit, or an alphanumeric character.
Matching a wild card character
Let's say we wanted to find a sequence where we have 1, and then any other character followed by 3, so that it would include 123, 1b3, 1 3, 133, and so on. For these types of situations, we need to use a vague matcher in our patterns.
In the preceding example, we want to be able to use the broadest matcher possible; we can choose to put no constraints on it if we wish to and it can include any character. For these kind of situations, we have the . matcher.
A period in Regex will match any character except a new line, so it can include letters, numbers, symbols, and so on. To test this out, let's implement the aforementioned example in our HTML utility. In the text field, let's enter a few combinations to test the pattern against 123 1b3 1 3 133 321, and then for the pattern, we can specify /1.3/g. Running it should give you something similar to this:
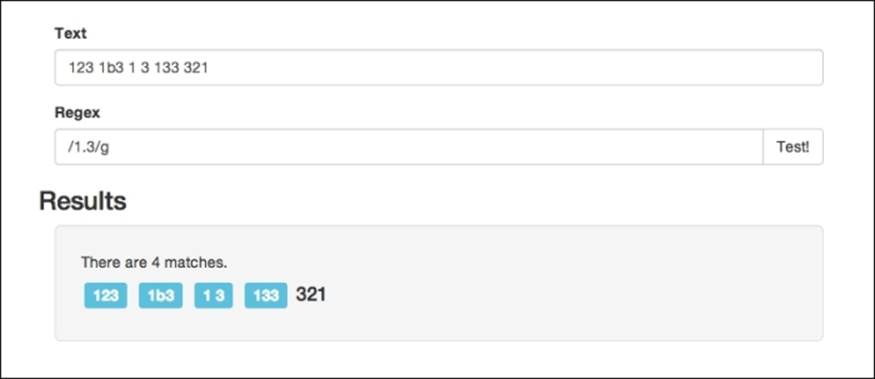
Matching digits
The wildcard character is not the only character to match vague patterns, nor is it always the right choice. For example, continuing from the previous example, let's say that the character in between 1 and 3 is a number. In this case, we might not care which digit ends up there, all we have to make sure of is that it's a number.
To accomplish this, we can use a \d. vague matcher The d backslash or digit special character will match any character between 0 to 9. Replacing the period with the backslash d character will give us the following results:
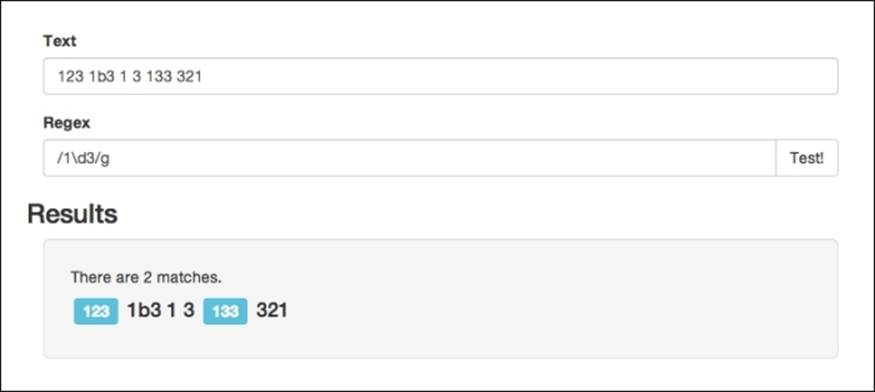
Matching alphanumeric chars
Only two out of the four matches mentioned earlier comply with the new constraint. The last main vague matcher is \w, which is a word character. It will match the underscore character, numbers, or any of the 26 letters of the alphabet (in both lowercase as well as uppercase letters). Running this in our app will give us the following results:
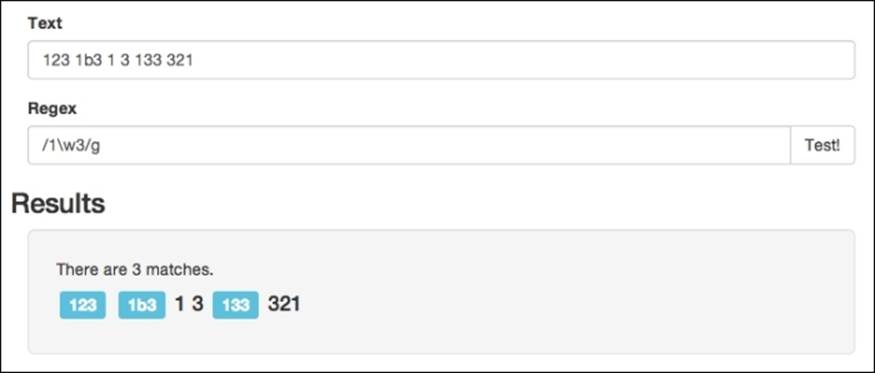
Negating alphanumeric chars and digits
Also, if you want the negated versions of the last two matchers, you can just use their uppercase counterparts. What I mean by this is that \d will match any number, but \D will match anything except a number, since they are compliments and the same goes for \wand \W.
Defining ranges in Regex
Ranges in Regex allow you to create your own custom constraints, much like the ones we just went through. In a range, you can specify exactly the characters that can be used or if it's faster, you can specify the inverse, that is, the characters that do not match.
For the sake of illustration, let's say we wanted to match only abc. In this case, we could create a range similar to [abc] and it will match a single character, which is either a, b, or c. Let's test it out with the bicycle text and the /[abc]/g pattern:
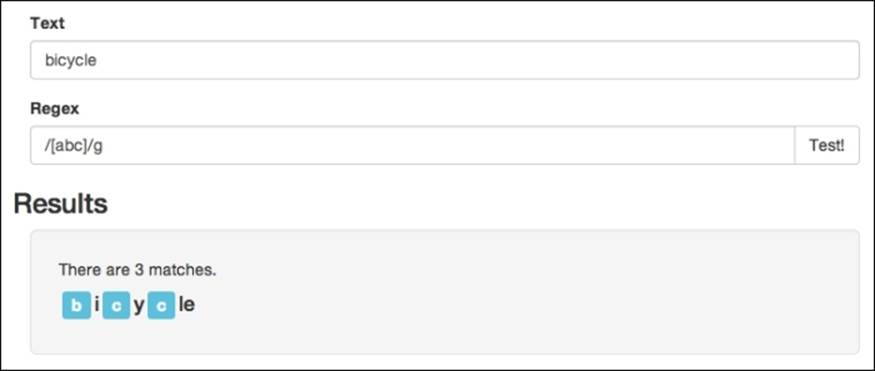
Defining a range
Now, this will work, however, if you have a lot of characters you need to match, your range will become long quickly. Luckily, Regex allows you to use the (-) dash character to specify a set of characters without needing to list them out. For example, let's say we want to check whether a three lettered name is formatted correctly, and we want the first letter to be a capital letter, followed by two lower case letters. Instead of specifying all 26 letters in each range, we can abbreviate it to [a-z] or [A-Z] for the uppercase letters. So, to implement a three letter name verifier, we could create a pattern similar to/[A-Z][a-z][a-z]/g:
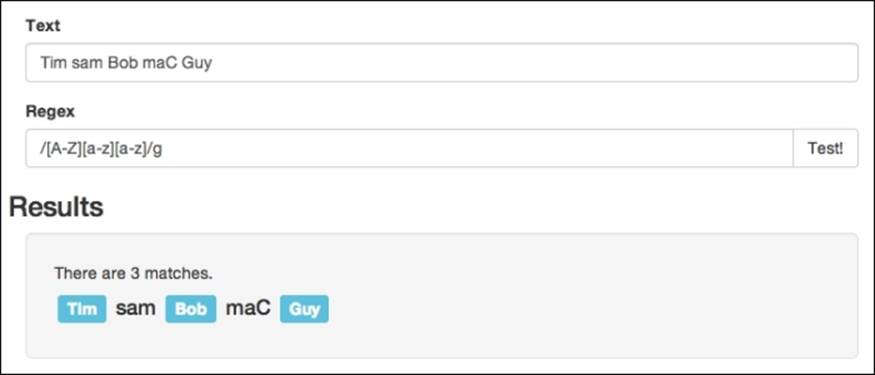
Matching the dash character
If you are trying to match the dash character itself, and you don't want JavaScript to interpret it as specifying a set, you can either start/end the range with the dash character or escape it with a backslash. For example to match both "hello world" and "hello-world,"we could write a pattern similar to /hello[- ]world/ or /hello[\- ]world/.
We can also use a wild character as a simple dot inside a rage. For example, this may occur when we want to match a number character and we don't mind having a period (forgetting for a second that a number can only have one period). So, to match 123 as well as 2.4 and .45, we could specify the /[\d.][\d.]\d/ pattern, and then both the first and second digits can be periods. Notice, JavaScript doesn't think that we are referring to the wildcard period inside the range, as this would defeat the purpose of a range, so JavaScript treats it as a standard period.
Defining negated ranges
The last thing to be covered in ranges is the negated range. A negated range is exactly what it sounds like. Instead of specifying what to match, we are specifying what not to match. It's very similar to adding a not (!) character to a Boolean value in JavaScript, in that it simply flips the return value of what you would have got earlier.
To create a negated range, you can start the range with a (^) caret character to match any character; however, for the first five letters of the alphabet, you would use something similar to /[^a-e]/.
This may not seem that useful by itself, but you might, for example, want to strip out all not alphabetical characters for a filename. In this case, you can type /[^a-z]/gi and combined with JavaScript's replace function, you can remove all of them.
Defining multipliers in Regex
Matchers are great but they only "scale" your pattern in one direction. I like to think of matchers as things that scale your pattern vertically, allowing you to match many more strings that fit into the same pattern, but they are still constrained in length, or scale the pattern horizontally. Multipliers allow you to match arbitrarily sized strings that you may receive as input, giving you a much greater range of freedom.
There are three basic multipliers in Regex:
· +: This matches one or more occurrences
· ?: This matches zero or one occurrence
· *: This matches zero or more occurrences
We will cover these three multipliers in this section, and also show you how to create a custom multiplier.
Matching one or more occurrences
The most basic multiplier would have to be the (+) plus operator. It tells JavaScript that the pattern used in the regular expression must appear one or more times. For example, we can build upon the formatted name pattern we used before, and instead of just matching a three letter name, we could match any length of name using /[A-Z][a-z]+/g:
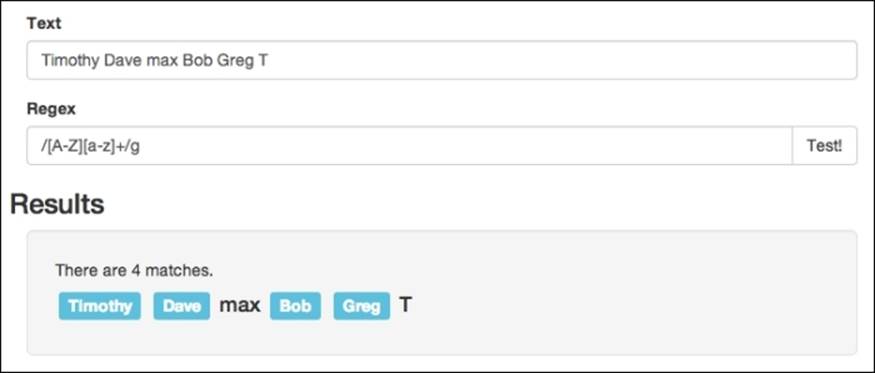
This pattern represents anything that starts with a capital letter and has at least one lowercase letter after it. The plus sign will continue to repeat the pattern until it no longer matches (which in our case occurs when it reaches a space character).
Matching zero or one occurrence
The next multiplier, which I guess can be called more of a quantifier, is the (?) question mark. Fittingly, this multiplier allows the preceding character to either show up or not, almost as if we are saying that its presence is questionable. I think the best way to explain this is by looking at an example. Let's say we want to receive Apple in either its singular or plural form, for this, we could use this pattern:
/apples?/gi
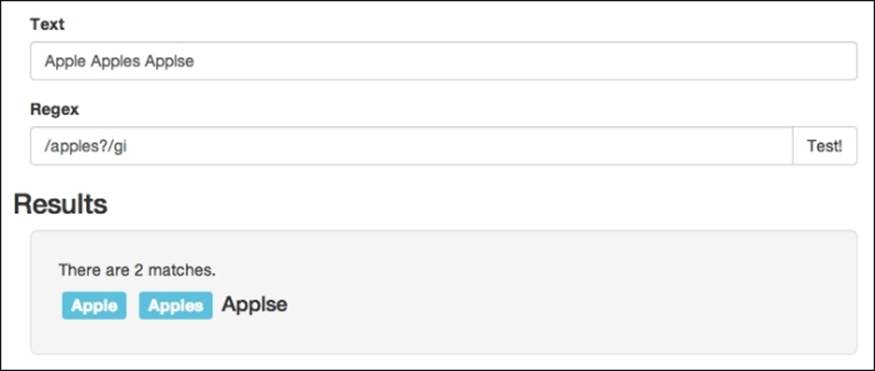
Now this may seem like the question mark is more of a conditional operator than a multiplier, but what it is really doing is saying that the preceding character can appear either once or zero times.
Matching zero or more occurrences
The next multiplier in our tool chain is the (*) asterisk. This asterisk is a combination of the previous two multipliers, allowing the previous character to appear anywhere between zero and infinity times. So, if you have an input that contains a word or a character many times, the pattern will match. If you have an input that does not contain a word or a character, the pattern will still match. For example, this can come in handy if you are parsing some kind of log for update. In situations like this, you might get update or mayupdate!!! and, depending on the time of day, you may even get update!!!!!!!!!!!!!!!!. To match all these strings, you can simply create the pattern /update!*/g pattern.
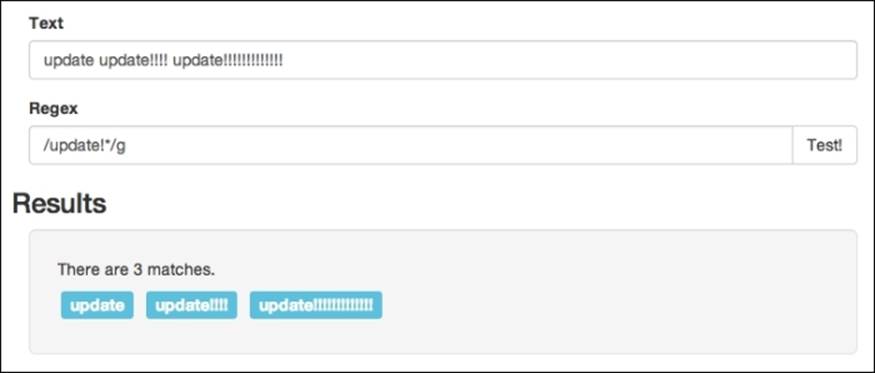
These are the three standard multipliers, similar to the ones that had built-in sets of characters for the (\d) ranges. Similarly, Regex allows you to specify and create your own multipliers.
Defining custom quantifiers
There is only one syntax to specify your own multipliers but because of the different parameter options available, you get three different functional options.
If you want to match a given character a concrete number of times, you can simply specify the number of allowed repetitions inside curly braces. This doesn't make your patterns more flexible, but it will make them shorter to read. For example, if we were implementing a phone number we could type /\d\d\d-\d\d\d\d/. This is, however, a bit long and instead, we can just use custom multipliers and type /\d{3}-\d{4}/, which really shorten it up making it more readable.
Matching n or more occurrences
Next, if you just want to set a minimum number of times that the pattern can appear, but don't really care about the actual length, you can just add a comma after the number. For example, let's say we want to create a pattern to make sure a user's password is at least six characters long; in such a situation, you may not want to enforce a maximum character limit, and can, therefore, type something similar to /.{6,}/:
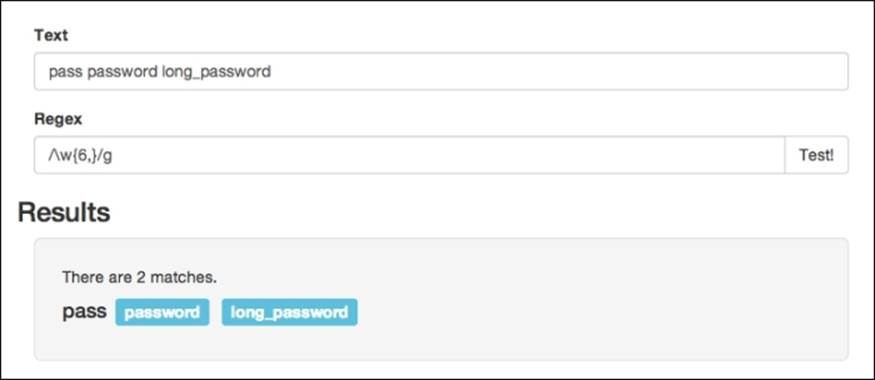
Matching n to m occurrences
The third variation on our custom multipliers is when you want to set a complete set of options, matching both, the minimum and maximum number of occurrences. You can do this by simply adding another number after the comma. For example, if we had some sort of comment system and we wanted to constrain the comments to be anywhere between 15 to 140 characters, we could create a Regex string to match this setup, for example, /.{15,140}/.
Now, I am not saying that the two previously mentioned examples are the best uses for this kind of Regex, because obviously, there is a much easier way to check text lengths. However, in the context of a larger pattern, this can be pretty useful.
Matching alternated options
At this stage, we know how to match any set of characters using vague matchers, and we have the ability to repeat the patterns for any kind of sequence using multipliers, which gives you a pretty good base for matching just about anything. However, even with all this in place, there is one situation that has a tendency to come up and can be an issue. It occurs when dealing with two different and completely separate acceptable forms of input.
Let's say we are parsing some kind of form data, and for each question, we want to extract either a yes or no to be stored somewhere. With our current level of expertise, we can create a pattern similar to /[yn][eo]s?/g, which would match both yes and no. The real problem with this is that it will also match all the other six configurations of these letters, which our app probably won't know how to handle:
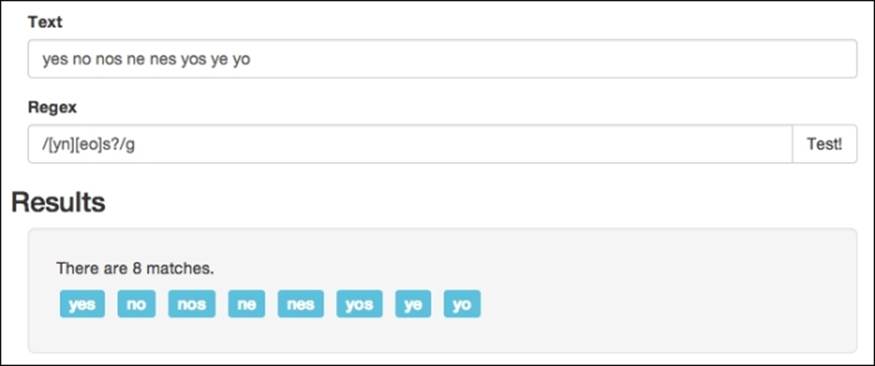
Luckily, Regex has a completely different system in place to hand situations like this and it is in the form of the (|) pipe character. It is similar to the OR operator you would use in an if statement, except instead of two, you just use one here. How it works is, you separate the different patterns you want to match by a pipe, and then any of the patterns can return a match. Changing our previous Regex pattern with /yes|no/g will then show the correct results:
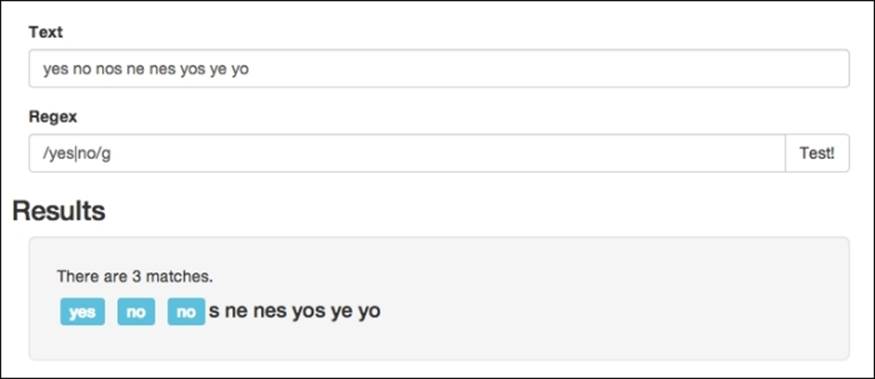
Well, at least it almost will, though it will still match no in nos. However, this is because we have been using open patterns and not really enforcing complete words (this is a topic in the next chapter).
The pipe character, though, is not limited to just two options, we can easily match a large array of values by splitting each of them by the pipe character. Also, we are not constrained to just using plain text, and each segment in our Regex split can be its own pattern using ranges and multipliers.
Creating a Regex for a telephone number
To tie up this chapter, let's put together a few of these features we just learned about and construct the phone number pattern we used in the previous chapter. To sum it up, we want to be able to match all the following number patterns:
123-123-1234
(123)-123-1234
1231231234
So, first off, we can see that there are optional brackets around the first three numbers (the area code), and we also have optional dashes between the numbers. This is a situation where the question mark character comes in handy. For the numbers themselves, we can use a built-in matcher to specify that they have to be numbers and a strong multiplier to specify exactly how many we need. The only special thing we need to know here is that the parenthesis contains special characters, so we will need to escape them (add a backslash):
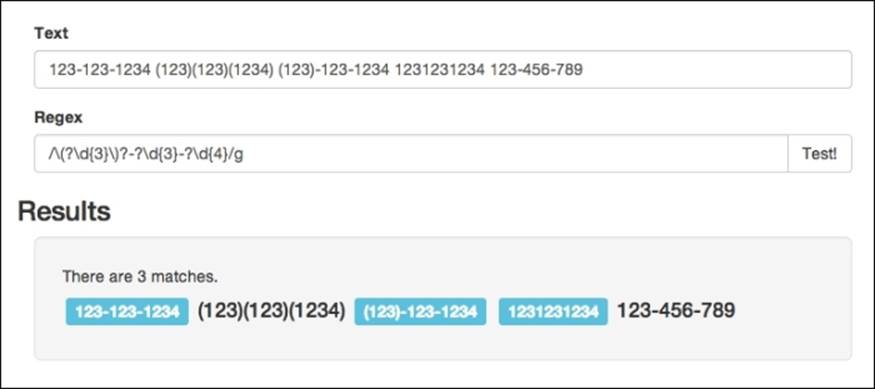
/\(?\d{3}\)?-?\d{3}-?\d{4}/g
Note
Parentheses are used to define groups in regular expressions, this is why they are special characters. We will learn about defining groups in Chapter 3, Special Characters.
Testing this regular expression with the test application that we developed in Chapter 1, Getting Started with Regex, and with the examples mentioned at the beginning of this topic will show that the regular expression matches all of the examples:
Summary
In this chapter, we learned how to use character classes to define a wild character match, a digit match, and an alphanumeric match. We also learned how to define quantifiers, which specify how many times a character or group can be present in an input.
In the next chapter, we will learn about boundaries (positions that can be used to match the Regex) and defining groups.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.