Java SE 8 for the Really Impatient (2014)
Chapter 6. Concurrency Enhancements
Topics in This Chapter
![]() 6.1 Atomic Values
6.1 Atomic Values
![]() 6.2 ConcurrentHashMap Improvements
6.2 ConcurrentHashMap Improvements
![]() 6.3 Parallel Array Operations
6.3 Parallel Array Operations
![]() 6.4 Completable Futures
6.4 Completable Futures
![]() Exercises
Exercises
Concurrent programming is hard, and it is harder without the right tools. Early Java releases had minimal support for concurrency, and programmers busily created code with deadlocks and race conditions. The robust java.util.concurrent package didn’t appear until Java 5. That package gives us threadsafe collections and thread pools, allowing many application programmers to write concurrent programs without using locks or starting threads. Unfortunately, java.util.concurrent is a mix of useful utilities for the application programmer and power tools for library authors, without much effort to separate the two. In this chapter, we focus squarely on the needs of the application programmer.
The key points of this chapter are:
• Updating atomic variables has become simpler with the updateAndGet/accumulateAndGet methods.
• LongAccumulator/DoubleAccumulator are more efficient than AtomicLong/AtomicDouble under high contention.
• Updating entries in a ConcurrentHashMap has become simpler with the compute and merge methods.
• ConcurrentHashMap now has bulk operations search, reduce, forEach, with variants operating on keys, values, keys and values, and entries.
• A set view lets you use a ConcurrentHashMap as a Set.
• The Arrays class has methods for parallel sorting, filling, and prefix operations.
• Completable futures let you compose asynchronous operations.
6.1. Atomic Values
Since Java 5, the java.util.concurrent.atomic package provided classes for lock-free mutation of variables. For example, you can safely generate a sequence of numbers like this:
public static AtomicLong nextNumber = new AtomicLong();
// In some thread ...
long id = nextNumber.incrementAndGet();
The incrementAndGet method atomically increments the AtomicLong and returns the post-increment value. That is, the operations of getting the value, adding 1, setting it, and producing the new value cannot be interrupted. It is guaranteed that the correct value is computed and returned, even if multiple threads access the same instance concurrently.
There are methods for atomically setting, adding, and subtracting values, but if you want to make a more complex update, you have to use the compareAndSet method. For example, suppose you want to keep track of the largest value that is observed by different threads. The following won’t work:
public static AtomicLong largest = new AtomicLong();
// In some thread...
largest.set(Math.max(largest.get(), observed)); // Error—race condition!
This update is not atomic. Instead, compute the new value and use compareAndSet in a loop:
do {
oldValue = largest.get();
newValue = Math.max(oldValue, observed);
} while (!largest.compareAndSet(oldValue, newValue));
If another thread is also updating largest, it is possible that it has beat this thread to it. Then compareAndSet will return false without setting the new value. In that case, the loop tries again, reading the updated value and trying to change it. Eventually, it will succeed replacing the existing value with the new one. This sounds tedious, but the compareAndSet method maps to a processor operation that is faster than using a lock.
In Java 8, you don’t have to write the loop boilerplate any more. Instead, you provide a lambda expression for updating the variable, and the update is done for you. In our example, we can call
largest.updateAndGet(x -> Math.max(x, observed));
or
largest.accumulateAndGet(observed, Math::max);
The accumulateAndGet method takes a binary operator that is used to combine the atomic value and the supplied argument.
There are also methods getAndUpdate and getAndAccumulate that return the old value.
![]() NOTE
NOTE
These methods are also provided for the classes AtomicInteger, AtomicIntegerArray, AtomicIntegerFieldUpdater, AtomicLongArray, AtomicLongFieldUpdater, AtomicReference, AtomicReferenceArray, andAtomicReferenceFieldUpdater.
When you have a very large number of threads accessing the same atomic values, performance suffers because the optimistic updates require too many retries. Java 8 provides classes LongAdder and LongAccumulator to solve this problem. A LongAdder is composed of multiple variables whose collective sum is the current value. Multiple threads can update different summands, and new summands are automatically provided when the number of threads increases. This is efficient in the common situation where the value of the sum is not needed until after all work has been done. The performance improvement can be substantial—see Exercise 3.
If you anticipate high contention, you should simply use a LongAdder instead of an AtomicLong. The method names are slightly different. Call increment to increment a counter or add to add a quantity, and sum to retrieve the total.
final LongAdder adder = new LongAdder();
for (...)
pool.submit(() -> {
while (...) {
...
if (...) adder.increment();
}
});
...
long total = adder.sum());
![]() NOTE
NOTE
Of course, the increment method does not return the old value. Doing that would undo the efficiency gain of splitting the sum into multiple summands.
The LongAccumulator generalizes this idea to an arbitrary accumulation operation. In the constructor, you provide the operation, as well as its neutral element. To incorporate new values, call accumulate. Call get to obtain the current value. The following has the same effect as aLongAdder:
LongAccumulator adder = new LongAccumulator(Long::sum, 0);
// In some thread...
adder.accumulate(value);
Internally, the accumulator has variables a1, a2, ..., an. Each variable is initialized with the neutral element (0 in our example).
When accumulate is called with value v, then one of them is atomically updated as ai = ai op v, where op is the accumulation operation written in infix form. In our example, a call to accumulate computes ai = ai + v for some i.
The result of get is a1 op a2 op ... op an. In our example, that is the sum of the accumulators, a1 + a2 + ... + an.
If you choose a different operation, you can compute maximum or minimum (see Exercise 4). In general, the operation must be associative and commutative. That means that the final result must be independent of the order in which the intermediate values were combined.
There are also DoubleAdder and DoubleAccumulator that work in the same way, except with double values.
![]() NOTE
NOTE
Another addition to Java 8 is the StampedLock class that can be used to implement optimistic reads. I don’t recommend that application programmers use locks, but here is how it is done. You first call tryOptimisticRead, upon which you get a “stamp.” Read your values and check whether the stamp is still valid (i.e., no other thread has obtained a write lock). If so, you can use the values. If not, get a read lock (which blocks any writers). Here is an example.
public class Vector {
private int size;
private Object[] elements;
private StampedLock lock = new StampedLock();
public Object get(int n) {
long stamp = lock.tryOptimisticRead();
Object[] currentElements = elements;
int currentSize = size;
if (!lock.validate(stamp)) { // Someone else had a write lock
stamp = lock.readLock(); // Get a pessimistic lock
currentElements = elements;
currentSize = size;
lock.unlockRead(stamp);
}
return n < currentSize ? currentElements[n] : null;
}
...
}
6.2. ConcurrentHashMap Improvements
A classic programmer’s saying is, “If you can only have one data structure, make it a hash table.” Since Java 5, the ConcurrentHashMap has been a workhorse of concurrent programming. A ConcurrentHashMap is, of course, threadsafe—multiple threads can add and remove elements without damaging the internal structure. Moreover, it is quite efficient, allowing multiple threads to update different parts of the table concurrently without blocking each other.
![]() NOTE
NOTE
Some applications use humongous concurrent hash maps, so large that the size method is insufficient because it returns an int. What is one to do with a map that has over two billion entries? Java 8 introduces a mappingCount method that returns the size as a long.
![]() NOTE
NOTE
A hash map keeps all entries with the same hash code in the same “bucket.” Some applications use poor hash functions, and as a result all entries end up in a small number of buckets, severely degrading performance. Even generally reasonable hash functions, such as that of the String class, can be problematic. For example, an attacker can slow down a program by crafting a large number of strings that hash to the same value. As of Java 8, the concurrent hash map organizes the buckets as trees, not lists, when the key type implementsComparable, guaranteeing O(log(n)) performance.
6.2.1. Updating Values
The original version of ConcurrentHashMap only had a few methods for atomic updates, which made for somewhat awkward programming. Suppose we want to count how often certain features are observed. As a simple example, suppose multiple threads encounter words, and we want to count their frequencies.
Can we use a ConcurrentHashMap<String, Long>? Consider the code for incrementing a count. Obviously, the following is not threadsafe:
Long oldValue = map.get(word);
Long newValue = oldValue == null ? 1 : oldValue + 1;
map.put(word, newValue); // Error—might not replace oldValue
Another thread might be updating the exact same count at the same time.
![]() NOTE
NOTE
Some programmers are surprised that a supposedly threadsafe data structure permits operations that are not threadsafe. But there are two entirely different considerations. If multiple threads modify a plain HashMap, they can destroy the internal structure (an array of linked lists). Some of the links may go missing, or even go in circles, rendering the data structure unusable. That will never happen with a ConcurrentHashMap. In the example above, the code for get and put will never corrupt the data structure. But, since the sequence of operations is not atomic, the result is not predictable.
One remedy is to use the replace operation, replacing a known old value with a new one, just as you have seen in the preceding section:
do {
oldValue = map.get(word);
newValue = oldValue == null ? 1 : oldValue + 1;
} while (!map.replace(word, oldValue, newValue));
Alternatively, you can use a ConcurrentHashMap<String, AtomicLong> or, with Java 8, a ConcurrentHashMap<String, LongAdder>. Then the update code is:
map.putIfAbsent(word, new LongAdder());
map.get(word).increment();
The first statement ensures that there is a LongAdder present that we can increment atomically. Since putIfAbsent returns the mapped value (either the existing one or the newly put one), you can combine the two statements:
map.putIfAbsent(word, new LongAdder()).increment();
Java 8 provides methods that make atomic updates more convenient. The compute method is called with a key and a function to compute the new value. That function receives the key and the associated value, or null if there is none, and it computes the new value. For example, here is how we can update a map of integer counters:
map.compute(word, (k, v) -> v == null ? 1 : v + 1);
![]() NOTE
NOTE
You cannot have null values in a ConcurrentHashMap. There are many methods that use a null value as an indication that a given key is not present in the map.
There are also variants computeIfPresent and computeIfAbsent that only compute a new value when there is already an old one, or when there isn’t yet one. A map of LongAdder counters can be updated with
map.computeIfAbsent(word, k -> new LongAdder()).increment();
That is almost like the call to putIfAbsent that you saw before, but the LongAdder constructor is only called when a new counter is actually needed.
You often need to do something special when a key is added for the first time. The merge method makes this particularly convenient. It has a parameter for the initial value that is used when the key is not yet present. Otherwise, the function that you supplied is called, combining the existing value and the initial value. (Unlike compute, the function does not process the key.)
map.merge(word, 1L, (existingValue, newValue) -> existingValue + newValue);
or, more simply,
map.merge(word, 1L, Long::sum);
It doesn’t get more concise than that. See Exercise 5 for another compelling application of the merge method.
![]() NOTE
NOTE
If the function that is passed to compute or merge returns null, the existing entry is removed from the map.
 CAUTION
CAUTION
When you use compute or merge, keep in mind that the function that you supply should not do a lot of work. While that function runs, some other updates to the map may be blocked. Of course, that function should also not update other parts of the map.
6.2.2. Bulk Operations
Java 8 provides bulk operations on concurrent hash maps that can safely execute even while other threads operate on the map. The bulk operations traverse the map and operate on the elements they find as they go along. No effort is made to freeze a snapshot of the map in time. Unless you happen to know that the map is not being modified while a bulk operation runs, you should treat its result as an approximation of the map’s state.
There are three kinds of operations:
• search applies a function to each key and/or value, until the function yields a non-null result. Then the search terminates and the function’s result is returned.
• reduce combines all keys and/or values, using a provided accumulation function.
• forEach applies a function to all keys and/or values.
Each operation has four versions:
• operationKeys: operates on keys.
• operationValues: operates on values.
• operation: operates on keys and values.
• operationEntries: operates on Map.Entry objects.
With each of the operations, you need to specify a parallelism threshold. If the map contains more elements than the threshold, the bulk operation is parallelized. If you want the bulk operation to run in a single thread, use a threshold of Long.MAX_VALUE. If you want the maximum number of threads to be made available for the bulk operation, use a threshold of 1.
Let’s look at the search methods first. Here are the versions:
U searchKeys(long threshold, BiFunction<? super K, ? extends U> f)
U searchValues(long threshold, BiFunction<? super V, ? extends U> f)
U search(long threshold, BiFunction<? super K, ? super V,? extends U> f)
U searchEntries(long threshold, BiFunction<Map.Entry<K, V>, ? extends U> f)
For example, suppose we want to find the first word that occurs more than 1,000 times. We need to search keys and values:
String result = map.search(threshold, (k, v) -> v > 1000 ? k : null);
Then result is set to the first match, or to null if the search function returns null for all inputs.
The forEach methods have two variants. The first one simply applies a consumer function for each map entry, for example
map.forEach(threshold,
(k, v) -> System.out.println(k + " -> " + v));
The second variant takes an additional transformer function, which is applied first, and its result is passed to the consumer:
map.forEach(threshold,
(k, v) -> k + " -> " + v, // Transformer
System.out::println); // Consumer
The transformer can be used as a filter. Whenever the transformer returns null, the value is silently skipped. For example, here we only print the entries with large values:
map.forEach(threshold,
(k, v) -> v > 1000 ? k + " -> " + v : null, // Filter and transformer
System.out::println); // The nulls are not passed to the consumer
The reduce operations combine their inputs with an accumulation function. For example, here is how you can compute the sum of all values.
Long sum = map.reduceValues(threshold, Long::sum);
As with forEach, you can also supply a transformer function. Here we compute the length of the longest key:
Integer maxlength = map.reduceKeys(threshold,
String::length, // Transformer
Integer::max); // Accumulator
The transformer can act as a filter, by returning null to exclude unwanted inputs. Here, we count how many entries have value > 1000:
Long count = map.reduceValues(threshold,
v -> v > 1000 ? 1L : null,
Long::sum);
![]() NOTE
NOTE
If the map is empty, or all entries have been filtered out, the reduce operation returns null. If there is only one element, its transformation is returned, and the accumulator is not applied.
There are specializations for int, long, and double outputs with suffix ToInt, ToLong, and ToDouble. You need to transform the input to a primitive value and specify a default value and an accumulator function. The default value is returned when the map is empty.
long sum = map.reduceValuesToLong(threshold,
Long::longValue, // Transformer to primitive type
0, // Default value for empty map
Long::sum); // Primitive type accumulator
CAUTION
These specializations act differently from the object versions where there is only one element to be considered. Instead of returning the transformed element, it is accumulated with the default. Therefore, the default must be the neutral element of the accumulator.
6.2.3. Set Views
Suppose you want a large, threadsafe set instead of a map. There is no ConcurrentHashSet class, and you know better than trying to create your own. Of course, you can use a ConcurrentHashMap with bogus values, but then you get a map, not a set, and you can’t apply operations of the Set interface.
The static newKeySet method yields a Set<K> that is actually a wrapper around a ConcurrentHashMap<K, Boolean>. (All map values are Boolean.TRUE, but you don’t actually care since you just use it as a set.)
Set<String> words = ConcurrentHashMap.<String>newKeySet();
Of course, if you have an existing map, the keySet method yields the set of keys. That set is mutable. If you remove the set’s elements, the keys (and their values) are removed from the map. But it doesn’t make sense to add elements to the key set, because there would be no corresponding values to add. Java 8 adds a second keySet method to ConcurrentHashMap, with a default value, to be used when adding elements to the set:
Set<String> words = map.keySet(1L);
words.add("Java");
If "Java" wasn’t already present in words, it now has a value of one.
6.3. Parallel Array Operations
The Arrays class now has a number of parallelized operations. The static Arrays.parallelSort method can sort an array of primitive values or objects. For example,
String contents = new String(Files.readAllBytes(
Paths.get("alice.txt")), StandardCharsets.UTF_8); // Read file into string
String[] words = contents.split("[\\P{L}]+"); // Split along nonletters
Arrays.parallelSort(words);
When you sort objects, you can supply a Comparator. With all methods, you can supply the bounds of a range, such as
values.parallelSort(values.length / 2, values.length); // Sort the upper half
![]() NOTE
NOTE
At first glance, it seems a bit odd that these methods have parallel in their name, since the user shouldn’t care how the sorting happens. However, the API designers wanted to make it clear that the sorting is parallelized. That way, users are on notice to avoid comparators with side effect.
The parallelSetAll method fills an array with values that are computed from a function. The function receives the element index and computes the value at that location.
Arrays.parallelSetAll(values, i -> i % 10);
// Fills values with 0 1 2 3 4 5 6 7 8 9 0 1 2 ...
Clearly, this operation benefits from being parallelized. There are versions for all primitive type arrays and for object arrays.
Finally, there is a parallelPrefix method that replaces each array element with the accumulation of the prefix for a given associative operation. Huh? Here is an example. Consider the array [1, 2, 3, 4, ...] and the × operation. After executingArrays.parallelPrefix(values, (x, y) -> x * y), the array contains
[1, 1 × 2, 1 × 2 × 3, 1 × 2 × 3 × 4, ...]
Perhaps surprisingly, this computation can be parallelized. First, join neighboring elements, as indicated here:
[1, 1 × 2, 3, 3 × 4, 5, 5 × 6, 7, 7 × 8]
The gray values are left alone. Clearly, one can make this computation in parallel in separate regions of the array. In the next step, update the indicated elements by multiplying them with elements that are one or two positions below:
[1, 1 × 2, 1 × 2 × 3, 1 × 2 × 3 × 4, 5, 5 × 6, 5 × 6 × 7, 5 × 6 × 7 × 8]
This can again be done in parallel. After log(n) steps, the process is complete. This is a win over the straightforward linear computation if sufficient processors are available. On special-purpose hardware, this algorithm is commonly used, and users of such hardware are quite ingenious in adapting it to a variety of problems. Exercise 9 gives a simple example.
6.4. Completable Futures
The java.util.concurrent library provides a Future<T> interface to denote a value of type T that will be available at some point in the future. However, up to now, futures were rather limited. In the following sections, you will see how completable futures make it possible to compose asynchronous operations.
6.4.1. Futures
Here is a quick refresher on futures. Consider a method
public void Future<String> readPage(URL url)
The method reads a web page in a separate thread, which is going to take a while. When you call
Future<String> contents = readPage(url);
the method returns right away, and you hold in your hands a Future<String>. Now suppose we want to extract all URLs from the page in order to build a web crawler. We have a class Parser with a method
public static List<URL> getLinks(String page)
How can we apply that method to the future object? Unfortunately, there is only one way. First, call the get method on the future to get its value when it becomes available. Then, process the result:
String page = contents.get();
List<URL> links = Parser.getLinks(page);
But the call to get is a blocking call. We are really no better off than with a method public String readPage(URL url) that blocks until the result is available.
Now in fairness, there has been some support for futures in java.util.concurrent, but an essential piece was missing. There was no easy way of saying: “When the result becomes available, here is how to process it.” This is the crucial feature that the newCompletableFuture<T> class provides.
6.4.2. Composing Futures
Let’s change the readPage method so that it returns a CompletableFuture<String>. Unlike a plain Future, a CompleteableFuture has a method thenApply to which you can pass the post-processing function.
CompletableFuture<String> contents = readPage(url);
CompletableFuture<List<String>> links = contents.thenApply(Parser::getLinks);
The thenApply method doesn’t block either. It returns another future. When the first future has completed, its result is fed to the getLinks method, and the return value of that method becomes the final result.
This composability is the key aspect of the CompletableFuture class. Composing future actions solves a serious problem in programming asynchronous applications. The traditional approach for dealing with nonblocking calls is to use event handlers. The programmer registers a handler for the next action after completion. Of course, if the next action is also asynchronous, then the next action after that is in a different event handler. Even though the programmer thinks in terms of “first do step 1, then step 2, then step 3,” the program logic becomes dispersed in different places. It gets worse when one has to add error handling. Suppose step 2 is “the user logs in”; then we may need to repeat that step since the user can mistype the credentials. Trying to implement such a control flow in a set of event handlers, or to understand it once it has been implemented, is challenging.
With completable futures, you just specify what you want to have done, and in which order. It won’t all happen right away, of course, but what is important is that all the code is in one place.
6.4.3. The Composition Pipeline
In Chapter 2, you saw how a stream pipeline starts with stream creation, then goes through one or more transformations, and finishes with a terminal operation. The same is true for a pipeline of futures.
Start out by generating a CompletableFuture, usually with the static method supplyAsync. That method requires a Supplier<T>, that is, a function with no parameters yielding a T. The function is called on a separate thread. In our example, we can start out the pipeline with
CompletableFuture<String> contents
= CompletableFuture.supplyAsync(() -> blockingReadPage(url));
There is also a static runAsync method that takes a Runnable, yielding a CompletableFuture<Void>. This is useful if you simply want to schedule one action after another, without passing data between them.
![]() NOTE
NOTE
All methods ending in Async have two variants. One of them runs the provided action on the common ForkJoinPool. The other has a parameter of type java.util.concurrent.Executor, and it uses the given executor to run the action.
Next, you can call thenApply or thenApplyAsync to run another action, either in the same thread or another. With either method, you supply a function and you get a CompletableFuture<U>, where U is the return type of the function. For example, here is a two-stage pipeline for reading and processing the web page:
CompletableFuture<List<String>> links
= CompletableFuture.supplyAsync(() -> blockingReadPage(url))
.thenApply(Parser::getLinks);
You can have additional processing steps. Eventually, you’ll be done, and you will need to save the results somewhere. Here, we just print the result.
CompletableFuture<Void> links
= CompletableFuture.supplyAsync(() -> blockingReadPage(url))
.thenApply(Parser::getLinks)
.thenAccept(System.out::println);
The thenAccept method takes a Consumer—that is, a function with return type void.
Ideally, you would never call get on a future. The last step in the pipeline simply deposits the result where it belongs.
![]() NOTE
NOTE
You don’t explicitly start the computation. The static supplyAsync method starts it automatically, and the other methods cause it to be continued.
6.4.4. Composing Asynchronous Operations
There is a large number of methods for working with completable futures. Let us first look at those that deal with a single future (see Table 6–1). For each method shown, there are also two Async variants that I don’t show. As noted in the preceding section, one of them uses the commonForkJoinPool, and the other has an Executor parameter. In the table, I use a shorthand notation for the ponderous functional interfaces, writing T -> U instead of Function<? super T, U>. These aren’t actual Java types, of course.
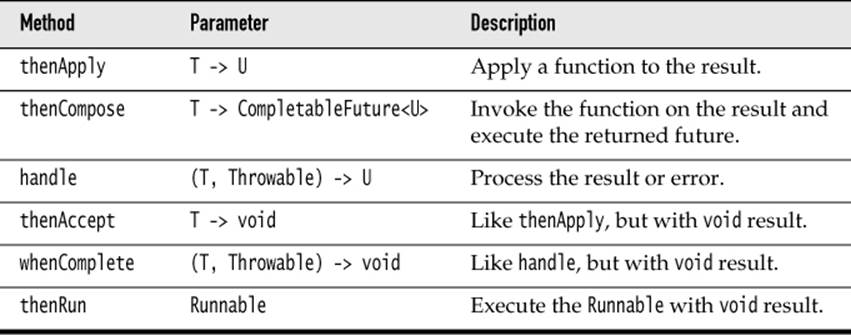
Table 6–1 Adding an Action to a CompletableFuture<T> Object
You have already seen the thenApply method. The calls
CompletableFuture<U> future.thenApply(f);
CompletableFuture<U> future.thenApplyAsync(f);
return a future that applies f to the result of future when it is available. The second call runs f in yet another thread.
The thenCompose method, instead of taking a function T -> U, takes a function T -> CompletableFuture<U>. That sounds rather abstract, but it can be quite natural. Consider the action of reading a web page from a given URL. Instead of supplying a method
public String blockingReadPage(URL url)
it is more elegant to have that method return a future:
public CompletableFuture<String> readPage(URL url)
Now, suppose we have another method that gets the URL from user input, perhaps from a dialog that won’t reveal the answer until the user has clicked the OK button. That, too, is an event in the future:
public CompletableFuture<URL> getURLInput(String prompt)
Here we have two functions T -> CompletableFuture<U> and U -> CompletableFuture<V>. Clearly, they compose to a function T -> CompletableFuture<V> by calling the second function when the first one has completed. That is exactly what thenCompose does.
The third method in Table 6–1 focuses on a different aspect that I have ignored so far: failure. When an exception is thrown in a CompletableFuture, it is captured and wrapped in an unchecked ExecutionException when the get method is called. But perhaps get is never called. In order to handle an exception, use the handle method. The supplied function is called with the result (or null if none) and the exception (or null if none), and it gets to make sense of the situation.
The remaining methods have void result and are usually used at the end of a processing pipeline.
Now let us turn to methods that combine multiple futures (see Table 6–2).
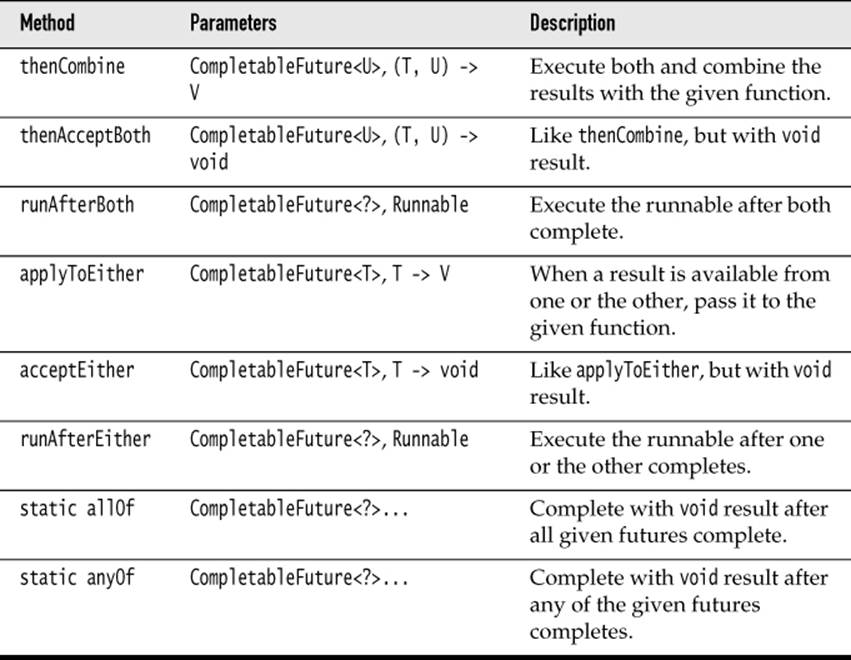
Table 6–2 Combining Multiple Composition Objects
The first three methods run a CompletableFuture<T> and a CompletableFuture<U> action in parallel and combine the results.
The next three methods run two CompletableFuture<T> actions in parallel. As soon as one of them finishes, its result is passed on, and the other result is ignored.
Finally, the static allOf and anyOf methods take a variable number of completable futures and yield a CompletableFuture<Void> that completes when all of them, or any one of them, completes. No results are propagated.
![]() NOTE
NOTE
Technically speaking, the methods in this section accept parameters of type CompletionStage, not CompletableFuture. That is an interface type with almost forty abstract methods, currently implemented only by CompletableFuture. Most programmers wouldn’t casually implement that interface, so I don’t dwell on the distinction.
Exercises
1. Write a program that keeps track of the longest string that is observed by a number of threads. Use an AtomicReference and an appropriate accumulator.
2. Does a LongAdder help with yielding a sequence of increasing IDs? Why or why not?
3. Generate 1,000 threads, each of which increments a counter 100,000 times. Compare the performance of using AtomicLong versus LongAdder.
4. Use a LongAccumulator to compute the maximum or minimum of the accumulated elements.
5. Write an application in which multiple threads read all words from a collection of files. Use a ConcurrentHashMap<String, Set<File>> to track in which files each word occurs. Use the merge method to update the map.
6. Repeat the preceding exercise, but use computeIfAbsent instead. What is the advantage of this approach?
7. In a ConcurrentHashMap<String, Long>, find the key with maximum value (breaking ties arbitrarily). Hint: reduceEntries.
8. How large does an array have to be for Arrays.parallelSort to be faster than Arrays.sort on your computer?
9. You can use the parallelPrefix method to parallelize the computation of Fibonacci numbers. We use the fact that the nth Fibonacci number is the top left coefficient of Fn, where ![]() . Make an array filled with 2 × 2 matrices. Define a Matrix class with a multiplication method, use parallelSetAll to make an array of matrices, and use parallelPrefix to multiply them.
. Make an array filled with 2 × 2 matrices. Define a Matrix class with a multiplication method, use parallelSetAll to make an array of matrices, and use parallelPrefix to multiply them.
10. Write a program that asks the user for a URL, then reads the web page at that URL, and then displays all the links. Use a CompletableFuture for each stage. Don’t call get. To prevent your program from terminating prematurely, call
ForkJoinPool.commonPool().awaitQuiescence(10, TimeUnit.SECONDS);
11. Write a method
public static <T> CompletableFuture<T> repeat(
Supplier<T> action, Predicate<T> until)
that asynchronously repeats the action until it produces a value that is accepted by the until function, which should also run asynchronously. Test with a function that reads a java.net.PasswordAuthentication from the console, and a function that simulates a validity check by sleeping for a second and then checking that the password is "secret". Hint: Use recursion.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.