JAVASCRIPT: A Beginner’s Guide to Learning the Basics of JavaScript Programming (2015)
Chapter 21. Regular Expressions in JavaScript
Regular Expressions in JavaScript are used to match the character combinations in strings. They are also referenced as objects, and they are used with the test and exec methods of RegExp with the split, search, replace, and match methods of String. In this chapter, we will discuss the JavaScript regular expressions.
Constructing a Regular Expression
You can create a regular expression in one of the two ways:
Using a regular expression that is composed of a pattern within slashes:
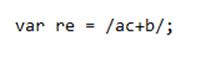
RegExp literals offer compilation of the regular expression if you load the script. If the regular expression could stay fixed, it is ideal to use this for better performance. You can also call the function constructor of the object RegExp as you can see below:
![]()
You can easily compile the runtime RegExp through the constructor function. You can use this function if you are aware that the pattern for regular expression could change, or if you are not aware of the pattern, and you are sourcing it from other avenues like user input.
Writing RegExp Pattern
A RegExp pattern is composed of basic characters like /abc/ or a mixture of simple and special symbols such as /cb*a/ or /Subject (\x)\.\x*/. This example uses parentheses that are used as a memory device. The match made through this composition of the pattern will be stored for future use.
Basic Patterns
Basic patterns are created of symbols for which that you like to look a direct match. For instance, the pattern /cba/ will match the combination of character in strings only if specifically the characters ‘cba’ are matched together and in the right series. This match will be successful in the string that includes ‘cba’.
Special Characters
If the search for a match needs something more than a direct match like finding one or more c’s or looking for white space, the pattern will also include special characters. For instance, the pattern /cb*a/ will match any combination of character, in which the c will be followed zero or more b’s. The character * means that zero or more instances of the earlier item, which will be followed by c.
The table below shows the complete list as well as the description of the special characters, which you can use in RegExp.
|
CHARACTER |
DESCRIPTION |
|
^ |
Will match the start of input. Can also match easily after the character line break if the multi-line flag is defined as true. For instance, /^B/ will not match the ‘B’ in “a B”, but will match the ‘A’ in “An I”. Also remember that ‘^’ has a different meaning if it is used as the first character in a set series. |
|
\ |
The character ‘\’ will match according to these rules: The character ‘\’ preceding a non-special character will signify that the next character is special and should not be interpreted literally. For instance, a ‘c’ without the character ‘\’ will match the lowercase c’s if they happen. However, the ‘\c’ in itself will not match any character, as it will form the special word character boundary. The character ‘\’ that precedes a special character will signify that the next character is not special and must be literally interpreted. For instance, the sequence /c*/ depends on the asterisk (*) to match zero or several c’s. Meanwhile, the series /a\*/ will ignore the * as a special character so the strings will match. |
|
* |
Will match the preceding expression 0 or several instances. This character is equal to {0,}. For instance, /co*/ will match the ‘cooooo’ in “The baby cooooooed” and ‘c’ in “The cat meowed”, but not in “The teen smirked.” |
|
$ |
Will match the end of the input. If the multi-line flag is set to true, this will also immediately match before the character line break. For instance, /g$/ will not match the ‘g’ in “digger”, but will match in “dog”. |
|
? |
Will match the preceding expression zero or one time. This is equal to {0,1}. For instance, /e?re?/ will match the ‘er’ in “ranger” as well as the ‘re’ in “ogre” and also the ‘r’ in “torso”. If you use this immediately after the quantifiers such as {}, ?, +, or *, this will make the quantifier non-greedy, which matches the fewest possible characters, in comparison to the default that could match characters as much as possible. For instance, if you use /\g+/ to “321def” will match 321. But adding /\g+?/ to the same string will only match 3. |
|
+ |
Will match the preceding expression once or several times. This is equal to {1,}. For instance, /r+/ will match the ‘r’ in “brandy” and all the r’s in “grrrrrrrrowl”, but not in “bndy” |
|
. |
The decimal point will match any single character aside from the newline character. For instance, /.s/ will match ‘as’ and ‘is’ “Say yes if you think he is smart” but not ‘say’. |
|
(x) |
Will match ‘x’ and will store the match, as shown below. The parentheses in this character are known as capturing parentheses. The ‘(cute)’ and ‘(bear)’ in the series /(cute) (bear) \1\2/ match and the series will store the first two words in the string “cute bear cute bear”. The \1 \2 in this pattern will match the last two words of the string. Notcie that the \1, \2, \n are used in the matching composition of the regex. |
|
x(?=y) |
Will match ‘x’ if ‘x’ is followed by ‘y’. For instance, /Jessica(?=Alba)/ will only match ‘Jessica’ if it is followed by ‘Alba’. /Jessica(?=Alba|Simpson)/ will match ‘Jessica’ if this is followed by ‘Alba’ or ‘Simpson’. But neither ‘Alba’ nor ‘Simpson’ is part of the matching results. |
|
(?:x) |
Will match ‘x’ but will not store it in memory. The parentheses used in this character are known as non-capturing parentheses. These will allow you to define subexpression for regexp operators to perform their function. Take a look at this example: /(?:bee){1,2}/ If this expression was /bee{1,2}/, the characters {1,2} will only apply to the last ‘e’ in ‘bee’. Because we have used non-capturing parentheses, the {1,2} function will apply for the whole word ‘bee’. |
|
x(?!y) |
This is known as a negated lookahead. Will match x if it is not followed by y. For instance, /\d+(?!\.)/ will match a number if it is only followed by a decimal point. The regexp /\d+(?!\.)/.exec(“2.564”) will match 564, but not 2.564. |
|
x|y |
Will match x or y. For instance, /yellow|black/ will match ‘yellow’ in “yellow flag” and ‘black’ in “black shirt”. |
|
{n,m} |
In this character, n and m are positive integers and n is lower than or equal to m. This will match at least n and at most instances of the preceding expression. If you omit m, it will be treated as infinity. |
|
For instance, /a{1,3}will match nothing in “brndy”, the ‘a’ in “brandy.” The first two a’s in “brandy,” and the first three a’s in “braaaaaaandy”. Take note than in matching “braaaaaaandy”, the match will be “aaa”, although the primary string carries more than a’s. |
|
|
{n} |
Wil match precisely n instances of the preceding expression. N should be a positive integer. For instance, /e{2} will not match the ‘e’ in “rent”, but it will match all the e’s in “reent” as well as the first two e’s in “reeent”. |
|
[^xyz] |
This is a complemented or a negated character set. It will match anything, which is not confined in the braces. You can define a range of characters through the use of a hyphen. Everything that will work in the regular character set will also function here. For instance, [^bod] is similar to [^b-d]. |
|
[xyz] |
This character set will match any character confined in the braces, which includes the escape series. Special characters such as the asterisk (*) and the dot (.) will lose their specialness when confined within the character set, so there is no need to escape them. You can define a range of characters through the use of a hyphen. For example, the pattern [d-g] functions similar to the match of [defg]. Hence, it will match the ‘e’ in “elephant” and ‘f’ in “fowl”. |
|
\b |
Will match a word boundary, which matches the position of the word character is not preceded or followed by another character-word. Remember, a matching word boundary will not be included in the match. To put it simply, the length of the word boundary match is 0. You should not confuse this with [\b].) For example: /\bs/ will match the ‘s’ in “soon”; /oo\b/ will not match the ‘oo’ in “soon”, as ‘oo’ is followed by ‘n’ that is a word character /oon\b/ will match the ‘oon’ in “soon” as the ‘oon’ is the string end, and not followed by the character word. /\w\b\w/ will not match anything, as the word character may never be followed by both word and non-word character. Take note that the RegExp in JavaScript will define the certain set of characters to be the character words. Characters that are not specified in the set will be regarded as break words. The character sets are fairly limited, and it solely composed of the Roman alphabet in lower and upper case, underscore symbol, and decimal units. Characters that are accented are considered as word breaks. |
|
\cX |
In this character, X refers to a range from A to Z. This will match a character control in a string. For instance, /\cM/ will match the string in control-M. |
|
\B |
This character will match a boundary non-word. This will match a position that the preceding and following character are the same, which are both non-words or words. The start and end string are regarded as non-words. |
|
\D |
Will match any character that is non-digit, which is equal to [^0-9] |
|
\d |
Will match any digit character, which is equal to [0-9] |
Use of Parentheses
Adding parentheses in any RegExp pattern will result to that section to be stored in memory. Through this, you can retrieve the substring for other purposes.
For instance, the series /Section (\d+)\.\d*/ shows added escaped and special characters and will indicate this section of the pattern should be stored in memory. This will precisely match the characters ‘Section’ followed by a single or several numeral character (\d refers to any numeral character while + refers once or more instances). This is followed by a decimal point that is a special character. This precedes the decimal point with \means the series should find the character ‘.’ literally.
If followed by any numeral character zero or more times, (\d refers to numeral character, while * refers to 0 or several times. Also, the parentheses can be used to store the memory for the first matched of numeral character. This series is found in “Read Section 3.4, line 5” while ‘3’ is stored in memory. The series is not found in Section 3 and 4, since these strings are not followed by the decimal point.
In order to match a substring without the storing it to the memory, inside the parentheses, you can preface the series with ?. For instance, (?:\d+) will match one or several numeral characters. However, this will not remember the characters that match.
Using Methods with RegExp
You can use regular expressions with RegExp methods exec and test alongside the String methods: split, search, replace, and match. Below is a short description of these methods:
|
Method |
Description |
|
Split |
This String method employs a fixed string or a RegExp in order to break a string into substring arrays |
|
Replace |
This String method can look up for a match in a string, and will replace this matched substring with another specified substring |
|
Search |
This String method can check for a string match. It will return the match index, or negative 1 if there is a failure in search |
|
Match |
This String method can look up for a string match and will return mismatch null or information array. |
|
Test |
This RegExp will check for a string match, which returns information array. |
|
Exec |
This RegExp method will launch a lookup for a string match, and will return information array. |
If you like to determine if a pattern is present in a string, you can use the search or test method. For more info you can use the match or exec methods. If you are using the match or exec and the former is successful, these methods will yield an array and will update the properties of the relevant RegExp object as well as the predefined regular expression object. If the match is a failure, the method exec will yield null that will coerce false.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.