Java Network Programming, 4th Edition (2013)
Chapter 1. Basic Network Concepts
Network programming is no longer the province of a few specialists. It has become a core part of every developer’s toolbox. Today, more programs are network aware than aren’t. Besides classic applications like email, web browsers, and remote login, most major applications have some level of networking built in. For example:
§ Text editors like BBEdit save and open files directly from FTP servers.
§ IDEs like Eclipse and IntelliJ IDEA communicate with source code repositories like GitHub and Sourceforge.
§ Word processors like Microsoft Word open files from URLs.
§ Antivirus programs like Norton AntiVirus check for new virus definitions by connecting to the vendor’s website every time the computer is started.
§ Music players like Winamp and iTunes upload CD track lengths to CDDB and download the corresponding track titles.
§ Gamers playing multiplayer first-person shooters like Halo gleefully frag each other in real time.
§ Supermarket cash registers running IBM SurePOS ACE communicate with their store’s server in real time with each transaction. The server uploads its daily receipts to the chain’s central computers each night.
§ Schedule applications like Microsoft Outlook automatically synchronize calendars among employees in a company.
Java was the first programming language designed from the ground up for network applications. Java was originally aimed at proprietary cable television networks rather than the Internet, but it’s always had the network foremost in mind. One of the first two real Java applications was a web browser. As the Internet continues to grow, Java is uniquely suited to build the next generation of network applications.
One of the biggest secrets about Java is that it makes writing network programs easy. In fact, it is far easier to write network programs in Java than in almost any other language. This book shows you dozens of complete programs that take advantage of the Internet. Some are simple textbook examples, while others are completely functional applications. One thing you’ll notice in the fully functional applications is just how little code is devoted to networking. Even in network-intensive programs like web servers and clients, almost all the code handles data manipulation or the user interface. The part of the program that deals with the network is almost always the shortest and simplest. In brief, it is easy for Java applications to send and receive data across the Internet.
This chapter covers the background networking concepts you need to understand before writing networked programs in Java (or, for that matter, in any language). Moving from the most general to the most specific, it explains what you need to know about networks in general, IP and TCP/IP-based networks in particular, and the Internet. This chapter doesn’t try to teach you how to wire a network or configure a router, but you will learn what you need to know to write applications that communicate across the Internet. Topics covered in this chapter include the nature of networks; the TCP/IP layer model; the IP, TCP, and UDP protocols; firewalls and proxy servers; the Internet; and the Internet standardization process. Experienced network gurus may safely skip this chapter, and move on to the next chapter where you begin developing the tools needed to write your own network programs in Java.
Networks
A network is a collection of computers and other devices that can send data to and receive data from one another, more or less in real time. A network is often connected by wires, and the bits of data are turned into electromagnetic waves that move through the wires. However, wireless networks transmit data using radio waves; and most long-distance transmissions are now carried over fiber-optic cables that send light waves through glass filaments. There’s nothing sacred about any particular physical medium for the transmission of data. Theoretically, data could be transmitted by coal-powered computers that send smoke signals to one another. The response time (and environmental impact) of such a network would be rather poor.
Each machine on a network is called a node. Most nodes are computers, but printers, routers, bridges, gateways, dumb terminals, and Coca-Cola™ machines can also be nodes. You might use Java to interface with a Coke machine, but otherwise you’ll mostly talk to other computers. Nodes that are fully functional computers are also called hosts. I will use the word node to refer to any device on the network, and the word host to refer to a node that is a general-purpose computer.
Every network node has an address, a sequence of bytes that uniquely identifies it. You can think of this group of bytes as a number, but in general the number of bytes in an address or the ordering of those bytes (big endian or little endian) is not guaranteed to match any primitive numeric data type in Java. The more bytes there are in each address, the more addresses there are available and the more devices that can be connected to the network simultaneously.
Addresses are assigned differently on different kinds of networks. Ethernet addresses are attached to the physical Ethernet hardware. Manufacturers of Ethernet hardware use preassigned manufacturer codes to make sure there are no conflicts between the addresses in their hardware and the addresses of other manufacturers’ hardware. Each manufacturer is responsible for making sure it doesn’t ship two Ethernet cards with the same address. Internet addresses are normally assigned to a computer by the organization that is responsible for it. However, the addresses that an organization is allowed to choose for its computers are assigned by the organization’s Internet service provider (ISP). ISPs get their IP addresses from one of four regional Internet registries (the registry for North America is ARIN, the American Registry for Internet Numbers), which are in turn assigned IP addresses by the Internet Corporation for Assigned Names and Numbers (ICANN).
On some kinds of networks, nodes also have text names that help human beings identify them such as “www.elharo.com” or “Beth Harold’s Computer.” At a set moment in time, a particular name normally refers to exactly one address. However, names are not locked to addresses. Names can change while addresses stay the same; likewise, addresses can change while the names stay the same. One address can have several names and one name can refer to several different addresses.
All modern computer networks are packet-switched networks: data traveling on the network is broken into chunks called packets and each packet is handled separately. Each packet contains information about who sent it and where it’s going. The most important advantage of breaking data into individually addressed packets is that packets from many ongoing exchanges can travel on one wire, which makes it much cheaper to build a network: many computers can share the same wire without interfering. (In contrast, when you make a local telephone call within the same exchange on a traditional phone line, you have essentially reserved a wire from your phone to the phone of the person you’re calling. When all the wires are in use, as sometimes happens during a major emergency or holiday, not everyone who picks up a phone will get a dial tone. If you stay on the line, you’ll eventually get a dial tone when a line becomes free. In some countries with worse phone service than the United States, it’s not uncommon to have to wait half an hour or more for a dial tone.) Another advantage of packets is that checksums can be used to detect whether a packet was damaged in transit.
We’re still missing one important piece: some notion of what computers need to say to pass data back and forth. A protocol is a precise set of rules defining how computers communicate: the format of addresses, how data is split into packets, and so on. There are many different protocols defining different aspects of network communication. For example, the Hypertext Transfer Protocol (HTTP) defines how web browsers and servers communicate; at the other end of the spectrum, the IEEE 802.3 standard defines a protocol for how bits are encoded as electrical signals on a particular type of wire. Open, published protocol standards allow software and equipment from different vendors to communicate with one another. A web server doesn’t care whether the client is a Unix workstation, an Android phone, or an iPad, because all clients speak the same HTTP protocol regardless of platform.
The Layers of a Network
Sending data across a network is a complex operation that must be carefully tuned to the physical characteristics of the network as well as the logical character of the data being sent. Software that sends data across a network must understand how to avoid collisions between packets, convert digital data to analog signals, detect and correct errors, route packets from one host to another, and more. The process is further complicated when the requirement to support multiple operating systems and heterogeneous network cabling is added.
To hide most of this complexity from the application developer and end user, the different aspects of network communication are separated into multiple layers. Each layer represents a different level of abstraction between the physical hardware (i.e., the wires and electricity) and the information being transmitted. In theory, each layer only talks to the layers immediately above and immediately below it. Separating the network into layers lets you modify or even replace the software in one layer without affecting the others, as long as the interfaces between the layers stay the same.
Figure 1-1 shows a stack of possible protocols that may exist in your network. While the middle layer protocols are fairly consistent across most of the Internet today, the top and the bottom vary a lot. Some hosts use Ethernet; some use WiFi; some use PPP; some use something else. Similarly, what’s on the top of the stack will depend completely on which programs a host is running. The key is that from the top of the stack, it doesn’t really matter what’s on the bottom and vice versa. The layer model decouples the application protocols (the main subject of this book) from the physics of the network hardware and the topology of the network connections.
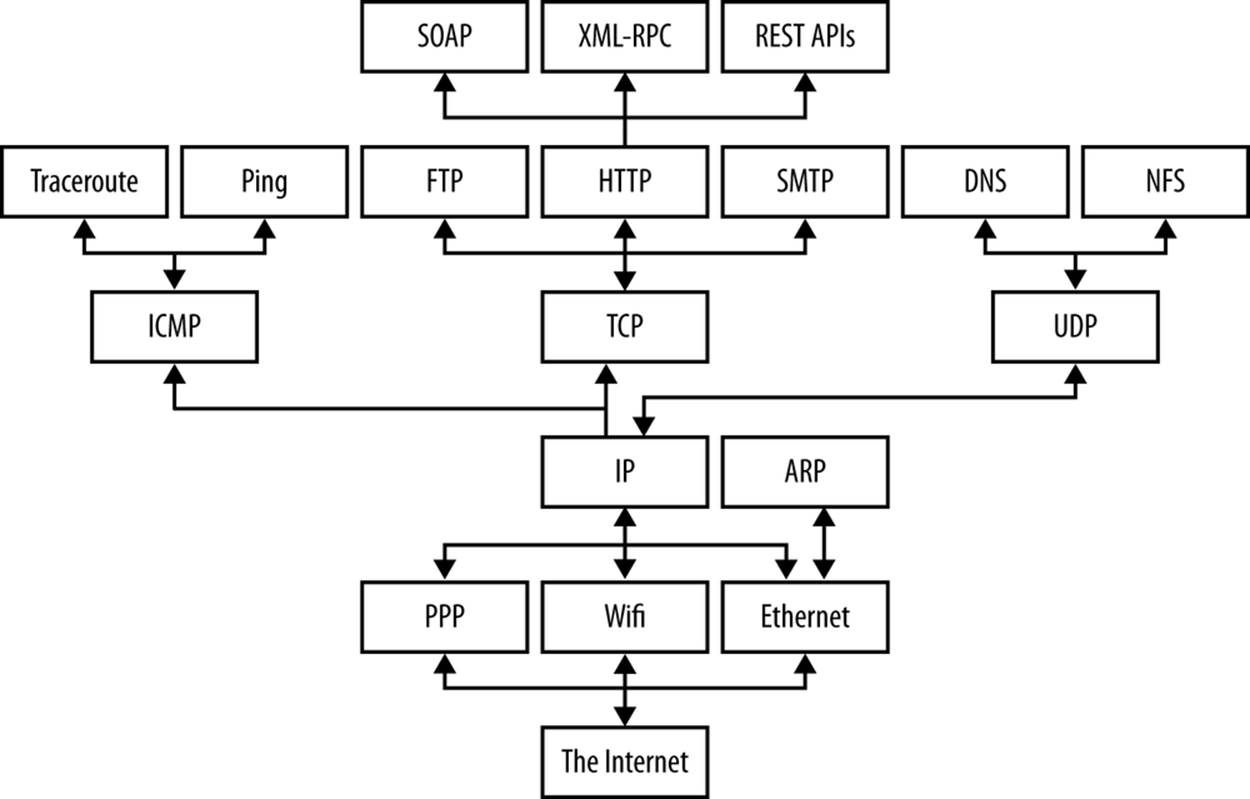
Figure 1-1. Protocols in different layers of a network
There are several different layer models, each organized to fit the needs of a particular kind of network. This book uses the standard TCP/IP four-layer model appropriate for the Internet, shown in Figure 1-2. In this model, applications like Firefox and Warcraft run in the application layer and talk only to the transport layer. The transport layer talks only to the application layer and the Internet layer. The Internet layer in turn talks only to the host-to-network layer and the transport layer, never directly to the application layer. The host-to-network layer moves the data across the wires, fiber-optic cables, or other medium to the host-to-network layer on the remote system, which then moves the data up the layers to the application on the remote system.
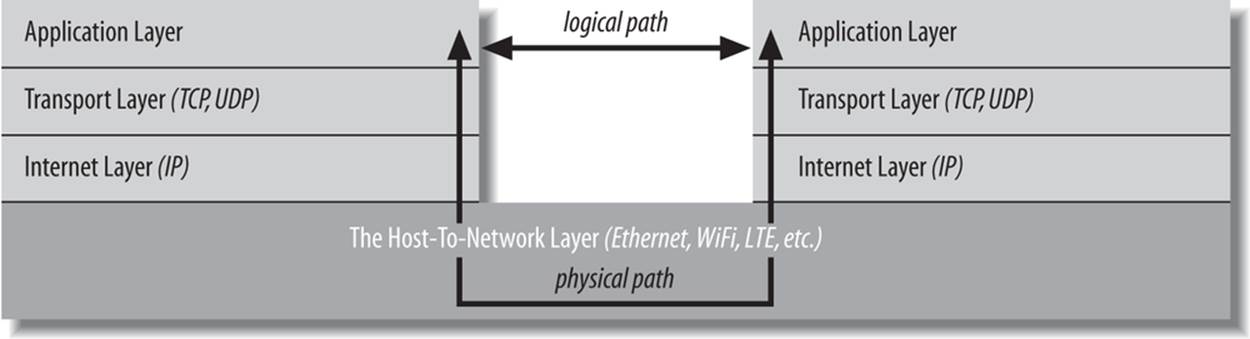
Figure 1-2. The layers of a network
For example, when a web browser sends a request to a web server to retrieve a page, the browser is actually talking to the transport layer on the local client machine. The transport layer breaks the request into TCP segments, adds some sequence numbers and checksums to the data, and then passes the request to the local internet layer. The internet layer fragments the segments into IP datagrams of the necessary size for the local network and passes them to the host-to-network layer for transmission onto the wire. The host-to-network layer encodes the digital data as analog signals appropriate for the particular physical medium and sends the request out the wire where it will be read by the host-to-network layer of the remote system to which it’s addressed.
The host-to-network layer on the remote system decodes the analog signals into digital data, then passes the resulting IP datagrams to the server’s internet layer. The internet layer does some simple checks to see that the IP datagrams aren’t corrupt, reassembles them if they’ve been fragmented, and passes them to the server’s transport layer. The server’s transport layer checks to see that all the data arrived and requests retransmission of any missing or corrupt pieces. (This request actually goes back down through the server’s internet layer, through the server’s host-to-network layer, and back to the client system, where it bubbles back up to the client’s transport layer, which retransmits the missing data back down through the layers. This is all transparent to the application layer.) Once the server’s transport layer has received enough contiguous, sequential datagrams, it reassembles them and writes them onto a stream read by the web server running in the server application layer. The server responds to the request and sends its response back down through the layers on the server system for transmission back across the Internet and delivery to the web client.
As you can guess, the real process is much more elaborate. The host-to-network layer is by far the most complex, and a lot has been deliberately hidden. For example, it’s entirely possible that data sent across the Internet will pass through several routers and their layers before reaching its final destination. It may need to be converted from radio waves in the air to electrical signals in copper wire to light pulses in fiber-optic cables and back again, possibly more than once. However, 90% of the time your Java code will work in the application layer and only need to talk to the transport layer. The other 10% of the time, you’ll be in the transport layer and talking to the application layer or the internet layer. The complexity of the host-to-network layer is hidden from you; that’s the point of the layer model.
TIP
If you read the network literature, you’re likely to encounter an alternative seven-layer model called the Open Systems Interconnection (OSI) Reference Model. For network programs in Java, the OSI model is overkill. The biggest difference between the OSI model and the TCP/IP model used in this book is that the OSI model splits the host-to-network layer into data link and physical layers and inserts presentation and session layers in between the application and transport layers. The OSI model is more general and better suited for non-TCP/IP networks, although most of the time it’s still overly complex. In any case, Java’s network classes only work on TCP/IP networks and always in the application or transport layers, so for the purposes of this book, absolutely nothing is gained by using the more complicated OSI model.
To the application layer, it seems as if it is talking directly to the application layer on the other system; the network creates a logical path between the two application layers. It’s easy to understand the logical path if you think about an IRC chat session. Most participants in an IRC chat would say that they’re talking to another person. If you really push them, they might say that they’re talking to their computer (really the application layer), which is talking to the other person’s computer, which is talking to the other person. Everything more than one layer deep is effectively invisible, and that is exactly the way it should be. Let’s consider each layer in more detail.
The Host-to-Network Layer
As a Java programmer, you’re fairly high up in the network food chain. A lot happens below your radar. In the standard reference model for IP-based Internets (the only kind of network Java really understands), the hidden parts of the network belong to the host-to-network layer (also known as the link layer, data link layer, or network interface layer). The host-to-network layer defines how a particular network interface—such as an Ethernet card or a WiFi antenna—sends IP datagrams over its physical connection to the local network and the world.
The part of the host-to-network layer made up of the hardware that connects different computers (wires, fiber-optic cables, radio waves, or smoke signals) is sometimes called the physical layer of the network. As a Java programmer, you don’t need to worry about this layer unless something goes wrong—the plug falls out of the back of your computer, or someone drops a backhoe through the T–1 line between you and the rest of the world. In other words, Java never sees the physical layer.
The primary reason you’ll need to think about the host-to-network layer and the physical layer, if you need to think about them at all, is performance. For instance, if your clients reside on fast, reliable fiber-optic connections, you will design your protocol and applications differently than if they’re on high-latency satellite connections on an oil rig in the North Sea. You’ll make still different choices if your clients are on a 3G data plan where they’re charged by the byte for relatively low bandwidth. And if you’re writing a general consumer application that could be used by any of these clients, you’ll try to hit a sweet spot somewhere in the middle, or perhaps even detect and dynamically adapt to individual client capabilities. However, whichever physical links you encounter, the APIs you use to communicate across those networks are the same. What makes that possible is the internet layer.
The Internet Layer
The next layer of the network, and the first that you need to concern yourself with, is the internet layer. In the OSI model, the internet layer goes by the more generic name network layer. A network layer protocol defines how bits and bytes of data are organized into the larger groups called packets, and the addressing scheme by which different machines find one another. The Internet Protocol (IP) is the most widely used network layer protocol in the world and the only network layer protocol Java understands.
In fact, it’s two protocols: IPv4, which uses 32-bit addresses, and IPv6, which uses 128-bit addresses and adds a few other technical features to assist with routing. At the time of this writing, IPv4 still accounts for more than 90% of Internet traffic, but IPv6 is catching on fast and may well surpass IPv4 before the next edition of this book. Although these are two very different network protocols that do not interoperate on the same network without special gateways and/or tunneling protocols, Java hides almost all of the differences from you.
In both IPv4 and IPv6, data is sent across the internet layer in packets called datagrams. Each IPv4 datagram contains a header between 20 and 60 bytes long and a payload that contains up to 65,515 bytes of data. (In practice, most IPv4 datagrams are much smaller, ranging from a few dozen bytes to a little more than eight kilobytes.) An IPv6 datagram contains a larger header and up to four gigabytes of data.
Figure 1-3 shows how the different quantities are arranged in an IPv4 datagram. All bits and bytes are big endian; most significant to least significant runs left to right.
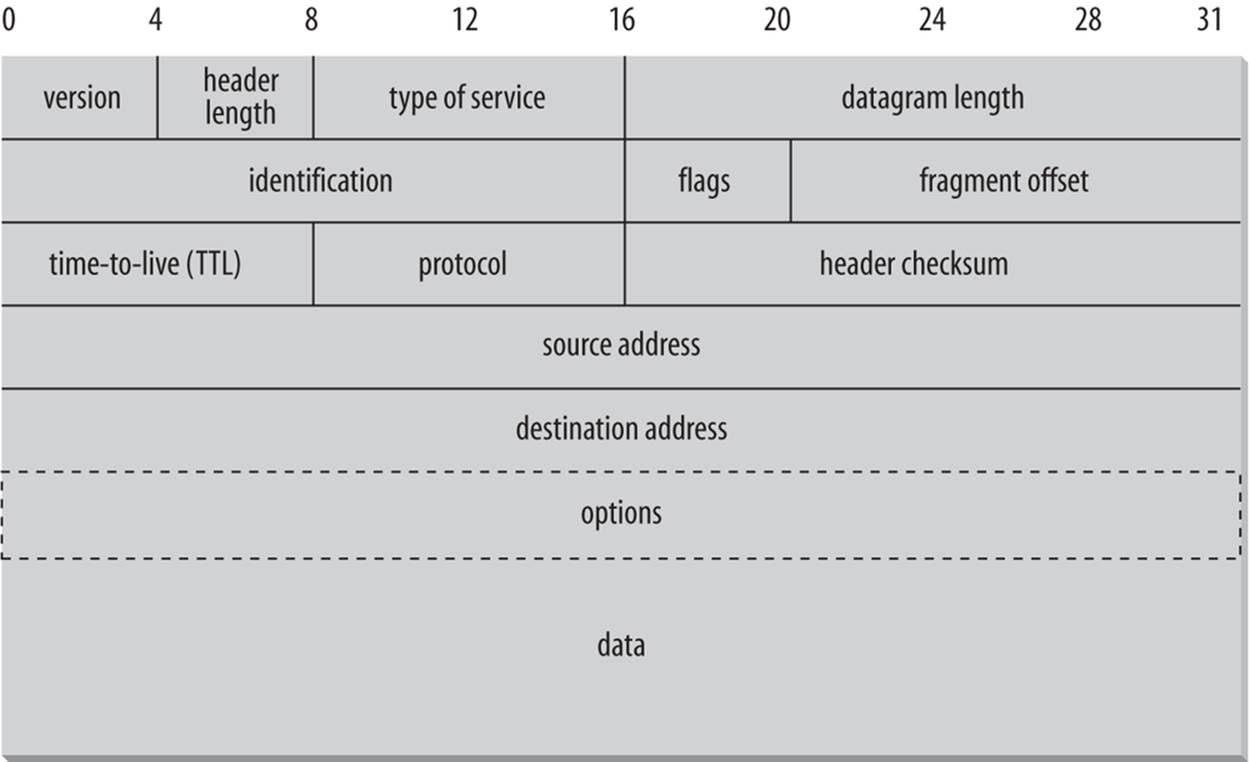
Figure 1-3. The structure of an IPv4 datagram
Besides routing and addressing, the second purpose of the Internet layer is to enable different types of Host-to-Network layers to talk to each other. Internet routers translate between WiFi and Ethernet, Ethernet and DSL, DSL and fiber-optic backhaul protocols, and so forth. Without the internet layer or something like it, each computer could only talk to other computers that shared its particular type of network. The internet layer is responsible for connecting heterogenous networks to each other using homogeneous protocols.
The Transport Layer
Raw datagrams have some drawbacks. Most notably, there’s no guarantee that they will be delivered. Even if they are delivered, they may have been corrupted in transit. The header checksum can only detect corruption in the header, not in the data portion of a datagram. Finally, even if the datagrams arrive uncorrupted, they do not necessarily arrive in the order in which they were sent. Individual datagrams may follow different routes from source to destination. Just because datagram A is sent before datagram B does not mean that datagram A will arrive before datagram B.
The transport layer is responsible for ensuring that packets are received in the order they were sent and that no data is lost or corrupted. If a packet is lost, the transport layer can ask the sender to retransmit the packet. IP networks implement this by adding an additional header to each datagram that contains more information. There are two primary protocols at this level. The first, the Transmission Control Protocol (TCP), is a high-overhead protocol that allows for retransmission of lost or corrupted data and delivery of bytes in the order they were sent. The second protocol, the User Datagram Protocol (UDP), allows the receiver to detect corrupted packets but does not guarantee that packets are delivered in the correct order (or at all). However, UDP is often much faster than TCP. TCP is called a reliable protocol; UDP is an unreliable protocol. Later, you’ll see that unreliable protocols are much more useful than they sound.
The Application Layer
The layer that delivers data to the user is called the application layer. The three lower layers all work together to define how data is transferred from one computer to another. The application layer decides what to do with the data after it’s transferred. For example, an application protocol like HTTP (for the World Wide Web) makes sure that your web browser displays a graphic image as a picture, not a long stream of numbers. The application layer is where most of the network parts of your programs spend their time. There is an entire alphabet soup of application layer protocols: in addition to HTTP for the Web, there are SMTP, POP, and IMAP for email; FTP, FSP, and TFTP for file transfer; NFS for file access; Gnutella and BitTorrent for file sharing; the Session Initiation Protocol (SIP) and Skype for voice communication; and many, many more. In addition, your programs can define their own application layer protocols as necessary.
IP, TCP, and UDP
IP, the Internet protocol, was developed with military sponsorship during the Cold War, and ended up with a lot of features that the military was interested in. First, it had to be robust. The entire network couldn’t stop functioning if the Soviets nuked a router in Cleveland; all messages still had to get through to their intended destinations (except those going to Cleveland, of course). Therefore, IP was designed to allow multiple routes between any two points and to route packets of data around damaged routers.
Second, the military had many different kinds of computers, and all of them had to be able to talk to one another. Therefore, IP had to be open and platform-independent; it wasn’t good enough to have one protocol for IBM mainframes and another for PDP-11s. The IBM mainframes needed to talk to the PDP-11s and any other strange computers that might be lying around.
Because there are multiple routes between two points, and because the quickest path between two points may change over time as a function of network traffic and other factors (such as the existence of Cleveland), the packets that make up a particular data stream may not all take the same route. Furthermore, they may not arrive in the order they were sent, if they even arrive at all. To improve on the basic scheme, TCP was layered on top of IP to give each end of a connection the ability to acknowledge receipt of IP packets and request retransmission of lost or corrupted packets. Furthermore, TCP allows the packets to be put back together on the receiving end in the same order they were sent.
TCP, however, carries a fair amount of overhead. Therefore, if the order of the data isn’t particularly important and if the loss of individual packets won’t completely corrupt the data stream, packets are sometimes sent without the guarantees that TCP provides using the UDP protocol. UDP is an unreliable protocol that does not guarantee that packets will arrive at their destination or that they will arrive in the same order they were sent. Although this would be a problem for uses such as file transfer, it is perfectly acceptable for applications where the loss of some data would go unnoticed by the end user. For example, losing a few bits from a video or audio signal won’t cause much degradation; it would be a bigger problem if you had to wait for a protocol like TCP to request a retransmission of missing data. Furthermore, error-correcting codes can be built into UDP data streams at the application level to account for missing data.
A number of other protocols can run on top of IP. The most commonly requested is ICMP, the Internet Control Message Protocol, which uses raw IP datagrams to relay error messages between hosts. The best-known use of this protocol is in the ping program. Java does not support ICMP, nor does it allow the sending of raw IP datagrams (as opposed to TCP segments or UDP datagrams). The only protocols Java supports are TCP and UDP, and application layer protocols built on top of these. All other transport layer, internet layer, and lower layer protocols such as ICMP, IGMP, ARP, RARP, RSVP, and others can only be implemented in Java programs by linking to native code.
IP Addresses and Domain Names
As a Java programmer, you don’t need to worry about the inner workings of IP, but you do need to know about addressing. Every computer on an IPv4 network is identified by a four-byte number. This is normally written in a dotted quad format like 199.1.32.90, where each of the four numbers is one unsigned byte ranging in value from 0 to 255. Every computer attached to an IPv4 network has a unique four-byte address. When data is transmitted across the network, the packet’s header includes the address of the machine for which the packet is intended (the destination address) and the address of the machine that sent the packet (the source address). Routers along the way choose the best route on which to send the packet by inspecting the destination address. The source address is included so the recipient will know who to reply to.
There are a little more than four billion possible IP addresses, not even one for every person on the planet, much less for every computer. To make matters worse, the addresses aren’t allocated very efficiently. In April 2011, Asia and Australia ran out. No more IPv4 addresses were available to be allocated to these regions; and they have since had to make do by recycling and reallocating from their existing supply. In September 2012, Europe ran out too. North America, Latin America, and Africa still have a few IP address blocks left to parcel out, but they’re not going to last much longer.
A slow transition is under way to IPv6, which will use 16-byte addresses. This provides enough IP addresses to identify every person, every computer, and indeed every device on the planet. IPv6 addresses are customarily written in eight blocks of four hexadecimal digits separated by colons, such as FEDC:BA98:7654:3210:FEDC:BA98:7654:3210. Leading zeros do not need to be written. A double colon, at most one of which may appear in any address, indicates multiple zero blocks. For example, FEDC:0000:0000:0000:00DC:0000:7076:0010 could be written more compactly as FEDC::DC:0:7076:10. In mixed networks of IPv6 and IPv4, the last four bytes of the IPv6 address are sometimes written as an IPv4 dotted quad address. For example, FEDC:BA98:7654:3210:FEDC:BA98:7654:3210 could be written asFEDC:BA98:7654:3210:FEDC:BA98:118.84.50.16.
Although computers are very comfortable with numbers, human beings aren’t very good at remembering them. Therefore, the Domain Name System (DNS) was developed to translate hostnames that humans can remember, such as “www.oreilly.com,” into numeric Internet addresses such as 208.201.239.101. When Java programs access the network, they need to process both these numeric addresses and their corresponding hostnames. Methods for doing this are provided by the java.net.InetAddress class, which is discussed in Chapter 4.
Some computers, especially servers, have fixed addresses. Others, especially clients on local area networks and wireless connections, receive a different address every time they boot up, often provided by a DHCP server. Mostly you just need to remember that IP addresses may change over time, and not write any code that relies on a system having the same IP address. For instance, don’t store the local IP address when saving application state. Instead, look it up fresh each time your program starts. It’s also possible, although less likely, for an IP address to change while the program is running (e.g., if a DHCP lease expires), so you may want to check the current IP address every time you need it rather than caching it. Otherwise, the difference between a dynamically and manually assigned address is not significant to Java programs.
Several address blocks and patterns are special. All IPv4 addresses that begin with 10., 172.16. through 172.31. and 192.168. are unassigned. They can be used on internal networks, but no host using addresses in these blocks is allowed onto the global Internet. These non-routable addresses are useful for building private networks that can’t be seen on the Internet. IPv4 addresses beginning with 127 (most commonly 127.0.0.1) always mean the local loopback address. That is, these addresses always point to the local computer, no matter which computer you’re running on. The hostname for this address is often localhost. In IPv6, 0:0:0:0:0:0:0:1 (a.k.a. ::1) is the loopback address. The address 0.0.0.0 always refers to the originating host, but may only be used as a source address, not a destination. Similarly, any IPv4 address that begins with 0. (eight zero bits) is assumed to refer to a host on the same local network.
The IPv4 address that uses the same number for each of the four bytes (i.e., 255.255.255.255), is a broadcast address. Packets sent to this address are received by all nodes on the local network, though they are not routed beyond the local network. This is commonly used for discovery. For instance, when an ephemeral client such as a laptop boots up, it will send a particular message to 255.255.255.255 to find the local DHCP server. All nodes on the network receive the packet, but only the DHCP server responds. In particular, it sends the laptop information about the local network configuration, including the IP address that laptop should use for the remainder of its session and the address of a DNS server it can use to resolve hostnames.
Ports
Addresses would be all you needed if each computer did no more than one thing at a time. However, modern computers do many different things at once. Email needs to be separated from FTP requests, which need to be separated from web traffic. This is accomplished through ports. Each computer with an IP address has several thousand logical ports (65,535 per transport layer protocol, to be precise). These are purely abstractions in the computer’s memory and do not represent anything physical, like a USB port. Each port is identified by a number between 1 and 65535. Each port can be allocated to a particular service.
For example, HTTP, the underlying protocol of the Web, commonly uses port 80. We say that a web server listens on port 80 for incoming connections. When data is sent to a web server on a particular machine at a particular IP address, it is also sent to a particular port (usually port 80) on that machine. The receiver checks each packet it sees for the port and sends the data to any program that is listening to that port. This is how different types of traffic are sorted out.
Port numbers between 1 and 1023 are reserved for well-known services like finger, FTP, HTTP, and IMAP. On Unix systems, including Linux and Mac OS X, only programs running as root can receive data from these ports, but all programs may send data to them. On Windows, any program may use these ports without special privileges. Table 1-1 shows the well-known ports for the protocols that are discussed in this book. These assignments are not absolutely guaranteed; in particular, web servers often run on ports other than 80, either because multiple servers need to run on the same machine or because the person who installed the server doesn’t have the root privileges needed to run it on port 80. On Unix systems, a fairly complete listing of assigned ports is stored in the file /etc/services.
Table 1-1. Well-known port assignments
|
Protocol |
Port |
Protocol |
Purpose |
|
echo |
7 |
TCP/UDP |
Echo is a test protocol used to verify that two machines are able to connect by having one echo back the other’s input. |
|
discard |
9 |
TCP/UDP |
Discard is a less useful test protocol in which all data received by the server is ignored. |
|
daytime |
13 |
TCP/UDP |
Provides an ASCII representation of the current time on the server. |
|
FTP data |
20 |
TCP |
FTP uses two well-known ports. This port is used to transfer files. |
|
FTP |
21 |
TCP |
This port is used to send FTP commands like put and get. |
|
SSH |
22 |
TCP |
Used for encrypted, remote logins. |
|
Telnet |
23 |
TCP |
Used for interactive, remote command-line sessions. |
|
smtp |
25 |
TCP |
The Simple Mail Transfer Protocol is used to send email between machines. |
|
time |
37 |
TCP/UDP |
A time server returns the number of seconds that have elapsed on the server since midnight, January 1, 1900, as a four-byte, unsigned, big-endian integer. |
|
whois |
43 |
TCP |
A simple directory service for Internet network administrators. |
|
finger |
79 |
TCP |
A service that returns information about a user or users on the local system. |
|
HTTP |
80 |
TCP |
The underlying protocol of the World Wide Web. |
|
POP3 |
110 |
TCP |
Post Office Protocol version 3 is a protocol for the transfer of accumulated email from the host to sporadically connected clients. |
|
NNTP |
119 |
TCP |
Usenet news transfer; more formally known as the “Network News Transfer Protocol.” |
|
IMAP |
143 |
TCP |
Internet Message Access Protocol is a protocol for accessing mailboxes stored on a server. |
|
dict |
2628 |
TCP |
A UTF-8 encoded dictionary service that provides definitions of words. |
The Internet
The Internet is the world’s largest IP-based network. It is an amorphous group of computers in many different countries on all seven continents (Antarctica included) that talk to one another using IP protocols. Each computer on the Internet has at least one IP address by which it can be identified. Many of them also have at least one name that maps to that IP address. The Internet is not owned by anyone, although pieces of it are. It is not governed by anyone, which is not to say that some governments don’t try. It is simply a very large collection of computers that have agreed to talk to one another in a standard way.
The Internet is not the only IP-based network, but it is the largest one. Other IP networks are called internets with a little i: for example, a high-security internal network that is not connected to the global Internet. Intranet loosely describes corporate practices of putting lots of data on internal web servers that are not visible to users outside the local network.
Unless you’re working in a high-security environment that’s physically disconnected from the broader network, it’s likely that the internet you’ll be using is the Internet. To make sure that hosts on different networks on the Internet can communicate with each other, a few rules need to be followed that don’t apply to purely internal internets. The most important rules deal with the assignment of addresses to different organizations, companies, and individuals. If everyone picked the Internet addresses they wanted at random, conflicts would arise almost immediately when different computers showed up on the Internet with the same address.
Internet Address Blocks
To avoid this problem, blocks of IPv4 addresses are assigned to Internet service providers (ISPs) by their regional Internet registry. When a company or an organization wants to set up an IP-based network connected to the Internet, their ISP assigns them a block of addresses. Each block has a fixed prefix. For instance if the prefix is 216.254.85, then the local network can use addresses from 216.254.85.0 to 216.254.85.255. Because this block fixes the first 24 bits, it’s called a /24. A /23 specifies the first 23 bits, leaving 9 bits for 29 or 512 total local IP addresses. A /30 subnet (the smallest possible) specifies the first 30 bits of the IP addresses within the subnetwork, leaving 2 bits for 22 or 4 total local IP addresses. However, the lowest address in all block used to identify the network itself, and the largest address is a broadcast address for the network, so you have two fewer available addresses than you might first expect.
Network Address Translation
Because of the increasing scarcity of and demand for raw IP addresses, most networks today use Network Address Translation (NAT). In NAT-based networks most nodes only have local, non-routable addresses selected from either 10.x.x.x, 172.16.x.x to 172.31.x.x, or 192.168.x.x. The routers that connect the local networks to the ISP translate these local addresses to a much smaller set of routable addresses.
For instance, the dozen or so IP nodes in my apartment all share a single externally visible IP address. The computer on which I’m typing this has the IP address 192.168.1.5, but on your network that address may refer to a completely different host, if it exists at all. Nor could you reach my computer by sending data to 192.168.1.5. Instead, you’d have to send to 216.254.85.72 (and even then, the data would only get through if I had configured my NAT router to pass incoming connections on to 192.168.1.5).
The router watches my outgoing and incoming connections and adjusts the addresses in the IP packets. For an outgoing packet, it changes the source address to the router’s external address (216.254.85.72 on my network). For an incoming packet, it changes the destination address to one of the local addresses, such as 192.168.1.12. Exactly how it keeps track of which connections come from and are aimed at which internal computers is not particularly important to a Java programmer. As long as your machines are configured properly, this process is mostly transparent. You just need to remember that the external and internal addresses may not be the same.
Eventually, IPv6 should make most of this obsolete. NAT will be pointless, though firewalls will still be useful. Subnets will still exist for routing, but they’ll be much larger.
Firewalls
There are some naughty people on the Internet. To keep them out, it’s often helpful to set up one point of access to a local network and check all traffic into or out of that access point. The hardware and software that sit between the Internet and the local network, checking all the data that comes in or out to make sure it’s kosher, is called a firewall. The firewall is often part of the router that connects the local network to the broader Internet and may perform other tasks, such as network address translation. Then again, the firewall may be a separate machine. Modern operating systems like Mac OS X and Red Hat Linux often have built-in personal firewalls that monitor just the traffic sent to that one machine. Either way, the firewall is responsible for inspecting each packet that passes into or out of its network interface and accepting it or rejecting it according to a set of rules.
Filtering is usually based on network addresses and ports. For example, all traffic coming from the Class C network 193.28.25.x may be rejected because you had bad experiences with hackers from that network in the past. Outgoing SSH connections may be allowed, but incoming SSH connections may not. Incoming connections on port 80 (web) may be allowed, but only to the corporate web server. More intelligent firewalls look at the contents of the packets to determine whether to accept or reject them. The exact configuration of a firewall—which packets of data are and to pass through and which are not—depends on the security needs of an individual site. Java doesn’t have much to do with firewalls—except insofar as they often get in your way.
Proxy Servers
Proxy servers are related to firewalls. If a firewall prevents hosts on a network from making direct connections to the outside world, a proxy server can act as a go-between. Thus, a machine that is prevented from connecting to the external network by a firewall would make a request for a web page from the local proxy server instead of requesting the web page directly from the remote web server. The proxy server would then request the page from the web server and forward the response back to the original requester. Proxies can also be used for FTP services and other connections. One of the security advantages of using a proxy server is that external hosts only find out about the proxy server. They do not learn the names and IP addresses of the internal machines, making it more difficult to hack into internal systems.
Whereas firewalls generally operate at the level of the transport or internet layer, proxy servers normally operate at the application layer. A proxy server has a detailed understanding of some application-level protocols, such as HTTP and FTP. (The notable exception are SOCKS proxy servers that operate at the transport layer, and can proxy for all TCP and UDP connections regardless of application layer protocol.) Packets that pass through the proxy server can be examined to ensure that they contain data appropriate for their type. For instance, FTP packets that seem to contain Telnet data can be rejected. Figure 1-4 shows how proxy servers fit into the layer model.
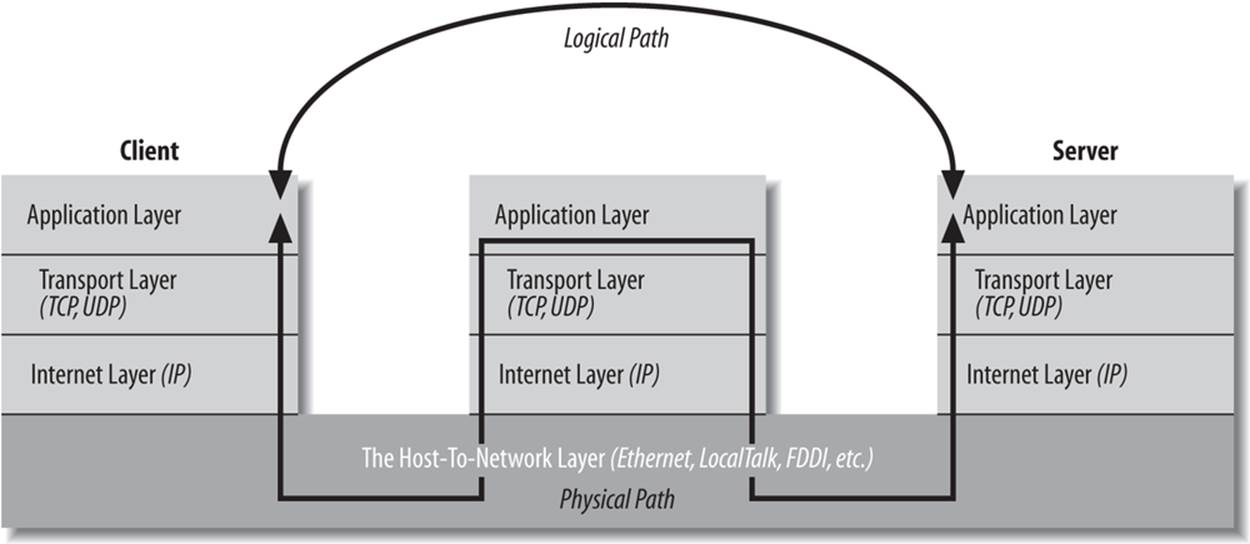
Figure 1-4. Layered connections through a proxy server
As long as all access to the Internet is forwarded through the proxy server, access can be tightly controlled. For instance, a company might choose to block access to www.playboy.com but allow access to www.microsoft.com. Some companies allow incoming FTP but disallow outgoing FTP so confidential data cannot be as easily smuggled out of the company. Other companies use proxy servers to track their employees’ web usage so they can see who’s using the Internet to get tech support and who’s using it to check out the Playmate of the Month.
Proxy servers can also be used to implement local caching. When a file is requested from a web server, the proxy server first checks to see if the file is in its cache. If the file is in the cache, the proxy serves the file from the cache rather than from the Internet. If the file is not in the cache, the proxy server retrieves the file, forwards it to the requester, and stores it in the cache for the next time it is requested. This scheme can significantly reduce load on an Internet connection and greatly improve response time. America Online runs one of the largest farms of proxy servers in the world to speed the transfer of data to its users. If you look at a web server logfile, you’ll probably find some hits from clients in the aol.com domain, but not as many as you’d expect given the more than three million AOL subscribers. That’s because AOL proxy servers supply many pages out of their cache rather than re-requesting them for one another. Many other large ISPs do similarly.
The biggest problem with proxy servers is their inability to cope with all but a few protocols. Generally established protocols like HTTP, FTP, and SMTP are allowed to pass through, while newer protocols like BitTorrent are not. (Some network administrators consider this a feature.) In the rapidly changing world of the Internet, this is a significant disadvantage. It’s a particular disadvantage for Java programmers because it limits the effectiveness of custom protocols. In Java, it’s easy and often useful to create a new protocol that is optimized for your application. However, no proxy server will ever understand these one-of-a-kind protocols. Consequently, some developers have taken to tunneling their protocols through HTTP, most notably with SOAP. However, this has a significant negative impact on security. The firewall is normally there for a reason, not just to annoy Java programmers.
Applets that run in web browsers normally use the proxy server settings of the web browser itself, though these can be overridden in the Java Control Panel. Standalone Java applications can indicate the proxy server to use by setting the socksProxyHost and socksProxyPort properties (if you’re using a SOCKS proxy server), or http.proxySet, http.proxyHost, http.proxyPort, https.proxySet, https.proxyHost, https.proxyPort, ftpProxySet, ftpProxyHost, ftpProxyPort, gopherProxySet, gopherProxyHost, and gopherProxyPortsystem properties (if you’re using protocol-specific proxies). You can set system properties from the command line using the -D flag, like this:
java -DsocksProxyHost=socks.cloud9.net -DsocksProxyPort=1080 MyClass
The Client/Server Model
Most modern network programming is based on a client/server model. A client/server application typically stores large quantities of data on an expensive, high-powered server or cloud of servers while most of the program logic and the user interface is handled by client software running on relatively cheap personal computers. In most cases, a server primarily sends data while a client primarily receives it; but it is rare for one program to send or receive exclusively. A more reliable distinction is that a client initiates a conversation while a server waits for clients to start conversations with it. Figure 1-5 illustrates both possibilities. In some cases, the same program may be both a client and a server.
You are already familiar with many examples of client/server systems. In 2013, the most popular client/server system on the Internet is the Web. Web servers like Apache respond to requests from web clients like Firefox. Data is stored on the web server and is sent out to the clients that request it. Aside from the initial request for a page, almost all data is transferred from the server to the client, not from the client to the server. FTP is an older service that fits the client/server model. FTP uses different application protocols and different software, but is still split into FTP servers that send files and FTP clients that receive files. People often use FTP to upload files from the client to the server, so it’s harder to say that the data transfer is primarily in one direction, but it is still true that an FTP client initiates the connection and the FTP server responds.
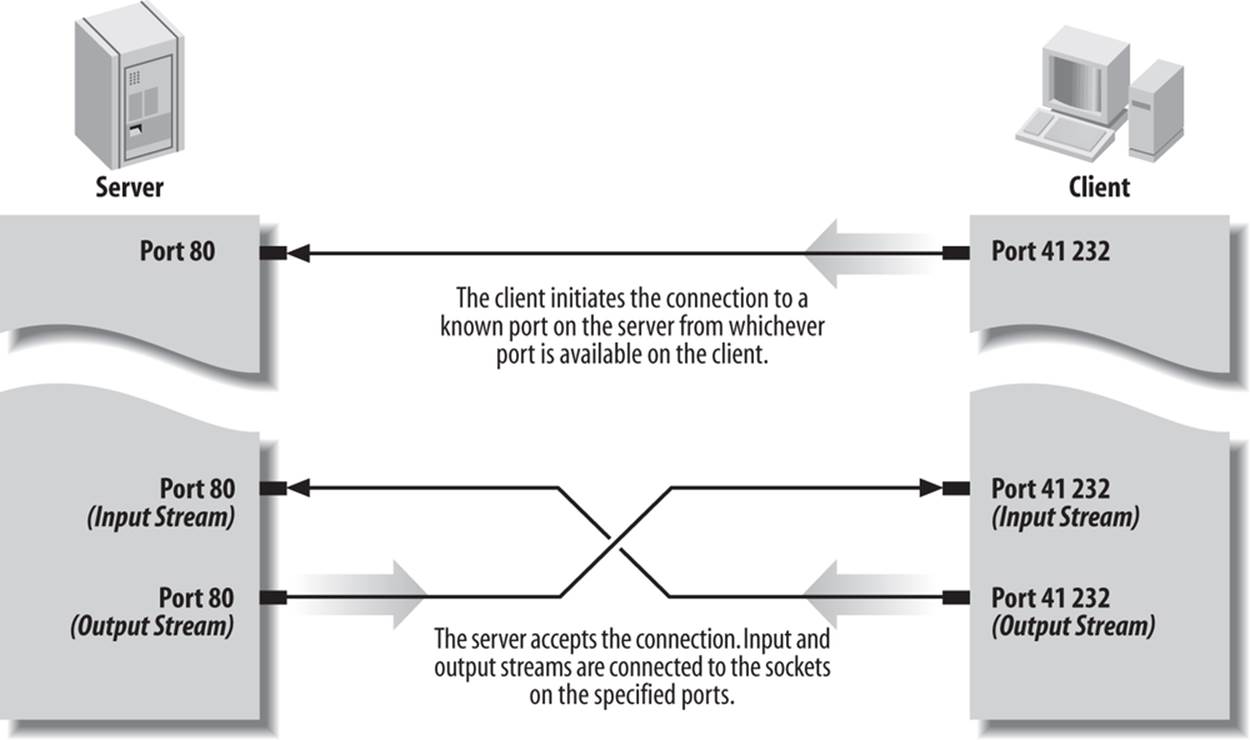
Figure 1-5. A client/server connection
Not all applications fit easily into a client/server model. For instance, in networked games, it seems likely that both players will send data back and forth roughly equally (at least in a fair game). These sorts of connections are called peer-to-peer. The telephone system is the classic example of a peer-to-peer network. Each phone can either call another phone or be called by another phone. You don’t have to buy one phone to send calls and another to receive them.
Java does not have explicit peer-to-peer communication in its core networking API. However, applications can easily offer peer-to-peer communications in several ways, most commonly by acting as both a server and a client. Alternatively, the peers can communicate with each other through an intermediate server program that forwards data from one peer to the other peers. This neatly solves the discovery problem of how two peers find each other.
Internet Standards
This book discusses several application layer Internet protocols, most notably HTTP. However, this is not a book about those protocols. If you need detailed information about any protocol, the definitive source is the standards document for the protocol.
Although there are many standards organizations in the world, the two that produce most of the standards relevant to application layer network programming and protocols are the Internet Engineering Task Force (IETF) and the World Wide Web Consortium (W3C). The IETF is a relatively informal, democratic body open to participation by any interested party. Its standards are based on “rough consensus and running code” and tend to follow rather than lead implementations. IETF standards include TCP/IP, MIME, and SMTP. The W3C, by contrast, is a vendor organization, controlled by dues-paying member corporations, that explicitly excludes participation by individuals. For the most part, the W3C tries to define standards in advance of implementation. W3C standards include HTTP, HTML, and XML.
IETF RFCs
IETF standards and near-standards are published as Requests for Comments (RFCs). Despite the name, a published RFC is a finished work. It may be obsoleted or replaced by a new RFC, but it will not be changed. IETF working documents that are subject to revision and open for development are called “Internet drafts.”
RFCs range from informational documents of general interest to detailed specifications of standard Internet protocols such as FTP. RFCs are available from many locations on the Internet, including http://www.faqs.org/rfc/ and http://www.ietf.org/rfc.html. For the most part, RFCs, (particularly standards-oriented RFCs), are very technical, turgid, and nearly incomprehensible. Nonetheless, they are often the only complete and reliable source of information about a particular protocol.
Most proposals for an RFC begin when a person or group gets an idea and builds a prototype. The prototype is incredibly important. Before something can become an IETF standard, it must actually exist and work. This requirement ensures that IETF standards are at least feasible, unlike the standards promulgated by some other organizations.
Table 1-2 lists the RFCs that provide formal documentation for the protocols discussed in this book.
Table 1-2. Selected Internet RFCs
|
RFC |
Title |
Description |
|
RFC 5000 |
Internet Official Protocol Standards |
Describes the standardization process and the current status of the different Internet protocols. Periodically updated in new RFCs. |
|
RFC 1122 RFC 1123 |
Host Requirements |
Documents the protocols that must be supported by all Internet hosts at different layers (data link layer, IP layer, transport layer, and application layer). |
|
RFC 791, RFC 919, RFC 922, RFC 950 |
Internet Protocol |
The IP internet layer protocol. |
|
RFC 768 |
User Datagram Protocol |
An unreliable, connectionless transport layer protocol. |
|
RFC 792 |
Internet Control Message Protocol (ICMP) |
An internet layer protocol that uses raw IP datagrams but is not supported by Java. Its most familiar uses are ping and traceroute. |
|
RFC 793 |
Transmission Control Protocol |
A reliable, connection-oriented, streaming transport layer protocol. |
|
RFC 2821 |
Simple Mail Transfer Protocol |
The application layer protocol by which one host transfers email to another host. This standard doesn’t say anything about email user interfaces; it covers the mechanism for passing email from one computer to another. |
|
RFC 822 |
Format of Electronic Mail Messages |
The basic syntax for ASCII text email messages. MIME is designed to extend this to support binary data while ensuring that the messages transferred still conform to this standard. |
|
RFC 854, RFC 855 |
Telnet Protocol |
An application layer remote login service for command-line environments based around an abstract network virtual terminal (NVT) and TCP. |
|
RFC 862 |
Echo Protocol |
An application layer protocol that echoes back all data it receives over both TCP and UDP; useful as a debugging tool. |
|
RFC 863 |
Discard Protocol |
An application layer protocol that receives packets of data over both TCP and UDP and sends no response to the client; useful as a debugging tool. |
|
RFC 864 |
Character Generator Protocol |
An application layer protocol that sends an indefinite sequence of ASCII characters to any client that connects over either TCP or UDP; also useful as a debugging tool. |
|
RFC 865 |
Quote of the Day |
An application layer protocol that returns a quotation to any user who connects over either TCP or UDP and then closes the connection. |
|
RFC 867 |
Daytime Protocol |
An application layer protocol that sends a human-readable ASCII string indicating the current date and time at the server to any client that connects over TCP or UDP. This contrasts with the various NTP and Time Server protocols, which do not return data that can be easily read by humans. |
|
RFC 868 |
Time Protocol |
An application layer protocol that sends the time in seconds since midnight, January 1, 1900, to a client connecting over TCP or UDP. The time is sent as a machine-readable, 32-bit unsigned integer. The standard is incomplete in that it does not specify how the integer is encoded in 32 bits, but in practice a big-endian integer is used. |
|
RFC 959 |
File Transfer Protocol |
An optionally authenticated, two-socket application layer protocol for file transfer that uses TCP. |
|
RFC 977 |
Network News Transfer Protocol |
The application layer protocol by which Usenet news is transferred from machine to machine over TCP; used by both news clients talking to news servers and news servers talking to each other. |
|
RFC 1034, RFC 1035 |
Domain Name System |
The collection of distributed software by which hostnames that human beings can remember, like www.oreilly.com, are translated into numbers that computers can understand, like 198.112.208.11. This RFC defines how domain name servers on different hosts communicate with each other using UDP. |
|
RFC 1112 |
Host Extensions for IP Multicasting |
The internet layer methods by which conforming systems can direct a single packet of data to multiple hosts. This is called multicasting. Java’s support for multicasting is discussed in Chapter 13. |
|
RFC 1288 |
Finger Protocol |
An application layer protocol for requesting information about a user at a remote site. It can be a security risk. |
|
RFC 1305 |
Network Time Protocol (Version 3) |
A more precise application layer protocol for synchronizing clocks between systems that attempts to account for network latency. |
|
RFC 1939 |
Post Office Protocol, Version 3 |
An application layer protocol used by sporadically connected email clients such as Eudora to retrieve mail from a server over TCP. |
|
RFC 1945 |
Hypertext Transfer Protocol (HTTP 1.0) |
Version 1.0 of the application layer protocol used by web browsers talking to web servers over TCP; developed by the W3C rather than the IETF. |
|
RFC 2045, RFC 2046, RFC 2047 |
Multipurpose Internet Mail Extensions |
A means of encoding binary data and non-ASCII text for transmission through Internet email and other ASCII-oriented protocols. |
|
RFC 2141 |
Uniform Resource Names (URN) Syntax |
Similar to URLs but intended to refer to actual resources in a persistent fashion rather than the transient location of those resources. |
|
RFC 2616 |
Hypertext Transfer Protocol (HTTP 1.1) |
Version 1.1 of the application layer protocol used by web browsers talking to web servers over TCP. |
|
RFC 2373 |
IP Version 6 Addressing Architecture |
The format and meaning of IPv6 addresses. |
|
RFC 3501 |
Internet Message Access Protocol Version 4rev1 |
A protocol for remotely accessing a mailbox stored on a server including downloading messages, deleting messages, and moving messages into and out of different folders. |
|
RFC 3986 |
Uniform Resource Identifiers (URI): Generic Syntax |
Similar to URLs but cut a broader path. For instance, ISBN numbers may be URIs even if the book cannot be retrieved over the Internet. |
|
RFC 3987 |
Internationalized Resource Identifiers (IRIs) |
URIs that can contain non-ASCII characters. |
The IETF has traditionally worked behind the scenes to codify and standardize existing practice. Although its activities are completely open to the public, it’s been very low profile. There simply aren’t that many people who get excited about network arcana like the Internet Gateway Message Protocol (IGMP). The participants in the process have mostly been engineers and computer scientists, including many from academia as well as the corporate world. Consequently, despite often vociferous debates about ideal implementations, most serious IETF efforts have produced reasonable standards.
Unfortunately, that can’t be said of the IETF’s efforts to produce web (as opposed to Internet) standards. In particular, the IETF’s early effort to standardize HTML was a colossal failure. The refusal of Netscape and other key vendors to participate or even acknowledge the process was a crucial problem. That HTML was simple enough and high profile enough to attract the attention of assorted market droids and random flamers didn’t help matters either. Thus, in October 1994, the World Wide Web Consortium was formed as a vendor-controlled body that might be able to avoid the pitfalls that plagued the IETF’s efforts to standardize HTML and HTTP.
W3C Recommendations
Although the W3C standardization process is similar to the IETF process (a series of working drafts hashed out on mailing lists resulting in an eventual specification), the W3C is a fundamentally different organization. Whereas the IETF is open to participation by anyone, only corporations and other organizations may become members of the W3C. Individuals are specifically excluded, though they may become invited experts on particular working groups. However, the number of such individuals is quite small relative to the number of interested experts in the broader community. Membership in the W3C costs $50,000 a year ($5,000 a year for nonprofits) with a minimum 3-year commitment. Membership in the IETF costs $0 a year with no commitment beyond a willingness to participate. And although many people participate in developing W3C standards, each standard is ultimately approved or vetoed by one individual, W3C director Tim Berners-Lee. IETF standards are approved by a consensus of the people who worked on the standard. Clearly, the IETF is a much more democratic (some would say anarchic) and open organization than the W3C.
Despite the W3C’s strong bias toward the corporate members that pay its bills, it has so far managed to do a better job of navigating the politically tricky waters of web standardization than the IETF. It has produced several HTML standards, as well as a variety of others such as HTTP, PICS, XML, CSS, MathML, and more. The W3C has had considerably less success in convincing vendors like Mozilla and Microsoft to fully and consistently implement its standards.
The W3C has five basic levels of standards:
Note
A note is generally one of two things: either an unsolicited submission by a W3C member (similar to an IETF Internet draft) or random musings by W3C staff or related parties that do not actually describe a full proposal (similar to an IETF informational RFC). Notes will not necessarily lead to the formation of a working group or a W3C recommendation.
Working drafts
A working draft is a reflection of the current thinking of some (not necessarily all) members of a working group. It should eventually lead to a proposed recommendation, but by the time it does so it may have changed substantially.
Candidate recommendation
A candidate recommendation indicates that the working group has reached consensus on all major issues and is ready for third-party comment and implementations. If the implementations do not uncover any obstructions, the spec can be promoted to a candidate recommendation.
Proposed recommendation
A proposed recommendation is mostly complete and unlikely to undergo more than minor editorial changes. The main purpose of a proposed recommendation is to work out bugs in the specification document rather than in the underlying technology being documented.
Recommendation
A recommendation is the highest level of W3C standard. However, the W3C is very careful not to actually call this a “standard” for fear of running afoul of antitrust statutes. The W3C describes a recommendation as a “work that represents consensus within W3C and has the Director’s stamp of approval. W3C considers that the ideas or technology specified by a Recommendation are appropriate for widespread deployment and promote W3C’s mission.”
PR STANDARDS
Companies seeking a little free press or perhaps a temporary boost to their stock price have sometimes abused both the W3C and IETF standards processes. The IETF will accept a submission from anyone, and the W3C will accept a submission from any W3C member. The IETF calls these submissions “Internet drafts” and publishes them for six months before deleting them. The W3C refers to such submissions as “acknowledged submissions” and publishes them indefinitely. However, neither organization actually promises to do more than acknowledge receipt of these documents. In particular, they do not promise to form a working group or begin the standardization process. Nonetheless, press releases invariably misrepresent the submission of such a document as a far more significant event than it actually is. PR reps can generally count on suckering at least a few clueless reporters who aren’t up to speed on the intimate details of the standardization process. However, you should recognize these ploys for what they are.