Java Network Programming, 4th Edition (2013)
Chapter 6. HTTP
The Hypertext Transfer Protocol (HTTP) is a standard that defines how a web client talks to a server and how data is transferred from the server back to the client. Although HTTP is usually thought of as a means of transferring HTML files and the pictures embedded in them, HTTP is data format agnostic. It can be used to transfer TIFF pictures, Microsoft Word documents, Windows .exe files, or anything else that can be represented in bytes. To write programs that use HTTP, you’ll need to understand HTTP at a deeper level than the average web page designer. This chapter goes behind the scenes to show you what actually happens when you type http://www.google.com into the browser’s address bar and press Return.
The Protocol
HTTP is the standard protocol for communication between web browsers and web servers. HTTP specifies how a client and server establish a connection, how the client requests data from the server, how the server responds to that request, and finally, how the connection is closed. HTTP connections use the TCP/IP protocol for data transfer. For each request from client to server, there is a sequence of four steps:
1. The client opens a TCP connection to the server on port 80, by default; other ports may be specified in the URL.
2. The client sends a message to the server requesting the resource at a specified path. The request includes a header, and optionally (depending on the nature of the request) a blank line followed by data for the request.
3. The server sends a response to the client. The response begins with a response code, followed by a header full of metadata, a blank line, and the requested document or an error message.
4. The server closes the connection.
This is the basic HTTP 1.0 procedure. In HTTP 1.1 and later, multiple requests and responses can be sent in series over a single TCP connection. That is, steps 2 and 3 can repeat multiple times in between steps 1 and 4. Furthermore, in HTTP 1.1, requests and responses can be sent in multiple chunks. This is more scalable.
Each request and response has the same basic form: a header line, an HTTP header containing metadata, a blank line, and then a message body. A typical client request looks something like this:
GET /index.html HTTP/1.1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:20.0)
Gecko/20100101 Firefox/20.0
Host: en.wikipedia.org
Connection: keep-alive
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
GET requests like this one do not contain a message body, so the request ends with a blank line.
The first line is called the request line, and includes a method, a path to a resource, and the version of HTTP. The method specifies the operation being requested. The GET method asks the server to return a representation of a resource. /index.html is the path to the resource requested from the server. HTTP/1.1 is the version of the protocol that the client understands.
Although the request line is all that is required, a client request usually includes other information as well in a header. Each line takes the following form:
Keyword: Value
Keywords are not case sensitive. Values sometimes are and sometimes aren’t. Both keywords and values should be ASCII only. If a value is too long, you can add a space or tab to the beginning of the next line and continue it.
Lines in the header are terminated by a carriage-return linefeed pair.
The first keyword in this example is User-Agent, which lets the server know what browser is being used and allows it to send files optimized for the particular browser type. The following line says that the request comes from version 2.4 of the Lynx browser:
User-Agent: Lynx/2.4 libwww/2.1.4
All but the oldest first-generation browsers also include a Host field specifying the server’s name, which allows web servers to distinguish between different named hosts served from the same IP address:
Host: www.cafeaulait.org
The last keyword in this example is Accept, which tells the server the types of data the client can handle (though servers often ignore this). For example, the following line says that the client can handle four MIME media types, corresponding to HTML documents, plain text, and JPEG and GIF images:
Accept: text/html, text/plain, image/gif, image/jpeg
MIME types are classified at two levels: a type and a subtype. The type shows very generally what kind of data is contained: is it a picture, text, or movie? The subtype identifies the specific type of data: GIF image, JPEG image, TIFF image. For example, HTML’s content type is text/html; the type is text, and the subtype is html. The content type for a JPEG image is image/jpeg; the type is image, and the subtype is jpeg. Eight top-level types have been defined:
§ text/* for human-readable words
§ image/* for pictures
§ model/* for 3D models such as VRML files
§ audio/* for sound
§ video/* for moving pictures, possibly including sound
§ application/* for binary data
§ message/* for protocol-specific envelopes such as email messages and HTTP responses
§ multipart/* for containers of multiple documents and resources
Each of these has many different subtypes.
The most current list of registered MIME types is available from http://www.iana.org/assignments/media-types/. In addition, nonstandard custom types and subtypes can be freely defined as long as they begin with x-. For example, Flash files are commonly assigned the type application/x-shockwave-flash.
Finally, the request is terminated with a blank line—that is, two carriage return/linefeed pairs, \r\n\r\n.
Once the server sees that blank line, it begins sending its response to the client over the same connection. The response begins with a status line, followed by a header describing the response using the same “name: value” syntax as the request header, a blank line, and the requested resource.A typical successful response looks something like this:
HTTP/1.1 200 OK
Date: Sun, 21 Apr 2013 15:12:46 GMT
Server: Apache
Connection: close
Content-Type: text/html; charset=ISO-8859-1
Content-length: 115
<html>
<head>
<title>
A Sample HTML file
</title>
</head>
<body>
The rest of the document goes here
</body>
</html>
The first line indicates the protocol the server is using (HTTP/1.1), followed by a response code. 200 OK is the most common response code, indicating that the request was successful. The other header lines identify the date the request was made in the server’s time frame, the server software (Apache), a promise that the server will close the connection when it’s finished sending, the MIME media type, and the length of the document delivered (not counting this header)—in this case, 107 bytes.
Table 6-1 lists the standard and experimental response codes you’re most likely to encounter, minus a few used by WebDAV.
Table 6-1. The HTTP 1.1 response codes
|
Code and message |
Meaning |
HttpURLConnection constant |
|
1XX |
Informational. |
|
|
100 Continue |
The server is prepared to accept the request body and the client should send it; allows clients to ask whether the server will accept a request before they send a large amount of data as part of the request. |
N/A |
|
101 Switching Protocols |
The server accepts the client’s request in the Upgrade header field to change the application protocol (e.g., from HTTP to WebSockets.) |
N/A |
|
2XX Successful |
Request succeeded. |
|
|
200 OK |
The most common response code. If the request method was GET or POST, the requested data is contained in the response along with the usual headers. If the request method was HEAD, only the header information is included. |
HTTP_OK |
|
201 Created |
The server has created a resource at the URL specified in the body of the response. The client should now attempt to load that URL. This code is only sent in response to POST requests. |
HTTP_CREATED |
|
202 Accepted |
This rather uncommon response indicates that a request (generally from POST) is being processed, but the processing is not yet complete, so no response can be returned. However, the server should return an HTML page that explains the situation to the user and provide an estimate of when the request is likely to be completed, and, ideally, a link to a status monitor of some kind. |
HTTP_ACCEPTED |
|
203 Non-authoritative Information |
The resource representation was returned from a caching proxy or other local source and is not guaranteed to be up to date. |
HTTP_NOT_AUTHORITATIVE |
|
204 No Content |
The server has successfully processed the request but has no information to send back to the client. This is normally the result of a poorly written form-processing program on the server that accepts data but does not return a response to the user. |
HTTP_NO_CONTENT |
|
205 Reset Content |
The server has successfully processed the request but has no information to send back to the client. Furthermore, the client should clear the form to which the request is sent. |
HTTP_RESET |
|
206 Partial Content |
The server has returned the part of the resource the client requested using the byte range extension to HTTP, rather than the whole document. |
HTTP_PARTIAL |
|
226 IM Used |
Response is delta encoded. |
N/A |
|
3XX Redirection |
Relocation and redirection. |
|
|
300 Multiple Choices |
The server is providing a list of different representations (e.g., PostScript and PDF) for the requested document. |
HTTP_MULT_CHOICE |
|
301 Moved Permanently |
The resource has moved to a new URL. The client should automatically load the resource at this URL and update any bookmarks that point to the old URL. |
HTTP_MOVED_PERM |
|
302 Moved Temporarily |
The resource is at a new URL temporarily, but its location will change again in the foreseeable future; therefore, bookmarks should not be updated. Sometimes used by proxies that require the user to log in locally before accessing the Web. |
HTTP_MOVED_TEMP |
|
303 See Other |
Generally used in response to a POST form request, this code indicates that the user should retrieve a resource from a different URL using GET. |
HTTP_SEE_OTHER |
|
304 Not Modified |
The If-Modified-Since header indicates that the client wants the document only if it has been recently updated. This status code is returned if the document has not been updated. In this case, the client should load the document from its cache. |
HTTP_NOT_MODIFIED |
|
305 Use Proxy |
The Location header field contains the address of a proxy that will serve the response. |
HTTP_USE_PROXY |
|
307 Temporary Redirect |
Similar to 302 but without allowing the HTTP method to change. |
N/A |
|
308 Permanent Redirect |
Similar to 301 but without allowing the HTTP method to change. |
N/A |
|
4XX |
Client error. |
|
|
400 Bad Request |
The client request to the server used improper syntax. This is rather unusual in normal web browsing but more common when debugging custom clients. |
HTTP_BAD_REQUEST |
|
401 Unauthorized |
Authorization, generally a username and password, is required to access this page. Either a username and password have not yet been presented or the username and password are invalid. |
HTTP_UNAUTHORIZED |
|
402 Payment Required |
Not used today, but may be used in the future to indicate that some sort of payment is required to access the resource. |
HTTP_PAYMENT_REQUIRED |
|
403 Forbidden |
The server understood the request, but is deliberately refusing to process it. Authorization will not help. This is sometimes used when a client has exceeded its quota. |
HTTP_FORBIDDEN |
|
404 Not Found |
This most common error response indicates that the server cannot find the requested resource. It may indicate a bad link, a document that has moved with no forwarding address, a mistyped URL, or something similar. |
HTTP_NOT_FOUND |
|
405 Method Not Allowed |
The request method is not allowed for the specified resource; for instance, you tried to PUT a file on a web server that doesn’t support PUT or tried to POST to a URI that only allows GET. |
HTTP_BAD_METHOD |
|
406 Not Acceptable |
The requested resource cannot be provided in a format the client is willing to accept, as indicated by the Accept field of the request HTTP header. |
HTTP_NOT_ACCEPTABLE |
|
407 Proxy Authentication Required |
An intermediate proxy server requires authentication from the client, probably in the form of a username and password, before it will retrieve the requested resource. |
HTTP_PROXY_AUTH |
|
408 Request Timeout |
The client took too long to send the request, perhaps because of network congestion. |
HTTP_CLIENT_TIMEOUT |
|
409 Conflict |
A temporary conflict prevents the request from being fulfilled; for instance, two clients are trying to PUT the same file at the same time. |
HTTP_CONFLICT |
|
410 Gone |
Like a 404, but makes a stronger assertion about the existence of the resource. The resource has been deliberately deleted (not moved) and will not be restored. Links to it should be removed. |
HTTP_GONE |
|
411 Length Required |
The client must but did not send a Content-length field in the client request HTTP header. |
HTTP_LENGTH_REQUIRED |
|
412 Precondition Failed |
A condition for the request that the client specified in the request HTTP header is not satisfied. |
HTTP_PRECON_FAILED |
|
413 Request Entity Too Large |
The body of the client request is larger than the server is able to process at this time. |
HTTP_ENTITY_TOO_LARGE |
|
414 Request-URI Too Long |
The URI of the request is too long. This is important to prevent certain buffer overflow attacks. |
HTTP_REQ_TOO_LONG |
|
415 Unsupported Media Type |
The server does not understand or accept the MIME content type of the request body. |
HTTP_UNSUPPORTED_TYPE |
|
416 Requested range Not Satisfiable |
The server cannot send the byte range the client requested. |
N/A |
|
417 Expectation Failed |
The server cannot meet the client’s expectation given in an Expect-request header field. |
N/A |
|
418 I’m a teapot |
Attempting to brew coffee with a teapot. |
N/A |
|
420 Enhance Your Calm |
The server is rate limiting the request. Nonstandard; used only by Twitter. |
N/A |
|
422 Unprocessable Entity |
The content type of the request body is recognized, and the body is syntactically correct, but nonetheless the server can’t process it. |
N/A |
|
424 Failed Dependency |
Request failed as a result of the failure of a previous request. |
N/A |
|
426 Upgrade Required |
Client is using a too old or insecure a version of the HTTP protocol. |
N/A |
|
428 Precondition Required |
Request must supply an If-Match header. |
N/A |
|
429 Too Many Requests |
The client is being rate limited and should slow down. |
N/A |
|
431 Request Header Fields Too Large |
Either the header as a whole is too large, or one particular header field is too large. |
N/A |
|
451 Unavailable For Legal Reasons |
Experimental; the server is prohibited by law from servicing the request. |
N/A |
|
5XX |
Server error. |
|
|
500 Internal Server Error |
An unexpected condition occurred that the server does not know how to handle. |
HTTP_SERVER_ERRORHTTP_INTERNAL_ERROR |
|
501 Not Implemented |
The server does not have a feature that is needed to fulfill this request. A server that cannot handle PUT requests might send this response to a client that tried to PUT form data to it. |
HTTP_NOT_IMPLEMENTED |
|
502 Bad Gateway |
This code is applicable only to servers that act as proxies or gateways. It indicates that the proxy received an invalid response from a server it was connecting to in an effort to fulfill the request. |
HTTP_BAD_GATEWAY |
|
503 Service Unavailable |
The server is temporarily unable to handle the request, perhaps due to overloading or maintenance. |
HTTP_UNAVAILABLE |
|
504 Gateway Timeout |
The proxy server did not receive a response from the upstream server within a reasonable amount of time, so it can’t send the desired response to the client. |
HTTP_GATEWAY_TIMEOUT |
|
505 HTTP Version Not Supported |
The server does not support the version of HTTP the client is using (e.g., the as-yet-nonexistent HTTP 2.0). |
HTTP_VERSION |
|
507 Insufficient Storage |
Server does not have enough space to store the supplied request entity; typically used for POST or PUT. |
|
|
511 Network Authentication Required |
The client needs to authenticate to gain network access (e.g., on a hotel wireless network). |
N/A |
Regardless of version, a response code from 100 to 199 always indicates an informational response, 200 to 299 always indicates success, 300 to 399 always indicates redirection, 400 to 499 always indicates a client error, and 500 to 599 indicates a server error.
Keep-Alive
HTTP 1.0 opens a new connection for each request. In practice, the time taken to open and close all the connections in a typical web session can outweigh the time taken to transmit the data, especially for sessions with many small documents. This is even more problematic for encrypted HTTPS connections using SSL or TLS, because the handshake to set up a secure socket is substantially more work than setting up a regular socket.
In HTTP 1.1 and later, the server doesn’t have to close the socket after it sends its response. It can leave it open and wait for a new request from the client on the same socket. Multiple requests and responses can be sent in series over a single TCP connection. However, the lockstep pattern of a client request followed by a server response remains the same.
A client indicates that it’s willing to reuse a socket by including a Connection field in the HTTP request header with the value Keep-Alive:
Connection: Keep-Alive
The URL class transparently supports HTTP Keep-Alive unless explicitly turned off. That is, it will reuse a socket if you connect to the same server again before the server has closed the connection. You can control Java’s use of HTTP Keep-Alive with several system properties:
§ Set http.keepAlive to “true or false” to enable/disable HTTP Keep-Alive. (It is enabled by default.)
§ Set http.maxConnections to the number of sockets you’re willing to hold open at one time. The default is 5.
§ Set http.keepAlive.remainingData to true to let Java clean up after abandoned connections (Java 6 or later). It is false by default.
§ Set sun.net.http.errorstream.enableBuffering to true to attempt to buffer the relatively short error streams from 400- and 500-level responses, so the connection can be freed up for reuse sooner. It is false by default.
§ Set sun.net.http.errorstream.bufferSize to the number of bytes to use for buffering error streams. The default is 4,096 bytes.
§ Set sun.net.http.errorstream.timeout to the number of milliseconds before timing out a read from the error stream. It is 300 milliseconds by default.
The defaults are reasonable, except that you probably do want to set sun.net.http.errorstream.enableBuffering to true unless you want to read the error streams from failed requests.
NOTE
HTTP 2.0, which is mostly based on the SPDY protocol invented at Google, further optimizes HTTP transfers through header compression, pipelining requests and responses, and asynchronous connection multiplexing. However, these optimizations are usually performed in a translation layer that shields application programmers from the details, so the code you write will still mostly follow the preceding steps 1–4. Java does not yet support HTTP 2.0; but when the capability is added, your programs shouldn’t need to change to take advantage of it, as long as you access HTTP servers via the URL and URLConnection classes.
HTTP Methods
Communication with an HTTP server follows a request-response pattern: one stateless request followed by one stateless response. Each HTTP request has two or three parts:
§ A start line containing the HTTP method and a path to the resource on which the method should be executed
§ A header of name-value fields that provide meta-information such as authentication credentials and preferred formats to be used in the request
§ A request body containing a representation of a resource (POST and PUT only)
There are four main HTTP methods, four verbs if you will, that identify the operations that can be performed:
§ GET
§ POST
§ PUT
§ DELETE
If that seems like too few, especially compared to the infinite number of object-oriented methods you may be accustomed to designing programs around, that’s because HTTP puts most of the emphasis on the nouns: the resources identified by URIs. The uniform interface provided by these four methods is sufficient for nearly all practical purposes.
These four methods are not arbitrary. They have specific semantics that applications should adhere to. The GET method retrieves a representation of a resource. GET is side-effect free, and can be repeated without concern if it fails. Furthermore, its output is often cached, though that can be controlled with the right headers, as you’ll see shortly. In a properly architected system, GET requests can be bookmarked and prefetched without concern. For example, one should not allow a file to be deleted merely by following a link because a browser may GET all links on a page before the user asks it to. By contrast, a well-behaved browser or web spider will not POST to a link without explicit user action.
The PUT method uploads a representation of a resource to the server at a known URL. It is not side-effect free, but it is idempotent. That is, it can be repeated without concern if it fails. Putting the same document in the same place on the same server twice in a row leaves the server in the same state as only putting it once.
The DELETE method removes a resource from a specified URL. It, too, is not side-effect free, but is idempotent. If you aren’t sure whether a delete request succeeded—for instance, because the socket disconnected after you sent the request but before you received a response—just send the request again. Deleting the same resource twice is not a mistake.
The POST method is the most general method. It too uploads a representation of a resource to a server at a known URL, but it does not specify what the server is to do with the newly supplied resource. For instance, the server does not necessarily have to make that resource available at the target URL, but may instead move it to a different URL. Or the server might use the data to update the state of one or more completely different resources. POST should be used for unsafe operations that should not be repeated, such as making a purchase.
Because GET requests include all necessary information in the URL, they can be bookmarked, linked to, spidered, and so forth. POST, PUT, and DELETE requests cannot be. This is deliberate. GET is intended for noncommital actions, like browsing a static web page. The other methods, especially POST, are intended for actions that commit to something. For example, adding an item to a shopping cart should send a GET, because this action doesn’t commit; the user can still abandon the cart. However, placing the order should send a POST because that action makes a commitment. This is why browsers ask you if you’re sure when you go back to a page that uses POST (as shown in Figure 6-1). Reposting data may buy two copies of a book and charge your credit card twice.
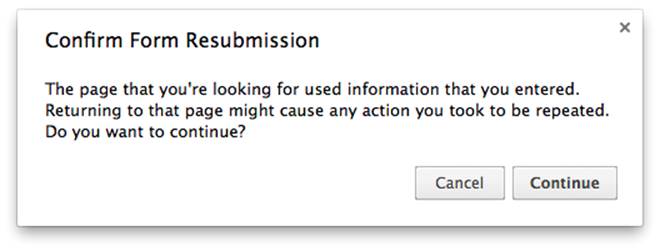
Figure 6-1. Repost confirmation
In practice, POST is vastly overused on the Web today. Any safe operation that does not commit the user to anything should use GET rather than POST. Only operations that commit the user should use POST.
One sometimes mistaken reason for preferring POST over GET is when forms require large amounts of input. There’s an outdated misconception that browsers can only work with query strings of a few hundred bytes. Although this was true in the mid-1990s, today all major browsers are good up to URL lengths of at least 2,000 characters. If you have more form data to submit than that, you may indeed need to support POST; but safe operations should still prefer GET for nonbrowser clients. This is less common than you might think, though. You usually only exceed those limits if you’re uploading data to the server to create a new resource, rather than merely locating an existing resource on the server; and in these cases POST or PUT is usually the right answer anyway.
In addition to these four main HTTP methods, a few others are used in special circumstances. The most common such method is HEAD, which acts like a GET except it only returns the header for the resource, not the actual data. This is commonly used to check the modification date of a file, to see whether a copy stored in the local cache is still valid.
The other two that Java supports are OPTIONS, which lets the client ask the server what it can do with a specified resource; and TRACE, which echoes back the client request for debugging purposes, especially when proxy servers are misbehaving. Different servers recognize other nonstandard methods including COPY and MOVE, but Java does not send these.
The URL class described in the previous chapter uses GET to communicate with HTTP servers. The URLConnection class (coming up in the Chapter 7) can use all four of these methods.
The Request Body
The GET method retrieves a representation of a resource identified by a URL. The exact location of the resource you want to GET from a server is specified by the various parts of the path and query string. How different paths and query strings map to different resources is determined by the server. The URL class doesn’t really care about that. As long as it knows the URL, it can download from it.
POST and PUT are more complex. In these cases, the client supplies the representation of the resource, in addition to the path and the query string. The representation of the resource is sent in the body of the request, after the header. That is, it sends these four items in order:
1. A starter line including the method, path and query string, and HTTP version
2. An HTTP header
3. A blank line (two successive carriage return/linefeed pairs)
4. The body
For example, this POST request sends form data to a server:
POST /cgi-bin/register.pl HTTP 1.0
Date: Sun, 27 Apr 2013 12:32:36
Host: www.cafeaulait.org
Content-type: application/x-www-form-urlencoded
Content-length: 54
username=Elliotte+Harold&email=elharo%40ibiblio.org
In this example, the body contains an application/x-www-form-urlencoded data, but that’s just one possibility. In general, the body can contain arbitrary bytes. However, the HTTP header should include two fields that specify the nature of the body:
§ A Content-length field that specifies how many bytes are in the body (54 in the preceding example)
§ A Content-type field that specifies the MIME media type of the bytes (application/x-www-form-urlencoded in the preceeding example).
The application/x-www-form-urlencoded MIME type used in the preceding example is common because it’s how web browsers encode most form submissions. Thus it’s used by a lot of server-side programs that talk to browsers. However, it’s hardly the only possible type you can send in the body. For example, a camera uploading a picture to a photo sharing site can send image/jpeg. A text editor might send text/html. It’s all just bytes in the end. For example, here’s a PUT request that uploads an Atom document:
PUT /blog/software-development/the-power-of-pomodoros/ HTTP/1.1
Host: elharo.com
User-Agent: AtomMaker/1.0
Authorization: Basic ZGFmZnk6c2VjZXJldA==
Content-Type: application/atom+xml;type=entry
Content-Length: 322
<?xml version="1.0"?>
<entry xmlns="http://www.w3.org/2005/Atom">
<title>The Power of Pomodoros</title>
<id>urn:uuid:101a41a6-722b-4d9b-8afb-ccfb01d77499</id>
<updated>2013-02-22T19:40:52Z</updated>
<author><name>Elliotte Harold</name></author>
<content>I hadn’t paid much attention to Pomodoro...</content>
</entry>
Cookies
Many websites use small strings of text known as cookies to store persistent client-side state between connections. Cookies are passed from server to client and back again in the HTTP headers of requests and responses. Cookies can be used by a server to indicate session IDs, shopping cart contents, login credentials, user preferences, and more. For instance, a cookie set by an online bookstore might have the value ISBN=0802099912&price=$34.95 to specify a book that I’ve put in my shopping cart. However, more likely, the value is a meaningless string such as ATVPDKIKX0DER, which identifies a particular record in a database of some kind where the real information is kept. Usually the cookie values do not contain the data but merely point to it on the server.
Cookies are limited to nonwhitespace ASCII text, and may not contain commas or semicolons.
To set a cookie in a browser, the server includes a Set-Cookie header line in the HTTP header. For example, this HTTP header sets the cookie “cart” to the value “ATVPDKIKX0DER”:
HTTP/1.1 200 OK
Content-type: text/html
Set-Cookie: cart=ATVPDKIKX0DER
If a browser makes a second request to the same server, it will send the cookie back in a Cookie line in the HTTP request header like so:
GET /index.html HTTP/1.1
Host: www.example.org
Cookie: cart=ATVPDKIKX0DER
Accept: text/html
As long as the server doesn’t reuse cookies, this enables it to track individual users and sessions across multiple, otherwise stateless, HTTP connections.
Servers can set more than one cookie. For example, a request I just made to Amazon fed my browser five cookies:
Set-Cookie:skin=noskin
Set-Cookie:ubid-main=176-5578236-9590213
Set-Cookie:session-token=Zg6afPNqbaMv2WmYFOv57zCU1O6Ktr
Set-Cookie:session-id-time=2082787201l
Set-Cookie:session-id=187-4969589-3049309
In addition to a simple name=value pair, cookies can have several attributes that control their scope including expiration date, path, domain, port, version, and security options.
For example, by default, a cookie applies to the server it came from. If a cookie is originally set by www.foo.example.com, the browser will only send the cookie back to www.foo.example.com. However, a site can also indicate that a cookie applies within an entire subdomain, not just at the original server. For example, this request sets a user cookie for the entire foo.example.com domain:
Set-Cookie: user=elharo;Domain=.foo.example.com
The browser will echo this cookie back not just to www.foo.example.com, but also to lothar.foo.example.com, eliza.foo.example.com, enoch.foo.example.com, and any other host somewhere in the foo.example.com domain. However, a server can only set cookies for domains it immediately belongs to. www.foo.example.com cannot set a cookie for www.oreilly.com, example.com, or .com, no matter how it sets the domain.
NOTE
Websites work around this restriction by embedding an image or other content hosted on one domain in a page hosted at a second domain. The cookies set by the embedded content, not the page itself, are called third-party cookies. Many users block all third-party cookies, and some web browsers are starting to block them by default for privacy reasons.
Cookies are also scoped by path, so they’re returned for some directories on the server, but not all. The default scope is the original URL and any subdirectories. For instance, if a cookie is set for the URL http://www.cafeconleche.org/XOM/, the cookie also applies inhttp://www.cafeconleche.org/XOM/apidocs/, but not in http://www.cafeconleche.org/slides/ or http://www.cafeconleche.org/. However, the default scope can be changed using a Path attribute in the cookie. For example, this next response sends the browser a cookie with the name “user” and the value “elharo” that applies only within the server’s /restricted subtree, not on the rest of the site:
Set-Cookie: user=elharo; Path=/restricted
When requesting a document in the subtree /restricted from the same server, the client echoes that cookie back. However, it does not use the cookie in other directories on the site.
A cookie can include both a domain and a path. For instance, this cookie applies in the /restricted path on any servers within the example.com domain:
Set-Cookie: user=elharo;Path=/restricted;Domain=.example.com
The order of the different cookie attributes doesn’t matter, as long as they’re all separated by semicolons and the cookie’s own name and value come first. However, this isn’t true when the client is sending the cookie back to the server. In this case, the path must precede the domain, like so:
Cookie: user=elharo; Path=/restricted;Domain=.foo.example.com
A cookie can be set to expire at a certain point in time by setting the expires attribute to a date in the form Wdy, DD-Mon-YYYY HH:MM:SS GMT. Weekday and month are given as three-letter abbreviations. The rest are numeric, padded with initial zeros if necessary. In the pattern language used by java.text.SimpleDateFormat, this is E, dd-MMM-yyyy H:m:s z. For instance, this cookie expires at 3:23 P.M. on December 21, 2015:
Set-Cookie: user=elharo; expires=Wed, 21-Dec-2015 15:23:00 GMT
The browser should remove this cookie from its cache after that date has passed.
The Max-Age attribute that sets the cookie to expire after a certain number of seconds have passed instead of at a specific moment. For instance, this cookie expires one hour (3,600 seconds) after it’s first set:
Set-Cookie: user="elharo"; Max-Age=3600
The browser should delete this cookie after this amount of time has elapsed.
Because cookies can contain sensitive information such as passwords and session keys, some cookie transactions should be secure. Most of the time this means using HTTPS instead of HTTP; but whatever it means, each cookie can have a secure attribute with no value, like so:
Set-Cookie: key=etrogl7*;Domain=.foo.example.com; secure
Browsers are supposed to refuse to send such cookies over insecure channels.
For additional security against cookie-stealing attacks like XSRF, cookies can set the HttpOnly attribute. This tells the browser to only return the cookie via HTTP and HTTPS and specifically not by JavaScript:
Set-Cookie: key=etrogl7*;Domain=.foo.example.com; secure; httponly
That’s how cookies work behind the scenes. Here’s a complete set of cookies sent by Amazon:
Set-Cookie: skin=noskin; path=/; domain=.amazon.com;
expires=Fri, 03-May-2013 21:46:43 GMT
Set-Cookie: ubid-main=176-5578236-9590213; path=/;
domain=.amazon.com; expires=Tue, 01-Jan-2036 08:00:01 GMT
Set-Cookie: session-token=Zg6afPNqbaMv2WmYFOv57zCU1O6KtrMMdskcmllbZ
cY4q6t0PrMywqO82PR6AgtfIJhtBABhomNUW2dITwuLfOZuhXILp7Toya+
AvWaYJxpfY1lj4ci4cnJxiuUZTev1WV31p5bcwzRM1Cmn3QOCezNNqenhzZD8TZUnOL/9Ya;
path=/; domain=.amazon.com; expires=Thu, 28-Apr-2033 21:46:43 GMT
Set-Cookie: session-id-time=2082787201l; path=/; domain=.amazon.com;
expires=Tue, 01-Jan-2036 08:00:01 GMT
Set-Cookie: session-id=187-4969589-3049309; path=/; domain=.amazon.com;
expires=Tue, 01-Jan-2036 08:00:01 GMT
Amazon wants my browser to send these cookie with the request for any page in the amazon.com domain, for the next 30–33 years. Of course, browsers are free to ignore all these requests, and users can delete or block cookies at any time.
CookieManager
Java 5 includes an abstract java.net.CookieHandler class that defines an API for storing and retrieving cookies. However, it does not include an implementation of that abstract class, so it requires a lot of grunt work. Java 6 fleshes this out by adding a concretejava.net.CookieManager subclass of CookieHandler that you can use. However, it is not turned on by default. Before Java will store and return cookies, you need to enable it:
CookieManager manager = new CookieManager();
CookieHandler.setDefault(manager);
If all you want is to receive cookies from sites and send them back to those sites, you’re done. That’s all there is to it. After installing a CookieManager with those two lines of code, Java will store any cookies sent by HTTP servers you connect to with the URL class, and will send the stored cookies back to those same servers in subsequent requests.
However, you may wish to be a bit more careful about whose cookies you accept. You can do this by specifying a CookiePolicy. Three policies are predefined:
§ CookiePolicy.ACCEPT_ALL All cookies allowed
§ CookiePolicy.ACCEPT_NONE No cookies allowed
§ CookiePolicy.ACCEPT_ORIGINAL_SERVER Only first party cookies allowed
For example, this code fragment tells Java to block third-party cookies but accept first-party cookies:
CookieManager manager = new CookieManager();
manager.setCookiePolicy(CookiePolicy.ACCEPT_ORIGINAL_SERVER);
CookieHandler.setDefault(manager);
That is, it will only accept cookies for the server that you’re talking to, not for any server on the Internet.
If you want more fine-grained control, for instance to allow cookies from some known domains but not others, you can implement the CookiePolicy interface yourself and override the shouldAccept() method:
public boolean shouldAccept(URI uri, HttpCookie cookie)
Example 6-1 shows a simple CookiePolicy that blocks cookies from .gov domains, but allows others.
Example 6-1. A cookie policy that blocks all .gov cookies but allows others
import java.net.*;
public class NoGovernmentCookies implements CookiePolicy {
@Override
public boolean shouldAccept(URI uri, HttpCookie cookie) {
if (uri.getAuthority().toLowerCase().endsWith(".gov")
|| cookie.getDomain().toLowerCase().endsWith(".gov")) {
return false;
}
return true;
}
}
CookieStore
It is sometimes necessary to put and get cookies locally. For instance, when an application quits, it can save the cookie store to disk and load those cookies again when it next starts up. You can retrieve the store in which the CookieManager saves its cookies with the getCookieStore()method:
CookieStore store = manager.getCookieStore();
The CookieStore class allows you to add, remove, and list cookies so you can control the cookies that are sent outside the normal flow of HTTP requests and responses:
public void add(URI uri, HttpCookie cookie)
public List<HttpCookie> get(URI uri)
public List<HttpCookie> getCookies()
public List<URI> getURIs()
public boolean remove(URI uri, HttpCookie cookie)
public boolean removeAll()
Each cookie in the store is encapsulated in an HttpCookie object that provides methods for inspecting the attributes of the cookie summarized in Example 6-2.
Example 6-2. The HTTPCookie class
package java.net;
public class HttpCookie implements Cloneable {
public HttpCookie(String name, String value)
public boolean hasExpired()
public void setComment(String comment)
public String getComment()
public void setCommentURL(String url)
public String getCommentURL()
public void setDiscard(boolean discard)
public boolean getDiscard()
public void setPortlist(String ports)
public String getPortlist()
public void setDomain(String domain)
public String getDomain()
public void setMaxAge(long expiry)
public long getMaxAge()
public void setPath(String path)
public String getPath()
public void setSecure(boolean flag)
public boolean getSecure()
public String getName()
public void setValue(String value)
public String getValue()
public int getVersion()
public void setVersion(int v)
public static boolean domainMatches(String domain, String host)
public static List<HttpCookie> parse(String header)
public String toString()
public boolean equals(Object obj)
public int hashCode()
public Object clone()
}
Several of these attributes are not actually used any more. In particular comment, comment URL, discard, and version are only used by the now obsolete Cookie 2 specification that never caught on.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.