Learn Scala for Java Developers (2015)
II. KEY SYNTACTICAL DIFFERENCES
This part of the book is about the key differences between Java and Scala language syntax. Given some typical Java code, we’ll look at equivalent Scala syntax. In Part III., we’ll look more at Scala features for which there is no direct equivalent in Java.
We’re going to look at:
· Lots of things around classes and objects, creating classes, fields, methods. We’ll do some round-tripping from Scala-generated bytecode back to Java, so that you can get a feel for how Scala relates to Java.
· Inheritance, interfaces, abstract classes and mixins.
· Common control structures like for loops.
· Generics.
Flexibility
Scala is very flexible. There are generally several ways to achieve the same thing. I don’t mean the difference between using a while loop or for loop; I mean that the language has different syntax options for expressing the same thing. This flexibility gives a lot of freedom but can be confusing when you’re reading code from different authors.
An example is the infix notation we saw earlier. You can often drop the dots and brackets when calling methods. Scala is opinion-less; it’s up to you if you want to use the dots or not.
Java, on the other hand, is very restrictive; there are generally very few ways to express the same things. It’s often easier to recognise things at a glance. You might have to work a little harder to recognise some of the more exotic syntax options in Scala.
This is true when it comes to the structure of your code too; you can create functions within functions, import statements in the middle of a class, or have a class live in a file with an unrelated name. It can all be a little disorienting when you’re used to the rigidity of Java.
Immutable and Declarative
Because Scala favours immutability, you might also notice a different approach to solving problems. For example, you might notice a lack of looping over mutable variables. Scala programs usually favour more functional idioms to achieve the same thing.
This more declarative way of doing things says “tell me what to do, not how to do it”. You may be more used to the Java / imperative way of doing things that says “tell me exactly how to do it”. Ultimately, when you give up the micro-management style of imperative programming, you allow the language more freedom in how it goes about its business.
For example, a traditional imperative for loop in Java looks like this:
// java
for (int count = 0; count < 100; count++) {
System.out.println(count);
}
It’s a typical imperative loop. We’re telling it explicitly to enumerate serially from zero to one hundred. If, on the other hand, we use a more declarative mechanism, like this:
// scala
(0 to 100).foreach(println(_))
…the enumeration is done within the foreach method, not by a language construct. We’re saying, “for a range of numbers, perform some function on each”. Although only subtly different, we’re not saying how to enumerate the sequence. It means Scala is free to implement the enumeration however it likes. (For example, it may choose to do it in parallel.)
Interestingly, Oracle has adopted these ideas in Java 8. If you’ve been using that, you’re probably already familiar with the concepts.
Classes and Fields
In this chapter, we’ll have a look at:
1. Creating classes
2. How Scala makes things easier when defining fields
3. What happens behind the scenes when Scala creates methods for you
Creating Classes
Creating a class in Java means writing something like this:
// java
public class Customer {
}
It makes sense for us to have a name and address for a customer. So adding these as fields and initialising via the constructor would give us something like this:
// java
public class Customer {
private final String name;
private final String address;
public Customer(String name, String address) {
this.name = name;
this.address = address;
}
}
We can instantiate an instance with the new keyword and create a new customer called Eric like this:
Customer eric = new Customer("Eric", "29 Acacia Road"); // java
In Scala, the syntax is much briefer; we can combine the class and constructor on a single line.
class Customer(val name: String, val address: String) // scala
We new it up in the same way, like this:
val eric = new Customer("Eric", "29 Acacia Road") // scala
Rather than define the fields as members within the class, the Scala version declares the variables as part of the class definition in what’s known as the primary constructor. In one line, we’ve declared the class Customer and, in effect, declared a constructor with two arguments.
Derived Setters and Getters
The val keyword on the class definition tells the compiler to treat the arguments as fields. It will create the fields and accessor methods for them.
We can prove this by taking the generated class file and decompiling it into Java. Round-tripping like this is a great way to explore what Scala actually produces behind the scenes. I’ve used the excellent CFR decompiler by Lee Benfield here, but you could also use the javap program that ships with Java to get the basic information.
To run the decompiler on the Scala generated class file for Customer, you do something like the following:
java -jar cfr_0_99.jar target/scala-2.11/classes/scala/demo/Customer.class
It produces the following:
1 // decompiled from scala to java
2 public class Customer {
3 private final String name;
4 private final String address;
5
6 public String name() {
7 return this.name;
8 }
9
10 public String address() {
11 return this.address;
12 }
13
14 public Customer(String name, String address) {
15 this.name = name;
16 this.address = address;
17 }
18 }
What’s important to notice is that Scala has generated accessor methods at lines 6 and 10, and a constructor at line 14. The accessors aren’t using the Java getter convention, but we’ve got the equivalent of getName and getAddress.
You might also want to define fields but not have them set via the constructor. For example, in Java, we might want to add an id to the customer to be set later with a setter method. This is a common pattern for tools like Hibernate when populating an object from the database.
// java
public class Customer {
private final String name;
private final String address;
private String id;
public Customer(String name, String address) {
this.name = name;
this.address = address;
}
public void setId(String id) {
this.id = id;
}
}
Is Scala, you do pretty much the same thing.
// scala
class Customer(val name: String, val address: String) {
var id = ""
}
You define a field, in this case a var, and magically Scala will create a setter method for you. The setter method it creates is called id_= rather than the usual setId. If we round-trip this through the decompiler, we see the following:
1 // decompiled from scala to java
2 public class Customer {
3 private final String name;
4 private final String address;
5 private String id;
6
7 public static Customer apply() {
8 return Customer$.MODULE$.apply();
9 }
10 public String name() {
11 return this.name;
12 }
13 public String address() {
14 return this.address;
15 }
16 public String id() { // notice it's public
17 return this.id;
18 }
19 public void id_$eq(String x$1) { // notice it's public
20 this.id = x$1;
21 }
22 public Customer(String name, String address) {
23 this.name = name;
24 this.address = address;
25 this.id = null;
26 }
27 }
Notice it has created a method called id_$eq on line 19 rather than id_=; that’s because the equals symbol isn’t allowed in a method name on the JVM, so Scala has escaped it and will translate it as required. You can call the setter method directly like this:
new Customer("Bob", "10 Downing Street").id_=("000001")
Scala offers a shorthand, however; you can just use regular assignment and Scala will call the auto-generated id_$eq setter method under the covers:
new Customer("Bob", "10 Downing Street").id = "000001"
If there are no modifiers in front of a field, it means it’s public. So as well as being able to call the auto-generated setter, clients could also work directly on the field, potentially breaking encapsulation. We’d like to be able to make the field private and allow updates only from within theCustomer class.
To do this, just use the private keyword with the field.
class Customer(val name: String, val address: String) {
private var id = ""
}
The decompiler shows that the setter and getter methods are now private.
1 // decompiled from scala to java
2 public class Customer {
3 private final String name;
4 private final String address;
5 private String id;
6
7 public String name() {
8 return this.name;
9 }
10
11 public String address() {
12 return this.address;
13 }
14
15 private String id() { // now it's private
16 return this.id;
17 }
18
19 private void id_$eq(String x$1) { // now it's private
20 this.id = x$1;
21 }
22
23 public Customer(String name, String address) {
24 this.name = name;
25 this.address = address;
26 this.id = "";
27 }
28 }
Redefining Setters and Getters
The advantage of using setters to set values is that we can use the method to preserve invariants or perform special processing. In Java, it’s straightforward: you create the setter method in the first place. It’s more laborious for Scala, as the compiler is generating the methods.
For example, once the id has been set, we might want to prevent it from being updated. In Java, we could do something like this:
// java
public void setId(String id) {
if (id.isEmpty())
this.id = id;
}
Scala, on the other hand, creates the setter method automatically, so how do we redefine it? If we try to just replace the setter directly in the Scala code, we’d get a compiler error:
// scala doesn't compile
class Customer(val name: String, val address: String) {
private var id = ""
def id_=(value: String) {
if (id.isEmpty)
this.id = value
}
}
Scala can’t know to replace the method so it creates a second method of the same name, and the compiler fails when it sees the duplicate:
ambiguous reference to overloaded definition,
both method id_= in class Customer of type (value: String)Unit
and method id_= in class Customer of type (x$1: String)Unit
match argument types (String)
this.id = value
method id_= is defined twice
conflicting symbols both originated in file 'Customer.scala'
def id_=(value: String) {
^ ^
To redefine the method, we have to jump through some hoops. Firstly, we have to rename the field (say to _id), making it private so as to make the getter and setters private. Then we create a new getter method called id and setter method called id_= that are public and are used to access the renamed private field.
class Customer(val name: String, val address: String) {
private var _id: String = ""
def id = _id
def id_=(value: String) {
if (_id.isEmpty)
_id = value
}
}
We’ve hidden the real field _id behind the private modifier and exposed a method called id_= to act as a setter. As there is no field called id any more, Scala won’t try to generate the duplicate method, and things compile.
// REPL session
scala> val bob = new Customer("Bob", "32 Bread Street")
bob: Customer = Customer@e955027
scala> bob.id = "001"
bob.id: String = 001
scala> println(bob.id)
001
scala> bob.id = "002"
bob.id: String = 001
scala> println(bob.id)
001
Looking at the decompiled version, you can see how to redefine the method. We’ve hidden the real field and exposed public methods to synthesize access to it under the guise of the field name.
1 // decompiled from scala to java
2 public class Customer {
3 private final String name;
4 private final String address;
5 private String _id;
6
7 public String name() {
8 return this.name;
9 }
10
11 public String address() {
12 return this.address;
13 }
14
15 private String _id() { // private
16 return this._id;
17 }
18
19 private void _id_$eq(String x$1) { // private
20 this._id = x$1;
21 }
22
23 public String id() { // public
24 return this._id();
25 }
26
27 public void id_$eq(String value) { // public
28 if (!this._id().isEmpty()) return;
29 this._id_$eq(value);
30 }
31
32 public Customer(String name, String address) {
33 this.name = name;
34 this.address = address;
35 this._id = "";
36 }
37 }
Why the Getter?
You might be wondering why we created the getter method def id(). Scala won’t allow us to use the shorthand assignment syntax to set a value unless the class has both the setter (id_=) and getter methods defined.
Summary
Creating classes is straightforward with Scala. You can add fields to the class simply by adding parameters to the class definition, and the equivalent Java constructor, getters and setters are generated for you by the compiler.
All fields in the class file are generated as private but have associated accessor methods generated. These generated methods are affected by the presence of val or var in the class definition.
· If val is used, a public getter is created but no setter is created. The value can only be set by the constructor.
· If var is used, a public getter and setter is created. The value can be set via the setter or the constructor.
· If neither val or var is used, no methods are generated and the value can only be used within the scope of the primary constructor; it’s not really a field in this case.
· Prefixing the class definition with private won’t change these rules, but will make any generated methods private.
This is summarised in the following table:
|
class Foo(? x) |
val x |
var x |
x |
private val x |
private var x |
|
Getter created (x()) |
Y (public) |
Y (public) |
N |
Y (private) |
Y (private) |
|
Setter created (x_=(y)) |
N |
Y (public) |
N |
N |
Y (private) |
|
Generated constructor includes x |
Y |
Y |
N |
Y |
Y |
If you need to override the generated methods, you have to rename the field and mark it as private. You then recreate the getter and setter methods with the original name. In practice, it’s not something you’ll have to do very often.
Classes and Objects
In this chapter we’ll look at:
· How you can define fields within the class body rather than on the class definition line and how this affects the generated methods.
· How you create additional constructors.
· Scala’s singleton objects defined with the object keyword.
· Companion objects, a special type of singleton object.
Classes Without Constructor Arguments
Let’s begin by looking at how we create fields within classes without defining them on the class definition line. If you were to create a class in Scala with no fields defined on the class definition, like this:
// scala
class Counter
…the Scala compiler would still generate a primary constructor with no arguments, a lot like Java’s default constructor. So the Java equivalent would look like this:
// java
public class Counter {
public Counter() {
}
}
In Java you might initialise a variable and create some methods.
// java
public class Counter {
private int count = 0;
public Counter() {
}
public void increment() {
count++;
}
public int getCount() {
return count;
}
}
You can do the same in Scala.
// scala
class Counter {
private var count = 0
def increment() { // brackets to denote this is a "mutator"
count += 1
}
def getCount = count
}
Within the primary constructor (i.e., not in the class definition but immediately afterwards in the class body), the val and var keywords will affect the bytecode like this:
|
Declared in primary constructor |
val x |
var x |
x |
private val x |
private var x |
|
Getter (x()) |
Y (public) |
Y (public) |
N/A |
Y (private) |
Y (private) |
|
Setter (x_=(y)) |
N |
Y (public) |
N/A |
N |
Y (private) |
As you can see, this is consistent with the table we saw earlier. Getters are generated by default for val and var types and will all be public. Adding private to the field declaration will make the generated fields private and setters are only generated for vars (which are, again, public by default).
Additional Constructors
Let’s create an alternative Java version of our Customer class, this time with additional constructors.
// java
public class Customer {
private final String fullname;
public Customer(String forename, String initial, String surname) {
this.fullname =
String.format("%s %s. %s", forename, initial, surname);
}
public Customer(String forename, String surname) {
this(forename, "", surname);
}
}
We’ve defaulted the customer’s initial and allowed clients to choose if they want to supply it.
We should probably tidy up the main constructor to reflect the fact that the variable could come through as an empty string. We’ll add an if-condition and format the string depending on the result.
// java
public class Customer {
private final String fullname;
public Customer(String forename, String initial, String surname) {
if (initial != null && !initial.isEmpty())
this.fullname =
String.format("%s %s. %s", forename, initial, surname);
else
this.fullname = String.format("%s %s", forename, surname);
}
public Customer(String forename, String surname) {
this(forename, "", surname);
}
public static void main(String... args) {
System.out.println(new Customer("Bob", "J", "Smith").fullname);
System.out.println(new Customer("Bob", "Smith").fullname);
}
}
Creating additional or auxiliary constructors in Scala is just a matter of creating methods called this. The one constraint is that each auxiliary constructor must call another constructor using this on its first line. That way, constructors will always be chained, all the way to the top.
Scala has the notion of a primary constructor; it’s the code in the class body. Any parameters passed in from the class definition are available to it and if you don’t write any auxiliary constructors, the class will still have a constructor; it’s the implicit primary constructor.
// scala
class Customer(forename: String, initial: String, surname: String) {
// primary constructor
}
So, if we create a field within the primary constructor and assign it some value,
// scala
class Customer(forename: String, initial: String, surname: String) {
val fullname = String.format("%s %s. %s", forename, initial, surname)
}
…it would be equivalent to the following Java:
// java
public class Customer {
private final String fullname;
public Customer(String forename, String initial, String surname) {
this.fullname =
String.format("%s %s. %s", forename, initial, surname);
}
}
If we can add an another auxiliary constructor to the Scala version, we can refer to this to chain the call to the primary constructor.
// scala
class Customer(forename: String, initial: String, surname: String) {
val fullname = String.format("%s %s. %s", forename, initial, surname)
def this(forename: String, surname: String) {
this(forename, "", surname)
}
}
Using Default Values
Scala has language support for default values on method signatures, so we could have written this using just parameters on the class definition, and avoided the extra constructor. We’d just default the value for initial to be an empty string. To make the implementation handle empty strings better, we can put some logic in the primary constructor like before.
class Customer(forename: String, initial: String = "", surname: String) {
val fullname = if (initial != null && !initial.isEmpty)
forename + " " + initial + ". " + surname
else
forename + " " + surname
}
When calling it, we may need to name default values; for example:
new Customer("Bob", "J", "Smith")
"Bob", "J", "Smith" is ok, but if we skip the initial variable, we’d need to name the surname variable like this:
new Customer("Bob", surname = "Smith")
Singleton Objects
In Java you can enforce a single instance of a class using the singleton pattern. Scala has made this idea as a feature of the language: as well as classes, you can define (singleton) objects.
The downside is that when we talk about “objects” in Scala, we’re overloading the term. We might mean an instance of a class (for example, a new ShoppingCart(), of which there could be many) or we might mean the one and only instance of a class; that is, a singleton object.
A typical use-case for a singleton in Java is if we need to use a single logger instance across an entire application.
// java
Logger.getLogger("example").log(INFO, "Everything is fine.");
We might implement the singleton like this:
// java
public final class Logger {
private static final Logger INSTANCE = new Logger();
private Logger() { }
public static Logger getLogger() {
return INSTANCE;
}
public void log(Level level, String string) {
System.out.printf("%s %s%n", level, string);
}
}
We create a Logger class, and a single static instance of it. We prevent anyone else creating one by using a private constructor. We then create an accessor to the static instance, and finally give it a rudimentary log method. We’d call it like this:
// java
Logger.getLogger().log(INFO, "Singleton loggers say YEAH!");
A more concise way to achieve the same thing in Java would be to use an enum.
// java
public enum LoggerEnum {
LOGGER;
public void log(Level level, String string) {
System.out.printf("%s %s%n", level, string);
}
}
We don’t need to use an accessor method; Java ensures a single instance is used and we’d call it like this:
// java
LOGGER.log(INFO, "An alternative example using an enum");
Either way, they prevent clients newing up an instance of the class and provide a single, global instance for use.
The Scala equivalent would look like this:
// scala
object Logger {
def log(level: Level, string: String) {
printf("%s %s%n", level, string)
}
}
The thing to notice here is that the singleton instance is denoted by the object keyword rather than class. So we’re saying “define a single object called Logger” rather than “define a class”.
Under the covers, Scala is creating basically the same Java code as our singleton pattern example. You can see this when we decompile it.
1 // decompiled from scala to java
2 public final class Logger$ {
3 public static final Logger$ MODULE$;
4
5 public static {
6 new scala.demo.singleton.Logger$();
7 }
8
9 public void log(Level level, String string) {
10 Predef..MODULE$.printf("%s %s%n", (Seq)Predef..MODULE$
11 .genericWrapArray((Object)new Object[]{level, string}));
12 }
13
14 private Logger$() {
15 Logger$.MODULE$ = this;
16 }
17 }
There are some oddities in the log method, but that’s the decompiler struggling to decompile the bytecode, and generally how Scala goes about things. In essence though, it’s equivalent; there’s a private constructor like the Java version, and a single static instance of the object. The class itself is even final.
There’s no need to new up a new Logger; Logger is already an object, so we can refer to it directly. In fact, you couldn’t new one up if you wanted to, because there’s no class definition and so no class to new up.
Incidentally, you replicate Java’s static main method by adding a main method to a Scala singleton object, not a class.
Companion Objects
You can combine objects and classes in Scala. When you create a class and an object with the same name in the same source file, the object is known as a companion object.
Scala doesn’t have a static keyword but members of singleton objects are effectively static. Remember that a Scala singleton object is just that, a singleton. Any members it contains will therefore be reused by all clients using the object; they’re globally available just like statics.
You use companion objects where you would mix statics and non-statics in Java.
The Java version of Customer has fields for the customer’s name and address, and an ID to identify the customer uniquely.
// java
public class Customer {
private final String name;
private final String address;
private Integer id;
public Customer(String name, String address) {
this.name = name;
this.address = address;
}
}
Now we may want to create a helper method to create the next ID in a sequence. To do that globally, we create a static field to capture a value for the ID and a method to return and increment it. We can then just call the method on construction of a new instance, assigning its ID to the freshly incremented global ID.
// java
public class Customer {
private static Integer sequenceOfIds;
private final String name;
private final String address;
private Integer id;
public Customer(String name, String address) {
this.name = name;
this.address = address;
this.id = Customer.nextId();
}
private static Integer nextId() {
return sequenceOfIds++;
}
}
It’s static because we want to share its implementation among all instances to create unique IDs for each.
In Scala, we’d separate the static from non-static members and put the statics in the singleton object and the rest in the class. The singleton object is the companion object to Customer.
We create our class with the two required fields and in the singleton object, create the nextId method. Next we create a private var to capture the current value, assigning it the value of zero so Scala can infer the type as an Integer. Adding a val here means no setter will be generated, and adding the private modifier means the generated getter will be private. We finish off by implementing the increment in the nextId method and calling it from the primary constructor.
// scala
class Customer(val name: String, val address: String) {
private val id = Customer.nextId()
}
object Customer {
private var sequenceOfIds = 0
private def nextId(): Integer = {
sequenceOfIds += 1
sequenceOfIds
}
}
The singleton object is a companion object because it has the same name and lives in the same source file as its class. This means the two have a special relationship and can access each other’s private members. That’s how the Customer object can define the nextId method as private but theCustomer class can still access it.
If you were to name the object differently, you wouldn’t have this special relationship and wouldn’t be able to call the method. For example, the class CustomerX object below is not a companion object to Customer and so can’t see the private nextId method.
// scala
class Customer(val name: String, val address: String) {
private val id = CustomerX.nextId() // compiler failure
}
object CustomerX {
private var sequenceOfIds = 0
private def nextId(): Integer = {
sequenceOfIds += 1
sequenceOfIds
}
}
Other Uses for Companion Objects
When methods don’t depend on any of the fields in a class, you can more accurately think of them as functions. Functions generally belong in a singleton object rather than a class, so one example of when to use companion objects is when you want to distinguish between functions and methods, but keep related functions close to the class they relate to.
Another reason to use a companion object is for factory-style methods — methods that create instances of the class companion. For example, you might want to create a factory method that creates an instance of your class but with less noise. If we want to create a factory for Customer, we can do so like this:
// scala
class Customer(val name: String, val address: String) {
val id = Customer.nextId()
}
object Customer {
def apply(name: String, address: String) = new Customer(name, address)
}
The apply method affords a shorthand notation for a class or object. It’s kind of like the default method for a class, so if you don’t call a method directly on an instance, but instead match the arguments of an apply method, it’ll call it for you. For example, you can call:
Customer.apply("Bob Fossil", "1 London Road")
…or you can drop the apply and Scala will look for an apply method that matches your argument. The two are identical.
Customer("Bob Fossil", "1 London Road")
You can still construct a class using the primary constructor and new, but implementing the companion class apply method as a factory means you can be more concise if you have to create a lot of objects.
You can even force clients to use your factory method rather than the constructor by making the primary constructor private.
class Customer private (val name: String, val address: String) {
val id = Customer.nextId()
}
The Java analog would have a static factory method, for example createCustomer, and a private constructor ensuring everyone is forced to use the factory method.
// java
public class Customer {
private static Integer sequenceOfIds;
private final String name;
private final String address;
private Integer id;
public static Customer createCustomer(String name, String address) {
return new Customer(name, address);
}
private Customer(String name, String address) {
this.name = name;
this.address = address;
this.id = Customer.nextId();
}
private static Integer nextId() {
return sequenceOfIds++;
}
}
Inheritance
In this chapter we’ll look at inheritance in Scala: how you create subclasses and override methods, the Scala equivalent of interfaces and abstract classes, and the mechanisms Scala offers for mixing in reusable behaviour. We’ll finish by discussing how to pick between all the options.
Subtype Inheritance
Creating a subtype of another class is the same as in Java. You use the extends keyword and you can prevent subclassing with the final modifier on a class definition.
Let’s suppose we want to extend the basic Customer class from earlier and create a special subtype to represent a DiscountedCustomer. A shopping basket might belong to the Customer super-class, along with methods to add items to the basket and total its value.
// java
public class Customer {
private final String name;
private final String address;
private final ShoppingBasket basket = new ShoppingBasket();
public Customer(String name, String address) {
this.name = name;
this.address = address;
}
public void add(Item item) {
basket.add(item);
}
public Double total() {
return basket.value();
}
}
Let’s say the DiscountedCustomer is entitled to a 10% discount on all purchases. We can extend Customer, creating a constructor to match Customer, and call super in it. We can then override the total method to apply the discount.
// java
public class DiscountedCustomer extends Customer {
public DiscountedCustomer(String name, String address) {
super(name, address);
}
@Override
public Double total() {
return super.total() * 0.90;
}
}
We do exactly the same thing in Scala. Here’s the basic Customer class:
// scala
class Customer(val name: String, val address: String) {
private final val basket: ShoppingBasket = new ShoppingBasket
def add(item: Item) {
basket.add(item)
}
def total: Double = {
basket.value
}
}
When it comes to extending Customer to DiscountedCustomer, there are a few things to consider. First, we’ll create the DiscountedCustomer class.
class DiscountedCustomer
If we try and extend Customer to create DiscountedCustomer, we get a compiler error.
class DiscountedCustomer extends Customer // compiler error
We get a compiler error because we need to call the Customer constructor with values for its arguments. We had to do the same thing in Java when we called super in the new constructor.
Scala has a primary constructor and auxiliary constructors. Auxiliary constructors must be chained to eventually call the primary constructor and in Scala, only the primary constructor can call the super-class constructor. We can add arguments to the primary constructor like this:
class DiscountedCustomer(name: String, address: String) extends Customer
But we can’t call super directly like we can in Java.
class DiscountedCustomer(val name: String, val address: String)
extends Customer {
super(name, address) // compiler error
}
In Scala, to call the super-class constructor you pass the arguments from the primary constructor to the super-class. Notice that the arguments to DiscountedCustomer aren’t set as val. They’re not fields; instead, they’re locally scoped to the primary constructor and passed directly to the super-class.
class DiscountedCustomer(name: String, address: String)
extends Customer(name, address)
Finally, we can implement the discounted total method in the subclass.
override def total: Double = {
super.total * 0.90
}
There are two things to note here: the override keyword is required, and to call the super-classes total method, we use super and a dot, just like in Java.
The override keyword is like the @Override annotation in Java. It allows the compiler to check for mistakes like misspelling the name of the method or providing the wrong arguments. The only real difference between the Java annotation and Scala’s is that it’s mandatory in Scala when you override non-abstract methods.
Anonymous Classes
You create anonymous subclasses in a similar way to Java.
In the Java version of the ShoppingBasket class, the add method takes an Item interface. So to add an item to your shopping basket, you could create an anonymous subtype of Item. Below, we’ve created a program to add two fixed-price items to Joe’s shipping basket. Each item is an anonymous subclass of Item. The basket total after discount would be $5.40.
// java
public class ShoppingBasket {
private final Set<Item> basket = new HashSet<>();
public void add(Item item) {
basket.add(item);
}
public Double value() {
return basket.stream().mapToDouble(Item::price).sum();
}
}
// java
public class TestDiscount {
public static void main(String... args) {
Customer joe = new DiscountedCustomer("Joe", "128 Bullpen Street");
joe.add(new Item() {
@Override
public Double price() {
return 2.5;
}
});
joe.add(new Item() {
@Override
public Double price() {
return 3.5;
}
});
System.out.println("Joe's basket will cost $ " + joe.total());
}
}
In Scala, it’s pretty much the same. You can drop the brackets on the class name when newing up an Item, and the type from the method signature of price. The override keyword in front of the price method is also optional.
// scala
object DiscountedCustomer {
def main(args: Array[String]) {
val joe = new DiscountedCustomer("Joe", "128 Bullpen Street")
joe.add(new Item {
def price = 2.5
})
joe.add(new Item {
def price = 3.5
})
println("Joe`s basket will cost $ " + joe.total)
}
}
You create anonymous instances of classes, abstract classes, or Scala traits in just the same way.
Interfaces / Traits
Interfaces in Java are similar to traits in Scala. You can use traits in much the same way as you can use an interface. You can implement specialised behaviour in implementing classes, yet still treat them polymorphically in code. However:
· Traits can have default implementations for methods. These are just like Java 8’s virtual extension methods (otherwise known as default methods) but there’s no equivalent pre-Java 8.
· Traits can also have fields and even default values for these, something which Java interfaces cannot do. Therefore, traits can have both abstract and concrete methods and have state.
· A class can implement any number of traits just as a class can implement any number of interfaces, although extending traits with default implementations in Scala is more like mixing in behaviours than traditional interface inheritance in Java.
· There’s a cross-over with Java 8 as you can mixin behaviour with Java 8, although there are some differences in semantics and how duplicate methods are handled.
In this section, we’ll look at these differences in more detail.
In Java, we might create an interface called Readable to read some data and copy it into a character buffer. Each implementation may read something different into the buffer. For example, one might read the content of a web page over HTTP whilst another might read a file.
// java
public interface Readable {
public int read(CharBuffer buffer);
}
In Scala, the Java interface would become a trait and it would look like this:
// scala
trait Readable {
def read(buffer: CharBuffer): Int
}
You just use trait rather than class when you define it. There’s no need to declare methods as abstract, as any unimplemented methods are automatically abstract.
Implementing the interface in Java uses the implements keyword. For example, if we implement a file reader, we might take a File object as a constructor argument and override the read method to consume the file. The read method would return the number of bytes read.
// java
public class FileReader implements Readable {
private final File file;
public FileReader(File file) {
this.file = file;
}
@Override
public int read(CharBuffer buffer) {
int read = 0;
// ...
return read;
}
}
In Scala, you use extends just like when you extend regular classes. You’re forced to use the override keyword when overriding an existing concrete method, but not when you override an abstract method.
// scala
class FileReader(file: File) extends Readable {
override def read(buffer: CharBuffer): Int = { // override optional
val linesRead: Int = 0
return linesRead
}
}
In Java, if you want to implement multiple interfaces you append the interface name to the Java class definition, so we could add AutoClosable behaviour to our FileReader.
// java
public class FileReader implements Readable, AutoCloseable {
private final File file;
public FileReader(File file) {
this.file = file;
}
@Override
public int read(CharBuffer buffer) {
int read = 0;
// ...
return read;
}
@Override
public void close() throws Exception {
// close
}
}
In Scala, you use the with keyword to add additional traits. You do this when you want to extend a regular class, abstract class or trait. Just use extends for the first and then with for any others. However, just like in Java, you can have only one super-class.
// scala
class FileReader(file: File) extends Readable with AutoCloseable {
def read(buffer: CharBuffer): Int = {
val linesRead: Int = 0
// ...
return linesRead
}
def close(): Unit = ???
}
What’s the Question?
The ??? above is actually a method. It’s a handy method you can use to say “I don’t know yet”. It throws a runtime exception if you call it, a bit like UnsupportedOperationException in Java. It gets things compiling when you really don’t know what you need yet.
Methods on Traits
Java 8 introduced default methods where you can create default implementations on interfaces. You can do the same thing in Scala with a few extra bits besides.
Let’s see where Java interfaces might benefit from having default implementations. We could start by creating a Sortable interface to describe any class that can be sorted. More specifically, any implementations should be able to sort things of the generic type A. This implies it’s only useful for collection classes so we’ll make the interface extend Iterable to make that more obvious.
// java
interface Sortable<A> extends Iterable<A> {
public List<A> sort();
}
If lots of classes implement this, many may well want similar sorting behaviour. Some will want finer-grained control over the implementation. With Java 8, we can provide a default implementation for the common case. We mark the interface method as default indicating that it has a default implementation, then go ahead and provide an implementation.
Below we’re taking advantage of the fact that the object is iterable, and copying its contents into a new ArrayList. We can then use the built-in sort method on List. The sort method takes a lambda to describe the ordering, and we can take a shortcut to reuse an object’s natural ordering if we say the objects to compare must be Comparable. A slight tweak to the signature to enforce this and then we can use the comparator’s compareTo method. It means that we have to make type A something that is Comparable, but it’s still in keeping with the intent of the Sortable interface.
// java
public interface Sortable<A extends Comparable> extends Iterable<A> {
default public List<A> sort() {
List<A> list = new ArrayList<>();
for (A elements: this)
list.add(elements);
list.sort((first, second) -> first.compareTo(second));
return list;
}
}
The default keyword above means that the method is no longer abstract and that any subclasses that don’t override it will use it by default. To see this, we can create a class, NumbersList extending Sortable, to contain a list of numbers, and use the default sorting behaviour to sort these. There’s no need to implement the sort method as we’re happy to use the default provided.
// java
public class NumbersUsageExample {
private static class NumberList implements Sortable<Integer> {
private Integer[] numbers;
private NumberList(Integer... numbers) {
this.numbers = numbers;
}
@Override
public Iterator<Integer> iterator() {
return Arrays.asList(numbers).iterator();
}
}
public static void main(String... args) {
Sortable<Integer> numbers = new NumberList(1, 34, 65, 23, 0, -1);
System.out.println(numbers.sort());
}
}
We can apply the same idea to our Customer example and create a Customers class to collect customers. All we have to do is make sure the Customer class is Comparable and we’ll be able to sort our list of customers without implementing the sort method ourselves.
// java
// You'll get a compiler error if Customer isn't Comparable
public class Customers implements Sortable<Customer> {
private final Set<Customer> customers = new HashSet<>();
public void add(Customer customer) {
customers.add(customer);
}
@Override
public Iterator<Customer> iterator() {
return customers.iterator();
}
}
In our Customer class, if we implement Comparable and the compareTo method, the default natural ordering will be alphabetically by name.
// java
public class Customer implements Comparable<Customer> {
// ...
@Override
public int compareTo(Customer other) {
return name.compareTo(other.name);
}
}
If we add some customers to the list in random order, we can print them sorted by name (as defined in the compareTo method above).
// java
public class CustomersUsageExample {
public static void main(String... args) {
Customers customers = new Customers();
customers.add(new Customer("Velma Dinkley", "316 Circle Drive"));
customers.add(new Customer("Daphne Blake", "101 Easy St"));
customers.add(new Customer("Fred Jones", "8 Tuna Lane,"));
customers.add(new DiscountedCustomer("Norville Rogers", "1 Lane"));
System.out.println(customers.sort());
}
}
In Scala, we can go through the same steps. Firstly, we’ll create the basic trait.
// scala
trait Sortable[A] {
def sort: Seq[A]
}
This creates an abstract method sort. Any extending class has to provide an implementation, but we can provide a default implementation by just providing a regular method body.
// scala
trait Sortable[A <: Ordered[A]] extends Iterable[A] {
def sort: Seq[A] = {
this.toList.sorted // built-in sorting method
}
}
We extend Iterable and give the generic type A a constraint that it must be a subtype of Ordered. Ordered is like Comparable in Java and is used with built-in sorting methods. The <: keyword indicates the upper bound of A. We’re using it here just as we did in the Java example to constrain the generic type to be a subtype of Ordered.
Recreating the Customers collection class in Scala would look like this:
// scala
class Customers extends Sortable[Customer] {
private val customers = mutable.Set[Customer]()
def add(customer: Customer) = customers.add(customer)
def iterator: Iterator[Customer] = customers.iterator
}
We have to make Customer extend Ordered to satisfy the upper-bound constraint, just as we had to make the Java version implement Comparable. Having done that, we inherit the default sorting behaviour from the trait.
// scala
object Customers {
def main(args: Array[String]) {
val customers = new Customers()
customers.add(new Customer("Fred Jones", "8 Tuna Lane,"))
customers.add(new Customer("Velma Dinkley", "316 Circle Drive"))
customers.add(new Customer("Daphne Blake", "101 Easy St"))
customers.add(new DiscountedCustomer("Norville Rogers", "1 Lane"))
println(customers.sort)
}
}
The beauty of the default method is that we can override it and specialise it if we need to. For example, if we want to create another sortable collection class for our customers but this time sort the customers by the value of their baskets, we can override the sort method.
In Java, we’d create a new class which extends Customers and overrides the default sort method.
// java
public class CustomersSortableBySpend extends Customers {
@Override
public List<Customer> sort() {
List<Customer> customers = new ArrayList<>();
for (Customer customer: this)
customers.add(customer);
customers.sort((first, second) ->
second.total().compareTo(first.total()));
return customers;
}
}
The general approach is the same as the default method, but we’ve used a different implementation for the sorting. We’re now sorting based on the total basket value of the customer. In Scala we’d do pretty much the same thing.
// scala
class CustomersSortableBySpend extends Customers {
override def sort: List[Customer] = {
this.toList.sorted(new Ordering[Customer] {
def compare(a: Customer, b: Customer) = b.total.compare(a.total)
})
}
}
We extend Customers and override the sort method to provide our alternative implementation. We’re using the built-in sort method again, but this time using a different anonymous instance of Ordering; again, comparing the basket values of the customers.
If you want to create a instance of the comparator as a Scala object rather than an anonymous class, we could do something like the following:
class CustomersSortableBySpend extends Customers {
override def sort: List[Customer] = {
this.toList.sorted(BasketTotalDescending)
}
}
object BasketTotalDescending extends Ordering[Customer] {
def compare(a: Customer, b: Customer) = b.total.compare(a.total)
}
To see this working we could write a little test program. We can add some customers to our CustomersSortableBySpend, and add some items to their baskets. I’m using the PricedItem class for the items, as it saves us having to create a stub class for each one like we saw before. When we execute it, we should see the customers sorted by basket value rather than customer name.
// scala
object AnotherExample {
def main(args: Array[String]) {
val customers = new CustomersSortableBySpend()
val fred = new Customer("Fred Jones", "8 Tuna Lane,")
val velma = new Customer("Velma Dinkley", "316 Circle Drive")
val daphne = new Customer("Daphne Blake", "101 Easy St")
val norville = new DiscountedCustomer("Norville Rogers", "1 Lane")
daphne.add(PricedItem(2.4))
daphne.add(PricedItem(1.4))
fred.add(PricedItem(2.75))
fred.add(PricedItem(2.75))
norville.add(PricedItem(6.99))
norville.add(PricedItem(1.50))
customers.add(fred)
customers.add(velma)
customers.add(daphne)
customers.add(norville)
println(customers.sort)
}
}
The output would look like this:
Norville Rogers $ 7.641
Daphne Blake $ 3.8
Fred Jones $ 2.75
Velma Dinkley $ 0.0
Converting Anonymous Classes to Lambdas
In the Java version of the sort method, we could use a lambda to effectively create an instance of Comparable. The syntax is new in Java 8 and in this case, is an alternative to creating an anonymous instance in-line.
// java
customers.sort((first, second) -> second.total().compareTo(first.total()));
To make the Scala version more like the Java one, we’d need to pass in a lambda instead of the anonymous instance of Ordering. Scala supports lambdas so we can pass anonymous functions directly into other functions, but the signature of the sort method wants an Ordering, not a function.
Luckily, we can coerce Scala into converting a lambda into an instance of Ordering using an implicit conversion. All we need to do is create a converting method that takes a lambda or function and returns an Ordering, and mark it as implicit. The implicit keyword tells Scala to try and use this method to convert from one to the other if otherwise things wouldn’t compile.
// scala
implicit def functionToOrdering[A](f: (A, A) => Int): Ordering[A] = {
new Ordering[A] {
def compare(a: A, b: A) = f.apply(a, b)
}
}
The signature takes a function and returns an Ordering[A]. The function itself has two arguments and returns an Int. So our conversion method is expecting a function with two arguments of type A, returning an Int ((A, A) => Int).
Now we can supply a function literal to the sorted method that would otherwise not compile. As long as the function conforms to the (A, A) => Int signature, the compiler will detect that it can be converted to something that does compile and call our implicit method to do so. We can therefore modify the sort method of CustomersSortableBySpend like this:
// scala
this.toList.sorted((a: Customer, b: Customer) => b.total.compare(a.total))
…passing in a lambda rather than an anonymous class. It’s very similar to the equivalent line of the Java version below.
// java
list.sort((first, second) -> first.compareTo(second));
Concrete Fields on Traits
We’ve looked at default methods on traits, but Scala also allows you to provide default values. You can specify fields in traits.
// scala
trait Counter {
var count = 0
def increment()
}
Here, count is a field on the trait. All classes that extend Counter will have their own instance of count copied in. It’s not inherited — it’s a distinct value specified by the trait as being required and supplied for you by the compiler. Subtypes are provided with the field by the compiler and it’s initialised (based on the value in the trait) on construction.
For example, count is magically available to the class below and we’re able to increment it in the increment method.
// scala
class IncrementByOne extends Counter {
override def increment(): Unit = count += 1
}
In this example, increment is implemented to multiply the value by some other value on each call.
// scala
class ExponentialIncrementer(rate: Int) extends Counter {
def increment(): Unit = if (count == 0) count = 1 else count *= rate
}
Incidentally, we can use protected on the var in Counter and it will have similar schematics as protected in Java. It gives visibility to subclasses but, unlike Java, not to other types in the same package. It’s slightly more restrictive than Java. For example, if we change it and try to access thecount from a non-subtype in the same package, we won’t be allowed.
// scala
trait Counter {
protected var count = 0
def increment()
}
class Foo {
val foo = new IncrementByOne() // a subtype of Counter but
foo.count // count is now inaccessible
}
Abstract Fields on Traits
You can also have abstract values on traits by leaving off the initialising value. This forces subtypes to supply a value.
// scala
trait Counter {
protected var count: Int // abstract
def increment()
}
class IncrementByOne extends Counter {
override var count: Int = 0 // forced to supply a value
override def increment(): Unit = count += 1
}
class ExponentialIncrementer(rate: Int) extends Counter {
var count: Int = 1
def increment(): Unit = if (count == 0) count = 1 else count *= rate
}
Notice that IncrementByOne uses the override keyword whereas ExponentialIncrementer doesn’t. For both fields and abstract methods, override is optional.
Abstract Classes
Vanilla abstract classes are created in Java with the abstract keyword. For example, we could write another version of our Customer class but this time make it abstract. We could also add a single method to calculate the customer’s basket value and mark that as abstract.
// java
public abstract class AbstractCustomer {
public abstract Double total();
}
In the DiscountedCustomer subclass, we could implement our discounted basket value like this:
// java
public class DiscountedCustomer extends AbstractCustomer {
private final ShoppingBasket basket = new ShoppingBasket();
@Override
public Double total() {
return basket.value() * 0.90;
}
}
In Scala, you still use the abstract keyword to denote a class that cannot be instantiated. However, you don’t need it to qualify a method; you just leave the implementation off.
// scala
abstract class AbstractCustomer {
def total: Double // no implementation means it's abstract
}
Then we can create a subclass in the same way we saw earlier. We use extends like before and simply provide an implementation for the total method. Any method that implements an abstract method doesn’t require the override keyword in front of the method, although it is permitted.
// scala
class DiscountedCustomer extends AbstractCustomer {
private final val basket = new ShoppingBasket
def total: Double = {
return basket.value * 0.90
}
}
Polymorphism
Where you might use inheritance in Java, there are more options available to you in Scala. Inheritance in Java typically means subtyping classes to inherit behaviour and state from the super-class. You can also view implementing interfaces as inheritance where you inherit behaviour but not state.
In both cases the benefits are around substitutability: the idea that you can replace one type with another to change system behaviour without changing the structure of the code. This is referred to as inclusion polymorphism.
Scala allows for inclusion polymorphism in the following ways:
· Traits without default implementations
· Traits with default implementations (because these are used to “mix in” behaviour, they’re often called mixin traits)
· Abstract classes (with and without fields)
· Traditional class extension
· Structural types, a kind of duck typing familiar to Ruby developers but which uses reflection
Traits vs. Abstract Classes
There are a couple of differences between traits and abstract classes. The most obvious is that traits cannot have constructor arguments. Traits also provide a way around the problem of multiple inheritance that you’d see if you were allowed to extend multiple classes directly. Like Java, a Scala class can only have a single super-class, but can mixin as many traits required. So despite this restriction, Scala does support multiple inheritance. Kind of.
Multiple inheritance can cause problems when subclasses inherit behaviour or fields from more than one super-class. In this scenario, with methods defined in multiple places, it’s difficult to reason about which implementation should be used. The is a relationship breaks down when a type has multiple super-classes.
Scala allows for a kind of multiple inheritance by distinguishing between the class hierarchy and the trait hierarchy. Although you can’t extend multiple classes, you can mixin multiple traits. Scala uses a process called linearization to resolve duplicate methods in traits. Specifically, Scala puts all the traits in a line and resolves calls to super by going from right to left along the line.
Does Scala Support Multiple-Inheritance?
If by “inheritance” you mean classic class extension, then Scala doesn’t support multiple inheritance. Scala allows only a single class to be “extended”. It’s the same as Java in that respect. However, if you mean can behaviour be inherited by other means, then yes, Scala does support multiple inheritance.
A Scala class can mixin behaviour from any number of traits, just as Java 8 can mixin behaviour from multiple interfaces with default methods. The difference is in how they resolve clashes. Scala uses linearization to predictably resolve a method call at runtime, whereas Java 8 relies on compilation failure.
Linearization means that the order in which traits are defined in a class definition is important. For example, we could have the following:
class Animal
trait HasWings extends Animal
trait Bird extends HasWings
trait HasFourLegs extends Animal
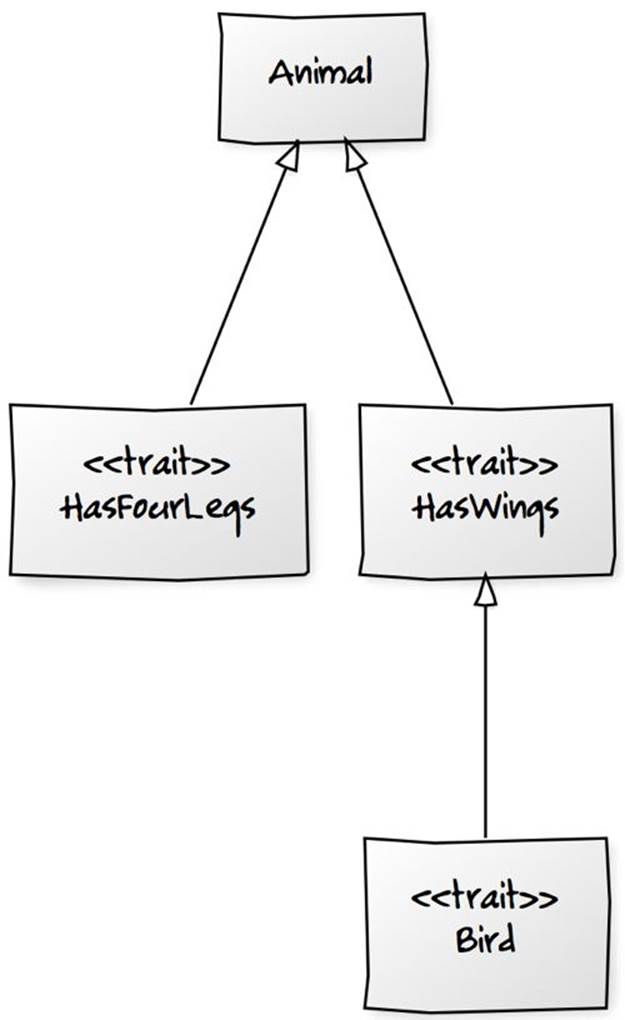
Fig. 2.1. Basic Animal class hierarchy.
If we add a concrete class that extends Animal but also Bird and HasFourLegs, we have a creature (FlyingHorse) which has all of the behaviours in the hierarchy.
class Animal
trait HasWings extends Animal
trait Bird extends HasWings
trait HasFourLegs extends Animal
class FlyingHorse extends Animal with Bird with HasFourLegs
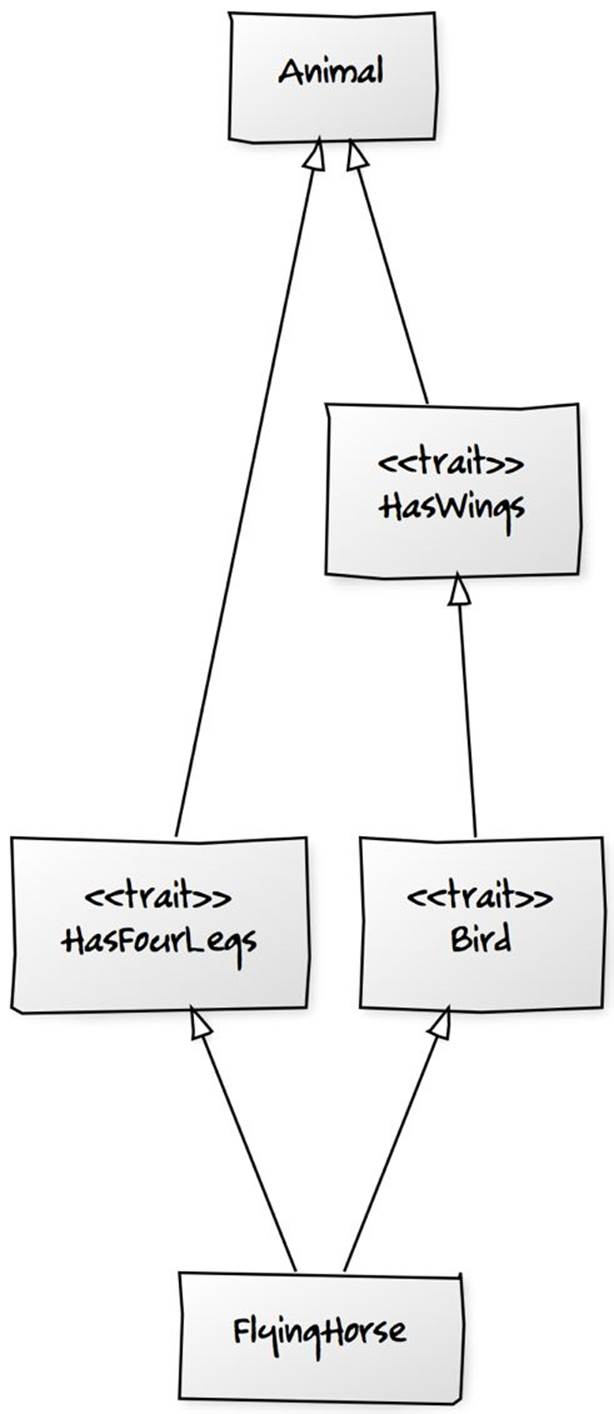
Fig. 2.2. Concrete class FlyingHorse extends everything.
The problem comes when we have a method that any of the classes could implement and potentially call that method on their super-class. Let’s say there’s a method called move. For an animal with legs, move might mean to travel forwards, whereas an animal with wings might travel upwards as well as forwards. If you call move on our FlyingHorse, which implementation would you expect to be called? How about if it in turn calls super.move?

Fig. 2.3. How should a call to move resolve?
Scala addresses the problem using the linearization technique. Flattening the hierarchy from right to left would give us FlyingHorse, HasForLegs, Bird, HasWings and finally Animal. So if any of the classes call a super-class’s method, it will resolve in that order.

Fig. 2.4. Class FlyingHorse extends Animal with Bird with HasFourLegs.
If we change the order of the traits and swap HasFourLegs with Birds, the linearization changes and we get a different evaluation order.

Fig. 2.5. Class FlyingHorse extends Animal with HasFourLegs with Bird.
So side by side, the examples look like this:
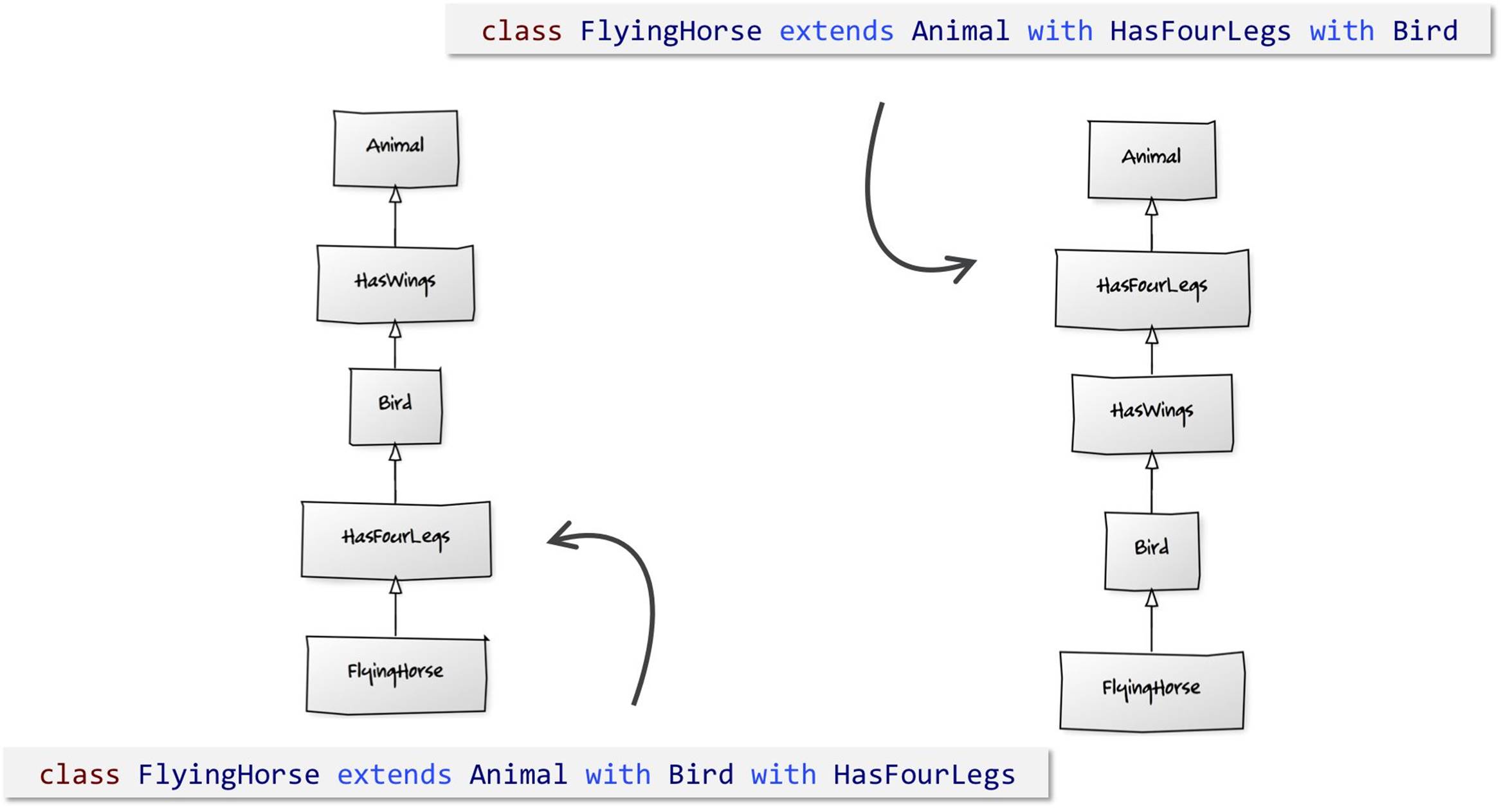
Fig. 2.6. The linearization of the two hierarchies.
With default methods in Java 8 there is no linearization process: any potential clash causes the compiler to error and the programmer has to refactor around it.
Apart from allowing multiple inheritance, traits can also be stacked or layered on top of each other to provide a call chain, similar to aspect-oriented programming, or using decorators. There’s a good section on layered traits in Scala for the Impatient by Cay S. Horstmann if you want to read more.
Deciding Between the Options
Here are some tips to help you choose when to use the different inheritance options.
Use traits without state when you would have used an interface in Java; namely, when you define a role a class should play where different implementations can be swapped in. For example, when you want to use a test double when testing and a “real” implementation in production. “Role” in this sense implies no reusable concrete behaviour, just the idea of substitutability.
When your class has behaviour and that behaviour is likely to be overridden by things of the same type, use a regular class and extend. Both of these are types of inclusion polymorphism.
Use an abstract class in the case when you’re more interested in reuse than in an OO is a relationship. For example, data structures might be a good place to reuse abstract classes, but our Customer hierarchy from earlier might be better implemented as non-abstract classes.
If you’re creating reusable behaviour that may be reused by unrelated classes, make it a mixin trait as they have fewer restrictions on what can use them compared to a abstract class.
Odersky also talks about some other factors, like performances and Java interoperability, in Programming in Scala
Control Structures
This chapter is all about control structures, like if statements, switch blocks, loops and breaks. Specifically, we’ll look at:
· Conditionals like if statements, ternary expressions and switches
· Looping structures; do, while and for
· Breaking control flow
· Exceptions, briefly
Conditionals
Ifs and Ternaries
Conditionals are straightforward.
// java
if (age > 55) {
retire();
} else {
carryOnWorking();
}
An if in Java looks exactly the same in Scala.
// scala
if (age > 55) {
retire()
} else {
carryOnWorking()
}
You’ll often find Scala developers dropping the braces for simple if blocks. For example:
if (age > 55)
retire()
else
carryOnWorking()
or even pulling it all onto one line.
if (age > 55) retire() else carryOnWorking()
This style is favoured because if/else is actually an expression in Scala and not a statement, and the more concise syntax makes it look more like an expression. What’s the difference? Well, an expression returns a value whereas a statement carries out an action.
Expressions vs. Statements
An expression returns a value whereas a statement carries out an action. Statements by their nature often have side effects whereas expressions are less likely to.
For example, let’s add a creation method to our Customer class that will create either a DiscountedCustomer or a regular Customer based on how long they’ve been a customer.
// java
public static Customer create(String name, String address,
Integer yearsOfCustom) {
if (yearsOfCustom > 2) {
return new DiscountedCustomer(name, address);
} else {
return new Customer(name, address);
}
}
In Java, we’re forced to return the new Customer from the method. The conditions are statements, things that execute, not expressions which return values. We could do it longhand and create a variable, set then return it, but the point is the same; the statements here have to cause a side effect.
public static Customer create(String name, String address,
Integer yearsOfCustom) {
Customer customer = null;
if (yearsOfCustom > 2) {
customer = new DiscountedCustomer(name, address);
} else {
customer = new Customer(name, address);
}
return customer;
}
Because conditionals in Scala are expressions, you don’t need to jump through these hoops. In the Scala equivalent, we can just create the if and both branches will return a customer. As the entire expression is the last statement in the method, it is what will be returned from the method.
// scala
object Customer {
def create(name: String, address: String, yearsOfCustom: Int) = {
if (yearsOfCustom > 2)
new DiscountedCustomer(name, address)
else
new Customer(name, address)
}
}
Longhand, we can assign the result of the if (remember it’s an expression not a statement) to a val and then return the value on the last line.
object Customer {
def create(name: String, address: String, yearsOfCustom: Int) = {
val customer = if (yearsOfCustom > 2)
new DiscountedCustomer(name, address)
else
new Customer(name, address)
customer
}
}
Another trivial example might be something like this:
val tall = if (height > 190) "tall" else "not tall" // scala
You may have noticed this behaves like a ternary expression in Java.
String tall = height > 190 ? "tall" : "not tall"; // java
So, ternaries are expressions in Java but if statements are not. Scala has no conditional operator (?:) because a regular Scala if is an expression; it’s equivalent to Java’s conditional operator. In fact, the bytecode generated for an if uses a ternary.
You don’t have to use an if in Scala like a ternary and assign it to anything, but it’s important to realise that it is an expression and has a value. In fact, everything in Scala is an expression. Even a simple block (denoted with curly braces) will return something.
Switch Statements
There are no switch statements as such in Scala. Scala uses match expressions instead. These look like they’re switching but differ, in that the whole thing is an expression and not a statement. So as we saw with the if, Scala’s switch-like construct has a value. It also uses something calledpattern matching which is a lot more powerful, as it allows you to select on more than just equality.
In Java, you might write a switch to work out which quarter a particular month falls in. So, January, February, March are in the first quarter, April, May, June in the second, and so on.
// java
public class Switch {
public static void main(String... args) {
String month = "August";
String quarter;
switch (month) {
case "January":
case "February":
case "March":
quarter = "1st quarter";
break;
case "April":
case "May":
case "June":
quarter = "2nd quarter";
break;
case "July":
case "August":
case "September":
quarter = "3rd quarter";
break;
case "October":
case "November":
case "December":
quarter = "4th quarter";
break;
default:
quarter = "unknown quarter";
break;
}
System.out.println(quarter);
}
}
The break is required to stop the statement execution falling through. When Java selects a case, it has to have a side effect to be useful. In this case, it assigns a value to a variable.
In Scala, we’d start with something like this:
// scala
object BrokenSwitch extends App {
val month = "August"
var quarter = "???"
month match {
case "January" =>
case "February" =>
case "March" => quarter = "1st quarter"
case "April" =>
case "May" =>
case "June" => quarter = "2nd quarter"
case "July" =>
case "August" =>
case "September" => quarter = "3rd quarter"
case "October" =>
case "November" =>
case "December" => quarter = "4th quarter"
case _ => quarter = "unknown quarter"
}
println(month + " is " + quarter)
}
The above is a direct syntactic translation. However, Scala doesn’t support the break keyword so we have to leave that out. Rather than switch we use match and we’re saying “does the month match any of these case clauses?”
Rather than the colon, we use => and the underscore at the bottom is the catch-all, the same as default in Java. Underscore is often used in Scala to mean an unknown value.
So although this is a direct translation, when we run it, something has gone wrong. The result hasn’t been set.
The output says:
August is ???
Unlike Java, if a case matches, the break is implicit — there is no fall-through to the next case. So we’ll have to add some code to the empty blocks.
// scala
object Switch extends App {
val month = "August"
var quarter = "???"
month match {
case "January" => quarter = "1st quarter"
case "February" => quarter = "1st quarter"
case "March" => quarter = "1st quarter"
case "April" => quarter = "2nd quarter"
case "May" => quarter = "2nd quarter"
case "June" => quarter = "2nd quarter"
case "July" => quarter = "3nd quarter"
case "August" => quarter = "3rd quarter"
case "September" => quarter = "3rd quarter"
case "October" => quarter = "4th quarter"
case "November" => quarter = "4th quarter"
case "December" => quarter = "4th quarter"
case _ => quarter = "unknown quarter"
}
println(month + " is " + quarter)
}
This time it works but we’ve duplicated a fair bit.
To remove some of the duplication, we can combine January, February, and March onto one line, separating them with an or. This means that the month can match either January, February, or March. In all of these cases, what follows the => will be executed.
case "January" | "February" | "March" => quarter = "1st quarter"
Doing this for the rest of the cases would give us the following:
// scala
object SwitchWithLessDuplication extends App {
val month = "August"
var quarter = "???"
month match {
case "January" | "February" | "March" => quarter = "1st quarter"
case "April" | "May" | "June" => quarter = "2nd quarter"
case "July" | "August" | "September" => quarter = "3rd quarter"
case "October" | "November" | "December" => quarter = "4th quarter"
case _ => quarter = "unknown quarter"
}
println(month + " is " + quarter)
}
We’ve condensed the code above by writing expressions within the case clauses themselves. This becomes more powerful when we think of these case clauses as patterns that we can use to build up more and more expressive conditions for the match.
Java can only switch on primitives, enums and from Java 7, string values. Thanks to pattern matching, Scala can match on almost anything, including objects. We’ll look more at pattern matching in Part III.
The other thing to note is that Scala’s version of the switch is an expression. We’re not forced to work with side effects and can drop the temporary variable and return a String to represent the quarter the month falls into. We can then change the quarter variable from being a var to a val.
// scala
object SwitchExpression extends App {
val month = "August"
val quarter = month match {
case "January" | "February" | "March" => "1st quarter"
case "April" | "May" | "June" => "2nd quarter"
case "July" | "August" | "September" => "3rd quarter"
case "October" | "November" | "December" => "4th quarter"
case _ => "unknown quarter"
}
println(month + " is " + quarter)
}
We could even do it in-line. We just need to add some parentheses around the match, like this:
// scala
object SwitchExpression extends App {
val month = "August"
println(month + " is " + (month match {
case "January" | "February" | "March" => "1st quarter"
case "April" | "May" | "June" => "2nd quarter"
case "July" | "August" | "September" => "3rd quarter"
case "October" | "November" | "December" => "4th quarter"
case _ => "unknown quarter"
}))
}
Looping Structures; do, while and for
Scala and Java share the same syntax for do and while loops. For example, this code uses a do and a while to print the numbers zero to nine.
// java
int i = 0;
do {
System.out.println(i);
i++;
} while (i < 10);
The Scala version would look like this. (There is no ++ incrementer so we use += instead.)
// scala
var i: Int = 0
do {
println(i)
i += 1
} while (i < 10)
And while loops are the same.
// java
int i = 0;
while (i < 10) {
System.out.println(i);
i++;
}
// scala
var i: Int = 0
while (i < 10) {
println(i)
i += 1
}
Things get more interesting when we look at for loops. Scala doesn’t have for loops like Java does; it has what’s referred to as the “generator-based for loop” and the related “for comprehension” instead. To all intents and purposes, these can be used like Java’s for loop construct, so for the most part you won’t have to worry about the technical differences.
Java’s for loop controls the iteration in three stages: initialise, check and update.
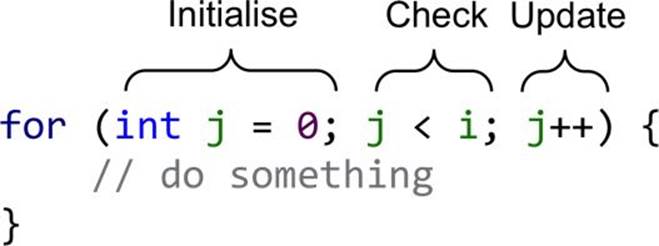
Fig. 2.7. The typical for loop iteration stages.
There is no direct analog in Scala. You’ve seen an alternative — using the while loop to initialise a variable, check a condition, then update the variable — but you can also use a generator-based for loop in Scala. So the following for in Java:
// java
for (int i = 0; i < 10; i++) {
System.out.println(i);
}
…would look like this using a generator-based for loop in Scala:
// scala
for (i <- 0 to 9) {
println(i)
}
The i variable has been created for us and is assigned a value on each iteration. The arrow indicates that what follows is a generator. A generator is something that can feed values into the loop. The whole thing is a lot like Java’s enhanced for loops where anything that is Iterable can be used. In the same way, anything that can generate a iteration in Scala can be used as a generator.
In this case, 0 to 9 is the generator. Zero is an Int literal and the class Int has a method called to that takes an Int and returns a range of numbers which can be enumerated. The example uses the infix shorthand, but we could have written it longhand like this:
for (i <- 0.to(9)) {
println(i)
}
It’s very similar to the following enhanced for loop in Java, using a list of numbers:
// java
List<Integer> numbers = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 9);
for (Integer i : numbers) {
System.out.println(i);
}
…which itself could be rewritten in Java as the following:
numbers.forEach(i -> System.out.println(i)); // java
or as a method reference.
numbers.forEach(System.out::println); // java
Unsurprisingly, Scala has a foreach method of its own.
(0 to 9).foreach(i => println(i)) // scala
We use the to method again to create a sequence of numbers. This sequence has the foreach method, which we call, passing in a lambda. The lambda function takes an Int and returns Unit.
We can even use Scala’s shorthand like we did with Java’s method reference:
(0 to 10).foreach(println(_)) // scala
For-Loop vs For Comprehension
What’s the difference between the generator-based for loop and the for comprehension?
The generator-based for loop will be converted by the compiler into a call to foreach against the collection. A for comprehension will be converted to a call to map on the collection. The for comprehension adds the keyword yield to the syntax:
for (i <- 0 to 5) yield i * 2 // results in (0, 2, 4, 6, 8, 10)
See the For Comprehensions chapter for more details.
Breaking Control Flow (break and continue)
Scala has no break or continue statements, and generally discourages you from breaking out of loops. However, you can use a library method to achieve the same thing. In Java, you might write something like this to break out of a loop early:
// java
for (int i = 0; i < 100; i++) {
System.out.println(i);
if (i == 10)
break;
}
In Scala, you need to import a Scala library class called Breaks. You can then enclose the code to break out from in a “breakable” block and call the break method to break out. It’s implemented by throwing an exception and catching it.
// scala
import scala.util.control.Breaks._
breakable { // breakable block
for (i <- 0 to 100) {
println(i)
if (i == 10)
break() // break out of the loop
}
}
Exceptions
Exceptions in Scala are handled in the same way as Java. They have all the same schematics in terms of interrupting control flow and aborting the program if not dealt with.
Exceptions in Scala extend java.lang.Throwable like their Java counterparts but Scala has no concept of checked exceptions. All checked exceptions thrown from existing Java libraries get converted to RuntimeExceptions. Any exceptions you throw don’t need to be dealt with to keep the compiler happy; all exceptions in Scala are runtime exceptions.
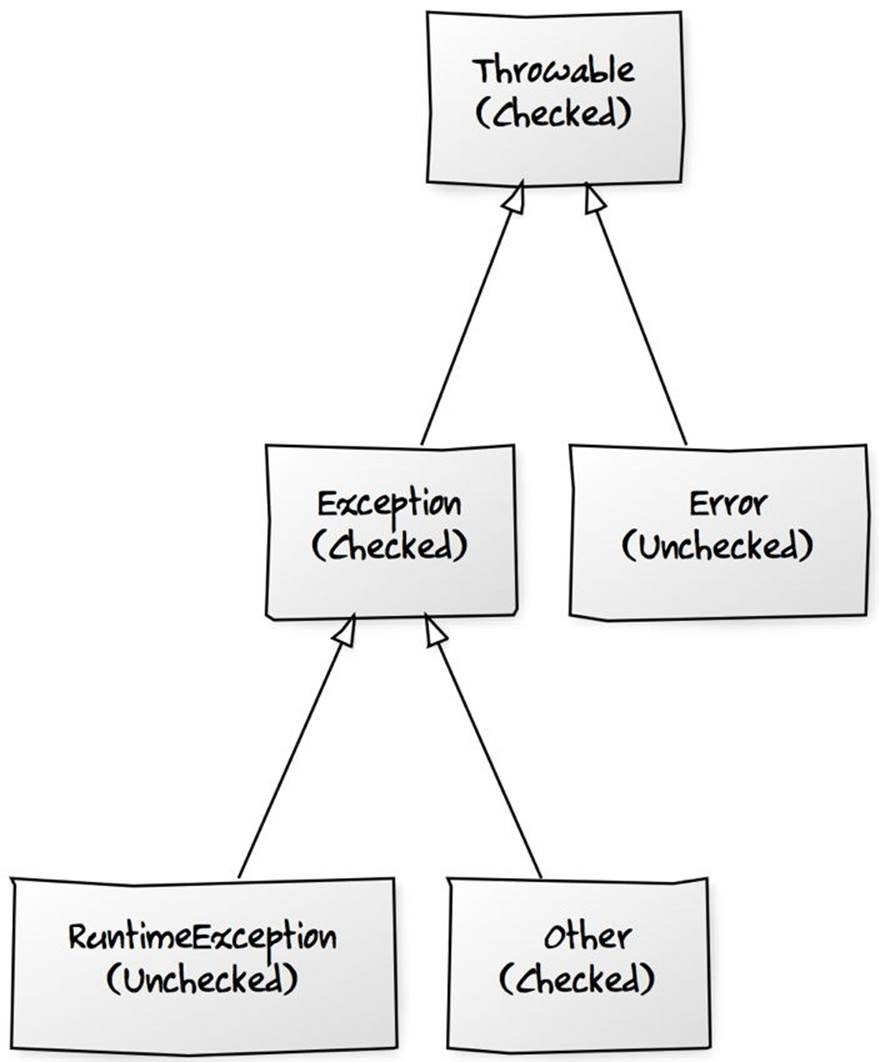
Fig. 2.8. The Java exception hierarchy. Scala doesn’t use checked exceptions.
Catching exceptions uses pattern matching like we saw earlier with match expressions. In Java you might do something like this to get the contents of a web page:
// java
try {
URL url = new URL("http://baddotrobot.com");
BufferedReader reader = new BufferedReader(
new InputStreamReader(url.openStream()));
try {
String line;
while ((line = reader.readLine()) != null)
System.out.println(line);
} finally {
reader.close();
}
} catch (MalformedURLException e) {
System.out.println("Bad URL");
} catch (IOException e) {
System.out.println("Problem reading data: " + e.getMessage());
}
We start with a URL to curl. This can throw a MalformedURLException. As it’s a checked exception, we’re forced to deal with it. We then create a Reader and open a stream from the URL ready for reading. This can throw another exception, so we’re forced to deal with that too. When we start reading, the readLine method can also throw an exception but that’s handled by the existing catch. To make sure we clean up properly in the event of an exception here, we close the reader in a finally block.
If we want to use Java 7’s try-with-resources construct, we can avoid the finally clause. The try-with-resources syntax will automatically call close on the reader.
// java
try {
URL url = new URL("http://baddotrobot.com");
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(url.openStream()))) {
String line;
while ((line = reader.readLine()) != null)
System.out.println(line);
}
} catch (MalformedURLException e) {
System.out.println("Bad URL");
} catch (IOException e) {
System.out.println("Problem reading data: " + e.getMessage());
}
In Scala things look pretty much the same.
// scala
try {
val url = new URL("http://baddotrobot.com")
val reader = new BufferedReader(new InputStreamReader(url.openStream))
try {
var line = reader.readLine
while (line != null) {
line = reader.readLine
println(line)
}
} finally {
reader.close()
}
} catch {
case e: MalformedURLException => println("Bad URL")
case e: IOException => println(e.getMessage)
}
We create the URL as before. Although it can throw an exception, we’re not forced to catch it. It’s a Java checked exception but Scala is converting it to a runtime exception.
Although we’re not forced to, we do actually want to deal with the exceptions. So we use the familiar try and catch statements. In the catch, the exceptions are dealt with using match expressions. We can tweak the pattern if we don’t actually need the exception in the code block by replacing the variable name with an underscore. That means we don’t care about the variable, only the class.
case _: MalformedURLException => println("Bad URL")
We just need to add the finally block back in. finally is just as it is in Java. There is no try-with-resources equivalent in Scala, although you can write your own method to achieve the same thing. (Hint: With something like the Loan pattern.)
Generics
In this chapter we’ll look at generics or type parameterisation or generic programming in Scala. We’ll look at:
· Syntax for generics: defining types and methods
· Bounded types, extends and super
· Wildcards in both Java and Scala
· Covariance and contravariance
Parametric Polymorphism
We talked briefly about subtype or inclusion polymorphism; the idea that subtypes can be substituted to stand in for their super-types. These stand-ins can provide different behaviour without changing the structure of your code. The types of polymorphism include:
· Inclusion polymorphism (see the Inheritance chapter)
· Ad hoc polymorphism (which is basically method overloading)
· Parametric polymorphism
Parametric polymorphism allows us to write code generically without depending on specific types, yet still maintain type safety. We use it all the time when we work with classes that work against multiple types. For example:
List<Customer> customers = new ArrayList<>(); // java
Parametric polymorphism will be familiar if you’ve ever created a list of something in Java. It’s more commonly referred to as generics; by giving a generic type (like List) a parameterised type, we can treat it as a list yet still refer to its contents in a type-safe way. Generics are at play even if you don’t specify the parameterised type in Java. So although you can write the following:
List collection = new ArrayList(); // java
You’re actually creating a generic List of type Object.
List<Object> collection = new ArrayList<>(); // java
Diamond Operator
You can create a list of Object in Java like this:
List<Object> collection = new ArrayList<>();
The diamond operator (<>) on the right-hand side of the assignment above was new in Java 7. Before Java 7, you were forced to repeat the generic type declaration on the right-hand side.
Class Generics
When you create a list of a specific type, Java will give you type safety on List methods that take parameters and return things of that type. For example, creating a list of customers but then trying to add an object that isn’t a customer will result in a compiler failure.
List<Customer> customers = new ArrayList<>();
customers.add(new HockeyPuck()); // compiler failure
The basic syntax for Scala will look familiar to Java developers; we just replace the chevrons with square brackets.
List<Customer> customers = new ArrayList<>(); // java
versus
val customers: List[Customer] = List() // scala
Creating a list in Scala like this also shows that it has the equivalent of the diamond operator. Scala’s type inference can work out that customers is of type Customer without repeating the generics on the right-hand side.
val customers: List[Customer] = List[Customer]()
^
// no need to repeat the type
Method Generics
You can define generic parameters for methods in a similar way. To define a generic parameter to a method without defining a generic type for the whole class, you’d do something like this in Java, where the generic type is defined straight after the public keyword and used as the type of the parameter a:
public <A> void add(A a) // java
versus this in Scala:
def add[A](a: A) // scala
Stack Example
As a slightly more expanded example, in Java, we could generalise a Stack class. We could create an interface Stack with a generic type T and ensure that the push method takes a T and the pop method returns a T.
// java
public interface Stack<T> {
void push(T t);
T pop();
}
In Scala:
// scala
trait Stack[T] {
def push(t: T)
def pop: T
}
For demonstration purposes, we could implement Stack using a list in Java like this:
// java
public class ListStack<T> implements Stack<T> {
private final List<T> elements = new ArrayList<>();
@Override
public void push(T t) {
elements.add(0, t);
}
@Override
public T pop() {
if (elements.isEmpty())
throw new IndexOutOfBoundsException();
return elements.remove(0);
}
}
We “bind” a concrete type to the generic type when we supply the compiler with a concrete type. Adding String to the declaration below (on line 3) “binds” what was the generic type T to String. The compiler knows to replace T with String and we can start using strings as arguments and return types. If we try to add a number to the stack in our example, we’d get a compiler error.
1 // java
2 public static void main(String... args) {
3 Stack<String> stack = new ListStack<>();
4 stack.push("C");
5 stack.push("B");
6 stack.push("A");
7 stack.push(12); // compilation failure
8 String element = stack.pop());
9 }
Creating the ListStack in Scala is straightforward. It would look something like this:
// scala
class ListStack[T] extends Stack[T] {
private var elements: List[T] = List()
override def push(t: T): Unit = {
elements = t +: elements
}
override def pop: T = {
if (elements.isEmpty) throw new IndexOutOfBoundsException
val head = elements.head
elements = elements.tail
head
}
}
We still use a List to store the elements but because Scala’s List is immutable, in the push method, we replace the instance with a new list with the element prepended.
Similarly, when we pop, we have to replace the elements with all but the first element using the tail method. We get and return the first element using the head method. You’ll come across the idea of head (the first) and tail (the remainder) a lot in Scala and functional programming.
Binding to a concrete type is just the same. In the example below, I’m not declaring the stack variable with a type, so we need to give the compiler a hint about what kind of List it will be by adding the parameterised type on line 3.
1 // scala
2 def main(args: String*) {
3 val stack = new ListStack[String]
4 stack.push("C")
5 stack.push("B")
6 stack.push("A")
7 val element: String = stack.pop
8 }
To demonstrate method-level generics, we could add a method to convert a Stack to an array. The thing to note here is that the generic is defined solely in terms of the method. A isn’t related to the generic type on the class definition.
// java
public interface Stack<T> {
static <A> A[] toArray(Stack<A> stack) {
throw new UnsupportedOperationException();
}
}
You define method-level generics in Scala in just the same way. Below, A is defined purely in scope for the method.
// scala
object Stack {
def toArray[A](a: Stack[A]): Array[A] = {
???
}
}
Bounded Classes
Let’s go back to the list example with a generic type of Customer.
List<Customer> customers = new ArrayList<>(); // java
The contents of the list can be any Customer or subtype of Customer, so we can add a DiscountedCustomer to the list.
List<Customer> customers = new ArrayList<>();
customers.add(new Customer("Bob Crispin", "15 Fleetwood Mack Road"));
customers.add(new DiscountedCustomer("Derick Jonar", "23 Woodfield Way"));
Type erasure sees the collection as containing only Objects. The compiler will ensure that only things of the correct type go into the collection and use a cast on the way out. That means that anything you take out of our example can only be treated as a Customer.
If all you’ve done is override Customer behaviour in the DiscountedCustomer, you can treat the objects polymorphically and you wouldn’t see a problem. If you’ve added methods to DiscountedCustomer, however, you can’t call them without an unchecked cast.
for (Customer customer : customers) { // some may be DiscountedCustomers
// total will be the discounted total for any DiscountedCustomers
System.out.println(customer.getName() + " : " + customer.total());
}
DiscountedCustomer customer = (DiscountedCustomer) customers.get(0);
System.out.println(customer.getDiscountAmount());
To get round this limitation, you can force generic types to be bound to specific types within a class hierarchy. These are called bounded types.
Upper Bounds (<U extends T>)
You can restrict a generic type using extends or super in Java. These set the bounds of that type to either be a subtype or super-type. You use extends to set the upper bounds and super, the lower bounds. They can refer to a class or an interface.
We’ve actually already seen an example of setting an upper bound in the Sortable interface we wrote back in the inheritance chapter. We created an interface describing generically that things can be sortable.
// java
public interface Sortable<A extends Comparable<A>> extends Iterable<A> {
default public List<A> sort() {
List<A> list = new ArrayList<>();
for (A elements: this)
list.add(elements);
list.sort((first, second) -> first.compareTo(second));
return list;
}
// etc
}
This does a couple of things with generics. It both defines a generic type A which must be a subclass of Comparable, and also says that implementing classes must be able to iterate over A. Comparable is the upper bound of A.
This is a good example of why bounded types are useful; because we want to define a general-purpose algorithm yet constrain the types enough that we can call known methods in that algorithm. In the example, we can’t implement the sort method unless the class has the compareTo method from Comparable and also is iterable.
We bind the type parameter when we implement the interface.
public class Customers implements Sortable<Customer> { ... } // java
It’s at this point that the compiler can start treating A as a Customer and check that Customer implements Comparable and that Customers implements Iterable.
In Scala, it would look like this:
// scala
trait Sortable[A <: Ordered[A]] extends Iterable[A] {
def sort: Seq[A] = {
this.toList.sorted
}
}
class Customers extends Sortable[Customer] { ... }
The upper bound tells you what you can get out of a data structure. In our example, the sorting algorithm needed to get something out and use it as a Comparable; it enforces type safety. It’s set using extends in Java and <: in Scala.
Lower Bounds (<U super T>)
Setting a lower bound means using the super keyword in Java, something like the following:
public class Example<T, U super T> { } // java
It’s saying that U has to be a super-type of T. It’s useful when we want to be flexible in our API design; you’ll see it a lot in Java library code or in libraries like Hamcrest. For example, suppose we have a class hierarchy to represent animals.
// java
static class Animal {}
static class Lion extends Animal {}
static class Zebra extends Animal {}
We might want collect the lions together in an enclosure.
// java
List<Lion> enclosure = new ArrayList<>();
enclosure.add(new Lion());
enclosure.add(new Lion());
Let’s say that we want to sort the lions, and that we already have a helper method, similar to the Sortable interface, that sorts anything that is Comparable.
// java
public static <A extends Comparable<A>> void sort(List<A> list) {
Collections.sort(list);
}
To sort our lions, we just make them comparable and call the sort method.
// java
static class Lion extends Animal implements Comparable<Lion> {
@Override
public int compareTo(Lion other) {
return this.age.compareTo(other.age);
}
}
sort(enclosure);
Great, but what if we expand our enclosure and create a zoo?
// java
List<Animal> zoo = new ArrayList<>();
zoo.add(new Lion());
zoo.add(new Lion());
zoo.add(new Zebra());
sort(zoo);
It won’t compile, as we can’t compare zebras and lions.
It would make sense to implement Comparable in terms of Animals rather than the subtypes. That way, we can compare zebras to lions and presumably keep them away from each other.
If we make the Lion and Zebra Comparable with Animal, in theory we should be able to compare them with each other and themselves. However, if we move the comparable implementation up to the super-type (i.e., Animal implements Comparable and remove it from Lion), like this:
// java
static class Animal implements Comparable<Animal> {
@Override
public int compareTo(Animal o) {
return 0;
}
}
static class Lion extends Animal { }
static class Zebra extends Animal { }
…we get a compiler error when trying to sort the Lion enclosure (a List<Lion>).
java: method sort in class Zoo cannot be applied to given types;
required: java.util.List<A>
found: java.util.List<Lion>
reason: inferred type does not conform to equality constraint(s)
inferred: Animal
equality constraints(s): Lion
Otherwise known as:
Inferred type 'Lion' for type parameter 'A' is not within its bounds;
should implement 'Lion'
This is because the sort method (public static <A extends Comparable<A>> void sort(List<A> list)) expects a type that is comparable to itself, and we’re trying to compare it to something higher up the class hierarchy. When A is bound to a concrete type, for example Lion, Lion must also be Comparable against Lion. The problem is that we’ve just made it comparable to Animal.
static class Lion extends Animal implements Comparable<Animal> { }
^
The zoo (a List<Animal>) can be sorted because the generic type of the collection is Animal.
We can fix it by adding ? super A to the signature of sort. This means that whilst A is still bound to a concrete type, say Lion, we’re now saying that it needs to be comparable to some super-type of Lion. As Animal is a super-type of Lion, it conforms and the whole thing compiles again.
public static <A extends Comparable<? super A>> void sort(List<A> list) { }
The upshot to all this is that our API method sort is much more flexible with a lower bound; without it, we wouldn’t be able to sort different types of animal.
In Scala, we can go through the same steps and create the Animal hierarchy.
// scala
class Animal extends Comparable[Animal] {
def compareTo(o: Animal): Int = 0
}
class Lion extends Animal
class Zebra extends Animal
Then we can create our sort method again and recreate our enclosure.
// scala
def sort[A <: Comparable[A]](list: List[A]) = { }
// scala
def main(args: String*) {
var enclosure = List[Lion]()
enclosure = new Lion +: enclosure
enclosure = new Lion +: enclosure
sort(enclosure) // compiler failure
var lion: Lion = enclosure(1)
var zoo = List[Animal]()
zoo = new Zebra +: zoo
zoo = new Lion +: zoo
zoo = new Lion +: zoo
sort(zoo) // compiles OK
var animal: Animal = zoo(1)
}
Like before, we get a compilation failure.
Error:(30, 5) inferred type arguments [Lion] do not conform to method
sort's type parameter bounds [A <: Comparable[A]] sort(enclosure)
^
It correctly enforces that A must be of the same type but we’re treating A as both Lion and Animal. So just like before, we need to constrain the generic type with a lower bound.
You might be tempted to try a direct equivalent: using an underscore with >: A:
def sort[A <: Comparable[_ >: A]](a: List[A]) = { } // compiler failure
But unfortunately, this would cause a compilation failure:
failure: illegal cyclic reference involving type A
It can’t cope with the reference to A; it sees it as cyclic. So you have to try and keep the relationship with the bounds but remove the cyclic reference. The answer is to define a new generic type U and write something like this:
def sort[A <: Comparable[U], U >: A](list: List[A]) = { }
So A must extend Comparable where the Comparable’s generic type U must itself be a super-type of A. This gets rid of the cyclic problem, but the compiler would still complain.
inferred type arguments [Lion,Lion] do not conform to method sort's
type parameter bounds [A <: Comparable[U], U >: A] sort(enclosure)
^
It’s saying that the inferred types for the enclosure don’t match the constraints we’ve set. It has inferred the two types to both be Lion because the inference engine just doesn’t have enough to go on. We can give it a hint if we specify the types we know to be true. So just like a type witness in Java, we can clarify that we want the types to be Lion and Animal.
var enclosure = List[Lion]()
enclosure = new Lion +: enclosure
enclosure = new Lion +: enclosure
sort[Lion, Animal](enclosure) // add a type hint
When you round-trip the byte code, the final version looks like this:
// java
public <T extends Comparable<U>, U> void sort(List<U> a) { }
Which is pretty much equivalent to the following:
// java
public <T extends Comparable<?>> void sort(List<T> a) { }
Which is pretty much the same as the Scala version:
def sort[A <: Comparable[_]](list: List[A]) { } // scala
So it treats it like an unbounded type under the covers. That’s not quite true, in the sense that the Scala compiler is doing all the hard work here and leaves U unbounded because it’s doing all the type checking. In this example, it doesn’t make complete sense to round-trip from byte code to Java, as it’s not like-for-like, but it’s interesting to see what’s going on behind the scenes.
A lower bound tells you what you can put in a data structure. In our Lion example, using a lower bound means you can put more than just lions in the zoo. You use super in Java and greater than colon (>:) in Scala.
Wildcard Bounds (<? extends T, <? super T>)
We’ve already seen some examples of wildcards: the ? in Java and the _ in Scala.
Wildcards with an upper bound look like this:
// java
void printAnimals(List<? extends Animal> animals) {
for (Animal animal : animals) {
System.out.println(animal);
}
}
// scala
def printAnimals(animals: List[_ <: Animal]) {
for (animal <- animals) {
println(animal)
}
}
Wildcards with a lower bound look like this:
// java
static void addNumbers(List<? super Integer> numbers) {
for (int i = 0; i < 100; i++) {
numbers.add(i);
}
}
// scala
def addNumbers(numbers: List[_ >: Int]) {
for (i <- 0 to 99) {
// ...
}
}
Unbounded wildcards look like this in Java:
List<?> list // java
…and like this in Scala:
List[_] // scala
An unbounded wildcard refers to an unknown generic type. For example, printing elements of a list of unknown type will work with all lists. Just add upper- or lower-bound constraints to limit the options.
// java
void printUnknown(List<?> list) {
for (Object element : list) {
System.out.println(element);
}
}
// scala
def printUnknown(list: List[_]) {
for (e <- list) {
val f: Any = e
println(f)
}
}
Although the implementation can treat the elements as Object because everything is an object, you can’t add anything to a list of unknown type.
// java
List<?> list = new ArrayList<String>();
list.add(new Object()); // compiler error
The one exception is null.
list.add(null);
You get the same effect in Scala, where you can’t even create a list without a valid type:
scala> val list = mutable.MutableList[_]()
<console>:7: error: unbound wildcard type
val list = mutable.MutableList[_]()
^
You mainly use wildcards when you really don’t care about the type parameter, just any constraints on an upper or lower bounding, or when you can treat the type as an instance of Object or Any.
Multiple Bounds
Types can also have multiple bounds in both Java and Scala.
· Java is limited to multiple upper bounds.
· Java can’t set a lower and upper bound on types (so you can’t have a generic type extend one thing and also be a super-type to another).
· Scala can set a single lower and an upper bound, unlike Java.
· However, it can’t set multiple upper or lower bounds. Instead it can constrain bounds by also forcing you to extend traits.
Using multiple bounds, another way to express the constraints on the Animal sorting method would be to explicitly state that A must extend Animal and be comparable to Animal, using the & symbol in Java.
// java
public static <A extends Animal & Comparable<Animal>> void sort(List<A> l)
This sets two upper bounds to the generic type A in Java. You can’t set two upper bounds on A in Scala, but you can achieve the same effect by specifying that your bound must also extend certain traits.
// scala
def sort[A <: Animal with Comparable[Animal]](list: List[A]) = { }
Because we’re being more explicit, we can remove the type hints when calling the sort method.
var enclosure = List[Lion]()
enclosure = new Lion +: enclosure
enclosure = new Lion +: enclosure
sort(enclosure)
In Scala, you can also set both a lower and upper bound using >: and <:, like this:
def example[A >: Lion <: Animal](a: A) = () // scala
^ ^
lower upper
…where A must be a super-type of Lion and a subtype of Animal.
Variance
Without involving generics, a simple class B that extends A can be assigned to an instance of A; it is after all, an A as well as a B. Obviously, subtyping is only in one direction; the other way round, and you get a compiler failure.
Fig. 2.9. B extends A.
// java
A a = new A();
B b = new B();
a = b;
b = a; // compiler failure
Generic classes, however, are not subclasses themselves just because their parameterised type may be. So, if B is a subclass of A, should List<B> be a subclass of List<A>? In Java List of B is not a subtype of List of A even though their parameterised types are.
Fig. 2.10. List<B> cannot extend List<A> in Java.
// java
List<B> a = new ArrayList<>();
List<A> b = new ArrayList<>();
a = b; // compiler failure
This is where variance comes in. Variance describes how subtyping generic types (like lists or “container” types) relates to subtyping their parameterised type.
There are three types of subtype relationship described by variance:
1. Invariant
2. Covariant
3. Contravariant
Invariance
Java only supports one of the three for its generic types: all generic types in Java are invariant which is why we can’t assign a List<B> to a List<A> above. Invariant generic types don’t preserve the subtype relationship of their parameterised types.
However, you can vary the parameterised types when you use wildcards with methods and variables.
The invariant relationship between generic types says that there is no relationship even if their contents have a subtype relationship. You can’t substitute one for another. Java and Scala share syntax here, as defining any generic type in chevrons (Java) or square brackets (Scala) describes the type as invariant.
public class List<T> { } // java
class List[T] { } // scala
Covariance
Covariant generic types preserve the relationship between two generic types as subtypes when their parameterised types are subtypes. So List<B> is a subtype of List<A> when a generic type is set up as covariant. Java doesn’t support covariance. Scala supports covariant generic types by using a + when you define a generic class.
class List[+T] { }
Contravariance
Contravariance reverses a subtype relationship. So if A is contravariant, List<A> is also a List<B>; it’s a subtype. The relationship of the parameterised types are reversed for their generic types. Java doesn’t support contravariant but in Scala you just add a - to the generic type definition.
class List[-T]
Variance Summary
In summary, invariant generic types are not related, regardless of the relationship of their parameterised types. Covariant types maintain the subtype relationship of their parameterised types, and contravariant types reverse it.
|
Description |
Scala Syntax |
|
|
Invariant |
List<A> and List<B> are not related |
[A] |
|
Covariant |
List<B> is a subclass of List<A> |
[+A] |
|
Contravariant |
List<A> is a subclass of List<B> |
[-T] |
The syntax for each is summarised below.
|
Invariant |
Covariant |
Contravariance |
|
|
Java |
<T> |
<? extends T> |
<? super T> |
|
Scala |
[T] |
[+T] |
[-T] |
|
Scala (wildcards) |
[T] |
[_ <: T] |
[_ >: T] |
Java Limitations
In Java all generic types are invariant, which means you can’t assign a List<Foo> to a List<Object>. You can vary the types where you use them with wildcards, but only for methods and variable definitions, not classes.