Speaking JavaScript (2014)
Part III. JavaScript in Depth
Chapter 24. Unicode and JavaScript
This chapter is a brief introduction to Unicode and how it is handled in JavaScript.
Unicode History
Unicode was started in 1987, by Joe Becker (Xerox), Lee Collins (Apple), and Mark Davis (Apple). The idea was to create a universal character set, as there were many incompatible standards for encoding plain text at that time: numerous variations of 8-bit ASCII, Big Five (Traditional Chinese), GB 2312 (Simplified Chinese), and more. Before Unicode, no standard for multilingual plain text existed, but there were rich-text systems (such as Apple’s WorldScript) that allowed you to combine multiple encodings.
The first Unicode draft proposal was published in 1988. Work continued afterward and the working group expanded. The Unicode Consortium was incorporated on January 3, 1991:
The Unicode Consortium is a non-profit corporation devoted to developing, maintaining, and promoting software internationalization standards and data, particularly the Unicode Standard [...]
The first volume of the Unicode 1.0 standard was published in October 1991, and the second in June 1992.
Important Unicode Concepts
The idea of a character may seem a simple one, but there are many aspects to it. That’s why Unicode is such a complex standard. The following are important basic concepts:
Characters and graphemes
These two terms mean something quite similar. Characters are digital entities, while graphemes are atomic units of written languages (alphabetic letters, typographic ligatures, Chinese characters, punctuation marks, etc.). Programmers think in characters, but users think in graphemes. Sometimes several characters are used to represent a single grapheme. For example, we can produce the single grapheme ô by combining the character o and the character ^ (the circumflex accent).
Glyph
This is a concrete way of displaying a grapheme. Sometimes, the same grapheme is displayed differently, depending on its context or other factors. For example, the graphemes f and i can be presented as a glyph f and a glyph i, connected by a ligature glyph, or without a ligature.
Code points
Unicode represents the characters it supports via numbers called code points. The hexadecimal range of code points is 0x0 to 0x10FFFF (17 times 16 bits).
Code units
To store or transmit code points, we encode them as code units, pieces of data with a fixed length. The length is measured in bits and determined by an encoding scheme, of which Unicode has several—for example, UTF-8 and UTF-16. The number in the name indicates the length of the code unit, in bits. If a code point is too large to fit into a single code unit, it must be broken up into multiple units; that is, the number of code units needed to represent a single code point can vary.
BOM (byte order mark)
If a code unit is larger than a single byte, byte ordering matters. The BOM is a single pseudocharacter (possibly encoded as multiple code units) at the beginning of a text that indicates whether the code units are big endian (most significant bytes come first) or little endian (least significant bytes come first). The default for texts without a BOM is big endian. The BOM also indicates the encoding that is used; it is different for UTF-8, UTF-16, and so on. Additionally, it serves as a marker for Unicode if web browsers have no other information regarding the encoding of a text. However, the BOM is not used very often, for several reasons:
§ UTF-8 is by far the most popular Unicode encoding and does not need a BOM, because there is only one way of ordering bytes.
§ Several character encodings specify a fixed byte ordering. Then a BOM must not be used. Examples include UTF-16BE (UTF-16 big endian), UTF-16LE, UTF-32BE, and UTF-32LE. This is a safer way of handling byte ordering, because metadata and data stay separate and can’t be mixed up.
Normalization
Sometimes the same grapheme can be represented in several ways. For example, the grapheme ö can be represented as a single code point or as an o followed by a combining character ¨ (diaeresis, double dot). Normalization is about translating a text to a canonical representation; equivalent code points and sequences of code points are all translated to the same code point (or sequence of code points). That is useful for text processing (e.g., to search for text). Unicode specifies several normalizations.
Character properties
Each Unicode character is assigned several properties by the specification, some of which are listed here:
§ Name. An English name, composed of uppercase letters A–Z, digits 0–9, hyphen (-), and <space>. Two examples:
§ “λ” has the name “GREEK SMALL LETTER LAMBDA.”
§ “!” has the name “EXCLAMATION MARK.”
§ General category. Partitions characters into categories such as letter, uppercase letter, number, and punctuation.
§ Age. With what version of Unicode was the character introduced (1.0, 1.1., 2.0, etc.)?
§ Deprecated. Is the use of the character discouraged?
§ And many more.
Code Points
The range of the code points was initially 16 bits. With Unicode version 2.0 (July 1996), it was expanded: it is now divided into 17 planes, numbered from 0 to 16. Each plane comprises 16 bits (in hexadecimal notation: 0x0000–0xFFFF). Thus, in the hexadecimal ranges that follow, digits beyond the four bottom ones contain the number of the plane.
§ Plane 0, Basic Multilingual Plane (BMP): 0x0000–0xFFFF
§ Plane 1, Supplementary Multilingual Plane (SMP): 0x10000–0x1FFFF
§ Plane 2, Supplementary Ideographic Plane (SIP): 0x20000–0x2FFFF
§ Planes 3–13, Unassigned
§ Plane 14, Supplementary Special-Purpose Plane (SSP): 0xE0000–0xEFFFF
§ Planes 15–16, Supplementary Private Use Area (S PUA A/B): 0x0F0000–0x10FFFF
Planes 1–16 are called supplementary planes or astral planes.
Unicode Encodings
UTF-32 (Unicode Transformation Format 32) is a format with 32-bit code units. Any code point can be encoded by a single code unit, making this the only fixed-length encoding; for other encodings, the number of units needed to encode a point varies.
UTF-16 is a format with 16-bit code units that needs one to two units to represent a code point. BMP code points can be represented by single code units. Higher code points are 20 bit (16 times 16 bits), after 0x10000 (the range of the BMP) is subtracted. These bits are encoded as two code units (a so-called surrogate pair):
Leading surrogate
Most significant 10 bits: stored in the range 0xD800–0xDBFF. Also called high-surrogate code unit.
Trailing surrogate
Least significant 10 bits: stored in the range 0xDC00–0xDFFF. Also called low-surrogate code unit.
The following table (adapted from Unicode Standard 6.2.0, Table 3-5) visualizes how the bits are distributed:
|
Code point |
UTF-16 code unit(s) |
|
xxxxxxxxxxxxxxxx (16 bits) |
xxxxxxxxxxxxxxxx |
|
pppppxxxxxxyyyyyyyyyy (21 bits = 5+6+10 bits) |
110110qqqqxxxxxx 110111yyyyyyyyyy (qqqq = ppppp − 1) |
To enable this encoding scheme, the BMP has a hole with unused code points whose range is 0xD800–0xDFFF. Therefore, the ranges of leading surrogates, trailing surrogates, and BMP code points are disjoint, making decoding robust in the face of errors. The following function encodes a code point as UTF-16 (later we’ll see an example of using it):
function toUTF16(codePoint) {
var TEN_BITS = parseInt('1111111111', 2);
function u(codeUnit) {
return '\\u'+codeUnit.toString(16).toUpperCase();
}
if (codePoint <= 0xFFFF) {
return u(codePoint);
}
codePoint -= 0x10000;
// Shift right to get to most significant 10 bits
var leadingSurrogate = 0xD800 | (codePoint >> 10);
// Mask to get least significant 10 bits
var trailingSurrogate = 0xDC00 | (codePoint & TEN_BITS);
return u(leadingSurrogate) + u(trailingSurrogate);
}
UCS-2, a deprecated format, uses 16-bit code units to represent (only!) the code points of the BMP. When the range of Unicode code points expanded beyond 16 bits, UTF-16 replaced UCS-2.
UTF-8 has 8-bit code units. It builds a bridge between the legacy ASCII encoding and Unicode. ASCII has only 128 characters, whose numbers are the same as the first 128 Unicode code points. UTF-8 is backward compatible, because all ASCII codes are valid code units. In other words, a single code unit in the range 0–127 encodes a single code point in the same range. Such code units are marked by their highest bit being zero. If, on the other hand, the highest bit is one, then more units will follow, to provide the additional bits for the higher code points. That leads to the following encoding scheme:
§ 0000–007F: 0xxxxxxx (7 bits, stored in 1 byte)
§ 0080–07FF: 110xxxxx, 10xxxxxx (5+6 bits = 11 bits, stored in 2 bytes)
§ 0800–FFFF: 1110xxxx, 10xxxxxx, 10xxxxxx (4+6+6 bits = 16 bits, stored in 3 bytes)
§ 10000–1FFFFF: 11110xxx, 10xxxxxx, 10xxxxxx, 10xxxxxx (3+6+6+6 bits = 21 bits, stored in 4 bytes). The highest code point is 10FFFF, so UTF-8 has some extra room.
If the highest bit is not 0, then the number of ones before the zero indicates how many code units there are in a sequence. All code units after the initial one have the bit prefix 10. Therefore, the ranges of initial code units and subsequent code units are disjoint, which helps with recovering from encoding errors.
UTF-8 has become the most popular Unicode format. Initially, its popularity was due to its backward compatibility with ASCII. Later, it gained traction because of its broad and consistent support across operating systems, programming environments, and applications.
JavaScript Source Code and Unicode
There are two ways in which JavaScript handles Unicode source code: internally (during parsing) and externally (while loading a file).
Source Code Internally
Internally, JavaScript source code is treated as a sequence of UTF-16 code units. According to Section 6 of the EMCAScript specification:
ECMAScript source text is represented as a sequence of characters in the Unicode character encoding, version 3.0 or later. [...] ECMAScript source text is assumed to be a sequence of 16-bit code units for the purposes of this specification. [...] If an actual source text is encoded in a form other than 16-bit code units, it must be processed as if it was first converted to UTF-16.
In identifiers, string literals, and regular expression literals, any code unit can also be expressed via a Unicode escape sequence \uHHHH, where HHHH are four hexadecimal digits. For example:
> var f\u006F\u006F = 'abc';
> foo
'abc'
> var λ = 123;
> \u03BB
123
That means that you can use Unicode characters in literals and variable names, without leaving the ASCII range in the source code.
In string literals, an additional kind of escape is available: hexadecimal escape sequences with two-digit hexadecimal numbers that represent code units in the range 0x00–0xFF. For example:
> '\xF6' === 'ö'
true
> '\xF6' === '\u00F6'
true
Source Code Externally
While UTF-16 is used internally, JavaScript source code is usually not stored in that format. When a web browser loads a source file via a <script> tag, it determines the encoding as follows:
§ If the file starts with a BOM, the encoding is a UTF variant, depending on what BOM is used.
§ Otherwise, if the file is loaded via HTTP(S), then the Content-Type header can specify an encoding, via the charset parameter. For example:
Content-Type: application/javascript; charset=utf-8
TIP
The correct media type (formerly known as MIME type) for JavaScript files is application/javascript. However, older browsers (e.g., Internet Explorer 8 and earlier) work most reliably with text/javascript. Unfortunately, the default value for the attribute type of <script> tags is text/javascript. At least you can omit that attribute for JavaScript; there is no benefit in including it.
§ Otherwise, if the <script> tag has the attribute charset, then that encoding is used. Even though the attribute type holds a valid media type, that type must not have the parameter charset (like in the aforementioned Content-Type header). That ensures that the values of charsetand type don’t clash.
§ Otherwise, the encoding of the document is used, in which the <script> tag resides. For example, this is the beginning of an HTML5 document, where a <meta> tag declares that the document is encoded as UTF-8:
§ <!doctype html>
§ <html>
§ <head>
§ <meta charset="UTF-8">
...
It is highly recommended that you always specify an encoding. If you don’t, a locale-specific default encoding is used. In other words, people will see the file differently in different countries. Only the lowest 7 bits are relatively stable across locales.
My recommendations can be summarized as follows:
§ For your own application, you can use Unicode. But you must specify the encoding of the app’s HTML page as UTF-8.
§ For libraries, it’s safest to release code that is ASCII (7 bit).
Some minification tools can translate source with Unicode code points beyond 7 bit to source that is “7-bit clean.” They do so by replacing non-ASCII characters with Unicode escapes. For example, the following invocation of UglifyJS translates the file test.js:
uglifyjs -b beautify=false,ascii-only=true test.js
The file test.js looks like this:
var σ = 'Köln';
The output of UglifyJS looks like this:
var \u03c3="K\xf6ln";
Consider the following negative example. For a while, the library D3.js was published in UTF-8. That caused an error when it was loaded from a page whose encoding was not UTF-8, because the code contained statements such as:
var π = Math.PI, ε = 1e-6;
The identifiers π and ε were not decoded correctly and not recognized as valid variable names. Additionally, some string literals with code points beyond 7 bit weren’t decoded correctly either. As a workaround, you could load the code by adding the appropriate charset attribute to the<script> tag:
<script charset="utf-8" src="d3.js"></script>
JavaScript Strings and Unicode
A JavaScript string is a sequence of UTF-16 code units. According to the ECMAScript specification, Section 8.4:
When a String contains actual textual data, each element is considered to be a single UTF-16 code unit.
Escape Sequences
As mentioned before, you can use Unicode escape sequences and hexadecimal escape sequences in string literals. For example, you can produce the character ö by combining an o with a diaeresis (code point 0x0308):
> console.log('o\u0308')
ö
This works in JavaScript command lines, such as web browser consoles and the Node.js REPL. You can also insert this kind of string into the DOM of a web page.
Refering to Astral Plane Characters via Escapes
There are many nice Unicode symbol tables on the Web. Take a look at Tim Whitlock’s “Emoji Unicode Tables” and be amazed by how many symbols there are in modern Unicode fonts. None of the symbols in the table are images; they are all font glyphs. Let’s assume you want to display a Unicode character via JavaScript that is in an astral plane (obviously, there is a risk when doing so: not all fonts support all such characters). For example, consider a cow, code point 0x1F404: 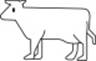 .
.
You can copy the character and paste it directly into your Unicode-encoded JavaScript source:
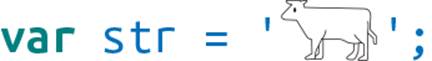
JavaScript engines will decode the source (which is most often in UTF-8) and create a string with two UTF-16 code units. Alternatively, you can compute the two code units yourself and use Unicode escape sequences. There are web apps that perform this computation, such as:
§ UTF Converter
§ “JavaScript escapes” by Mathias Bynens
The previously defined function toUTF16 performs it, too:
> toUTF16(0x1F404)
'\\uD83D\\uDC04'
The UTF-16 surrogate pair (0xD83D, 0xDC04) does indeed encode the cow:

Counting Characters
If a string contains a surrogate pair (two code units encoding a single code point), then the length property doesn’t count graphemes anymore. It counts code units:

This can be fixed via libraries, such as Mathias Bynens’s Punycode.js, which is bundled with Node.js:
> var puny = require('punycode');
> puny.ucs2.decode(str).length
1
Unicode Normalization
If you want to search in strings or compare them, then you need to normalize—for example, via the library unorm (by Bjarke Walling).
JavaScript Regular Expressions and Unicode
Support for Unicode in JavaScript’s regular expressions (see Chapter 19) is very limited. For example, there is no way to match Unicode categories such as “uppercase letter.”
Line terminators influence matching. A line terminator is one of four characters, specified in the following table:
|
Code unit |
Name |
Character escape sequence |
|
\u000A |
Line feed |
\n |
|
\u000D |
Carriage return |
\r |
|
\u2028 |
Line separator |
|
|
\u2029 |
Paragraph separator |
The following regular expression constructs are based on Unicode:
§ \s \S (whitespace, nonwhitespace) have Unicode-based definitions:
§ > /^\s$/.test('\uFEFF')
true
§ . (dot) matches all code units (not code points!) except line terminators. See the next section to learn how to match any code point.
§ Multiline mode /m: In multiline mode, the assertion ^ matches at the beginning of the input and after line terminators. The assertion $ matches before line terminators and at the end of the input. In nonmultiline mode, they match only at the beginning or the end of the input, respectively.
Other important character classes have definitions that are based on ASCII, not on Unicode:
§ \d \D (digits, nondigits): A digit is equivalent to [0-9].
§ \w \W (word characters, nonword characters): A word character is equivalent to [A-Za-z0-9_].
§ \b \B (at word breaks, inside words): Words are sequences of word characters ([A-Za-z0-9_]). For example, in the string 'über', the character class escape \b sees the character b as starting a word:
§ > /\bb/.test('über')
true
Matching Any Code Unit and Any Code Point
To match any code unit, you can use [\s\S]; see Atoms: General.
To match any code point, you need to use:[18]
([\0-\uD7FF\uE000-\uFFFF]|[\uD800-\uDBFF][\uDC00-\uDFFF])
The preceding pattern works like this:
([BMP code point]|[leading surrogate][trailing surrogate])
As all of these ranges are disjoint, the pattern will correctly match code points in well-formed UTF-16 strings.
Libraries
A few libraries help with handling Unicode in JavaScript:
§ Regenerate helps with generating ranges like the preceding one, for matching any code unit. It is meant to be used as part of a build tool, but also works dynamically, for trying out things.
§ XRegExp is a regular expression library that has an official add-on for matching Unicode categories, scripts, blocks, and properties via one of the following three constructs:
\p{...} \p{^...} \P{...}
For example, \p{Letter} matches letters in various alphabets while \p{^Letter} and \P{Letter} both match all other code points. Chapter 30 contains a brief overview of XRegExp.
§ The ECMAScript Internationalization API (see The ECMAScript Internationalization API) provides Unicode-aware collation (sorting and searching of strings) and more.
Recommended Reading and Chapter Sources
For more information on Unicode, see the following:
§ Wikipedia has several good entries on Unicode and its terminology.
§ Unicode.org, the official website of the Unicode Consortium, and its FAQ are also good resources.
§ Joel Spolsky’s introductory article “The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)” is helpful.
For information on Unicode support in JavaScript, see:
§ “JavaScript’s internal character encoding: UCS-2 or UTF-16?” by Mathias Bynens
§ “JavaScript, Regex, and Unicode” by Steven Levithan
ACKNOWLEDGMENTS
The following people contributed to this chapter: Mathias Bynens (@mathias), Anne van Kesteren (@annevk), and Calvin Metcalf (@CWMma).
[18] Strictly speaking, any Unicode scalar value.