Ubuntu: Questions and Answers (2014)
Filesystem
Questions
Q: Why is defragmentation unnecessary?
Tags: filesystem (Next Q)
Why is defragmenting unnecessary in Ubuntu?
Tags: filesystem (Next Q)
User: zango
Answer by dave-child
The underlying filesystems used by Ubuntu, like ext2 and ext3, simply don't need defragmenting because they don't fragment files in the same way as NTFS. There are more details at ext3 - Wikipedia, the free encyclopedia
Answer by popey
Some argue that it's actually a myth that we don't need defragmentation. It's argued that we do in fact need it, but only once the filesystem gets pretty full (i.e. less than ~10% free space). Tools are available for defragging such as e2defrag.
Answer by eduard-grebe
Fragmentation is the product of writing files in the first available open blocks on a drive. Over time, as files get created and deleted, small sections of disk open up, which causes newly written files to be split over several such openings. This can reduce performance, although it was much more of a problem in the past with slow hardware and slow disks.
The default filesystem in Ubuntu, ext4 (and until recently, ext3) are designed to limit fragmentation of files as far as possible. When writing files, it tries to keep the blocks used sequential or close together. This renders defragmentation effectively unnecessary.
Tags: filesystem (Next Q)
Q: How to find (and delete) duplicate files
Tags: filesystem (Next Q)
I have a largish music collection and there are some duplicates in there. Is there any way to find duplicate files. At a minimum by doing a hash and seeing if two files have the same hash.
Bonus points for also finding files with the same name apart from the extension - I think I have some songs with both mp3 and ogg format versions.
I'm happy using the command line if that is the easiest way.
Tags: filesystem (Next Q)
User: hamish-downer
Answer by qbi
I use fdupes for this. It is a commandline program. You can call it like fdupes -r /dir/ect/ory and it will print out a list of dupes. fdupes has also a Wikipedia article, which lists some more programs.
Answer by dominik
FSlint has a GUI and some other features. The explanation of the duplicate checking algorithm from their FAQ:
1. exclude files with unique lengths
2. handle files that are hardlinked to each other
3. exclude files with unique md5(first_4k(file))
4. exclude files with unique md5(whole file)
5. exclude files with unique sha1(whole file) (in case of md5 collisions).
Answer by v2r
List of programs/scripts/bash-solutions, that can find duplicates and run under nix:
dupedit - Compares many files at once without checksumming. Avoids comparing files against themselves when multiple paths point to the same file.
dupmerge - runs on various platforms (Win32/64 with Cygwin, *nix, Linux etc.)
dupseek - Perl with algorithm optimized to reduce reads.
fdf - Perl/c based and runs across most platforms (Win32, *nix and probably others). Uses MD5, SHA1 and other checksum algorithms
freedups - shell script, that searches through the directories you specify. When it finds two identical files, it hard links them together. Now the two or more files still exist in their respective directories, but only one copy of the data is stored on disk; both directory entries point to the same data blocks.
fslint - has command line interface and GUI.
liten - Pure Python deduplication command line tool, and library, using md5 checksums and a novel byte comparison algorithm. (Linux, Mac OS X, *nix, Windows)
liten2 - A rewrite of the original Liten, still a command line tool but with a faster interactive mode using SHA-1 checksums (Linux, Mac OS X, *nix)
rdfind - One of the few which rank duplicates based on the order of input parameters (directories to scan) in order not to delete in "original/well known" sources (if multiple directories are given). Uses MD5 or SHA1.
rmlint - Fast finder with command line interface and many options to find other lint too (uses MD5)
ua - Unix/Linux command line tool, designed to work with find (and the like).
findrepe - free Java-based command-line tool designed for an efficient search of duplicate files, it can search within zips and jars.(GNU/Linux, Mac OS X, *nix, Windows)
fdupe - a small script written in Perl. Doing its job fast and efficiently.1
ssdeep - identify almost identical files using Context Triggered Piecewise Hashing
Tags: filesystem (Next Q)
Q: What is the difference between /etc/init/ and /etc/init.d/?
Tags: filesystem (Next Q)
What is the difference between /etc/init/ and /etc/init.d/? More generally, what meaning does the ".d" suffix convey to a directory?
Tags: filesystem (Next Q)
User: olivier-lalonde
Answer by gilles
/etc/init.d contains scripts used by the System V init tools (SysVinit). This is the traditional service management package for Linux, containing the init program (the first process that is run when the kernel has finished initializing) as well as some infrastructure to start and stop services and configure them. Specifically, files in /etc/init.d are shell scripts that respond to start, stop, restart, and (when supported) reload commands to manage a particular service. These scripts can be invoked directly or (most commonly) via some other trigger (typically the presence of a symbolic link in /etc/rc?.d/).
/etc/init contains configuration files used by Upstart. Upstart is a young service management package championed by Ubuntu. Files in /etc/init are configuration files telling Upstart how and when to start, stop, reload the configuration, or query the status of a service. As of lucid, Ubuntu is transitioning from SysVinit to Upstart, which explains why many services come with SysVinit scripts even though Upstart configuration files are preferred. In fact, the SysVinit scripts are processed by a compatibility layer in Upstart.
.d in directory names typically indicates a directory containing many configuration files or scripts for a particular situation (e.g. /etc/apt/sources.list.d contains files that are concatenated to make a virtual sources.list; /etc/network/if-up.d contains scripts that are executed when a network interface is activated). This structure is usually used when each entry in the directory is provided by a different source, so that each package can deposit its own plug-in without having to parse a single configuration file to reference itself. In this case, it just happens that init is a logical name for the directory, SysVinit came first and used init.d, and Upstart used plain init for a directory with a similar purpose (it would have been more mainstream, and perhaps less arrogant, if they'd used /etc/upstart.d instead).
not counting initrd
Tags: filesystem (Next Q)
Q: How can I securely erase a hard drive?
Tags: filesystem (Next Q)
I'm planning on selling a USB external hard drive that currently contains an old Ubuntu installation with stored passwords and banking information.
How can I securely erase the drive before selling it?
Tags: filesystem (Next Q)
User: ændrük
Answer by frxstrem
Securely erasing a storage device
There's a command-line utility in Ubuntu called shred, which overwrites data in a file or on a device with random bits and bytes, making it nearly impossible to recover.
First of all, you need to identify the name of the device. This might be something like /dev/sdb or /dev/hdb (but not like /dev/sdb1, as that's a partition on that device). You can use sudo fdisk -l to list all connected storage devices, and try to find your external hard drive there. Make sure that this is the correct device, as picking the wrong device will erase data on that device instead. Make sure to unmount all currently mounted partitions on that device, if any.
Then type:
sudo shred -v /dev/sdb
(replacing /dev/sdb with the name of your device). shred would then overwrite all the data on the device with random data three times. You can add the option -nN to only do this N times, to save time on large capacity devices. This might take a while, depending on the size of your external hard drive (I think it takes twenty minutes or so for my 4 GB flash drive).
You can also set all bits to zero after the last iteration by adding the option -z - I prefer to do this.
After this, you would have to repartition the device. The easiest way is to install GParted and use it:
sudo apt-get install gparted
gksu gparted
Choose your device in the upper-right corner list. Then select Device -> Create partition table to create a partition table on the device.
Then add a single partition that uses all of the unallocated space on the device, choosing fat32 as the file system. Apply the changes by click the Apply button (the green checkmark) in the toolbar.
Tips
· Read the manpage for shred here or by typing man shred in the terminal.
Answer by htorque
Just 'zero' it using the dd tool:
1. Start the Disk Utility via System > Administration > Disk Utility
2. Find your disk in the left panel, select it, and on the right find the device path (eg. /dev/sdb )
3. Run the following command from a gnome-terminal (Applications > Accessories > Terminal):
sudo dd if=/dev/zero of=/dev/sdb bs=1M
Make sure you use the right device path and not just copy this line!
This will overwrite the whole disk with zeros and is considerably faster than generating gigabytes of random data. Like all the other tools this won't take care of blocks that were mapped out for whatever reason (write errors, reserved, etc.), but it's highly unlikely your buyer will have the tools and the knowledge to recover anything from those blocks.
PS: Before you Bruce Schneier fanboys downvote me: I want proof that it's possible to recover data from a non-ancient rotational hard drive that has been overwritten with zeros. Don't even think about commenting otherwise! :P
Answer by rory-alsop
Have a look at this definitive question on Security Stack Exchange
How can I reliably erase all information on a hard drive
This discusses various secure deletion options, along with physical destruction and wiping so you can decide which option may be your best bet.
Remember though that the current recovery status for different storage is as follows:
· Very old hard drives: there were gaps between tracks so you could potentially pick up bleed into these gaps (if you had a scanning electron microscope handy). Overwriting multiple times was potentially useful.
· New hard drives: no technology currently exists that can read after even one overwrite.
· Solid state hard drives: wear levelling means you cannot overwrite securely. Instead you either encrypt the entire volume and dispose of the key to wipe, or you destroy the device.
Tags: filesystem (Next Q)
Q: How is the /tmp directory cleaned up?
Tags: filesystem (Next Q)
How is the /tmp directory cleaned up? Is it automatic? If so, how frequently is it cleaned up?
Tags: filesystem (Next Q)
User: olivier-lalonde
Answer by max
The directory is cleared by default at every boot, because TMPTIME is 0 by default.
Here you can change the time in the following file:
/etc/default/rcS
TMPTIME says how frequent the tmp dir sould be cleared in days
Answer by hhlp
While the /tmp folder is not a place to store files long-term, occasionally you want to keep things a little longer than the next time you reboot, which is the default on Ubuntu systems. I know a time or two Ive downloaded something to /tmp during testing, rebooted after making changes and then lost the original data again. This can be changed if youd like to keep your /tmp files a little bit longer.
Changing the /tmp Cleanup Frequency
The default setting that tells your system to clear /tmp at reboot is held in the /etc/default/rcS file. The value well look at is TMPTIME.
The current value of TMPTIME=0 says delete files at reboot despite the age of the file. Changing this value to a different (positive) number will change the number of days a file can survive in /tmp.
TMPTIME=7
This setting would allow files to stay in /tmp until they are a week old, and then delete them on the next reboot. A negative number (TMPTIME=-1) tells the system to never delete anything in /tmp. This is probably not something you want, but is available.
Answer by lesmana
The cleaning of /tmp is done by the upstart script /etc/init/mounted-tmp.conf. The script is run by upstart everytime /tmp is mounted. That basically means at every boot.
The script does roughly the following: if a file in /tmp is older than $TMPTIME days it will be deleted.
$TMPTIME is an environment variable defined in /etc/default/rcS. The default value of $TMPTIME is 0, which means every file and directory in /tmp gets deleted.
Tags: filesystem (Next Q)
Q: Why has /var/run been migrated to /run?
Tags: filesystem (Next Q)
From the technical overview of Ubuntu 11.10 Oneiric:
Ubuntu 11.10 has migrated away from /var/run, /var/lock and /dev/shm and now uses /run, /run/lock and /run/shm instead (respectively).
· I hardcode these paths in my applications, why is this change made to Oneiric?
· What can I do to make my applications backwards- and forward-compatible? Is there a better way other than checking first for the existence of /run, and then /var/run?
Tags: filesystem (Next Q)
User: lekensteyn
Answer by james-henstridge
The intent is to reduce the number of tmpfs file systems. On 11.04, there are separate tmpfs file systems at /var/lock, /var/run and /dev/shm. If these directories were all under a single parent directory, then only a single tmpfs would be needed. It also provides an obvious location for further runtime state data that shouldn't persist over reboots.
Unless your application depends on canonical paths of files, your application should run without modification since the old locations will be symlinked to the new ones. The AppArmor policies are one case that does depend on the real path names, which is why it was mentioned specifically.
The following links should help explain the rationale:
· http://lists.fedoraproject.org/pipermail/devel/2011-March/150031.html
· https://bugs.linuxfoundation.org/show_bug.cgi?id=718
· https://lists.linuxfoundation.org/pipermail/fhs-discuss/2011-May/000061.html
· http://wiki.debian.org/ReleaseGoals/RunDirectory
Answer by rinzwind
1. /run is a new cross-distribution tmpfs location for the storage of transient state filesthat is, files containing run-time information that may or may not need to be written early in the boot process and which does not require preserving across reboots.
Making the /run directory available brings us a step closer to the point where it is possible to use the system normally with the root filesystem mounted read-only, without requiring any clunky workarounds such as aufs/unionfs overlays.
/run replaces several existing locations described in the Filesystem Hierarchy Standard:
o /var/run /run
o /var/lock /run/lock
o /dev/shm /run/shm [currently only Debian plans to do this]
o /tmp /run/tmp [optional; currently only Debian plans to offer this]
o /run also replaces some other locations that have been used for transient files:
o /lib/init/rw /run
o /dev/.* /run/*
o /dev/shm/* /run/*
o writable files under /etc /run/*
(so you probably can expect these to move aswell).
Source:debian release goals
2. I would advice on creating a part in your software where you set these directories in variables, change your code to use these variables and then alter the variables based on the system it is used on (but I bet you knew that already).
Tags: filesystem (Next Q)
Q: How to understand the Ubuntu file system layout?
Tags: filesystem
In Windows therere perhaps only a couple of important folders (by important I mean important in my logical picture of the Windows file system) in the installation drive (in my case C:\). Namely Program Files and Windows. I simply stay away from Windows folder and the add remove program files is good enough to handle the program files folder of Windows. Of course theres a folder named Users where the users (who are not admins) can access only their folders.
Thus theres a clear picture at some level in my mind of the Windows file system. In Ubuntu, when I reach the location /, theres a huge list of folders, most of which I have no clue as to what they contain. The /bin folder seems to be the equivalent of the Windows folder in windows. The /usr folder seems like its the equivalent of the Users folder in Windows. But even the /home folder looks like it can fit the bill.
Please understand that I do understand, that Ubuntu (Linux) has a different character than that of Windows, i.e., there need not be exact equivalent of Windows functions, in Ubuntu. All I am looking for is a bit more clearer picture of the Ubuntu file system.
This question is a part of a bigger question which I am splitting up to make it more answerable. The original question can be found here:
http://sgsawant.wordpress.com/2012/05/17/whats-the-equivalent-of-add-or-remove-programs-in-ubuntu/
Tags: filesystem
User: shashank-sawant
Answer by rinzwind
You can read up on this on for instance wikipedia. An excerpt:
The Filesystem Hierarchy Standard (FHS) defines the main directories and their contents in Linux operating systems. For the most part, it is a formalization and extension of the traditional BSD filesystem hierarchy.
The FHS is maintained by the Linux Foundation, a non-profit organization consisting of major software and hardware vendors, such as HP, Red Hat, IBM and Dell. The current version is 2.3, announced on January 29, 2004.
A visual representation with a short description:
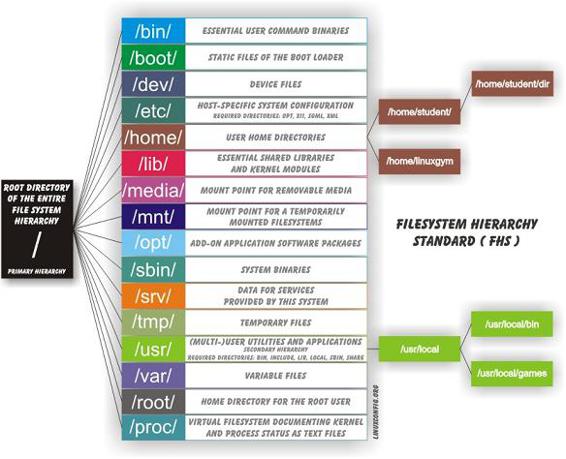
Basically Linux has divided the directory structure based on the function of what is needed to make the system as secure as possible with the minimum amount of permissions needed. Otherwise someone is bound to have to do alot of avoidable work.
Remember that Unix and Linux where made as multi-user systems and Windows was created for a single user. Everything else can be explained from that idea. You can explain every directory when thinking about it being multi-user and security.
3 examples:
· You will see that files and directories that are admin only are gathered in the same directory: the s in /sbin and /usr/sbin and /usr/local/sbin stands for system. A normal user can not even start programs that are in there. Files a normal user can start are in /bin, /usr/bin, /usr/local/bin based on where it most logically should reside. But if they are admin only they should go to the s version of that directory. There is a famous utility called fuser. You can kill processes with it. If a normal user could use this (s)he would be able to kill your session.
· The same goes for /home: /home/user1 is property of user1. /home/user2 is property of user2. user2 has no business doing stuff in user1's home (and the other way around is also true: user1 has no business doing stuff in user2's home). If all the files would be in /home with no username underneath it you would have to give permissions to every file and asses if someone is allowed to write/remove those files. A nightmare if you have tens of users.
· Addition regarding libraries.
/lib/, /usr/lib/, and /usr/local/lib/ are the original locations, from before multilib systems existed and the exist to prevent breaking things. /usr/lib32, /usr/lib/64, /usr/local/lib32/, /usr/local/lib64/ are 32-/64-bit multilib inventions.
It is not a static concept by any means. Other Linux flavours made tweaks to this lay-out. For instance; currently you will see debian and Ubuntu changing a lot in the lay-out of the FHS since SSD is better off with read only files. There is a movement towards a new lay-out where files are split in to a 'read only' and a 'writable' directory/group so we can have a root partition that can be mounted read only (partition for a ssd) and writable (sata hdd). The new directory that is used for this (not in the image) is /run/.
Answer by pritesh-wadhia
Give this command a try...
man hier
Hope it helps
Answer by mtk
This following text shows the directory structure.
Skip code block
mtk4@laptop:/$ pwd
/
mtk4@laptop:/$ tree -L 1
.
|-- bin
|-- boot
|-- cdrom
|-- dev
|-- etc
|-- home
|-- lib
|-- lost+found
|-- media
|-- mnt
|-- opt
|-- proc
|-- root
|-- run
|-- sbin
|-- selinux
|-- srv
|-- sys
|-- tmp
|-- usr
|-- var
The main components here are:
1. /boot : Contains the boot loader
2. /home : Contains the home directories of users.
3. /bin : All the executable binaries and commands used by all the users on the system are located here.
4. /sbin : This contains the system executable binaries typically used by system administrators.
5. /lib : Contains the system libraries that support the binaries in /bin and /sbin.
6. /etc : Contains the configuration files for network, boot-time, etc.
7. /dev : This has the device files i.e. usb, terminal device or any other device attached to the system are shown here.
8. /proc : Contains information about the process running.
9. /tmp : This is the temporary directory where many processes create the temporary files required. This is purged each time the machine is booted.
For more details, Thegeekstuff link perfectly explain the generic linux file-system.
Tags: filesystem
Q: Why is defragmentation unnecessary?
Q: How do I determine the total size of a directory (folder) from the command line?
Q: How to find (and delete) duplicate files
Q: What is the difference between /etc/init/ and /etc/init.d/?
Q: How can I securely erase a hard drive?
Q: How is the /tmp directory cleaned up?
Q: Why has /var/run been migrated to /run?
Q: How to understand the Ubuntu file system layout?
Q: Differences between /bin, /sbin, /usr/bin, /usr/sbin, /usr/local/bin, /usr/local/sbin