Microsoft .NET Architecting Applications for the Enterprise, Second Edition (2014)
Part III: Supporting architectures
Chapter 13. Implementing event sourcing
It is not about bits, bytes and protocols, but profits, losses and margins.
—Lou Gerstner
Events are a new trend in the software industry, and new patterns and practices have been defined lately to work with events. Events go hand in hand with Command/Query Responsibility Segregation (CQRS) and help model today’s complex business domains more effectively. To the application’s eyes, an event is the notification of something that happened in the past. Some events are plain, data-less notifications of user actions and system reactions; other events carry additional data.
In some business scenarios, though, events represent more than just notifications and are close to being the true data source of the application. Whenever it makes sense for the business to keep track of “what happened” and not just the “last known good state,“ event sourcing—namely, logging the sequence of events in the lifetime of the application—becomes a relevant pattern.
In the last chapter, we discussed the theory of event sourcing; in this chapter, we go through a couple of examples. In the first example, we present the classic approach of event sourcing in which logged events related to an aggregate are replayed to build the current state of the aggregate. In the second example, we use a more optimized approach, one that probably builds on top of what a few developers with more gray hair than the two of us used to do in the past without giving it a fancy name like event sourcing. In particular, we will record events for tracking purposes, but we will also save the last known state of the aggregates of interest. In this way, rehydrating aggregates for further processing is much faster, because you can skip the replay of events entirely. We practiced this approach in a couple of projects without encountering any issues and, instead, gaining benefits in terms of simplicity and speed.
Event sourcing: Why and when
In past chapters, we worked out an online store example called I-Buy-Stuff. We first designed it around an ASP.NET MVC application and a full Domain Model. Next, we refactored it to CQRS and a command-based architecture. In the definition of the business logic, we identified a few core domain events such as goods-not-in-stock and customer-reached-gold-status. In a broader perspective, that also includes additional bounded contexts for site administration, shipping, and payment. We could also easily identify integration events to make the site context communicate with external bounded contexts.
This is not enough, however, to say that I-Buy-Stuff needs event sourcing.
 Note
Note
Recognizing events in the business domain and events for integrating different bounded contexts is not the same as needing and supporting event sourcing. Event sourcing is needed only when you find it beneficial for the expression of the business logic to use events as the real data source of the application. Event sourcing is about persisting events and rebuilding the state of the aggregates from recorded events.
Why event sourcing is a resource
Event sourcing is a relatively new design resource for architects and developers. While the name event sourcing is new, the core concepts behind it are not. Event sourcing, for example, is just a more effective way of doing CRUD (Create, Read, Update, Delete).
Going beyond CRUD
Nearly all business applications are concerned with data, and they save and read it. The data of an application describes the state of the application and, as the application evolves, it stores the latest consistent data. In other words, data is continuously overwritten. This is the essence of CRUD.
CRUD is a widely used approach in software and, in most cases, it just works. However, there are a few structural limitations in the CRUD approach. First and foremost, the history of changes is not maintained unless ad hoc countermeasures are taken, such as arranging a custom logging mechanism. Second, especially in highly collaborative applications, data-update conflicts can occur on a regular basis as multiple users possibly work on the same data.
Note
It might seem that we’re presenting ourselves as those smart guys who, all of a sudden, spotted issues with CRUD. This is not the case, of course. With its pros and cons, CRUD is part of the history of software and widely used in the present day. What we’re trying to do is put event sourcing in perspective and guide you to seeing the whole point of it—which is, as we see things, a way to surpass CRUD. In light of today’s real-world complexity, going beyond CRUD will surely bring benefits to architects and end users.
Track everything, and rebuild as appropriate
As a design pattern, event sourcing formalizes an approach to data-driven systems that consists of tracking all data operations sequentially in an append-only store. The log of events becomes the primary data source. Any workable representation of data is built (and rebuilt) from the log of events.
Subsequently, event sourcing is a resource for architects and developers because it allows you to track everything that happens around the system and remains flexible enough to let architects extrapolate context and content for the application logic to process. Last but not least, context and content can be rebuilt any time using different business rules without touching the log of events. And the log of events can—with a quick change—start tracking new events.
Today’s line-of-business applications
The real world is full of enterprise, line-of-business systems that in one way or another perform audit trails and track every single event around their data entities. Think, for example, of banking applications that don’t simply tell you the balance of the account; instead, they list decades of transactions, and the tracked operations are used to replay the state of the account at any given date. Think also of accounting applications that must track all possible changes to invoices (change of date, address, credit note) to the point that printing an invoice can result only from replaying all events that affected the invoice over time.
You can also think of betting applications that, from a list of events, can extract pending bets and easily enable what-if scenarios to make predictions and generate statistics. A few years ago in Italy, a football match was decided by a harshly criticized penalty goal. Probably to gain more visibility, a betting agency decided to pay bets as if the penalty were never awarded. More recently, during World Cup 2014 Uruguay beat Italy. However, some controversial decisions of the referee inspired the same betting agency to also pay bets made on the draw. Rather than because of inspiration, we “bet” they made that decision on the wings of some what-if software simulation.
Event sourcing as a pattern was formalized only a few years ago. All such aforementioned applications existed for decades; some even were written in COBOL or Visual Basic 6. This is to say that event sourcing—in spite of the rather hyped-up name—is not heralding any new concept in software. For decades, each team worked out a solution for the same problem the best they possibly could. Finally, someone formalized it as a pattern.
As explained in Chapter 4, “Writing software of quality,” patterns are not the law and are still subject to interpretation, adaptation, and refactoring. Event sourcing as a pattern goes hand in hand with storing events and replaying events to build up some state. This is just the mainstream approach; your way of dealing with these things might be a bit different and still equally effective.
When event sourcing is appropriate
Using events as the primary data source might not be ideal for all systems. Let’s briefly think over the I-Buy-Stuff online store. Is it really crucial for all stakeholders to know about products added to and deleted from the shopping cart? Or what the most-viewed products are? Is it crucial to track the gold status of a customer and the entire history of that customer, such as when the status was first acquired, when it was lost, and maybe when it was re-acquired?
The answers are not obvious. They fall into the classic “It depends” category. So let’s review suitable scenarios for event sourcing.
Suitable scenarios
The most compelling scenario for an event-sourcing implementation is when the business demands that the intent and purpose of data operations be captured. For example, if you are requested to display the activity of a user within a system—say, all travel-related bookings she made, modified, or canceled and all changes she made to her personal record (address, preferences, or credit card data)—then it is key that you track any operation and save it within the context of an event, such as user-modified-home-address event.
Other suitable scenarios for event sourcing exist too. One is when you need to perform some work on top of recorded events. You might want to be able to replay events to restore the (partial) state of the system, undo actions or roll back to specific points. More generally, event sourcing works well in all situations in which you need to decouple the storage of raw data from materialized models and aggregates built on top of that and strictly follow the business requirements.
As a pleasant side effect, event sourcing also might save you from the burden of controlling conflicting updates to data. All you do in this case is let each concurrent client just record an event and then replay events to build the resulting state of the involved aggregate.
Finally, you might want to use event sourcing when the domain itself is inherently event-based. In this case, storing events comes as a natural feature of the domain and requires minimal implementation effort. This is precisely the case of our first example.
Less-than-ideal scenarios
Event sourcing requires ad hoc software architecture and tools, and it needs architects and developers to do things they don’t usually do. In a nutshell, you need a good reason to take the event sourcing route. Our general rule is that you don’t need event sourcing unless your scenario matches one of the scenarios in the preceding paragraphs. More in detail, we’d also say the following:
![]() You don’t need event sourcing if a classic CRUD system can do the job well.
You don’t need event sourcing if a classic CRUD system can do the job well.
![]() You don’t need event sourcing if audit trails, rollback, and replay actions are not strictly required.
You don’t need event sourcing if audit trails, rollback, and replay actions are not strictly required.
Interestingly, event sourcing is also often associated with the idea of eventual consistency and, subsequently, many suggest that event sourcing is not ideal for scenarios where you need real-time updates to the views. Based on our experience, we would say, “It actually depends.”
Eventual consistency stems from the latency between recording the event and processing it. If synchronous processing of events is arranged, or if latency is kept to a bare minimum, you can happily have event sourcing in the context of real-time systems. Or at least this is what we’ve done on a couple of projects.
In the end, the key determining factor we recommend for deciding whether to use event sourcing is whether or not tracking events is relevant in the business domain.
Event sourcing and real-time systems
A real-time system is simply a system that must provide a valid response to a request within an agreed-upon amount of time. Failure is not an option for such a system. Failing to provide a usable response in the given interval might have significant repercussions on the business. For this reason, real-time systems are critical systems.
However, a real-time system is not necessarily a system that must provide a usable response instantaneously or in just a few milliseconds. If real-time meant just two or three milliseconds of tolerance, probably no implementation would be suitable. Any system constrained to return a response within a fixed amount of time is real-time regardless of the length of the interval.
Dino successfully applied event sourcing in a couple of systems that can easily be labeled as real-time. One is the infrastructure for generating live scores of professional tennis tournaments. Every single event for a given match is saved, and the score and statistics are calculated in the background. The calculated score, as well as up-to-date statistics and overlays, are offloaded to a distinct database for live-score clients to consume. We’ll see a demo version of a live-score system later in the chapter.
Another example is the software used for monitoring room of wind-power plants. In this case, data captured by hardware sensors flows continually into the system and is just logged. Next, data is processed and grouped in data clumps that are logically more relevant and served to presentation clients.
Event sourcing with replay
There’s little value in using event sourcing within the I-Buy-Stuff online store, at least given the limited set of requirements we assumed in past chapters. We could have just forced the demo to use event sourcing with the excuse that all we want, ultimately, is to give a practical demo of how to store and replay events. We decided, instead, to change examples—precisely pursuing the point that event sourcing is a resource and not a must, even for the demos of a book.
Likewise, we don’t want to lead you to the wrong assumption: that e-commerce and online stores is not a domain where event sourcing can be successfully applied. It all depends on the bounded contexts you have and their requirements. If it is crucial for all stakeholders to know about the products a given user viewed or temporarily added to a shopping cart, event sourcing becomes the ideal way to implement that part of the system.
Once you determine that tracking events is useful for your application, implementing event sourcing follows the guidelines discussed next.
A live-scoring system
The first example we’ll present is a live-scoring system for a water polo game. A live-scoring system generally consists of two distinct stacks: one that collects events taking place in the context of the game, and one that presents the current state of the game to clients such as web browsers and mobile apps.
This is quite a good example of an application that is naturally based on events. Using event sourcing here is straightforward and, given the relatively small number of events, using replay to rebuild the state of relevant aggregates is a no-brainer.
Overall layout of the system
Figure 13-1 presents the overall layout of the WaterpoloScoring sample system. It is based on an ASP.NET MVC application that referees (or, more likely, assistant referees or scorekeepers) use to tally goals. In a more realistic version, the system will also track players’ fouls and penalties as well as shots that scored or missed.
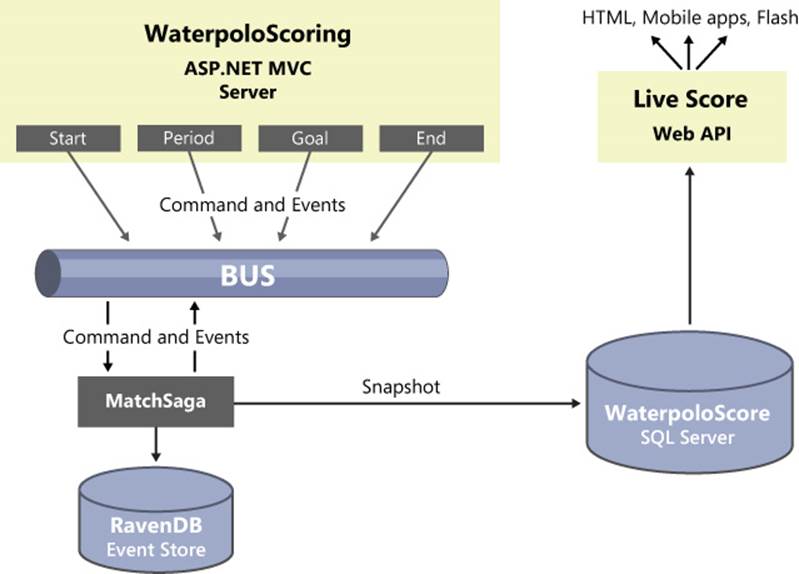
FIGURE 13-1 An overview of the WaterpoloScoring system.
The system consists of two main components: scoring and live-score modules. In the example, however, both components are managed as distinct screens within the same ASP.NET MVC application. In the end, the live-score view just invokes a Web API front end fed by snapshots created on top of recorded events.
Functional requirements
The scoring screen must provide the following functions:
![]() Start a match
Start a match
![]() End a match
End a match
![]() Start a period
Start a period
![]() End a period
End a period
![]() Score a goal for either team
Score a goal for either team
![]() The ability to undo any of the previous actions
The ability to undo any of the previous actions
Each action generates an event that is saved to the event store. Each action also generates an event that indicates the need to refresh the snapshot database. The snapshot database contains the current state of the match in a format that is suited for live score applications—team names, current score, current period, whether the ball is in play, and a partial score for past periods.
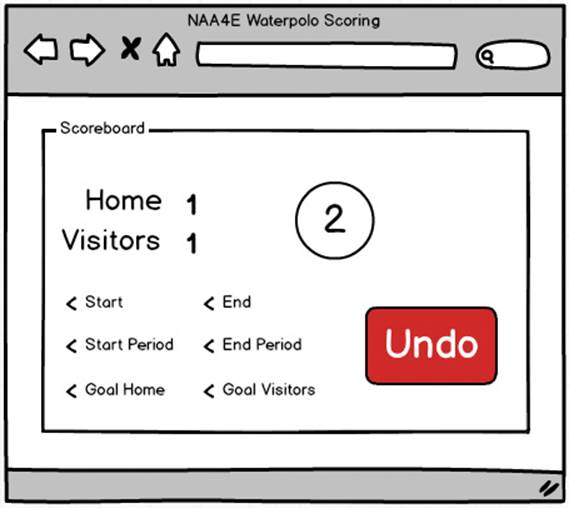
FIGURE 13-2 A mockup for the scoring page of the sample application.
Implementation of the system
The water polo scoring system receives a bunch of UI messages when a button is clicked. Each button click is essentially the notification for a relevant match event, such as start, end, period, or goal. The request generated with the click is dispatched to the application layer and processed. The request is then redirected to the home page.
public ActionResult Action(String id)
{
// We use a dispatcher here only because all buttons belong to
// the same HTML form; subsequently, the same action is requested
// regardless of the clicked button. We use this code here to
// disambiguate.
var action = MakeSenseOfWhatTheUserDid(Request);
_service.Dispatch(id, action);
return RedirectToAction(“index”, new {id = id});
}
The home page just reads back the current state of the match and refreshes the user interface accordingly:
public ActionResult Index(String id)
{
var model = _service.GetCurrentState(id);
return View(model);
}
The current state of the ongoing match is read, all events are replayed, and all of them are applied to a freshly created instance of the related aggregate. Let’s find out more details.
The command bus
A scoring system is not rocket science; the most complex part is implementing the scoring rules. For a water polo match, scoring rules are trivial—you just sum up scored goals and that’s it. However, a scoring system is hardly limited to just calculating the score. Often, you might want to generate statistics or overlays to be displayed by live clients such as mobile applications, HTML pages, or even Flash video clips displayed on LED walls.
You can easily implement the workflow behind each scoring event with plain, transaction script code. However, in this case, having a command bus and events doesn’t really add a lot more complexity and keeps extensibility high. Once you have a command bus, everything comes together easily. For the command bus, we use the same component we discussed in Chapter 10, “Introducing CQRS.” Here’s the source code:
public class Bus
{
private static readonly Dictionary<Type, Type> SagaStarters =
new Dictionary<Type, Type>();
private static readonly Dictionary<string, object> SagaInstances =
new Dictionary<string, object>();
private static readonly EventRepository EventStore = new EventRepository();
public static void RegisterSaga<TStartMessage, TSaga>()
{
SagaStarters.Add(typeof(TStartMessage), typeof(TSaga));
}
public static void Send<T>(T message) where T : Message
{
// Check if the message can start one of the registered sagas
if (SagaStarters.ContainsKey(typeof(T)))
{
// Start the saga, creating a new instance of the type
var typeOfSaga = SagaStarters[typeof(T)];
var instance = (IStartWithMessage<T>)Activator.CreateInstance(typeOfSaga);
instance.Handle(message);
// At this point the saga has been given an ID;
// let’s persist the instance to a (memory) dictionary for later use.
SagaInstances[instance.SagaId] = instance;
}
// Check if the message can be handled by one of the existing sagas.
if (message.SagaId == null)
return;
if (SagaInstances.ContainsKey(message.SagaId))
{
// Check compatibility between saga and message: can the saga handle THIS message?
var sagaType = SagaInstances[message.SagaId].GetType();
if (!typeof(ICanHandleMessage<T>).IsAssignableFrom(sagaType))
return;
var saga = (ICanHandleMessage<T>) SagaInstances[message.SagaId];
saga.Handle(message);
}
// Publish and persist the event
if (message is DomainEvent)
{
// Persist the event
EventStore.Save(message as DomainEvent);
// Invoke all registered sagas and give each
// a chance to handle the event.
foreach (var sagaEntry in SagaInstances)
{
var sagaType = sagaEntry.Value.GetType();
if (!typeof(ICanHandleMessage<T>).IsAssignableFrom(sagaType))
return;
// Give other sagas interested in the event a chance to handle it.
// Current saga already had its chance to handle the event.
var handler = (ICanHandleMessage<T>) sagaEntry.Value;
if (sagaEntry.Key != message.SagaId)
handler.Handle(message);
}
}
}
}
As you might have noticed, the list of saga instances is not stored in a permanent form of storage; instead, saga instances are kept in memory. This means that, while debugging the application, you won’t be able to deliver messages to an existing saga; that works only within the same session.
The bus is the core of the scoring module; it receives messages from the application layer following the user’s activity in the browser.
Supported events and commands
The user interface of the scoring application is shown in Figure 13-3. The page contains six buttons for the key events: match started, match ended, period started, period ended, goal scored by home, and goal scored by visitors. In addition, the user interface contains two more buttons: one to undo last action, and one to clear the event store for debugging purposes.
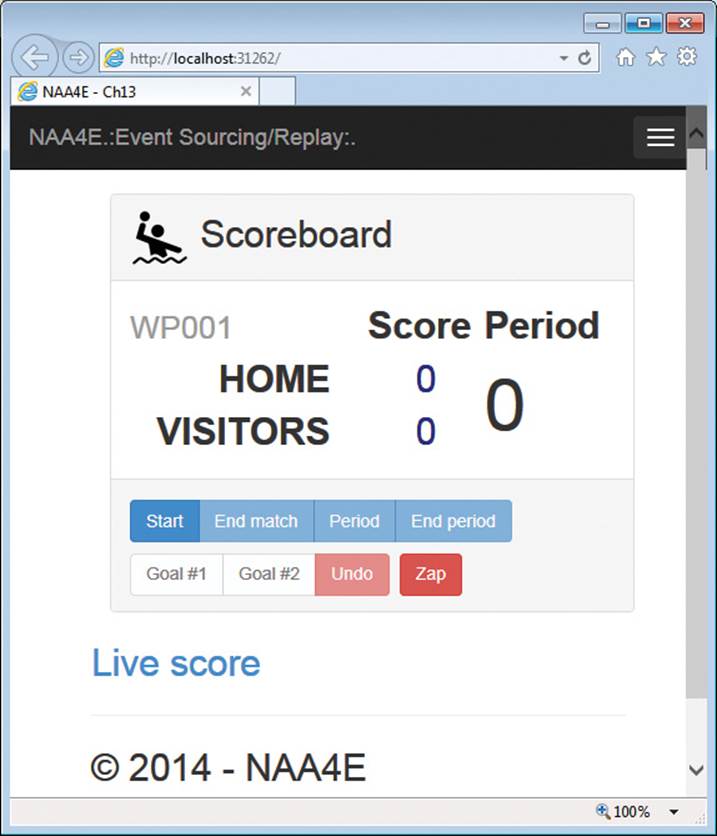
FIGURE 13-3 The home page of the sample application.
The click on the Zap button doesn’t push any message to the bus; the action is handled directly within the application layer. Clicking on the Undo button pushes a command to the bus that the related saga handles. Clicking on any other buttons in the user interface pushes a plain event to the bus. The event is recorded by the bus and then published to registered sagas.
Right after each button click, the page collects the current state of the match and passes that to the view. The view looks at the state of the match and its score, and it enables or disables buttons as appropriate. The following code shows the implementation of the saga:
public class MatchSaga : SagaBase<MatchData>,
IStartWithMessage<MatchStartedEvent>,
ICanHandleMessage<MatchEndedEvent>,
ICanHandleMessage<PeriodStartedEvent>,
ICanHandleMessage<PeriodEndedEvent>,
ICanHandleMessage<GoalScoredEvent>,
ICanHandleMessage<MatchInfoChangedEvent>,
ICanHandleMessage<UndoLastActionCommand>
{
private readonly EventRepository _repo = new EventRepository();
public void Handle(MatchStartedEvent message)
{
// Set the ID of the saga
SagaId = message.MatchId;
// Signal that match information has changed
NotifyMatchInfoChanged(message.MatchId);
}
public void Handle(UndoLastActionCommand message)
{
_repo.UndoLastAction(message.MatchId);
// Signal that match information has changed
NotifyMatchInfoChanged(message.MatchId);
}
public void Handle(MatchEndedEvent message)
{
// Signal that match information has changed
NotifyMatchInfoChanged(message.MatchId);
}
public void Handle(PeriodStartedEvent message)
{
// Signal that match information has changed
NotifyMatchInfoChanged(message.MatchId);
}
public void Handle(PeriodEndedEvent message)
{
// Signal that match information has changed
NotifyMatchInfoChanged(message.MatchId);
}
public void Handle(GoalScoredEvent message)
{
// Signal that match information has changed
NotifyMatchInfoChanged(message.MatchId);
}
public void Handle(MatchInfoChangedEvent message)
{
SnapshotHelper.Update(message.MatchId);
}
private static void NotifyMatchInfoChanged(string matchId)
{
var theEvent = new MatchInfoChangedEvent(matchId);
Bus.Send(theEvent);
}
}
The saga starts when the MatchStartedEvent is pushed to the bus. The saga ID coincides with the unique ID of the match:
// This message pushed to the bus starts the saga
var domainEvent = new MatchStartedEvent(matchId);
Bus.Send(domainEvent);
As you can see from the source code, most messages are plain notifications and don’t require much more than just persistence. That’s why we coded them as events. For example, here’s how the application layer generates a notification that a goal has been scored:
// TeamId is an enum type defined in the domain model for the command stack
var command = new GoalScoredEvent(matchId, TeamId.Home);
Bus.Send(command);
In addition to plain persistence, the saga method for these events fires another event—the MatchInfoChanged event. The MatchInfoChanged event causes the saga to trigger the process that updates the snapshot database for live-score clients.
Undoing the last action
When the user clicks the Undo button in the user interface, a command is pushed to the bus instead. The Undo button sends a message through which the user actually tells the system to do something: delete the last recorded action as if it never happened.
var command = new UndoLastActionCommand(matchId);
Bus.Send(command);
The command is handled by the saga placing a call to the API that wraps up the event store. In general, the event store is append-only; in this case, we remove the last stored item because the undo functionality for the domain just means that the last action should be treated as if it never happened. However, nothing really prevents you from implementing the undo through a logical deletion. Some advanced scoring systems do exactly that to audit the activity of referees and collect usability information.
public void Handle(UndoLastActionCommand message)
{
_repo.UndoLastAction(message.MatchId);
// Signal that match information has changed
NotifyMatchInfoChanged(message.MatchId);
}
The UndoLastAction method uses the storage API (either a classic SQL Server or a NoSQL document database) to retrieve the last event object and delete it. In our example, we use RavenDB for the event store. Here’s the code we use:
public void UndoLastAction(String id)
{
var lastEvent = (from e in GetEventStream(id) select e).LastOrDefault();
if (lastEvent != null)
{
DocumentSession.Delete(lastEvent);
DocumentSession.SaveChanges();
}
}
The GetEventStream method is a helper method exposed by the event store application interface to retrieve the entire list of events for a given aggregate. Let’s find out more about the event store.
Persisting events
The event store is just a persistent store where you save information about events. In general, an event is a data-transfer object (DTO)—a plain collection of properties. In light of this, an event can be easily persisted as a record of a SQL Server database table or to a NoSQL data store. (SeeChapter 14, “The persistence layer,“ for more information about alternative data stores and polyglot persistence.)
When it comes to event stores, there are two main issues related to relational stores. One issue is the inherent cost of licenses for most popular relational stores. This might or might not be a problem, depending on the context, the business, the costs of software, the financial strength of customers, and so forth. The other issue is more technical: not all events have the same structure and set of properties. How would you go about modeling a table schema for all possible events of an application?
You can probably create a fixed schema of columns that accommodates known events. What if a new event is added or an event’s description changes? Another approach entails having a relational table made of a few columns—such as aggregate ID, type of event, and a JSON-serialized dictionary with property values that characterize the event.
Yet another approach is not using a relational store and resorting to a document database such as RavenDB. This is what we did in our example. The following code shows what it takes to persist an event in a RavenDB store:
public class EventRepository
{
private IDocumentSession DocumentSession { get; set; }
public EventRepository()
{
DocumentSession = RavenDbConfig.Instance.OpenSession();
}
public void Save(DomainEvent domainEvent)
{
var eventWrapper = new EventWrapper(domainEvent);
DocumentSession.Store(eventWrapper);
DocumentSession.SaveChanges();
return;
}
...
}
You first initialize RavenDB in global.asax at the startup of the application and then use the created engine instance to open a session. Through the interface of the session, you then save and delete objects. Note that you might want to wrap events into a container class—the EventWrapperclass of our example—so that all stored objects look to be of the same type regardless of the actual type:
public class EventWrapper
{
public EventWrapper(DomainEvent theEvent)
{
TheEvent = theEvent;
}
public DomainEvent TheEvent { get; private set; }
}
Another solution that is gaining momentum is the NEventStore project. (See http://neventstore.org.) NEventStore is a persistence library specifically designed to address event-sourcing issues. It offers a unified API to persist events that intelligently hides different storage mechanisms.
Replaying events
In addition to saving events, the other key function one expects out of an event store is returning the full or partial stream of events. This function is necessary to rebuild the state of an aggregate out of recorded events. In RavenDB, getting the stream of events is as easy as in the following code:
public IEnumerable<EventWrapper> GetEventStream(String id)
{
return DocumentSession
.Query<EventWrapper>()
.Where(t => t.MatchId == id)
.OrderBy(t => t.Timestamp).ToList();
}
Replaying events consists of looping through the stream of events and applying them to a fresh instance of the related aggregate. In our example, we have a small domain model centered on the Match aggregate. The Match class has a method for nearly any significant change of state: start, end, new period, end of period, goal, and more.
Materializing an instance of Match consistent with tracked events requires the following pseudo-code.
Note
We call it pseudo-code because it essentially outlines the algorithm being used. The implementation would probably be slightly different and require some ad hoc design in the domain model classes.
public class EventHelper
{
public static Match PlayEvents(String id, IEnumerable<DomainEvent> events)
{
var match = new Match(id);
foreach (var e in events)
{
if (e == null)
return match;
if (e is MatchStartedEvent)
match.Start();
if (e is MatchEndedEvent)
match.Finish();
if (e is PeriodStartedEvent)
match.StartPeriod();
if (e is PeriodEndedEvent)
match.EndPeriod();
var @event = e as GoalScoredEvent;
if (@event != null)
{
var actual = @event;
match.Goal(actual.TeamId);
}
}
return match;
}
}
This code shows two aspects of event sourcing. First, it tells you that once you have events recorded you can do nearly everything. For example, you can easily enable a What-If analysis on your data; more importantly, you can do that at any time. In addition, you can materialize nearly any object out of events. It’s just like having a lower level data source that can be used to populate any objects that make sense in your business domain. In this regard, an event data source is likely more powerful than a relational data model because it focuses on domain events rather than on a given data model for a given scenario.
Second, replaying events to build the state of an aggregate every time you need it can be quite a costly operation. It all depends on the number of events, actually. Replaying is not an issue in a scoring system—even in a sport like tennis that is one of the richest in terms of data and most frequently updated. A plain replay of events might not be suitable when the history of an aggregate lasts months or years for system activity, such as for a bank account.
Finally, regardless of the number of events you need to store and manage, the frequency at which you need to rebuild might be a constraint and an aspect to optimize to keep the application lean, mean, and scalable. This is where snapshots fit in.
Before we leap into snapshots, though, let’s review a more realistic implementation of the pseudo-code just shown. When you design a domain model to support the replay of events, you typically define a set of Apply methods—overloaded—to take an event class parameter. Here’s a possible implementation related to the Match class:
public void Apply(MatchStartedEvent theEvent)
{
Start();
}
public void Apply(MatchEndedEvent theEvent)
{
Finish();
}
...
Replaying events is then a plain loop that calls into Apply and passes the event object.
Creating data snapshots
In event sourcing, data snapshots are just snapshots of the state of an aggregate taken at a given time. You use snapshots to make it faster for an application to consume data that is stored only in the raw format of domain events. You can also see data snapshots as business-specific models built out of raw events.
There are no strict rules as far as data snapshots are concerned. You can decide to have no snapshots at all or multiple snapshots. You are also free of needing to choose the format and the persistence mechanism. A common way of using snapshots is to simplify queries and to expose data comfortably to other bounded contexts. Depending on the business domain, a snapshot can be updated after each operation (as in our example) or periodically through a scheduled job or even via a manual operation.
In our example, we use a SQL Server table to hold data ready for live-score clients that just shows the current state of a given match. Live-score clients don’t access the event store; instead, they access a Web API front end that exposes the content of the data snapshot. It is up to you to decide the latency between any writing in the event store and updates to the live-score snapshot. Here’s how the sample application updates the SQL Server snapshot database:
public class SnapshotHelper
{
public static void Update(String matchId)
{
var repo = new EventRepository();
var events = repo.GetEventStreamForReplay(matchId);
var matchInfo = EventHelper.PlayEvents(matchId, events.ToList());
using (var db = new WaterpoloContext())
{
var lm = (from m in db.Matches where m.Id == matchId select m).FirstOrDefault();
if (lm == null)
{
var liveMatch = new LiveMatch
{
Id = matchId,
Team1 = matchInfo.Team1,
Team2 = matchInfo.Team2,
State = matchInfo.State,
IsBallInPlay = matchInfo.IsBallInPlay,
CurrentScore = matchInfo.CurrentScore,
CurrentPeriod = matchInfo.CurrentPeriod
};
db.Matches.Add(liveMatch);
}
else
{
lm.State = matchInfo.State;
lm.IsBallInPlay = matchInfo.IsBallInPlay;
lm.CurrentScore = matchInfo.CurrentScore;
lm.CurrentPeriod = matchInfo.CurrentPeriod;
lm.ScorePeriod1 = matchInfo.GetPartial(1).ToString();
lm.ScorePeriod2 = matchInfo.GetPartial(2).ToString();
lm.ScorePeriod3 = matchInfo.GetPartial(3).ToString();
lm.ScorePeriod4 = matchInfo.GetPartial(4).ToString();
}
db.SaveChanges();
}
}
}
In the sample application, we use Entity Framework Code First to create the snapshot. Figure 13-4 shows the web live score client in action.
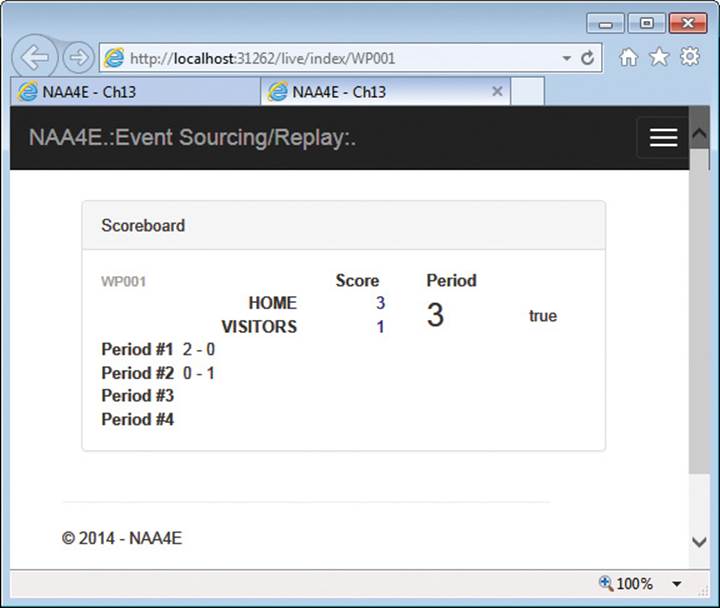
FIGURE 13-4 The live-score client in action.
Note that the information presented by the live-score client is the current state of the match, but it doesn’t reflect the actual data stored in the event store—the data source of the application. The event store only signals that, say, Home scored a goal and that a new period has started. All the details about the current score and current period are figured out while replaying events to build a Match instance.
The rebuilt Match instance is used to refresh the user interface of the scoring page (as in Figure 13-3). It is also used to serialize a LiveMatch object to a denormalized SQL Server database made to measure for just the information required by live-score clients—expanded name of teams, partial scores of periods, the current score, the current period, statistics, overlays, and whatever else your customers can think of.
Event sourcing with aggregate snapshots
The second example we offer uses a different approach for rehydrating instances of aggregates. The system maintains a log of events, and each recorded event has a unique ID that refers to the aggregate. The ID of the aggregate is also used to identify the saga. Whenever an event is tracked that relates to the aggregate instance, a reference to it is added to an internal aggregate collection. In this way, each aggregate instance carries its own list of events. At some point, the aggregate with its current state is persisted and the next time it is requested it will be retrieved from the persistence layer. In this way, there’s no need to replay events to build a valid aggregate instance; all you do is materialize the aggregate from an additional persistence layer. In other words, you have a first level of snapshots represented by plain instances of readymade aggregates. These snapshots might be enough to serve the need of the presentation; if not, you add a second level of snapshots specifically designed for the purposes of the read model and presentation layers.
A mini enterprise resource planning system
The primary point of this example is to show an alternate technique for persisting events and rebuilding a valid aggregate instance. Setting up a fully functional, albeit partial, enterprise resource planning (ERP) system is beyond the scope of this chapter.
Managing job orders and extensions
The system is based on a single entity—the JobOrder entity—which is characterized by properties like customer ID, name and number, price, date of start, due date, and state. As you start on a project—whatever type of project—it is not unusual that requests for change are made and approved. So from the perspective of the architect of an ERP system, the JobOrder has its price change over time and also the due date might be postponed.
Other requirements you likely have on an ERP system are managing payments, installment payments, invoices, and credit notes, In a nutshell, ERP is a good domain to exercise events and the persistence of events. This is because the domain model cannot really be frozen and because the nature of the domain itself supports maintaining entities with its own bag of events that can alter the state.
Modeling a job order
How would you model a job order? The following is probably a good starting point for a realistic JobOrder class:
public class JobOrder : Aggregate
{
public decimal Price { get; private set; }
public int CustomerId { get; private set; }
public string Number { get; private set; }
public DateTime DateOfStart { get; private set; }
public DateTime DueDate { get; private set; }
public string Name { get; private set; }
public bool IsCompleted { get; private set; }
protected JobOrder()
{
}
// Possibly more code here
...
}
How would you handle changes in the implementation of the job, such as a new due date and a new price? In this case, it is key to be able to track when the extension was requested and the terms of it. Also, in this business domain you must be ready to handle multiple extensions to a job order. Events are ideal.
When a new job order is registered in the system, you log an event with all the details of the order. When an extension is registered, you just log the new due date and price. Let’s say the JobOrder class has a method like the one shown here:
public void Extend(DateTime newDueDate, decimal price)
{
this.DueDate = newDueDate;
this.Price = price;
// Do something here to cause this event to be logged
// so that the system knows that the current instance of JobOrder
// was actually extended.
}
As you can see, the domain lends itself to having plain instances extended with some events. In this business domain, there’s no need for undo functionalities as in the previous demo. When undo is an option, you might want to always replay all events to determine the actual state. When undo is not an option, you can save yourself a lot of work by not replaying events and, instead, saving snapshots of aggregates.
Implementation of the system
The mini ERP sample application is a CQRS system with a command-based architecture. There’s a bus that receives commands from the application layer and triggers a saga. Figure 13-5 summarizes the main points of the architecture.
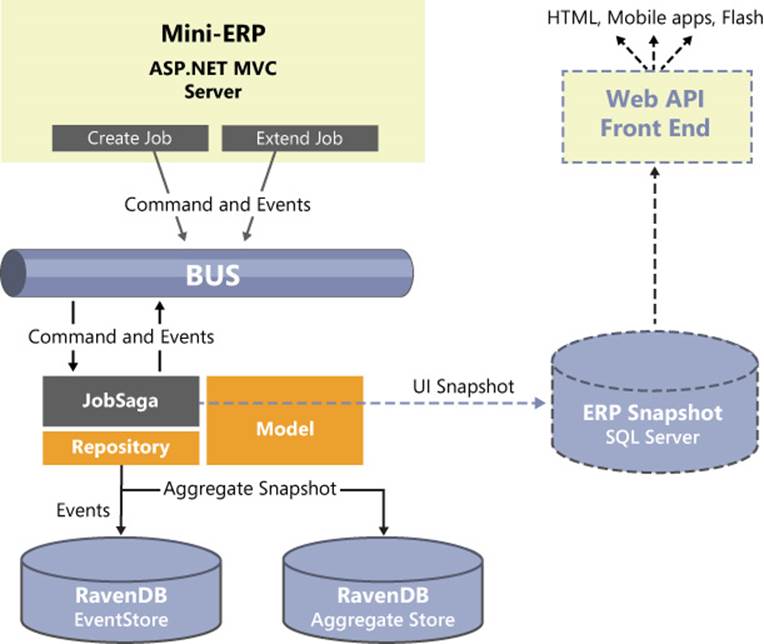
FIGURE 13-5 An overview of the mini-ERP system.
As you can see for yourself, the architecture is similar to Figure 13-1. The main difference is a second database that stores the state of aggregate instances with the declared intent of not replaying all events for the same aggregate. This requires the definition of an ad hoc repository and also some changes to the structure of the aggregate classes.
Revised definition of aggregates
Our mini-ERP example uses a domain model in the command stack. The most prominent class in the domain model is JobOrder, which is clearly an aggregate. In past chapters, we gave a very basic definition of the IAggregateRoot interface used to mark aggregate roots. Let’s consider now a revised definition that also incorporates events.
public interface IAggregateRoot
{
Guid Id { get; }
bool IsChanged { get; }
IEnumerable<DomainEvent> GetUncommittedEvents();
void ClearUncommittedEvents();
}
In particular, we have a Boolean property to indicate pending changes to the aggregate and a method to return the list of pending events that relate to the instance but have not been persisted and notified yet. Finally, we also need a method to clear the list of pending events. Here’s an abstract class that can be used as the starting point for concrete aggregate implementations:
public abstract class Aggregate : IAggregateRoot
{
public Guid Id { get; protected set; }
private IList<DomainEvent> uncommittedEvents = new List<DomainEvent>();
Guid IAggregateRoot.Id
{
get { return Id; }
}
bool IAggregateRoot.IsChanged
{
get { return this.uncommittedEvents.Any(); }
}
IEnumerable<DomainEvent> IAggregateRoot.GetUncommittedEvents()
{
return uncommittedEvents.ToArray();
}
void IAggregateRoot.ClearUncommittedEvents()
{
uncommittedEvents.Clear();
}
protected void RaiseEvent(DomainEvent @event)
{
uncommittedEvents.Add(@event);
}
}
Note the protected method RaiseEvent, which is used to add an event to the list of uncommitted events of the aggregate. This method will be invoked from within the aggregate to add events internally as methods on the public interface are invoked in sagas.
The JobOrder class we mentioned and partially unveiled earlier in the chapter is completed by the following code:
public void Extend(DateTime newDueDate, decimal price)
{
this.DueDate = newDueDate;
this.Price = price;
// Raise the JobOrderExtended event and add it to the
// internal list of uncommitted events maintained by the aggregate.
var theEvent = new JobOrderExtendedEvent(this.Id, this.DueDate, this.Price);
RaiseEvent(theEvent);
}
When an existing order is extended, the JobOrderExtended event is fired. This is a plain domain event and is added to the list of events managed by the aggregate instance. When the aggregate is saved, the event is persisted and notified to all registered listeners, if any.
Revised definition of the aggregate repository
In a CQRS system with a command-stack domain model, you typically have a repository that saves aggregates to some relational store via Entity Framework or any other Object/Relational Mapper (O/RM). When you adopt event sourcing, you typically replace the canonical relational data model with a log of events. As you saw in the previous example, you create an EventRepository class to manage the persistence of events in an append-only fashion.
In an architecture like that shown in Figure 13-5, you need an event repository but also a canonical aggregate repository. The aggregate repository, however, needs to have a slightly different structure than in the previous chapters:
public class Repository<T> where T : IAggregate
{
public void Save(T item)
{
// Apply pending events to the current
// instance of the aggregate
item.GetUncommittedEvents()
.ToList()
.ForEach(e => ManageEvent(e));
item.ClearUncommittedEvents();
// Persist aggregate snapshot here
...
}
private void ManageEvent(DomainEvent e)
{
// Log the event to the event store
...
// Notify the event via the bus
...
}
public T GetById(Guid id)
{
// Rehydrate the aggregate snapshot
...
}
}
When the saga attempts to save the aggregate, all events attached to the instance are processed, each is logged, and notification is sent to the handlers. Next, the state of the aggregate is persisted as usual. In the end, the persisted aggregate is a snapshot created for the purposes of the command stack.
How sagas deal with aggregates and events
Let’s find out how a saga can deal with aggregates and bind domain events to instances. Here are a couple of handlers for commands that create a new job-order and extend it:
public void Handle(CreateJobOrderCommand message)
{
var jobOrder = new JobOrder(
message.CustomerId,
message.Price,
message.DateOfStart,
message.DueDate,
message.JobOrderName);
var repository = new Repository<JobOrder>();
repository.Save(jobOrder);
// Sets the saga ID
this.Id = jobOrder.Id;
// Notify the “created” event to all listeners
var theEvent = new JobOrderCreatedEvent(
jobOrder.Id,
jobOrder.CustomerId,
jobOrder.Price,
jobOrder.DateOfStart,
jobOrder.DueDate,
jobOrder.Name,
jobOrder.Number);
Bus.RaiseEvent(theEvent);
}
public void Handle(ExtendJobOrderCommand message)
{
var repository = new Repository<JobOrder>();
var jobOrder = repository.GetById(message.JobOrderId);
// This line modifies the state of the aggregate and causes
// the “extended” event to be added to the aggregate list
jobOrder.Extend(message.NewDueDate, message.Price);
// Persisting the aggregate will log/notify pending events
repository.Save(jobOrder);
}
In the previous live-scoring example, the aggregate Match was not maintaining the list of related events internally. The event was processed by the saga, saved, and notification was sent outside the aggregate. In this example, we’re taking a route that is becoming increasingly popular: giving each aggregate the chance to handle its own events. Both approaches work; choosing which one to use is up to you. Keep in mind that your choice should be made to preserve and improve clarity and readability. And, why not, also performance!
Event replays vs. aggregate snapshots
Event sourcing should be a natural choice—you just use it if it is important to track events and easier to do that and build state from there. When it comes to this, you have two options: replay events to build the state of the aggregate, or persist the aggregate as a snapshot. At the moment, you can read opinions—mostly strong opinions—about either approach. It might seem like replaying events is the only way to go. In the end, replaying events seems like the approach that works in all situations. However, optimizations are often possible, depending on the characteristics of the domain. There’s no reason for not pursuing optimizations.
In our opinion, it is desirable to arrive at a point in which any aggregate chooses its own rehydration strategy—replay or snapshots—and to have an underlying repository that behaves accordingly. In general, we tend to recommend snapshots for general event sourcing and event replay when there’s the chance in the business domain that something happened to invalidate the persisted state. A good example of this is when some undo functionality should be implemented. Another good example is when you need to build the state of an aggregate until a given date. In these cases, there’s no alternative to the plain replay of events.
Summary
Event sourcing is certainly about using events; however, much more than this, event sourcing is about using events as the persistence layer of the system. When you opt for event sourcing, you don’t store data according to a canonical, object-oriented or relational model. You just log events as they happen instead.
Next, when business logic should be applied, you need to materialize programmable objects from the event store. How do you do this? You can start from blank instances of aggregates (if you’re using a domain model) or plain entities and apply all logged events. In this way, you rebuild the entire history of the application for each and every request. As you can see, this approach might work just fine in some scenarios (for example, in a live-scoring system) but not in others (for example, in a banking application). It all depends on the number of events and how easy it could be to apply their effect to objects. Sometimes, it is also a matter of performance.
Another approach is logging events and snapshots of the key aggregates. In this case, you don’t replay events but just deserialize an object from some database—either a NoSQL or relational database. The two strategies can also be mixed by having snapshots up to time T and replaying all successive events.
This chapter closes the part of the book dedicated to modeling. In the next chapter, we address persistence and focus on technologies and patterns for saving data. In particular, we’ll talk about NoSQL and Entity Framework as well as polyglot persistence.
Finishing with a smile
Events are part of life, and their occurrence is usually considered to be quite an important thing for the people involved. For this reason, getting some fun quotes about events related to programming was not that hard. Here are some we took from here and there on the Internet:
![]() Give a man a program, frustrate him for a day. Teach a man to program, frustrate him for a lifetime. (Muhammad Waseem)
Give a man a program, frustrate him for a day. Teach a man to program, frustrate him for a lifetime. (Muhammad Waseem)
![]() The most disastrous thing that you can ever learn is your first programming language. (Alan Kay)
The most disastrous thing that you can ever learn is your first programming language. (Alan Kay)
![]() Programs must be written for people to read, and only incidentally for machines to execute. (Hal Abelson)
Programs must be written for people to read, and only incidentally for machines to execute. (Hal Abelson)
![]() What is the object-oriented way of getting rich? Inheritance, of course. (Anonymous)
What is the object-oriented way of getting rich? Inheritance, of course. (Anonymous)
![]() When in doubt, use brute force. (Ken Thompson)
When in doubt, use brute force. (Ken Thompson)
![]() If brute force doesn’t solve your problems, then you aren’t using enough. (Ken Thompson)
If brute force doesn’t solve your problems, then you aren’t using enough. (Ken Thompson)
![]() Good judgment comes from experience, and experience comes from bad judgment. (Fred Brooks)
Good judgment comes from experience, and experience comes from bad judgment. (Fred Brooks)
![]() Computers are like bikinis. They save people a lot of guesswork. (Sam Ewing)
Computers are like bikinis. They save people a lot of guesswork. (Sam Ewing)
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.