NoSQL For Dummies (2015)
Part IV. Document Databases
In this part. . .
· Creating tree structures.
· Distributing information.
· Sharing information with the world.
· Examining document database products.
· Visit www.dummies.com/extras/nosql for great Dummies content online.
Chapter 14. Common Features of Document Databases
In This Chapter
![]() Expanding tree structures
Expanding tree structures
![]() Emulating key-value stores
Emulating key-value stores
![]() Creating partial updates
Creating partial updates
When talking about document databases, the word document refers to a hierarchical structure of data that can contain substructures. This is a more general term than being, for example, like Microsoft Word documents or web pages, although they are certainly two types of documents that can be managed in a document-oriented NoSQL database.
Documents can consist of only binary data or plain text. They can be semi-structured when self-describing data formats like JavaScript Object Notation (JSON) or Extensible Markup Language (XML) are used. They can even be well-structured documents and always conform to a particular data model, such as an XML Schema Definition (XSD).
Document NoSQL databases are flexible and schema agnostic, which means you can load any type of document without the database needing to know the document’s structure up front.
Document databases have many uses and share common features, which I explain in the chapter. As you read this chapter, you may be surprised to find out that a document NoSQL database will meet your needs over the other types of NoSQL database mentioned in this book.
Using a Tree-Based Data Model
In Chapter 9, I explain that Bigtable databases require at least some information about the data schema — at a minimum, the table name and column families, although the columns can be variable.
In a document NoSQL database, you can load any type of data without the database having prior knowledge of the data’s structure or what the values mean. This flexibility makes these databases great both for prototyping a solution in an “agile” development process and for permitting changes in the stored data after a system goes live. No need for a complex schema redesign within the database for every little change. This isn’t the case in traditional relational database management systems (RDBMS).
Bigtable clones allow you to manage sets of data sets; that is, when a Bigtable clone is given a row key, it returns a set of column families. When a Bigtable receives a row key and a column family qualifier, it returns a set of columns, each with a cell value (some with multiple cell values at different timestamps).
Bigtable clones effectively give you three levels of sets: row, family, and column, which can be represented in a tree model. Figure 14-1 shows an example of the online ordering application mentioned in Chapters 7 and 8 structured for a Bigtable clone.
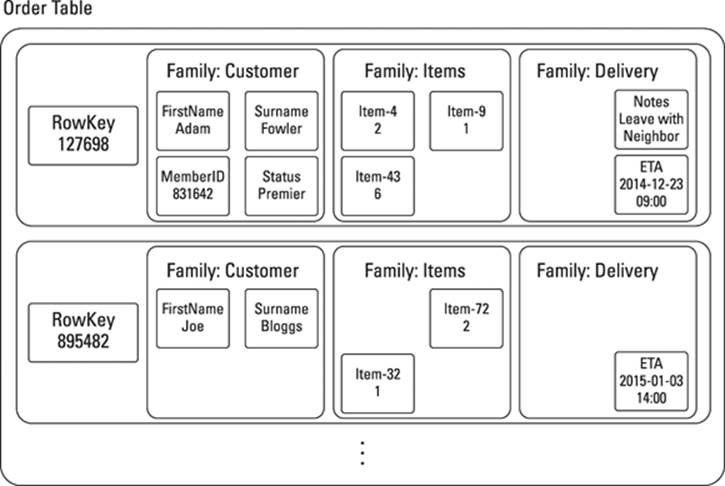
Figure 14-1: Example structure of an order table in a Bigtable clone.
What if you want to go down another level? Or another still? This is where a document database comes in, by providing the flexibility you need. Listing 14-1 is an example of an order document with enhanced information and ample flexibility.
Listing 14-1: Order XML Document
<order id=”1234”>
<customer id=”52”>Adam Fowler</customer>
<items>
<item qty=”2” id=”456” unit_price=”2.00” price=”4.00”>Hammer</item>
<item qty=”1” id=”111” unit_price=”0.79” price=”0.79”>Hammer Time</item>
</items>
<delivery_address lon=”-43.24” lat=”54.12”>
<street>Some Place</street>
<town>My City</town>
…
</delivery_address>
</order>
Of course, you are free to use a less hierarchical, flatter, structure. Listing 14-2 shows a log file management as a tree structure.
Listing 14-2: A mock Log File in a JSON tree structure
{
“source”: {
“host”: “192.168.1.3”, “process”: “tomcat”, “format”: “tomcat-error-log”
}, “entry”: {
“timestamp”: “2014-09-04 T10:00:43Z”, “level”: “error”,
“summary”: “Null Pointer Exception at com.package.MyClass:110:2”,
“trace”: [
“com.package.MyClass:110:2”,
“com.package.OtherClass:45:7”,
“com.sun.util.HashtableImpl”
]
}
}
In this case, a stack trace error report can be a tree structure. You could, for example, dump information about every live executing process into a file, rather than just the section of code that reported the error. This approach is particularly useful for parallel debugging.
In a Bigtable clone, your application must manage converting the preceding hierarchical document structure to and from a tree structure, whereas a document database can manage it natively.
 Storage of document data without “shredding” data across a set of tables is potentially useful if you want to query for a count of error reports to see which applications caused the most errors in a particular code module. Doing so requires a batch analysis job in a Bigtable — but a simple aggregation query in a document database with element indexing enabled.
Storage of document data without “shredding” data across a set of tables is potentially useful if you want to query for a count of error reports to see which applications caused the most errors in a particular code module. Doing so requires a batch analysis job in a Bigtable — but a simple aggregation query in a document database with element indexing enabled.
Handling article documents
Tree structures vary greatly. A semi-structured format like XHTML (the format used by web pages) has, as its name implies, some structure, but you can model the individual paragraphs, headings, and sections in a variety of ways.
A common practice in document databases is to index a property, or an element, no matter where it occurs within a document. For example, you could index all h1 (main headings) and h2 (subheadings) elements regardless of where they occur. Both MarkLogic Server and Microsoft DocumentDB allow this style of indexing.
Document databases are great at providing consistent query over these variable structures. There are many real-life examples of querying over document structures:
· Stack traces in log files may have a class name field at varying depths in a tree structure.
· A patient’s medical records may mention a drug or condition anywhere in the text notes field.
Managing trades in financial services
One of the most common document formats in the commercial industry is the Financial products Markup Language (FpML). FpML documents are a particular XML schema structure. They’re used for trading in long-running financial derivatives.
There are a couple of reasons that FpML need an XML oriented document database rather than a JSON oriented one, or need to be stored in a relational database:
· JSON doesn’t work for storing FpML documents because it doesn’t support namespaces, and FpML documents always include elements using the standard FpML namespace and a bank’s own internal information in another element namespace — both in the same document.
· XML Schema Definitions (XSDs) can have parent-child inheritance. A “place,” for example, could be a parent class of a “town” or “bridge,” with the document mentioning the elements “town” or “bridge,” but not “place.” This information isn’t available for JSON structures, so you can’t infer inheritance in a JSON model.
JSON documents are the lingua franca of web applications, though. Having a document NoSQL database that supports JSON documents natively, perhaps alongside other formats like XML or plain text, is useful. Don’t discount XML given the number of enterprise systems that use it as a native format.
Discovering document structure
Document databases tend to store documents in a compressed on-disk format. In order to do so, the databases need to understand the format of the documents they receive. When you submit JSON or XML documents, for example, a database uses that structure to better manage the data on disk.
Here is an example of a JSON document that represents an online order:
{ _id: 1234, customer: 52, customer_name: “Adam Fowler”, items: [
{qty: 2, item: {id: 456, title: “Hammer”, unit_price: 2.00}, price: 4.00},
{qty: 1, item: {id: 111, title: “Hammer Time”, unit_price: 0.79}, price: 0.79}
], delivery_address: {street: “some place”, town: “My City”, … }
}
MongoDB stores documents in its own BSON binary representation, which is useful because JSON, like that in the preceding JSON example, has a lot of text in property names. You can save space by compressing or managing these property names as simple numeric identifiers, rather than as long strings.
MarkLogic Server takes a similar approach with XML documents — that is, it stores a compressed representation. All elements and attributes are treated as a term. Each term is assigned a unique ID. This allows MarkLogic to use its own binary tree structure, which saves space when storing XML documents versus storing them as long strings. Listing 14-3 shows an XML representation of the same online order document.
Listing 14-3 An XML Document
<order id=”1234”>
<customer id=”52”>Adam Fowler</customer>
<items>
<item qty=”2” id=”456” unit_price=”2.00” price=”4.00”>Hammer</item>
<item qty=”1” id=”111” unit_price=”0.79” price=”0.79”>Hammer Time</item>
</items>
<delivery_address>
<street>Some Place</street>
<town>My City</town>
…
</delivery_address>
</order>
Saving space is more important for XML than it is for JSON because XML has closing and starting tags, as you can see in delivery_address in the above XML document.
Rather than simply compress data on disk, MarkLogic Server uses these term ids within its search indexes, which are built automatically when a document is written to MarkLogic Server. MarkLogic Server’s universal index indexes all structures: elements and attributes, parent and child element relationships, and exact element values.
The universal index indexes everything it finds. This speeds up querying for documents where an element has a particular value, without you having to add specific indexes or instructing the database about the document structure in advance. The universal index also indexes text (words, phrases, and stems). You can find more on MarkLogic’s universal index in Part VII.
Microsoft’s DocumentDB is a JSON document NoSQL database that also includes a universal index, but only for JSON documents.
Supporting unstructured documents
Fully unstructured information is actually rare. It’s more typical to use a container format like JSON or XML and to store large quantities of plain text in particular properties and elements.
There are situations, though, when you receive a lot of text or binary data (think about the average My Documents folder). Here are a couple of ways to manage groups of documents collected from such a hierarchical storage device:
· Collections of files may contain a combination of
· Structured files (such as CSV expense information)
· Semi-structured files (such as XML and saved HTML web pages)
· Unstructured files (such as JPEG images, movies, MP3s, word documents, PDFs, and plain text files)
· In reality, unstructured formats are actually semi-structured; it’s just that you don’t normally instruct your database to understand them. However, you may be missing some useful information that you might want to extract and search. For example, JPEG images may contain metadata about
· The camera that took the images
· The prevailing conditions when the image was shot
· The GPS coordinates and elevation where the image was taken
· Some databases come with built-in support for extracting this metadata and plain text from binary files. This is great for indexing the plain text for search or to provide for more-structured management of the files’ metadata.
· MarkLogic Server, for example, includes support for more than 200 binary formats through its use of binary data extraction libraries. These provide an XHTML output, using meta tags for metadata and the body tag for text content. You can integrate other solutions with other document databases to allow automatic extraction of information on ingest.
· Many document databases support the concept of a URI path as a primary key, or a unique document ID. Think of this path as being a file system path with an innate hierarchy. Some document databases allow you to list the documents stored under a particular, partial URI. In this way, you can represent a file system in a document database. Some NoSQL databases consider the unique ID as external to the document (MarkLogic), whereas others (MongoDB and Microsoft DocumentDB) use a special id property within the document.
Document Databases as Key-Value Stores
Document databases make great key-value stores. You can use a document URI path to represent a composite key like those in a key-value store. You can use document properties/elements, or metadata fields, to control how the database partitions data.
Document databases also provide a deeper level of data management functionality. This comes at the cost of processing time, which is why key-value stores are used for some JSON document storage use cases — where fast storage and retrieval is more important than advanced management functionality.
Modeling values as documents
Values can be binary information stored as a document. In many uses of a key-value store, though, values are JSON or XML structures. If you want to do advanced processing or indexing of values in a JSON or XML document, then a document database may be a better option.
Document databases provide in-memory read caches, with some (MongoDB) even providing read-only replicas to allow greater parallel reads of the same data. If you have data that’s read often, then a document database may provide speedy access to documents that’s equivalent to key-value stores’ access speed.
Automatic caching of parts of the database is particularly useful if all your data can’t fit in the memory of a key-value store, such as Redis.
Using value information
Once the elements/attributes (XML) or properties (JSON) — which I call elements from now on to distinguish them from a document’s metadata — are indexed, you can perform data queries and aggregation processes over them.
Document databases like MarkLogic Server and Microsoft DocumentDB provide range queries for their typed indexes. This means that, rather than being limited to “element equals X,” you can say “element is less than X” or “between X and Y inclusive.”
Both MarkLogic Server and Microsoft DocumentDB provide user-defined functions (UDFs). These are server-side functions that take the set of documents matching a query and perform aggregation calculations on them.
These aggregations can be a mean average, a standard deviation, or any other scalar output you devise. These operations are very fast, too, typically operating on the indexes rather than opening each document. This operation contrasts to the Hadoop or internal map/reduce mechanisms of other document databases and key-value stores, which must load the data from disk to perform these calculations.
You can also use these range indexes for fast sorting and filtering operations on result sets. They are immensely useful and allow for more advanced functionality. MarkLogic Server, for example, uses range indexes as the basis for 2D geospatial search.
Patching Documents
In some applications, rather than update and replace a whole document, you may want to change part of it, or a single value. A read, modify, update (RMU) operation on the entire content of a document is quite expensive in terms of processing time, and in many NoSQL databases isn’t ACID — meaning another operation could update the document between your application’s read and update steps!
Supporting partial updates
A partial update is one where you are updating just one of two values in a document, rather than replacing the whole thing. Perhaps there is a field that holds the number of times a document has been read, or the current product quantity in a warehouse.
Examples of partial updates may be as simple as replacing one element, which is similar to how a RBMS works. Consider the following query:
UPDATE Pages SET view_count = view_count + 1 WHERE id = “Page2”
If the record is modeled as a document, then a similar patch operation in MarkLogic Server might look like this:
<rapi:patch xmlns:rapi="http://marklogic.com/rest-api">
<rapi:replace select="/view_count" apply="ml.add">1</rapi:replace>
</rapi:patch>
Or the equivalent in JSON might look like this:
{"patch": [
{"replace": {
"select": "$.view_count",
"apply": "ml.add",
"content": 1
} }
] }
 Document NoSQL databases could be enhanced to implement this functionality in their REST API layer rather than within the database. This implementation would do an internal read, modify, update operation within a transaction, which could lead to a disk I/O penalty similar to an insert of the full document. You want to ensure that these multiple requests per update won’t impact your application’s performance by performing application load testing at the same level of concurrent requests as the peak period will be in your future production application.
Document NoSQL databases could be enhanced to implement this functionality in their REST API layer rather than within the database. This implementation would do an internal read, modify, update operation within a transaction, which could lead to a disk I/O penalty similar to an insert of the full document. You want to ensure that these multiple requests per update won’t impact your application’s performance by performing application load testing at the same level of concurrent requests as the peak period will be in your future production application.
Patching operations can also include appending elements to a parent element within a tree structure. Consider a shopping cart document where a user on a website adds an item to his cart. This could be an append operation at the end of an orderItems element using a document patch.
Streaming changes
The append operation enables you to handle a range of streaming cases efficiently. This operation will identify where in a document new data needs adding, and insert the data. This prevents performance impacts caused by the alternative read-modify-update approach.
For applications that require live information streaming with nearly real-time analysis by an application or human expert, supporting append operations is a potentially game-changing feature.
Consider a video recording that is being analyzed on the fly. Image that you’re receiving a video stream from a remotely controlled hexacopter. Along with the video, you’re receiving a metadata stream that includes the altitude, position, viewing angle (multiple axes), and the camera’s zoom level. You can index this metadata stream by time and append it to a video metadata document’s metastream element. For very long videos, to load the whole document and store it temporarily in your system’s memory for an update may use up too much RAM — you must load, modify, and then update the whole document’s content.
Instead of a very RAM costly read-modify-update cycle, you can stream the changes into the document using an append operation. Moreover, the document is visible to queries in the system while it’s being streamed in live, rather than having to wait until the entire stream activity is complete before being made available for query.
Providing alternate structures in real time
NoSQL databases don’t use joins to other documents like relational databases do, although some (MarkLogic Server, OrientDB) do allow building of a merged view at the time a document is read.
Instead, an approach called denormalization is used. Denormalization duplicates some information at ingestion time in order to provide access to high-speed reads and queries. Duplication of data is done so that the database doesn’t have to process joins at query time.
You may want to quickly produce alternative or merged views as new data arrives in the database. Doings so requires you to use a database trigger to spot the new document and to generate the one or more structures you need.
 Relational database management systems provide a similar concept called views. You can construct these on the fly or prebuild them. Prebuilt views are called materialized views. These views trade the use of extra disk space for the ability to save memory and processing power at query time. They are, in practical terms, equivalent to adding extra denormalized documents in a NoSQL document database.
Relational database management systems provide a similar concept called views. You can construct these on the fly or prebuild them. Prebuilt views are called materialized views. These views trade the use of extra disk space for the ability to save memory and processing power at query time. They are, in practical terms, equivalent to adding extra denormalized documents in a NoSQL document database.
Examples of using denormalization include
· Updating a summary document showing the latest five news items when a new item arrives.
· Updating multiple searchable program-availability documents on a catchup TV service when a new scheduling document arrives. This merges data from an episode, genre, brand, and scheduling set of documents into multiple program-availability documents.
· Taking an order document and splitting it into multiple order-item documents in order to allow a relational business intelligence tool to query at a lower granularity.
These use cases require the following database features:
· If they’re easy to update, you can generate these alternative structures in a pre-commit trigger.
This means the denormalizations are generated as the new document arrives. When the transaction to add documents ends, the denormalizations will become visible at exactly the same time.
· You can use a post-commit trigger if either of the following occur:
· Immediate consistency in these views isn’t required.
· Ingest speed is more important than consistency.
· A post-commit trigger allows the transaction to complete and guarantees that from that point, the denormalizations are generated. This improves the speed of writes at the cost of a few seconds of inconsistency.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.