NoSQL For Dummies (2015)
Part I. Getting Started with NoSQL
Chapter 2. NoSQL Database Design and Terminology
In This Chapter
![]() Identifying and handling different types of data
Identifying and handling different types of data
![]() Describing NoSQL and its terminology
Describing NoSQL and its terminology
![]() Encompassing the range of consistency options available
Encompassing the range of consistency options available
![]() Integrating related technologies
Integrating related technologies
New data management challenges have triggered a new database technology — NoSQL. NoSQL thinking and technology mark a shift away from traditional data management technologies. With all the new terms and techniques and the wide variety of options, it’s not easy to come up with a succinct description of NoSQL.
NoSQL databases aren’t a mere layer on top of existing technologies used to address a slightly different use case. They’re different beasts entirely. Each type of NoSQL database is designed to manage different types of data. Understanding the data you want to manage will help you apply the right NoSQL solution.
The popularity of NoSQL databases lies largely in the speed they provide for developers. NoSQL solutions are quicker to build, update, and deploy than their relational forerunners. Their design is tuned to ensure fast response times to particular queries and how data is added to them.
This speed comes with tradeoffs in other areas, including ensuring data consistency — that is, data that has just been added or updated may not be immediately available for all users. Understanding where consistency should and shouldn’t be applied is important when deciding to deploy a NoSQL solution.
Modern computer systems don’t exist in a vacuum; they’re always communicating with someone or something. NoSQL databases are commonly paired with particular complementary computer software, from search engines to semantic web technologies and Hadoop. Leveraging these technologies can make deployment of NoSQL more productive and useful.
Managing Different Data Types
I like to think in lists. When describing something, I list its properties and the values for those properties. When describing a set of objects, I use a table with a row for each object and a column for each property. You probably do something similar, for example, when you use Microsoft Excel or a similar program to store important information about a set of objects.
Sometimes some of these properties relate objects to other objects. Perhaps you have a set of drop-down lists, such as Expense Type, on your personal finance sheet. This Expense Type drop-down list is defined in another sheet called Reference. This linking, therefore, represents a relationship between two sheets, or tables.
The relational database management system (RDBMS) was introduced in the 1970s to handle this exact type of data. Today, the RDBMS underpins most organizations’ applications. Examples of such systems include customer relationship management (CRM) systems that hold details on prospects, customers, products, and sales; and banking systems that include a list of transactions on your bank accounts.
NoSQL databases aren’t restricted to a rows-and-columns approach. They are designed to handle a great variety of data, including data whose structure changes over time and whose interrelationships aren’t yet known.
NoSQL databases come in four core types — one for each type of data the database is expected to manage:
· Columnar: Extension to traditional table structures. Supports variable sets of columns (column families) and is optimized for column-wide operations (such as count, sum, and mean average).
· Key-value: A very simple structure. Sets of named keys and their value(s), typically an uninterpreted chunk of data. Sometimes that simple value may in fact be a JSON or binary document.
· Triple: A single fact represented by three elements:
· The subject you’re describing
· The name of its property or relationship to another subject
· The value — either an intrinsic value (such as an integer) or the unique ID of another subject (if it’s a relationship)
For example, Adam likes Cheese. Adam is the subject, likes is the predicate, and Cheese is the object.
· Document: XML, JSON, text, or binary blob. Any treelike structure can be represented as an XML or JSON document, including things such as an order that includes a delivery address, billing details, and a list of products and quantities.
Some document NoSQL databases support storing a separate list (or document) of properties about the document, too.
Most data problems can be described in terms of the preceding data structures. Indeed, nearly all computer programs ever written fall into these categories. It is therefore important to understand how you can best store, retrieve and query that data.
The good news is that there’s now a set of databases to properly manage each different type of data, so you don’t have to shred data into a fixed relational schema (by shred, I mean convert complex data structures to simple excel like table structures with relationships, which has always seemed like the wrong thing to do). I don’t like writing plumbing code just to store and retrieve data — and that’s despite my father being a plumber!
In addition to the preceding NoSQL data types, here are two other developments worth mentioning:
· Search engines: If you’re storing information that has a variable structure or copious text, you need a common way across structures to find relevant information, which search engines provide.
· Hybrid NoSQL databases: These databases provide a mix of the core features of multiple NoSQL database types — such as key-value, document, and triple stores — all in the same product.
Several search engines and hybrid databases apply general themes present in NoSQL products — namely, allowing variable data types and being horizontally scalable on commodity hardware. As the internal designs of search engines and hybrid NoSQL databases are similar and complementary, I’m including them in this book. (For information on what I’m not covering, see the upcoming sidebar named, you guessed it, “What I’m not covering.”)
What I’m not covering
Because the NoSQL world is awash with a range of products, I had to carefully select which products to include and which to exclude. Conversely, I wanted to provide more content than you might find in other NoSQL books.
I mention several products in each type of NoSQL database and complementary technologies. I had to draw the line somewhere, though, so here's what I’m not covering, and why:
· In-memory and flash databases: Some great advances have been made in real-time online transaction processing (OLTP) and analytics using in-memory databases. In-memory databases are very specialized and are targeted to particular problem domains. I have, though, mentioned NoSQL databases that take advantage of flash or memory caching to aid real-time analytics.
· Complex proprietary stacks: Large multinational vendors may be inclined to think they have a solution that fits in this book. Typically, this solution involves integrating multiple products. I want to cover NoSQL databases that provide a platform, not technical jigsaw pieces that you have to cobble together to provide similar functionality, which is why these guys aren’t included. I do mention single-product commercial NoSQL software such as Oracle NoSQL, MarkLogic, Microsoft’s Document DB, and IBM Cloudant, though.
· NewSQL: This is a new database access paradigm. It applies the software design lessons of NoSQL to RDBMS, creating a new breed of products, which is a great idea, but fundamentally these products still use traditional relational math and structures, which is why they aren’t included. Hopefully, someone will write a For Dummiesbook about these new databases!
· Every possible NoSQL database out there: Finally, there are just too many. I picked the ones you’re most likely to come across or that I believe provide the most promise for solving mission-critical enterprise problems. I do mention the key differences among many products in each NoSQL category, but I concentrate on one or two real-world examples for each to show their business value.
Columnar
Column stores are similar at first appearance to traditional relational DBMS. The concepts of rows and columns are still there. You also define column families before loading data into the database, meaning that the structure of data must be known in advance.
However, column stores organize data differently than relational databases do. Instead of storing data in a row for fast access, data is organized for fast column operations. This column-centric view makes column stores ideal for running aggregate functions or for looking up records that match multiple columns.
Aggregate functions are data combinations or analysis functions. They can be as simple as counting the number of results, summing them, or calculating their mean average. They could be more complex, though — for example, returning a complex value describing an overarching range of time.
 Column stores are also sometimes referred to as Big Tables or Big Table clones, reflecting their common ancestor, Google’s Bigtable.
Column stores are also sometimes referred to as Big Tables or Big Table clones, reflecting their common ancestor, Google’s Bigtable.
Perhaps the key difference between column stores and a traditional RDBMS is that, in a column store, each record (think row in an RDBMS) doesn’t require a single value per column. Instead, it’s possible to model column families. A single record may consist of an ID field, a column family for “customer” information, and another column family for “order item” information.
Each one of these column families consists of several fields. One of these column families may have multiple “rows” in its own right. Order item information, for example, has multiple rows — one for each line item. These rows will contain data such as item ID, quantity, and unit price.
A key benefit of a column store over an RDBMS is that column stores don’t require fields to always be present and don’t require a blank padding null value like an RDBMS does. This feature prevents the sparse data problem I mentioned in Chapter 1, preserving disk space. An example of a variable and sparse data set is shown in Figure 2-1.
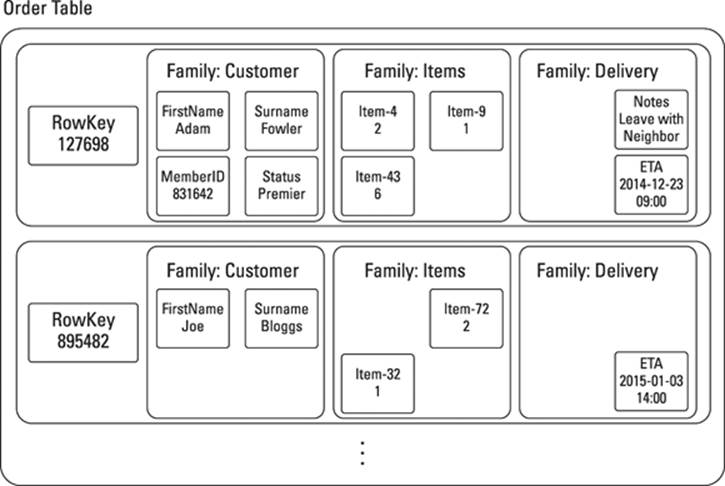
Figure 2-1: Column families at work.
The great thing about column stores is that you can retrieve all related information using a single record ID, rather than using the complex Structured Query Language (SQL) join as in an RDBMS. Doing so does require a little upfront modeling and data analysis, though.
In the example in Figure 2-1, I can retrieve all order information by selecting a single column store row, which means the developer doesn’t need to be aware of the exact complex join syntax of a query in a column store, unlike they would have to be using complex SQL joins in an RDBMS.
So, for complex and variable relational data structures, a column store may be more efficient in storage and less error prone in development than its RDBMS ancestors.
Note that, in my item column family, each item’s ID is represented within the key, and the value is the quantity ordered. This setup allows for fast lookup of all orders containing this item ID. You can find more on structuring your data for fast lookup in Chapters 9 and 10.
 If you know the data fields involved up front and need to quickly retrieve related data together as a single record, then consider a column store.
If you know the data fields involved up front and need to quickly retrieve related data together as a single record, then consider a column store.
Key-value stores
Key-value stores also have a record with an ID field — the key in key-value stores — and a set of data. This data can be one of the following:
· An arbitrary piece of data that the application developer interprets (as opposed to the database)
· Any set of name-value pairs (called bins)
 Think of it as a shared mailbox in an apartment building. All you see from the outside is a set of numbered holes. Using a key, you access whatever is in the mailbox. After looking at the mail, you decide what to do with it (probably just throw it away, if it’s junk like most of my mail).
Think of it as a shared mailbox in an apartment building. All you see from the outside is a set of numbered holes. Using a key, you access whatever is in the mailbox. After looking at the mail, you decide what to do with it (probably just throw it away, if it’s junk like most of my mail).
In this way, key-value stores are similar to column stores in that it’s possible to store varying data structures in the same logical record set. Key-value stores are the simplest type of storage in the NoSQL world — you’re just storing keys for the data you provide.
Some key-value stores support typing (such as integers, strings, and Booleans) and more complex structures for values (such as maps and lists). This setup aids developers because they don’t have to hand-code or decode string data held in a key-value store.
 In computer science, a “list” is zero or more data values. These values may or may not be stored in a sorted representation that allows for fast match processing.
In computer science, a “list” is zero or more data values. These values may or may not be stored in a sorted representation that allows for fast match processing.
Maps are a simple type of key-value storage. A unique key in a map has a single arbitrary value associated with it. The value could be a list of another map. So, it’s possible to store tree structures within key-value stores, if you’re willing to do the data processing yourself.
If you have numerous maps in your key-value store, consider a document store instead, which will likely minimize the amount of code required to operate on your data and make search and retrieval easier.
Key-value stores are optimized for speed of ingestion and retrieval. If you need very high ingest speed on a limited numbers of nodes and can afford to sacrifice complex ad hoc query support, then a key-value store may be for you.
Triple and graph stores
Although it’s just now becoming prominent, the concept of triples has been around since 1998, thanks to the World Wide Web Consortium (W3C) and Sir Tim Berners-Lee (one of my British heroes).
Before reading this book you may not have heard of triple (or graph) stores, but if you’re experienced with LinkedIn or Facebook, you’re probably familiar with the term social graph.
Under the hood of these approaches is a simple concept: every fact (or more correctly, assertion) is described as a triple of subject, predicate, and object:
· A subject is the thing you’re describing. It has a unique ID called an IRI. It may also have a type, which could be a physical object (like a person) or a concept (like a meeting).
· A predicate is the property or relationship belonging to the subject. This again is a unique IRI that is used for all subjects with this property.
· An object is the intrinsic value of a property (such as integer or Boolean, text) or another subject IRI for the target of a relationship.
Figure 2-2 illustrates a single subject, predicate, object triple.

Figure 2-2: A simple semantic assertion.
Therefore, Adam likes Cheese is a triple. You can model this data more descriptively, as shown here:
AdamFowler is_a Person
AdamFowler likes Cheese
Cheese is_a Foodstuff
More accurately, though, such triple information is conveyed with full IRI information in a format such as Turtle, like this:
<http://www.mydomain.org/people#AdamFowler> a <http://www.mydomain.org/rdftypes#Person> .
<http://www.mydomain.org/people#AdamFowler> <http://www.mydomain.org/predicates#likes> <http://www.mydomain.org/foodstuffs#Cheese> .
<http://www.mydomain.org/foodstuffs#Cheese> a <http://www.mydomain.org/rdftypes#Foodstuff> .
The full Turtle example shows a set of patterns in a single information domain for the URIs of RDF types, people, relationships, and foodstuffs. A single information domain is referred to as an ontology. Multiple ontologies can coexist in the same triple store.
It’s even possible for the same subject to have multiple IRIs, with a sameAs triple asserting that both subjects are equivalent.
You can quickly build this simple data structure into a web of facts, which is called a directed graph in computer science. I could be a friend_of Jon Williams or married_to Wendy Fowler. Wendy Fowler may or may not have a knows relationship with Jon Williams.
These directed graphs can contain complex and changing webs of relationships, or triples. Being able to store and query them efficiently, either on their own or as part of a larger multi-data structure application, is very useful for solving particular data storage and analytics problems.
Figure 2-3 shows an example of a complex web of interrelated facts.
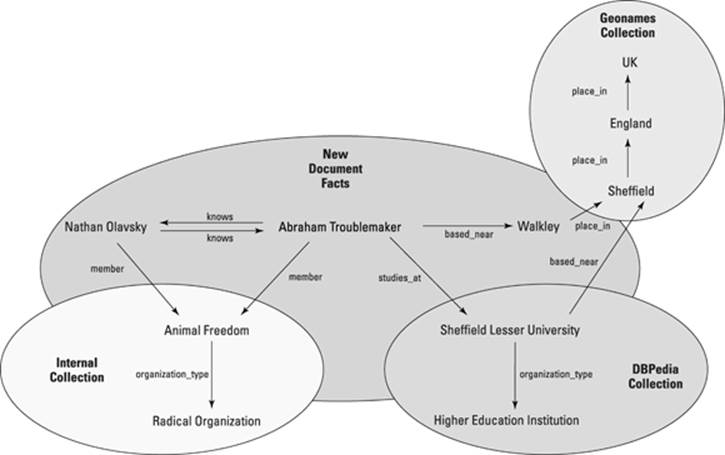
Figure 2-3: Web of interrelated facts across different ontologies.
I focus on triple stores in this book rather than graph stores. I think of graph stores as a subset of triple stores that are optimized for queries of relationships, rather than just the individual assertions, or facts, themselves.
Graph math is complex and specialized and may not be required in all situations where storing triples are required. Throughout this book, I point out where the difference matters. The query types supported also affect the design of a graph store, which I talk about in Chapter 19.
If you need to store facts, dynamically changing relationships, or provenance information, then consider a triple store. If you need to know statistics about the graph (such as how many degrees of separation are between two subjects or how many third level social connections a person has), then you should consider a graph store.
Document
Document databases are sometimes called aggregate databases because they tend to hold documents that combine information in a single logical unit — an aggregate. You might have a document that includes a TV episode, series, channel, brand, and scheduling and availability information, which is the total set of result data you expect to see when you search an online TV catch-up service.
Retrieving all information from a single document is easier with a database (no complex joins as in an RDBMS) and is more logical for applications (less complex code).
The world is awash with documents. Documents are important as they are generally created for a high-value purpose. Unfortunately many of them are tax documents and bills, but that’s totally out of my control. I just help organizations manage the things!
Loosely, a document is any unstructured or tree-structured piece of information. It could be a recipe (for cheesecake, obviously), financial services trade, PowerPoint file, PDF, plain text, or JSON or XML document.
Although an online store’s orders and the related delivery and payment addresses and order items can be thought of as a tree structure, you may instead want to use a column store for these. This is because the data structures are known up front, and it’s likely they won’t vary and that you’ll want to do column operations over them. Most of the time, a column store is a better fit for this data.
Some NoSQL databases provide the best of both worlds — poly-structured document storage and fast field (column) operations (see the “Hybrid NoSQL databases” section in this chapter, for details on heterogeneous data management).
This makes a document database a bit of a catchall. Interestingly, because of its treelike nature, an effective document store is also capable of storing simpler data structures.
A table, for example, can be modeled as a very flat XML document — that is, one with only a single set of elements, and no sub-element hierarchies. A set of triples (aka subgraph) can be stored within a single document, or across documents, too. The utility of doing so depends, of course, on the indexing and query mechanisms supported. There’s no point storing triples in documents if you can’t query them.
Search engines
It may seem strange to include search engines in this chapter, but many of today’s search engines use an architecture very similar to NoSQL databases. Their indexes and query processing are highly distributed. Many search engines are even capable of acting as a key-value or document store in their own right.
NoSQL databases are often used to store unstructured data, documents, or data that may be stored in a variety of structures, such as social media posts or web pages. The structures of this indexed data vary greatly.
Also, document databases are appropriate in cases where system administrators or developers frequently don’t have control of the structures. This situation is common in publishing, where one storefront receives feeds of new books and their metadata from many publishers.
Although publishers use similar standards such as PDF and ePub for documents and ONIX XML files for metadata, they all produce documents in slightly different ways. As a result, consistent handling of data is difficult, and publishing is a great use case for a Document database.
Similar problems occur in the defense and intelligence realms. An agency may receive data from an ally or a terrorist’s hard disk in a variety of formats. Waiting six months to develop a revised relational database schema to handle a new type of target is not viable! This is where document NoSQL databases can be used.
Storing many structures in a single database necessitates a way to provide a standard query mechanism over all content. Search engines are great for that purpose. Consider search as a key requirement to unstructured data management with NoSQL Document databases.
Search technology is different from traditional query database interface technology. SQL is not a search technology; it’s a query language. Search deals with imperfect matches and relevancy scoring, whereas query deals with Boolean exact matching logic (that is, all results of a query are equally relevant).
Hybrid NoSQL databases
Given the range of data types being managed by NoSQL databases, you’re forgiven if you think you need three different databases to manage all your data. However, although each NoSQL database has its core audience, several can be used to manage two or more of the previously mentioned data structures. Some even provide search on top of this core all-data platform.
A recent claim in relational circles is that NoSQL databases cannot manage a range of NoSQL data types. Throughout this book, I explain the core capabilities of each type of NoSQL database. Use this information to separate vendor claims from facts.
Hybrid databases can easily handle document and key-value storage needs, while also allowing fast aggregate operations similar to how column stores work. Typically, this goal is achieved by using search engine term indexes, rather than tabular field indexes within a table column in the database schema design itself.
The functionality provided, though, is often the same as in column stores. So, these products have three or four of the preceding types covered: key-value, document, and column stores, as well as search engines.
Many databases are moving in this direction. In Part 7, I highlight the databases that are leading the way.
Available NoSQL products
At my last count, there were more than 250 databases described by analysts in the NoSQL field. With so many (and because of this book’s page count, plus the risk of repetitive strain injury), I had to select only a few of them. Here is a condensed list of the leaders in providing NoSQL databases:
· Columnar: DataStax, Apache Cassandra, HBase, Apache Accumulo, Hypertable
· Key-value: Basho Riak, Redis, Voldemort, Aerospike, Oracle NoSQL
· Triple/graph: Neo4j, Ontotext’s GraphDB (formerly OWLIM), MarkLogic, OrientDB, AllegroGraph, YarcData
· Document: MongoDB, MarkLogic, CouchDB, FoundationDB, IBM Cloudant, Couchbase
· Search engine: Apache Solr, Elasticsearch, MarkLogic
· Hybrid: OrientDB, MarkLogic, ArangoDB
In Parts II through VII, I deal with each type of NoSQL database in turn, describing the key unique features of each option and reviewing one product of each type in detail.
Describing NoSQL
If you studied databases in school, you may have been indoctrinated in a relational way of thinking. Say database to most people, and they think relational database management system. This is natural because during the past 30 years, the RDBMS has been so dominant.
Getting your head around NoSQL can be a bit hard, but this book was created to make it as easy as possible.
To aid you on this journey, I want to introduce some key terms that are prevalent in the following chapters, as well as what they mean when applied to NoSQL databases.
· Database construction
· Database: A single logical unit, potential spread over multiple machines, into which data can be added and that can be queried for data it contains.
The relational term tablespace could also be applied to a NoSQL database or collection.
· Data farm: A term from RDBMS referring to a set of read-only replica sets stored across a managed cluster of machines.
In an RDBMS, these typically can’t have machines added without down time. In NoSQL clusters, it’s desirable to quickly scale out.
· Partition: A set of data to be stored together on a single node for processing efficiency, or to be replicated.
Could also be used for querying. In this case, it can be thought of as a collection.
· Database structure
· Collection: A set of records, typically documents, that are grouped together. This is based not on a property within the record set, but within its metadata. Assigning a record to a collection is usually done at creation or update time.
· Schema: In RDBMS and to a certain extent column stores. The structure of the data must be configured in the database before any data is loaded.
In document databases, although any structure can be stored, it is sometimes better to limit the structures by enforcing schema, such as in an XML Schema Definition. NoSQL generally, though, is regarded as schema-free, or as supporting variable schema.
· Records
· Record: A single atomic unit of data representation in the particular database being described.
In an RDBMS, this would be a row, as it is in column stores. This could also be a value in a key-value store, a document in a document store, or a subject (not triple) in a triple store.
· Row: Atomic unit of record in an RDBMS or column store.
Could be modeled as an element within a document store or as a map in a key-value store.
· Field: A single field within a record. A column in an RDBMS.
May not be present in all records, but when present should be of the same type or structure.
· Table: A single class of record. In Bigtable, they are also called tables. In a triple store, they may be called subject RDF types or named be graphs, depending on the context. In a document store, they may be collections. I’m using record type generically to refer to this concept.
· Record associations
· Primary key: A guaranteed unique value in a particular table that can be used to always reference a record. A key in a key-value store, URI in a document store, or IRI in a triple or graph store.
· Foreign key: A data value that indicates a record is related to a record in a different table or record set. Has the same value as the primary key in the related table.
· Relationship: A link, or edge in graph theory, that indicates two records have a semantic link. The relationship can be between two records in the same or different tables.
In RDBMS, it’s normally other tables, whereas in a triple store it’s common to relate subjects of the same type (people in a social graph, for example). Some databases, mainly graph stores, support adding metadata to the relationships.
· Storage organization
· Server: A single computer node within a cluster. Typically runs a single instance of a database server’s code.
· Cluster: A physical grouping or servers that are managed together in the same data center to provide a single service. May replicate its databases to clusters in other data centers.
· Normal form: A method of normalizing, or minimizing duplication, in data in an RDBMS.
NoSQL databases typically lead to a denormalized data structure in order to provide faster querying or data access.
· Replication technology
· Disk replication: Transparent replication of data between nodes in a single cluster to provide high-availability resilience in the case of a failure of a single node.
· Database replication: Replication between databases in different clusters. Replicates all data in update order from one cluster to another. Always unidirectional.
· Flexible replication: Provides application controlled replication of data between databases in different clusters. Updates may not arrive in the same order they were applied to the first database. Typically involves some custom processing, such as prioritization of data updates to be sent next. Can be bi-directional with appropriate update conflict resolution code.
· Search tools
· Index: An ordered list of values present in a particular record.
· Reverse index: An ordered list of values (terms), and a list of primary keys of records that use these terms.
Provides for efficient unstructured text search and rapid aggregation functions and sorting when cached in memory.
· Query: A set of criteria that results in a list of records that match the query exactly, returned in order of particular field value(s).
· Search: A set of criteria that results in a relevancy-ordered list that match the query.
The search criteria may not require an exact match, instead returning a relevancy calculation weighted by closeness of the match to the criteria. This is what Google does when you perform a search.
Applying Consistency Methods
The consistency property of a database means that once data is written to a database successfully, queries that follow are able to access the data and get a consistent view of the data. In practice, this means that if you write a record to a database and then immediately request that record, you’re guaranteed to see it. It’s particularly useful for things like Amazon orders and bank transfers.
Consistency is a sliding scale, though, and a subject too deep to cover here. However, in the NoSQL world, consistency generally falls into one of two camps:
· ACID Consistency (ACID stands for Atomicity, Consistency, Isolation, Durability): ACID means that once data is written, you have full consistency in reads.
· Eventual Consistency (BASE): BASE means that once data is written, it will eventually appear for reading.
A battle has been raging between people who believe strong consistency in a database isn’t required and those who believe it absolutely is required (translate people to NoSQL companies’ marketing departments!).
The reality is somewhere in between. Does it matter that a person’s Facebook post isn’t seen by all his friends for five minutes? No, probably not. Change “Facebook post” to “billion-dollar-financial transaction,” though, and your attitude changes rapidly! Which consistency approach you pick depends on the situation. In my experience, though, strong consistency is always the choice in mission-critical enterprise system situations.
 When you finish this book, one of the things I hope you take away is the difference between eventual consistency (BASE) and strong consistency (ACID), which I cover next.
When you finish this book, one of the things I hope you take away is the difference between eventual consistency (BASE) and strong consistency (ACID), which I cover next.
ACID
ACID is a general set of principles for transactional systems, not something linked purely to relational systems, or even just databases, so it’s well worth knowing about. ACID basically means, “This database has facilities to stop you from corrupting or losing data,” which isn’t a given for all databases. In fact, the vast majority of NoSQL databases don’t provide ACID guarantees.
 Foundation DB, MarkLogic, and Neo4j are notable exceptions. Some NoSQL databases provide a lower-grade guarantee called Check and Set that verifies whether someone else has altered a document before allowing a transaction to complete. This behavior is usually limited because it tends to be implemented on a single-record basis.
Foundation DB, MarkLogic, and Neo4j are notable exceptions. Some NoSQL databases provide a lower-grade guarantee called Check and Set that verifies whether someone else has altered a document before allowing a transaction to complete. This behavior is usually limited because it tends to be implemented on a single-record basis.
MongoDB is a notable database that provides Check and Set capabilities. With MongoDB, an entire node-worth of data can be locked during an update, thereby preventing all read and all write operations until the operation completes. The company is working on removing this limitation, though.
 How ACID works
How ACID works
ACID is a four-letter acronym, as explained here:
· Atomicity: Each operation affects the specified data, and no other data, in the database.
· Consistency: Each operation moves the database from one consistent state to another.
· Isolation: One operation in-flight does not affect the others.
· Durability: The database will not lose your data once the transaction reports success.
ACID transactional consistency can be provided various ways:
· In the locking model, you stop data from being read or written on the subset of information being accessed until the transaction is complete, which means that during longer-running transactions, the data won’t be available until all of the update is committed.
· An alternative mechanism is multiversion concurrency control (MVCC), which bears no resemblance to document versioning; instead, it’s a way of adding new data without read locking.
In MVCC, each record gets a creation and deletion timestamp. When a record is created, it’s given a creation timestamp. When a new transaction starts that alters that record, a new record is created with different information — the original data isn’t altered or locked.
This behavior means the original can still be read with all original values, even during a long-running transaction. Only when the transaction completes is the old record given a deletion timestamp.
The database shows only the latest undeleted record at the time you start your query. Therefore, transactions don’t interfere with each other. MVCC provides for fully serializable transactions, which is a hard beast to implement!
The downside is that your database periodically needs a merge operation to remove deleted records, although this is usually managed automatically, so generally only a small storage price is paid for rapid ingestions or updates. This approach, however, does require that the database administrator plan for this occasional extra read and write load when sizing the hardware required for a particular NoSQL database application.
BASE
BASE means that rather than make ACID guarantees, the database has a tunable balance of consistency and data availability. This is typically the case when nodes in a given database cluster act as primary managers of a part of the database, and other nodes hold read-only replicas.
To ensure that every client sees all updates (that is, they have a consistent view of the data), a write to the primary node holding the data needs to lock until all read replicas are up to date. This is called a two-phase commit — the change is made locally but applied and confirmed to the client only when all other nodes are updated.
BASE relaxes this requirement, requiring only a subset of the nodes holding the same data to be updated in order for the transaction to succeed. Sometime after the transaction is committed, the read-only replica is updated.
The advantage of this approach is that transactions are committed faster. Having readable live replicas also means you can spread your data read load, making reading quicker.
The downside is that clients connecting to some of the read replicas may see out-of-date information for an unspecified period of time. In some scenarios, this state is fine. If you post a new message on Facebook and some of your friends don’t see it for a couple of minutes, it’s not a huge loss. If you send a payment order to your bank, though, you may want an immediate transaction.
 An alternative approach to read-only replicas is to have a shared-nothing cluster in which only one node on a cluster always serves a particular part of the database.
An alternative approach to read-only replicas is to have a shared-nothing cluster in which only one node on a cluster always serves a particular part of the database.
Shared-nothing doesn’t mean you lose replication, though. Databases that employ this method typically do replicate their data to a secondary area on another primary node or nodes — but only one node is the master for reads and writes at any time.
Shared-nothing clusters have the advantage of a simpler consistency model but require a two-phase commit to replicas. This fact means the transaction locks while all replicas are updated. (An internal lock plus locking for other nodes gives you two phases.)
This typically has less impact than shared data clusters with read-only replicas, though, because shared-nothing replica data areas don’t receive read requests for that part of the database. Therefore, two-phase commits are faster on a shared-nothing cluster than on a cluster with readable replicas.
Choosing ACID or BASE?
As you might expect, much of the argument is because NoSQL vendors can differentiate themselves from their competitors by claiming a different, unique approach. It’s interesting to note, however, the number of NoSQL vendors with ACID-compliance on their roadmap.
Some NoSQL databases have ACID-compliance on their roadmap, even though they are proponents of BASE, which shows how relevant ACID guarantees are to enterprise, mission-critical systems.
 Many companies use BASE-consistency products when testing ideas because they are free but then migrate to an ACID-compliant paid-for database when they want to go live on a mission-critical system.
Many companies use BASE-consistency products when testing ideas because they are free but then migrate to an ACID-compliant paid-for database when they want to go live on a mission-critical system.
The easiest way to decide whether you need ACID is to consider the interactions people and other systems have with your data. For example, if you add or update data, is it important that the very next query is able to see the change? In other words, are important decisions hanging on the current state of the database? Would seeing slightly out-of-date data mean that those decisions could be fatally flawed?
In financial services, the need for consistency is obvious. Think of traders purchasing stock. They need to check the cash balance before trading to ensure that they have the money to cover the trade. If they don’t see the correct balance, they will decide to spend money on another transaction. If the database they’re querying is only eventually consistent, they may not see a lack of sufficient funds, thus exposing their organization to financial risk.
Similar cases can be built for ACID over BASE in health care, defense, intelligence, and other sectors. It all boils down to the data, though, and the importance of both timeliness and data security.
Availability approaches
Consistency is a sliding scale, not an absolute. Many NoSQL databases allow tuning between levels of consistency and availability, which relates to the CAP theorem.
The CAP theorem is a computer science conjecture, now proven, that shows the list of options as to how the balance between consistency, availability, and partitioning can be maintained in a BASE database system.
Eric Brewer has a lot to answer for! He came up with the CAP conjecture in 2000. It was later proved in 2002, and so is now a theorem. The CAP theorem in computer science is fundamental to how many NoSQL databases manage data.
CAP stands for Consistency, Availability, and Partitioning, which are aspects of data management in databases. Here are some questions to consider when considering a BASE and thus CAP approach:
· Consistency: Is the database fully (ACID) consistent, or eventually consistent, or without any consistency guarantees?
· Availability: During a partition, is all data still available (that is, can a partitioned node still successfully respond to requests)?
· Partitioning: If some parts of the same database cluster aren’t communicating with each other, can the database still function separately and correct itself when communication is restored?
 The CAP theorem states that you cannot have all features of all three at the same time. Most of the time, this is claimed to mean that you can have only two of the three. The reality is that each is a sliding scale. You may be able to trade off a little of one for more of another.
The CAP theorem states that you cannot have all features of all three at the same time. Most of the time, this is claimed to mean that you can have only two of the three. The reality is that each is a sliding scale. You may be able to trade off a little of one for more of another.
A traditional RDBMS typically provides strong consistency. Some clustered RDBMS also provide good availability, but they don’t provide partitioning.
Availability in the CAP theorem is a different concept from high availability as used to describe services. In CAP, I’m talking about data availability.
Also, remember that the definition of consistency in ACID isn’t the same definition as in CAP:
· In ACID, it means that the database is always in a consistent state.
· In CAP, it means that a single copy of the data has been updated.
Therefore, in CAP, a system that supports BASE can be consistent.
On the other hand, some NoSQL products, such as Cassandra, are partition-tolerant. Each part of the database continues to operate if one is not communicating with the rest of the nodes. This typically occurs because of networking outages rather than outright system failure.
When you allow part of a database to be updated when partitioned, you’re saying that the other part of the database cannot see this update. Consequently, allowing partitioning means you always lose some consistency.
Typically, the tradeoff is between consistency and partitioning when you talk about cross data-center database replication use. A particular NoSQL database generally provides either
· CA (consistency and availability)
· AP (availability and partition tolerance)
A pragmatic approach to this problem is to allow a data center to operate at full consistency but to make the other data centers’ replicas lag their primary stores, thus becoming eventually consistent. In the real world, this setup is the best you can hope for — even permanent fiber cables get dug up by humans!
Within a single data center, you can trade consistency and availability. Some NoSQL databases allow you to tune consistency, usually by adding read-only replicas of data on additional nodes. Replicas are updated outside the transaction boundary and, therefore, are eventually consistent. The upside to this approach is improved read performance and greater availability (at least for read, not write).
Some NoSQL databases don’t relax the consistency model when performing this local disk replication between nodes. The MarkLogic NoSQL database, for example, updates its replicas in the local data center within a transaction boundary using a two-phase commit. This means the replicas are always consistent, so if an outage occurs that affects the primary node for data, the secondary node takes over and provides ACID consistency and availability for both write and read operations.
These replicas in MarkLogic are held on nodes that manage their own primary data. Other NoSQL databases’ same data-center replicas are stored on nodes that are only for failover — they are read replicas only. As a result, more hardware is needed in these products, just in case of an outage.
It’s worth taking into account how NoSQL databases provide local data replicas, as well as how (or if) they have data management or catalog nodes, particularly in terms of their support for high availability and also cost. In this case, you could have three primary nodes and two replicas for each, with a total of nine systems. In this way, you basically triple your computing costs! These are important points when comparing apparently low-cost options to other databases. Don’t worry, though, in Parts II through VII, you find out about these and other enterprise issues you need to be aware of.
Developing applications on NoSQL
One of the most common conclusions about the emergence of NoSQL databases is that of polyglot persistence. Polyglot persistence means that, in order to write a single complete application, the application’s developer must use multiple types of databases, each for its most appropriate data type.
I am a polyglot persistence sceptic because I think multiple databases are only required because hybrid NoSQL databases are in their infancy, which I’m not convinced will last; however, people are practicing implementing polyglot persistence now, and no discussion of NoSQL’s relevance is complete without including this topic. Moreover, this discussion may influence decisions you make about which software to purchase over the next 5 to 25 years.
Martin Fowler (no relation to me, honest!) writes in his book with Pramod Sadalage, NoSQL Distilled, about the era of polyglot persistence. In this book he describes how he believes that polyglot persistence will be a long-term need in enterprise systems. Whatever the truth turns out to be, you need to be aware of the current limitations to data type handling in NoSQL databases.
Polyglot persistence
The database world has gone through a steady evolution over the last 40 years. When relational databases first became popular, developers wondered if they would replace mainframe systems and would require them to write applications using data from both types of systems, or replace them entirely.
Of course, mainframes still run many more financial transactions than relational databases do. These mainframes are generally hidden under corporate systems, away from the prying eyes of application developers. Both RDBMS and mainframe systems are used in modern systems such as online banking. The mainframe systems manage bank account balances whereas the RDBMS manage online banking user preferences and application form filling data.
Using both mainframe and RDBMS databases in the same application is what we term polyglot persistence.
On the other hand, you rarely see four or five different relational databases for the same application. Even when used together, they are typically hidden under a data access layer, so an application developer learns how to set up communication with, for example, two SOAP (Simple Object Access protocol) web services, not two different database systems.
Polyglot persistence explained
If you need to store a web of facts, a set of documents, and shopping cart datasets, you can’t do so in one NoSQL database. Or when you can store them, it’s hard to retrieve all data with a single query. Instead, you must use a single data access layer to handle the various data storage demands, and that’s where polyglot persistence comes in.
Polyglot persistence is the idea that a single application that uses different types of data needs to use multiple databases behind that application. Nobody sat down and decided that polyglot persistence was the way forward. It’s currently the case that no single database provides all the functionality of a column, key-value, document, or triple store.
Unlike the relational database world where the structural support hasn’t changed much in years (except for XML field support), NoSQL databases are gradually crossing over and covering multiple data types. For example, the Elasticsearch search engine is positioning itself as a JSON document store. MongoDB, CouchDB, and MarkLogic have the concept of primary keys or URIs. In this way, they act as key-value stores — the value is just a document.
If you look closely at document NoSQL databases, you can see that they provide some or a majority of the functionality you expect from a column or key-value store.
· If you’re considering a key-value store but some features are missing that handle specifics of the data, then consider a column store.
· If a column store can’t handle a very complex structure in your application, then consider a document store.
· If you need to manage relationships or facts in your data, then you need features of a triple store, too.
MarkLogic and OrientDB are interesting because they work as a document store and also act as triple and key-value stores. Traditional relational database rows and modern NoSQL column families can be represented easily as a document (JSON or XML).
Column stores are very good at holding a lexicon of data for a field across all record instances. These lexicons can then be used to calculate aggregation values quickly — for example, statistical operations like mean average, standard deviation, or even just listing unique values and their counts.
Some document databases expose their internal field indexes for similar operations. MarkLogic, for example, allows a search to be executed with faceted results returned. These facets are normally just counts of the frequency of mentions of values within search results, and are used to power search applications. Custom user-defined functions (UDFs) and statistical aggregate operations are also supported, though, just as with column stores.
Document databases achieve fast aggregate operations by allowing you to index the structure (XML element or JSON property name and location) and the value of data within a document, which expands the database capabilities beyond just doing a search.
These indexes may be held or cached in memory, making the speed of statistical operations equivalent to those in a column store. If you have data structures that could be held in a document store but that you want to perform calculations for, don’t discount document databases without looking at their lexicon and index functions. You may find a single database to answer multiple business problems.
You can take this scenario even further. If you apply search engine technology over your indexes and provide a well-designed query planner, then you can limit your aggregate functions using query terms efficiently.
If these indexes and queries are handled across a cluster, then you have a very fast in-database MapReduce capability that is efficient for high-speed operational database workloads, as well as for analytic workloads.
NoSQL databases are progressively improving their internal search support. In this regard, document databases and search engines in particular are strongly linked technologies.
NoSQL vendors are trying to add all the preceding features to their products. MarkLogic, for example, already provides these functions within a single product.
I fully expect all NoSQL databases to follow suit. Once this happens, there will be little reason to use multiple databases for non-relational workloads. I predict that by 2017, polyglot persistence in NoSQL will largely be a thing of the past.
The death of the RDBMS?
It’s tempting to think that once NoSQL databases evolve to handle more data and query types, the RDBMS will no longer be needed. Nothing could be further from the truth because NoSQL databases can’t provide all the functionality of a relational database.
When I was just a glint in my father’s eye, a lot of the world’s data was stored on hierarchical mainframe systems. These days, you’re forgiven if you think that all major systems use relational databases to store their data. Actually this isn’t the case. The financial services industry is powered today by mainframe systems. They are the core of all banking transactions that happen today. They haven’t been replaced by relational databases because mainframes are better suited for these particular loads.
The same will happen with relational databases. Those applications that are better served by using NoSQL will migrate to those databases. An RDBMS will still run structured, known data loads. Sales force management platforms like Siebel, Salesforce, and Sugar CRM are good examples. Each sales cycle has opportunities, accounts, deal teams, and product line items. There’s no need for a schema agnostic approach in these systems. So why would people migrate from a relational database to a NoSQL database?
The answer is, they won’t. The majority of today’s applications will stay on relational databases. On the other hand, NoSQL databases can be used for the following:
· New business problems
· Data loads where the schema isn’t known upfront or varies wildly
· Situations where existing relational databases aren’t providing the performance required for the data being managed
Therefore, polyglot persistence’s outlook is similar to the state of affairs for today’s traditional applications. You may have polyglot persistence over mainframe, relational, and NoSQL systems, but you won’t have multiple types of each database for each type of data store.
Some organizations do have legacy systems, though. So, they may have a corporate direction to use Oracle’s relational database but still run IBM’s DB2 as well. It’s possible, therefore, that some applications do run polyglot persistence over the same type of database, which reflects the slow pace of data migrations, not the fact that each database is designed for a different data type.
Integrating Related Technologies
As I mentioned, NoSQL databases are adapting to support more data types. As this is happening, their capabilities around this data will also expand.
These trends will allow organizations to simplify their overall architectures. By analyzing their needs early, organizations can find a single product to meet all their needs, rather than use three products that they must glue together. For example, some current products may provide basic text-search functionality but not all the functionality, such as word stemming, that a full-fledged search engine provides. Understanding your own needs first allows you to select the correct product, or product set, for solving your business needs.
Nothing exists in a vacuum. Pizza needs cheese. Hardware needs software. NoSQL databases are no different. Consequently, in this section, I cover a few complementary technologies that you can consider using in NoSQL projects. I mention them here because they’re fundamental to some of the NoSQL databases I discuss later in this book.
Search engine techniques
NoSQL databases are used to manage volumes of unstructured content. Be they long string fields, tweet content (all 140 characters), XML medical notes, or plain text and PDF files. As a result, search functionality is important. Whether the functionality is built in (for example, by embedding Lucene), developed through an optimized search engine, or provided by links to external search platforms (such as Solr or Elasticsearch) varies according to each NoSQL vendor’s strategy.
People generally associate search engines only with full-text searches. However, there are many other uses for search engines.
MarkLogic, for example, comes with a built-in search engine developed specifically for the data it was designed to store — documents. The database indexes are the same as those used for full-text search. MarkLogic includes a universal index. As well as indexing text content, it indexes exact field values, XML and JSON elements, and attribute and property names, and it maintains document ID (URIs in MarkLogician-speak) and collection lexicons.
Range indexes can be added to this mix after data is loaded and explored. Range indexes enable you to take advantage of less-than and greater-than style queries with integers and times, as well as more complex mathematics such as geospatial searches.
Range index support enables MarkLogic to have one set of indexes to satisfy simple document metadata queries, full-text content queries, or complex search queries, including geospatial or bi-temporal queries.
Other NoSQL databases, though, are often linked to search engines. The most common reason to do so is for full-text search, so it’s no surprise that search engines are often integrated to the document NoSQL databases.
Some NoSQL databases embed the common Apache Lucene engine to add full-text indexes for string fields. In some situations, this is enough; but in others, a full-featured distributed search engine is required to run alongside your distributed NoSQL database.
Solr is a distributed search platform that uses Lucene internally to do the indexes. Solr developers have applied many horizontal scalability tricks that NoSQL databases are known for.
Solr can also be used as a simple document store, saving and indexing JSON documents natively, similar to MarkLogic’s database.
The lines will continue to be blurred between document NoSQL databases and distributed search platforms, which is why I include search engines alongside the core types of NoSQL search.
Business Intelligence, dashboarding, and reporting
Storing data is all very well and good, but it’d be nice to reuse it for strategic work as well as for operational workloads. In the RDBMS world, an entire second tier of databases is used to allow this type of historical analytics and reporting.
I’m speaking of course of data warehouses. These warehouses hold the same information as an operational system but in a structure that’s more useful for reporting tools to query.
The problem with this approach is that the source system and the warehouse are never up to date. Typically, this report required an overnight batch update, but sometimes the update occurs only once a week. You might think this isn’t a big deal. However, with today’s fast pace, institutions are finding that even a 24-hour lag is too slow. Financial services, in particular, must answer questions from regulators on the same day, sometimes within five minutes of being asked!
So, there’s a need to perform business intelligence-style queries of data held in operational data stores, showing the current real-time state of the database (for example, “What’s my current risk exposure to Dodgy Banking, Incorporated?”).
In NoSQL column stores, data is still held in tables, rows, and column families in a structure suited for the operational system, not a warehousing one. Column databases, though, often provide the capability to update aggregations on the fly.
Logging databases are a good example. Cassandra has been used to store log files from systems as events occur. These live events are aggregated automatically to provide hourly, daily, weekly, and monthly statistics.
Document NoSQL databases take a different approach. They store primary copies of data but allow data transformation on query and allow denormalizations to be computed on the fly (see Chapter 14 for more on providing alternative structures of data held in a document NoSQL database).
Regardless of the approach taken, NoSQL databases can be used simultaneously because both the operational data store and for warehousing workloads.
Naturally, you don’t want 25 Business Intelligence (BI) reporting users retrieving vast copies of the data on an operational system. This use case can be achieved by using a BI tool that understands the internal NoSQL databases structure. Tableau, for example, has native connectors to several NoSQL databases.
Alternatively, you can create read-only replicas of your NoSQL database. You can allow your reporting users to query that database rather than the live one.
In many situations, though, reporting needs are a lot less complex than people might like to think. Many people simply want a solid operational view of the current state of the world — in other words, dashboards.
You can create dashboards by using aggregate functions over indexes of column or document stores. You can use search to restrict which data is aggregated — for example, just give aggregates of sales from the Pacific Northwest.
Having a NoSQL database with a rich REST (REpresentational State Transfer — a simple way of invoking networked services) API that you can rapidly plug into web widgets is advantageous when building out dashboarding apps, and it’s even better if internal data structures (like search results, for example) are supported by a NoSQL vendors’ JavaScript API. Using these API removes a lot of the plumbing code you will need to write to power a dashboard.
Batch processing with Hadoop Map/Reduce
Hadoop technology is designed for highly distributed data management and batch analysis. The batch analysis part is called map/reduce. The idea is that any operation, or chained operations, consists of two parts:
· The map phase fetches data stored in a record that matches a request.
· The reduce phase boils the data down to a single answer, which is done by distributing the query to all nodes that contain relevant data. Consequently, the work is massively parallelized.
Map/reduce is a way to spread workloads across nodes, assimilate them, and boil them down to unique data before passing it to the client.
In a database context, this means farming a query to all the nodes that hold data for that database and then merging data and removing duplicates when they arrive.
A lot of the time, though, these queries only extract a subset of the data to return as the answer to the caller or perform an aggregate match over the data. Examples are typically counts, sums, and averages of elements or values within each record (whether it’s a Bigtable column or a document element).
Many NoSQL database vendors provide an in-database map/reduce-like capability for farming out queries within the cluster and performing similar analyses. In this way, they can take advantage of distributed querying without always having to process all the data on the servers; instead in-memory indexes are evaluated, making index-driven NoSQL databases faster than map/reduce process-driven HBase.
Hadoop HDFS
Hadoop uses a storage technology called the Hadoop Distributed File System (HDFS). This functionality is particularly applicable to NoSQL.
NoSQL databases are highly distributed operational data stores, usually with indexing. Hadoop is a highly distributed store, too, but currently is best suited to batch processing.
The HDFS file system is a great way to use distributed storage and is a cheaper alternative to SANs and NAS storage. You achieve a cost reduction by using commodity servers without expensive RAID disk arrays.
RAID stands for Redundant Array of Inexpensive Disks. It means data is distributed among disks such that if one disk fails, the system can continue to operate. True enough, the disks are inexpensive, but the RAID controller can be costly!
Although the HDFS approach is slower in terms of query-processing, for long-tail historical data, the tradeoff in cost of storage versus retrieval time may be acceptable.
A NoSQL database that supports automated data tiering based on values can help organizations manage the movement of information during its lifecycle, from being added, updated during use (say financial data in the same quarter), moved to low cost storage for historical low volume reporting, and deletion.).
NoSQL vendors are moving to support HDFS in order to provide operational databases to replace HBase. Accumulo, MongoDB, and MarkLogic are just three examples of these products.
The trend, therefore, is for NoSQL databases to support Hadoop HDFS as one of many types of storage tier while providing their own optimized query processing. As long as the query returns the data you ask for, you don’t need to be concerned about whether it uses Hadoop map/reduce or a database’s internal query engine — as long as it fast!
Semantics
Semantic technology is a pet love of mine. Weirdly, it predates NoSQL by years! Sir Tim Berners-Lee came up with the principles of the semantic web way back in 1998.
The concept models distributed data in such a way that computers can traverse links among datasets on the web much like users traverse hyperlinks among web pages.
Technologies like RDF and SPARQL are used to model and query shared data, respectively. Resource Description Framework (RDF) is a common mechanism for modeling assertions (known as triples). The query language SPARQL is designed to be to triples what Structured Query Language (SQL) is to relational databases. These triples are stored in a triple store or a graph store.
These technologies have particular relevance for NoSQL. In an RDBMS, people are used to querying across tables using relationships. NoSQL databases don’t provide this construct.
However, triple stores provide relationships that can be dynamic, subclassed, and described in their own right, and where the relationships possible among records may not be known at the time a database is designed.
Triple stores, therefore, provide the flexibility in storing relationships that other NoSQL databases provide for the data itself — namely, schema agnosticism and the ability to store different data and relationships without schema definition up front.
So, graph and triple stores hold the promise of providing the answer to cross-record joins currently lacking in other NoSQL databases. A particularly good, albeit not widely used, example is OrientDB.
OrientDB allows you to define document attributes whose value may relate to another document. This is similar to the primary/foreign key relationships from the relational database world. What OrientDB does, though, is to automatically generate the triples to describe this relationship when it recognizes the data in documents.
Furthermore, OrientDB allows you to query this data and dynamically generate a merged document from the result of a set of relationships held in its triple store. It’s a very cool approach that other NoSQL vendors are sure to begin applying to their own databases.
Semantic technology also holds the promise of providing more context around search. Rather than return documents that mention “Thatcher,” you may want to say “Job Role: Thatcher” or “Politician (subclass of Person): Thatcher.” This provides disambiguation of search terms.
Several products exist, including Temis, Smartlogic, and Open Calais, that use text analytics to extract entities (people, places, and so on) and generate semantic assertions so they can be stored in a triple store, linked to the source text it describes in the NoSQL database.
Public cloud
Something worth considering alongside adoption of NoSQL technology is the public cloud. Companies like Amazon and Microsoft offer flexible infrastructure that can be provisioned and shut down rapidly, on demand. A cloud approach aligns well with NoSQL because of NoSQL’s ability to scale across many commodity systems.
Adopting NoSQL means you will have a database that naturally fits in a cloud environment. Many NoSQL database products can have nodes added and removed from a cluster dynamically with no down time, which means that during periods of peak usage, you can deploy the hardware dynamically using Amazon Web Services, for example, and also add extra database storage or query capacity on demand, too.
Although many NoSQL databases have their roots in open-source, enterprise features — including cloud management utilities — these database features though are available only as commercial add-ons.
Some databases may be able to scale to any number of nodes, but providing that extra capability may require the database to shut down, or at least negatively affect short-term performance.
These concerns and others are detailed alongside the products in Parts II through VII of this book.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.