Apache Flume: Distributed Log Collection for Hadoop, Second Edition (2015)
Chapter 1. Overview and Architecture
If you are reading this book, chances are you are swimming in oceans of data. Creating mountains of data has become very easy, thanks to Facebook, Twitter, Amazon, digital cameras and camera phones, YouTube, Google, and just about anything else you can think of being connected to the Internet. As a provider of a website, 10 years ago, your application logs were only used to help you troubleshoot your website. Today, this same data can provide a valuable insight into your business and customers if you know how to pan gold out of your river of data.
Furthermore, as you are reading this book, you are also aware that Hadoop was created to solve (partially) the problem of sifting through mountains of data. Of course, this only works if you can reliably load your Hadoop cluster with data for your data scientists to pick apart.
Getting data into and out of Hadoop (in this case, the Hadoop File System, or HDFS) isn't hard; it is just a simple command, such as:
% hadoop fs --put data.csv .
This works great when you have all your data neatly packaged and ready to upload.
However, your website is creating data all the time. How often should you batch load data to HDFS? Daily? Hourly? Whatever processing period you choose, eventually somebody always asks "can you get me the data sooner?" What you really need is a solution that can deal with streaming logs/data.
Turns out you aren't alone in this need. Cloudera, a provider of professional services for Hadoop as well as their own distribution of Hadoop, saw this need over and over when working with their customers. Flume was created to fill this need and create a standard, simple, robust, flexible, and extensible tool for data ingestion into Hadoop.
Flume 0.9
Flume was first introduced in Cloudera's CDH3 distribution in 2011. It consisted of a federation of worker daemons (agents) configured from a centralized master (or masters) via Zookeeper (a federated configuration and coordination system). From the master, you could check the agent status in a web UI as well as push out configuration centrally from the UI or via a command-line shell (both really communicating via Zookeeper to the worker agents).
Data could be sent in one of three modes: Best effort (BE), Disk Failover (DFO), and End-to-End (E2E). The masters were used for the E2E mode acknowledgements and multimaster configuration never really matured, so you usually only had one master, making it a central point of failure for E2E data flows. The BE mode is just what it sounds like: the agent would try to send the data, but if it couldn't, the data would be discarded. This mode is good for things such as metrics, where gaps can easily be tolerated, as new data is just a second away. The DFO mode stores undeliverable data to the local disk (or sometimes, a local database) and would keep retrying until the data could be delivered to the next recipient in your data flow. This is handy for those planned (or unplanned) outages, as long as you have sufficient local disk space to buffer the load.
In June, 2011, Cloudera moved control of the Flume project to the Apache Foundation. It came out of the incubator status a year later in 2012. During the incubation year, work had already begun to refactor Flume under the Star-Trek-themed tag, Flume-NG (Flume the Next Generation).
Flume 1.X (Flume-NG)
There were many reasons why Flume was refactored. If you are interested in the details, you can read about them at https://issues.apache.org/jira/browse/FLUME-728. What started as a refactoring branch eventually became the main line of development as Flume 1.X.
The most obvious change in Flume 1.X is that the centralized configuration master(s) and Zookeeper are gone. The configuration in Flume 0.9 was overly verbose, and mistakes were easy to make. Furthermore, centralized configuration was really outside the scope of Flume's goals. Centralized configuration was replaced with a simple on-disk configuration file (although the configuration provider is pluggable so that it can be replaced). These configuration files are easily distributed using tools such as cf-engine, Chef, and Puppet. If you are using a Cloudera distribution, take a look at Cloudera Manager to manage your configurations. About two years ago, they created a free version with no node limit, so it may be an attractive option for you. Just be sure you don't manage these configurations manually, or you'll be editing these files manually forever.
Another major difference in Flume 1.X is that the reading of input data and the writing of output data are now handled by different worker threads (called Runners). In Flume 0.9, the input thread also did the writing to the output (except for failover retries). If the output writer was slow (rather than just failing outright), it would block Flume's ability to ingest data. This new asynchronous design leaves the input thread blissfully unaware of any downstream problem.
The first edition of this book covered all the versions of Flume up till Version 1.3.1. This second edition will cover till Version 1.5.2 (the current version at the time of writing this).
The problem with HDFS and streaming data/logs
HDFS isn't a real filesystem, at least not in the traditional sense, and many of the things we take for granted with normal filesystems don't apply here, such as being able to mount it. This makes getting your streaming data into Hadoop a little more complicated.
In a regular POSIX-style filesystem, if you open a file and write data, it still exists on the disk before the file is closed. That is, if another program opens the same file and starts reading, it will get the data already flushed by the writer to the disk. Furthermore, if this writing process is interrupted, any portion that made it to disk is usable (it may be incomplete, but it exists).
In HDFS, the file exists only as a directory entry; it shows zero length until the file is closed. This means that if data is written to a file for an extended period without closing it, a network disconnect with the client will leave you with nothing but an empty file for all your efforts. This may lead you to the conclusion that it would be wise to write small files so that you can close them as soon as possible.
The problem is that Hadoop doesn't like lots of tiny files. As the HDFS filesystem metadata is kept in memory on the NameNode, the more files you create, the more RAM you'll need to use. From a MapReduce prospective, tiny files lead to poor efficiency. Usually, each Mapper is assigned a single block of a file as the input (unless you have used certain compression codecs). If you have lots of tiny files, the cost of starting the worker processes can be disproportionally high compared to the data it is processing. This kind of block fragmentation also results in more Mapper tasks, increasing the overall job run times.
These factors need to be weighed when determining the rotation period to use when writing to HDFS. If the plan is to keep the data around for a short time, then you can lean toward the smaller file size. However, if you plan on keeping the data for a very long time, you can either target larger files or do some periodic cleanup to compact smaller files into fewer, larger files to make them more MapReduce friendly. After all, you only ingest the data once, but you might run a MapReduce job on that data hundreds or thousands of times.
Sources, channels, and sinks
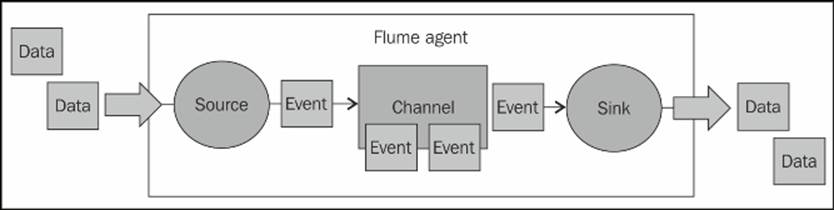
The Flume agent's architecture can be viewed in this simple diagram. Inputs are called sources and outputs are called sinks. Channels provide the glue between sources and sinks. All of these run inside a daemon called an agent.
Note
Keep in mind:
· A source writes events to one or more channels.
· A channel is the holding area as events are passed from a source to a sink.
· A sink receives events from one channel only.
· An agent can have many channels.
Flume events
The basic payload of data transported by Flume is called an event. An event is composed of zero or more headers and a body.
The headers are key/value pairs that can be used to make routing decisions or carry other structured information (such as the timestamp of the event or the hostname of the server from which the event originated). You can think of it as serving the same function as HTTP headers—a way to pass additional information that is distinct from the body.
The body is an array of bytes that contains the actual payload. If your input is comprised of tailed log files, the array is most likely a UTF-8-encoded string containing a line of text.
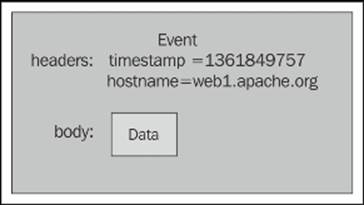
Flume may add additional headers automatically (like when a source adds the hostname where the data is sourced or creating an event's timestamp), but the body is mostly untouched unless you edit it en route using interceptors.
Interceptors, channel selectors, and sink processors
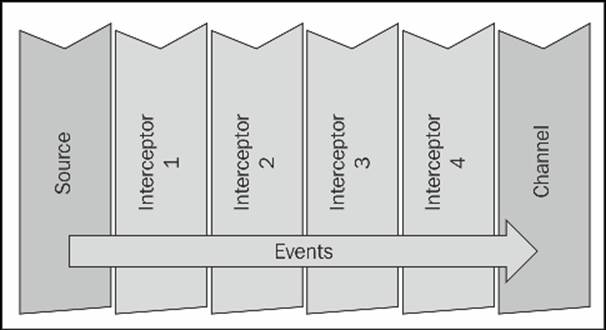
An interceptor is a point in your data flow where you can inspect and alter Flume events. You can chain zero or more interceptors after a source creates an event. If you are familiar with the AOP Spring Framework, think MethodInterceptor. In Java Servlets, it'ssimilar to ServletFilter. Here's an example of what using four chained interceptors on a source might look like:
Channel selectors are responsible for how data moves from a source to one or more channels. Flume comes packaged with two channel selectors that cover most use cases you might have, although you can write your own if need be. A replicating channel selector (the default) simply puts a copy of the event into each channel, assuming you have configured more than one. In contrast, a multiplexing channel selector can write to different channels depending on some header information. Combined with some interceptor logic, this duo forms the foundation for routing input to different channels.
Finally, a sink processor is the mechanism by which you can create failover paths for your sinks or load balance events across multiple sinks from a channel.
Tiered data collection (multiple flows and/or agents)
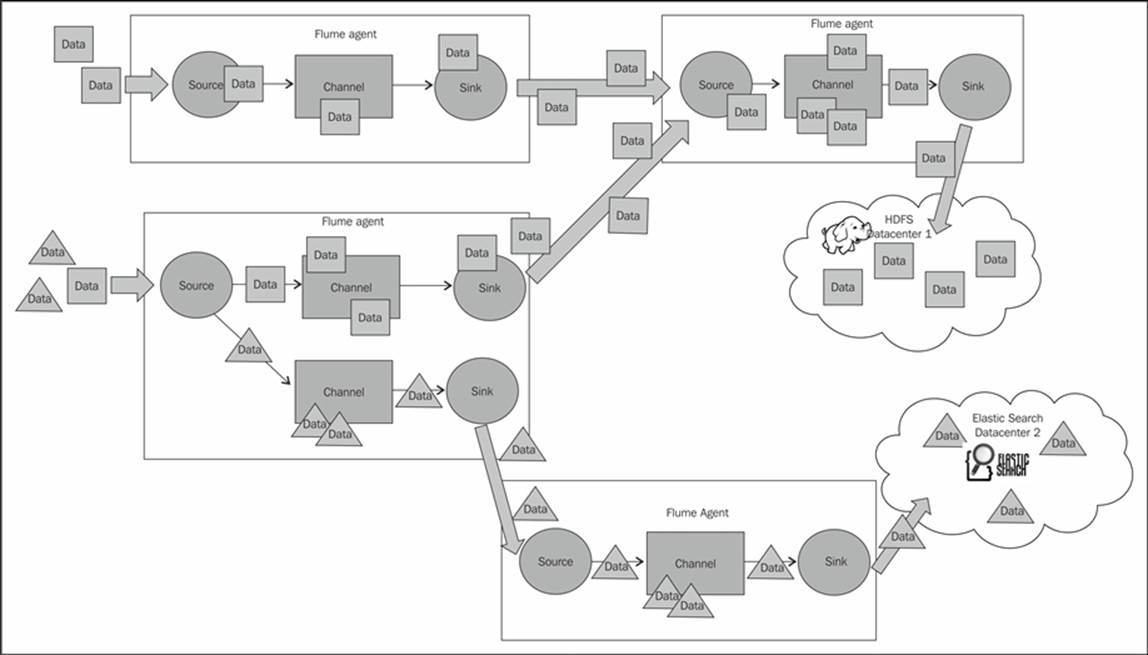
You can chain your Flume agents depending on your particular use case. For example, you may want to insert an agent in a tiered fashion to limit the number of clients trying to connect directly to your Hadoop cluster. More likely, your source machines don't have sufficient disk space to deal with a prolonged outage or maintenance window, so you create a tier with lots of disk space between your sources and your Hadoop cluster.
In the following diagram, you can see that there are two places where data is created (on the left-hand side) and two final destinations for the data (the HDFS and ElasticSearch cloud bubbles on the right-hand side). To make things more interesting, let's say one of the machines generates two kinds of data (let's call them square and triangle data). You can see that in the lower-left agent, we use a multiplexing channel selector to split the two kinds of data into different channels. The rectangle channel is then routed to the agent in the upper-right corner (along with the data coming from the upper-left agent). The combined volume of events is written together in HDFS in Datacenter 1. Meanwhile, the triangle data is sent to the agent that writes to ElasticSearch in Datacenter 2. Keep in mind that data transformations can occur after any source. How all of these components can be used to build complicated data workflows will be become clear as we proceed.
The Kite SDK
One of the new technologies incorporated in Flume, starting with Version 1.4, is something called a Morphline. You can think of a Morphline as a series of commands chained together to form a data transformation pipe.
If you are a fan of pipelining Unix commands, this will be very familiar to you. The commands themselves are intended to be small, single-purpose functions that when chained together create powerful logic. In many ways, using a Morphline command chain can be identical in functionality to the interceptor paradigm just mentioned. There is a Morphline interceptor we will cover in Chapter 6, Interceptors, ETL, and Routing, which you can use instead of, or in addition to, the included Java-based interceptors.
Note
To get an idea of how useful these commands can be, take a look at the handy grok command and its included extensible regular expression library at https://github.com/kite-sdk/kite/blob/master/kite-morphlines/kite-morphlines-core/src/test/resources/grok-dictionaries/grok-patterns
Many of the custom Java interceptors that I've written in the past were to modify the body (data) and can easily be replaced with an out-of-the-box Morphline command chain. You can get familiar with the Morphline commands by checking out their reference guide athttp://kitesdk.org/docs/current/kite-morphlines/morphlinesReferenceGuide.html
Flume Version 1.4 also includes a Morphline-backed sink used primarily to feed data into Solr. We'll see more of this in Chapter 4, Sinks and Sink Processors, Morphline Solr Search Sink.
Morphlines are just one component of the KiteSDK included in Flume. Starting with Version 1.5, Flume has added experimental support for KiteData, which is an effort to create a standard library for datasets in Hadoop. It looks very promising, but it is outside the scope of this book.
Note
Please see the project home page for more information, as it will certainly become more prominent in the Hadoop ecosystem as the technology matures. You can read all about the KiteSDK at http://kitesdk.org.
Summary
In this chapter, we discussed the problem that Flume is attempting to solve: getting data into your Hadoop cluster for data processing in an easily configured, reliable way. We also discussed the Flume agent and its logical components, including events, sources, channel selectors, channels, sink processors, and sinks. Finally, we briefly discussed Morphlines as a powerful new ETL (Extract, Transform, Load) library, starting with Version 1.4 of Flume.
The next chapter will cover these in more detail, specifically, the most commonly used implementations of each. Like all good open source projects, almost all of these components are extensible if the bundled ones don't do what you need them to do.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.