Apache Flume: Distributed Log Collection for Hadoop, Second Edition (2015)
Chapter 4. Sinks and Sink Processors
By now, you should have a pretty good idea where the sink fits into the Flume architecture. In this chapter, we will first learn about the most-used sink with Hadoop, the HDFS sink. We will then cover two of the newer sinks that support common Near Real Time(NRT) log processing: the ElasticSearchSink and the MorphlineSolrSink. As you'd expect, the first writes data into Elasticsearch and the latter to Solr. The general architecture of Flume supports many other sinks we won't have space to cover in this book. Some come bundled with Flume and can write to HBase, IRC, and, as we saw in Chapter 2, A Quick Start Guide to Flume, a log4j and file sink. Other sinks are available on the Internet and can be used to write data to MongoDB, Cassandra, RabbitMQ, Redis, and just about any other data store you can think of. If you can't find a sink that suits your needs, you can write one easily by extending the org.apache.flume.sink.AbstractSink class.
HDFS sink
The job of the HDFS sink is to continuously open a file in HDFS, stream data into it, and at some point, close that file and start a new one. As we discussed in Chapter 1, Overview and Architecture, the time between files rotations must be balanced with how quickly files are closed in HDFS, thus making the data visible for processing. As we've discussed, having lots of tiny files for input will make your MapReduce jobs inefficient.
To use the HDFS sink, set the type parameter on your named sink to hdfs.
agent.sinks.k1.type=hdfs
This defines a HDFS sink named k1 for the agent named agent. There are some additional parameters you must specify, starting with the path in HDFS you want to write the data to:
agent.sinks.k1.hdfs.path=/path/in/hdfs
This HDFS path, like most file paths in Hadoop, can be specified in three different ways: absolute, absolute with server name, and relative. These are all equivalent (assuming your Flume agent is run as the flume user):
|
absolute |
/Users/flume/mydata |
|
absolute with server |
hdfs://namenode/Users/flume/mydata |
|
relative |
mydata |
I prefer to configure any server I'm installing Flume on with a working hadoop command line by setting the fs.default.name property in Hadoop's core-site.xml file. I don't keep persistent data in HDFS user directories but prefer to use absolute paths with some meaningful path name (for example, /logs/apache/access). The only time I would specify a NameNode specifically is if the target was a different Hadoop cluster entirely. This allows you to move configurations you've already tested in one environment into another without unintended consequences such as your production server writing data to your staging Hadoop cluster because somebody forgot to edit the target in the configuration. I consider externalizing environment specifics a good best practice to avoid situations such as these.
One final required parameter for the HDFS sink, actually any sink, is the channel that it will be doing take operations from. For this, set the channel parameter with the channel name to read from:
agent.sinks.k1.channel=c1
This tells the k1 sink to read events from the c1 channel.
Here is a mostly complete table of configuration parameters you can adjust from the default values:
|
Key |
Required |
Type |
Default |
|
type |
Yes |
String |
hdfs |
|
channel |
Yes |
String |
|
|
hdfs.path |
Yes |
String |
|
|
hdfs.filePrefix |
No |
String |
FlumeData |
|
hdfs.fileSuffix |
No |
String |
|
|
hdfs.minBlockReplicas |
No |
int |
See the dfs.replication property in your inherited Hadoop configuration, usually, 3. |
|
hdfs.maxOpenFiles |
No |
long |
5000 |
|
hdfs.closeTries |
No |
int |
0 (0=try forever, otherwise a count) |
|
hdfs.retryInterval |
No |
int |
180 Seconds (0=don't retry) |
|
hdfs.round |
No |
boolean |
false |
|
hdfs.roundValue |
No |
int |
1 |
|
hdfs.roundUnit |
No |
String (second, minute or hour) |
second |
|
hdfs.timeZone |
No |
String |
Local time |
|
hdfs.useLocalTimeStamp |
No |
boolean |
False |
|
hdfs.inUsePrefix |
No |
String |
Blank |
|
hdfs.inUseSuffix |
No |
String |
.tmp |
|
hdfs.rollInterval |
No |
long (seconds) |
30 Seconds (0=disable) |
|
hdfs.rollSize |
No |
long (bytes) |
1024 bytes (0=disable) |
|
hdfs.rollCount |
No |
long |
10 (0=disable) |
|
hdfs.batchSize |
No |
long |
100 |
|
hdfs.codeC |
No |
String |
Remember to always check the Flume User Guide for the version you are using at http://flume.apache.org/, as things might change between the release of this book and the version you are actually using.
Path and filename
Each time Flume starts a new file at hdfs.path in HDFS to write data into, the filename is composed of the hdfs.filePrefix, a period character, the epoch timestamp at which the file was started, and optionally, a file suffix specified by the hdfs.fileSuffix property (if set), for example:
agent.sinks.k1.hdfs.path=/logs/apache/access
The preceding command would result in a file such as /logs/apache/access/FlumeData.1362945258
However, in the following configuration, your filenames would be more like /logs/apache/access/access.1362945258.log:
agent.sinks.k1.hdfs.path=/logs/apache/access
agent.sinks.k1.hdfs.filePrefix=access
agent.sinks.k1.hdfs.fileSuffix=.log
Over time, the hdfs.path directory will get very full, so you will want to add some kind of time element into the path to partition the files into subdirectories. Flume supports various time-based escape sequences, such as %Y to specify a four-digit year. I like to use sequences in the year/month/day/hour form (so that they are sorted oldest to newest), so I often use this for a path:
agent.sinks.k1.hdfs.path=/logs/apache/access/%Y/%m/%d/%H
This says I want a path like /logs/apache/access/2013/03/10/18/.
Note
For a complete list of time-based escape sequences, see the Flume User Guide.
Another handy escape sequence mechanism is the ability to use Flume header values in your path. For instance, if there was a header with a key of logType, I could split Apache access and error logs into different directories while using the same channel, by escaping the header's key as follows:
agent.sinks.k1.hdfs.path=/logs/apache/%{logType}/%Y/%m/%d/%H
The preceding line of code would result in access logs going to /logs/apache/access/2013/03/10/18/, and error logs going to /logs/apache/error/2013/03/10/18/. However, if I preferred both log types in the same directory path, I could have used logType in myhdfs.filePrefix instead, as follows:
agent.sinks.k1.hdfs.path=/logs/apache/%Y/%m/%d/%H
agent.sinks.k1.hdfs.filePrefix=%{logType}
Obviously, it is possible for Flume to write to multiple files at once. The hdfs.maxOpenFiles property sets the upper limit for how many can be open at once, with a default of 5000. If you should exceed this limit, the oldest file that's still open is closed. Remember that every open file incurs overhead both at the OS level and in HDFS (NameNode and DataNode connections).
Another set of properties you might find useful allow for rounding down event times at an hour, minute, or second granularity while still maintaining these elements in file paths. Let's say you had a path specification as follows:
agent.sinks.k1.hdfs.path=/logs/apache/%Y/%m/%d/%H%M
However, if you wanted only four subdirectories per day (at 00, 15, 30, and 45 past the hour, each containing 15 minutes of data), you could accomplish this by setting the following:
agent.sinks.k1.hdfs.round=true
agent.sinks.k1.hdfs.roundValue=15
agent.sinks.k1.hdfs.roundUnit=minute
This would result in logs between 01:15:00 and 01:29:59 on March 10, 2013 being written to files contained in /logs/apache/2013/03/10/0115/. Logs from 01:30:00 to 01:44:59 would be written in files contained in /logs/apache/2013/03/10/0130/.
The hdfs.timeZone property is used to specify the time zone that you want time interpreted for your escape sequences. The default is your computer's local time. If your local time is affected by daylight savings time adjustments, you will have twice as much data when %H == 02 (in the fall) and no data when %H == 02 (in the spring). I think it is a bad idea to introduce time zones into things that are meant for computers to read. I believe time zones are a concern for humans alone and computers should only converse in universal time. For this reason, I set this property on my Flume agents to make the time zone issue just go away:
-Duser.timezone=UTC
If you don't agree, you are free to use the default (local time) or set hdfs.timeZone to whatever you like. The value you passed is used in a call to java.util.Timezone.getTimeZone(…), so check the Javadocs for acceptable values to be used here.
The other time-related property is the hdfs.useLocalTimeStamp boolean property. By default, its value is false, which tells the sink to use the event's timestamp header when calculating date-based escape sequences in file paths, as shown previously. If you set the property to true, the current system time will be used instead, effectively telling Flume to use the transport arrival time rather than the original event time. You would not set this in cases where HDFS was the final target for the streamed events. This way, delayed events will still be placed correctly (where users would normally look for them) regardless of their arrival time. However, there may be a use case where events are temporarily written to Hadoop and processed in batches, on some interval (perhaps daily). In this case, the transport time would be preferred, so your postprocessing job doesn't need to scan older folders for delayed data.
Remember that files in HDFS are broken into file blocks that are replicated across the DataNodes. The default number of replicas is usually three (as set in the Hadoop base configuration). You can override this value up or down for this sink with thehdfs.minBlockReplicas property. For example, if I have a data stream that I feel only needs two replicas instead of three, I can override this as follows:
agent.skinks.k1.hdfs.minBlockReplicas=2
Note
Don't set the minimum replica count higher than the number of data nodes you have, otherwise you'll create a degraded state HDFS. You also don't want to set it so high that a downed box for maintenance would trigger this situation. Personally, I've never set this higher than the default of three, but I have set it lower on less important data in order to save space.
Finally, while files are being written to HDFS, a .tmp extension is added. When the file is closed, the extension is removed. You can change the extension used by setting the hdfs.inUseSuffix property, but I've never had a reason to do so:
agent.sinks.k1.hdfs.inUseSuffix=flumeiswriting
This allows you to see which files are being written to simply by looking at a directory listing in HDFS. As you typically specify a directory for input in your MapReduce job (or because you are using Hive), the temporary files will often be picked up as empty or garbled input by mistake. To avoid having your temporary files picked up before being closed, set the prefix to either a dot or an underscore character as follows:
agent.sinks.k1.hdfs.inUsePrefix=_
That said, there are occasions where files were not closed properly due to some HDFS glitch, so you might see files with the in-use prefix/suffix that haven't been used in some time. A few new properties were added in Version 1.5 to change the default behavior of closing files. The first is the hdfs.closeTries property. The default of zero actually means "try forever", so it is a little confusing. Setting it to 4 means try 4 times before giving up. You can adjust the interval between retries by setting the hdfs.retryInterval property. Setting it too low could swamp your NameNode with too many requests, so be careful if you lower this from the default of 3 minutes. Of course, if you are opening files too quickly, you might need to lower this just to keep from going over the hdfs.maxOpenFiles setting which was covered previously. If you actually didn't want any retries, you can set hdfs.retryInterval to zero seconds (again, not to be confused with closeTries=0, which means try forever). Hopefully in a future version, they will use the more commonly used convention of a negative number (usually, -1) when infinite is desired.
File rotation
By default, Flume will rotate actively written-to files every 30 seconds, 10 events, or 1024 bytes. This is done by setting the hdfs.rollInterval, hdfs.rollCount, and hdfs.rollSize properties, respectively. One or more of these can be set to zero to disable this particular rolling mechanism. For instance, if you only wanted a time-based roll of 1 minute, you would set the following:
agent.sinks.k1.hdfs.rollInterval=60
agent.sinks.k1.hdfs.rollCount=0
agent.sinks.k1.hdfs.rollSize=0
If your output contains any amount of header information, the HDFS size per file can be larger than what you expect, because the hdfs.rollSize rotation scheme only counts the event body length. Clearly, you might not want to disable all three mechanisms for rotation at the same time, or you will have one directory in HDFS overflowing with files.
Finally, a related parameter is hdfs.batchSize. This is the number of events that the sink will read per transaction from the channel. If you have a large volume of data in your channel, you might see a performance increase by setting this higher than the default of 100, which decreases the transaction overhead per event.
Now that we've discussed the way files are managed and rolled in HDFS, let's look into how the event contents get written.
Compression codecs
Codecs (Coder/Decoders) are used to compress and decompress data using various compression algorithms. Flume supports gzip, bzip2, lzo, and snappy, although you might have to install lzo yourself, especially if you are using a distribution such as CDH, due to licensing issues.
If you want to specify compression for your data, set the hdfs.codeC property if you want the HDFS sink to write compressed files. The property is also used as the file suffix for the files written to HDFS. For example, if you specify the following, all files that are written will have a .gzip extension, so you don't need to specify the hdfs.fileSuffix property in this case:
agent.sinks.k1.hdfs.codeC=gzip
The codec you choose to use will require some research on your part. There are arguments for using gzip or bzip2 for their higher compression ratios at the cost of longer compression times, especially if your data is written once but will be read hundreds or thousands of times. On the other hand, using snappy or lzo results in faster compression performance but results in a lower compression ratio. Keep in mind that the splitability of the file, especially if you are using plain text files, will greatly affect the performance of your MapReduce jobs. Go pick up a copy of Hadoop Beginner's Guide, Garry Turkington, Packt Publishing (http://amzn.to/14Dh6TA) or Hadoop: The Definitive Guide, Tom White, O'Reilly (http://amzn.to/16OsfIf) if you aren't sure what I'm talking about.
Event Serializers
An Event Serializer is the mechanism by which a FlumeEvent is converted into another format for output. It is similar in function to the Layout class in log4j. By default, the text serializer, which outputs just the Flume event body, is used. There is another serializer,header_and_text, which outputs both the headers and the body. Finally, there is an avro_event serializer that can be used to create an Avro representation of the event. If you write your own, you'd use the implementation's fully qualified class name as the serializerproperty value.
Text output
As mentioned previously, the default serializer is the text serializer. This will output only the Flume event body, with the headers discarded. Each event has a newline character appender unless you override this default behavior by setting theserializer.appendNewLine property to false.
|
Key |
Required |
Type |
Default |
|
Serializer |
No |
String |
text |
|
serializer.appendNewLine |
No |
boolean |
true |
Text with headers
The text_with_headers serializer allows you to save the Flume event headers rather than discard them. The output format consists of the headers, followed by a space, then the body payload, and finally, terminated by an optionally disabled newline character, for instance:
{key1=value1, key2=value2} body text here
|
Key |
Required |
Type |
Default |
|
serializer |
No |
String |
text_with_headers |
|
serializer.appendNewLine |
No |
boolean |
true |
Apache Avro
The Apache Avro project (http://avro.apache.org/) provides a serialization format that is similar in functionality to Google Protocol Buffers but is more Hadoop friendly as the container is based on Hadoop's SequenceFile and has some MapReduce integration. The format is also self-describing using JSON, making for a good long-term data storage format, as your data format might evolve over time. If your data has a lot of structure and you want to avoid turning it into Strings only to then parse them in your MapReduce job, you should read more about Avro to see whether you want to use it as a storage format in HDFS.
The avro_event serializer creates Avro data based on the Flume event schema. It has no formatting parameters as Avro dictates the format of the data, and the structure of the Flume event dictates the schema used:
|
Key |
Required |
Type |
Default |
|
serializer |
No |
String |
avro_event |
|
serializer.compressionCodec |
No |
String (gzip, bzip2, lzo, or snappy) |
|
|
serializer.syncIntervalBytes |
No |
int (bytes) |
2048000 (bytes) |
If you want your data compressed before being written to the Avro container, you should set the serializer.compressionCodec property to the file extension of an installed codec. The serializer.syncIntervalBytes property determines the size of the data buffer used before flushing the data to HDFS, and therefore, this setting can affect your compression ratio when using a codec. Here is an example using snappy compression on Avro data using a 4 MB buffer:
agent.sinks.k1.serializer=avro_event
agent.sinks.k1.serializer.compressionCodec=snappy
agent.sinks.k1.serializer.syncIntervalBytes=4194304
agent.sinks.k1.hdfs.fileSuffix=.avro
For Avro files to work in an Avro MapReduce job, they must end in .avro or they will be ignored as input. For this reason, you need to explicitly set the hdfs.fileSuffix property. Furthermore, you would not set the hdfs.codeC property on an Avro file.
User-provided Avro schema
If you want to use a different schema from the Flume event schema used with the avro_event type, starting in Version 1.4, the closely named AvroEventSerializer will let you do this. Keep in mind that using this implementation only, the event's body is serialized and headers are not passed on.
Set the serializer type to the fully qualified org.apache.flume.sink.hdfs.AvroEventSerializer class name:
agent.sinks.k1.serializer=org.apache.flume.sink.hdfs.AvroEventSerializer
Unlike the other serializers that take additional parameters in the Flume configuration file, this one requires that you pass the schema information via a Flume header. This is a byproduct of one of the Avro-aware sources we'll see in Chapter 6, Interceptors, ETL, and Routing, where schema information is sent from the source to the final destination via the event header. You can fake this if you are using a source that doesn't set these by using a static header interceptor. We'll talk more about interceptors in Chapter 6,Interceptors, ETL, and Routing, so flip back to this part later on.
To specify the schema directly in the Flume configuration file, use the flume.avro.schema.literal header as shown in this example (using a map of strings schema):
agent.sinks.k1.serializer=org.apache.flume.sink.hdfs.AvroEventSerializer
agent.sinks.k1.interceptors=i1
agent.sinks.k1.interceptors.i1.type=static
agent.sinks.k1.interceptors.i1.key=flume.avro.schema.literal
agent.sinks.k1.interceptors.i1.value="{\"type\":\"map\",\"values\":\"string\"}"
If you prefer to put the schema file in HDFS, use the flume.avro.schema.url header instead, as shown in this example:
agent.sinks.k1.serializer=org.apache.flume.sink.hdfs.AvroEventSerializer
agent.sinks.k1.interceptors=i1
agent.sinks.k1.interceptors.i1.type=static
agent.sinks.k1.interceptors.i1.key=flume.avro.schema.url
agent.sinks.k1.interceptors.i1.value=hdfs://path/to/schema.avsc
Actually, in this second form, you can pass any URL including a file:// URL, but this would indicate a file local to where you are running the Flume agent, which might create additional setup work for your administrators. This is also true of configuration served up by a HTTP web server or farm. Rather than creating additional setup dependencies, just use the dependency you cannot remove, which is HDFS, using a hdfs:// URL.
Be sure to only set either the flume.avro.schema.literal header or the flume.avro.schema.url header both not both.
File type
By default, the HDFS sink writes data to HDFS as Hadoop's SequenceFile. This is a common Hadoop wrapper that consists of a key and value field separated by binary field and record delimiters. Usually, text files on a computer make assumptions like a newlinecharacter terminates each record. So, what do you do if your data contains a newline character, such as some XML? Using a sequence file can solve this problem because it uses nonprintable characters for delimiters. Sequence files are also splittable, which makes for better locality and parallelism when running MapReduce jobs on your data, especially on large files.
SequenceFile
When using a SequenceFile file type, you need to specify how you want the key and value to be written on the record in the SequenceFile. The key on each record will always be a LongWritable type and will contain the current timestamp, or if the timestamp event header is set, it will be used instead. By default, the format of the value is a org.apache.hadoop.io.BytesWritable type, which corresponds to the byte[] Flume body:
|
Key |
Required |
Type |
Default |
|
hdfs.fileType |
No |
String |
SequenceFile |
|
hdfs.writeFormat |
No |
String |
writable |
However, if you want the payload interpreted as a String, you can override the hdfs.writeFormat property, so org.apache.hadoop.io.Text will be used as the value field:
|
Key |
Required |
Type |
Default |
|
hdfs.fileType |
No |
String |
SequenceFile |
|
hdfs.writeFormat |
No |
String |
text |
DataStream
If you do not want to output a SequenceFile file because your data doesn't have a natural key, you can use a DataStream to output only the uncompressed value. Simply override the hdfs.fileType property:
agent.sinks.k1.hdfs.fileType=DataStream
This is the file type you would use with Avro serialization, as any compression should have been done in the Event Serializer. To serialize gzip-compressed Avro files, you would set these properties:
agent.sinks.k1.serializer=avro_event
agent.sinks.k1.serializer.compressionCodec=gzip
agent.sinks.k1.hdfs.fileType=DataStream
agent.sinks.k1.hdfs.fileSuffix=.avro
CompressedStream
CompressedStream is similar to a DataStream, except that the data is compressed when it's written. You can think of this as running the gzip utility on an uncompressed file, but all in one step. This differs from a compressed Avro file whose contents are compressedand then written into an uncompressed Avro wrapper:
agent.sinks.k1.hdfs.fileType=CompressedStream
Remember that only certain compressed formats are splittable in MapReduce should you decide to use CompressedStream. The compression algorithm selection doesn't have a Flume configuration but is dictated by the zlib.compress.strategy and zlib.compress.levelproperties in core Hadoop instead.
Timeouts and workers
Finally, there are two miscellaneous properties related to timeouts and two for worker pools that you can change:
|
Key |
Required |
Type |
Default |
|
hdfs.callTimeout |
No |
long (milliseconds) |
10000 |
|
hdfs.idleTimeout |
No |
int (seconds) |
0 (0=disable) |
|
hdfs.threadsPoolSize |
No |
int |
10 |
|
hdfs.rollTimerPoolSize |
No |
int |
1 |
The hdfs.callTimeout property is the amount of time the HDFS sink will wait for HDFS operations to return a success (or failure) before giving up. If your Hadoop cluster is particularly slow (for instance, a development or virtual cluster), you might need to set this value higher in order to avoid errors. Keep in mind that your channel will overflow if you cannot sustain higher write throughput than the input rate of your channel.
The hdfs.idleTimeout property, if set to a nonzero value, is the time Flume will wait to automatically close an idle file. I have never used this as hdfs.fileRollInterval handles the closing of files for each roll period, and if the channel is idle, it will not open a new file. This setting seems to have been created as an alternative roll mechanism to the size, time, and event count mechanisms that have already been discussed. You might want as much data written to a file as possible and only close it when there really is no more data. In this case, you can use hdfs.idleTimeout to accomplish this rotation scheme if you also set hdfs.rollInterval, hdfs.rollSize, and hdfs.rollCount to zero.
The first property you can set to adjust the number of workers is hdfs.threadsPoolSize and it defaults to 10. This is the maximum number of files that can be written to at the same time. If you are using event headers to determine file paths and names, you might have more than 10 files open at once, but be careful when increasing this value too much so as not to overwhelm HDFS.
The last property related to worker pools is the hdfs.rollTimerPoolSize. This is the number of workers processing timeouts set by the hdfs.idleTimeout property. The amount of work to close the files is pretty small, so increasing this value from the default of one worker is unlikely. If you do not use a rotation based on hdfs.idleTimeout, you can ignore the hdfs.rollTimerPoolSize property, as it is not used.
Sink groups
In order to remove single points of failures in your data processing pipeline, Flume has the ability to send events to different sinks using either load balancing or failover. In order to do this, we need to introduce a new concept called a sink group. A sink group is used to create a logical grouping of sinks. The behavior of this grouping is dictated by something called the sink processor, which determines how events are routed.
There is a default sink processor that contains a single sink which is used whenever you have a sink that isn't part of any sink group. Our Hello, World! example in Chapter 2, A Quick Start Guide to Flume, used the default sink processor. No special configuration is required for single sinks.
In order for Flume to know about the sink groups, there is a new top-level agent property called sinkgroups. Similar to sources, channels, and sinks, you prefix the property with the agent name:
agent.sinkgroups=sg1
Here, we have defined a sink group called sg1 for the agent named agent.
For each named sink group, you need to specify the sinks it contains using the sinks property consisting of a space-delimited list of sink names:
agent.sinkgroups.sg1.sinks=k1 k2
This defines that the k1 and k2 sinks are part of the sg1 sink group for the agent named agent.
Often, sink groups are used in conjunction with the tiered movement of data to route around failures. However, they can also be used to write to different Hadoop clusters, as even a well-maintained cluster has periodic maintenance.
Load balancing
Continuing the preceding example, let's say you want to load balance traffic to k1 and k2 evenly. There are some additional properties you need to specify, as listed in this table:
|
Key |
Type |
Default |
|
processor.type |
String |
load_balance |
|
processor.selector |
String (round_robin, random) |
round_robin |
|
processor.backoff |
boolean |
false |
When you set processor.type to load_balance, round robin selection will be used, unless otherwise specified by the processor.selector property. This can be set to either round_robin or random. You can also specify your own load balancing selector mechanism, which we won't cover here. Consult the Flume documentation if you need this custom control.
The processor.backoff property specifies whether an exponential backup should be used when retrying a sink that threw an exception. The default is false, which means that after a thrown exception, the sink will be tried again the next time its turn is up based on round robin or random selection. If set to true, then the wait time for each failure is doubled, starting at 1 second up to a limit of around 18 hours (216 seconds).
Note
In an earlier version of Flume, the default in the code for processor.backoff was stated as false, but the documentation stated it as true. This error has been fixed, however, it may save you a headache by specifying what you want for property settings rather than relying on the defaults.
Failover
If you would rather try one sink and if that one fails to try another, then you want to set processor.type to failover. Next, you'll need to set additional properties to specify the order by setting the processor.priority property, followed by the sink name:
|
Key |
Type |
Default |
|
processor.type |
String |
failover |
|
processor.priority.NAME |
int |
|
|
processor.maxpenality |
int (milliseconds) |
30000 |
Let's look at the following example:
agent.sinkgroups.sg1.sinks=k1 k2 k3
agent.sinkgroups.sg1.processor.type=failover
agent.sinkgroups.sg1.processor.priority.k1=10
agent.sinkgroups.sg1.processor.priority.k2=20
agent.sinkgroups.sg1.processor.priority.k3=20
Lower priority numbers come first, and in the case of a tie, order is arbitrary. You can use any numbering system that makes sense to you (by ones, fives, tens—whatever). In this example, the k1 sink will be tried first, and if an exception is thrown, either k2 or k3 will be tried next. If k3 was selected first for trial and it failed, k2 will still be tried. If all sinks in the sink group fail, the transaction with the channel is rolled back.
Finally, processor.maxPenality sets an upper limit to an exponential backoff for failed sinks in the group. After the first failure, it will be 1 second before it can be used again. Each subsequent failure doubles the wait time until processor.maxPenality is reached.
MorphlineSolrSink
HDFS is not the only useful place to send your logs and data. Solr is a popular real-time search platform used to index large amounts of data, so full text searching can be performed almost instantaneously. Hadoop's horizontal scalability creates an interesting problem for Solr, as there is now more data than a single instance can handle. For this reason, a horizontally scalable version of Solr was created, called SolrCloud. Cloudera's Search product is also based on SolrCloud, so it should be no surprise that Flume developers created a new sink specifically to write streaming data into Solr.
Like most streaming data flows, you not only transport the data, but you also often reformat it into a form more consumable to the target of the flow. Typically, this is done in a Flume-only workflow by applying one or more interceptors just prior to the sink writing the data to the target system. This sink uses the Morphline engine to transform the data, instead of interceptors.
Internally, each Flume event is converted into a Morphline record and passed to the first command in the Morphline command chain. A record can be thought of as a set of key/value pairs with string keys and arbitrary object values. Each of the Flume headers is passed as a Record Field with the same header keys. A special Record Field key _attachment_body is used for the Flume event body. Keep in mind that the body is still a byte array (Java byte[]) at this point and must be specifically processed in the Morphline command chain.
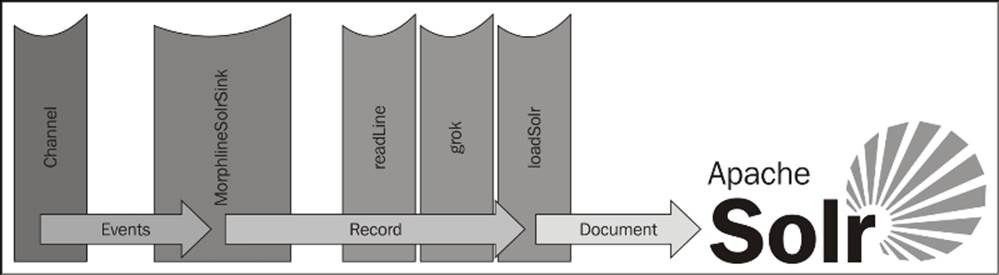
Each command processes the record in turn, passing the output to the input of the next command in line with the final command responsible for terminating the flow. In many ways, it is similar in functionally to Flume's Interceptor functionality, which we'll see inChapter 6, Interceptors, ETL, and Routing. In the case of writing to Solr, we use the loadSolr command to convert the Morphline record into a Solr Document and write to the Solr cluster. Here is what this simplified flow might look like in a picture form:
Morphline configuration files
Morphline configuration files use the HOCON format, which is similar to JSON but has a less strict syntax, making them less error-prone when used for configuration files over JSON.
Note
HOCON is an acronym for Human Optimized Configuration Object Notation. You can read more about HOCON on this GitHub page: https://github.com/typesafehub/config/blob/master/HOCON.md
The configuration file contains a single key with the morphlines value. The value is an array of Morphline configurations. Each individual entry is comprised of three keys:
· id
· importCommands
· commands
If your configuration contains multiple Morphlines, the value of id must be provided to the Flume sink by way of the morphlineId property. The value of importCommands specifies the Java classes to import when the Morphine is evaluated. The double star indicates that all paths and classes from that point in the package hierarchy should be included. All classes that implement com.cloudera.cdk.morphline.api.CommandBuilder are interrogated for their names via the getNames() method. These names are the command names you use in the next section. Don't worry; you don't need to sift through the source code to find them, as they have a well-documented reference guide online. Finally, the commands key references a list of command dictionaries. Each command dictionary has a single key consisting of the name of the Morphline command followed by its specific properties.
Note
For a list of Morphline commands and associated configuration properties, see the reference guide at http://kitesdk.org/docs/current/kite-morphlines/morphlinesReferenceGuide.html
Here is what a skeleton configuration file might look like:
morphlines : [
{
id : transform_my_data
importCommands : [
"com.cloudera.**",
"org.apache.solr.**"
]
commands : [
{
COMMAND_NAME1 : {
property1 : value1
property2 : value2
}
}
{ COMMAND_NAME2 : {
property1 : value1
}
]
}
]
Typical SolrSink configuration
Here is the preceding skeleton configuration applied to our Solr use case. This is not meant to be complete, but it is sufficient to discuss the flow in the preceding diagram:
morphlines : [
{
id : solr_flow
importCommands : [
"com.cloudera.**",
"org.apache.solr.**"
]
commands : [
{
readLine : {
charset : UTF-8
}
{
grok : {
GROK_PROPERTIES_HERE
}
}
{
loadSolr : {
solrLocator : {
collection : my_collection
zkHost : "solr.example.com:2181/solr"
}
}
}
]
}
]
You can see the same boilerplate configuration where we define a single Morphline with the solr_flow identifier. The command sequence starts with the readLine command. This simply reads the event body from the _attachment_body field and converts byte[] toString using the configured encoding (in this case, UTF-8). The resulting String value is set to the field with the key message. The next command in the sequence, which is the grok command, uses regular expressions to extract additional fields to make a more interesting Solr Document. I couldn't possibly do this command justice by trying to explain everything you can do with it. For that, please see the KiteSDK documentation.
Note
See the reference guide for a complete list of Morphline commands, their properties, and usage information at http://kitesdk.org/docs/current/kite-morphlines/morphlinesReferenceGuide.html
Suffice to say, grok lets me take a webserver log line such as this:
10.4.240.176 - - [14/Mar/2014:12:02:17 -0500] "POST http://mysite.com/do_stuff.php HTTP/1.1" 500 834
Then, it lets me turn it into more structured data like this:
{
ip : 10.4.240.176
timestamp : 1413306137
method : POST
url : http://mysite.com/do_stuff.php
protocol : HTTP/1.1
status_code : 500
length : 834
}
If you wanted to search for all the times this page threw a 500 status code, having these fields broken out makes the task easy for Solr.
Finally, we call the loadSolr command to insert the record into our Solr cluster. The solrLocator property indicates the target Solr cluster (by way of its Zookeeper server(s)) and the data collection to write these documents into.
Sink configuration
Now that you have a basic idea of how to create a Morphline configuration file, let's apply this to the actual sink configuration.
The following table details the sink's parameters and default values:
|
Key |
Required |
Type |
Default |
|
type |
Yes |
String |
org.apache.flume.sink.solr.morphline. MorphlineSolrSink |
|
channel |
Yes |
String |
|
|
morphlineFile |
Yes |
String |
|
|
morphlineId |
No |
String |
Required if the Morphline configuration file contains more than one Morphline. |
|
batchSize |
No |
int |
1000 |
|
batchDurationMillis |
No |
long |
1000 (milliseconds) |
|
handlerClass |
No |
String |
org.apache.flume.sink.solr.morphline.MorphlineHandlerImpl |
The MorphlineSolrSink does not have a short type alias, so set the type parameter on your named sink to org.apache.flume.sink.solr.morphline.MorphlineSolrSink:
agent.sinks.k1.type=org.apache.flume.sink.solr.morphline.MorphlineSolrSink
This defines a MorphlineSolrSink named k1 for the agent named agent.
The next required parameter is the channel property. This specifies which channel to read events from for processing.
agent.sinks.k1.channel=c1
This tells the k1 sink to read events from the c1 channel.
The only other required parameter is the relative or absolute path to the Morphline configuration file. This cannot be a path in HDFS; it must accessible on the server the Flume agent is running on (local disk, NFS disk, and so on).
To specify the configuration file path, set the morphlineFile property:
agent.sinks.k1.morphlineFile=/path/on/local/system/morphline.conf
As a Morphline configuration file can contain multiple Morphlines, you must specify the identifier if more than one exists, using the morphlineId property:
agent.sinks.k1.morphlineId=transform_my_data
The next two properties are fairly common among sinks. They specify how many events to remove at a time for processing, also known as a batch. The batchSize property defaults to 1000 events, but you might need to set this higher if you aren't consuming events from the channel faster than they are being inserted. Clearly, you can only increase this so much, as the thing you are writing to—in this case, Solr—will have some record consumption limit. Only through testing will you be able to stress your systems to see where the limits are.
The related batchDurationMillis property specifies the maximum time to wait before the sink proceeds with the processing when fewer than the batchSize number of events have been read. The default value is 1 second and is specified in milliseconds in the configuration properties. In a situation with a light data flow (using the defaults, less than 1000 records per second), setting batchDurationMillis higher can make things worse. For instance, if you are using a memory channel with this sink, your Flume agent could be sitting there with data to write to the sink's target but is waiting for more, only to show up when a crash happens, resulting in lost data. That said, your downstream entity might perform better on larger batches, which might push both these configuration values higher, so there is no universally correct answer. Start with the defaults if you are unsure, and use hard data that you'll collect using techniques in Chapter 8, Monitoring Flume, to adjust based on facts and not guesses.
Finally, you should never need to touch the handlerClass property unless you plan to write an alternate implementation of the Morphline processing class. As there is only one Morphline engine implementation to date, I'm not really sure why this is a documented property in Flume. I'm just mentioning it for completeness.
ElasticSearchSink
Another common target to stream data to be searched in NRT is Elasticsearch. Elasticsearch is also a clustered searching platform based on Lucene, like Solr. It is often used along with the logstash project (to create structured logs) and the Kibana project (a web UI for searches). This trio is often referred to as the acronym ELK (Elasticsearch/Logstash/Kibana).
Note
Here are the project home pages for the ELK stack that can give you a much better overview than I can in a few short pages:
· Elasticsearch: http://elasticsearch.org/
· Logstash: http://logstash.net/
· Kibana: http://www.elasticsearch.org/overview/kibana/
In Elasticsearch, data is grouped into indices. You can think of these as being equivalent to databases in a single MySQL installation. The indices are composed of types (similar to tables in databases), which are made up of documents. A document is like a single row in a database, so, each Flume event will become a single document in ElasticSearch. Documents have one or more fields (just like columns in a database).
This is by no means a complete introduction to Elasticsearch, but it should be enough to get you started, assuming you already have an Elasticsearch cluster at your disposal. As events get mapped to documents by the sink's serializer, the actual sink configuration needs only a few configuration items: where the cluster is located, which index to write to, and what type the record is.
This table summarizes the settings for ElasticSearchSink:
|
Key |
Required |
Type |
Default |
|
type |
Yes |
String |
org.apache.flume.sink.elasticsearch.ElasticSearchSink |
|
hostNames |
Yes |
String |
A comma-separated list of Elasticsearch nodes to connect to. If the port is specified, use a colon after the name. The default port is 9300. |
|
clusterName |
No |
String |
elasticsearch |
|
indexName |
No |
String |
flume |
|
indexType |
No |
String |
log |
|
ttl |
No |
String |
Defaults to never expire. Specify the number and unit (5m = 5 minutes). |
|
batchSize |
No |
int |
100 |
With this information in mind, let's start by setting the sink's type property:
agent.sinks.k1.type=org.apache.flume.sink.elasticsearch. ElasticSearchSink
Next, we need to set the list of servers and ports to establish connectivity using the hostNames property. This is a comma-separated list of hostname:port pairs. If you are using the default port of 9300, you can just specify the server name or IP, for example:
agent.sinks.k1.hostNames=es1.example.com,es2.example.com:12345
Now that we can communicate with the Elasticsearch servers, we need to tell them which cluster, index, and type to write our documents to. The cluster is specified using the clusterName property. This corresponds with the cluster.name property in Elasticsearch'selasticsearch.yml configuration file. It needs to be specified, as an Elasticsearch node can participate in more than one cluster. Here is how I would specify a nondefault cluster name called production:
agent.sinks.k1.clusterName=production
The indexName property is really a prefix used to create a daily index. This keeps any single index from becoming too large over time. If you use the default index name, the index on September 30, 2014 will be named flume-2014-10-30.
Lastly, the indexType property specifies the Elasticsearch type. If unspecified, the log default value will be used.
By default, data written into Elasticsearch will never expire. If you want the data to automatically expire, you can specify a time-to-live value on the records with the ttl property. Values are a numeric number in milliseconds or a number with units. The units are given in this table:
|
Unit string |
Definition |
Example |
|
ms |
Milliseconds |
5ms = 5 milliseconds |
|
not specified |
Milliseconds |
10000 = 10 seconds |
|
m |
Minutes |
10m = 10 minutes |
|
h |
Hours |
1h = 1 hour |
|
d |
Days |
7d = 7 days |
|
w |
Weeks |
4w = 4 weeks |
Keep in mind that you also need to enable the TTL features on the Elasticsearch cluster, as it disabled by default. See the Elasticsearch documentation for how to do this.
Finally, like the HDFS sink, the batch property is the number of events per transaction that the sink will read from the channel. If you have a large volume of data in your channel, you should see a performance increase by setting this higher than the default of 100, due to the reduced overhead per transaction.
The sink's serializer does the work of transforming the Flume event to the Elasticsearch document. There are two Elasticsearch serializers that come packaged with Flume, neither has additional configuration properties since they mostly use existing headers to dictate field mappings.
We'll see more of this sink in action in Chapter 7, Putting It All Together.
LogStash Serializer
The default serializer, if not specified, is ElasticSearchLogStashEventSerializer:
agent.sinks.k1.serializer=org.apache.flume.sink.elasticsearch. ElasticSearchLogStashEventSerializer
It writes data in the same format that Logstash uses in conjunction with Kibana. Here is a table of the commonly used fields and their associated mappings from Flume events:
|
Elasticsearch field |
Taken from the Flume header |
Notes |
|
@timestamp |
timestamp |
From the header, if present |
|
@source |
source |
From the header, if present |
|
@source_host |
source_host |
From the header, if present |
|
@source_path |
source_path |
From the header, if present |
|
@type |
type |
From the header, if present |
|
@host |
host |
From the header, if present |
|
@fields |
all headers |
A dictionary of all Flume headers, including the ones that might have been mapped to the other fields, such as the host |
|
@message |
Flume Body |
While you might think the document's @type field will be automatically set to the sink's indexType configuration property, you'd be incorrect. If you had only one type of log, it would be wasteful to write this over and over again for every document. However, if you had more than one log type going through your Flume channel, you can designate its type in Elasticsearch using the Static interceptor we'll see in Chapter 6, Interceptors, ETL, and Routing, to set the type (or @type) Flume header on the event.
Dynamic Serializer
Another serializer is the ElasticSearchDynamicSerializer serializer. If you use this serializer, the event's body is written to a field called body. All other Flume header keys are used as field names. Clearly, you want to avoid having a flume header key called body, as this will conflict with the actual event's body when transformed into the Elasticsearch document. To use this serializer, specify the fully qualified class name, as shown in this example:
agent.sinks.k1.serializer=org.apache.flume.sink.elasticsearch. ElasticSearchDynamicSerializer
For completeness, here is a table that shows you the breakdown of how Flume headers and body get mapped to Elasticsearch fields:
|
Flume entity |
Elasticsearch field |
|
All headers |
same as Flume headers |
|
Body |
body |
As the version of Elasticsearch can be different for each user, Flume doesn't package the Elasticsearch client and corresponding Lucene libraries. Find out from your administrator which versions should be included on the Flume classpath, or check out the Mavenpom.xml file on GitHub for the corresponding version tag or branch at https://github.com/elasticsearch/elasticsearch/blob/master/pom.xml. Make sure the library versions used by Flume match with Elasticsearch or you might see serialization errors.
Note
As Solr and Elasticsearch have similar capabilities, check out Kelvin Tan's appropriately-named side-by-side detailed feature breakdown webpage. It should help get you started with what is most appropriate for your specific use case:
http://solr-vs-elasticsearch.com/
Summary
In this chapter, we covered the HDFS sink in depth, which writes streaming data into HDFS. We covered how Flume can separate data into different HDFS paths based on time or contents of Flume headers. Several file-rolling techniques were also discussed, including time rotation, event count rotation, size rotation, and rotation on idle only.
Compression was discussed as a means to reduce storage requirements in HDFS, and should be used when possible. Besides storage savings, it is often faster to read a compressed file and decompress in memory than it is to read an uncompressed file. This will result in performance improvements in MapReduce jobs run on this data. The splitability of compressed data was also covered as a factor to decide when and which compression algorithm to use.
Event Serializers were introduced as the mechanism by which Flume events are converted into an external storage format, including text (body only), text and headers (headers and body), and Avro serialization (with optional compression).
Next, various file formats, including sequence files (Hadoop key/value files), Data Streams (uncompressed data files, like Avro containers), and Compressed Data Streams, were discussed.
Next, we covered sink groups as a means to route events to different sources using load balancing or failover paths, which can be used to eliminate single points of failure in routing data to its destination.
Finally, we covered two new sinks added in Flume 1.4 to write data to Apache Solr and Elastic Search in a Near Real Time (NRT) way. For years, MapReduce jobs have served us well, and will continue to do so, but sometimes it still isn't fast enough to search large datasets quickly and look at things from different angles without reprocessing data. KiteSDK Morphlines were also introduced as a way to prepare data for writing to Solr. We will revisit Morphlines again in Chapter 6, Interceptors, ETL, and Routing, when we look at a Morphline-powered interceptor.
In the next chapter, we will discuss various input mechanisms (sources) that will feed your configured channels which were covered back in Chapter 3, Channels.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.