Functional PHP (2017)
Chapter 11. Designing a Functional Application
Creating a whole application respecting the precepts of functional programming might seem like an impossible task. How can you write any meaningful software if you cannot have any side-effects? In order to perform any kind of computation, you will need at least some inputs and display results.
Functional languages have various mechanisms to circumvent those limitations. We will quickly present some of them so that you can have a better idea about how an application can be written in a purely functional way.
We will then learn more in depth about a paradigm called Functional Reactive Programming (FRP), as a way to design an application having a user interface. We will lay the foundation for using this technique in PHP to see if it is possible to use it to write a complete application.
In this chapter, you will learn about the following topics:
· Writing a complete application in a purely functional language
· Functional Reactive Programming
· Designing a PHP application using FRP
Architecture of a purely functional application
Applications are like functions. If you have an application without any input, its outcome will always be the same. You have the possibility of modifying some values in the source code and recompiling your software to change its result, but this is contrary to the main reason we write applications in the first place.
This is why you need a way to feed data to an application in order for it to perform any kind of meaningful computation. Those inputs can be of multiple types:
· Command-line parameters
· File content
· Database content
· Fields in a graphical interface
· Third-party services
· Network request
Out of all those, only the first one could be considered as not breaking the referential transparency of our whole application. If you consider your application as one big function, feeding data on the command line could be considered as its parameters, thus keeping everything pure. All other kinds of input are de facto impure, since two subsequent retrievals of the data could lead to different values.
The canonical Haskell way to solve this issue is to use the IO monad. Instead of performing its operations immediately, the IO monad stores all steps in a queue. If you name this IO operation main, Haskell will know it has to run it when the compiled program is executed.
Obviously, the application itself is not pure anymore if you perform any kind of IO operation inside the monad. However, the code itself can be written in a referentially transparent way. It's the Haskell runtime that will perform all impure operations when the IO monad is run and will then pass the various obtained values around. Using this trick, you can write pure functional code with all the benefits it brings and still perform IO operations.
This approach is usable in Haskell because you can use monad transformers to combine multiple monads. The do notation also helps a lot by writing code encapsulated in the IO monad without all the overhead associated with it. For example, here is a small program reading lines in the Terminal and printing them with the words in reverse order:
main = do
line <- getLine
if null line
then return ()
else do
putStrLn $ reverseWords line
main
reverseWords :: String -> String
reverseWords = unwords . map reverse . words
It reads mostly like any imperative source code performing the same task. PHP lacks the syntactic sugar and there exists no implementation of monad transformers, so it is quite hard to do this. This is why we make compromises as discussed in the previous chapter, or we need some other approach, as we will see in the following section.
The idea at play can be generalized. Any impure function can be split into two functions, one pure and one encapsulating the side causes and side effects. This is exactly what we were referring to in the previous chapter when we stated that most impure functions should be contained in the MVC application's controller.
If you have an impure function f taking A as a parameter and returning B, you can create the following two functions:
· A pure function g, which takes A and returns D parameter. The parameter D is being a description of the IO operations that need to be performed.
· An impure function h taking D and performing the described operations like an interpreter would do.
If we take the example of a Haskell application, the Haskell runtime itself would be our impure h function. If our source were to return an instance of the IO monad, as our example on just above is doing, it would be used as the D parameter and the side-effects would be interpreted.
If you are writing a web application using the Symfony framework, we could consider the framework as the the impure h function and the D parameter would be the result of executing your controller for example. Another possibility would be to add our custom impure wrapper around our functional code.
The main idea is to reduce the number of functions like h to the minimum. Haskell forces you to have only one such function and it's even hidden inside the runtime. If you are using PHP, it's up to you to enforce this rule as effectively as possible.
This concept of having a description of the computations and an interpreter to perform them is central to a lot of the more advanced techniques in the functional world. It is also quite important in computer programming as a whole. If we take a bit of distance, we can see the following:
· The description is like an Abstract Syntax Tree (AST)
· The interpreter takes the AST and runs it
This is how most modern compilers work, first they parse the source code to transform it in an AST and then interpret it to create the binary file. You will also find the same pattern again and again in most complex applications.
An advanced construct using this structure is the free monad. This monad is currently a hot topic in the functional world and its usage is growing fast. We are missing quite a bit of theory to approach the topic here, but if you are interested you will surely find a lot of information on the Internet, for example, http://underscore.io/blog/posts/2015/04/14/free-monads-are-simple.html.
However, this pattern is problematic when you accept user interaction during the lifecycle of the application. Since the main idea is to delay the execution of effective computations by describing them instead, you cannot perform part of the computation to display a user interface and then react to user input. This is one of the issues that FRP tries to solve.
From Functional Reactive Animation to Functional Reactive Programming
As is often the case when it comes to functional programming, the foundations behind the subject at hand date back a bit. In 1997, Conal Elliott and Paul Hudak published a paper called Functional Reactive Animation, or Fran.
The main goal of Fran is to allow the modeling of animations with two concepts called behaviors and events. Behaviors are values based on the current time, and events are conditions based on external or internal stimuli. Those two notions allow us to represent any kind of animation at any point in time although the animation itself is continuous.
Instead of directly creating the representation of your animation as it is usually the case, you describe it using behaviors and events. The interpretation, and thus representation, is then left to the underlying implementation. This is similar to what we just described. As events such as keyboard inputs or mouse clicks can be encoded inside Fran, the model you are creating allows for a pure functional application to respond to external inputs like those.
Reactive programming
Before we go any further, let's speak a bit about what reactive means in the programming world. It's an idea that has gotten quite a lot of traction in the last few years.
First, there is the Reactive Manifesto (http://www.reactivemanifesto.org/), which presents a list of properties that are really interesting to have for any software. Those properties are: responsiveness, resilience, elasticity, and being message-driven.
The Wikipedia (https://en.wikipedia.org/wiki/Reactive_programming) definition states something quite different:
In computing, reactive programming is a programming paradigm oriented around data flows and the propagation of change. This means that it should be possible to express static or dynamic data flows with ease in the programming languages used, and that the underlying execution model will automatically propagate changes through the data flow.
An example is then given of the expression a = b + c, where the value of a is automatically updated when any of b or c changes.
The JavaScript world is in effervescence about the idea, with libraries such as Bacon.js or RxJS. The core idea shared by all of those libraries revolves around events or event-streams.
As we can see, there are multiple definitions of what reactive programming is. Sadly, none of them really quite match what we just learned about Fran. As it has been floating around at least since the seventies, the definition that we will keep for the remainder of this chapter is the academic one, which can be found on Wikipedia.
I am not saying the other ones are invalid, just that we need to have a common ground here. Also, next time you speak of reactive programming with someone, first make sure you are on the same page concerning what the topic is.
As a final example of reactive programming, let's consider the following piece of code:
<?php
$a = 10;
$b = 5;
$c = $a + $b;
echo $c;
// 15
$a = 23;
echo $c;
In a traditional imperative language, the last line will still display 15. However, if our application were to follow the rules set by reactive programming, the new value of $a would also affect the value of $c and the program would display 28.
Functional Reactive Programming
As you can probably guess, values changing over time when other changes are made are far from being referentially transparent. Also, the concept of variables is completely missing from some functional languages. How can we reconcile reactive and functional programming?
The core idea is to make the time component and the previous events parameters of your functions when they need them. This is exactly what Fran proposed with behaviors and events. Both time and events are usually proposed for consumption as a stream. Using functional mapping and filtering, you are able to decide which events on the stream interest you.
Your functions take one or multiple inputs from this stream alongside the current state of the application. They must then return the new state of the application. The runtime will take care of calling the various registered functions when the events happen.
You might have the impression that it is similar to event-driven programming. In a way it is, but there is a big difference. In a traditional event-driven application, events are triggered, but the return value of the handlers is often of no importance; they need to have side-effects to perform something.
When doing FRP, the runtime takes care of orchestrating all registered handlers. Keeping the current state of the application, passing it to each handler, and updating it with their results. This allows for the functions to be pure.
Another programming paradigm that might be a bit closer than event-driven programming is the actor model. I won't describe it here as it will be out of scope for this book, but for people aware of it, I will just say that there are two main differences:
· As you have pure functions instead of actors, you cannot have a private state influencing the way you respond to a given message, or event
· The runtime manages the event stream; there is no way for the handlers to send new messages to other parts of the application
Time traveling
FRP also has another benefit. If you record the sequence of events leading to a particular application state, you can replay them. Where it gets better is that you can implement what is called a time traveling debugger. Since your application is using pure functions, you can go back to any point in time and get the exact same state as you've had before.
This kind of debugger also allows you to replay any number of steps back and forth until you can pinpoint exactly what is happening. Also, you can make changes to your code and play the same events to see how your modification affected your software.
If you want to see such a debugger in action, you can head over to the one proposed by the Elm language, specifically their online version with a naive implementation of the Mario platform game (http://debug.elm-lang.org/edit/Mario.elm).
The Elm debugger is probably one of the first of its kind. Although similar ideas have been implemented in traditional languages, the very nature of imperative programming requires us to record a lot more than just the stream of events. This is why it is a really costly operation, slowing down the execution of the program a lot.
You also need to restart the program from the beginning in order to be sure to attain the same state. However, in a pure application, you can do this in a more straightforward way. Implementations more akin to the one found in Elm are now being created, for example, for the React JavaScript library.
Disclaimer
There are FRP and FRP, but instead of paraphrasing the creator of the idea, let me instead quote him:
Over the last few years, something about FRP has generated a lot of interest among programmers, inspiring several so-called "FRP" systems implemented in various programming languages. Most of these systems, however, lack both of FRP's fundamental properties.
You can see the full text alongside related slides and video on GitHub (https://github.com/conal/talk-2015-essence-and-origins-of-frp).
As often, there is some kind of divergence between the academical world and the usage people make of the research results. I won't dwell on the details as this is supposed to be only an introductory chapter. However, it is important that you are aware of this fact.
The main point of contention is the fact that FRP is about continuous time, whereas most implementations consider only discrete events or values. If you want to know more about those differences, I strongly suggest you watch the previously linked video, available on the GitHub repository of Elliot Conal, the creator of Fran and FRP.
Going further
There are a lot of other things to say about Functional Reactive Programming. In fact, whole books are dedicated to the subject. This is, however, just an introduction so we will stop there. If you want a general approach to the topic not tied to a specific language, I can recommend the newly published Functional Reactive Programming by Stephen Blackheath and Anthony Jones.
On the implementation side, the ReactiveX project tries to federate libraries available on multiple projects. You can find more information on the official website at http://reactivex.io/. At the time of writing, the following languages are covered; Java, Swift, Python, PHP, Scala, JavaScript, Ruby, Clojure, Rust, Go, C#, C++, and Lua.
As stated in the previous disclaimer, and the introduction on the ReactiveX website, there is currently a conflation of the academic concept of FRP as extended from the original Fran paper and what today's programmer means by the term. Both the aforementioned book and the ReactiveX libraries speak about the latter rather than the original meaning. It does not mean those are bad ideas, quite the contrary; it is just that it is not real FRP.
ReactiveX primer
The Rx* libraries made the choice of implementing the functional reactive paradigm by extending the classical Observer pattern into the Observable model. For a given stream of values, represented by an instance of the Observable model, you can define up to three different handlers:
· The onNext handler will be called each time there is a new value available
· The onError handler will be called when an exception arises
· The onCompleted handler will be called when the stream is closed
This approach makes it easy to work with multiple asynchronous events without having to write complex boilerplate code to manage dependencies between them. Contrary to the traditional Observer pattern, the ability to signal the end of the stream and errors is added to reconcile the interface with iterables.
ReactiveX also defines a bunch of operators to both manipulate observables and their values. There are helper methods to create various kinds of streams, from ranges to arrays, passing by infinitively repeating values and timed release events.
You can also manipulate the stream itself by mapping functions to each emitted value, grouping them into new observables or into arrays of values. You can also filter the values, skip or take a certain number of them, limit the number of emissions for a certain amount of time, and suppress duplicates.
The documentation (http://reactivex.io/documentation/operators.html) has a complete list of what manipulations are available, along with a nice decision tree to decide which one to use based on the context.
RxPHP
Before we start having a look at some examples of RxPHP, I would like to point out that Packt Publishing also published a complete book, PHP Reactive Programming, about the topic. You can find more information on their website at https://www.packtpub.com/web-development/php-reactive-programming. This is why we will only explore some basic examples to give you a feel for how using the library might look. If the subject is of interest to you, I strongly suggest you read the dedicated book.
After this very brief introduction to ReactiveX, let's see how it can be used. First we will need to install the required library. We will use a small wrapper around ReachPHP's stream library to make it usable with RxPHP so we can demonstrate accessing files on disk. The following composer invocation should install all needed dependencies:
composer require rx/stream
Now that the library is installed, you can parse data from any PHP stream. For example, a CSV file:
<?php
use \Rx\React\FromFileObservable;
use \Rx\Observer\CallbackObserver;
$data = new FromFileObservable("11-example.csv");
$data = $data
->cut()
->map('str_getcsv')
->map(function (array $row) { return $row; });
$data->subscribe(new CallbackObserver(
function ($data) { echo $data[0]."\n"; },
function ($e) { echo "error\n"; },
function () { echo "done\n"; }
));
We first create a stream Observable for the file we want to read, then we apply some transformation: separating the input by line, parsing the CSV string in an array, and applying any other data processing you might want. As you can infer from the fact that we reassign the result to $data variable, the operation is not made in place, but a new instance is returned each time.
Then, we can subscribe handlers to our stream. In our case, we simply print the first row of each element. Not really functional, but effective enough for a small example.
If you are using PostgreSQL, a package allowing you to use Rx to access your database exists. You can use it to retrieve data using a stream. You can install it using the composer invocation:
composer require voryx/pgasync
Creating queries is fairly easy. It is a matter of creating a client with the connection credentials and then calling one of the methods on it to create an Observable instance on which you can subscribe:
<?php
$client = new PgAsync\Client([ "user" => "user", "database" => "db" ]);
$client->query('SELECT * FROM my_table')->subscribe(new CallbackObserver(
function ($row) { },
function ($e) { },
function () { }
));
Here is a final example demonstrating some of the more advanced filtering and transformation possibilities offered by Rx on the streams themselves. Try to guess what the output will be before running it:
<?php
use \React\EventLoop\StreamSelectLoop;
use \Rx\Observable;
use \Rx\Scheduler\EventLoopScheduler;
// Those are needed in order to create a timed interval
$loop = new StreamSelectLoop();
$scheduler = new EventLoopScheduler($loop);
// This will emit an infinite sequence of growing integer every 50ms.
$source = Observable::interval(50, $scheduler);
$first = $source
->throttle(150, $scheduler) // do not emit more than one item per 150ms
->filter(function($i) { return $i % 2 == 0; }) // keep only odd numbers
->bufferWithCount(3) // buffer 3 items together before emitting them
->take(3); // take the 10 first items only
$second = $source
->throttle(150, $scheduler)
->take(10);
$first->merge($second) // merge both observable
->subscribe(new CallbackObserver(
function ($i) { var_dump($i); },
function ($e) { },
function () { }
));
$loop->run();
If you try to run this last piece of code, you need to have the development version of RxPHP, as throttle was only recently implemented. If your minimum stability parameter is set to the dev edition, you can install it using:
composer require reactivex/rxphp:dev-master
Achieving referential transparency
As the examples demonstrated, creating streams and subscribing to them is fairly trivial. It is also quite easy to imagine how we can factorize handlers in a way that will allow reuse between multiple observable instances.
The issue that Rx does not solve for us, however, is the application architecture needed to achieve referential transparency as much as possible. It does not suffice creating a new database query as an Observable to be pure.
The advice I can give you is the same you already heard in the last chapter that is to try to segregate all impure code in one place. In our case, this can be achieved by creating all streams in a unique file, like your index.php file, for example, and declaring the handlers somewhere else.
The various handlers can be tested in isolation and you can quickly build up confidence about them as they will be referentially transparent. The integration and functional tests will then take care of testing the streams themselves and the application as a whole.
If you try to use Rx in an existing framework, you can declare streams in your controllers and keep the handlers separated the same way as described previously.
Summary
Functional reactive programming allows us to reconcile pure functions with event management. This means it is possible to create applications requiring inputs from the user or access to third-party services and external data sources. This is especially important as more and more websites make use of web sockets and other such technologies to continually push data to the users.
Besides access to data sources, FRP is great when doing user interface work. A task is usually done with JavaScript on the Web, as PHP is mostly used to treat the request itself and serves an HTML response. PHP might, however, be used more on the desktop with initiative, such as the wrapper around libui available in beta for PHP 7 (https://github.com/krakjoe/ui).
Desktop applications in PHP, being a fairly new topic in the community, now might be a great time to create some best practices around it based on state-of-the-art that is functional reactive programming.
We just brushed the surface of this new way of designing applications as it would require a lot more than a chapter to do so fully. Both books mentioned previously are a great starting point if you want to learn more about the topic.
In this chapter, we've learned a bit about the history of FRP. We also tried to discover the differences between traditional reactive programming and its functional counterpart. We quickly spoke about time-traveling debugging and then showed a few examples in PHP.
You have just finished the last chapter of this book. I hope you've had as much fun reading it as it was for me writing it. I also hope I was able to interest you in the topic of functional programming and that you will try to implement the various techniques we've seen in this book in your future projects. There would be no better reward for me than knowing I was able to get a fellow developer interested in this wonderful topic.
Before we part, may I suggest you read the Appendix, What are we Talking About When we Talk About Functional Programming. It contains a more thorough definition of what functional programming is, its benefits, and its history. You will also find a glossary at the end explaining various terms, some of them seen in this book and others new.
So long, and thanks for all the fish.
Chapter 12. What Are We Talking about When We Talk about Functional Programming
Functional programming has gained a lot of traction in the last few years. Various big tech companies have started using functional languages:
· Twitter on Scala: http://www.artima.com/scalazine/articles/twitter_on_scala.html
· WhatsApp being written in Erlang: http://www.fastcompany.com/3026758/inside-erlang-the-rare-programming-language-behind-whatsapps-success
· Facebook using Haskell: https://code.facebook.com/posts/302060973291128/open-sourcing-haxl-a-library-for-haskell/1
There has been some really wonderful and successful work done on functional languages that compile to JavaScript: the Elm and PureScript languages, to name a couple. There are efforts to create new languages that either extend or compile to some more traditional languages; we can cite the Hy and Coconut languages for Python.
Even Apple's new language for iOS development, Swift, has multiple concepts from functional programming integrated into its core.
However, this book is not about using a new language, it is about benefiting from functional techniques without having to change our whole stack or learn a whole new technology. By just applying some principles to our everyday PHP, we can greatly improve the quality of our life and our code.
But before going further, let's start with a gentle introduction to what the functional paradigm really is and explain where it comes from.
What is functional programming all about?
If you try searching the Internet for a definition of functional programming, chances are you will at some point find the Wikipedia article (https://en.wikipedia.org/wiki/Functional_programming). Among other things, functional programming is described as follows:
In computer science, functional programming is a programming paradigm-a style of building the structure and elements of computer programs-that treats computation as the evaluation of mathematical functions and avoids changing-state and mutable data.
The Haskell wiki (https://wiki.haskell.org/Functional_programming) describes it like this:
In functional programming, programs are executed by evaluating expressions, in contrast with imperative programming where programs are composed of statements which change global state when executed. Functional programming typically avoids using mutable state.
Although our take might be a bit different, we can outline some key definitions of functional programming from them:
· Evaluation of mathematical functions or expressions
· Avoiding mutable states
From those two core ideas, we can derive a lot of interesting properties and benefits, which you will discover in this book.
Functions
You're probably aware of what a function is in a programming language, but how it is different from a mathematical function, or as Haskell calls it, an expression?
A mathematical function does not care about the outside world, or the state of the program. For a given set of inputs, the outputs will always be exactly the same. To avoid confusion, developers often use the terms pure functions in this case. We discussed this in Chapter 2, Pure Functions, Referential Transparency and Immutability.
Declarative programming
Another difference is that functional programming is also sometimes called declarative programming, in contrast to imperative programming. These are called programming paradigms. Object-oriented programming is also a paradigm, but one that is strongly tied to the imperative one.
Instead of explaining the difference at length, let's demonstrate it with an example. First an imperative one using PHP:
<?php
function getPrices(array $products) {
// let's assume the $products parameter is an array of products.
$prices = [];
foreach($products as $p) {
if($p->stock > 0) {
$prices[] = $p->price;
}
}
return $prices;
}
Now let's see how you can do the same with SQL, which is, among other things, a declarative language:
SELECT price FROM products WHERE stock > 0;
Notice the difference? In the first example, you tell the computer what to do step by step, taking care of storing intermediary results yourselves. The second example only describes what you want; it will then be the role of the database engine to return the results.
In a way, functional programming looks a lot more like SQL than it does the PHP code we just saw.
Without any explanation, here is how you could do it with PHP in a more functional approach:
<?php
function getPrices2(array $products) {
return array_map(function($p) {
return $p->price;
}, array_filter(function($p) {
return $p->stock > 0;
}));
}
I'll readily admit that this code might not be really clearer than the first one. This can be improved by using dedicated libraries. We will also see in detail the advantages of such an approach.
Avoiding mutable state
As the name itself implies, functions are the most important building block of functional programming. The purest of functional languages will only allow you to use functions, no variables at all, thus avoiding any problems with state and mutating it, and at the same time making any kind of imperative programming impossible.
Although nice, the idea is not practical; this is why most functional languages allow you to have some kind of variable. However, those are often immutable, meaning that, once assigned, their value can't change.
Why is functional programming the future of software development?
As we just saw, the functional world is moving, its adoption by the enterprise world is growing, and even new imperative languages take inspiration from functional languages. But why it is so?
Reducing the cognitive burden on developers
You've probably often read or heard that a programmer should not be interrupted because even a small interruption can lead to literally tens of minutes being lost. One of my favorite illustrations of this is the following comic:

This is partly due to the cognitive burden, or in other words, the amount of information you have to keep in memory in order to understand the problem or function at hand.
If we were able to reduce this issue, the benefits would be huge:
· Code will take less time to understand and will be easier to reason about
· Interruption will lead to less disruption in the mental process
· Fewer errors will be introduced due to forgetting a piece of information
· Small learning curve for newcomers on the project
I posit that functional programming can greatly help.
Keeping the state away
One of the main contenders when it comes to the cognitive burden, as is depicted very well in the comic shown previously, is keeping all these little bits of state information in mind when trying to understand what a piece of code does.
Each time you access a variable or call a method on an object, you have to ask yourself what its value would be and keep that in mind until you reach the end of the piece of code you're currently reading.
By using pure functions, nearly all of this goes away. All your parameters are right there, in the function signature. Moreover, you have the absolute certainty that any subsequent call with the same parameters will have exactly the same outcome, because your function doesn't rely on external data or any object state.
To drive the nail further, let's cite Out of the Tar Pit by Ben Moseley and Peter Marks:
[...] it is our belief that the single biggest remaining cause of complexity in most contemporary large systems is state, and the more we can do to limit and manage state, the better.
You can read the whole paper at http://shaffner.us/cs/papers/tarpit.pdf.
Small building blocks
When you do functional programming, you usually create a lot of small functions. You can then compose them like Lego blocks. Each of those small pieces of code is often easier to understand than this big messy method that tries to do a lot of things.
I am not saying that all imperative code is a big mess, just that having a functional mindset really encourages writing small and concise functions that are easier to work with.
Locality of concerns
Let's have a look at the two following examples:
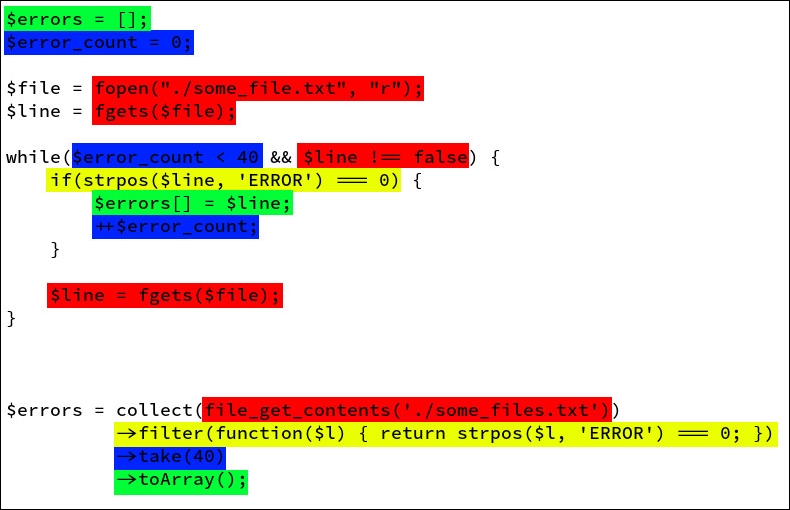
Imperative versus functional-separation of concerns
As illustrated previously in both fictional code snippets, functional techniques help you organize your code in a way that encourages locality of concerns. In the snippets, we can separate the concerns as follows:
· Creating a list
· Getting data from a file
· Filtering all lines starting with ERROR text
· Taking the first 40 errors
The second snippet clearly has a better locality for each of those concerns; they are not spread out in the code.
One can argue that the first code is not optimal and could be rewritten to achieve the same results. Yes, it's probably true. But as for the previous point, a functional mindset encourages this kind of architecture from the get-go.
Declarative programming
We saw that declarative programming is about the what instead of the how. This helps understanding new code a lot, because our minds have a much easier time thinking about what we want instead of how to do it.
When you order something online or at a restaurant, you don't imagine how, what you want will be created or delivered, you just think of what you want. Functional programming is the same-you start with some data and you tell the language what you want done with it.
This kind of code is also often easier to understand for non-programmers or people with less experience in the language, because we can visualize what will happen to the data. Here is another citation from Out of the Tar Pit illustrating this:
When a programmer is forced (through use of a language with implicit control flow) to specify the control, he or she is being forced to specify an aspect of how the system should work rather than simply what is desired. Effectively they are being forced to over-specify the problem
Software with fewer bugs
We already saw that functional programming reduces the cognitive burden and makes your code easier to reason about. This is already a huge win when it comes to bugs, because it will allow you to spot issues quickly as you will spend less time understanding how the code works to focus on what it should do.
But all the benefits we've just seen have another advantage. They make testing a lot easier too! If you have a pure function and you test it with a given set of values, you have the absolute certainty that it will always return exactly the same thing in production.
How many times have you thought your test was fine, only to discover you had some kind of hidden dependency to an obscure state deep in your application that triggered an issue in some particular circumstances? This ought to happen a lot less with pure functions.
We also learn about property-based testing later in the book. Although the technique can be used on any imperative codebase, the idea behind it came from the functional world.
Easier refactoring
Refactoring is never easy. But since the only inputs of a pure function are its parameters and its sole output is the returned value, things are simpler.
If your refactored function continues to return the same output for a given input, you can have the guarantee that your software will continue to work. You cannot forget to set some state somewhere in an object, because your functions are side-effect free.
Parallel execution
Our computers have more and more cores and the cloud has made it a lot easier to share work across a bunch of nodes. The challenge, however, is ensuring that a computation can be distributed.
Techniques such as mapping and folding, coupled with immutability and the absence of state, make this pretty easy.
Sure, you will still have issues related to distributed computing itself, such as partitions and failure detection, but splitting the computation into multiple workloads will be made a lot easier! If you want to learn more about distributed systems, I can recommend this article (http://videlalvaro.github.io/2015/12/learning-about-distributed-systems.html) by a former colleague.
Enforcing good practices
This book is the proof that functional programming is more about the way we do things instead of a particular language. You can use functional techniques in nearly any language that has functions. Your language still needs to have certain properties, but not that many. I like to talk about having a functional mindset.
If this is so, why do companies move to functional languages? Because those languages enforce the best practice we will learn in this book. In PHP, you will have to always remember to use functional techniques. In Haskell, you cannot do anything else; the language forces you to write pure functions.
Sure, you can still write bad code in any language, even the purest ones. But usually, people, and developers especially, like to take the path of least resistance. And if this path is the one that leads to quality code, they will take it.
A quick history of the functional world
Historically, functional programming has its roots in the academic world. It's only in recent years that more mainstream companies started using it to develop consumer-facing applications. Some new research into the field is now even done by people outside of universities. But let's begin at the beginning.
The first years
Our story starts in the 1930s when Alonzo Church formalized the Lambda Calculus, a way to solve mathematical problems using functions accepting other functions as parameters. Although this is the foundation of functional programming, it took 20 years for the concept to be first used to implement a programming language when Lisp was released in 1958 by John McCarthy. To be fair, Fortran, considered the first programming language, was released in 1957.
Although LISP is considered a multi-paradigm language, it is often cited as the first functional language. Quickly, others took the hint and started working around the idea of functional programming, leading to the creation of APL (1964), Scheme (1970), ML (1973), FP (1977), and many others.
FP in itself is more or less dead right now, but the lecture in which it was presented by John Backus was pivotal to the research into the functional paradigm. It might not be the easiest read, but it's really interesting nonetheless. I can only suggest you give the whole paper a try at http://worrydream.com/refs/Backus-CanProgrammingBeLiberated.pdf.
The Lisp family
Scheme, first released in 1970, is an attempt to fix some of the shortcomings of Lisp. In the meantime, Lisp gave birth to a programming language family or dialects:
Common Lisp (1984): an attempt to write a language specification to reunite all the Lisp dialects that were being written at the time.
Emacs Lisp (1985): the scripting language used to customize and extend the Emacs editor.
Racket (1994): first created to be a platform around language design and creation, it's now used in multiple areas such as game scripting, education, and research.
Clojure (2007): created by Rich Hickey after a lengthy reflection to create the perfect language. Clojure targets the Java Virtual Machine (JVM). It is interesting to note that Clojure can also now have other targets, for example, JavaScript (ClojureScript) and the .NET virtual machine.
Hy (2013): a dialect that targets the Python runtime, allowing the use of all Python libraries.
ML
ML also spawned some children, most notably Standard ML and OCaml (1996) which are still in use today. It is also often cited as influence in the design of a lot of modern languages. To name a few: Go, Rust, Erlang, Haskell, and Scala.
The rise of Erlang
I said earlier that the mainstream use of functional language is something that started happening in the last few years. This is not entirely true. Ericsson started working on Erlang as soon as 1986, interested in the stability and robustness promised by a functional language.
At first, Erlang was implemented on top of Prolog and it proved too slow, but a rewrite to use a virtual machine compiling Erlang to C in 1992, allowed Ericsson to use Erlang on production telephony system as early as 1995. Since then, it has been used worldwide by telecom companies and is considered one of the best languages when it comes to high availability.
Haskell
The year 1990 marked the first release of Haskell, the result of specification work done by academics around the world to create the first open standard around lazy purely functional languages. The idea was to consolidate existing functional languages into a common one so that it could be the basis for further research in functional language design.
Since then, Haskell has grown from a purely academic language in to one of the leading functional languages.
Scala
Scala development was started in 2001 by former Java core developer Martin Odersky. The main idea was to make functional programming more approachable by mixing it with more traditional imperative concepts. The first public release in 2004 targeted both the JVM and the Common Runtime Language (CRM) used by .NET (this second target was later dropped in 2012).
Scala source code can use its language construct alongside those from the target virtual machine. The ability to use existing Java libraries directly and the ability to fall back to an imperative style is one of the reasons Scala quickly gained ground in the enterprise world.
Since Android uses a Java-compatible virtual machine, Scala is well suited for mobile development and there's also an initiative to compile it to JavaScript, meaning you can use it on both the server and the client for web development.
The newcomers
Nowadays, functional programming languages are starting to gain more mainstream acceptance and new languages are created outside of the academic world. Here is a quick overview of what is being actively worked on by people around the world.
Elm is a serious attempt to create a functional language compiling to JavaScript besides ClojureScript. It is the result of a thesis by Evan Czaplicki trying to create a functional reactive language, a concept we will look into in the last chapter of the book. It gained some coverage when a time-traveling debugger (http://debug.elm-lang.org/) was first presented some years ago, an idea that has since been implemented with much more pain in JavaScript frameworks such as React. The barrier of entry is greatly eased by an online editor, really great tutorials, and the fact that you can use npm to install it.
PureScript is another functional language compiling to JavaScript. It is closer to Haskell than Elm is and follows a more mathematical approach. The community is smaller, but a lot of work is going on to make the language user-friendly. The PureScript compiler was written in Haskell, it's a bit harder to get started but it's worth it if you want to have robust client-side code.
Idris is, in my opinion, not really ready to shine in a production environment. It has its place in this list, however, as it is one of the more advanced functional languages implementing dependent types. A dependent type is an advanced typing concept that is mostly seen in purely academic languages. It's beyond scope of this book to explain it in detail, but let's do a quick example: a pair of integers is a type; a pair of integers where the second one is greater than the first is a dependent type because the type depends on the value of the variable. The advantages of such a typing system is that you can prove more thoroughly that your data is correct and thus the result of your software is also correct. This is, however, a really advanced technique and such languages are rare and hard to learn.
Functional jargon
Like every other field, functional programming comes with its own jargon. This small glossary has the goal to make reading the book easier and also provide you with more understanding of the resources you will find online.
Arity
The number of parameters a function takes. The terms nullary, unary, binary, and ternary are also used to denote functions that take 0, 1, 2, and 3 parameters respectively. See also variadic as follows.
Higher-order functions
A function that returns another function. Chapter 1, Functions as First Class Citizens, further explain the concepts of higher-order functions as this is one of the foundations of functional programming.
Side effects
Anything that affects the world outside the current function: changing a global state, a variable passed by reference, a value in an object, writing to the screen or a file, taking user inputs. This concept is an important one and will be explored further in multiple chapters of the book.
Purity
A function is said to be pure if it only uses the explicit parameters and has no side effects. A pure function is a function that will always yield exactly the same result when called with the same parameters. A pure language is a language allowing only pure functions. This concept is an angular stone of functional programing as discussed in Chapter 2, Pure Functions, Referential Transparency, and Immutability.
Function composition
Composing functions is a useful technique to reuse various functions as building blocks to achieve more complex operations. Instead of always calling the function g on the result of the function f, you can compose both functions to create a new function h. Chapter 4, Composing Functions, demonstrates how this idea can be used.
Immutability
An immutable variable is a variable that cannot be changed once it has been assigned a value.
Partial application
The process of assigning a given value to some parameters of a function to create a new function of a smaller arity. This is sometimes called fixing or binding a value to a parameter. This is a bit difficult to achieve in PHP, but Chapter 4, Composing Functions, gives some idea of how to do it.
Currying
Akin to partial application, currying is the process of transforming a function with multiple parameters into multiple unary functions composed to achieve the same result. The reason and idea behind currying were presented in Chapter 4, Composing Functions.
Fold/reduce
The process of reducing a collection to a single value. This is an often-used concept in functional programming and was demonstrated at length in Chapter 3, Functional Basis in PHP.
Map
The process of applying a function on all values of a collection. This is an often-used concept in functional programming and was demonstrated at length in Chapter 3, Functional Basis in PHP.
Functor
Any type of value or collection to which you can apply a mapping operation. The functor, given a function, is responsible for applying it to its inner value. It is said that the functor wraps the value. This concept was presented in Chapter 5, Functors, Applicatives, and Monads.
Applicative
A data structure holding a function inside a context. The applicative, given a value, is responsible for applying the "inner" function to it. It is said that the functor wraps the function. This concept was presented in Chapter 5, Functors, Applicatives, and Monads.
Semigroup
Any type for which you can associate values two by two. For example, strings are a semigroup because you can concatenate them.
Integers have multiple semigroups:
· The Addition semigroup, where you add integers together
· The Multiplication semigroup, where you multiply the integers together
Monoid
A monoid is a semigroup that also has an identity value. The identity value is a value that when associated with an object of the same type does not change its value. The Addition identity for integers is 0 and the identity for strings is the empty string.
A monoid also requires that the order of association to multiple values does not change the result, for example, (1 + 2) + 3 == 1 + (2 + 3).
Monad
A monad can act both as a functor or as an applicative; refer to the dedicated Chapter 5, Functors, Applicatives, and Monads, for more information.
Lift/LiftA/LiftM
The process of taking something and putting it inside a functor, applicative, or monad respectively.
Morphism
A transformation function. We can distinguish multiple kinds of morphisms:
· Endomorphism: The type of the input and output stays the same, for example, making a string uppercase.
· Isomorphism: The type changes, but the data stays the same, for example, transforming an array containing coordinates to a Coordinate object.
Algebraic type / union type
The combination of two types into a new one. Scala calls those either types.
Option type / maybe type
A union type that contains a valid value and the equivalent of null. This kind of type is used when a function is not sure to return a valid value. Chapter 3, Functional Basis in PHP, explains how to use these to simplify error management.
Idempotence
A function is said to be idempotent if reapplying it to its result does not produce a different result. If you compose an idempotent function with itself, it will still yield the same result.
Lambda
A synonym for an anonymous function, that is, a function assigned to a variable.
Predicate
A function that returns either true or false for a given set of parameters. Predicates are often used to filter collections.
Referential transparency
An expression is said to be referentially transparent if it can be replaced by its value without changing the outcome of the program. The concept is tightly linked to purity. Chapter 2, Pure functions, Referential Transparency, and Immutability, explores the slight differences between the two.
Lazy evaluations
A language is said to be lazily evaluated if the result of an expression is only computed when it's needed. This allows you to create an infinite list and is only possible if an expression is referentially transparent.
Non-strict language
A non-strict language is a language where all constructs are lazily evaluated. Only a handful of languages are non-strict, mostly due to the fact that the language has to be pure in order to be non-strict and it poses non-trivial implementation issues. The most well-known non-strict language is probably Haskell.
Nearly all commonly seen languages are strict: C, Java, PHP, Ruby, Python, and so on.
Variadic
A function with dynamic arity is called variadic. This means the function accepts a variable number of parameters.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.